题目描述(困难难度)
给定两个字符串 S 和T,从 S 中选择字母,使得刚好和 T 相等,有多少种选法。
解法一 递归之分治
S 中的每个字母就是两种可能选他或者不选他。我们用递归的常规思路,将大问题化成小问题,也就是分治的思想。
如果我们求 S[0,S_len - 1] 中能选出多少个 T[0,T_len - 1],个数记为 n。那么分两种情况,
S[0] == T[0],需要知道两种情况从
S中选择当前的字母,此时S跳过这个字母,T也跳过一个字母。去求
S[1,S_len - 1]中能选出多少个T[1,T_len - 1],个数记为n1S不选当前的字母,此时S跳过这个字母,T不跳过字母。去求
S[1,S_len - 1]中能选出多少个T[0,T_len - 1],个数记为n2
S[0] != T[0]S只能不选当前的字母,此时S跳过这个字母,T不跳过字母。去求
S[1,S_len - 1]中能选出多少个T[0,T_len - 1],个数记为n1
也就是说如果求 S[0,S_len - 1] 中能选出多少个 T[0,T_len - 1],个数记为 n。转换为数学式就是
if(S[0] == T[0]){ n = n1 + n2; }else{ n = n1; } 推广到一般情况,我们可以先写出递归的部分代码。
public int numDistinct(String s, String t) { return numDistinctHelper(s, 0, t, 0); } private int numDistinctHelper(String s, int s_start, String t, int t_start) { int count = 0; //当前字母相等 if (s.charAt(s_start) == t.charAt(t_start)) { //从 S 选择当前的字母,此时 S 跳过这个字母, T 也跳过一个字母。 count = numDistinctHelper(s, s_start + 1, t, t_start + 1, map) //S 不选当前的字母,此时 S 跳过这个字母,T 不跳过字母。 + numDistinctHelper(s, s_start + 1, t, t_start, map); //当前字母不相等 }else{ //S 只能不选当前的字母,此时 S 跳过这个字母, T 不跳过字母。 count = numDistinctHelper(s, s_start + 1, t, t_start, map); } return count; } 递归出口的话,因为我们的S和T的开始下标都是增长的。
如果S[s_start, S_len - 1]中, s_start 等于了 S_len ,意味着S是空串,从空串中选字符串T,那结果肯定是0。
如果T[t_start, T_len - 1]中,t_start等于了 T_len,意味着T是空串,从S中选择空字符串T,只需要不选择 S 中的所有字母,所以选法是1。
综上,代码总体就是下边的样子
public int numDistinct(String s, String t) { return numDistinctHelper(s, 0, t, 0); } private int numDistinctHelper(String s, int s_start, String t, int t_start) { //T 是空串,选法就是 1 种 if (t_start == t.length()) { return 1; } //S 是空串,选法是 0 种 if (s_start == s.length()) { return 0; } int count = 0; //当前字母相等 if (s.charAt(s_start) == t.charAt(t_start)) { //从 S 选择当前的字母,此时 S 跳过这个字母, T 也跳过一个字母。 count = numDistinctHelper(s, s_start + 1, t, t_start + 1) //S 不选当前的字母,此时 S 跳过这个字母,T 不跳过字母。 + numDistinctHelper(s, s_start + 1, t, t_start); //当前字母不相等 }else{ //S 只能不选当前的字母,此时 S 跳过这个字母, T 不跳过字母。 count = numDistinctHelper(s, s_start + 1, t, t_start); } return count; } 遗憾的是,这个解法对于如果S太长的 case 会超时。
原因就是因为递归函数中,我们多次调用了递归函数,这会使得我们重复递归很多的过程,解决方案就很简单了,Memoization 技术,把每次的结果利用一个map保存起来,在求之前,先看map中有没有,有的话直接拿出来就可以了。
map的key的话就标识当前的递归,s_start 和 t_start 联合表示,利用字符串 s_start + '@' + t_start。
value的话就保存这次递归返回的count。
public int numDistinct(String s, String t) { HashMap<String, Integer> map = new HashMap<>(); return numDistinctHelper(s, 0, t, 0, map); } private int numDistinctHelper(String s, int s_start, String t, int t_start, HashMap<String, Integer> map) { //T 是空串,选法就是 1 种 if (t_start == t.length()) { return 1; } //S 是空串,选法是 0 种 if (s_start == s.length()) { return 0; } String key = s_start + "@" + t_start; //先判断之前有没有求过这个解 if (map.containsKey(key)) { return map.get(key); } int count = 0; //当前字母相等 if (s.charAt(s_start) == t.charAt(t_start)) { //从 S 选择当前的字母,此时 S 跳过这个字母, T 也跳过一个字母。 count = numDistinctHelper(s, s_start + 1, t, t_start + 1, map) //S 不选当前的字母,此时 S 跳过这个字母,T 不跳过字母。 + numDistinctHelper(s, s_start + 1, t, t_start, map); //当前字母不相等 }else{ //S 只能不选当前的字母,此时 S 跳过这个字母, T 不跳过字母。 count = numDistinctHelper(s, s_start + 1, t, t_start, map); } //将当前解放到 map 中 map.put(key, count); return count; } 解法二 递归之回溯
回溯的思想就是朝着一个方向找到一个解,然后再回到之前的状态,改变当前状态,继续尝试得到新的解。可以类比于二叉树的DFS,一路走到底,然后回到之前的节点继续递归。
对于这道题,和二叉树的DFS很像了,每次有两个可选的状态,选择S串的当前字母和不选择当前字母。
当S串的当前字母和T串的当前字母相等,我们就可以选择S的当前字母,进入递归。
递归出来以后,继续尝试不选择S的当前字母,进入递归。
代码可以是下边这样。
public int numDistinct3(String s, String t) { numDistinctHelper(s, 0, t, 0); } private void numDistinctHelper(String s, int s_start, String t, int t_start) { //当前字母相等,选中当前 S 的字母,s_start 后移一个 //选中当前 S 的字母,意味着和 T 的当前字母匹配,所以 t_start 后移一个 if (s.charAt(s_start) == t.charAt(t_start)) { numDistinctHelper(s, s_start + 1, t, t_start + 1); } //出来以后,继续尝试不选择当前字母,s_start 后移一个,t_start 不后移 numDistinctHelper(s, s_start + 1, t, t_start); } 递归出口的话,就是两种了。
当
t_start == T_len,那么就意味着当前从S中选择的字母组成了T,此时就代表一种选法。我们可以用一个全局变量count,count计数此时就加一。然后return,返回到上一层继续寻求解。当
s_start == S_len,此时S到达了结尾,直接 return。
int count = 0; public int numDistinct(String s, String t) { numDistinctHelper(s, 0, t, 0); return count; } private void numDistinctHelper(String s, int s_start, String t, int t_start) { if (t_start == t.length()) { count++; return; } if (s_start == s.length()) { return; } //当前字母相等,s_start 后移一个,t_start 后移一个 if (s.charAt(s_start) == t.charAt(t_start)) { numDistinctHelper(s, s_start + 1, t, t_start + 1); } //出来以后,继续尝试不选择当前字母,s_start 后移一个,t_start 不后移 numDistinctHelper(s, s_start + 1, t, t_start); }
好吧,这个熟悉的错误又出现了,同样是递归中调用了两次递归,会重复计算一些解。怎么办呢?Memoization 技术。
map的key和之前一样,标识当前的递归,s_start 和 t_start 联合表示,利用字符串 s_start + '@' + t_start。
map的value的话?存什么呢。区别于解法一,我们每次都得到了当前条件下的count,然后存起来了。而现在我们只有一个全局变量,该怎么办呢?存全局变量count吗?
如果递归过程中
if (map.containsKey(key)) { ... ... } 遇到了已经求过的解该怎么办呢?
我们每次得到一个解后增加全局变量count,所以我们map的value存两次递归后 count 的增量。这样的话,第二次遇到同样的情况的时候,就不用递归了,把当前增量加上就可以了。
if (map.containsKey(key)) { count += map.get(key); return; } 综上,代码就出来了
int count = 0; public int numDistinct(String s, String t) { HashMap<String, Integer> map = new HashMap<>(); numDistinctHelper(s, 0, t, 0, map); return count; } private void numDistinctHelper(String s, int s_start, String t, int t_start, HashMap<String, Integer> map) { if (t_start == t.length()) { count++; return; } if (s_start == s.length()) { return; } String key = s_start + "@" + t_start; if (map.containsKey(key)) { count += map.get(key); return; } int count_pre = count; //当前字母相等,s_start 后移一个,t_start 后移一个 if (s.charAt(s_start) == t.charAt(t_start)) { numDistinctHelper(s, s_start + 1, t, t_start + 1, map); } //出来以后,继续尝试不选择当前字母,s_start 后移一个,t_start 不后移 numDistinctHelper(s, s_start + 1, t, t_start, map); //将增量存起来 int count_increment = count - count_pre; map.put(key, count_increment); } 解法三 动态规划
让我们来回想一下解法一做了什么。s_start 和 t_start 不停的增加,一直压栈,压栈,直到
//T 是空串,选法就是 1 种 if (t_start == t.length()) { return 1; } //S 是空串,选法是 0 种 if (s_start == s.length()) { return 0; } T 是空串或者 S 是空串,我们就直接可以返回结果了,接下来就是不停的出栈出栈,然后把结果通过递推关系取得。
递归的过程就是由顶到底再回到顶。
动态规划要做的就是去省略压栈的过程,直接由底向顶。
这里我们用一个二维数组 dp[m][n] 对应于从 S[m,S_len) 中能选出多少个 T[n,T_len)。
当 m == S_len,意味着S是空串,此时dp[S_len][n],n 取 0 到 T_len - 1的值都为 0。
当 n == T_len,意味着T是空串,此时dp[m][T_len],m 取 0 到 S_len的值都为 1。
然后状态转移的话和解法一分析的一样。如果求dp[s][t]。
S[s] == T[t],当前字符相等,那就对应两种情况,选择S的当前字母和不选择S的当前字母dp[s][t] = dp[s+1][t+1] + dp[s+1][t]S[s] != T[t],只有一种情况,不选择S的当前字母dp[s][t] = dp[s+1][t]
代码就可以写了。
public int numDistinct(String s, String t) { int s_len = s.length(); int t_len = t.length(); int[][] dp = new int[s_len + 1][t_len + 1]; //当 T 为空串时,所有的 s 对应于 1 for (int i = 0; i <= s_len; i++) { dp[i][t_len] = 1; } //倒着进行,T 每次增加一个字母 for (int t_i = t_len - 1; t_i >= 0; t_i--) { dp[s_len][t_i] = 0; // 这句可以省去,因为默认值是 0 //倒着进行,S 每次增加一个字母 for (int s_i = s_len - 1; s_i >= 0; s_i--) { //如果当前字母相等 if (t.charAt(t_i) == s.charAt(s_i)) { //对应于两种情况,选择当前字母和不选择当前字母 dp[s_i][t_i] = dp[s_i + 1][t_i + 1] + dp[s_i + 1][t_i]; //如果当前字母不相等 } else { dp[s_i][t_i] = dp[s_i + 1][t_i]; } } } return dp[0][0]; } 对比于解法一和解法二,如果Memoization 技术我们不用hash,而是用一个二维数组,会发现其实我们的递归过程,其实就是在更新下图中的二维表,只不过更新的顺序没有动态规划这么归整。这也是不用Memoization 技术会超时的原因,如果把递归的更新路线画出来,会发现很多路线重合了,意味着我们进行了很多没有必要的递归,从而造成了超时。
我们画一下动态规划的过程。
S = "babgbag", T = "bag"
T 为空串时,所有的 s 对应于 1。 S 为空串时,所有的 t 对应于 0。
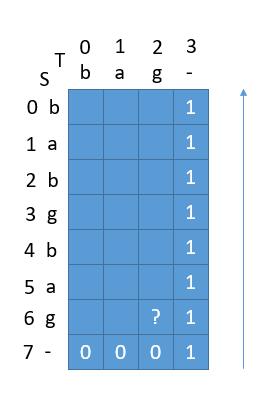
此时我们从 dp[6][2] 开始求。根据公式,因为当前字母相等,所以 dp[6][2] = dp[7][3] + dp[7][2] = 1 + 0 = 1 。
接着求dp[5][2],当前字母不相等,dp[5][2] = dp[6][2] = 1。
一直求下去。
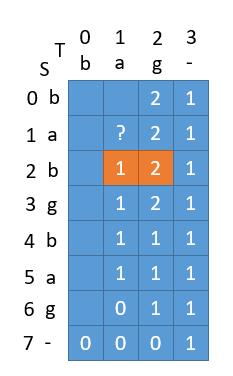
求当前问号的地方的值的时候,我们只需要它的上一个值和斜对角的值。
换句话讲,求当前列的时候,我们只需要上一列的信息。比如当前求第1列,第3列的值就不会用到了。
所以我们可以优化算法的空间复杂度,不需要二维数组,需要一维数组就够了。
此时需要解决一个问题,就是当求上图的dp[1][1]的时候,需要dp[2][1]和dp[2][2]的信息。但是如果我们是一维数组,dp[2][1]之前已经把dp[2][2]的信息覆盖掉了。所以我们需要一个pre变量保存之前的值。
public int numDistinct(String s, String t) { int s_len = s.length(); int t_len = t.length(); int[]dp = new int[s_len + 1]; for (int i = 0; i <= s_len; i++) { dp[i] = 1; } //倒着进行,T 每次增加一个字母 for (int t_i = t_len - 1; t_i >= 0; t_i--) { int pre = dp[s_len]; dp[s_len] = 0; //倒着进行,S 每次增加一个字母 for (int s_i = s_len - 1; s_i >= 0; s_i--) { int temp = dp[s_i]; if (t.charAt(t_i) == s.charAt(s_i)) { dp[s_i] = dp[s_i + 1] + pre; } else { dp[s_i] = dp[s_i + 1]; } pre = temp; } } return dp[0]; } 利用temp和pre两个变量实现了保存之前的值。
其实动态规划优化空间复杂度的思想,在 5题,10题,53题,72题 等等都已经用了,是非常经典的。
上边的动态规划是从字符串末尾倒着进行的,其实我们只要改变dp数组的含义,用dp[m][n]表示S[0,m)和T[0,n),然后两层循环我们就可以从 1 往末尾进行了,思想是类似的,leetcode 高票答案也都是这样的,如果理解了上边的思想,代码其实也很好写。这里只分享下代码吧。
public int numDistinct(String s, String t) { int s_len = s.length(); int t_len = t.length(); int[] dp = new int[s_len + 1]; for (int i = 0; i <= s_len; i++) { dp[i] = 1; } for (int t_i = 1; t_i <= t_len; t_i++) { int pre = dp[0]; dp[0] = 0; for (int s_i = 1; s_i <= s_len; s_i++) { int temp = dp[s_i]; if (t.charAt(t_i - 1) == s.charAt(s_i - 1)) { dp[s_i] = dp[s_i - 1] + pre; } else { dp[s_i] = dp[s_i - 1]; } pre = temp; } } return dp[s_len]; } 总
这道题太经典了,从递归实现回溯,递归实现分治,Memoization 技术对递归的优化,从递归转为动态规划再到动态规划空间复杂度的优化,一切都是理所当然,不需要什么特殊技巧,一切都是这么优雅,太棒了。
自己一开始是想到回溯的方法,然后卡到了超时的问题上,看了这篇 和 这篇 的题解后才恍然大悟,一切才都联通了,解法一、解法二、解法三其实本质都是在填充那个二维矩阵,最终殊途同归,不知为什么脑海中有宇宙大爆炸,然后万物产生联系的画面,2333。
这里自己需要吸取下教训,自己开始在回溯卡住了以后,思考了动态规划的方法,dp数组的含义已经定义出来了,想状态转移方程的时候在脑海里一直想,又卡住了。所以对于这种稍微复杂的动态规划还是拿纸出来画一画比较好。