Downloaded 17 times

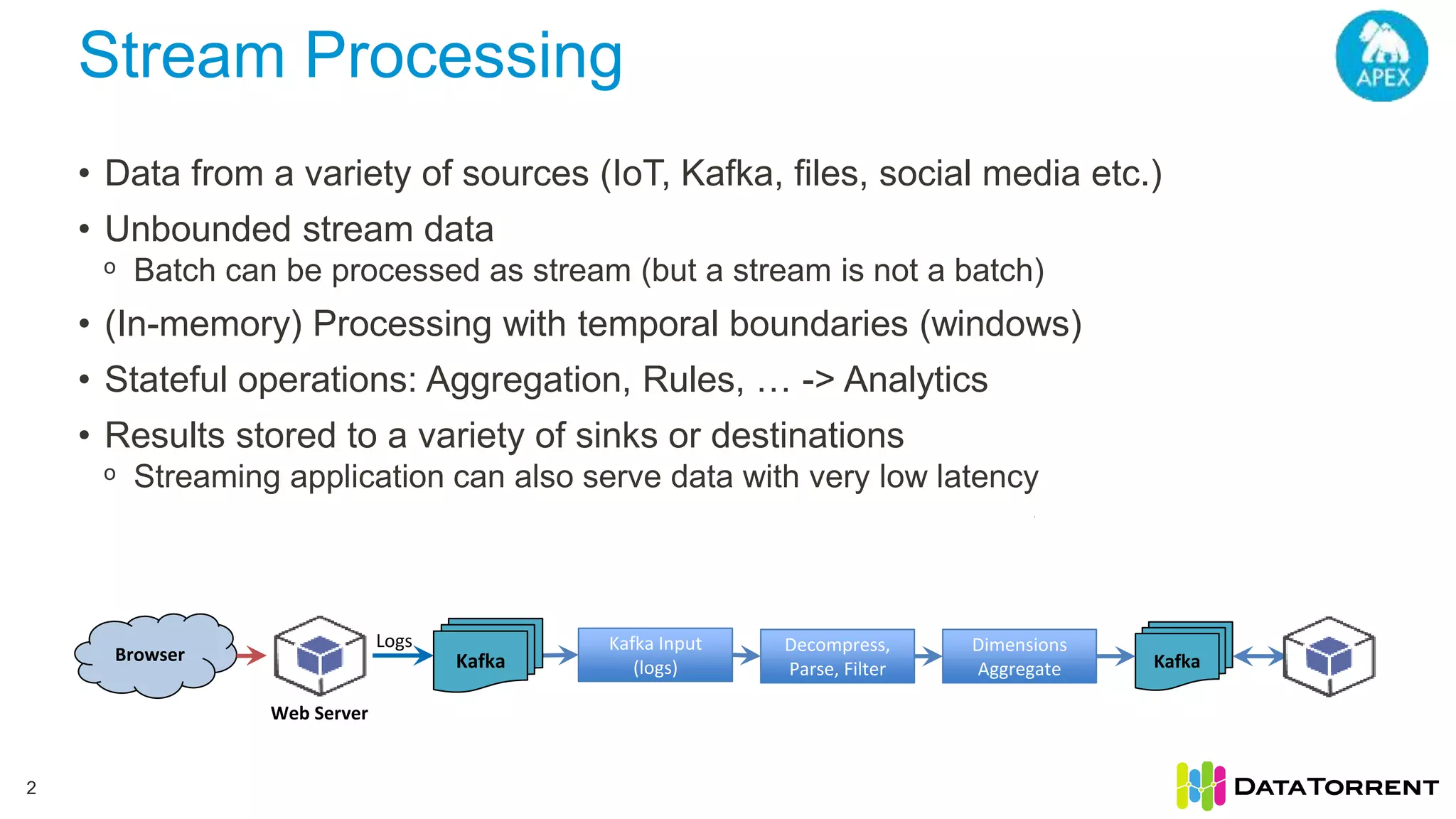


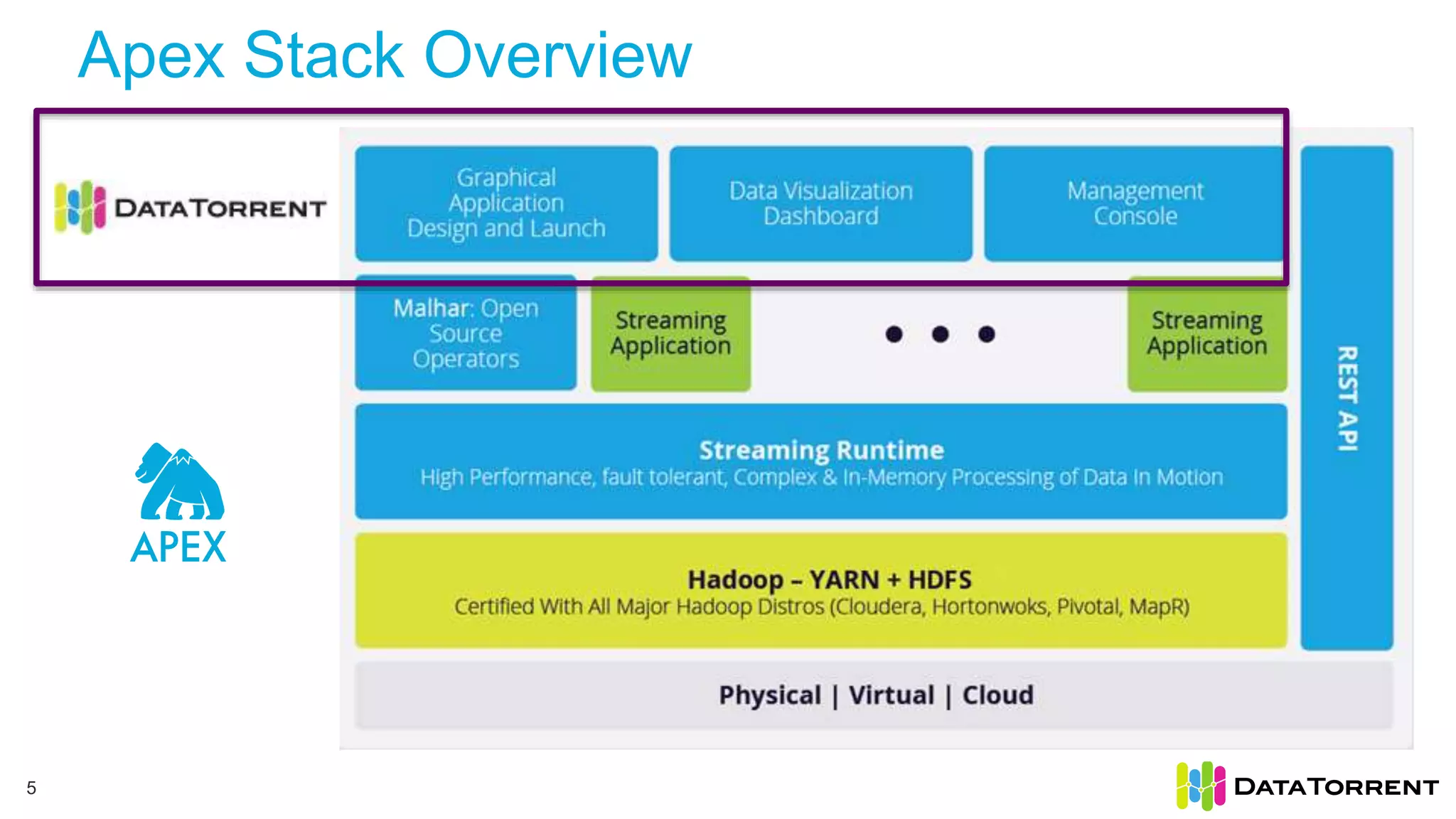
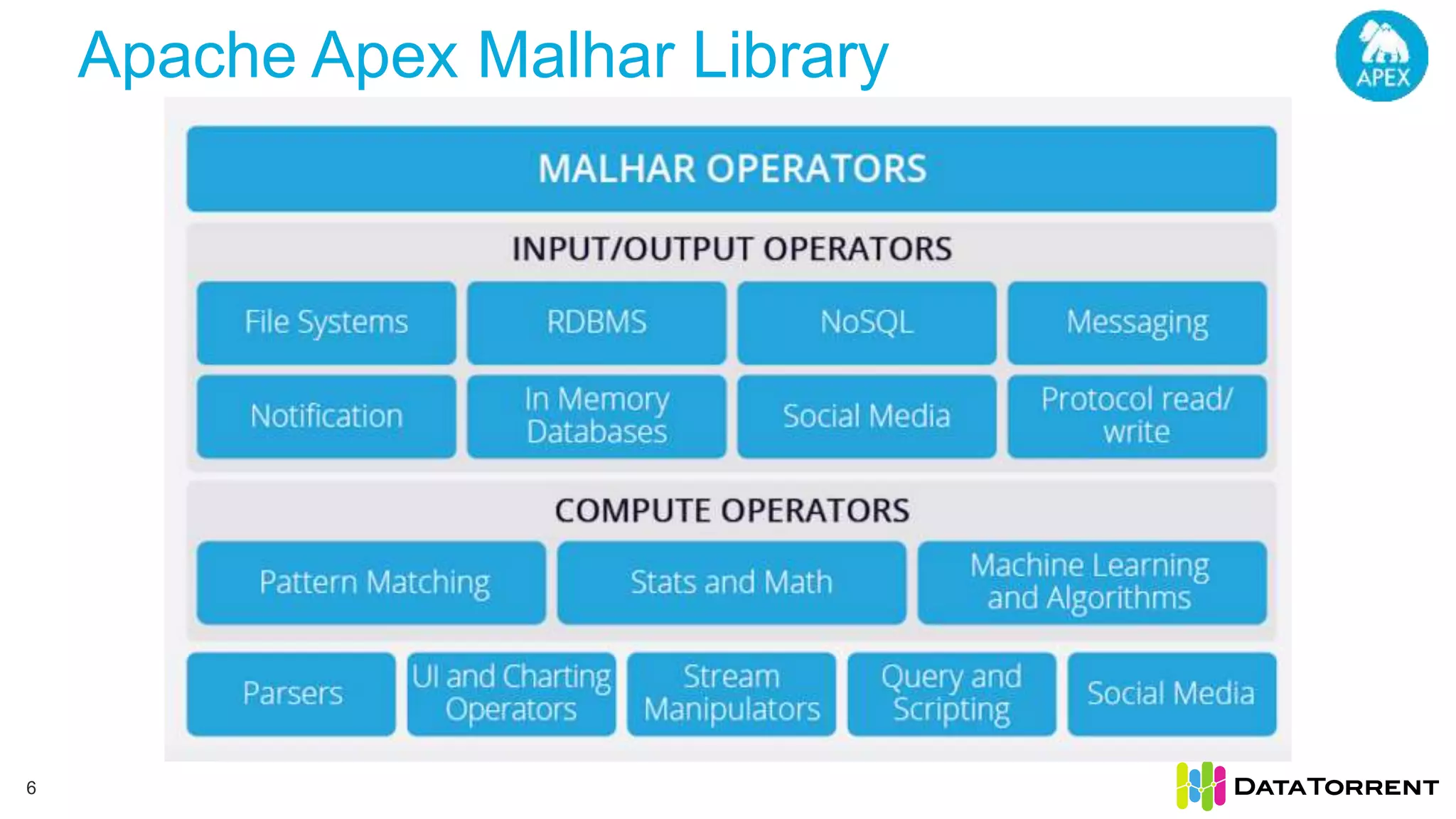
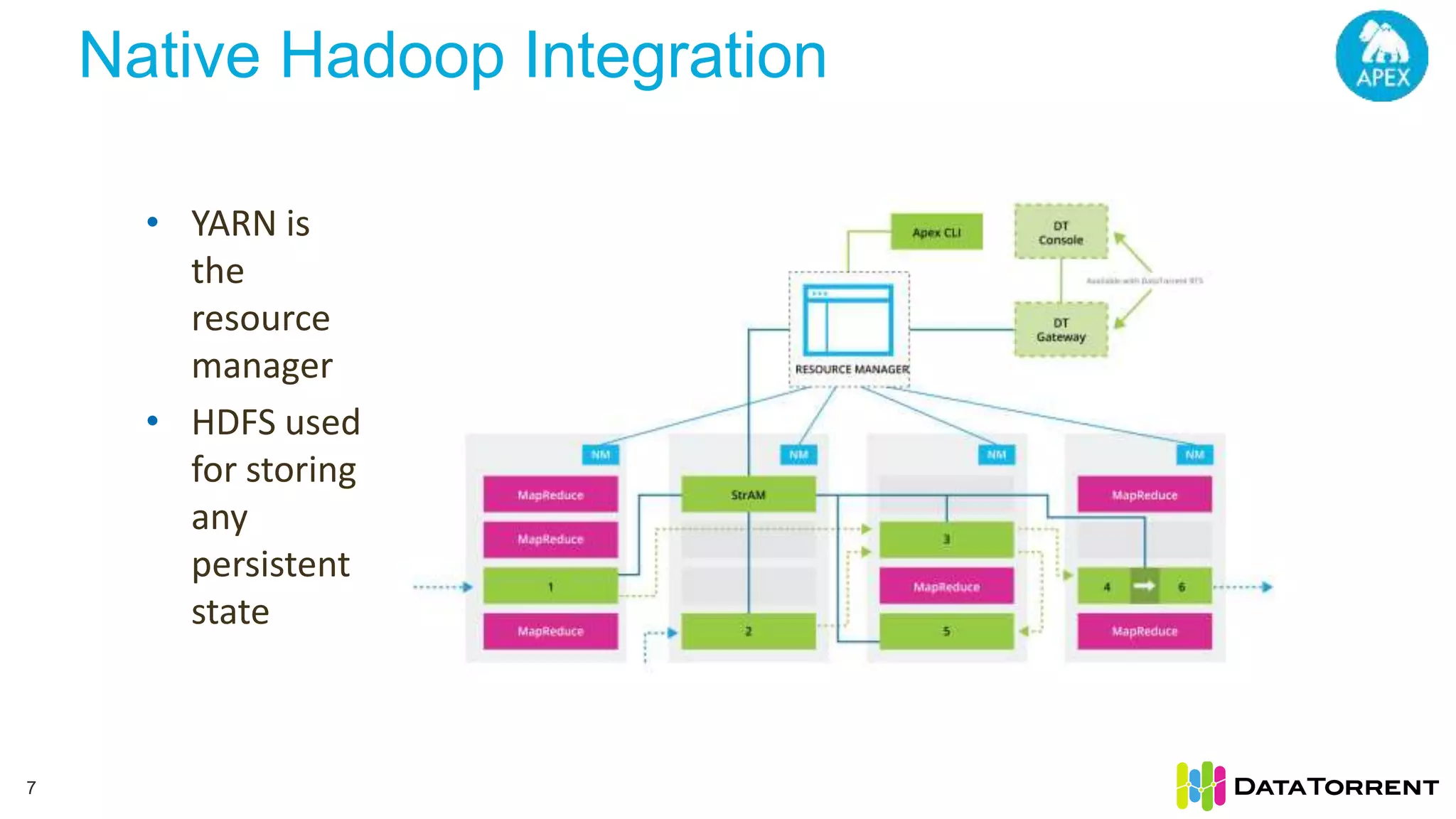
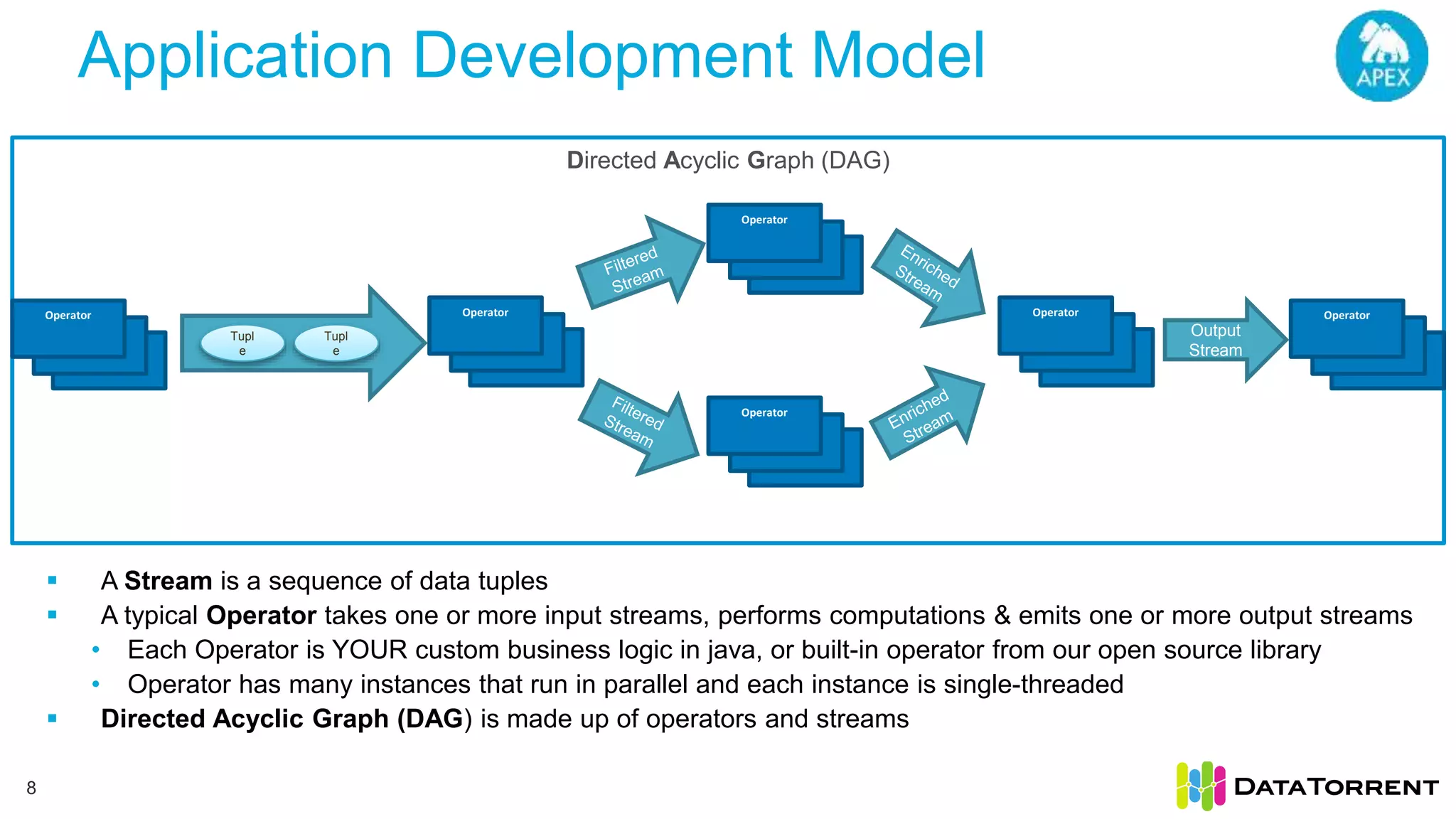
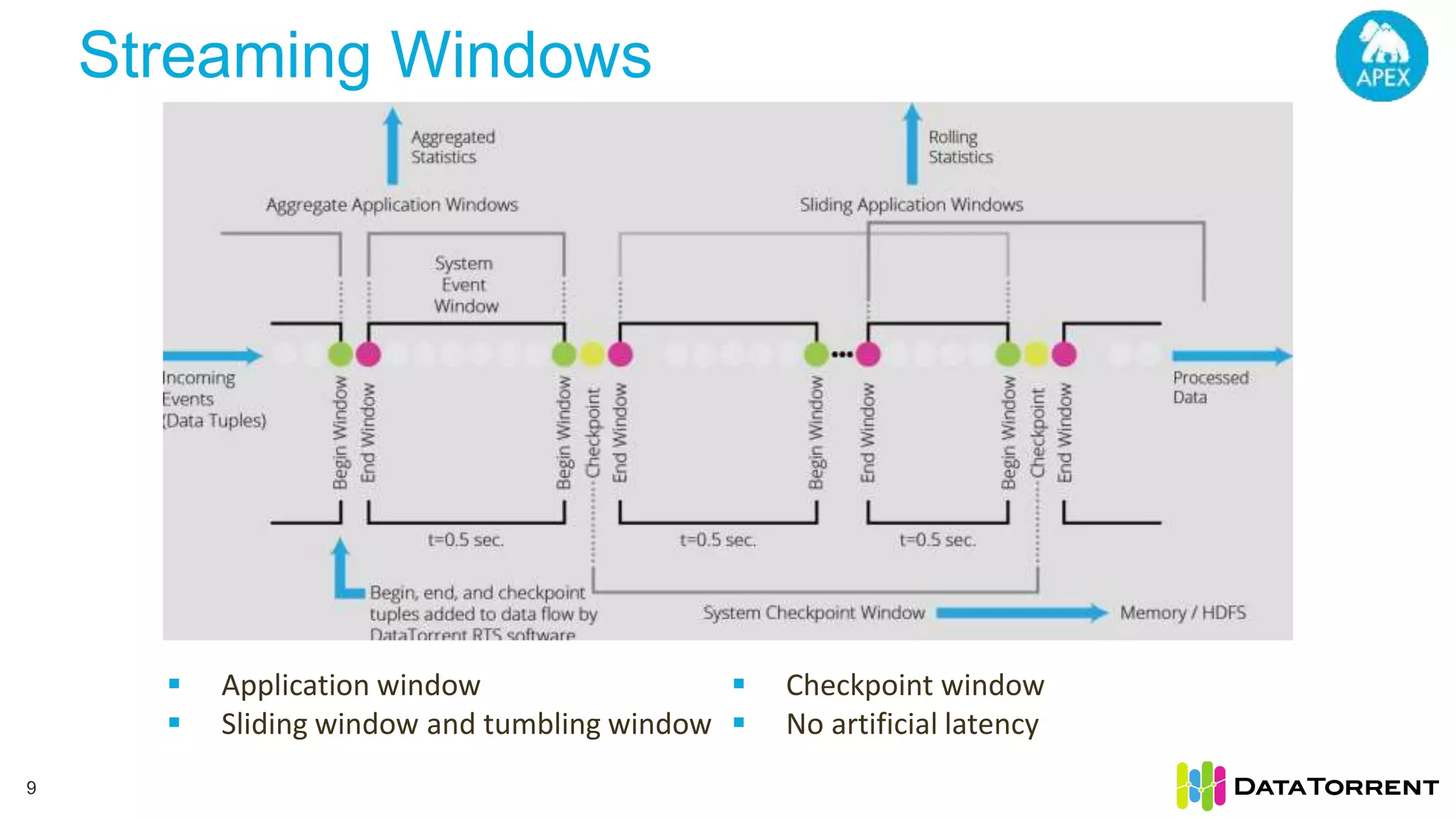
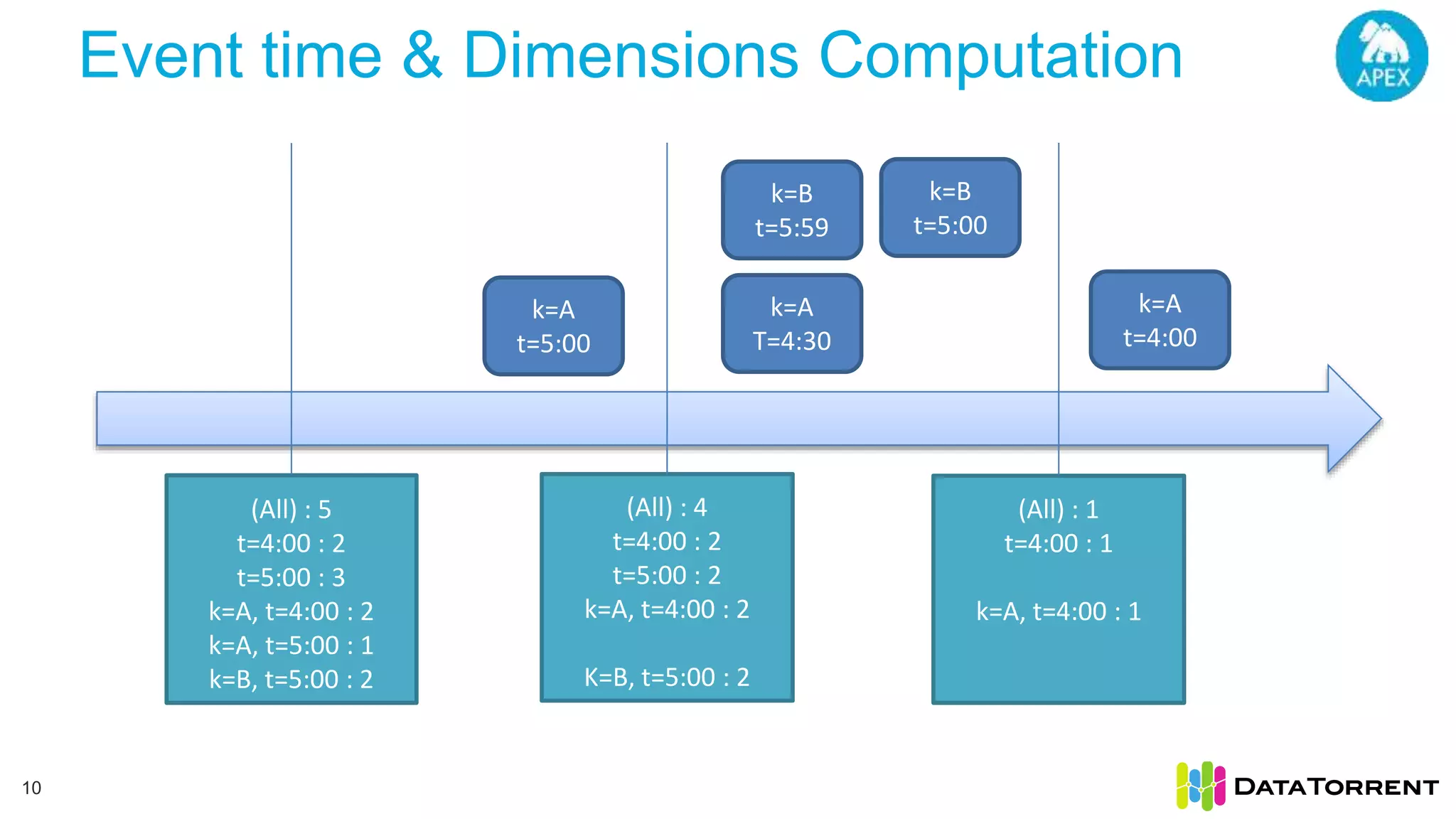



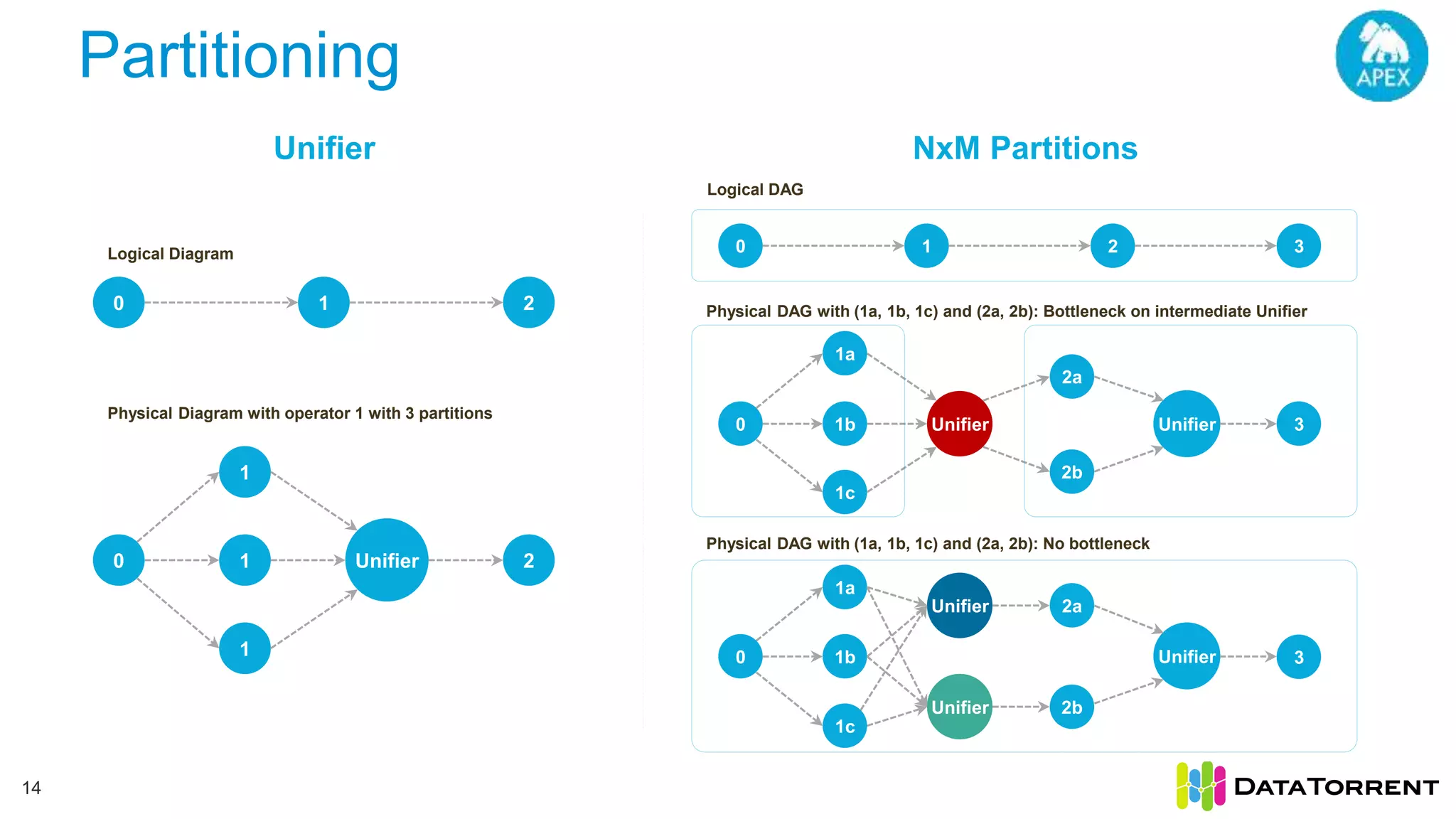
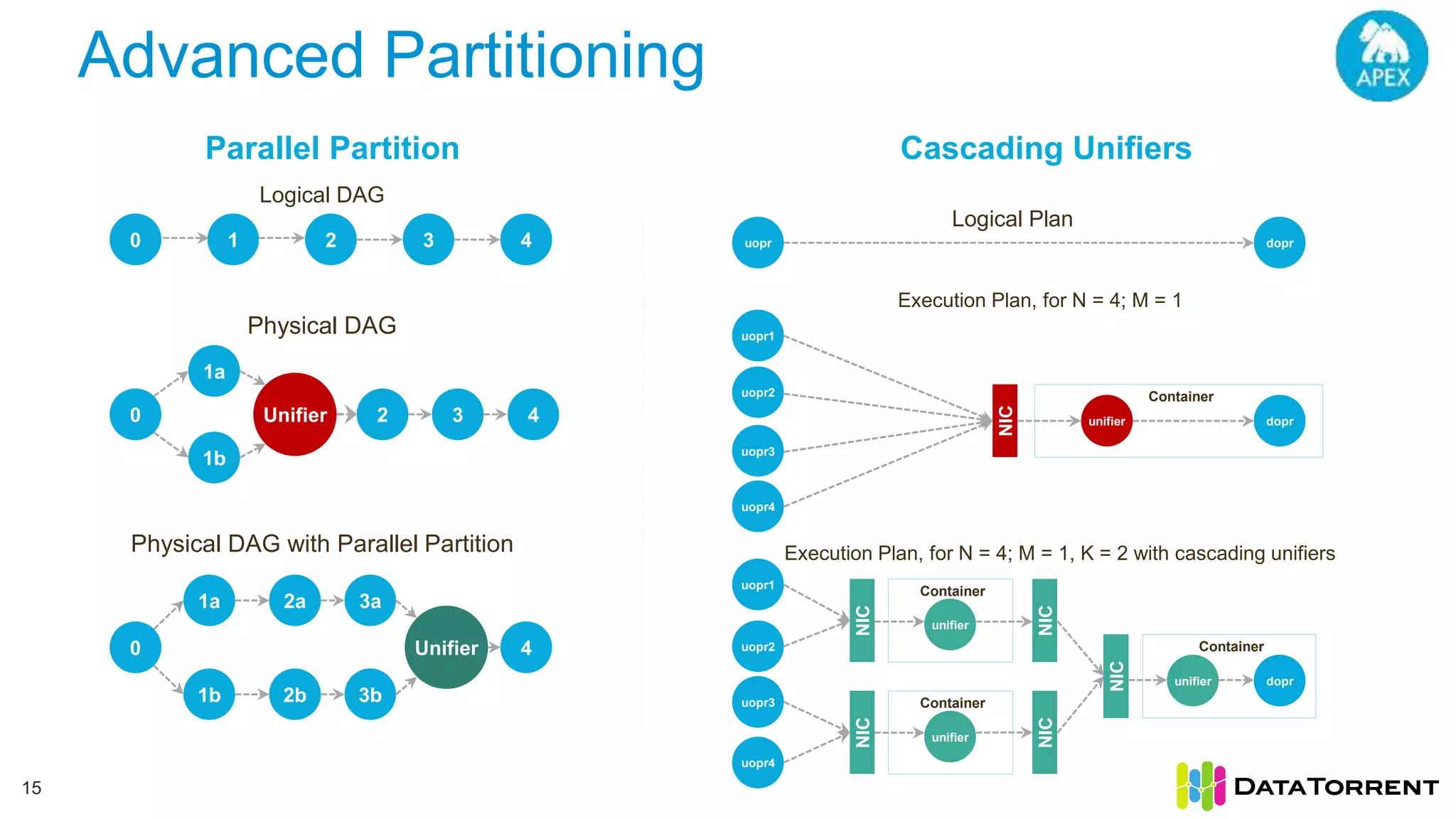
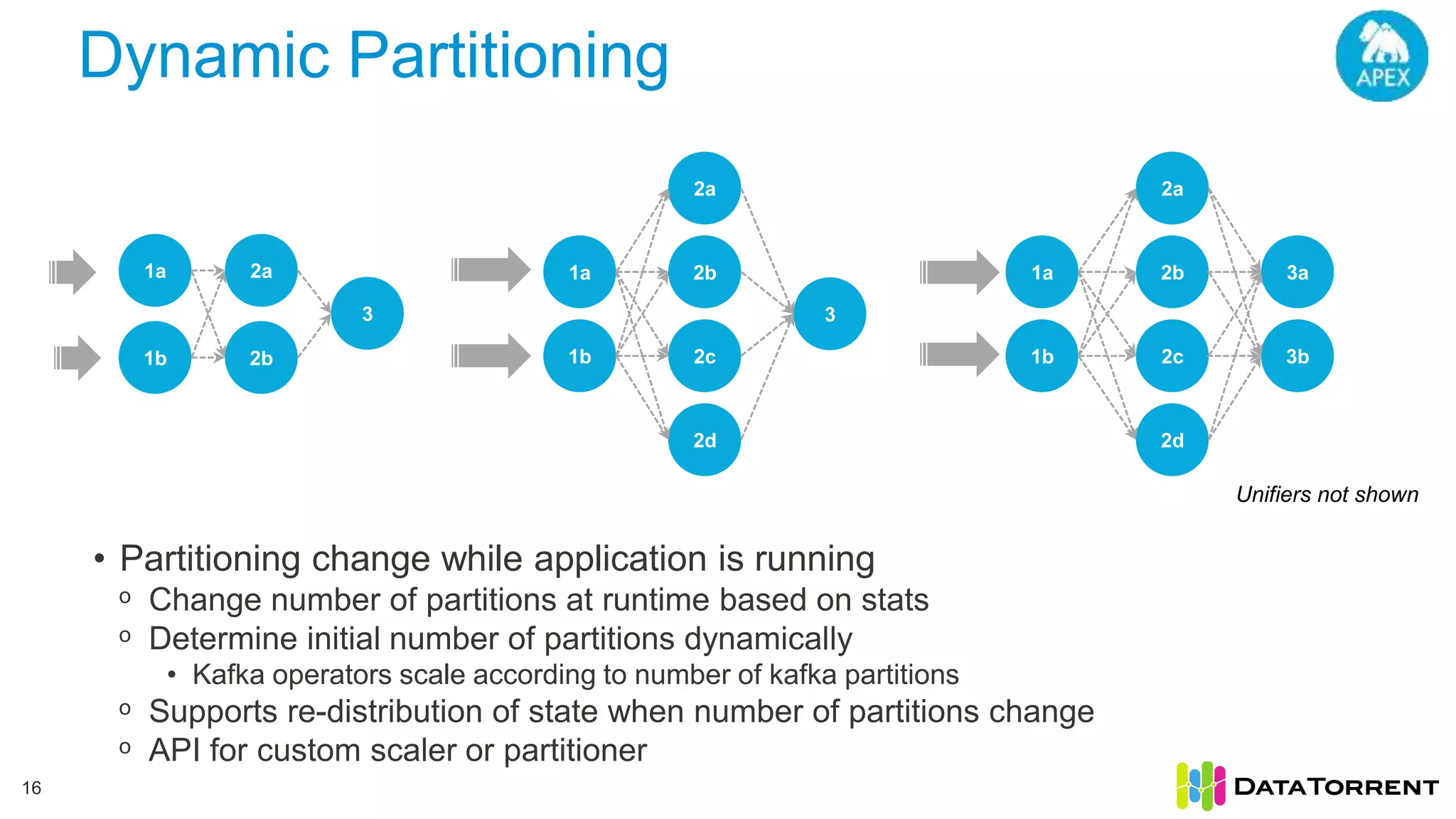


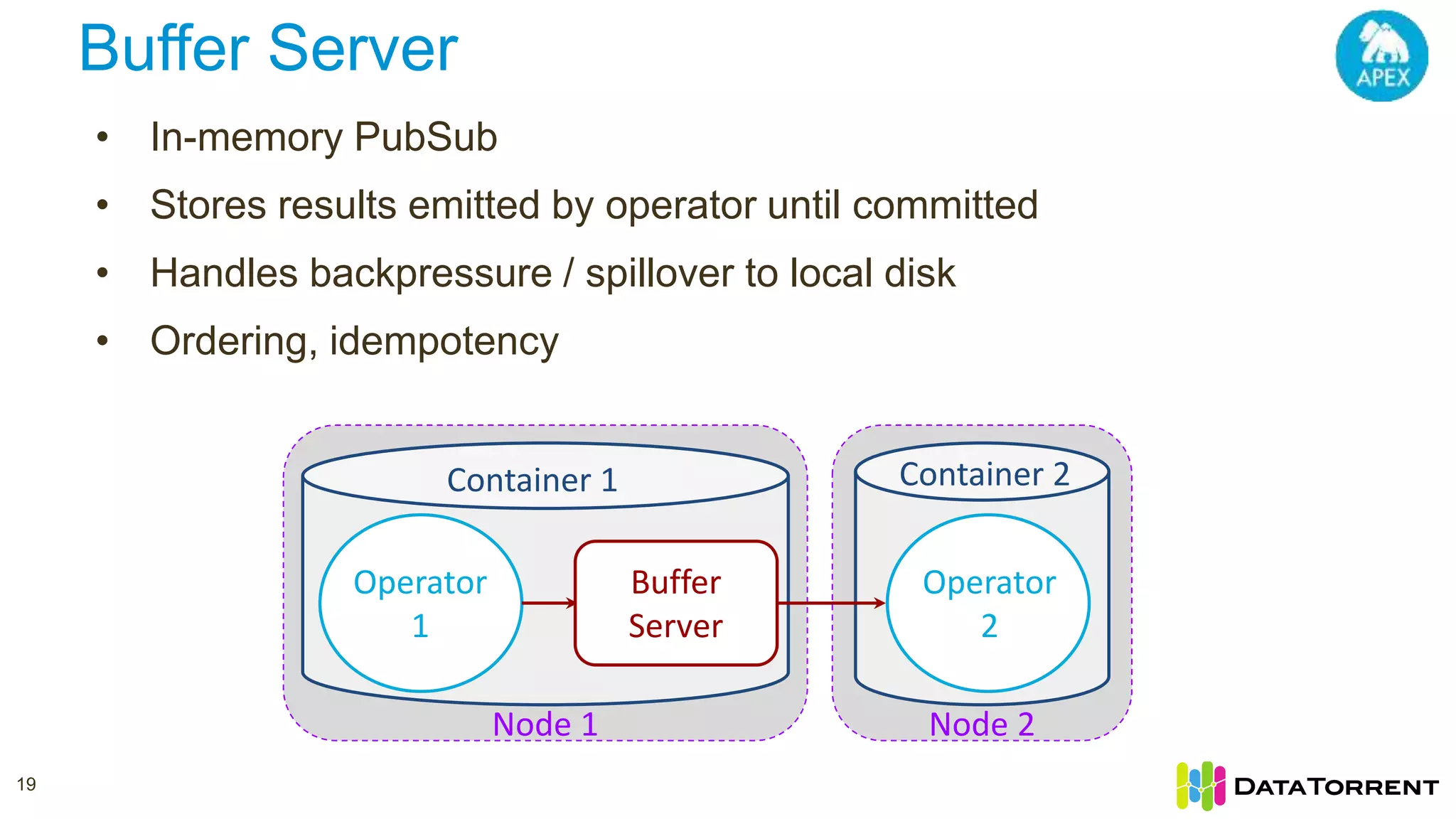
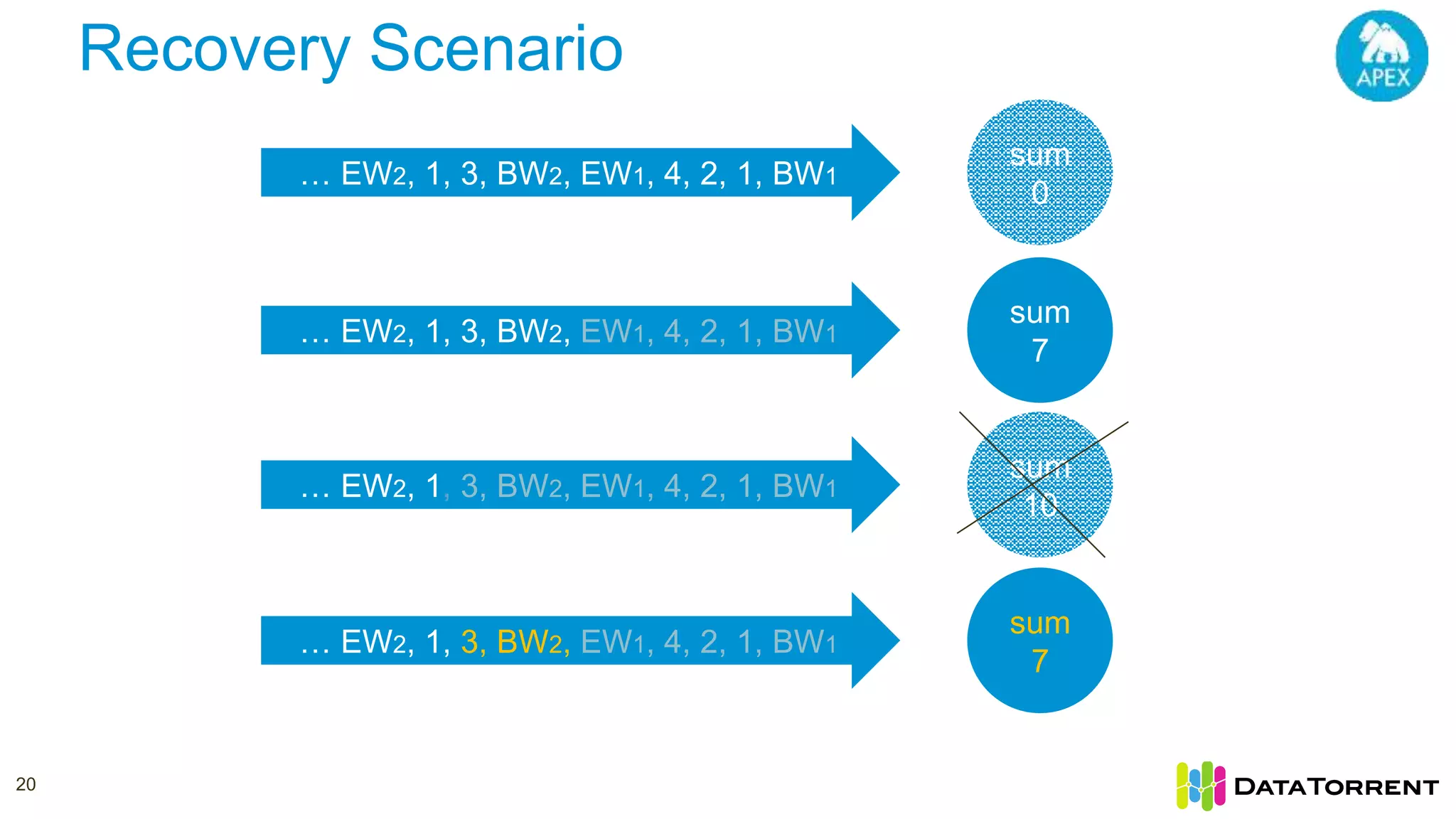



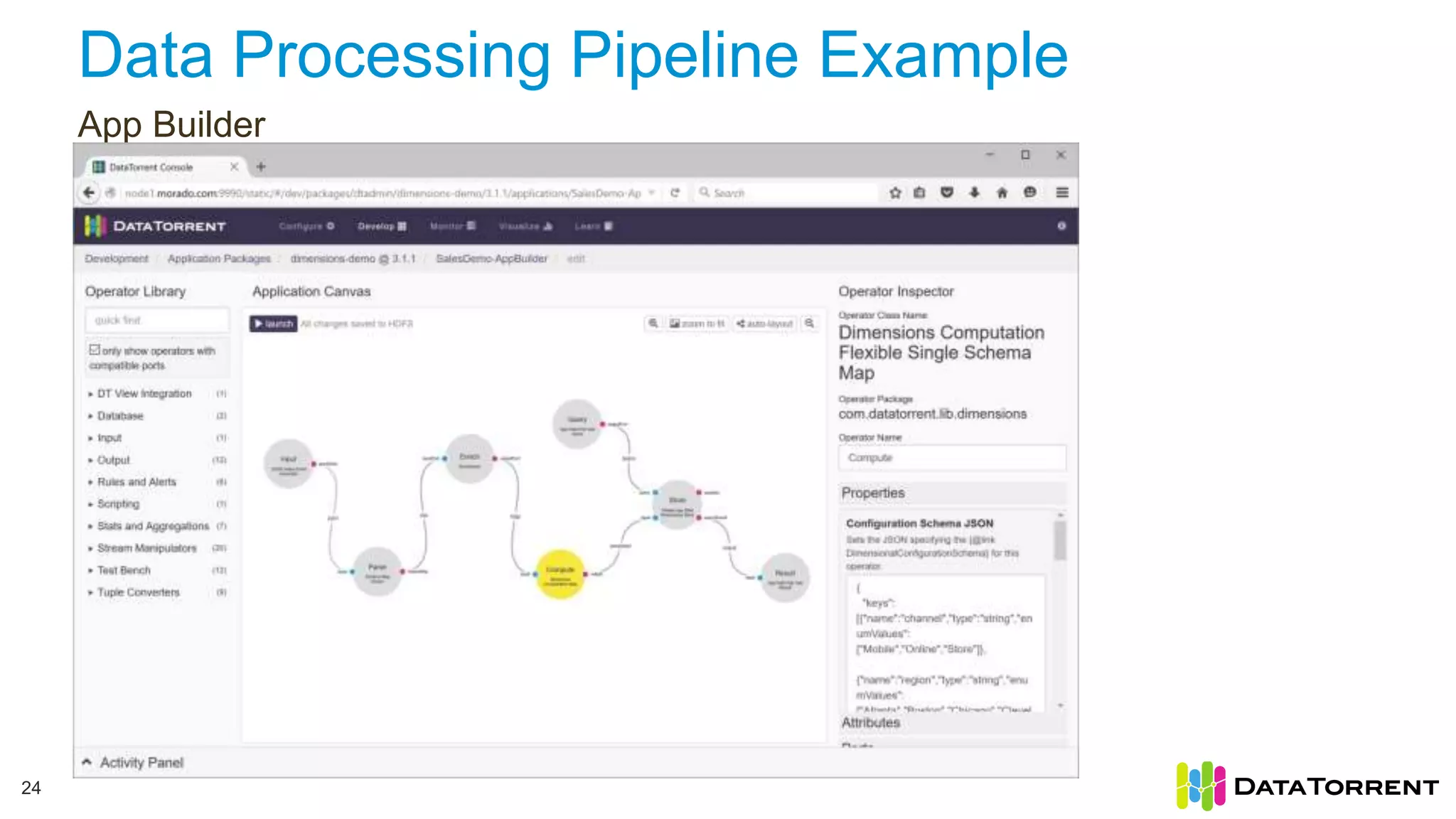
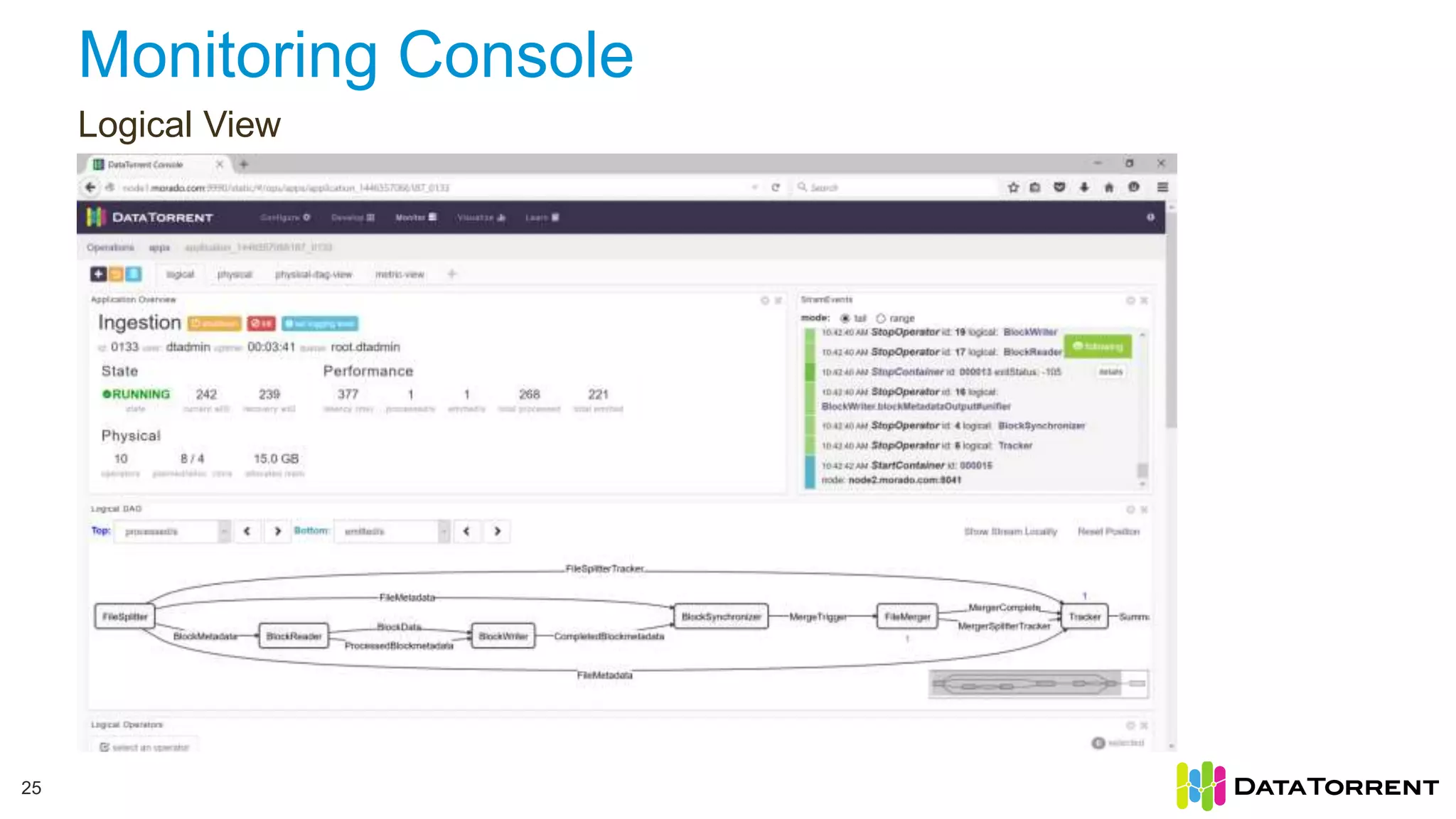
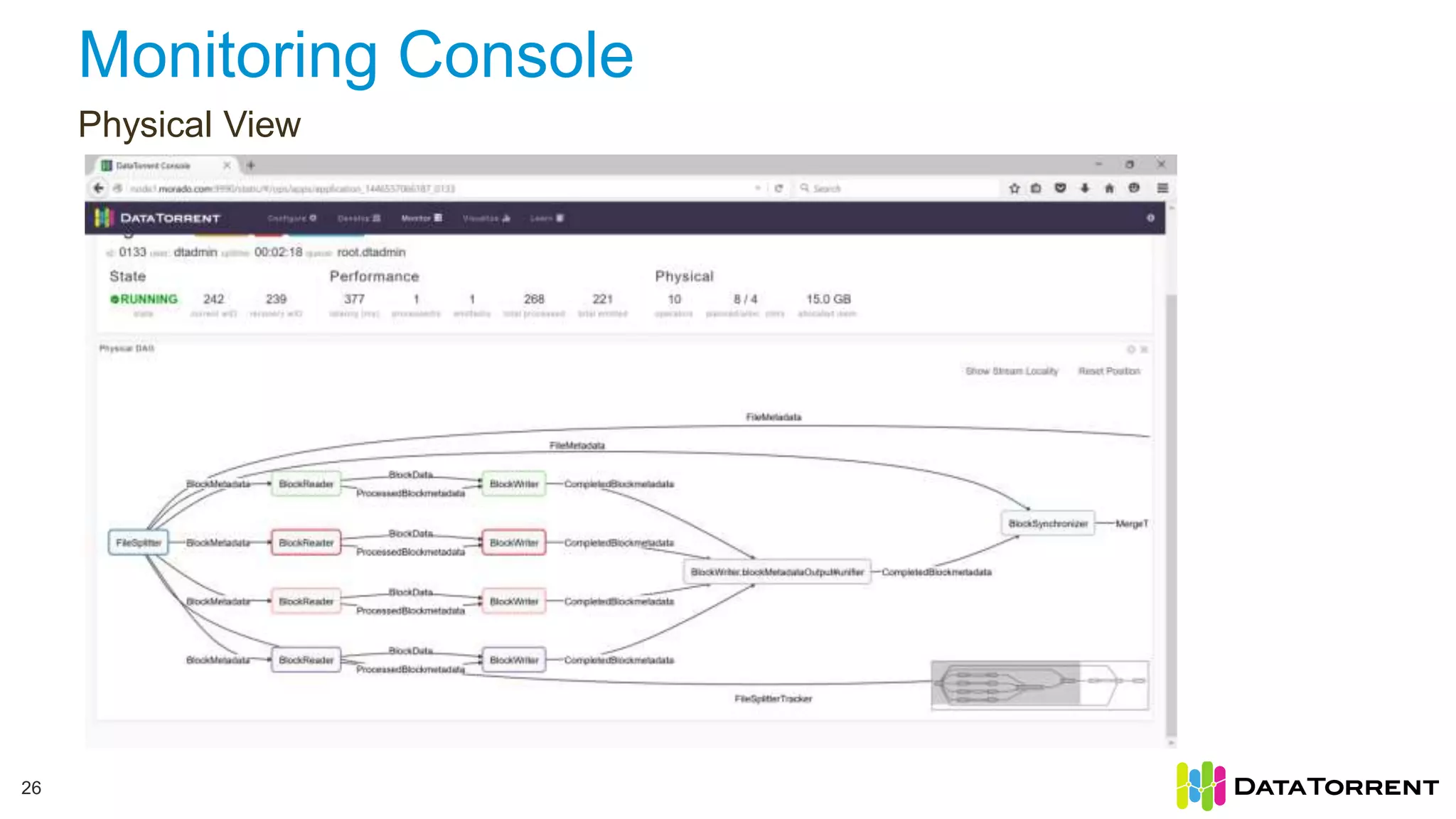
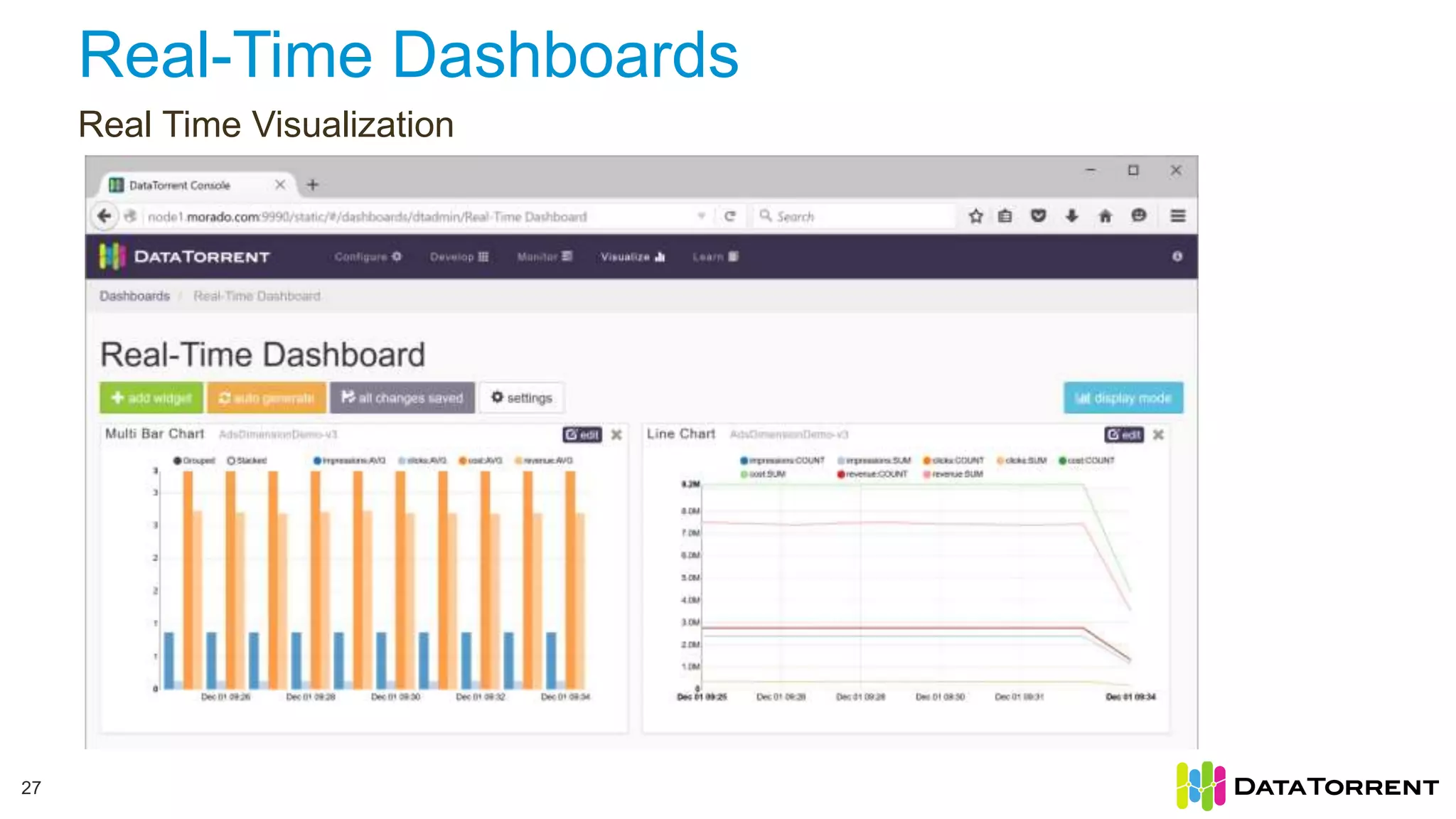
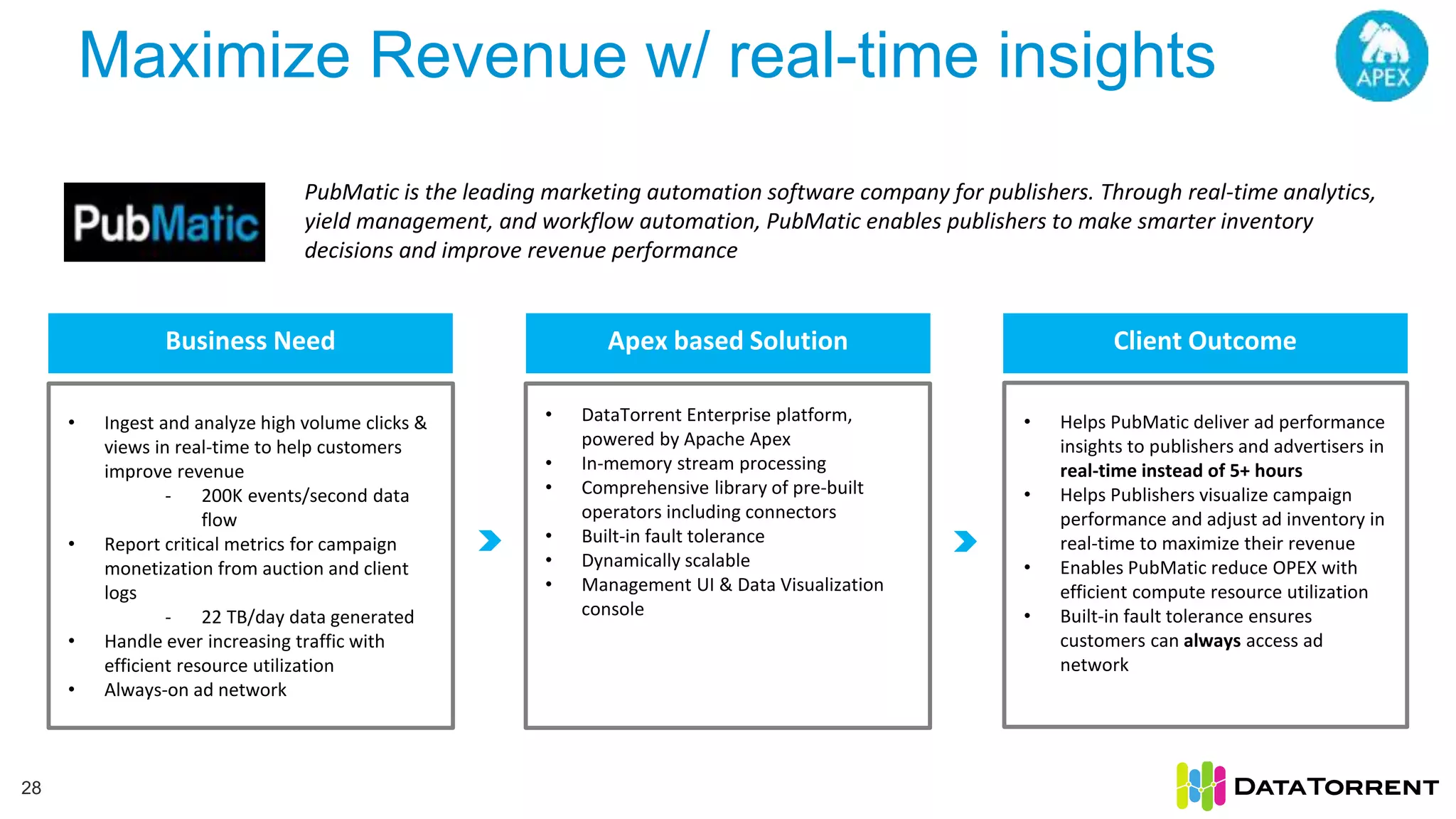
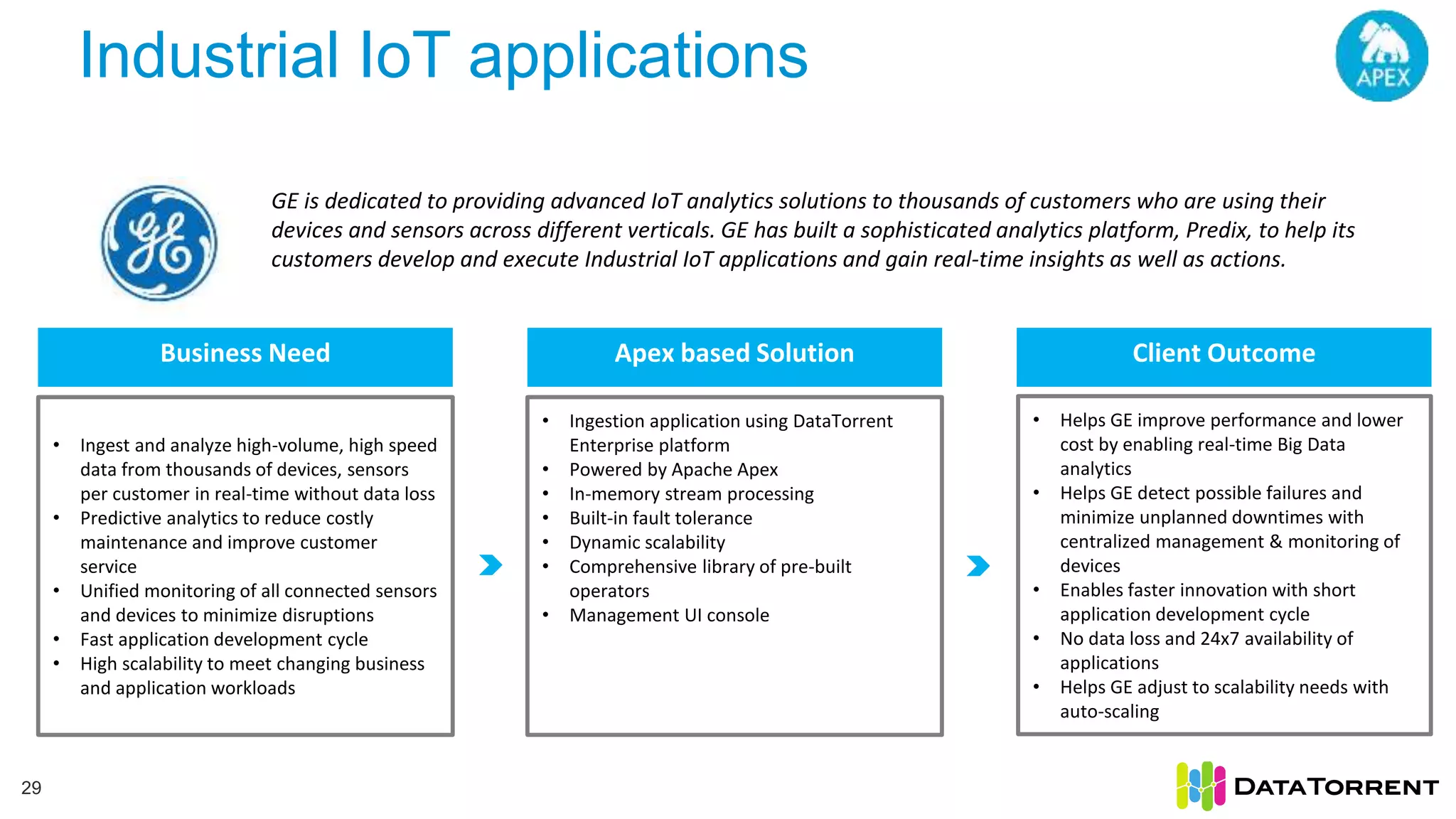
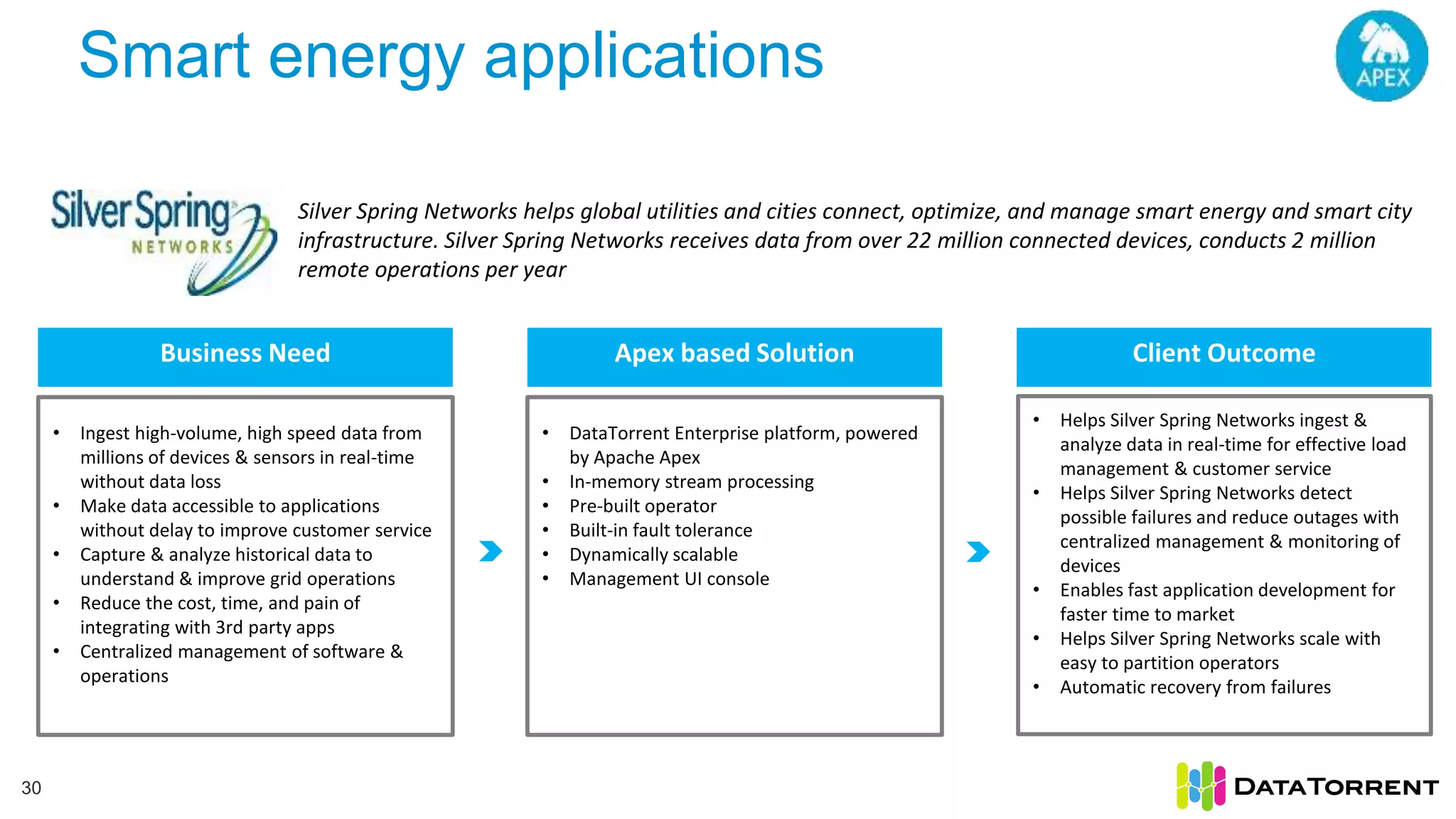




This document discusses Apache Apex, an in-memory stream processing platform designed for handling unbounded data streams from various sources with high throughput and low latency. It emphasizes features like fault tolerance, dynamic scalability, and operational insight, illustrating applications in real-time analytics across industries such as advertising, IoT, and smart energy. The presentation also covers the architecture, including operators, partitioning, and data processing guarantees, exemplified by use cases demonstrating effective data management and analytics.