Download as PDF, PPTX










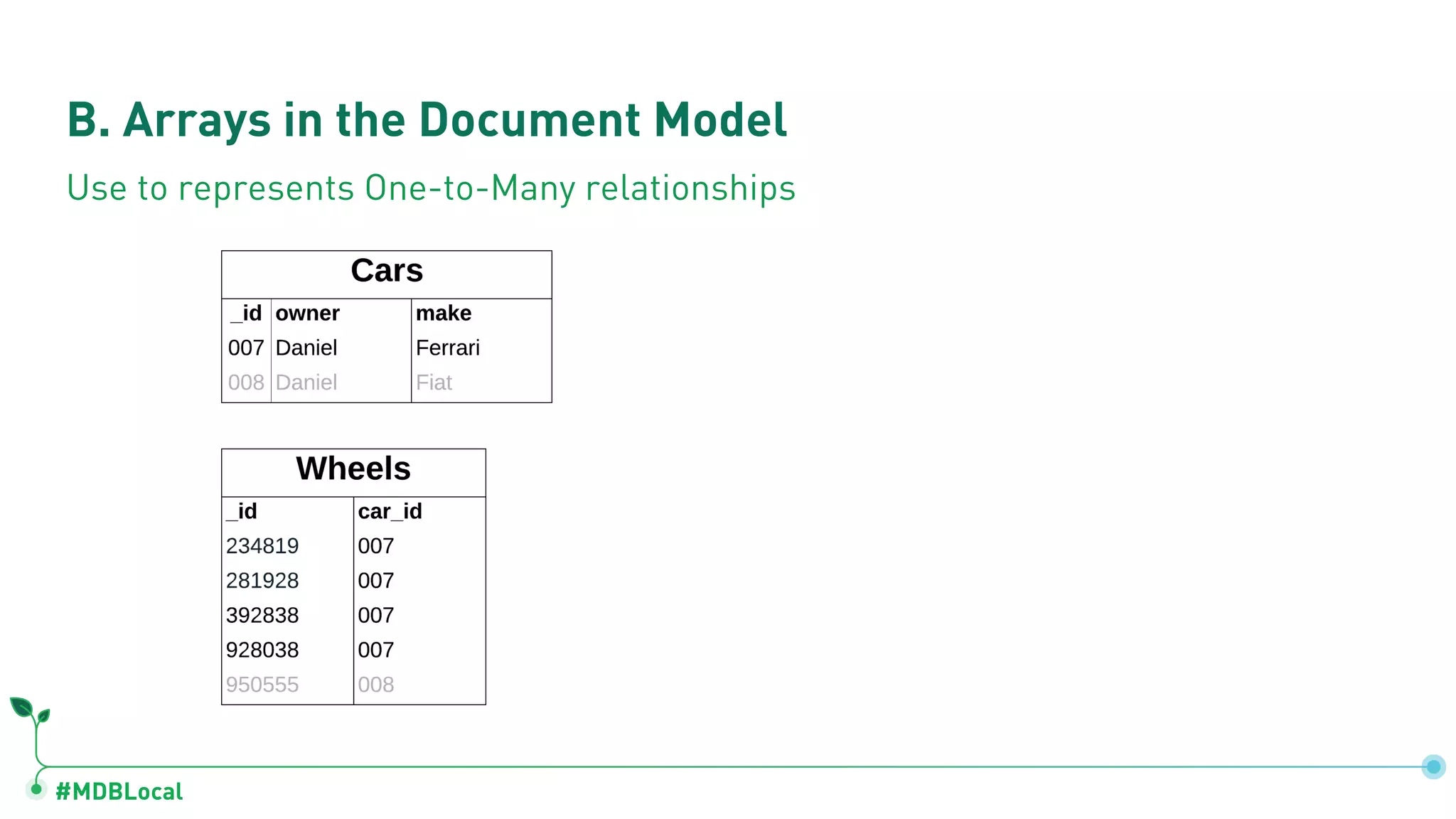
![#MDBLocal B. Arrays in the Document Model { owner: "Daniel", make: "Ferrari", wheels: [ partNo: 234819, partNo: 281928, partNo: 392838, partNo: 928038 ], ... } Use to represents One-to-Many relationships](https://image.slidesharecdn.com/mongodblocalsocal2020-completemethodologyofdatamodeling-200220155047/75/MongoDB-SoCal-2020-A-Complete-Methodology-of-Data-Modeling-for-MongoDB-14-2048.jpg)



























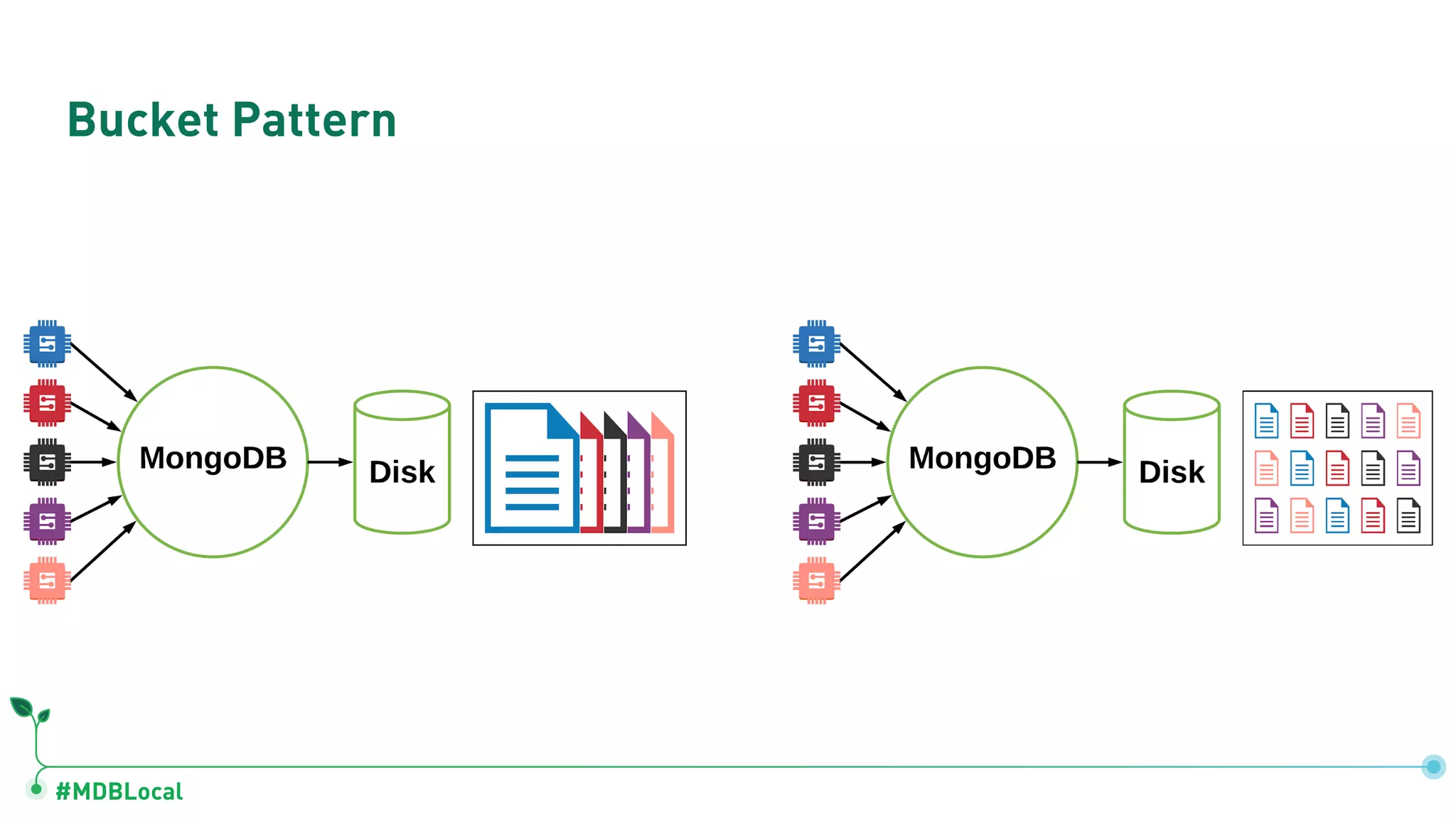
![#MDBLocal Bucket Pattern { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02"), "temp": [ [ 20.0, 20.1, 20.2, ... ], [ 22.1, 22.1, 22.0, ... ], ... ] } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-03"), "temp": [ [ 20.1, 20.2, 20.3, ... ], [ 22.4, 22.4, 22.3, ... ], ... ] } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02T13"), "temp": { 1: 20.0, 2: 20.1, 3: 20.2, ... } } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02T14"), "temp": { 1: 22.1, 2: 22.1, 3: 22.0, ... } } Bucket per Day Bucket per Hour](https://image.slidesharecdn.com/mongodblocalsocal2020-completemethodologyofdatamodeling-200220155047/75/MongoDB-SoCal-2020-A-Complete-Methodology-of-Data-Modeling-for-MongoDB-79-2048.jpg)















The document outlines a comprehensive methodology for data modeling in MongoDB, contrasting document-based with tabular modeling approaches. It details various modeling patterns, such as the use of fields, arrays, and sub-documents, through specific use cases like a coffee shop franchise and social networks. The document also emphasizes the importance of schema design patterns and practical considerations for schema evolution and workload management.
Introduction to the methodology for data modeling in MongoDB focusing on differences between document and tabular databases, methodology steps, and use case.
Explains the distinctions when modeling for Document databases versus Relational/Tabular databases.
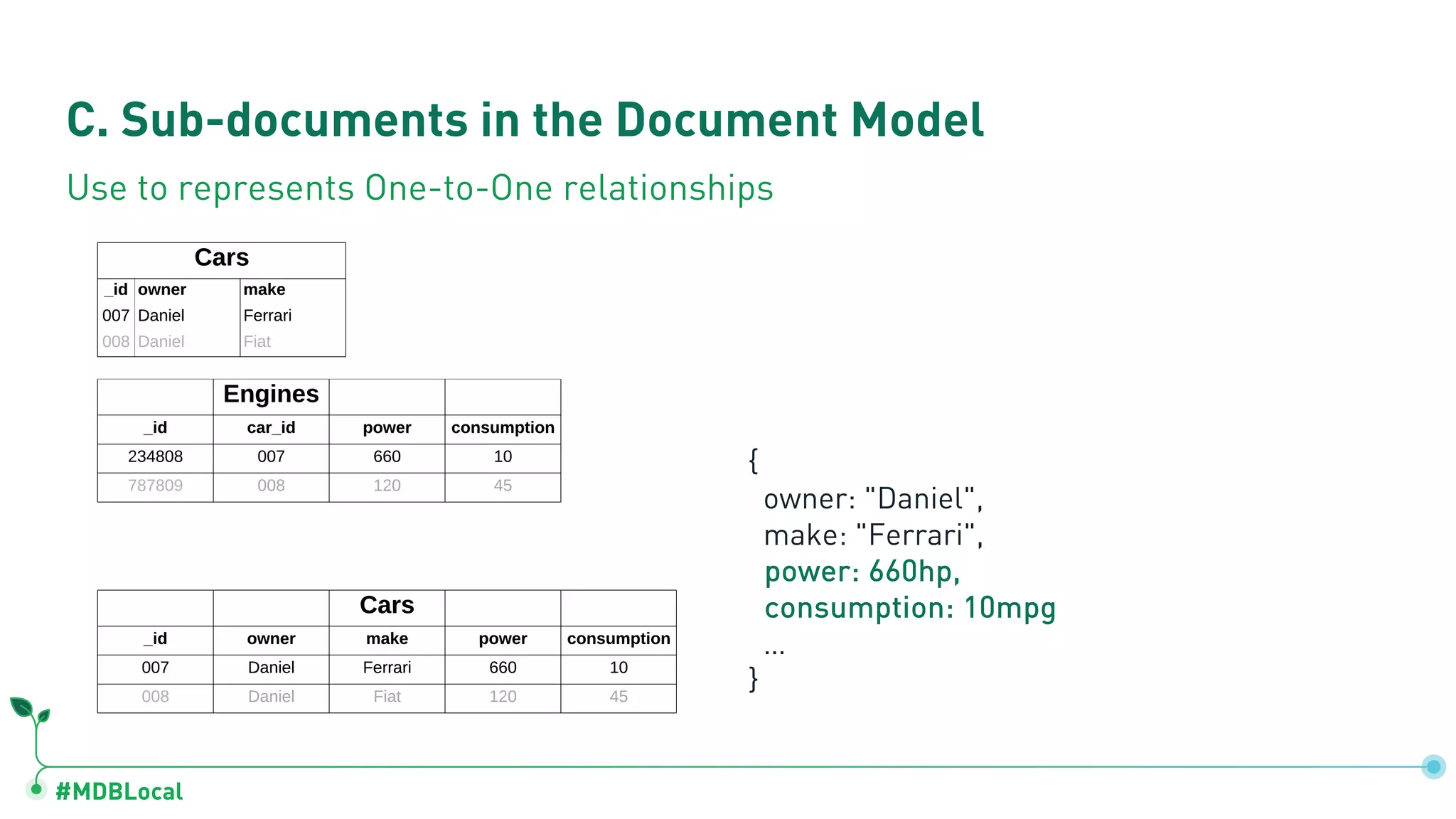
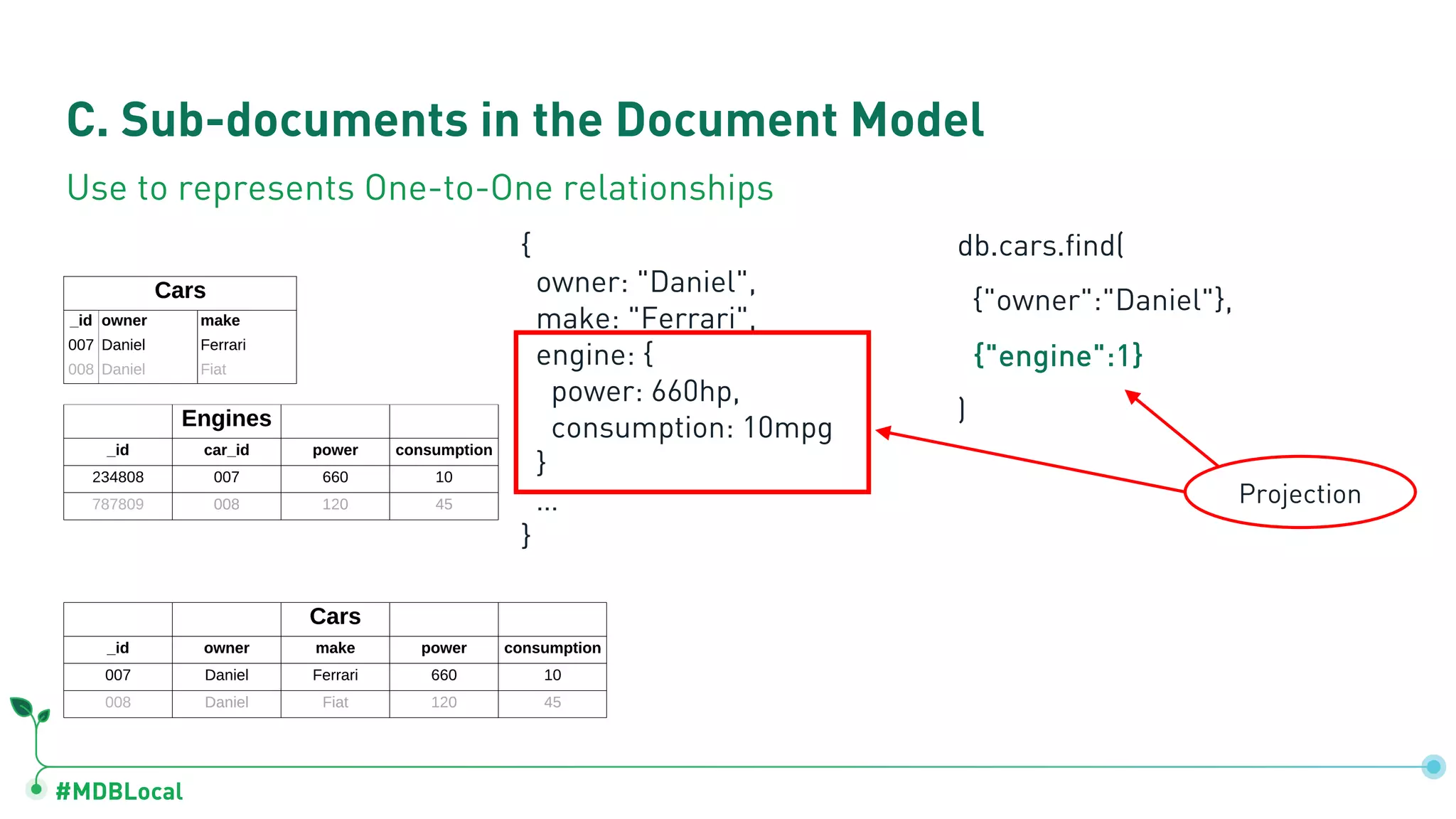
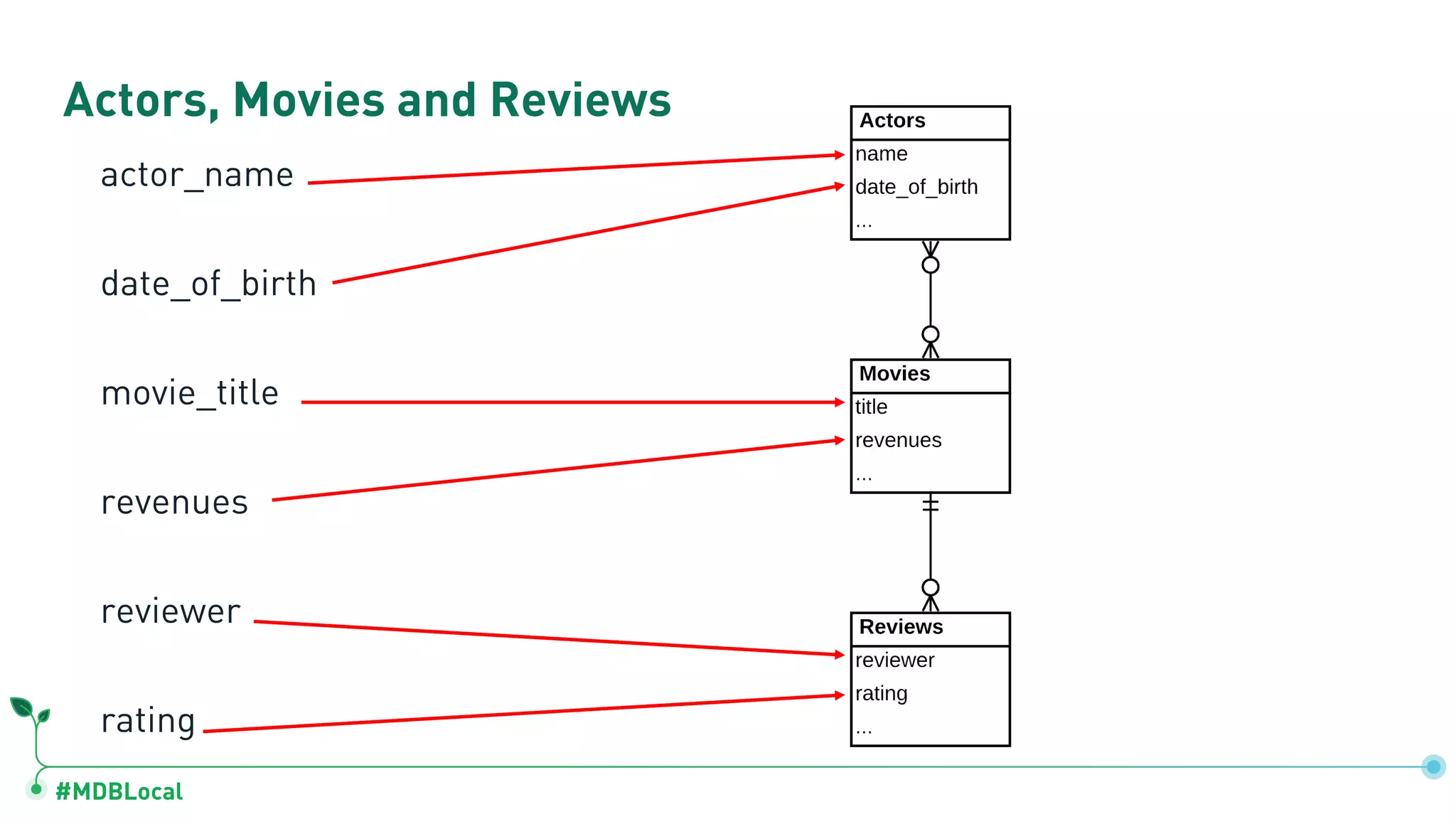
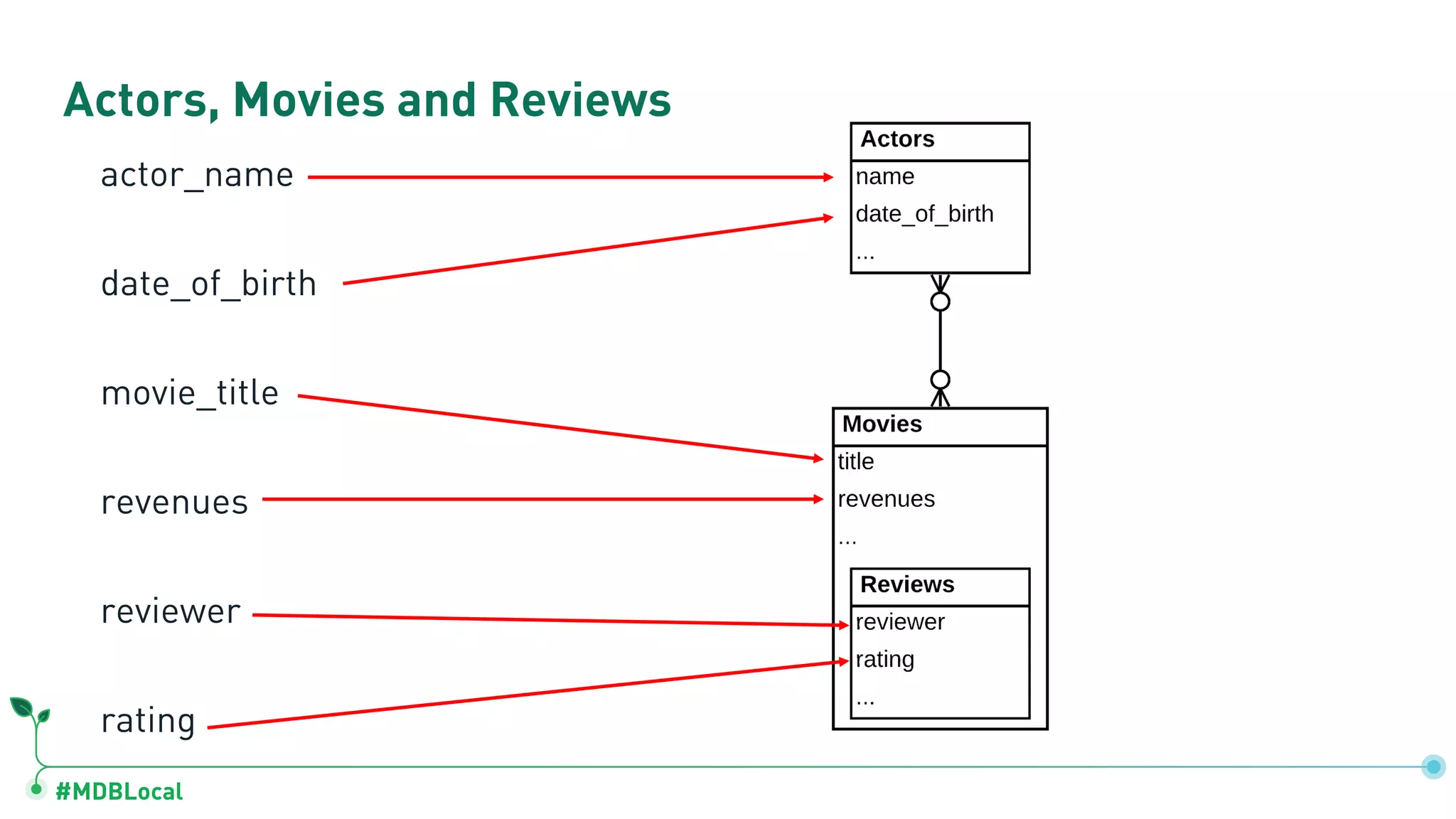
Details on document model components: fields, arrays for one-to-many relations, and sub-documents for one-to-one relationships.
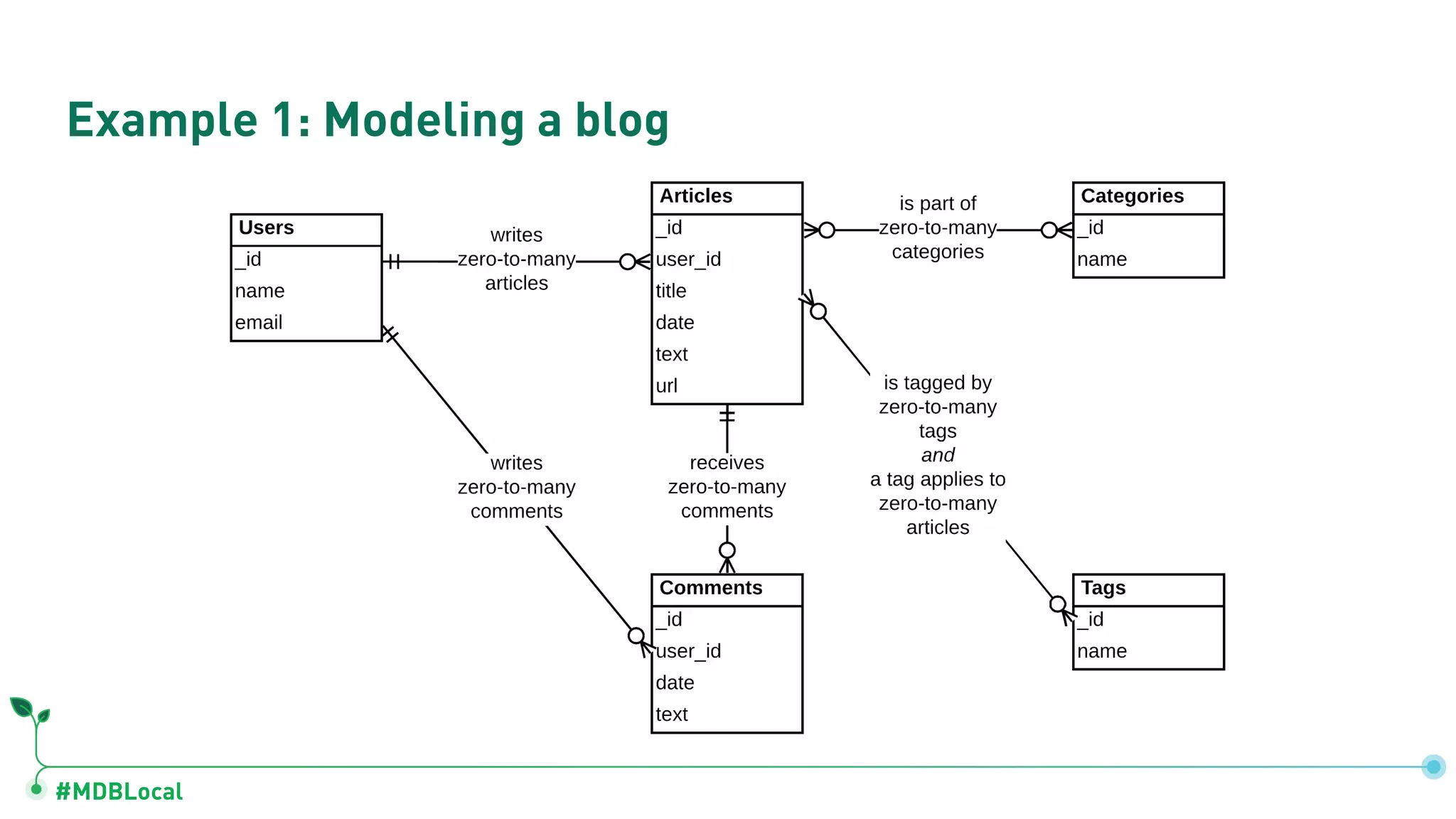
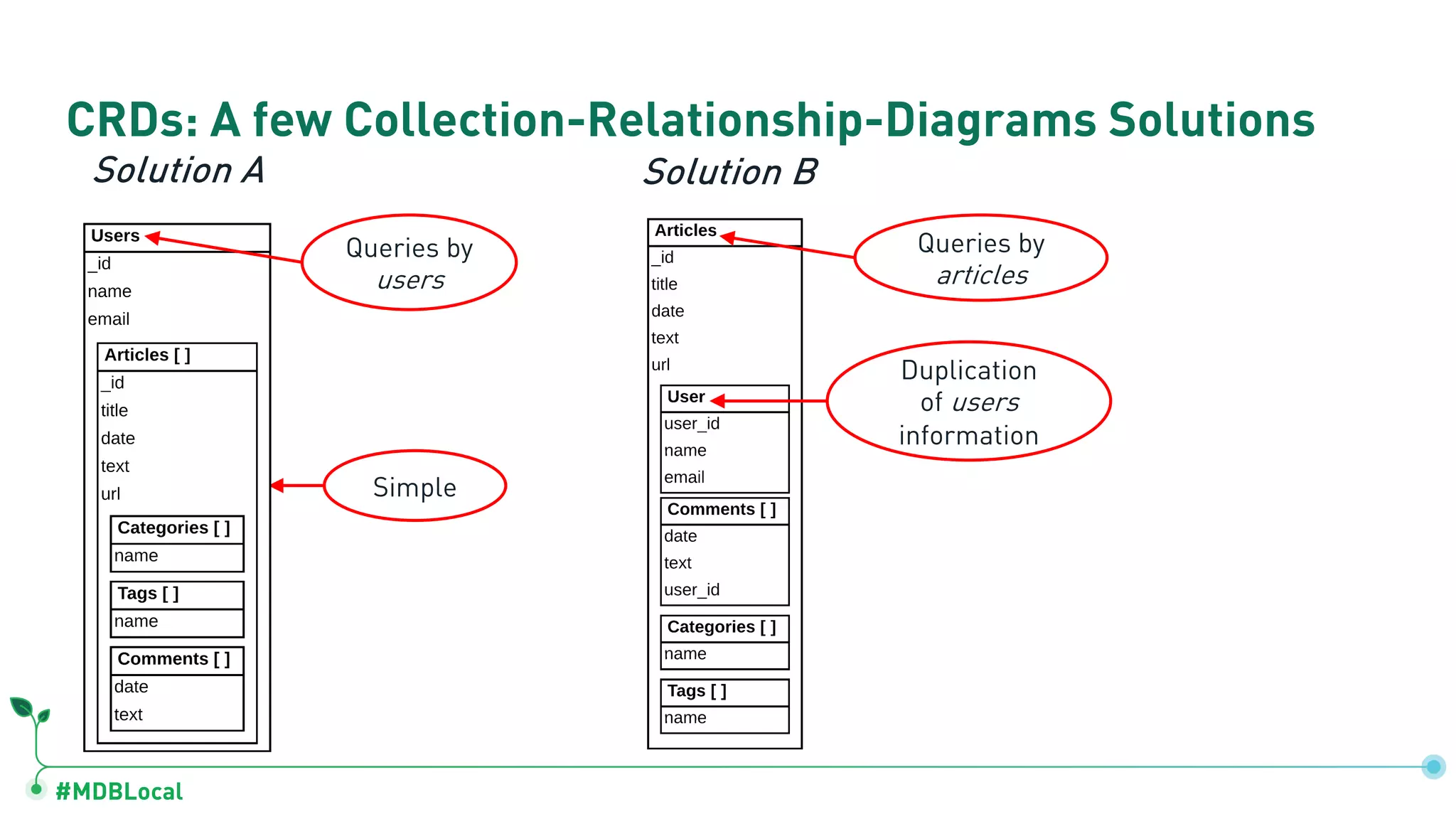
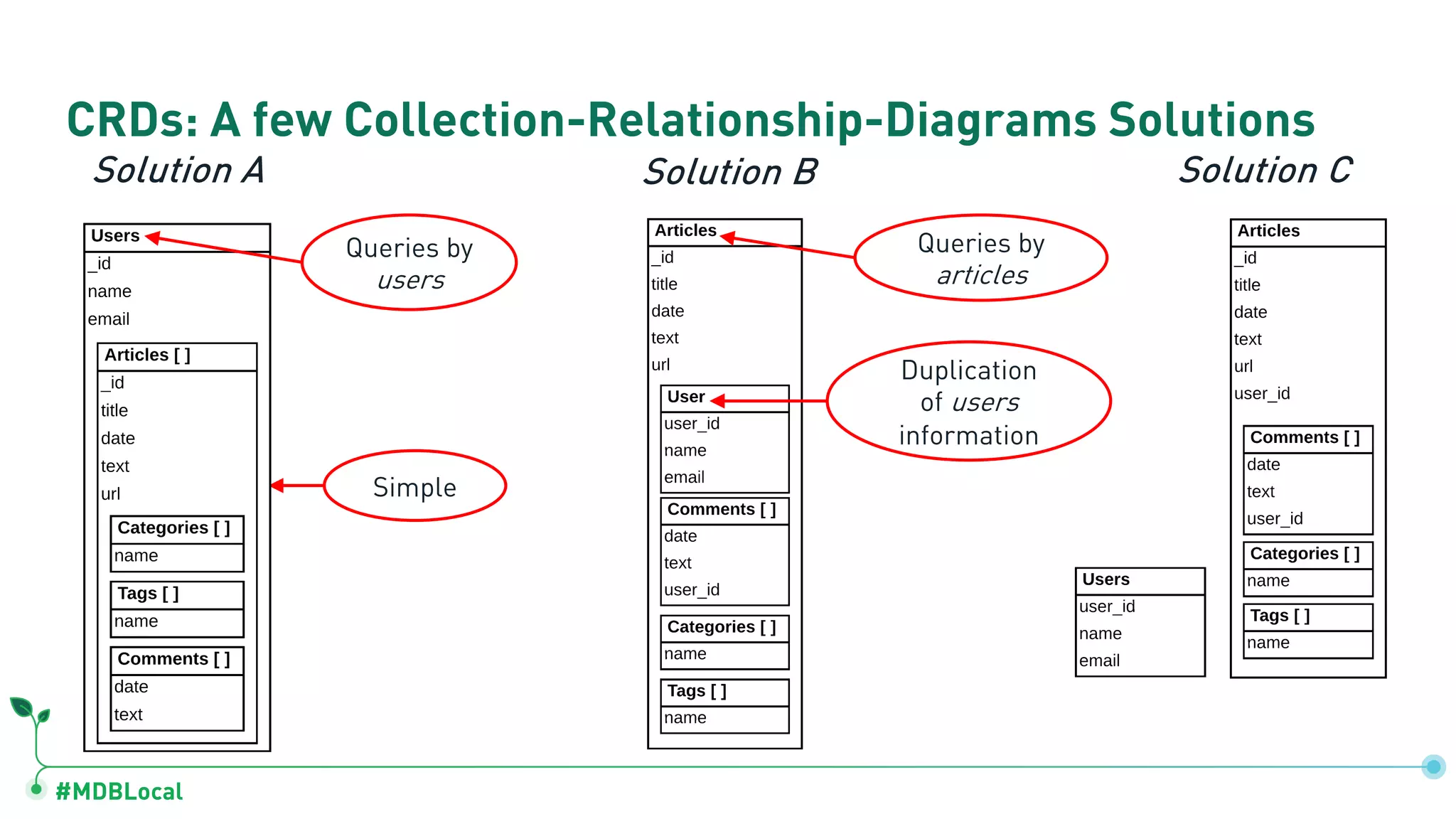
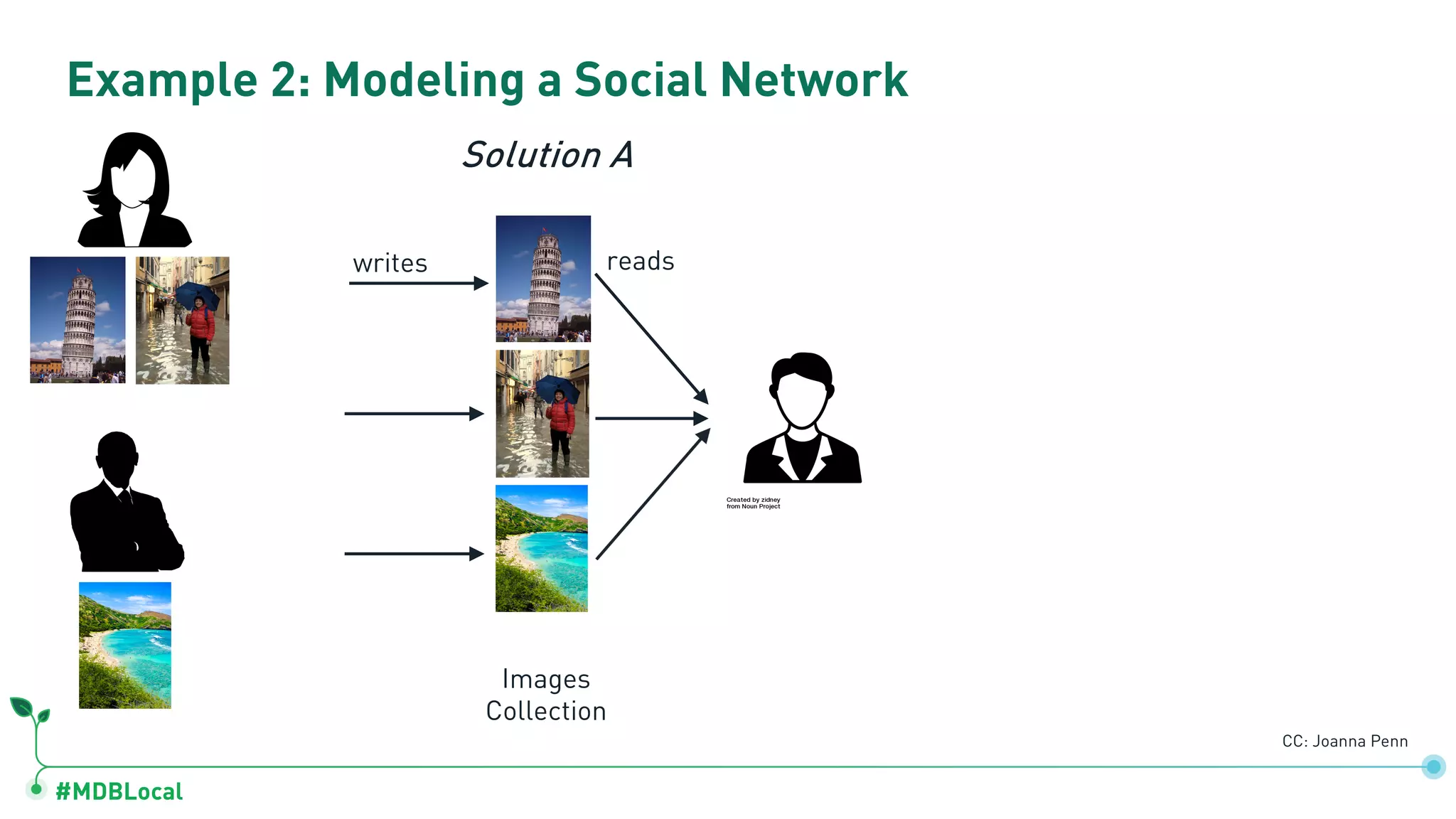
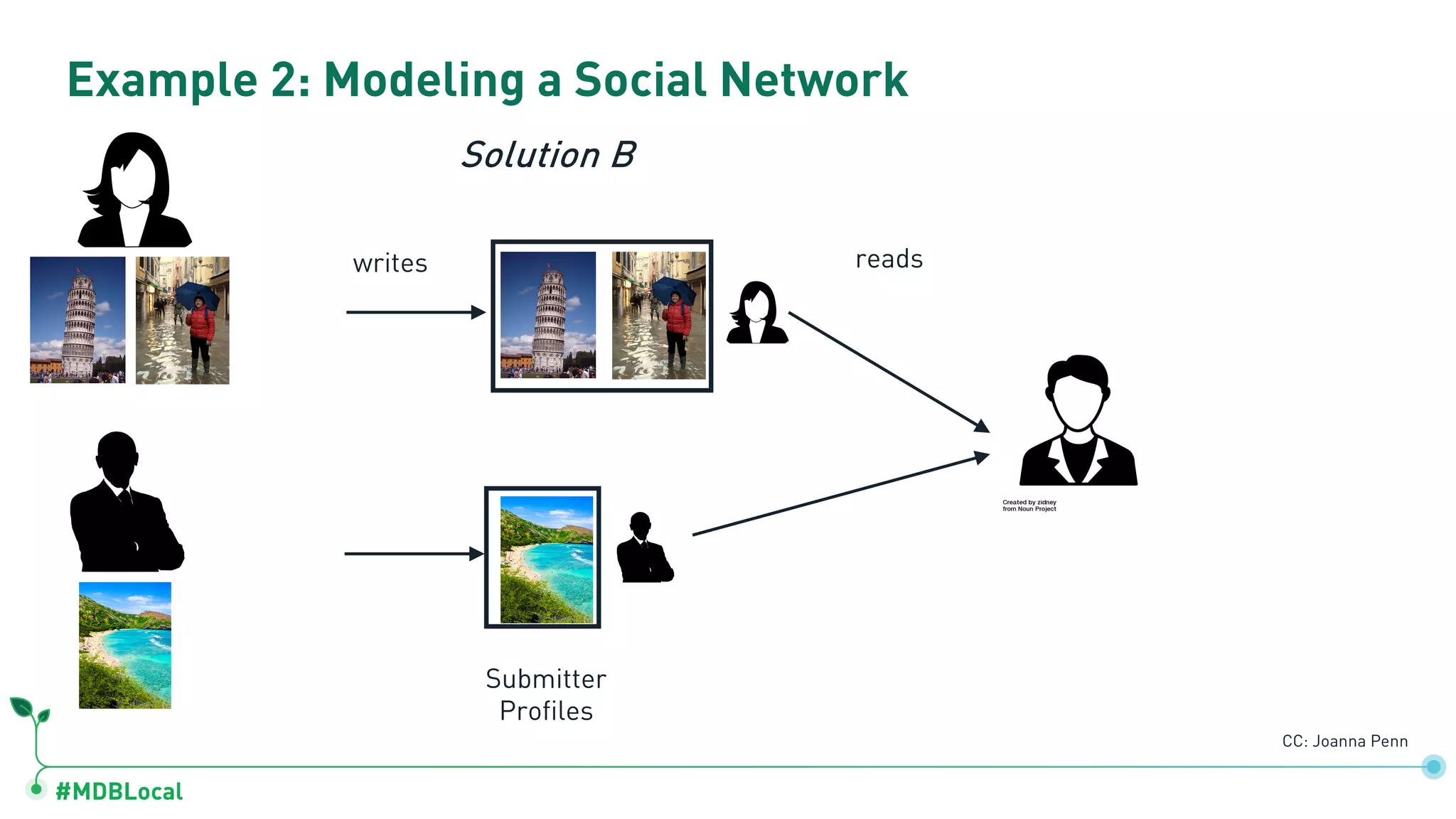
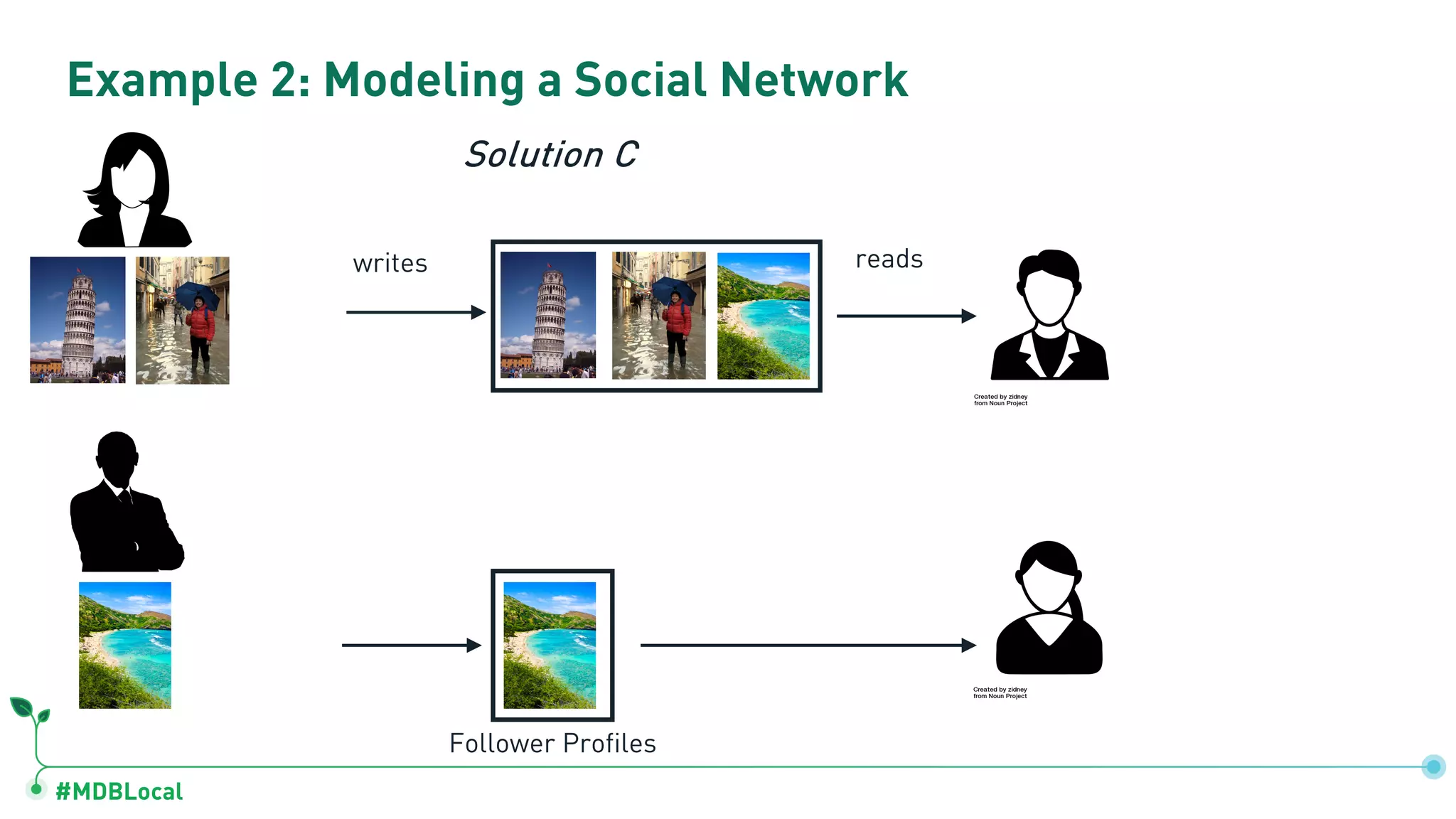
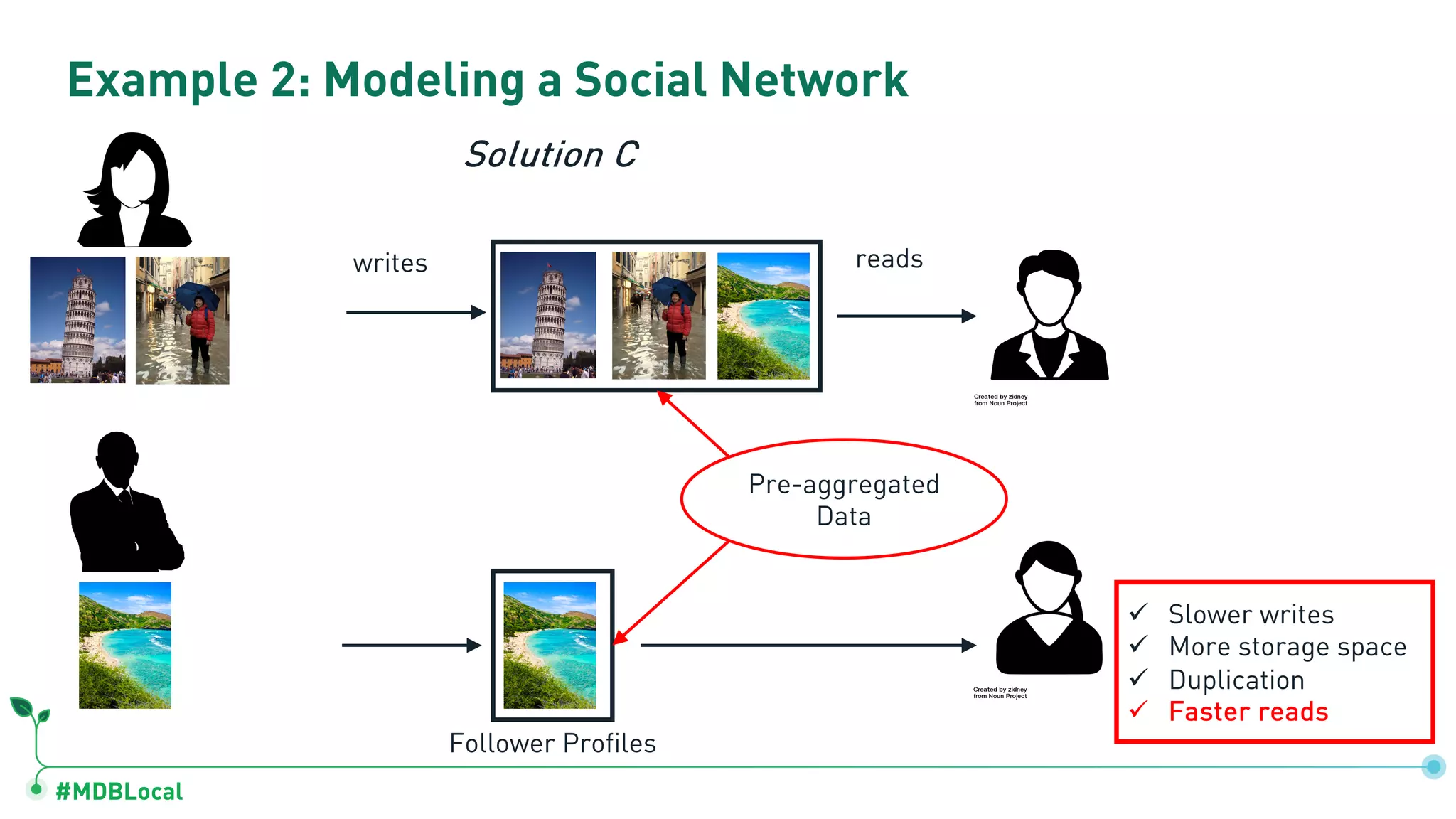
Contrasts data storage in relational and document databases and provides examples of modeling a blog and a social network.
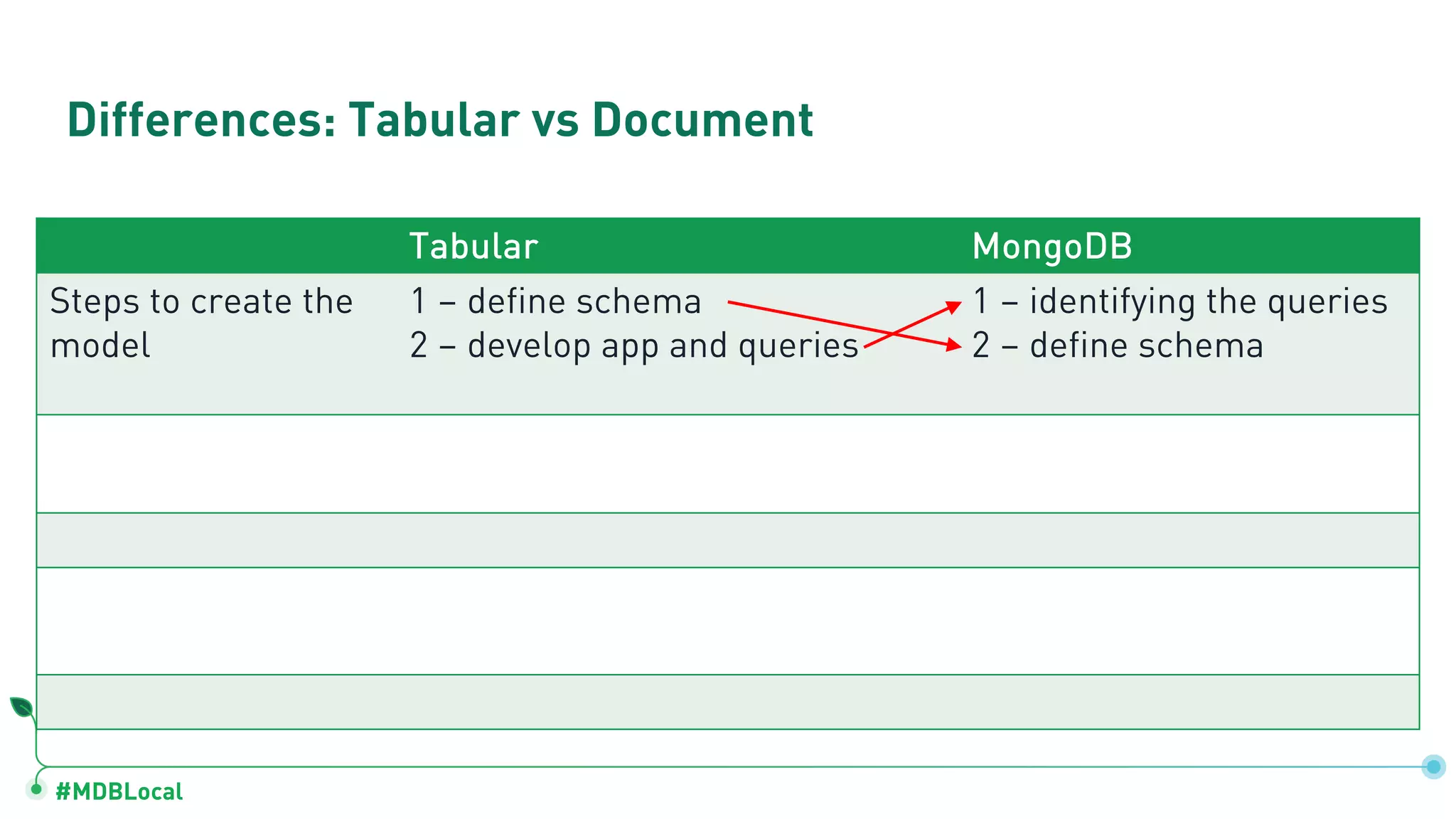
Highlights differences in modeling steps for tabular and MongoDB, detailing schema creation and evolution.
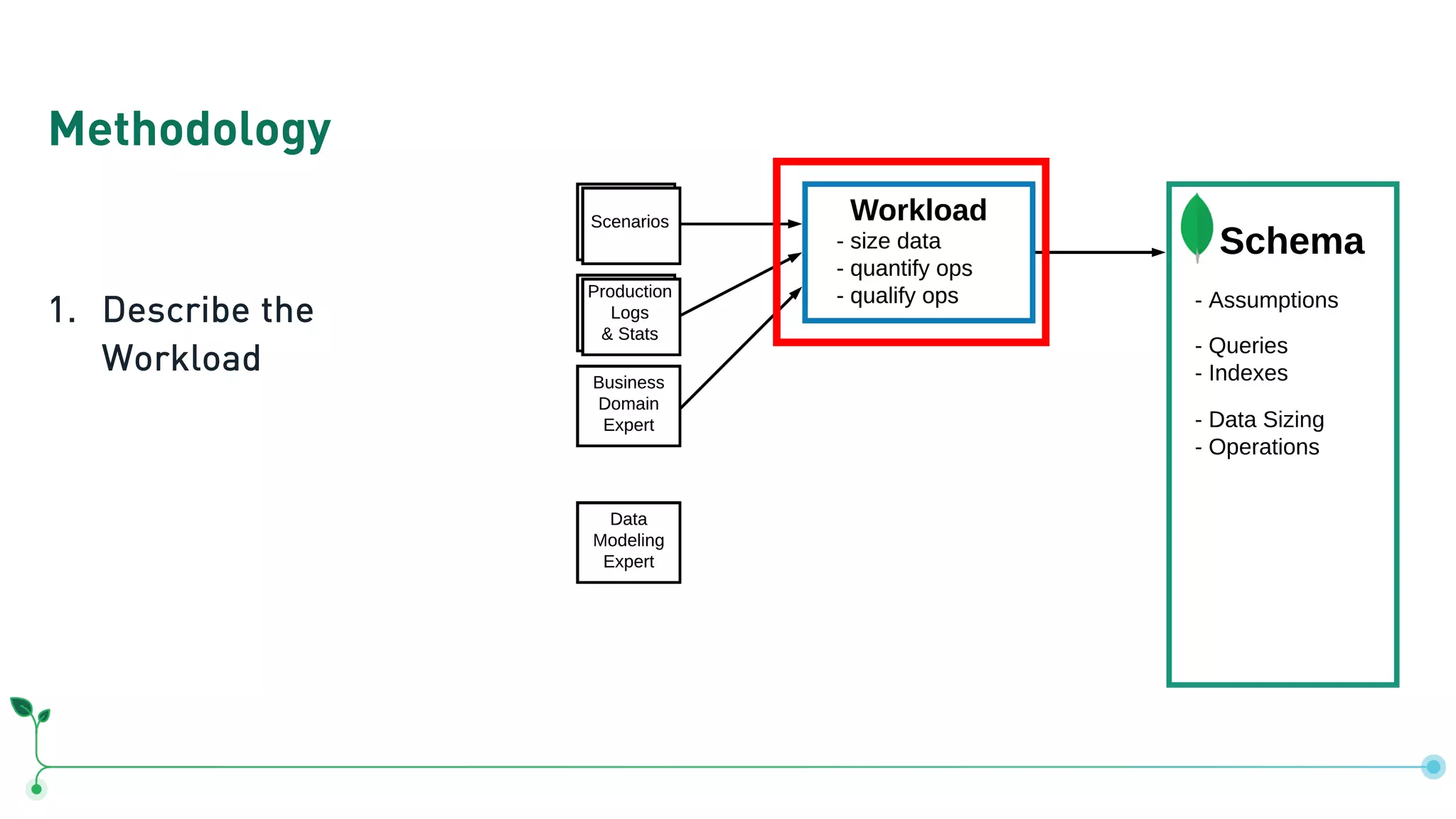
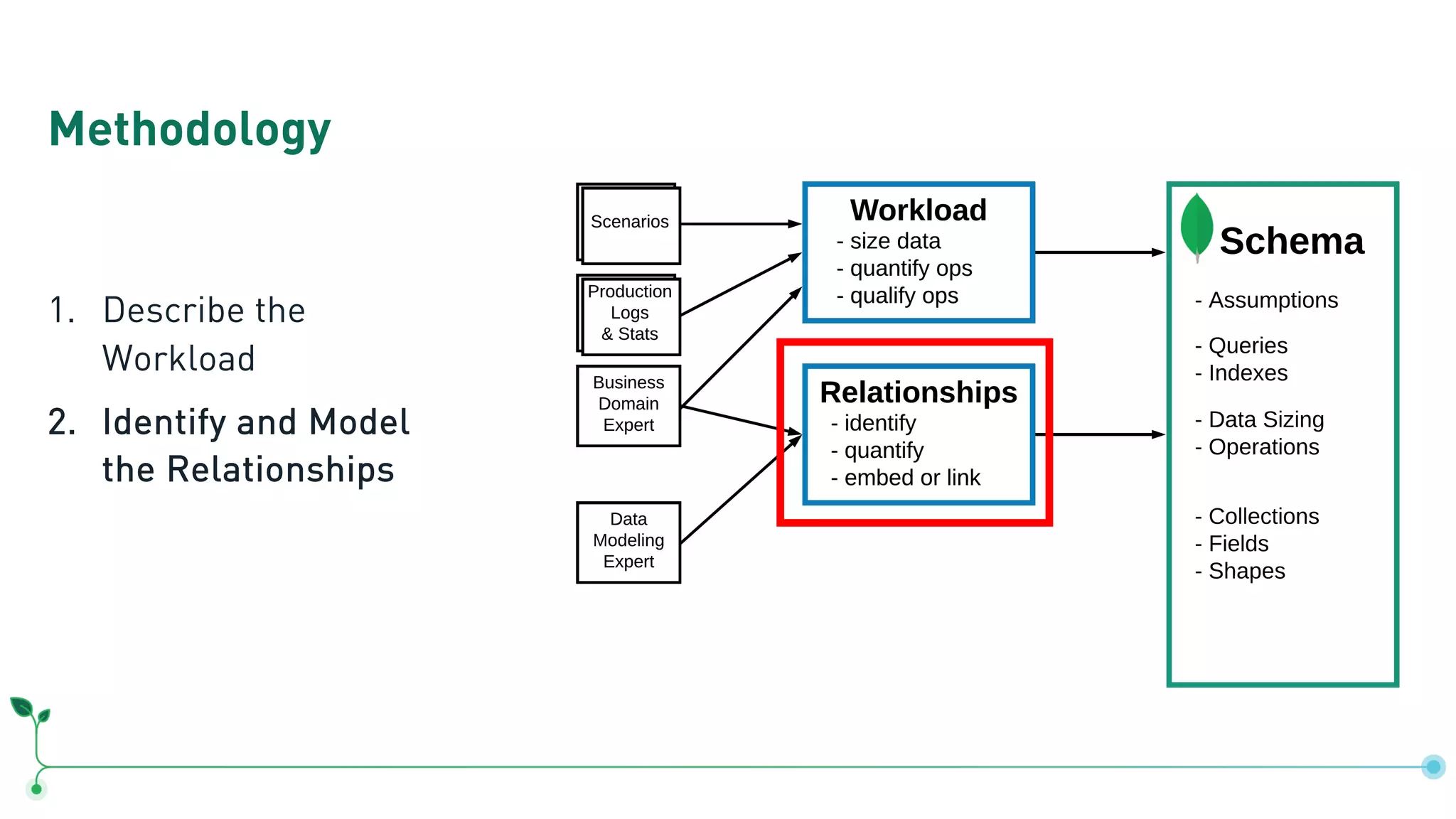
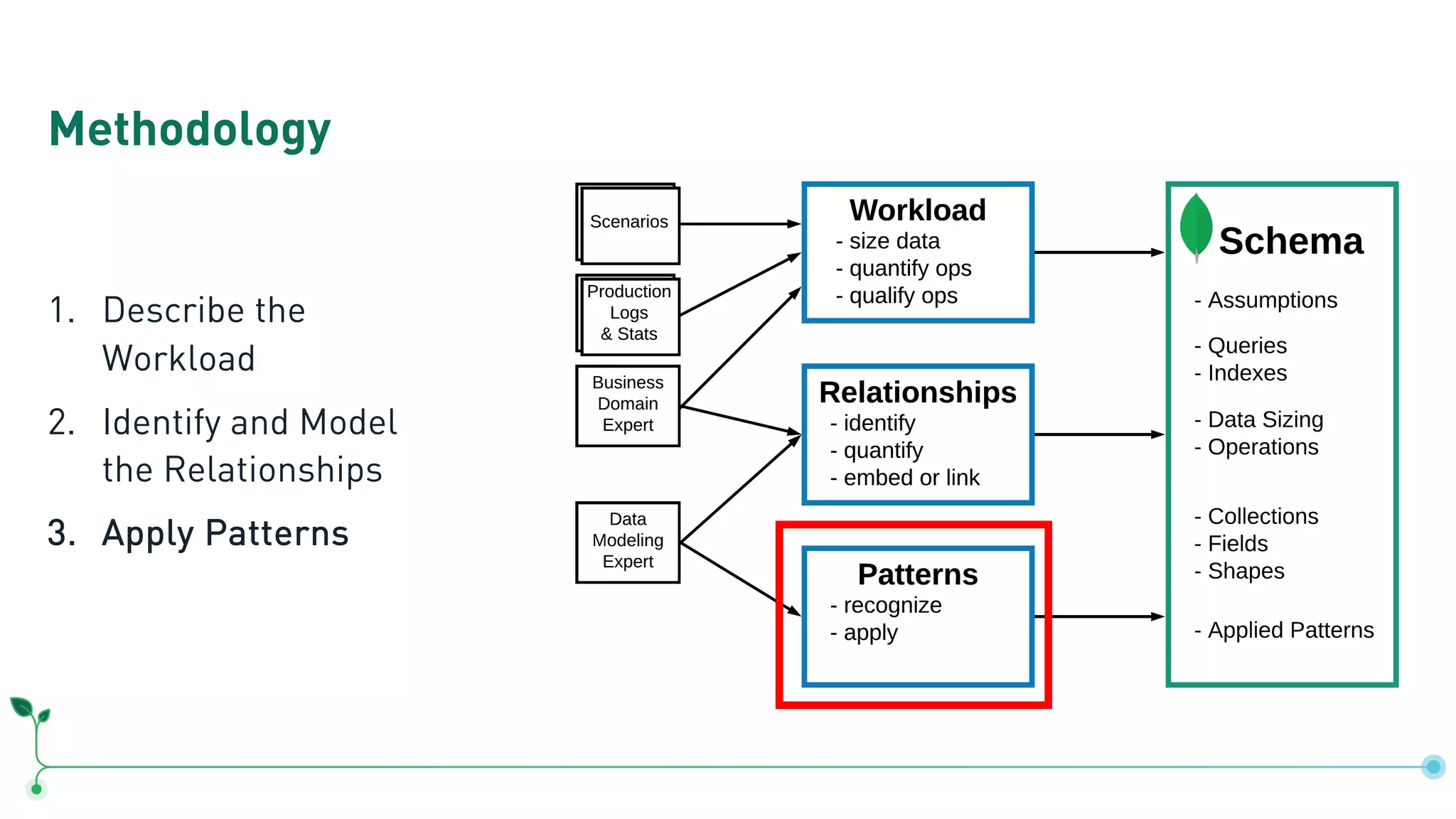
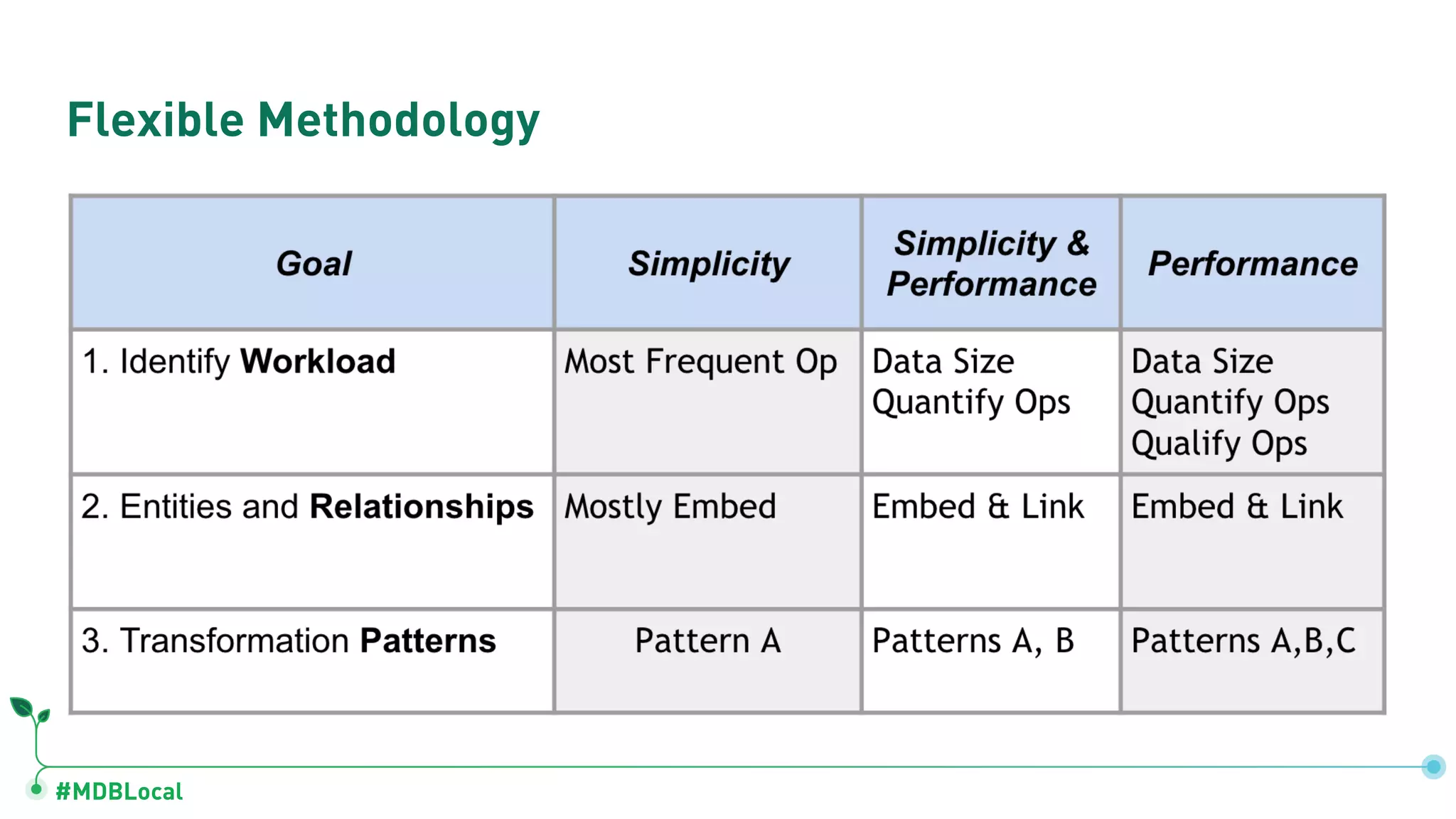
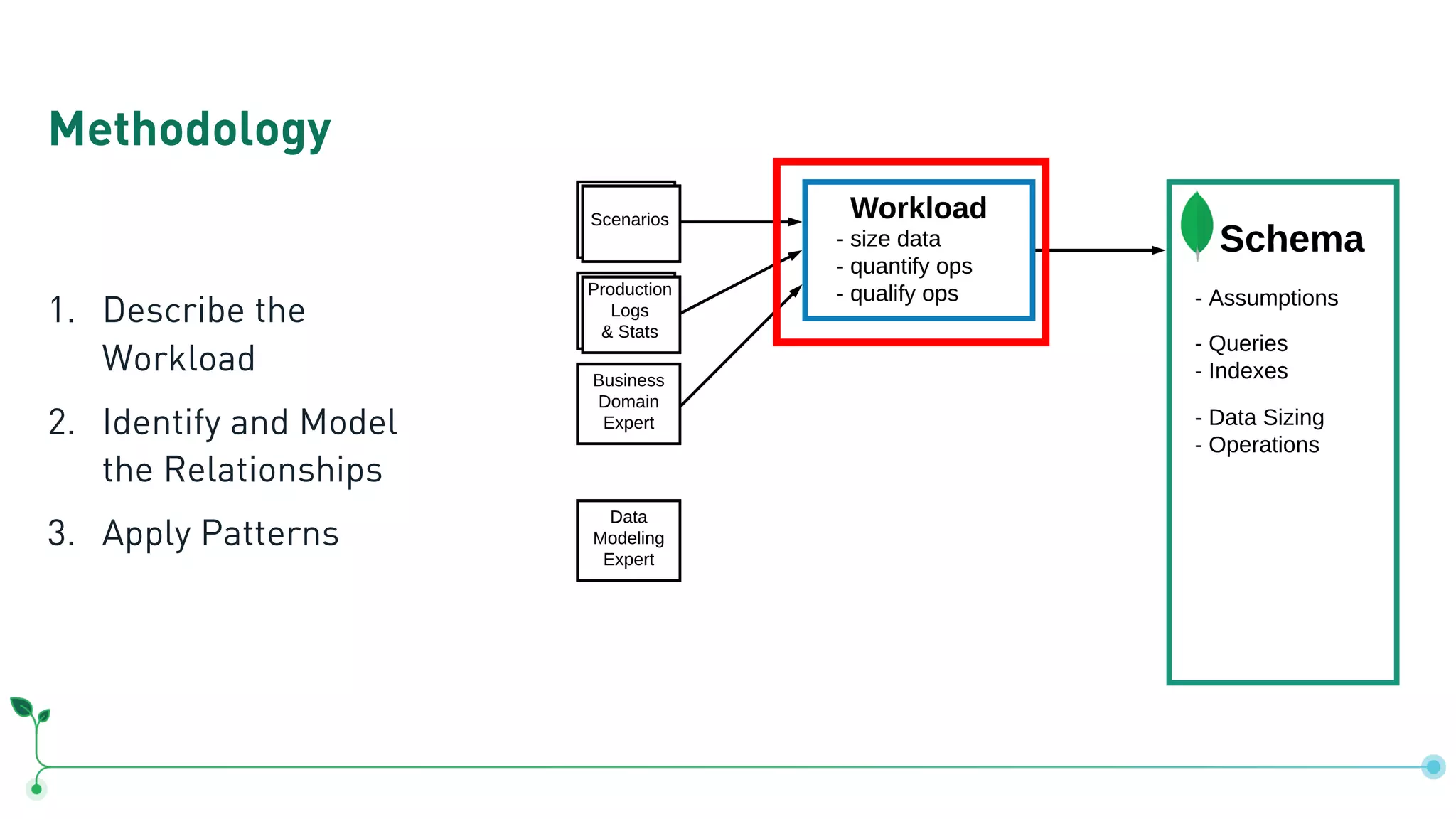
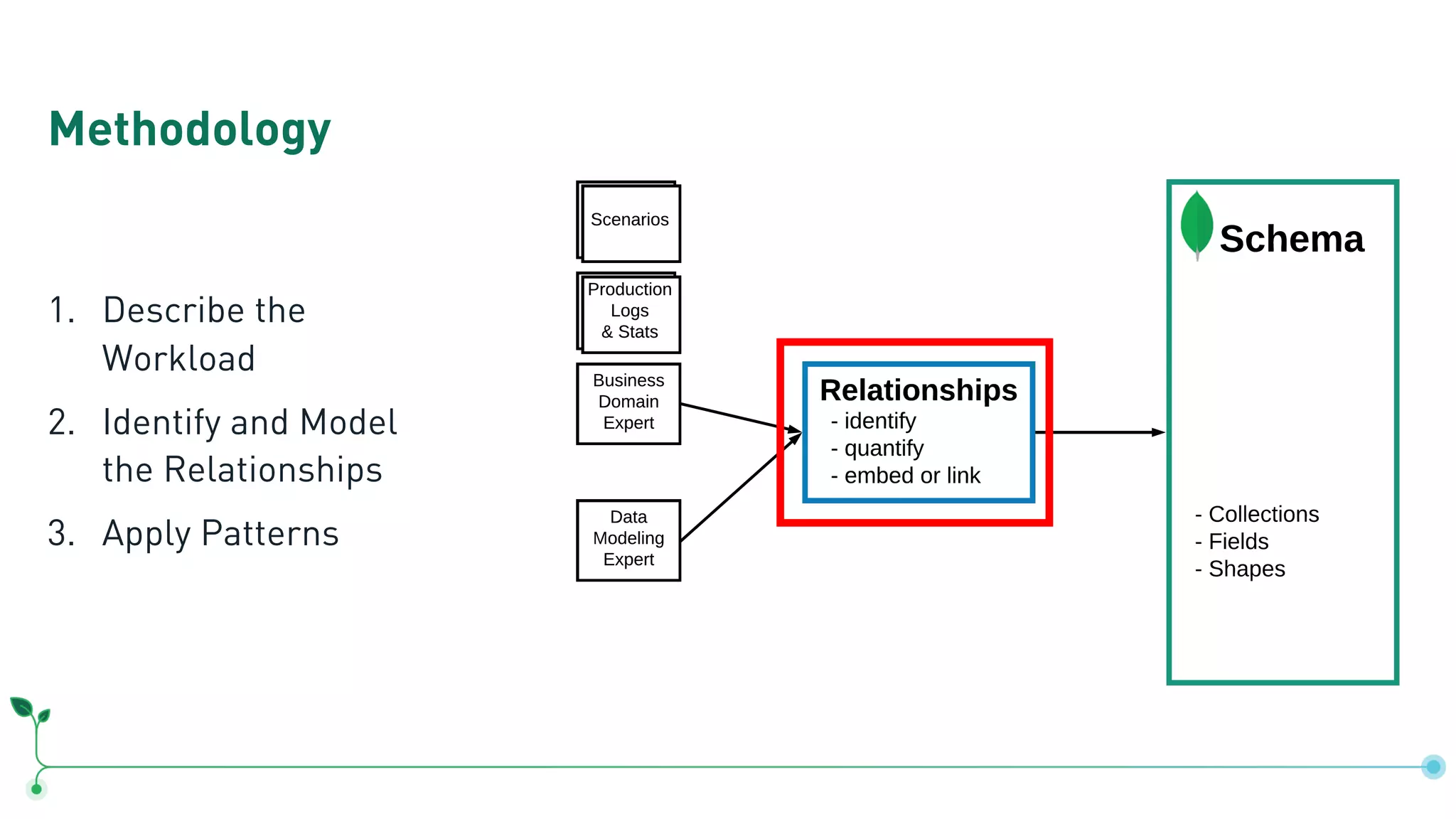
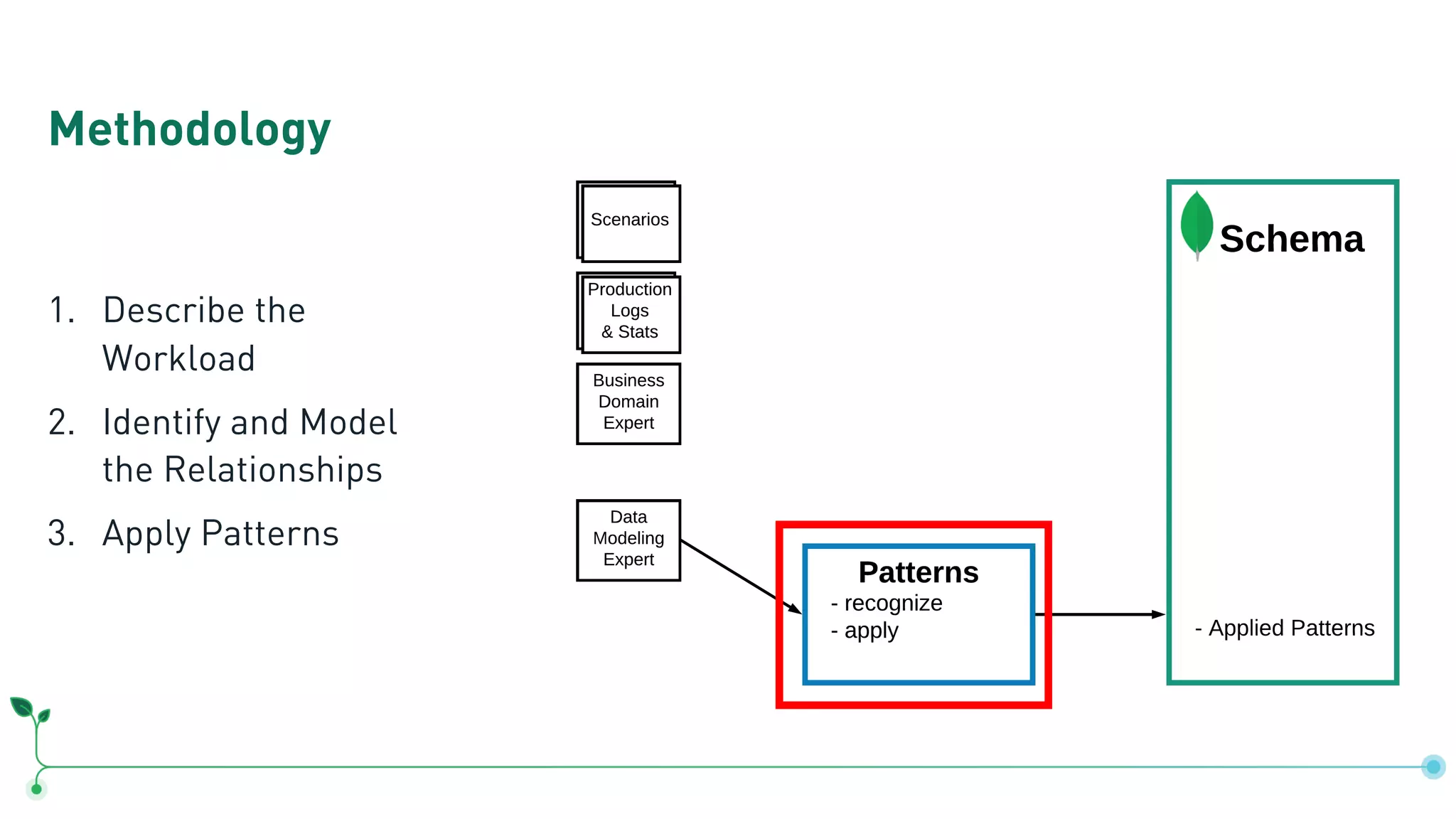
Outlines a methodology for MongoDB: describing workloads, modeling relationships, and applying patterns.
Introduces a case study on a coffee shop franchise aiming for 10,000 stores, detailing objectives and success factors.
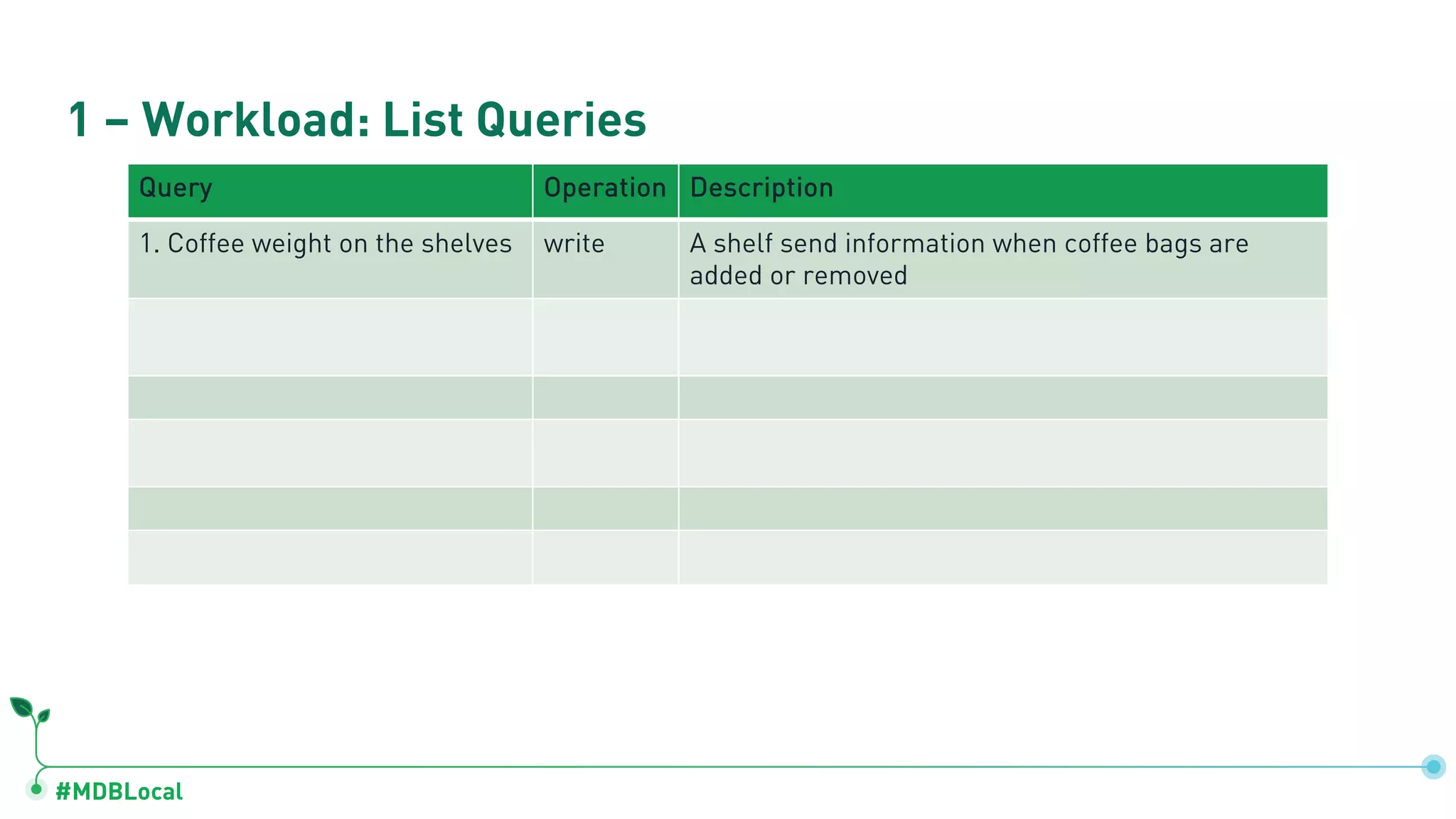
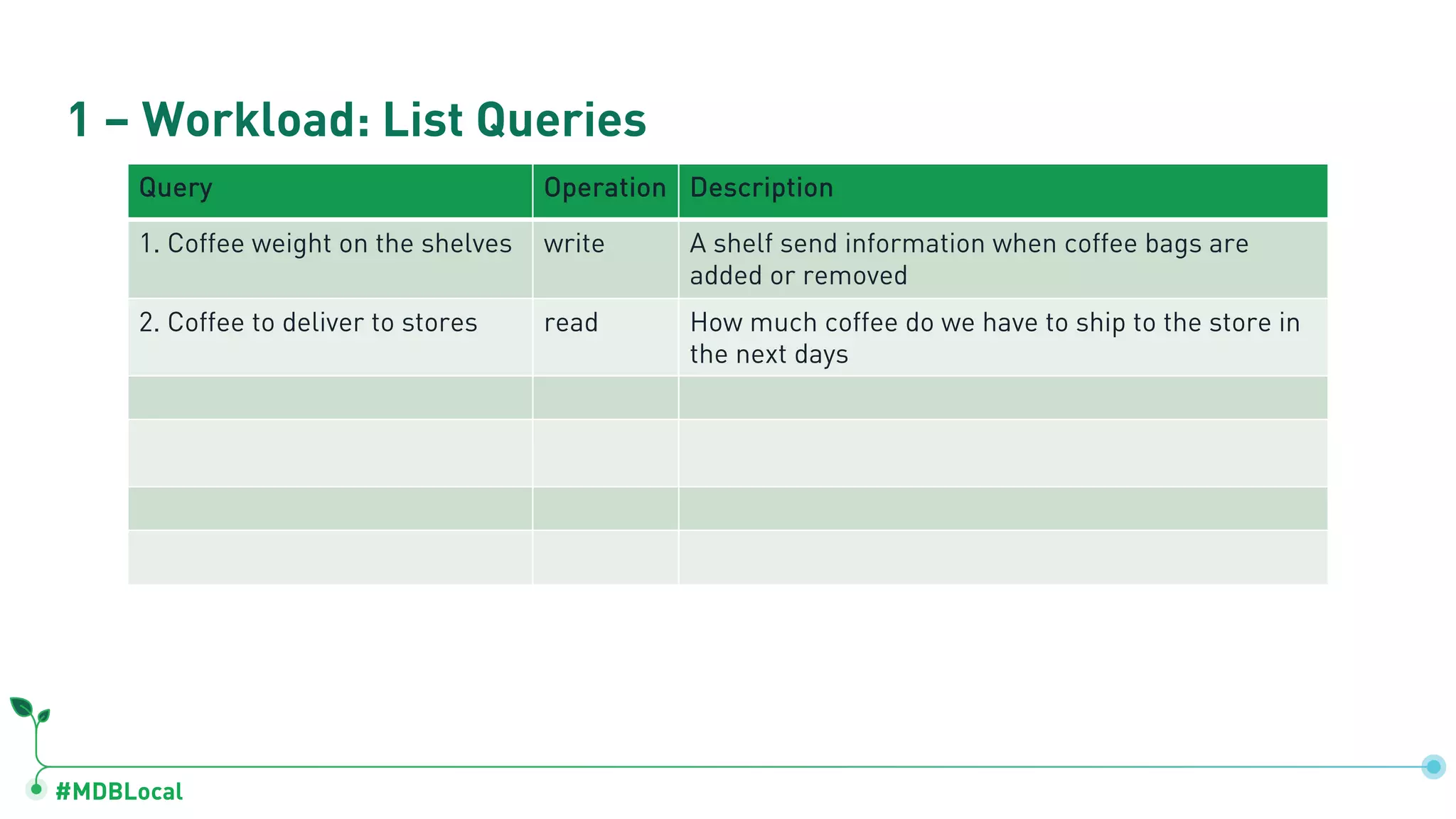
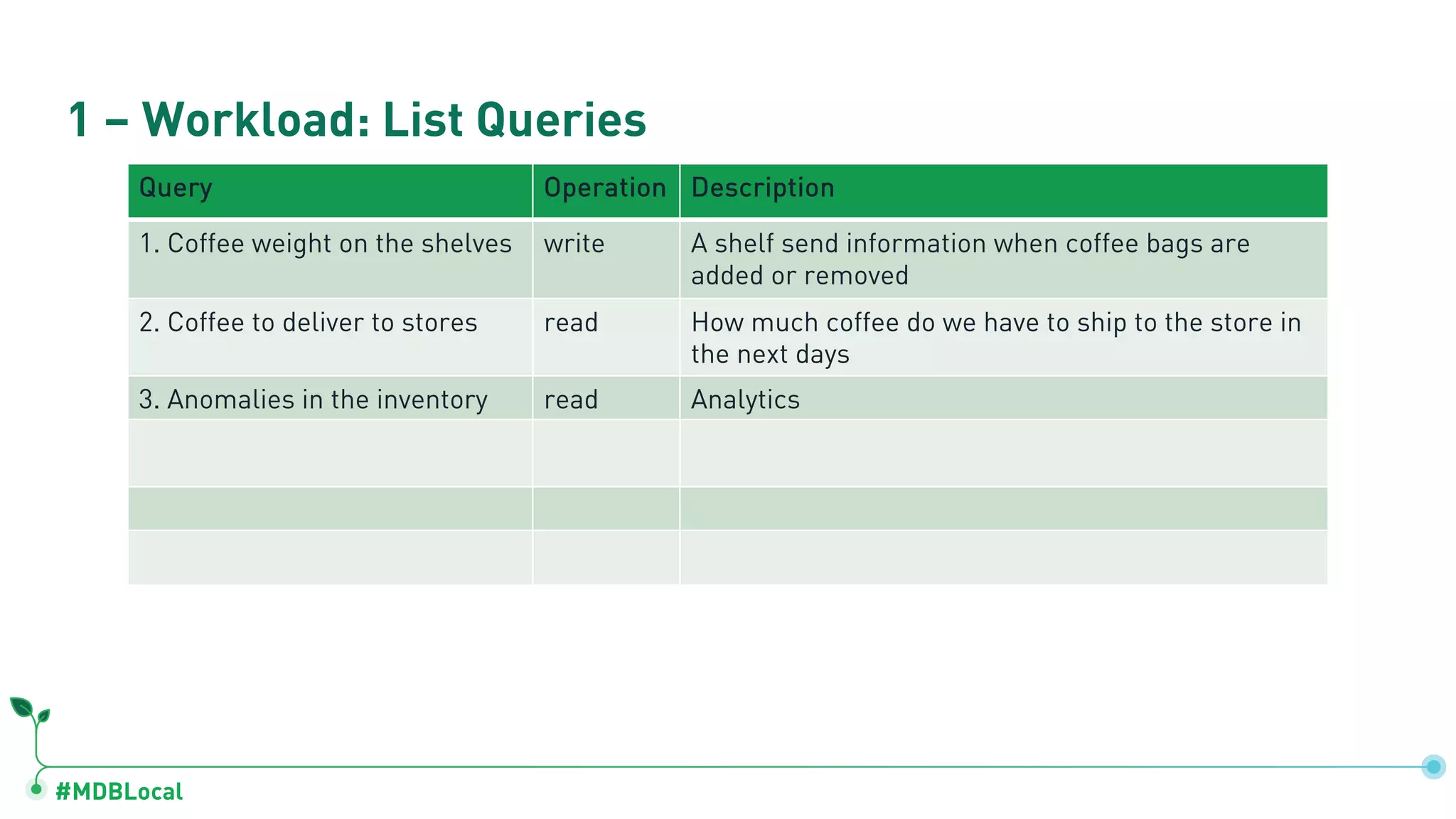
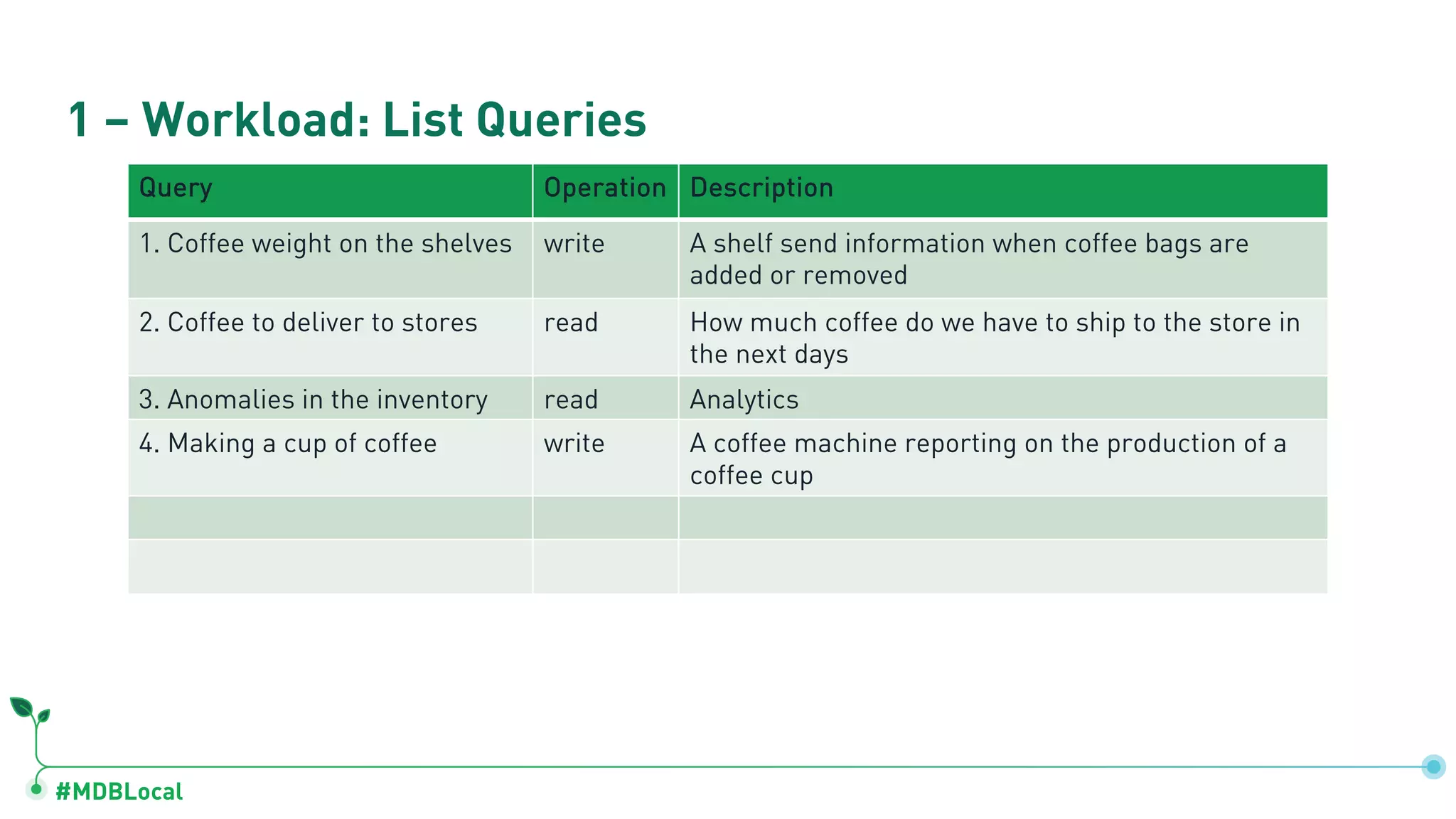
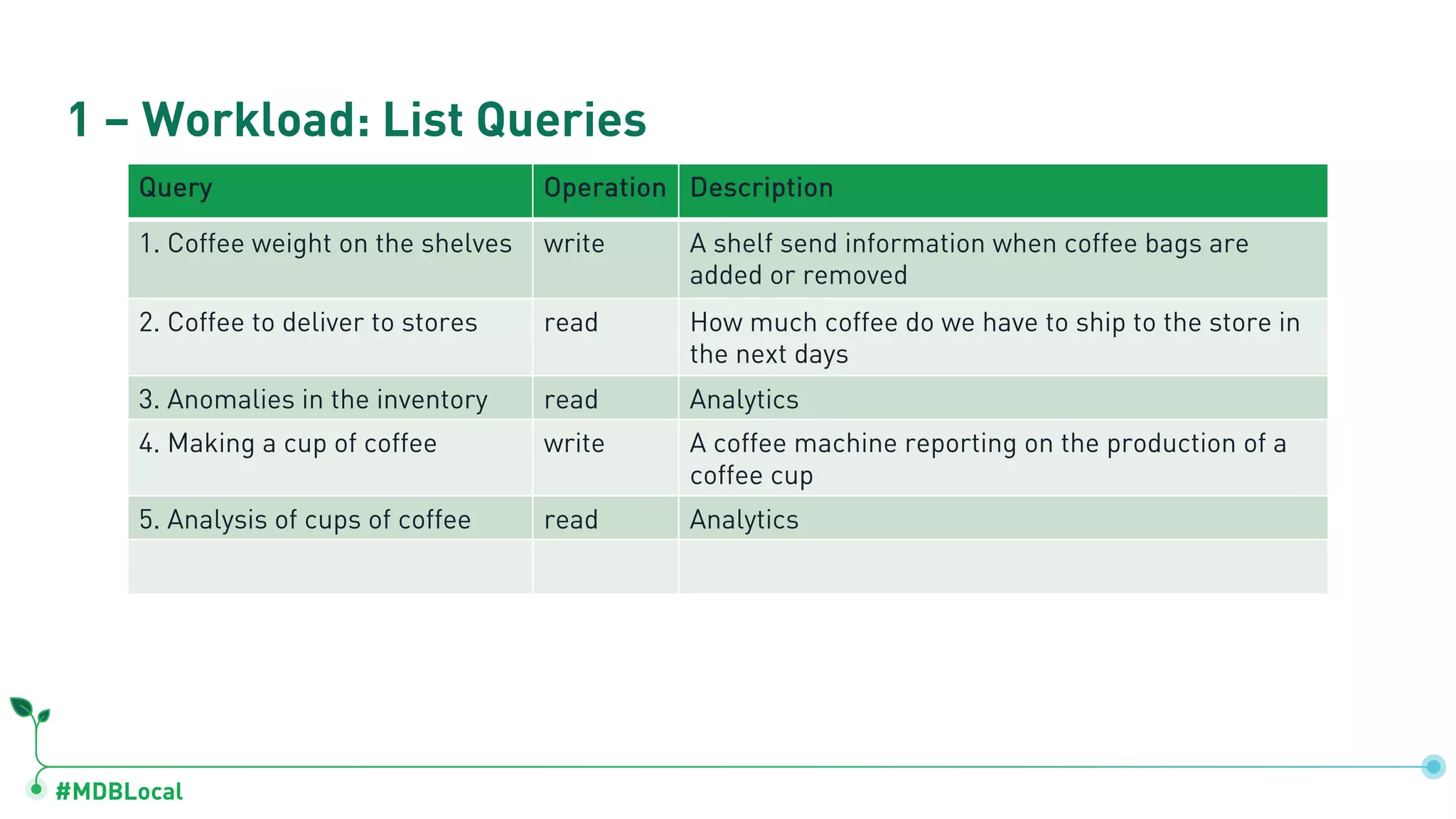
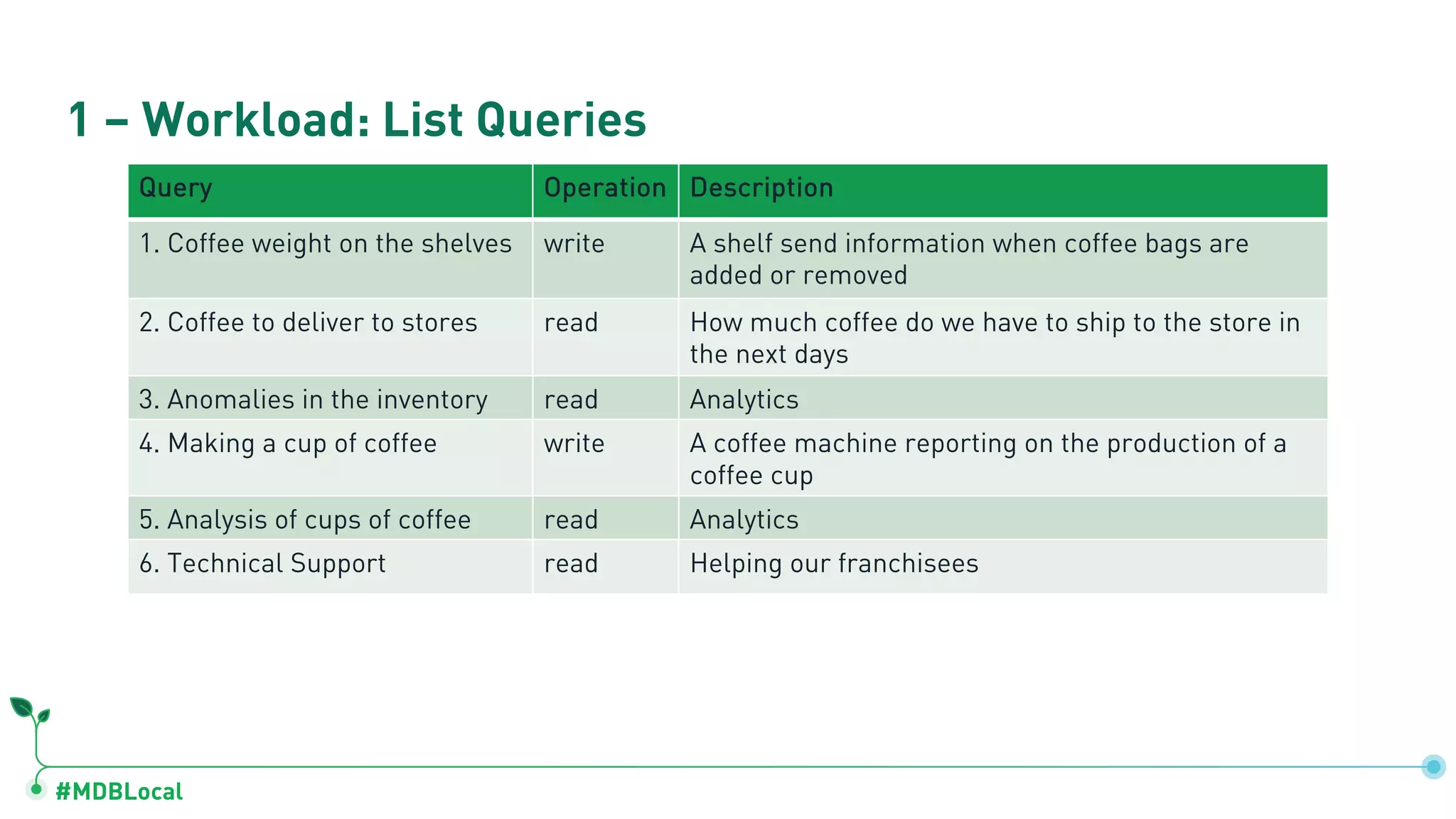
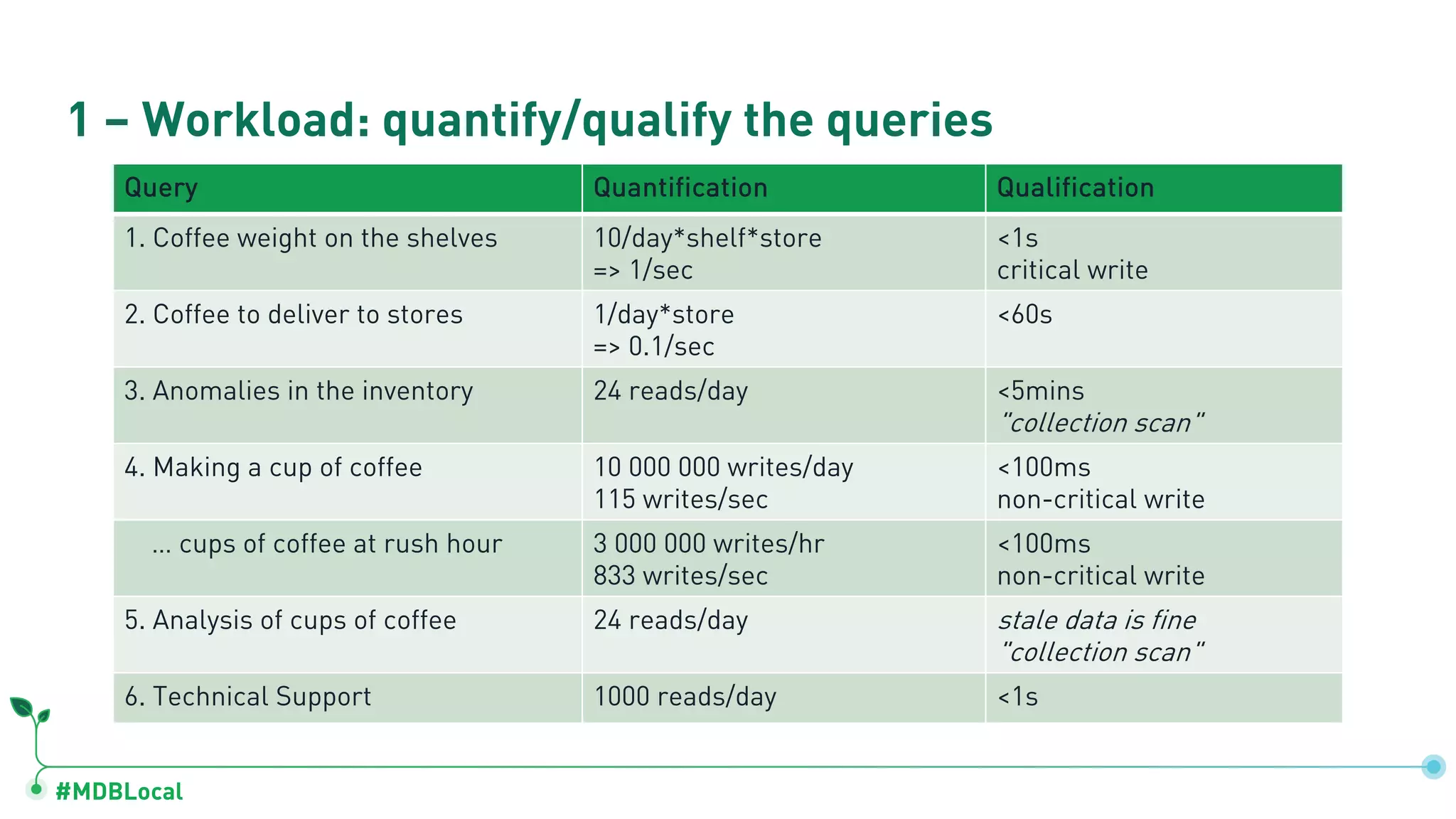
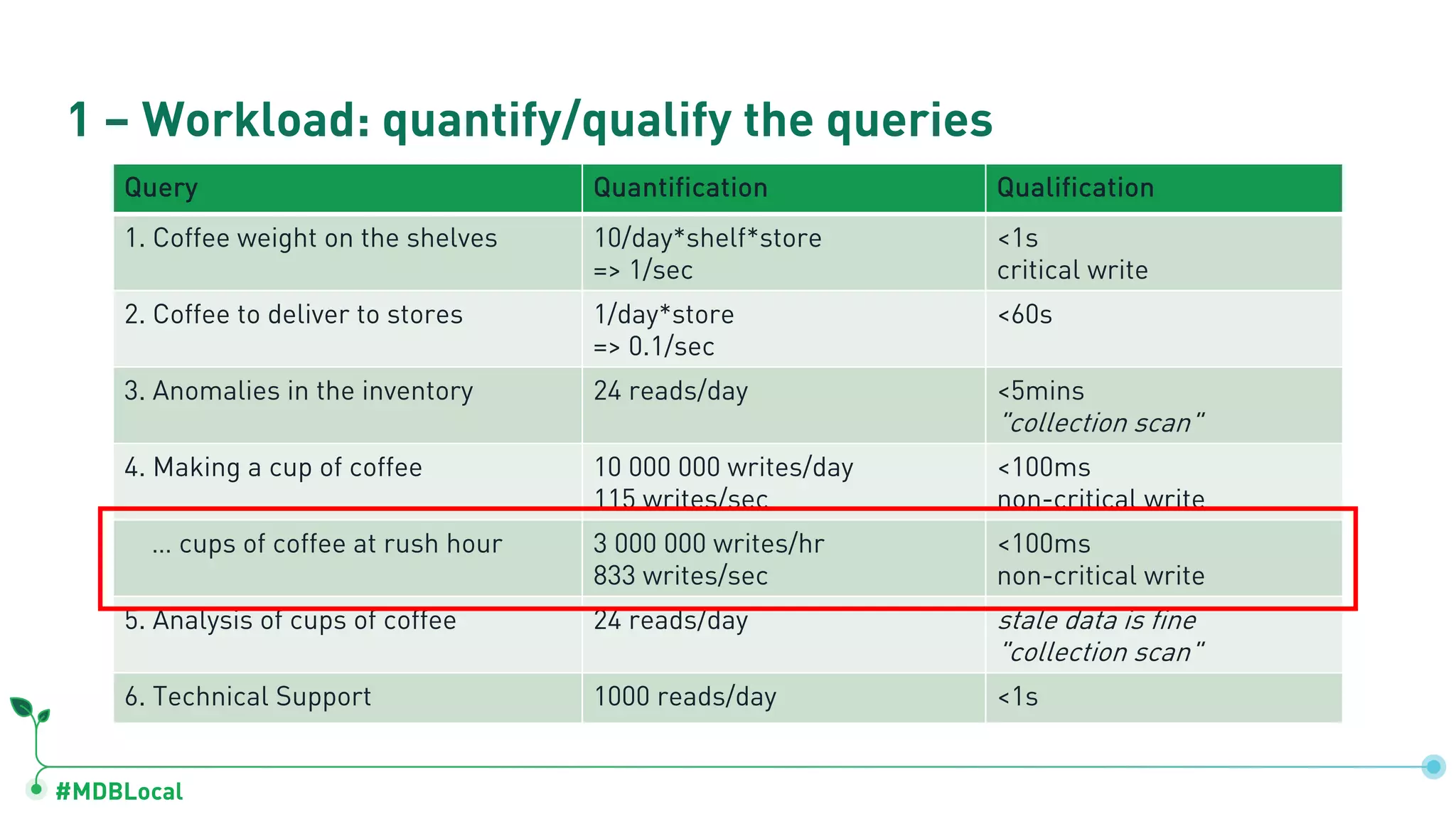
Lists queries used in operations and quantification of workloads like coffee weights and inventory anomalies.
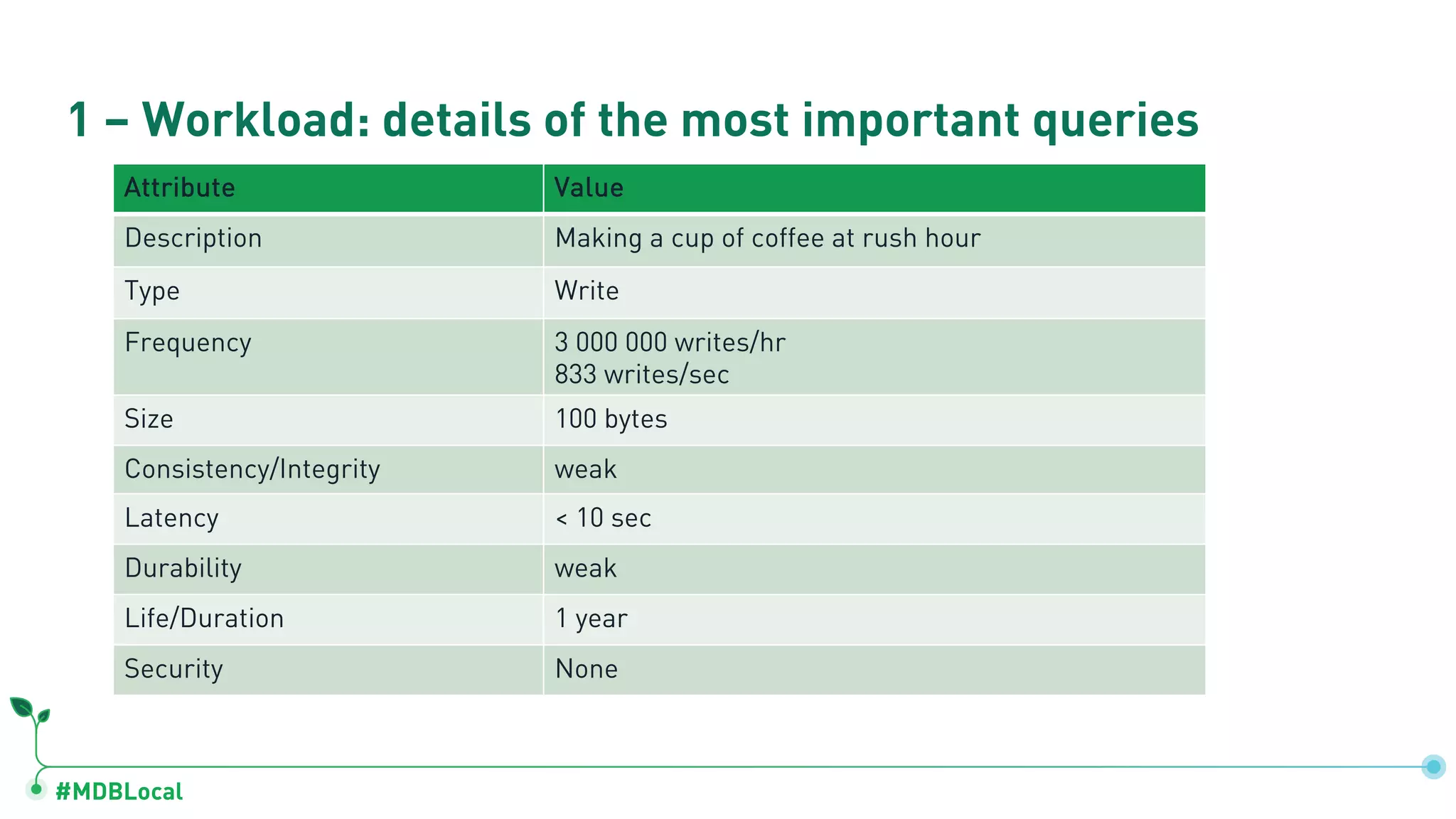
Analyzes critical queries’ characteristics and estimated disk space utilization for coffee-related data.
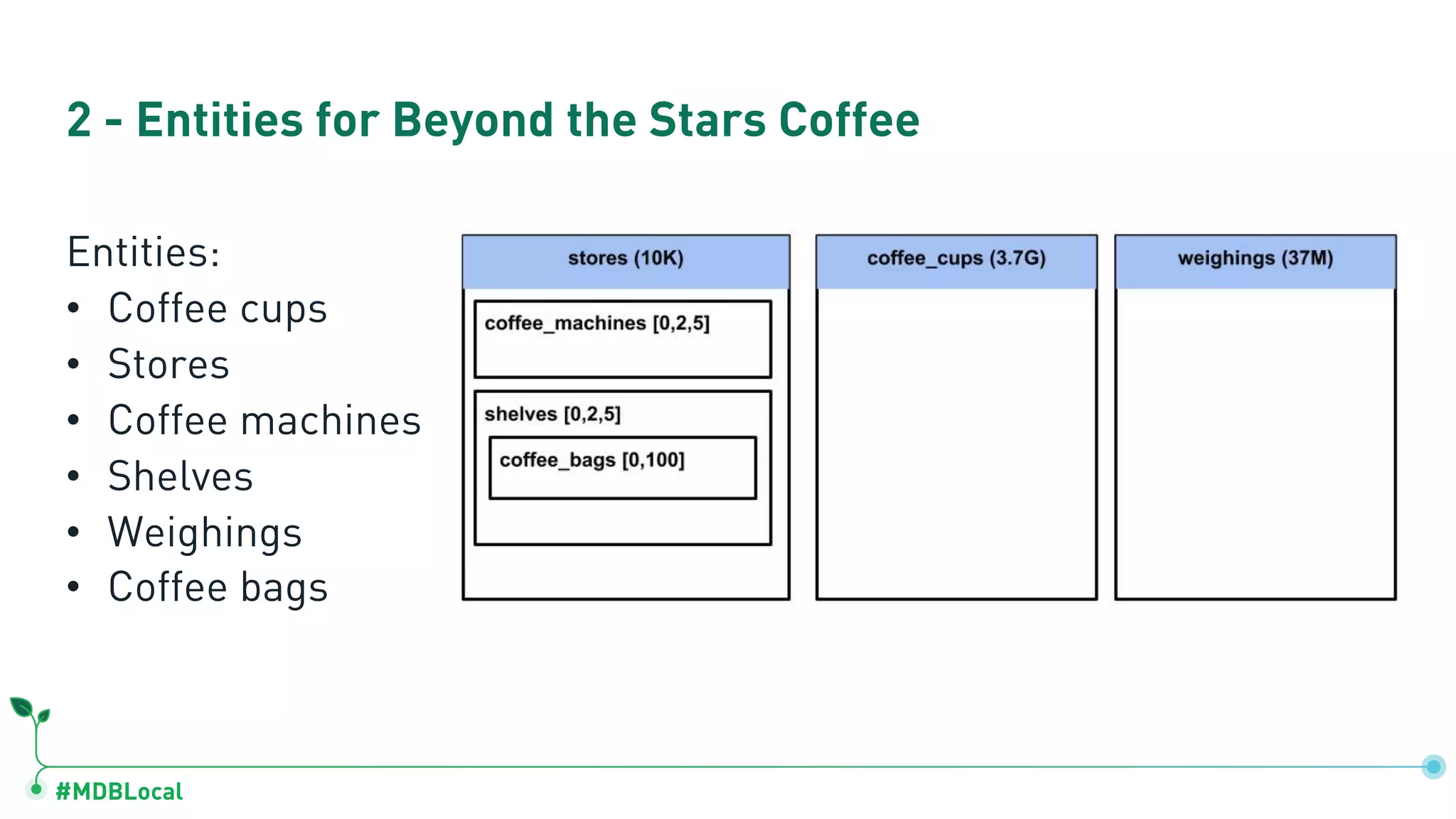
Discusses the importance of relationships in document modeling and identifies key entities pertinent to the coffee shop case.
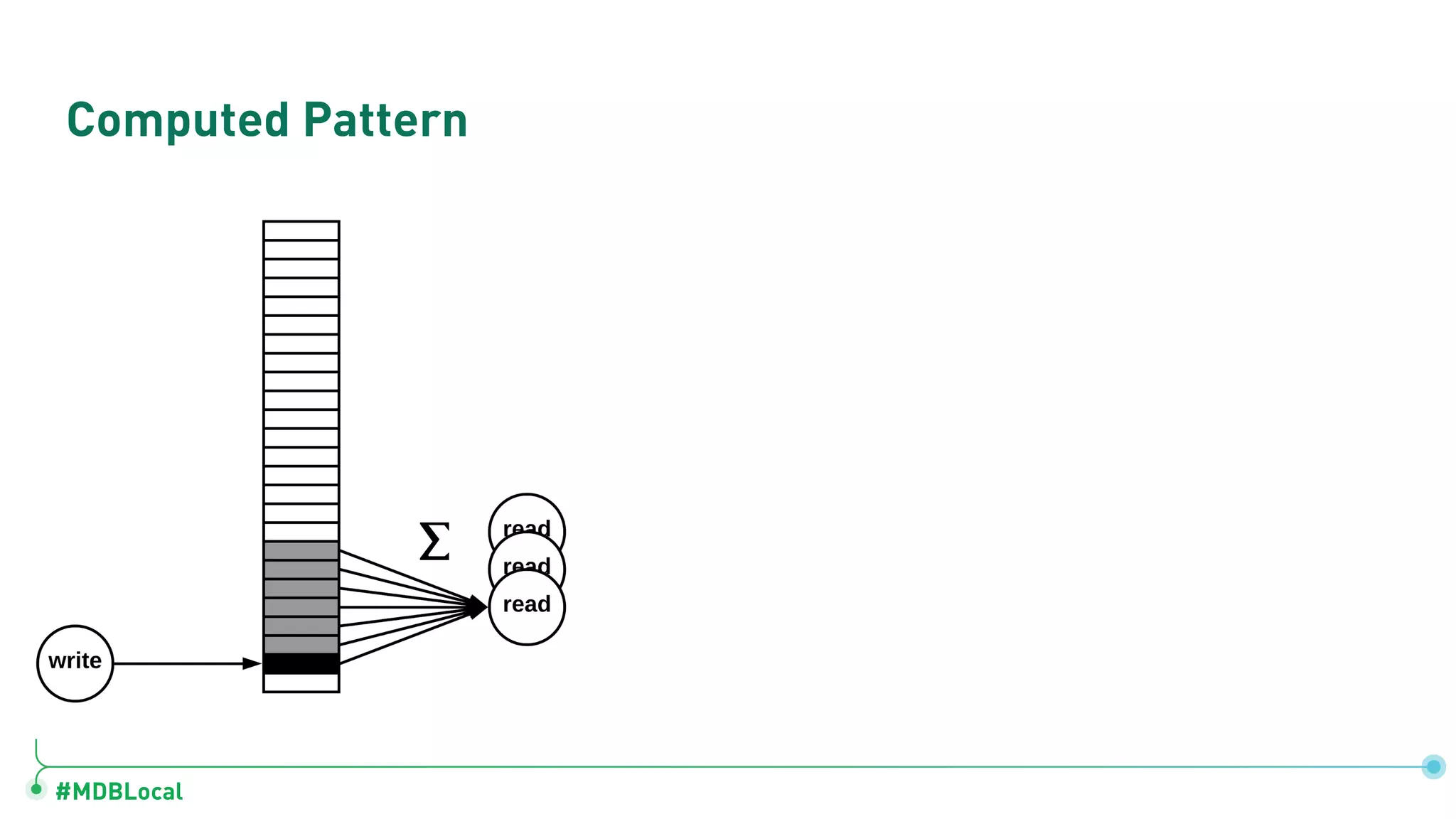
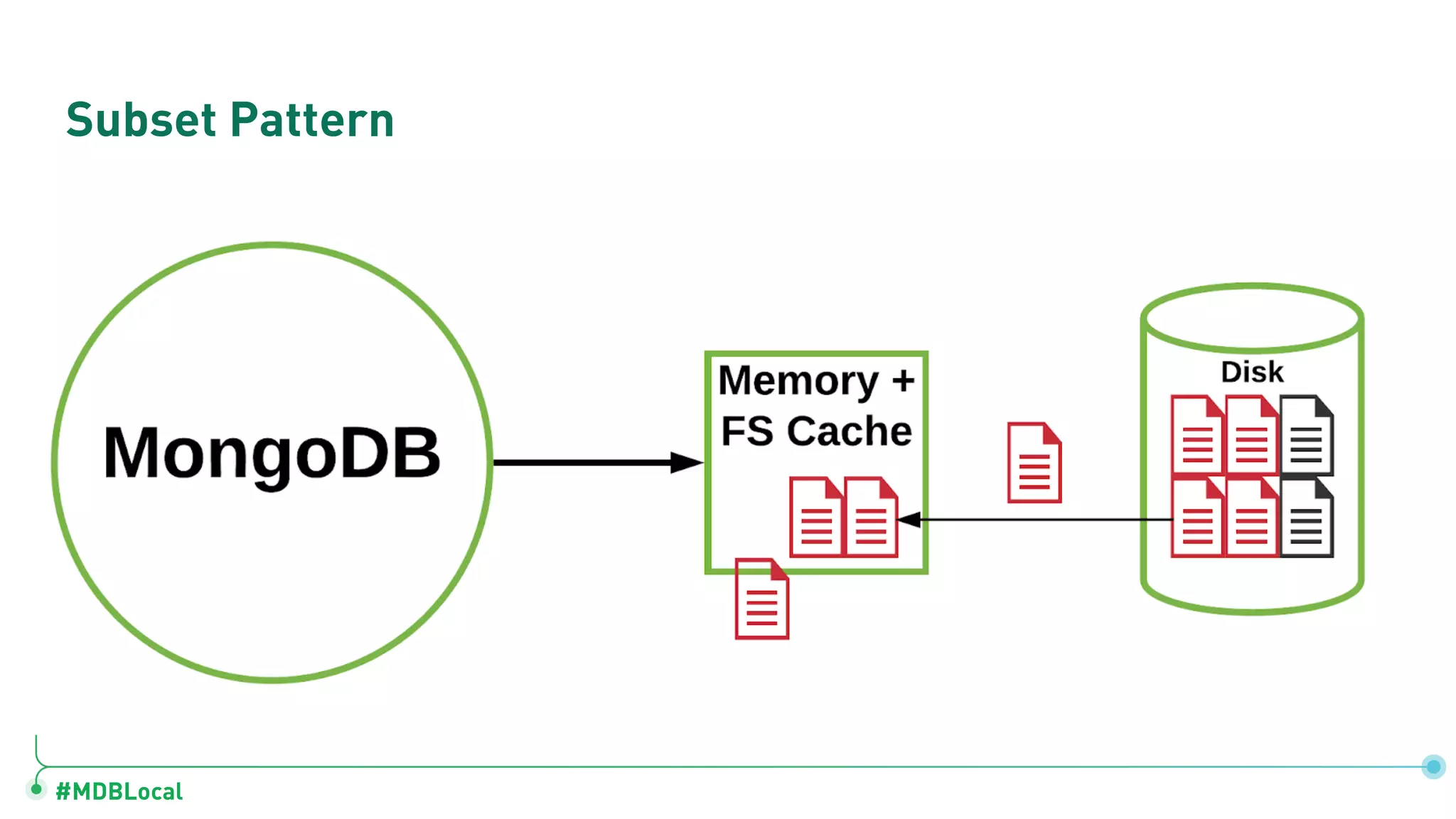
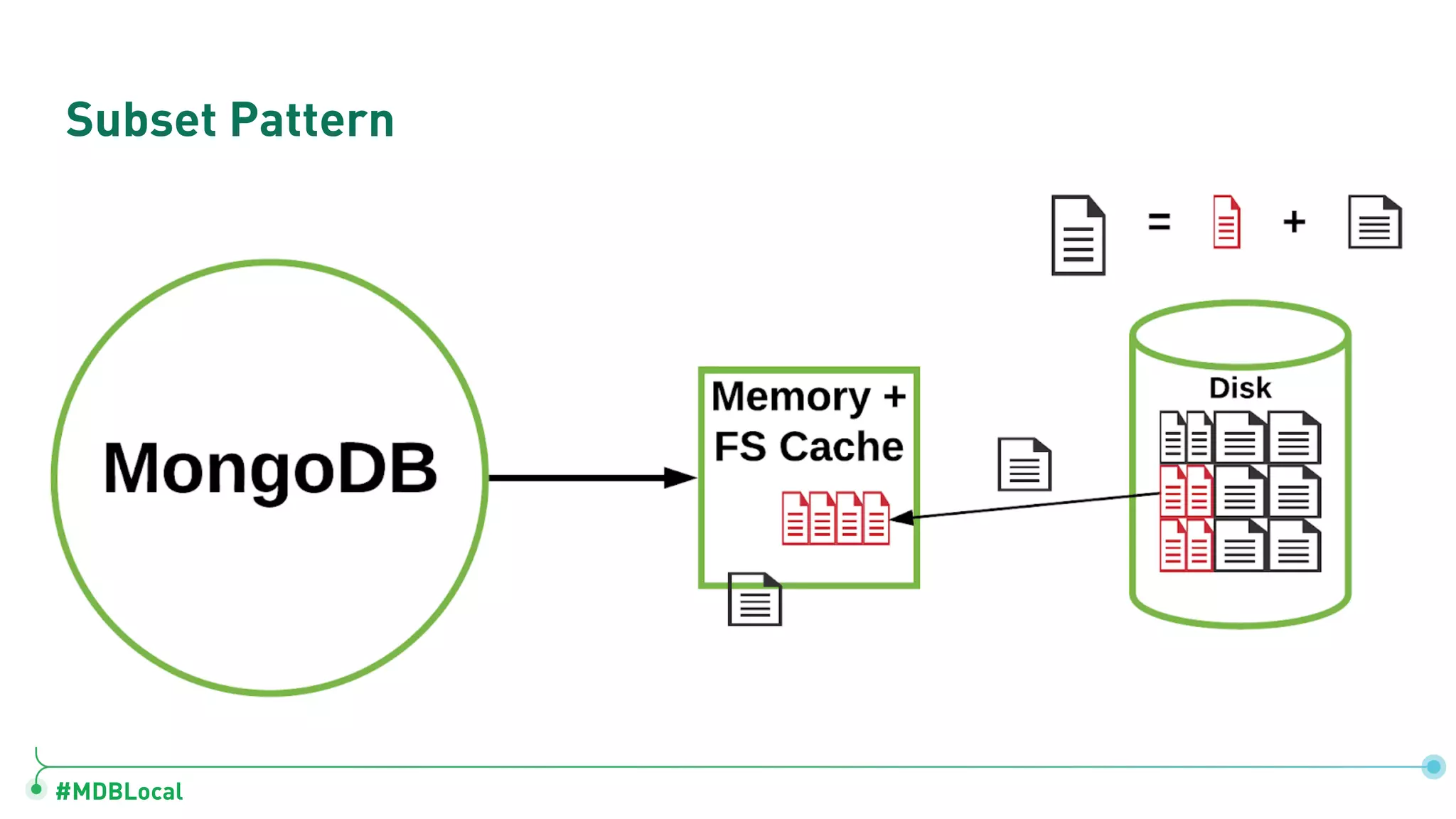
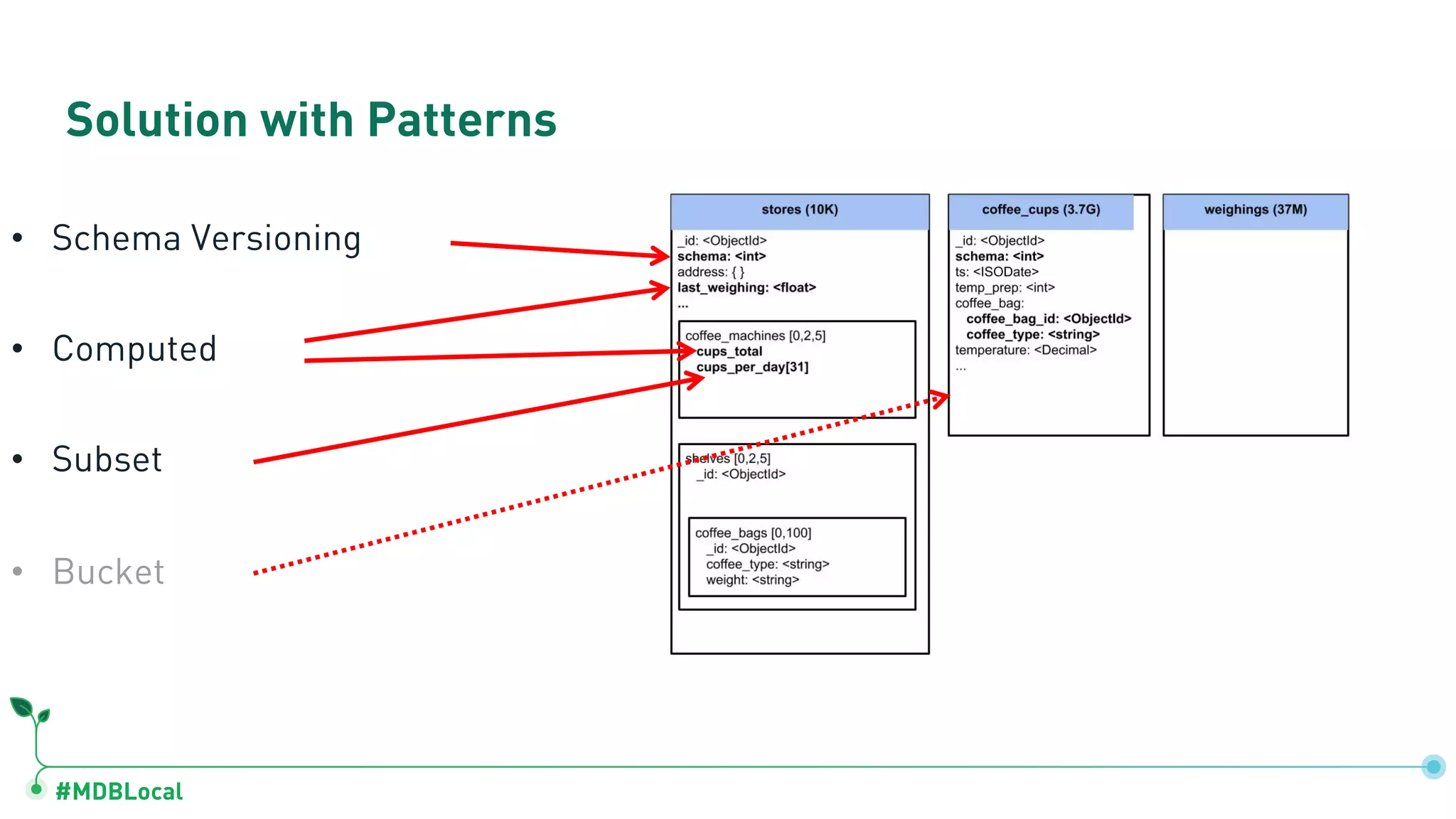
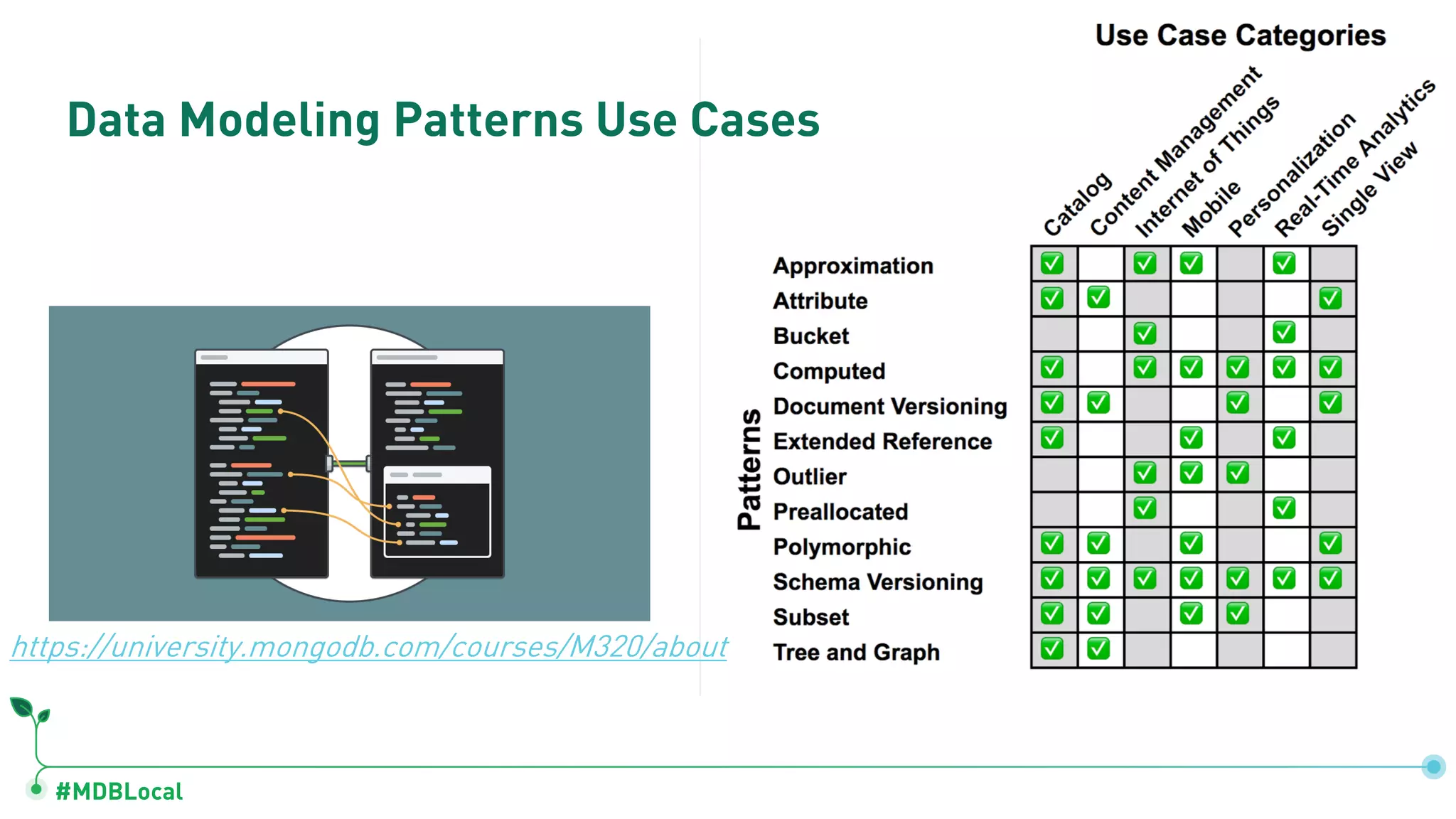
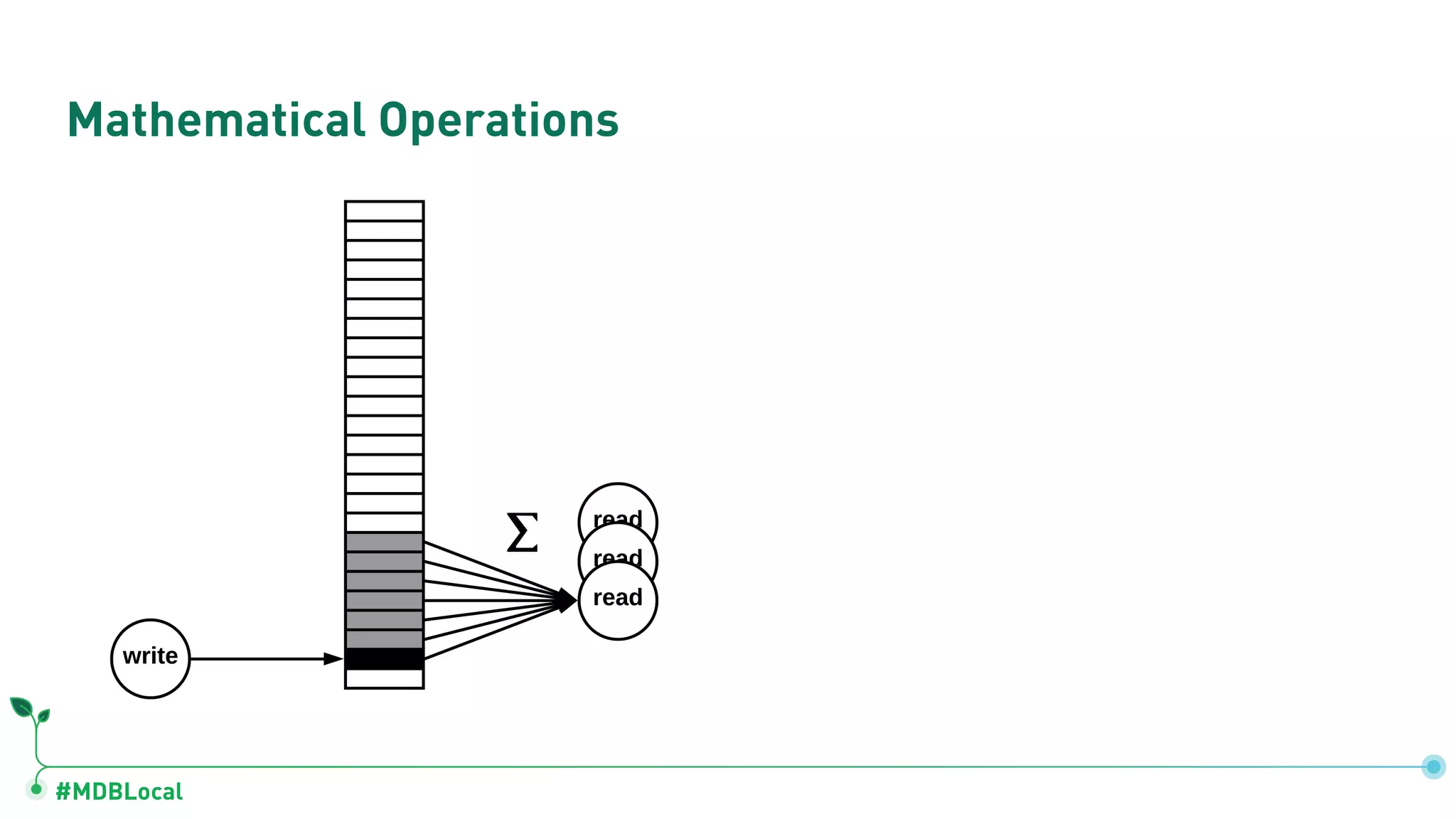
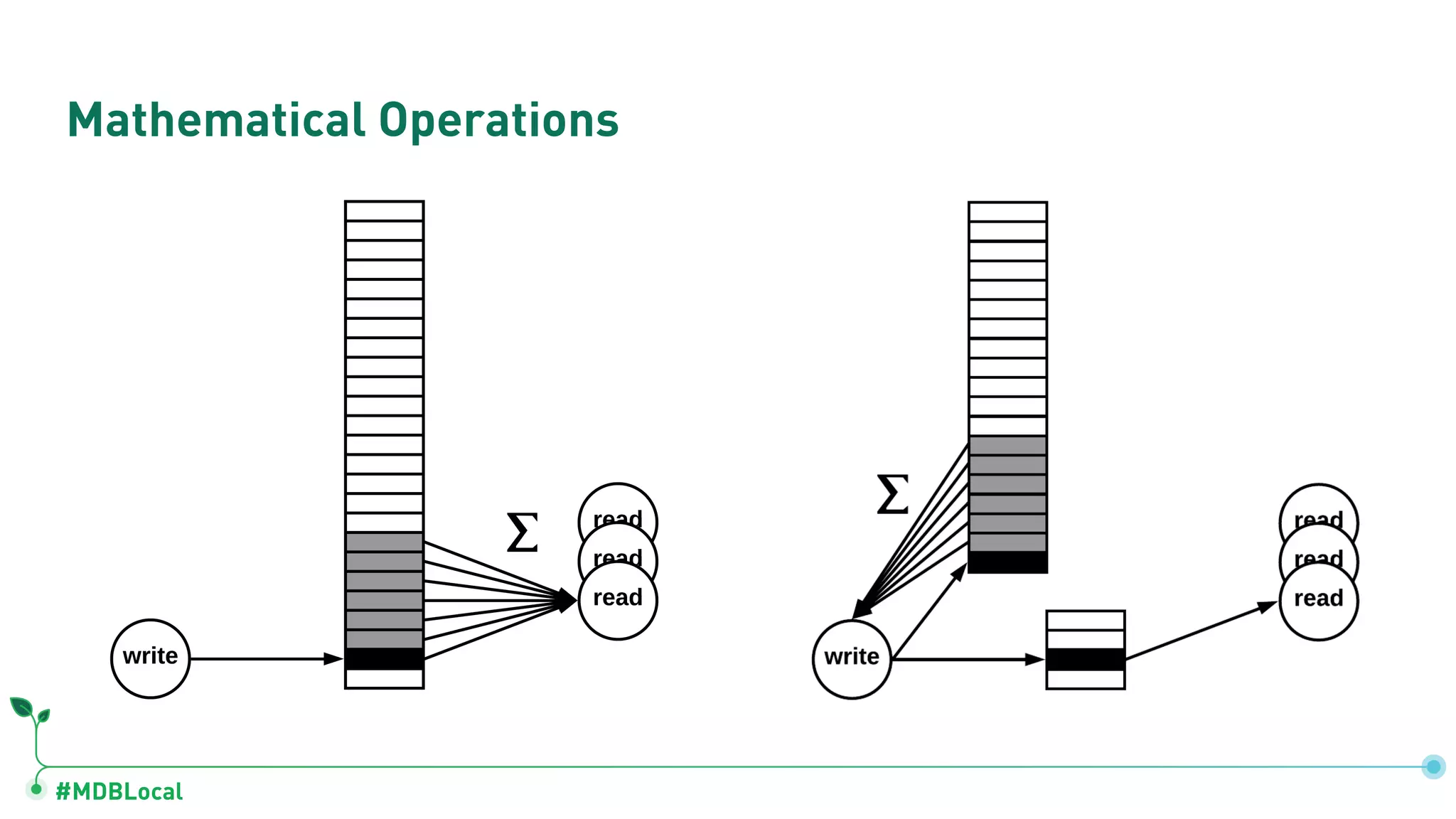
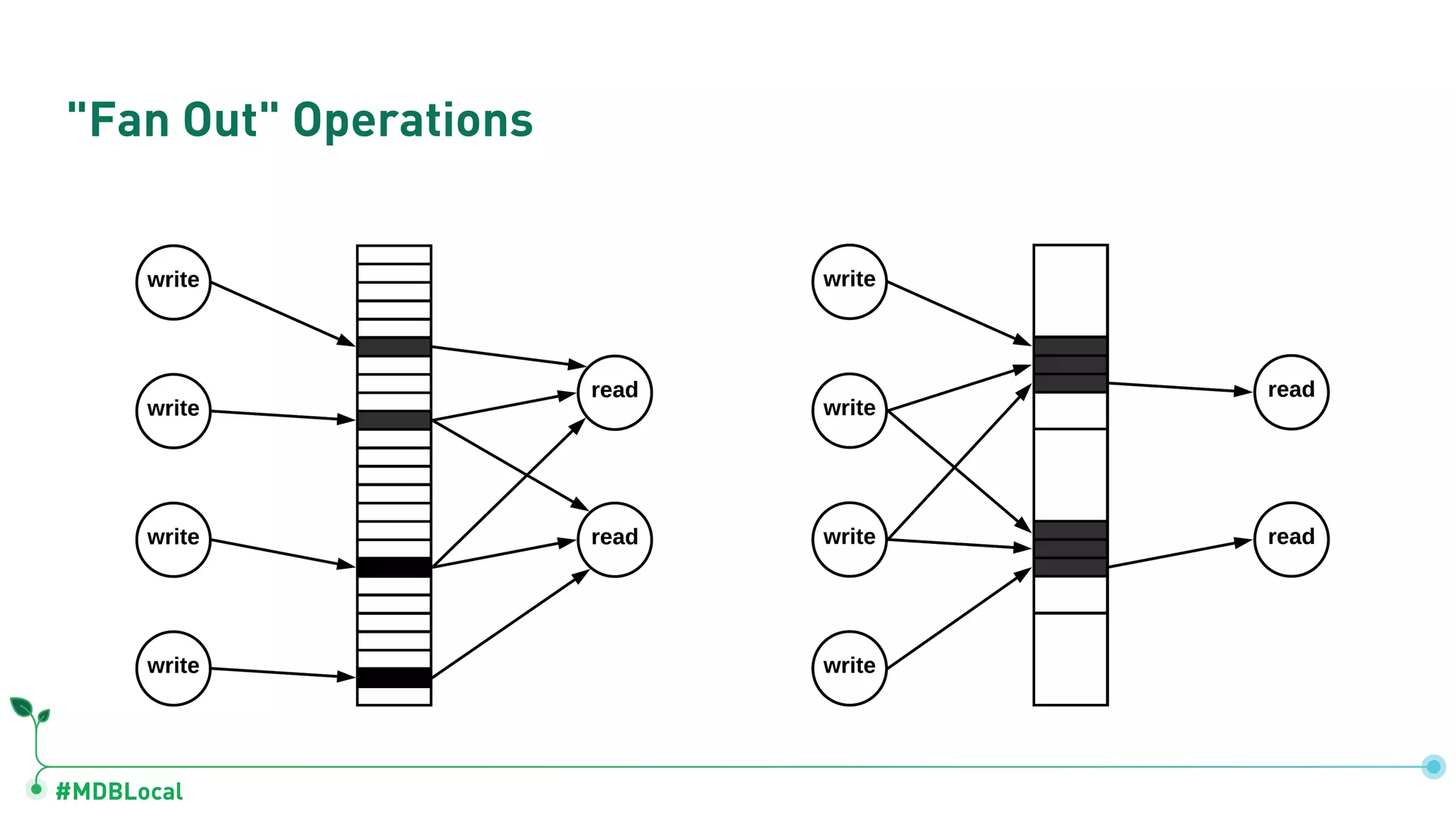
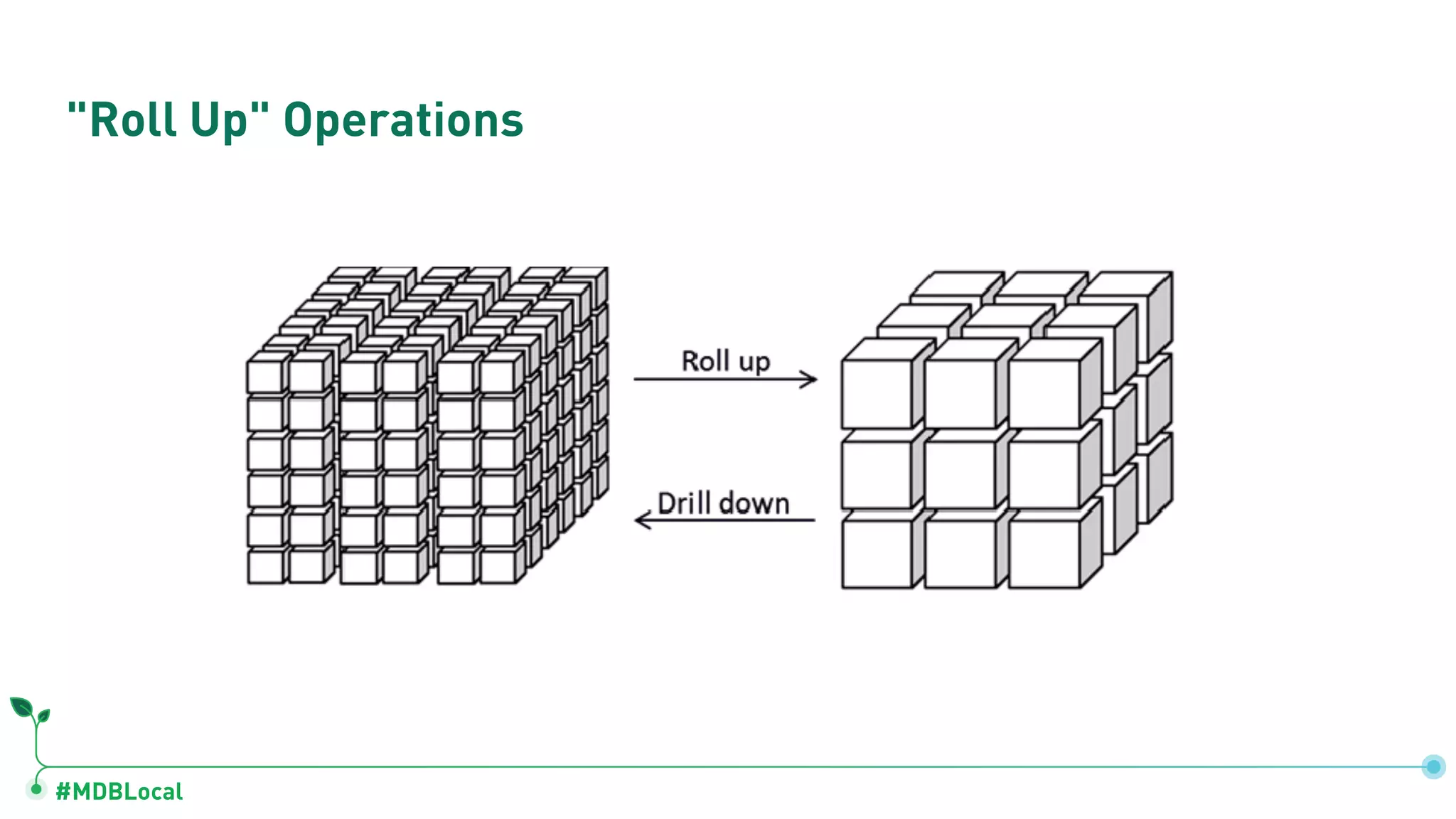
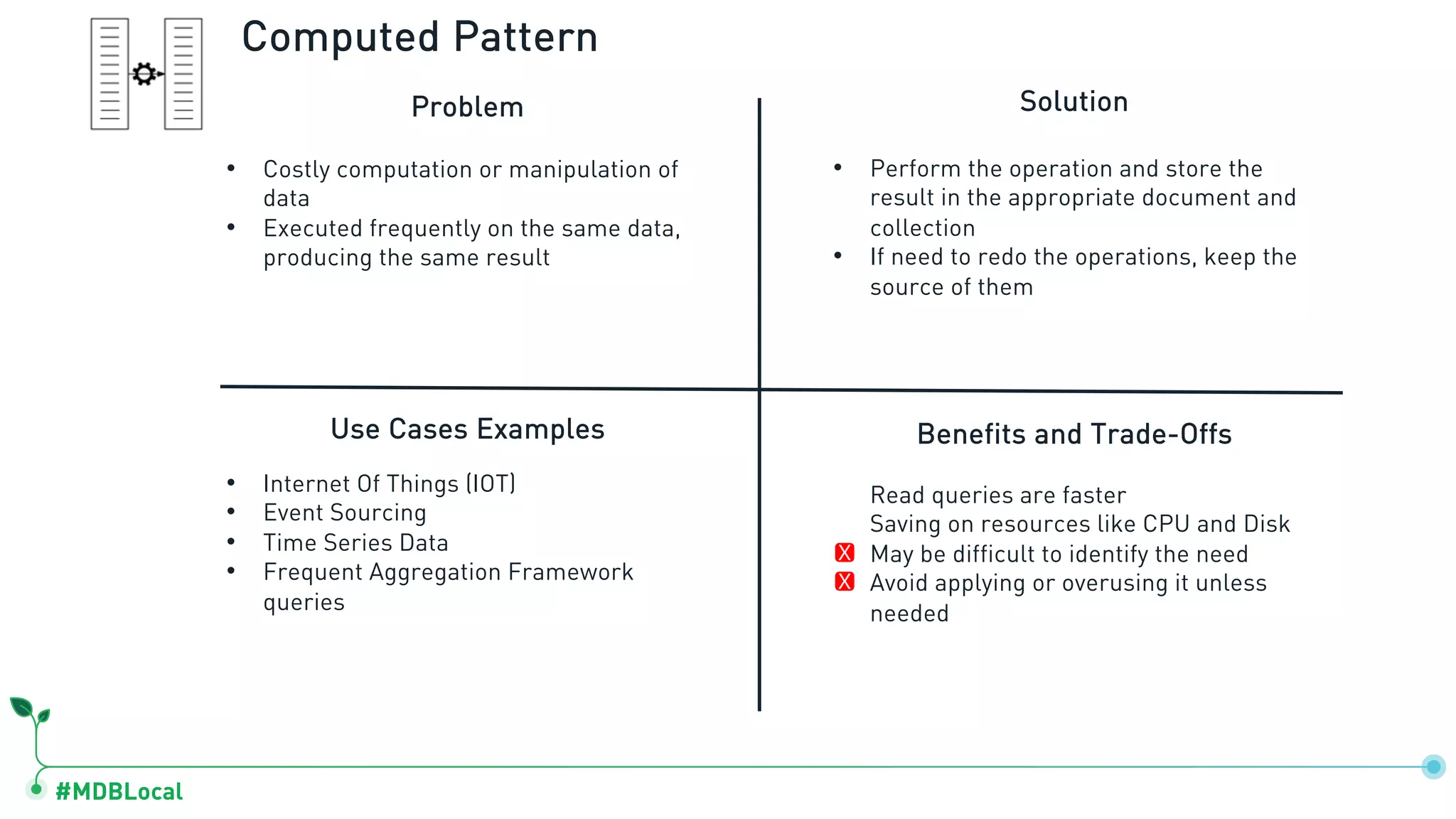
Introduces and demonstrates various schema design patterns utilized in MongoDB to enhance data modeling.
Summarizes key insights from the presentation regarding differences in data models, methodologies, and patterns.
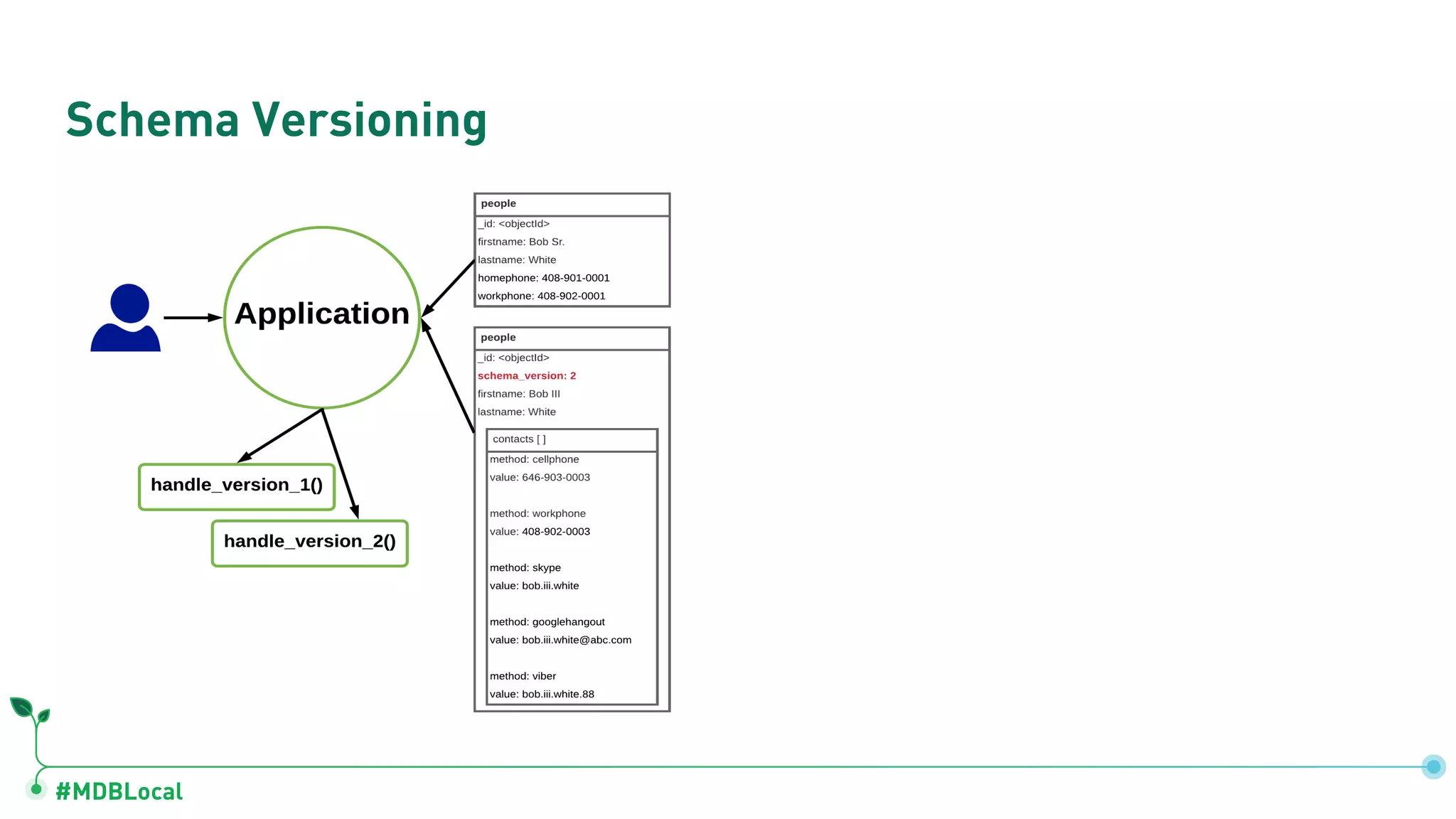
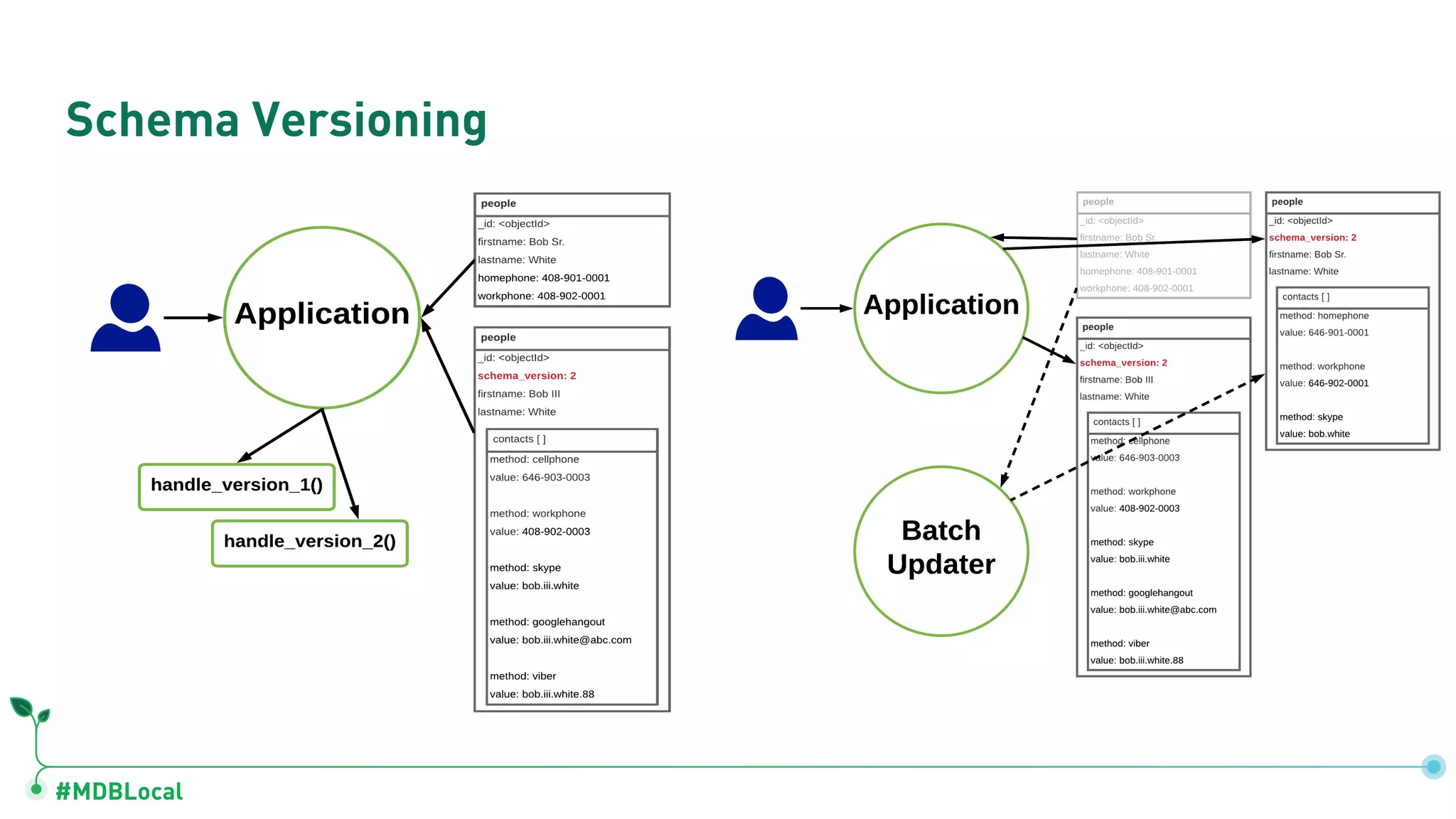
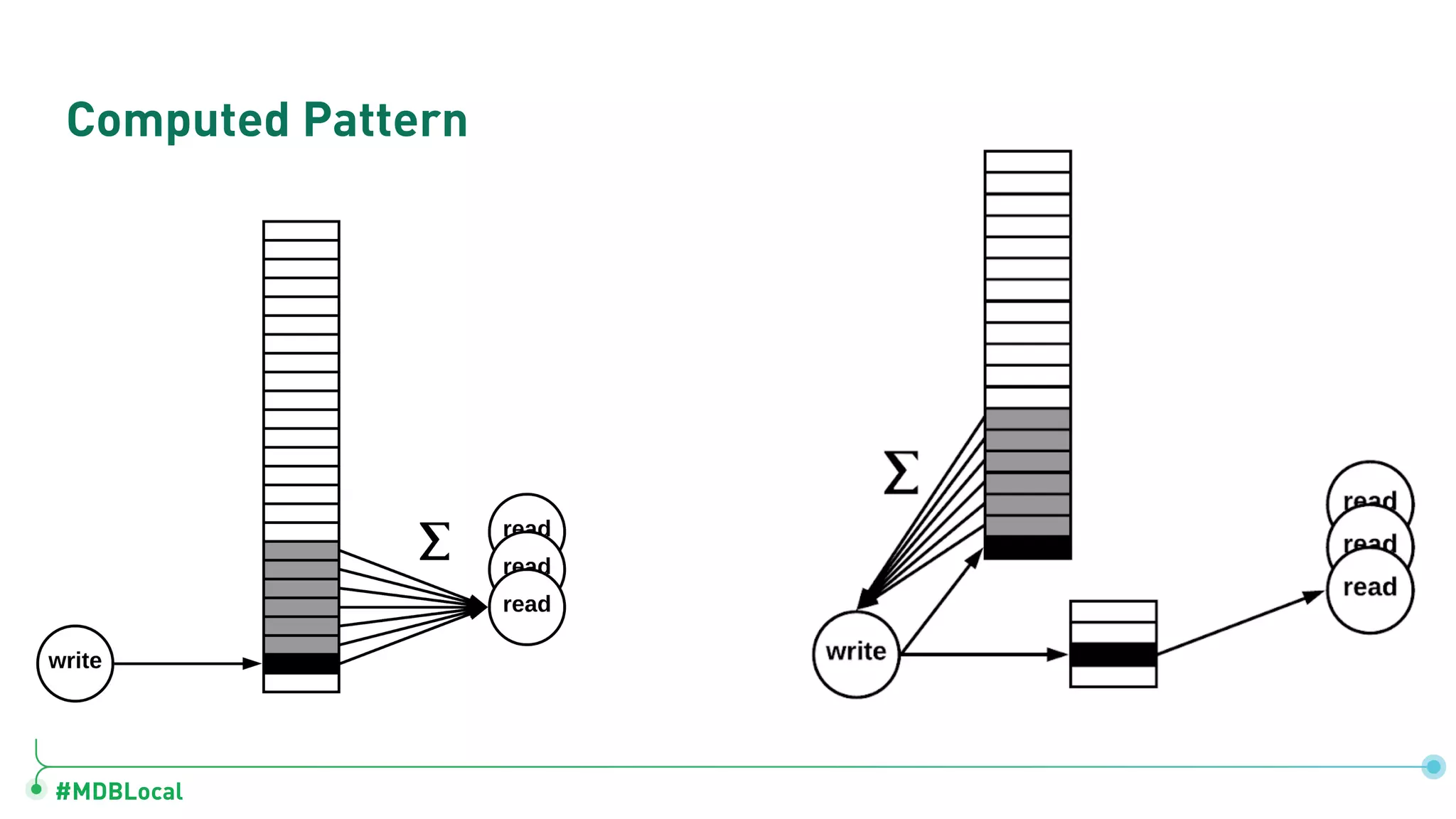
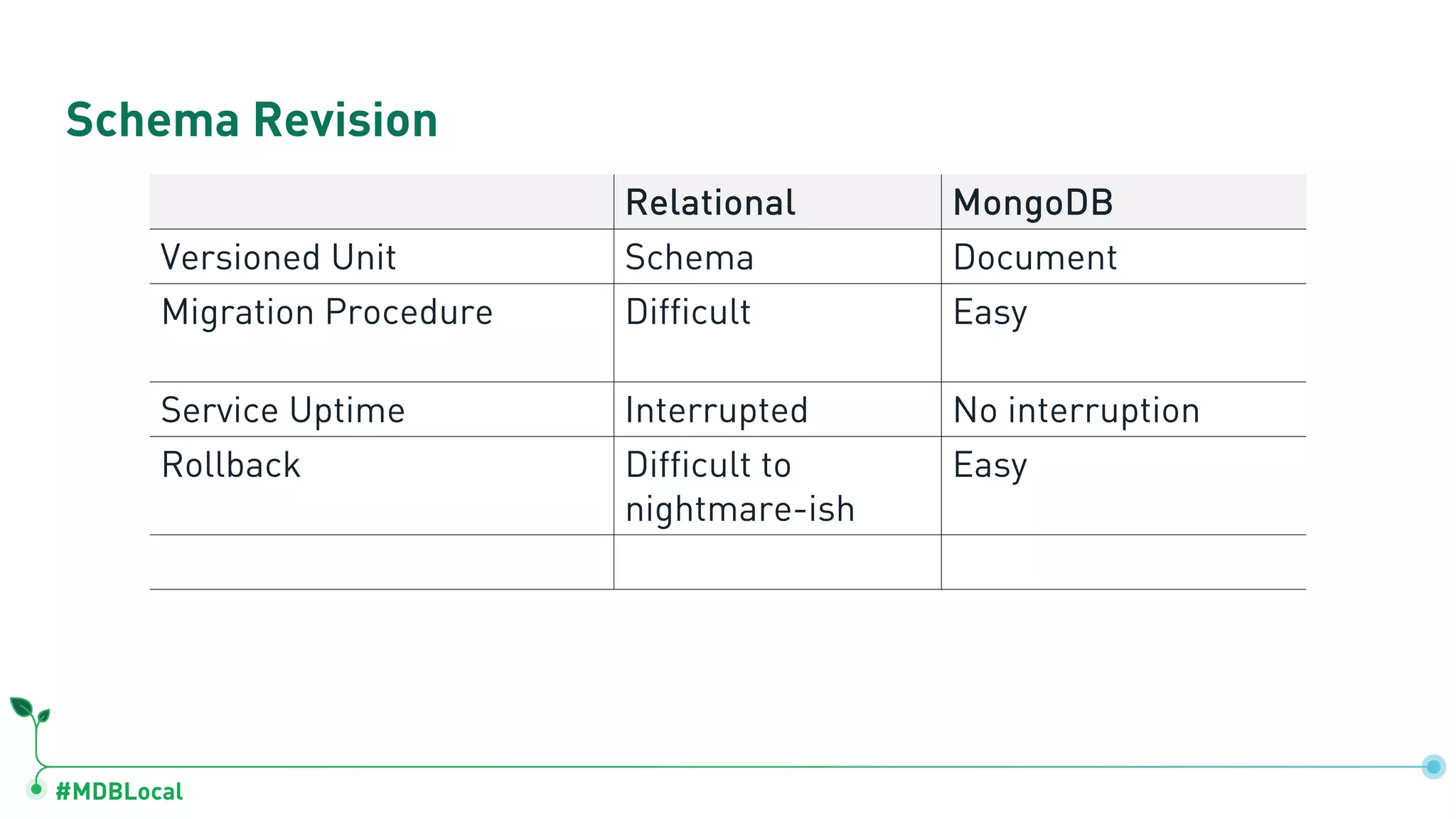
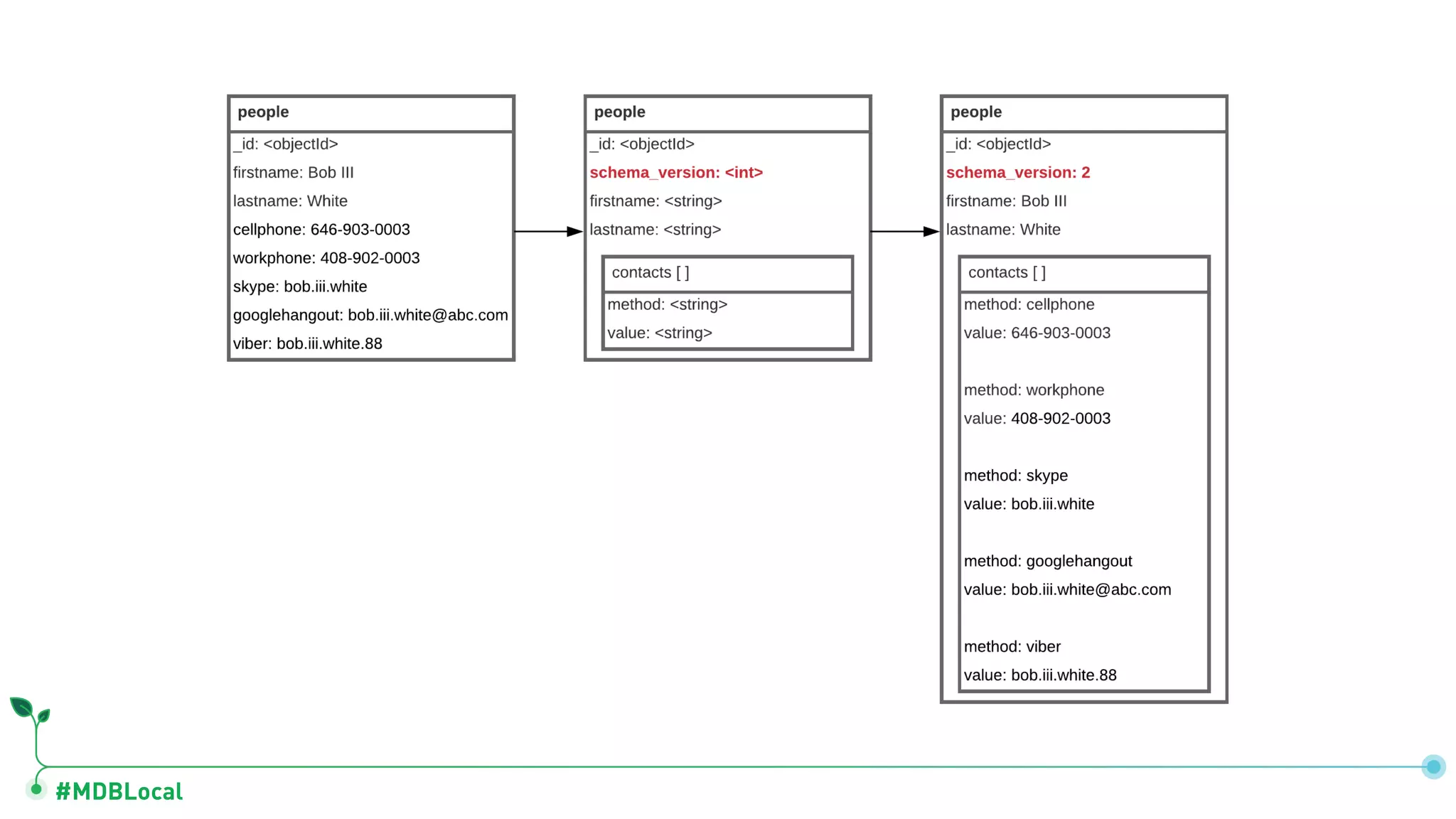
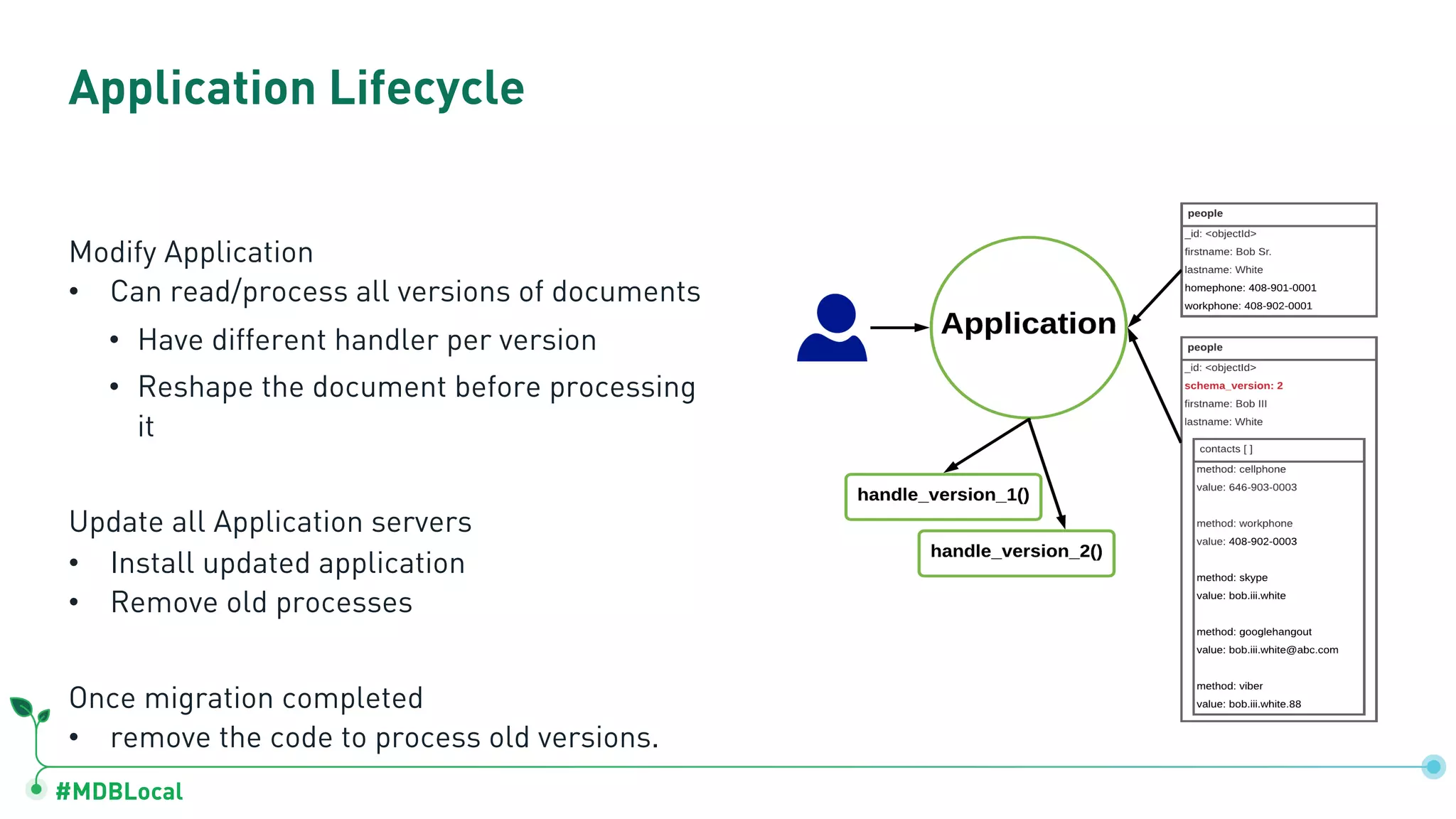
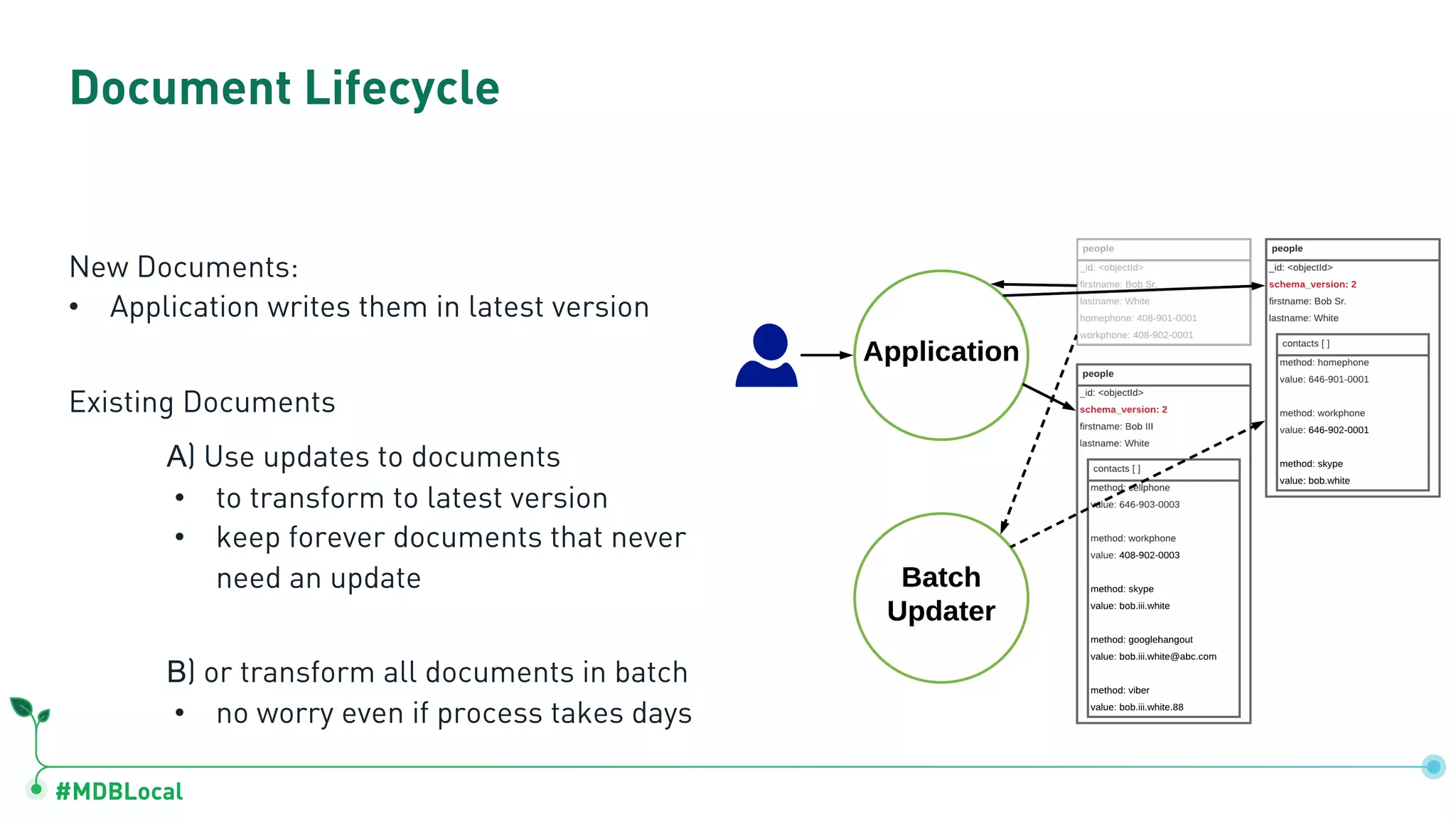
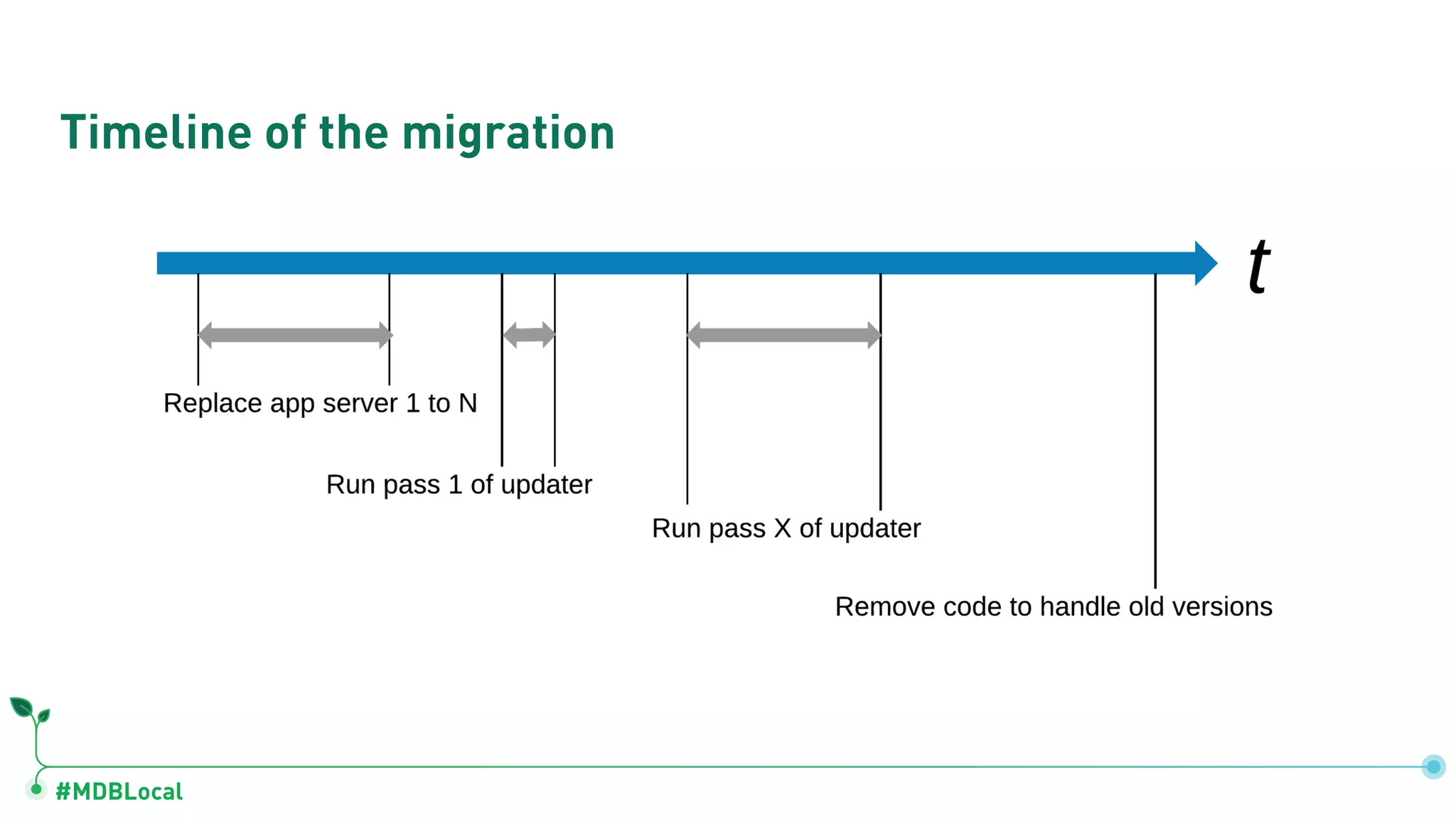
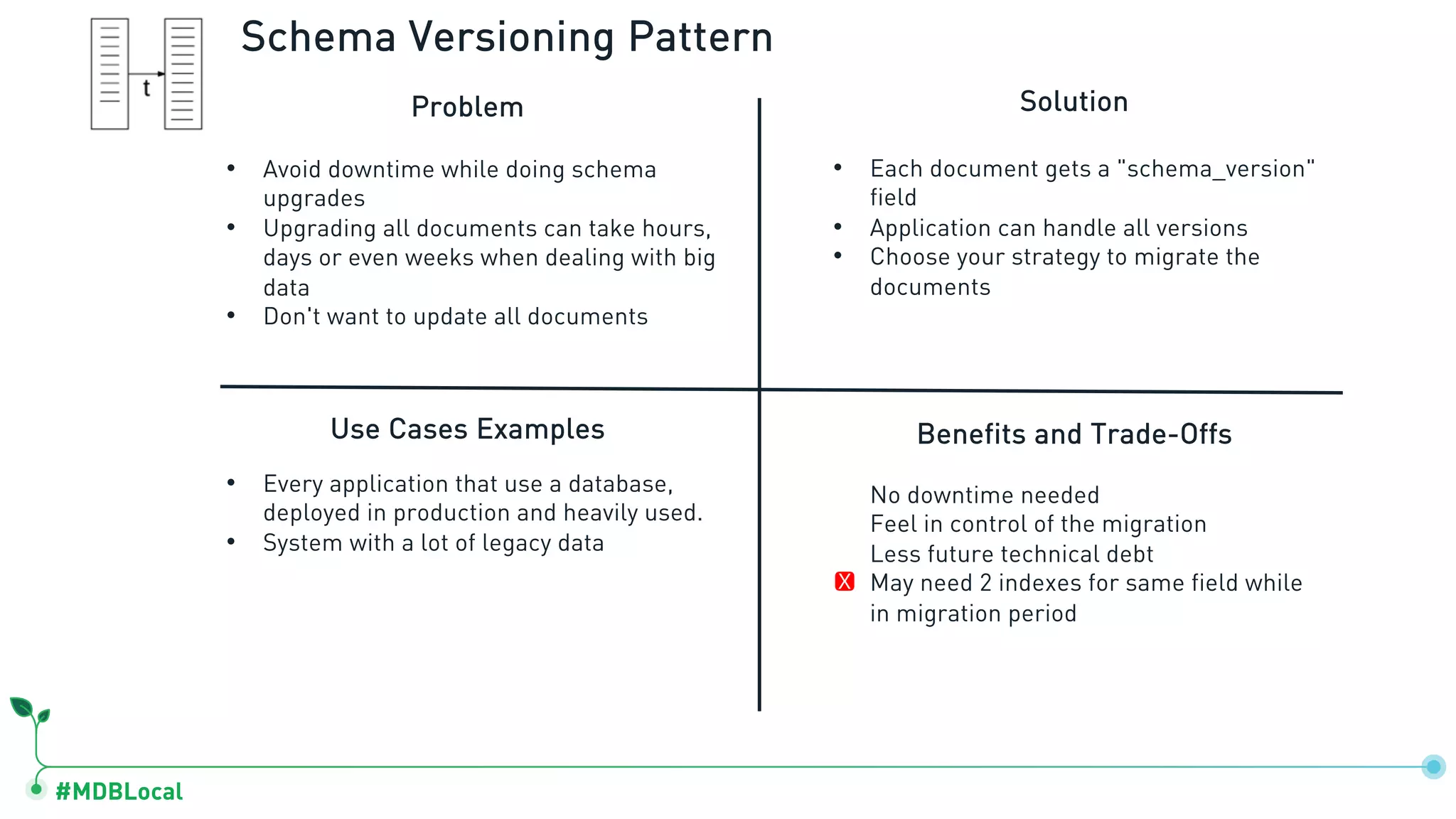
Details schema versioning and computed patterns as part of advanced data modeling techniques in MongoDB.