Download as PDF, PPTX









![18#UnifiedAnalytics #SparkAISummit val collect (TaskContext, Iterator[T]) => (Int, Array[T]) = { val result = new mutable.ArrayBuffer[T] while (itr.hasNext) { result.append(itr.next) } result.toArray } val collect (TaskContext, Iterator[T]) => (Int, Array[T]) = { coroutine {(context: TaskContext, itr: Iterator[T]) => { val result = new mutable.ArrayBuffer[T] while (itr.hasNext) { result.append(itr.next) if (context.isPaused()) yieldval(0) } result.toArray } } Subroutine Coroutine Suspendable tasks](https://image.slidesharecdn.com/012007panagiotisgarefalakiskonstantinoskaranasos-190507232622/75/Cooperative-Task-Execution-for-Apache-Spark-18-2048.jpg)
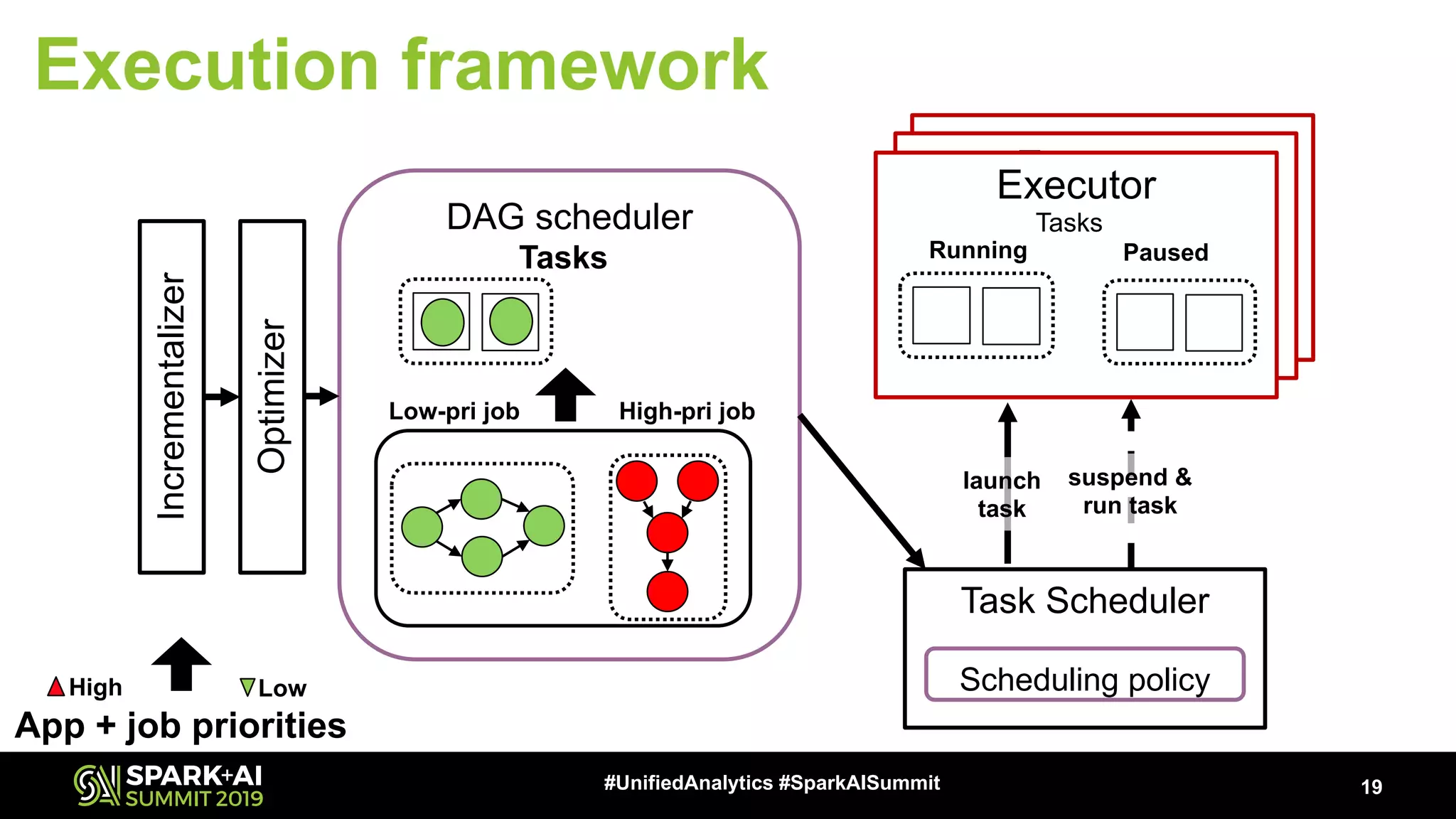




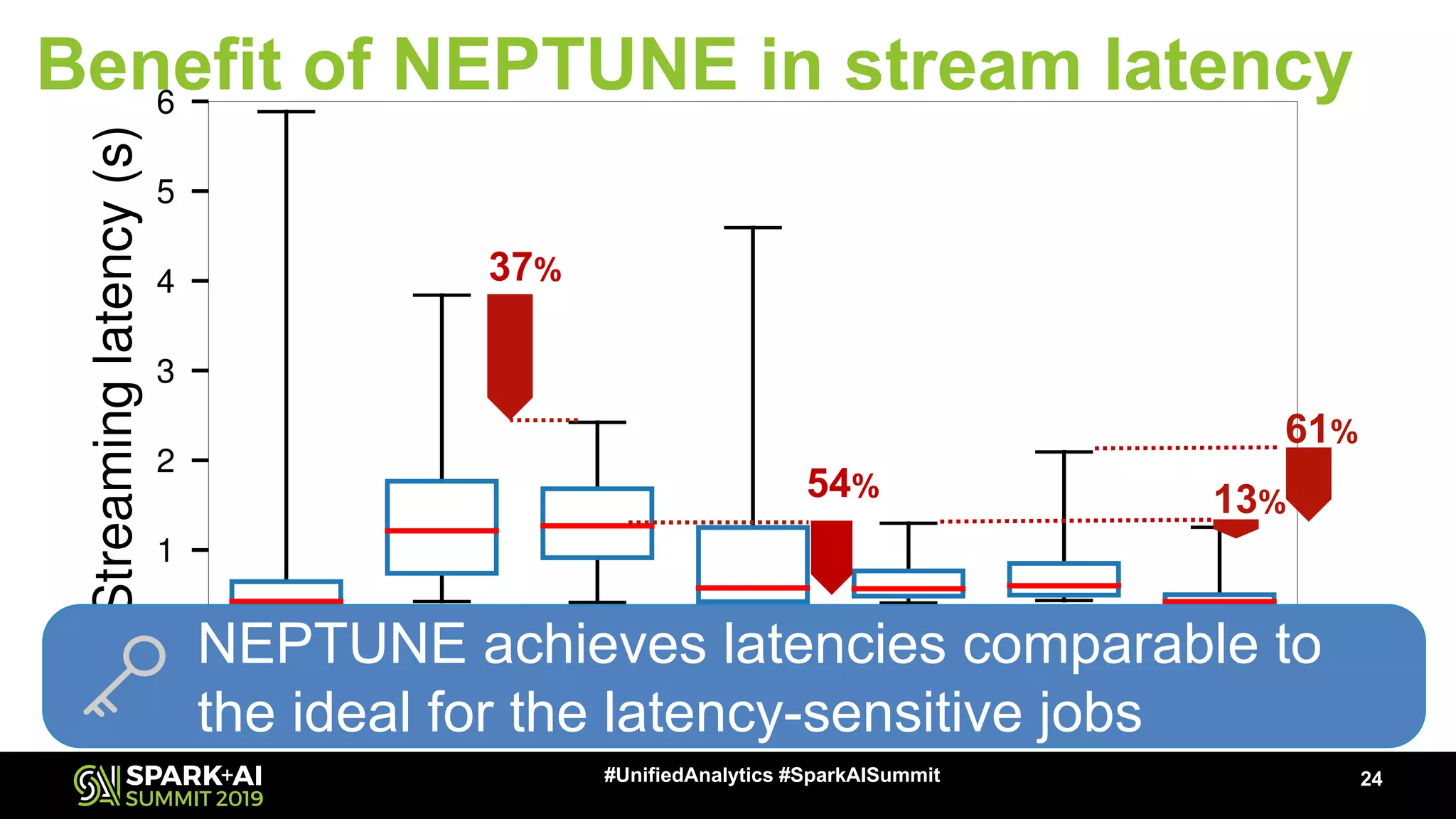
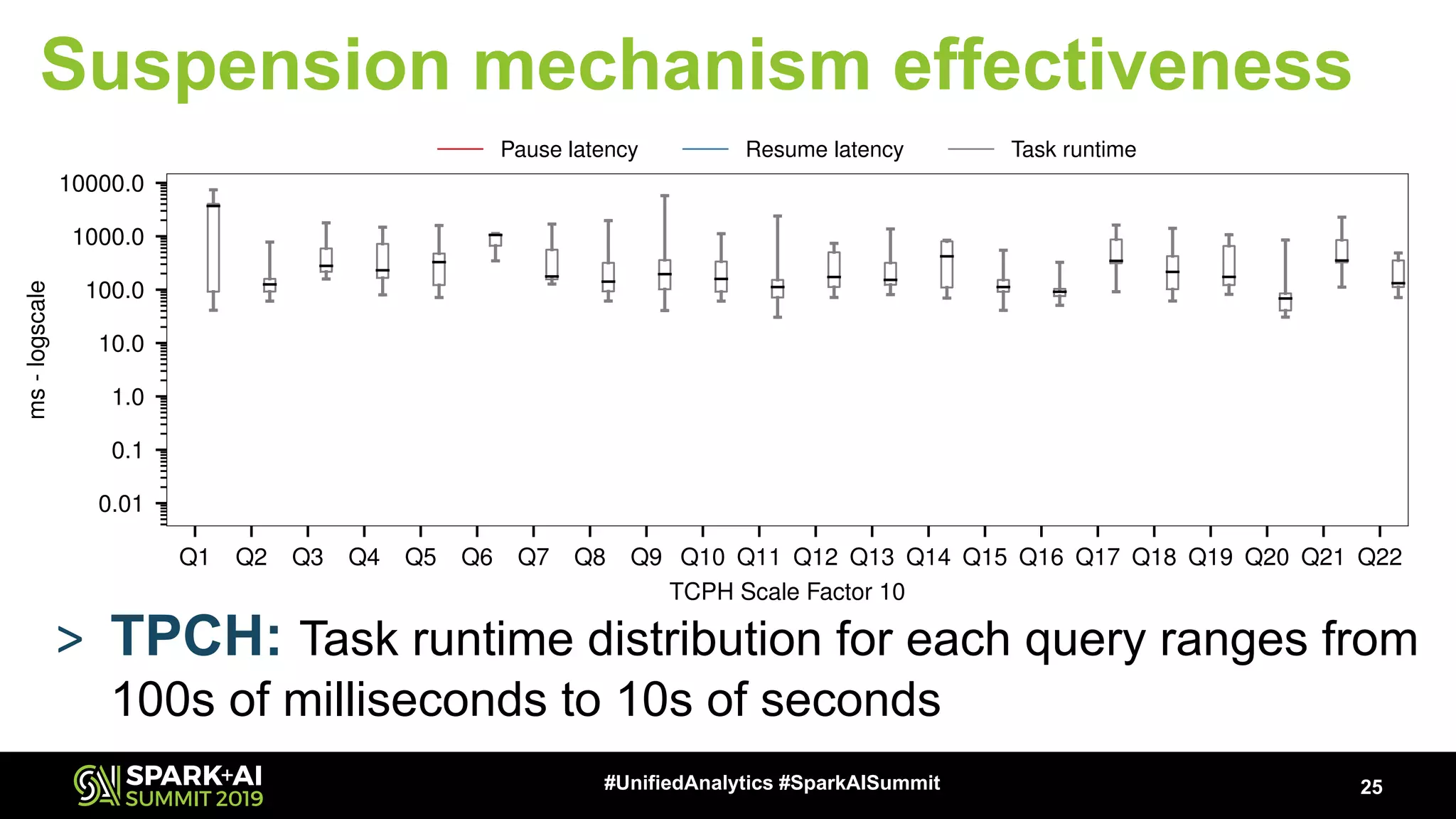
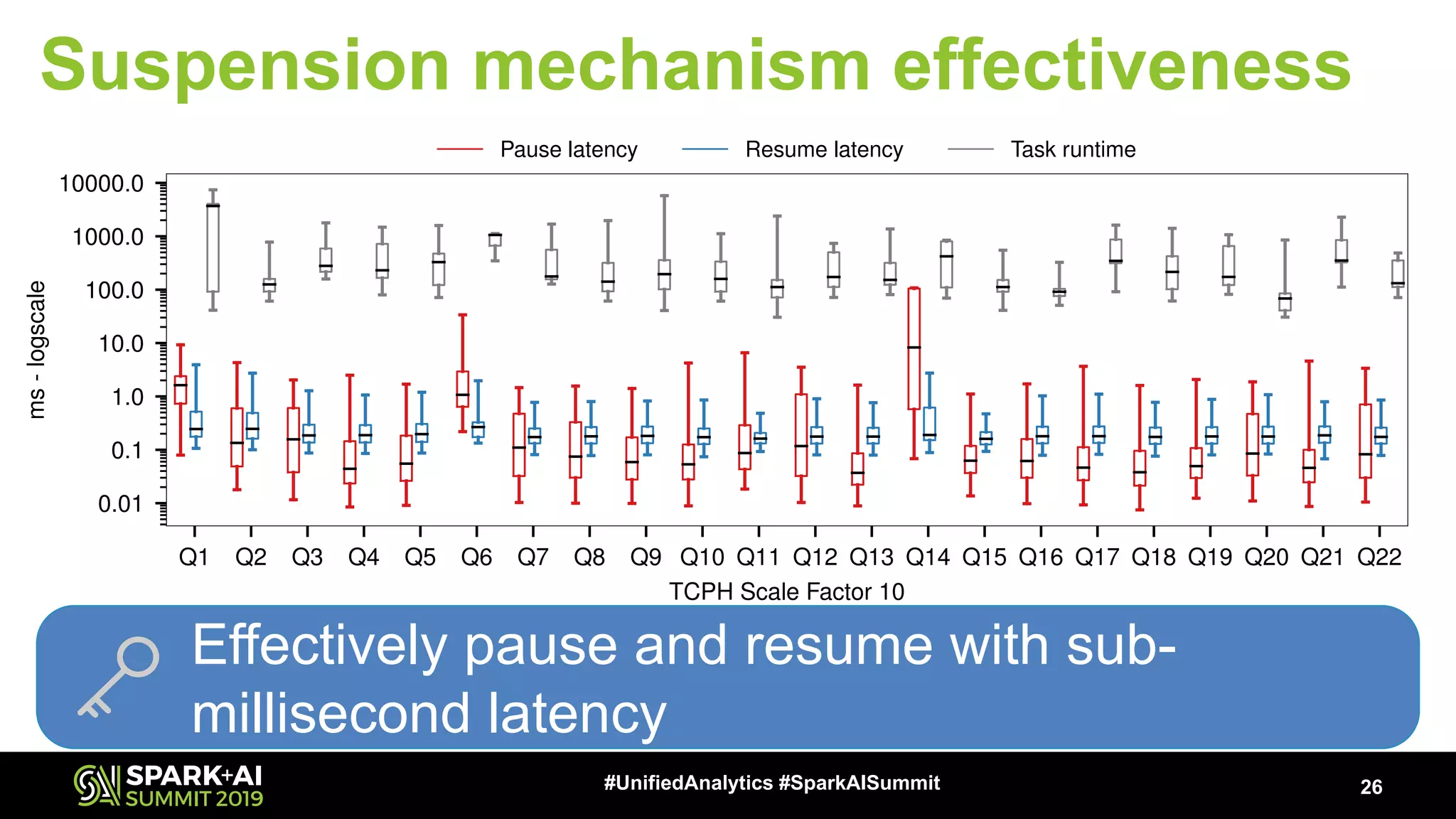
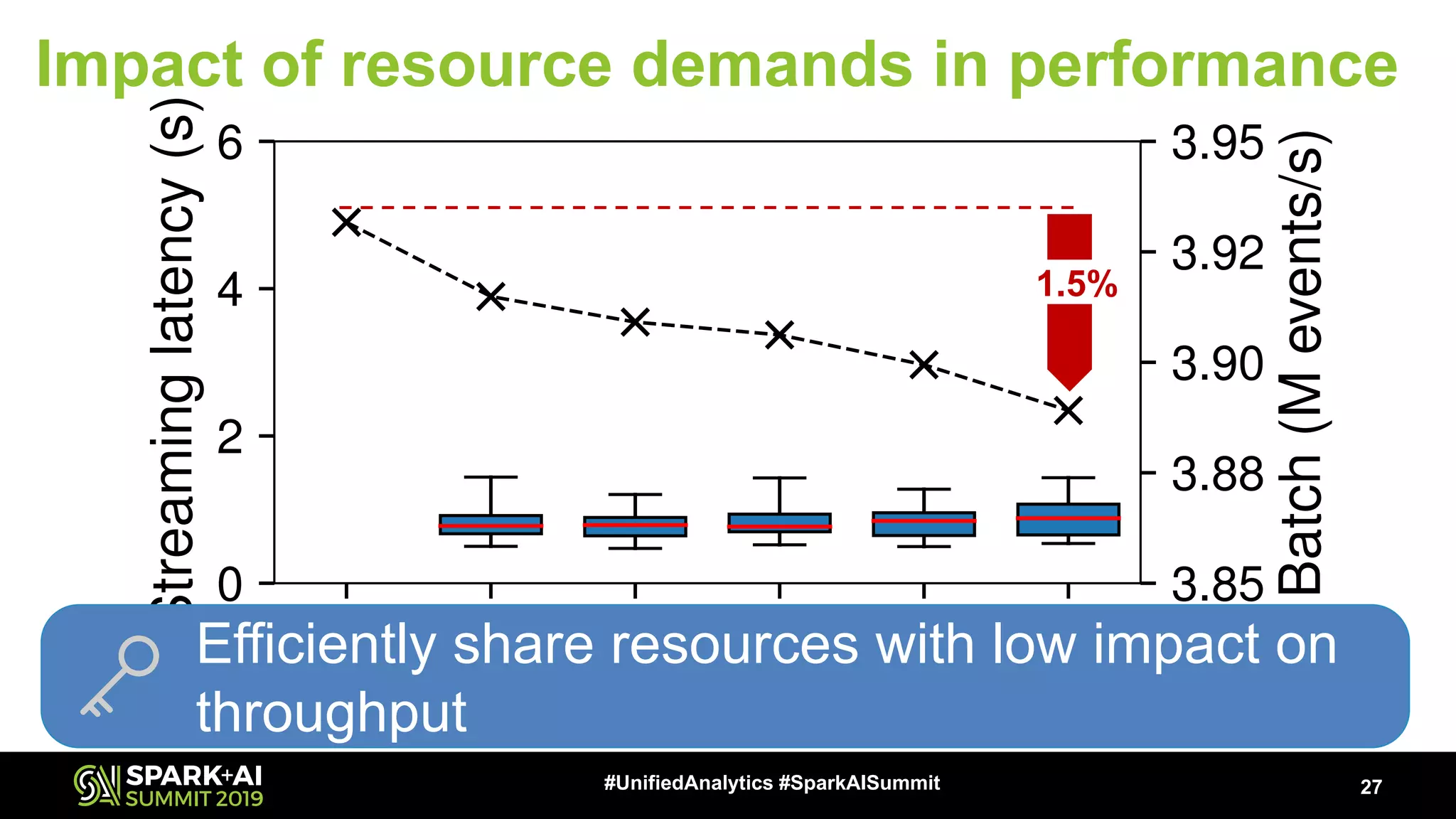



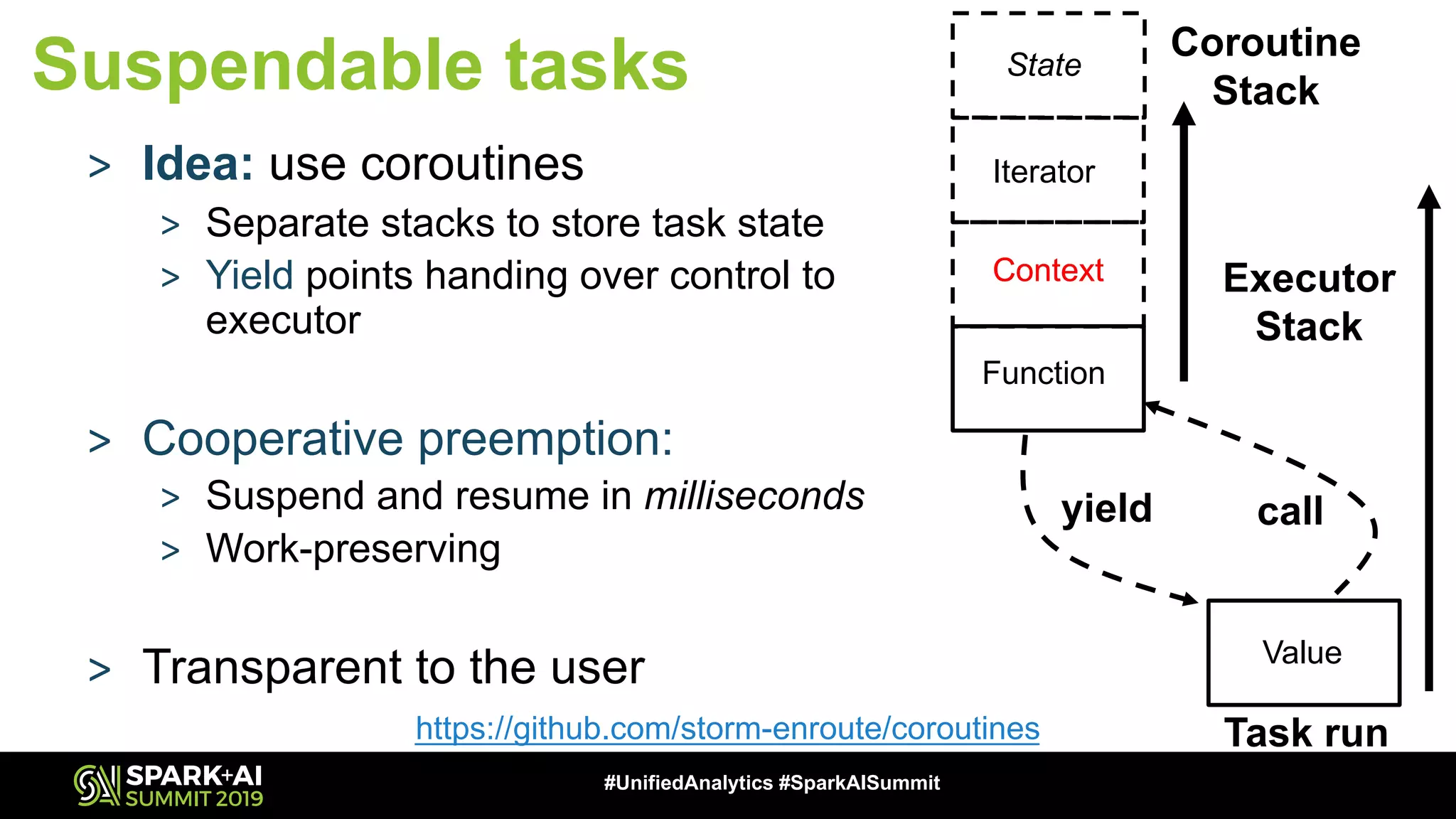
The document discusses an innovative execution framework called Neptune for stream/batch applications that emphasizes cooperative task execution in Apache Spark. It highlights the advantages of unified applications, such as consistency and efficiency, while addressing challenges in scheduling diverse job requirements. Key features include suspendable tasks using coroutines and pluggable scheduling policies to minimize latency for sensitive jobs and optimize resource utilization.