Downloaded 61 times






















![Bucket Pattern { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02"), "temp": [ [ 20.0, 20.1, 20.2, ... ], [ 22.1, 22.1, 22.0, ... ], ... ] } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-03"), "temp": [ [ 20.1, 20.2, 20.3, ... ], [ 22.4, 22.4, 22.3, ... ], ... ] } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02T13"), "temp": { 1: 20.0, 2: 20.1, 3: 20.2, ... } } { "device_id": 000123456, "type": "2A", "date": ISODate("2018-03-02T14"), "temp": { 1: 22.1, 2: 22.1, 3: 22.0, ... } } Bucket per Day Bucket per Hour](https://image.slidesharecdn.com/datamodellingformongodb-norbertoleite-190529122117/75/Data-Modeling-for-MongoDB-44-2048.jpg)








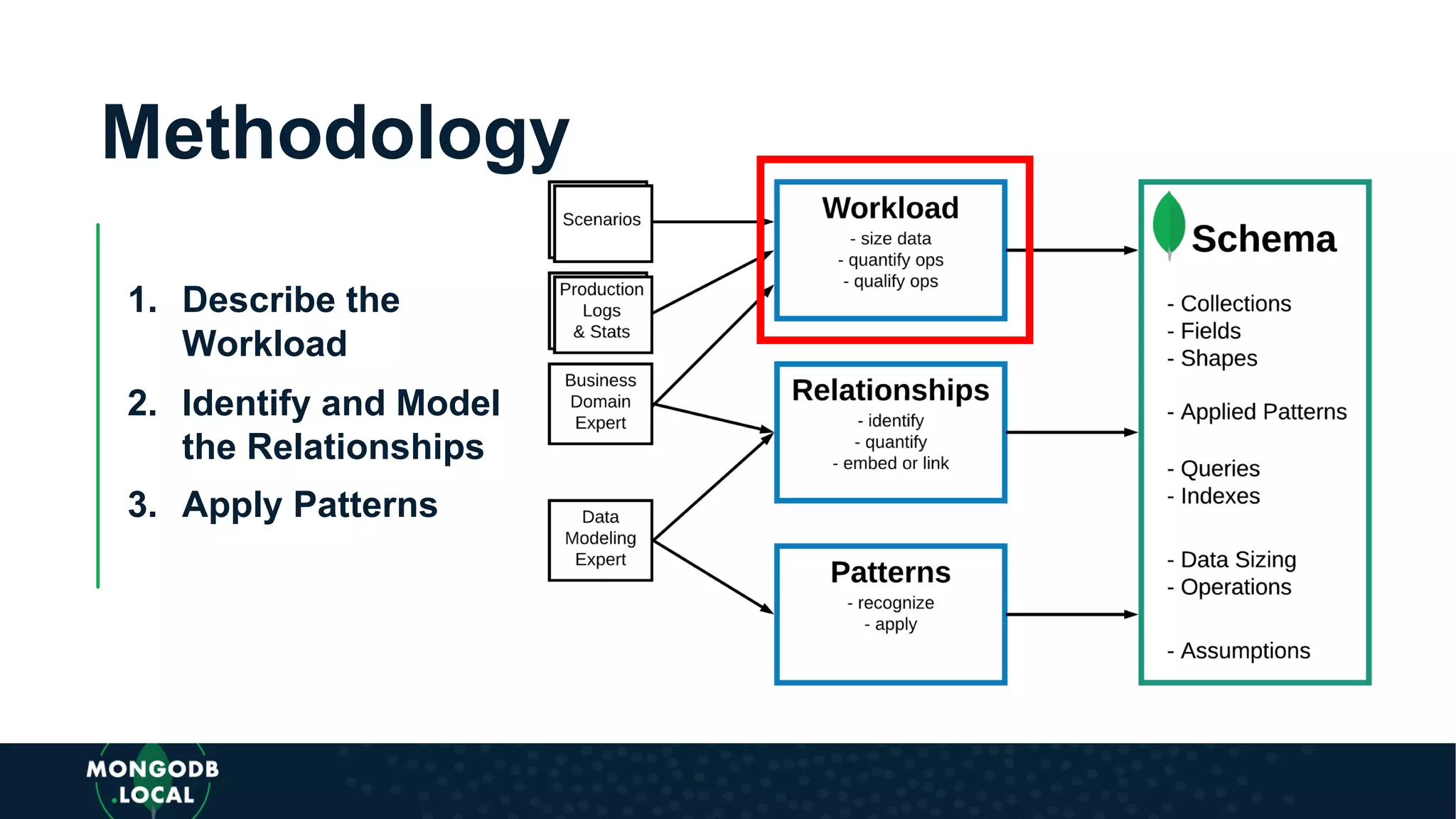
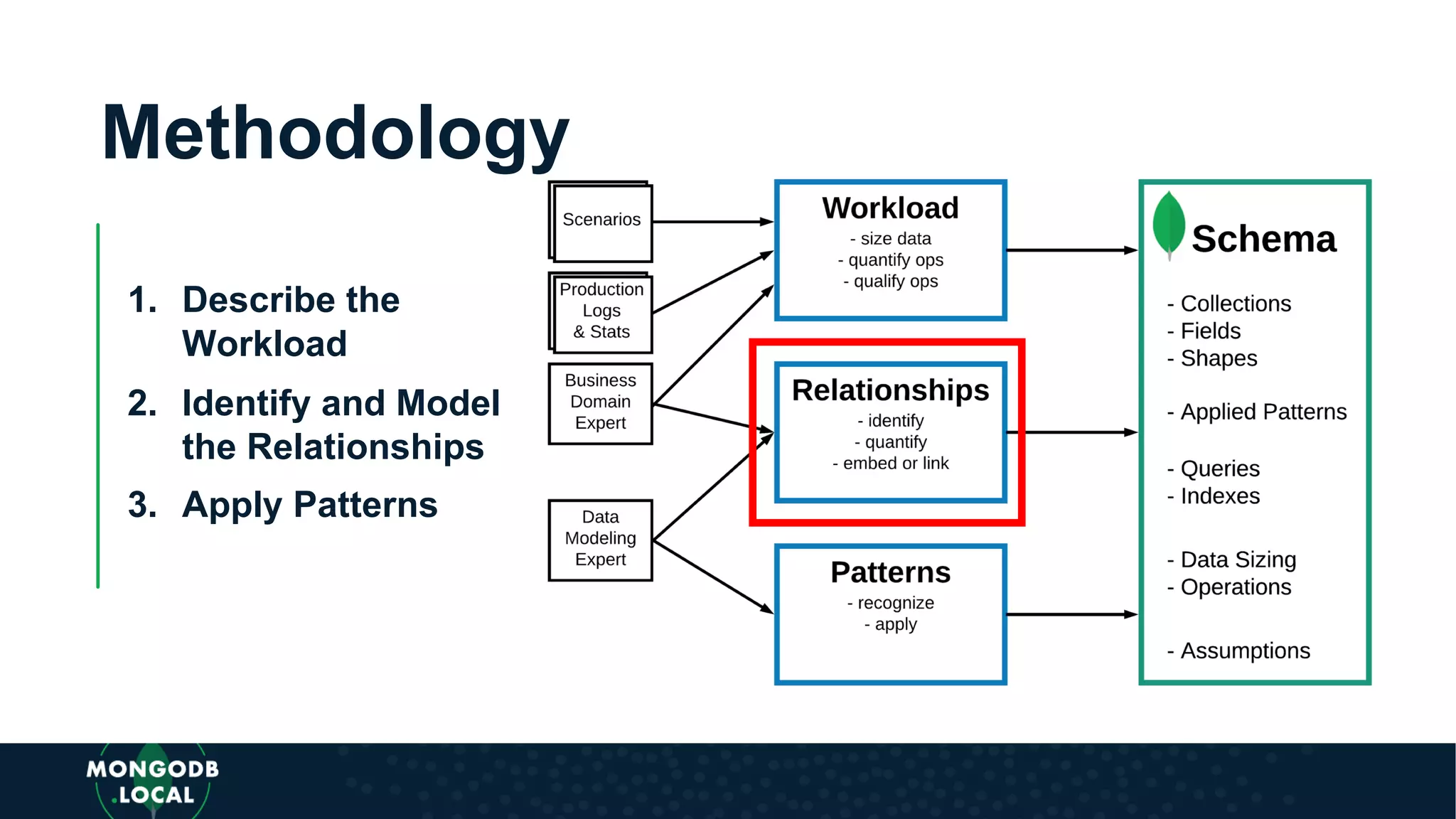
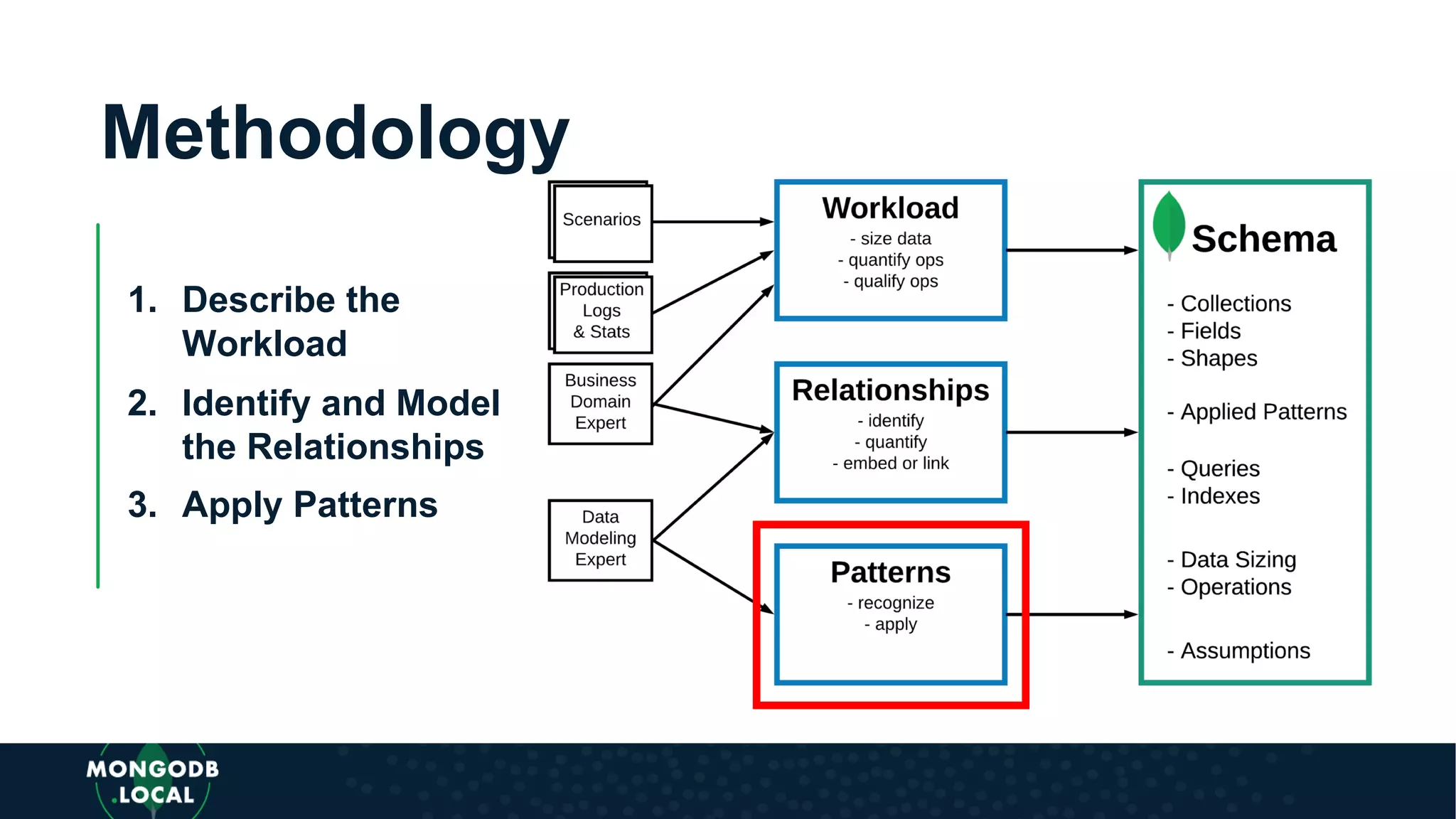
The document discusses data modeling for MongoDB. It begins by recognizing the differences between modeling for a document database versus a relational database. It then outlines a flexible methodology for MongoDB modeling including defining the workload, identifying relationships between entities, and applying schema design patterns. Finally, it recognizes the need to apply patterns like schema versioning, subset, computed, bucket, and external reference when modeling for MongoDB.
Introduction to the presentation, including the speaker's information and resources for MongoDB.
Outlines the main goals including differences in modelling for Document vs Relational Databases and methodology for MongoDB.
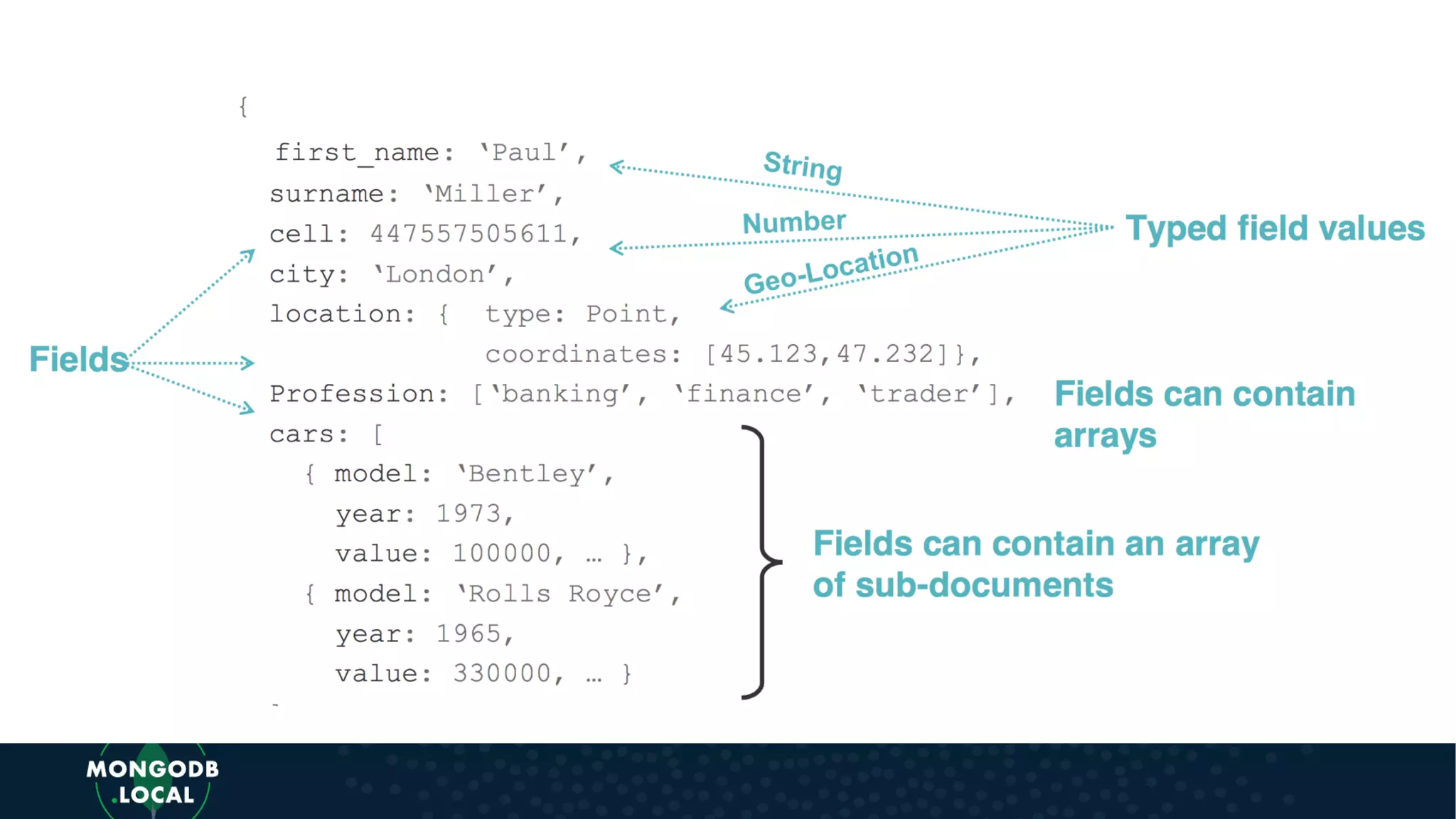
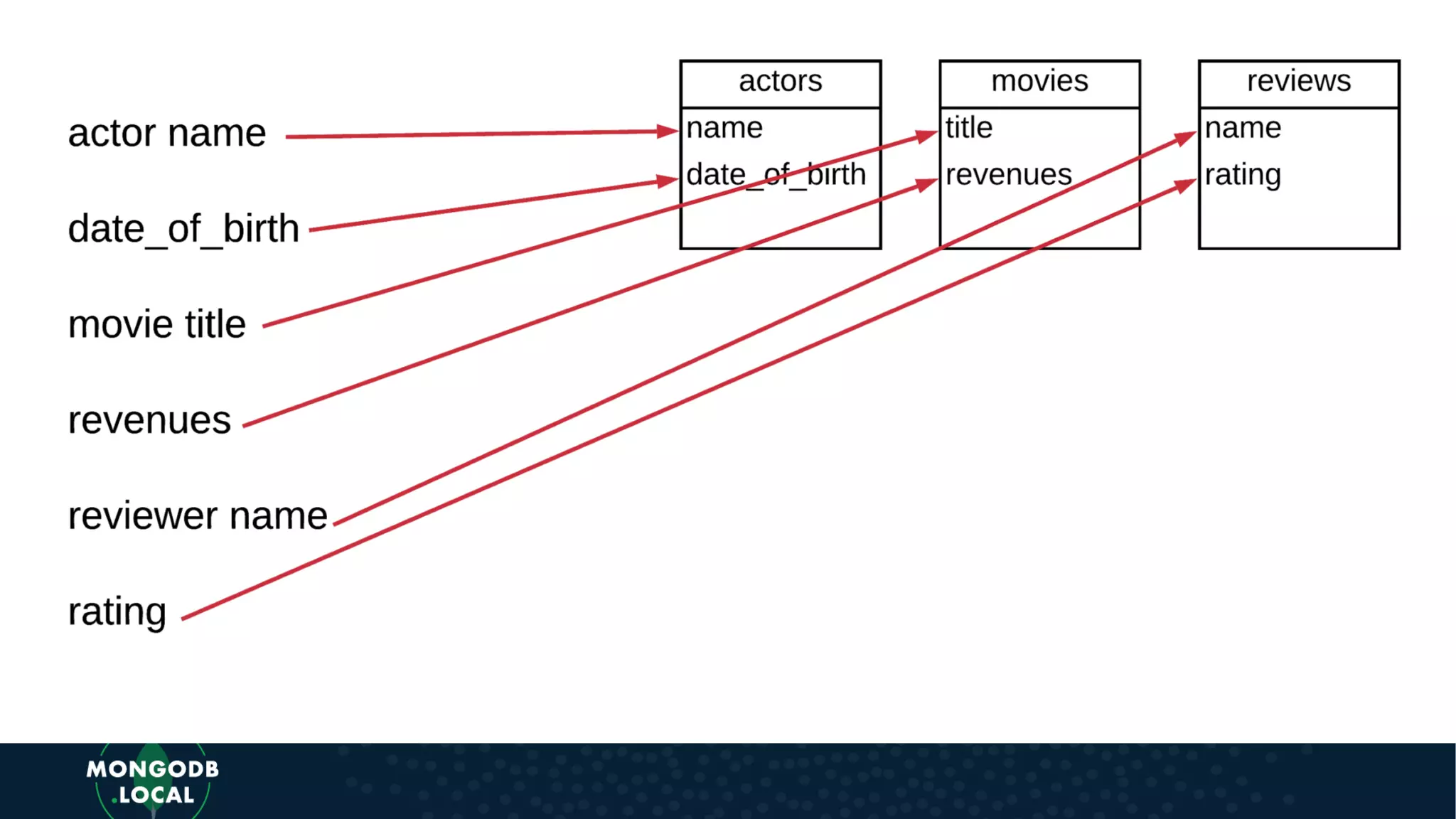
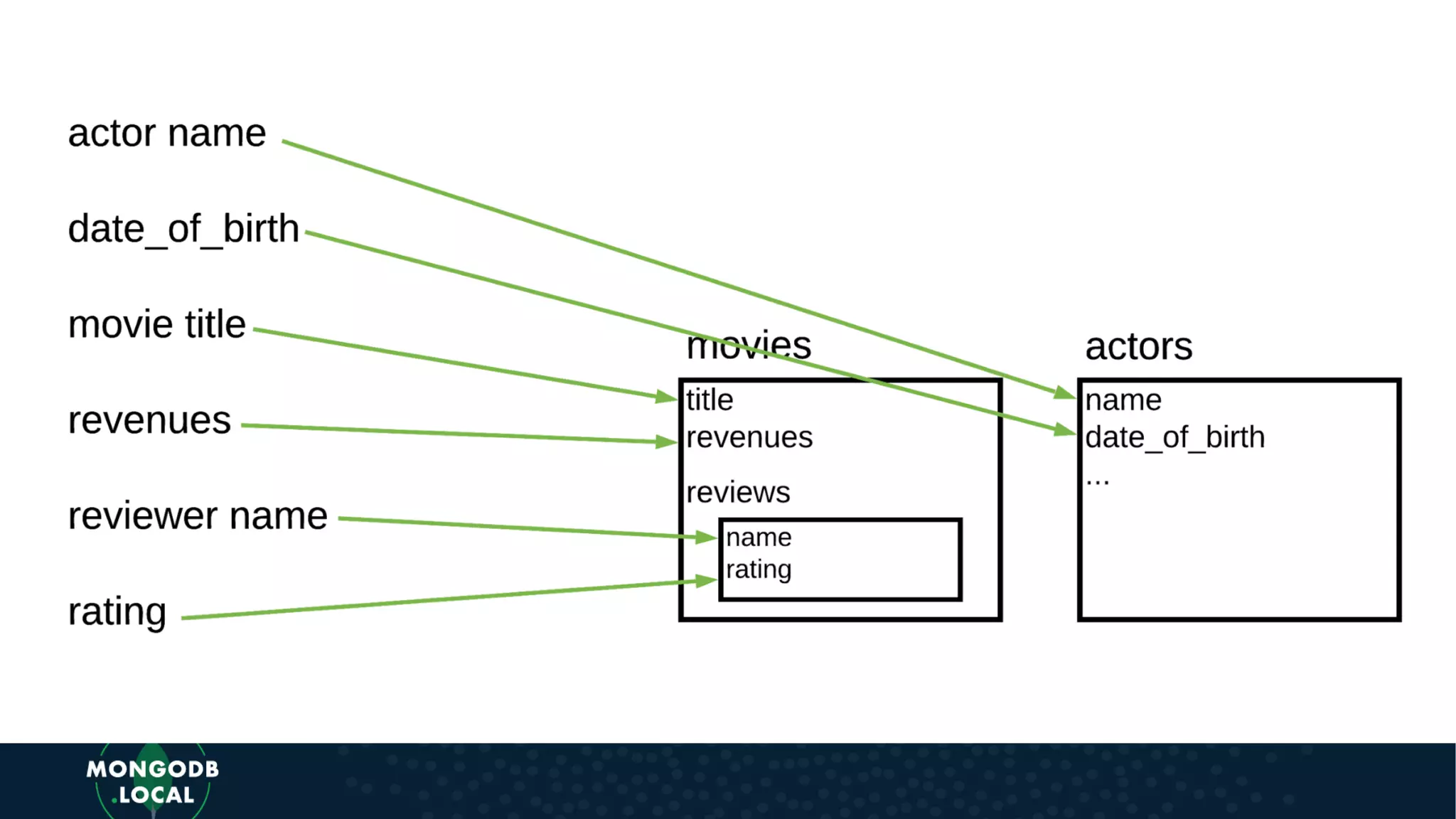
Discusses key differences when modelling for Document Databases versus Relational, emphasizing structures like arrays and sub-documents.
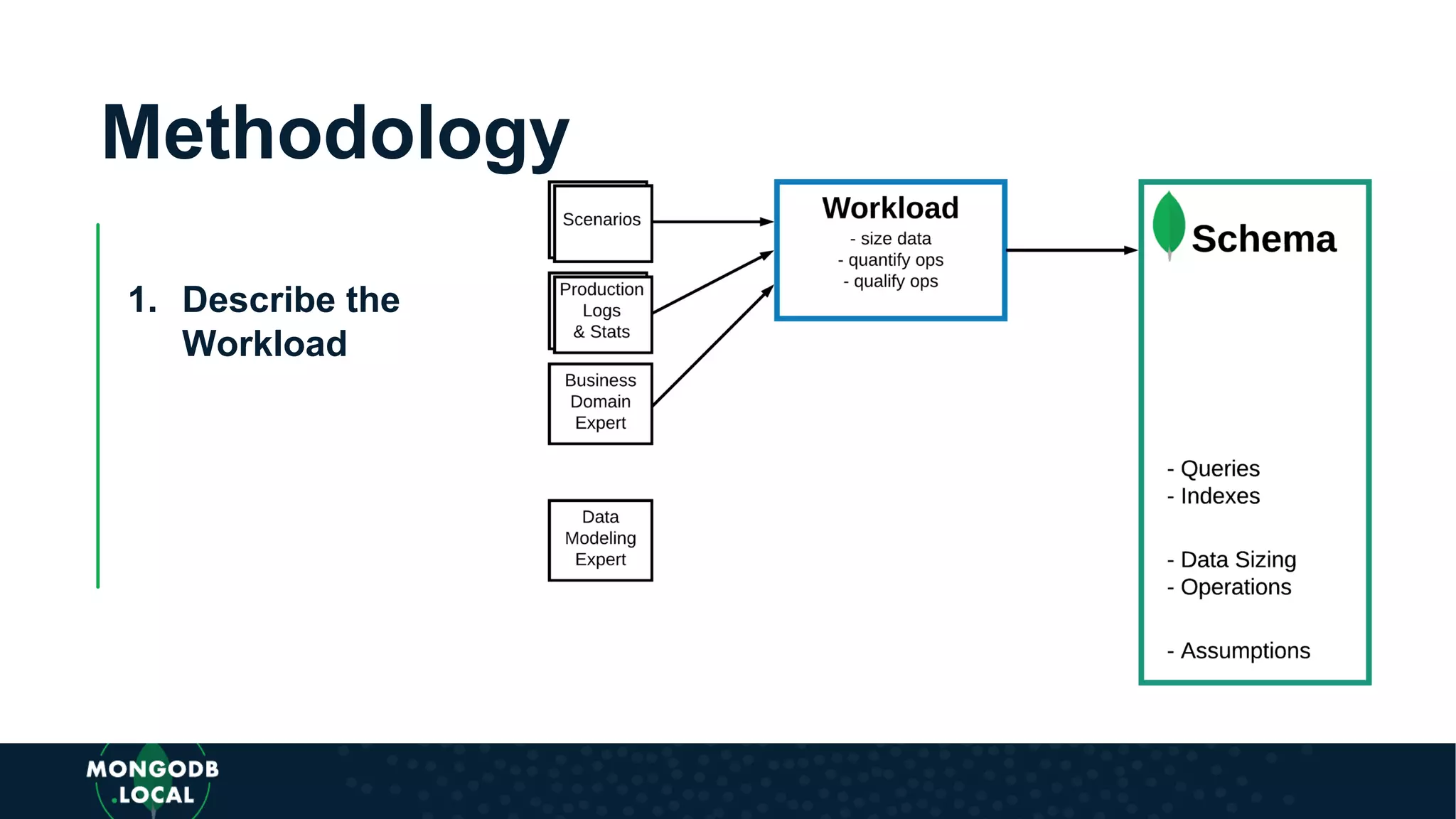
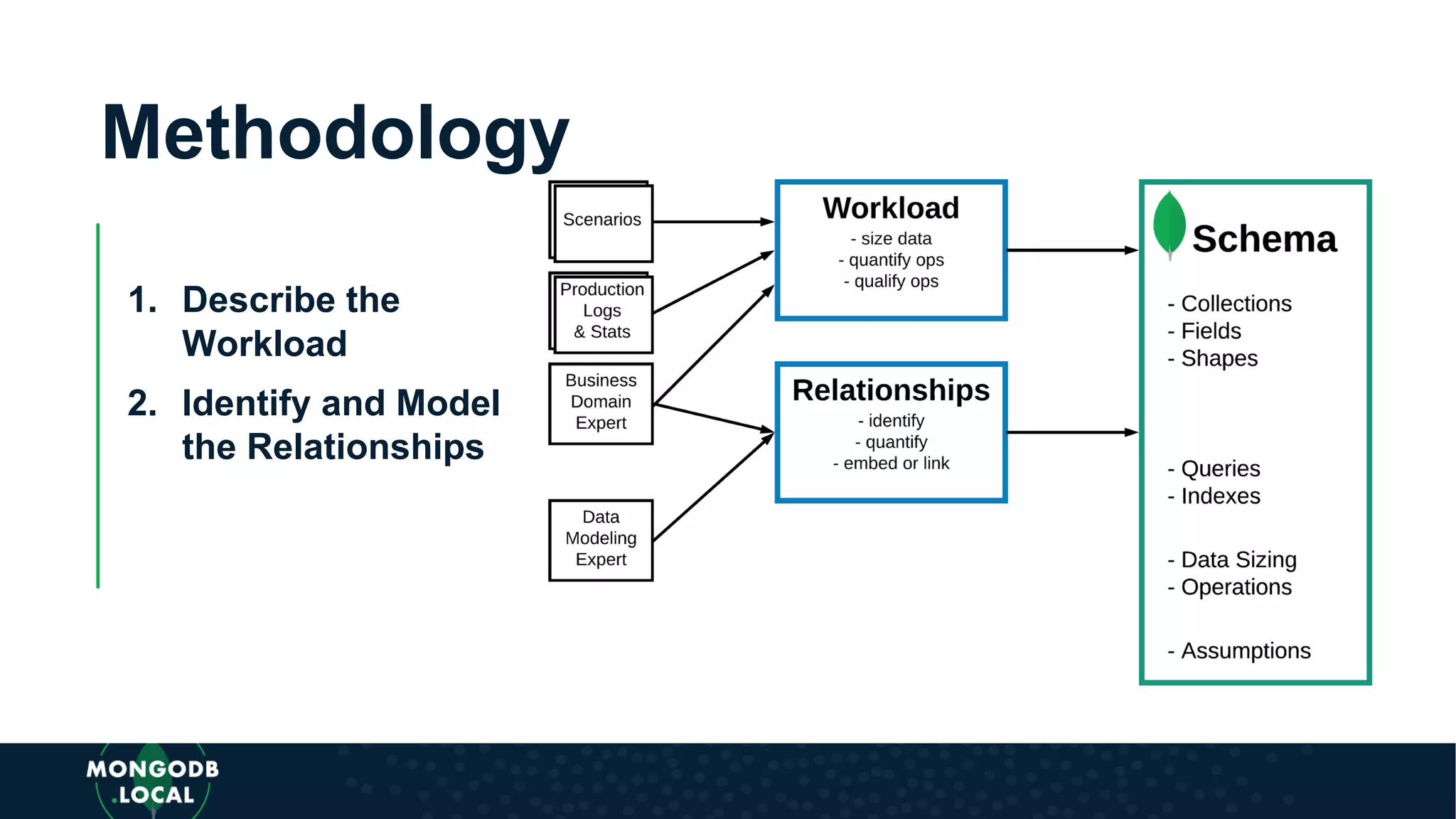
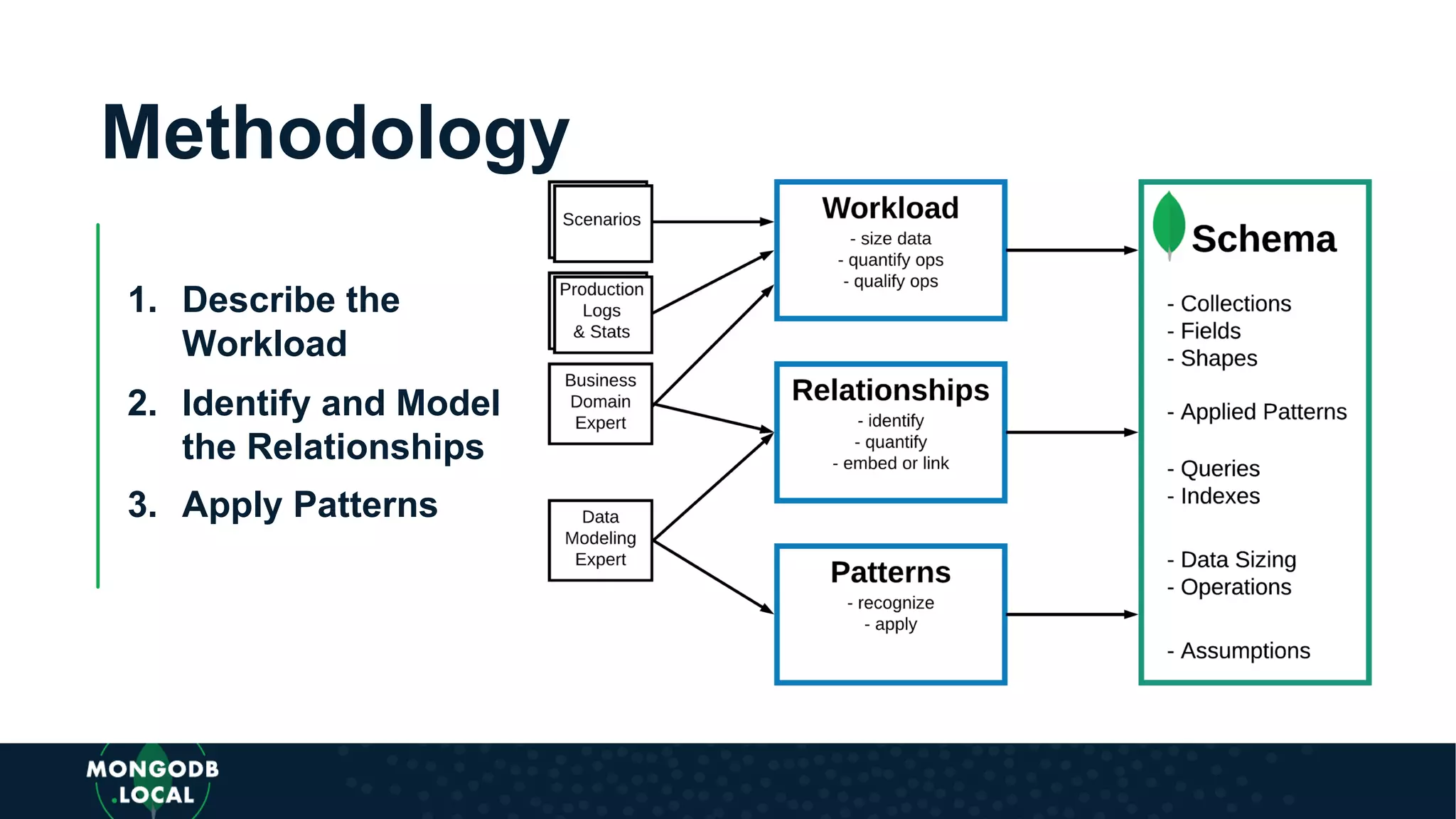
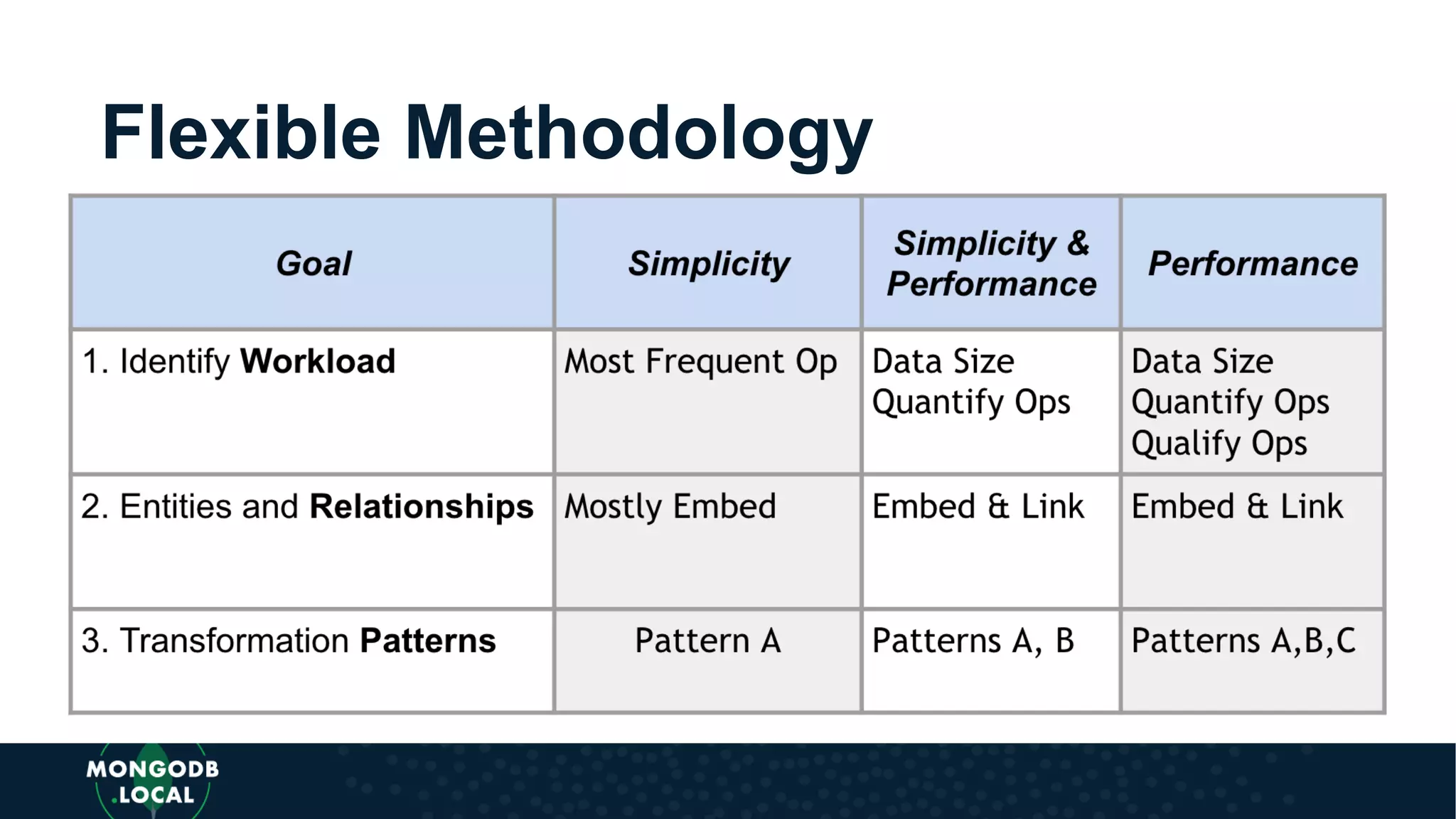
Introduces a flexible methodology for MongoDB modelling, focusing on workload description and relationship identification.
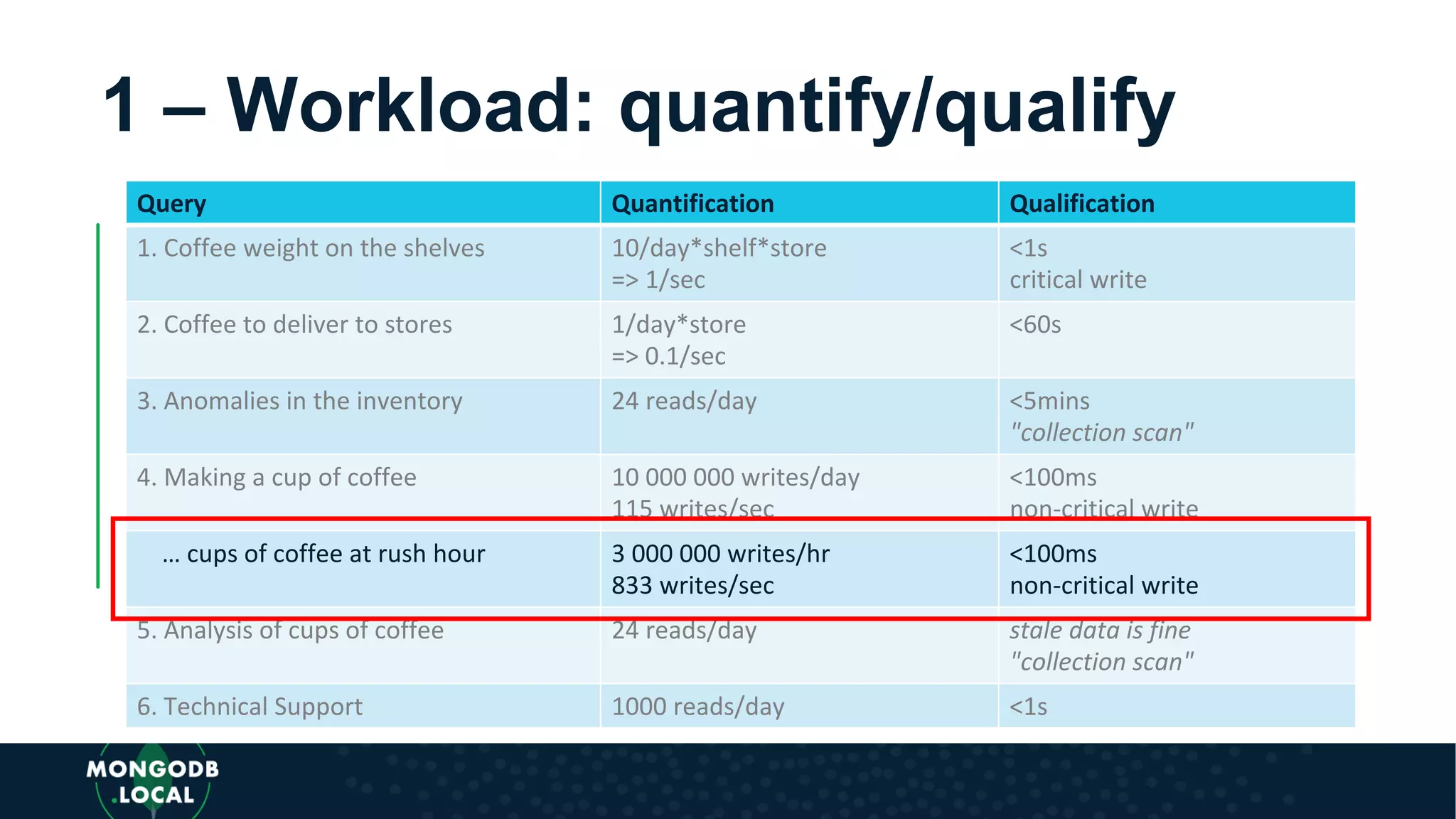
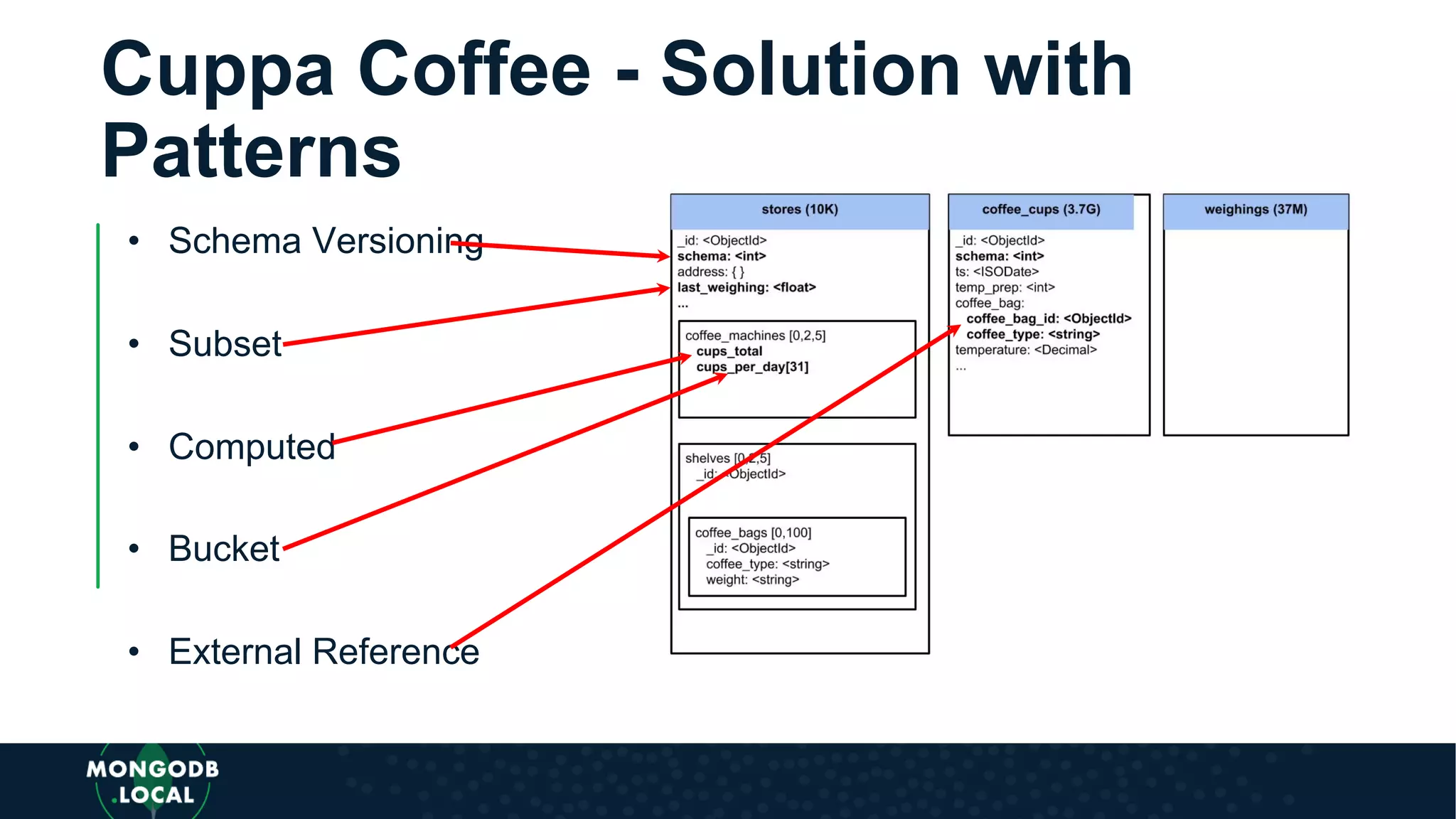
Case study about Cuppa Coffee's objectives and operational technology, including inventory and data analysis needs. Detailed workload quantification with queries about coffee production, deliveries, and inventory analysis.
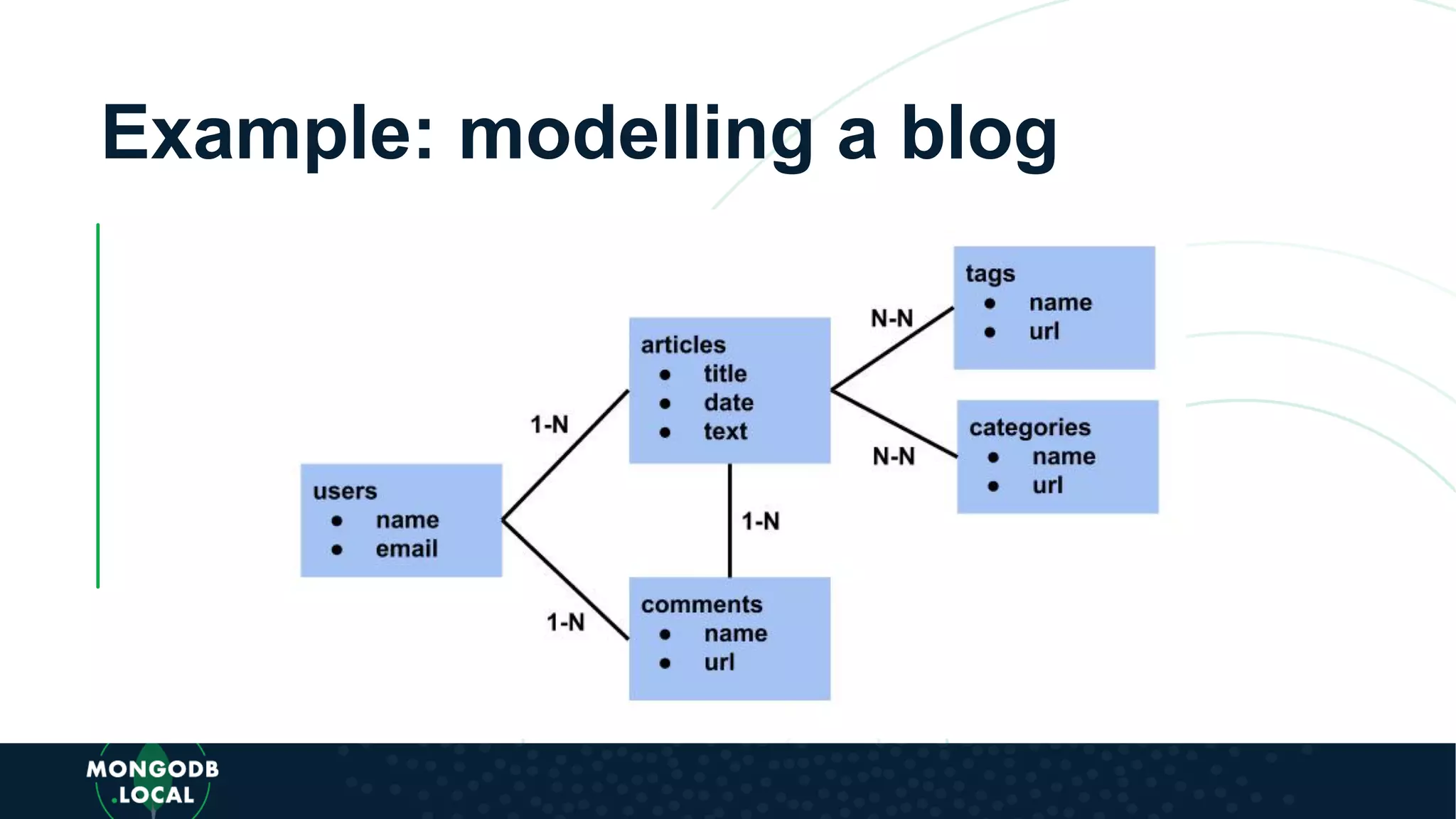
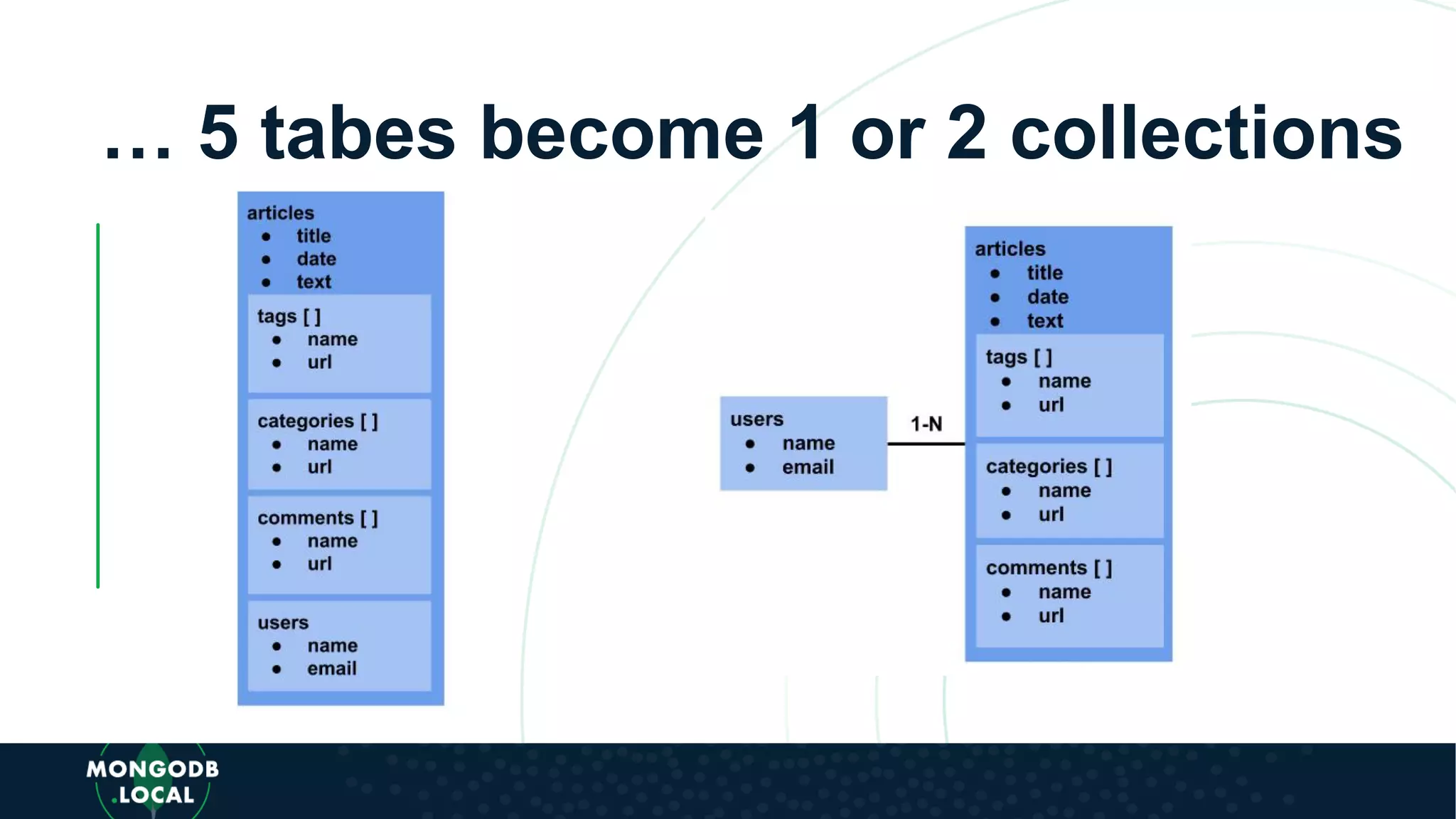
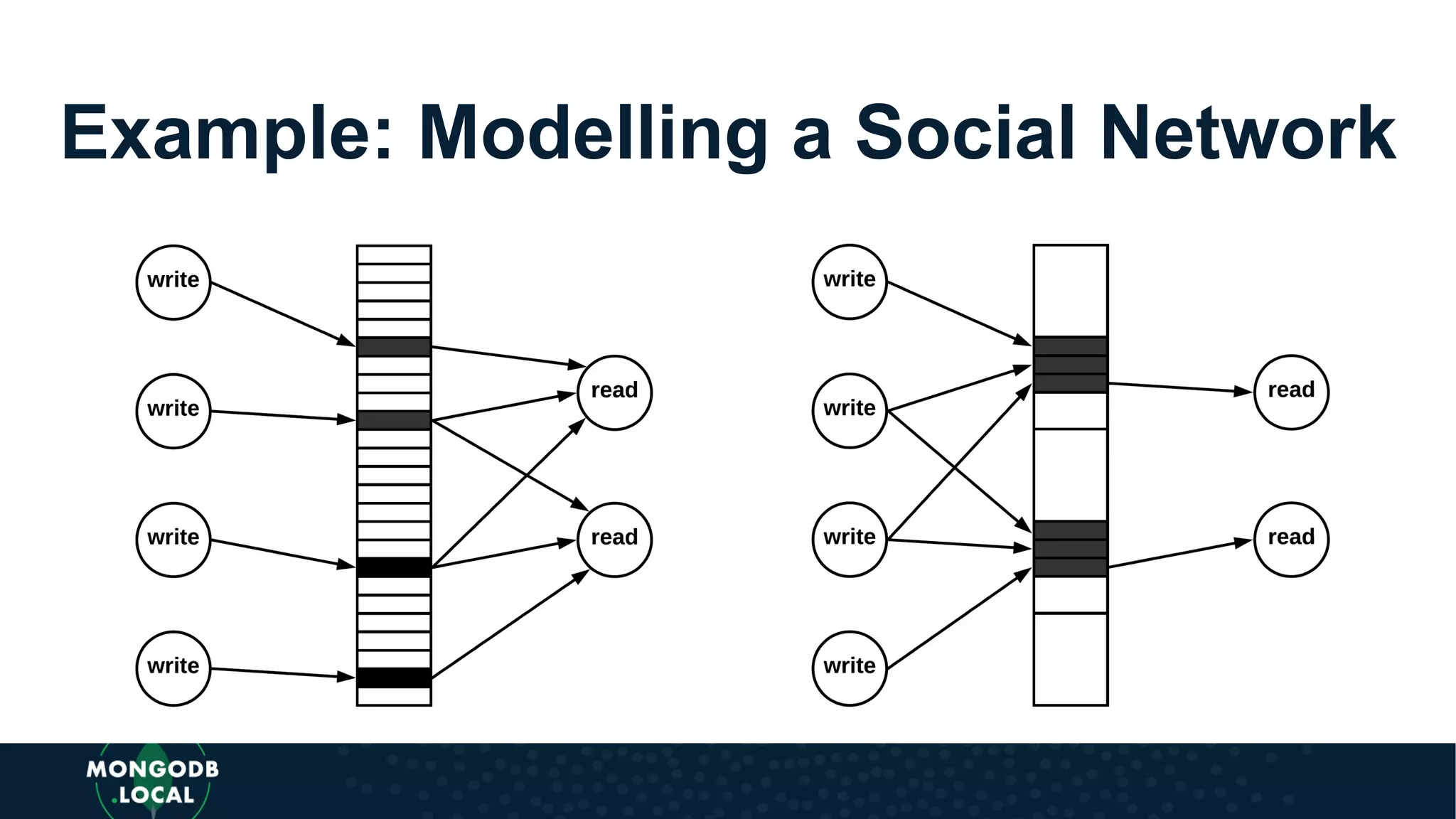
Emphasis on the importance of relationships in document modelling including one-to-one and one-to-many relationships.
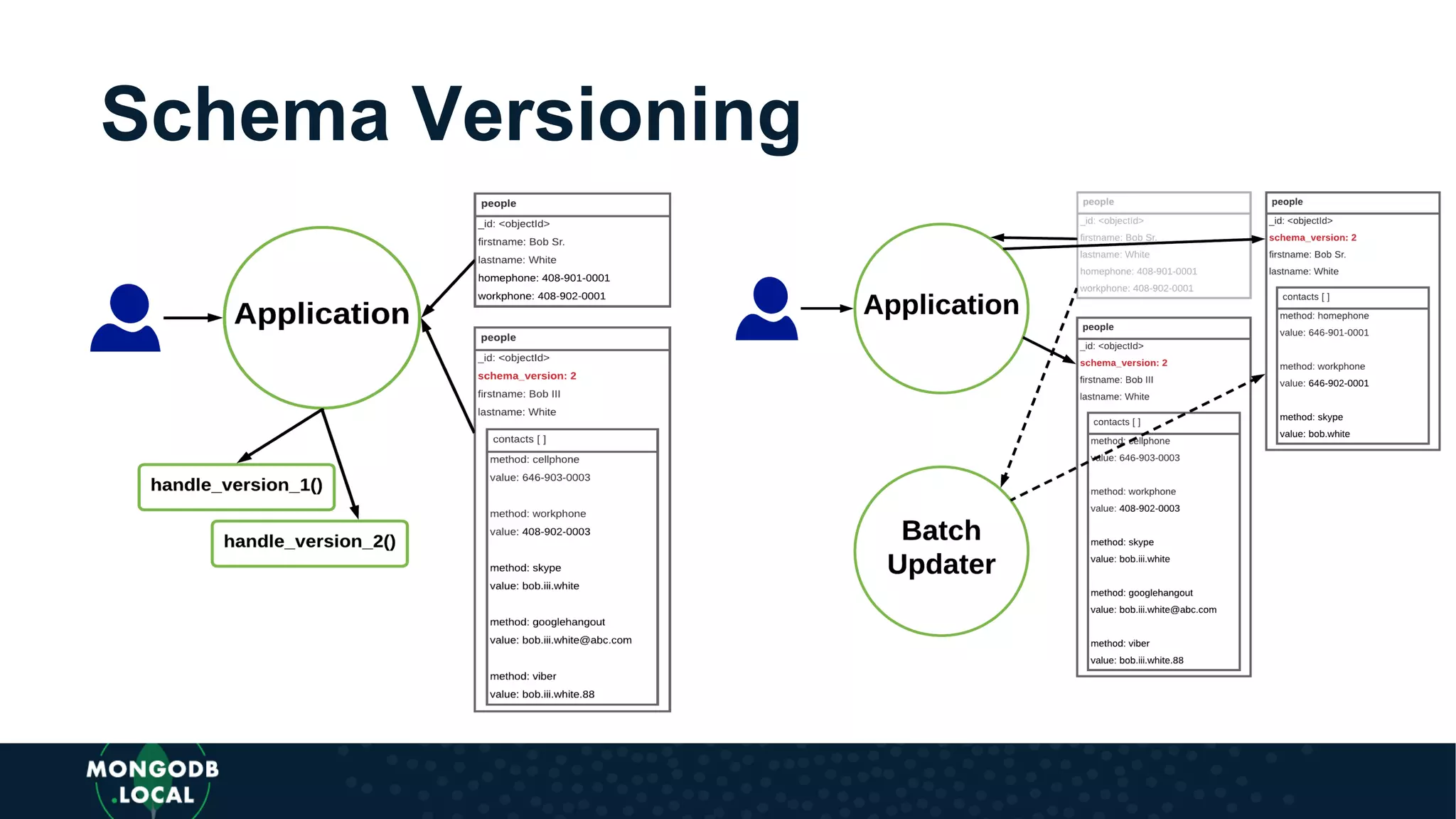
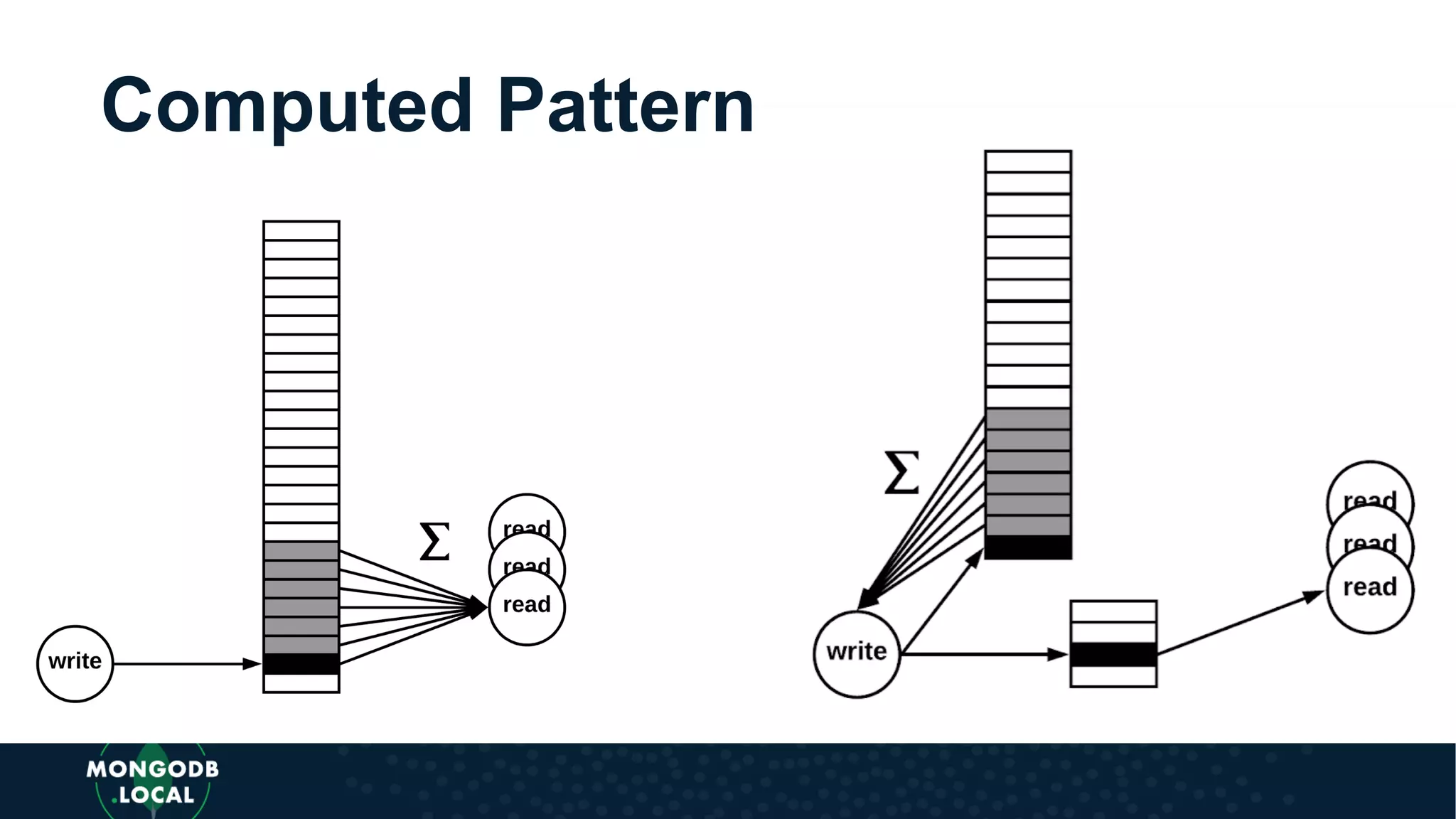
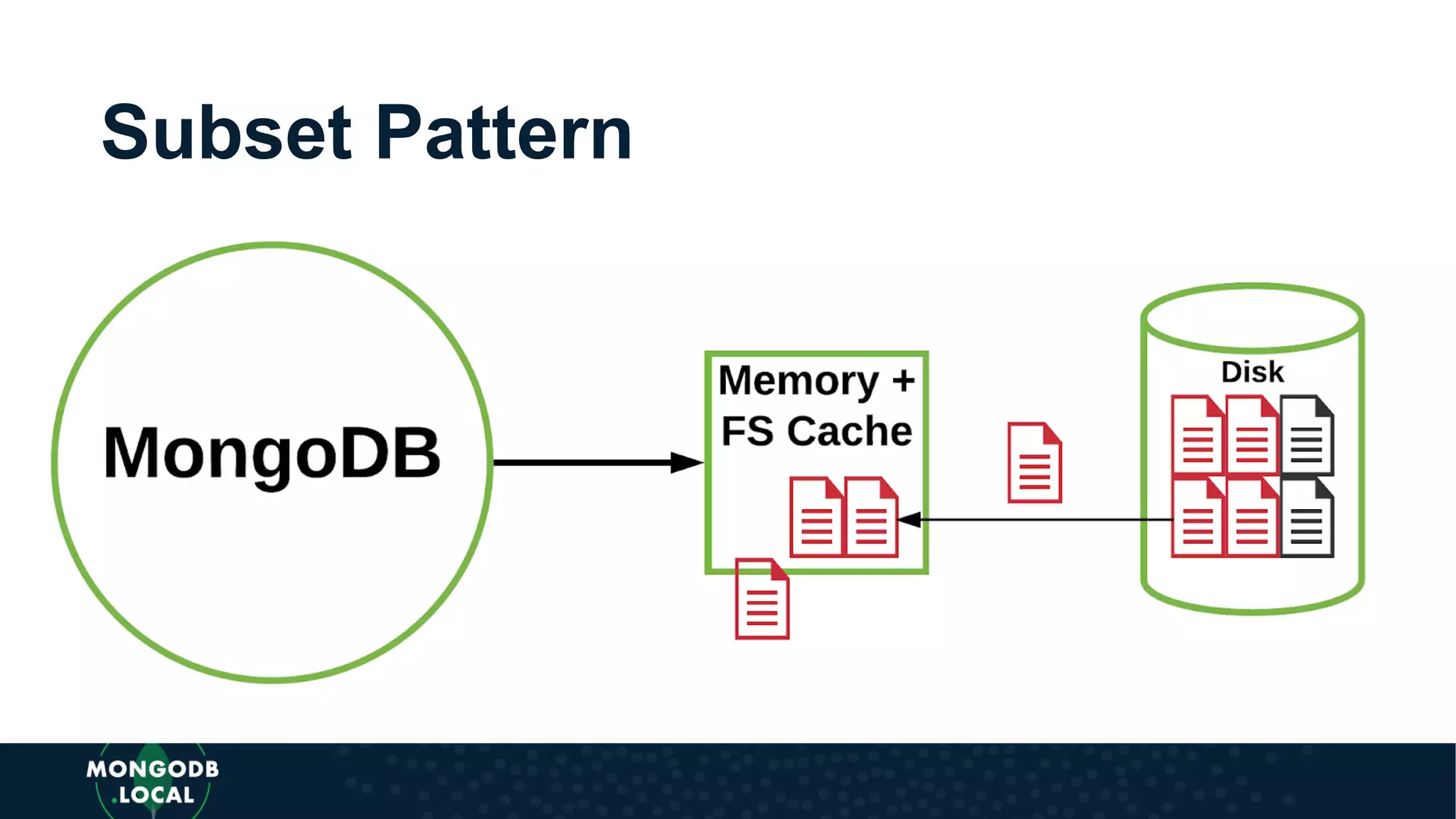
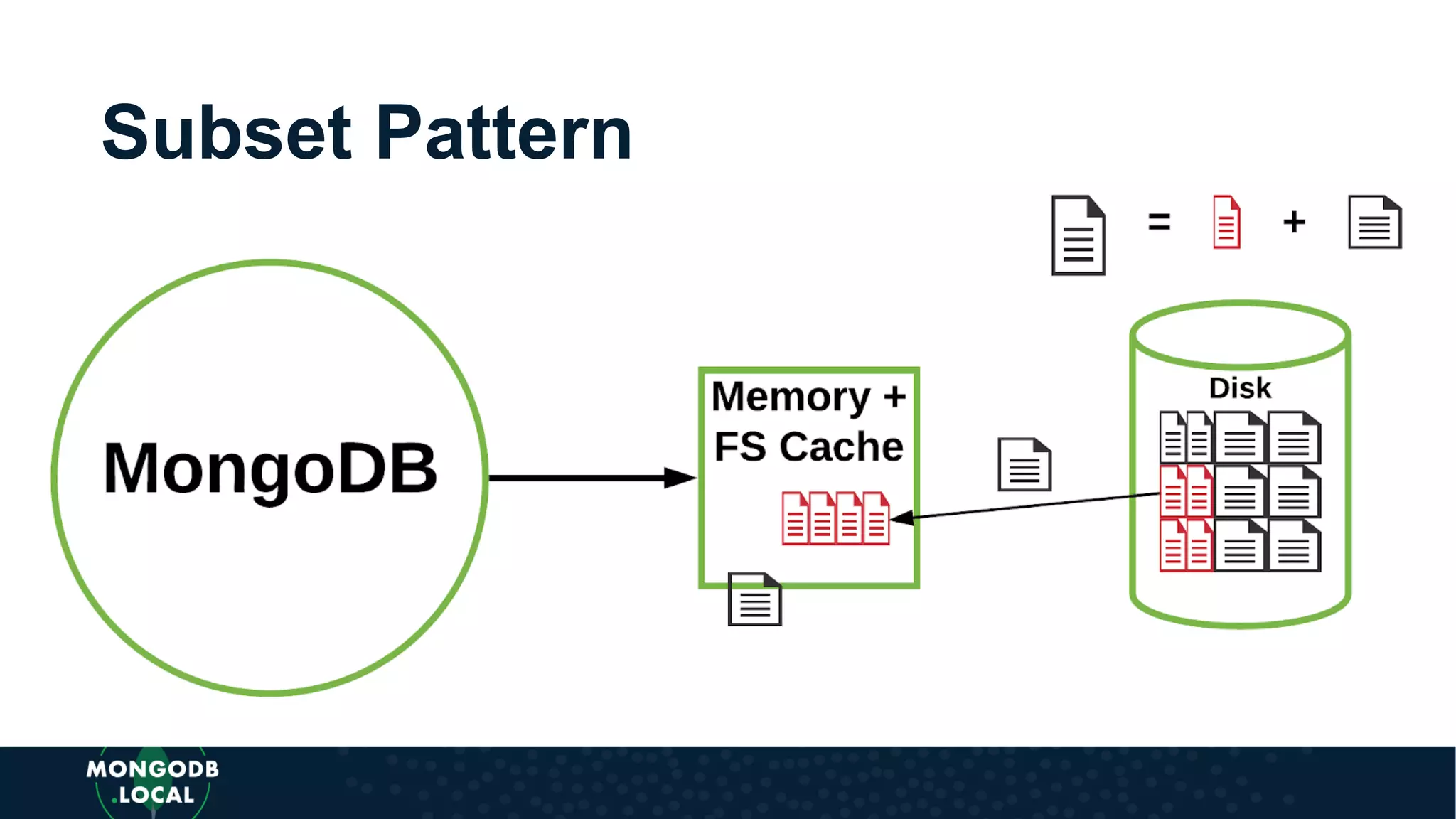
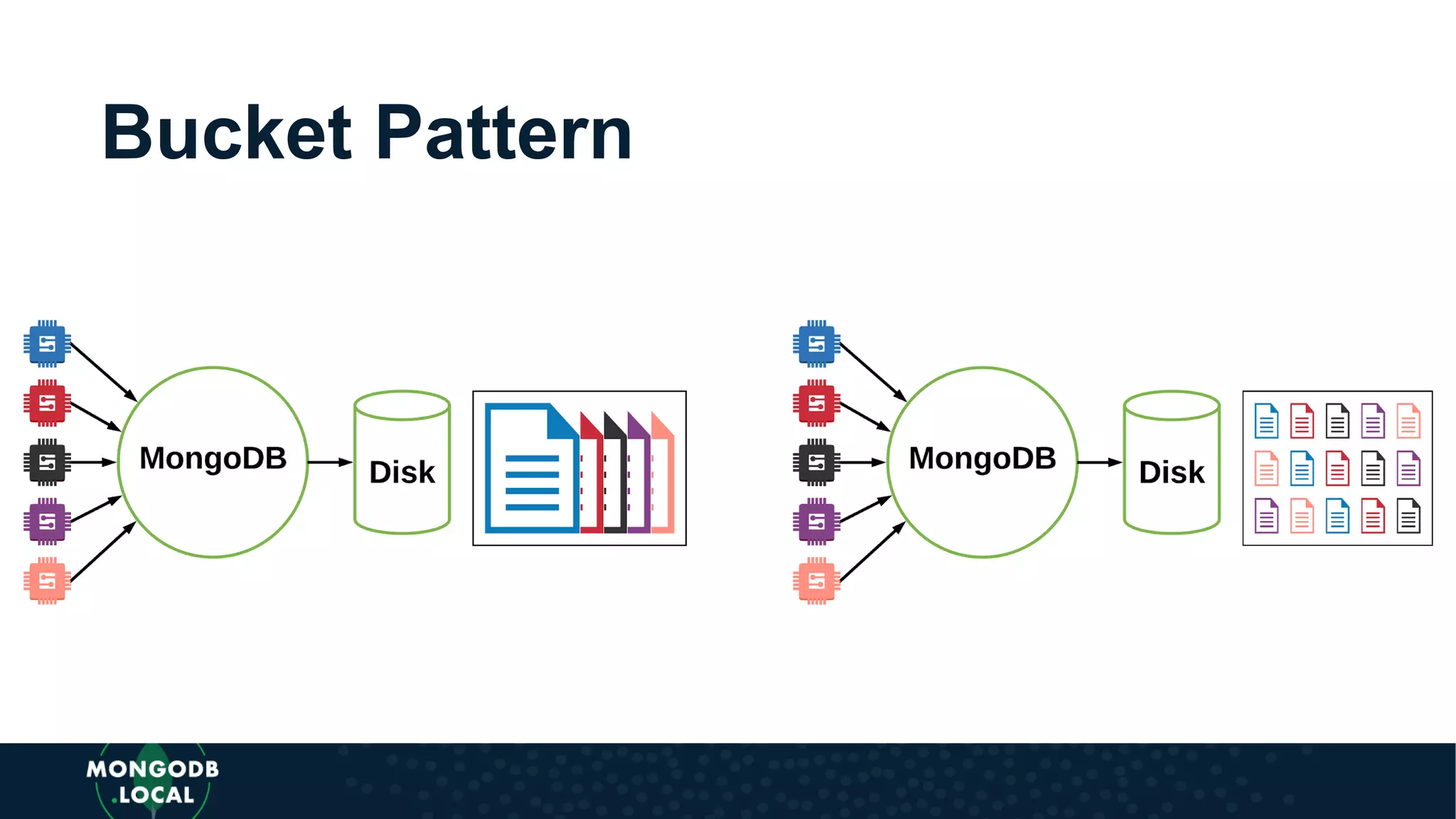
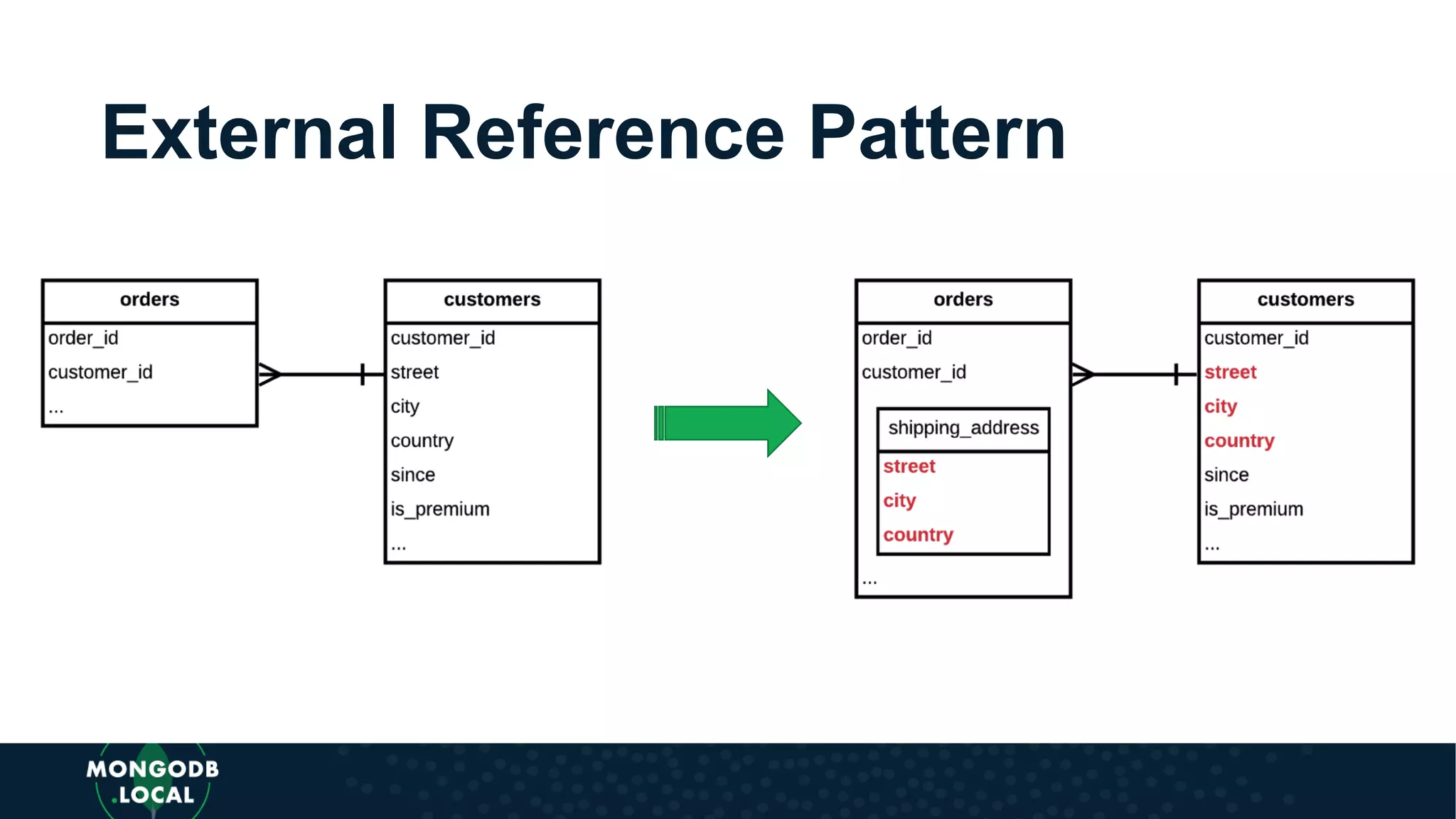
Covers various schema design patterns such as versioning, computed, subset, and bucket patterns with practical applications.
Summarizes key takeaways regarding modelling differences, methodology steps, and schema design patterns.
Announcement of an upcoming course on Data Modelling at MongoDB University, including speaker’s contact information.