Downloaded 14 times








![Ad Event public AdEvent(String publisherId, String campaignId String location, double cost, double revenue, long impressions, long clicks, long time….) { this.publisherId = publisherId; this.campaignId = campaignId; this.location = location; this.cost = cost; this.revenue = revenue; this.impressions = impressions; this.clicks = clicks; this.time = time; …. } /* Getters and setters go here */ {"keys":[{"name":"campaignId","type":"integer"}, {"name":"adId","type":"integer"}, {"name":"creativeId","type":"integer"}, {"name":"publisherId","type":"integer"}, {"name":"adOrderId","type":"integer"}], "timeBuckets":["1h","1d"], "values": [{"name":"impressions","type":"integer","aggregators":["SUM"]} , {"name":"clicks","type":"integer","aggregators":["SUM"]}, {"name":"revenue","type":"integer"}], "dimensions": [{"combination":["campaignId","adId"]}, {"combination":["creativeId","campaignId"]}, {"combination":["campaignId"]}, {"combination":["publisherId","adOrderId","campaignId"], "additionalValues":["revenue:SUM"]}] } The Dimensional Model 14](https://image.slidesharecdn.com/apexdimensionscomputedev-170605000812/75/Actionable-Insights-with-Apache-Apex-at-Apache-Big-Data-2017-by-Devendra-Tagare-14-2048.jpg)


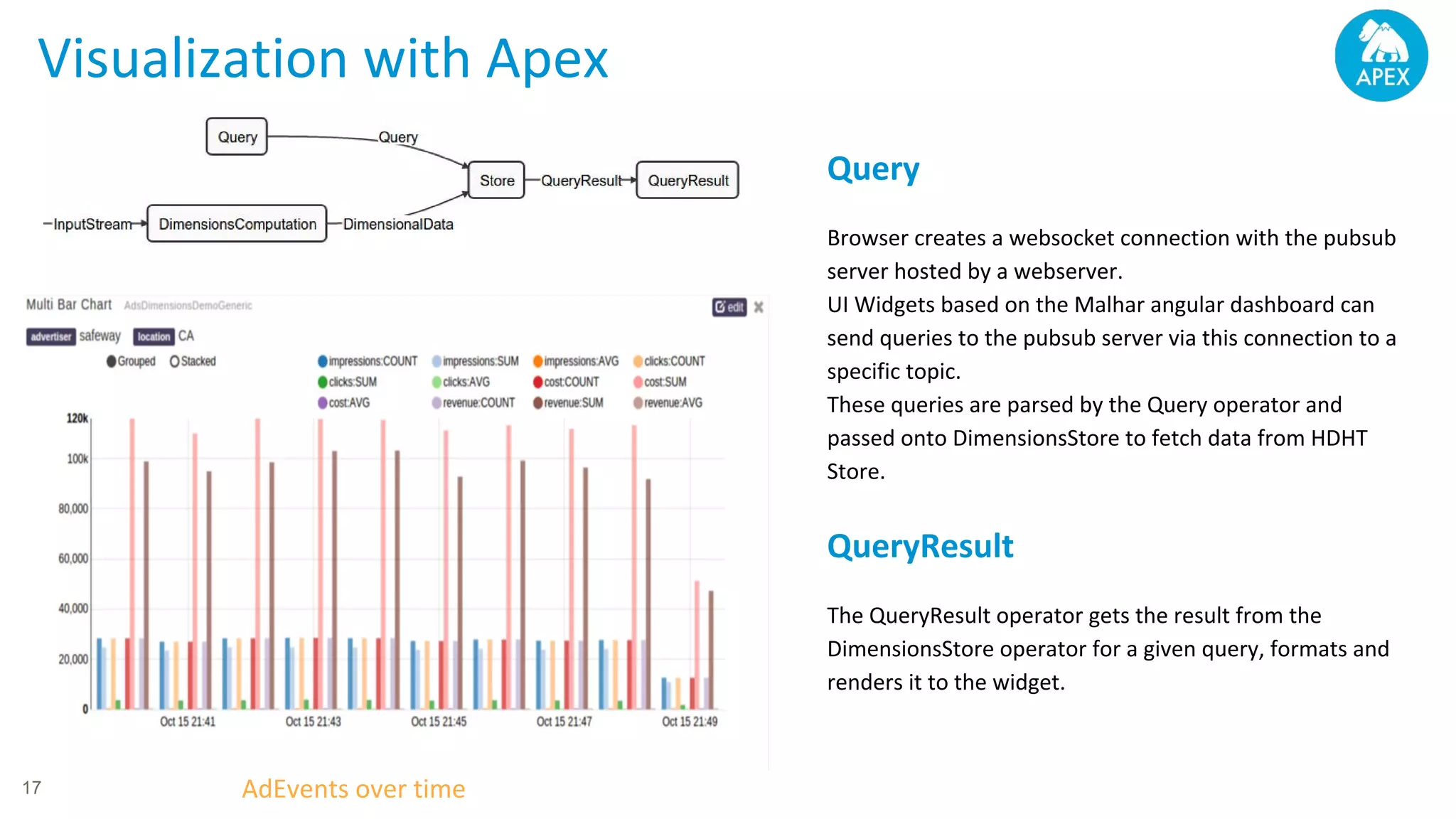
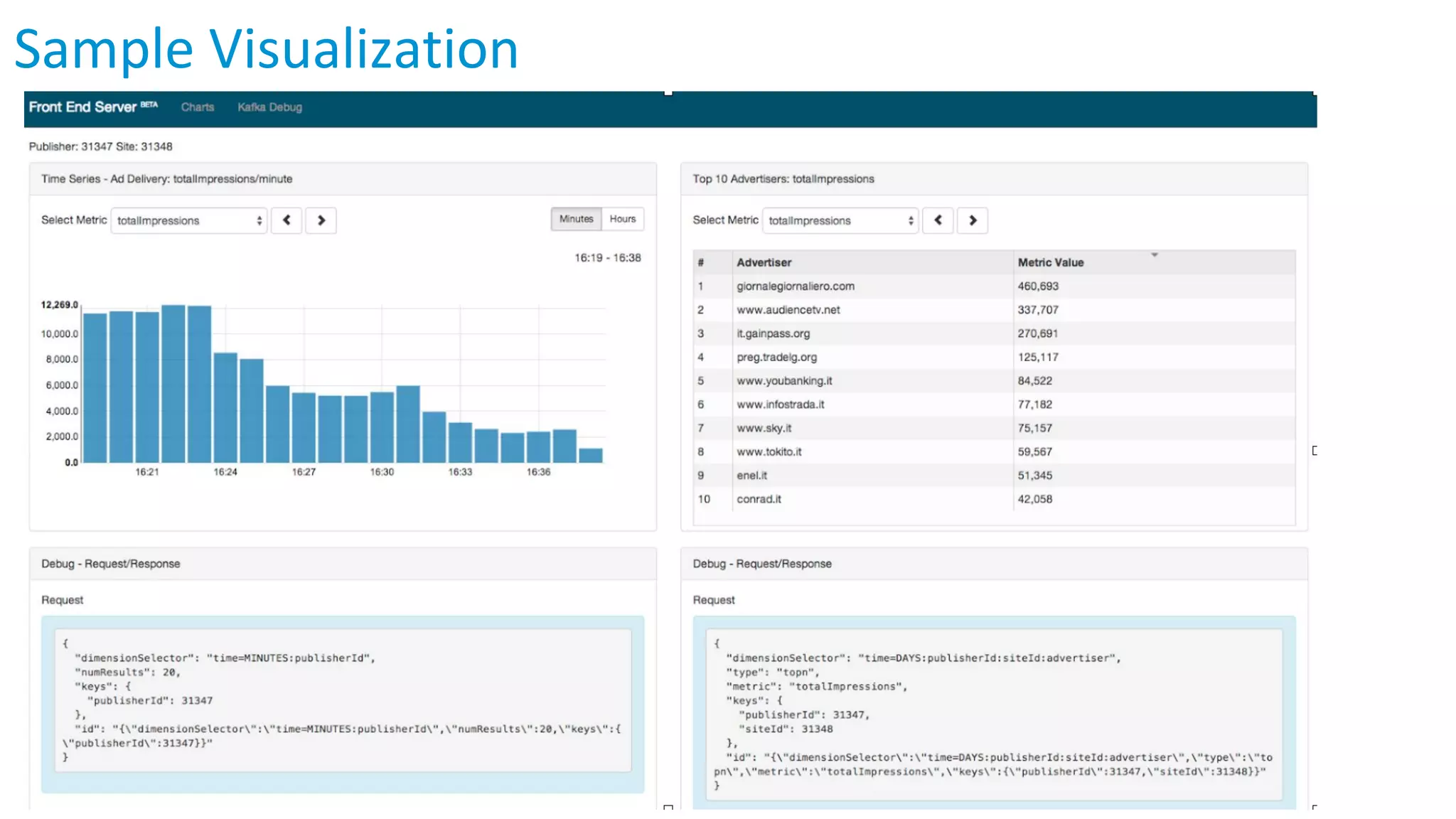


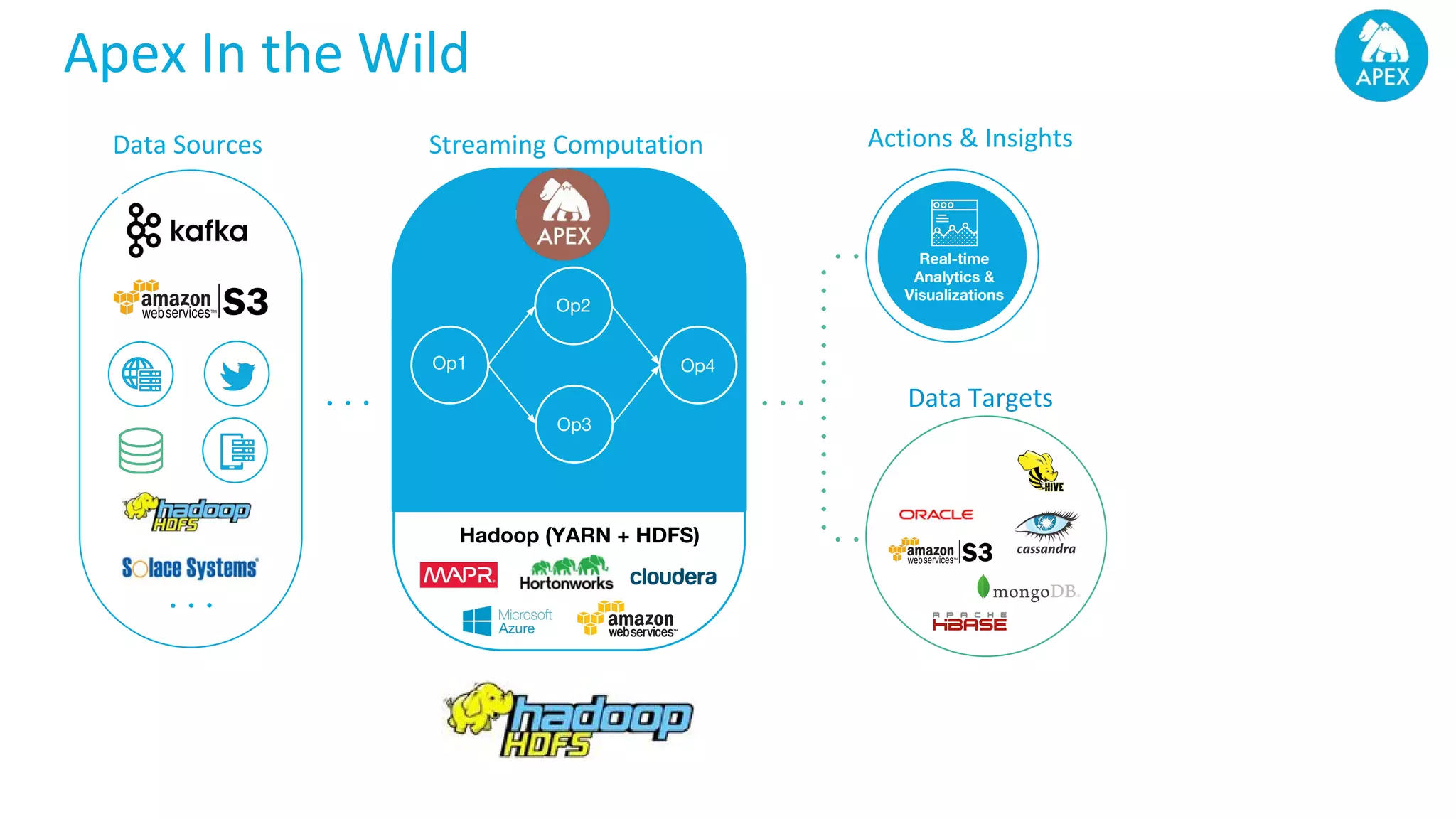
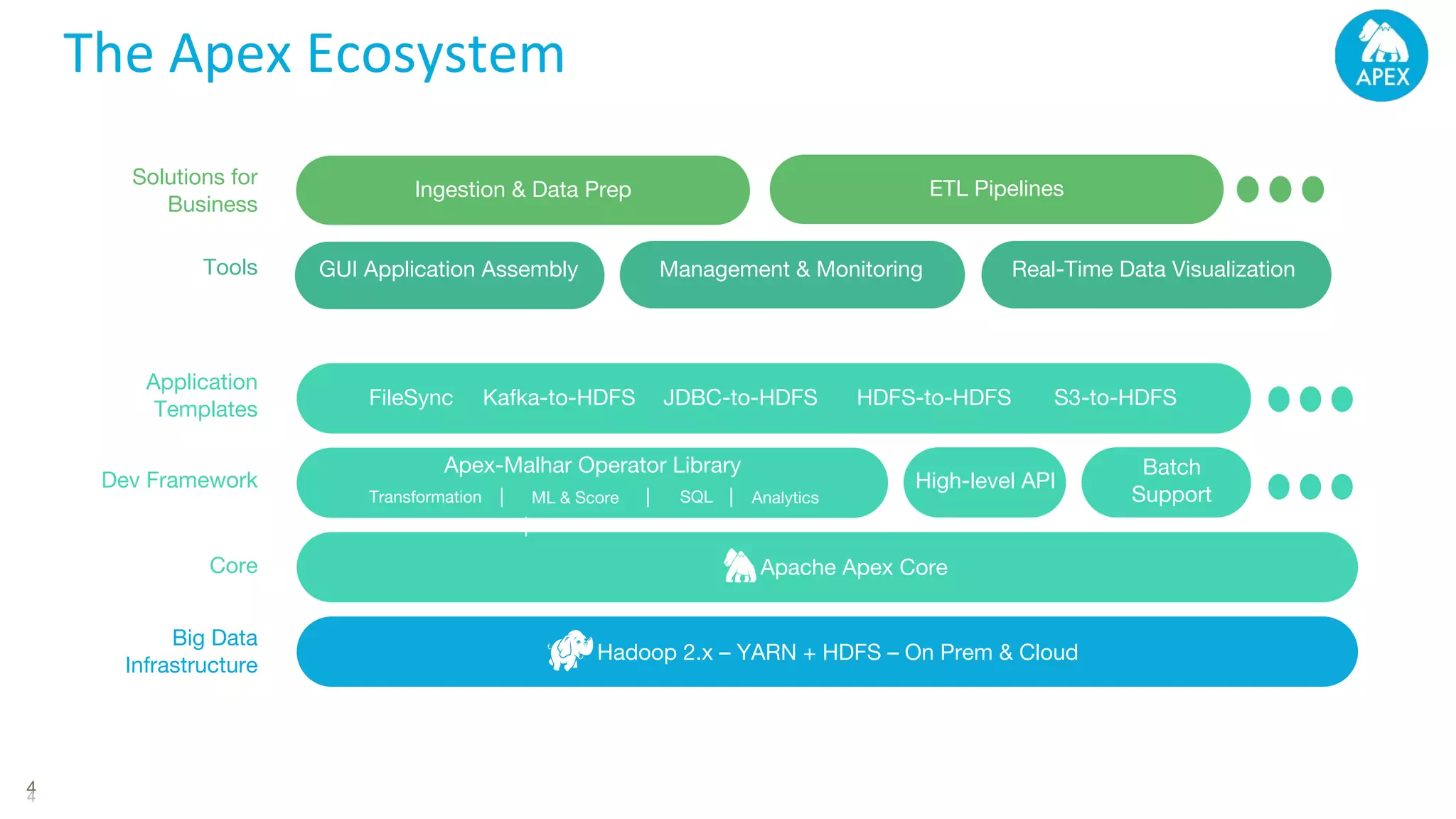
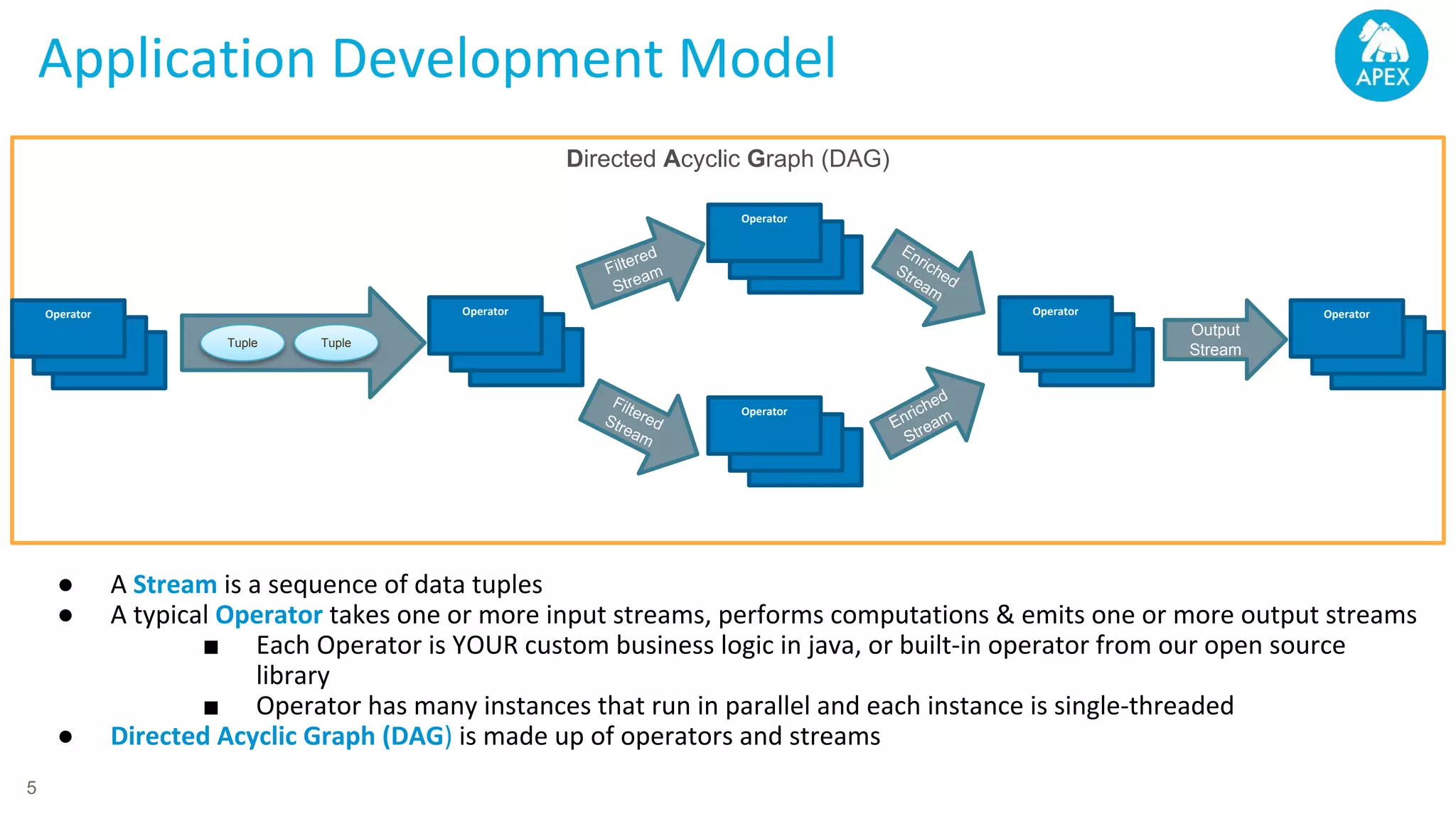
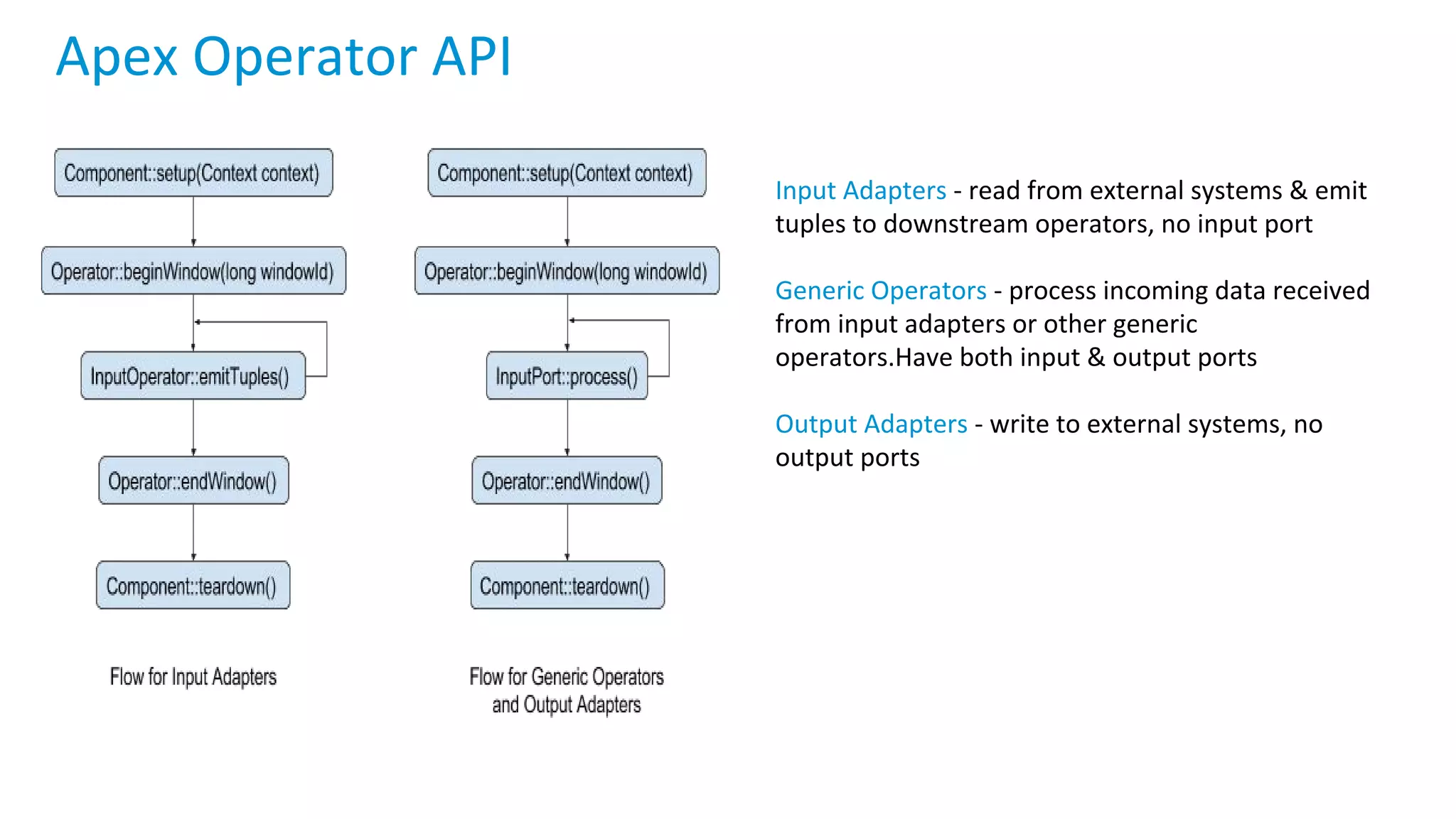
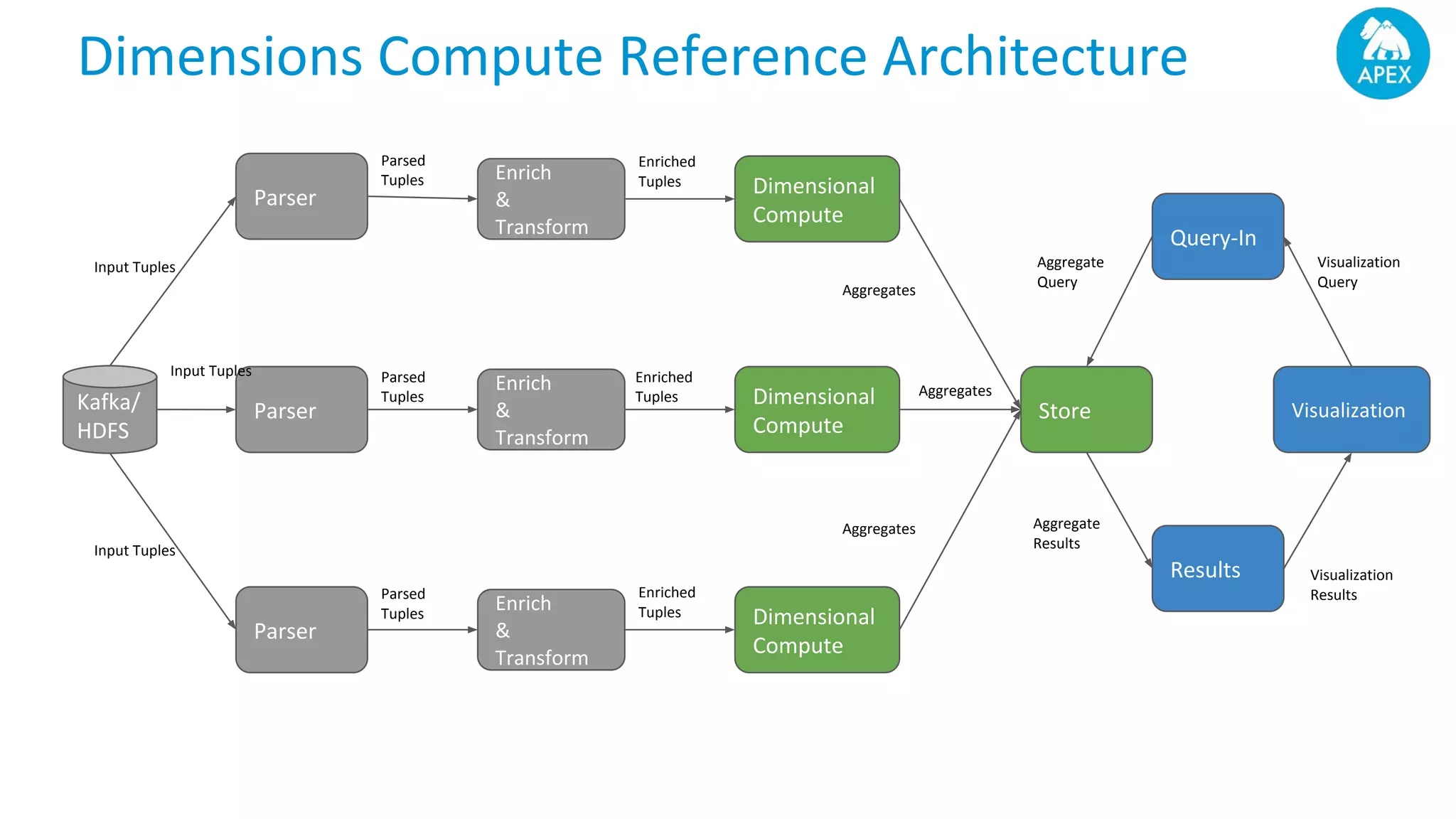
Apache Apex is a scalable and fault-tolerant platform for developing distributed applications that process streaming and batch data using a high-level API. It automates resource negotiation with Hadoop YARN and guarantees stateful computations through fault recovery mechanisms, enabling efficient data ingestion, transformation, and visualization. The document outlines the dimensional compute model, aggregation phases, and application development frameworks, emphasizing scalability and performance in real-time data processing.