Download as PDF, PPTX





![Architecture Details: Microbatch Fault Tolerance 9#UnifiedAnalytics #SparkAISummit Spark Worker Server Request Queue Epoch 1 History Store Partition 1 Partition 2 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request] 1. Handler adds request to queue](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-9-2048.jpg)
![Architecture Details: Microbatch Fault Tolerance 10#UnifiedAnalytics #SparkAISummit Spark Worker Server Request Queue Epoch 1 History Store Partition 1 Partition 2 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request] 1. Handler adds request to queue 2. Partitions pull request](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-10-2048.jpg)
![Architecture Details: Microbatch Fault Tolerance 11#UnifiedAnalytics #SparkAISummit Spark Worker Server Request Queue Epoch 1 History Store Partition 1 Partition 2 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request] 1. Handler adds request to queue 2. Partitions pull request 3. Partitions add to history store](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-11-2048.jpg)
![Spark Worker Architecture Details: Microbatch Fault Tolerance 12#UnifiedAnalytics #SparkAISummit Server Request Queue Epoch 1 History Store Partition 1 Partition 2 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request]](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-12-2048.jpg)
![Spark Worker Architecture Details: Microbatch Fault Tolerance 13#UnifiedAnalytics #SparkAISummit Server Request Queue Epoch 1 History Store Partition 1 Partition 2 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request]](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-13-2048.jpg)
![Spark Worker Architecture Details: Microbatch Fault Tolerance 14#UnifiedAnalytics #SparkAISummit Server Request Queue Epoch 1 History Store Partition 1 Partition 2, Retry 1 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request] 4. Retry partition pulls from history store](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-14-2048.jpg)
![Architecture Details: Microbatch Fault Tolerance 15#UnifiedAnalytics #SparkAISummit Spark Worker Server Request Queue Epoch 1 History Store Partition 1 Partition 2 Partition 3 (Epoch, Partition) → List[Request]LinkedBlockingQueue[Request] 1. Handler adds request to queue Request Queue Epoch 2](https://image.slidesharecdn.com/032014markhamilton-190510164214/75/03-2014-Apache-Spark-Serving-Unifying-Batch-Streaming-and-RESTful-Serving-15-2048.jpg)

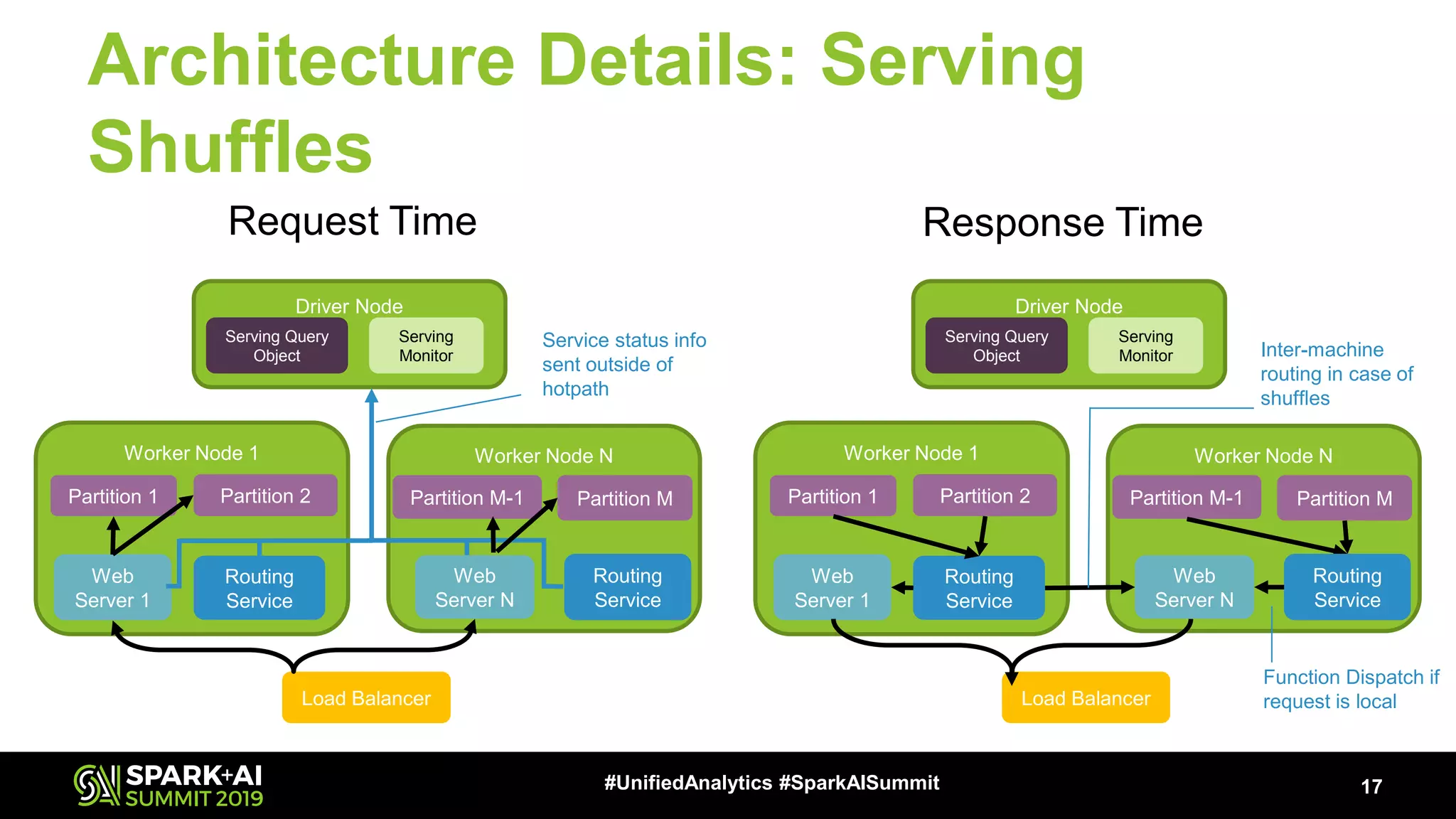

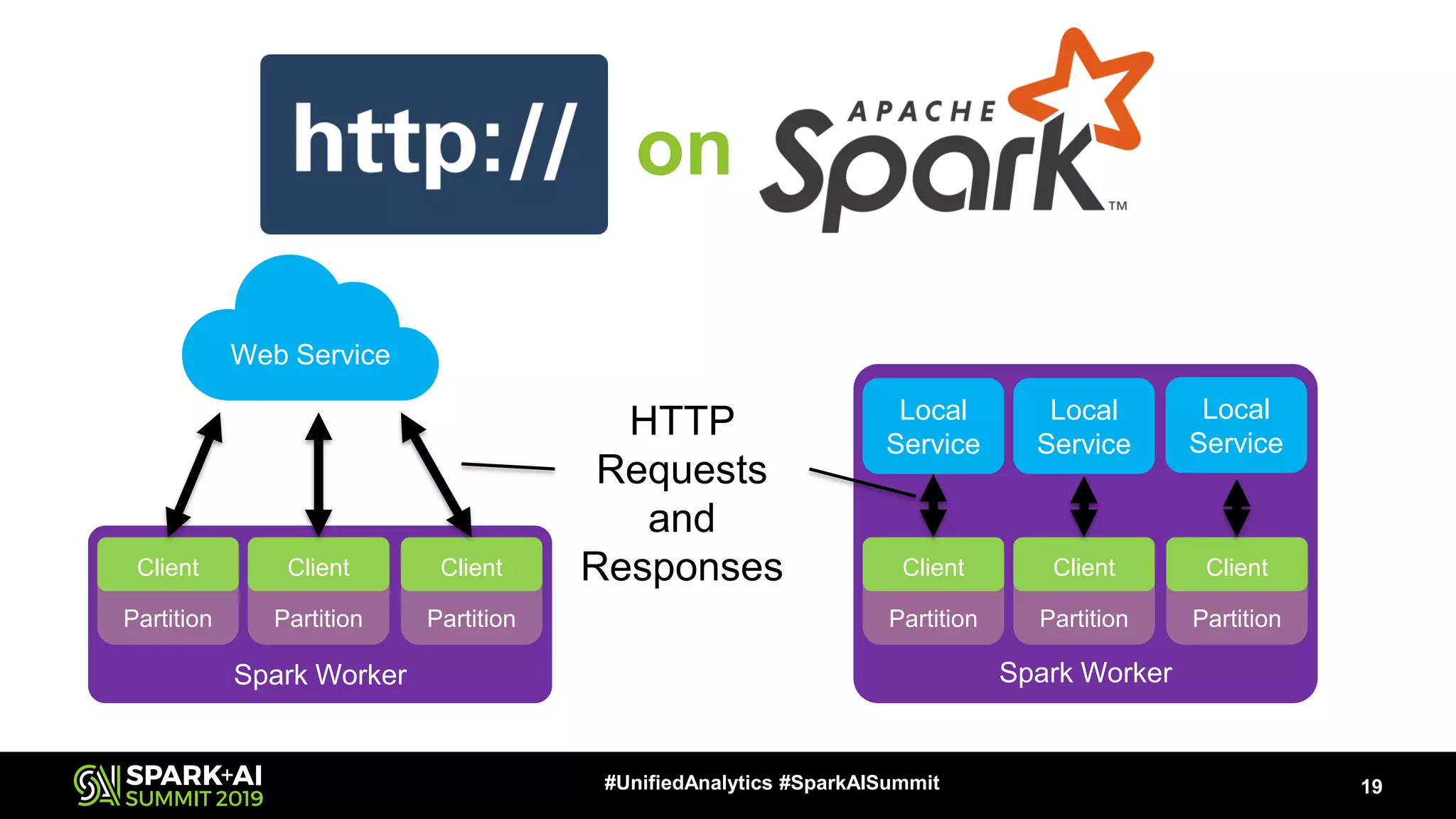
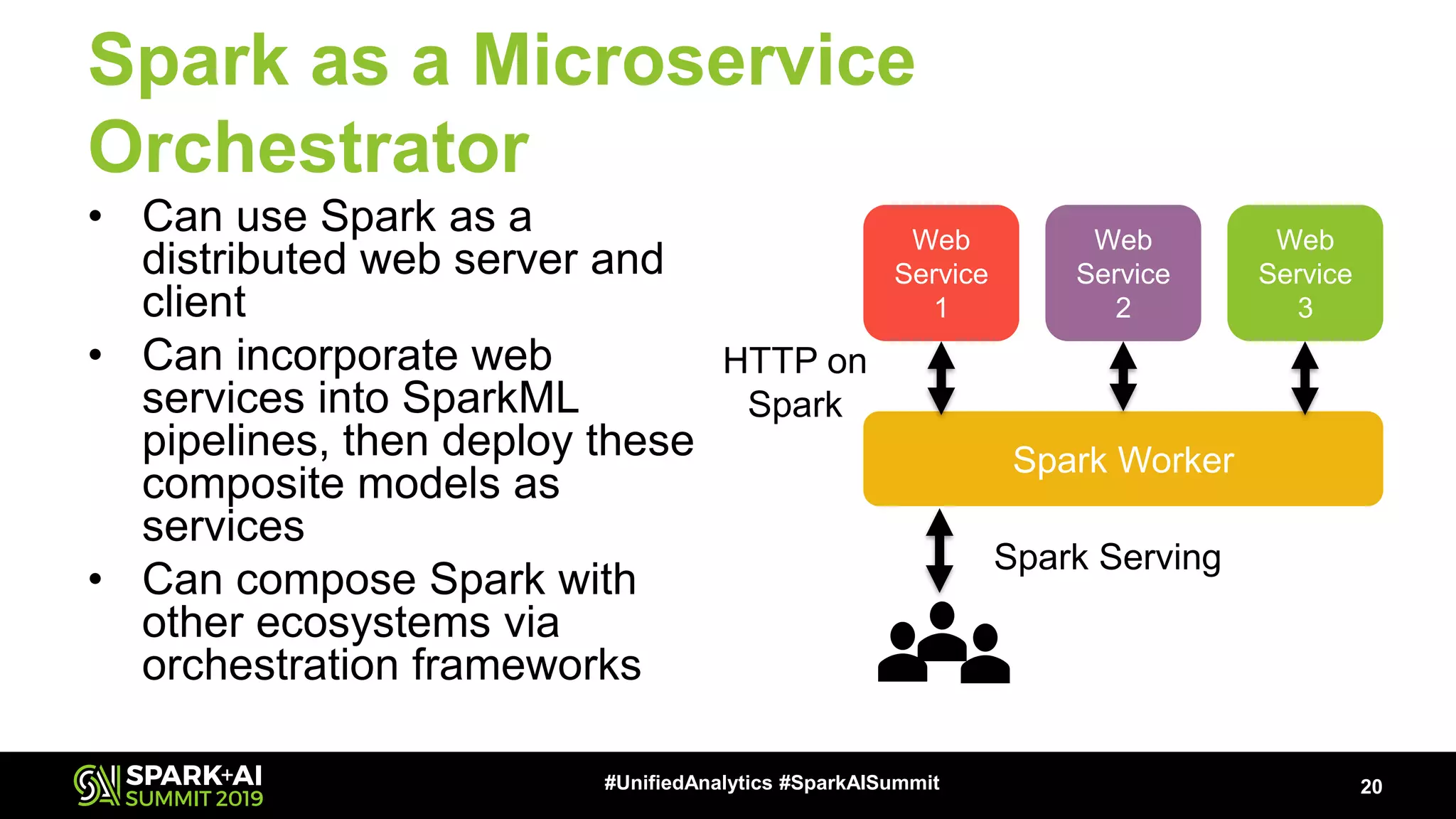
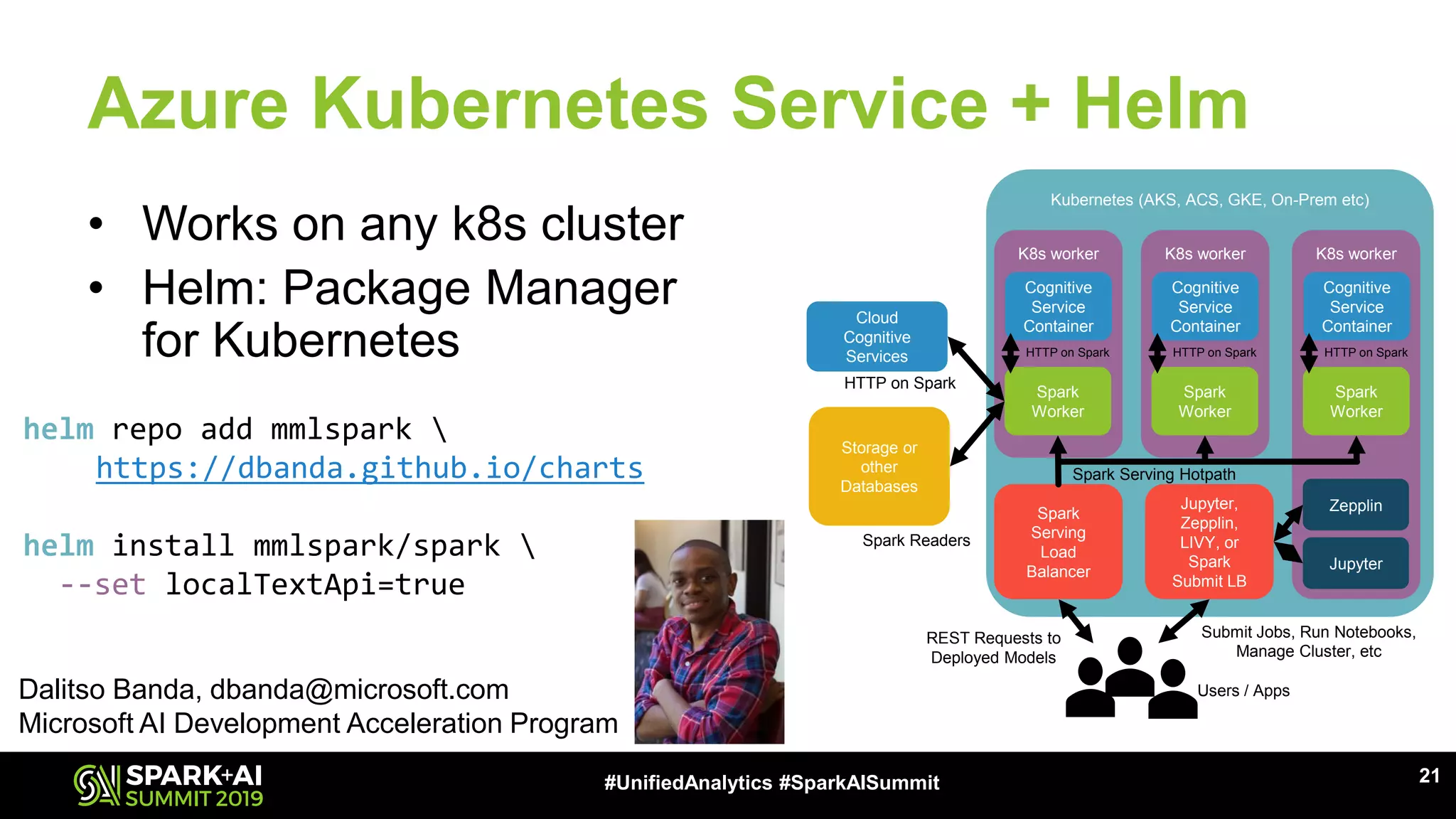
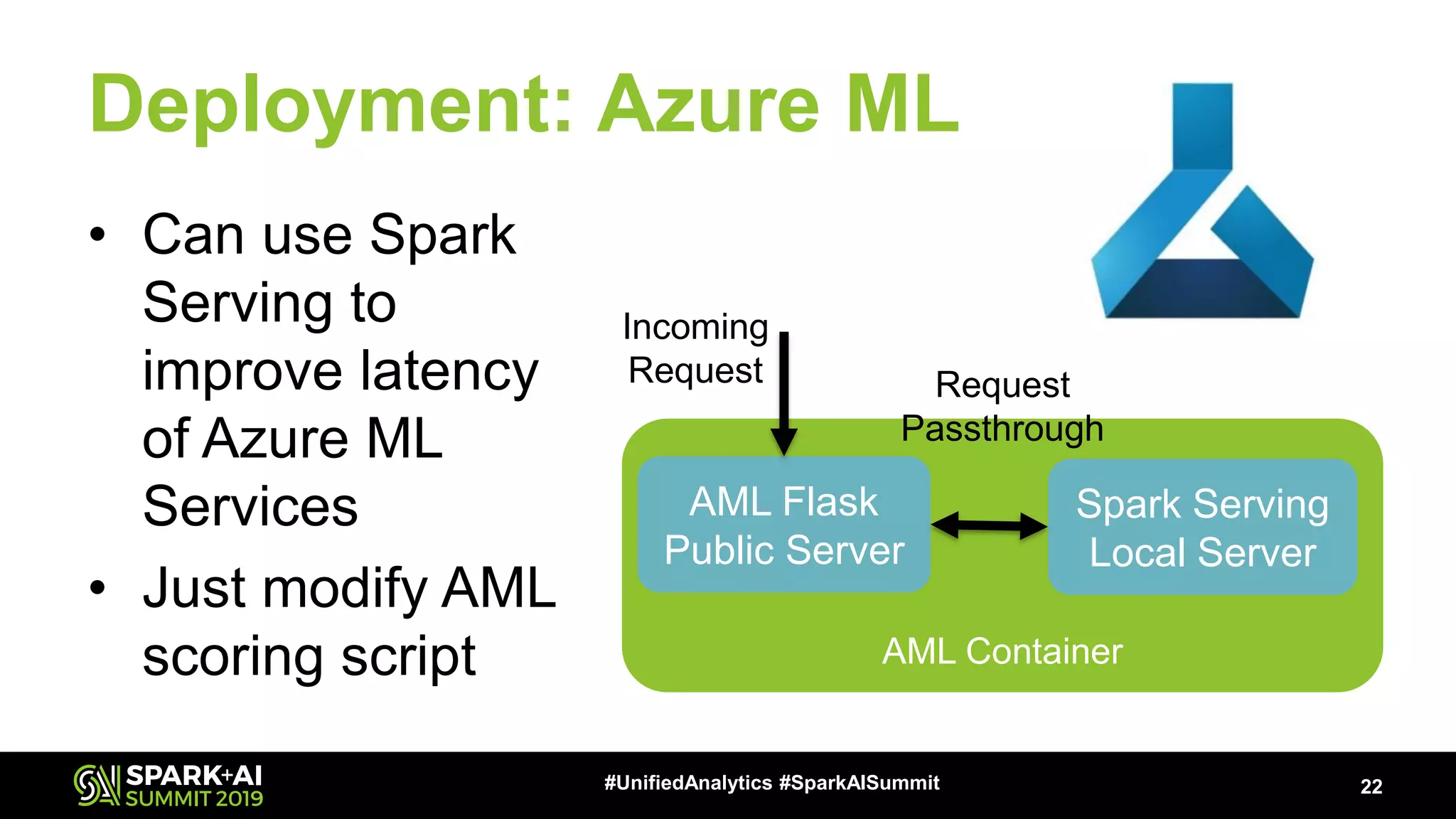




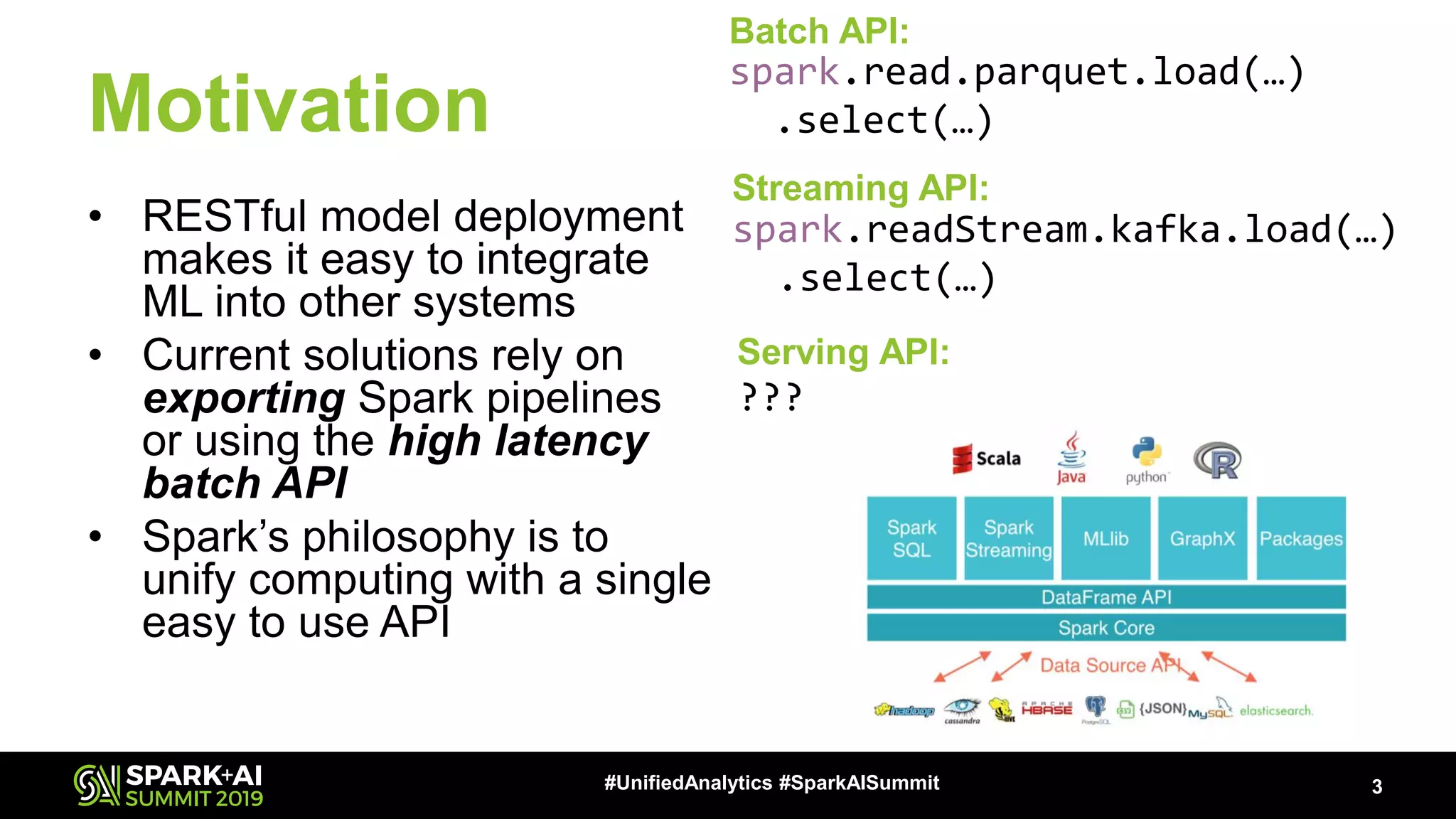
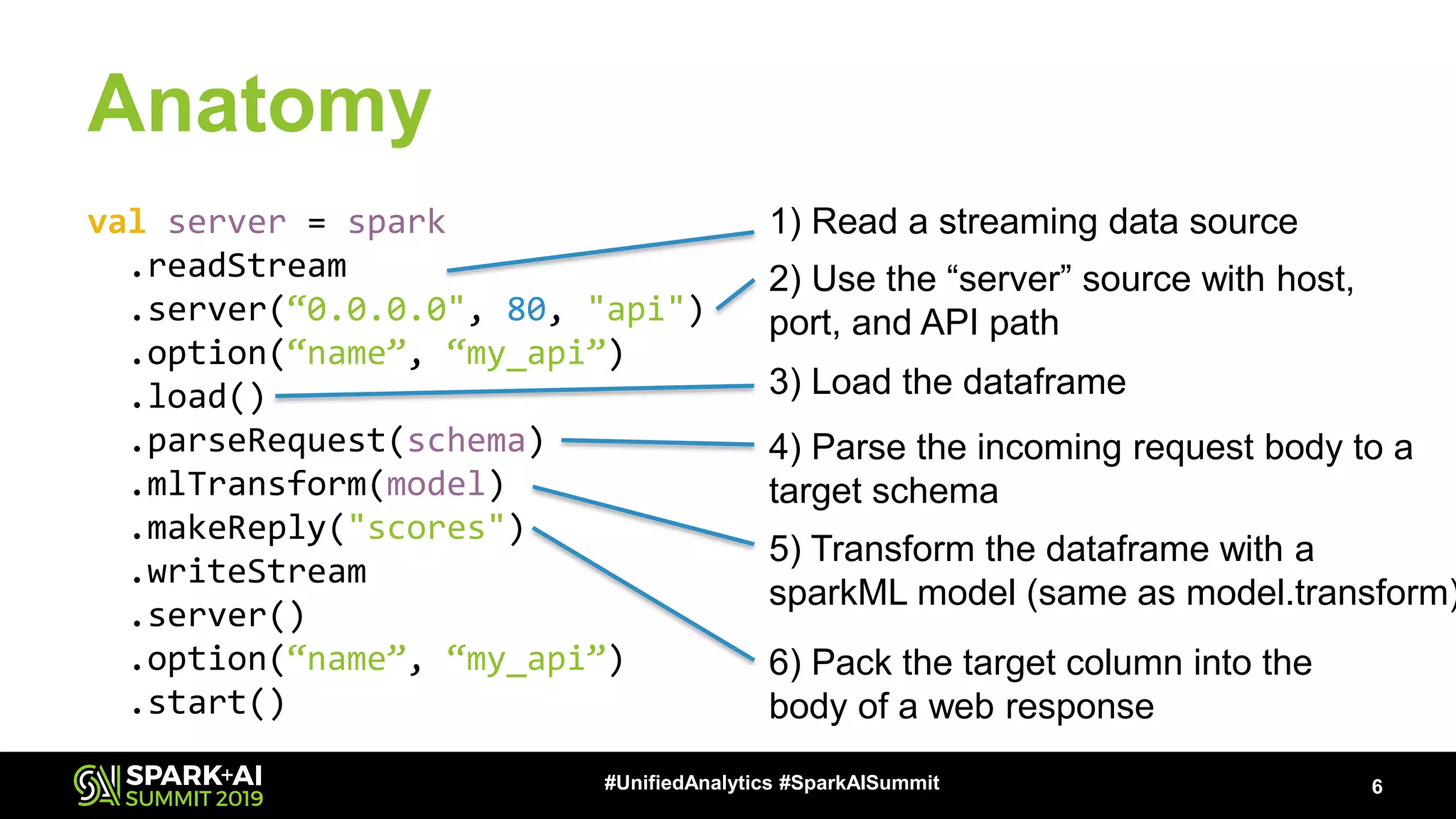
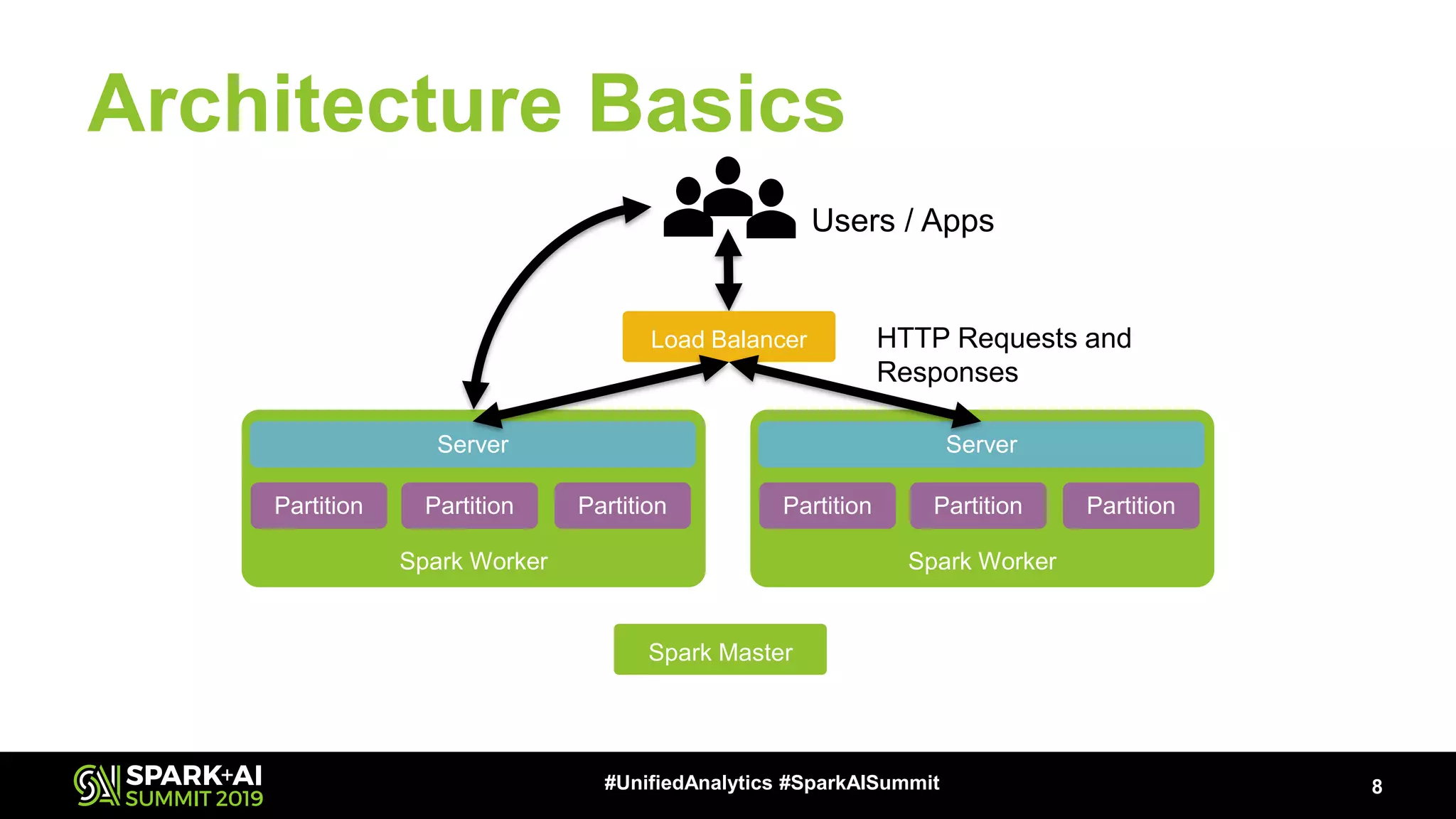
The document provides an overview of Apache Spark Serving, emphasizing its capabilities in integrating batch, streaming, and RESTful serving into a unified framework. Key features include sub-millisecond latency, ease of deployment through Kubernetes, and its ability to serve machine learning models efficiently. It also discusses architecture elements such as fault tolerance, micro-batching, and integrating Spark with various ecosystems for optimal performance.