Download as PDF, PPTX




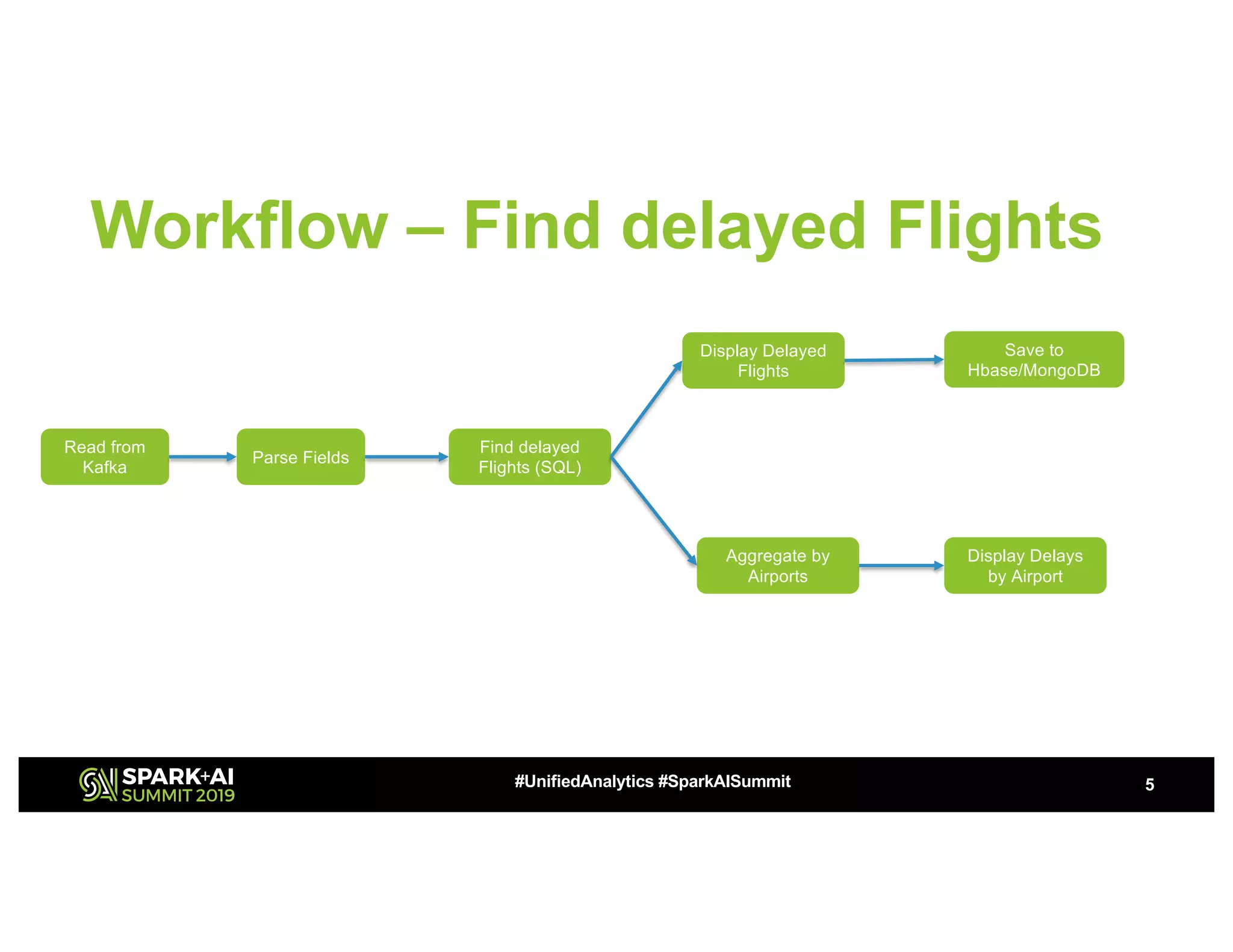


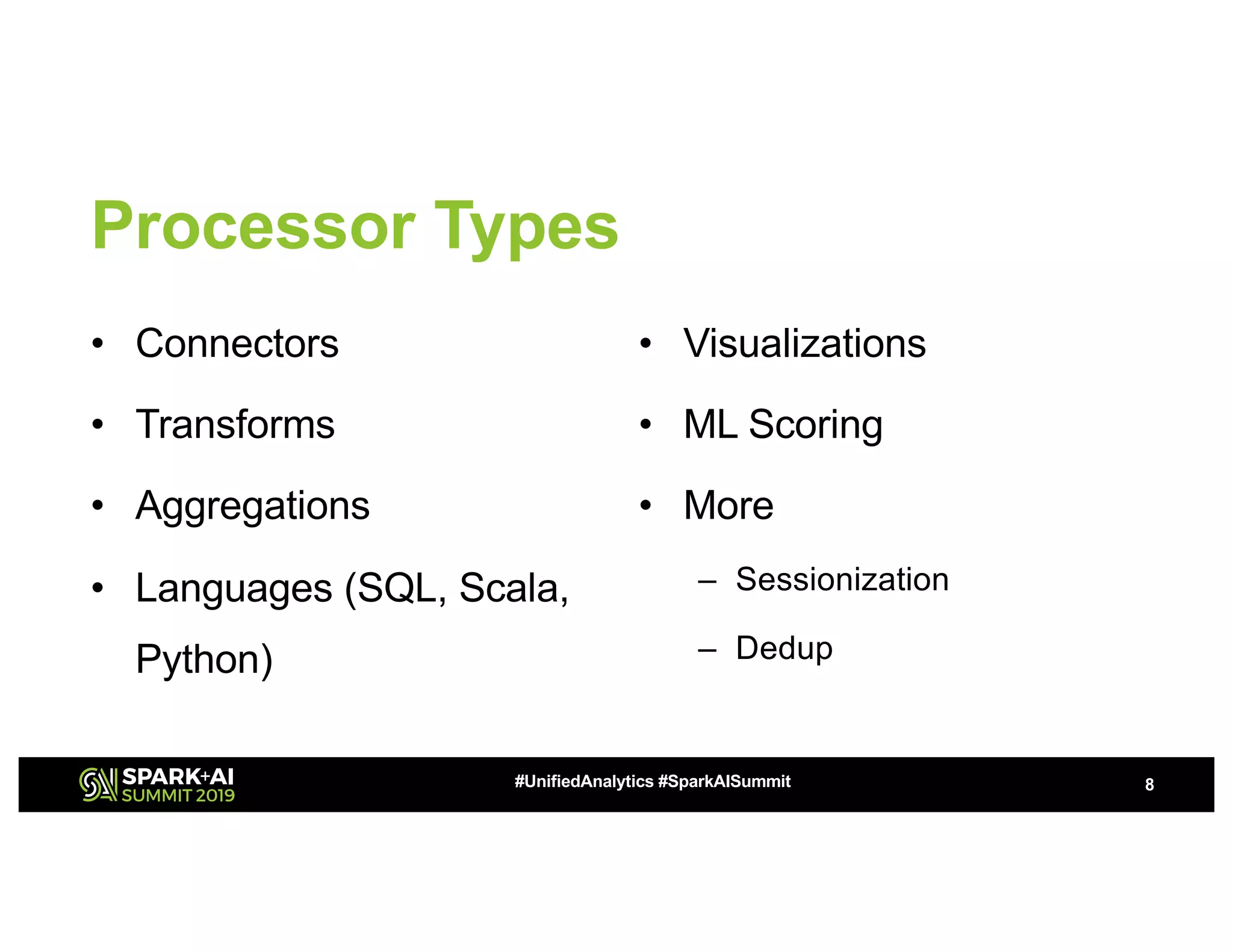

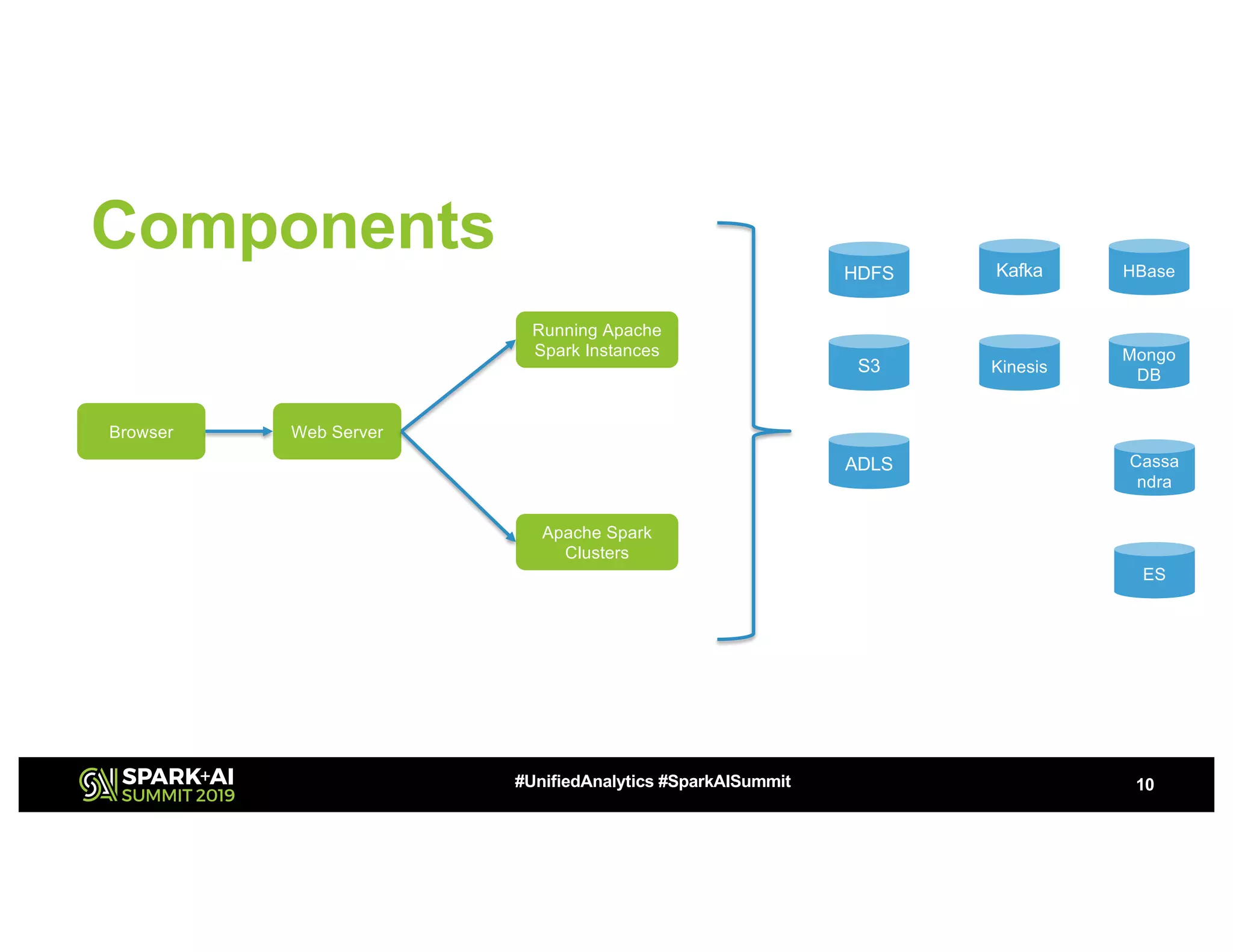

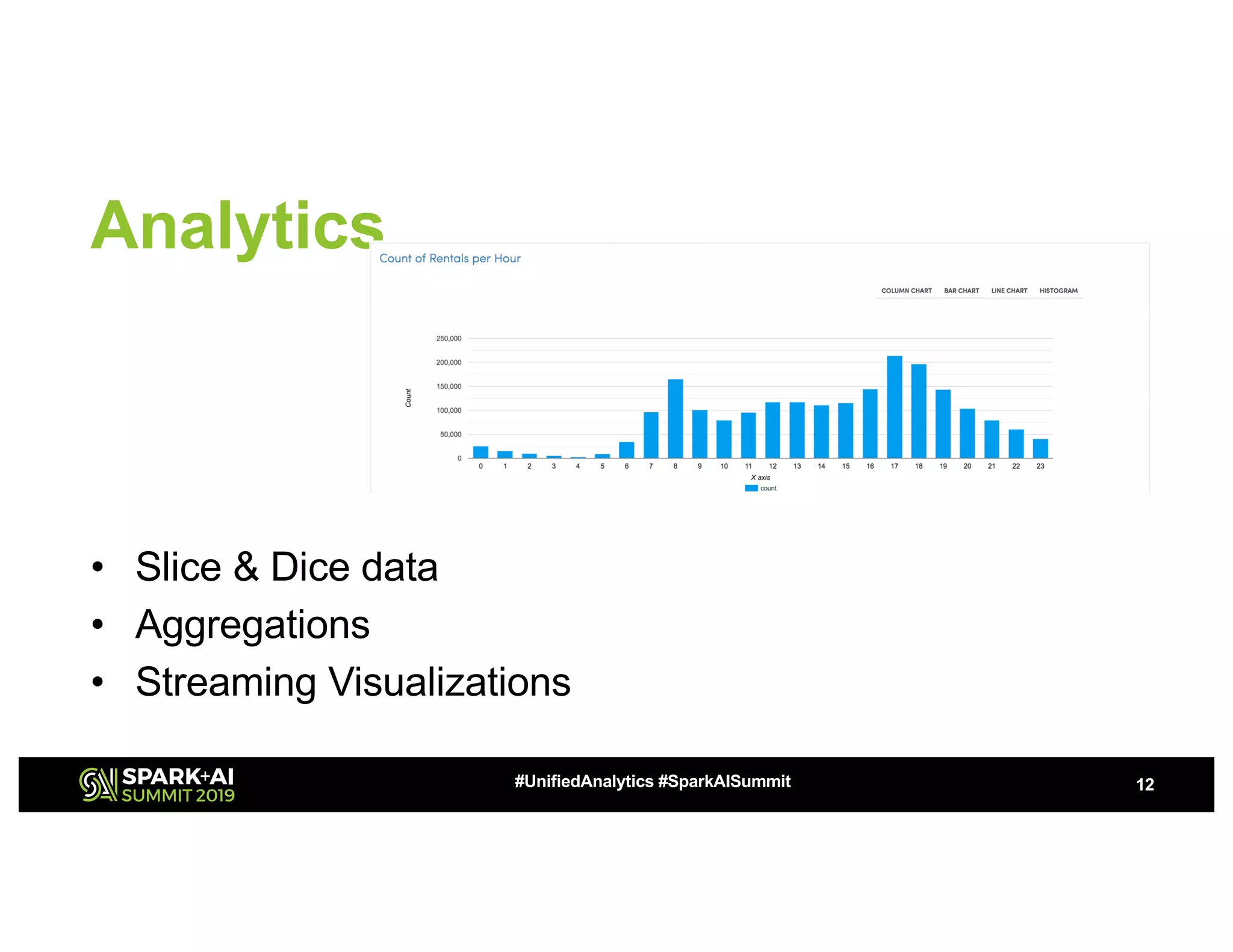




















The document outlines the capabilities of self-service Apache Spark for structured streaming applications and analytics, highlighting use cases such as IoT analytics, fraud detection, and real-time data processing. It emphasizes quick debugging, operationalization, and the ability to build and deploy workflows efficiently while incorporating various data sources and machine learning techniques. Additionally, it discusses deployment, monitoring, scheduling, and performance optimization strategies to enhance user experience and streamline complex processes.