Downloaded 1,297 times












 => U)) 3. Fn to produce results 14](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-14-2048.jpg)
 => U)) 3. Fn to produce results 15](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-15-2048.jpg)
 => U)) 3. Fn to produce results 16](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-16-2048.jpg)
 => U)) 3. Fn to produce results 17](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-17-2048.jpg)


![Seeing this on your own scala> counts.toDebugString res84: String = (2) ShuffledRDD[296] at reduceByKey at <console>:17 +-(3) MappedRDD[295] at map at <console>:17 | FilteredRDD[294] at filter at <console>:15 | MappedRDD[293] at map at <console>:15 | input.text MappedRDD[292] at textFile at <console>:13 | input.text HadoopRDD[291] at textFile at <console>:13 25 (indentations indicate a shuffle boundary)](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-25-2048.jpg)

![Example: take(N) action class RDD { def take(n: Int) { val results = new ArrayBuffer[T] var partition = 0 while (results.size < n) { result ++= sc.runJob(this, partition, it => it.toArray) partition = partition + 1 } return results.take(n) } } 27](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-27-2048.jpg)




![Choice of Serializer Serialization is sometimes a bottleneck when shuffling and caching data. Using the Kryo serializer is often faster. val conf = new SparkConf() conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // Be strict about class registration conf.set("spark.kryo.registrationRequired", "true") conf.registerKryoClasses(Array(classOf[MyClass], classOf[MyOtherClass])) 33](https://image.slidesharecdn.com/stratadebuggingtalk-150221160850-conversion-gate02/75/Tuning-and-Debugging-in-Apache-Spark-33-2048.jpg)














The document discusses tuning and debugging of Apache Spark, detailing its execution model, RDD API, and the importance of understanding Spark's internal mechanisms for optimizing performance. It emphasizes tasks, stages, jobs, and data shuffling while suggesting strategies to improve execution speed, such as using built-in operators and managing data partitioning effectively. The talk is geared towards participants familiar with Spark's core API, and mentions further resources and a conference for deeper insights.
Introduction to tuning and debugging in Apache Spark, speaker background, overview of Databricks, and talk objectives.
Outline of Spark's execution model emphasizing key concepts like jobs, stages, and tasks.
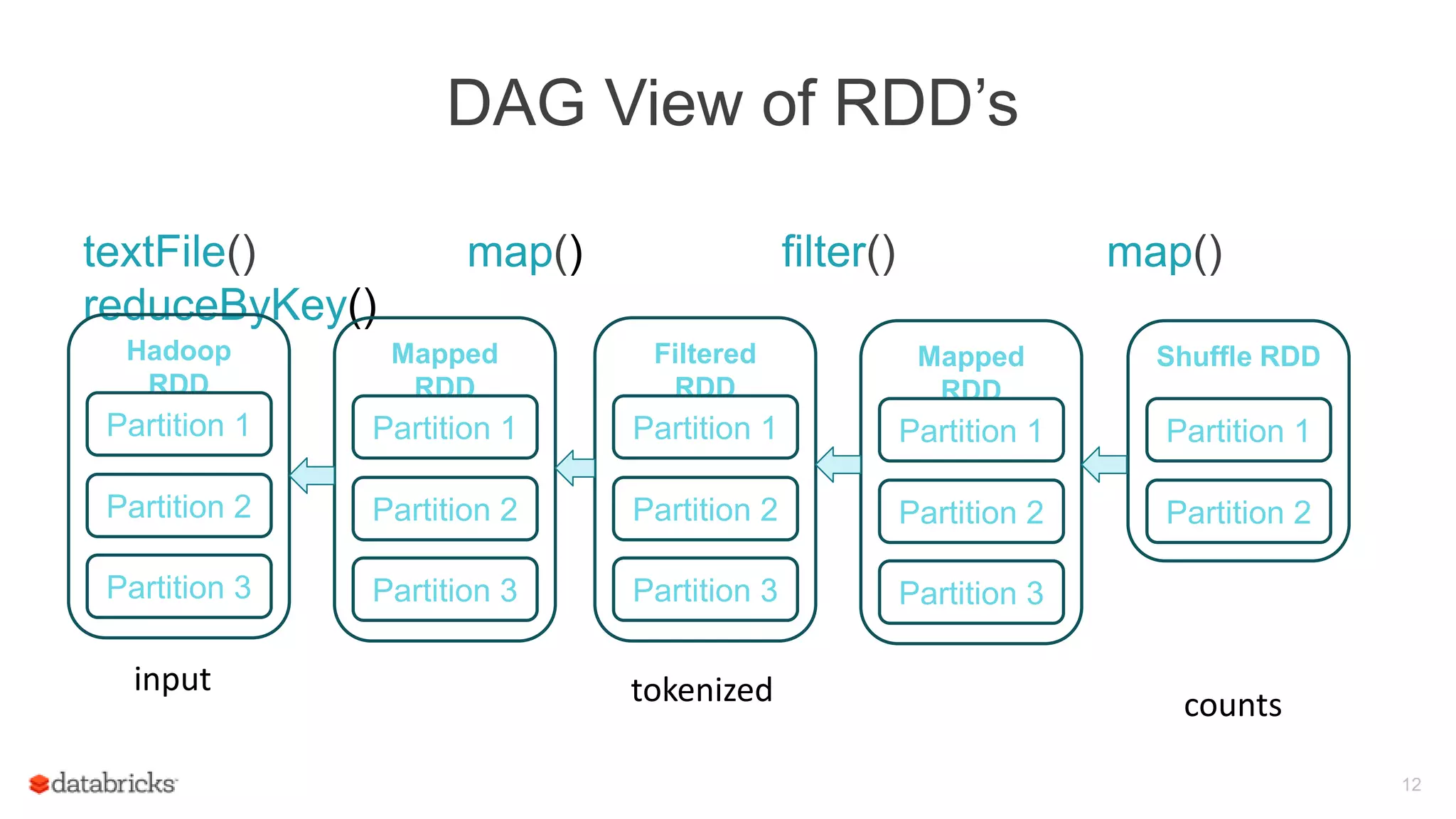
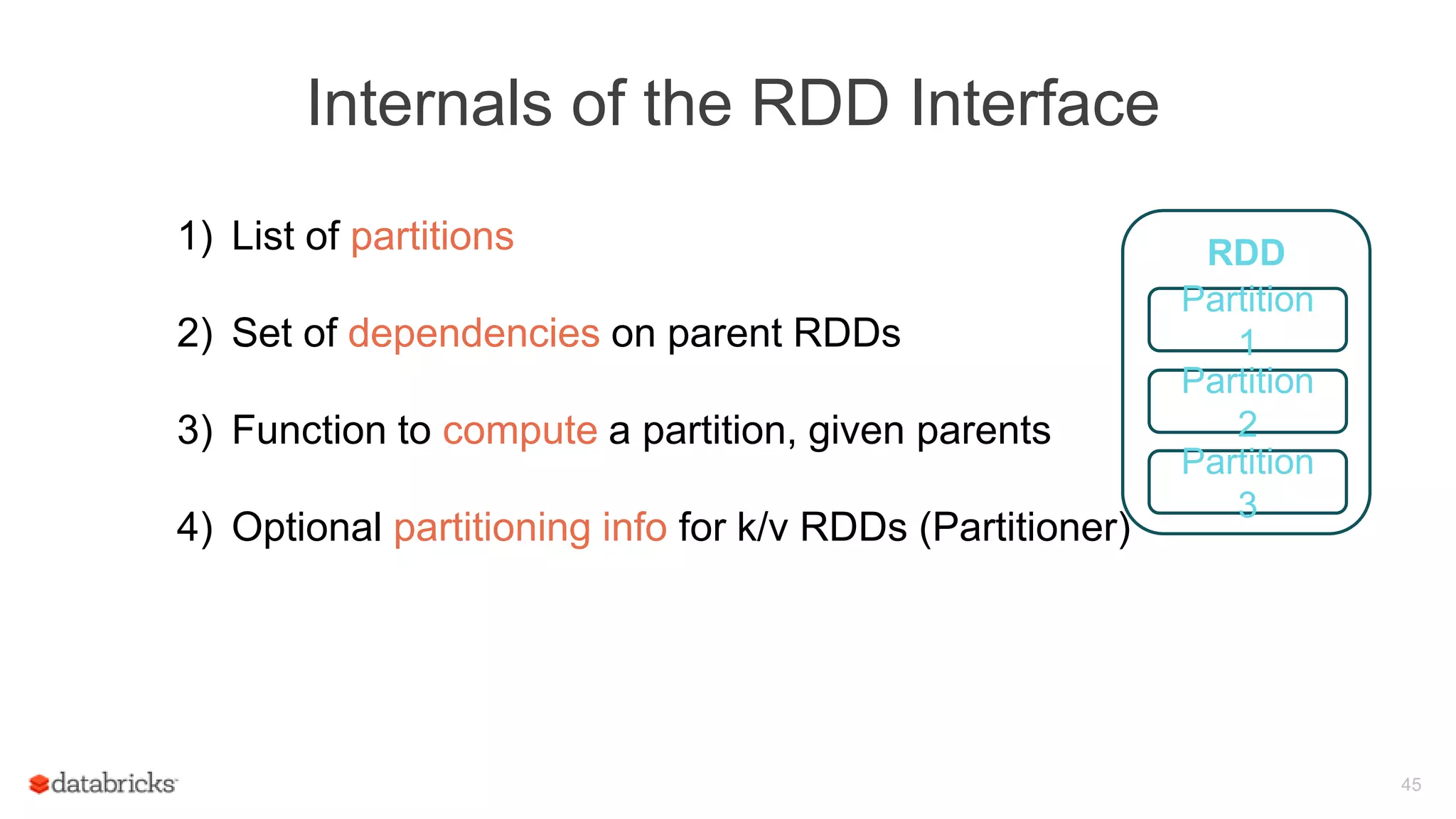
Overview of RDD API, illustrating how RDD transformations work and their representation as a Directed Acyclic Graph (DAG).
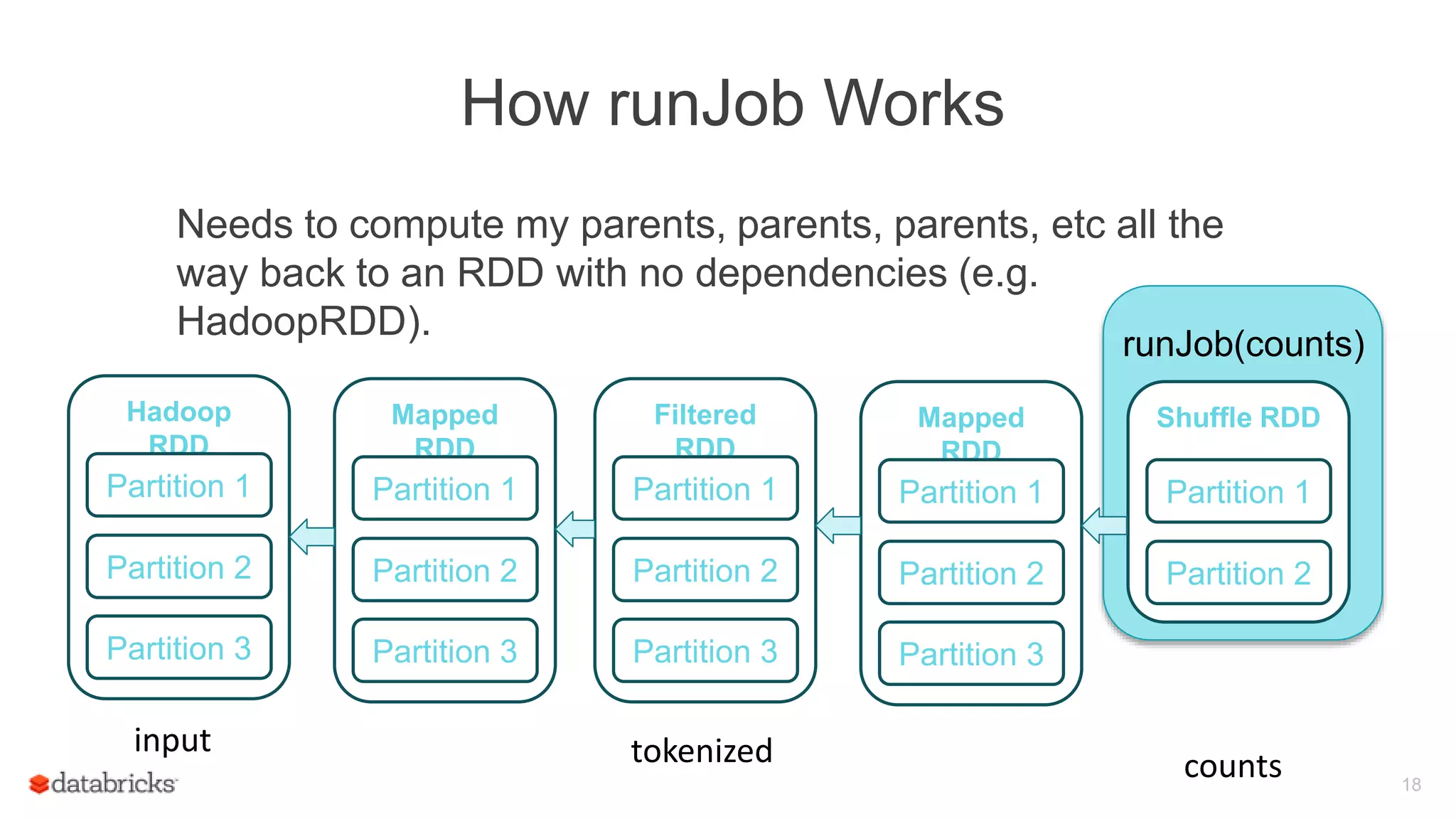
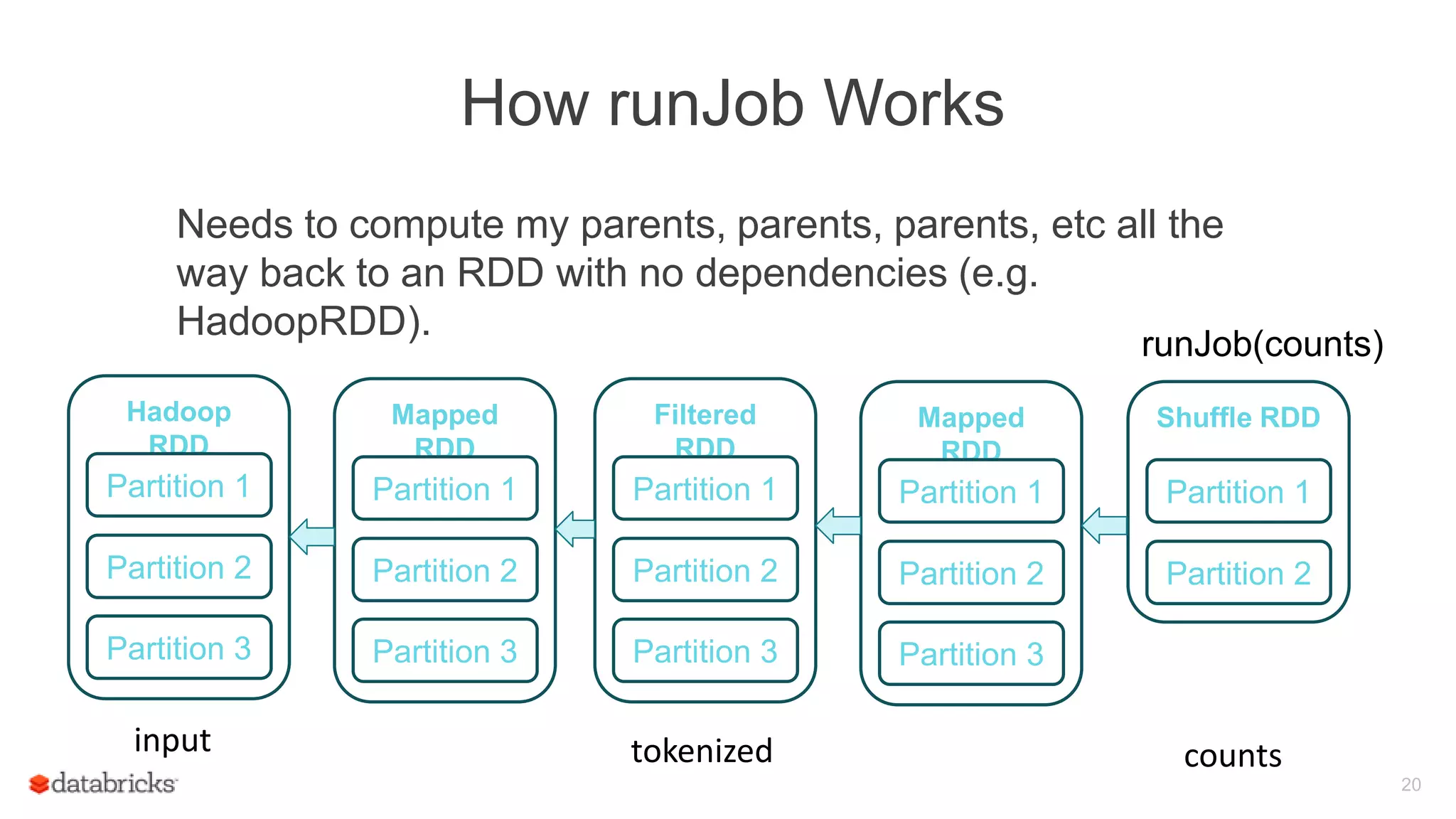
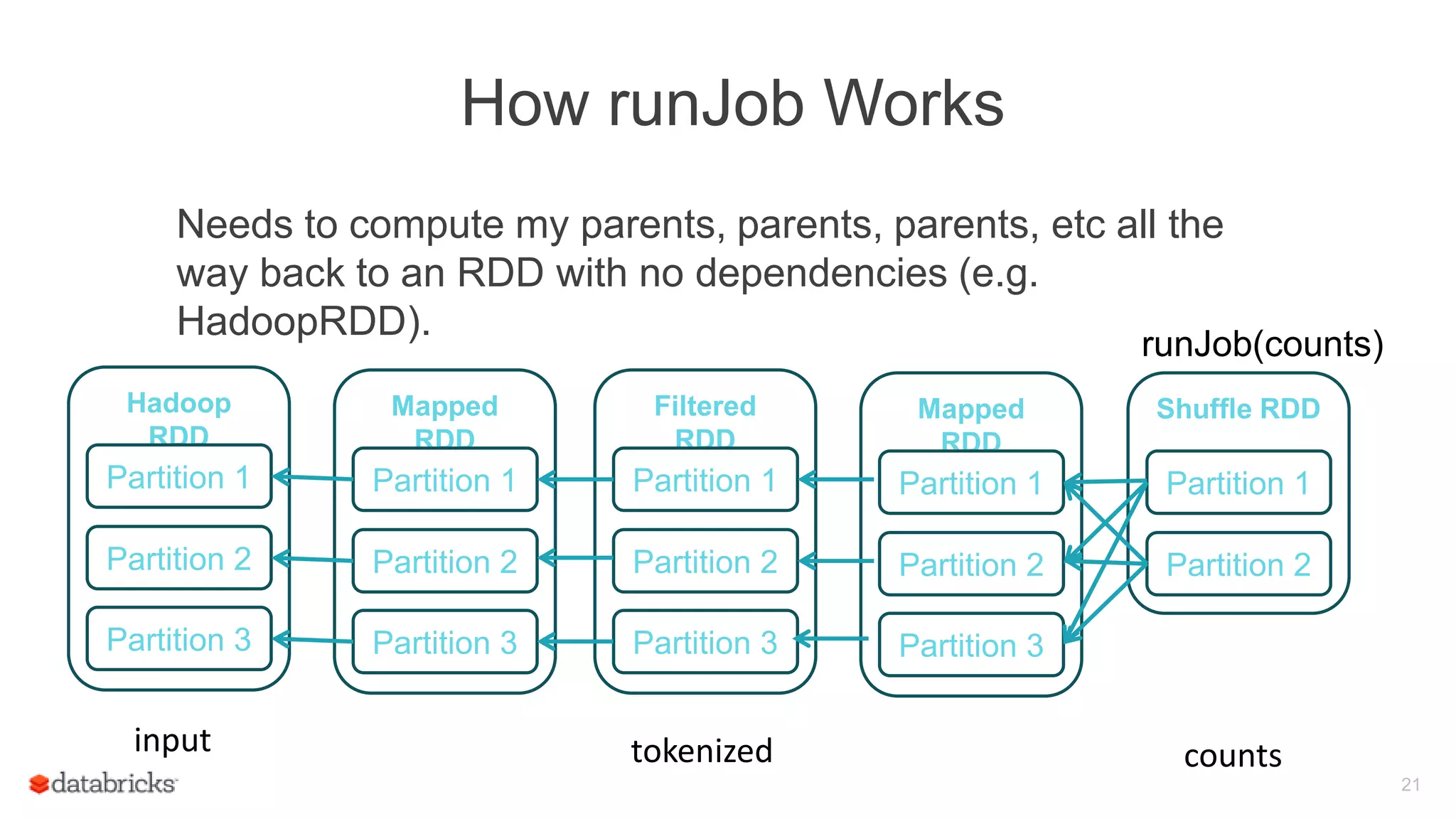
Process of evaluating a DAG in Spark using the runJob method and the importance of actions.
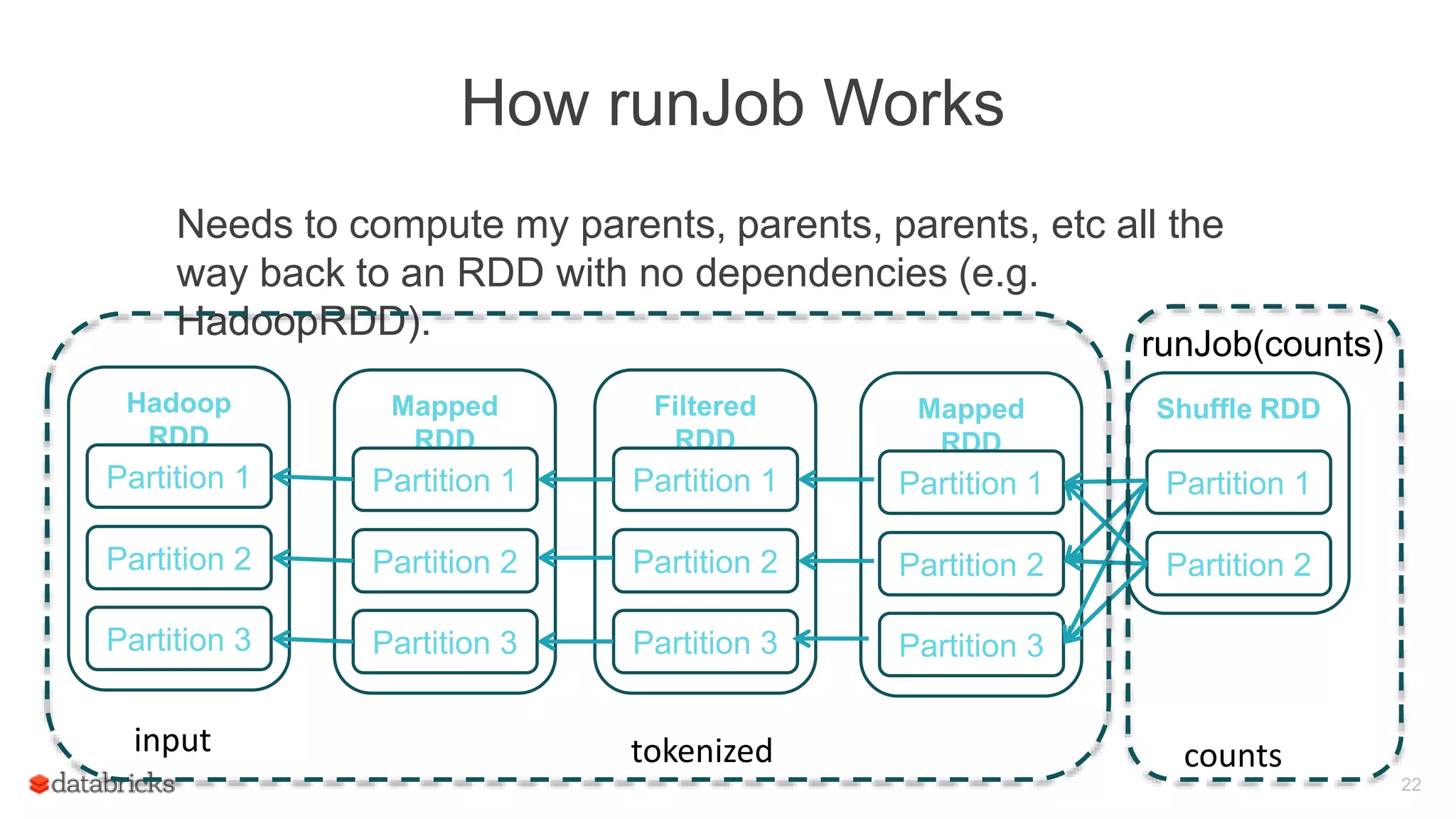
Illustration of the runJob method's operation, including the need to compute dependencies back to parent RDDs.
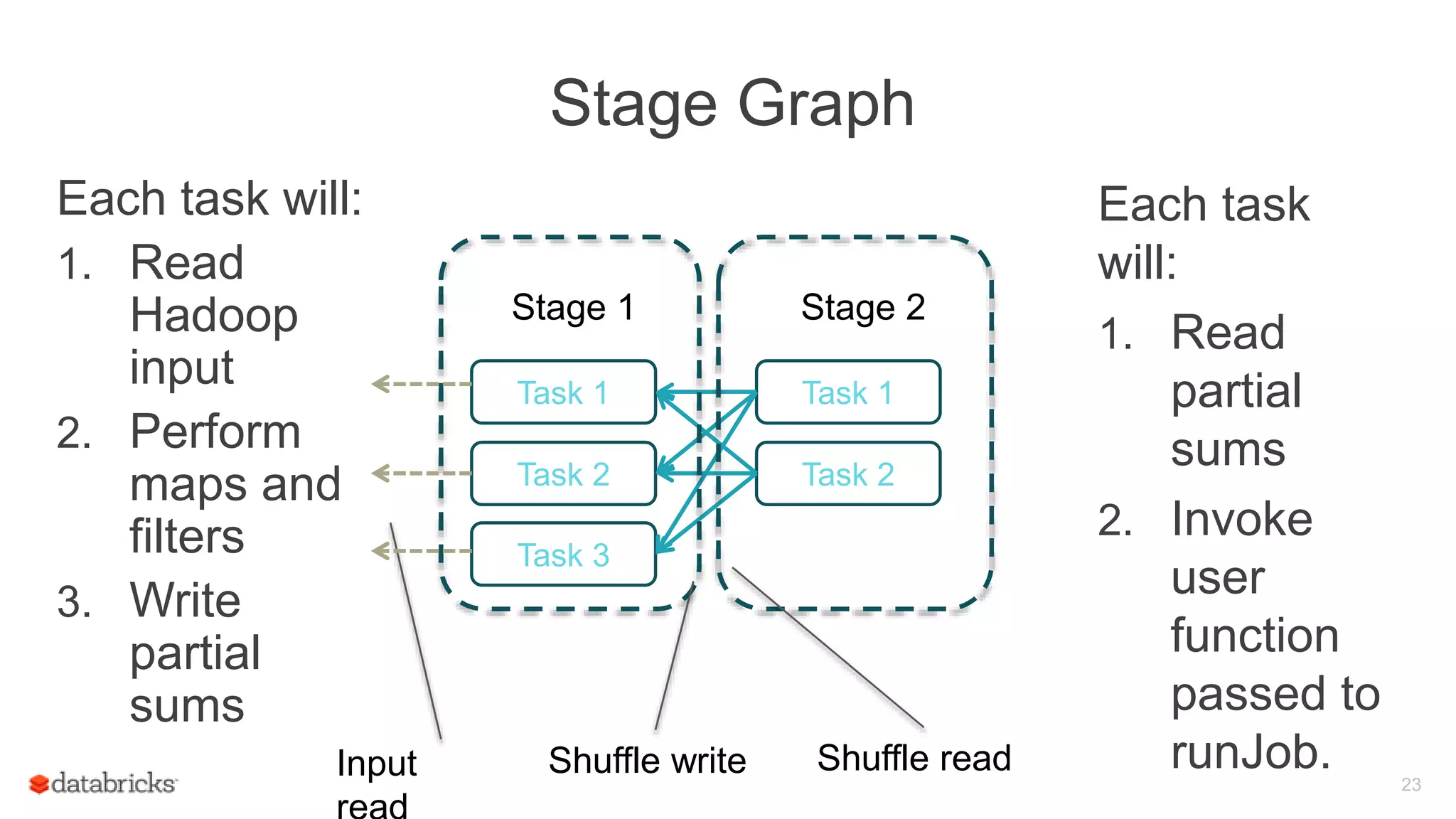
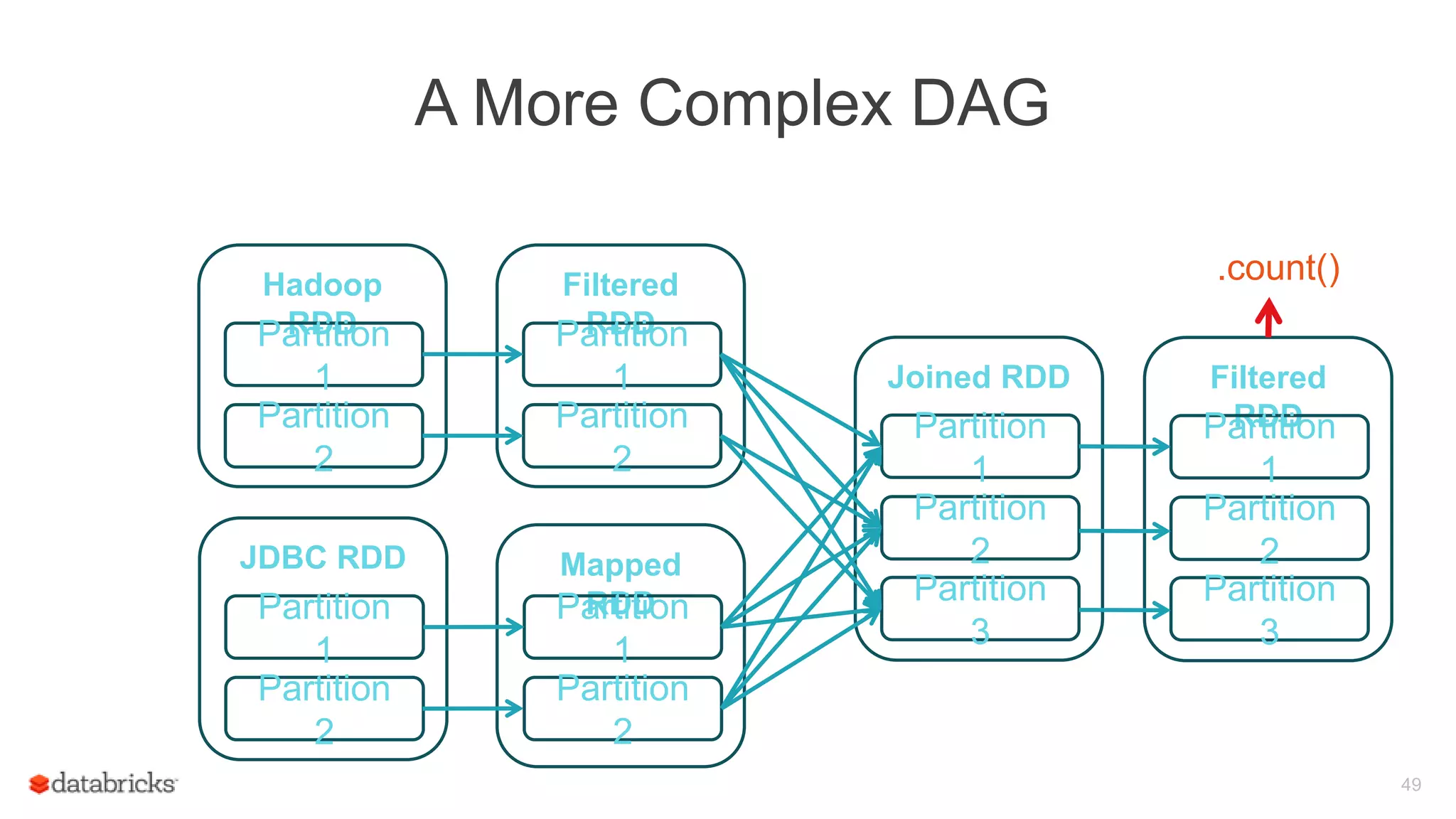
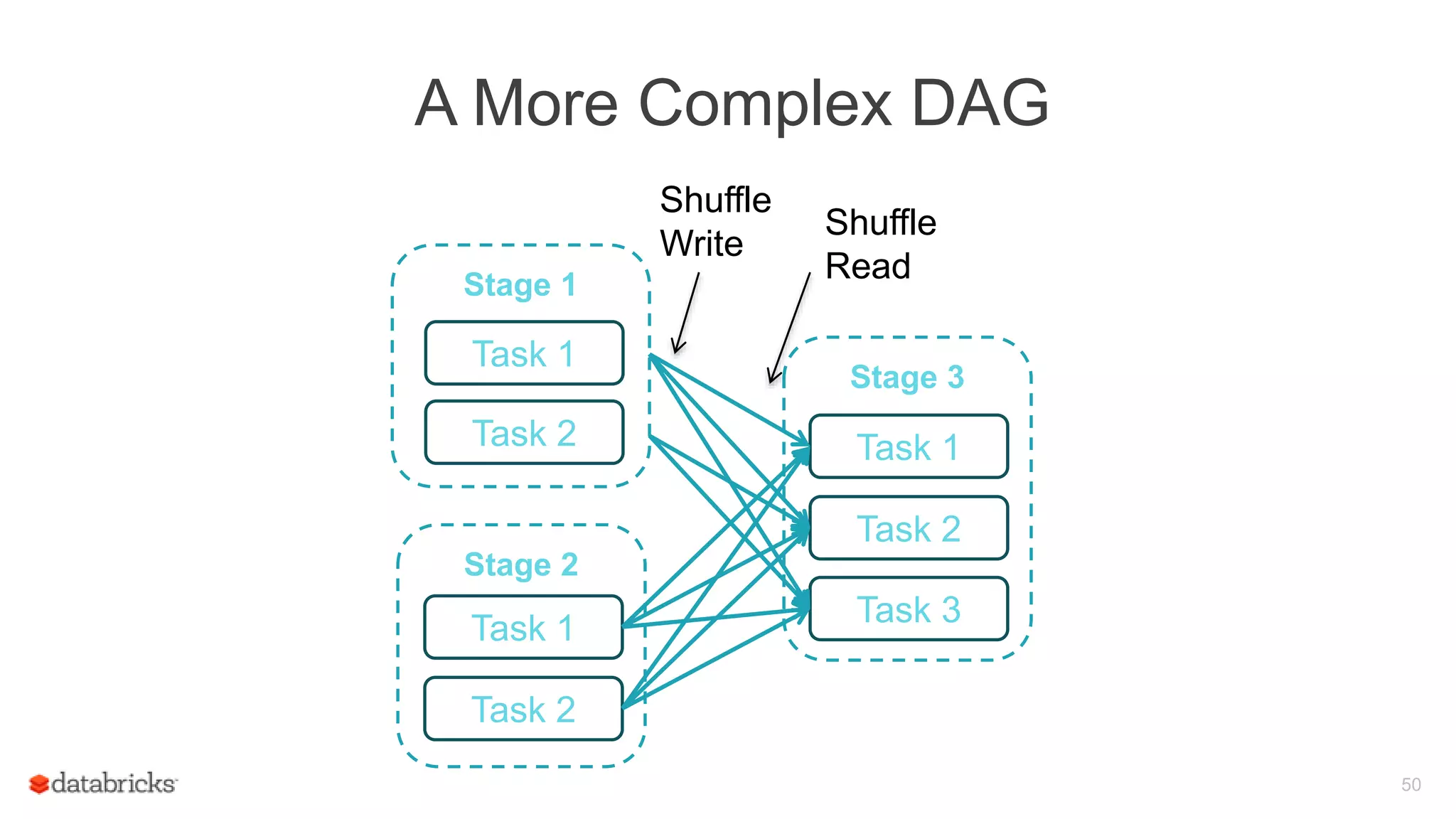
Description of the stage graph, detailing the tasks involved in processing RDDs and their execution relationship.
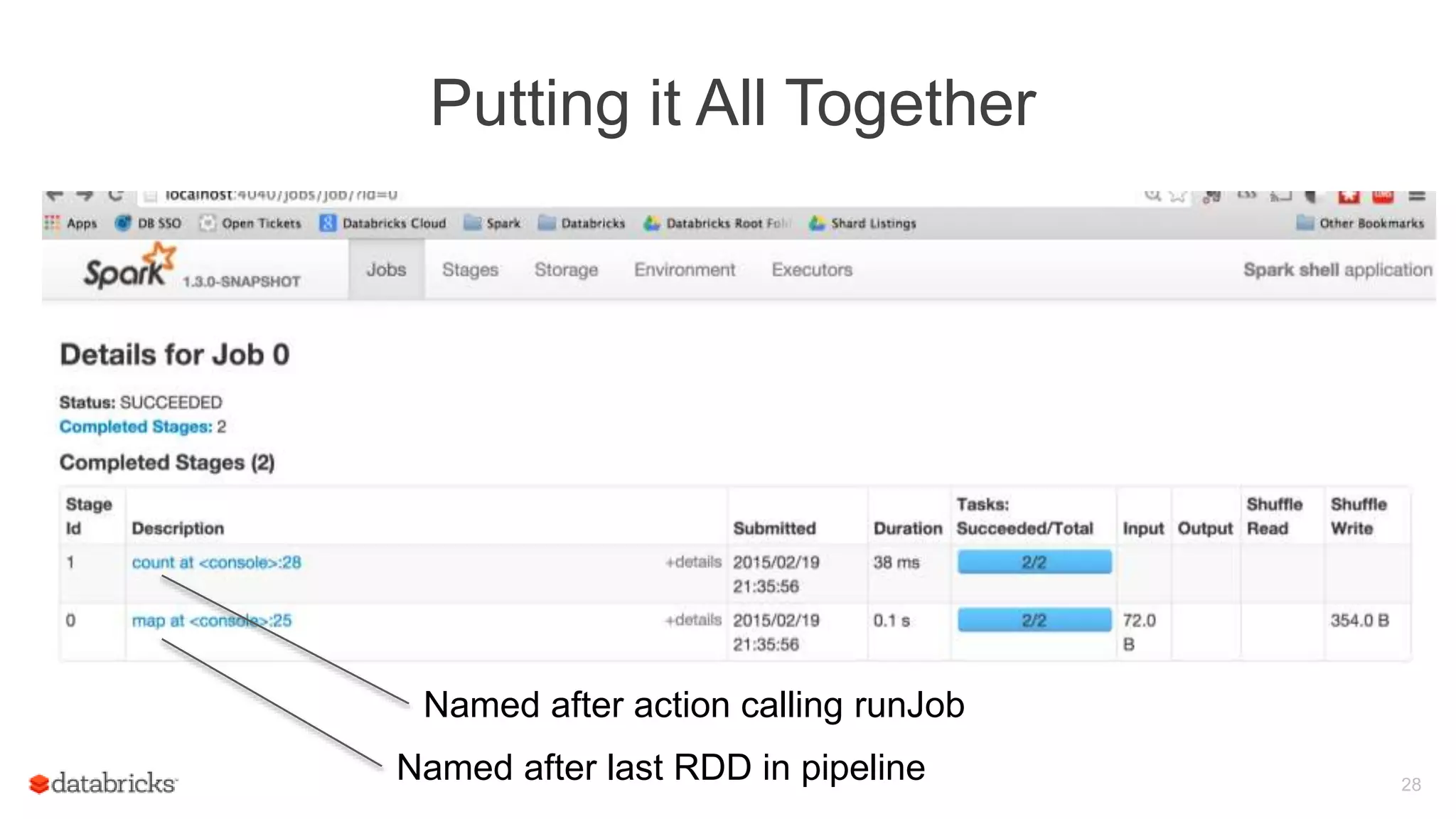
Understanding Spark operations with RDD actions like count() and take(), and how they relate to runJob.
Discuss factors affecting Spark performance including data shuffling, parallelism, serialization, caching formats, and hardware considerations.
Advocacy for using higher-level Spark APIs, such as DataFrame and Spark SQL, for improved processing efficiency.
Information about references for further learning, upcoming event schedules, and concluding remarks.
Details on internal mechanics of RDD interface, examples including Hadoop RDD, Filtered RDD, and Joined RDD within complex DAG structures.
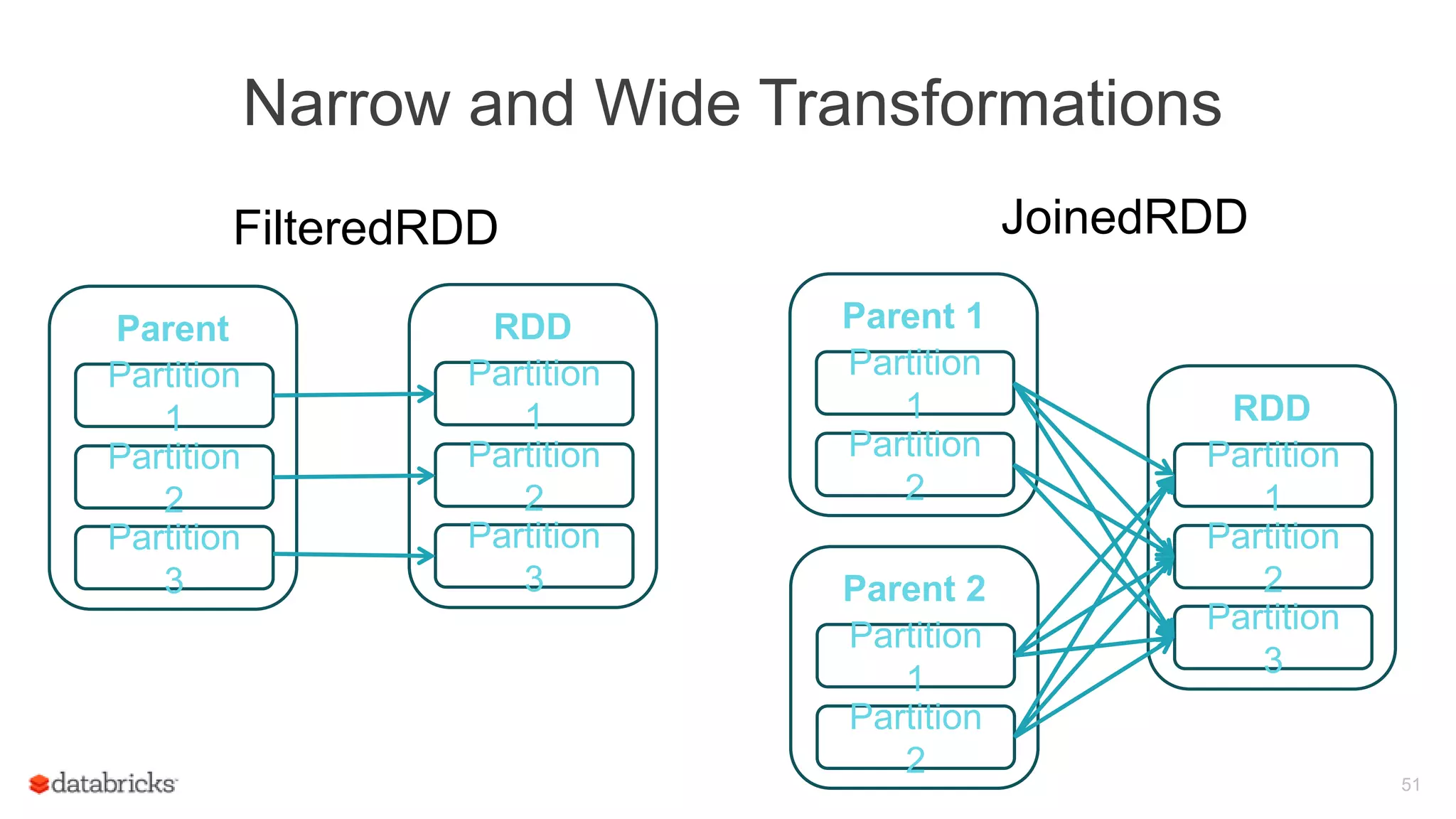
Explains narrow and wide transformations within RDDs, using examples of joined and filtered RDDs to illustrate performance differences.