Downloaded 12 times








![.NET provides full-spectrum Spark support Spark DataFrames with SparkSQL works with Spark v2.3.x/v2.4.[0/1] and includes ~300 SparkSQL functions Grouped Map (Reducer, v0.4) .NET Spark UDFs Batch & streaming including Spark Structured Streaming and all Spark-supported data sources .NET Standard 2.0 works with .NET Framework v4.6.1+ and .NET Core v2.1+ and includes C#/F# support .NET Standard Machine Learning Including access to ML.NET Speed & productivity Performance optimized interop, as fast or faster than pySpark, Support for HW Vectorization (v0.4) https://github.com/dotnet/spark/examples](https://image.slidesharecdn.com/sparkdotnetvsliveredmond2019-190813201309/75/Bringing-the-Power-and-Familiarity-of-NET-C-and-F-to-Big-Data-Processing-in-Apache-Spark-11-2048.jpg)
![.NET for Apache Spark programmability var spark = SparkSession.Builder().GetOrCreate(); var dataframe = spark.Read().Json(“input.json”); dataframe.Filter(df["age"] > 21) .Select(concat(df[“age”], df[“name”]).Show(); var concat = Udf<int?, string, string>((age, name)=>name+age);](https://image.slidesharecdn.com/sparkdotnetvsliveredmond2019-190813201309/75/Bringing-the-Power-and-Familiarity-of-NET-C-and-F-to-Big-Data-Processing-in-Apache-Spark-13-2048.jpg)
![Language comparison: TPC-H Query 2 val europe = region.filter($"r_name" === "EUROPE") .join(nation, $"r_regionkey" === nation("n_regionkey")) .join(supplier, $"n_nationkey" === supplier("s_nationkey")) .join(partsupp, supplier("s_suppkey") === partsupp("ps_suppkey")) val brass = part.filter(part("p_size") === 15 && part("p_type").endsWith("BRASS")) .join(europe, europe("ps_partkey") === $"p_partkey") val minCost = brass.groupBy(brass("ps_partkey")) .agg(min("ps_supplycost").as("min")) brass.join(minCost, brass("ps_partkey") === minCost("ps_partkey")) .filter(brass("ps_supplycost") === minCost("min")) .select("s_acctbal", "s_name", "n_name", "p_partkey", "p_mfgr", "s_address", "s_phone", "s_comment") .sort($"s_acctbal".desc, $"n_name", $"s_name", $"p_partkey") .limit(100) .show() var europe = region.Filter(Col("r_name") == "EUROPE") .Join(nation, Col("r_regionkey") == nation["n_regionkey"]) .Join(supplier, Col("n_nationkey") == supplier["s_nationkey"]) .Join(partsupp, supplier["s_suppkey"] == partsupp["ps_suppkey"]); var brass = part.Filter(part["p_size"] == 15 & part["p_type"].EndsWith("BRASS")) .Join(europe, europe["ps_partkey"] == Col("p_partkey")); var minCost = brass.GroupBy(brass["ps_partkey"]) .Agg(Min("ps_supplycost").As("min")); brass.Join(minCost, brass["ps_partkey"] == minCost["ps_partkey"]) .Filter(brass["ps_supplycost"] == minCost["min"]) .Select("s_acctbal", "s_name", "n_name", "p_partkey", "p_mfgr", "s_address", "s_phone", "s_comment") .Sort(Col("s_acctbal").Desc(), Col("n_name"), Col("s_name"), Col("p_partkey")) .Limit(100) .Show(); Similar syntax – dangerously copy/paste friendly! $”col_name” vs. Col(“col_name”) Capitalization Scala C# C# vs Scala (e.g., == vs ===)](https://image.slidesharecdn.com/sparkdotnetvsliveredmond2019-190813201309/75/Bringing-the-Power-and-Familiarity-of-NET-C-and-F-to-Big-Data-Processing-in-Apache-Spark-14-2048.jpg)


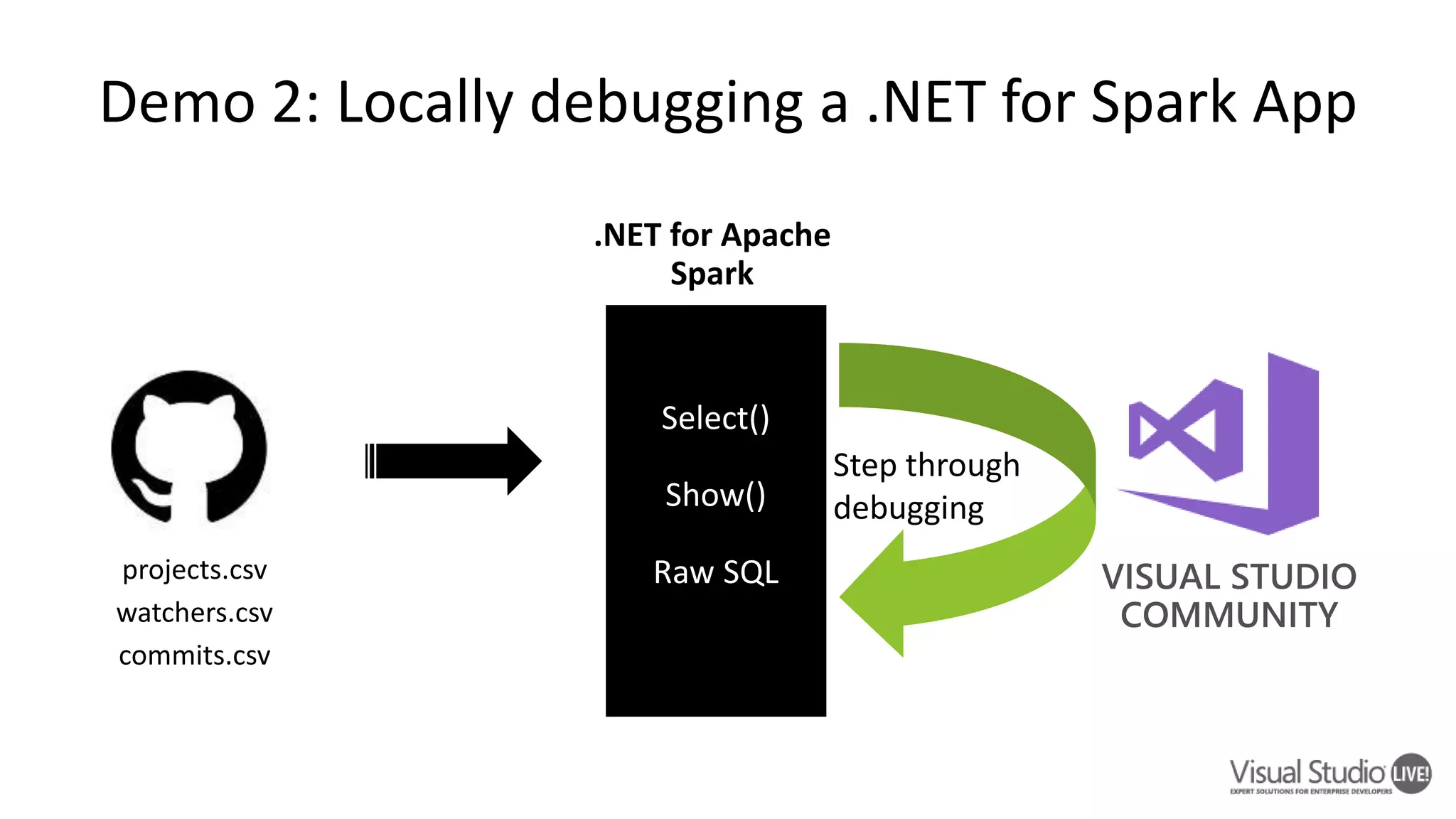
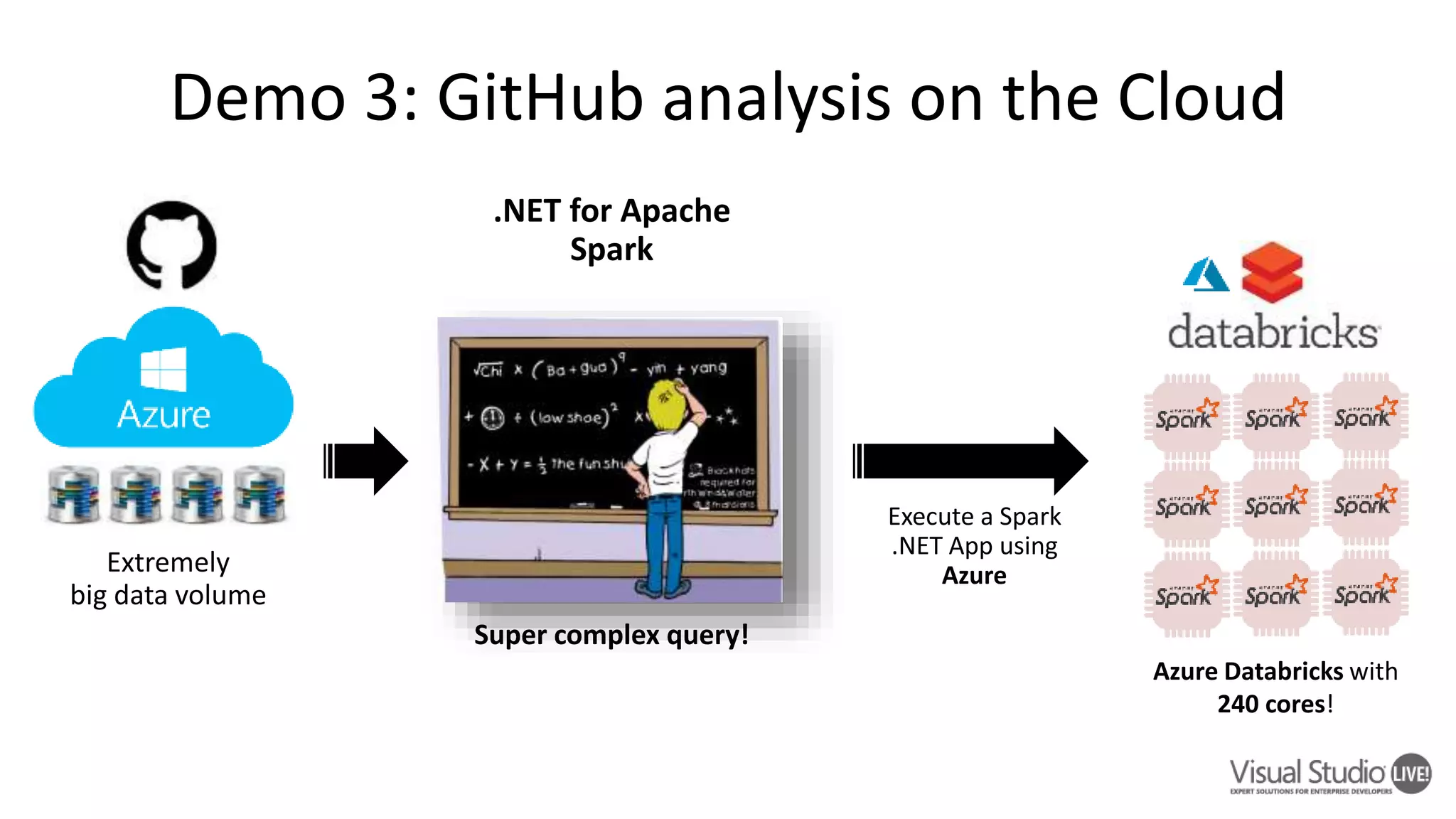


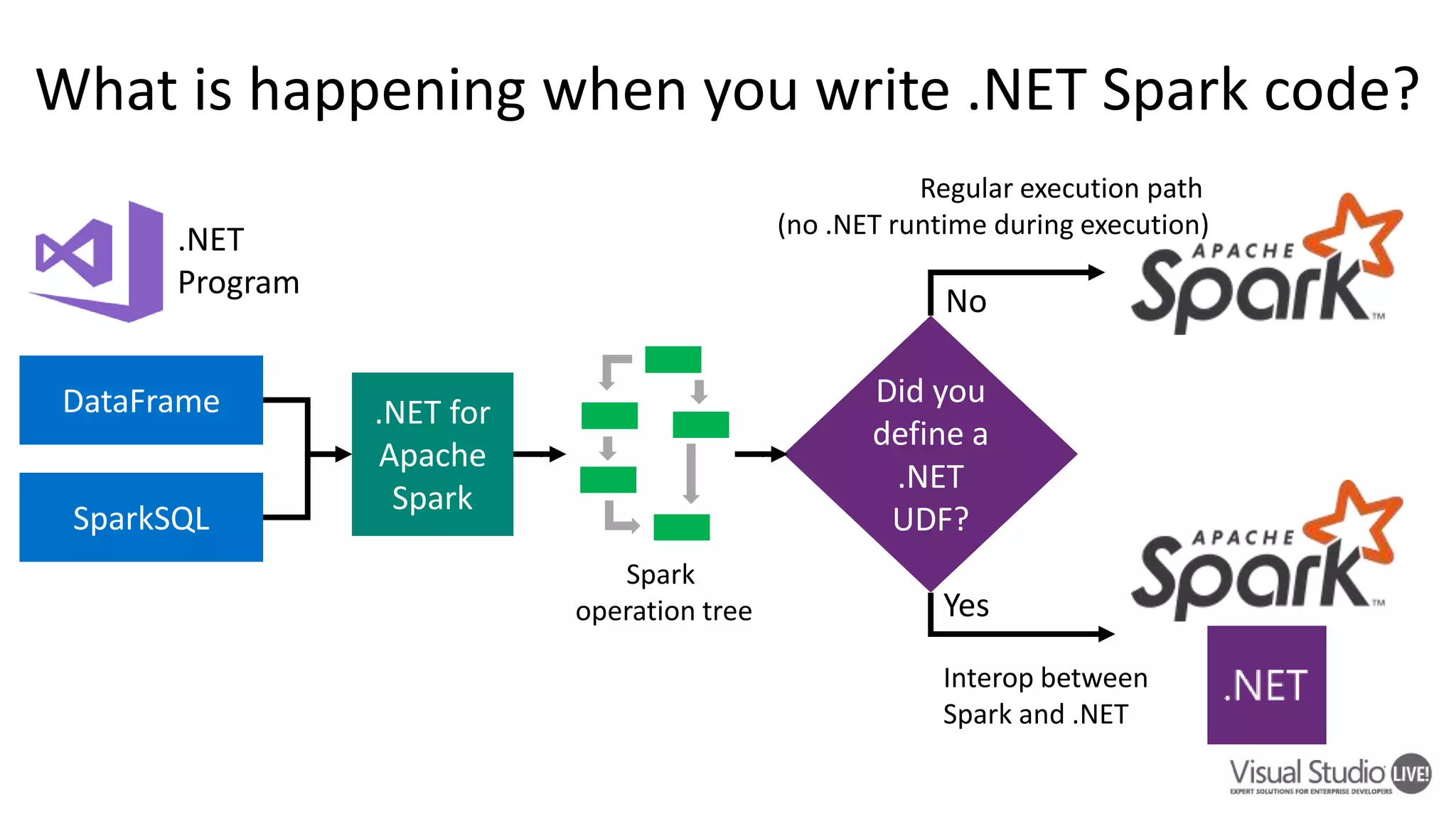
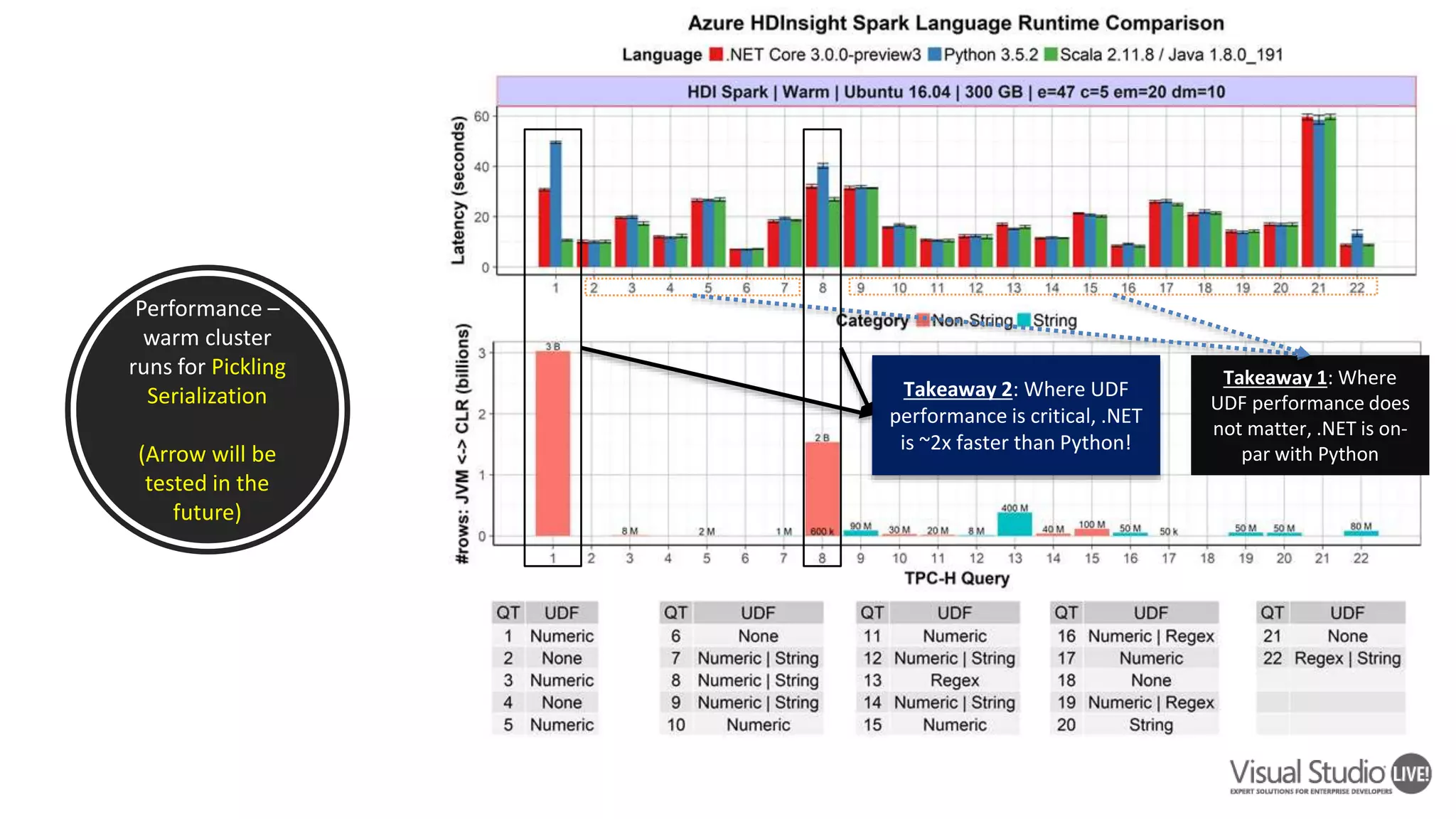
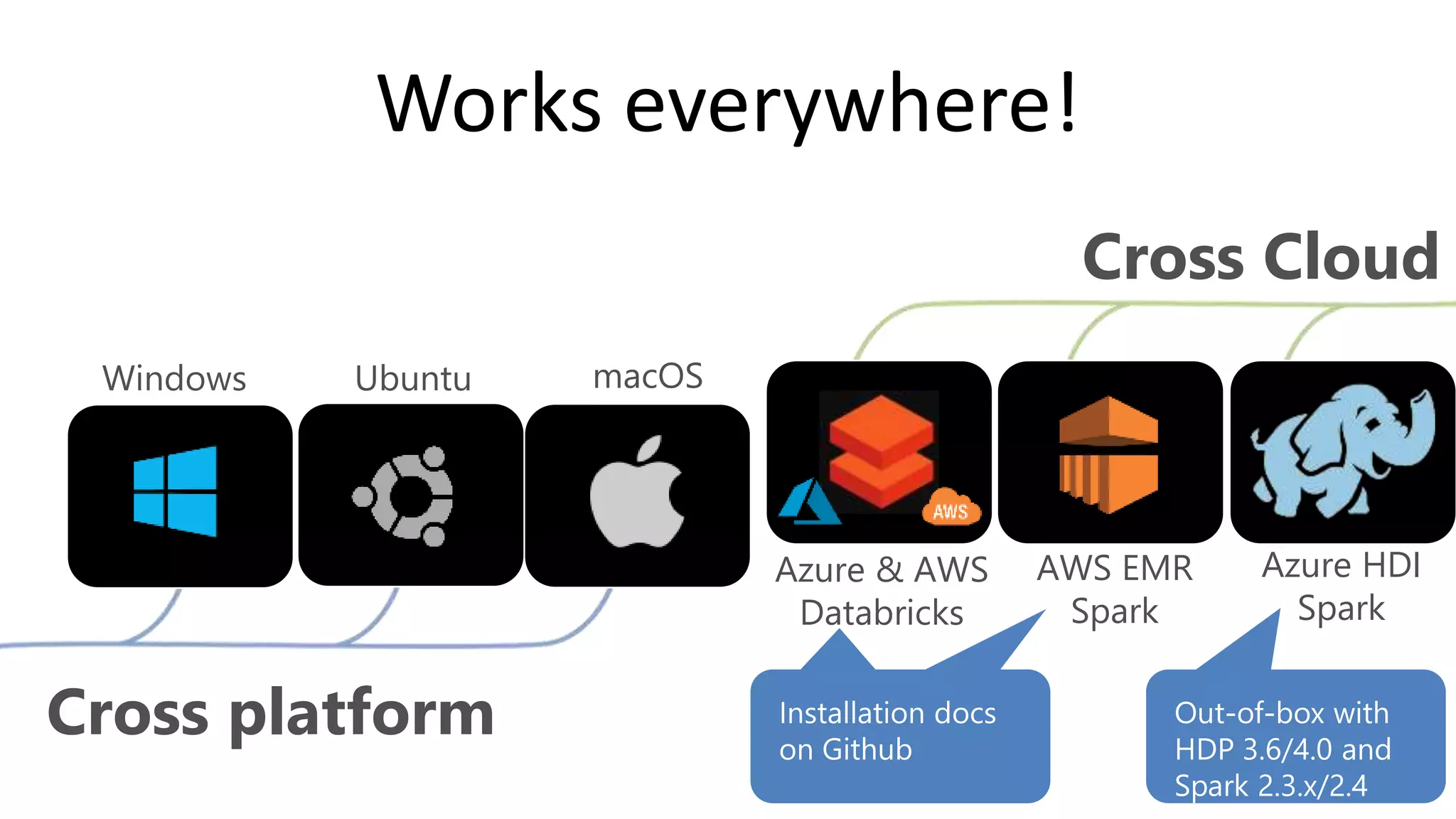






This document introduces .NET for Apache Spark, which allows .NET developers to use the Apache Spark analytics engine for big data and machine learning. It discusses why .NET support is needed for Apache Spark given that much business logic is written in .NET. It provides an overview of .NET for Apache Spark's capabilities including Spark DataFrames, machine learning, and performance that is on par or faster than PySpark. Examples and demos are shown. Future plans are discussed to improve the tooling, expand programming experiences, and provide out-of-box experiences on platforms like Azure HDInsight and Azure Databricks. Readers are encouraged to engage with the open source project and provide feedback.