Downloaded 91 times








![Create Train/Test Datasets using the Feature Store from hops import featurestore as fs sample_data = fs.get_features([“name”, “Pclass”, “Sex”, “Balance”, “Survived”]) fs.create_training_dataset(sample_data, “titanic_training_dataset", data_format="tfrecords“, training_dataset_version=1)](https://image.slidesharecdn.com/554jimdowlingfabiobuso-200709193939/75/Building-a-Feature-Store-around-Dataframes-and-Apache-Spark-16-2048.jpg)






![fg = dev_fs.get_feature_group(“temperature”, version=1) # Returns a dataframe object fg.read() # Show a sample of 10 rows in the feature group fg.show(10) fg.select(["date", "location", "avg"]).show(10) fg.select(["date”, “location”,”avg”]).read() .filter(col(“location”) == “Stockholm”).show(10) Exploratory Data Analysis](https://image.slidesharecdn.com/554jimdowlingfabiobuso-200709193939/75/Building-a-Feature-Store-around-Dataframes-and-Apache-Spark-24-2048.jpg)
![Joins - Pandas Style API crop_fg = prod_fs.get_feature_group(“crop”, version = 1) temperature = dev_fs.get_feature_group(“temperature”, version = 1) rain = dev_fs.get_feature_group(“rain”, version = 1) joined_features = crop_fg.select(["location", "yield"]) .join(temperature.select(["location", “season_avg"])) .join(rain.select(["location", "avg_mm"]), on=["location"], join_type="left") dataframe = joined_features.read()](https://image.slidesharecdn.com/554jimdowlingfabiobuso-200709193939/75/Building-a-Feature-Store-around-Dataframes-and-Apache-Spark-25-2048.jpg)


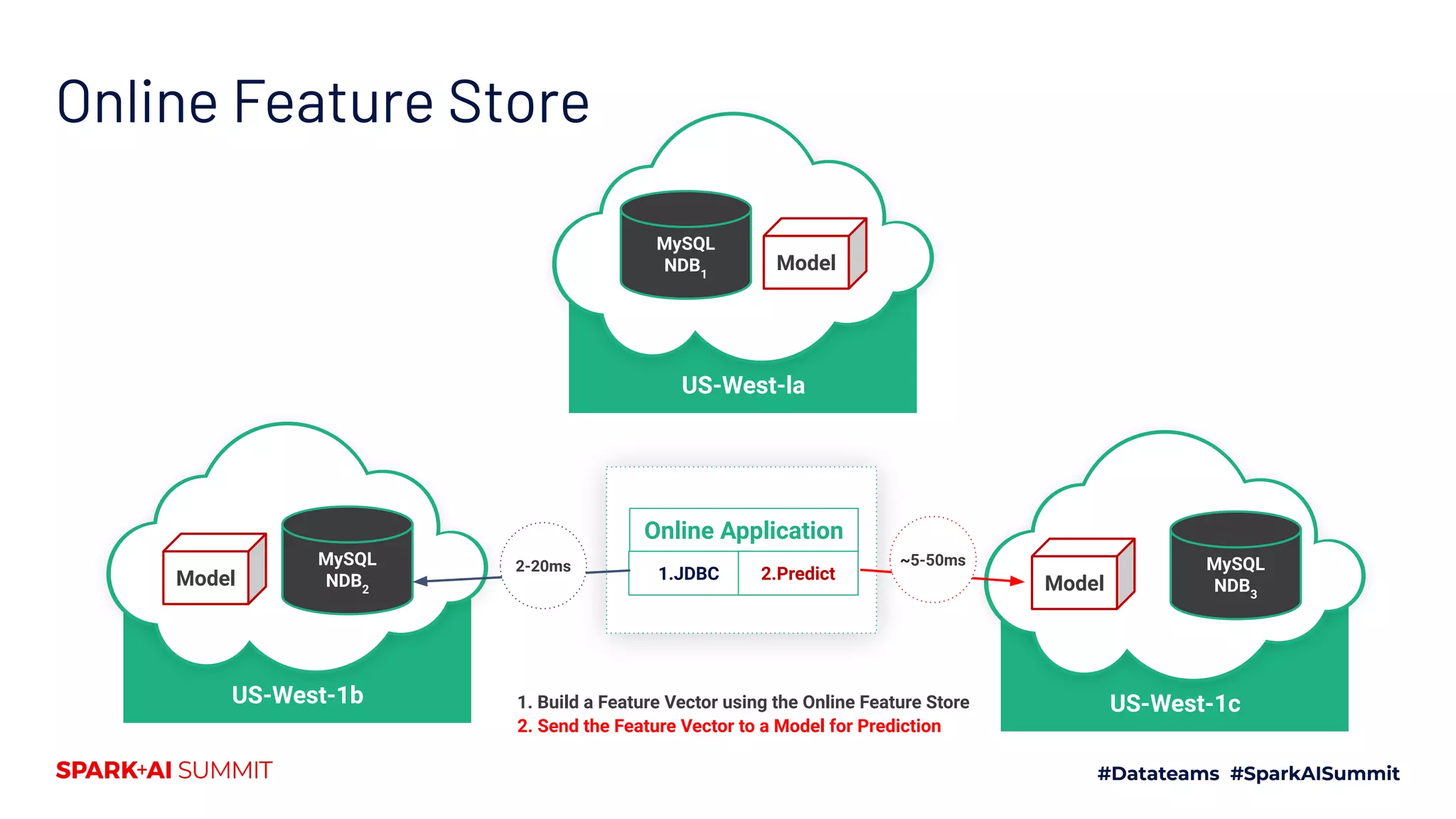
![fs.get_feature_vector(training_dataset=”crop”, id = [{ ‘location’: ‘Stockholm’, ‘crop’: ‘wheat’ }]) Get feature vector for online serving ▪ Return feature vector from the online feature store ▪ Feature order is maintained](https://image.slidesharecdn.com/554jimdowlingfabiobuso-200709193939/75/Building-a-Feature-Store-around-Dataframes-and-Apache-Spark-28-2048.jpg)




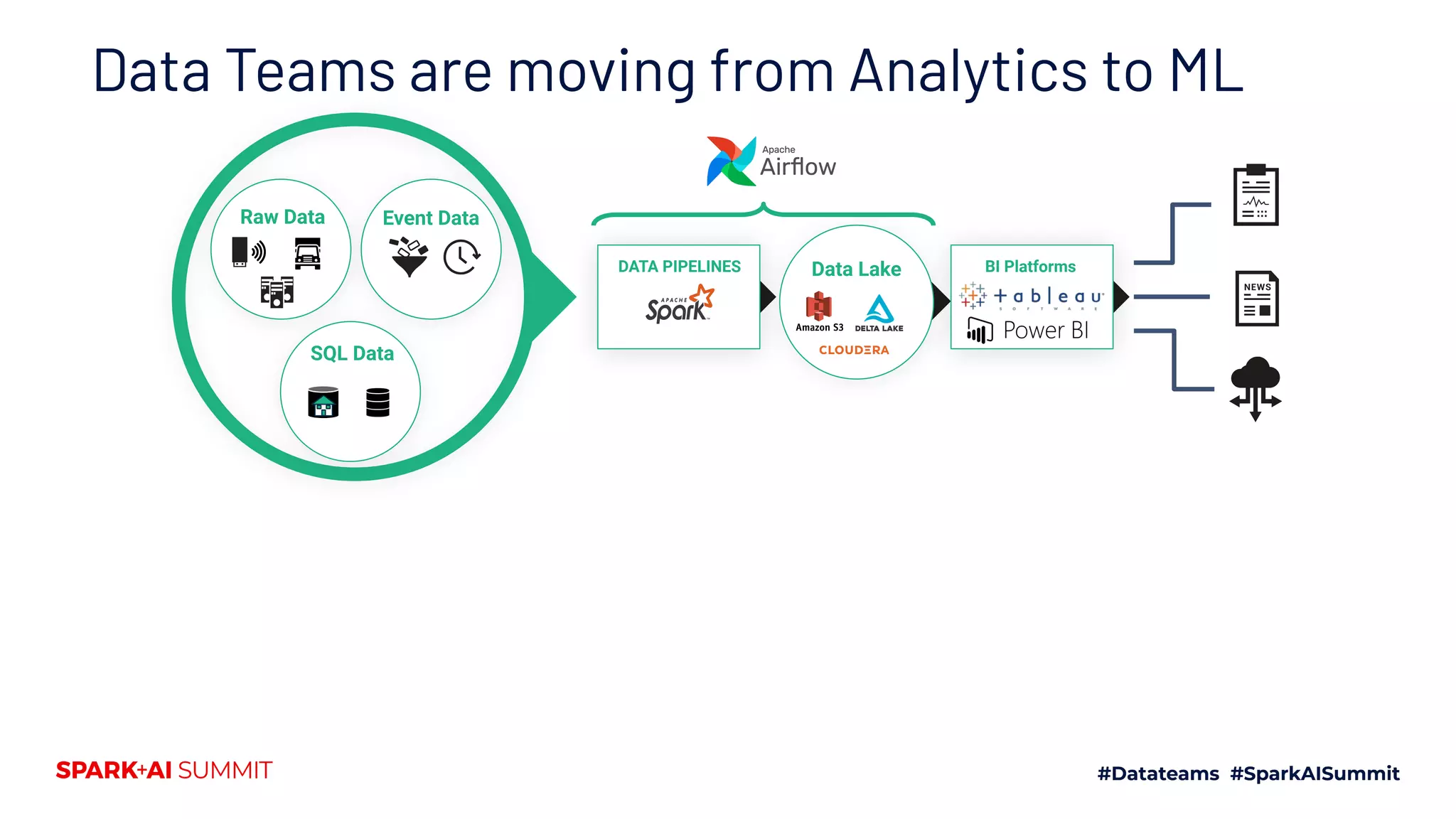
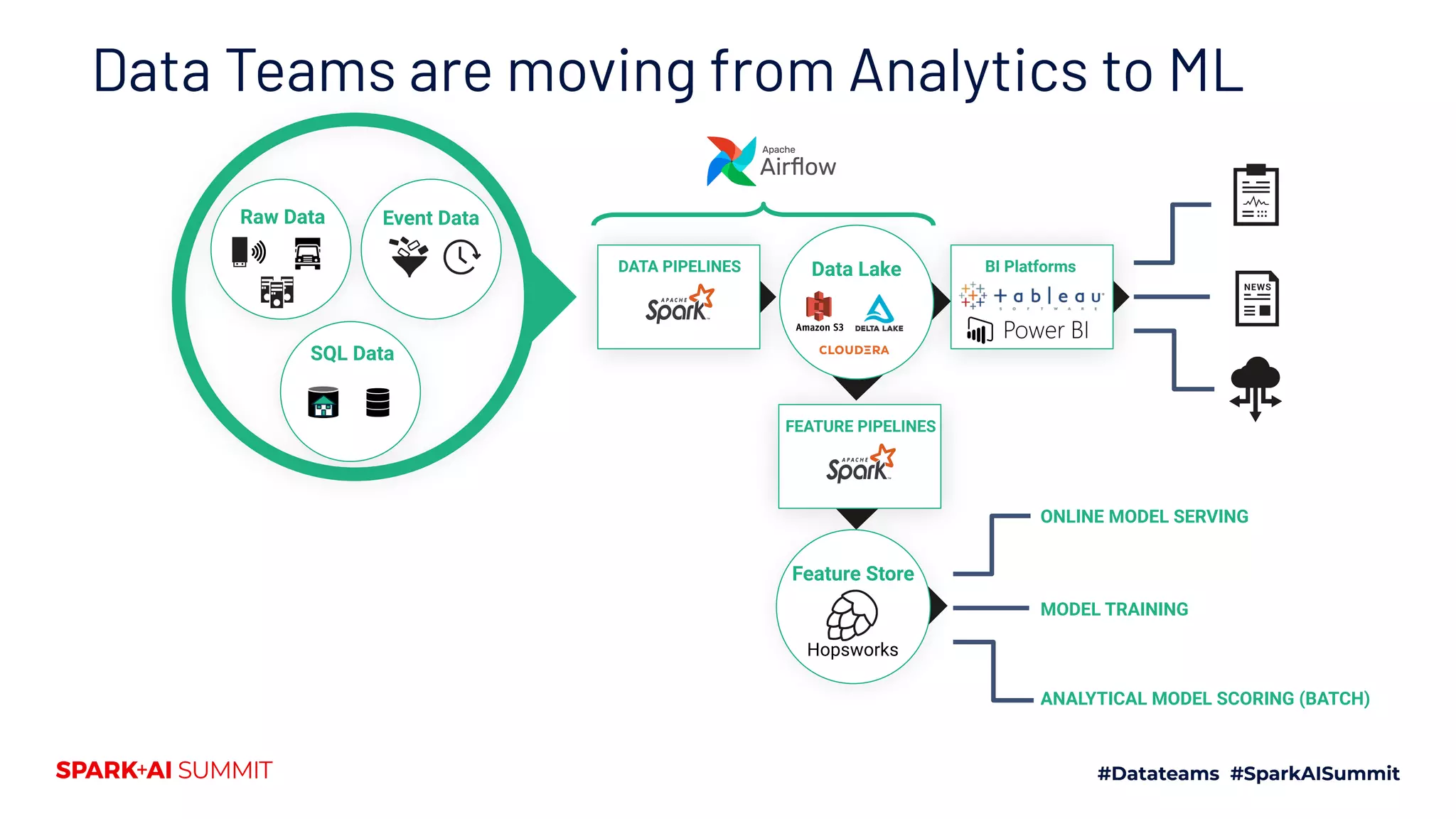
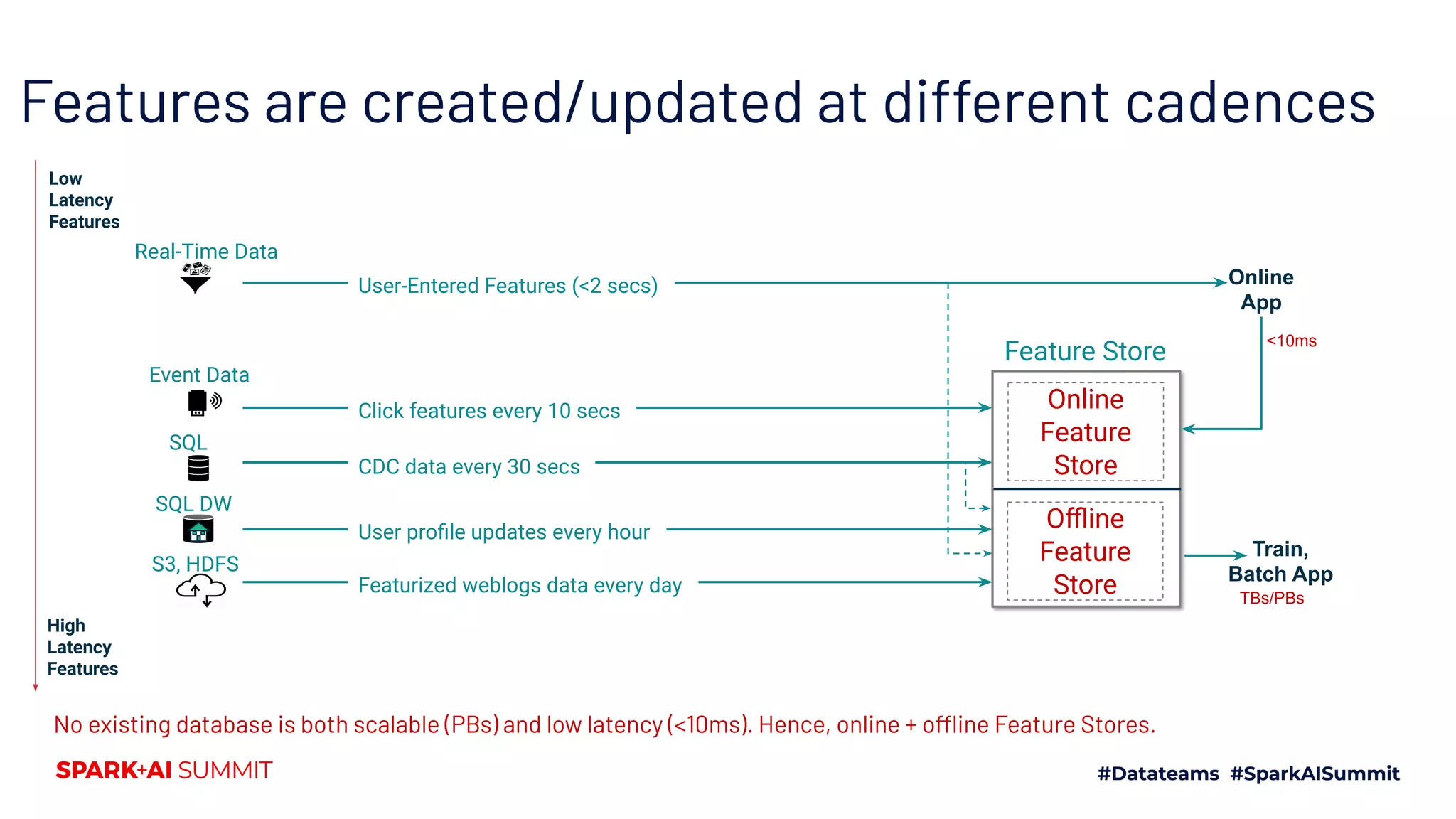
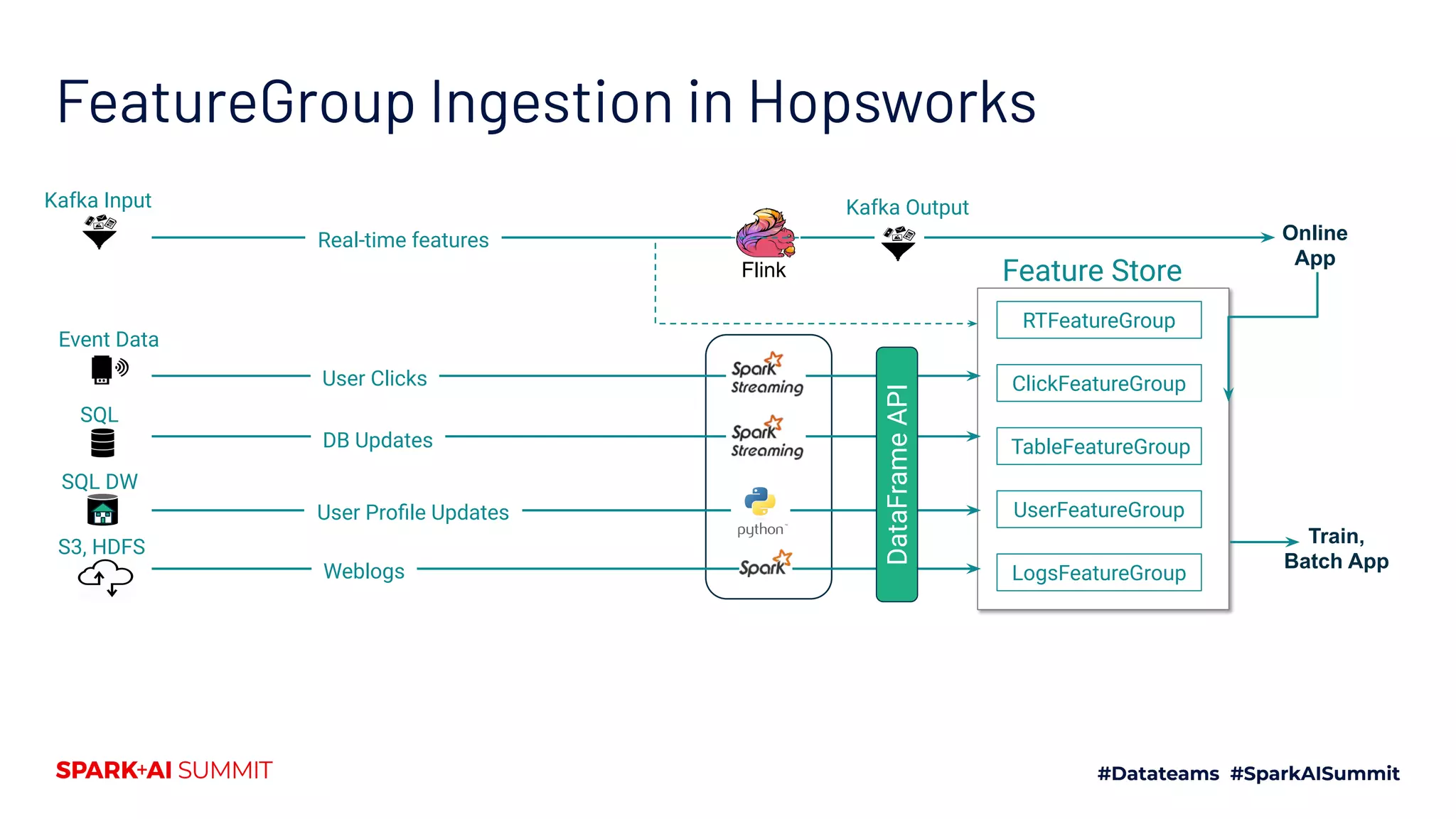
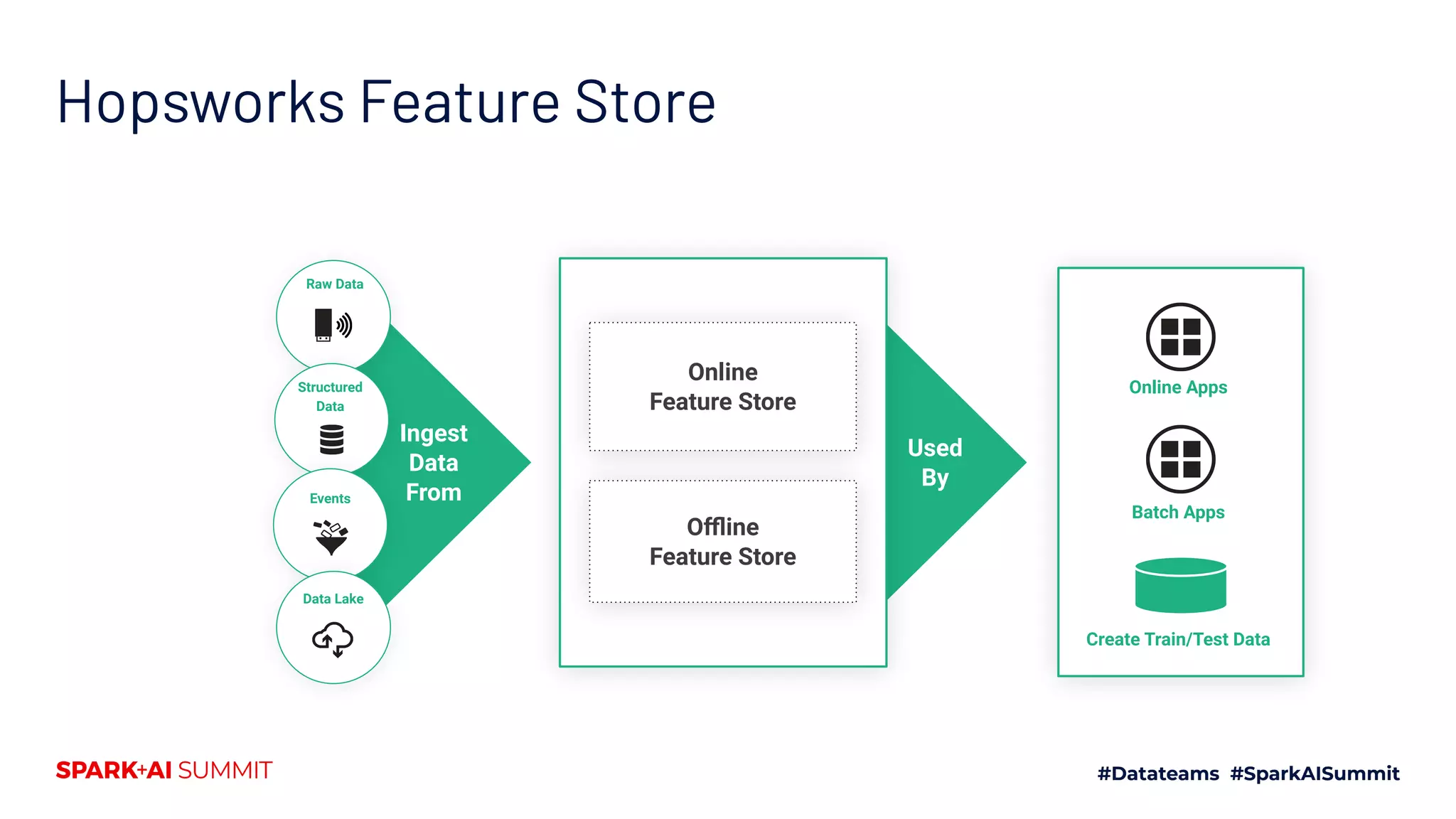
This document discusses the implementation of a feature store using Apache Spark and dataframes, specifically focusing on Hopsworks by Logical Clocks. It highlights the challenges of managing large datasets for machine learning applications, such as fraud detection in banking, and emphasizes the importance of both online and offline feature stores to support different application needs. Key concepts include feature versioning, data ingestion, and the API capabilities of the feature store for optimal data management and model training.