Downloaded 300 times






























The document discusses concepts, functions, architecture, and design of distributed database management systems (DDBMS). It covers topics such as data allocation strategies, distributed relational database design, levels of transparency provided by DDBMSs, and Date's 12 rules for distributed database management. The overall goal of a DDBMS is to manage distributed databases across a computer network while hiding the distribution from users.
Overview of concepts and design in distributed databases and DBMSs.
Learning objectives covering concepts, advantages, functions, architecture, and design of DDBMS.
Introduction to networking concepts: LAN vs WAN, focusing on connectivity and performance.
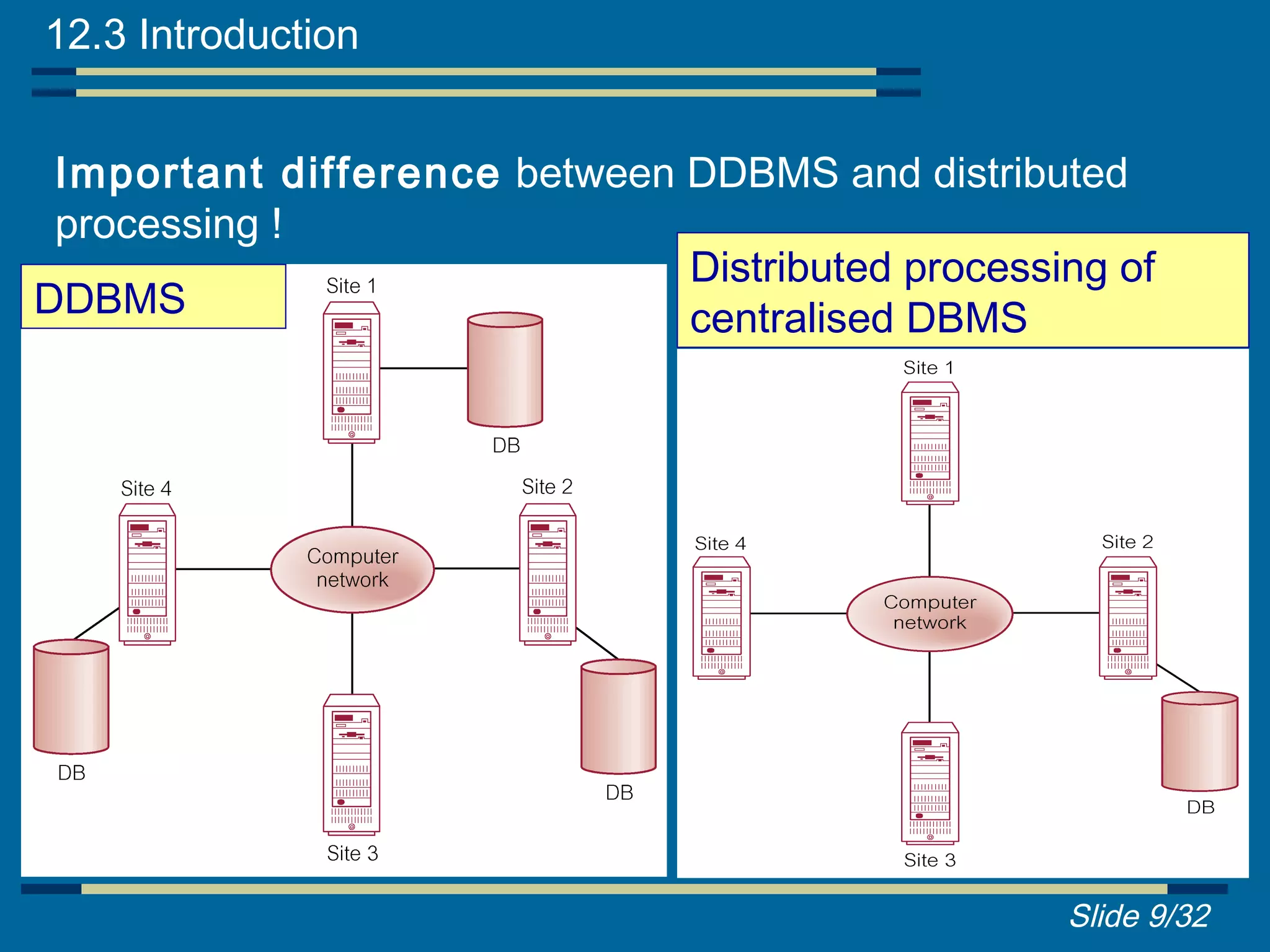
Definition of DDBMS, its characteristics, advantages, disadvantages, and types of DDBMS.
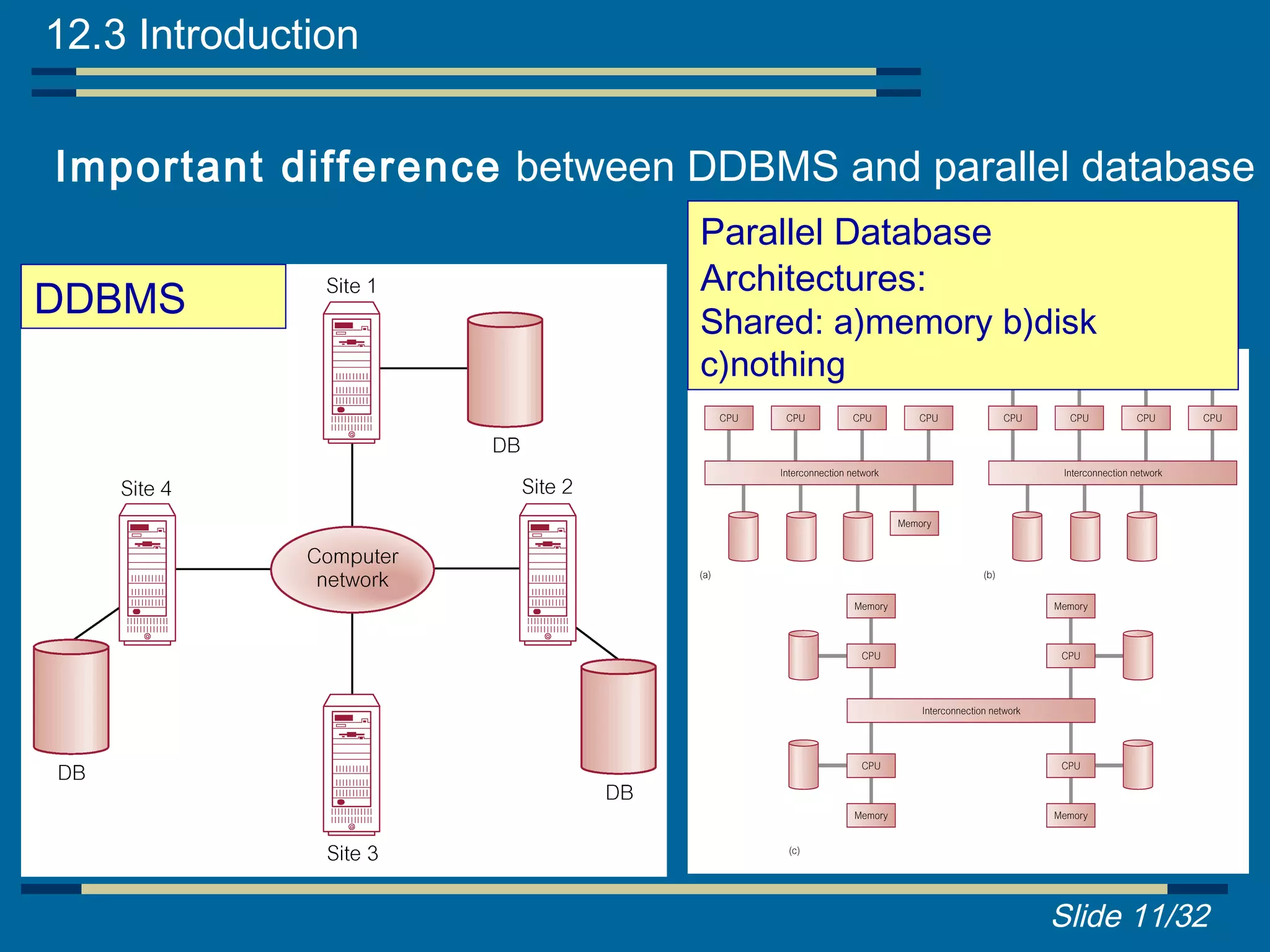
Functions, reference architecture, and comparison between DDBMS and federated MDBS.
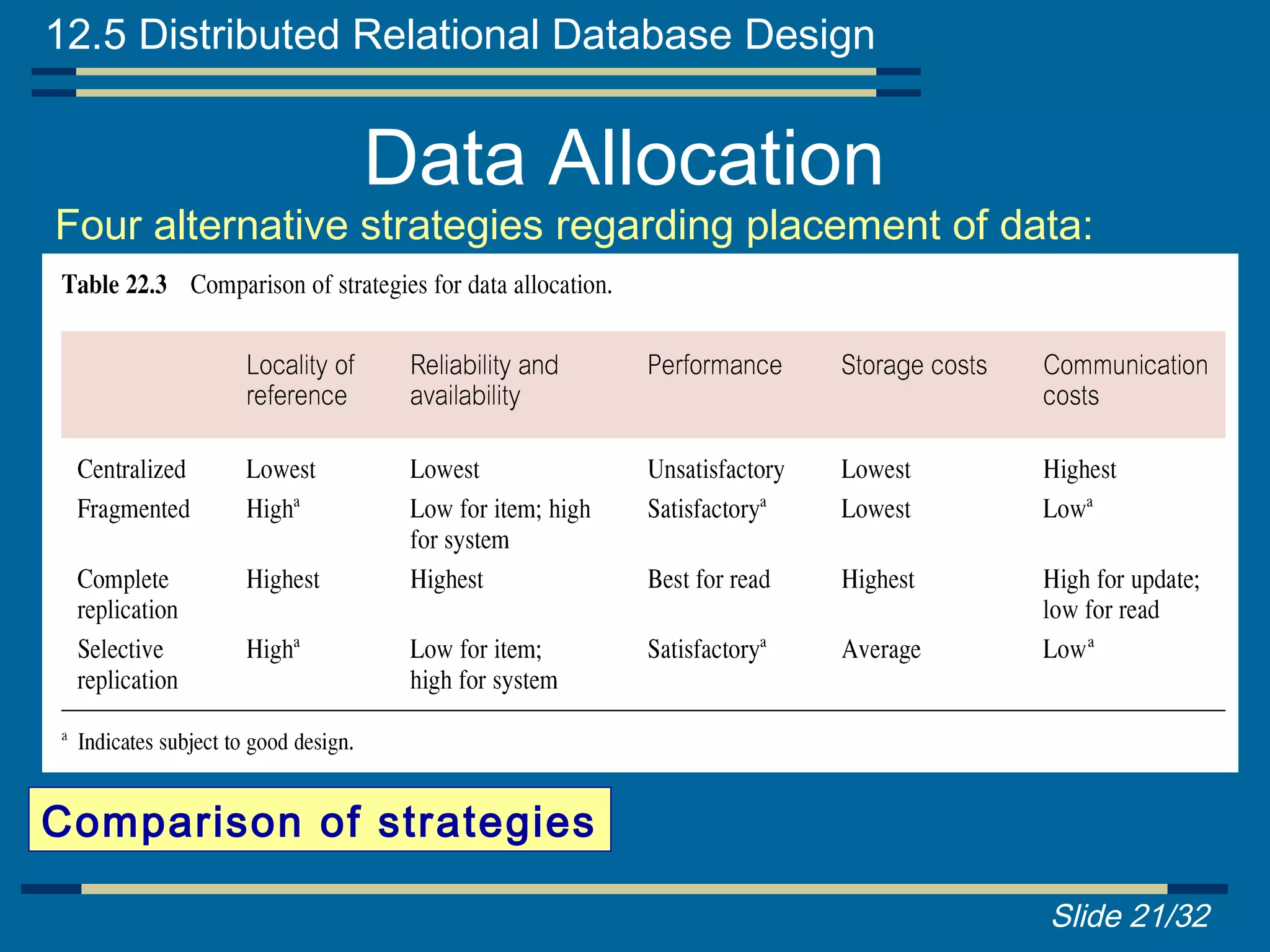
Exploration of data allocation strategies: centralized, partitioned, complete replication, and selective replication.
Strategies and rules for data fragmentation and its implications for performance and integrity.
Types of transparency: distribution, transaction, and performance transparency, emphasizing user accessibility.
Fundamental guidelines ensuring a seamless user experience in distributed systems.
Recap of key points from previous slides, summarizing objectives, design, and principles of DDBMS.