Download as PDF, PPTX
























![Traditional ETL • Raw, dirty, un/semi-structured is data dumped as files • Periodic jobs run every few hours to convert raw data to structured data ready for further analytics • Problem: • Hours of delay beforetaking decisions on latest data • Unacceptablewhen timeis ofessence – [intrusion , anomaly or fraud detection, monitoring IoTdevices, etc.] file dump seconds hours table SQL Web ML10101010...](https://image.slidesharecdn.com/062018julesdamji-190508001044/75/Writing-Continuous-Applications-with-Structured-Streaming-PySpark-API-33-2048.jpg)

![Reading from Kafka raw_data_df = spark.readStream .format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() rawData dataframe has the following columns key value topic partition offset timestamp [binary] [binary] "topicA" 0 345 1486087873 [binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/062018julesdamji-190508001044/75/Writing-Continuous-Applications-with-Structured-Streaming-PySpark-API-38-2048.jpg)



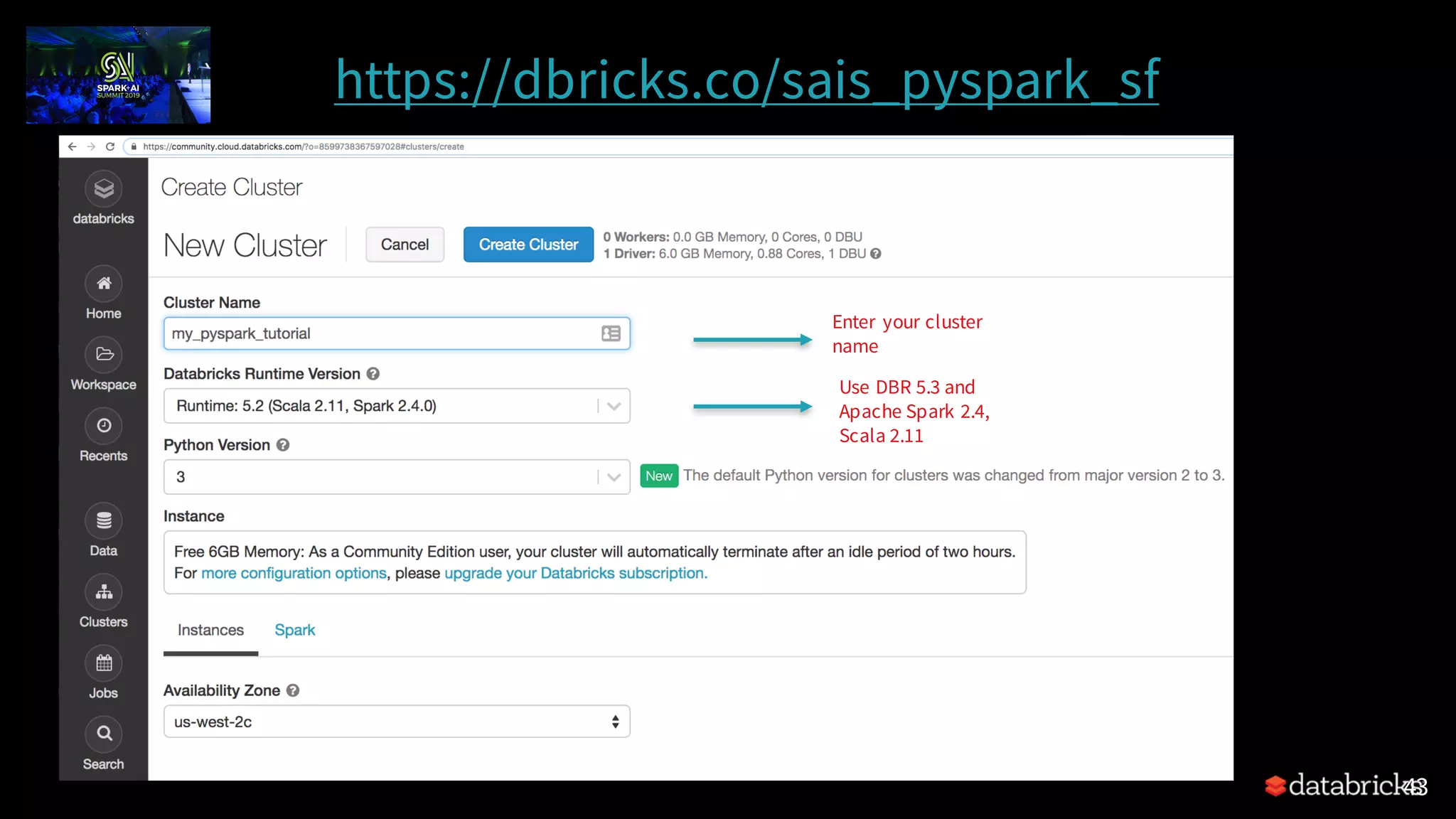




The document discusses the development of continuous applications using Structured Streaming in Apache Spark, highlighting its benefits, complexities, and capabilities in handling diverse data. It explains the architecture of Structured Streaming, including the process of reading, transforming, and writing data streams, as well as the importance of features like checkpointing for fault tolerance. The presentation includes tutorials and emphasizes the unification of batch and streaming processing to enable real-time data handling and analytics.
Overview of the presentation by Jules S. Damji on Continuous Applications using Structured Streaming in PySpark at the Spark + AI Summit.
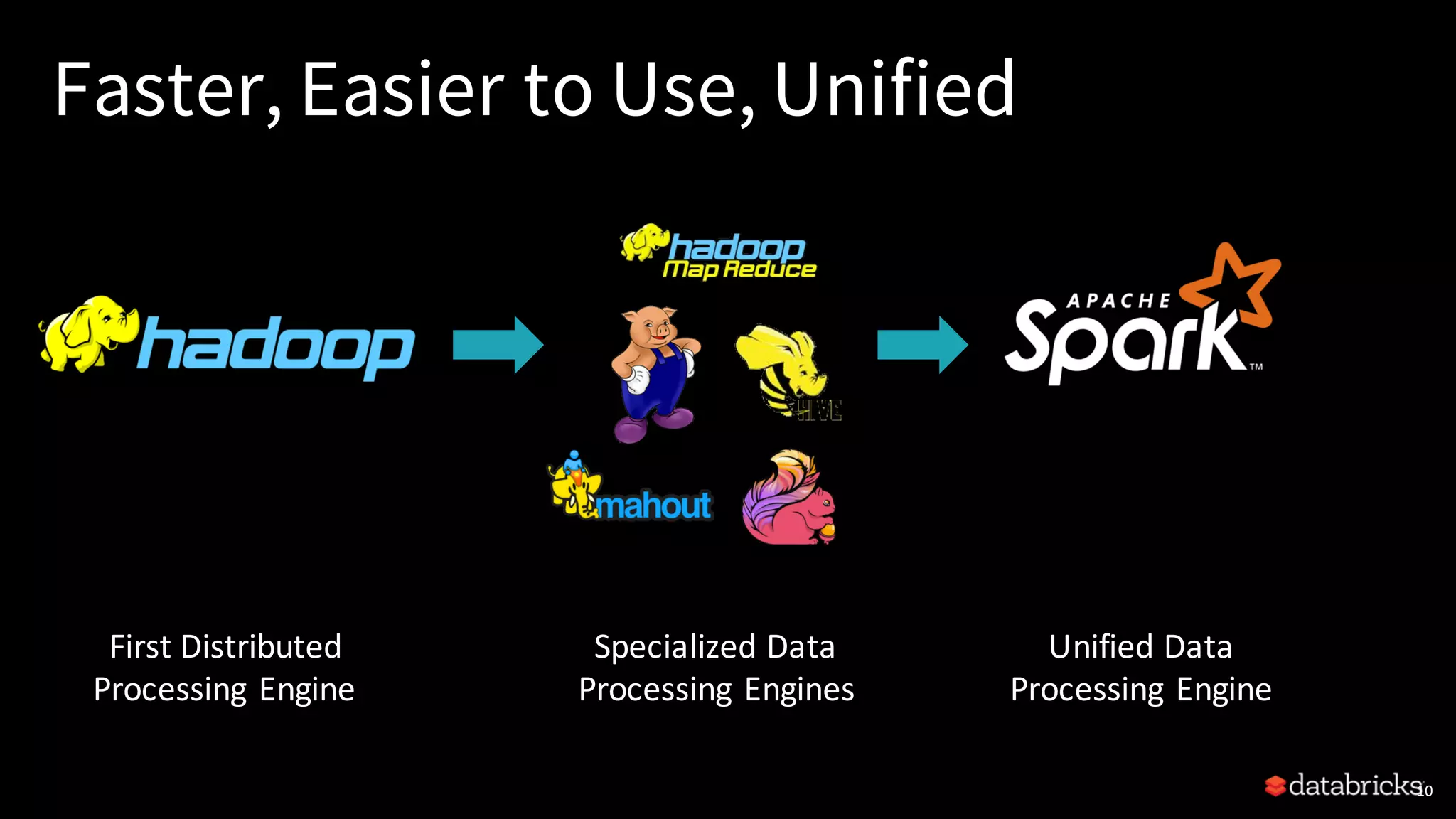
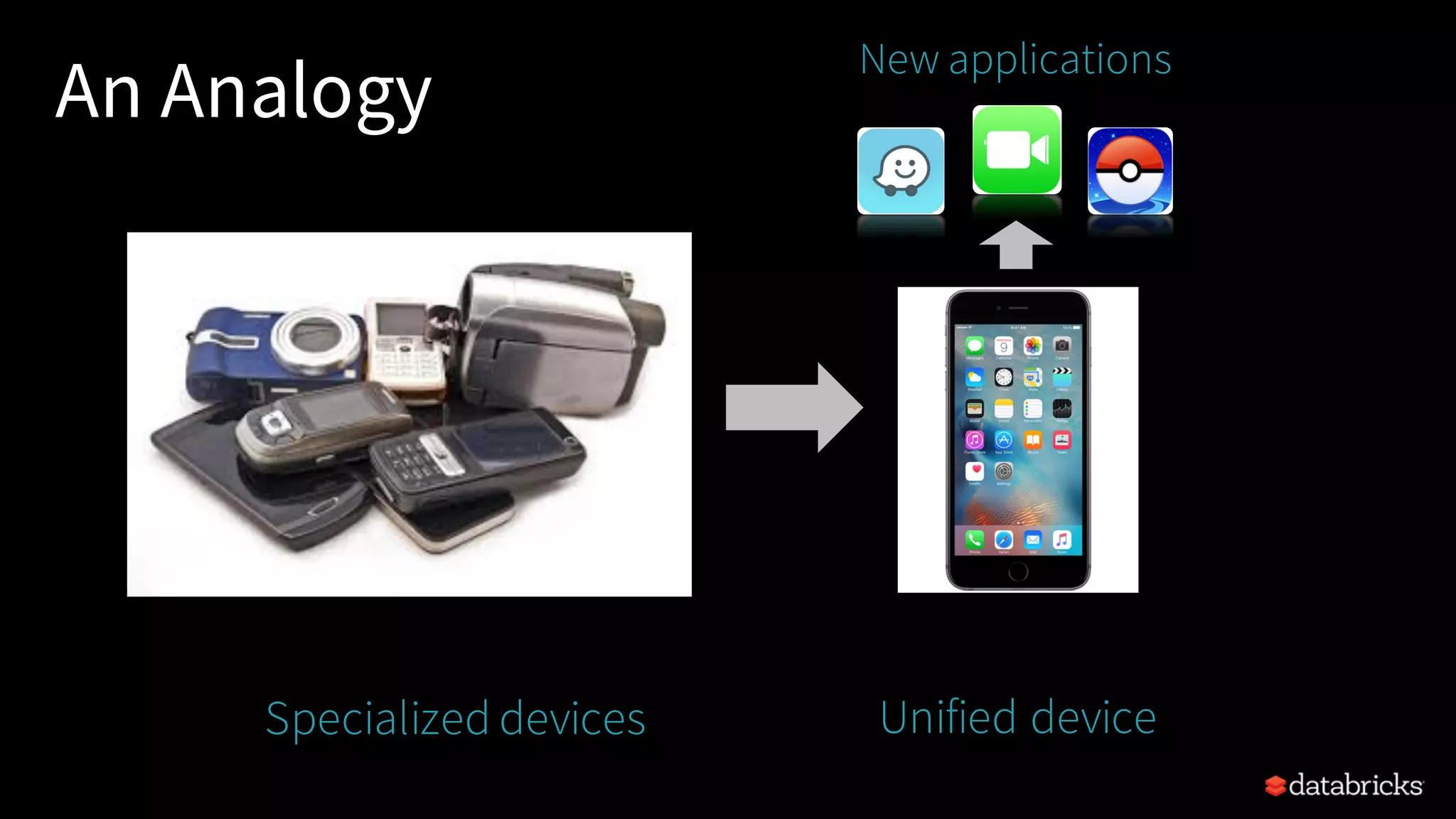
Introduction to Apache Spark, its unified analytics platform, benefits of unification, and its capabilities in handling diverse data processing.
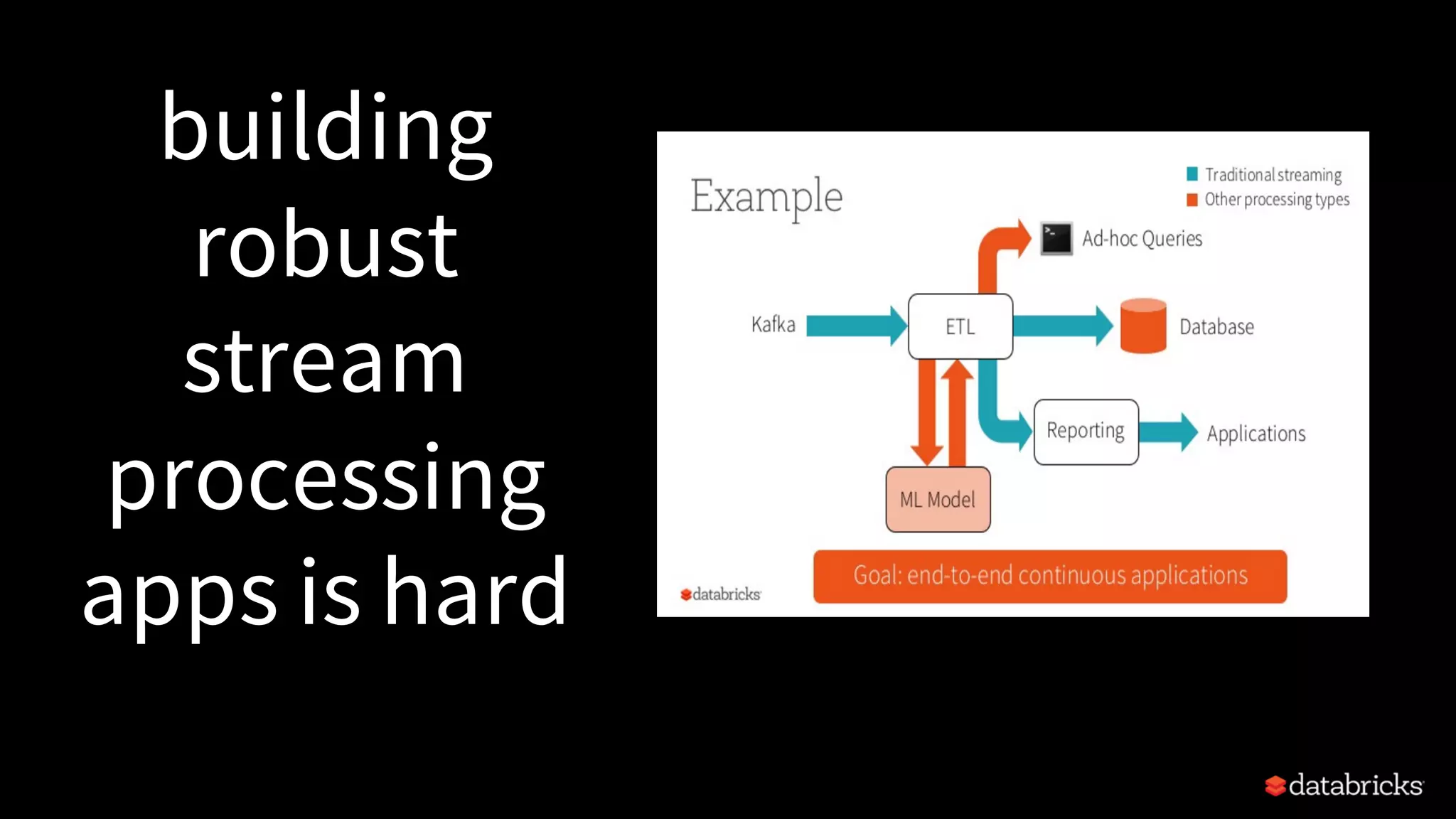
Identifies the inherent difficulties in building robust streaming applications due to complexities in data, systems, and workloads.
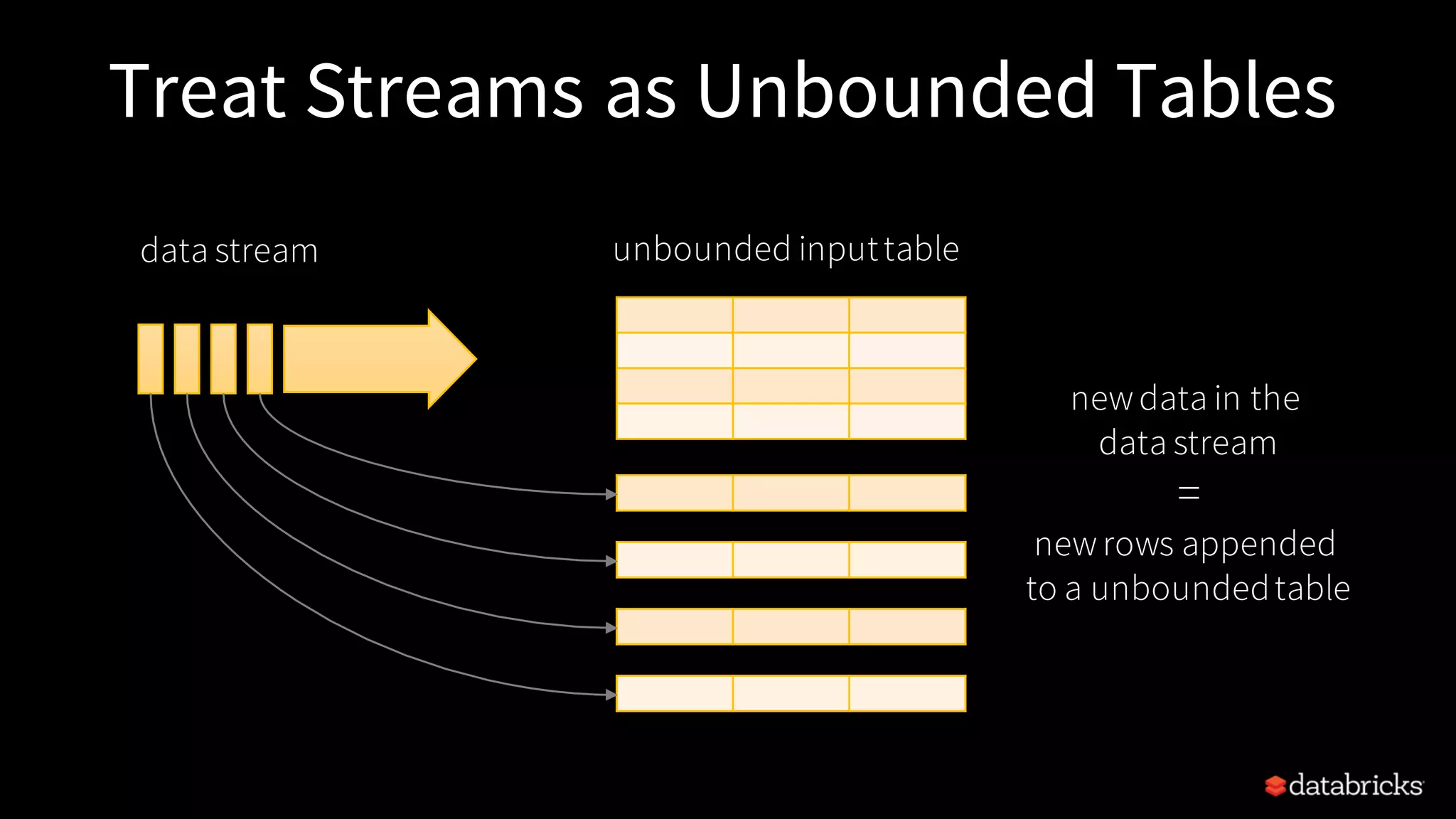
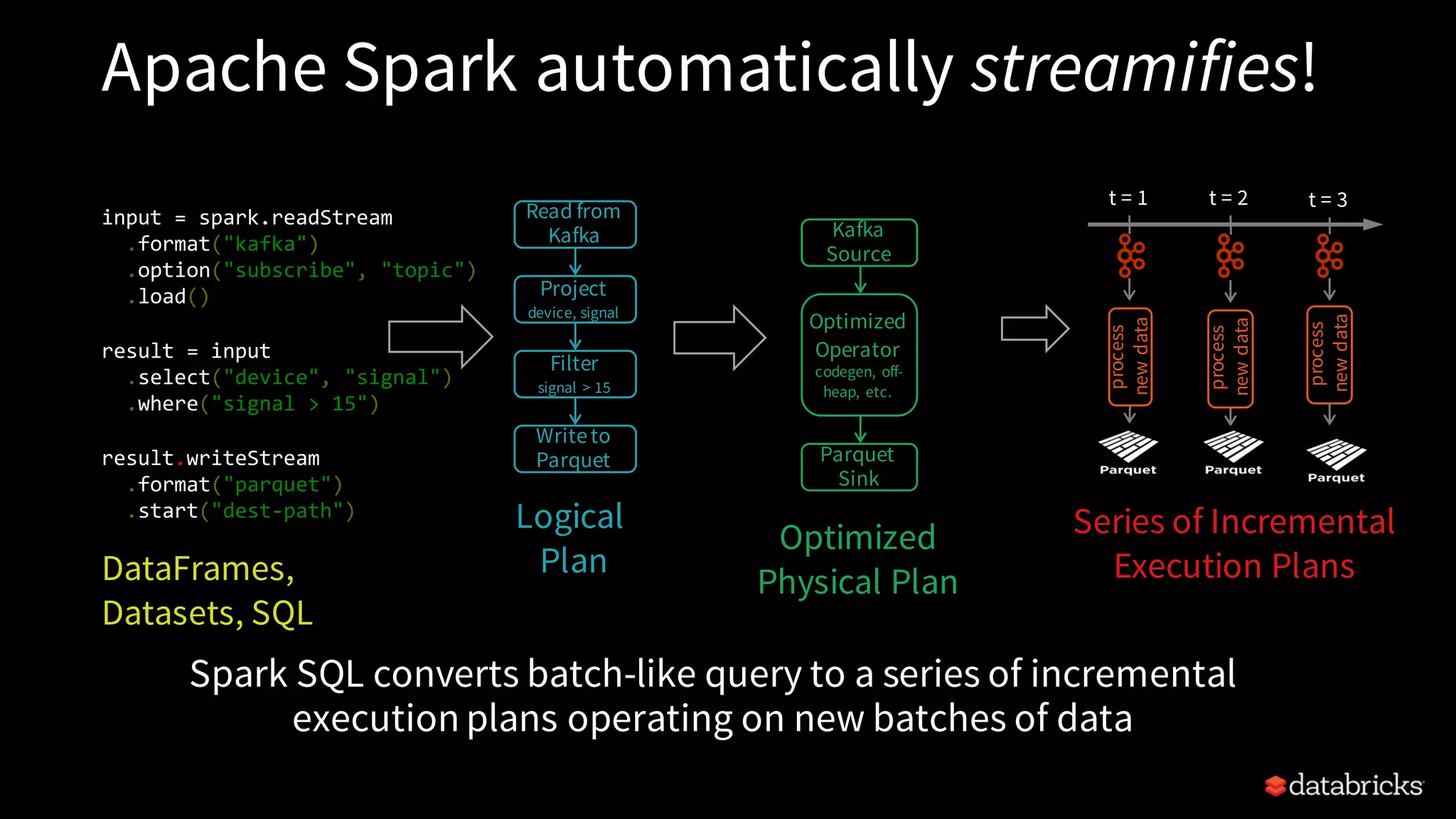
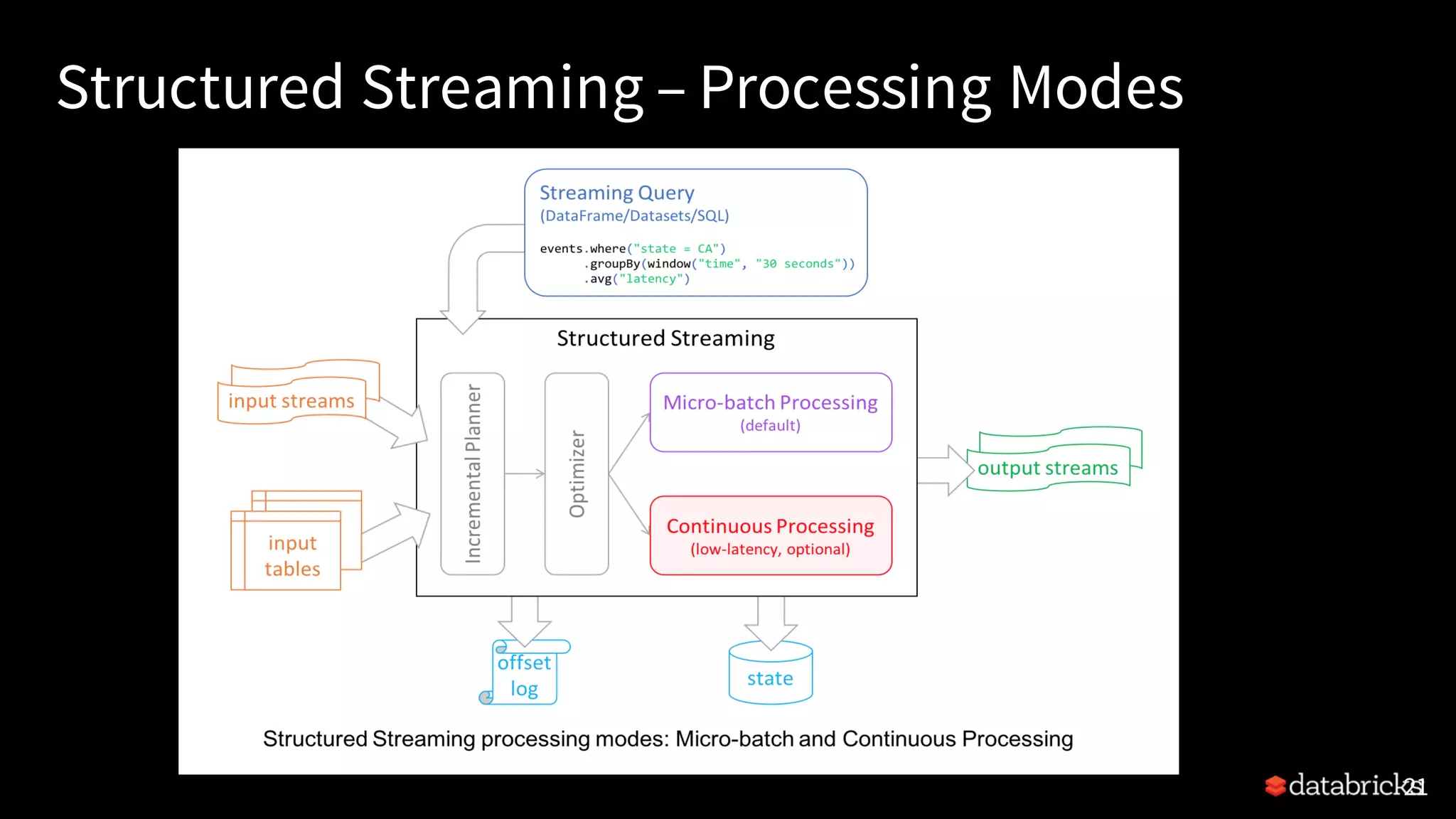
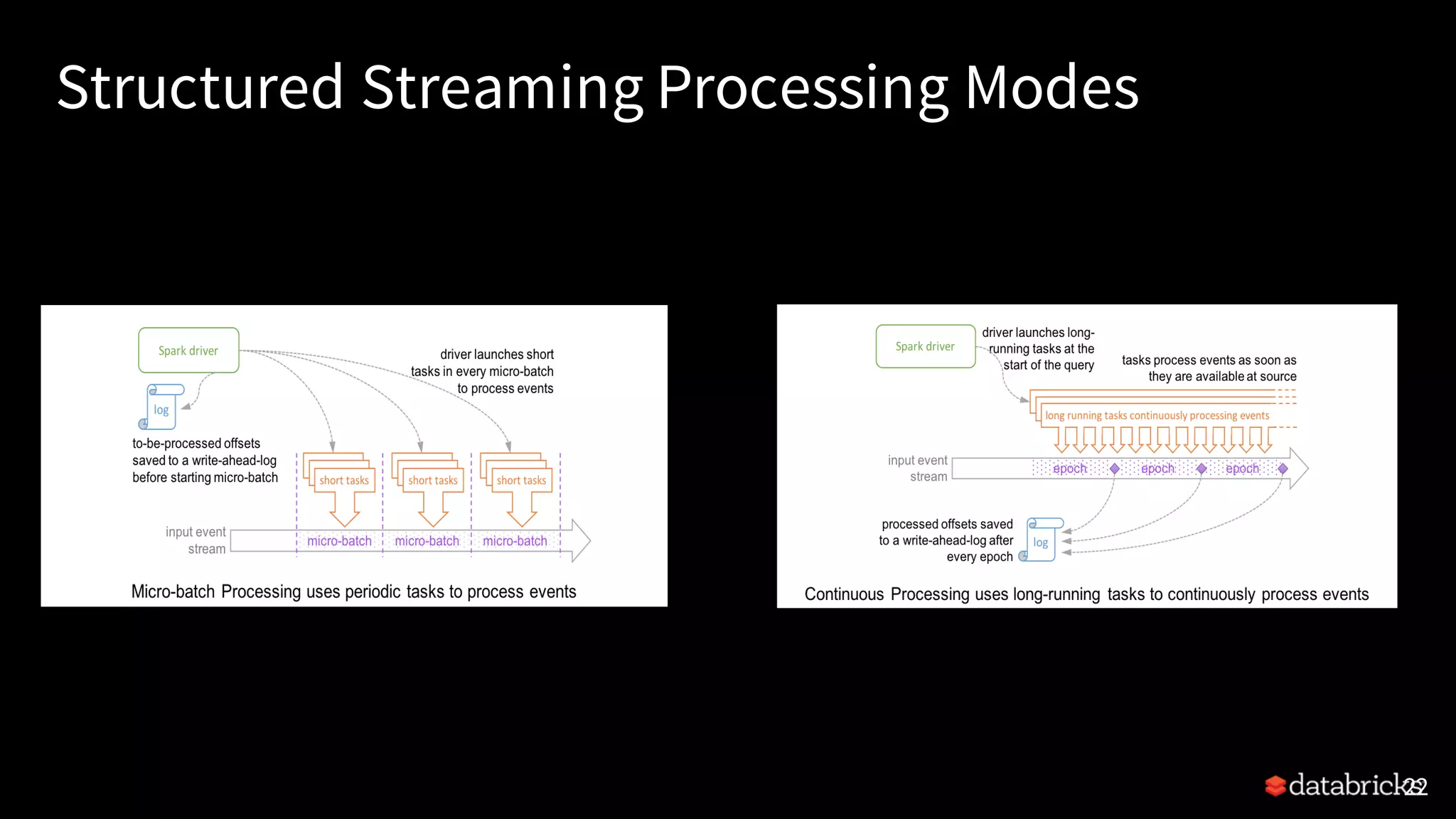
Detailed description of Structured Streaming capabilities, treating streams as unbounded tables, and the continuous update feature.
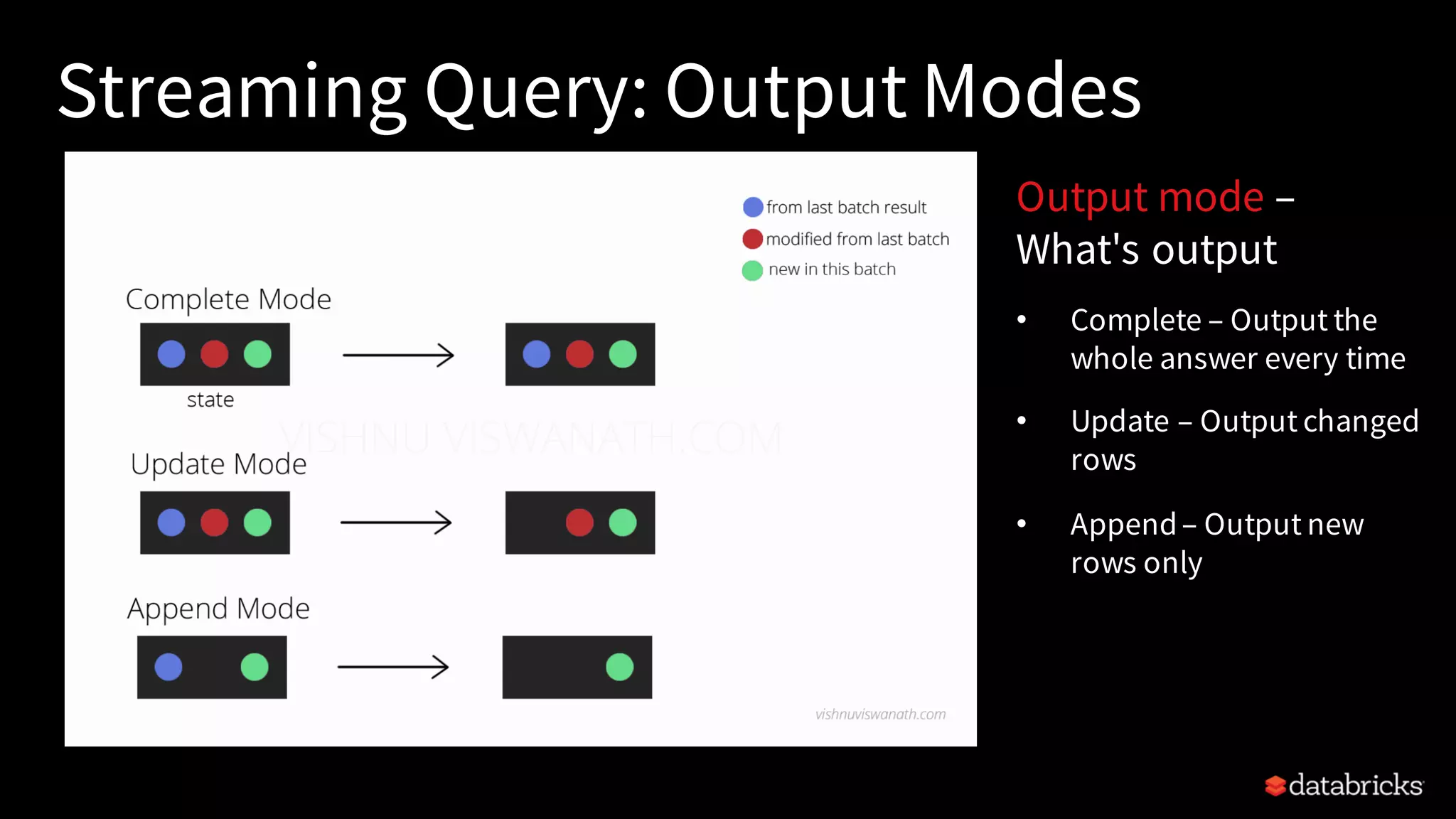
The structure and steps of a Streaming Query in PySpark, including sources, transformations, and sink modes.
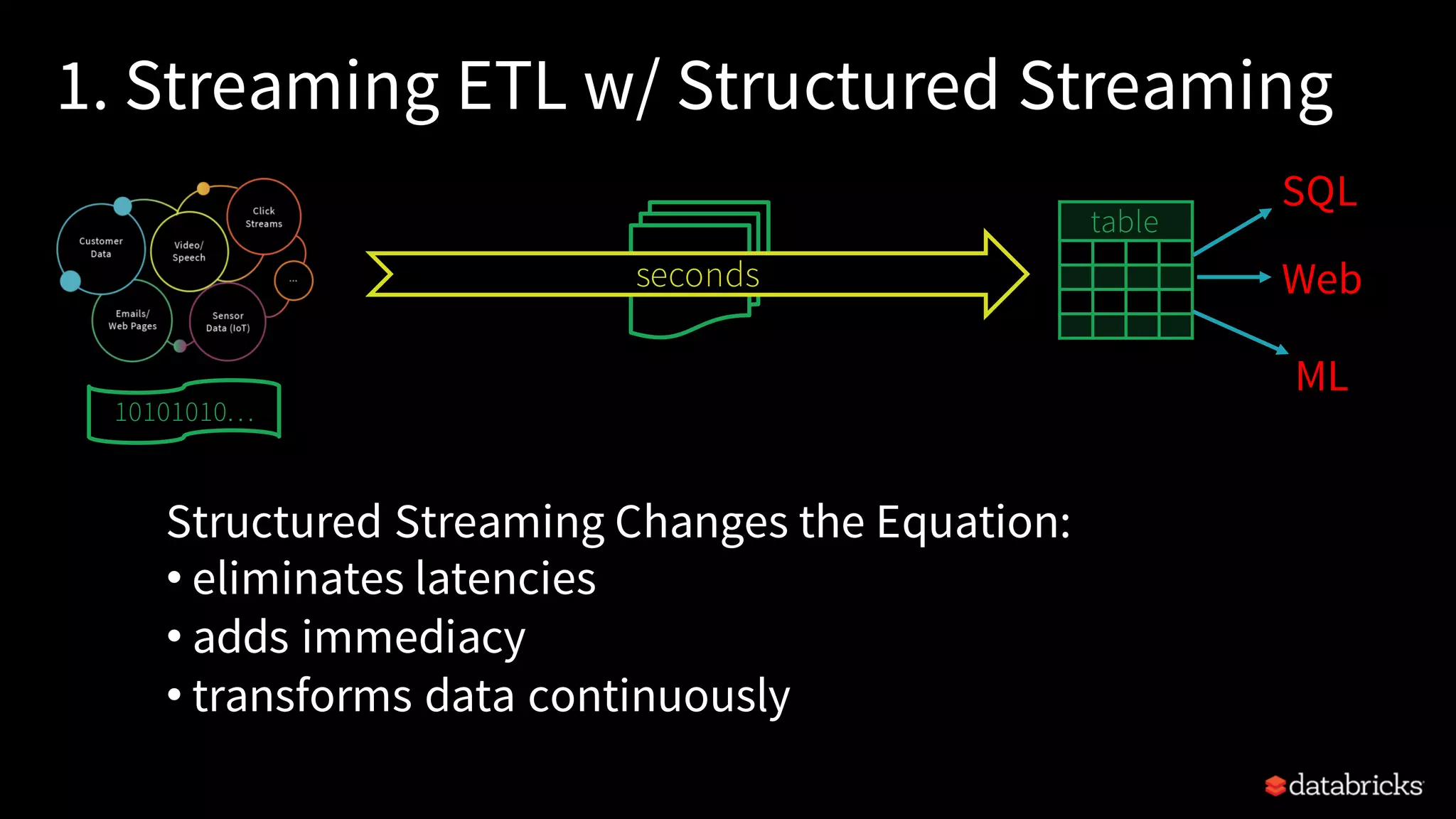
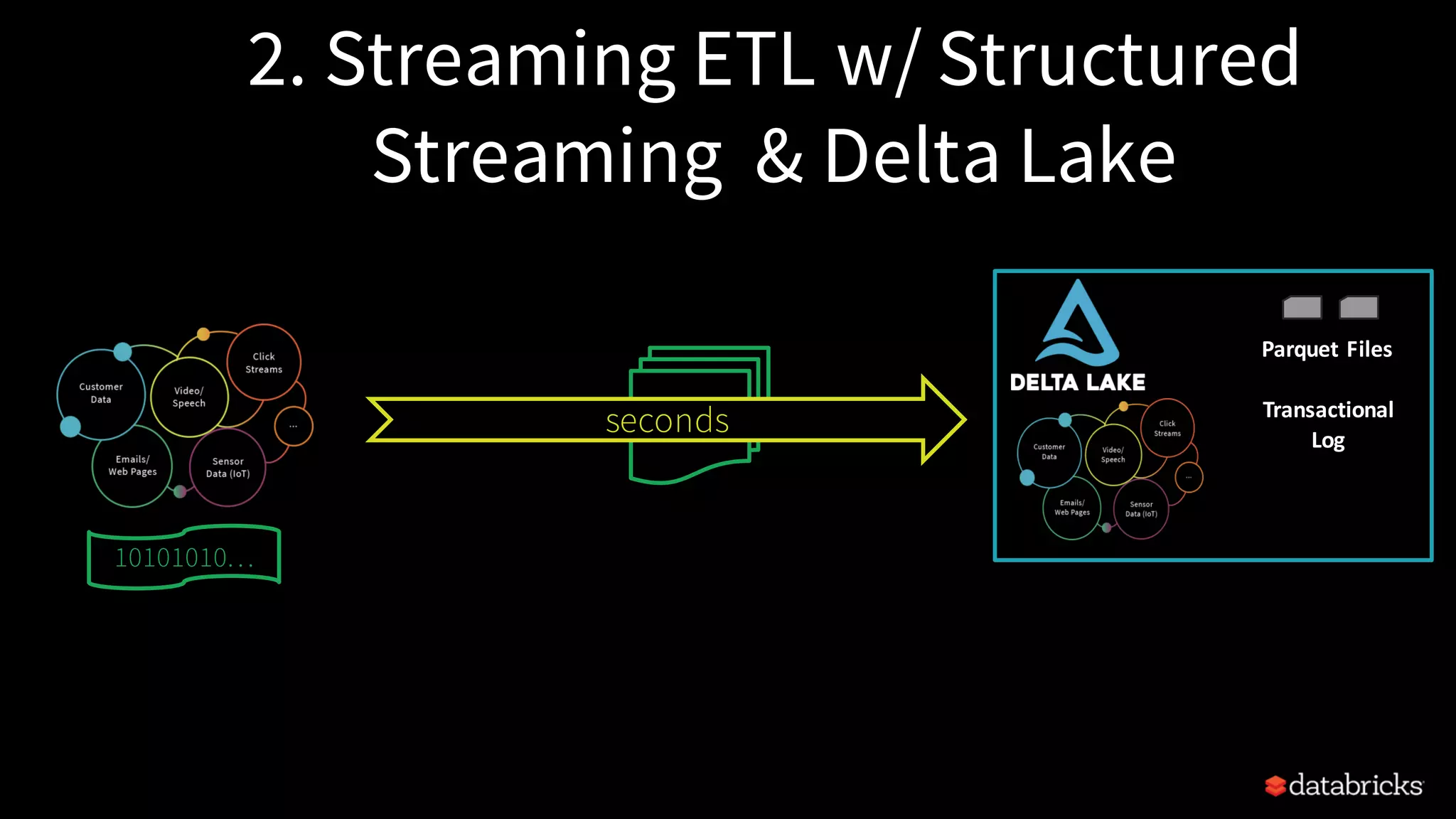
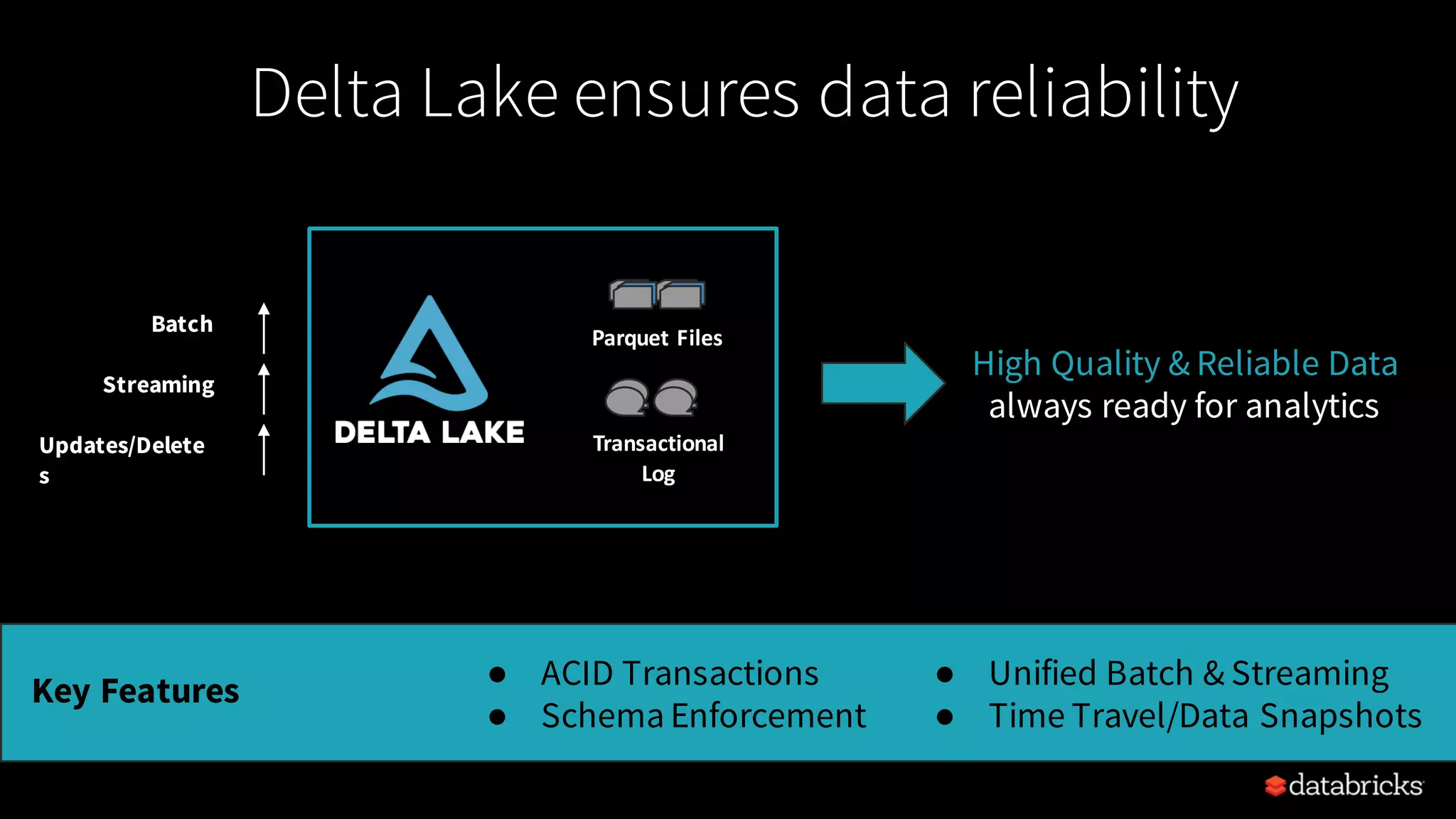
Comparison of traditional ETL vs streaming ETL using Structured Streaming, highlighting its immediacy, reliability, and transactional features.
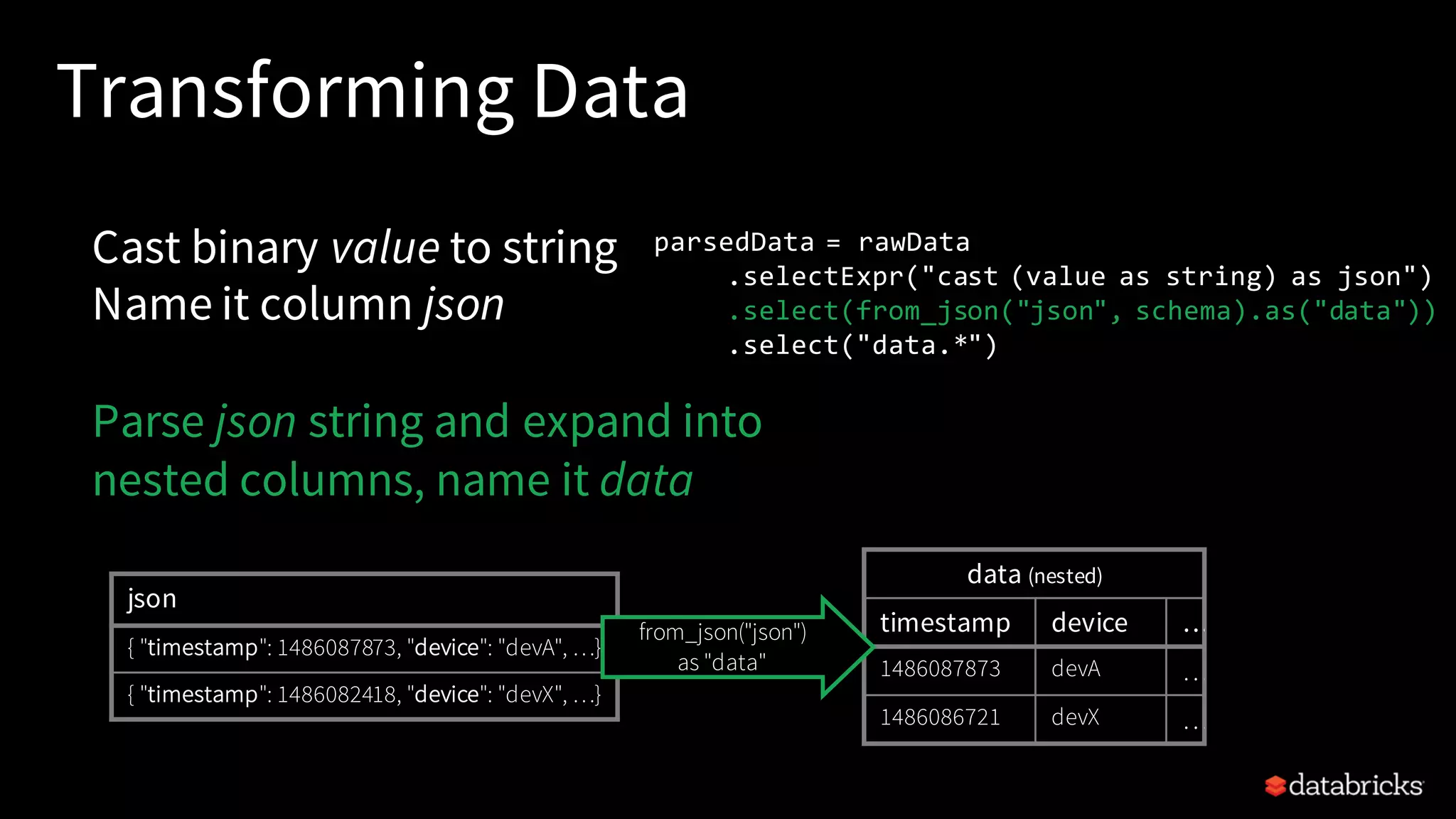
Steps to read, transform, and write streaming data using PySpark, focusing on data parsing and saving in Parquet or Delta tables.
Summary of key points discussed, including resources for getting started with Apache Spark and Continuous Applications.