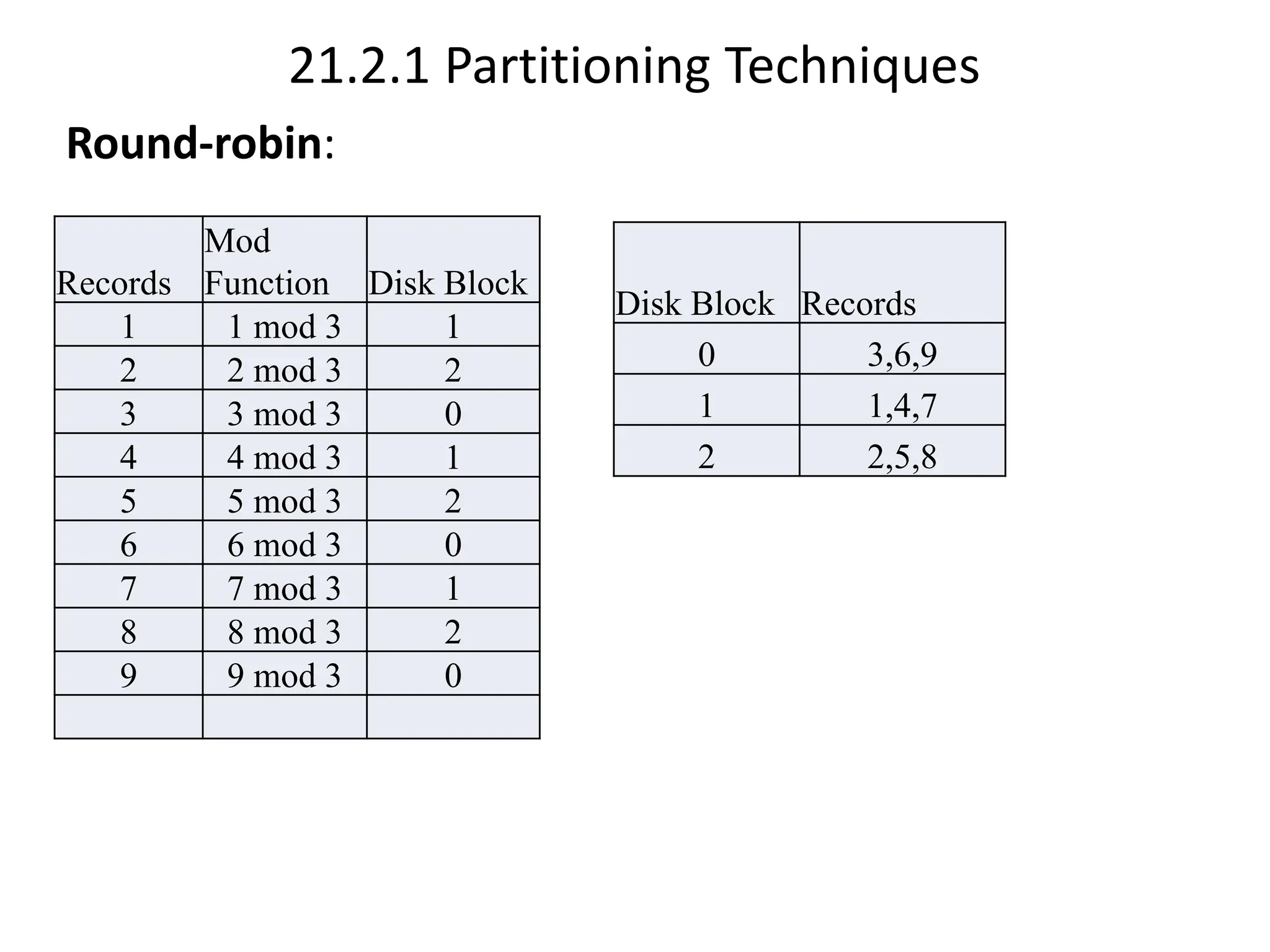
The document discusses parallel databases, focusing on data partitioning techniques such as round-robin, hash, and range partitioning which enhance I/O parallelism, leading to faster data retrieval. It also examines skew handling in partitioning and different forms of parallelism, including interquery and intraquery parallelism, detailing their advantages and methods of execution. The material emphasizes the efficiency gained through parallel processing in database systems and the challenges of maintaining data consistency.