Downloaded 11 times


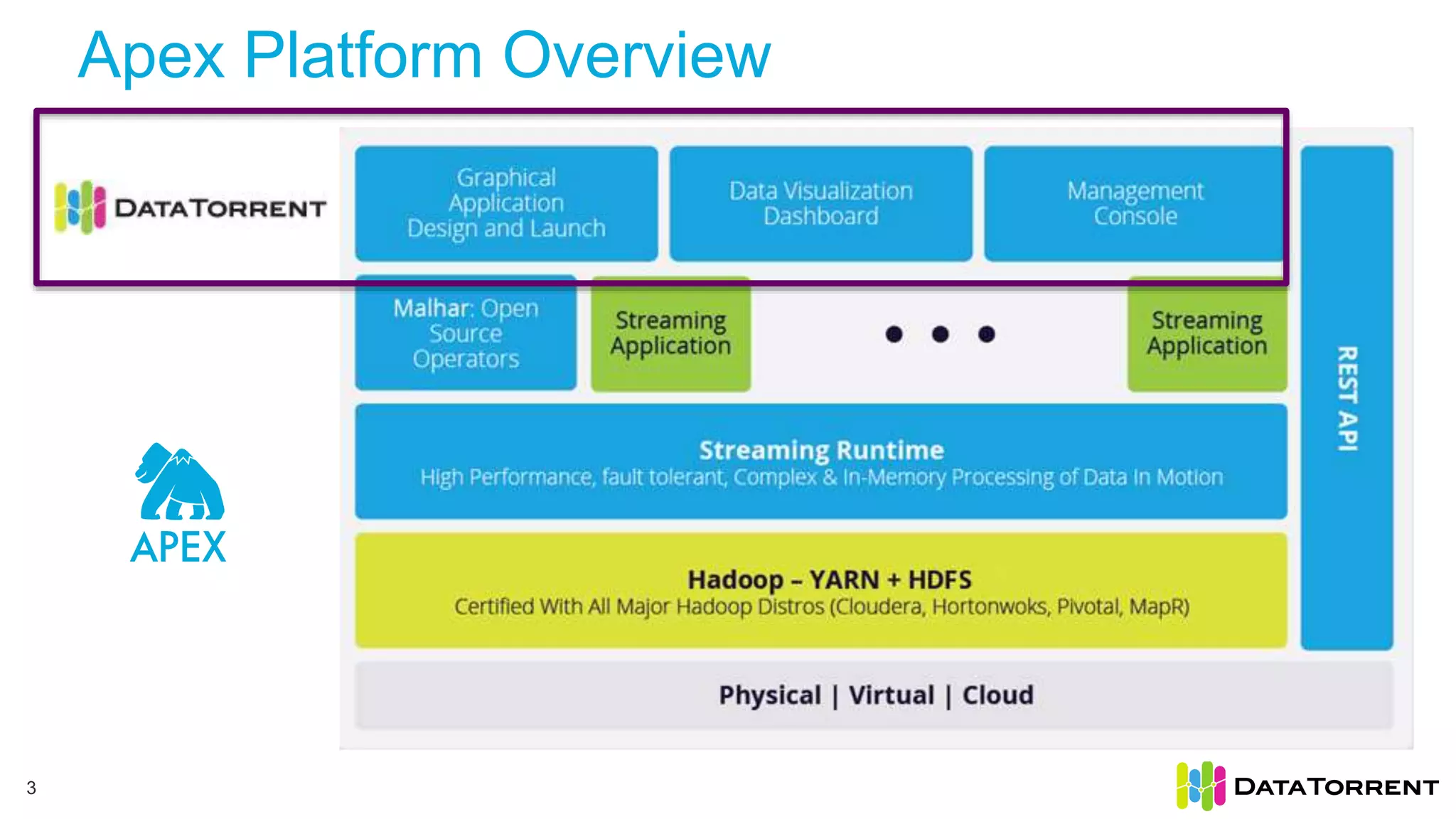
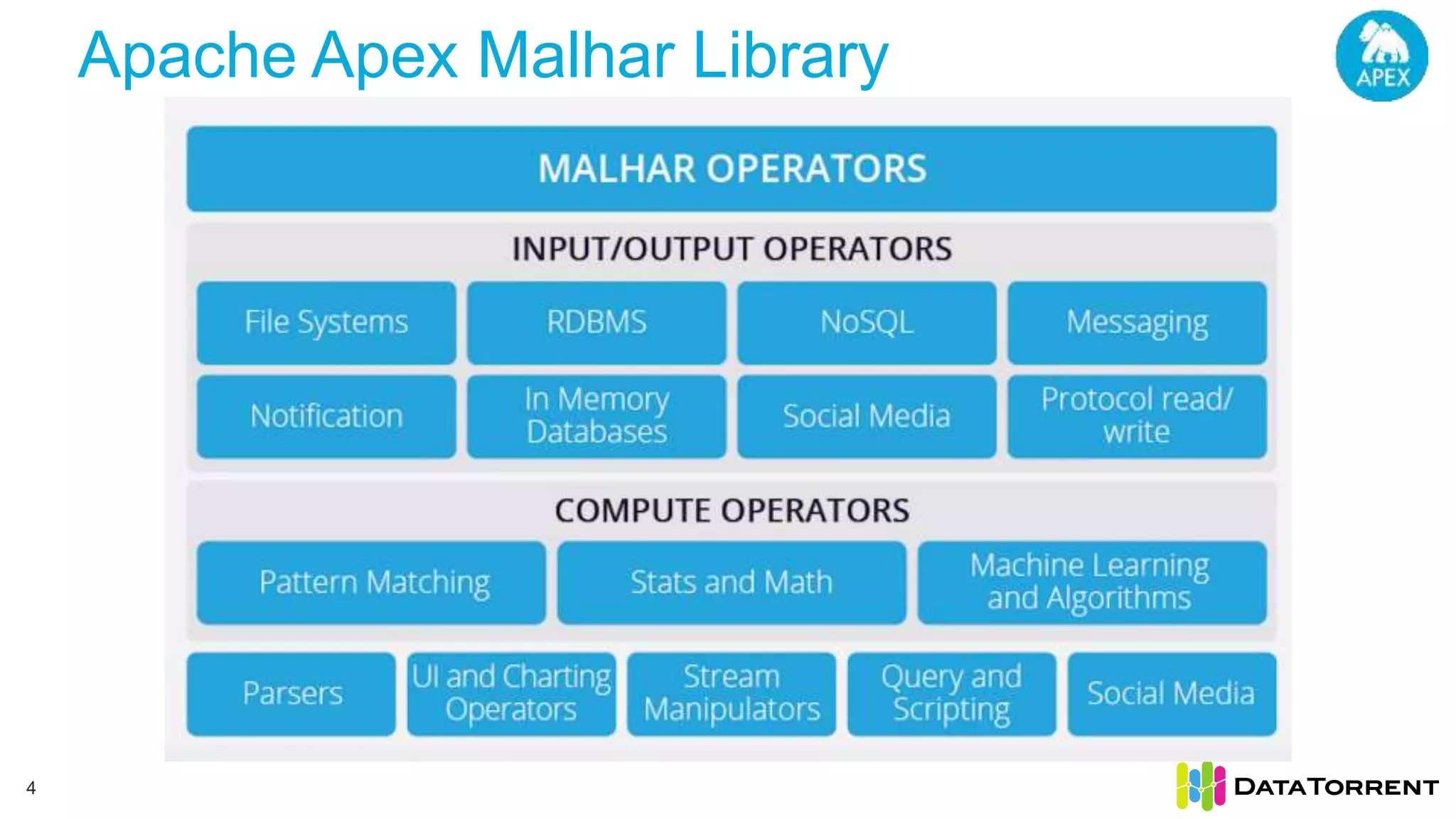
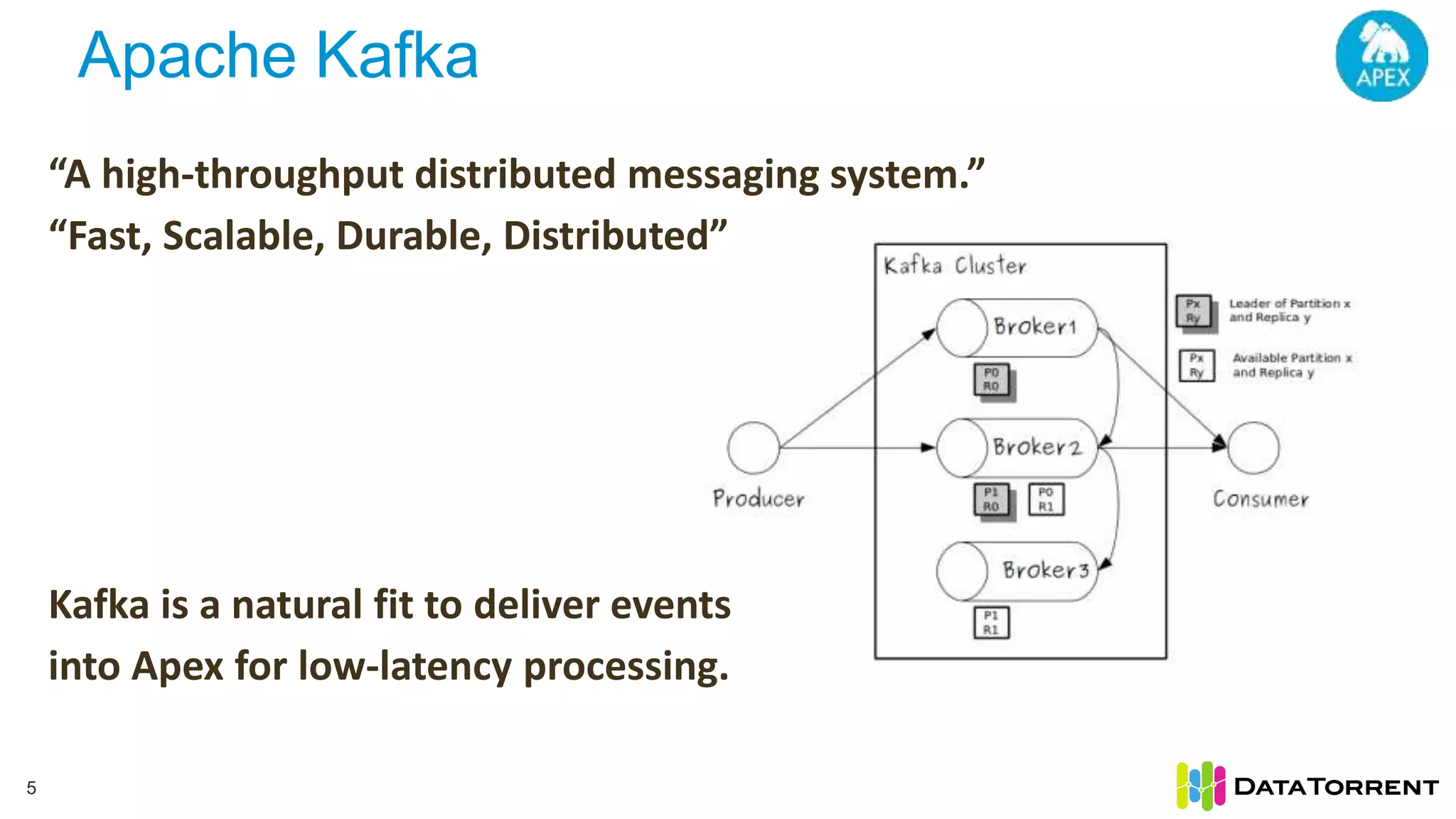



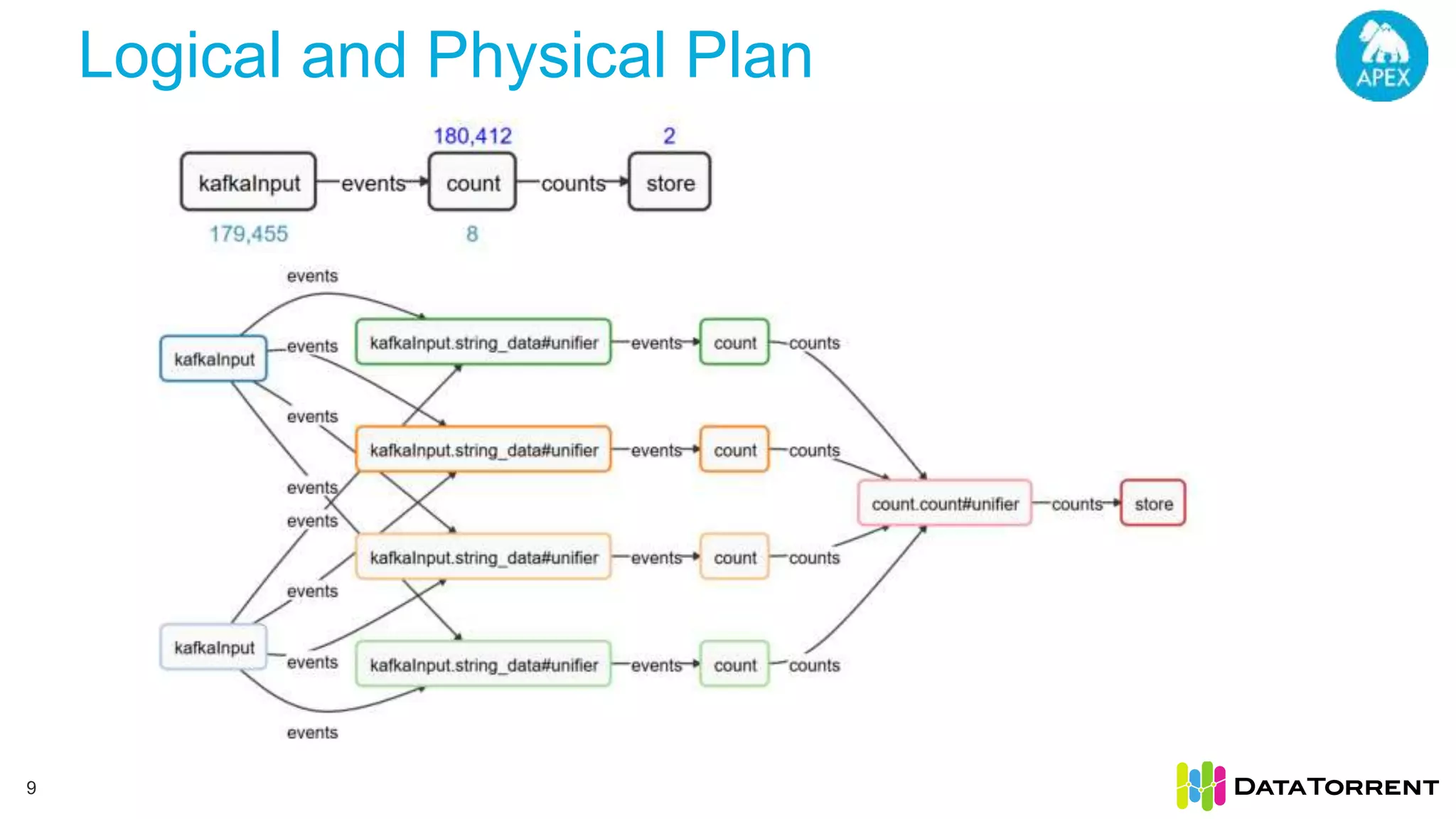
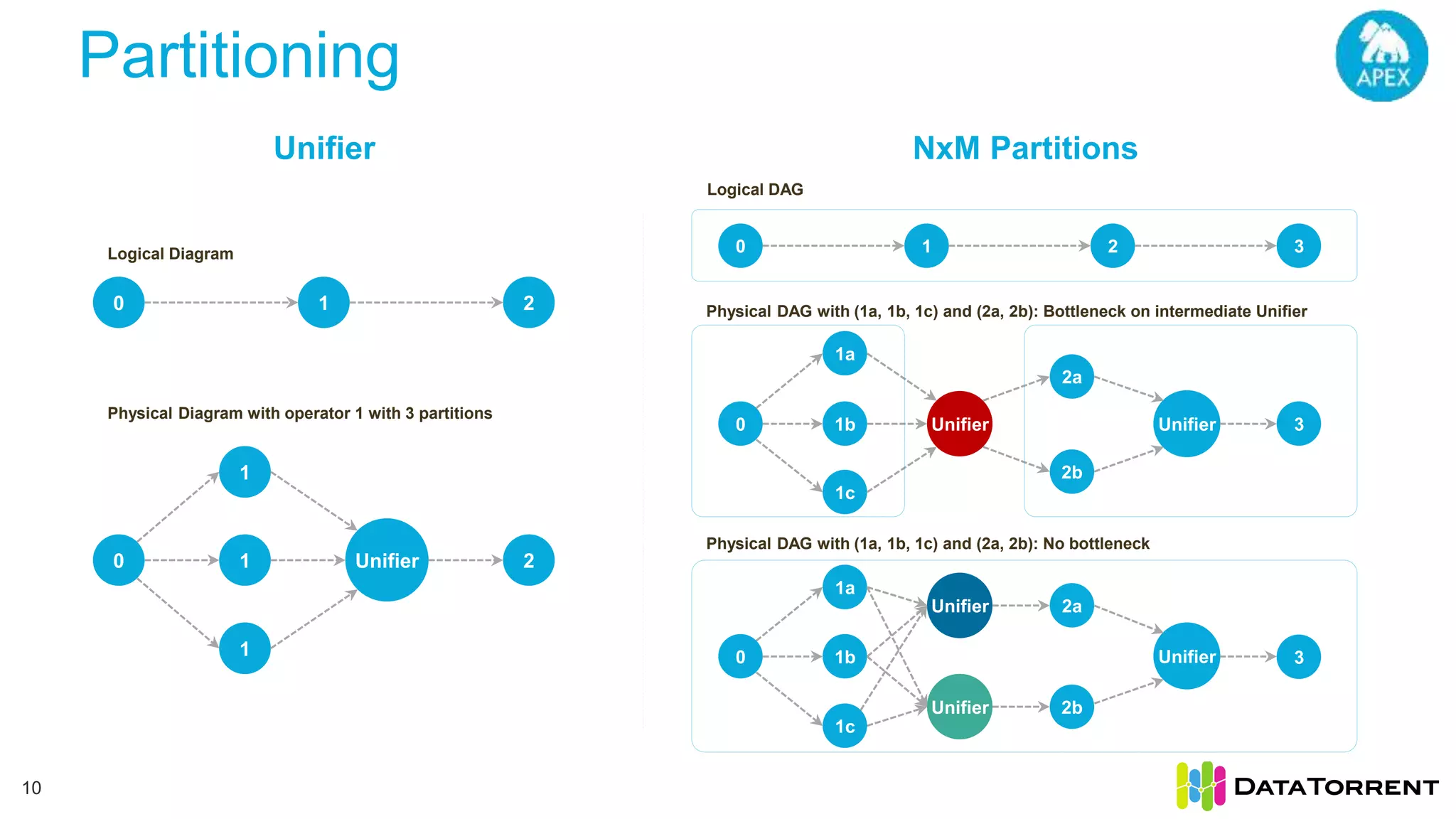
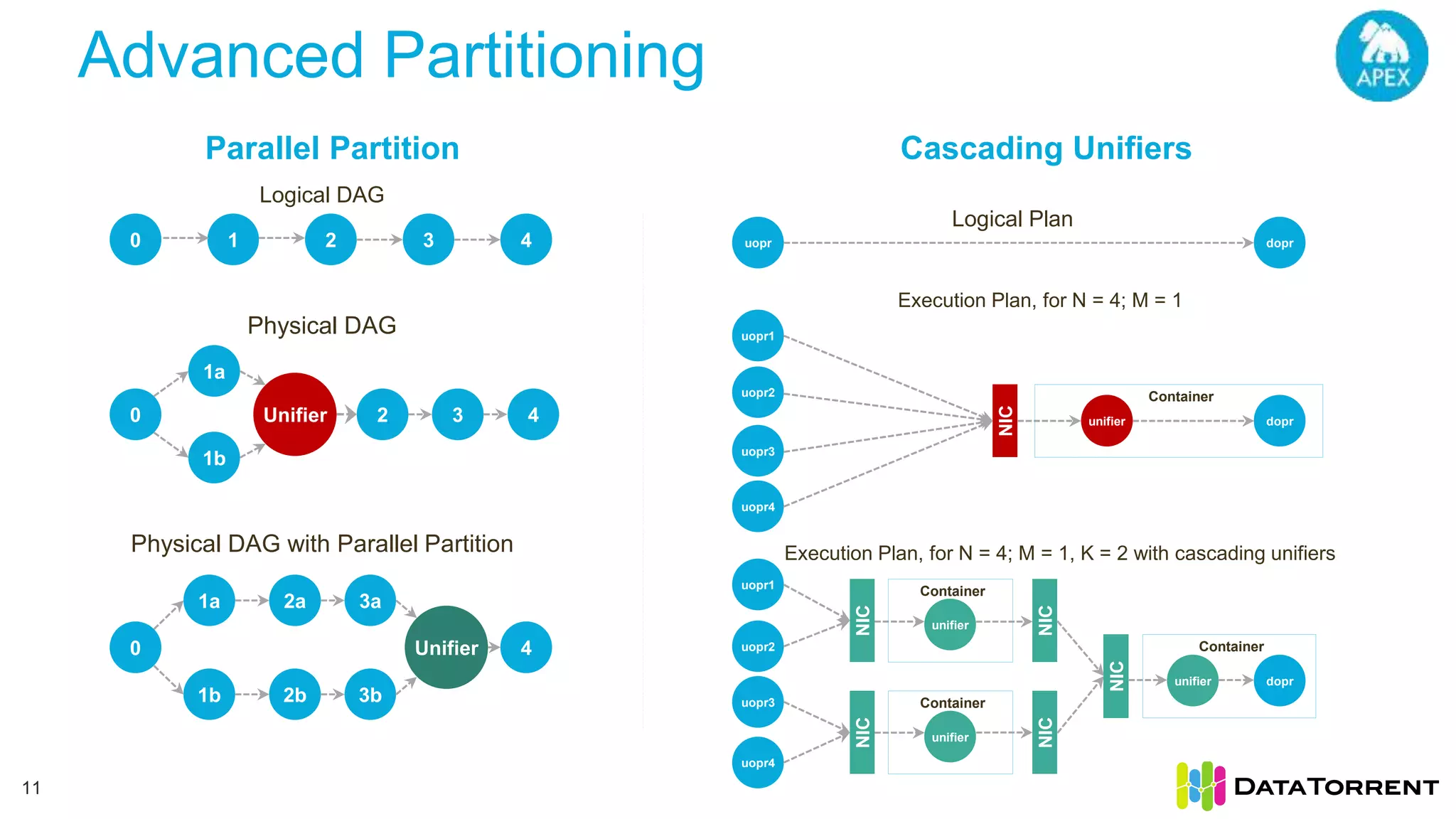
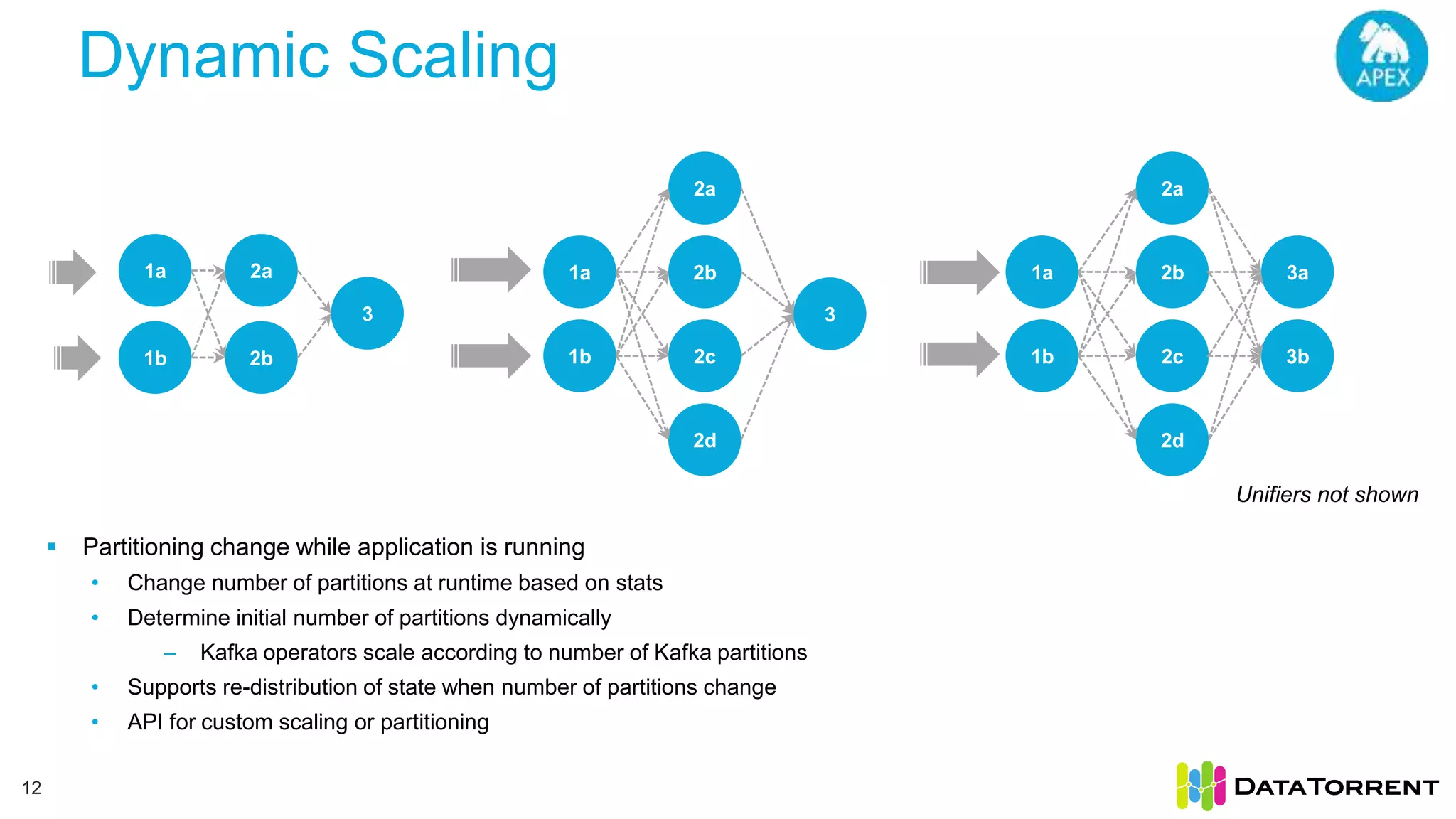

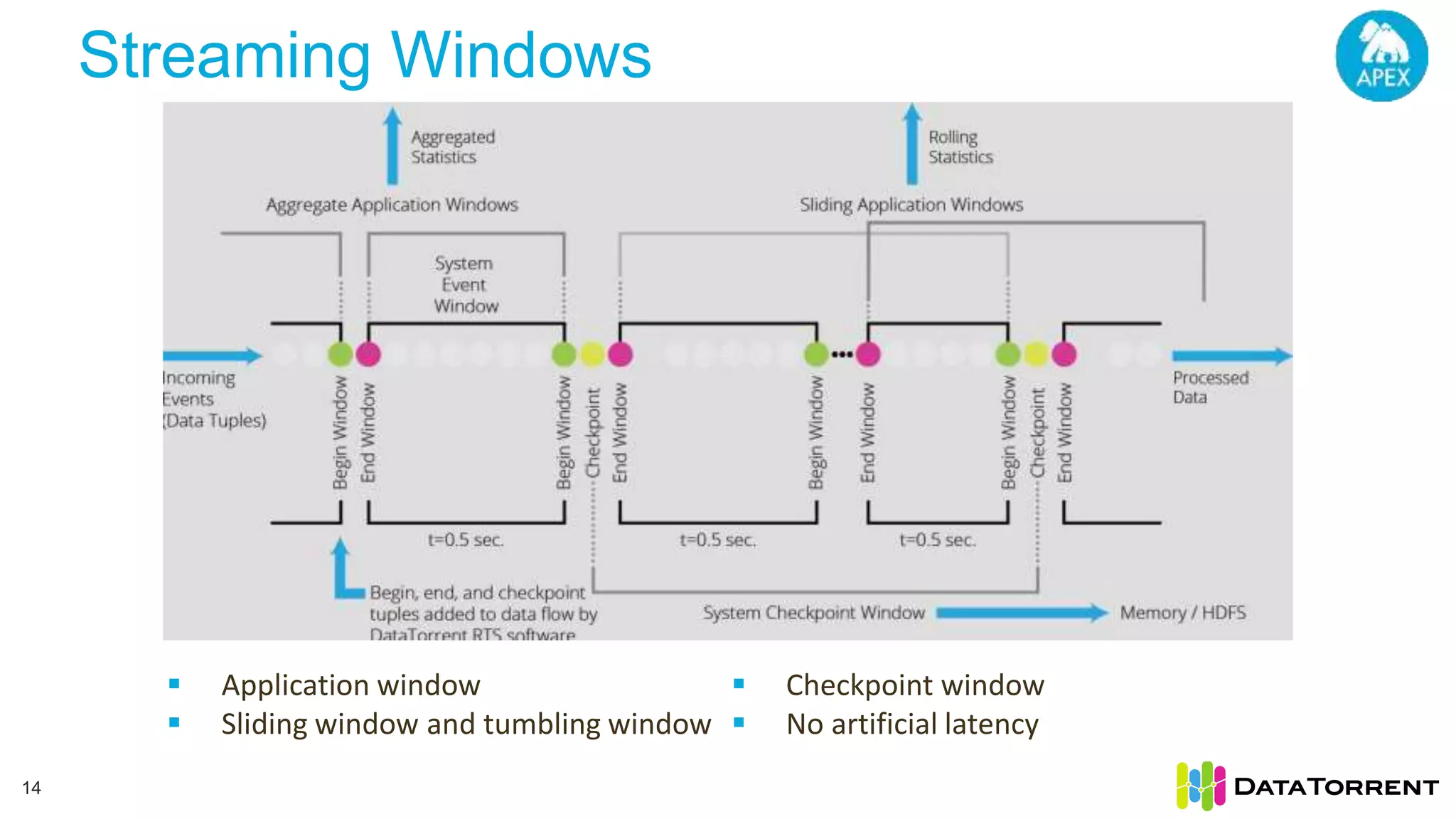


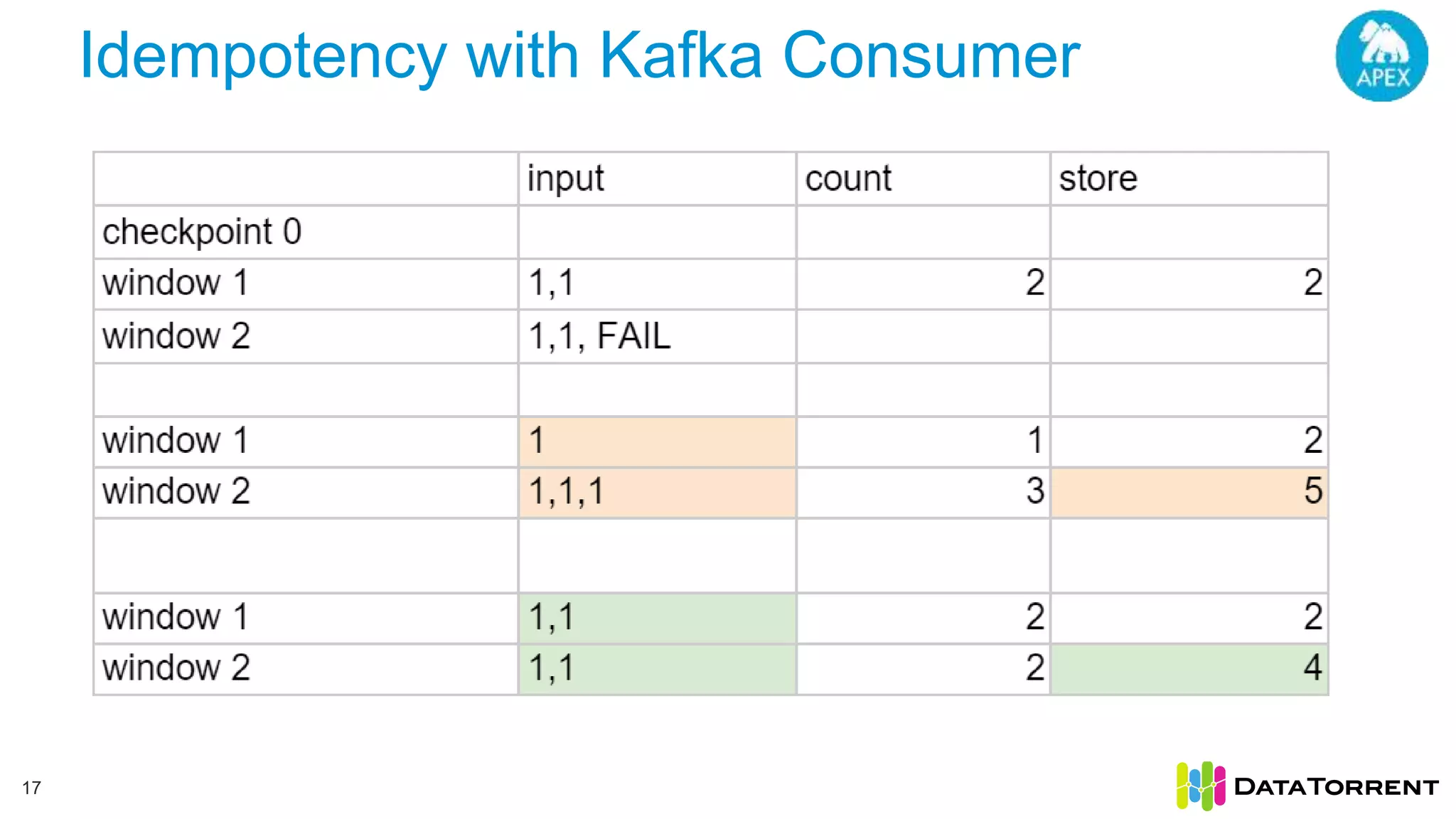

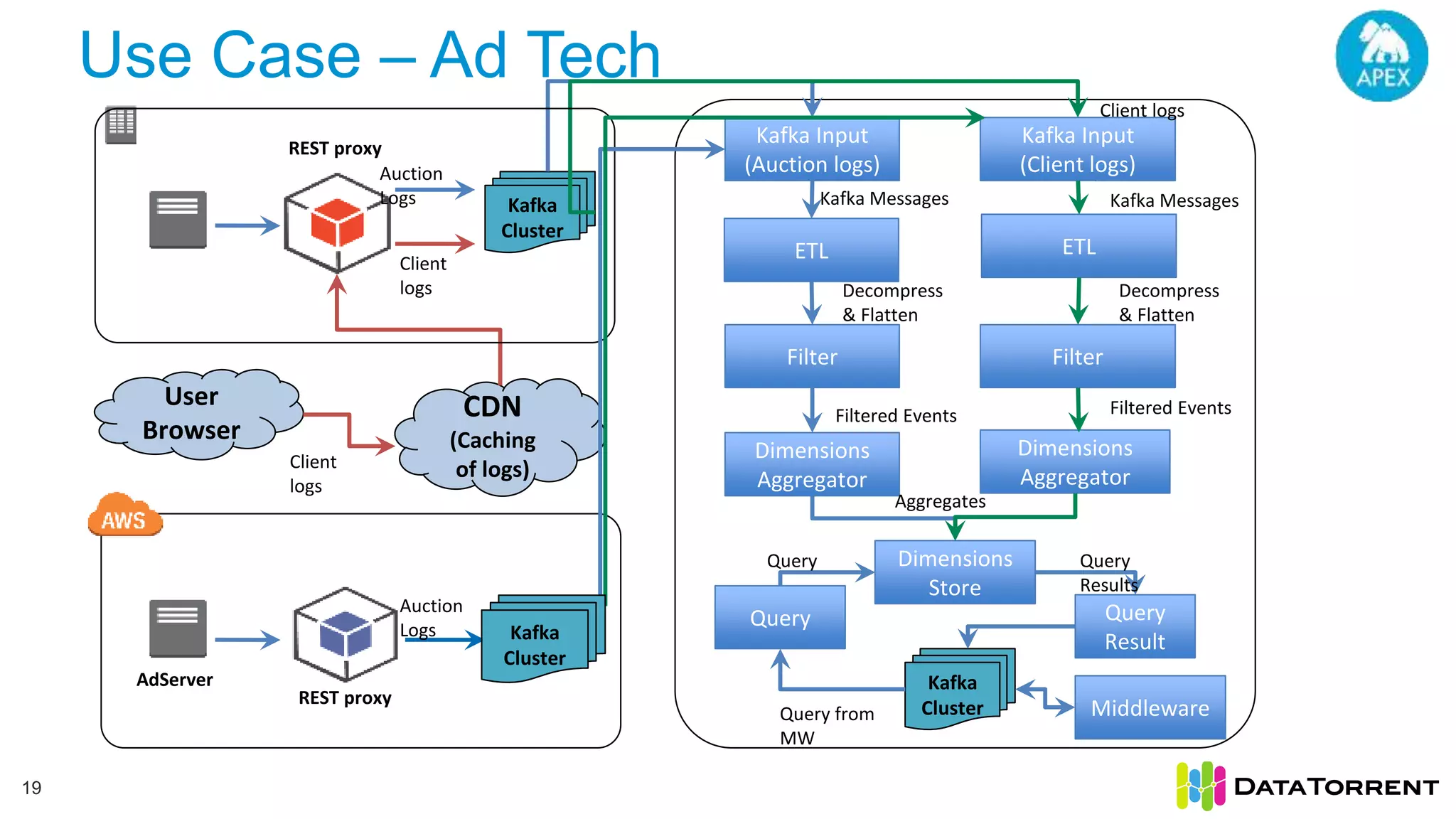
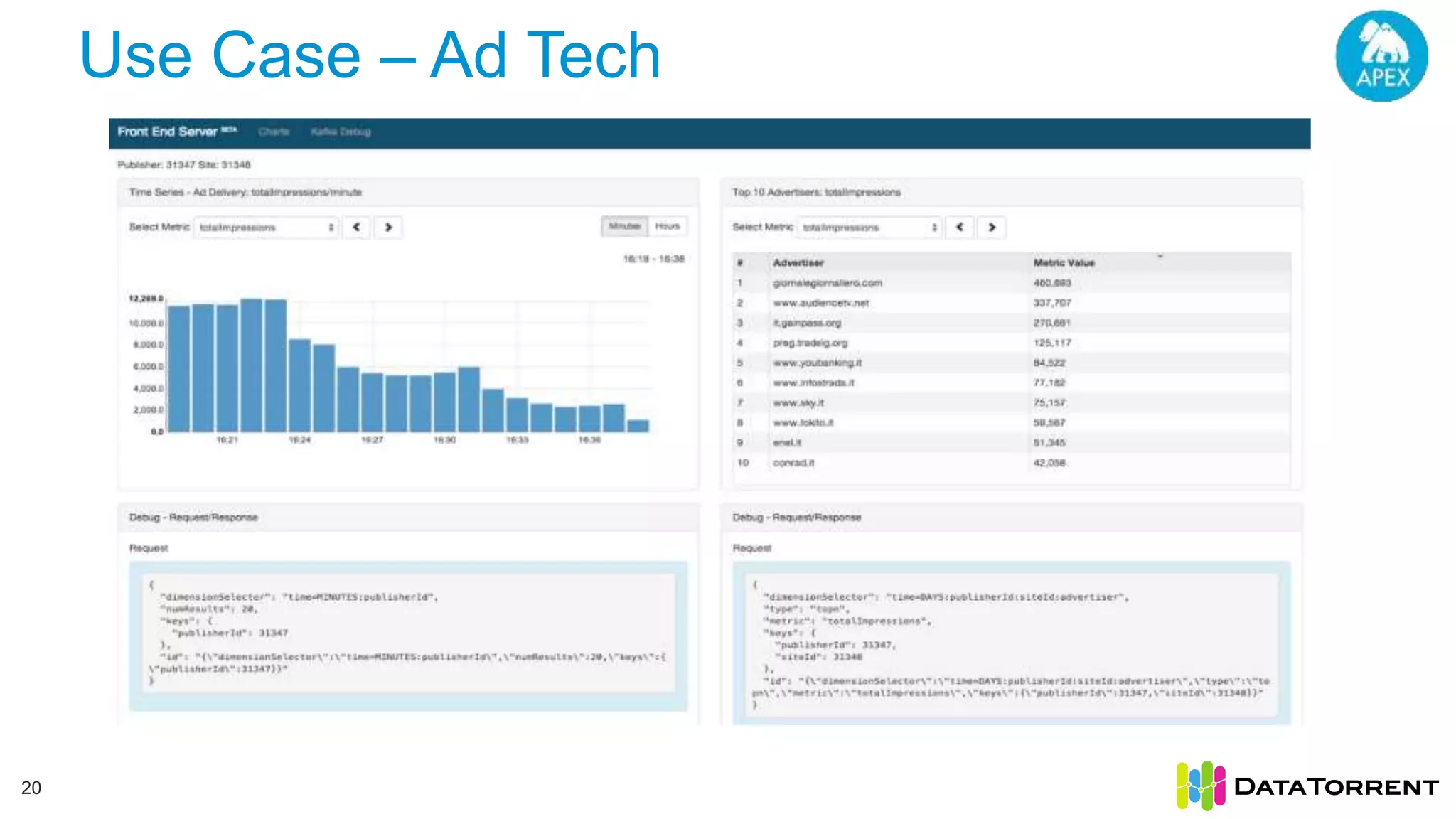




The document discusses low-latency ingestion and analytics using Apache Kafka and Apache Apex, highlighting features such as in-memory stream processing, fault tolerance, and dynamic updates. It elaborates on Kafka's integration with Apex for high-throughput message processing, including producer and consumer strategies that ensure data consistency. Additionally, it outlines partitioning, checkpointing, and use cases, particularly in the ad tech industry, showcasing examples of high data inflows and system architecture.