Download as PDF, PPTX


![Where does the Data come from? 5 “Data is the hardest part of ML and the most important piece to get right. Modelers spend most of their time selecting and transforming features at training time and then building the pipelines to deliver those features to production models.” [Uber on Michelangelo]](https://image.slidesharecdn.com/jimdowlingkimhammar-191101052517/75/End-to-End-Spark-TensorFlow-PyTorch-Pipelines-with-Databricks-Delta-5-2048.jpg)
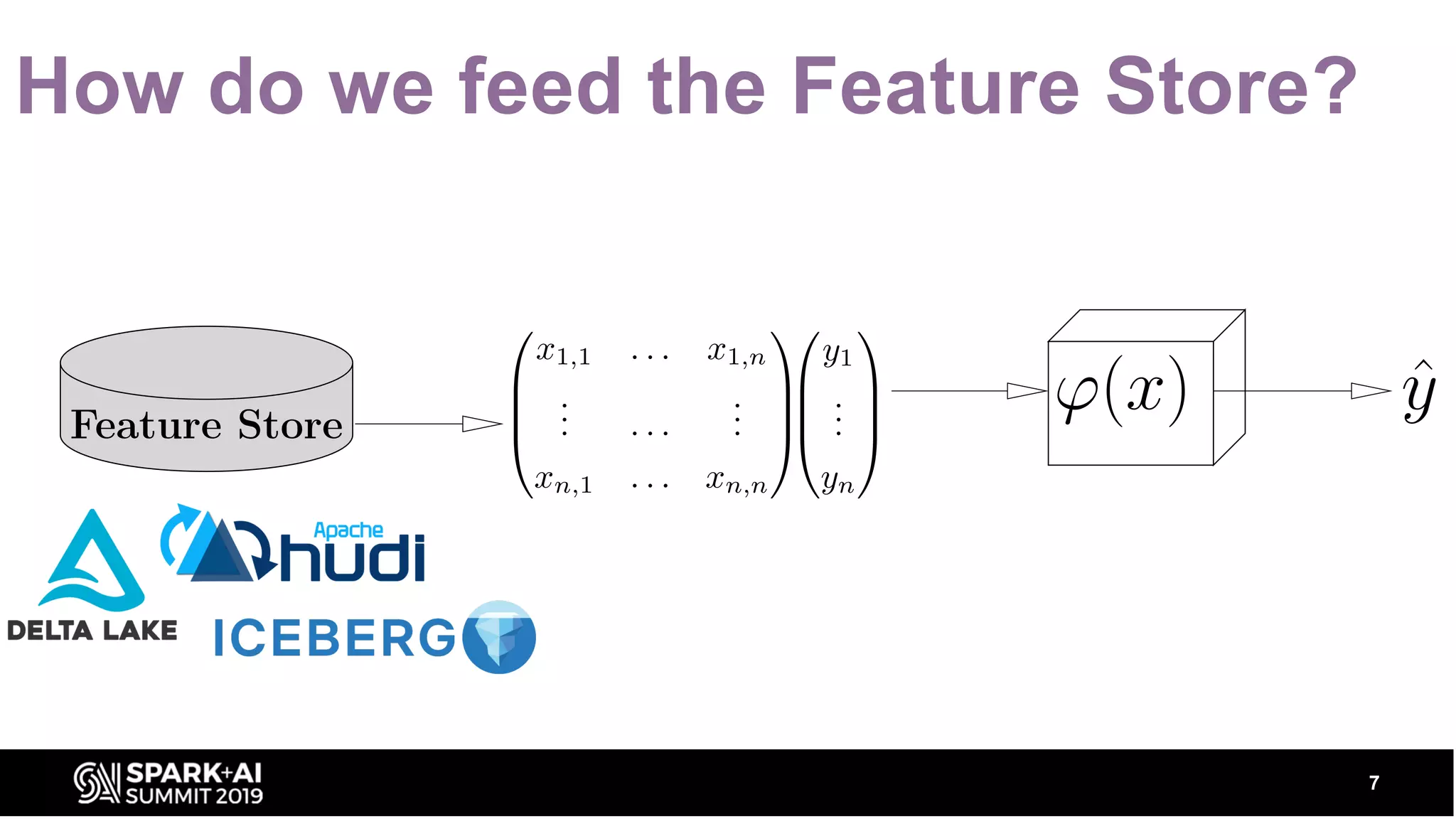

















The document discusses the importance of data in machine learning and presents an overview of tools like Hopsworks, Databricks Delta, and various feature stores. It highlights advancements in data lakes with ACID transactions, incremental ingestion, and efficient querying using frameworks such as Delta, Hudi, and Iceberg. The Hopsworks feature store is emphasized as the world's first open-source feature store, supporting end-to-end ML pipelines with reliable and timely data access.
Introduction of WIFI details, presenters Kim Hammar and Jim Dowling, topic focus on ML Pipelines with Databricks and Hopsworks.
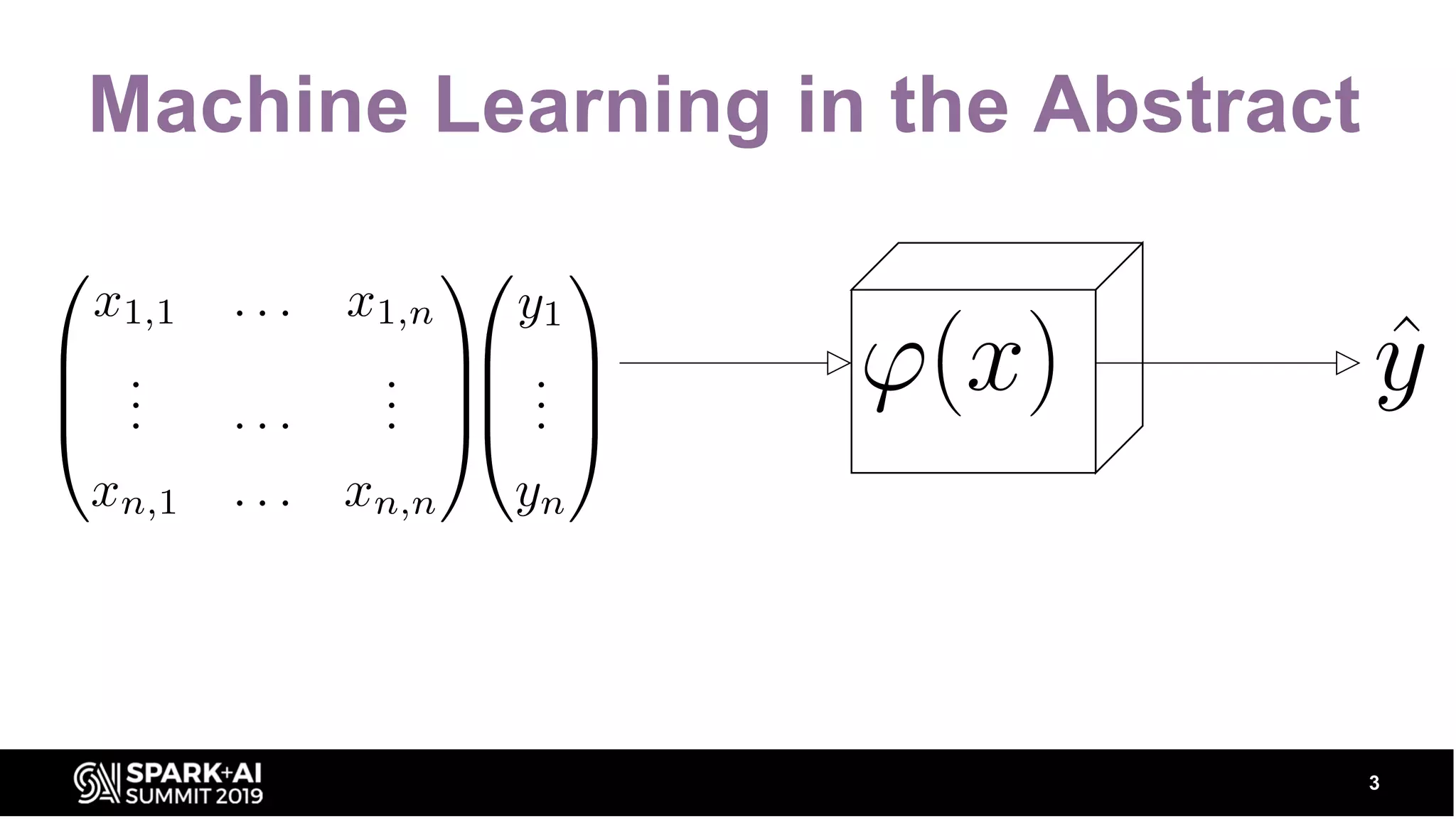
Explains the significance of data in ML, stating it's the hardest part, with modelers focusing on feature selection and transformation.
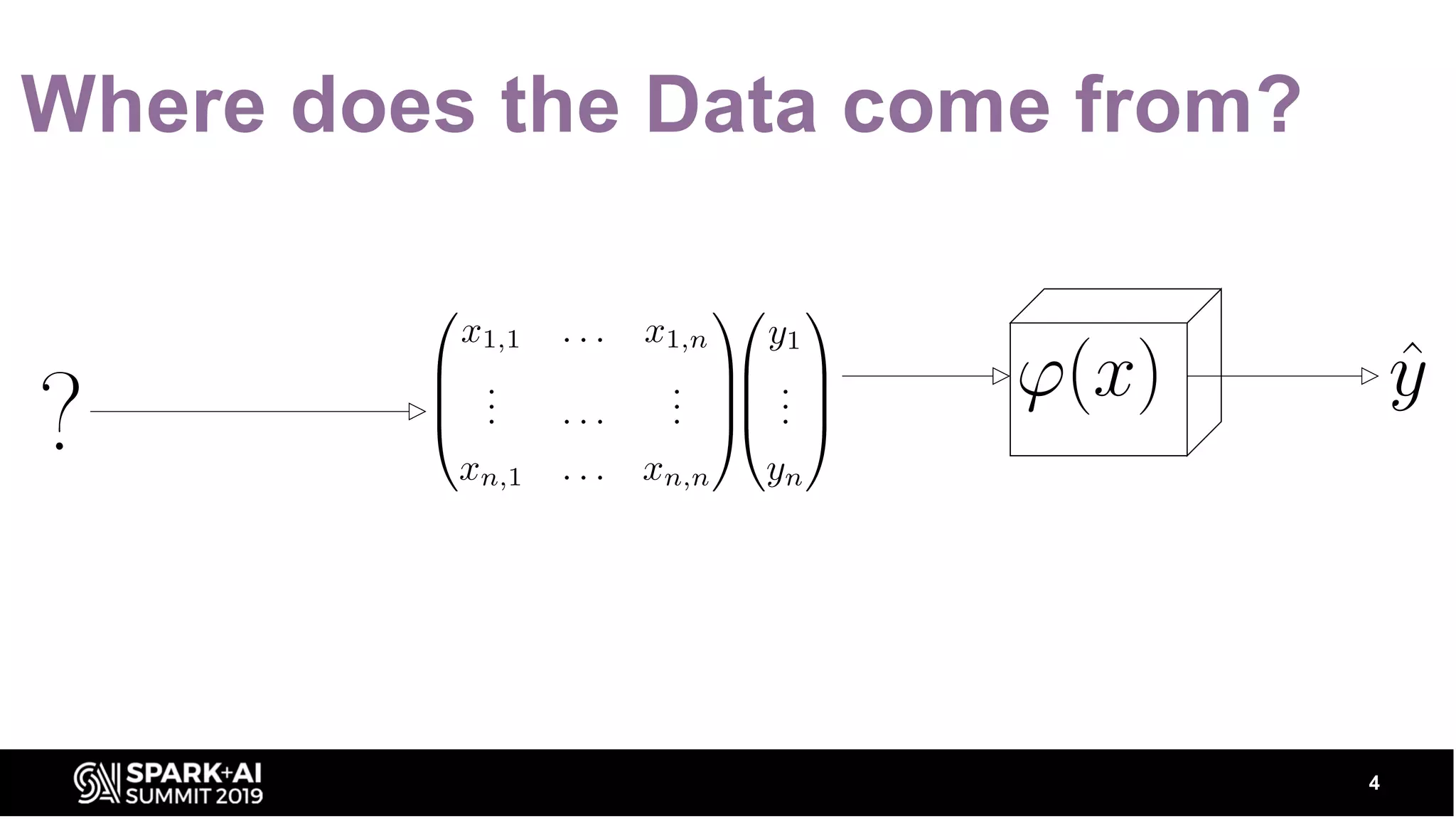
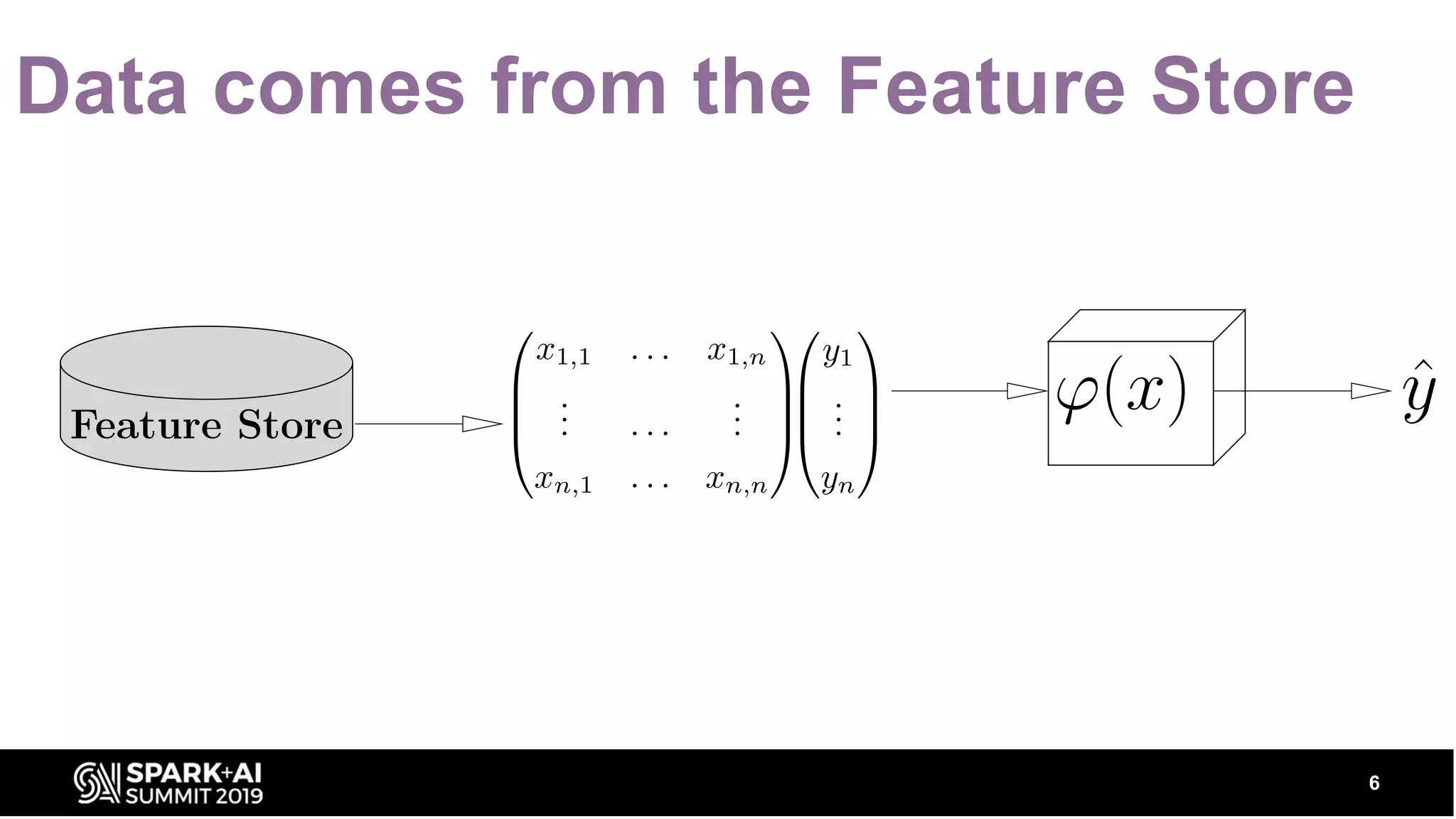
Introduction to data sourcing from the Feature Store, emphasizing its vital role in ML operations.
An outline of the presentation covering Hopsworks, Databricks Delta, Feature Store, demo, and summary.
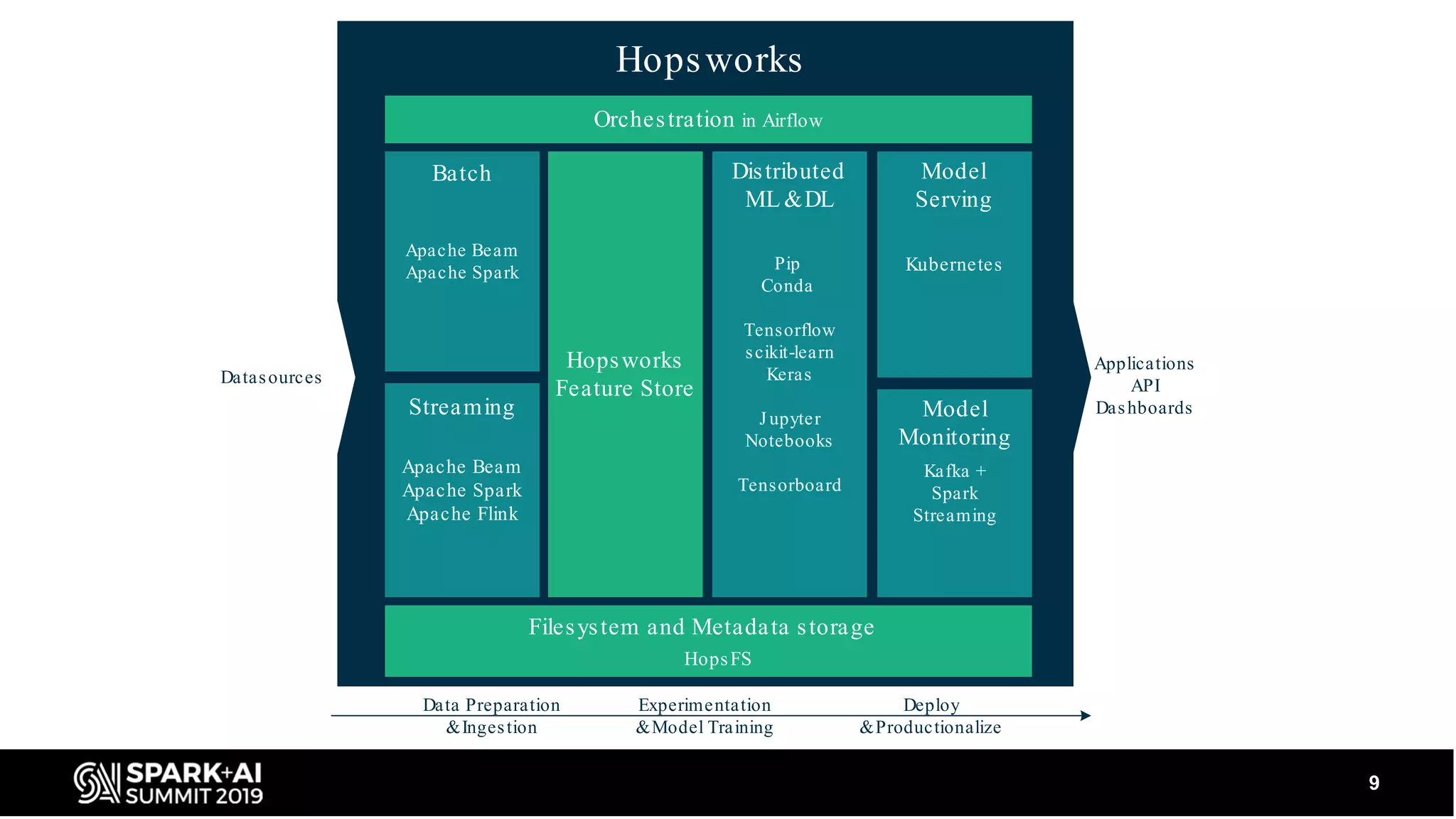
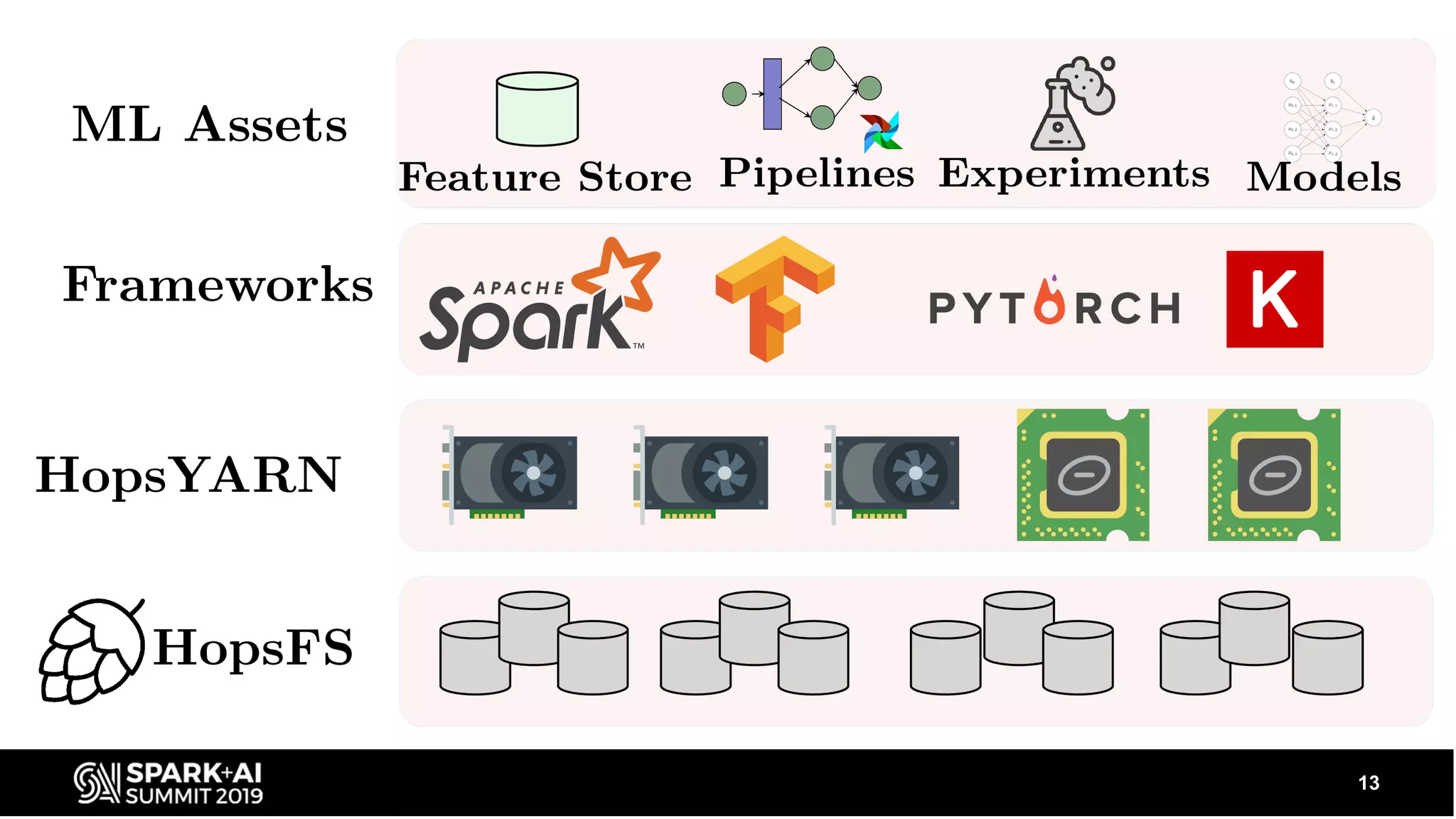
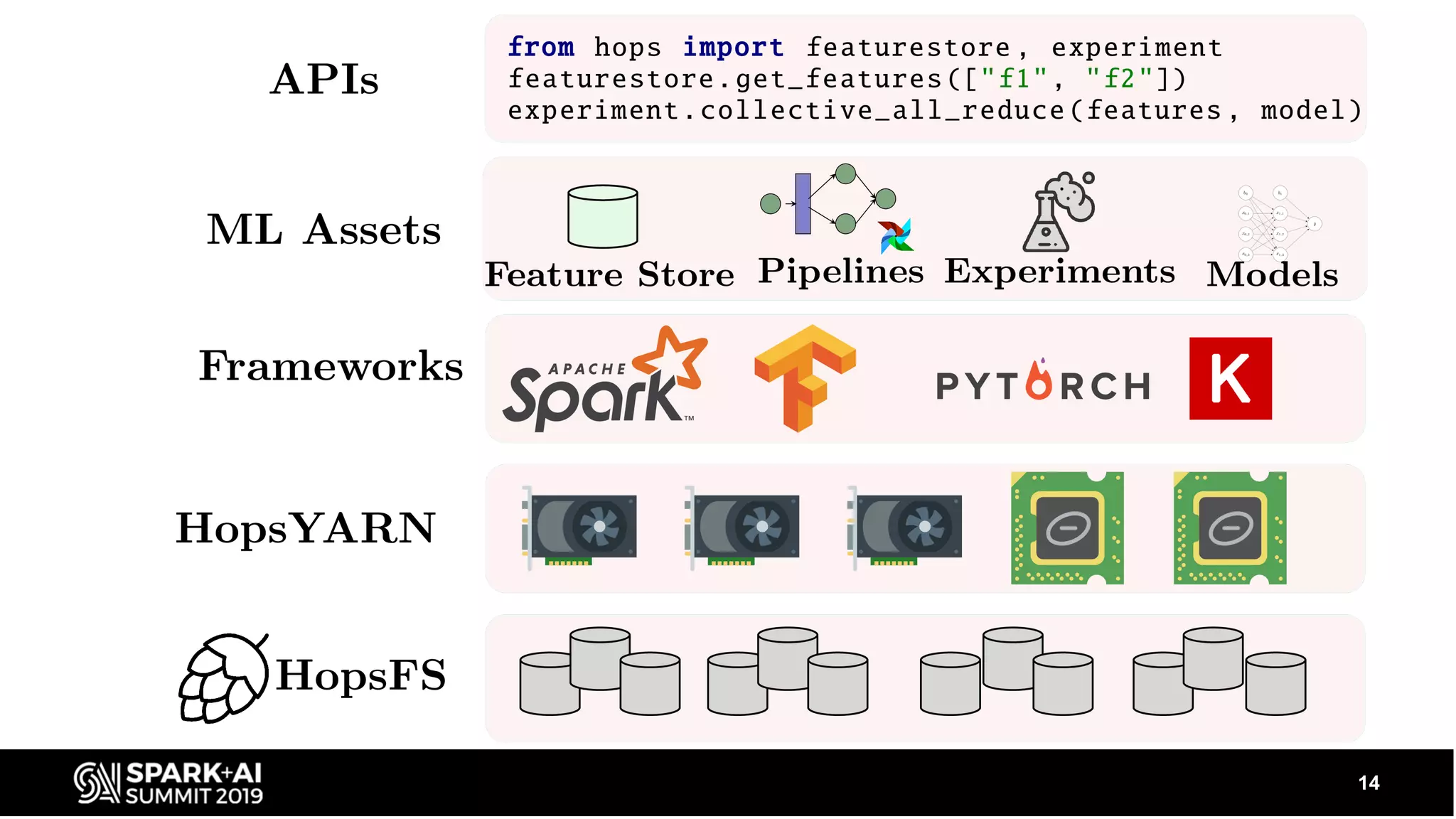
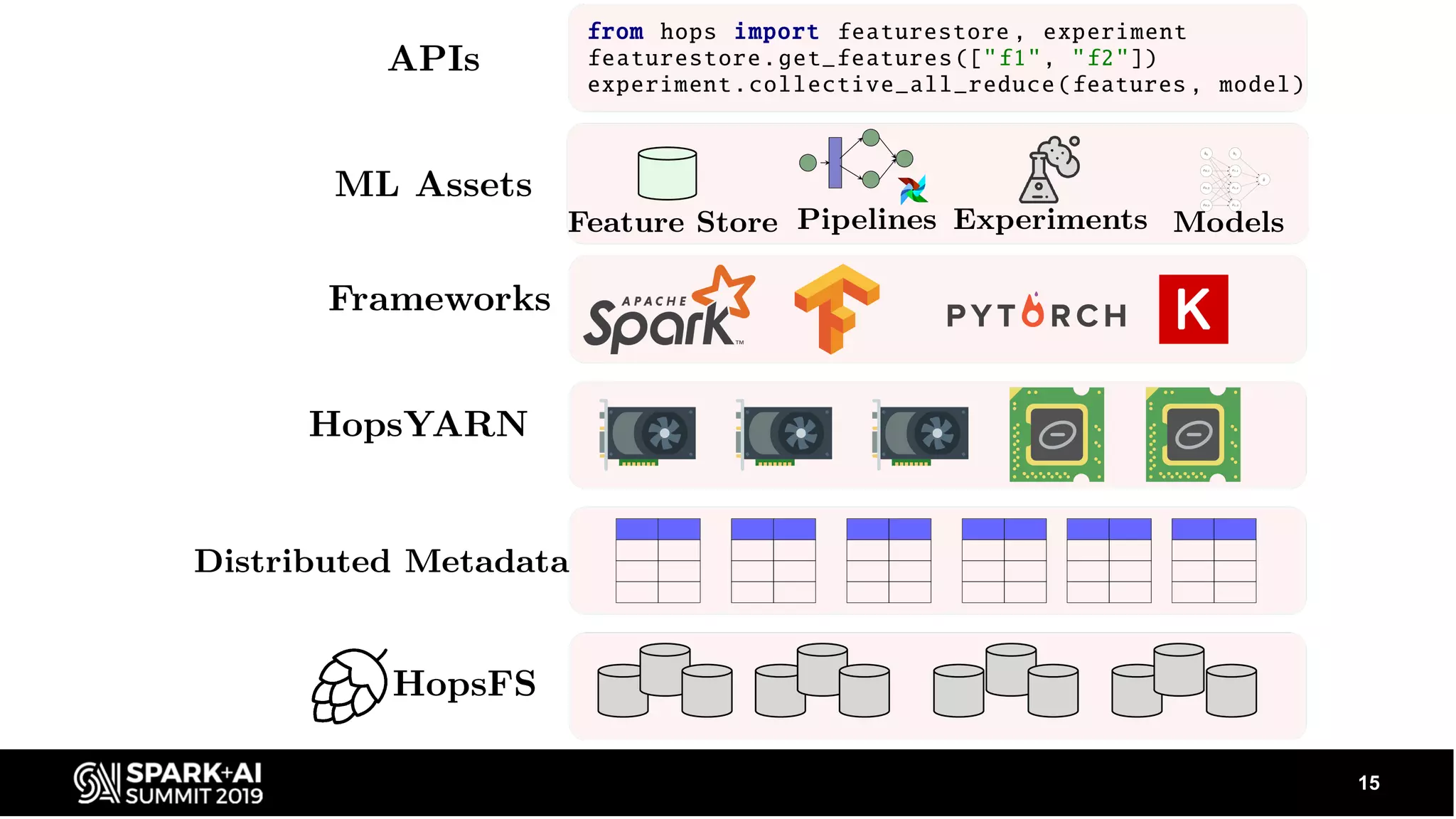
Describes the ecosystem including data sources and applications, and how Hopsworks integrates various technologies like Apache Beam, Spark, and TensorFlow.
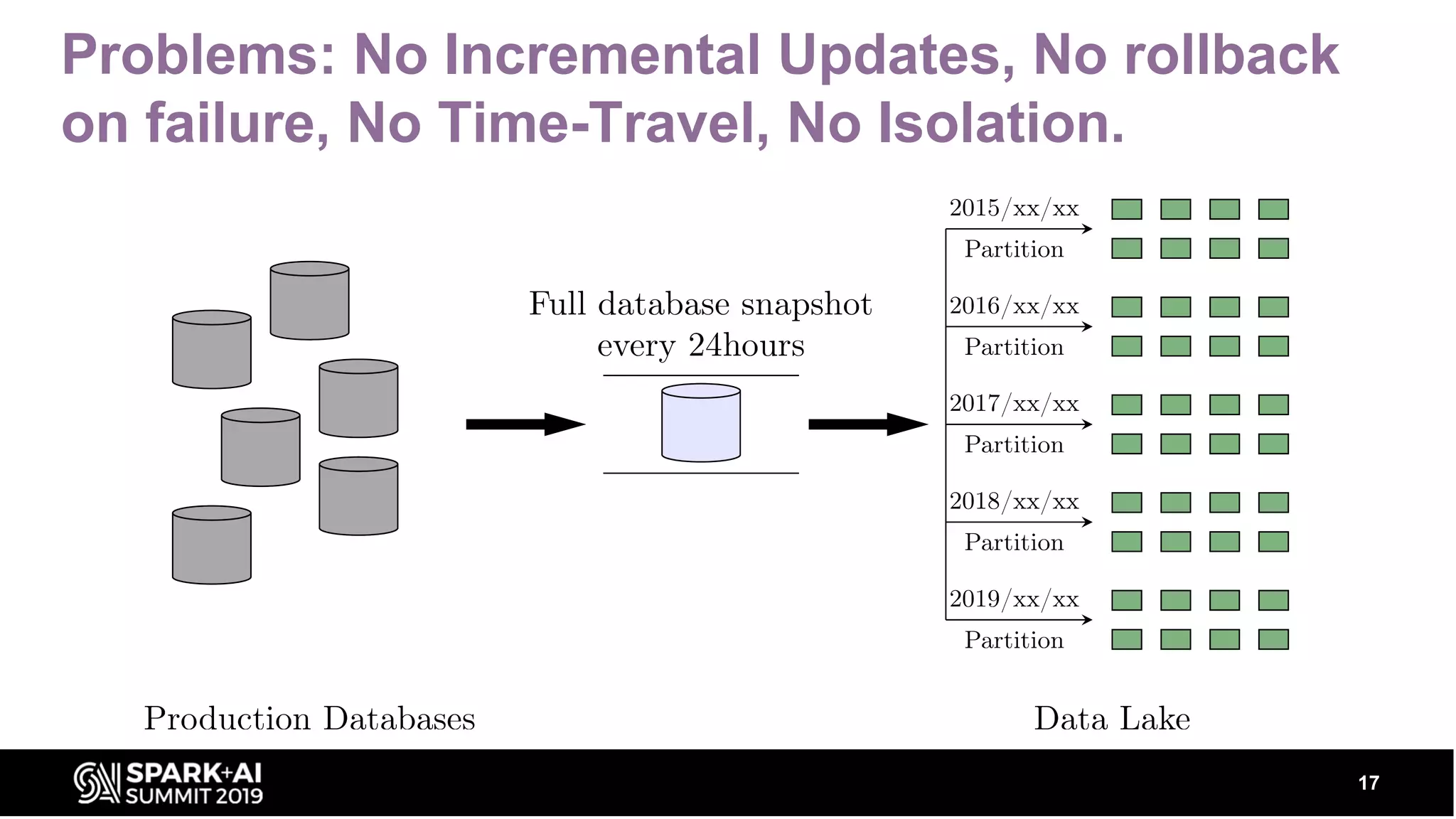
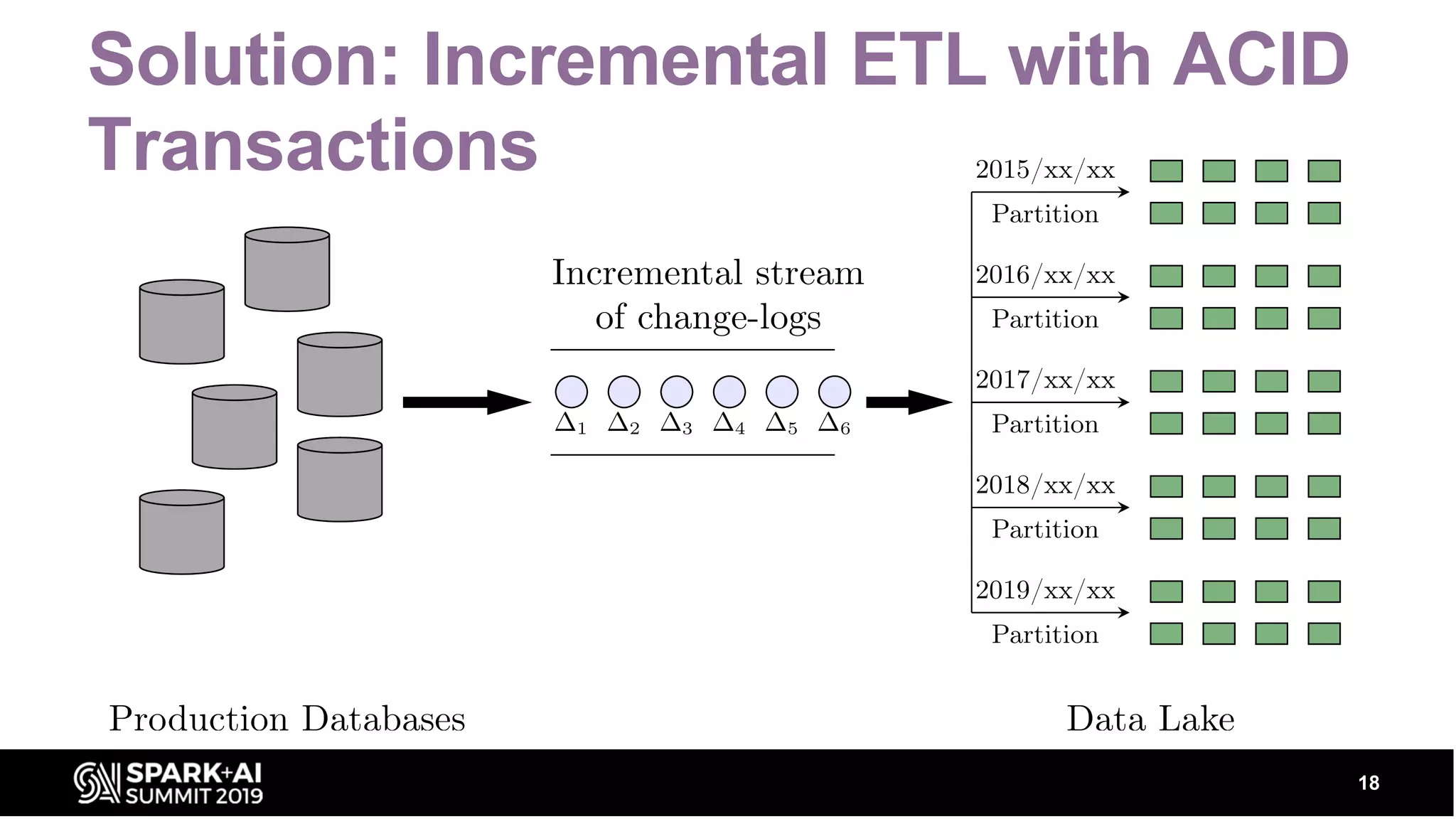
Defines new characteristics of Data Lakes, like ACID transactional layers, and solutions for issues like incremental updates and rollback failures.
Details on Upsert and Time Travel functionalities in data management, providing examples of how these concepts work.
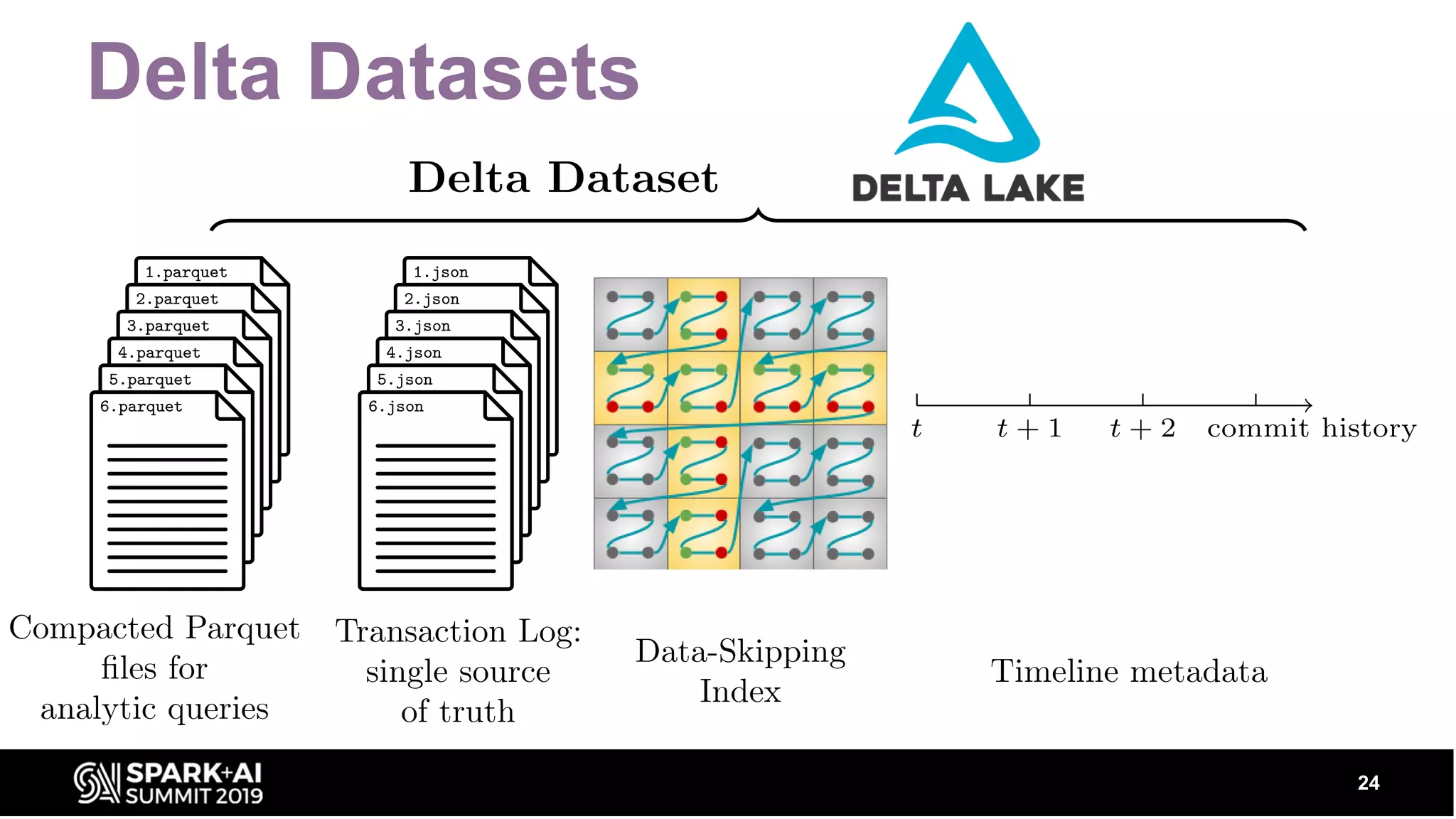
Discusses Delta Lake's transactional layer, ACID transactions, open format storage, and time-travel capabilities.
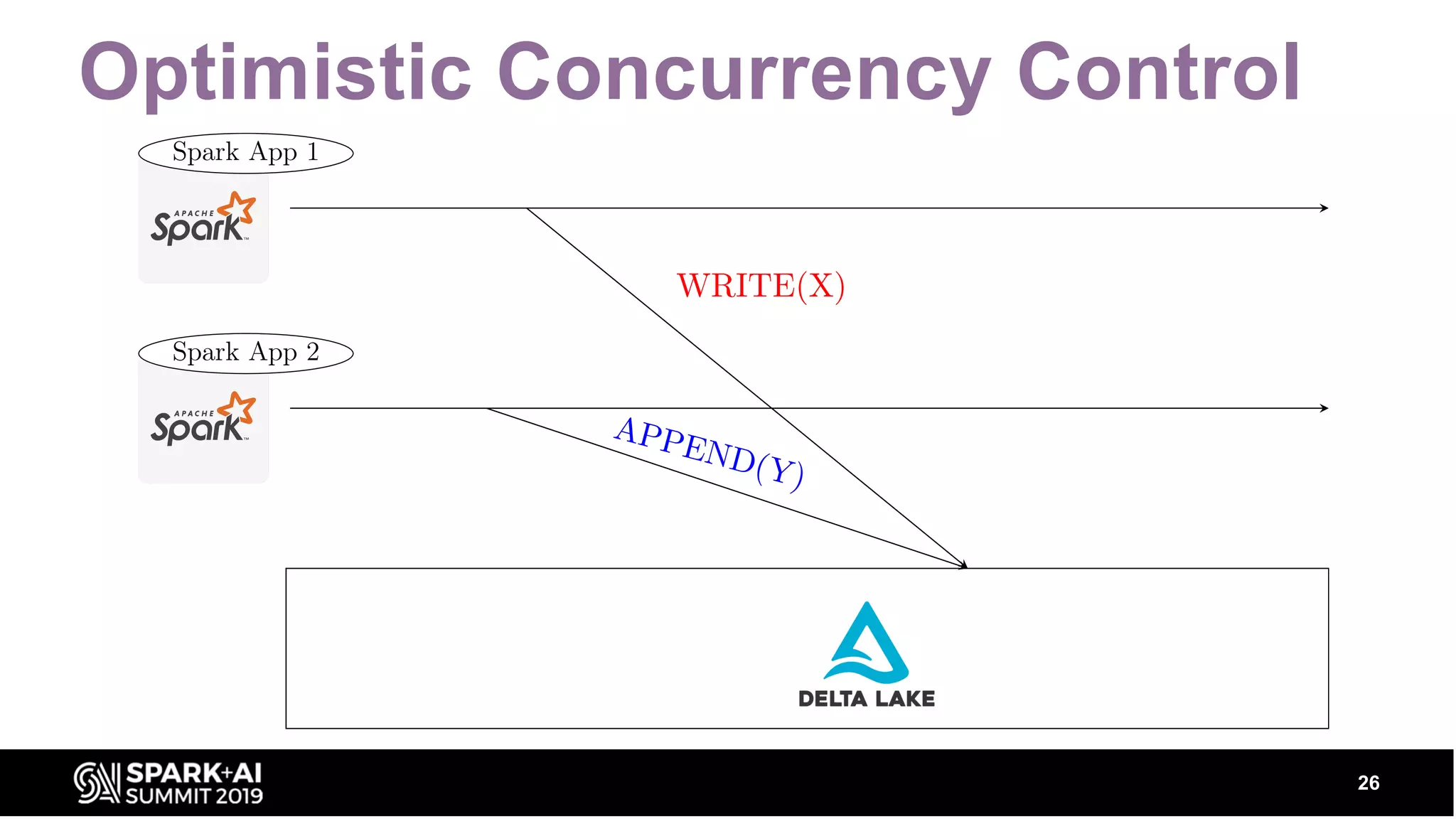
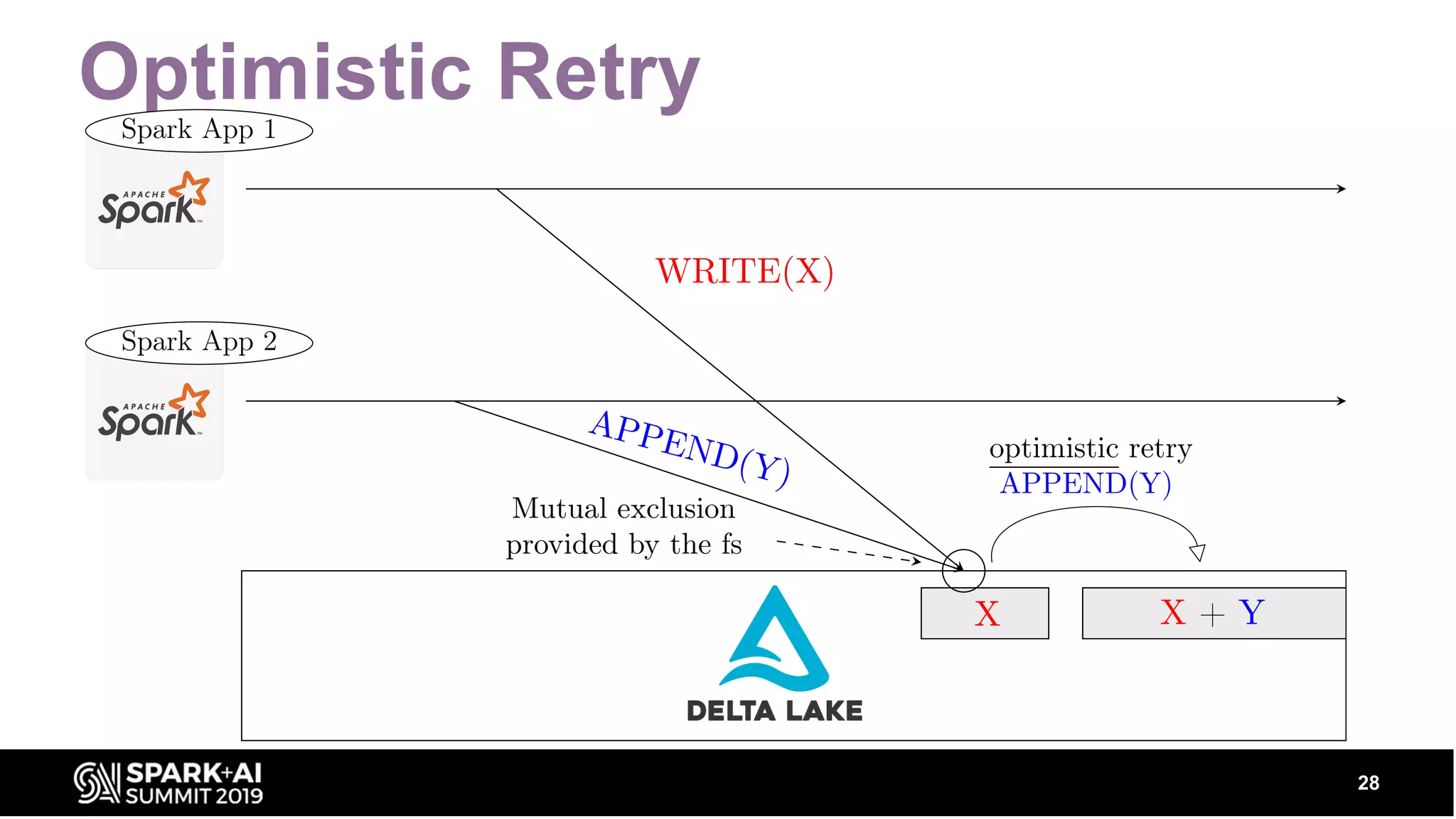
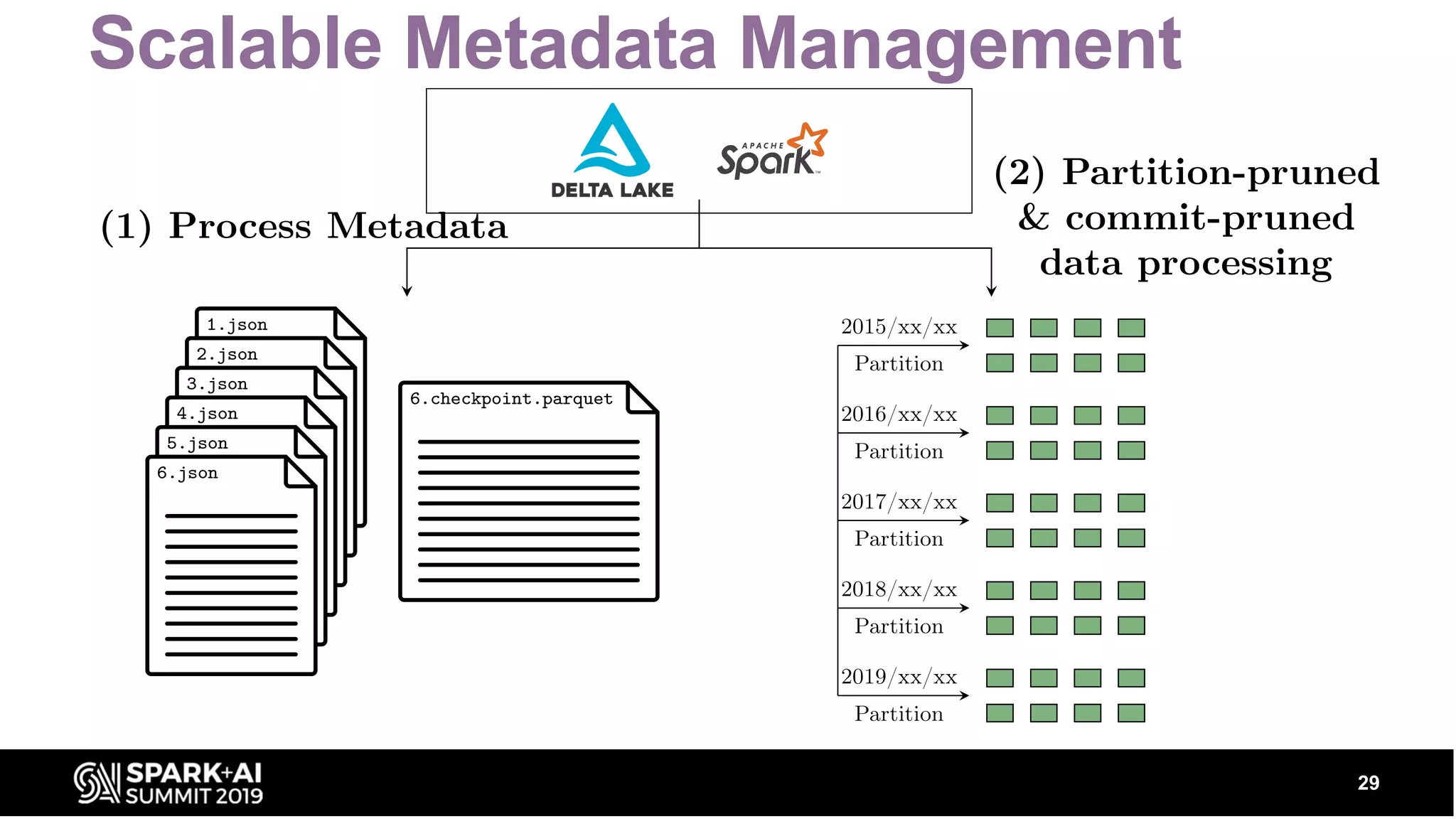
Covers optimistic concurrency control, mutual exclusion, retrial strategies, and how scalable metadata management works.
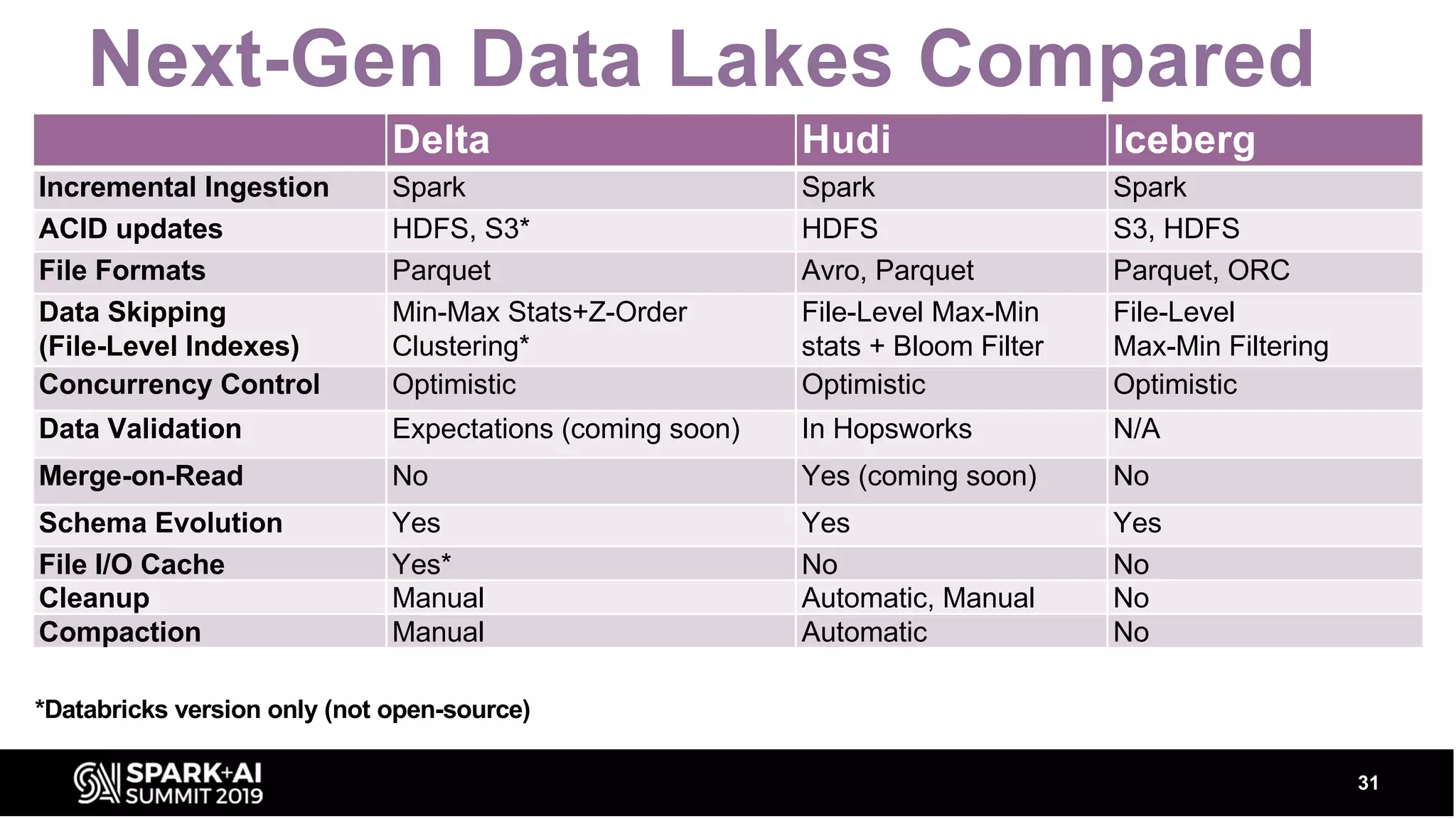
Comparison of Delta, Hudi, and Iceberg frameworks, highlighting their common goals of reliable updates and storage efficiency.
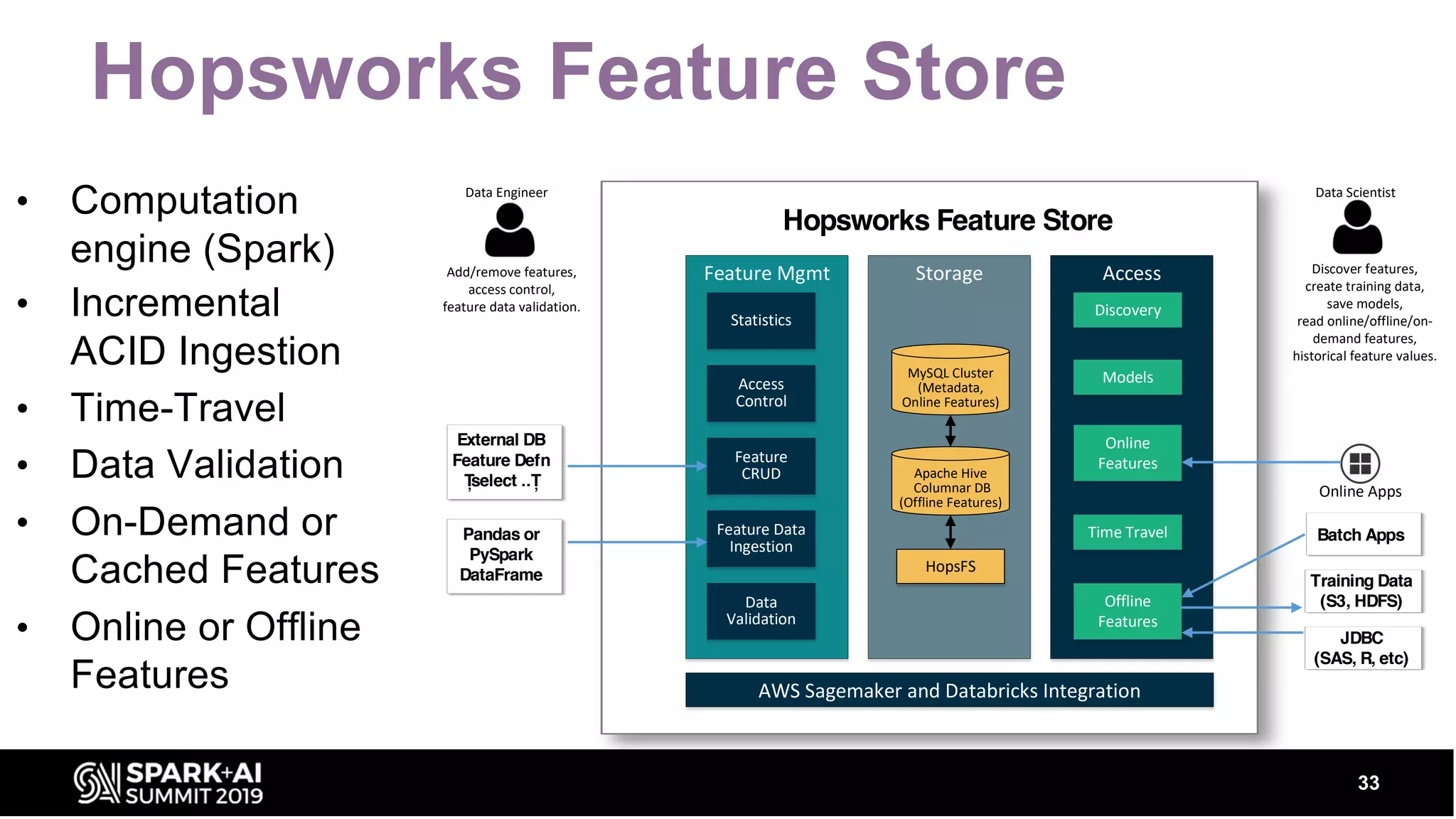
Discusses how Feature Stores can utilize log-structured storage, integration with Databricks for incrementing ACID ingestion and data validation.
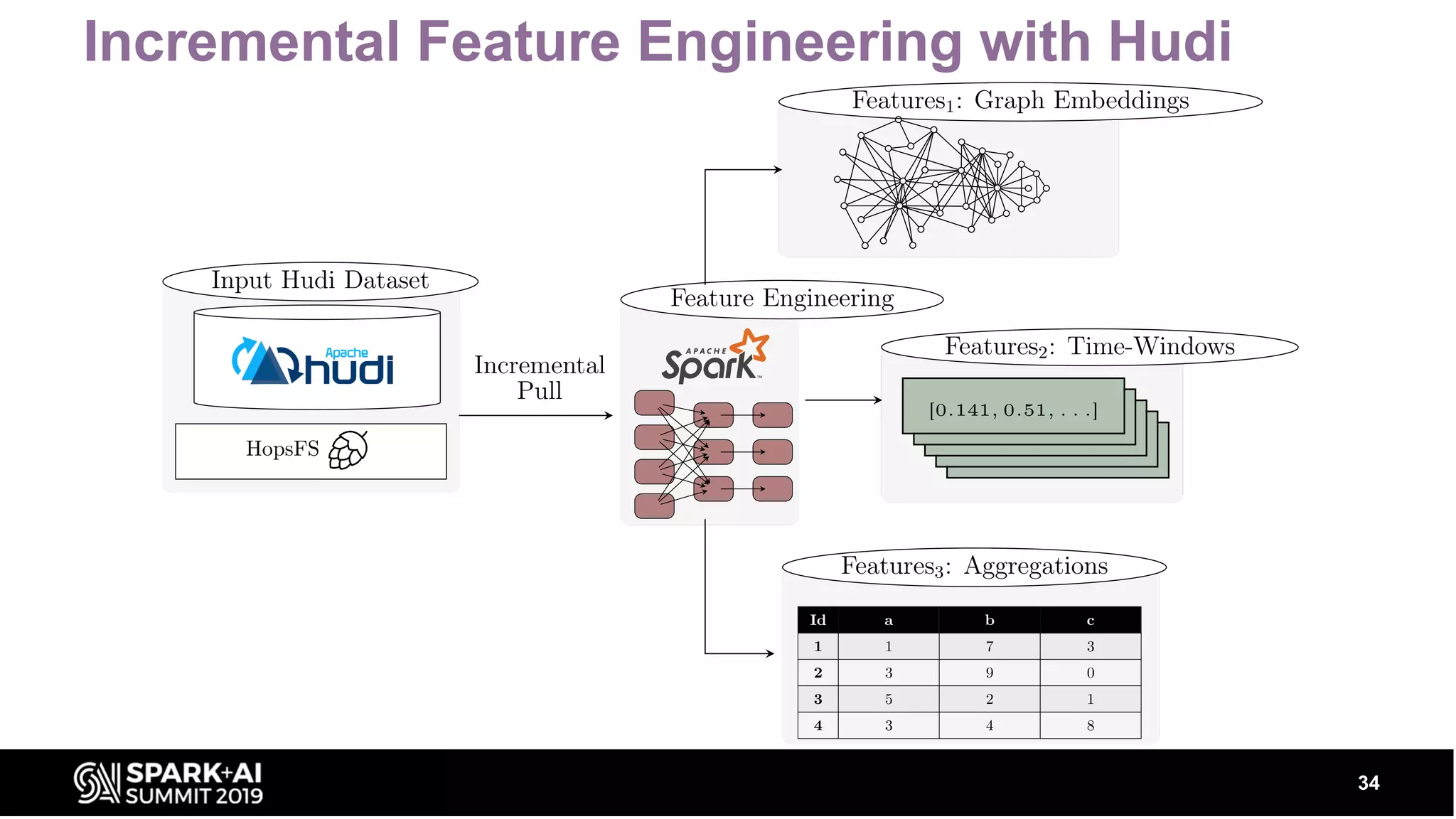
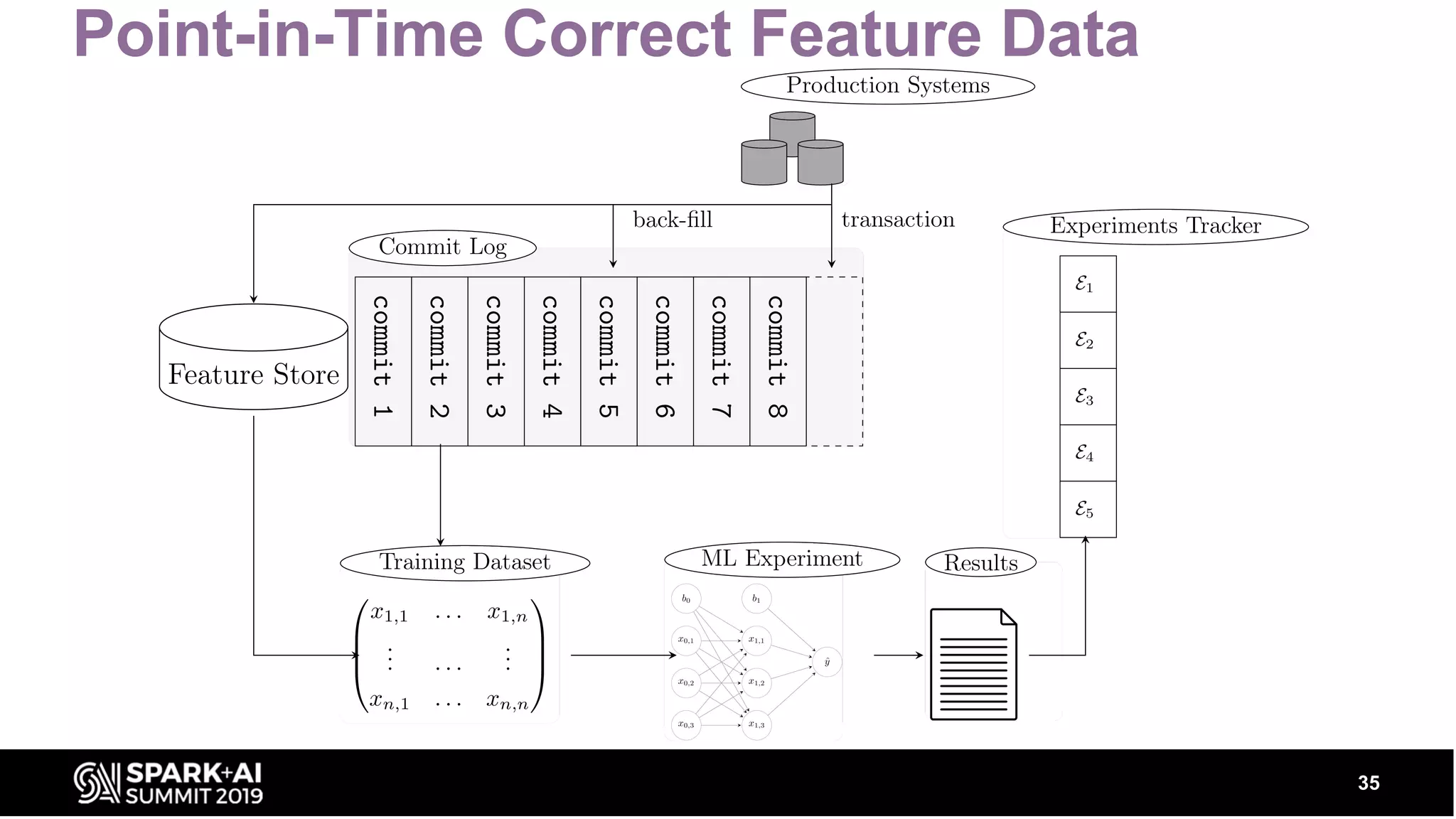
Explains incremental feature engineering and point-in-time correct data with examples using Hudi and Hopsworks.
Demonstrates the integration of Hopsworks Feature Store and Databricks platform in action.
Summarizes key functionalities of Delta, Hudi, Iceberg for data lakes and introduces Hopsworks as an open-source feature store supporting end-to-end ML.
Provides company information, resources for further reading, and thanks to team members involved in the project.