Downloaded 49 times










![Spark DataFrames with SparkSQL works with Spark v2.3.x/v2.4.[0/1] and includes ~300 SparkSQL functions .NET Spark UDFs Batch & streaming including Spark Structured Streaming and all Spark-supported data sources .NET Standard 2.0 works with .NET Framework v4.6.1+ and .NET Core v2.1+ and includes C#/F# support .NET Standard Machine Learning Including access to ML.NET Speed & productivity Performance optimized interop, as fast or faster than pySpark https://github.com/dotnet/spark/examples](https://image.slidesharecdn.com/brk3055rysv05-190508194339/75/Building-data-pipelines-for-modern-data-warehouse-with-Apache-Spark-and-NET-in-Azure-Microsoft-Build-2019-15-2048.jpg)
![var spark = SparkSession.Builder().GetOrCreate(); var dataframe = spark.Read().Json(“input.json”); dataframe.Filter(df["age"] > 21) .Select(concat(df[“age”], df[“name”]).Show(); var concat = Udf<int?, string, string>((age, name)=>name+age);](https://image.slidesharecdn.com/brk3055rysv05-190508194339/75/Building-data-pipelines-for-modern-data-warehouse-with-Apache-Spark-and-NET-in-Azure-Microsoft-Build-2019-16-2048.jpg)
![val europe = region.filter($"r_name" === "EUROPE") .join(nation, $"r_regionkey" === nation("n_regionkey")) .join(supplier, $"n_nationkey" === supplier("s_nationkey")) .join(partsupp, supplier("s_suppkey") === partsupp("ps_suppkey")) val brass = part.filter(part("p_size") === 15 && part("p_type").endsWith("BRASS")) .join(europe, europe("ps_partkey") === $"p_partkey") val minCost = brass.groupBy(brass("ps_partkey")) .agg(min("ps_supplycost").as("min")) brass.join(minCost, brass("ps_partkey") === minCost("ps_partkey")) .filter(brass("ps_supplycost") === minCost("min")) .select("s_acctbal", "s_name", "n_name", "p_partkey", "p_mfgr", "s_address", "s_phone", "s_comment") .sort($"s_acctbal".desc, $"n_name", $"s_name", $"p_partkey") .limit(100) .show() var europe = region.Filter(Col("r_name") == "EUROPE") .Join(nation, Col("r_regionkey") == nation["n_regionkey"]) .Join(supplier, Col("n_nationkey") == supplier["s_nationkey"]) .Join(partsupp, supplier["s_suppkey"] == partsupp["ps_suppkey"]); var brass = part.Filter(part["p_size"] == 15 & part["p_type"].EndsWith("BRASS")) .Join(europe, europe["ps_partkey"] == Col("p_partkey")); var minCost = brass.GroupBy(brass["ps_partkey"]) .Agg(Min("ps_supplycost").As("min")); brass.Join(minCost, brass["ps_partkey"] == minCost["ps_partkey"]) .Filter(brass["ps_supplycost"] == minCost["min"]) .Select("s_acctbal", "s_name", "n_name", "p_partkey", "p_mfgr", "s_address", "s_phone", "s_comment") .Sort(Col("s_acctbal").Desc(), Col("n_name"), Col("s_name"), Col("p_partkey")) .Limit(100) .Show(); Similar syntax – dangerously copy/paste friendly! $”col_name” vs. Col(“col_name”) Capitalization Scala C# C# vs Scala (e.g., == vs ===)](https://image.slidesharecdn.com/brk3055rysv05-190508194339/75/Building-data-pipelines-for-modern-data-warehouse-with-Apache-Spark-and-NET-in-Azure-Microsoft-Build-2019-17-2048.jpg)




![CREATE EXTERNAL DATA SOURCE MyADLSGen2 WITH (TYPE = Hadoop, LOCATION = ‘abfs://<filesys>@<account_name>.dfs.core.windows.net’, CREDENTIAL = <Database scoped credential>); CREATE EXTERNAL FILE FORMAT ParquetFile WITH ( FORMAT_TYPE = PARQUET, DATA_COMPRESSION = 'org.apache.hadoop.io.compress.GzipCodec’, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)); CREATE EXTERNAL TABLE [dbo].[Customer_import] ( [SensorKey] int NOT NULL, int NOT NULL, [Speed] float NOT NULL) WITH (LOCATION=‘/Dimensions/customer', DATA_SOURCE = MyADLSGen2, FILE_FORMAT = ParquetFile) Once per store account (WASB, ADLS G1, ADLS G2) Once per file format, supports Parquet (snappy or Gzip), ORC, RC, CSV/TSV Folder path](https://image.slidesharecdn.com/brk3055rysv05-190508194339/75/Building-data-pipelines-for-modern-data-warehouse-with-Apache-Spark-and-NET-in-Azure-Microsoft-Build-2019-29-2048.jpg)
![CREATE TABLE [dbo].[Customer] WITH ( DISTRIBUTION = ROUND_ROBIN , CLUSTERED INDEX (customerid) ) AS SELECT * FROM [dbo].[Customer_import] INSERT INTO [dbo].[Customer] SELECT * FROM [dbo].[Customer_import] WHERE <predicate to determine new data>](https://image.slidesharecdn.com/brk3055rysv05-190508194339/75/Building-data-pipelines-for-modern-data-warehouse-with-Apache-Spark-and-NET-in-Azure-Microsoft-Build-2019-30-2048.jpg)







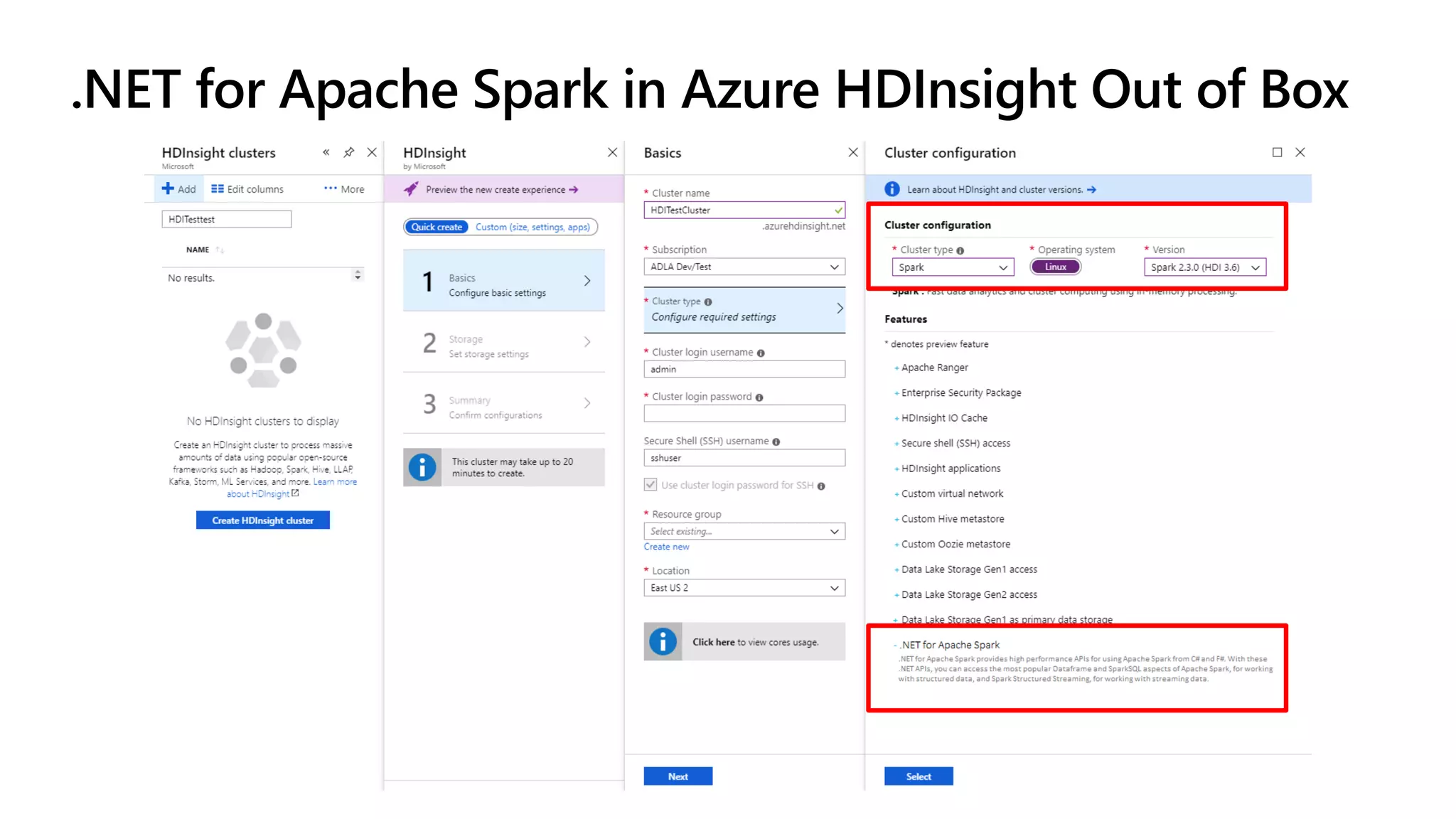

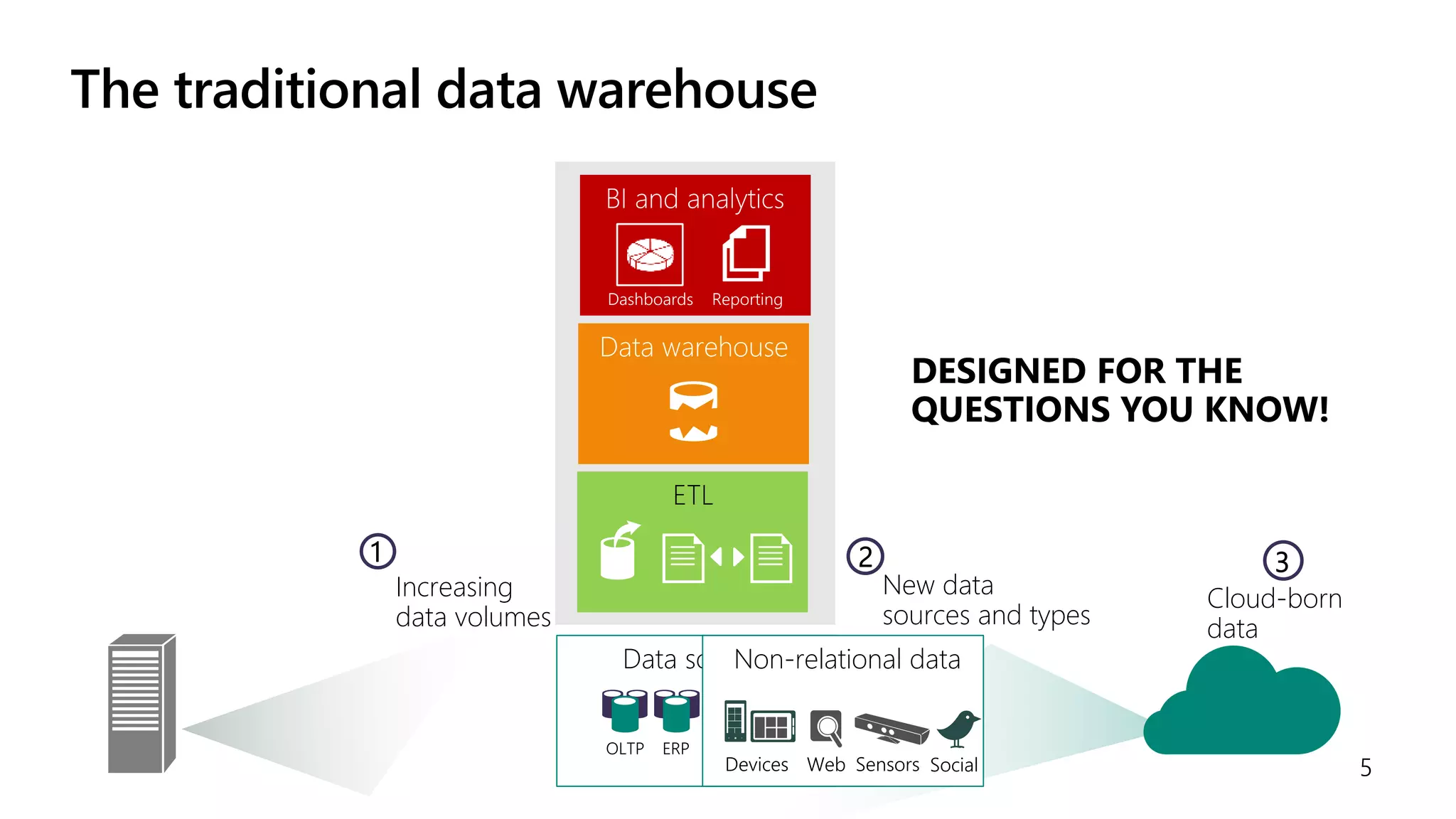
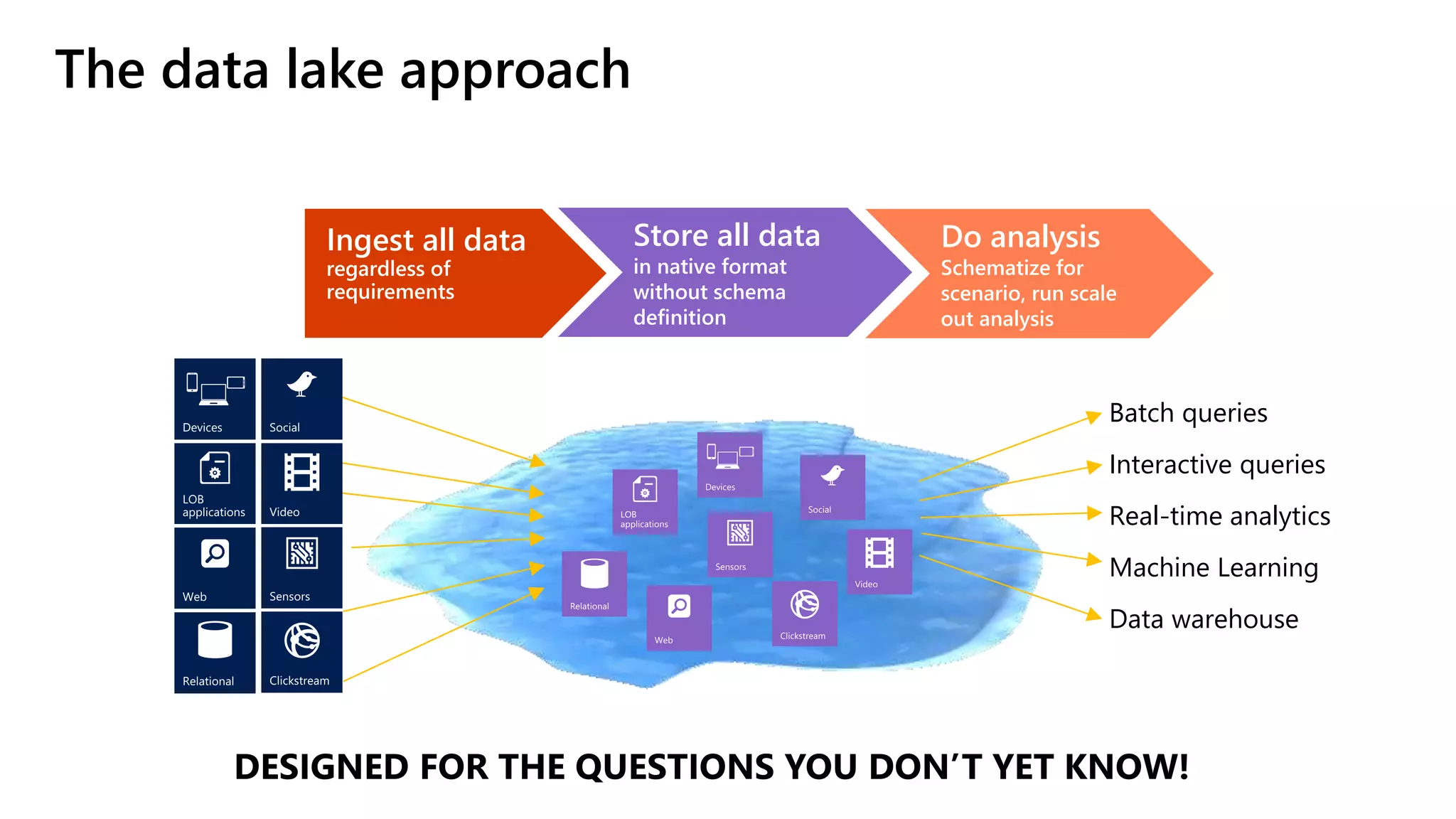
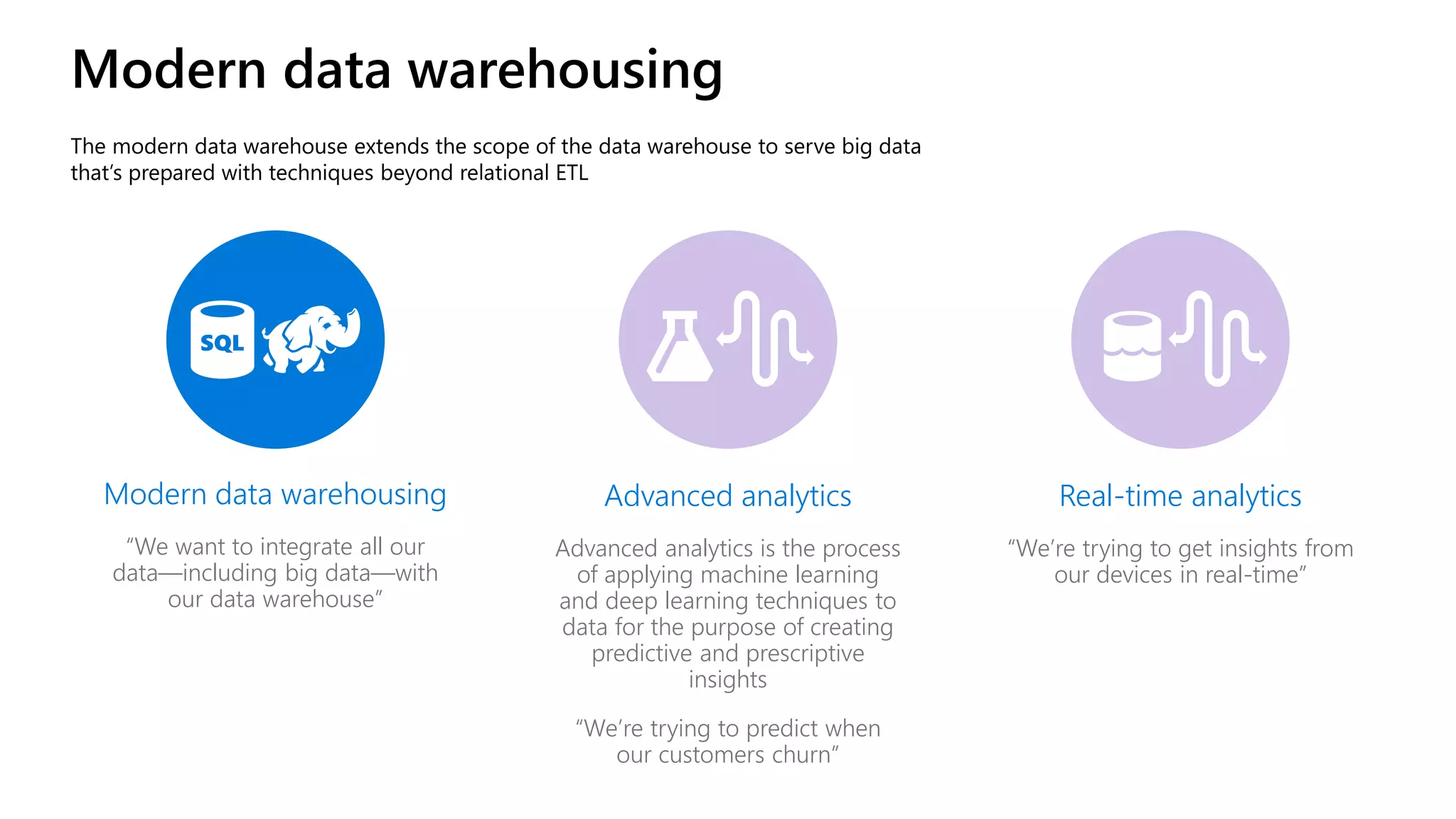
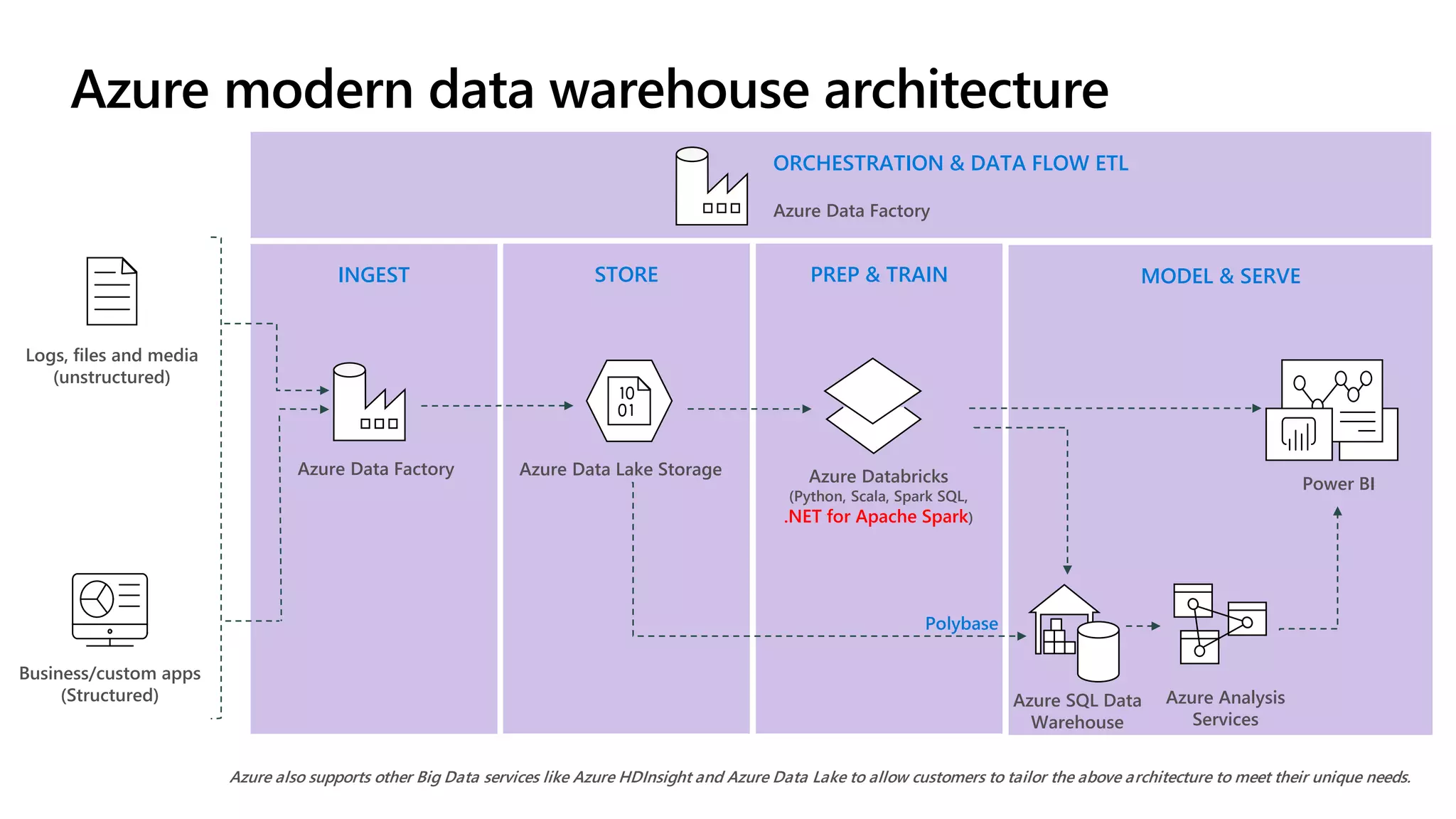
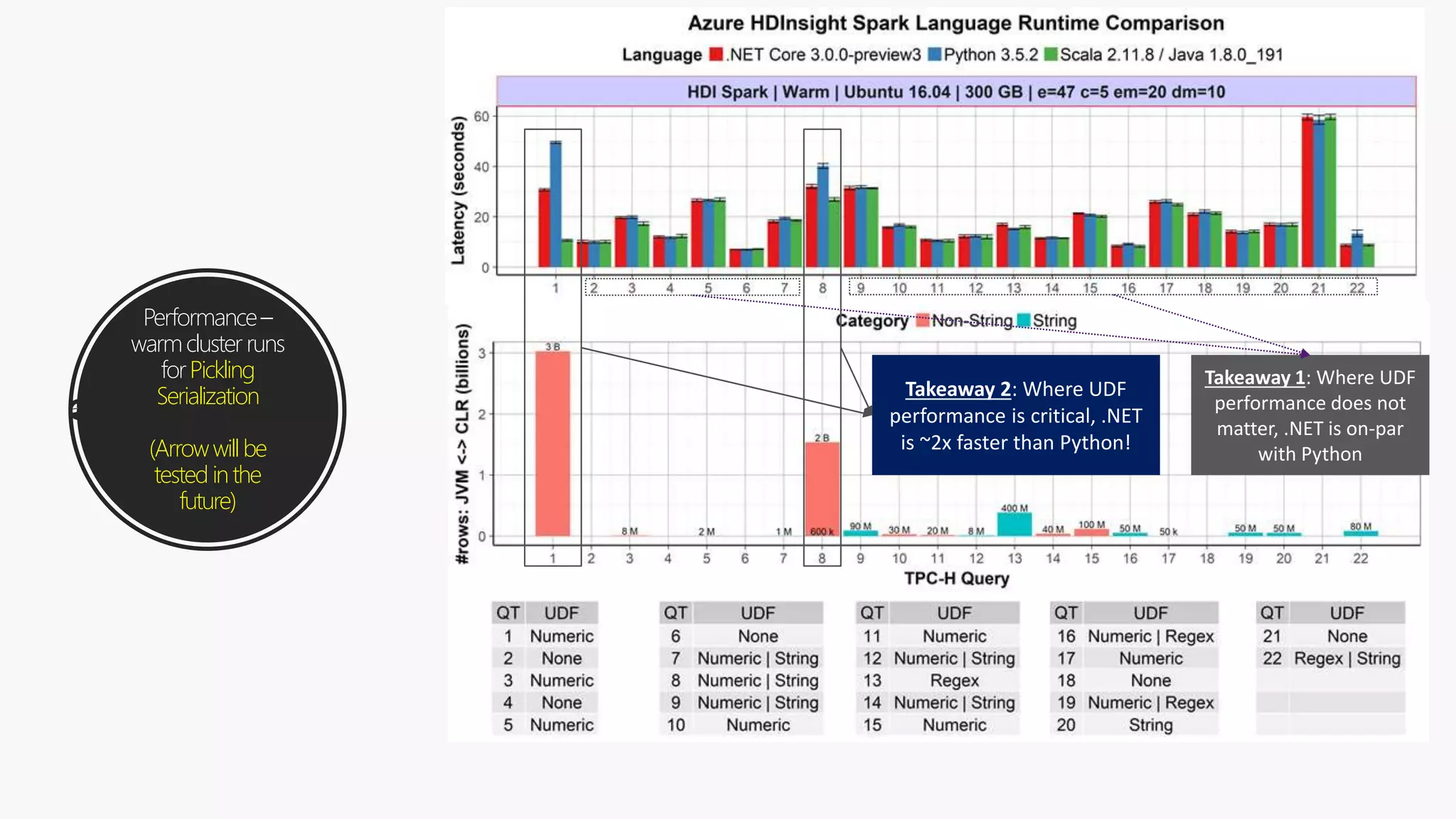
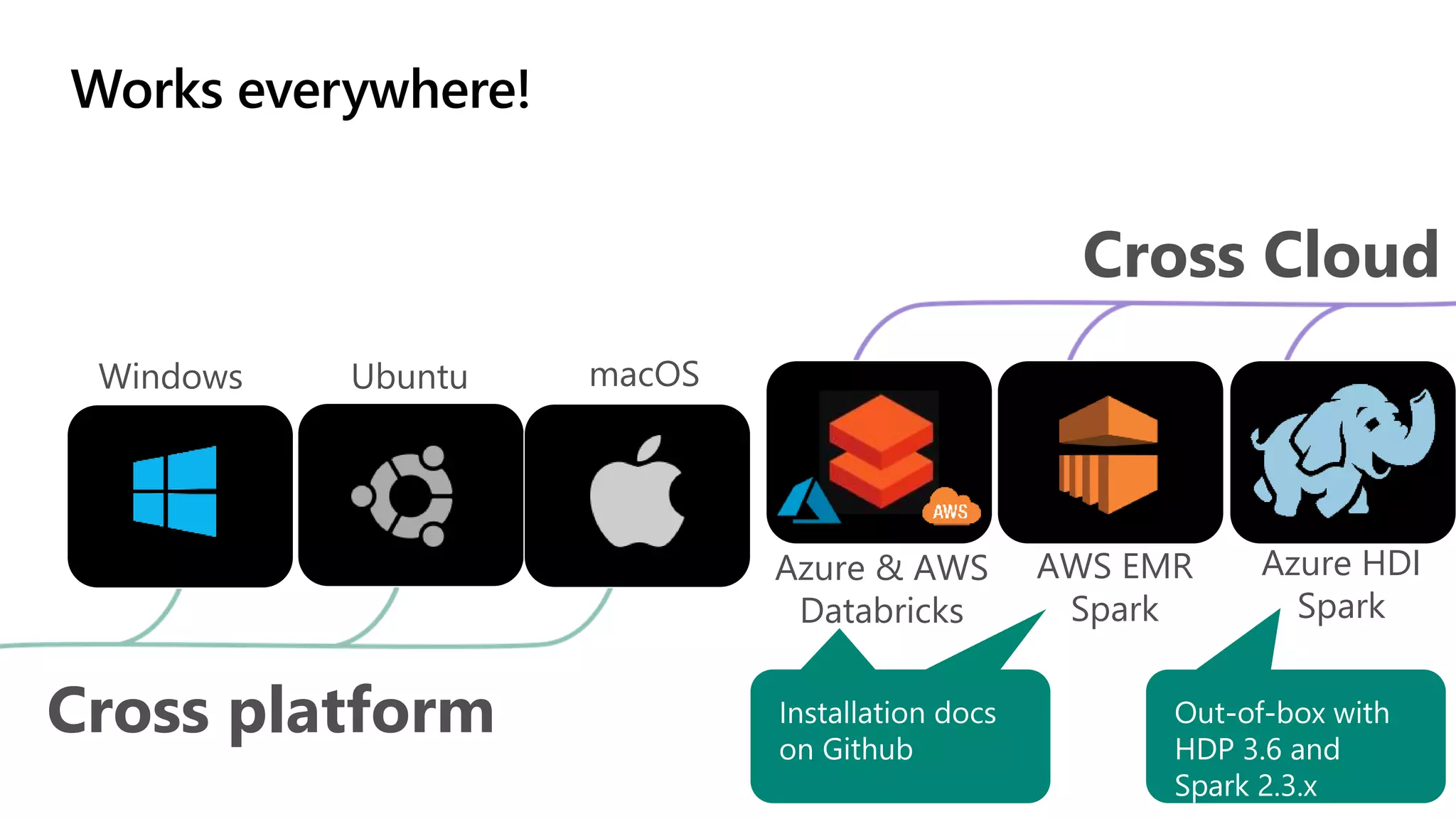
The document discusses the integration of .NET with Apache Spark to enhance data processing capabilities, particularly for .NET developers interested in big data applications. It highlights the benefits of modern data warehousing, advanced analytics, and real-time insights, while also outlining the support and interoperability for .NET within the Spark ecosystem. Additionally, it covers architecture components, programming experiences, performance optimizations, and the commitment of Microsoft to open source projects related to Apache Spark.