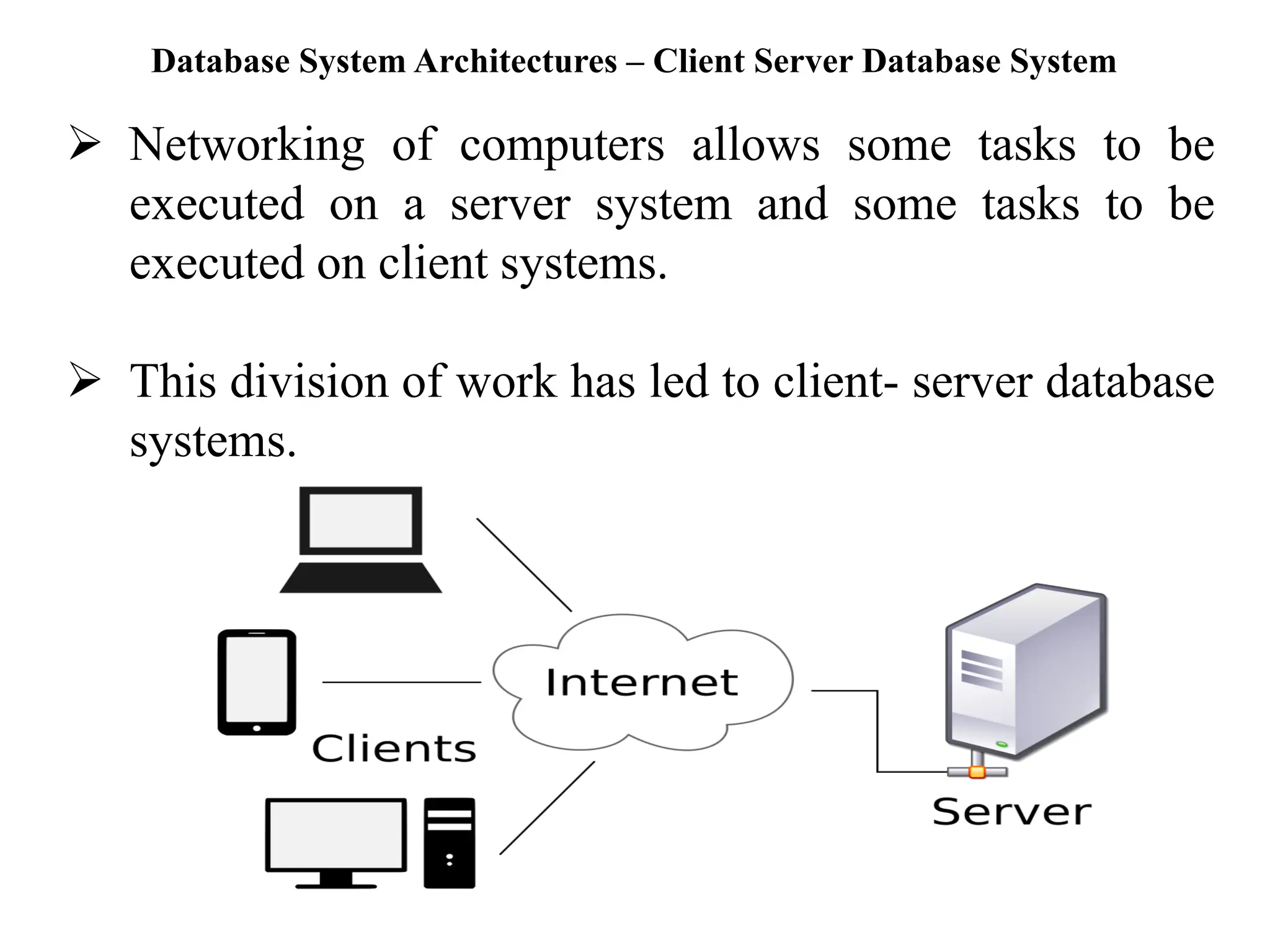
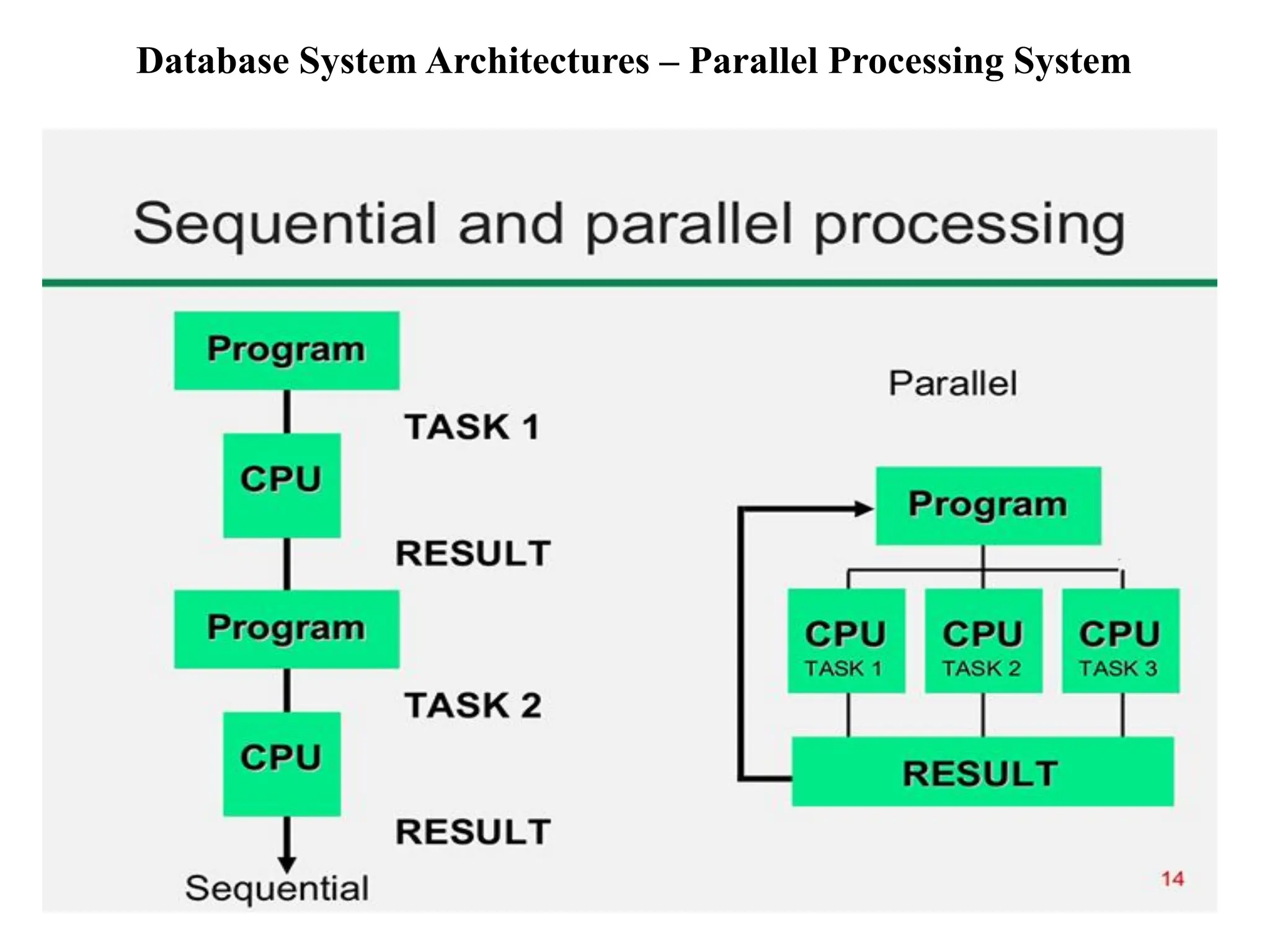
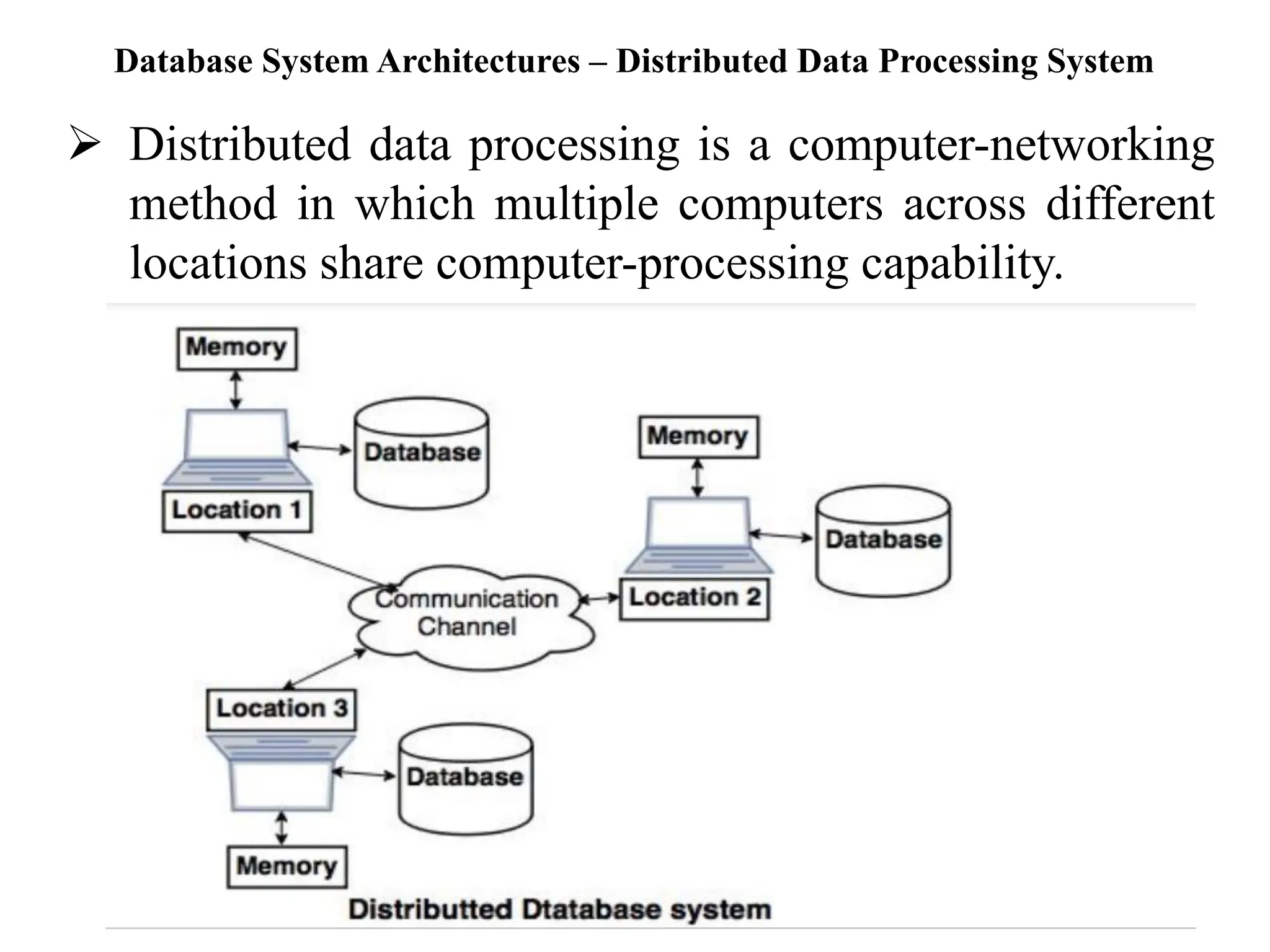
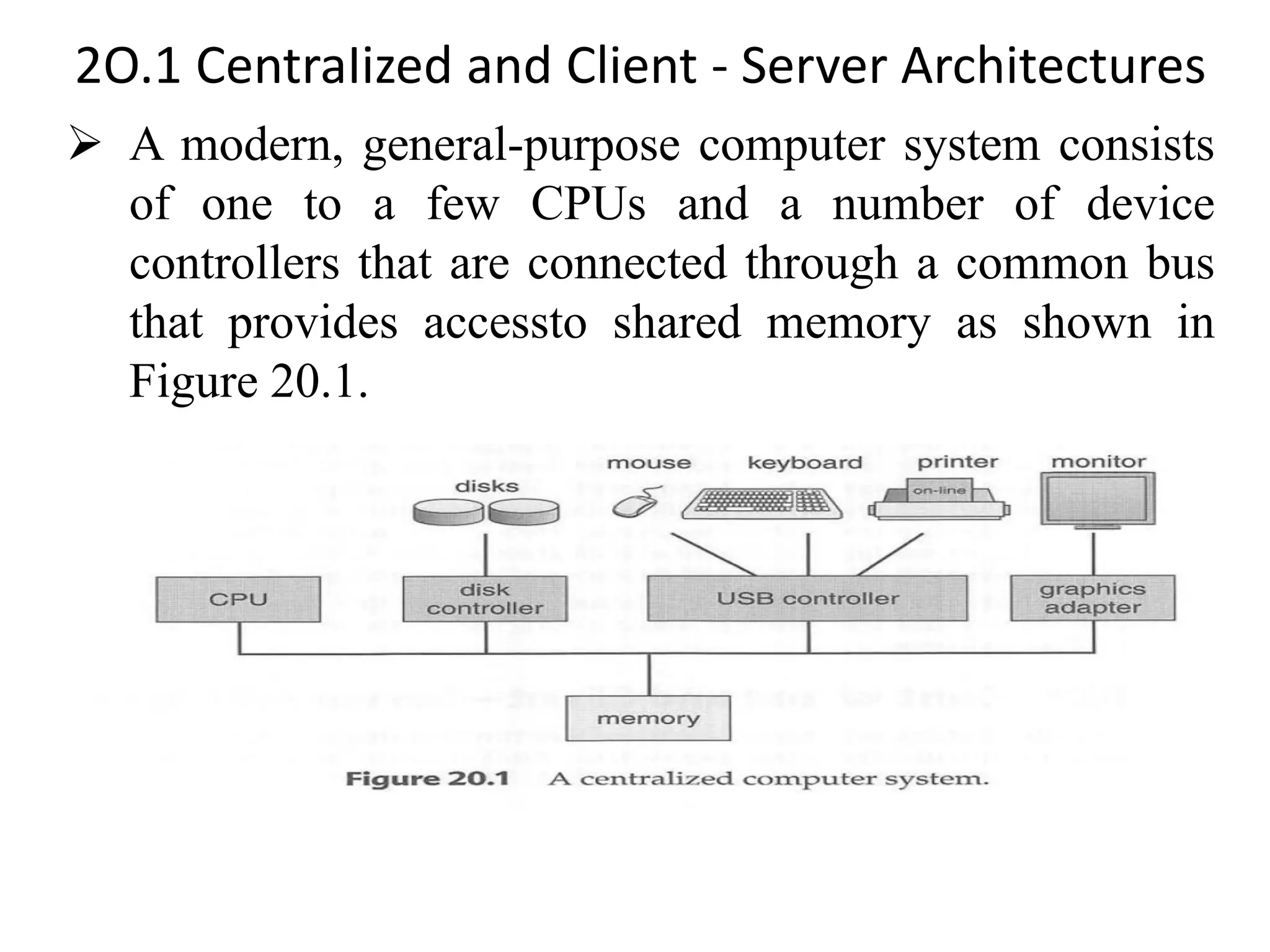
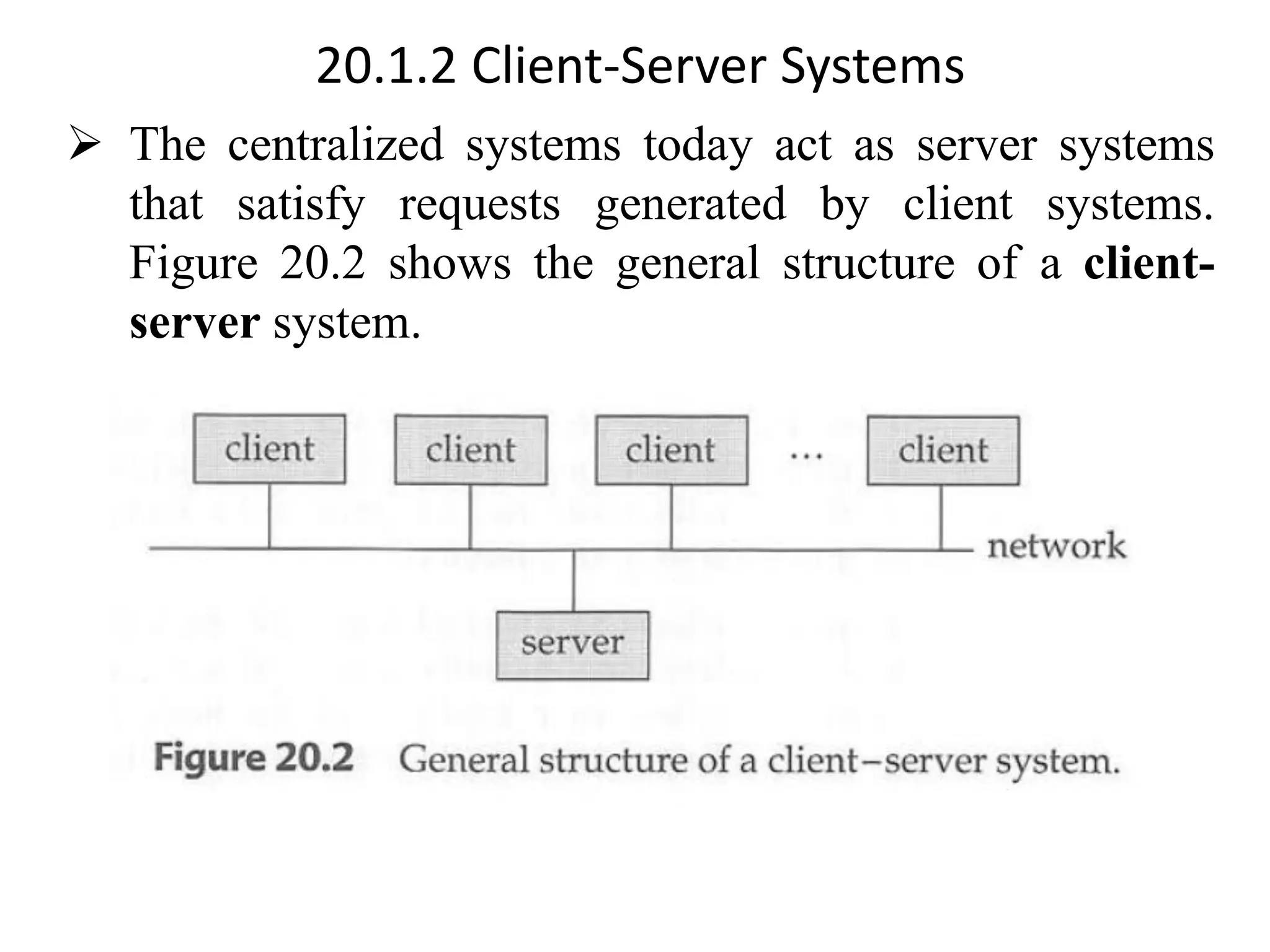
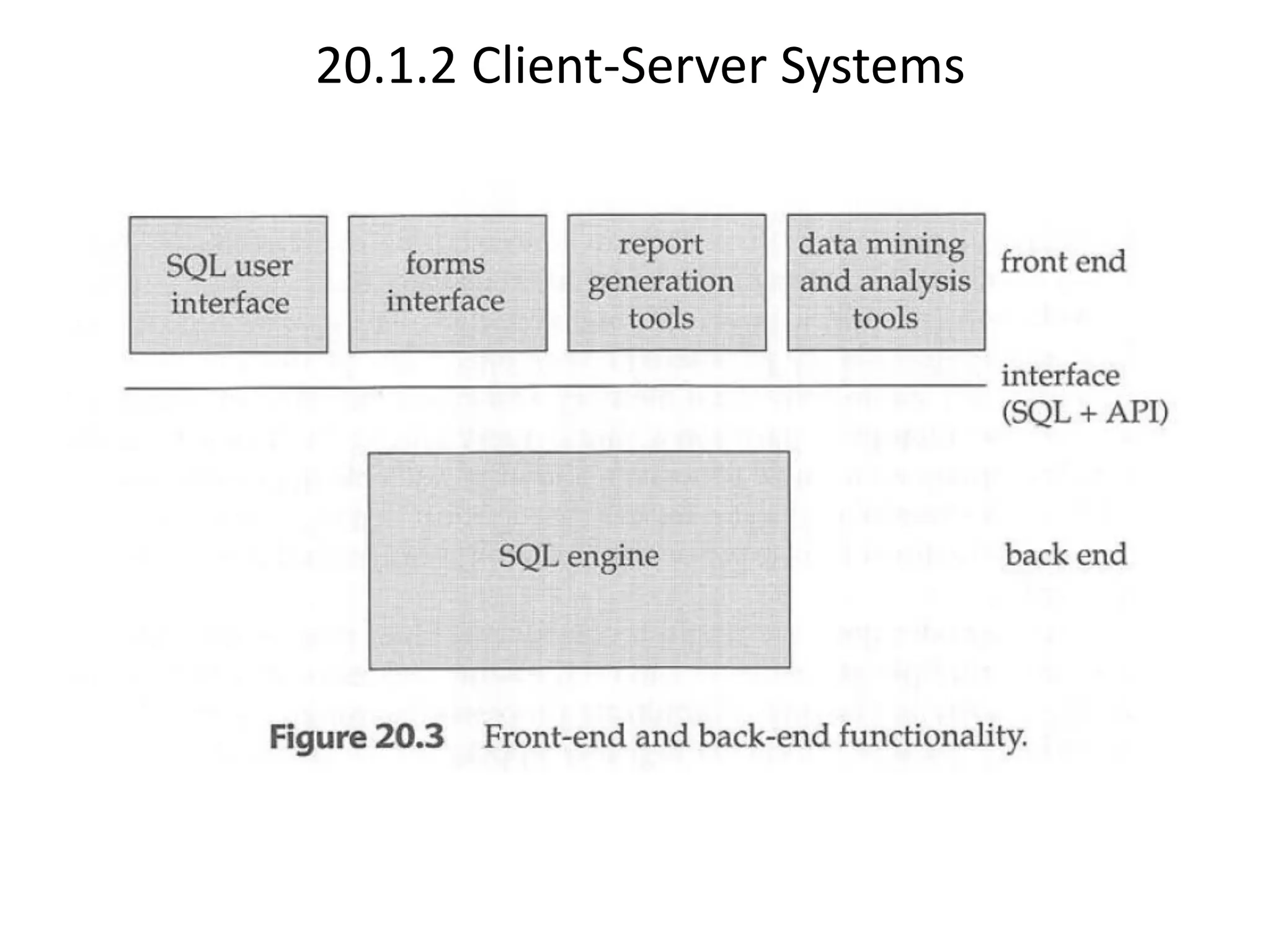
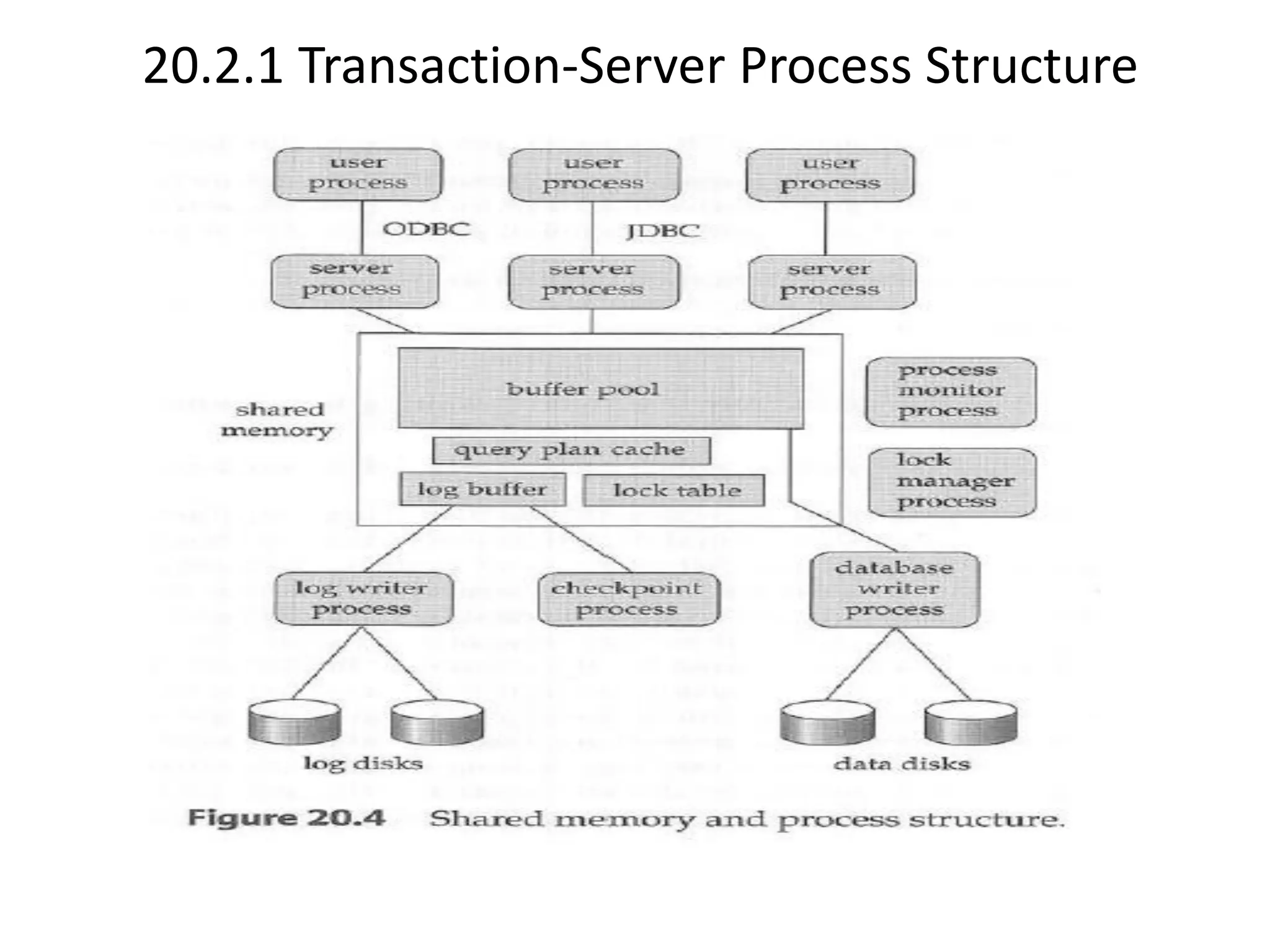
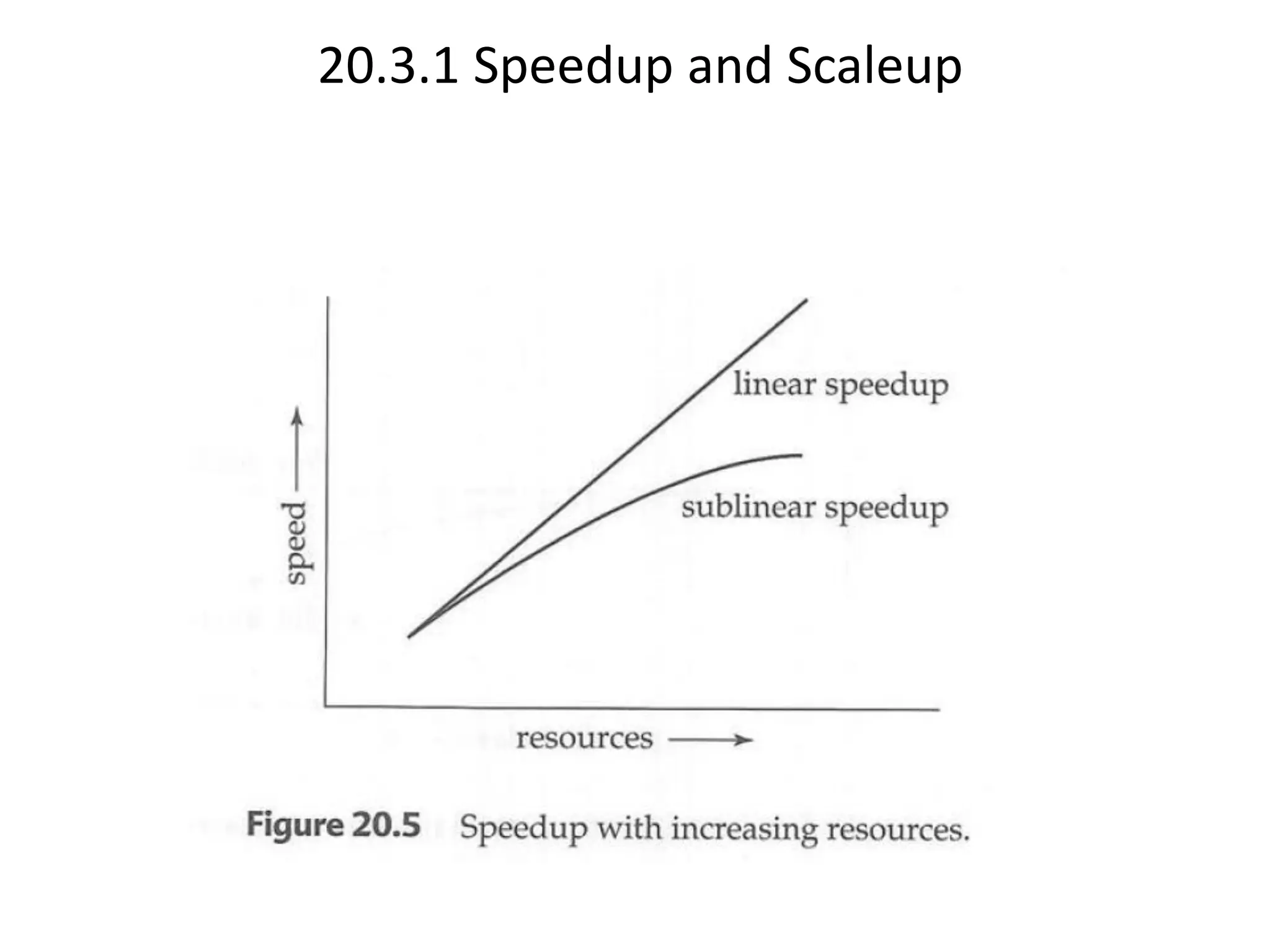
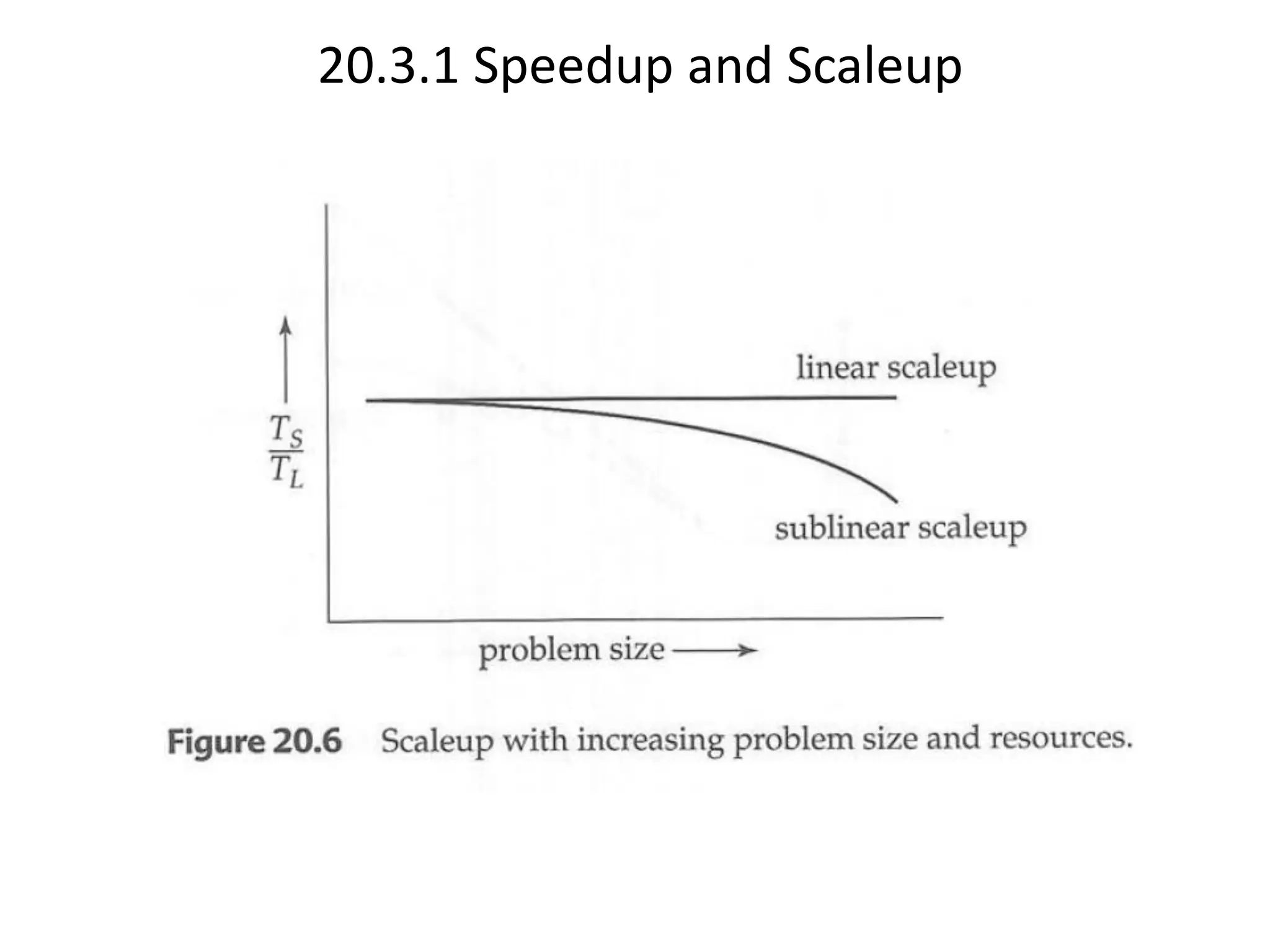
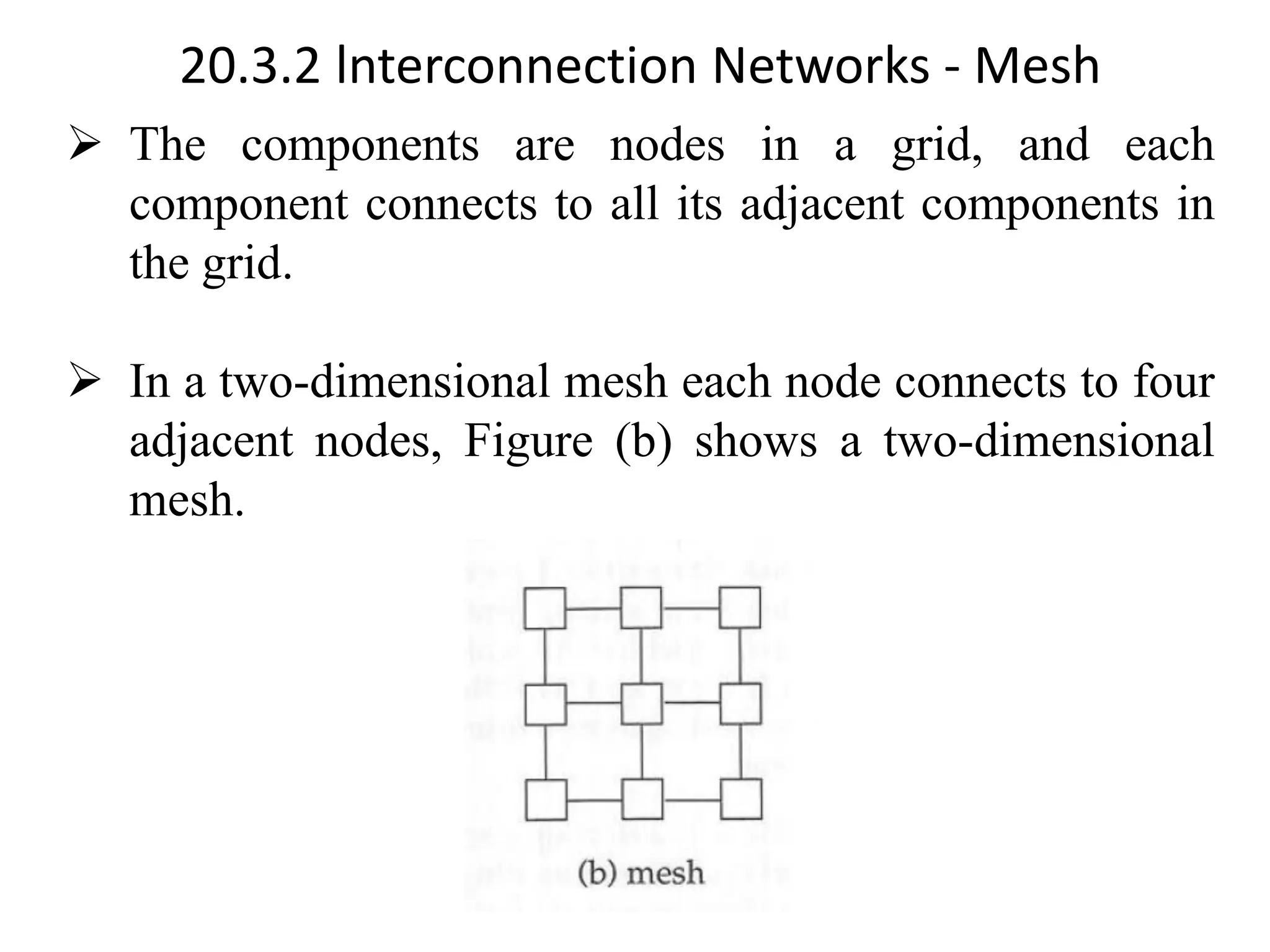
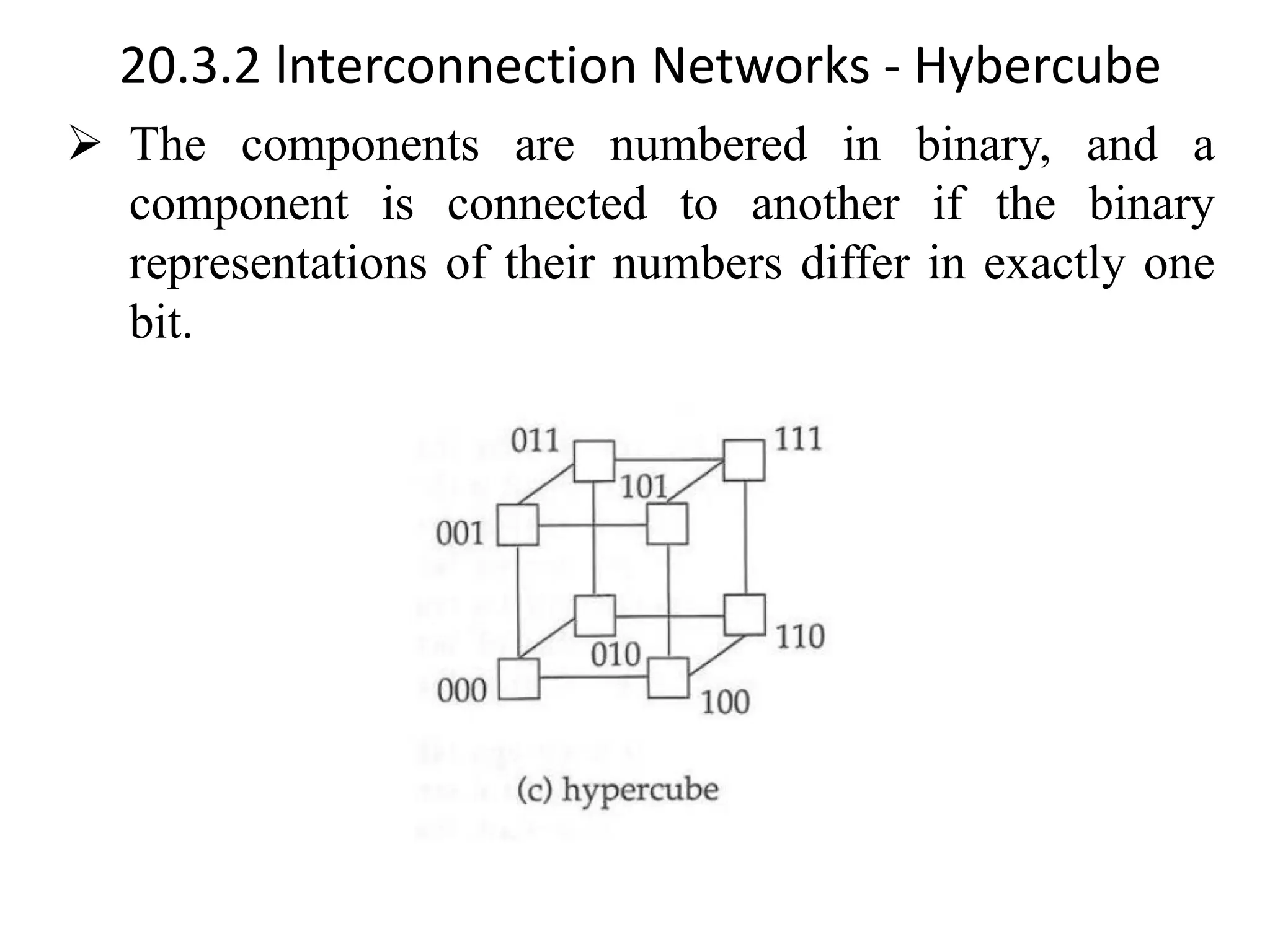
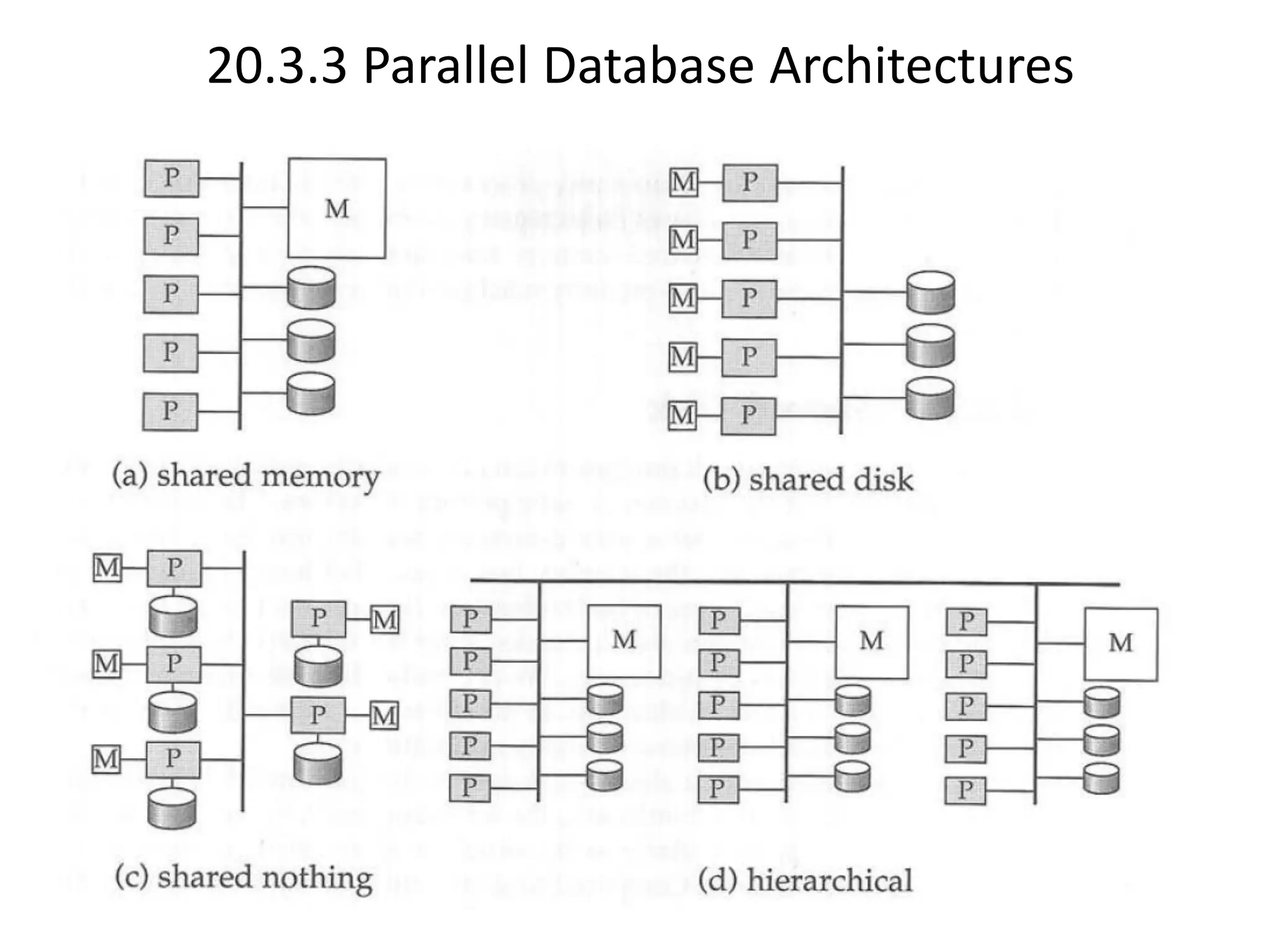
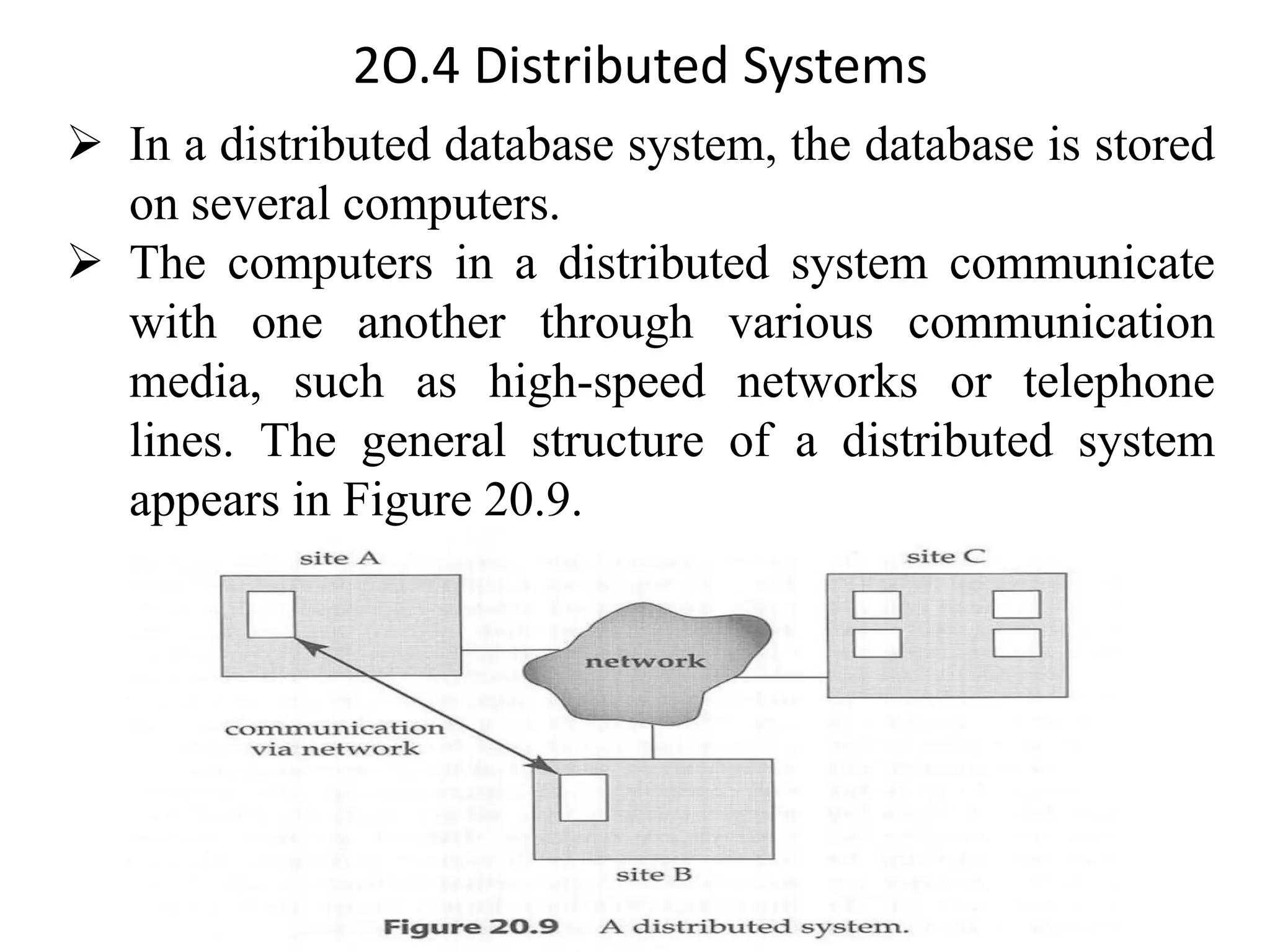
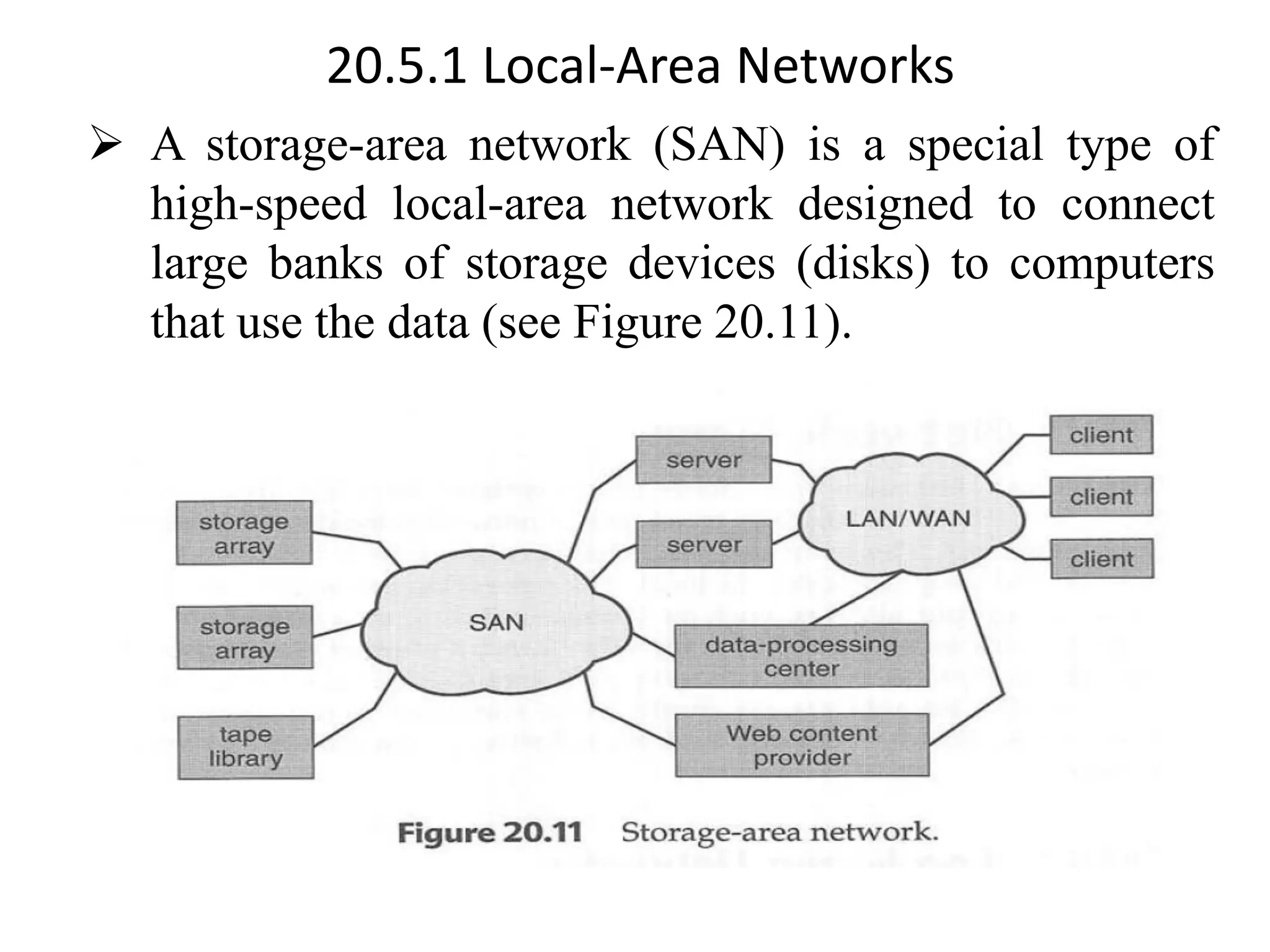
The document discusses various database system architectures, including client-server systems, parallel processing systems, and distributed data processing systems. It outlines the roles of front-end and back-end functionalities in client-server systems and elaborates on transaction-server and data-server classifications. Furthermore, it addresses implementation issues in distributed databases and provides insights into local-area and wide-area networks.