Downloaded 32 times

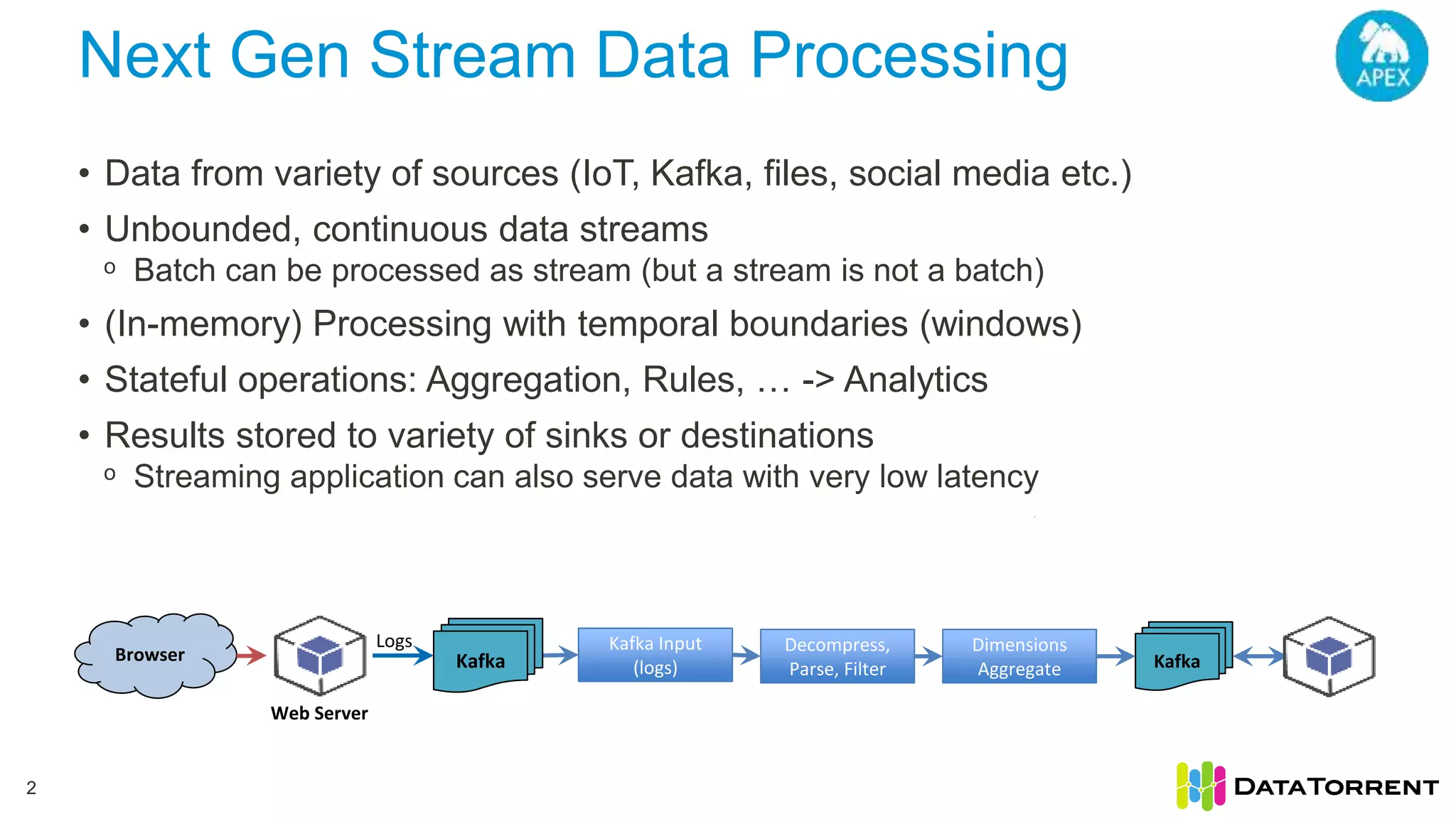

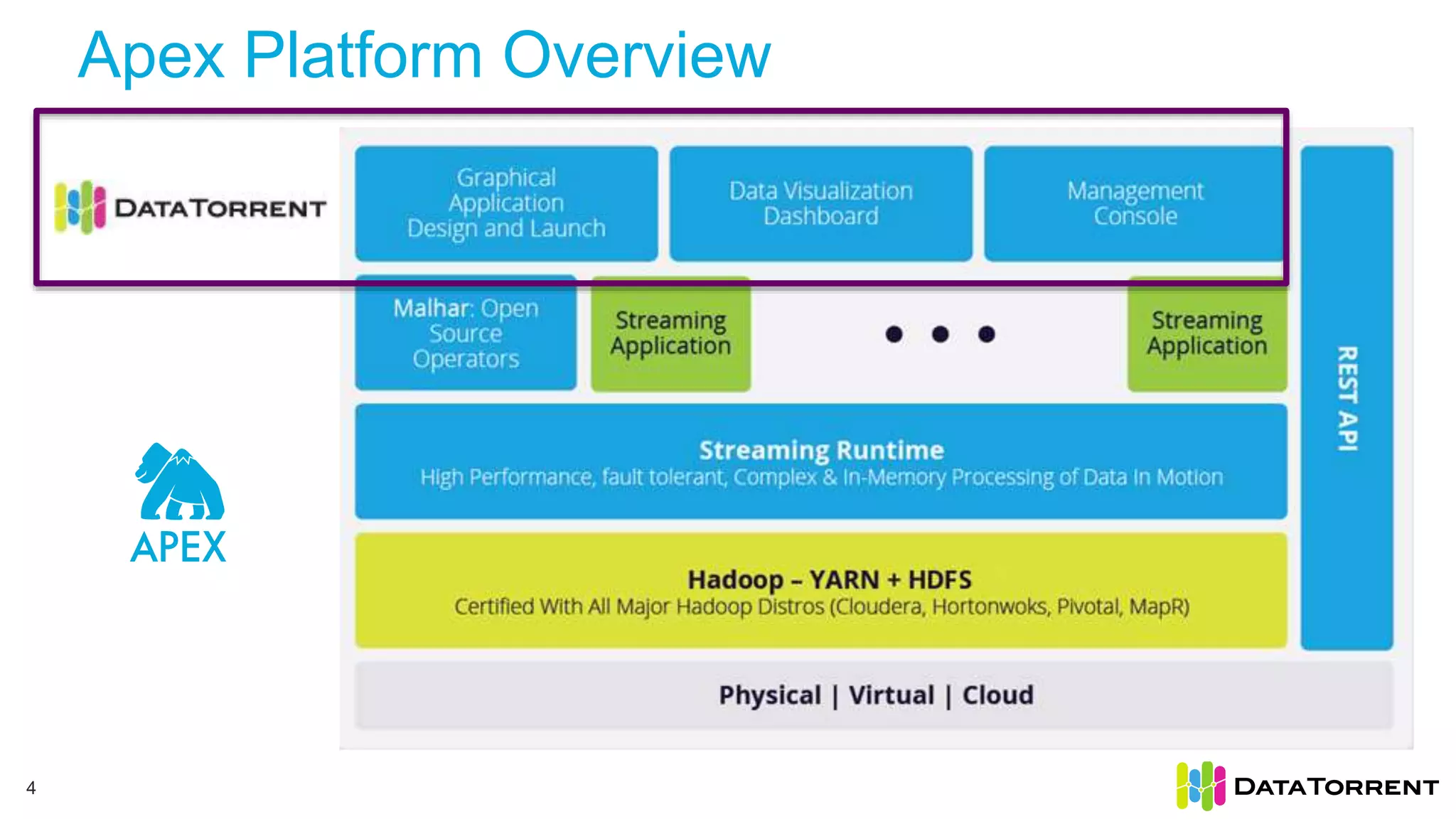
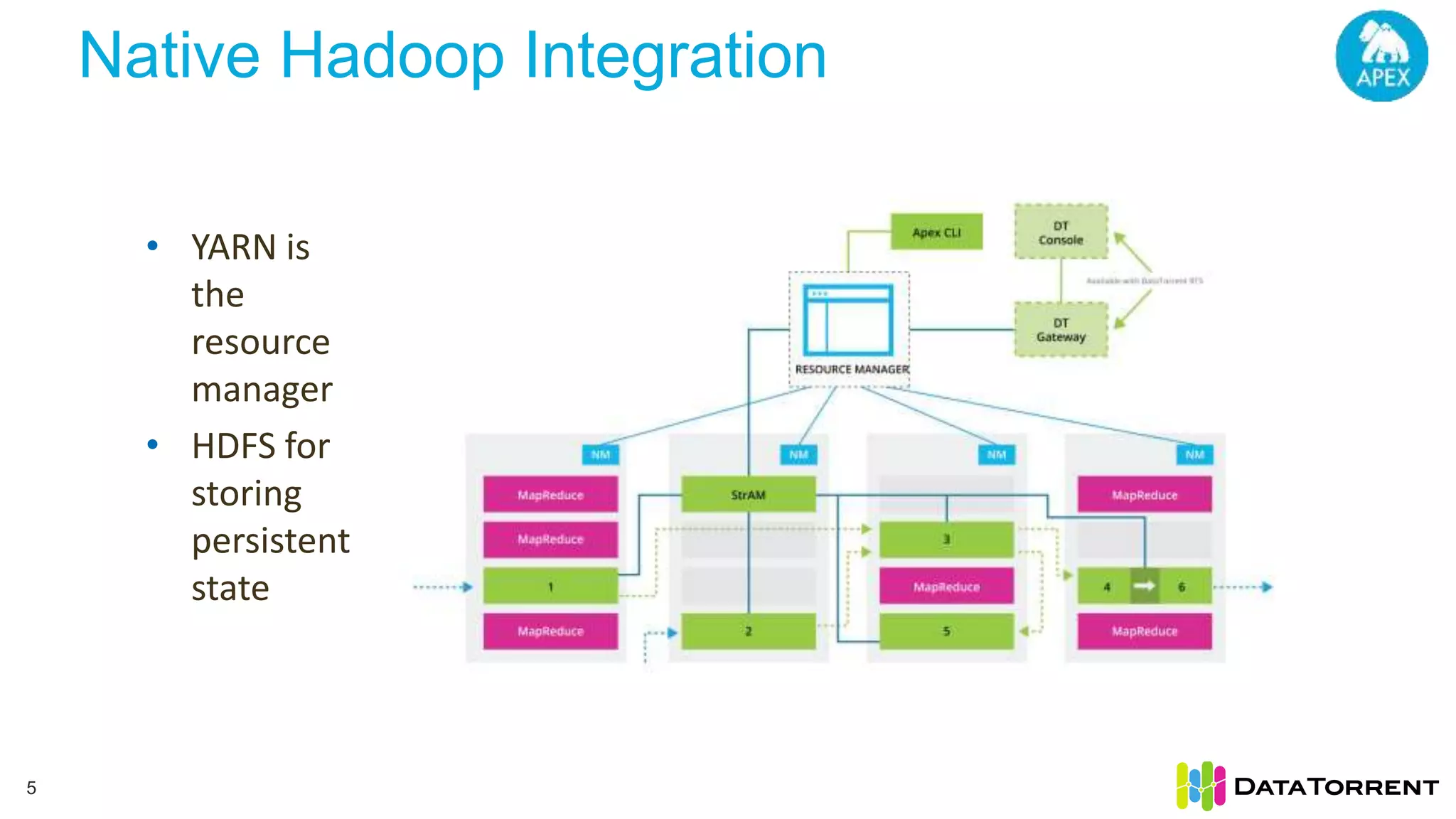
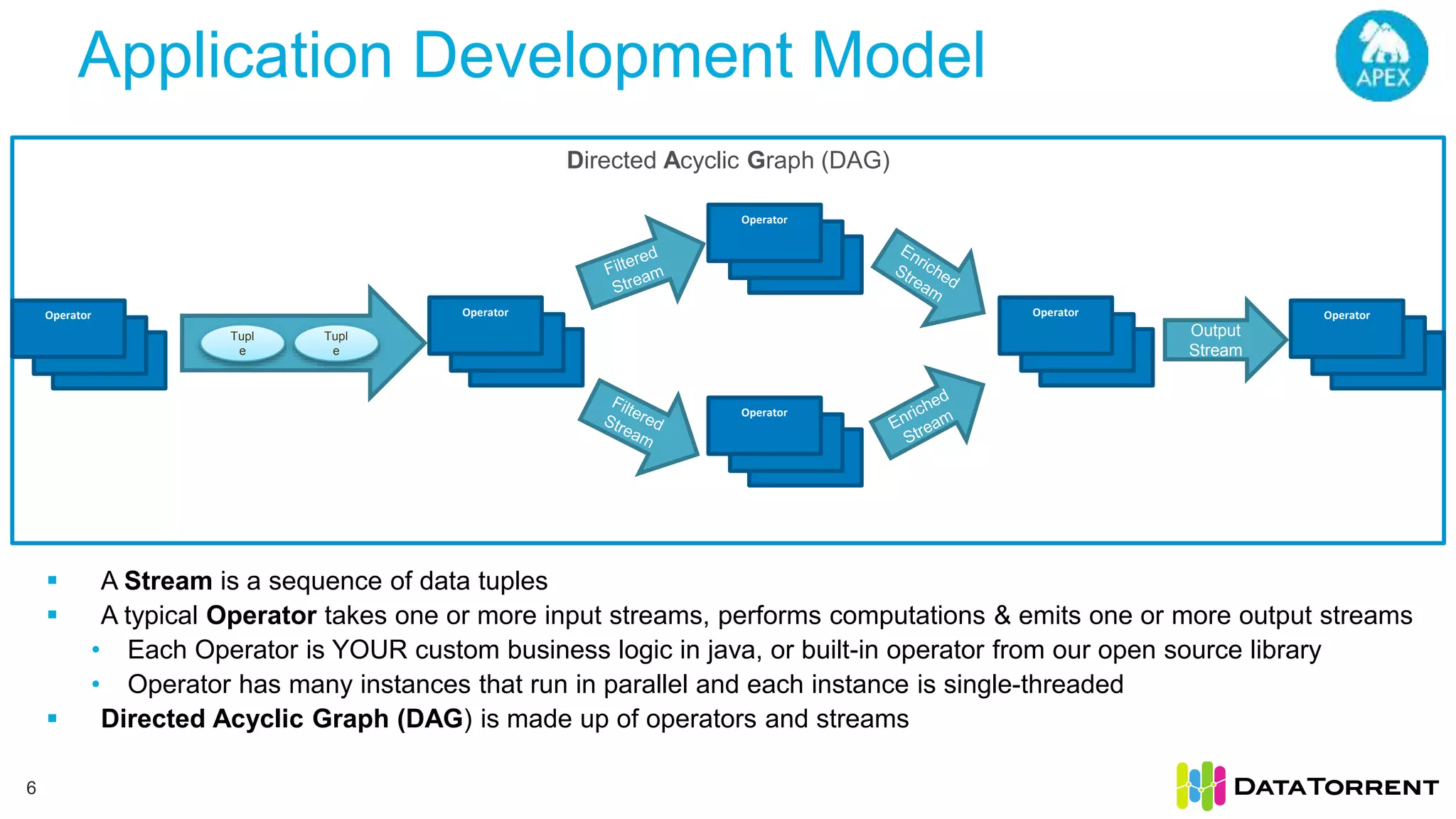










Next Gen Big Data Analytics with Apache Apex discusses Apache Apex, an open source stream processing framework. It provides an overview of Apache Apex's capabilities for processing continuous, real-time data streams at scale. Specifically, it describes how Apache Apex allows for in-memory, distributed stream processing using a programming model of operators in a directed acyclic graph. It also covers Apache Apex's features for fault tolerance, dynamic scaling, and integration with Hadoop and YARN.