Download as PDF, PPTX



























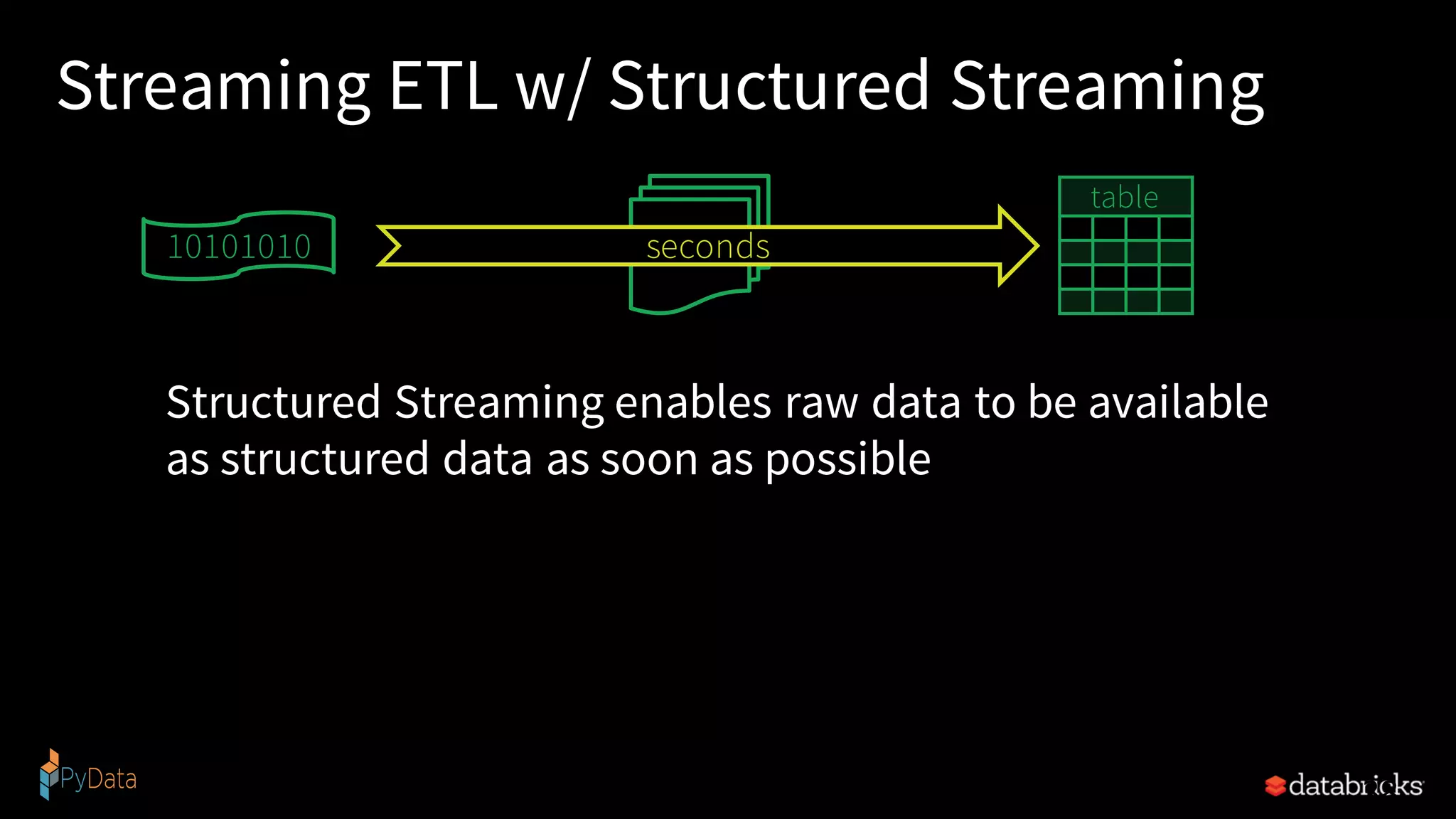
![Traditional ETL • Raw, dirty, un/semi-structured is data dumped as files • Periodic jobs run every few hours to convert raw data to structured data ready for further analytics • Hours of delay before taking decisions on latest data • Problem: Unacceptable when time is of essence • [intrusion , anomaly or fraud detection,monitoringIoT devices, etc.] 37 file dump seconds hours table 10101010](https://image.slidesharecdn.com/pysparkstructuredstreamingfinal-190112225329/75/Writing-Continuous-Applications-with-Structured-Streaming-Python-APIs-in-Apache-Spark-37-2048.jpg)

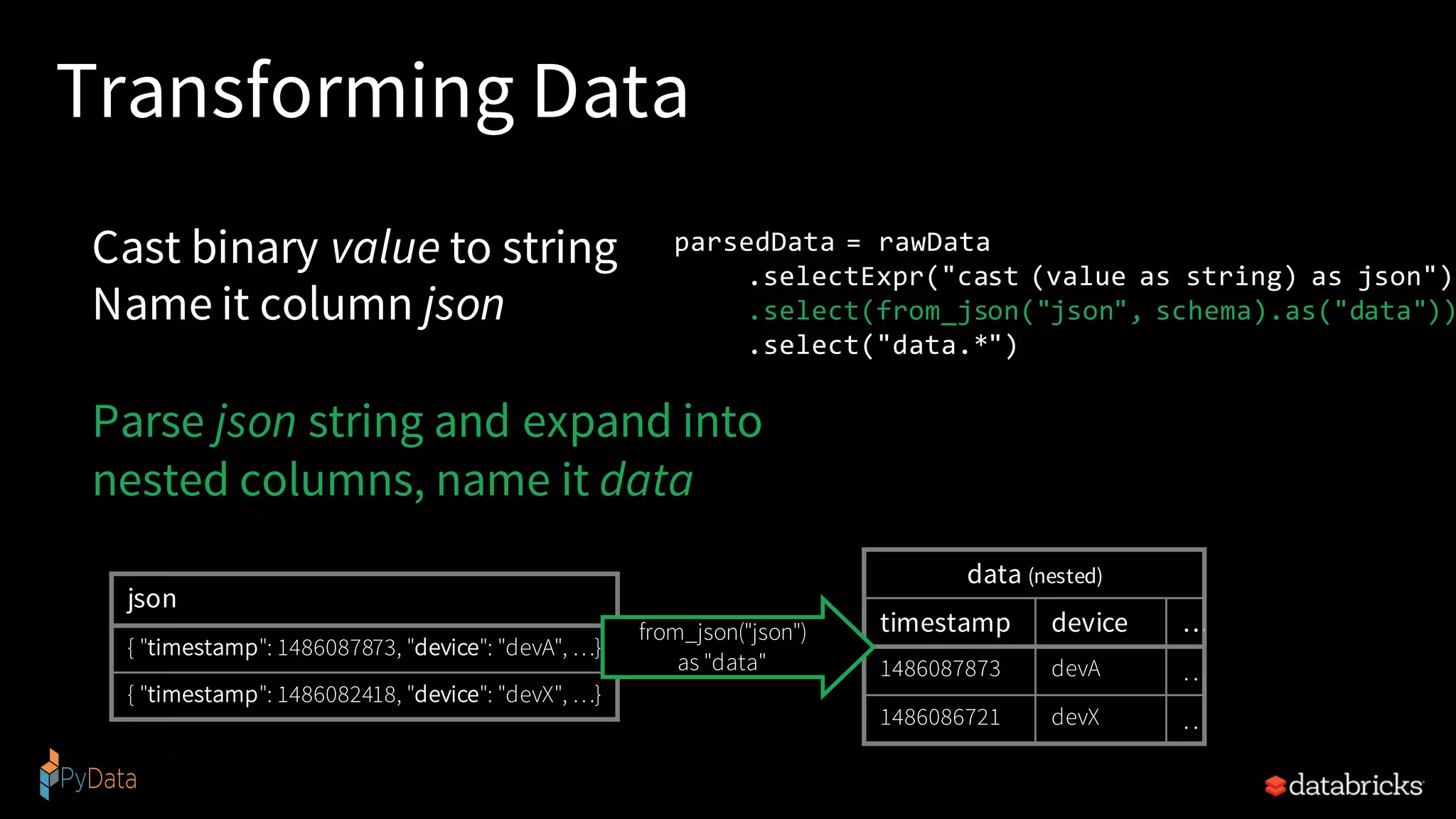
![Reading from Kafka raw_data_df = spark.readStream .format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() rawData dataframe has the following columns key value topic partition offset timestamp [binary] [binary] "topicA" 0 345 1486087873 [binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/pysparkstructuredstreamingfinal-190112225329/75/Writing-Continuous-Applications-with-Structured-Streaming-Python-APIs-in-Apache-Spark-40-2048.jpg)









The document discusses the use of Apache Spark for building continuous streaming applications using structured streaming in PySpark, highlighting its benefits, challenges, and integration capabilities. It explains how Spark unifies various data processing needs and provides a detailed overview of constructing a streaming application with example code snippets. The session also covers topics such as data ingestion from sources like Kafka, processing data transformations, and writing results to output sinks while ensuring fault tolerance and efficient querying.