Downloaded 28 times

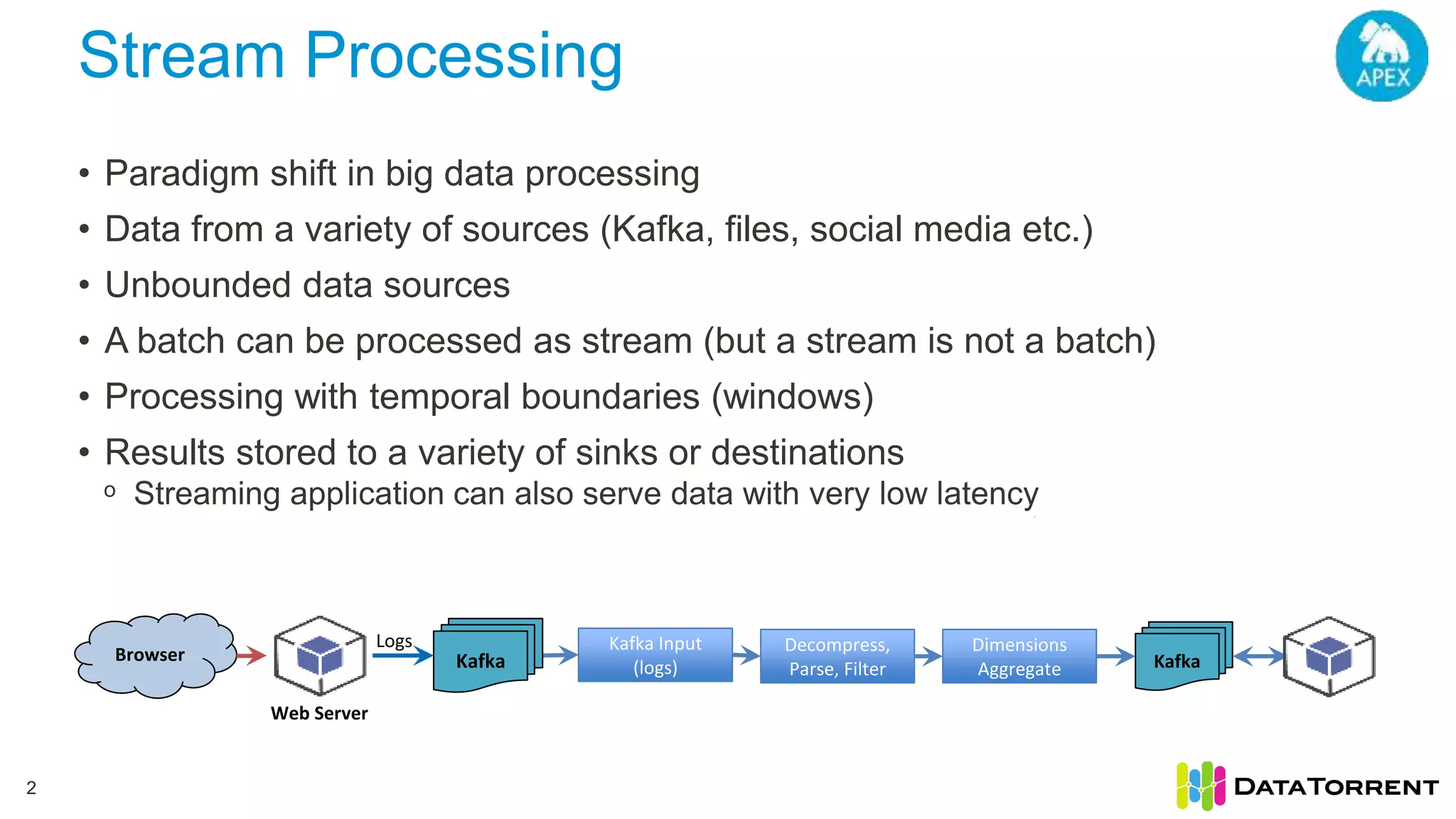

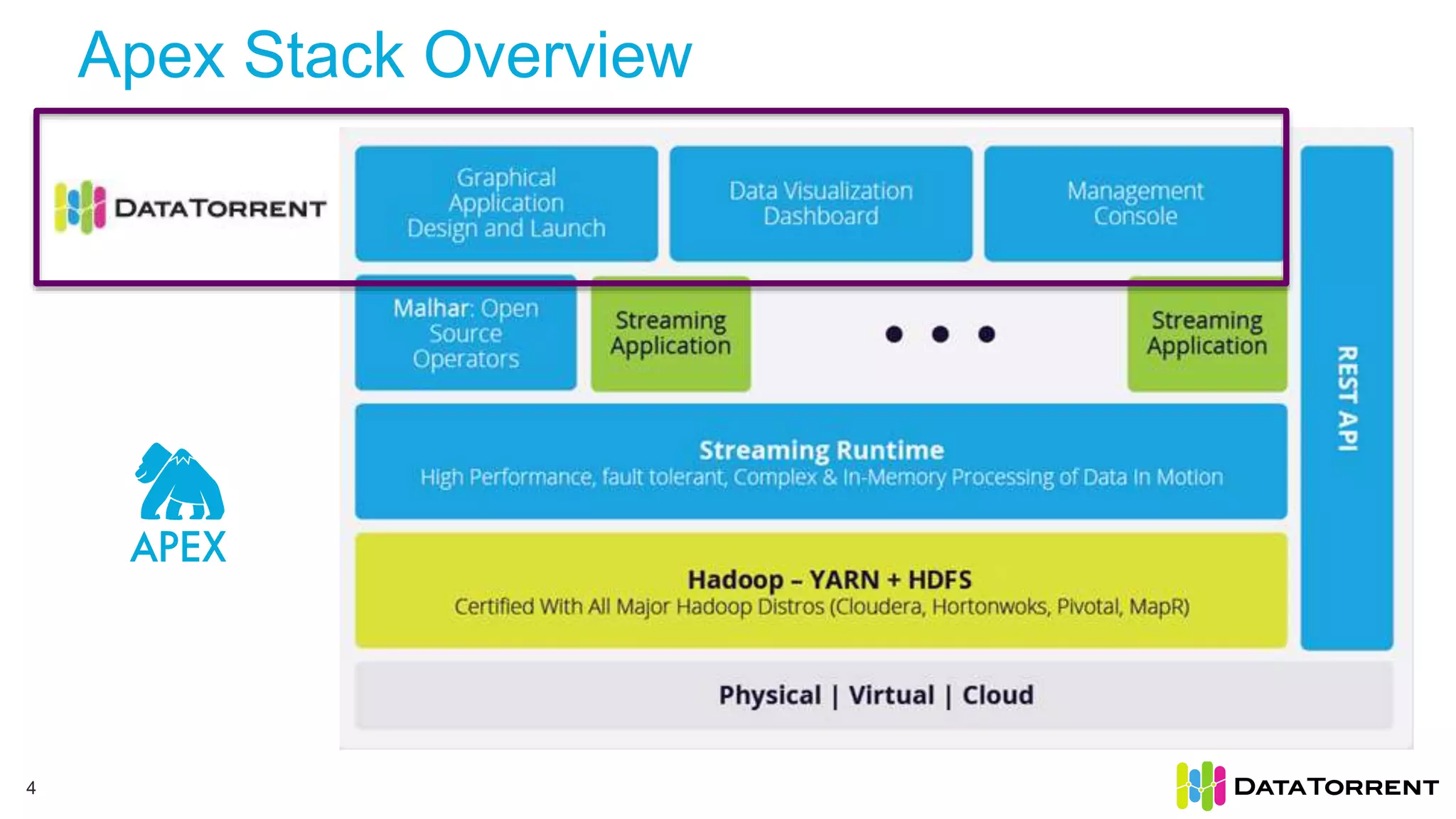
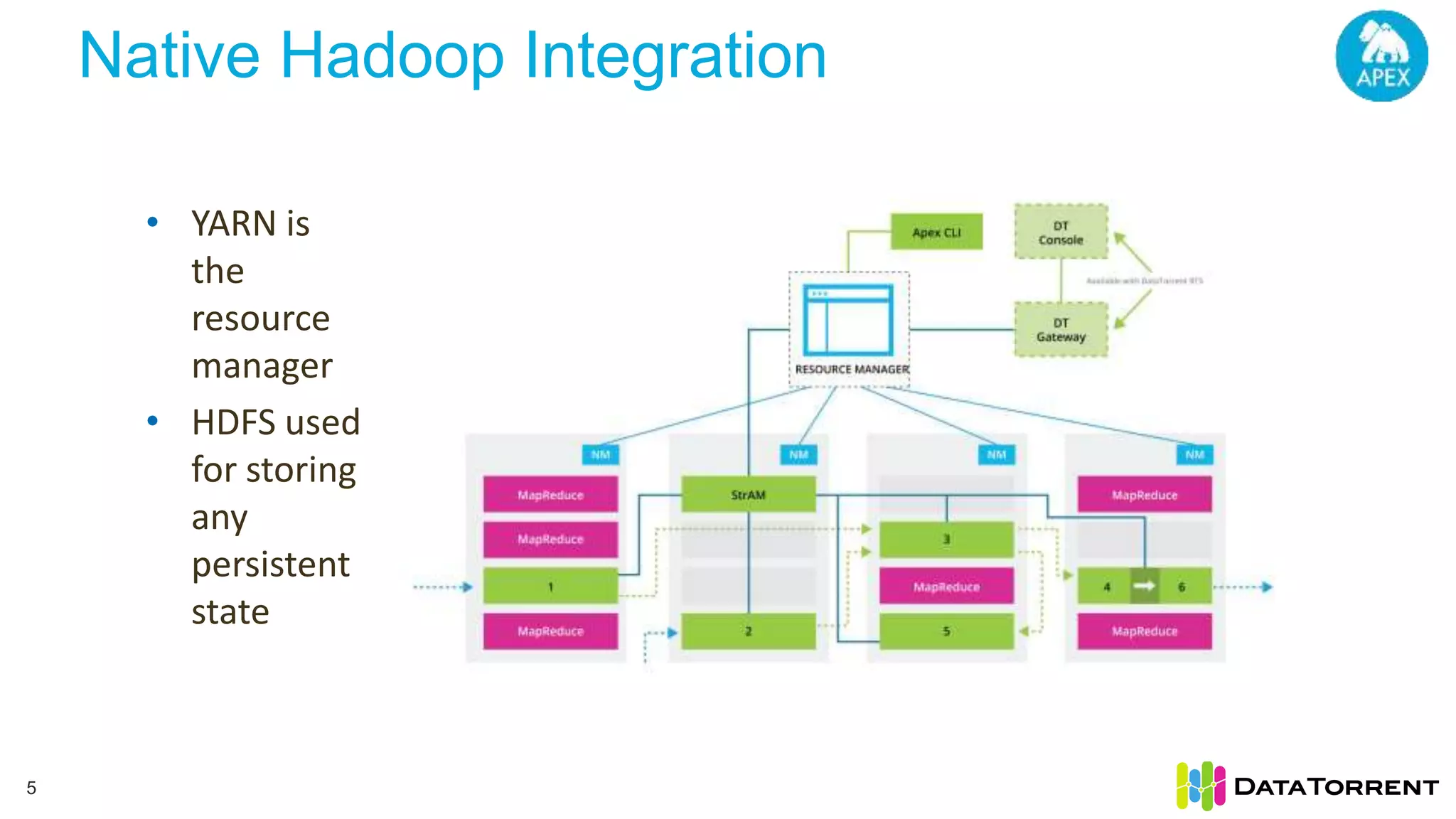
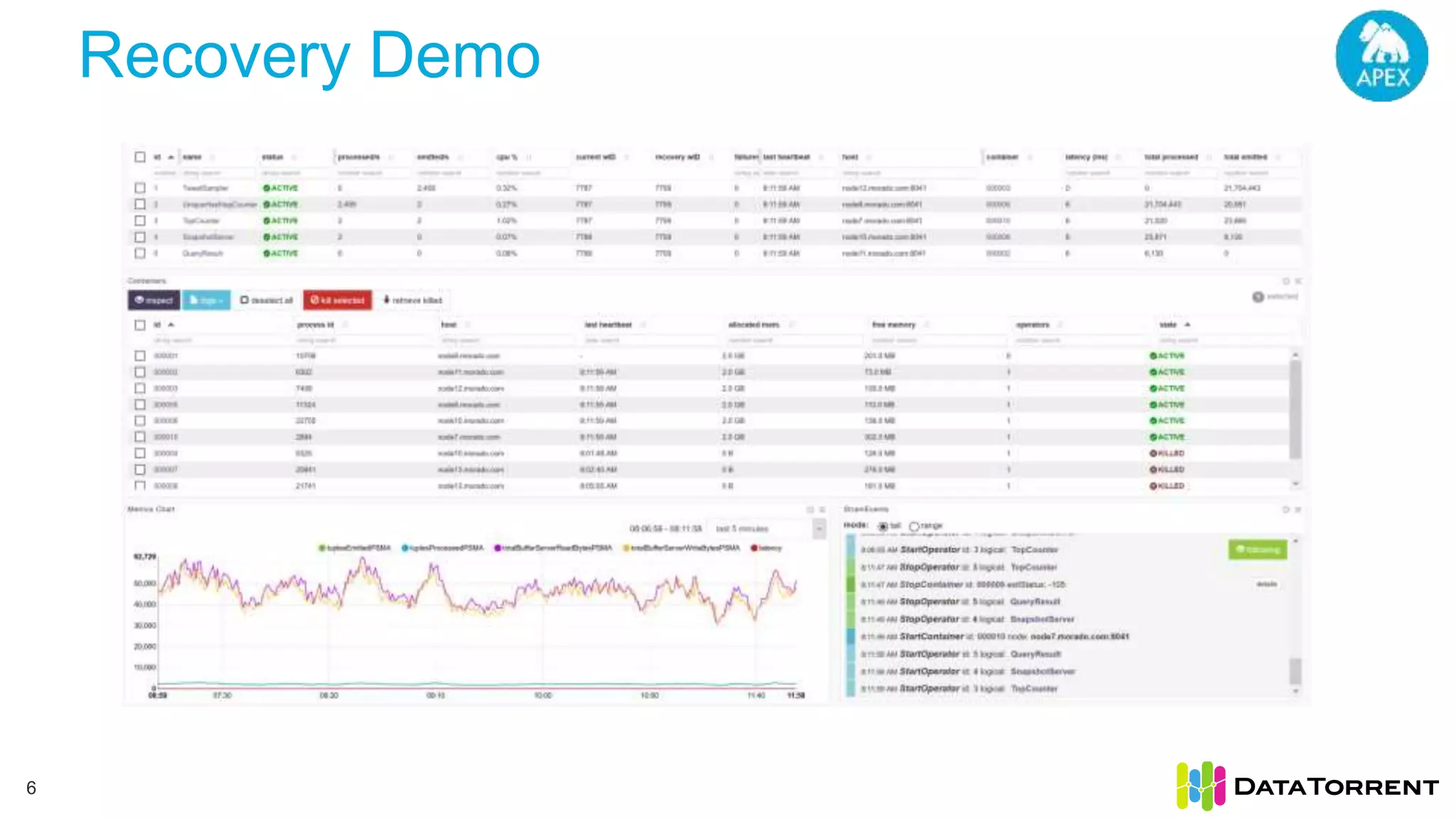
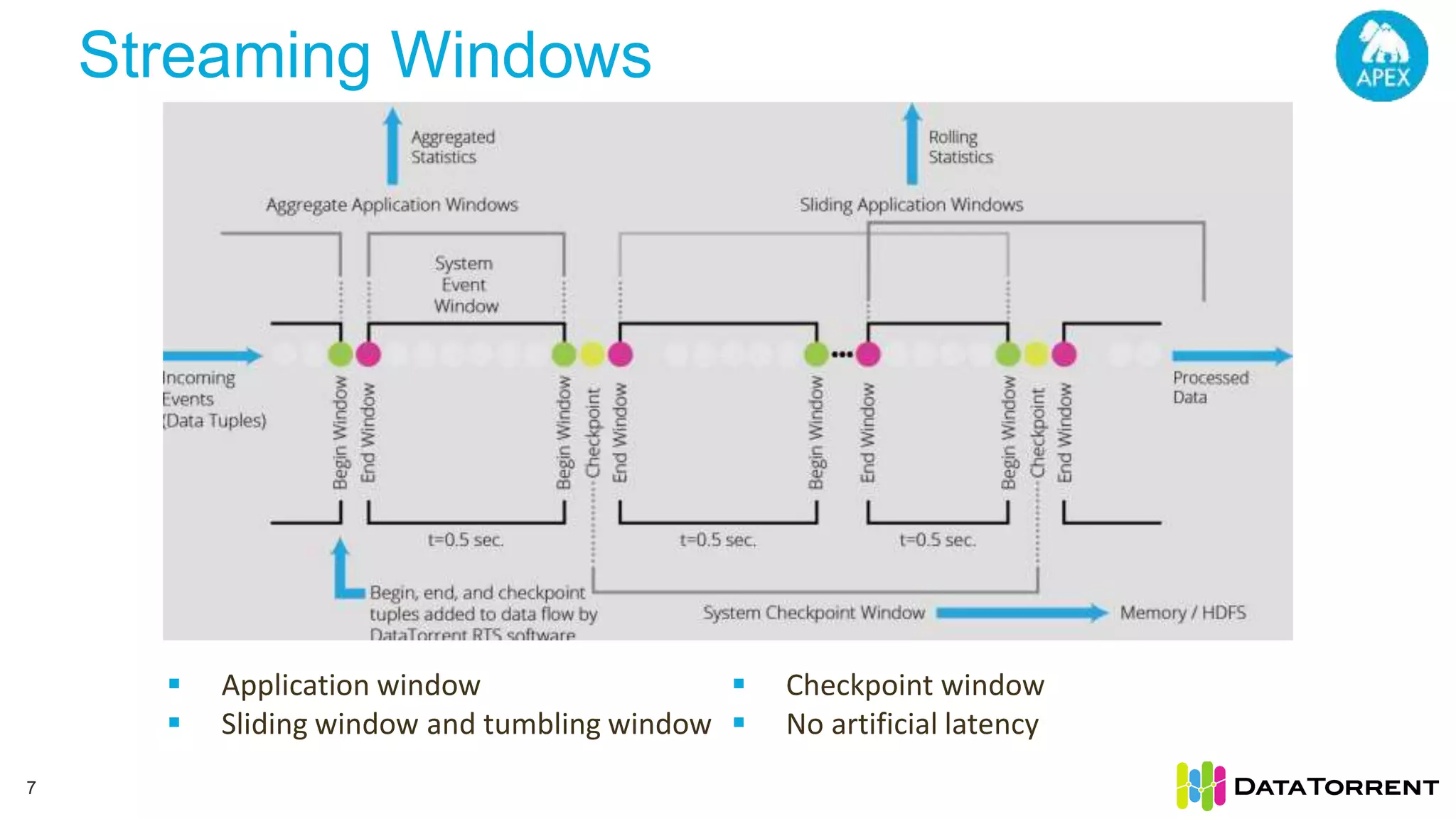


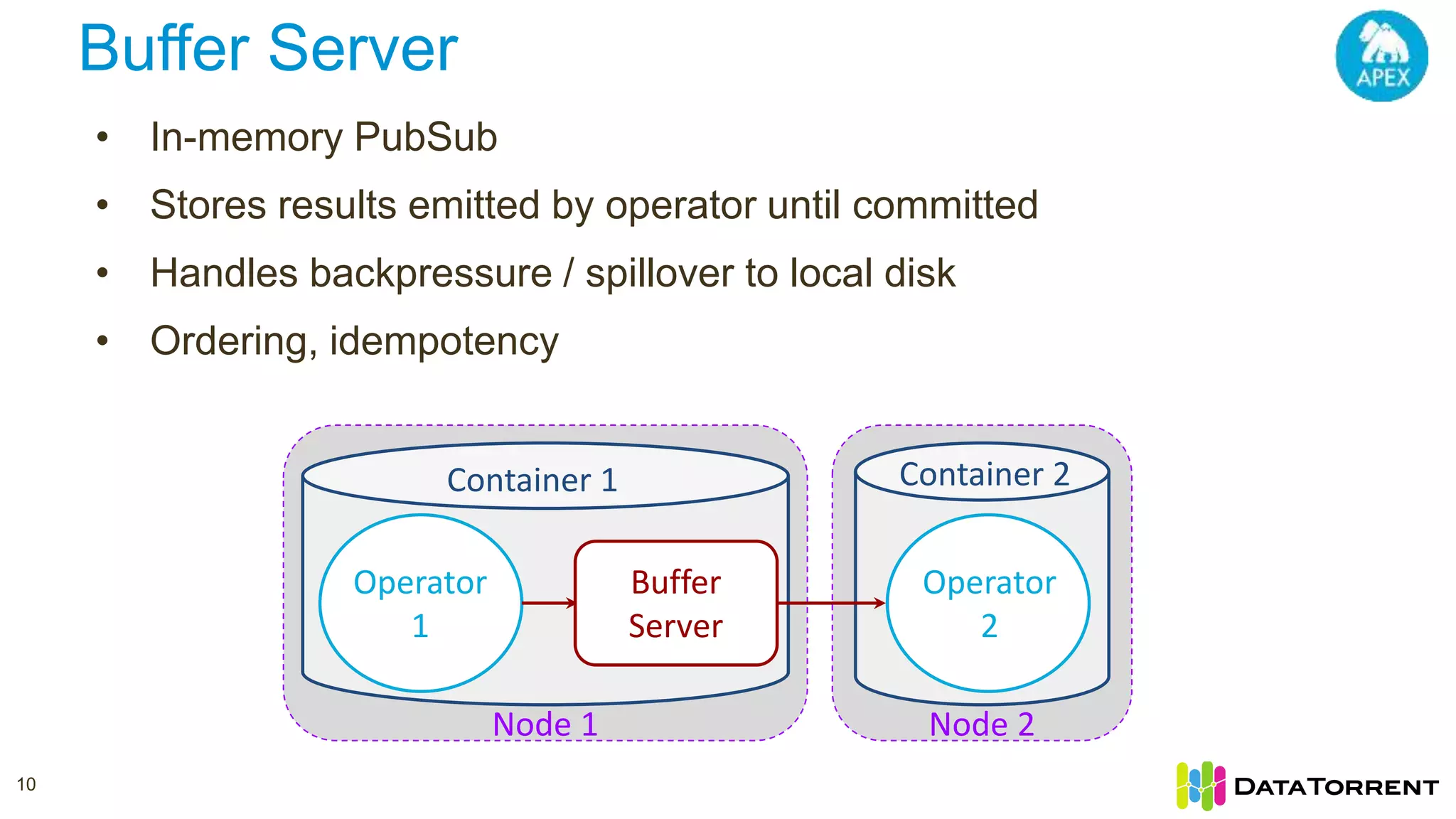


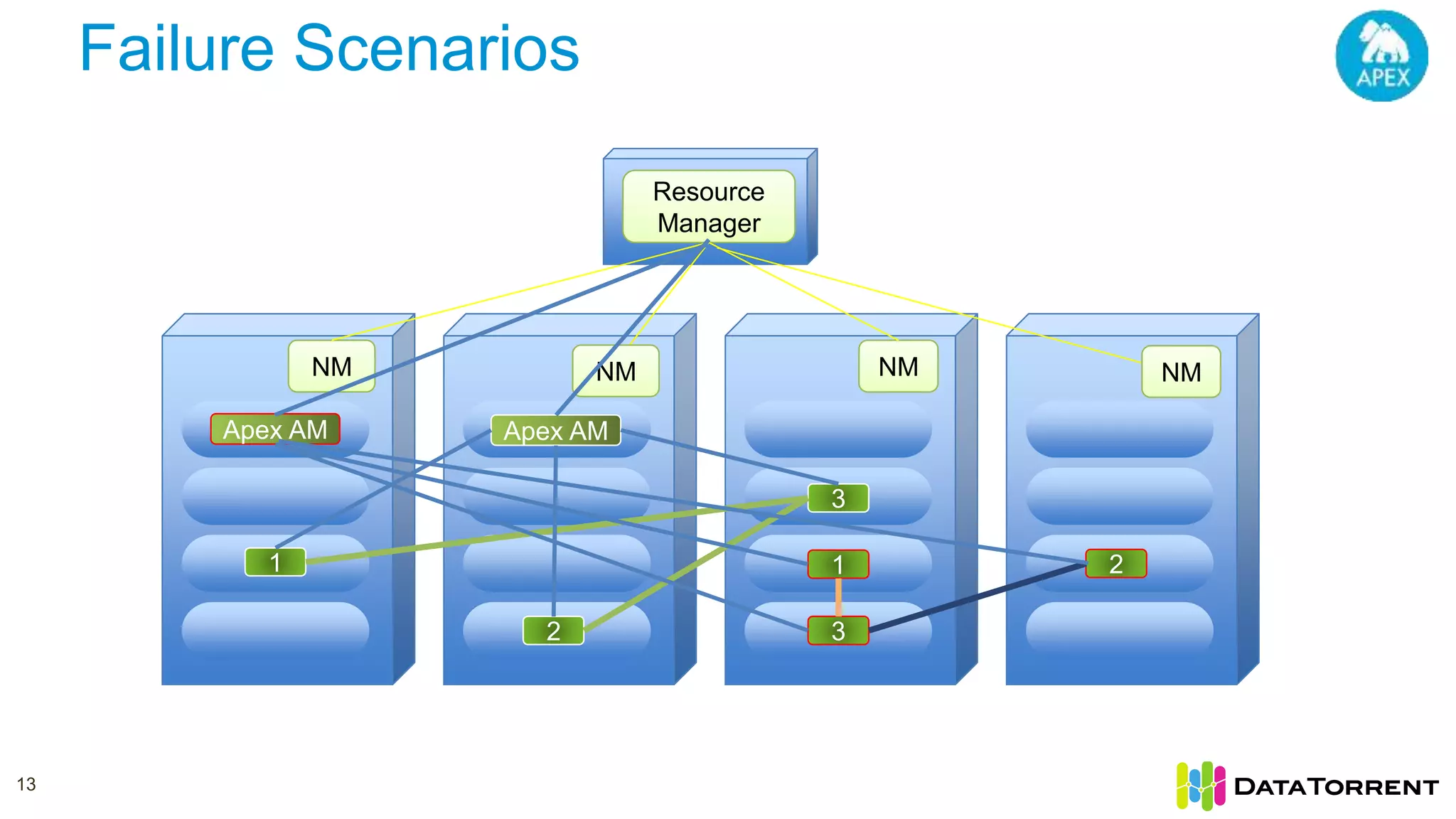
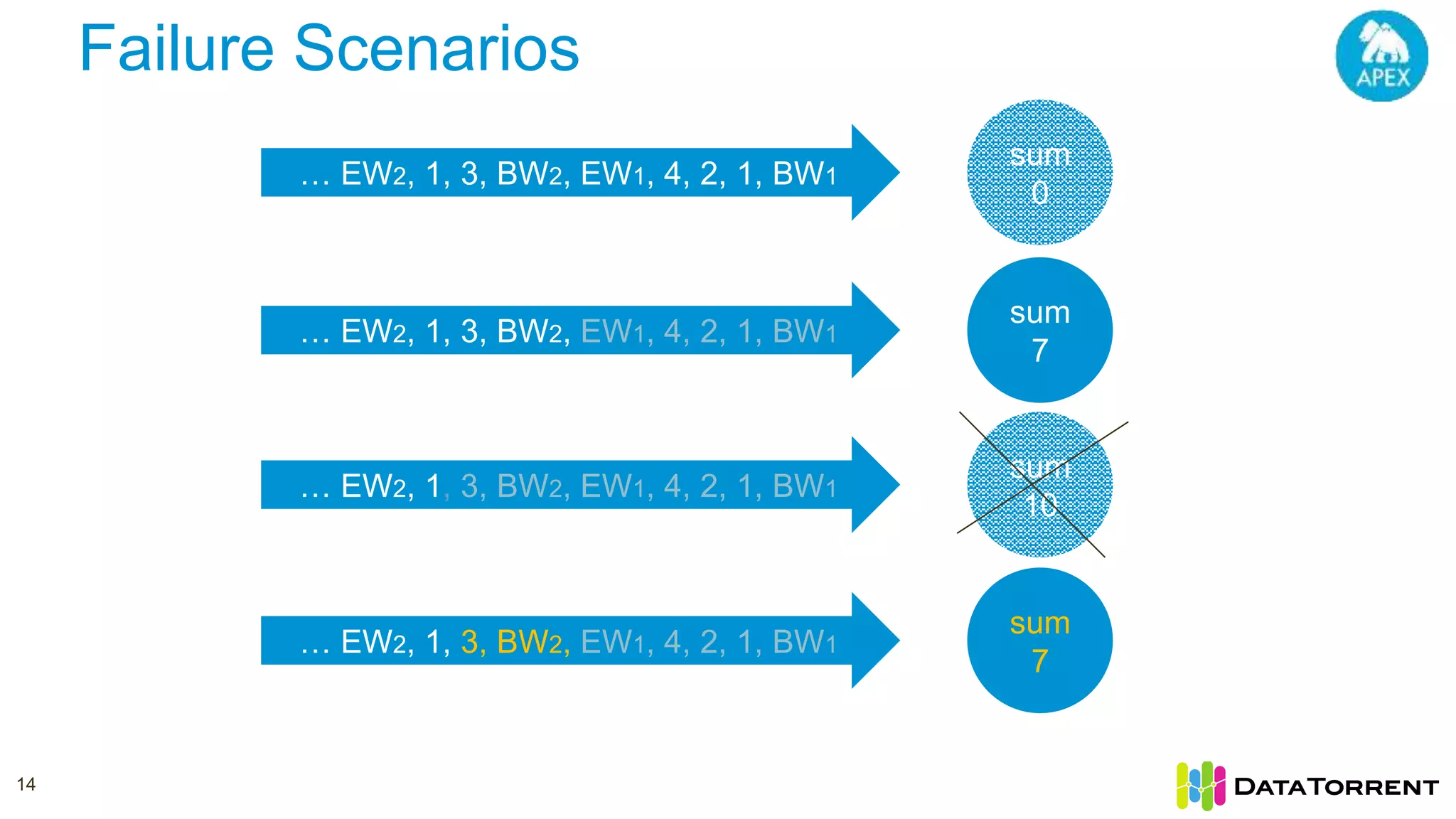



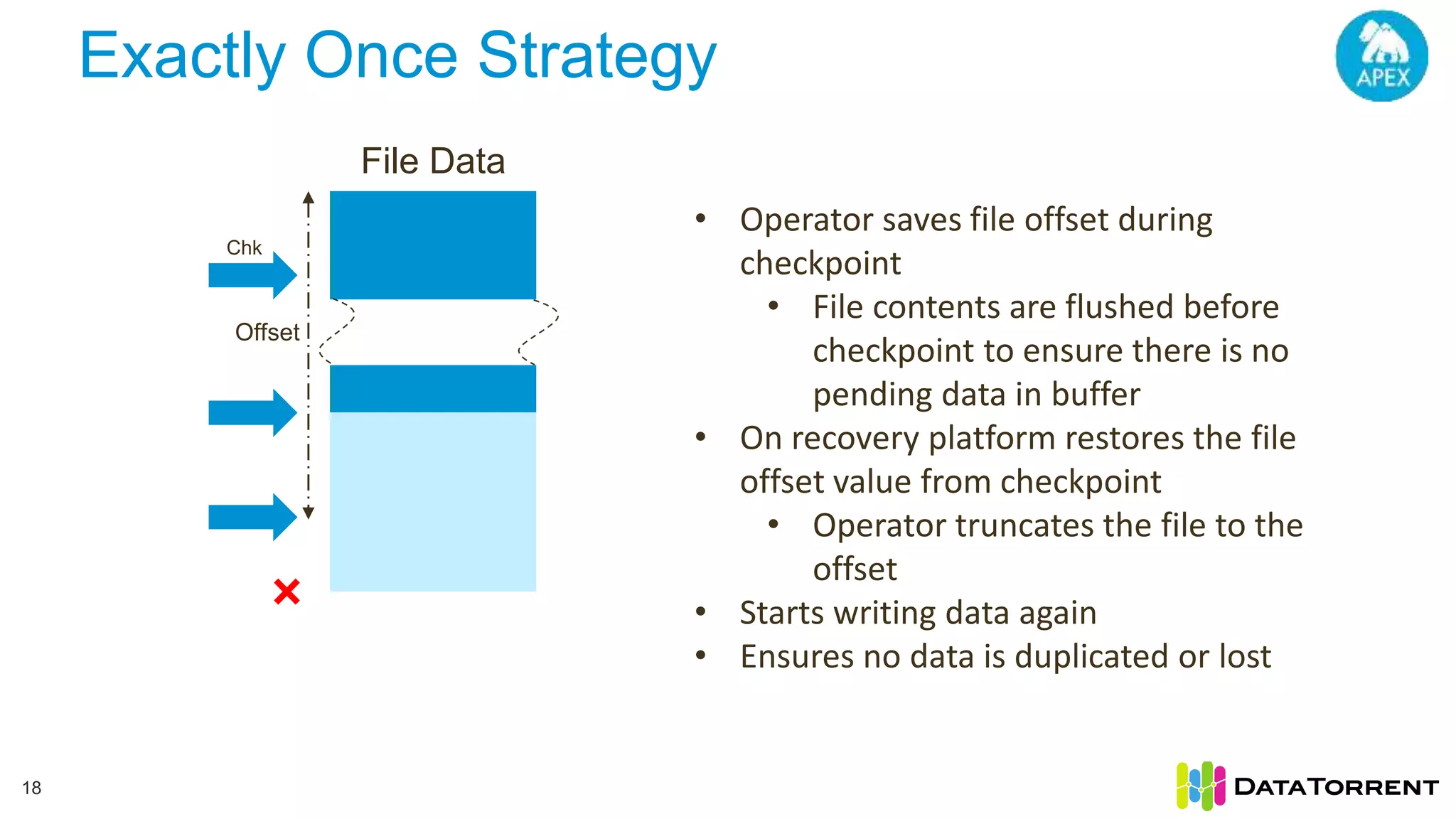

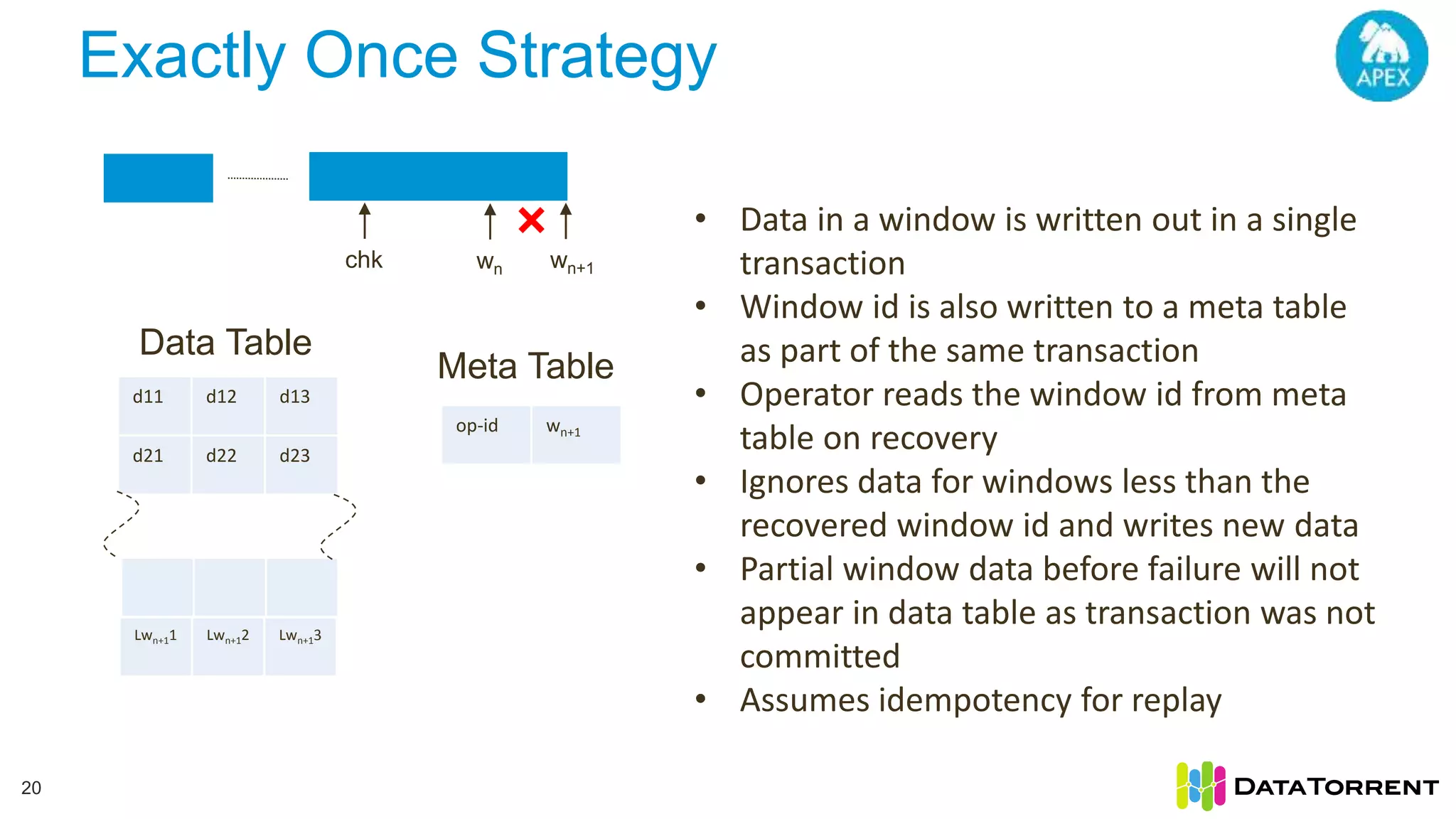




The document discusses Apache Apex, a stream processing framework, highlighting its fault tolerance and processing semantics. It covers key features such as in-memory stream processing, reliability, and checkpointing for recovery from failures, while explaining different processing guarantees, like at-least-once and exactly-once scenarios. Additionally, it outlines strategies for ensuring data integrity during failures across various output systems, including file and database operations.