Download as PDF, PPTX






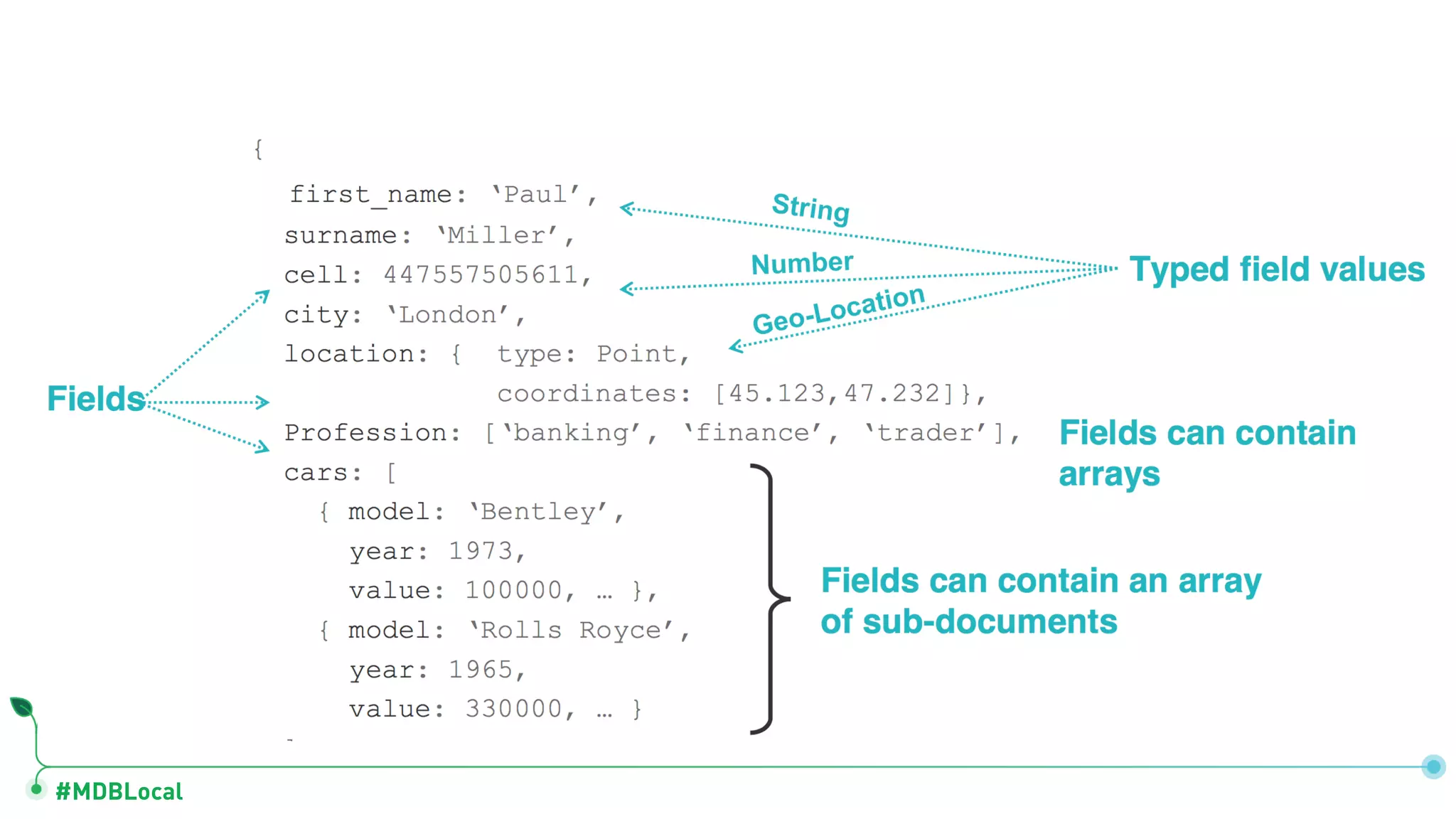







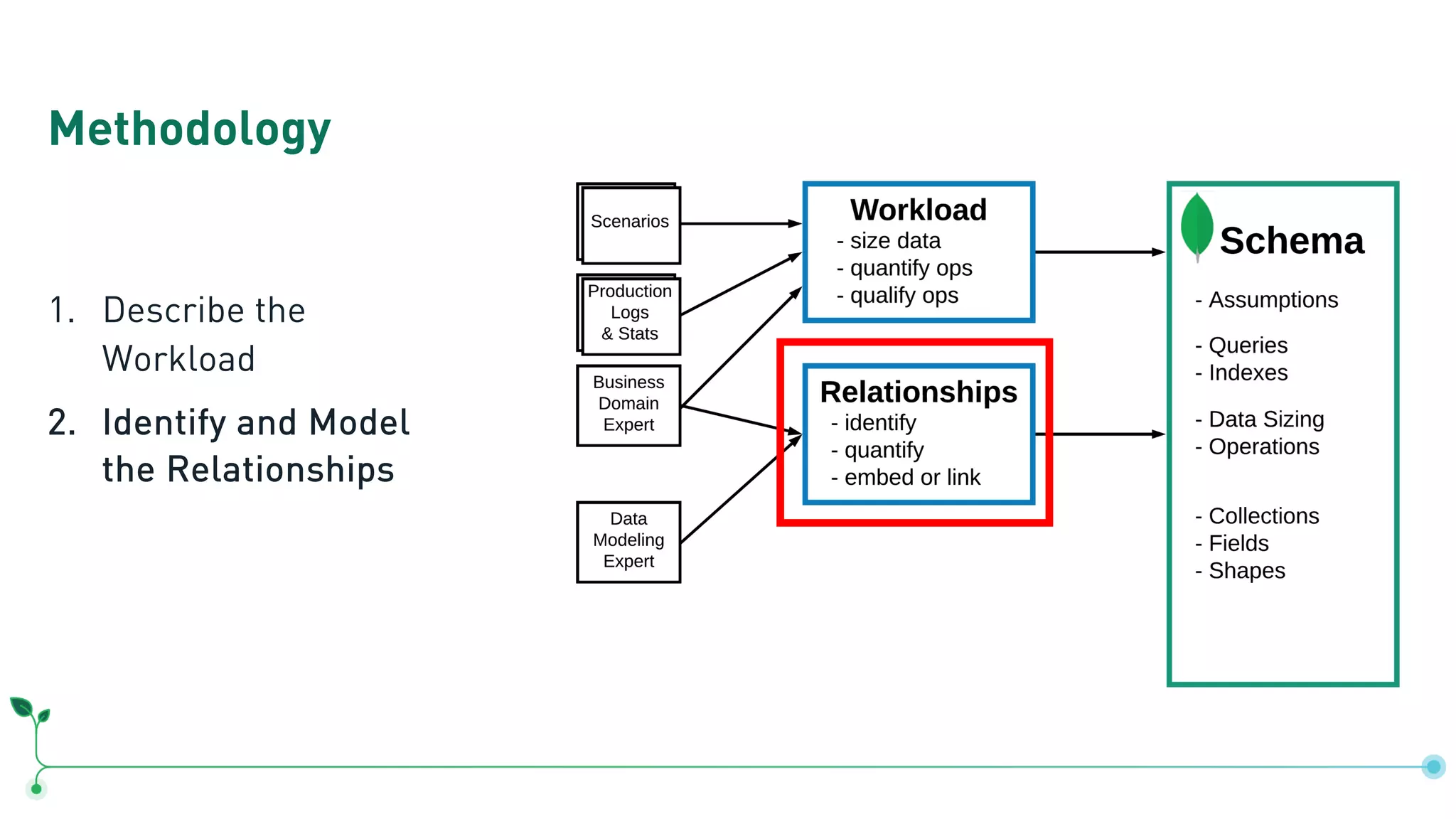

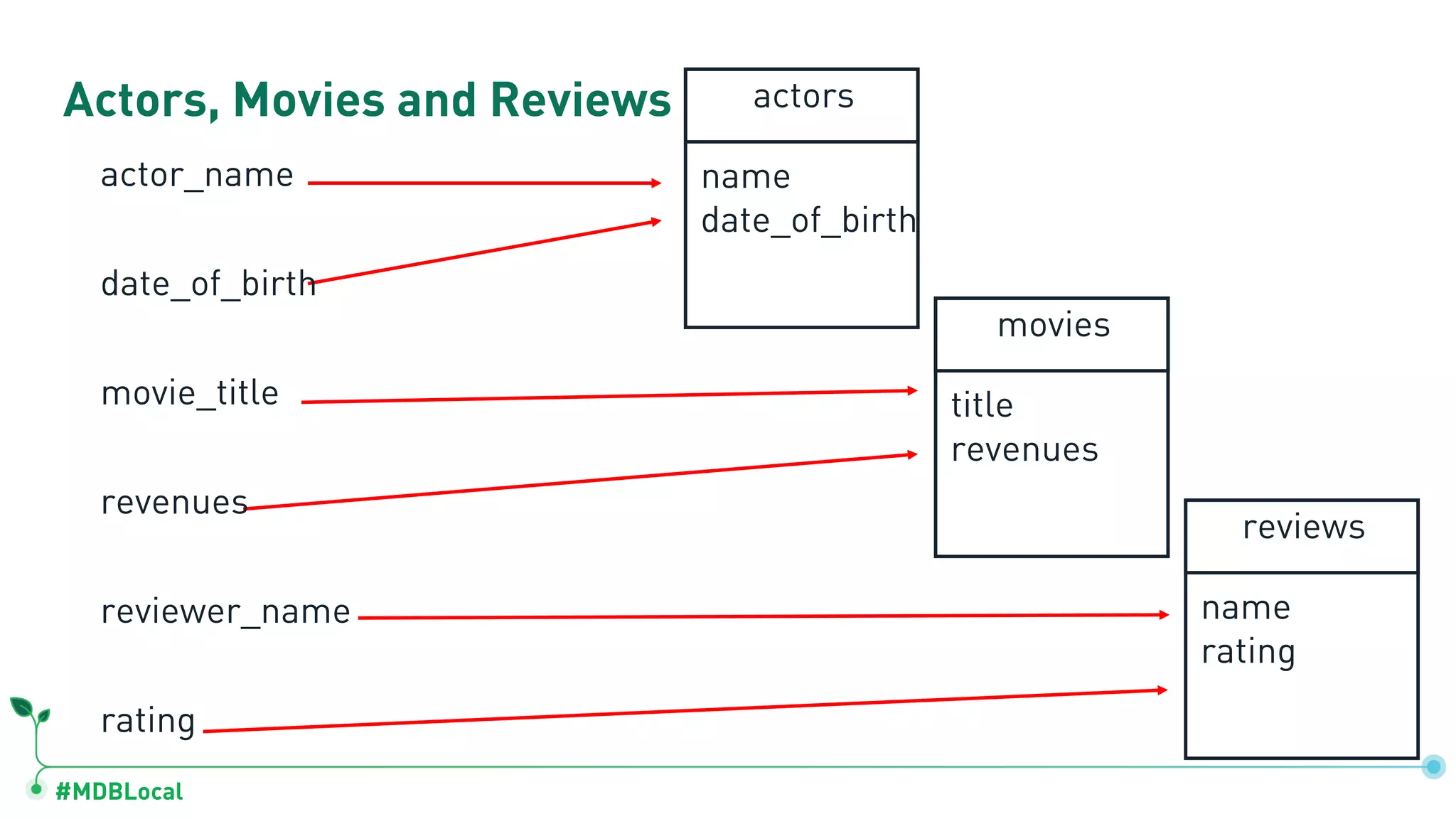
![#MDBLocal Actors, Movies and Reviews actors name date_of_birth movies : [ .. ] movies title revenues actors: [ ..] name rating actor_name date_of_birth movie_title revenues reviewer_name rating](https://image.slidesharecdn.com/mongodblocalchicago2019-completemethodologytodatamodeling-191025171826/75/MongoDB-local-Chicago-2019-A-Complete-Methodology-to-Data-Modeling-for-MongoDB-25-2048.jpg)














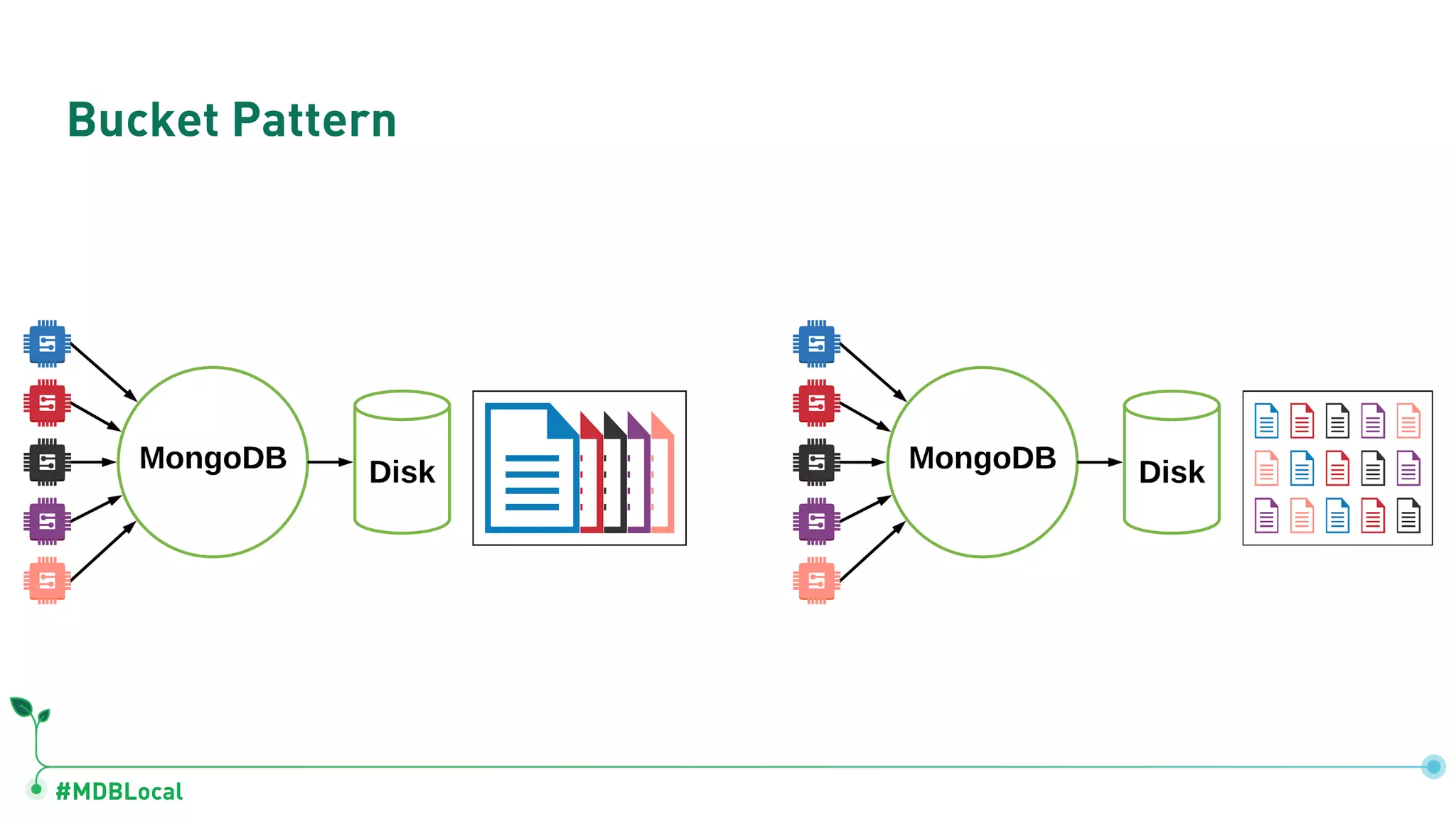
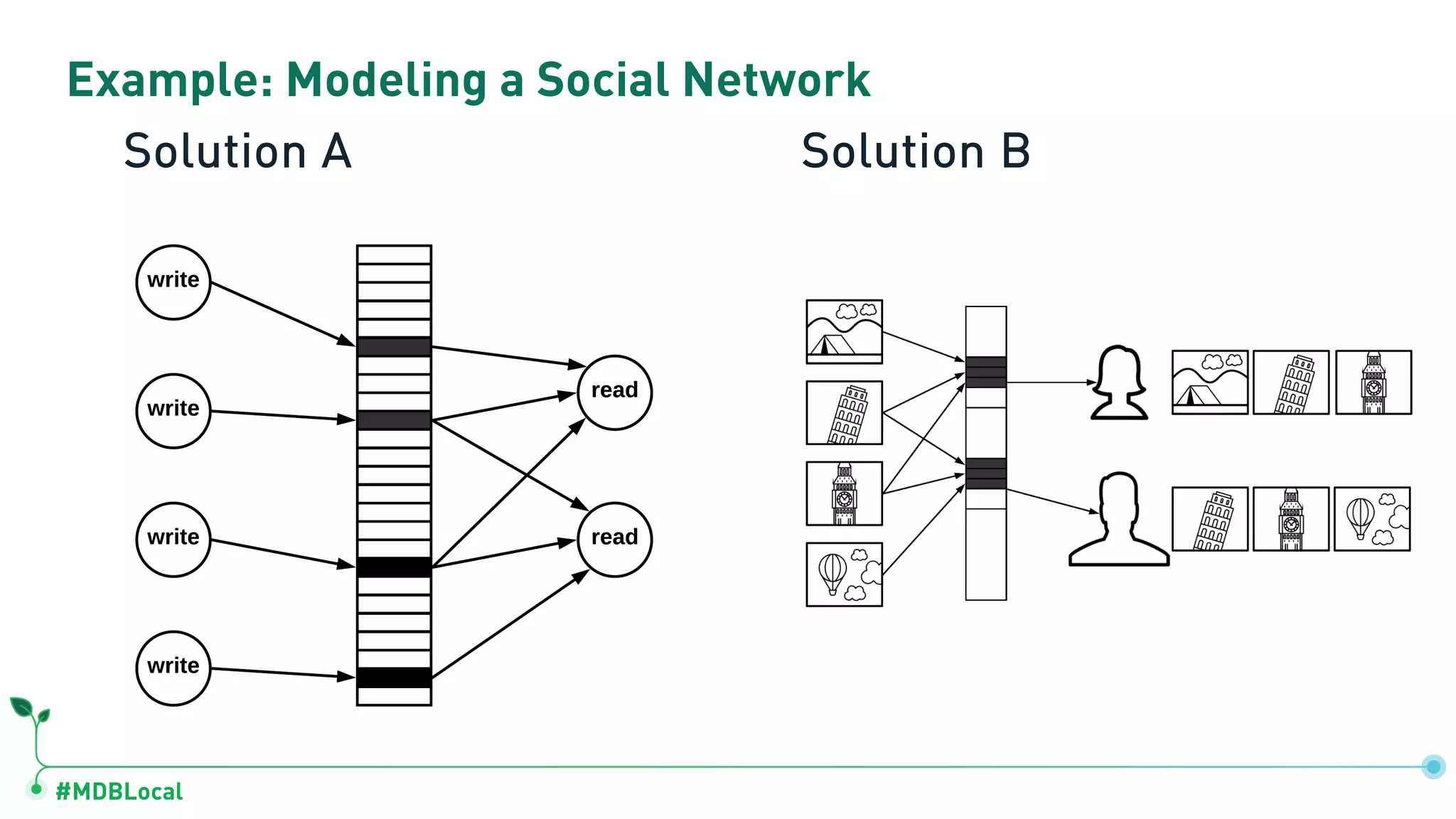
![#MDBLocal Bucket Pattern { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02"), "temp": [ [ 20.0, 20.1, 20.2, ... ], [ 22.1, 22.1, 22.0, ... ], ... ] } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-03"), "temp": [ [ 20.1, 20.2, 20.3, ... ], [ 22.4, 22.4, 22.3, ... ], ... ] } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02T13"), "temp": { 1: 20.0, 2: 20.1, 3: 20.2, ... } } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02T14"), "temp": { 1: 22.1, 2: 22.1, 3: 22.0, ... } } Bucket per Day Bucket per Hour](https://image.slidesharecdn.com/mongodblocalchicago2019-completemethodologytodatamodeling-191025171826/75/MongoDB-local-Chicago-2019-A-Complete-Methodology-to-Data-Modeling-for-MongoDB-59-2048.jpg)






![#MDBlocal A Complete Methodology of Data Modeling for MongoDB [DEV] Daniel Coupal](https://image.slidesharecdn.com/mongodblocalchicago2019-completemethodologytodatamodeling-191025171826/75/MongoDB-local-Chicago-2019-A-Complete-Methodology-to-Data-Modeling-for-MongoDB-68-2048.jpg)





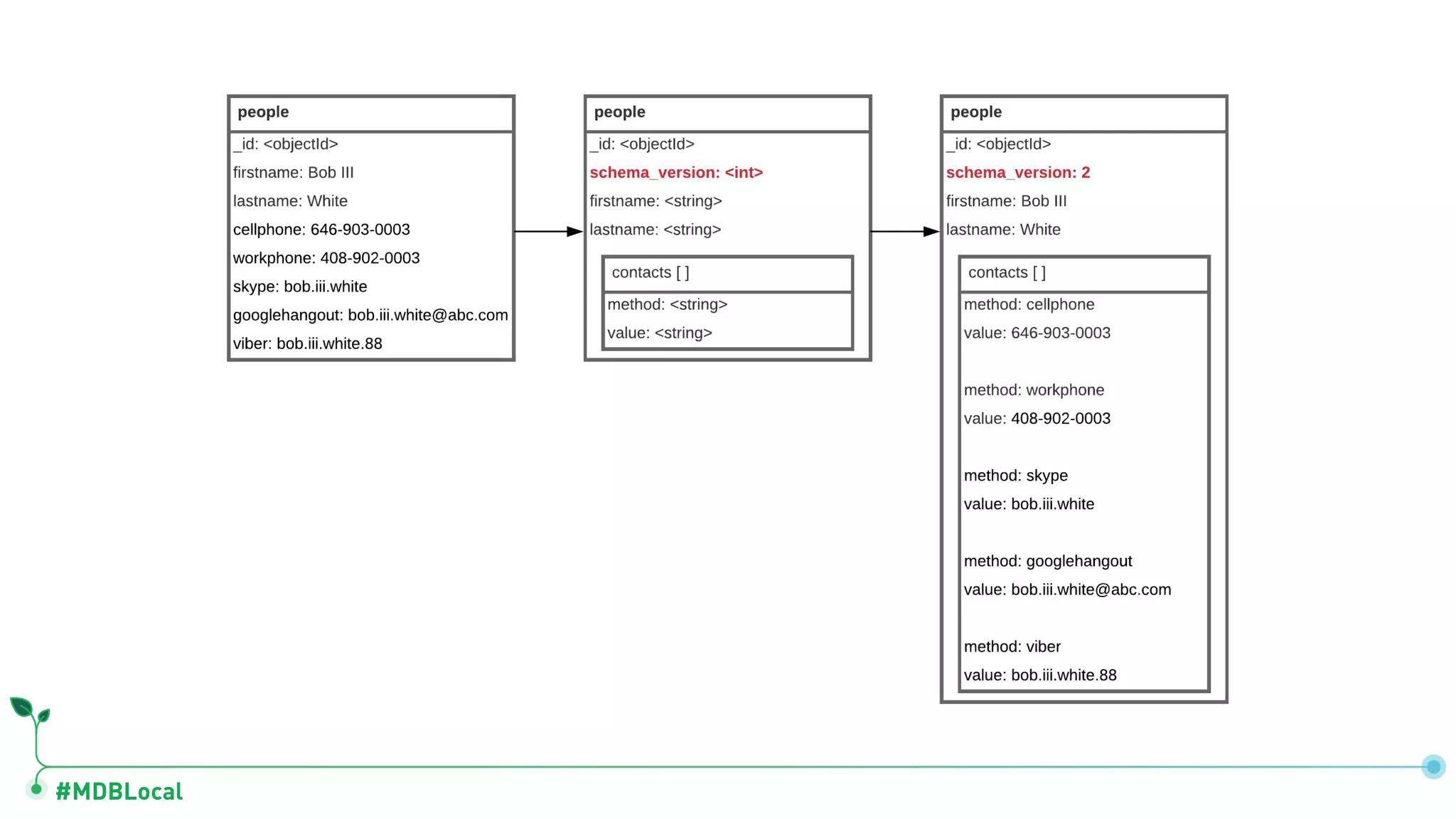
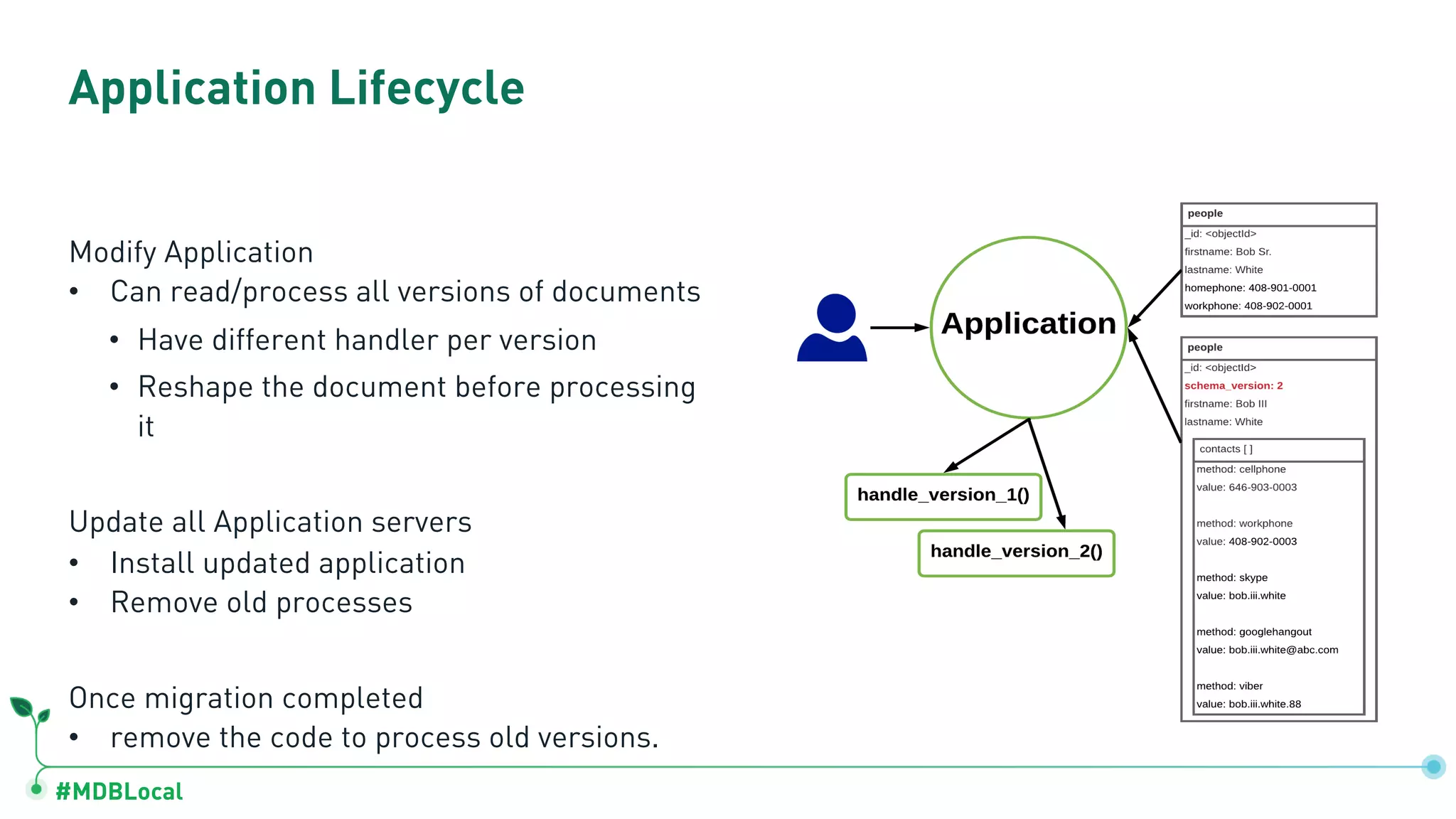
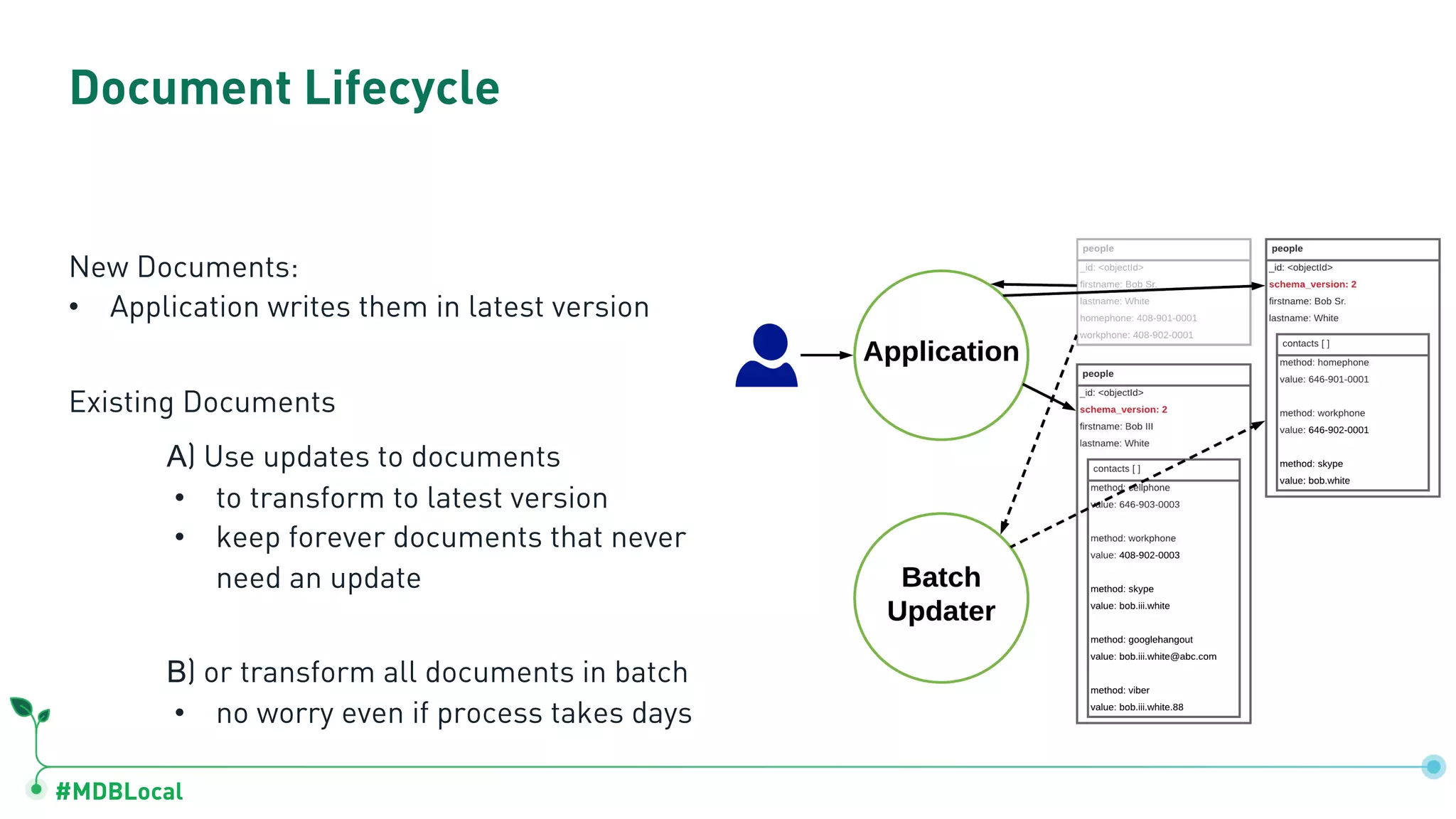
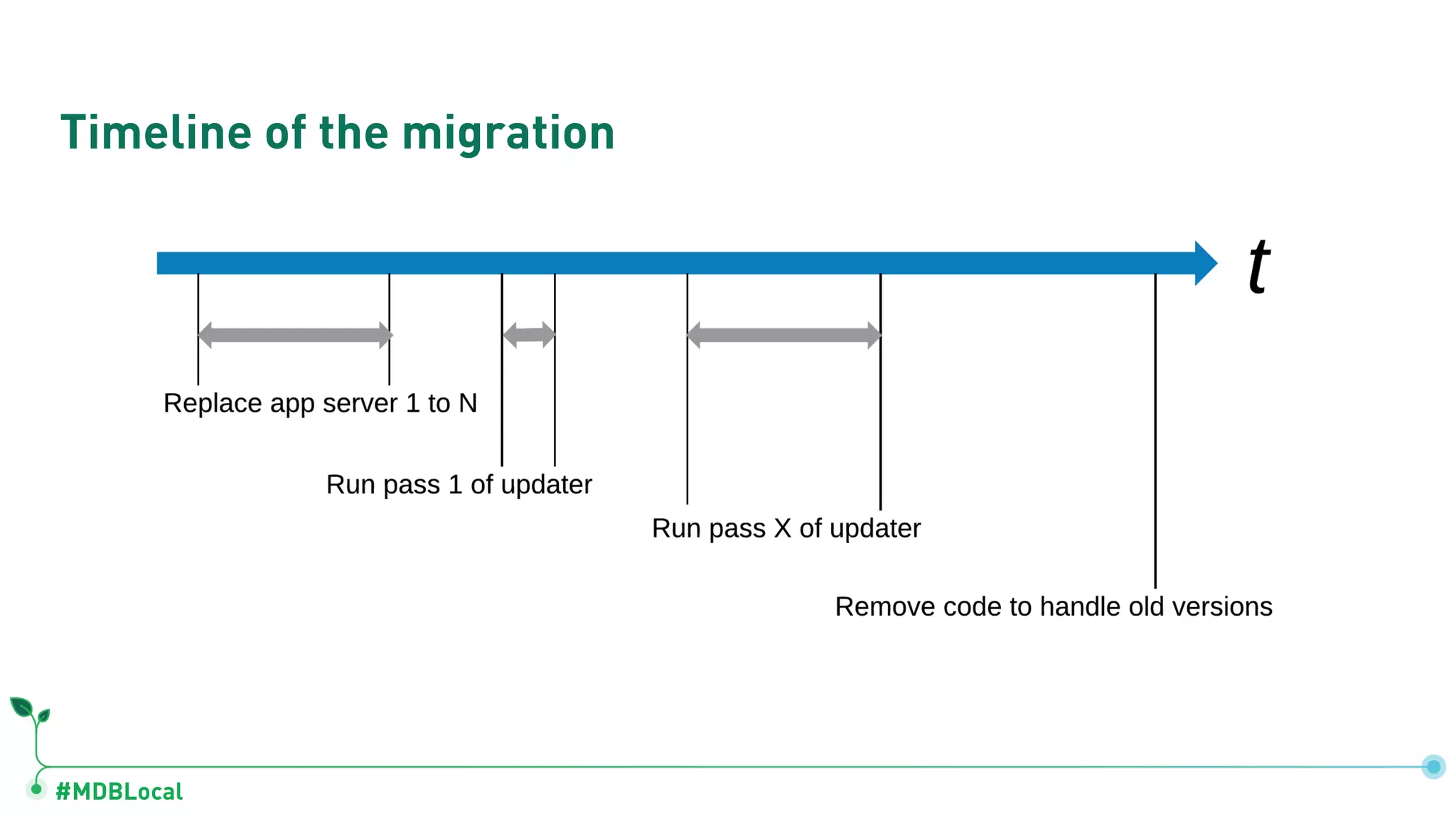
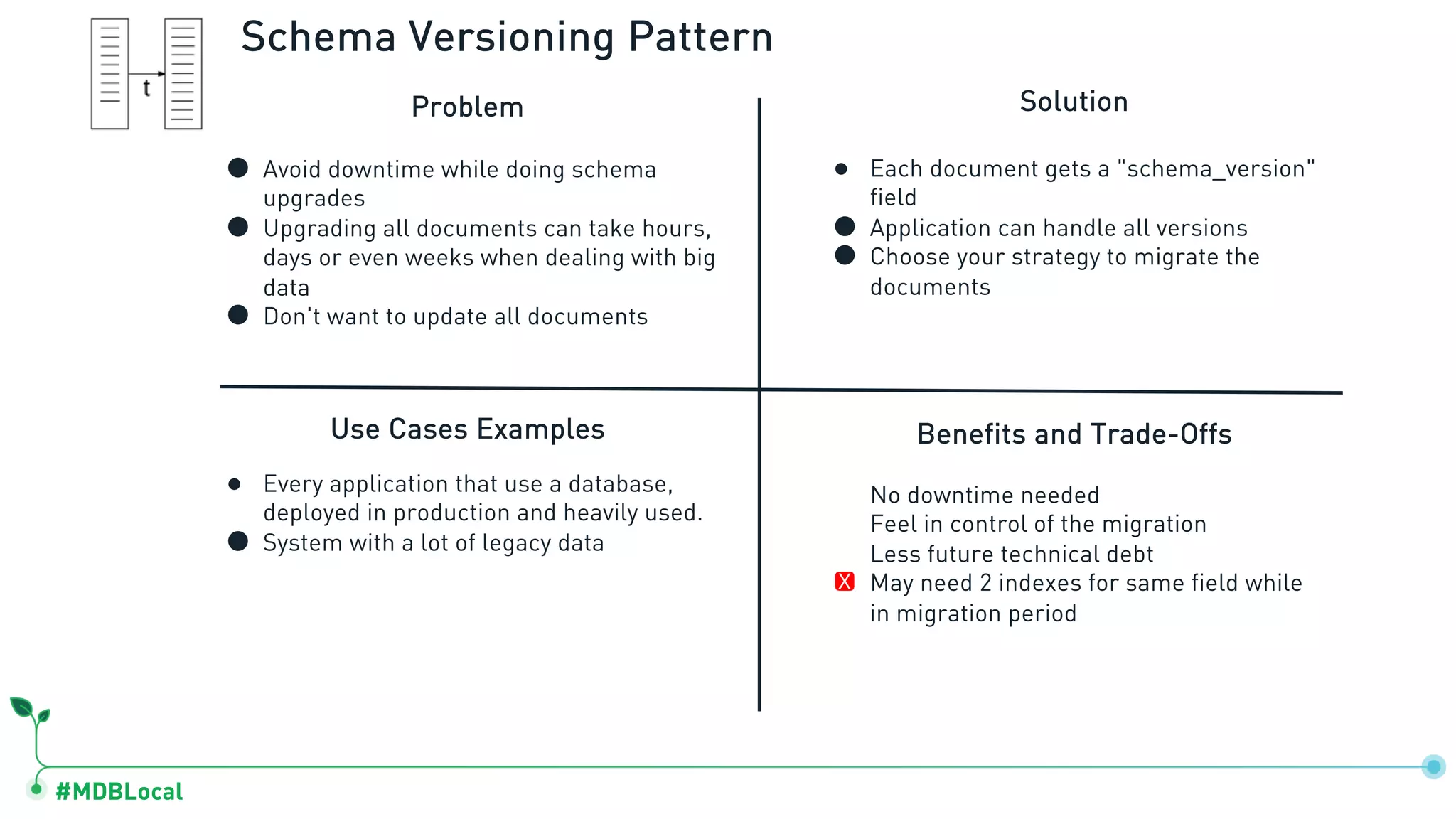

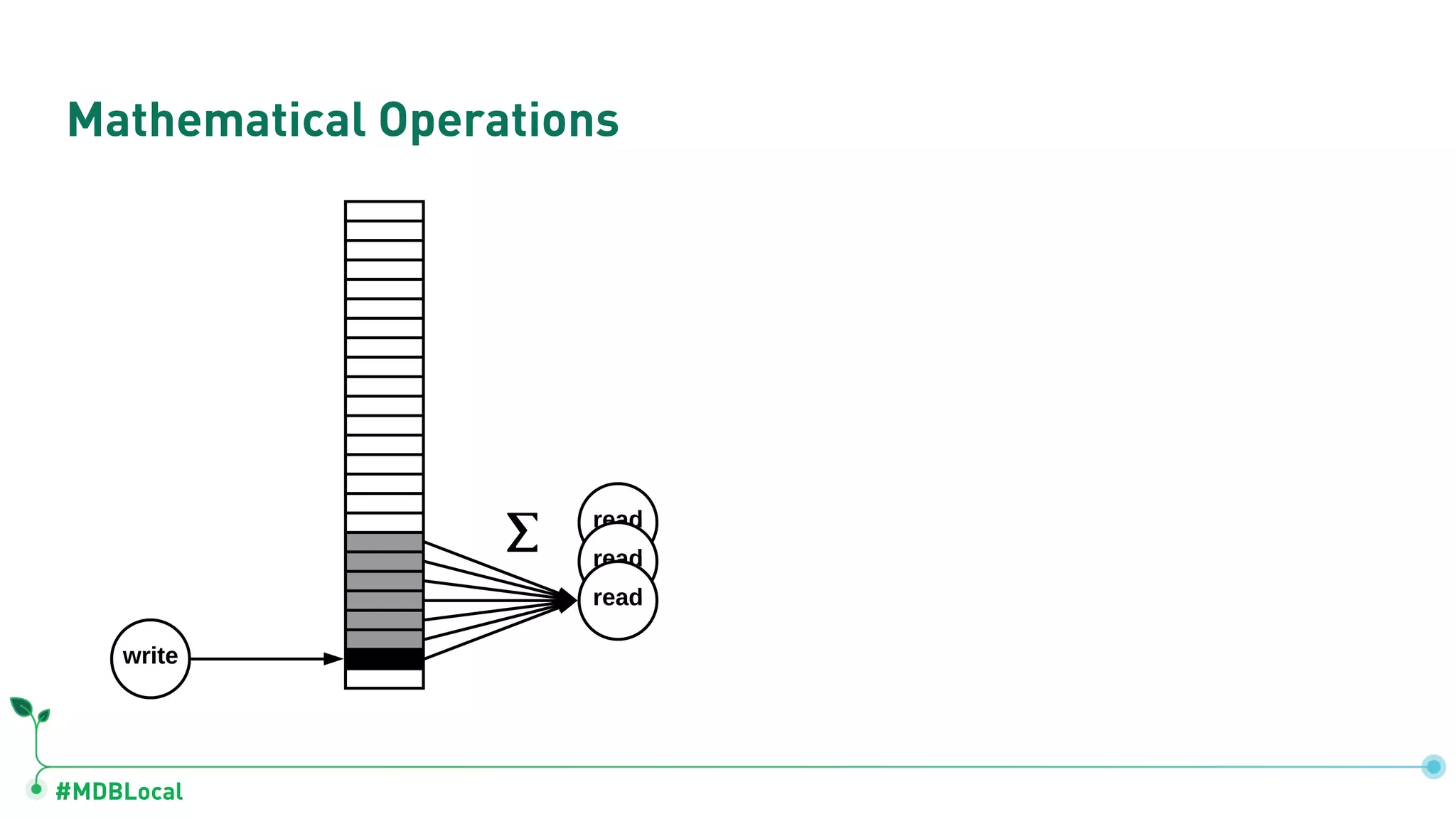
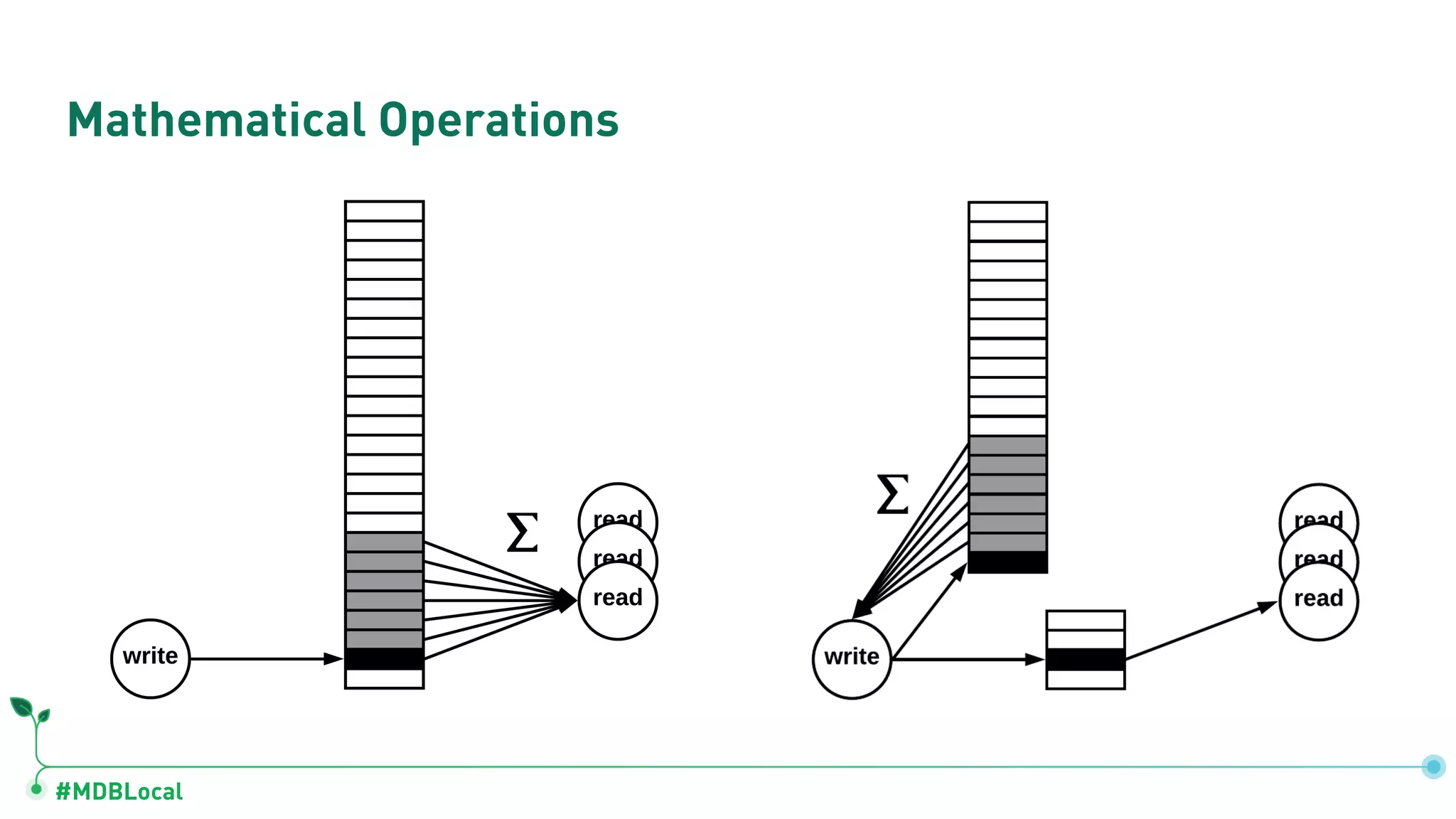
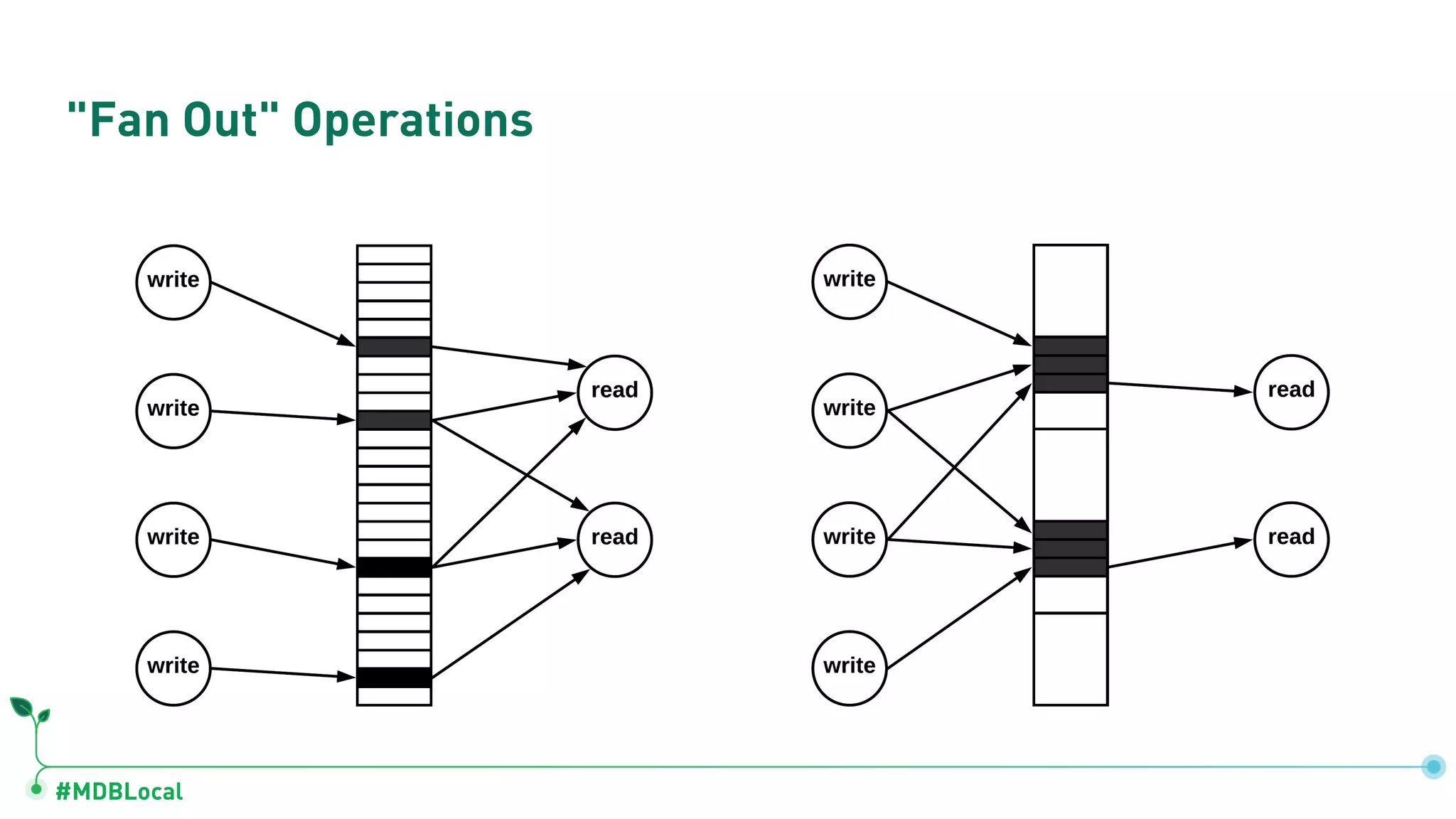
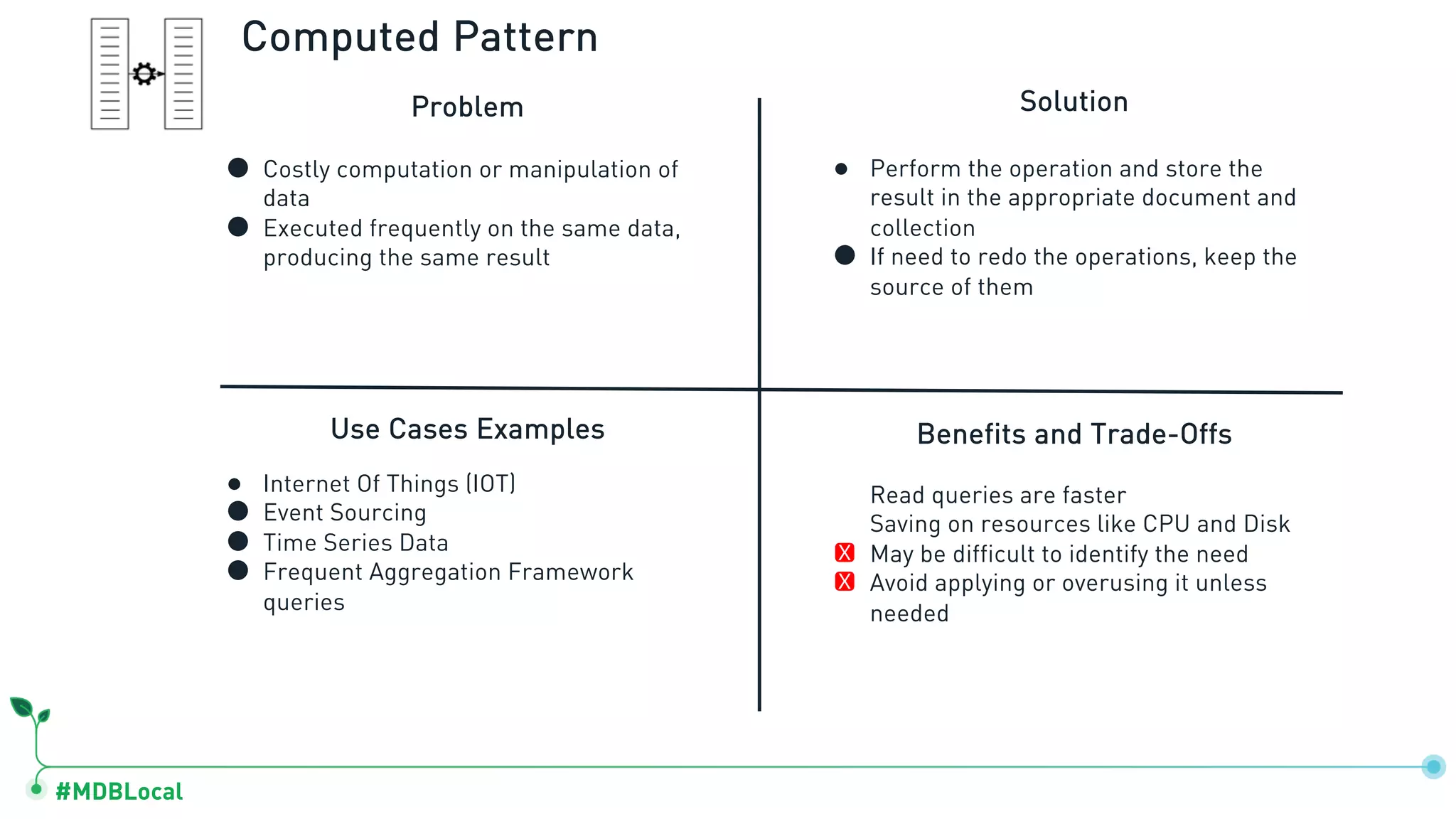


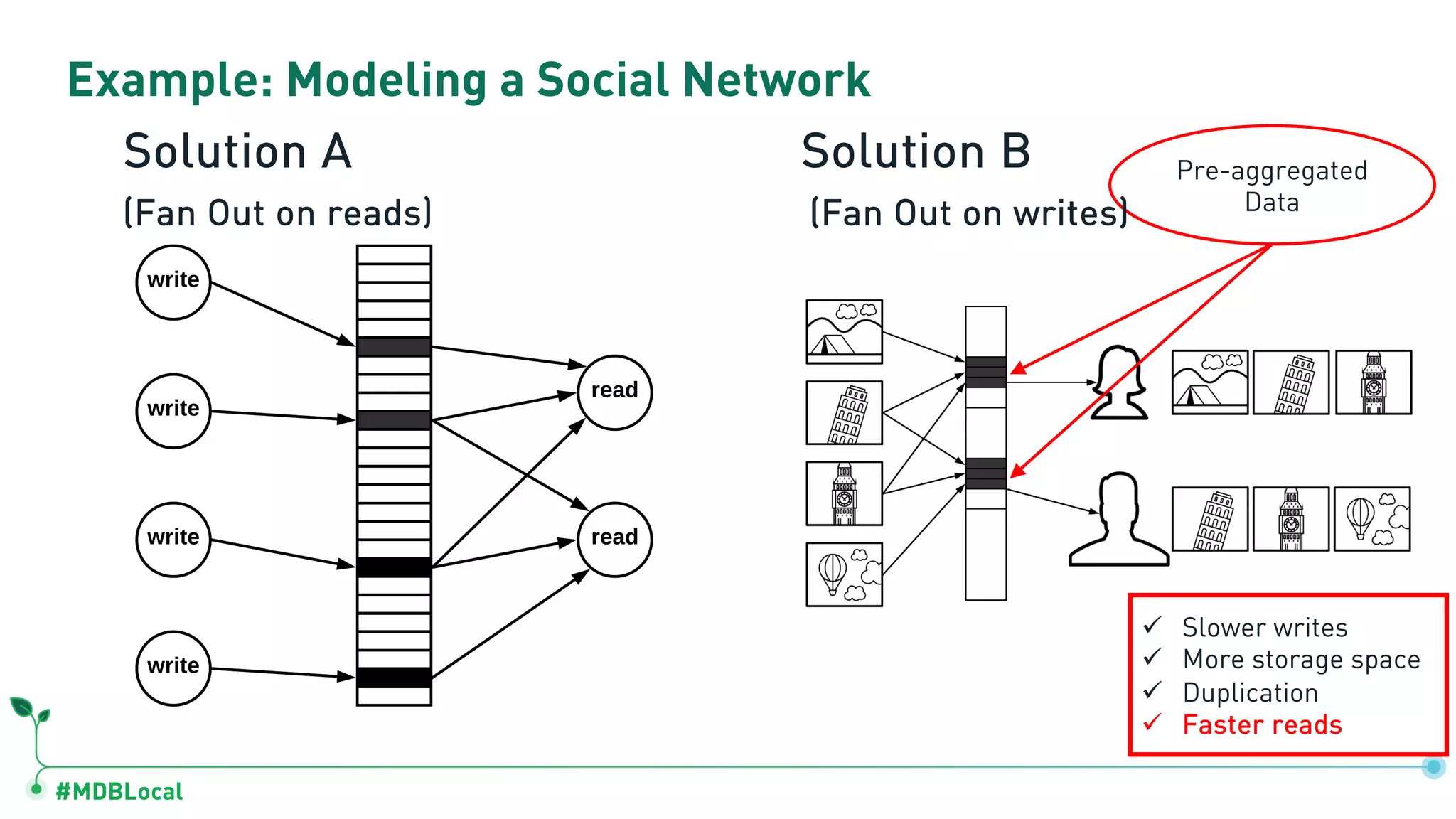
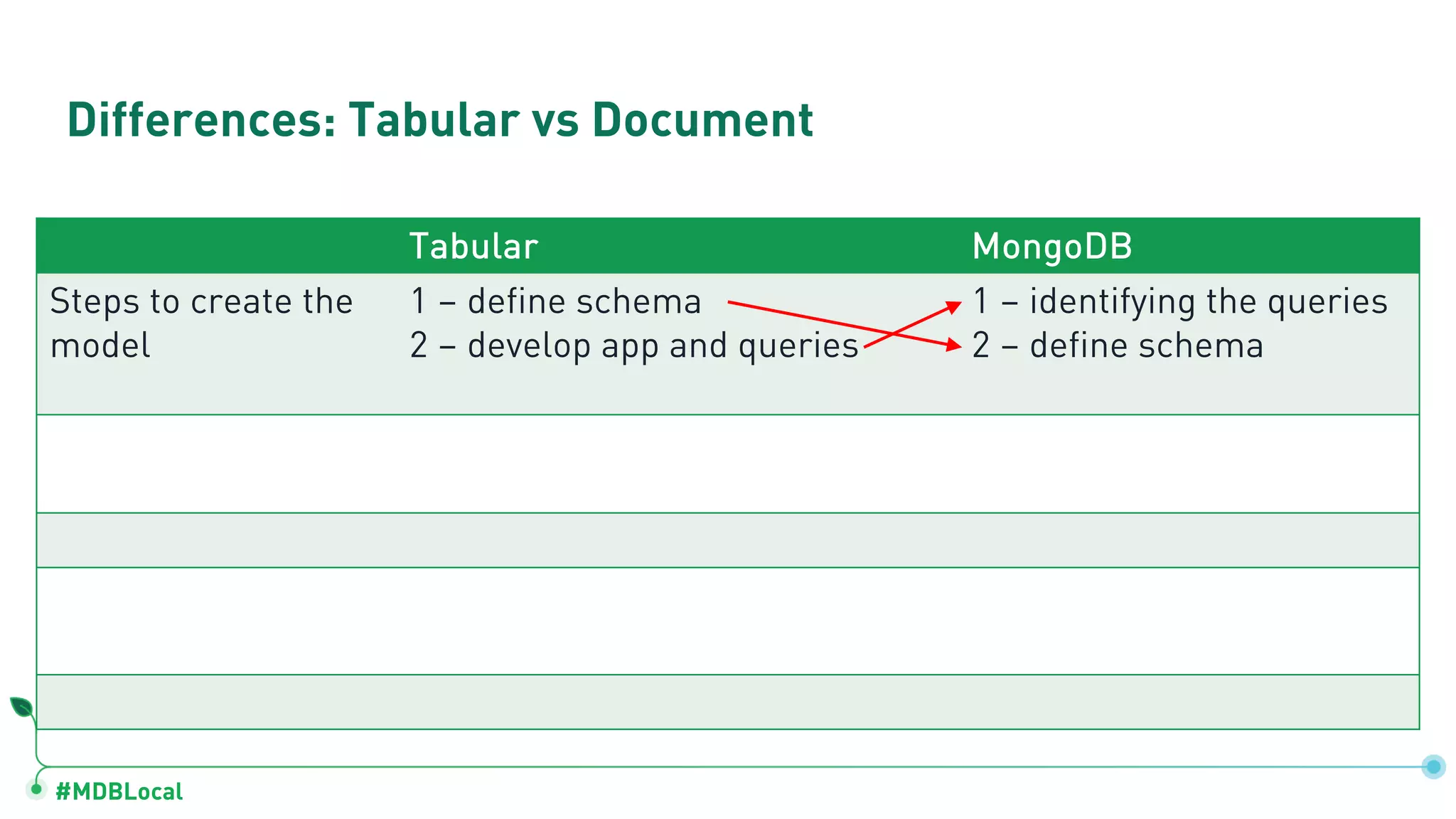
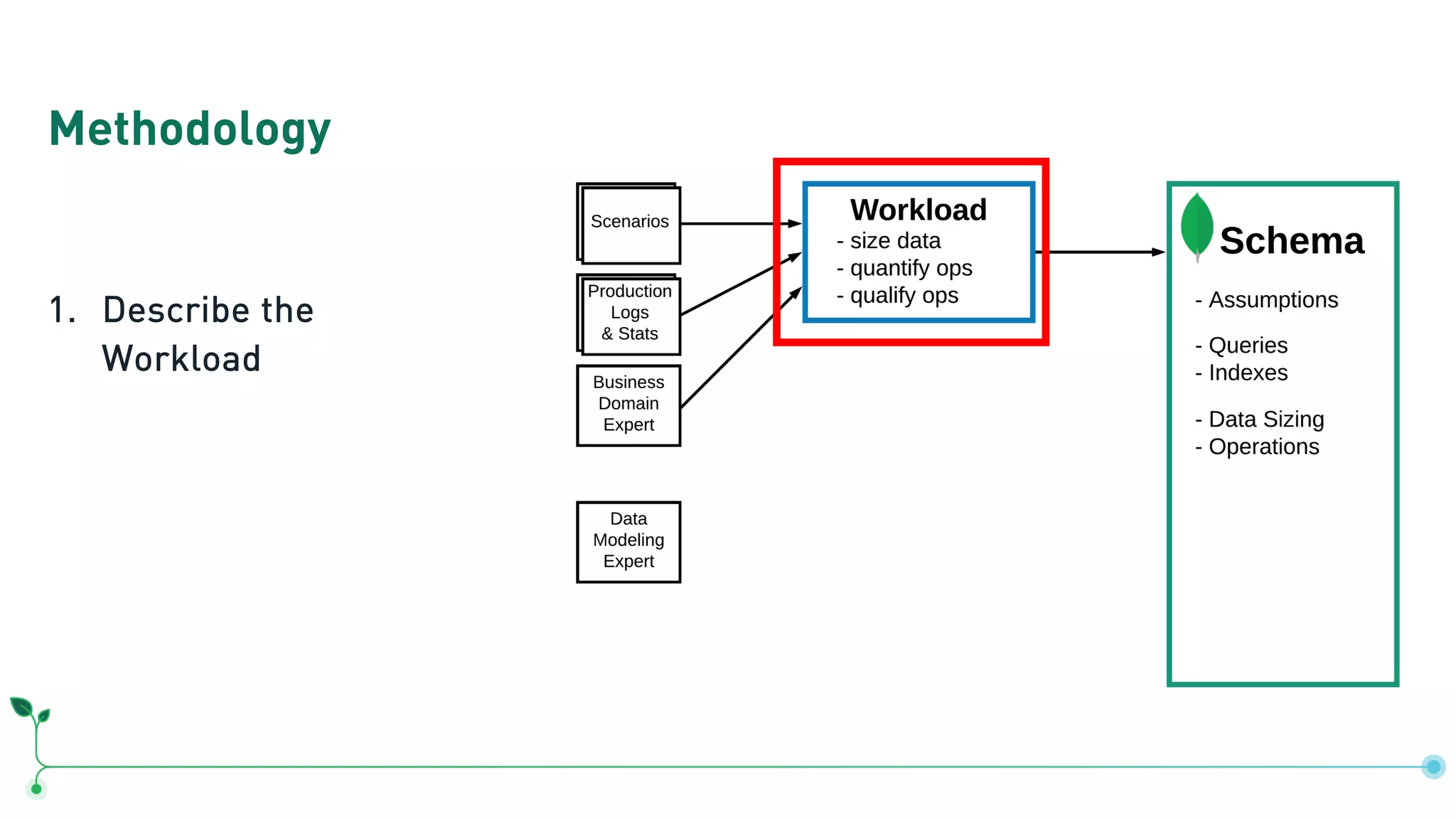
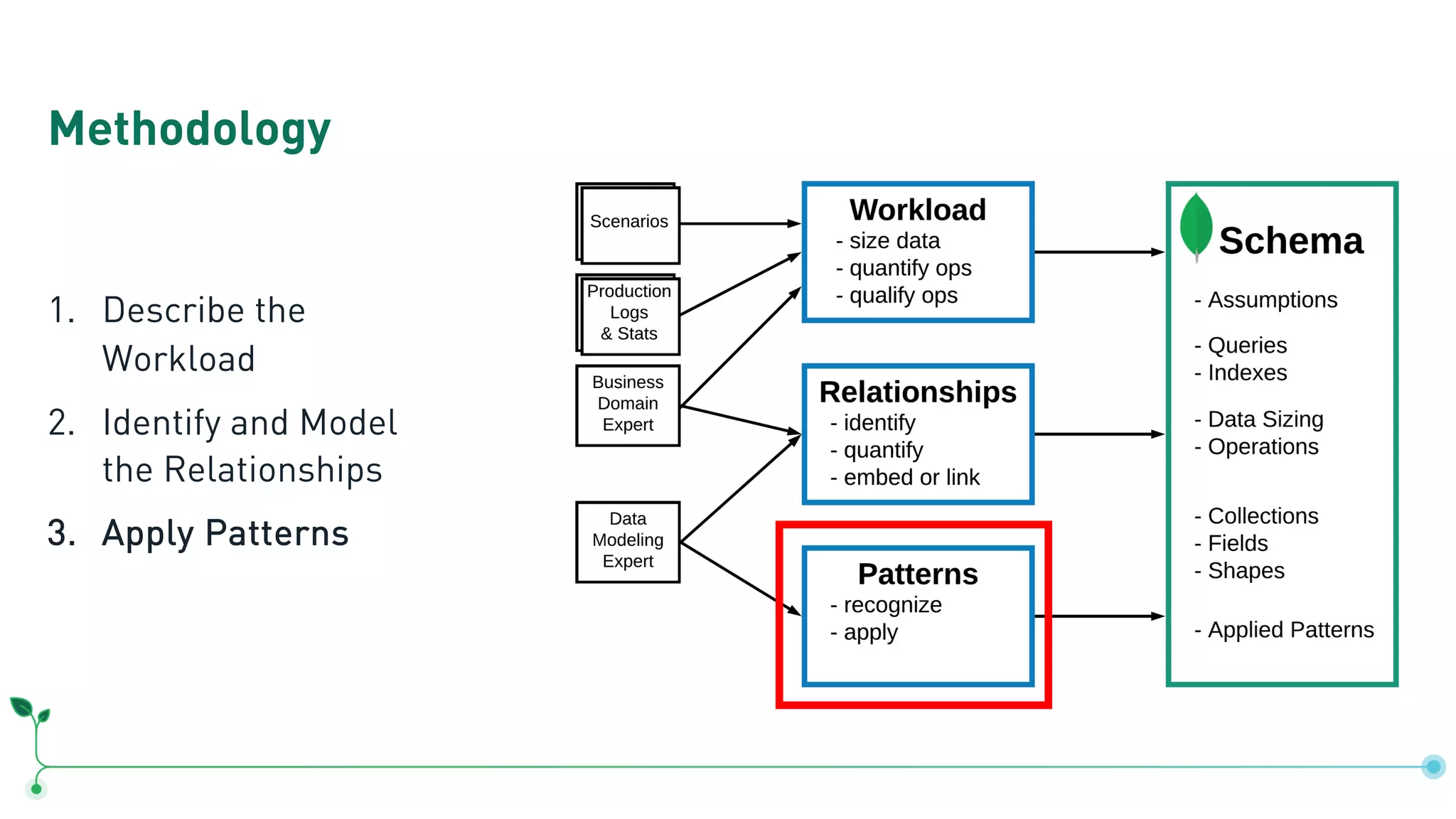
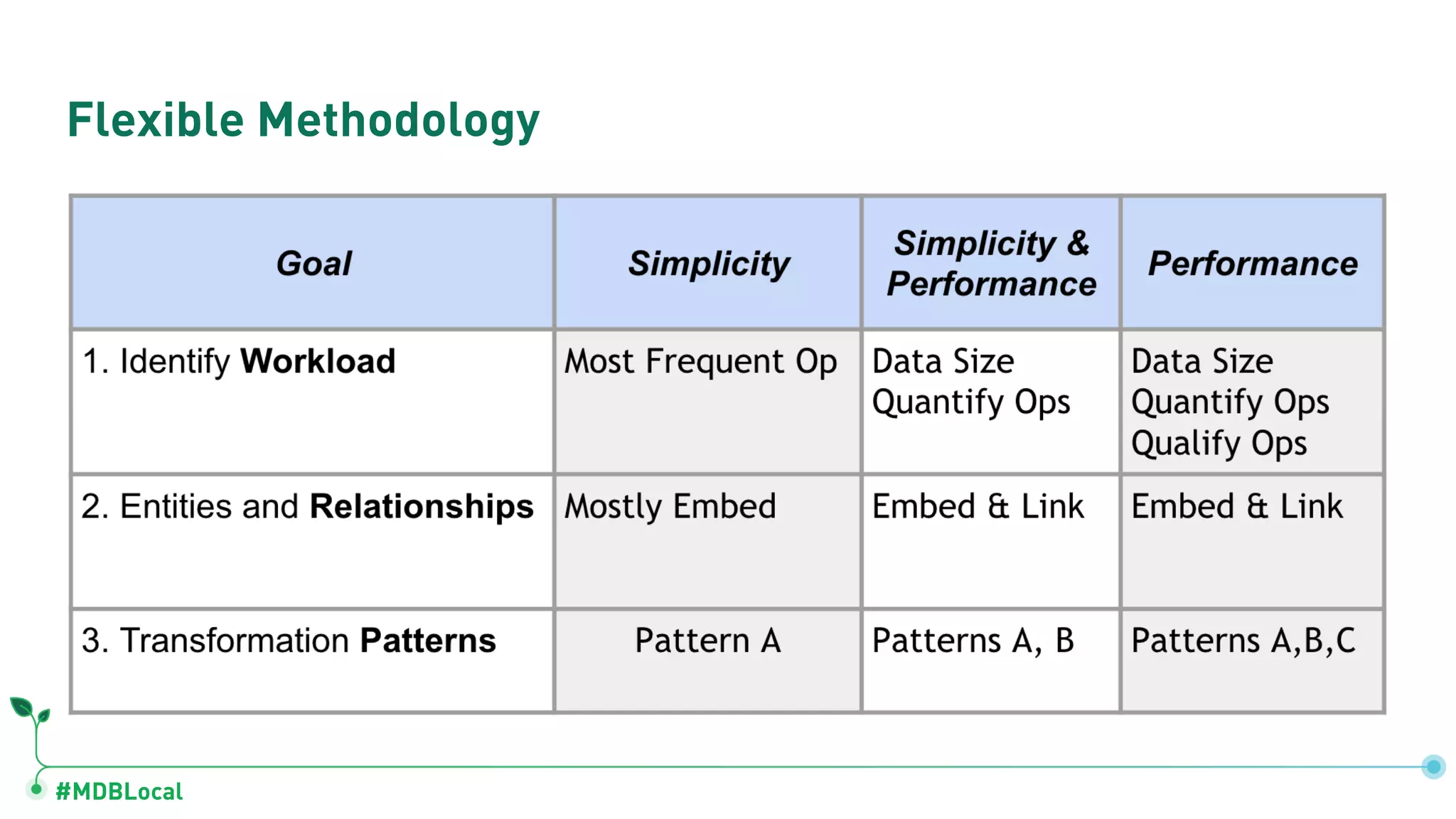
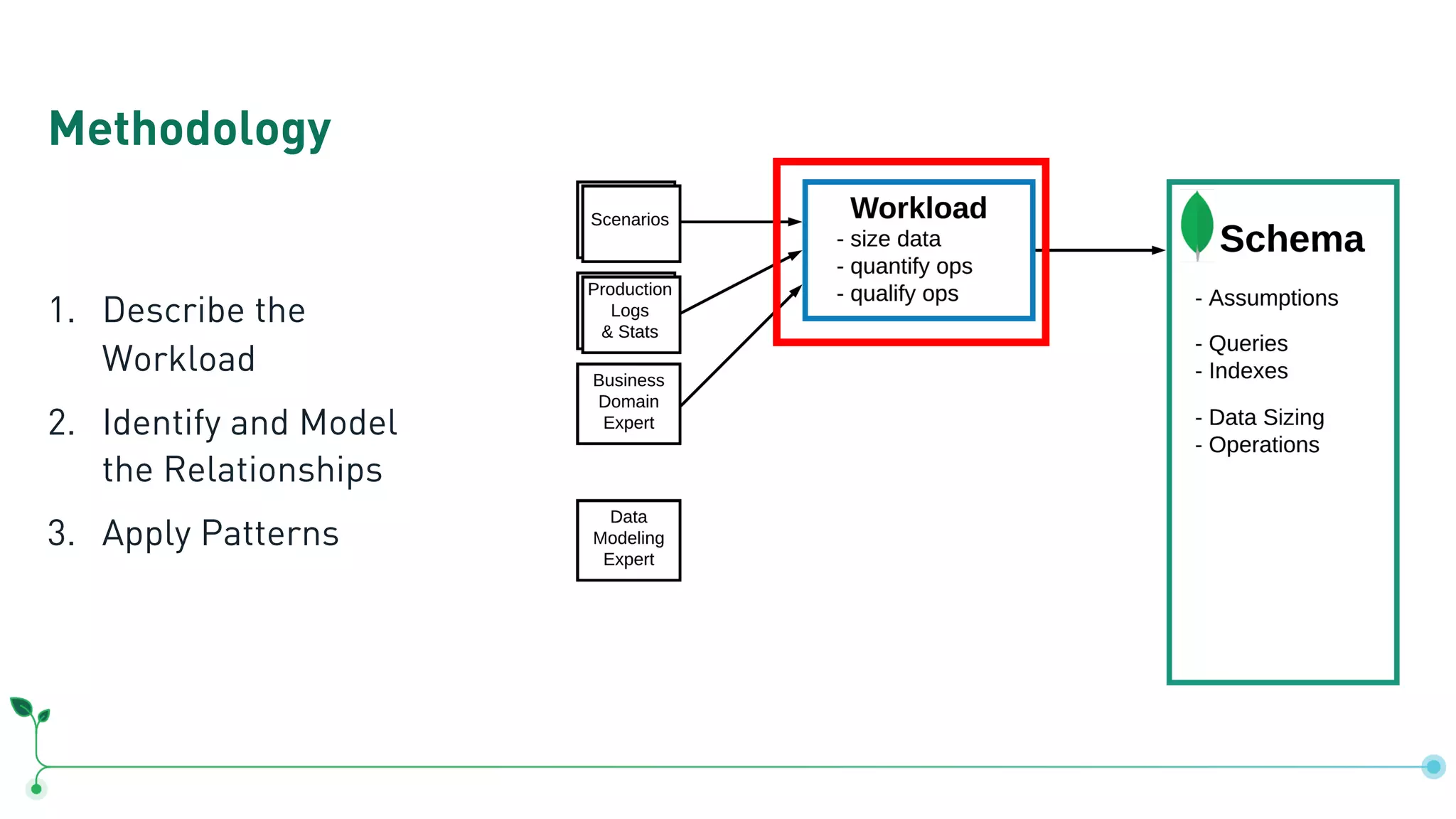
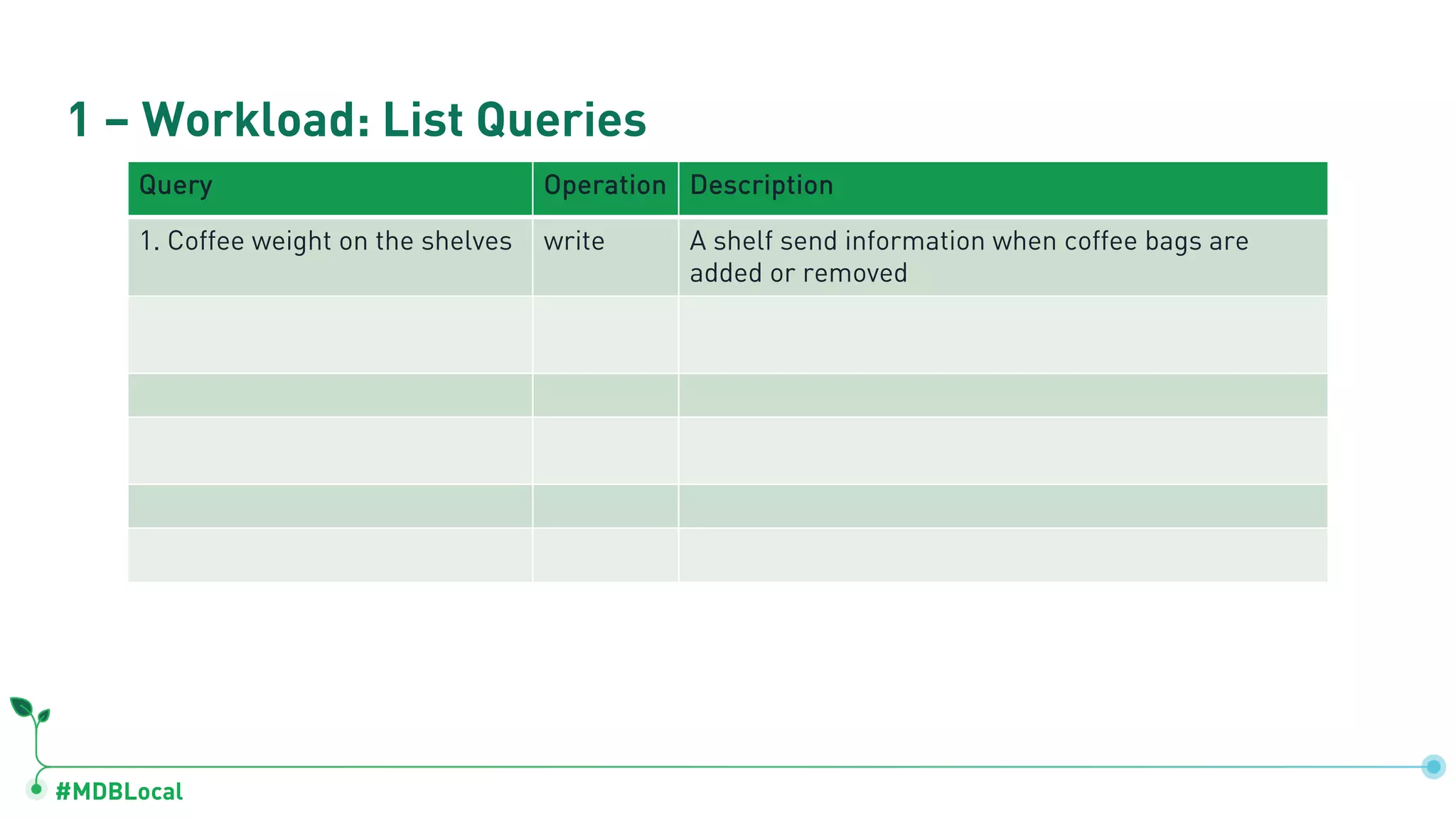
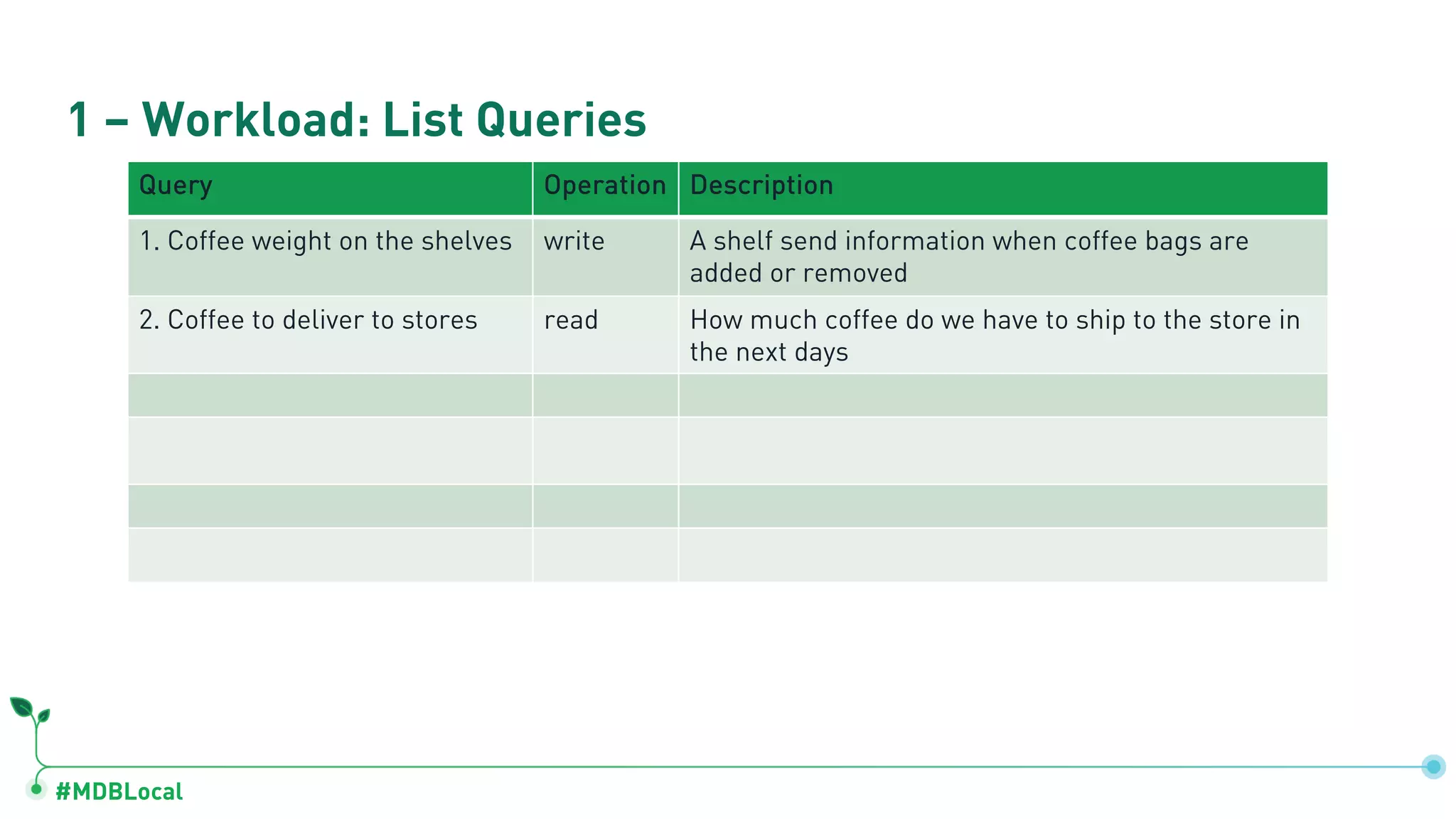
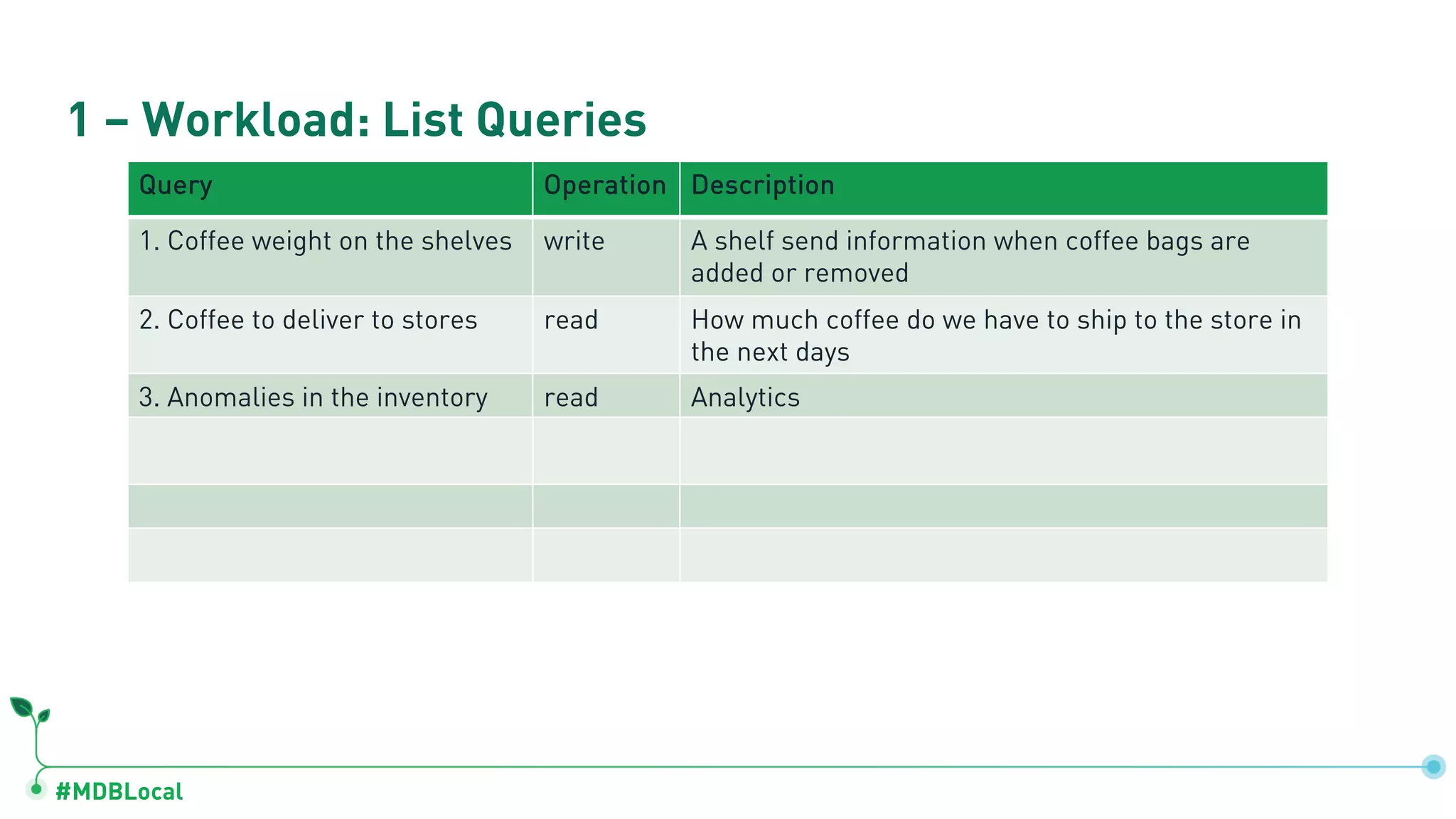
The document outlines a comprehensive methodology for data modeling in MongoDB, comparing it with tabular database structures. It discusses various modeling patterns, schema evolution, and practical case studies, including a coffee shop franchise example, detailing workload descriptions, relationship modeling, and performance considerations. Additionally, it emphasizes the importance of recognizing schema design patterns and executing efficient data management strategies.