Download as PDF, PPTX



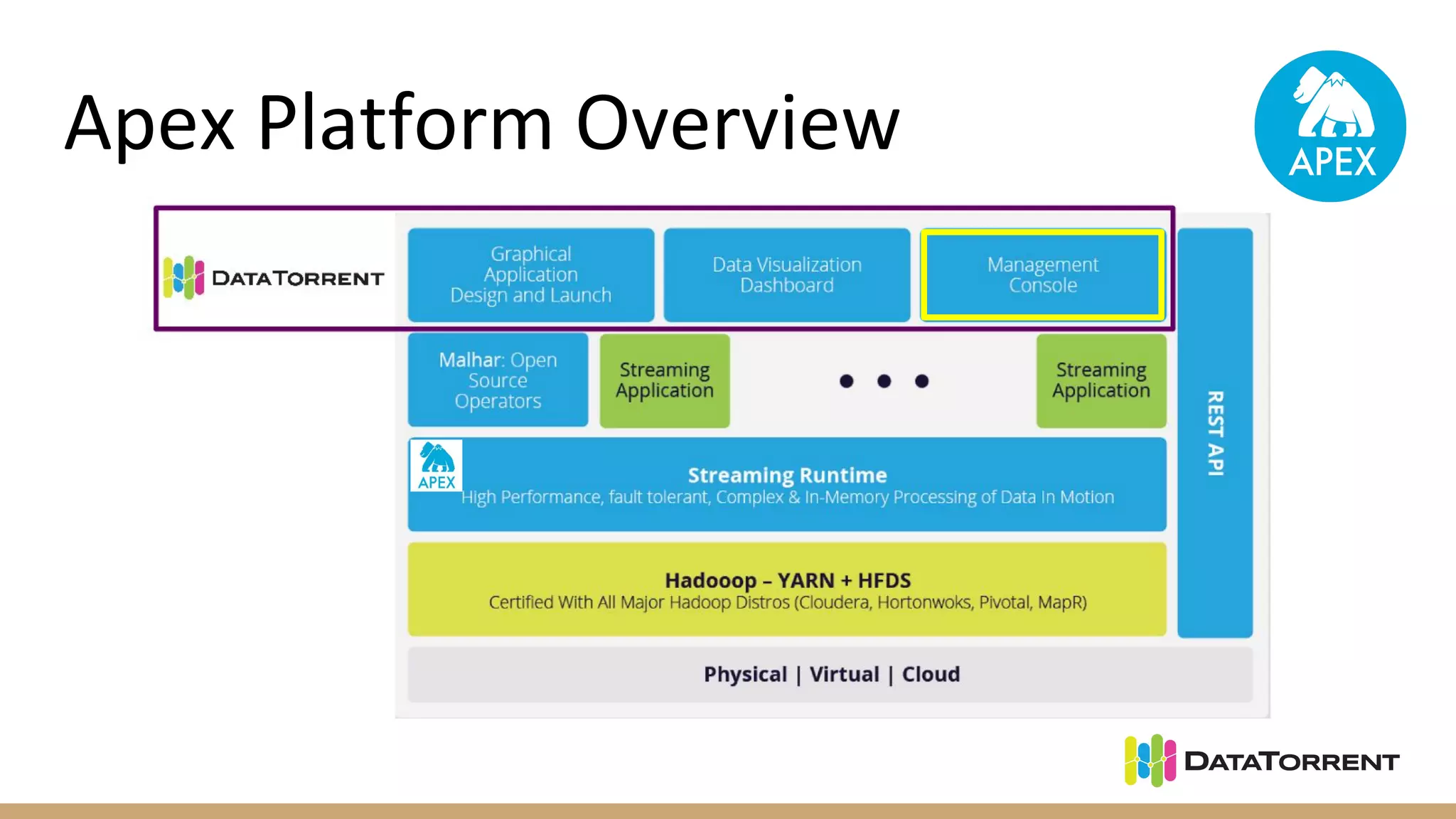
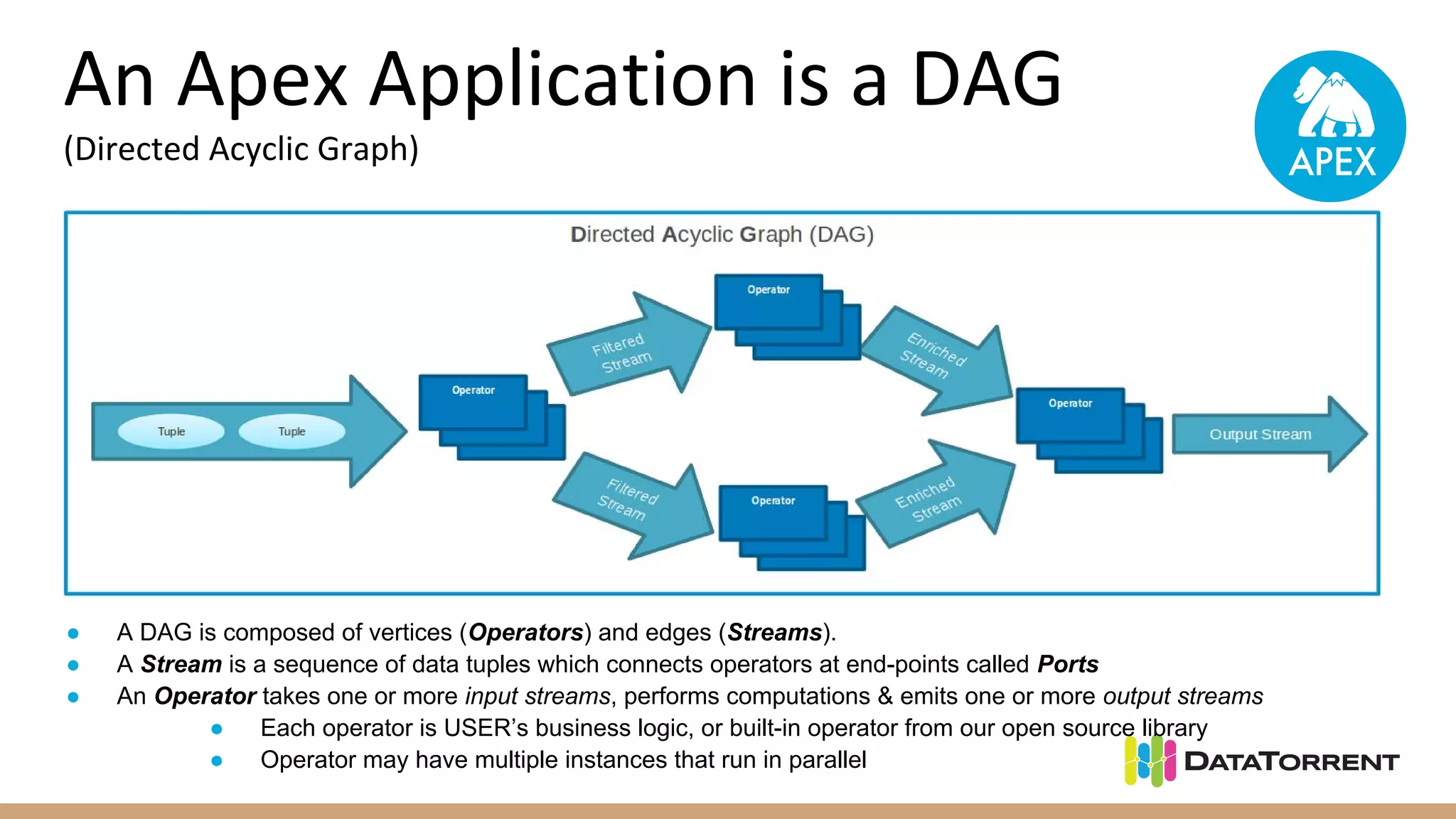
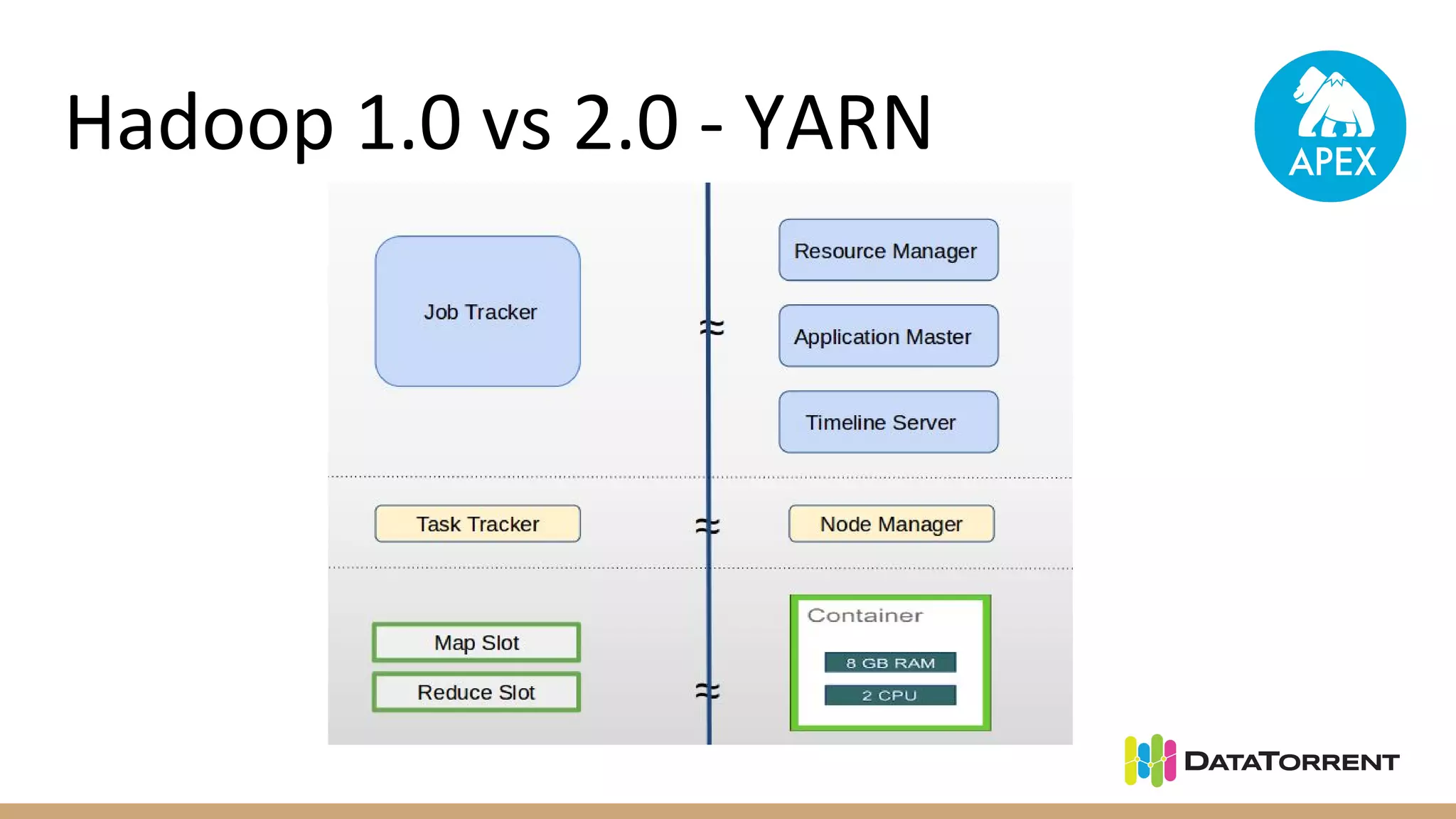
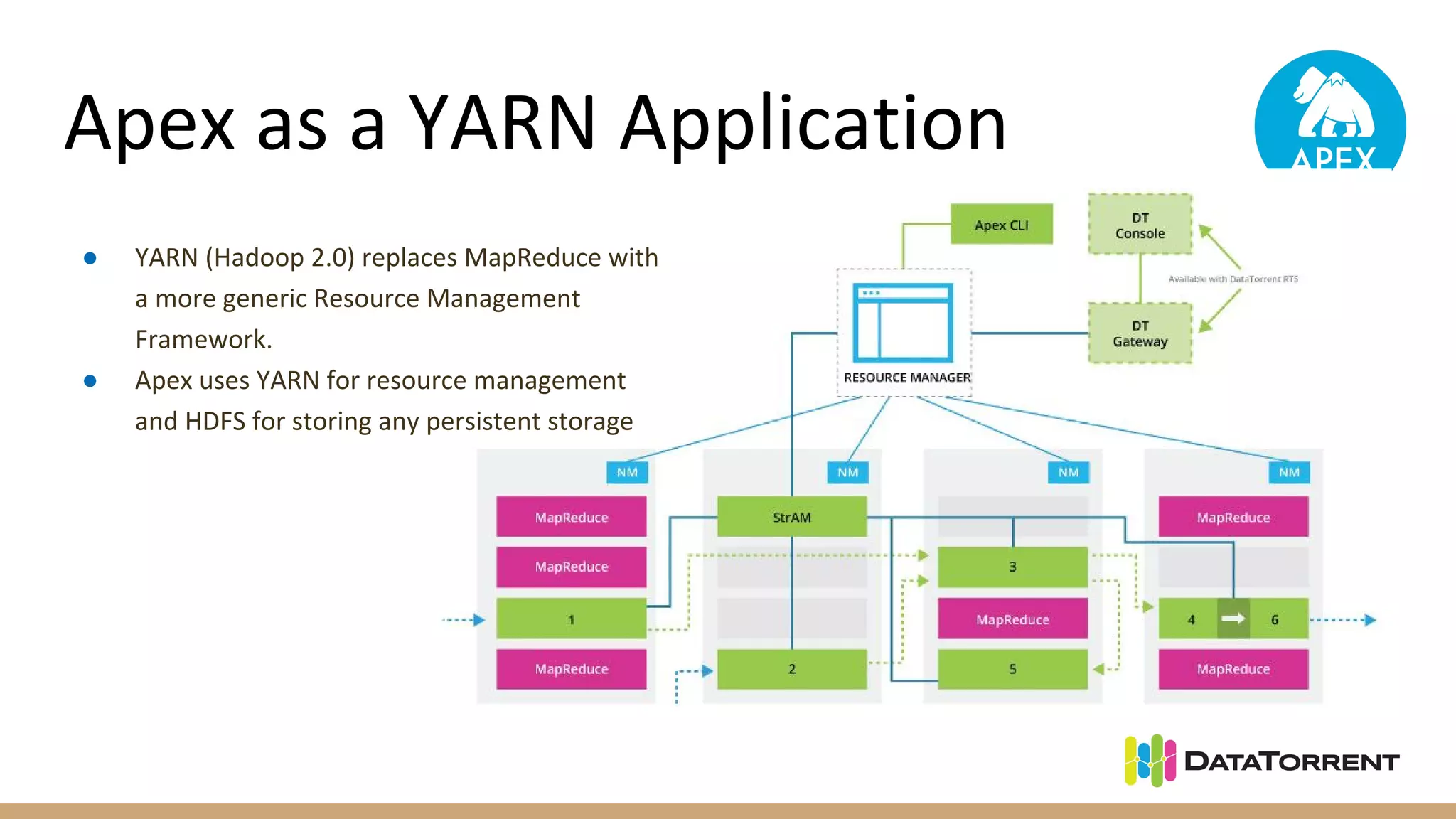

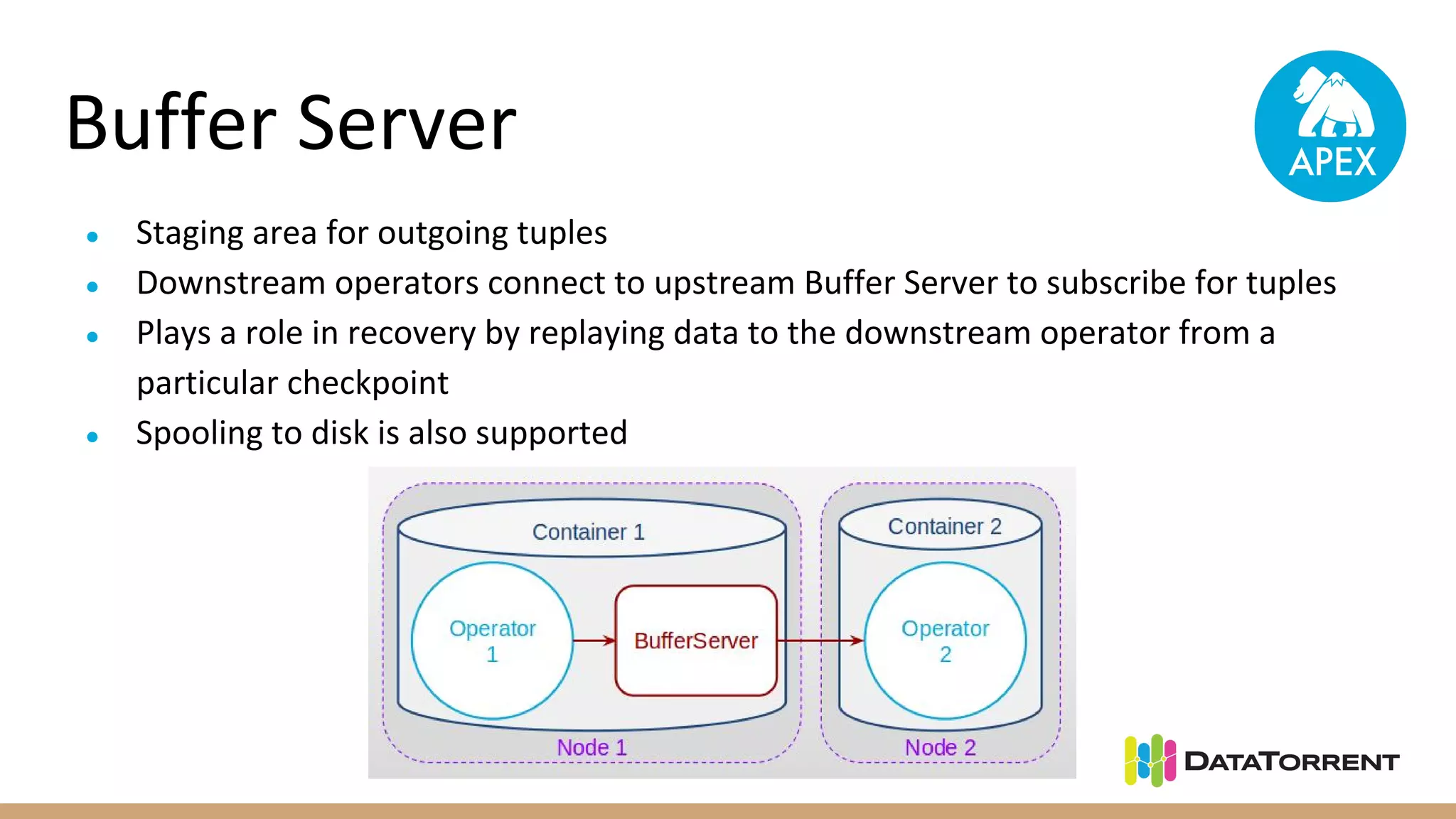

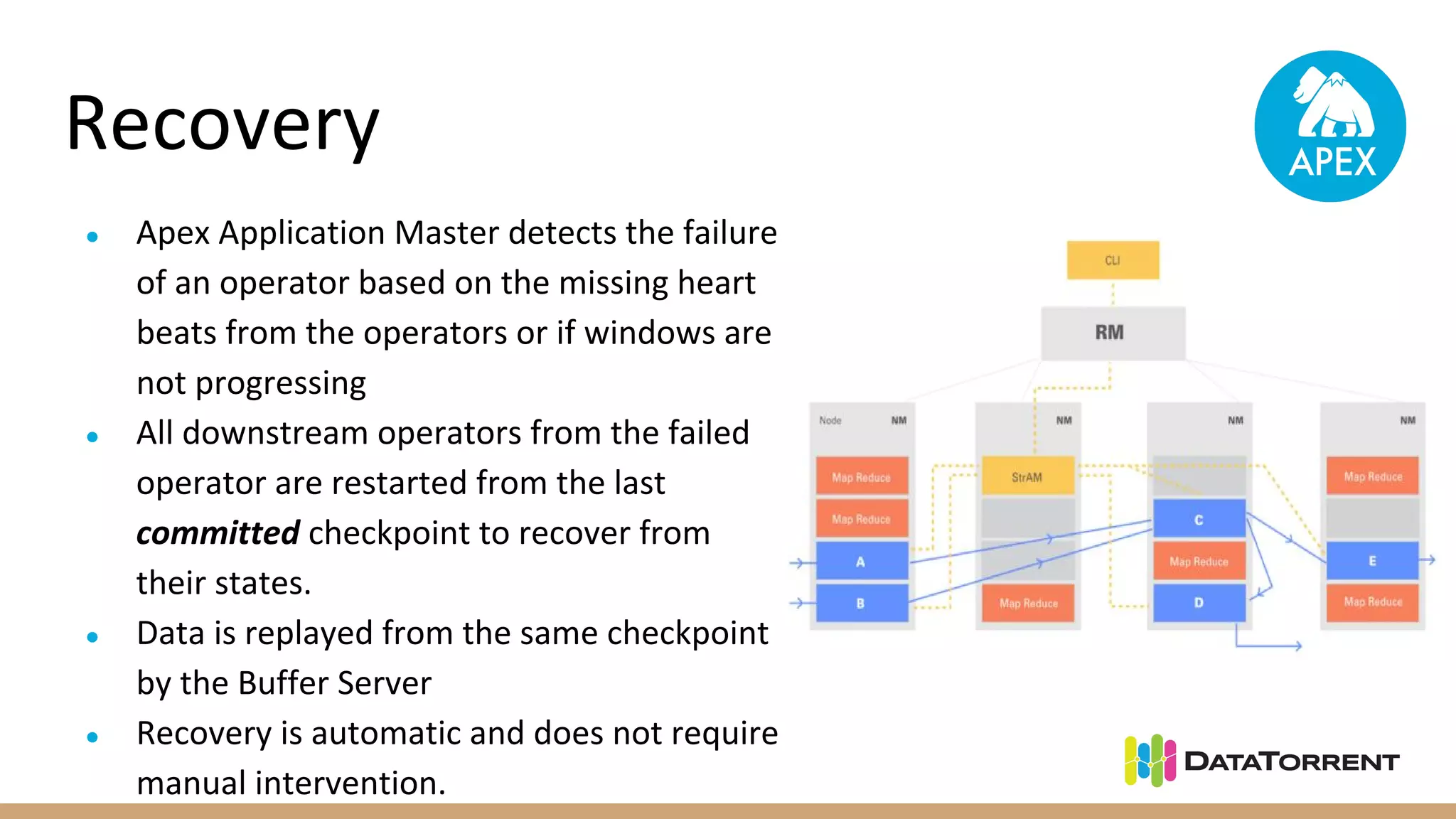
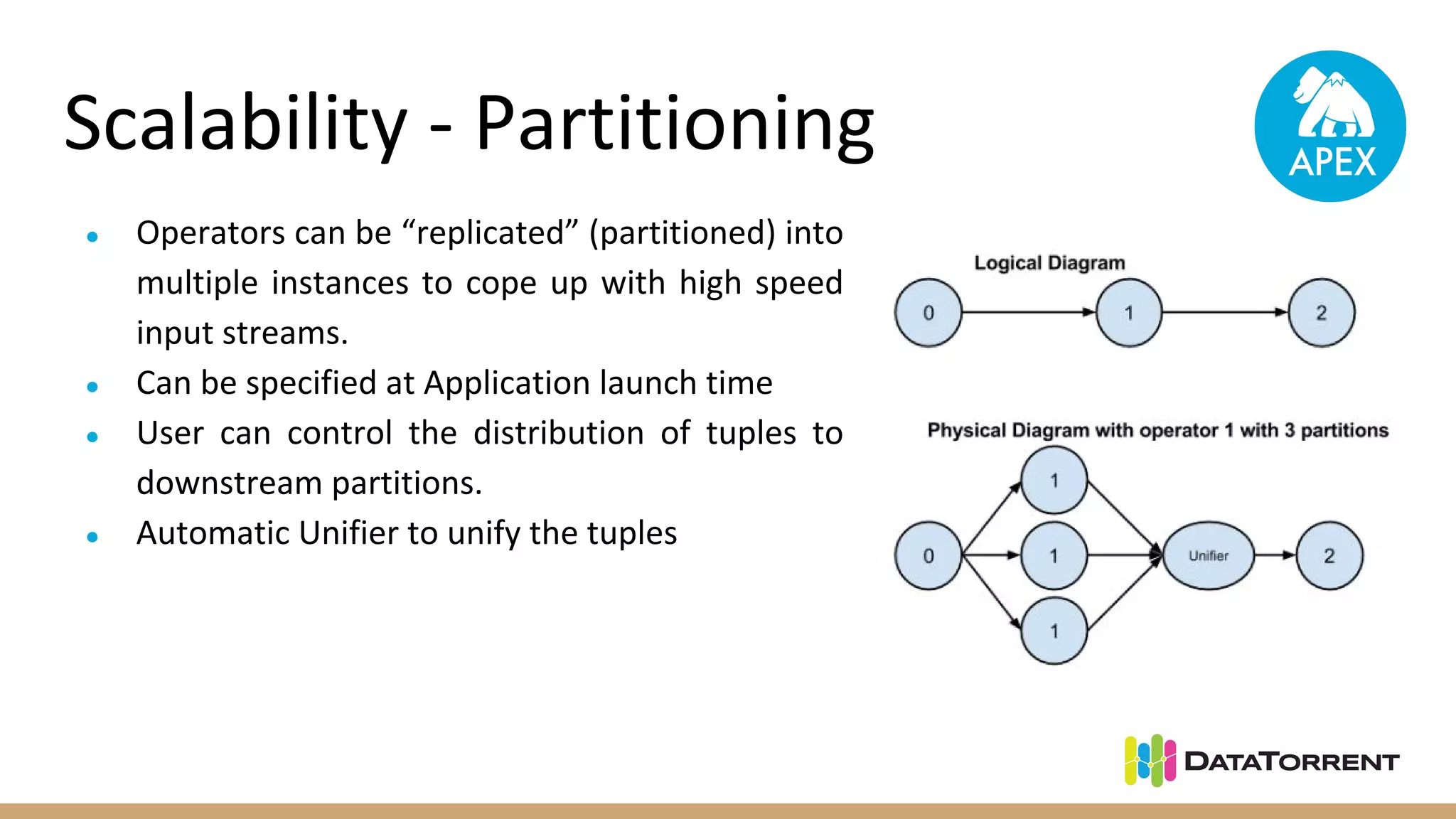
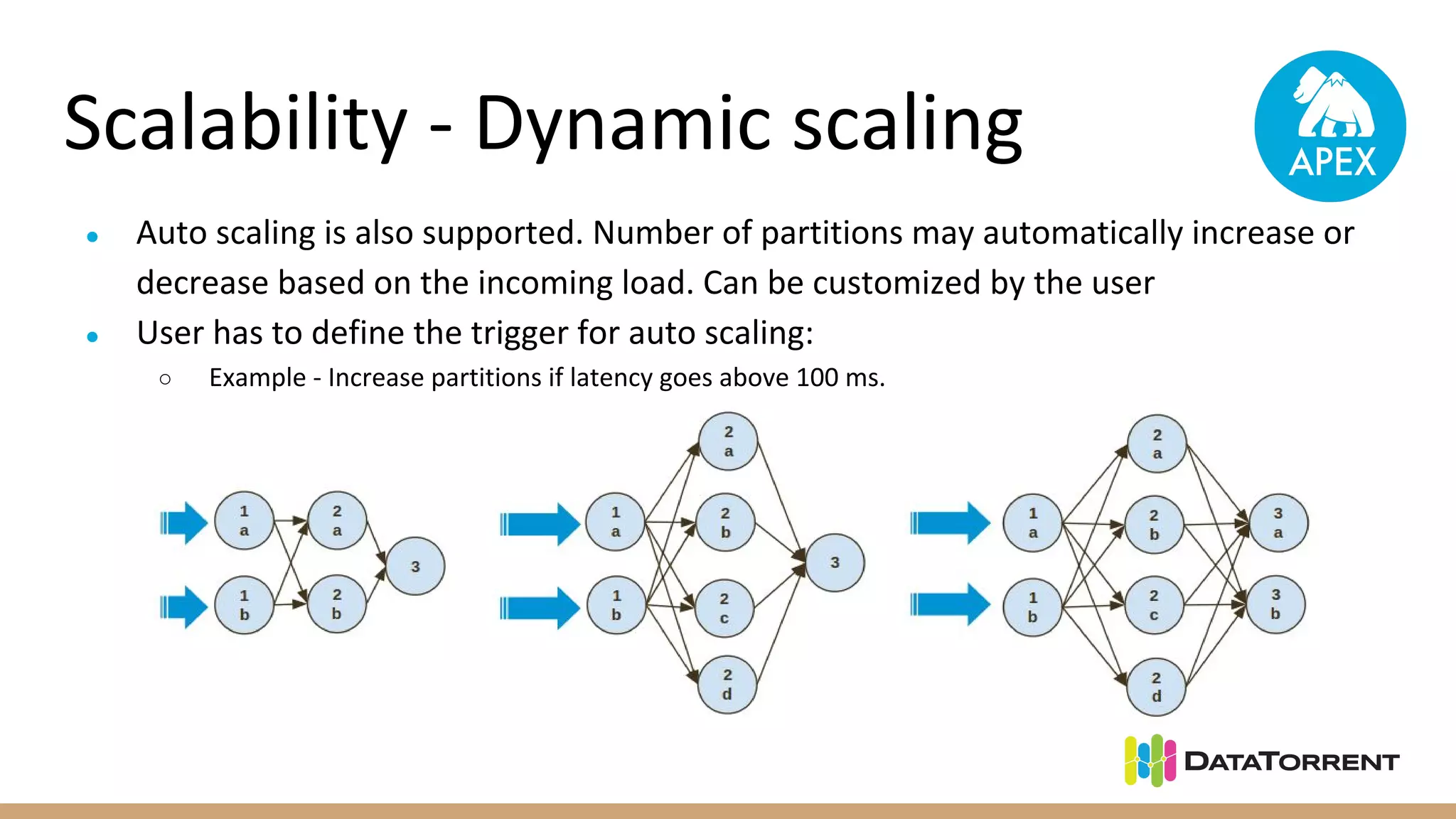



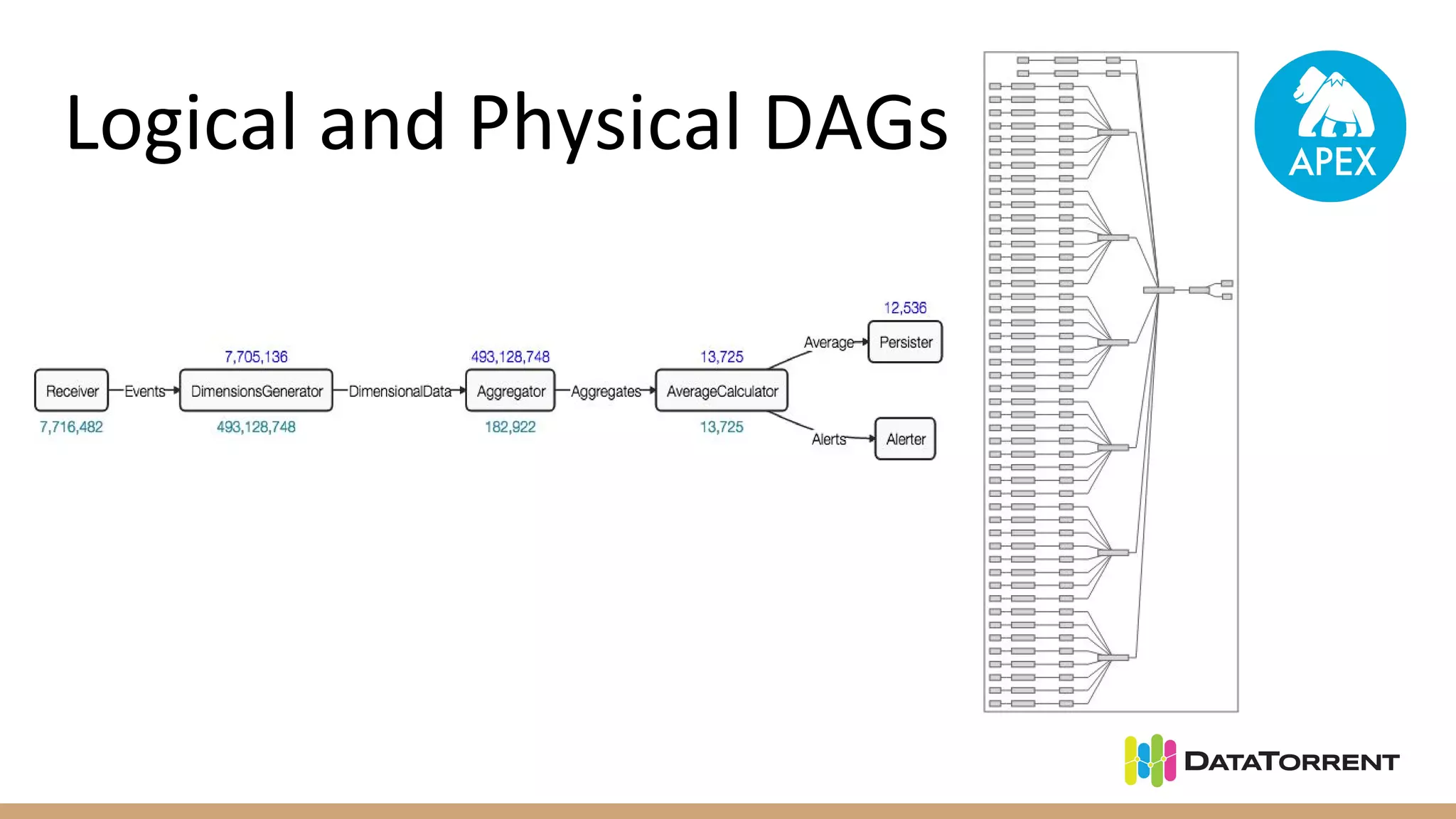
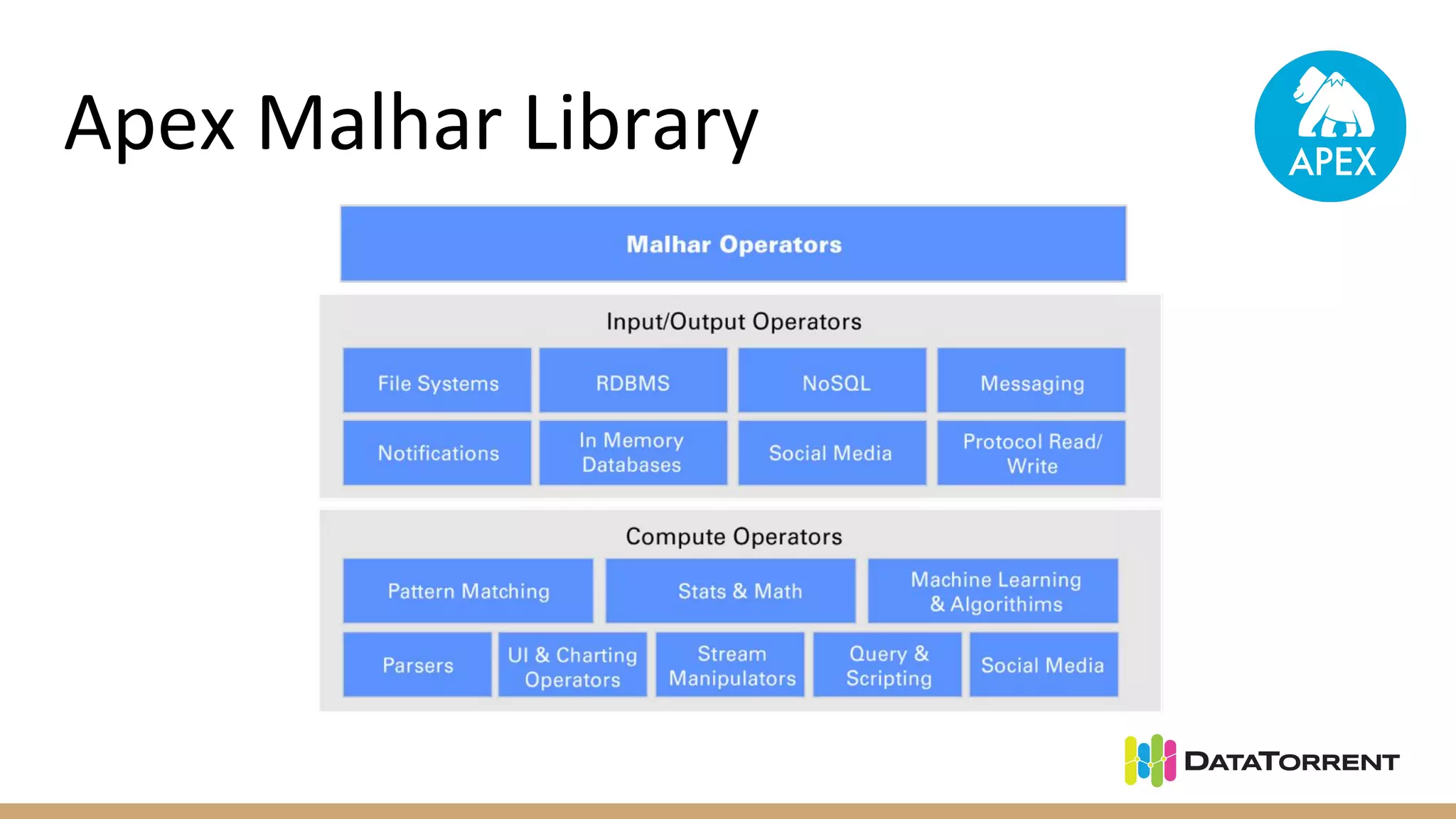





Apache Apex is a stream processing framework that provides high performance, scalability, and fault tolerance. It uses YARN for resource management, can achieve single digit millisecond latency, and automatically recovers from failures without data loss through checkpointing. Apex applications are modeled as directed acyclic graphs of operators and can be partitioned for scalability. It has a large community of committers and is in the process of becoming a top-level Apache project.