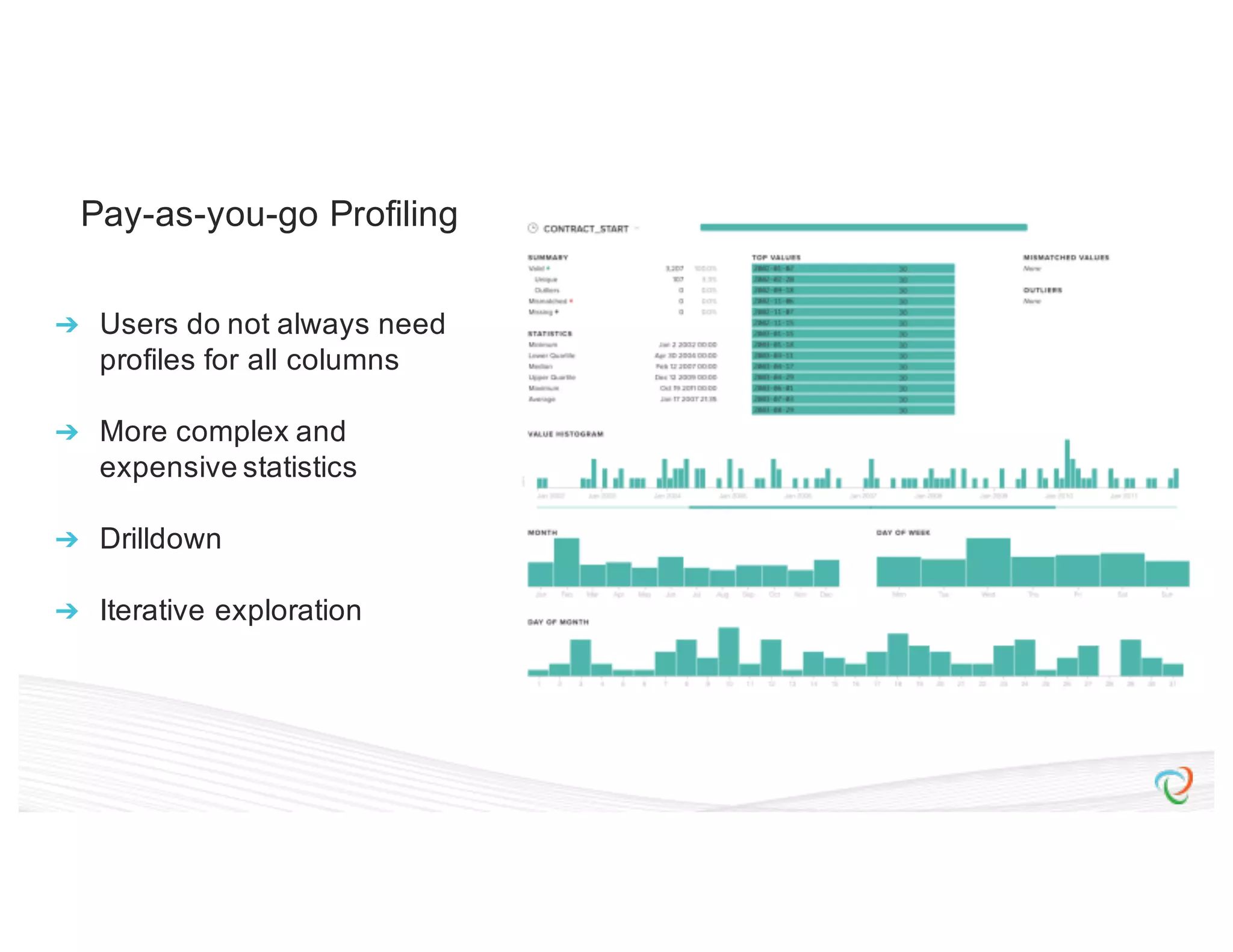
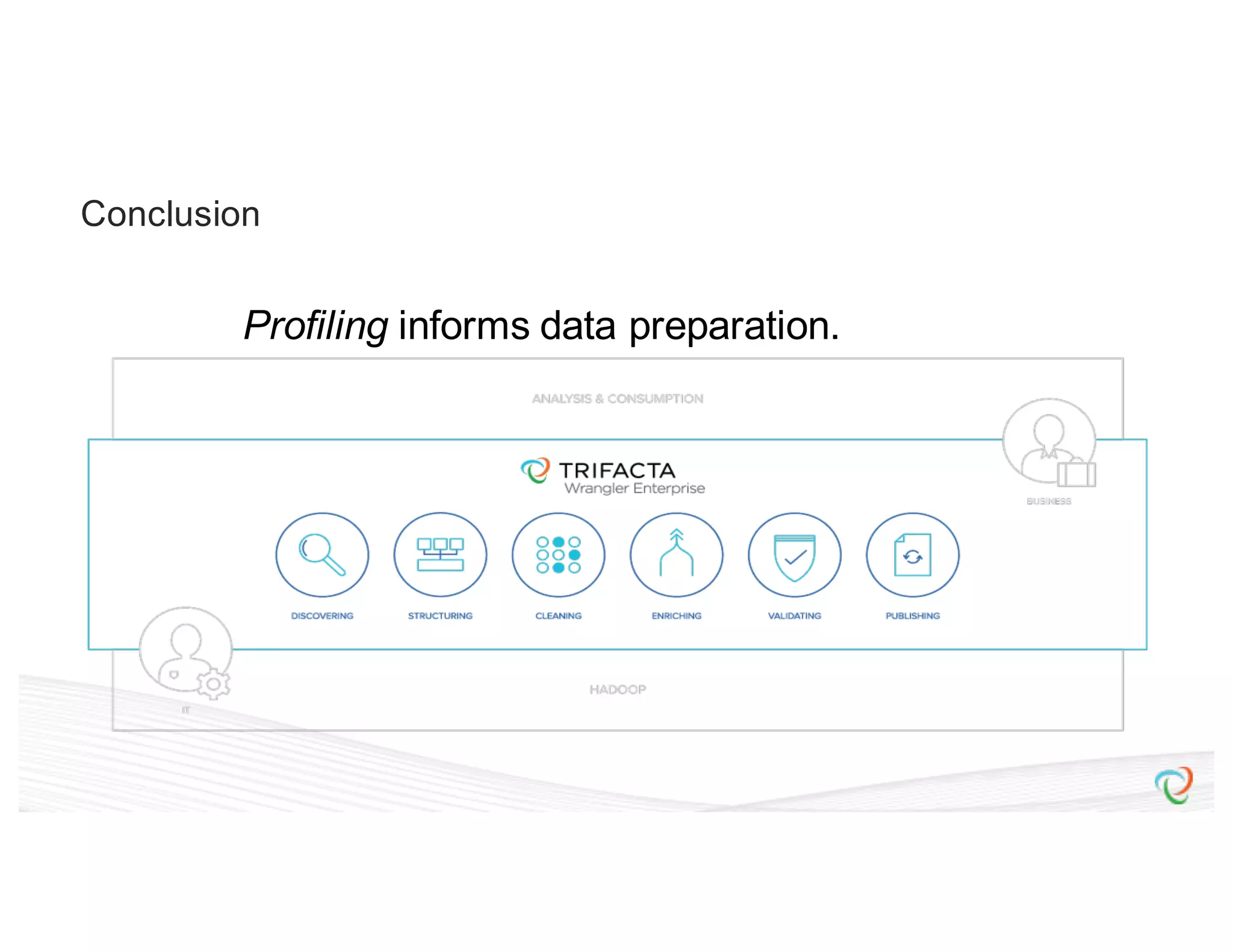
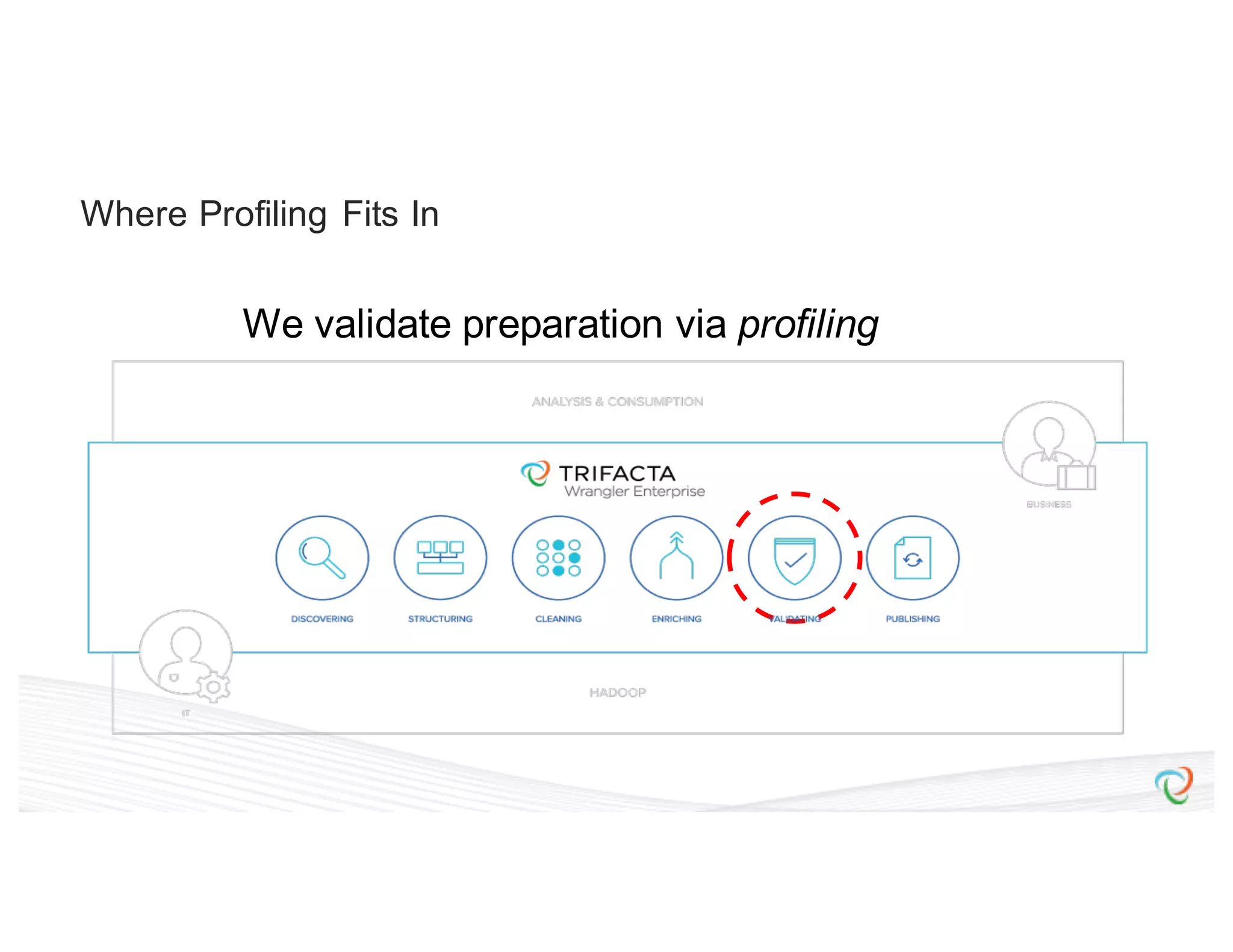
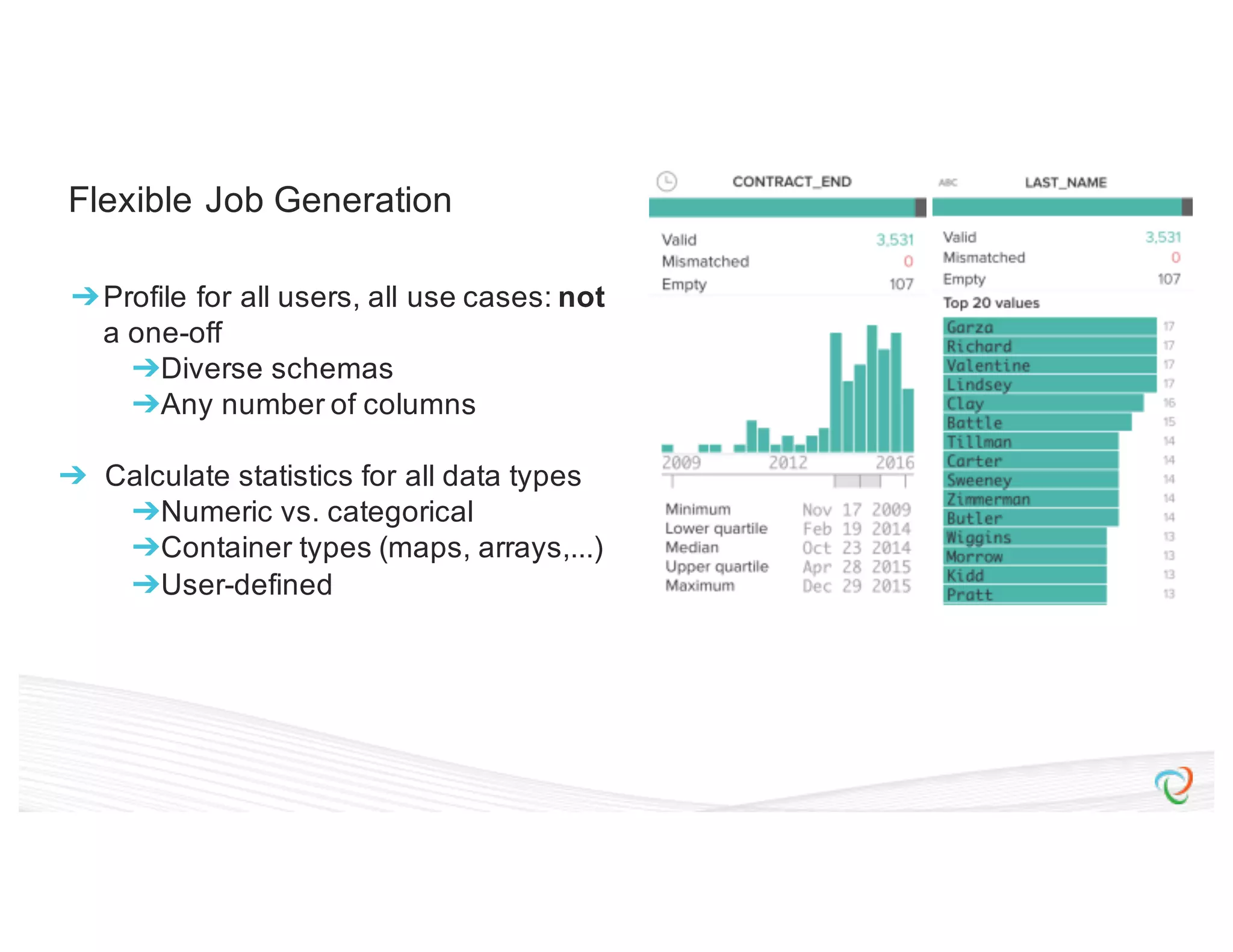
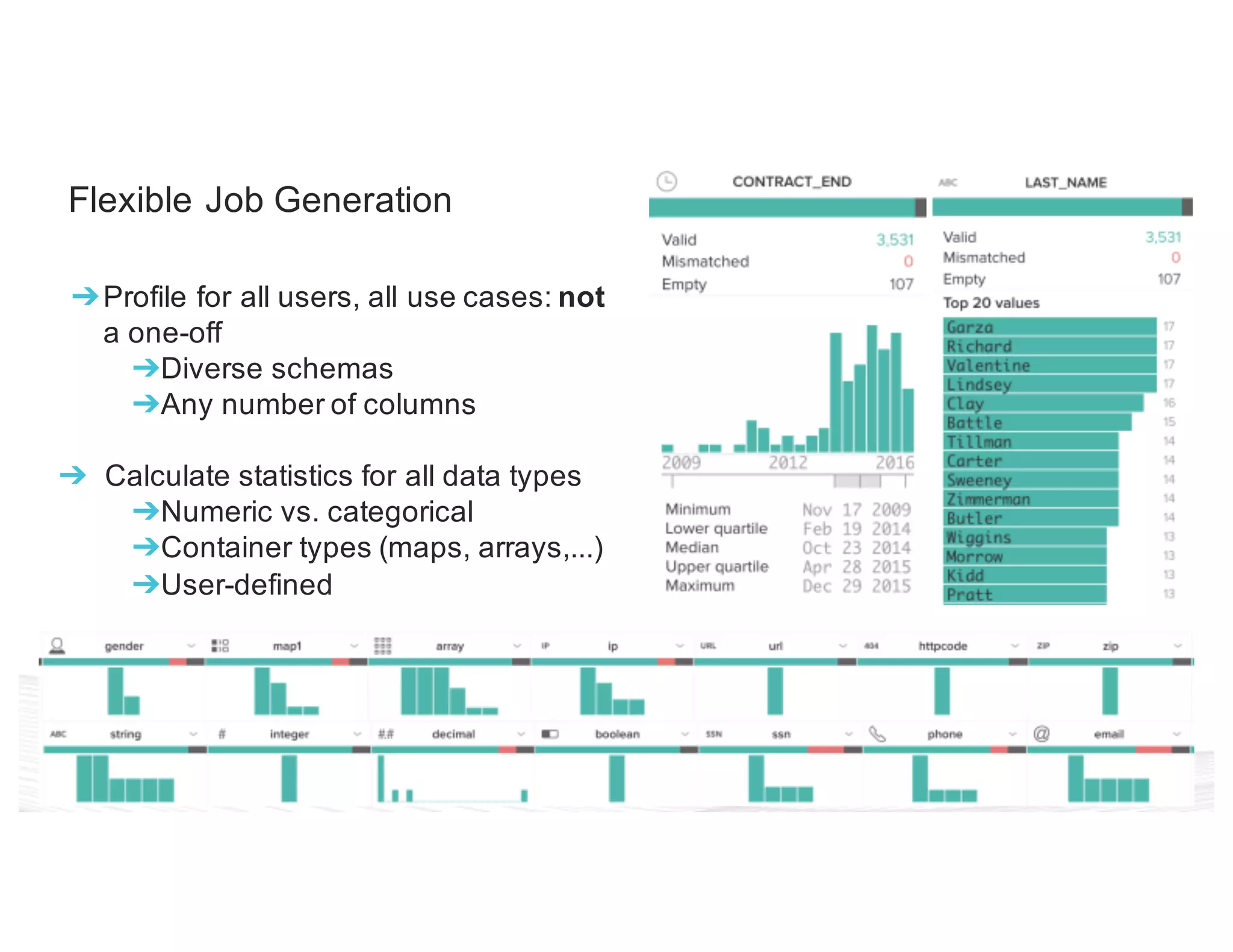
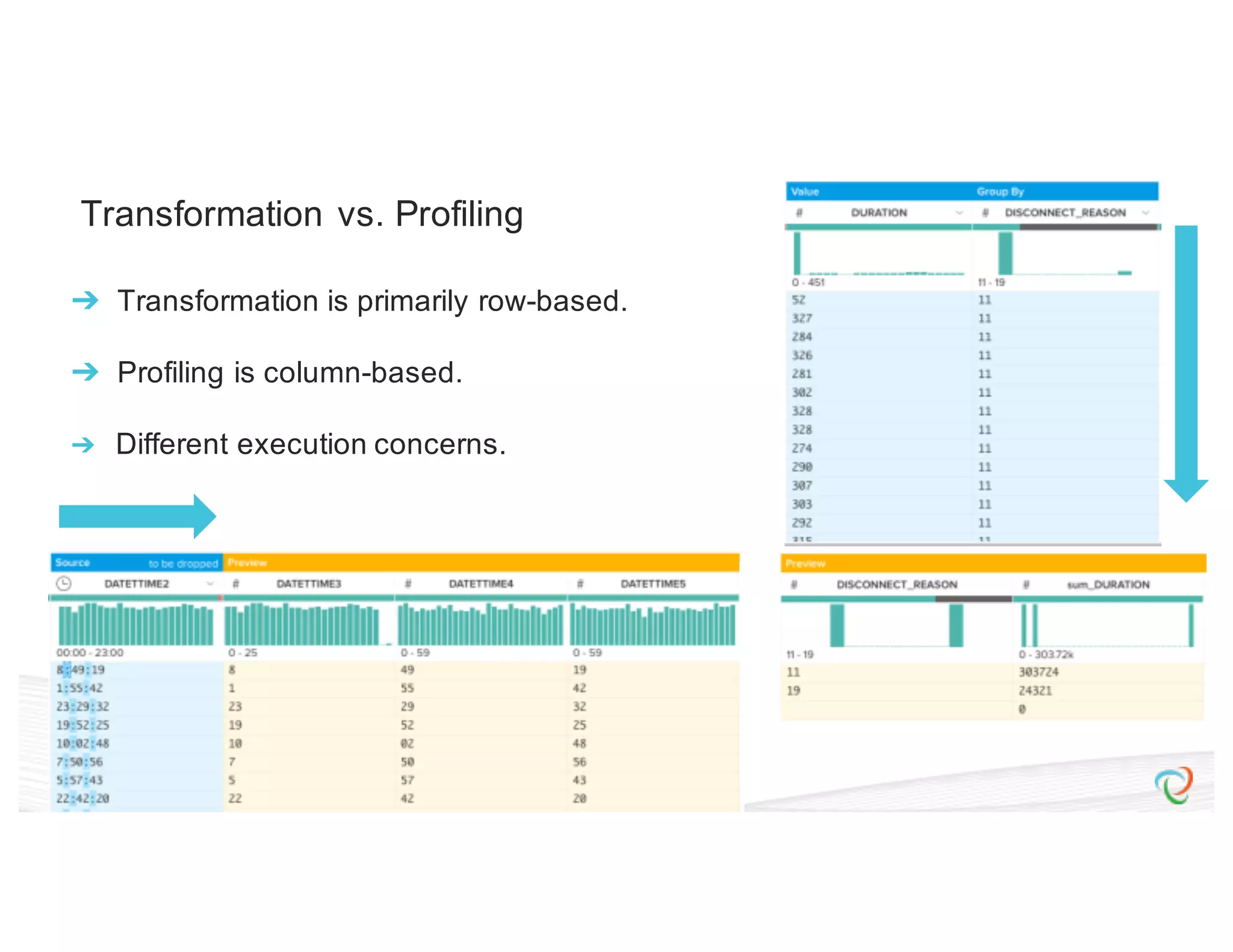
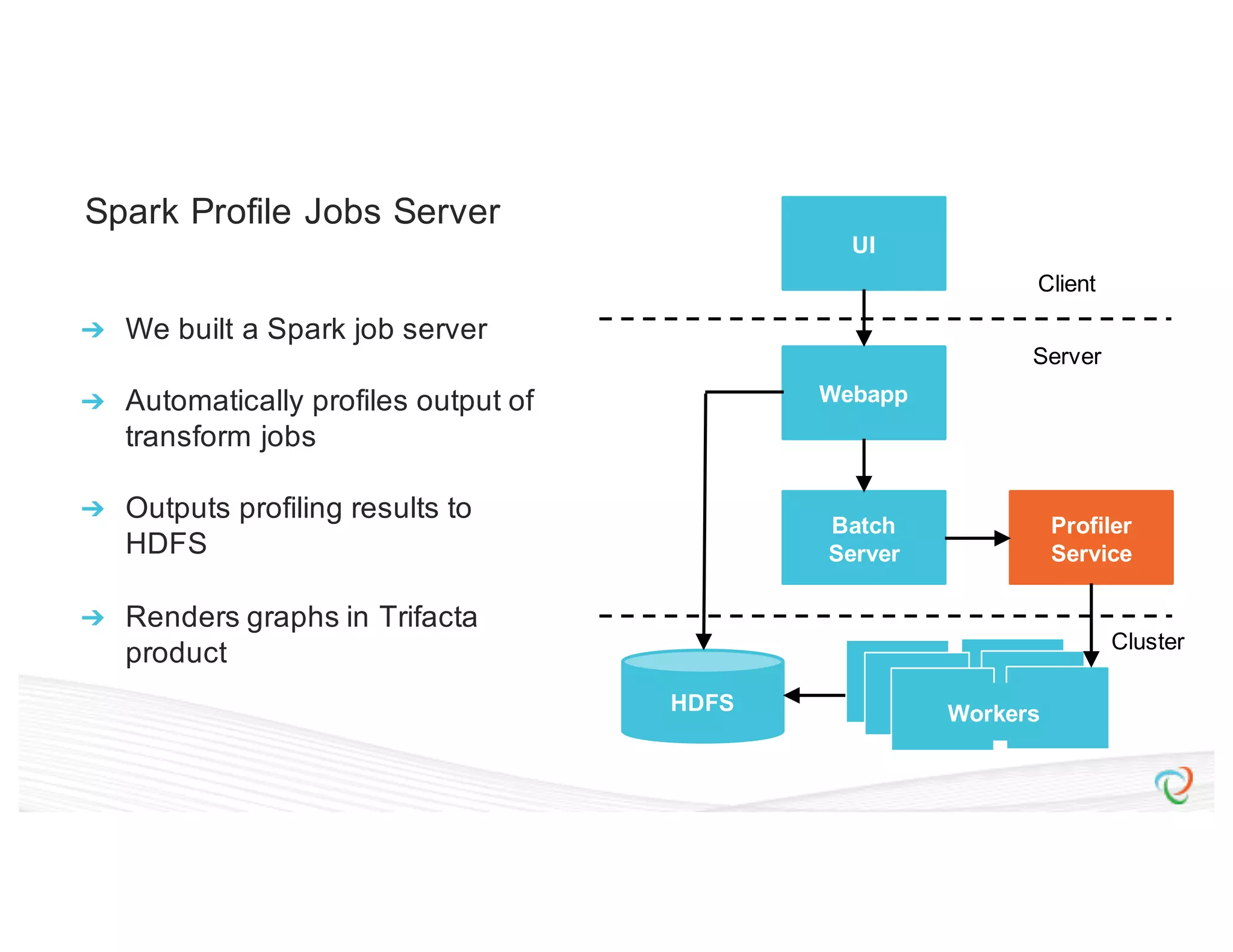
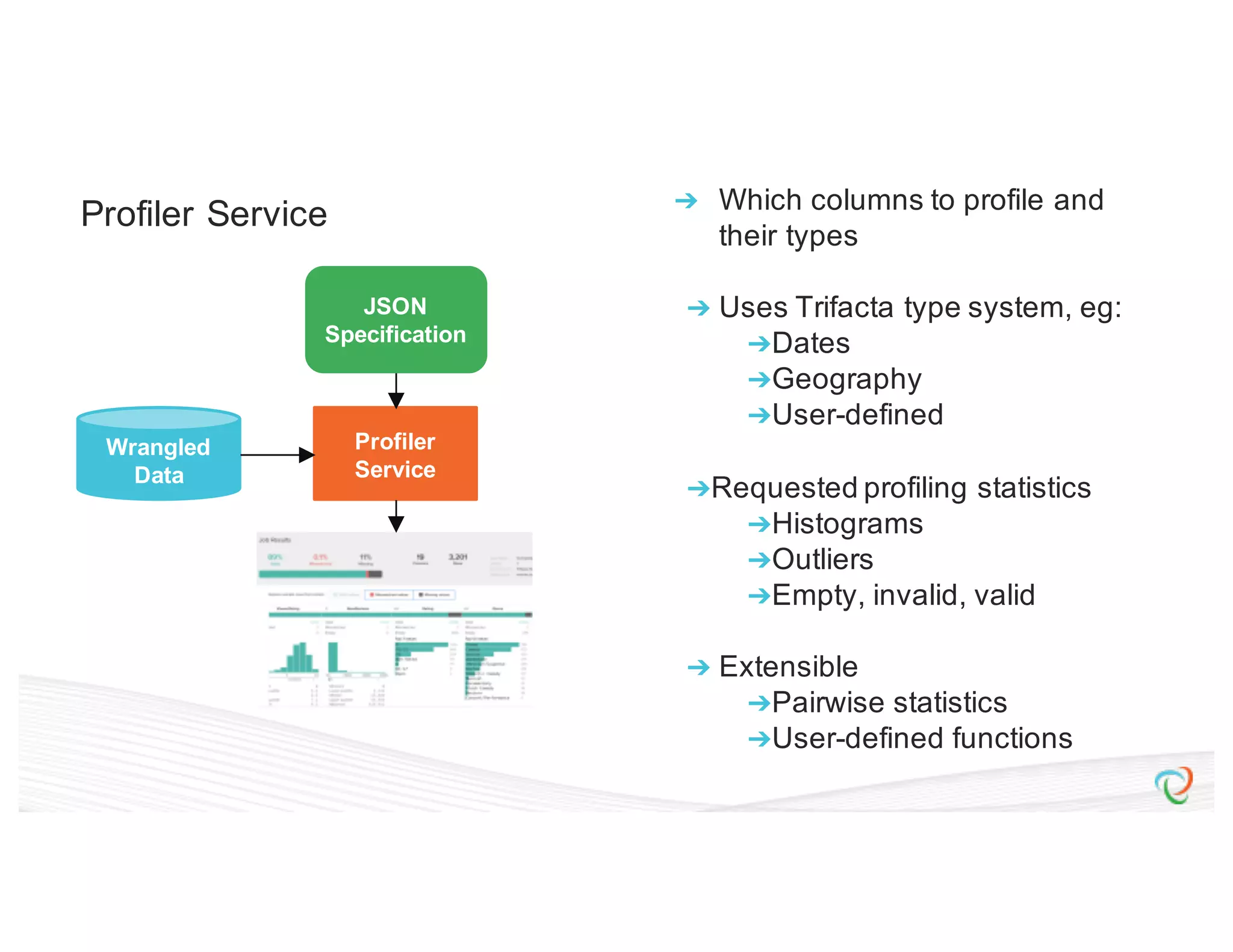
This document discusses how Trifacta uses Spark to enable scalable and incremental data profiling. It describes challenges in profiling large datasets, such as performance and generating flexible jobs. Trifacta addresses these by building a Spark profiling job server that takes profiling specifications as JSON, runs jobs on Spark, and outputs results to HDFS. This pay-as-you-go approach allows profiling to scale to large datasets and different user needs in a flexible manner.




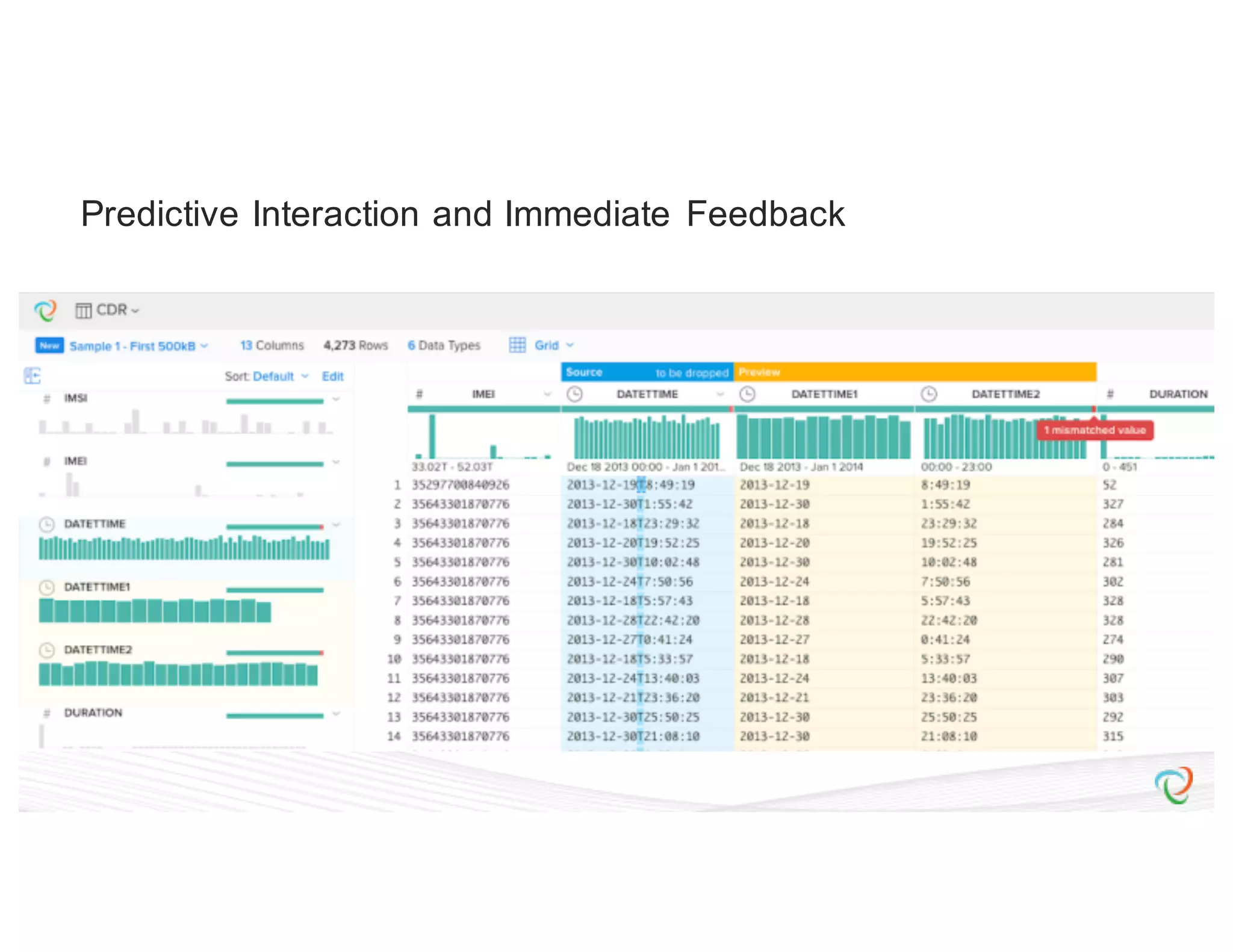

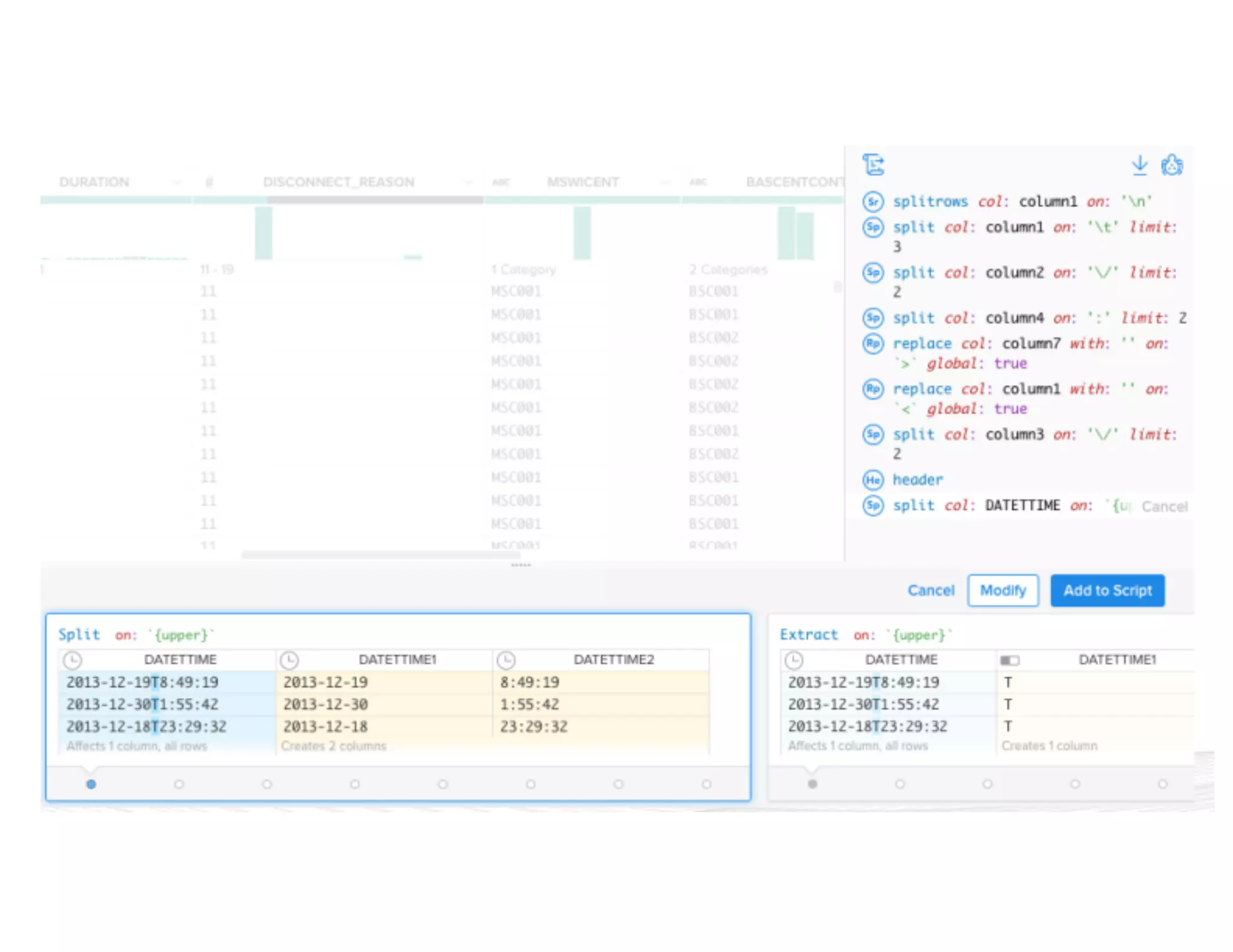








![{ “input”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “schema”: { “order”: [“column1”, “column2”, “column3”], “types”: { “column1”: [“Datetime”, {“regexes”: , “groupLocs”: {...}}], “column2”: [...], “column3”: [...] } }, “commands”: [ { “column”: “*”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “histogram”, “params”: {...} }, { “column”: “column1”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “type-check”, “params”: {...} } ] } Profiling DSL](https://image.slidesharecdn.com/6farbissersilberstein-160614004846/75/Scalable-And-Incremental-Data-Profiling-With-Spark-33-2048.jpg)
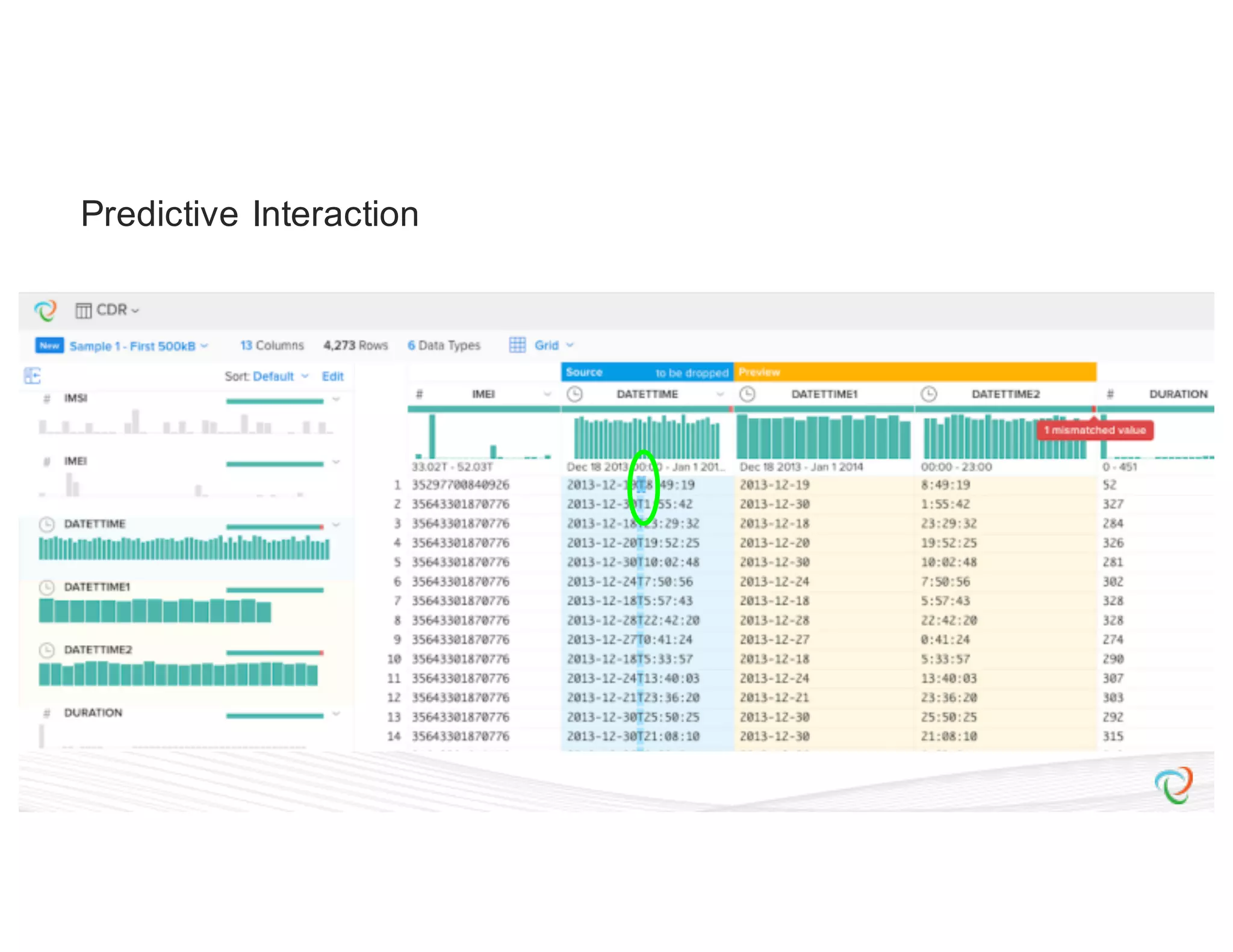
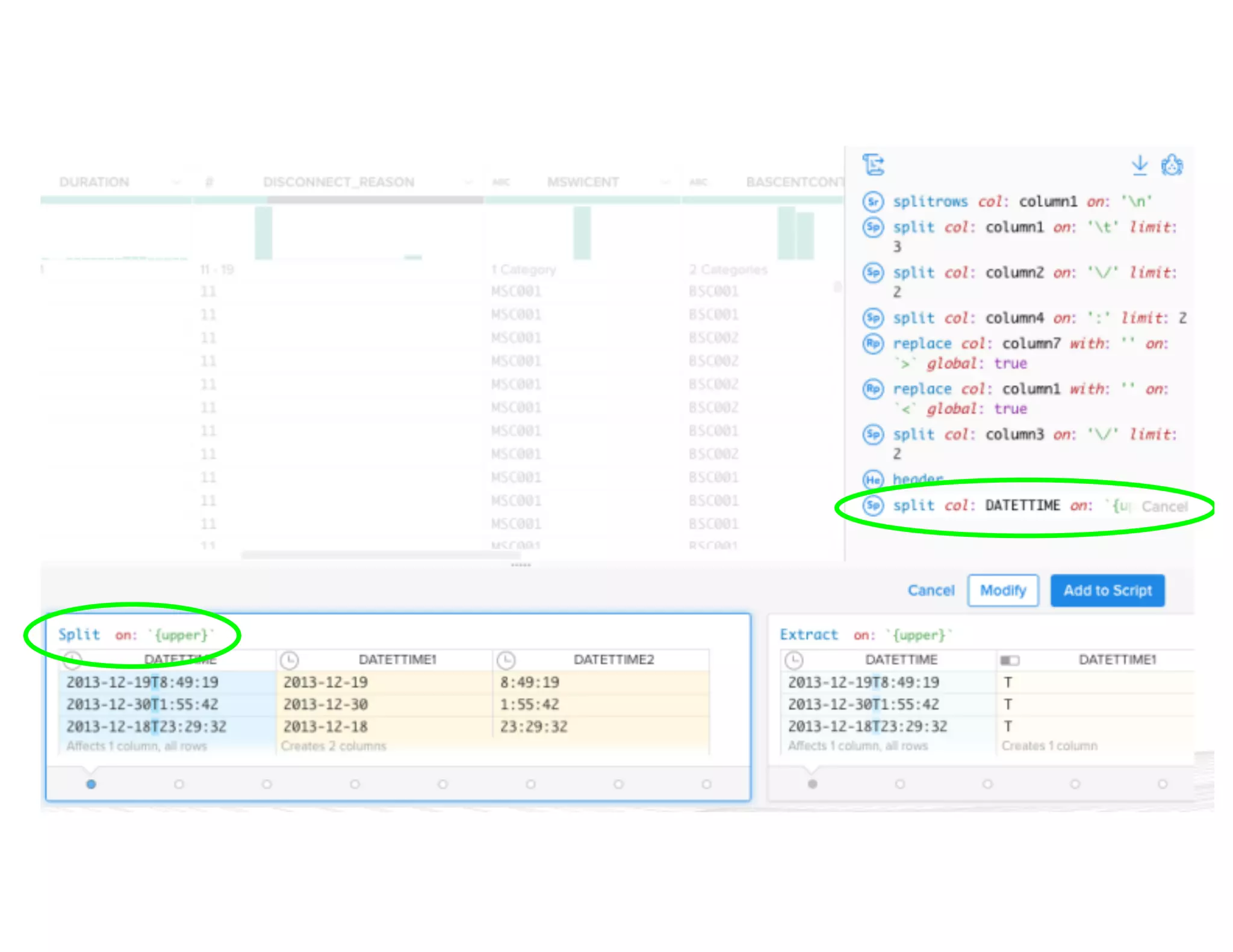
![{ “input”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “schema”: { “order”: [“column1”, “column2”, “column3”], “types”: { “column1”: [“Datetime”, {“regexes”: , “groupLocs”: {...}}], “column2”: [...], “column3”: [...] } }, “commands”: [ { “column”: “*”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “histogram”, “params”: {...} }, { “column”: “column1”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “type-check”, “params”: {...} } ] } Profiling DSL](https://image.slidesharecdn.com/6farbissersilberstein-160614004846/75/Scalable-And-Incremental-Data-Profiling-With-Spark-34-2048.jpg)
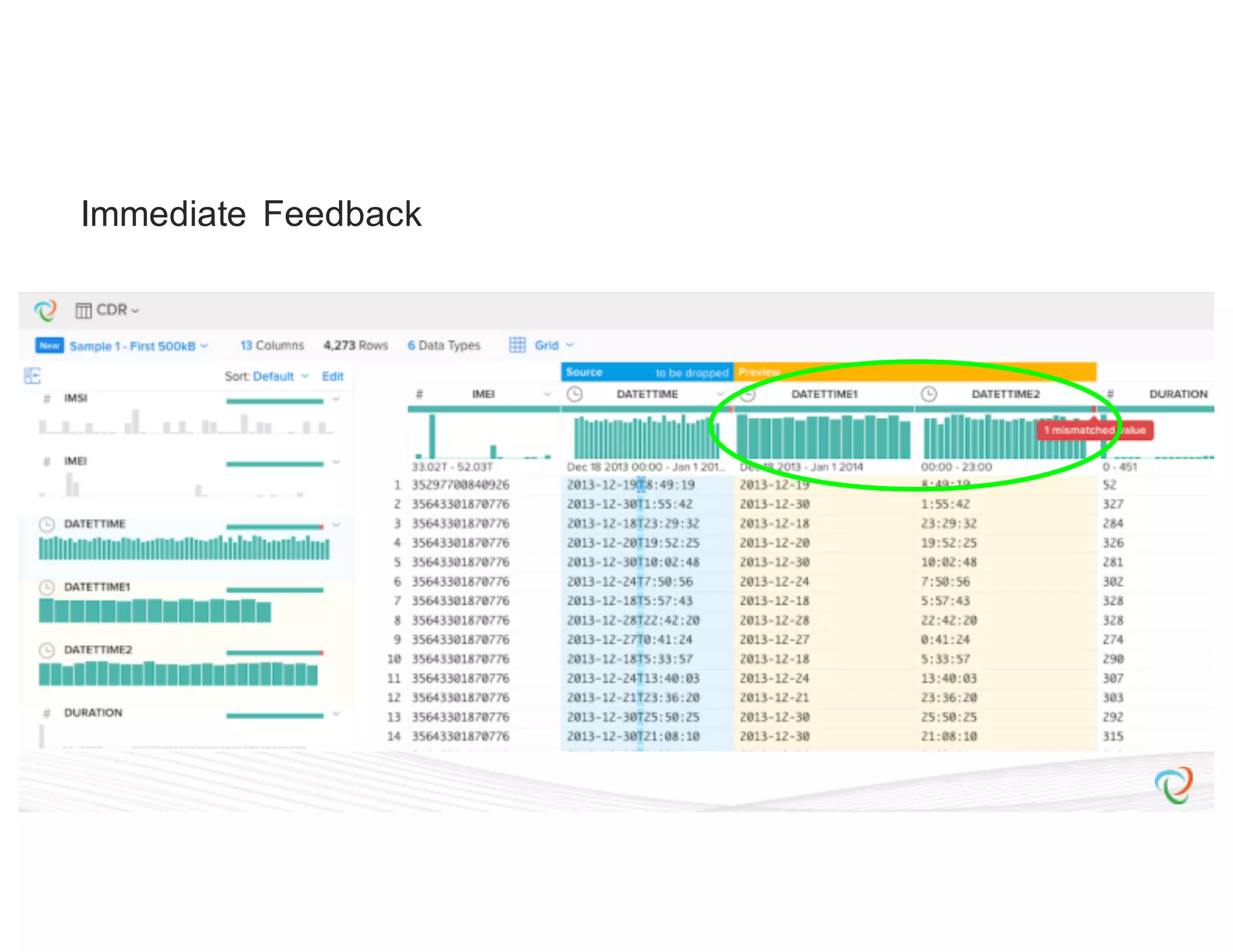
![{ “input”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “schema”: { “order”: [“column1”, “column2”, “column3”], “types”: { “column1”: [“Datetime”, {“regexes”: , “groupLocs”: {...}}], “column2”: [...], “column3”: [...] } }, “commands”: [ { “column”: “*”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “histogram”, “params”: {...} }, { “column”: “column1”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “type-check”, “params”: {...} } ] } Profiling DSL](https://image.slidesharecdn.com/6farbissersilberstein-160614004846/75/Scalable-And-Incremental-Data-Profiling-With-Spark-35-2048.jpg)
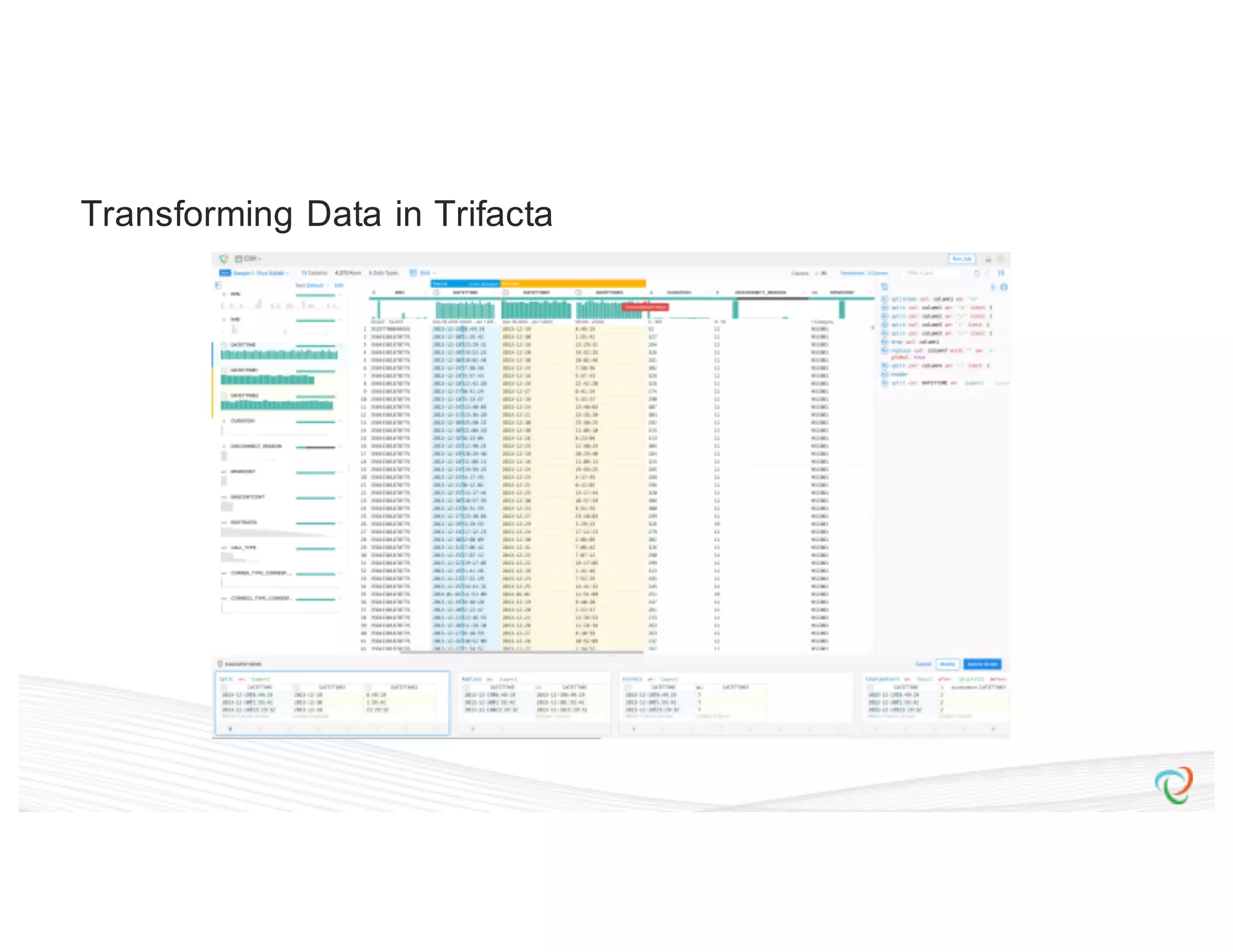
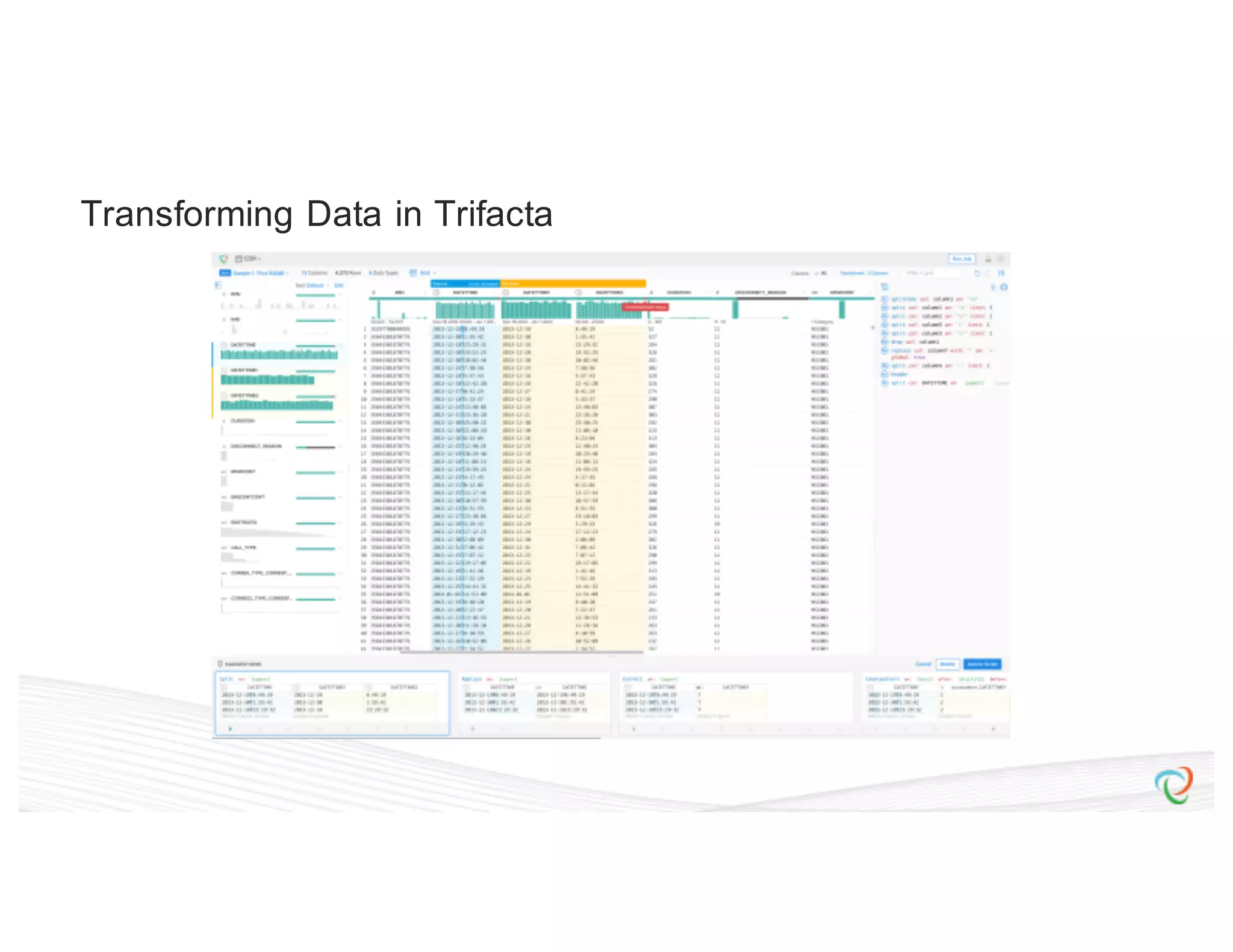
![{ “input”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “schema”: { “order”: [“column1”, “column2”, “column3”], “types”: { “column1”: [“Datetime”, {“regexes”: , “groupLocs”: {...}}], “column2”: [...], “column3”: [...] } }, “commands”: [ { “column”: “*”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “histogram”, “params”: {...} }, { “column”: “column1”, “output”: “hdfs://hadoop.trifacta-dev.net:8020:/trifacta…”, “profiler-type”: “type-check”, “params”: {...} } ] } Profiling DSL](https://image.slidesharecdn.com/6farbissersilberstein-160614004846/75/Scalable-And-Incremental-Data-Profiling-With-Spark-36-2048.jpg)