Download as PDF, PPTX



















![Native Spark App in K8S • New Spark scheduler backend • Driver runs in a Kubernetes pod created by the submission client and creates pods that run the executors in response to requests from the Spark scheduler. [K8S-34377] [SPARK-18278] • Make direct use of Kubernetes clusters for multi-tenancy and sharing through Namespaces and Quotas, as well as administrative features such as Pluggable Authorization, and Logging. 29](https://image.slidesharecdn.com/sparkstaturdayworkshopbayareafinal-180803225509/75/Spark-Saturday-Spark-SQL-DataFrame-Workshop-with-Apache-Spark-2-3-29-2048.jpg)






















![Background: What is in an RDD? •Dependencies • Partitions (with optional localityinfo) • Compute function: Partition =>Iterator[T] Opaque Computation & Opaque Data](https://image.slidesharecdn.com/sparkstaturdayworkshopbayareafinal-180803225509/75/Spark-Saturday-Spark-SQL-DataFrame-Workshop-with-Apache-Spark-2-3-67-2048.jpg)


![Easy to write code... Believe it! from pyspark.sql.functions import avg dataRDD = sc.parallelize([("Jim", 20), ("Anne", 31), ("Jim", 30)]) dataDF = dataRDD.toDF(["name", "age"]) # Using RDD code to compute aggregate average (dataRDD.map(lambda (x,y): (x, (y,1))) .reduceByKey(lambda x,y: (x[0] +y[0], x[1] +y[1])) .map(lambda (x, (y, z)): (x, y / z))) # Using DataFrame dataDF.groupBy("name").agg(avg("age")) name age Jim 20 Ann 31 Jim 30](https://image.slidesharecdn.com/sparkstaturdayworkshopbayareafinal-180803225509/75/Spark-Saturday-Spark-SQL-DataFrame-Workshop-with-Apache-Spark-2-3-72-2048.jpg)

![Type-safe:operate on domain objects with compiled lambda functions 8 Dataset API in Spark 2.x v a l d f = s p a r k .r e ad.j s on( "pe opl e.js on ") / / Convert data to domain o b j e c ts . case c l a s s Person(name: S tr i n g , age: I n t ) v a l d s : Dataset[Person] = d f.a s [P e r s on ] v a l fi l te r D S = d s . f i l t e r ( p = > p . a g e > 30)](https://image.slidesharecdn.com/sparkstaturdayworkshopbayareafinal-180803225509/75/Spark-Saturday-Spark-SQL-DataFrame-Workshop-with-Apache-Spark-2-3-74-2048.jpg)















The document outlines a Spark SQL and DataFrames workshop led by Jules S. Damji, focusing on the features, benefits, and architecture of Apache Spark 2.3. It includes an agenda for the day covering topics such as DataFrames, Spark SQL labs, and developer certification, highlighting Spark's unified engine for diverse workloads and its performance advantages. Additionally, it discusses the evolution of Spark APIs and the importance of certification in validating skills for potential employers.
Introduction to Spark SQL & DataFrames Workshop led by Jules S. Damji, including participant background and agenda.
Daily agenda covering DataFrames introduction, labs, certification, Databricks overview, and breaks.
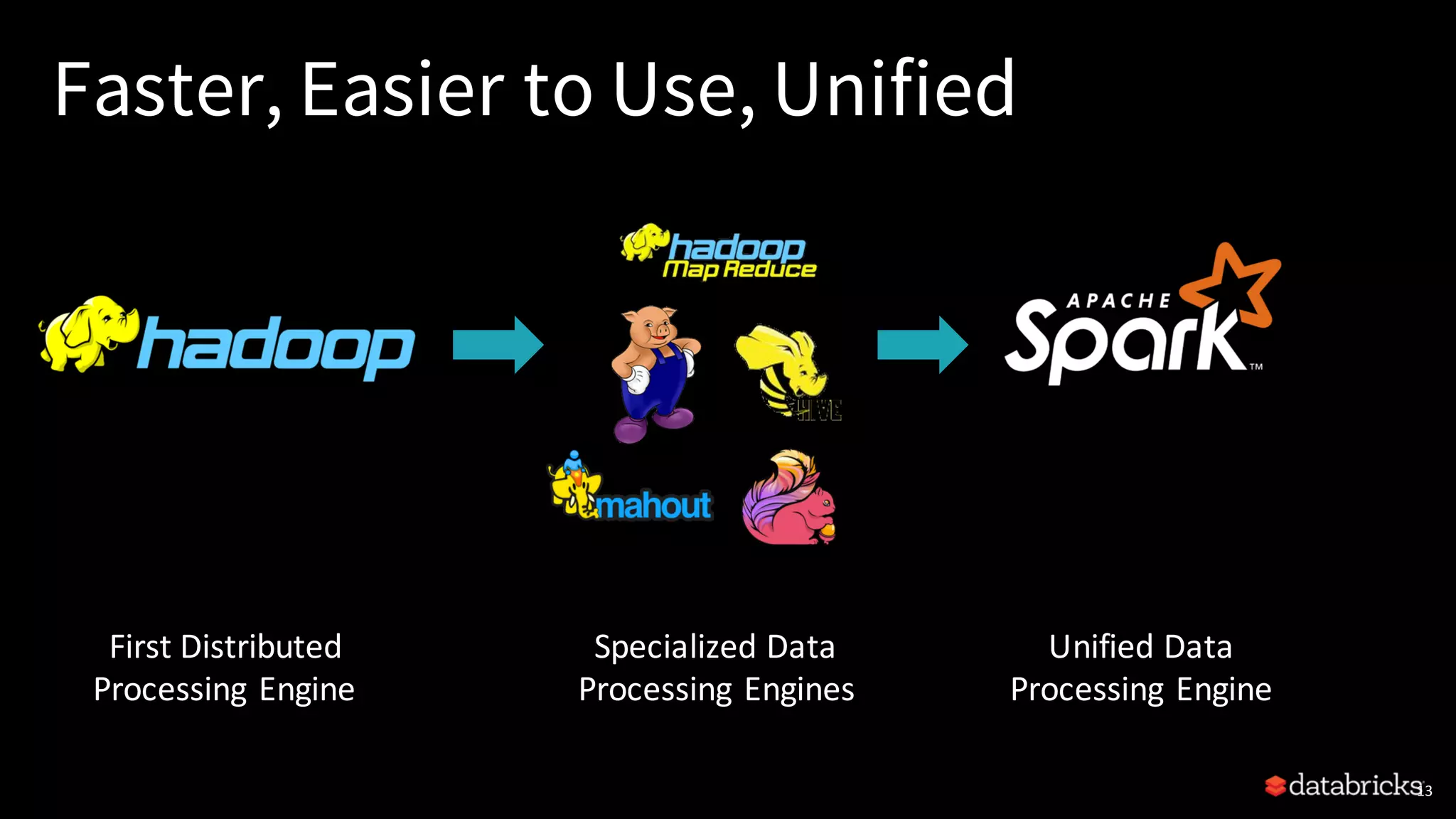
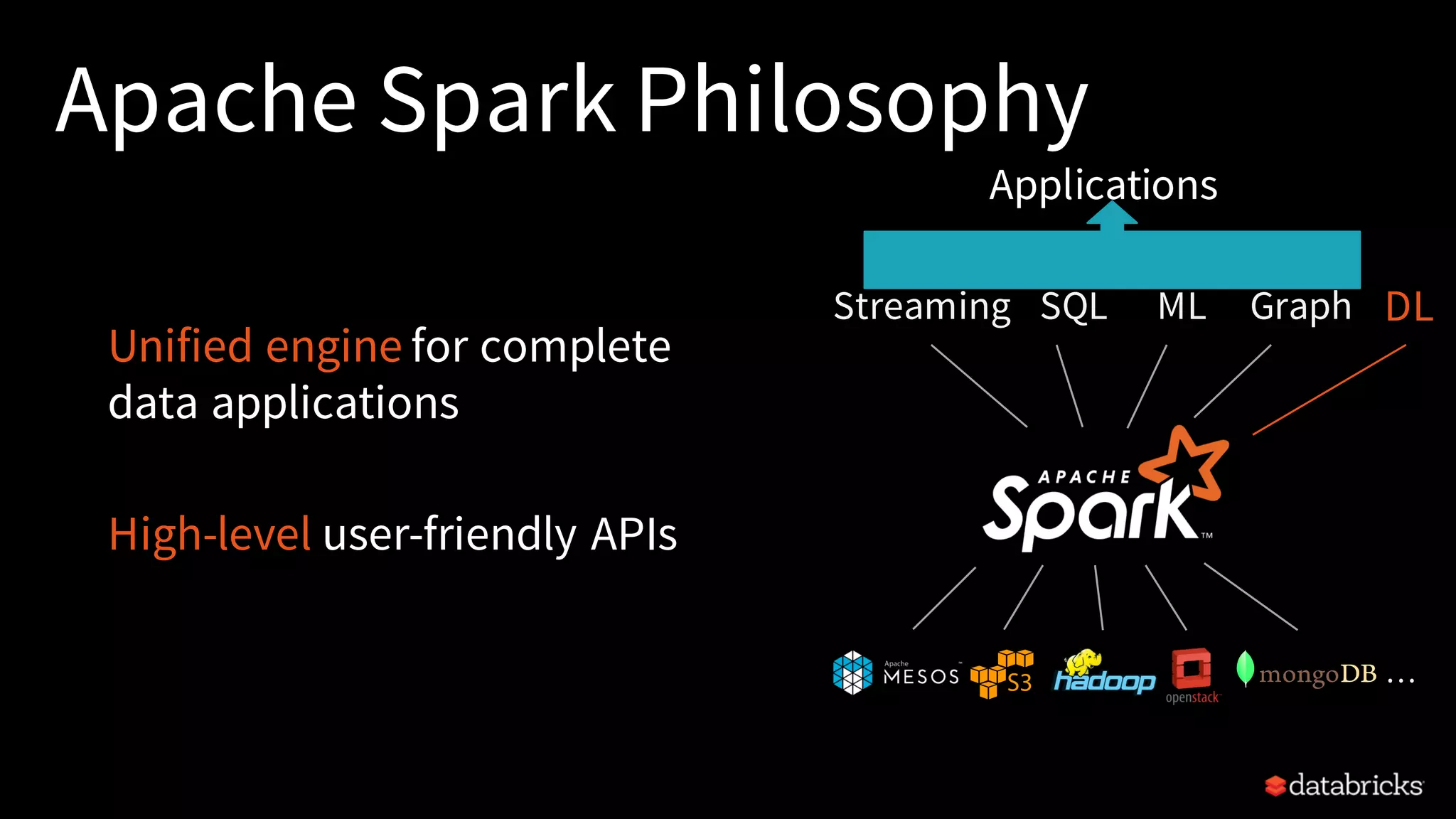
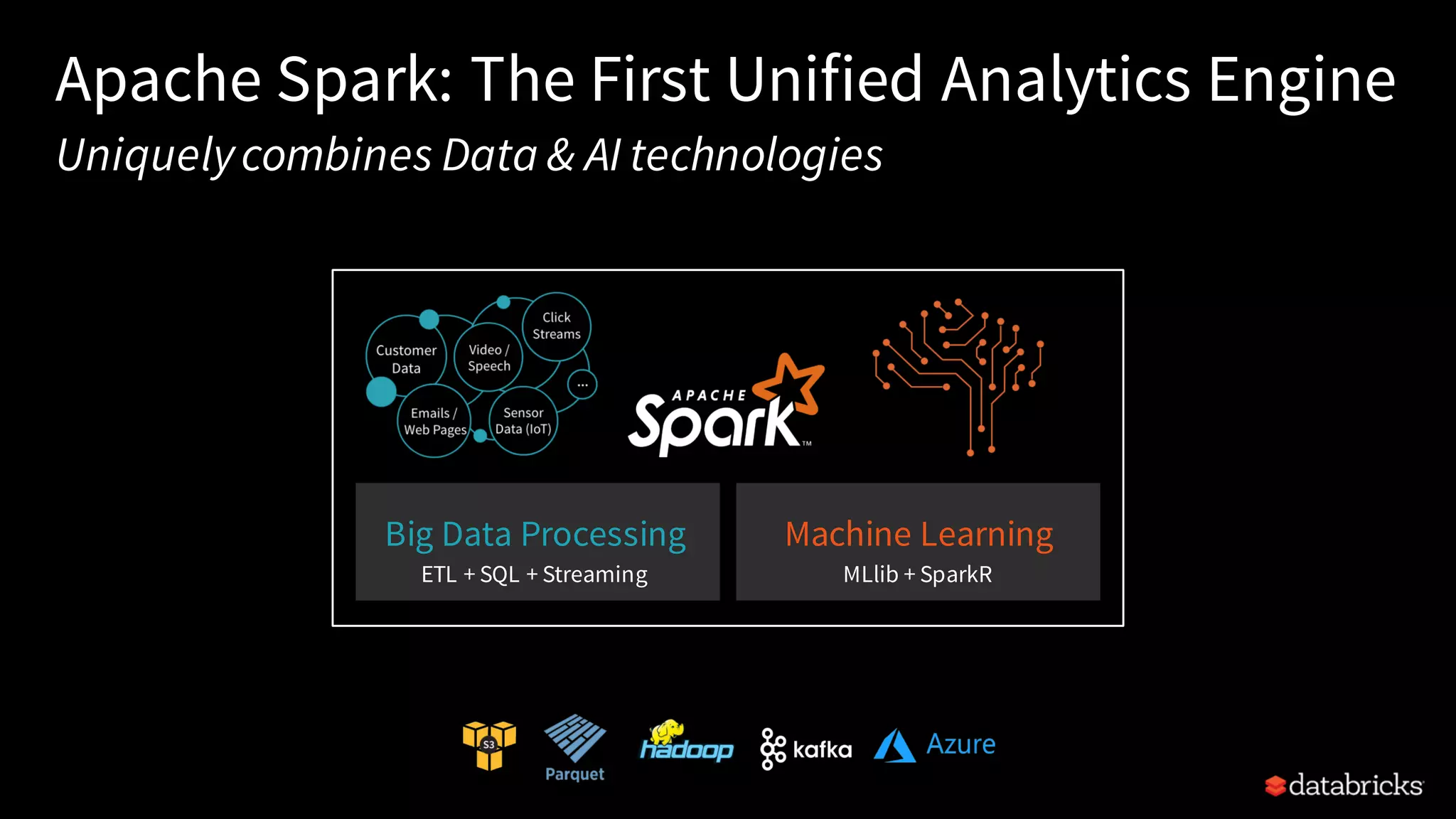
Discussion on the evolution of big data systems leading to Apache Spark, emphasizing its unified processing engine.
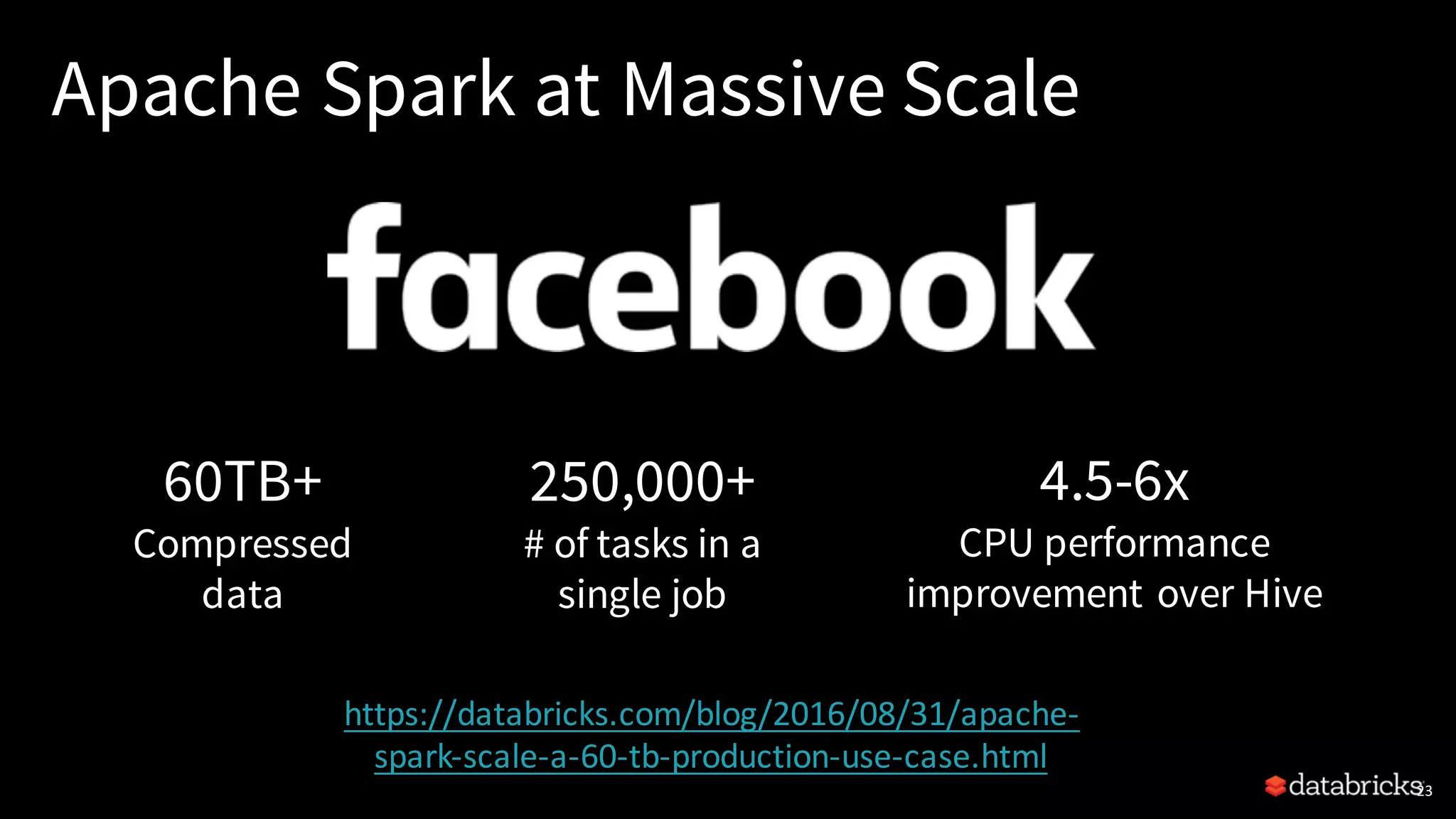
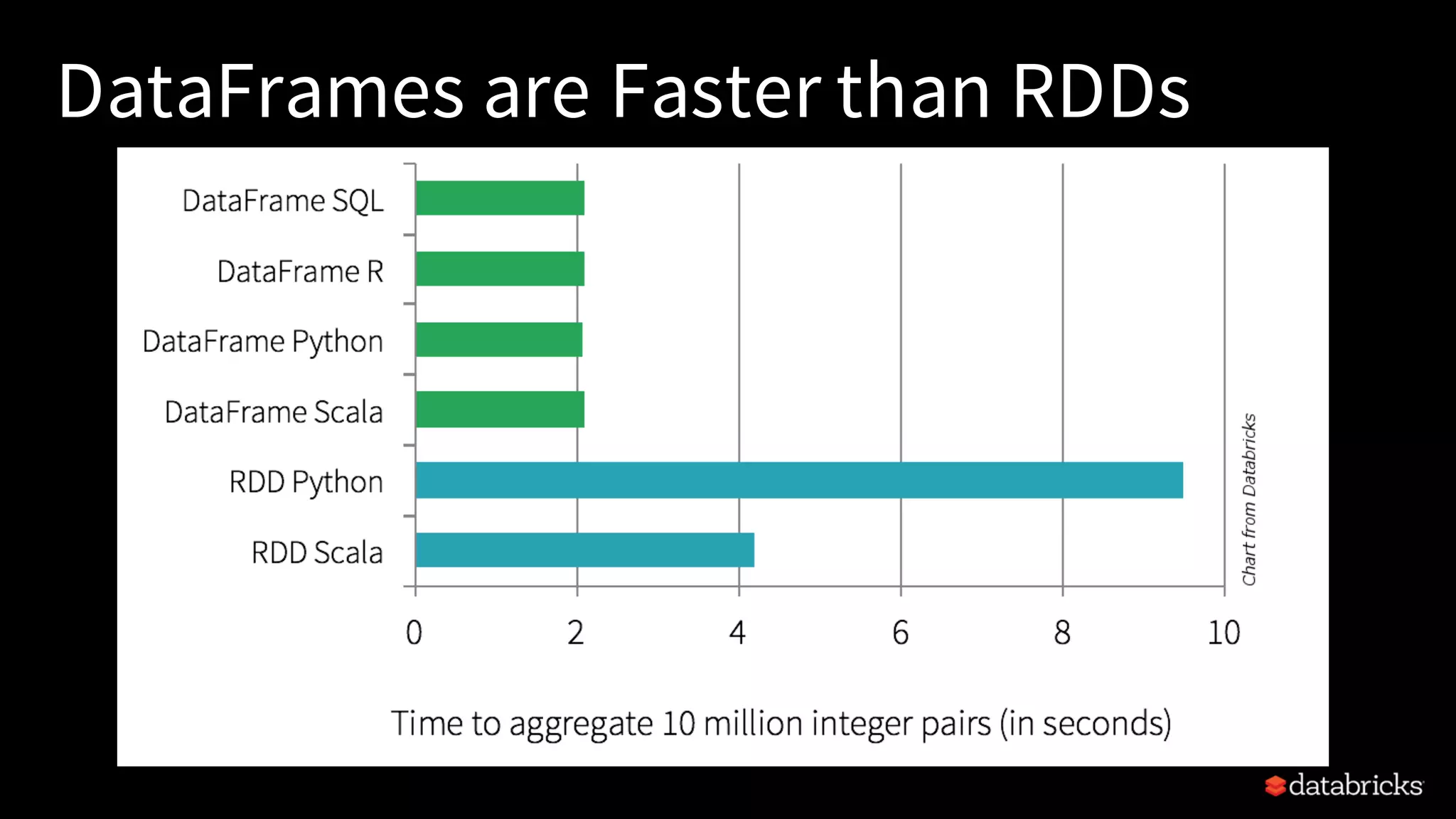
Explains common use cases like ETL, machine learning, SQL analytics, and the speed advantage of Spark over Hadoop.
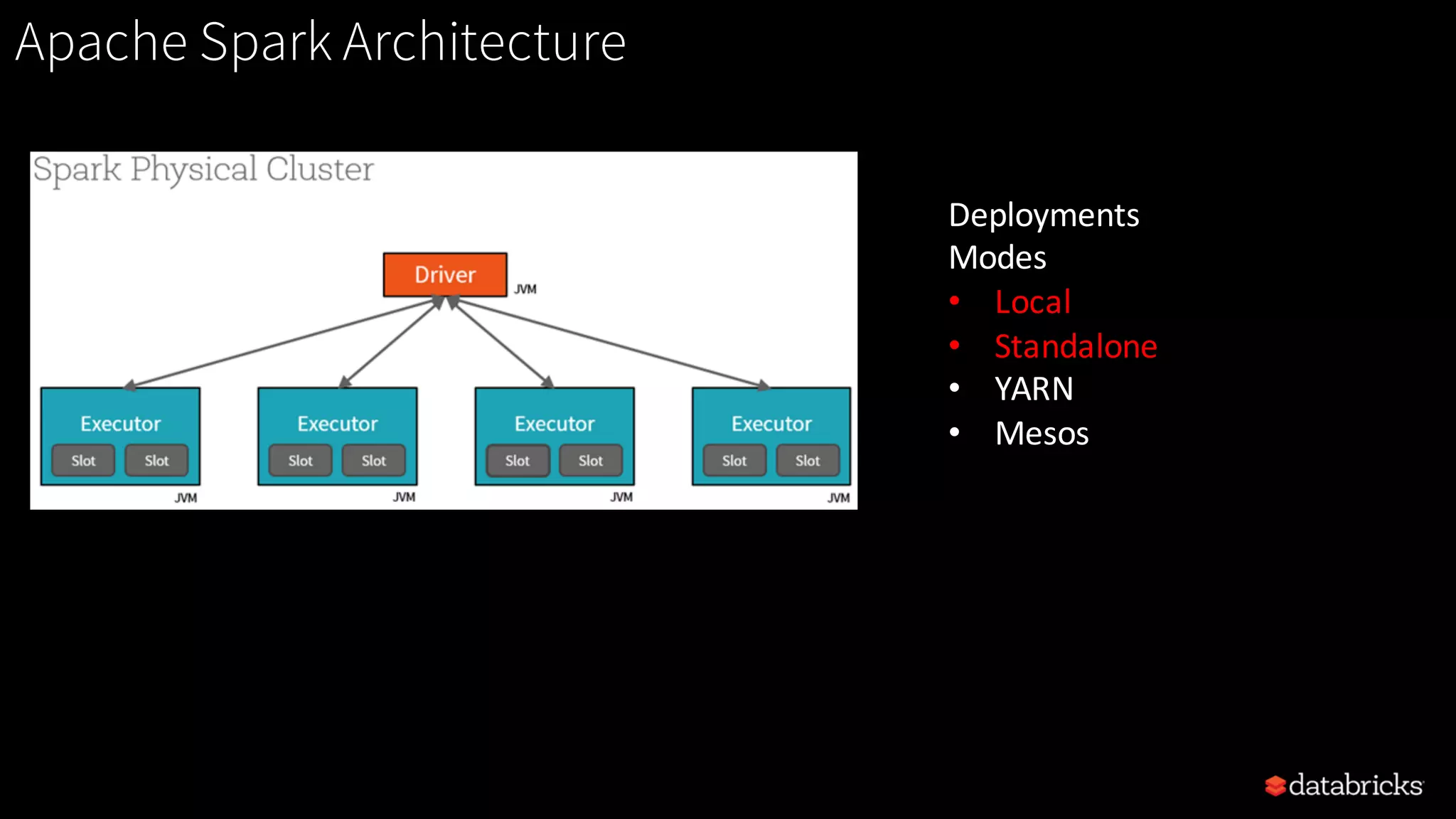
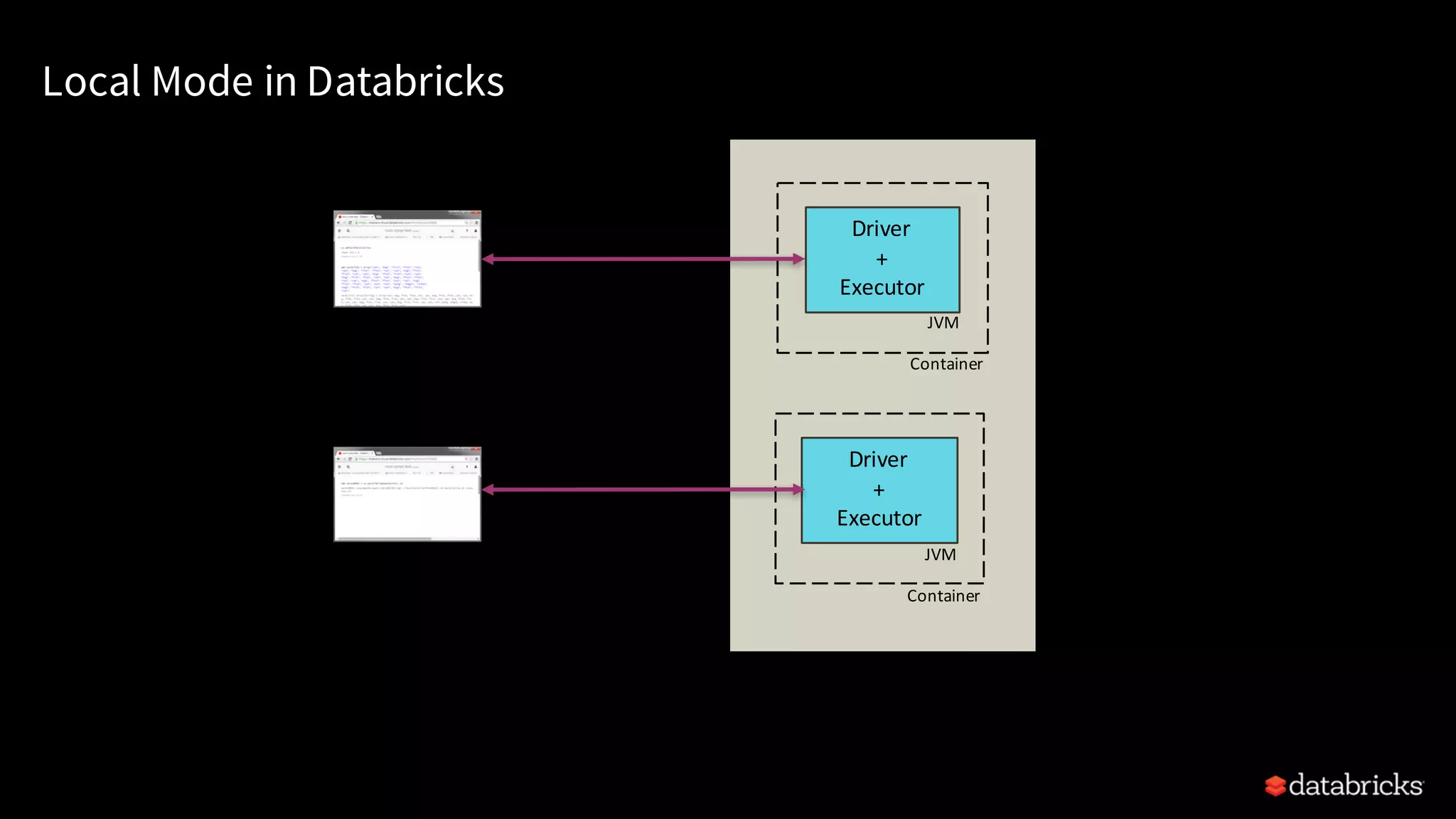
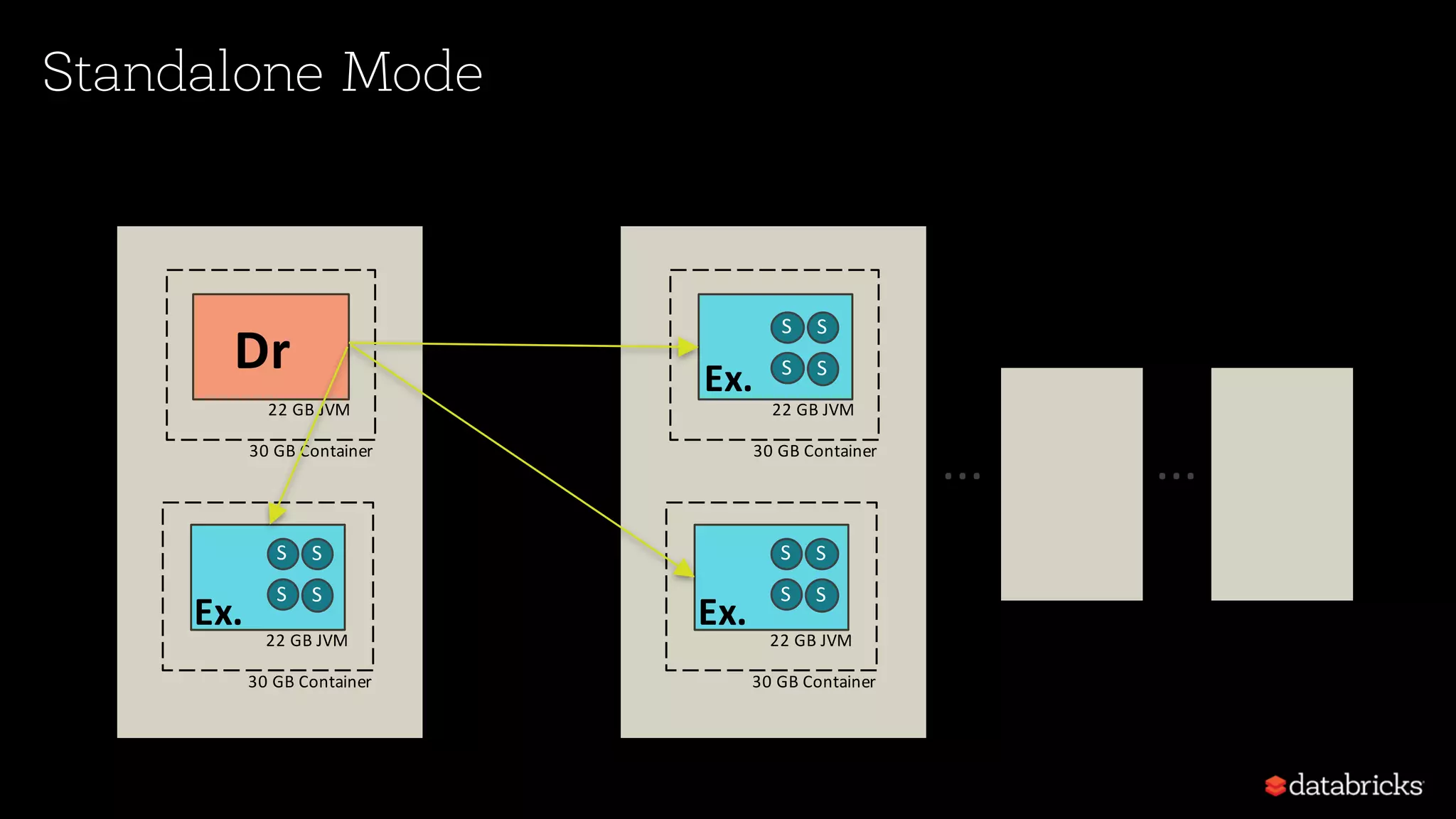
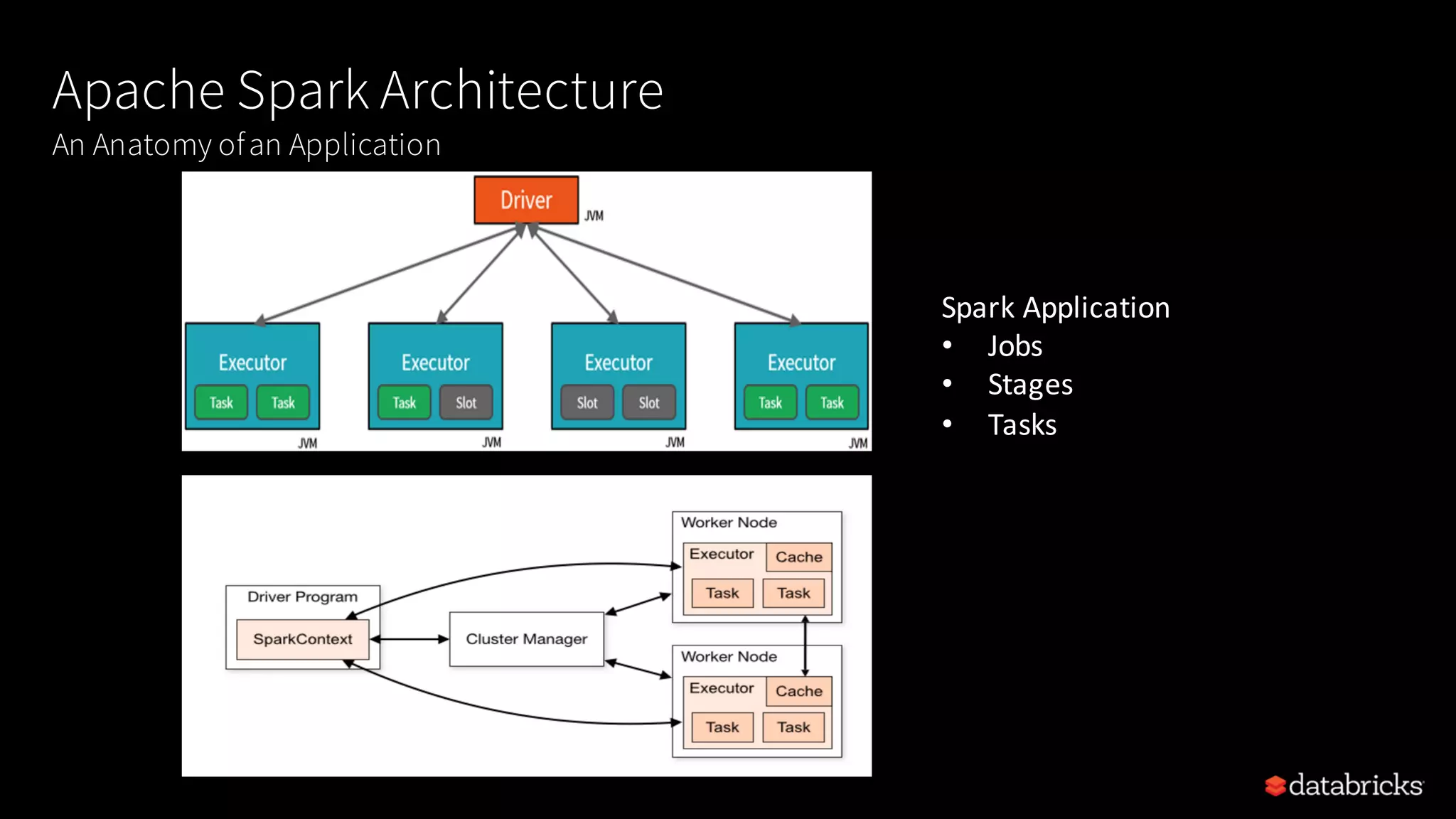
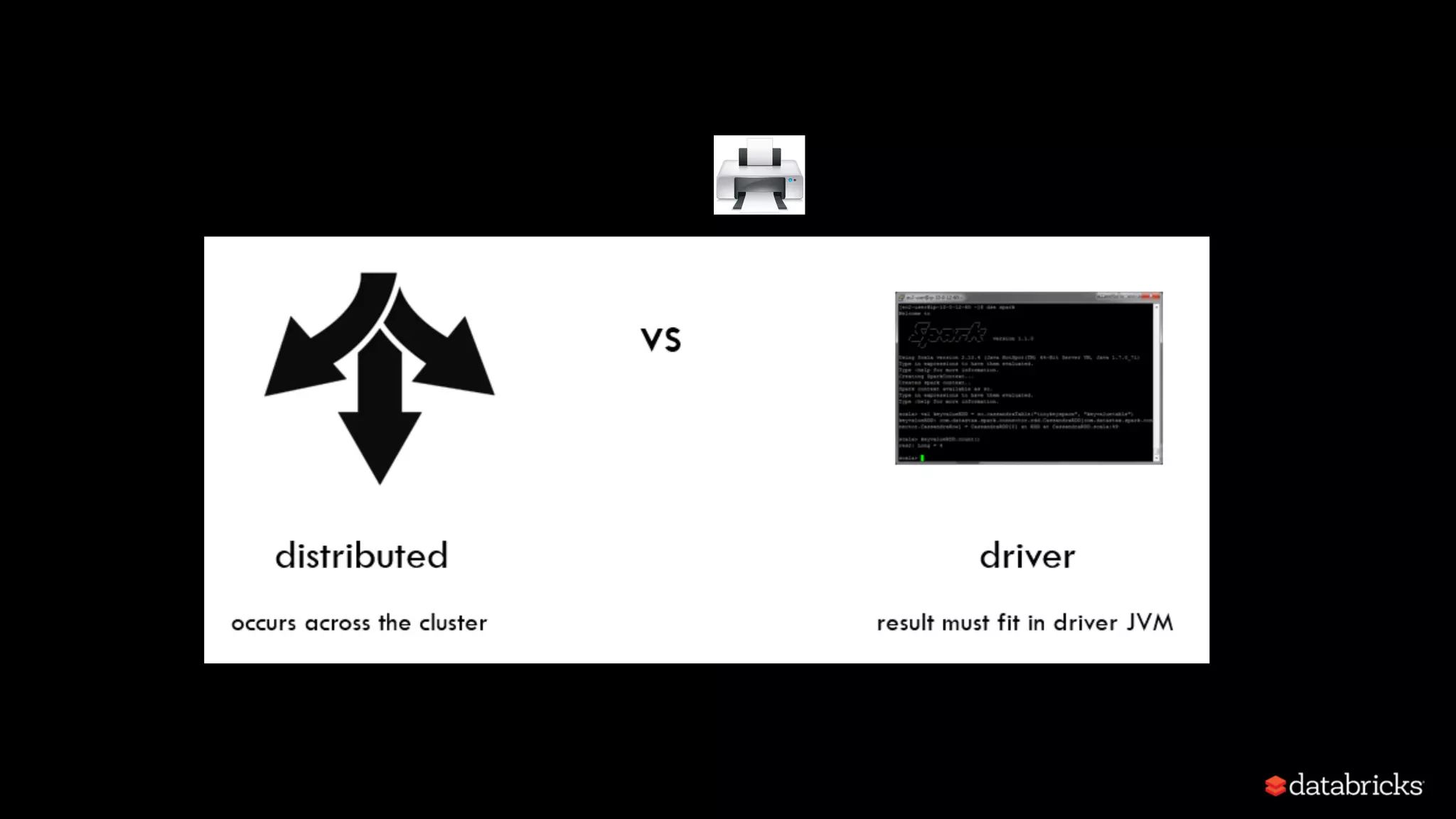
Details of Spark architecture, deployment modes including local, standalone, YARN, and Kubernetes.
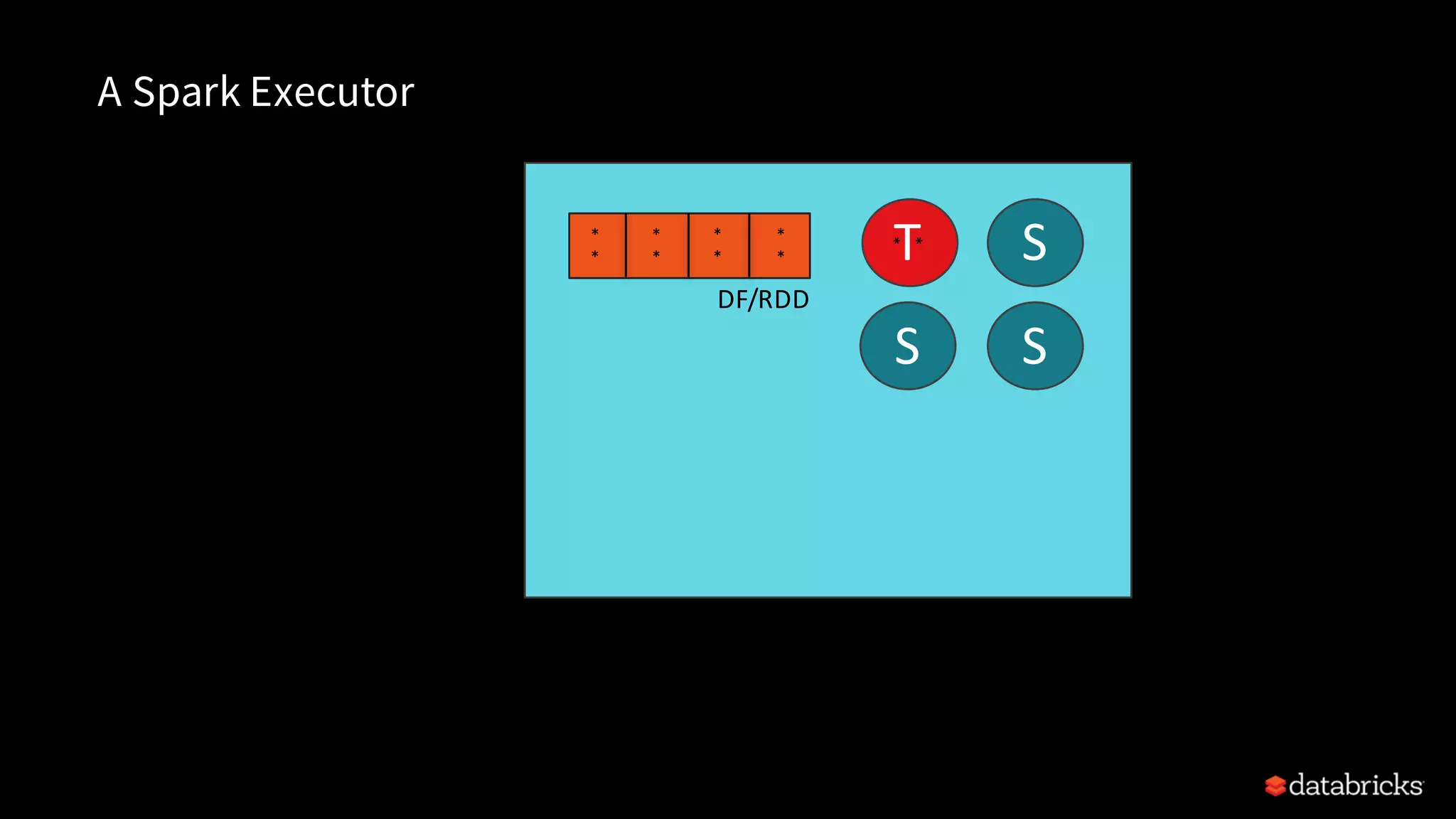
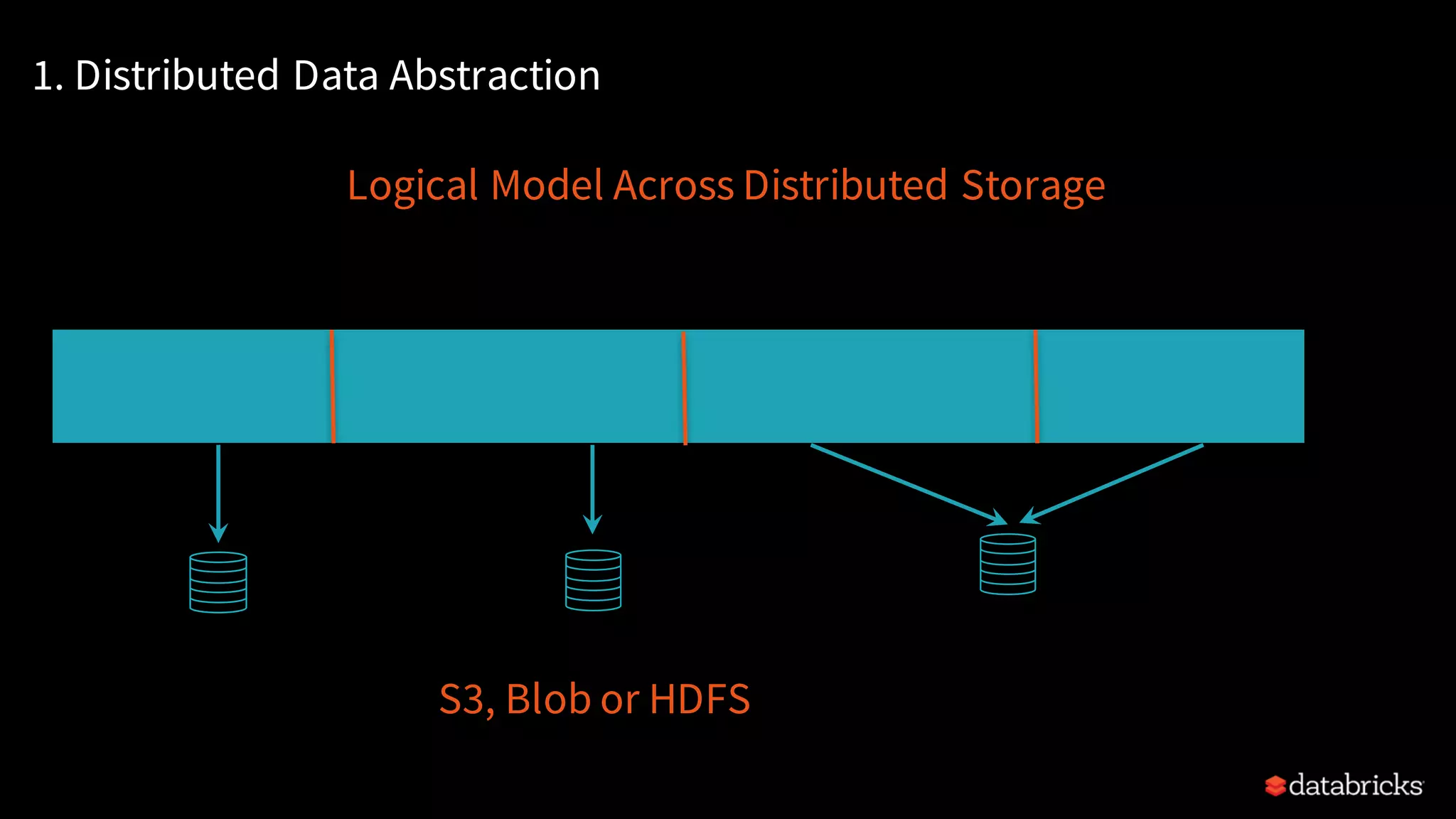
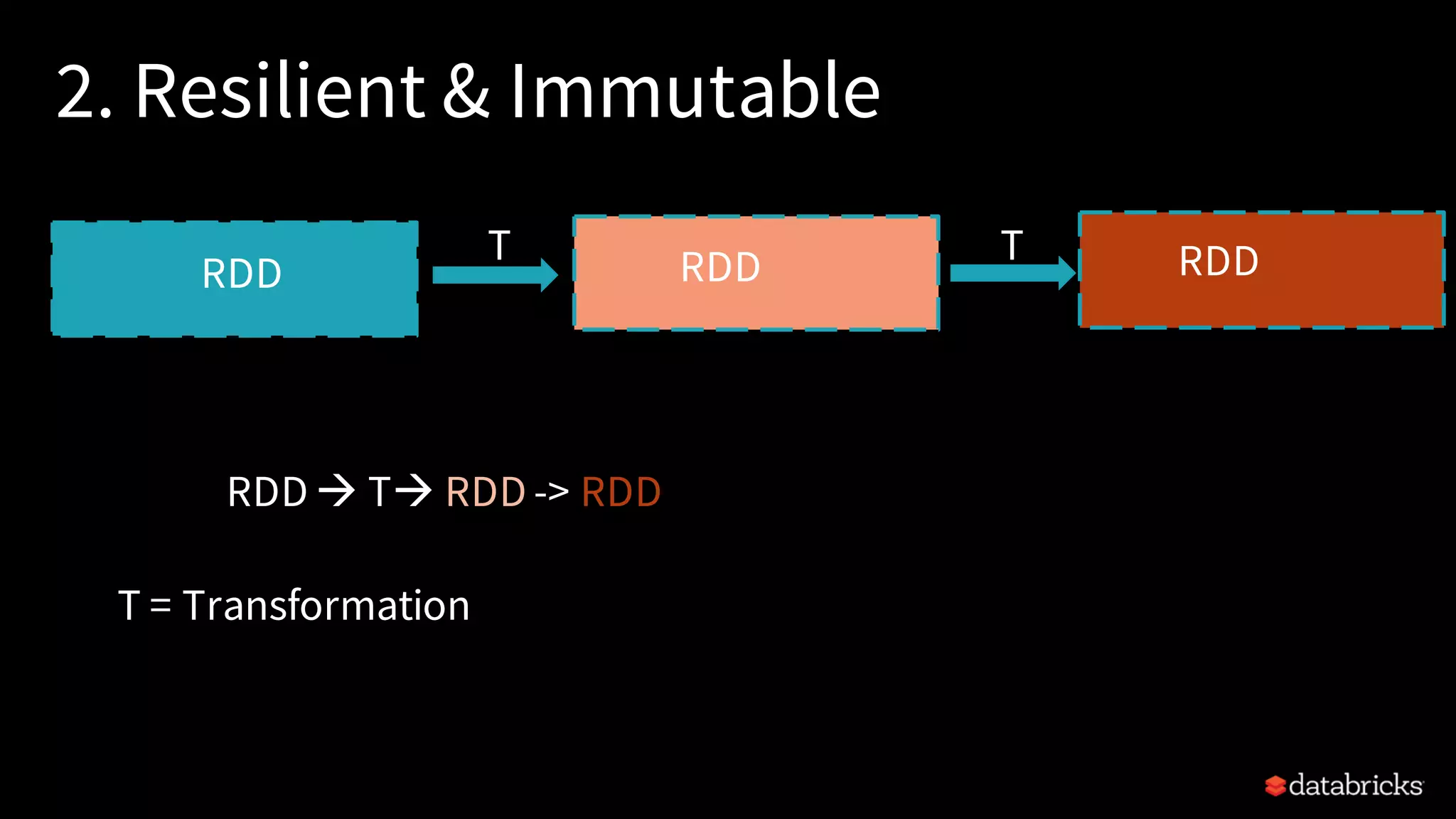
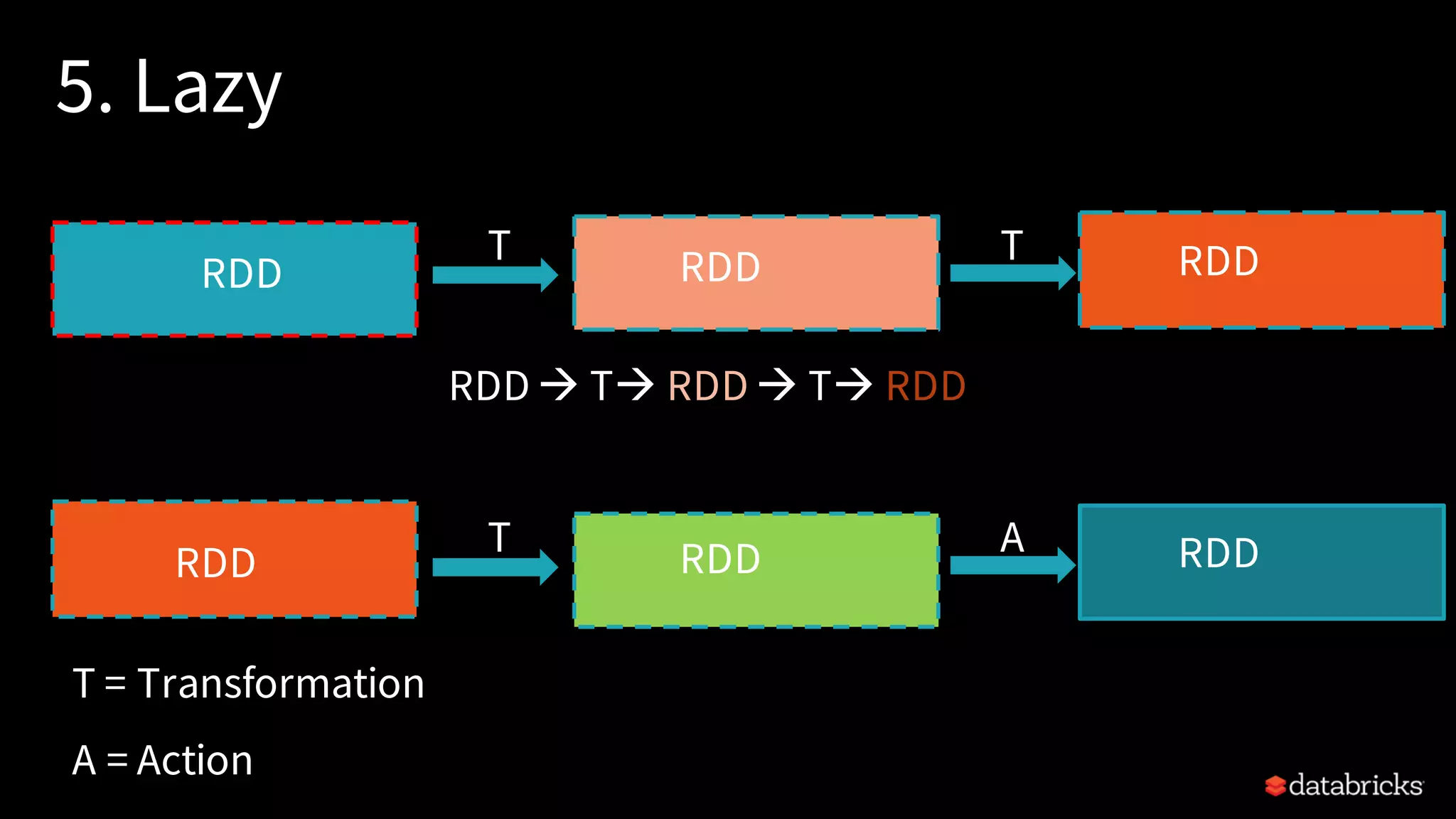
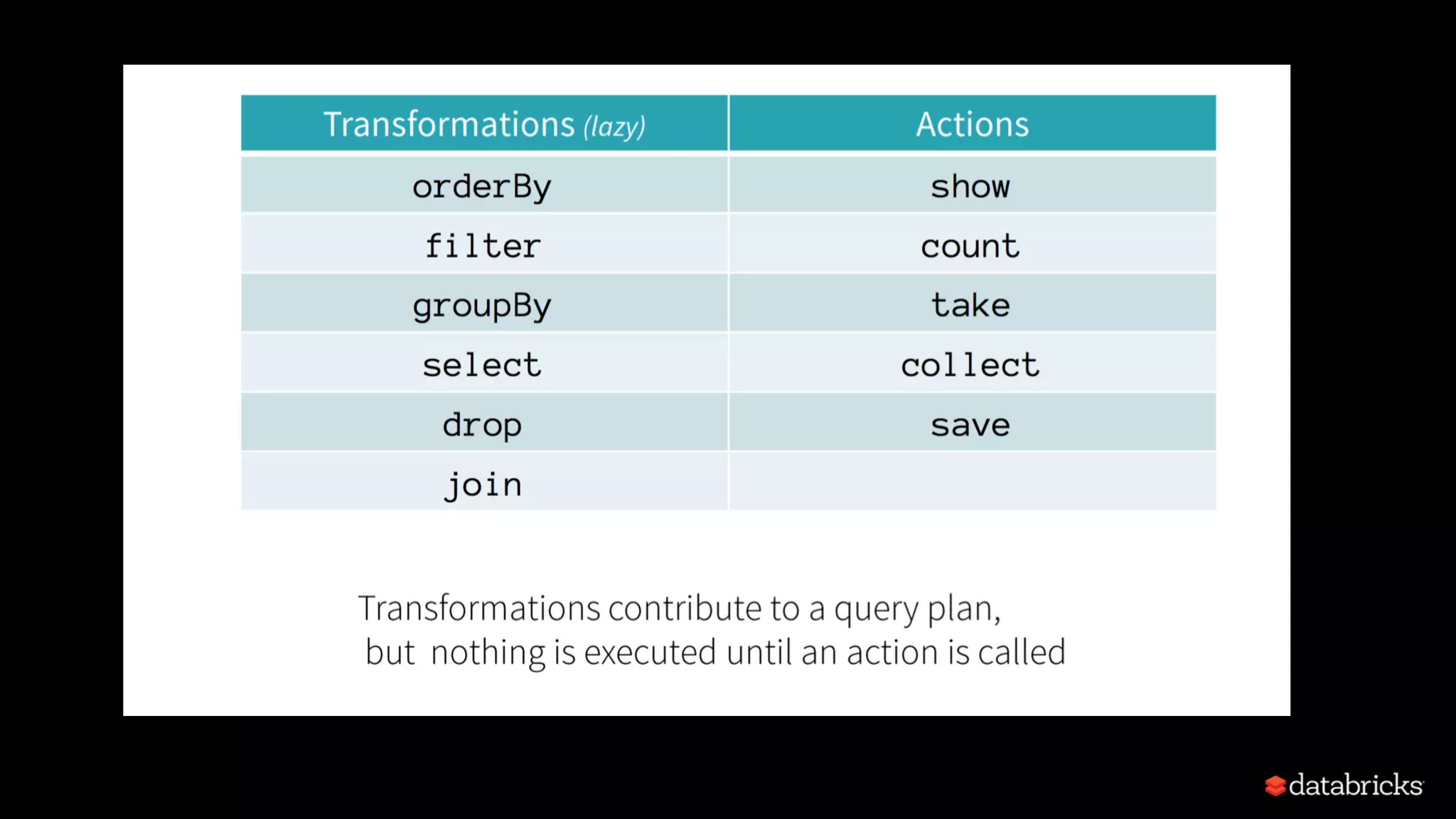
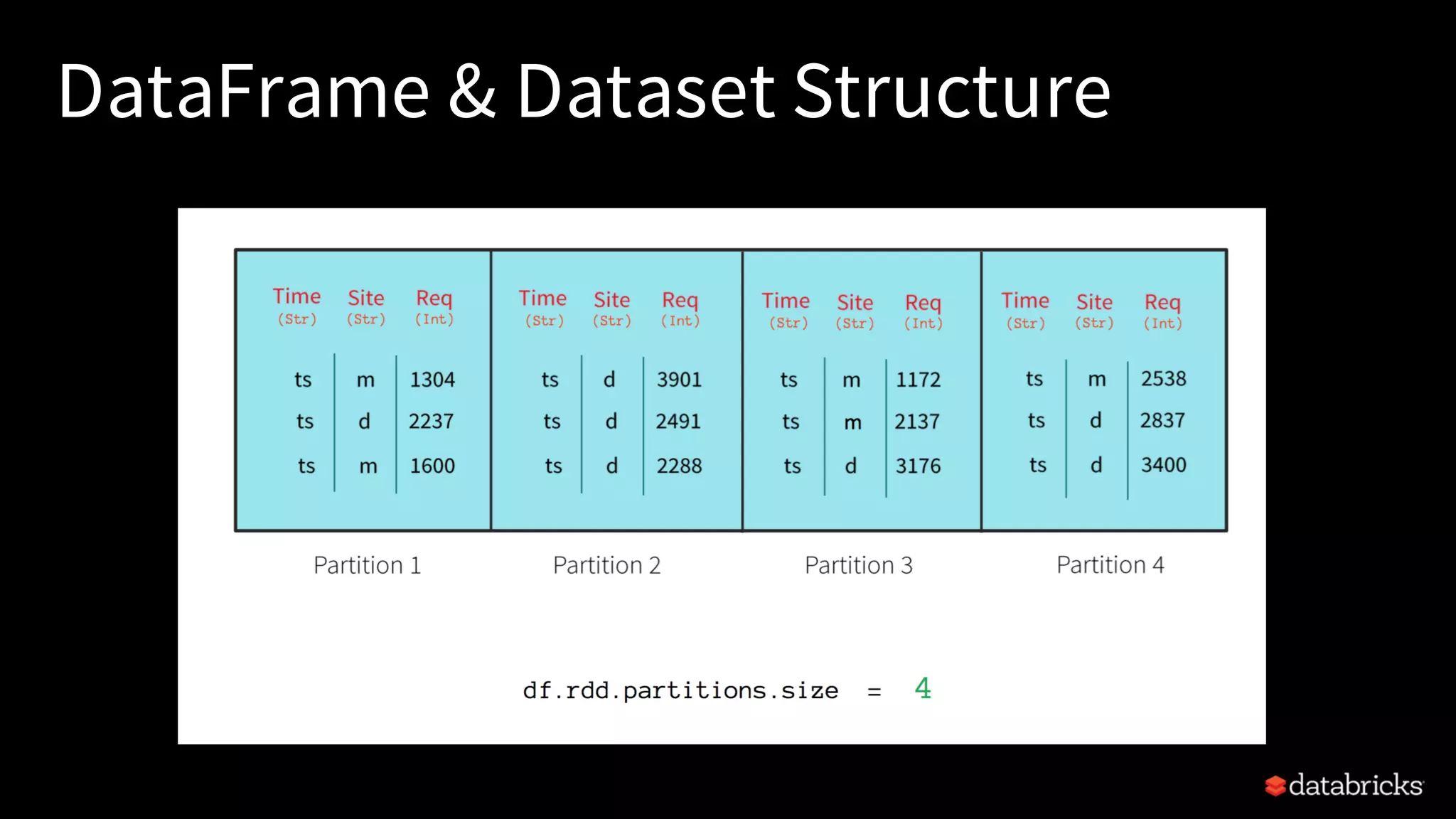
Explains Resilient Distributed Datasets (RDDs), their properties, transformations, and actions.
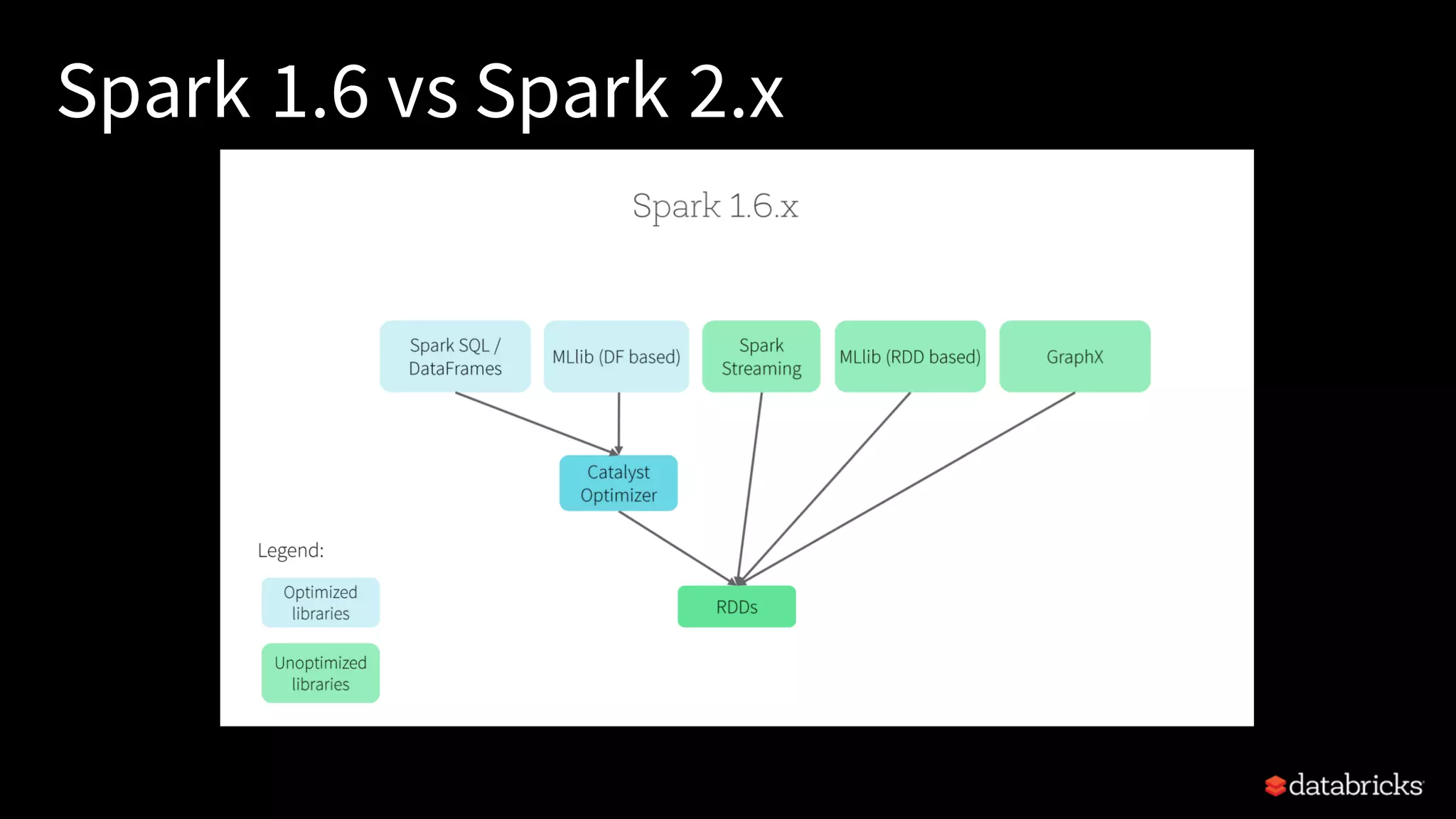
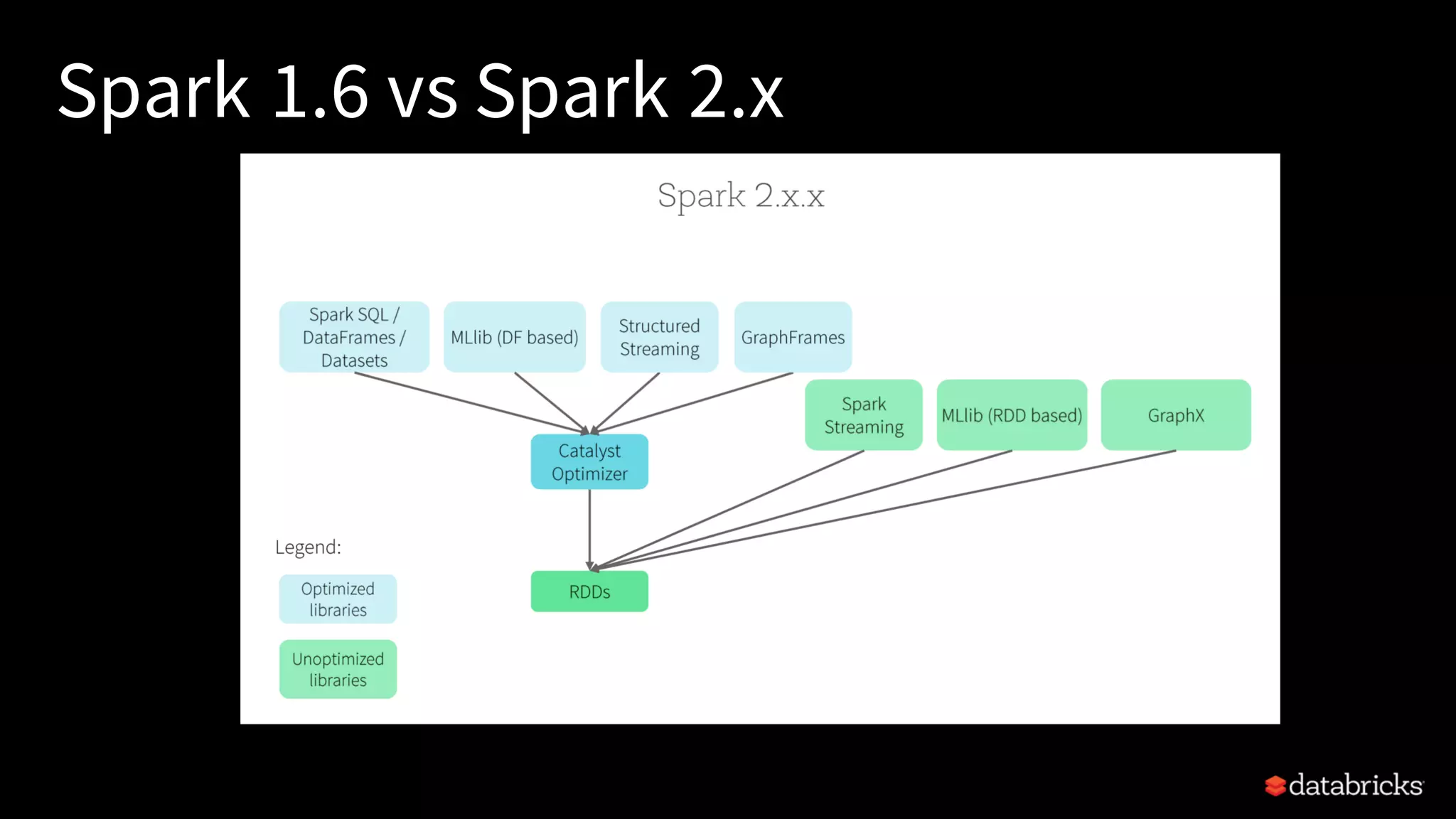
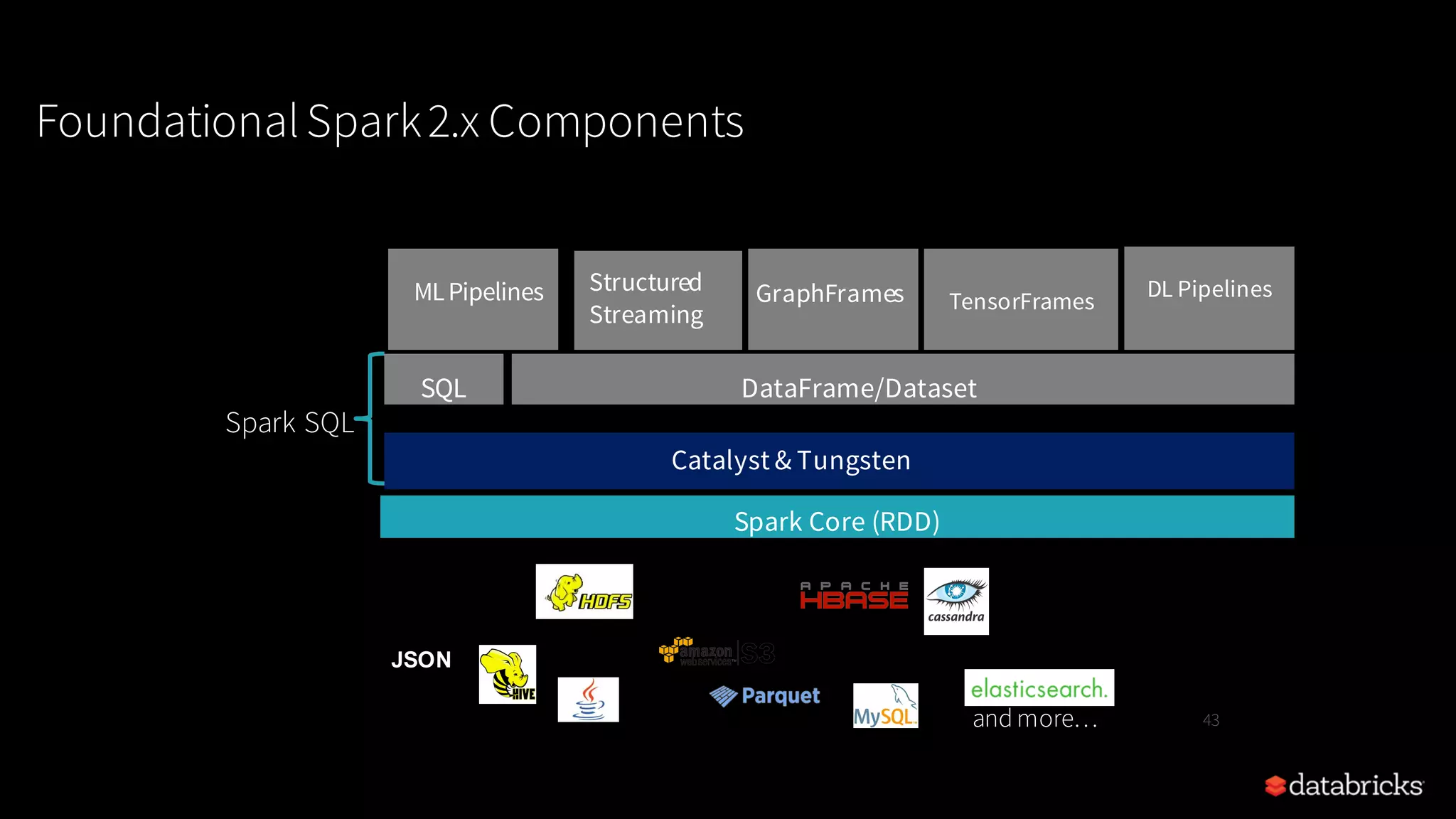
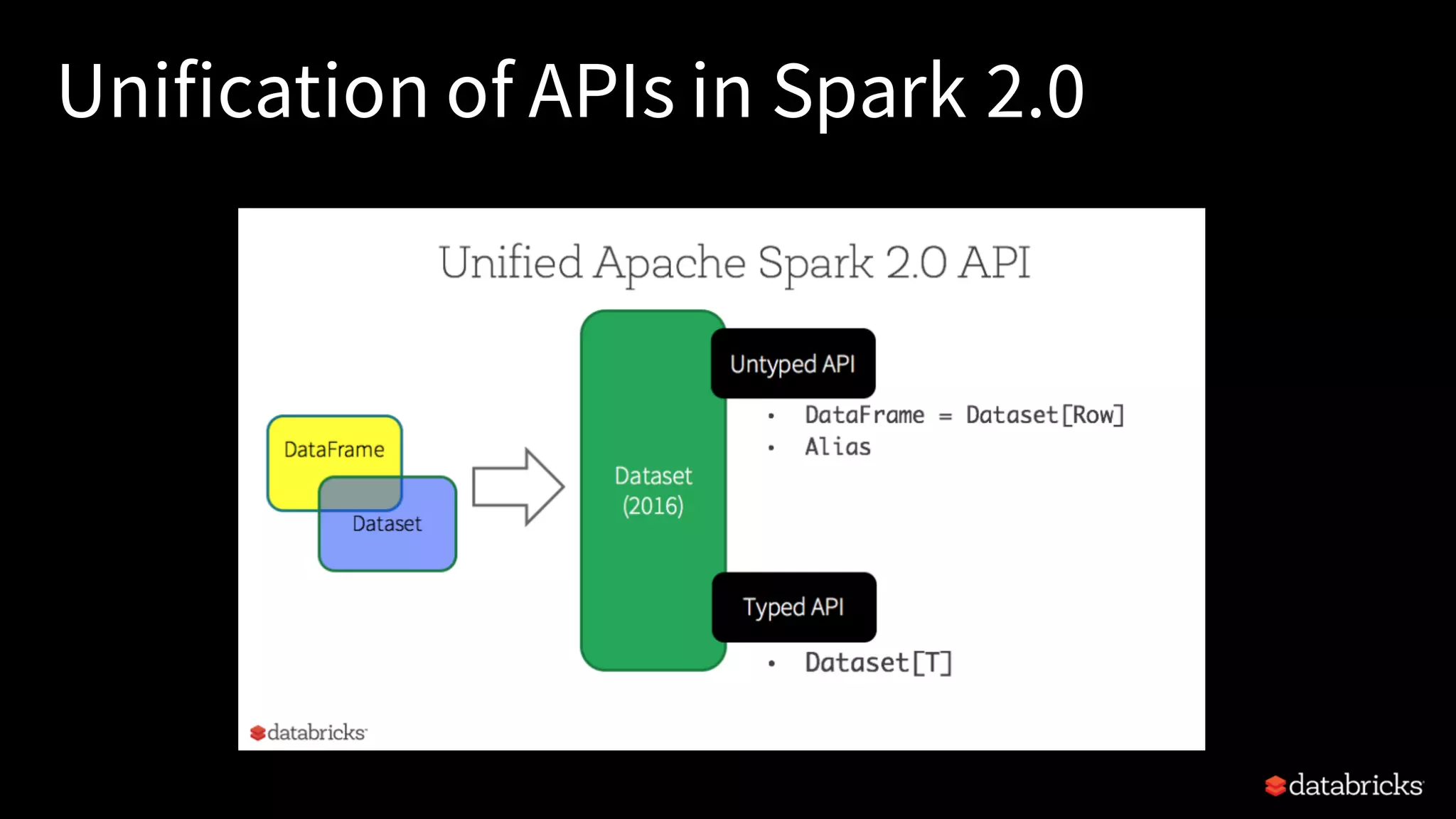
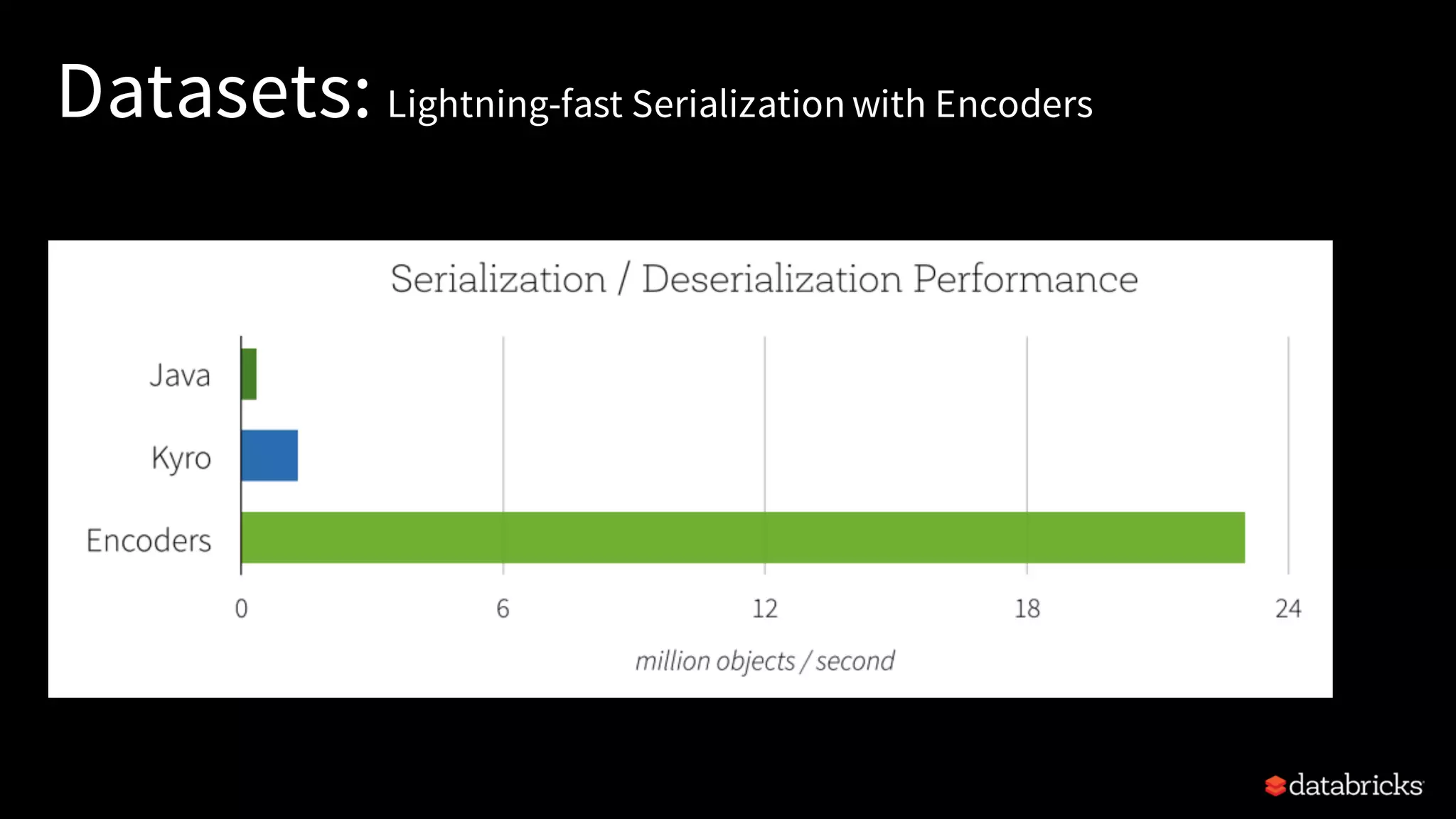
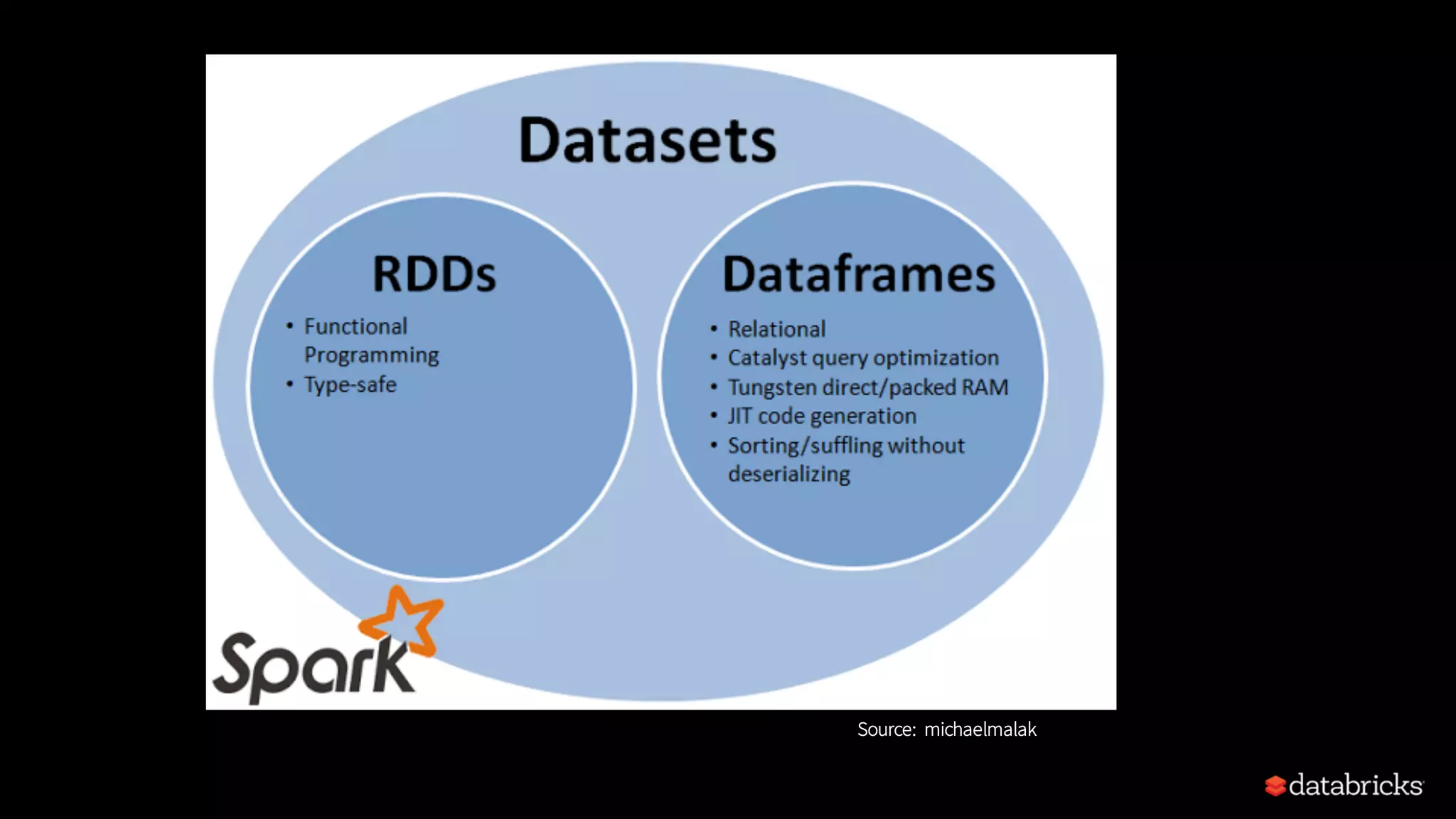
Describes the unification of APIs in Spark 2.x, focusing on DataFrames, Datasets, and their benefits.
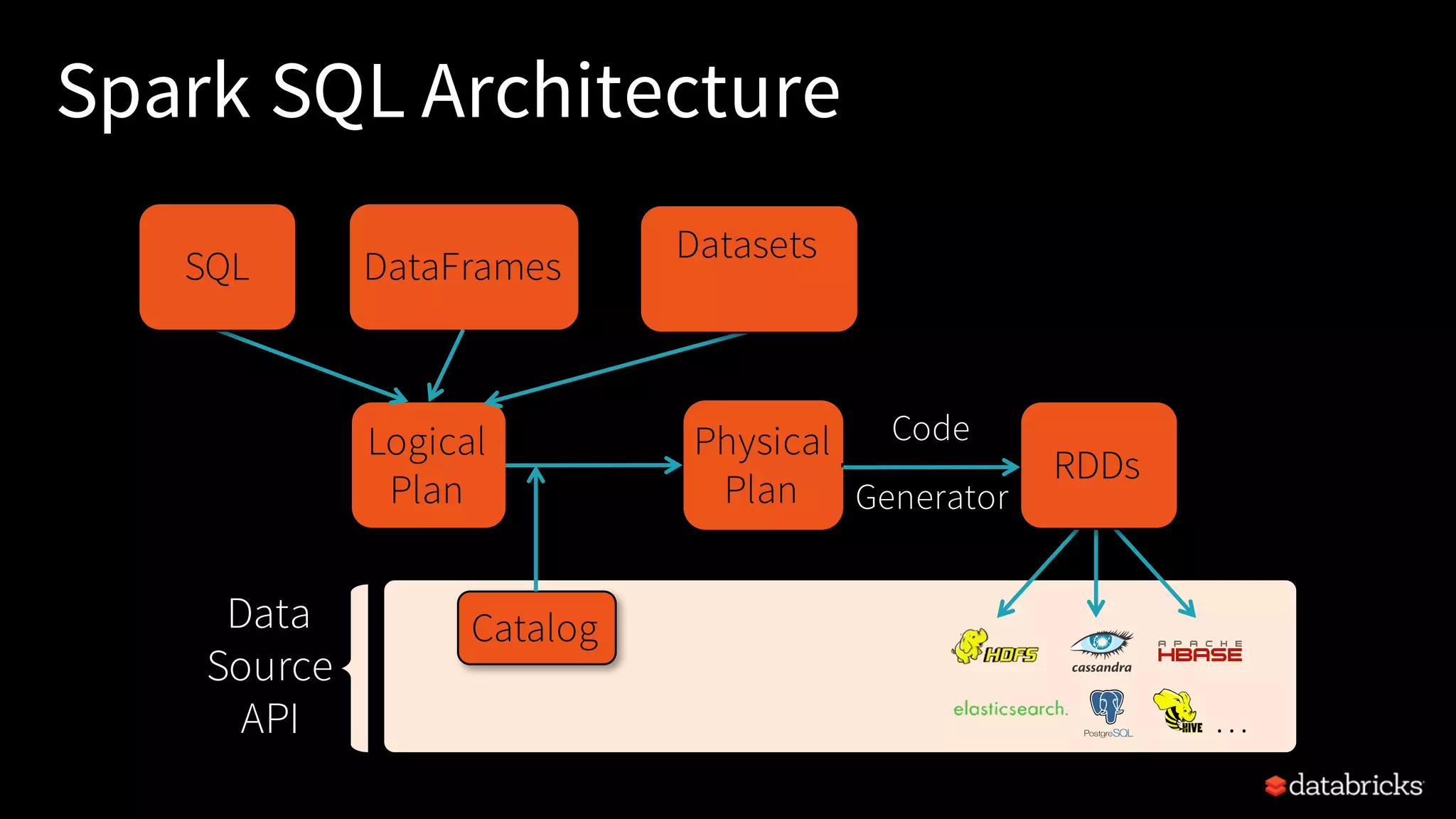
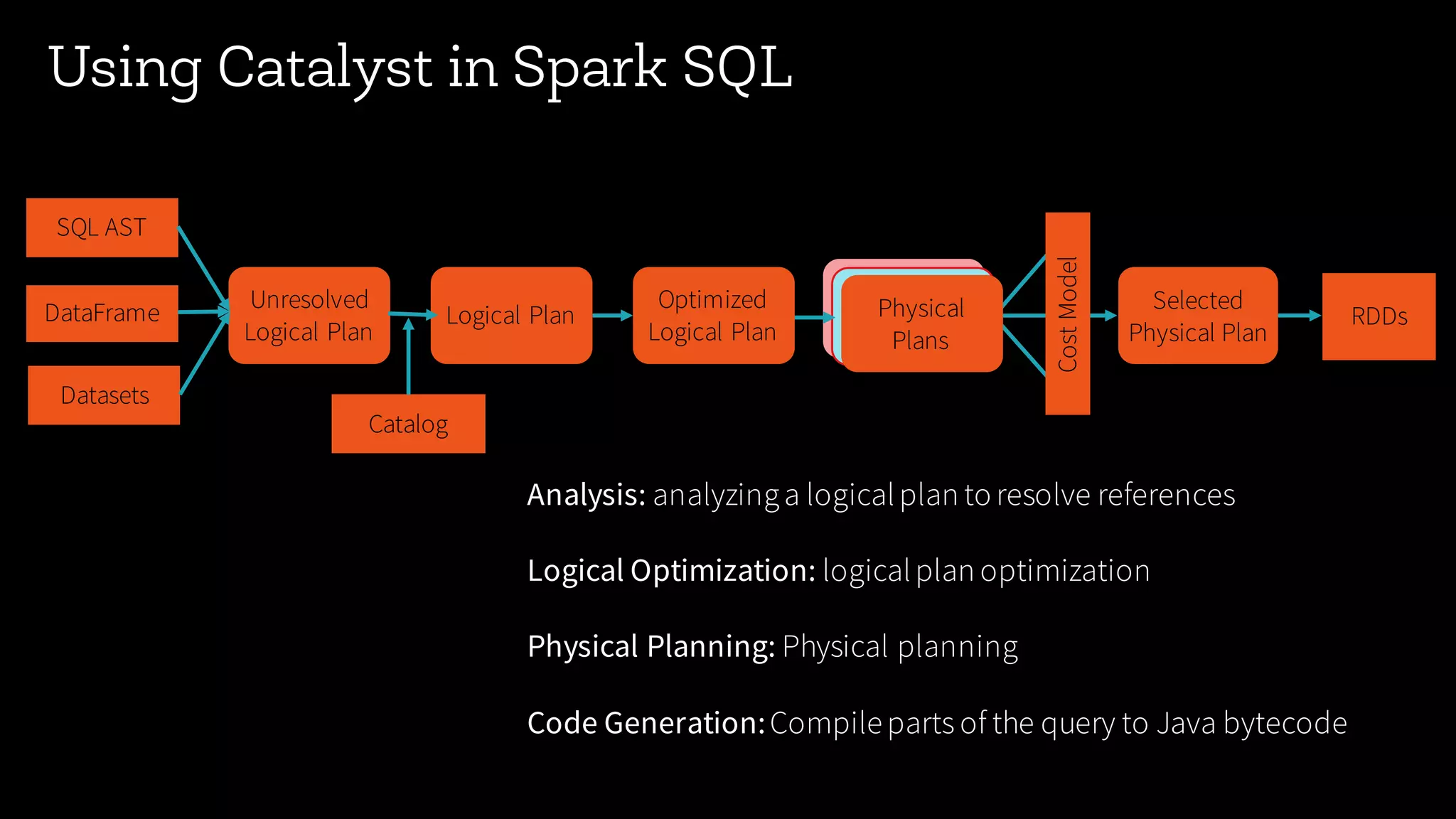
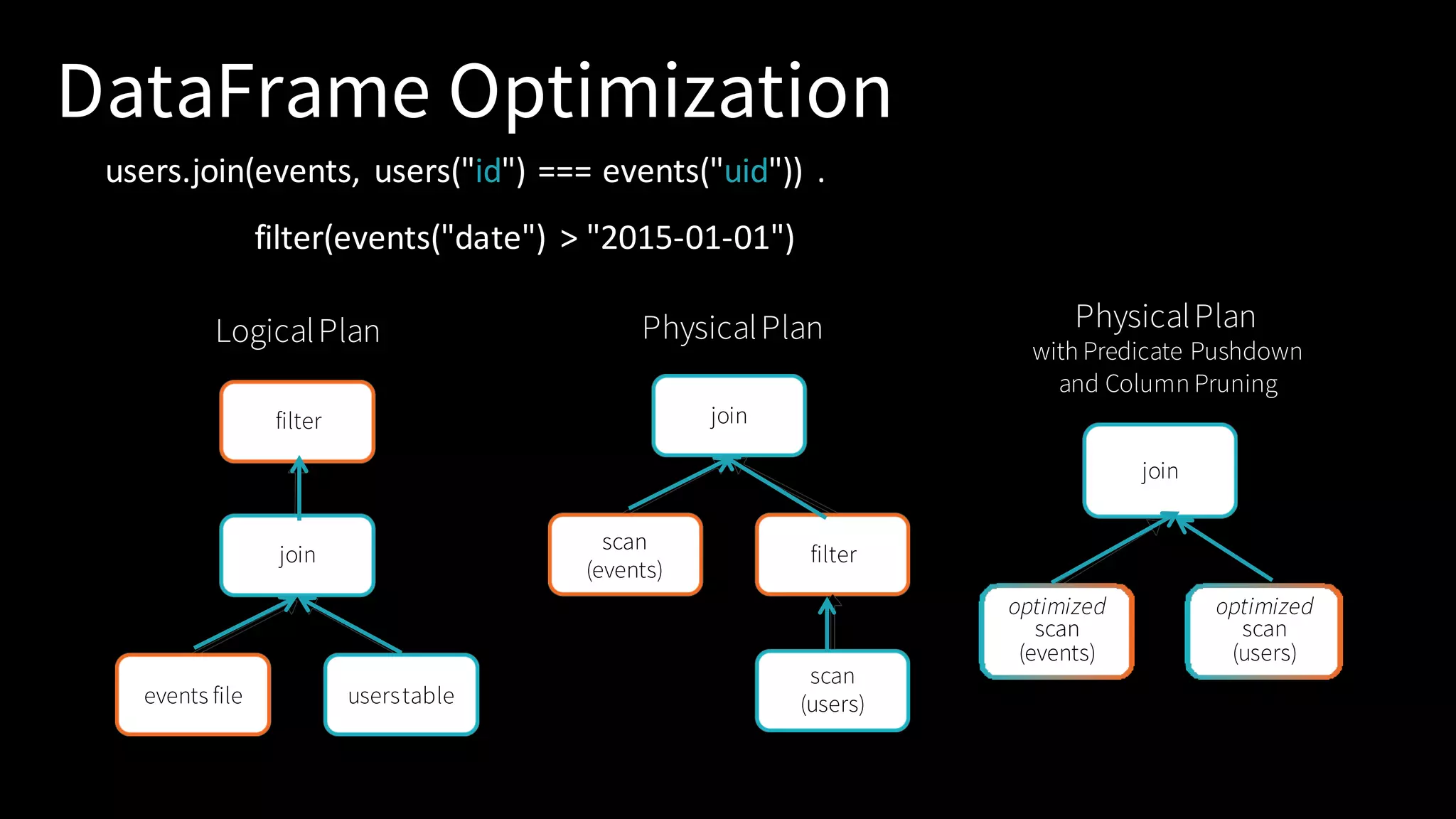
Insight into Spark SQL, its architecture, logical, and physical optimization features using the Catalyst Optimizer.
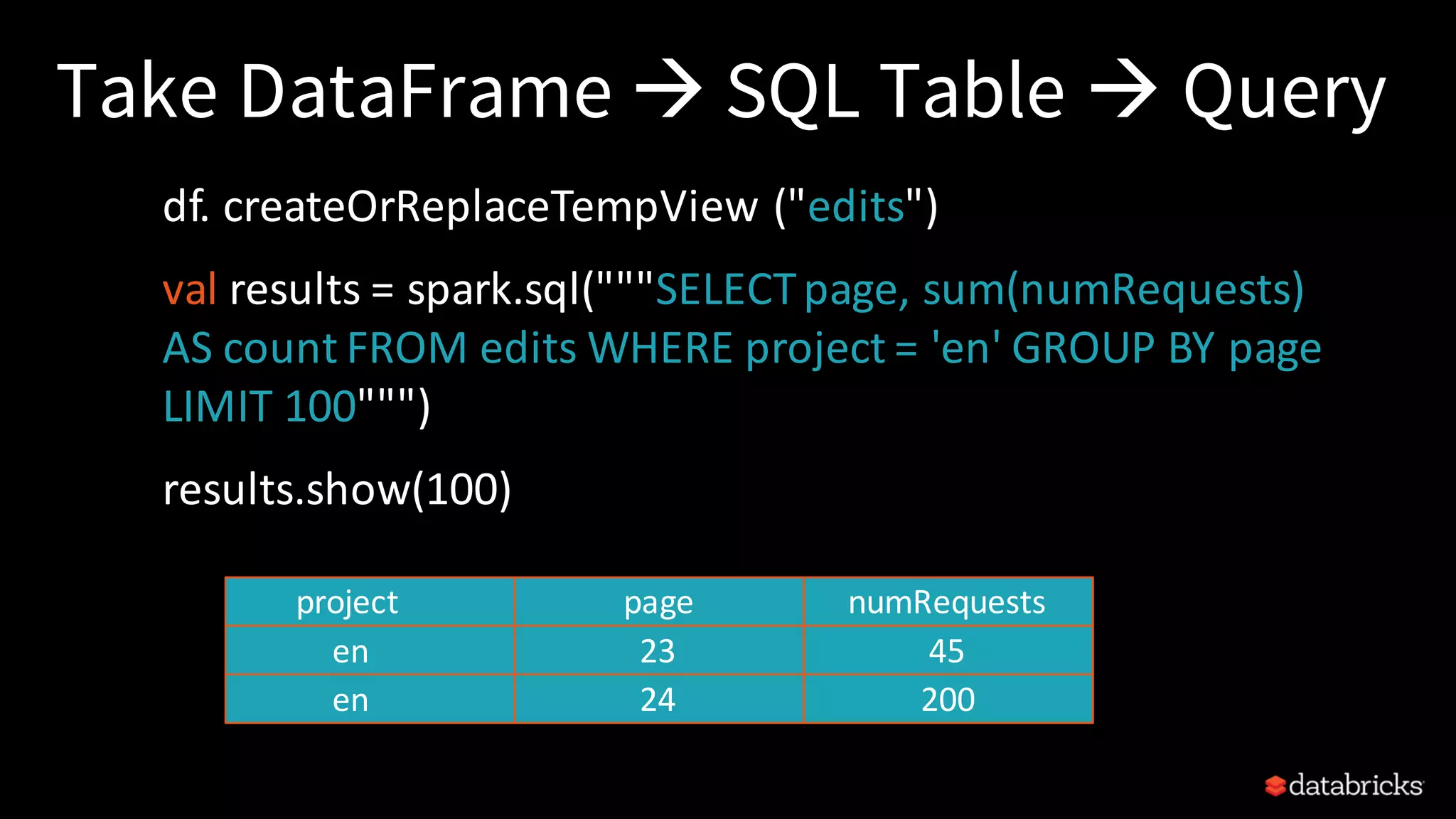
Demonstrates practical coding examples for DataFrames, SQL queries, and the advantages of using structured APIs.
Information about Databricks certification, test preparation, resources for learning Spark, and supporting documents.
Conclusion of the presentation with an invitation for questions from the audience.