Download as PDF, PPTX





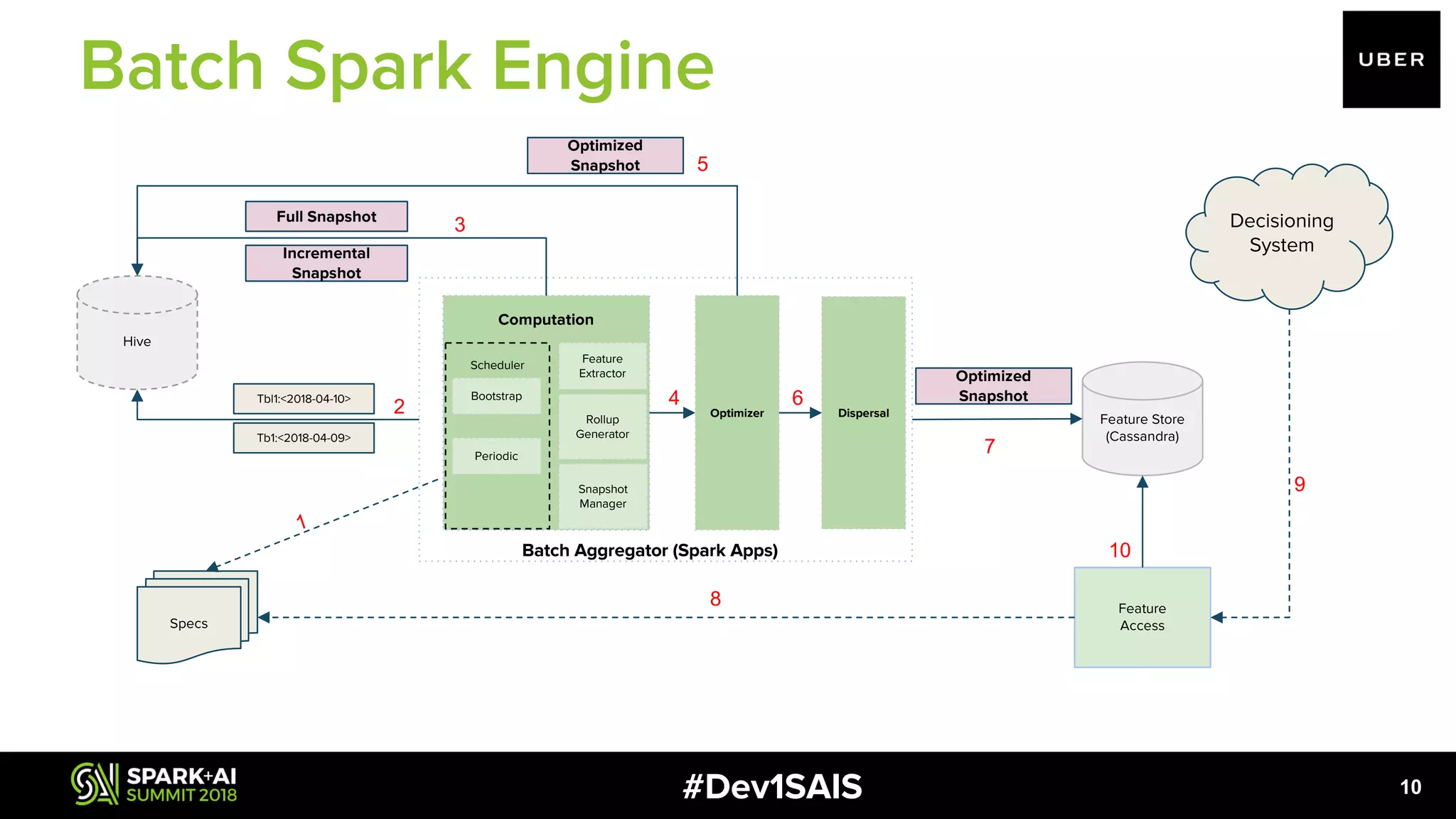
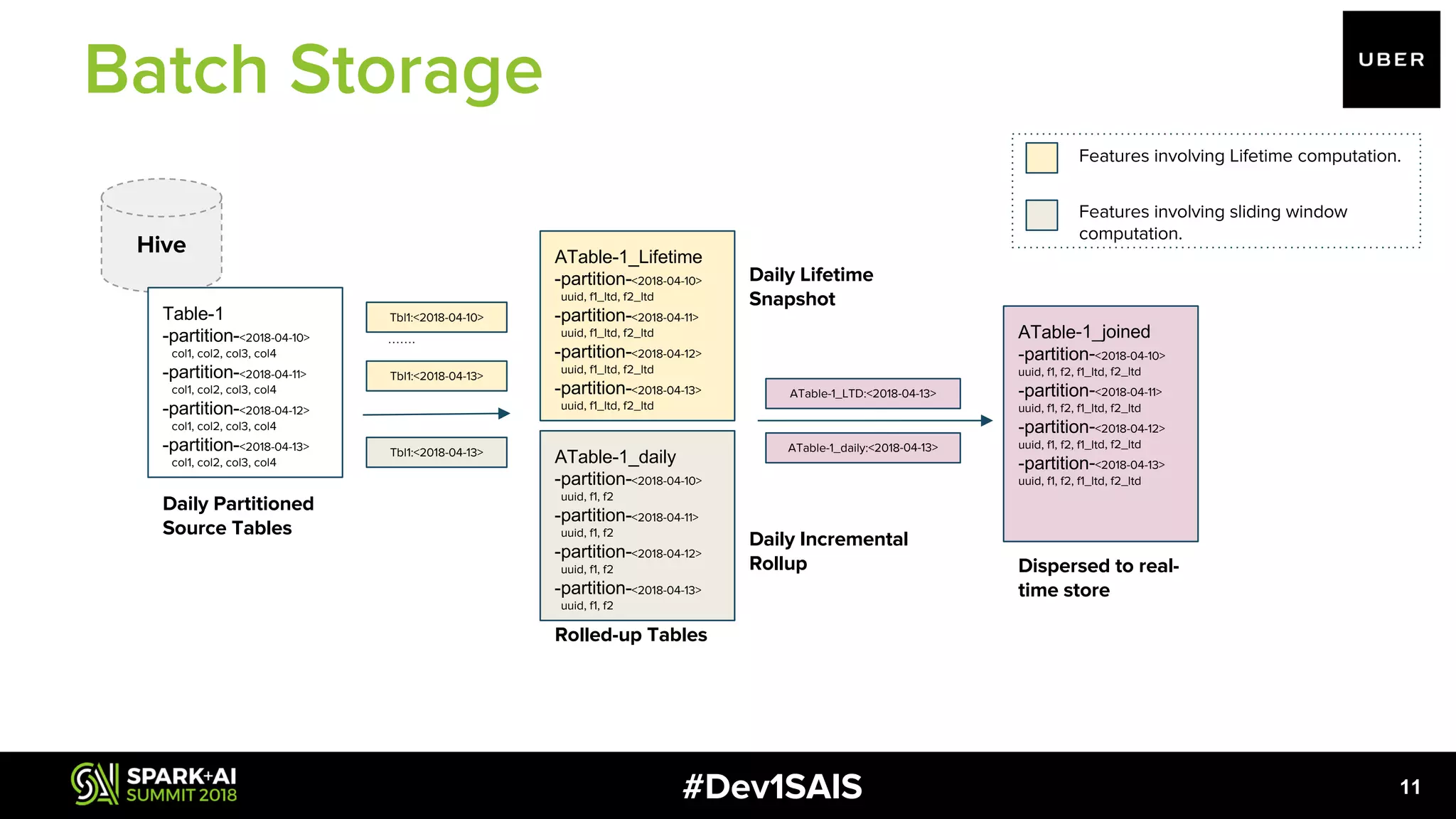
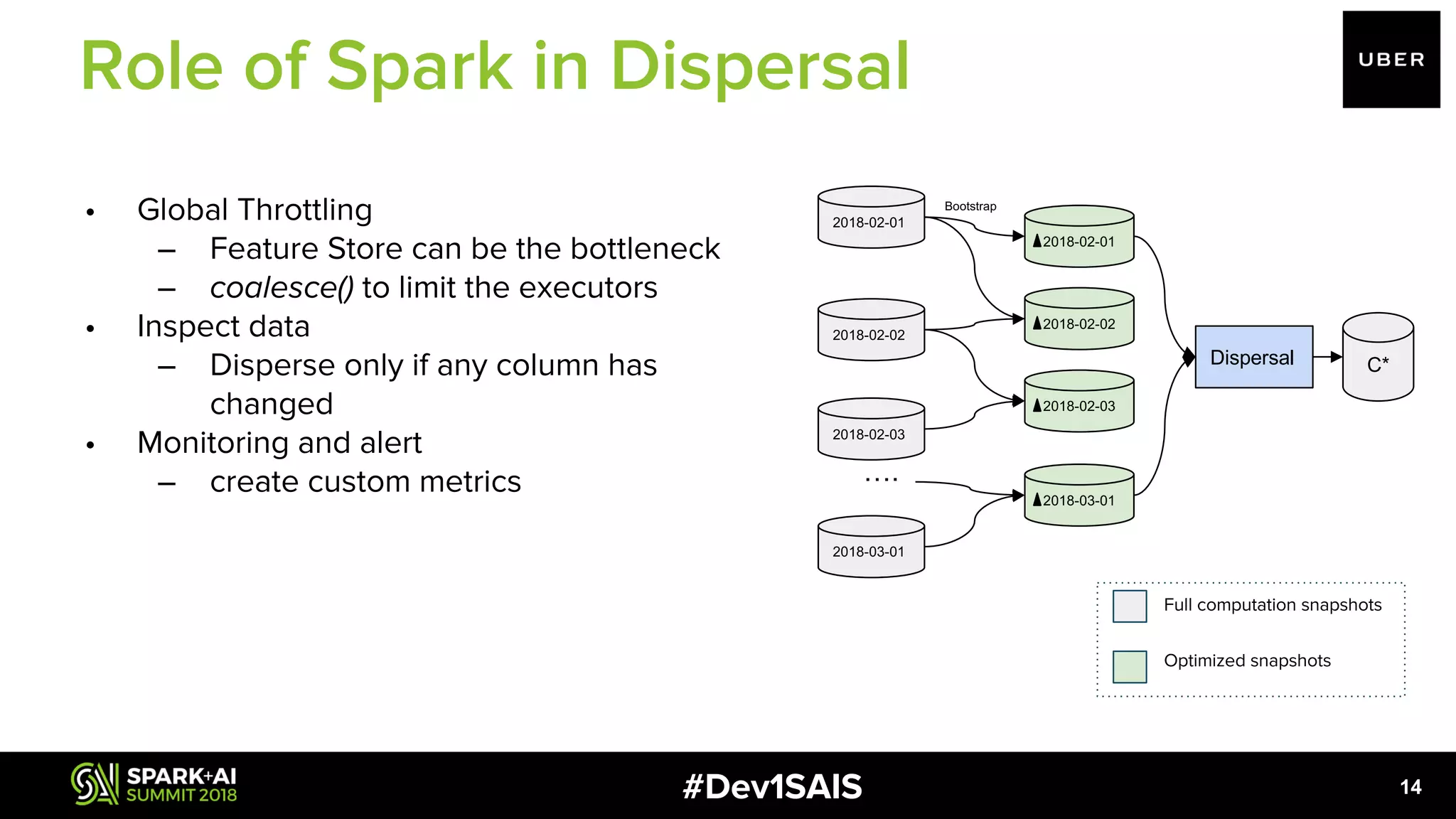
![#Dev1SAIS 12 ● Orchestrator of ETL pipelines ○ Scheduling of subtasks ○ Record incremental progress ● Optimally resize HDFS files: scale with size of data set. ● Rich set of APIs to enable complex optimizations e.g of an optimization in bootstrap dispersal dailyDataset.join( ltdData, JavaConverters.asScalaIteratorConverter( Arrays.asList(pipelineConfig.getEntityKey()).iterator()) .asScala() .toSeq(), "outer"); uuid _ltd daily_buckets 44b7dc88 1534 [{"2017-10-24":"4"},{"2017-08- 22":"3"},{"2017-09-21":"4"},{"2017- 08-08":"3"},{"2017-10- 03":"3"},{"2017-10-19":"5"},{"2017- 09-06":"1"},{"2017-08- 17":"5"},{"2017-09-09":"12"},{"2017- 10-05":"5"},{"2017-09- 25":"4"},{"2017-09-17":"13"}] Role of Spark](https://image.slidesharecdn.com/1pulkitbhanotamitnene-180613003428/75/Large-Scale-Feature-Aggregation-Using-Apache-Spark-with-Pulkit-Bhanot-and-Amit-Nene-12-2048.jpg)

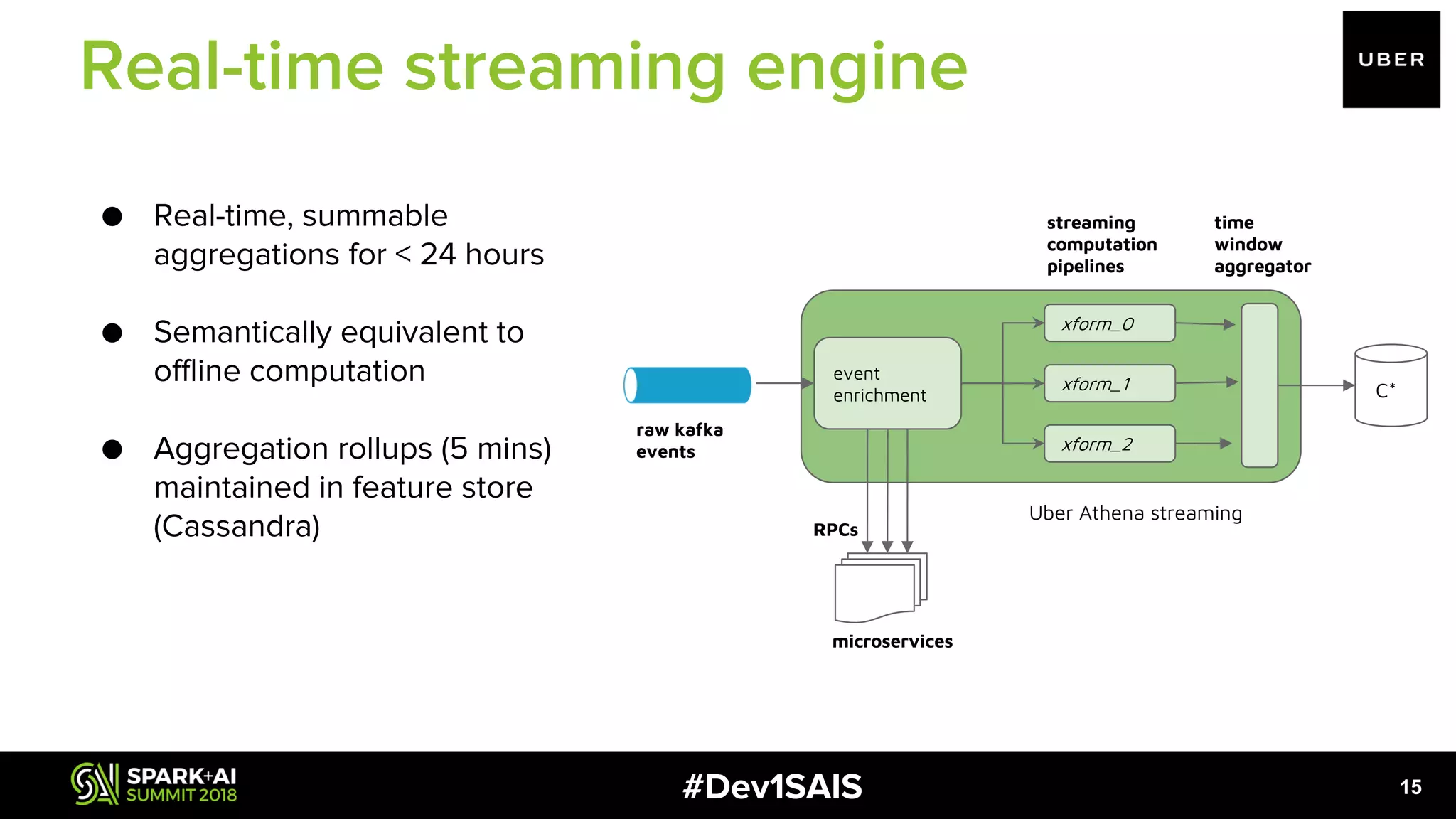
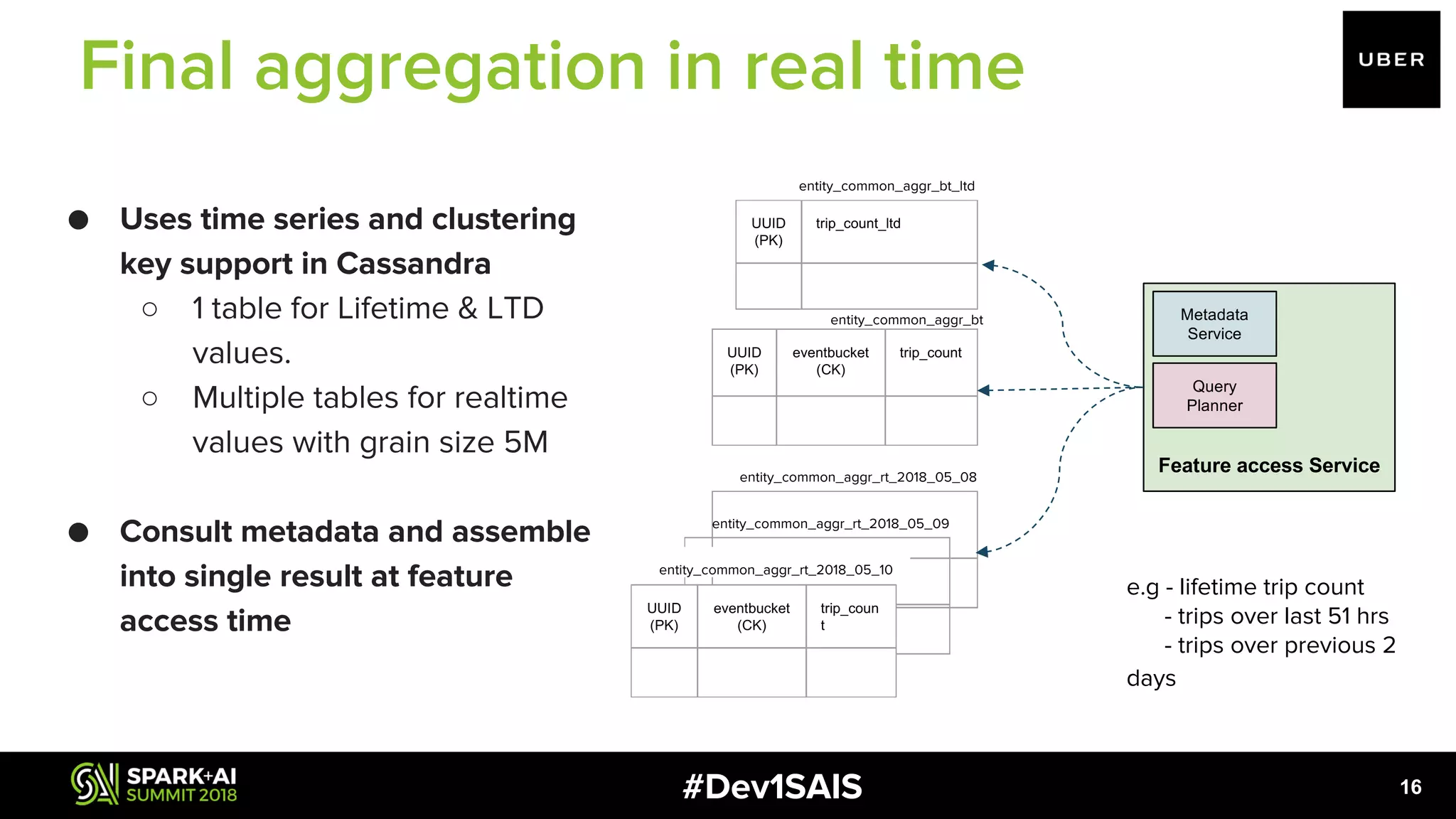

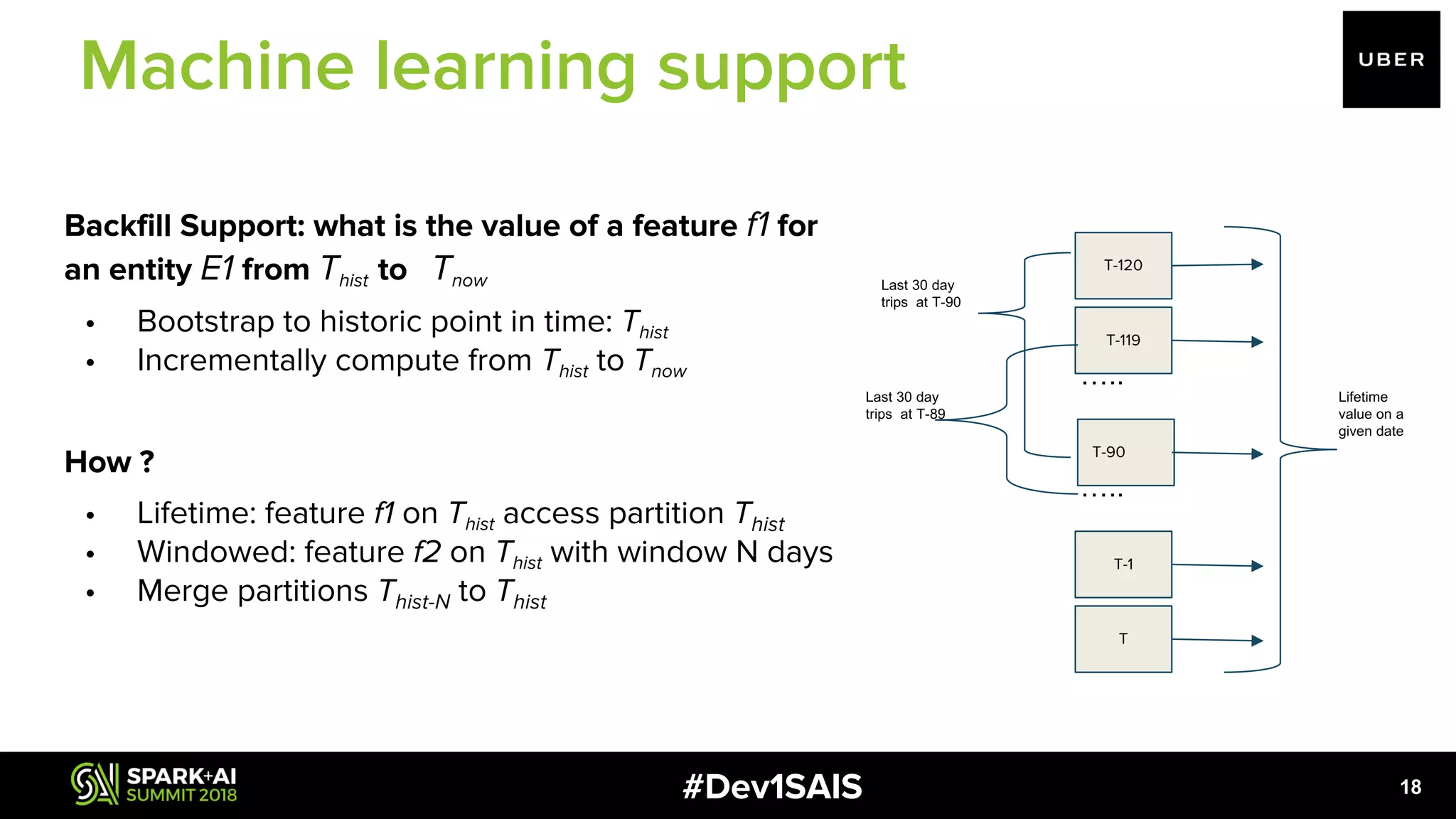



The document discusses the development of a scalable, self-service feature engineering platform for predictive decision-making at Uber using Apache Spark. It highlights the challenges of aggregating features for real-time fraud detection, the architecture of the system, and the role of Spark in processing large volumes of data efficiently. Key takeaways include improvements in computational costs and the ability to offer low-latency access to features for machine learning applications.