Downloaded 154 times









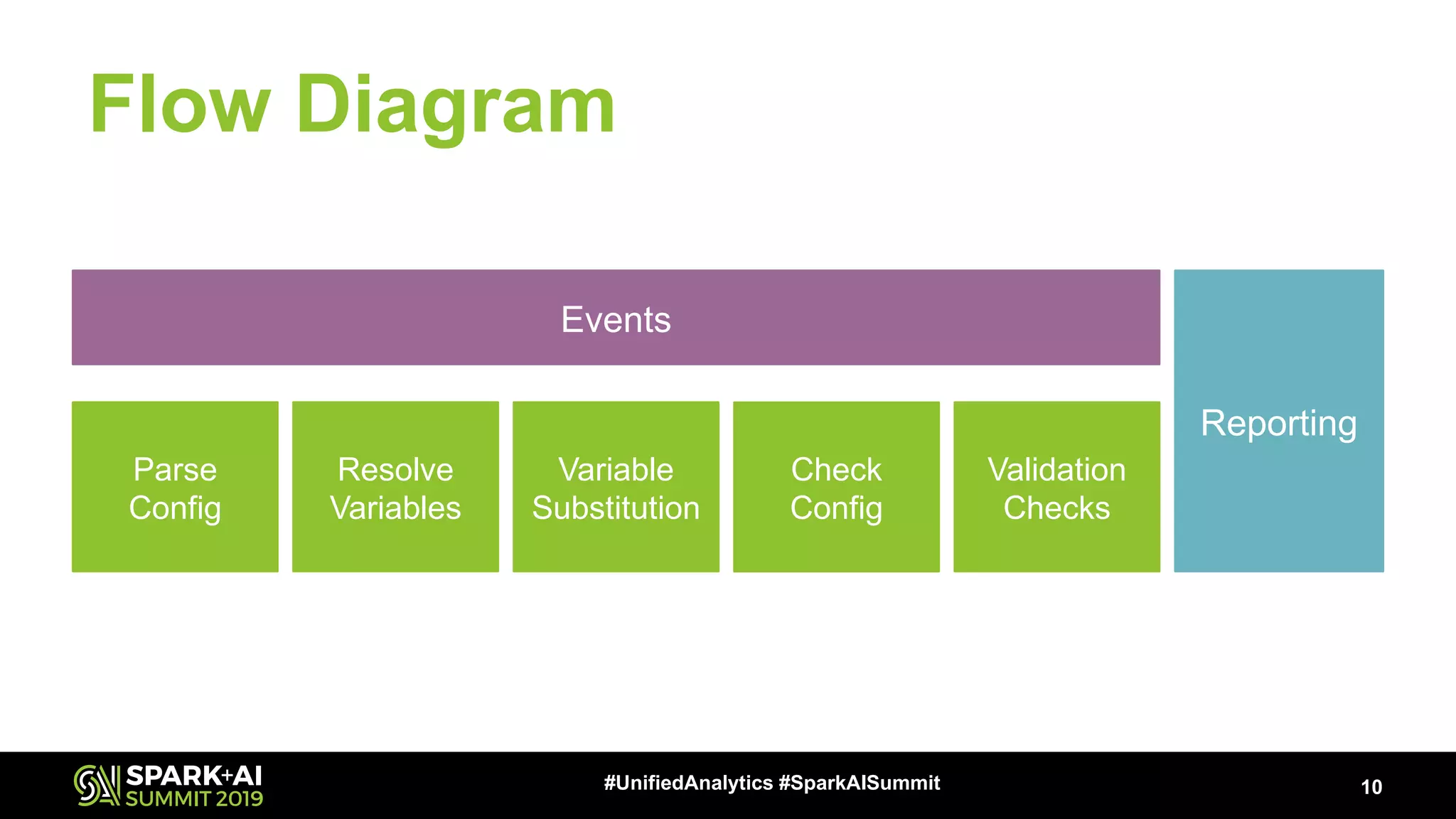





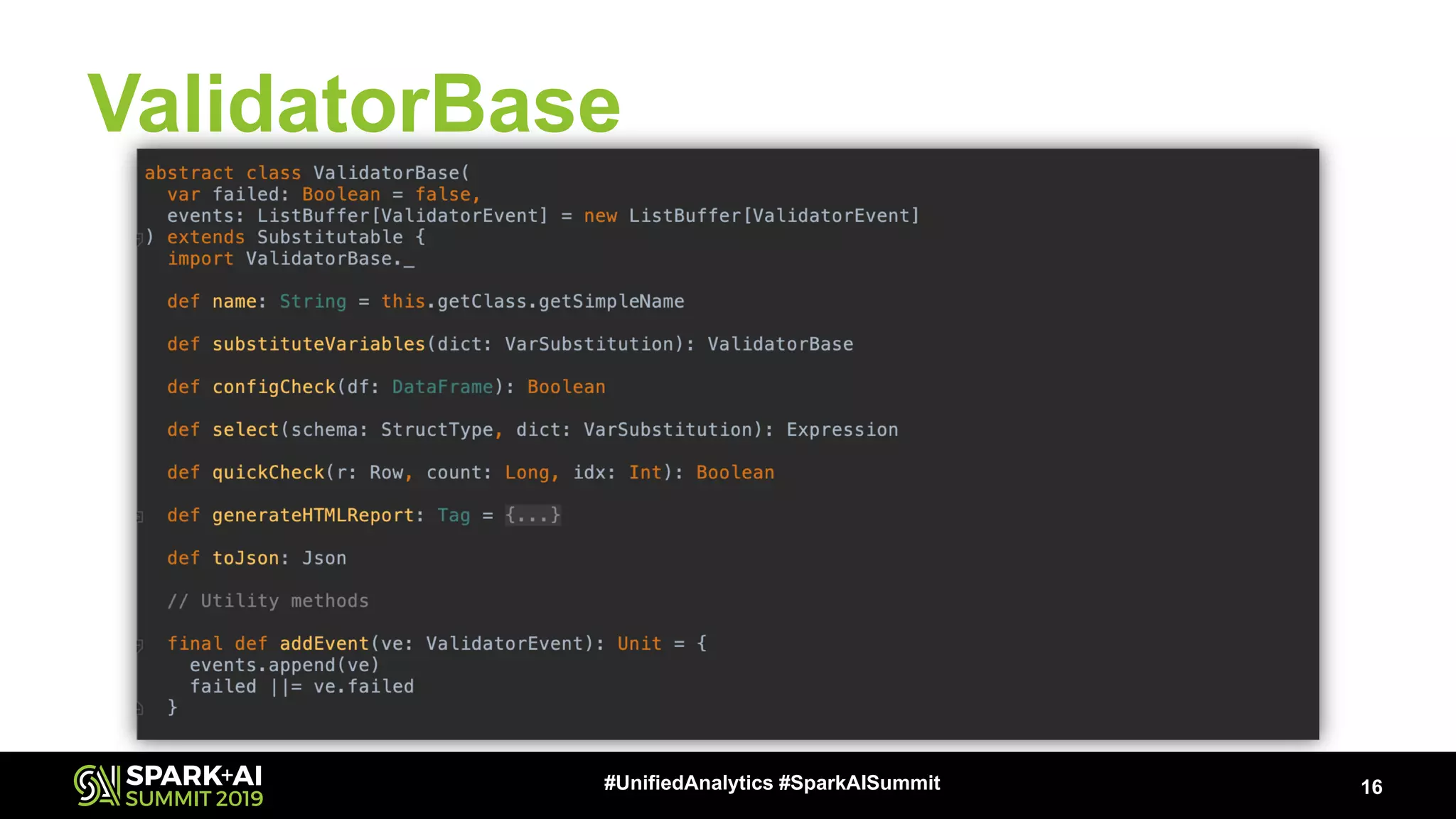
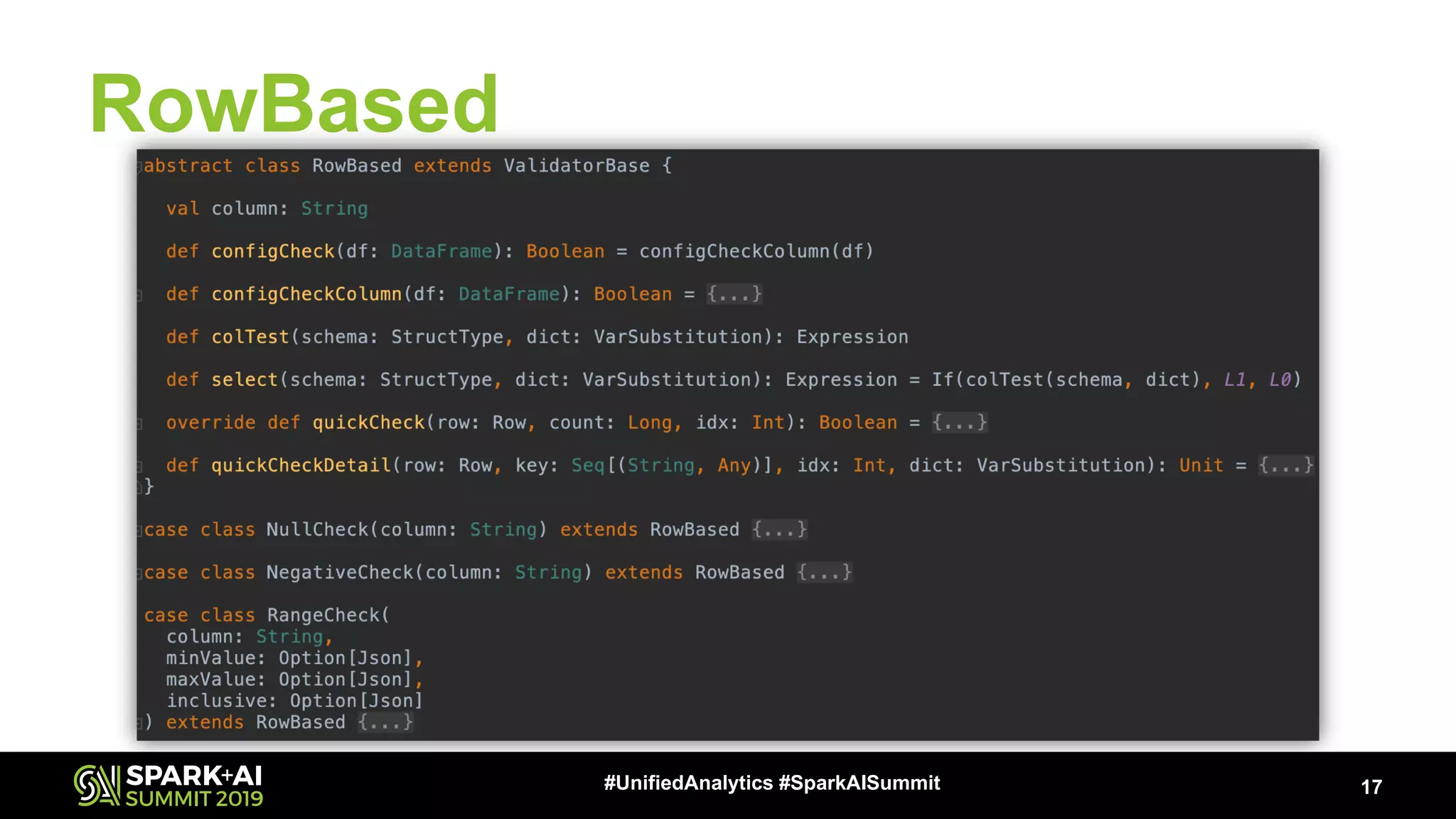



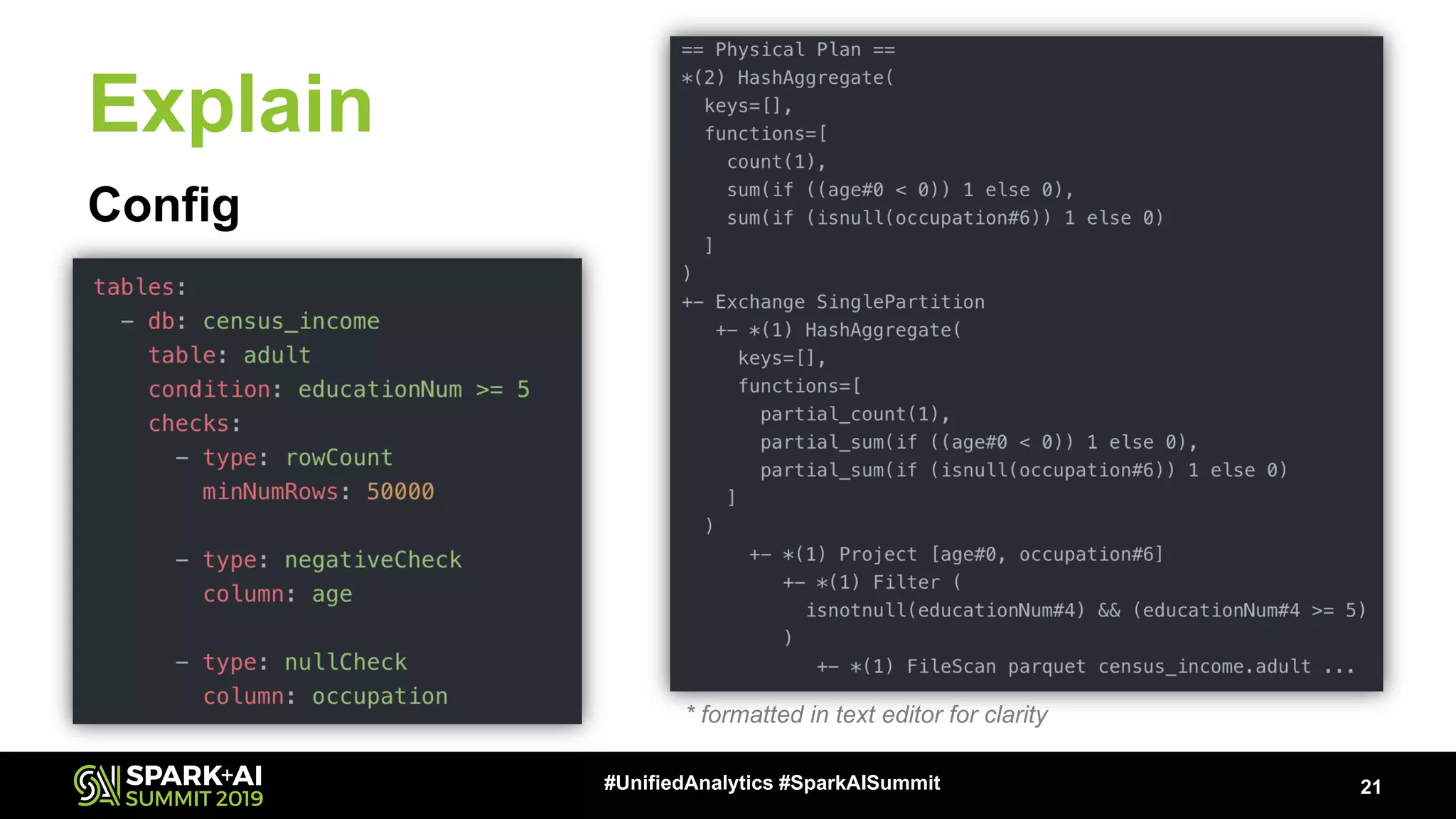

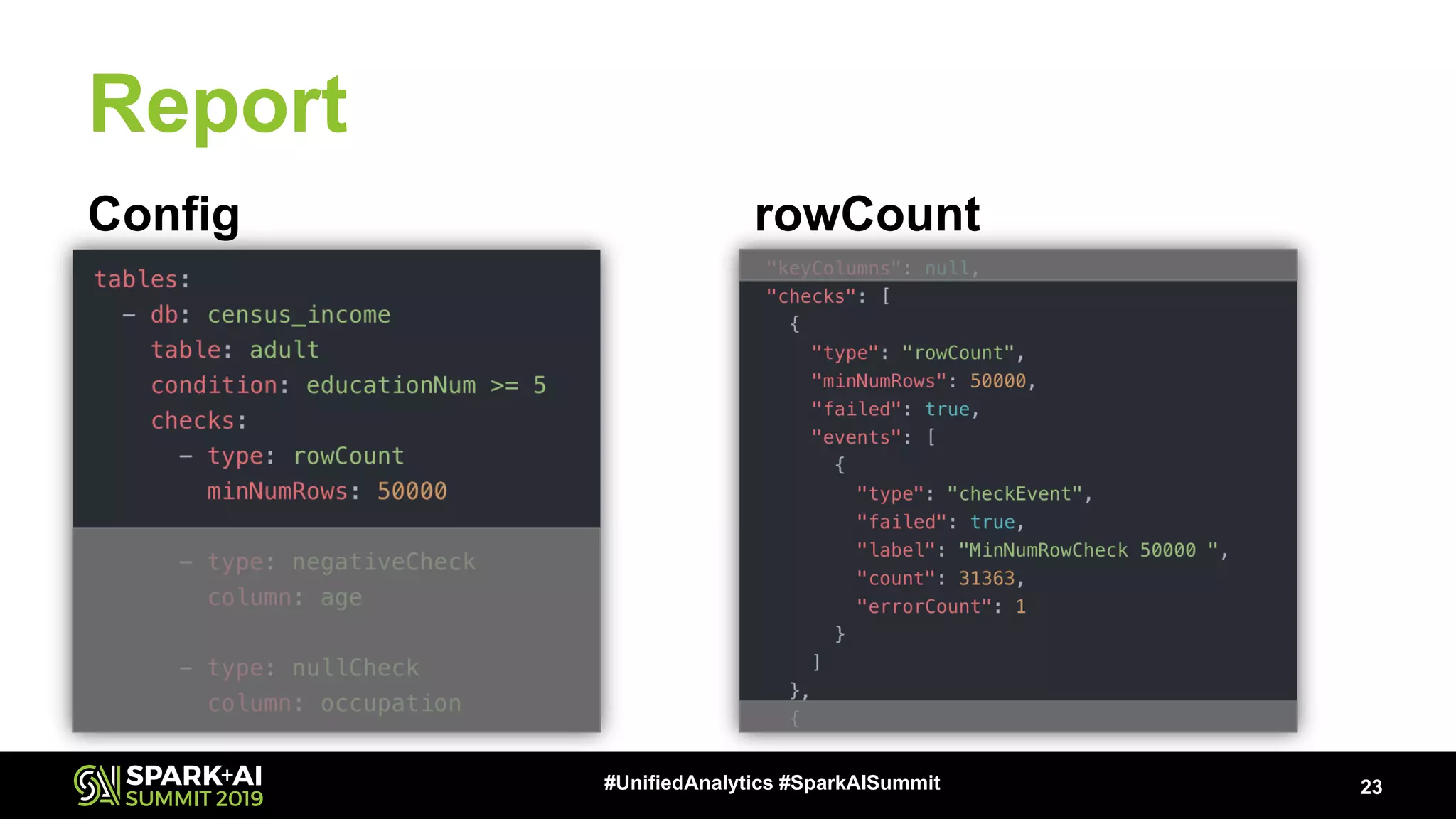












The document presents a talk by Patrick Pisciuneri and Doug Balog from Target on a data validation tool for Apache Spark, highlighting its features, configuration options, and motivations for implementation. It emphasizes the tool's ability to detect errors early in data pipelines, promote best practices, and its ease of adoption within various data management systems. The talk also discusses the tool's open-source nature, future enhancements, and solicits community input for further development.