Download as PDF, PPTX














![Spark Streaming Spark Streaming - Word Count - SBT ● cd ~/bigdata/spark/examples/streaming/word_count_sbt ● # Build the JAR ● sbt package ● # Run the JAR ● spark-submit --class "WordCount" --master "local[2]" target/scala-2.10/word-count_2.10-1.0.jar](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-27-2048.jpg)
![Spark Streaming Spark Streaming - Word Count - Python ● cd ~/cloudxlab/spark/examples/streaming/word_count ● # Run the code ● spark-submit word_count.py ● spark-submit --master "local[*]" word_count.py ● spark-submit --master "local[2]" word_count.py ● spark-submit --master yarn word_count.py](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-28-2048.jpg)

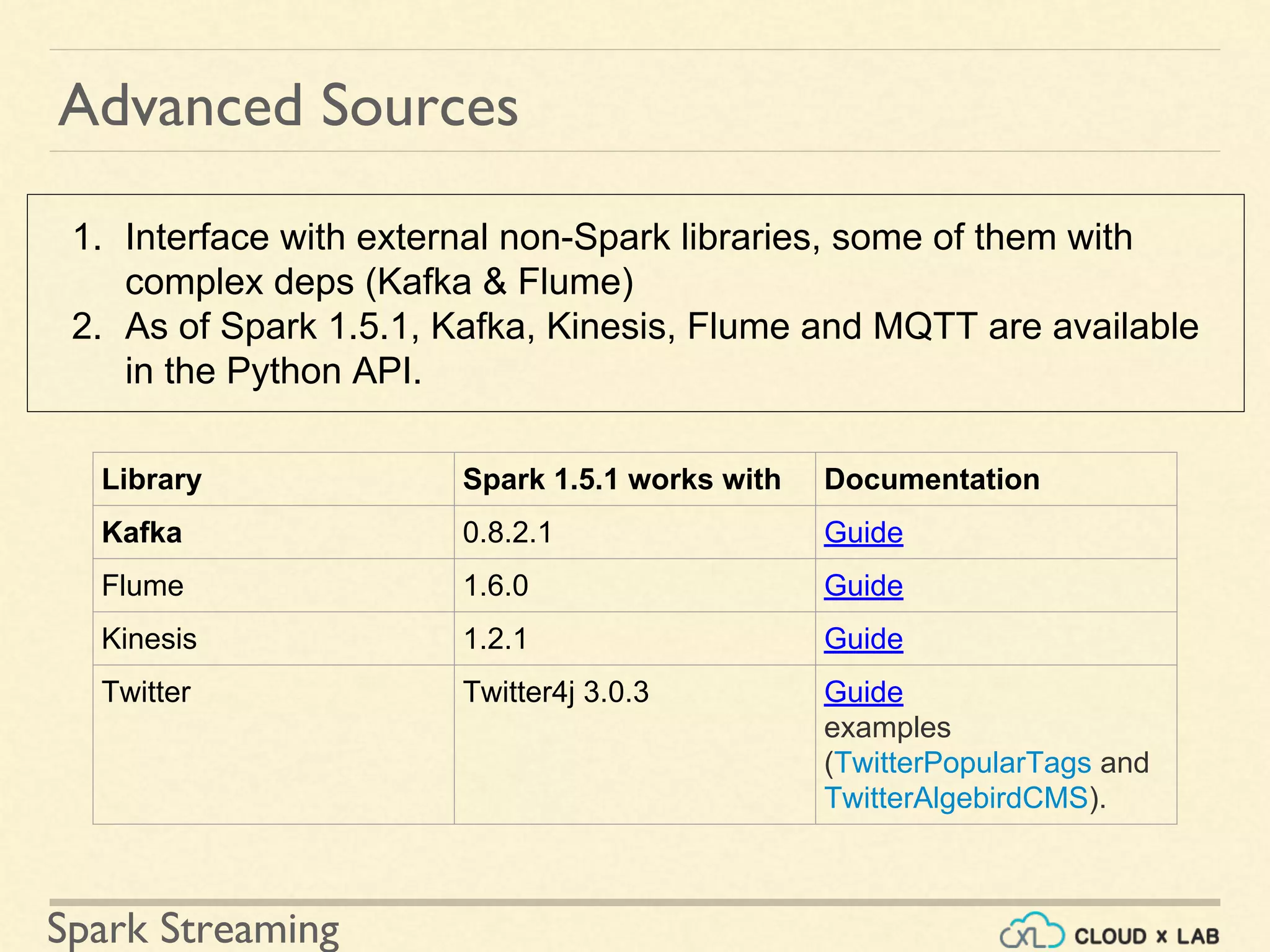
![Spark Streaming Spark Streaming - Adding Dependencies Source Artifact Kafka spark-streaming-kafka_2.10 Flume spark-streaming-flume_2.10 Kinesis spark-streaming-kinesis-asl_2.10 [Amazon Software License] Twitter spark-streaming-twitter_2.10 ZeroMQ spark-streaming-zeromq_2.10 MQTT spark-streaming-mqtt_2.10](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-30-2048.jpg)


![Spark Streaming Spark Streaming - Running Locally For running locally, ● Do not use “local” or “local[1]” as the master URL. ○ As it uses only one thread for receiving the data ○ Leaves no thread for processing the received data ● So, Always use “local[n]” as the master URL , where n > no. of receivers](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-34-2048.jpg)
















![Spark Streaming Spark Streaming + Kafka Integration Transformation Meaning reduce(func) Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel. countByValue() When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. reduceByKey(func, [numTasks]) When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config propertyspark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. join(otherStream, [numTasks]) When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key.](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-54-2048.jpg)
![Spark Streaming Spark Streaming + Kafka Integration Transformation Meaning cogroup(otherStream , [numTasks]) When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. transform(func) Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. updateStateByKey(fu nc) Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key.](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-55-2048.jpg)





















![Spark Streaming Join Operations Stream-stream joins val stream1: DStream[String, String] = ... val stream2: DStream[String, String] = ... val joinedStream = stream1.join(stream2)](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-88-2048.jpg)
![Spark Streaming Join Operations Stream-stream joins val stream1: DStream[String, String] = ... val stream2: DStream[String, String] = ... val joinedStream = stream1.join(stream2) ● Here is each interval, the RDD generated by stream1 will be joined with the RDD generated by stream2](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-89-2048.jpg)
![Spark Streaming Join Operations Stream-stream joins val stream1: DStream[String, String] = ... val stream2: DStream[String, String] = ... val joinedStream = stream1.join(stream2) ● Here is each interval, the RDD generated by stream1 will be joined with the RDD generated by stream2 ● We can also do leftOuterJoin, rightOuterJoin and fullOuterJoin](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-90-2048.jpg)
![Spark Streaming Join Operations Stream-dataset joins val dataset: RDD[String, String] = ... val windowedStream = stream.window(Seconds(20))... val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-92-2048.jpg)



![Spark Streaming Output Operations on DStreams print() ● Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. ● This is useful during development and debugging saveAsTextFiles(prefix, [suffix]) ● Saves DStream's contents as text files. ● The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]"](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-97-2048.jpg)
![Spark Streaming Output Operations on DStreams saveAsObjectFiles(prefix, [suffix]) ● Saves DStream's contents as SequenceFiles of serialized Java objects. ● The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-98-2048.jpg)
![Spark Streaming Output Operations on DStreams saveAsObjectFiles(prefix, [suffix]) ● Save this DStream's contents as SequenceFiles of serialized Java objects. ● The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". saveAsHadoopFiles(prefix, [suffix]) ● Save this DStream's contents as Hadoop files. ● The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-99-2048.jpg)













![Spark Streaming Spark Streaming - Word Count - Python Problem: do the word count every second. Step 1: Create a connection to the service from pyspark import SparkContext from pyspark.streaming import StreamingContext # Create a local StreamingContext with two working thread and # batch interval of 1 second sc = SparkContext("local[2]", "NetworkWordCount") ssc = StreamingContext(sc, 1) # Create a DStream that will connect to hostname:port, # like localhost:9999 lines = ssc.socketTextStream("localhost", 9999)](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-120-2048.jpg)






![Spark Streaming Spark Streaming + Kafka Integration Step 2: Create the streaming objects Problem: do the word count every second from kafka sc = SparkContext(appName="KafkaWordCount") ssc = StreamingContext(sc, 1) #Read name of zk from arguments zkQuorum, topic = sys.argv[1:] #Listen to the topic kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1})](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-133-2048.jpg)
![Spark Streaming Spark Streaming + Kafka Integration Step 3: Create the RDDs by Transformations & Actions Problem: do the word count every second from kafka #read lines from stream lines = kvs.map(lambda x: x[1]) # Split lines into words, words to tuples, reduce counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a+b) #Do the print counts.pprint()](https://image.slidesharecdn.com/sparkstreamingkafka-180514105708/75/Introduction-to-Spark-Streaming-Apache-Kafka-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-134-2048.jpg)








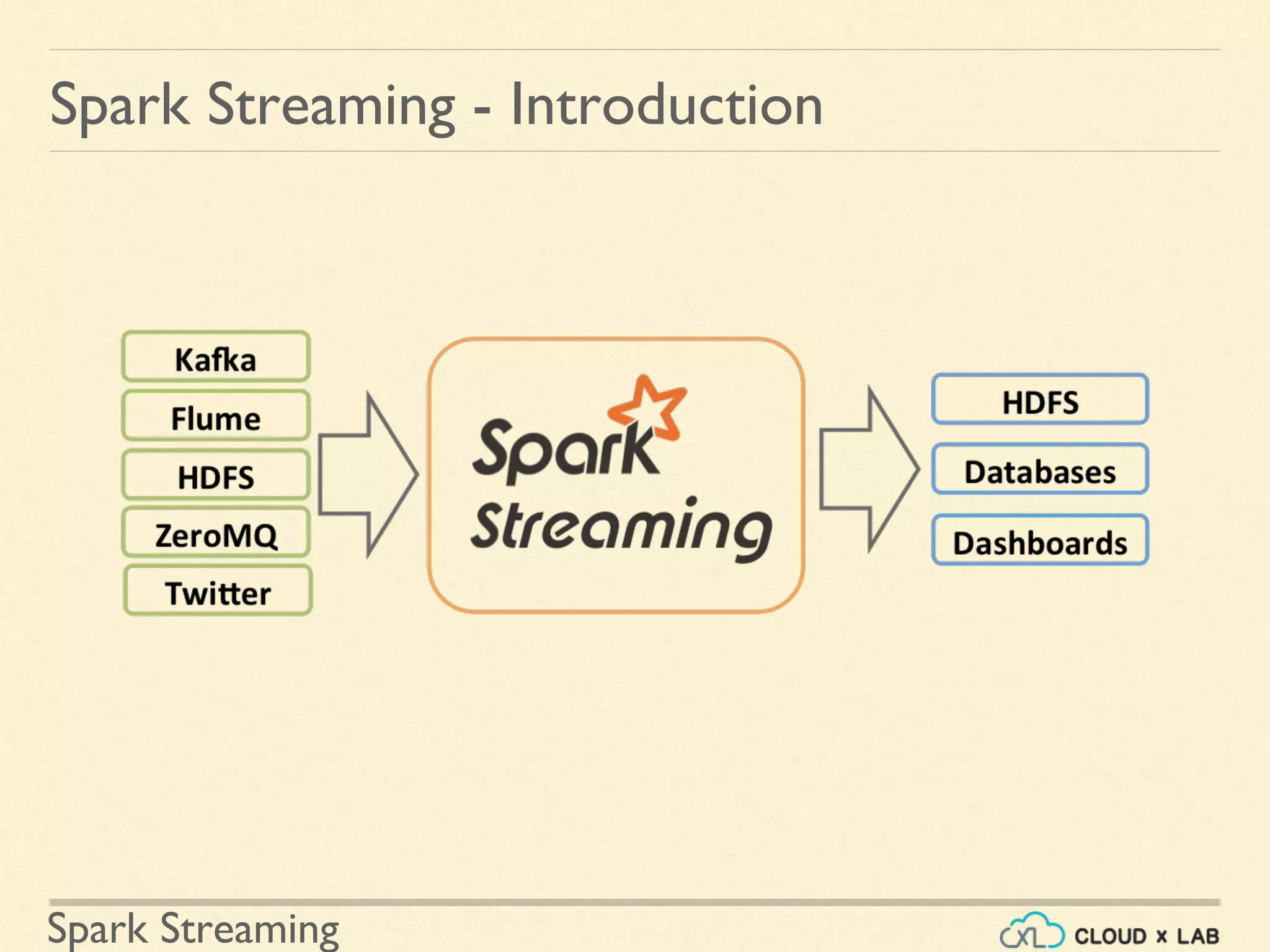
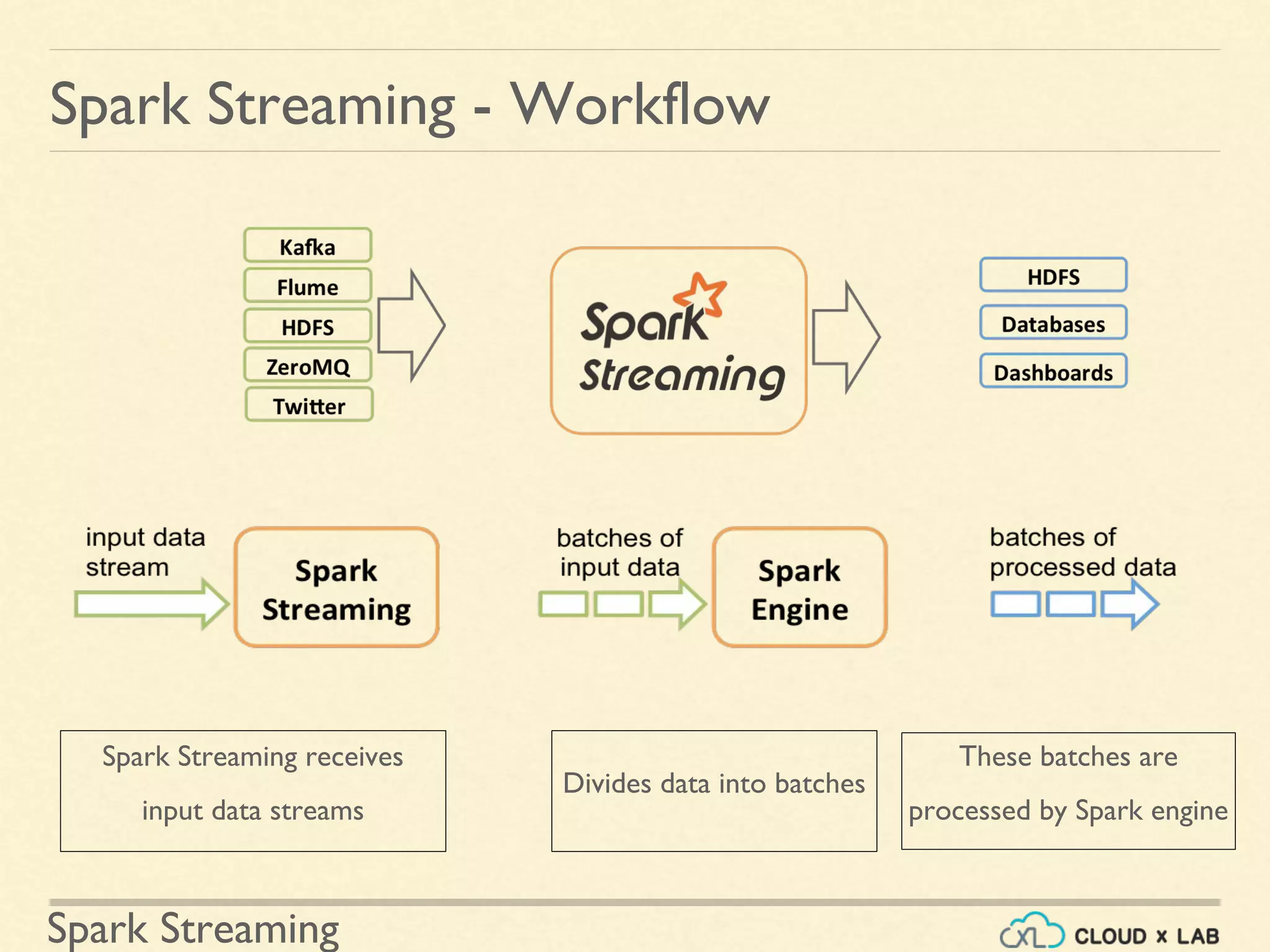
The document provides an introduction to Spark Streaming, a scalable and fault-tolerant extension of the Spark API for real-time data processing. It covers various use cases including real-time analytics, sentiment analysis, fraud detection, and the integration with Apache Kafka. Additionally, it includes hands-on examples of word count implementations and details about DStream transformations, state management, and the functionality of Kafka in real-time applications.
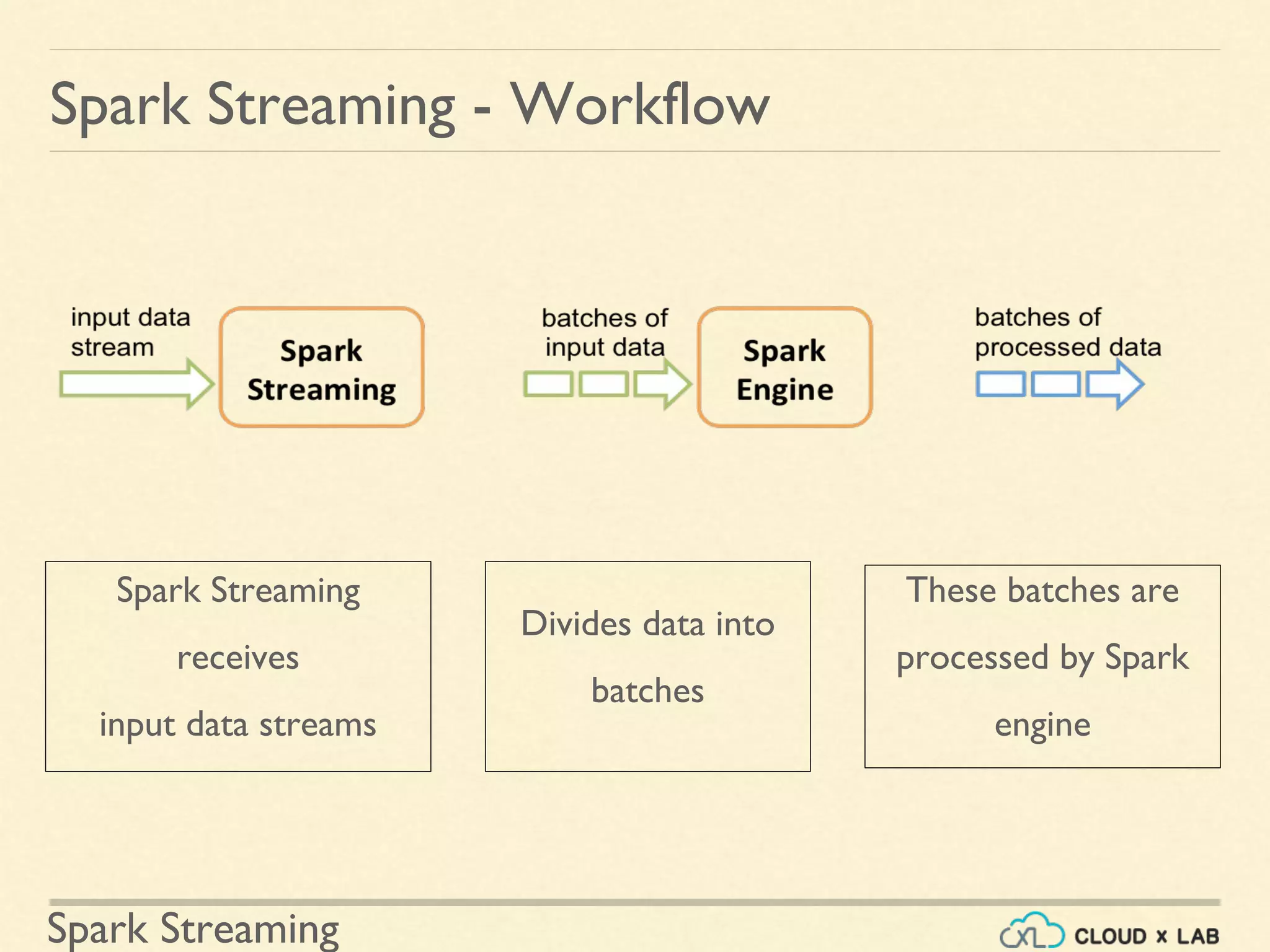
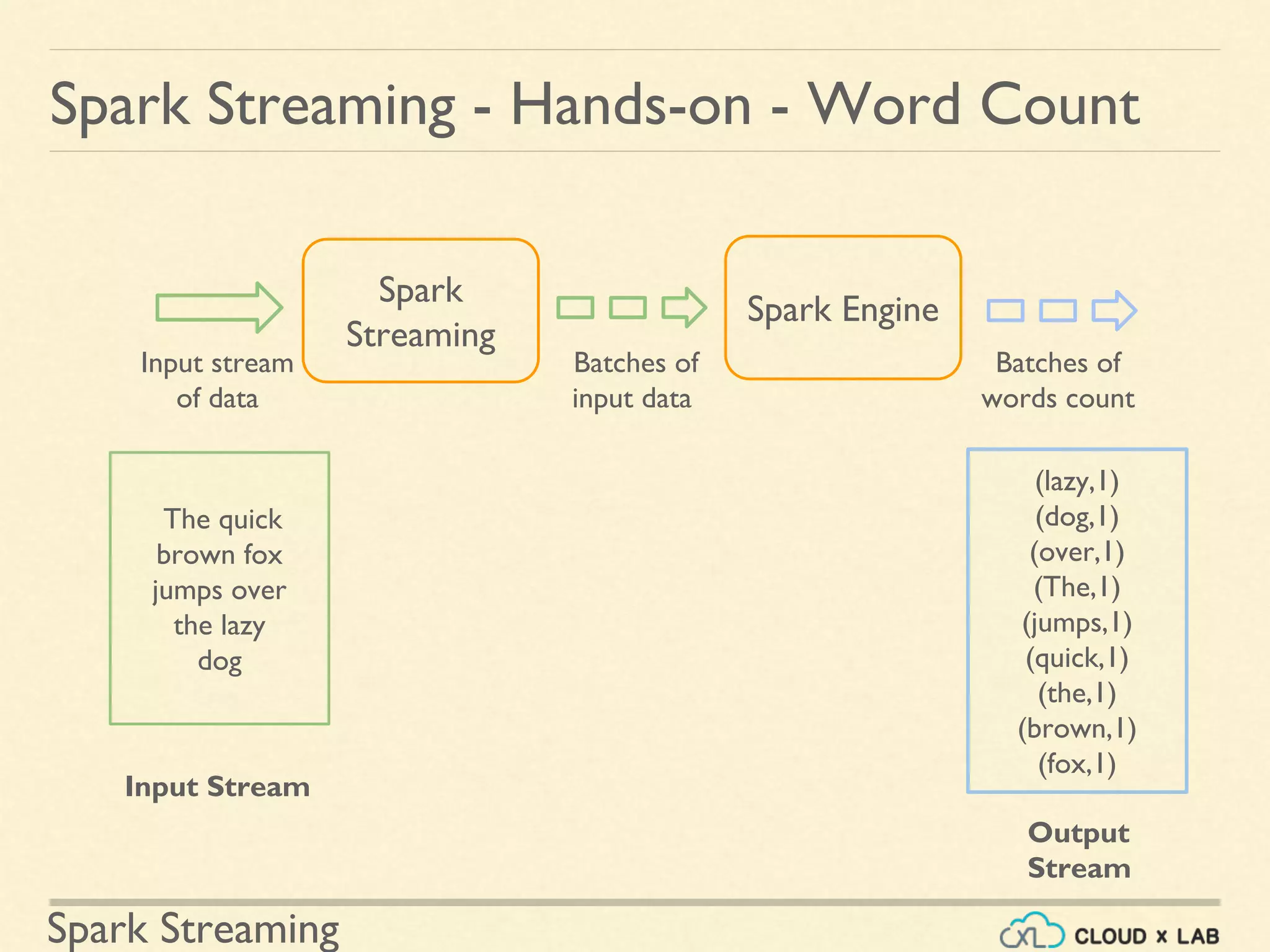
Introductory content on Spark Streaming as an extension of Spark API for scalable, fault-tolerant stream processing. Detailing the workflow of Spark Streaming where input data streams are divided into batches for processing.
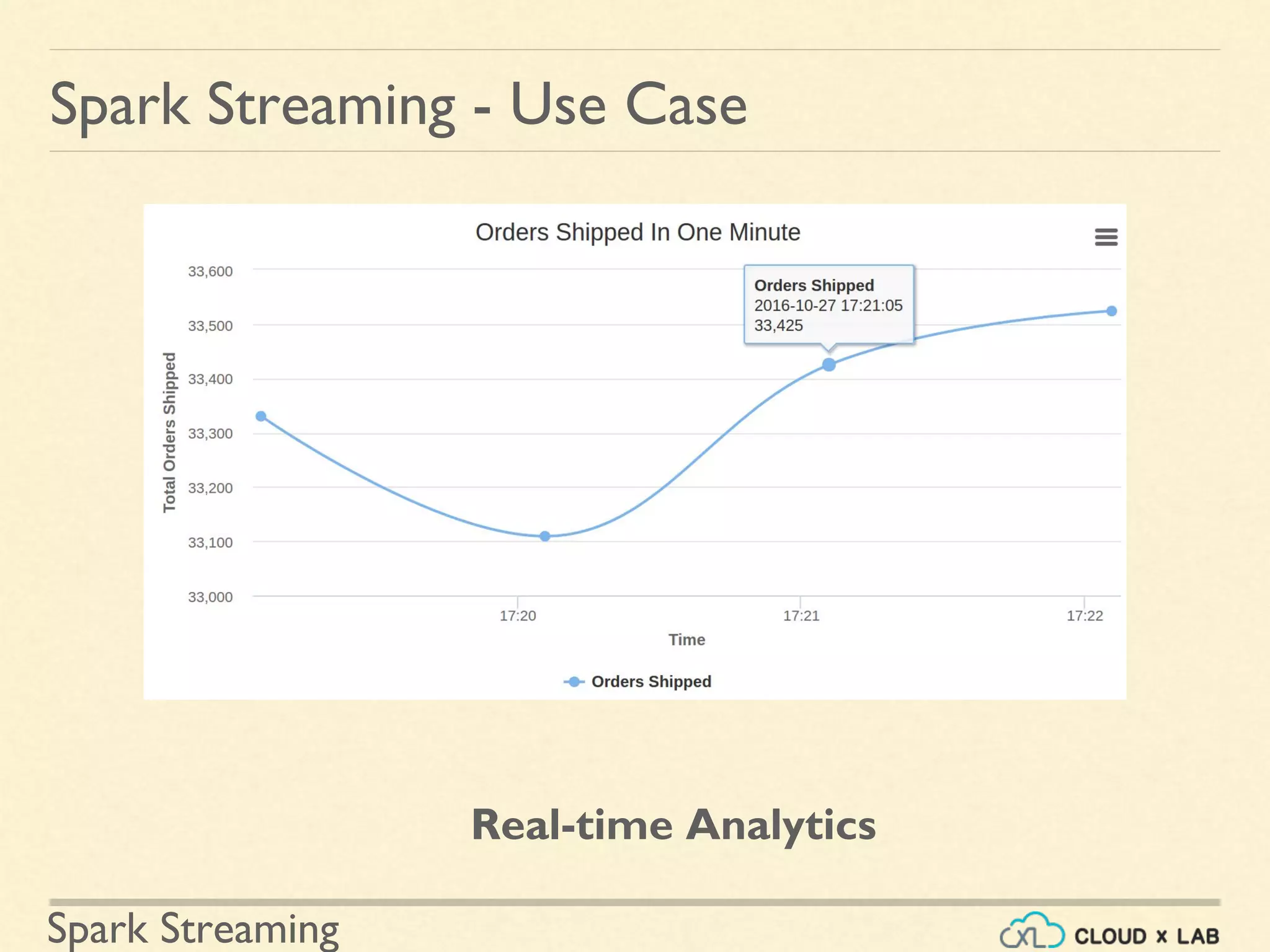
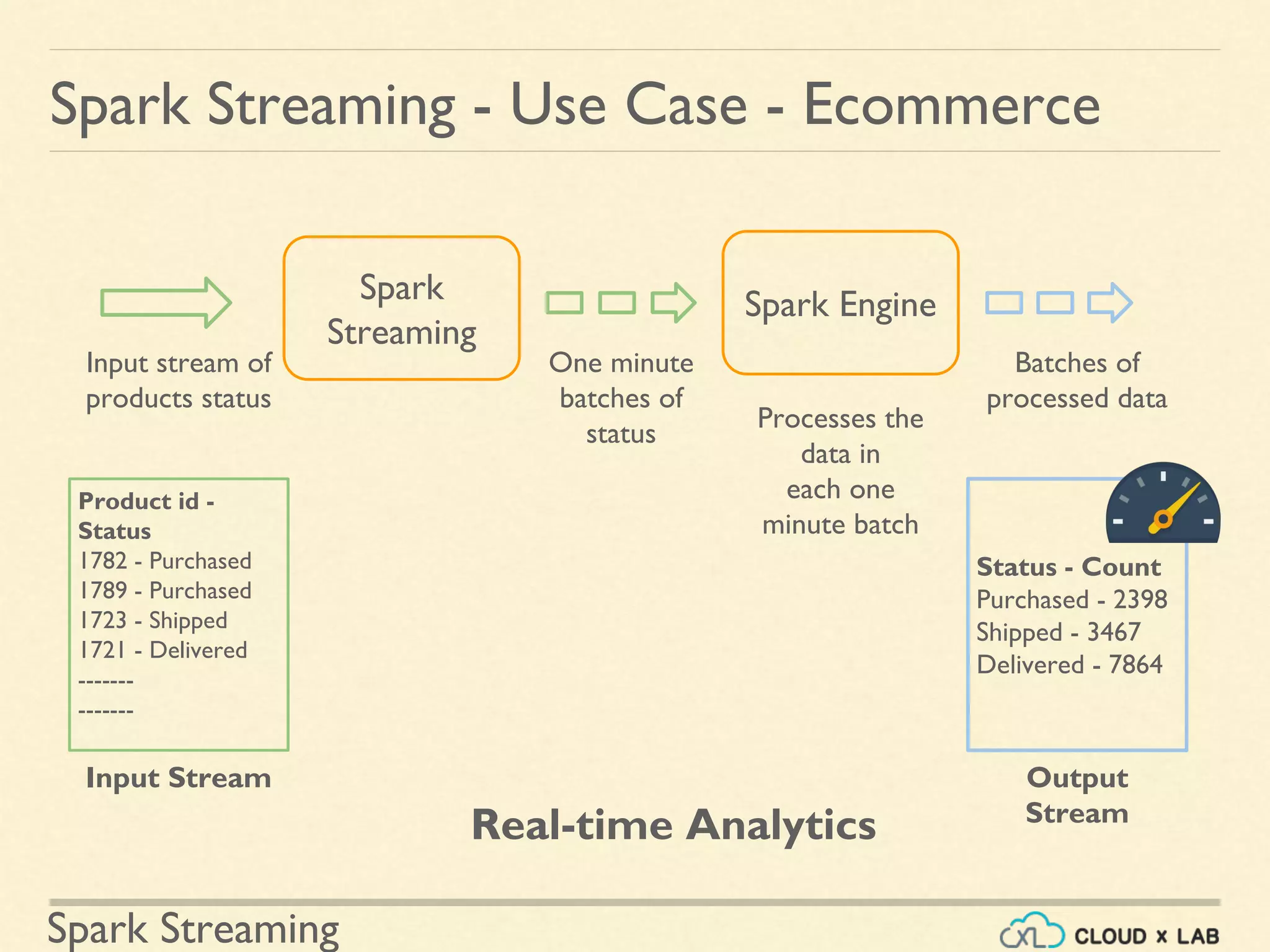
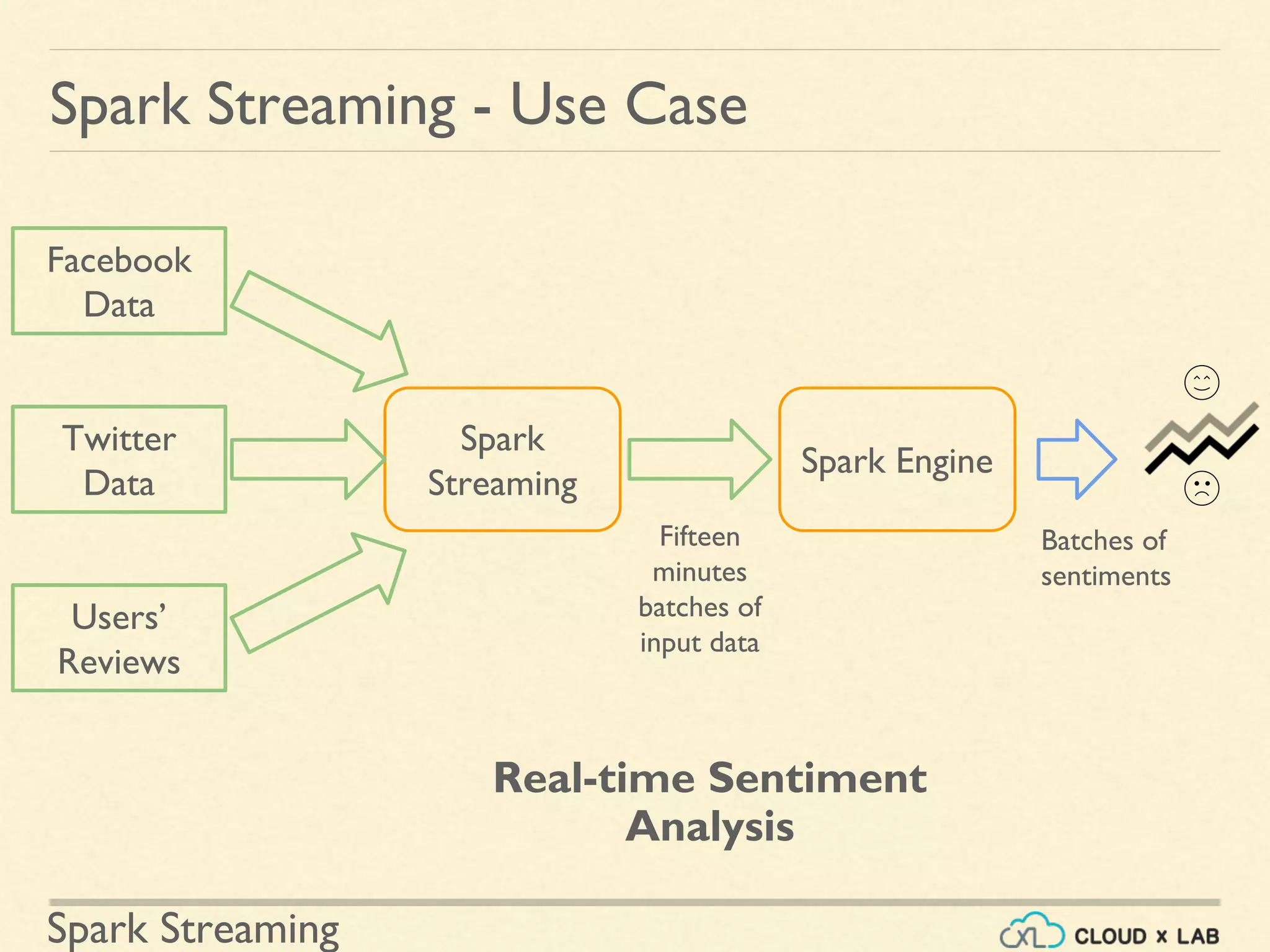
Real-time analytics use cases including e-commerce product tracking and sentiment analysis.
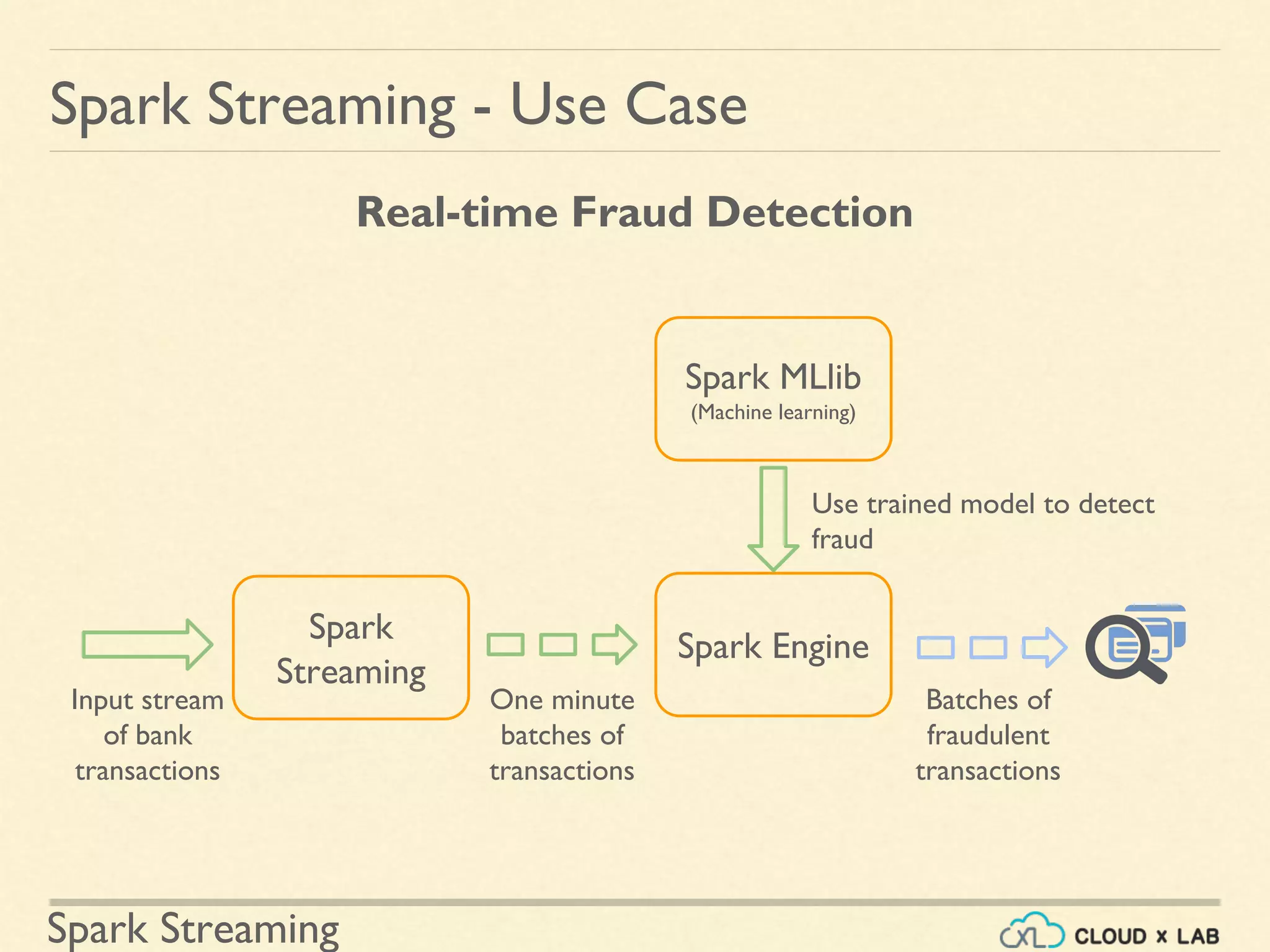
Building a real-time fraud detection system for financial transactions utilizing Spark Streaming.
Real-time analytics applications at Uber, Pinterest, and Netflix showcasing the versatility of Spark Streaming.
Explanation of DStream as a continuous stream of data represented by RDD sequences in Spark.
A hands-on example of counting words from a data stream including code structure and basic operations.
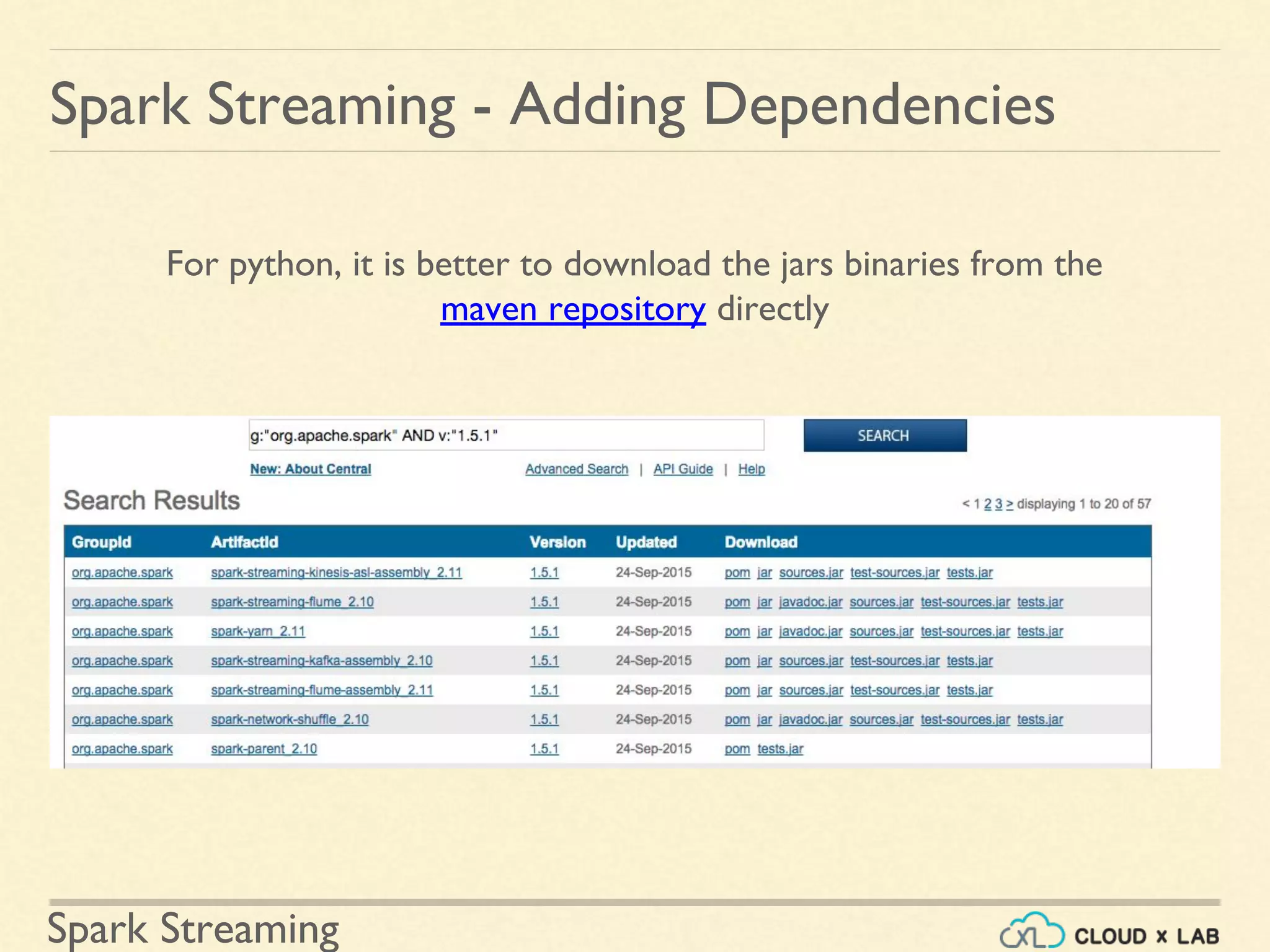
Adding necessary dependencies and preparation for Python programming environment in Spark Streaming.
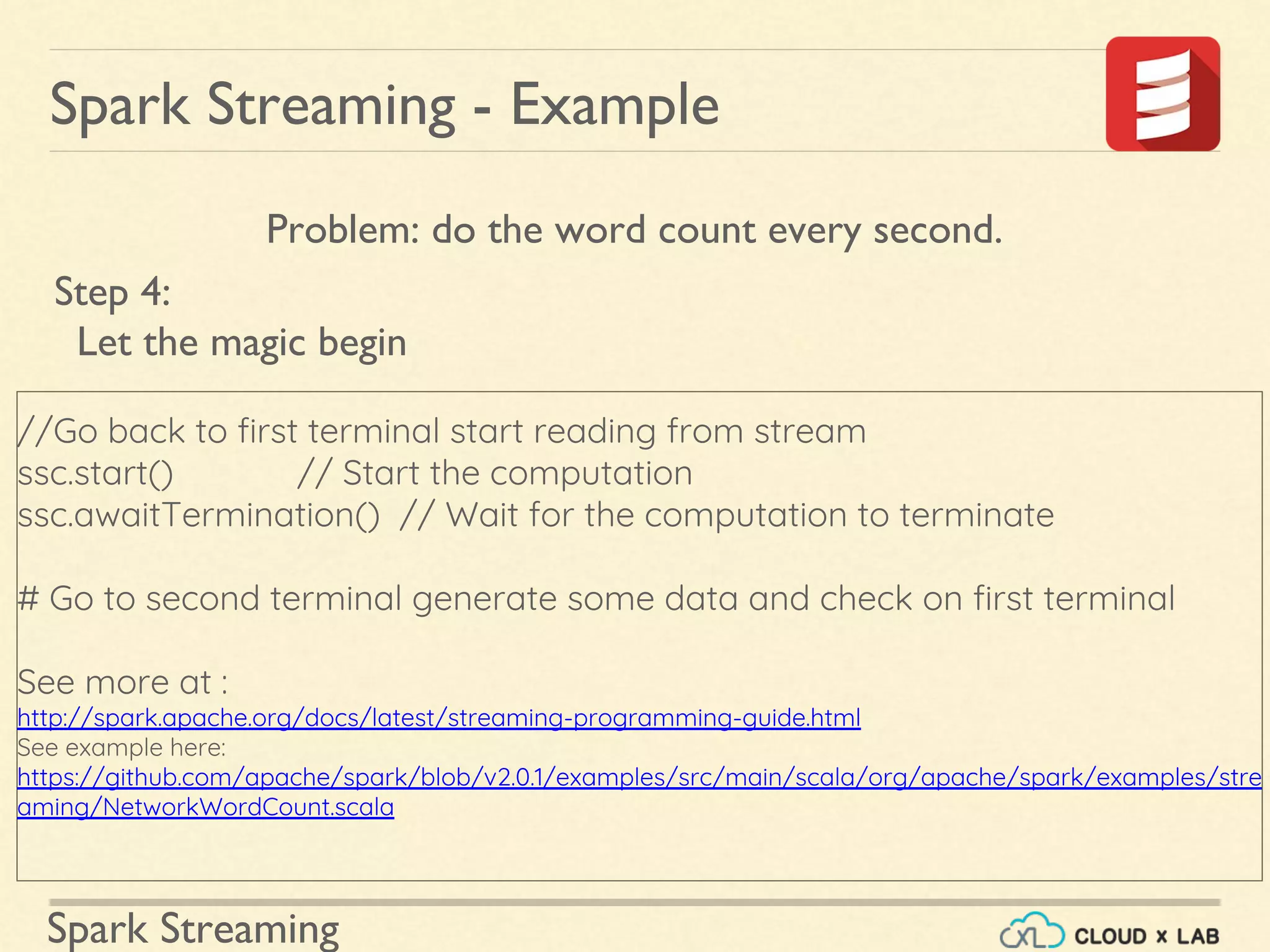
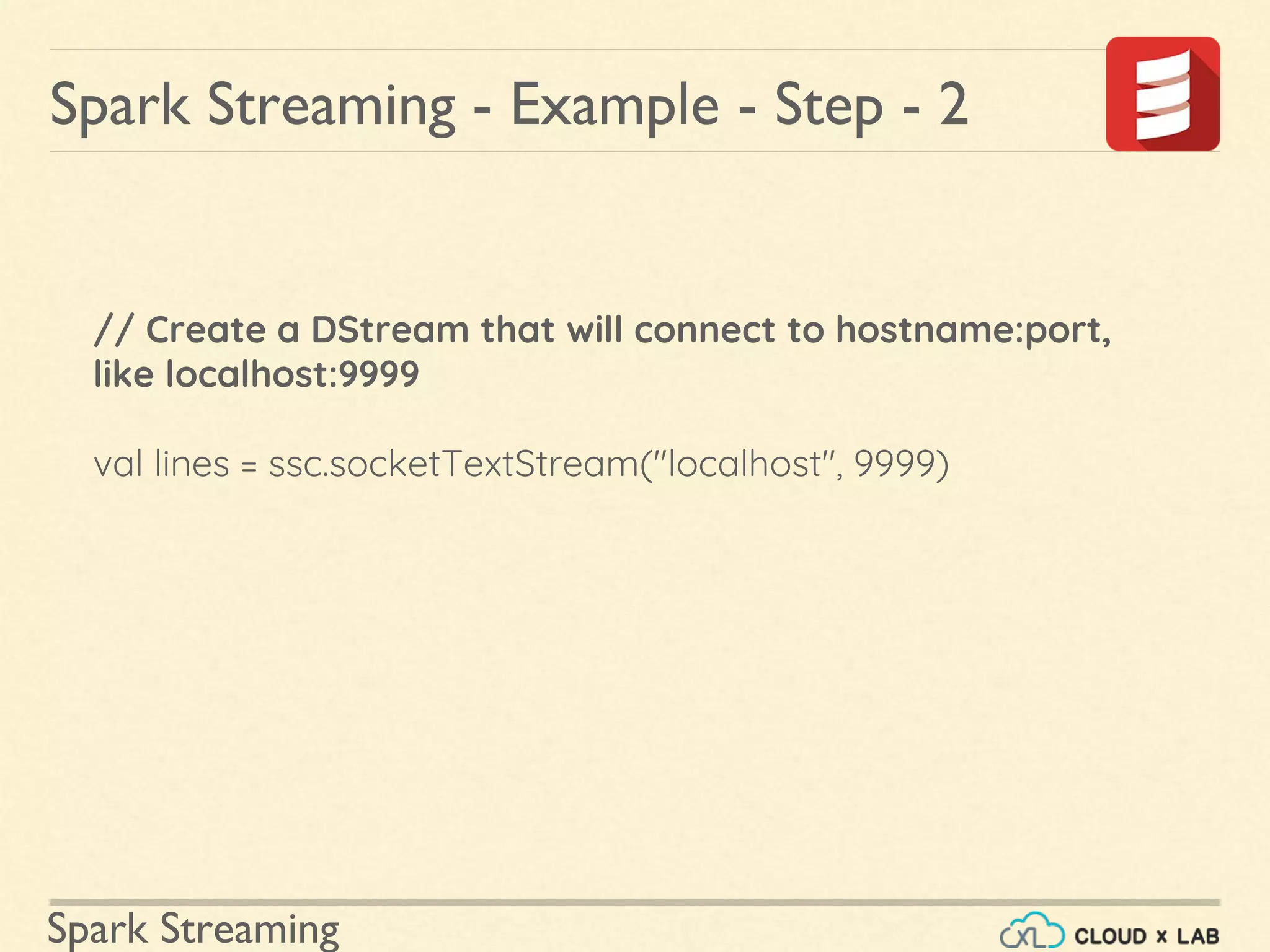
Overview of initializing StreamingContext, defining input sources, and managing processing.
Overview of Kafka as a distributed messaging system designed for real-time data streams.
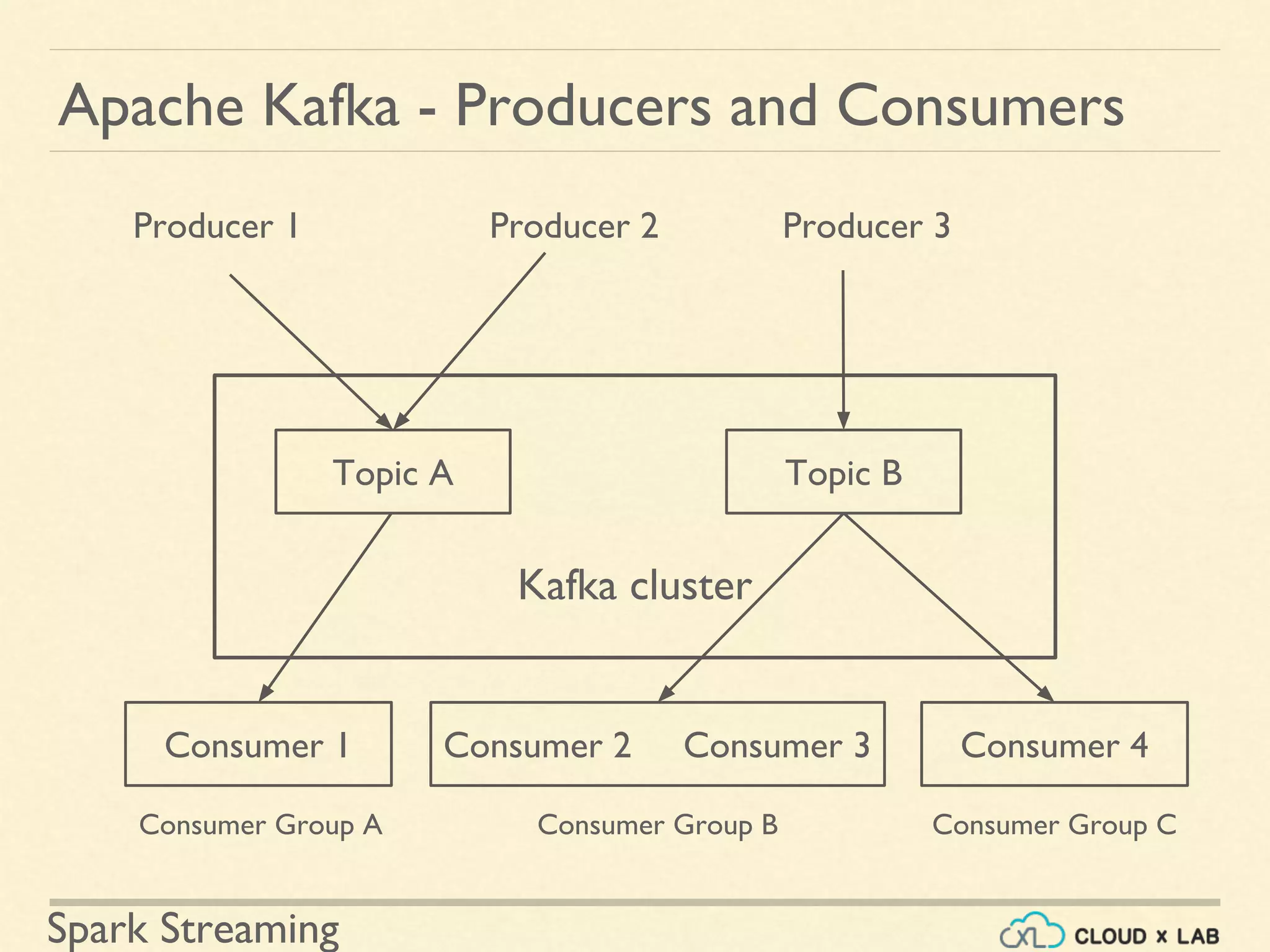
Understanding Kafka's architecture including brokers, topics, and partitions for data management.
Detailing Kafka's model of producers producing and consumers subscribing to topics.
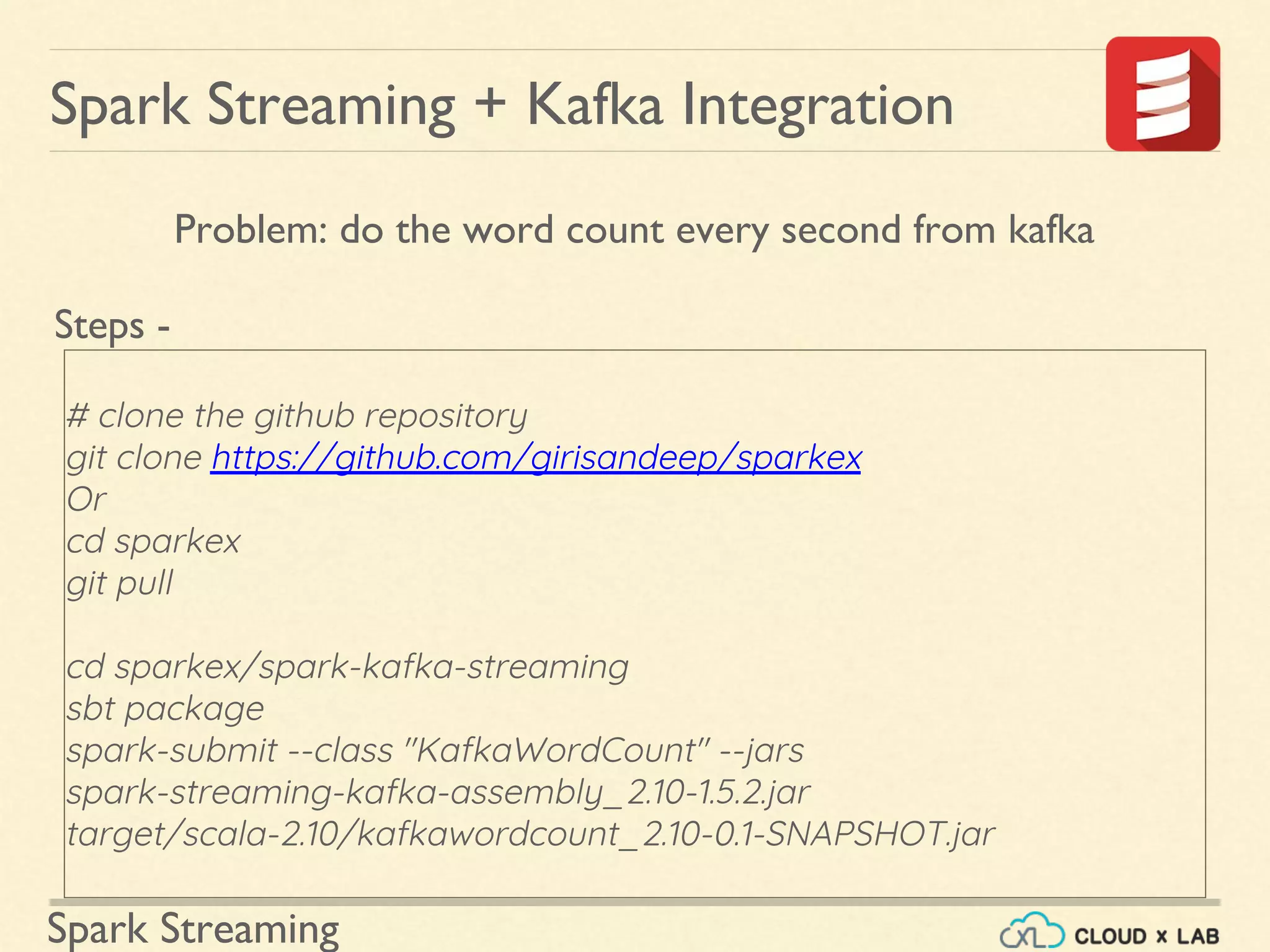
Steps explaining how to integrate Spark Streaming with Kafka for real-time data processing.
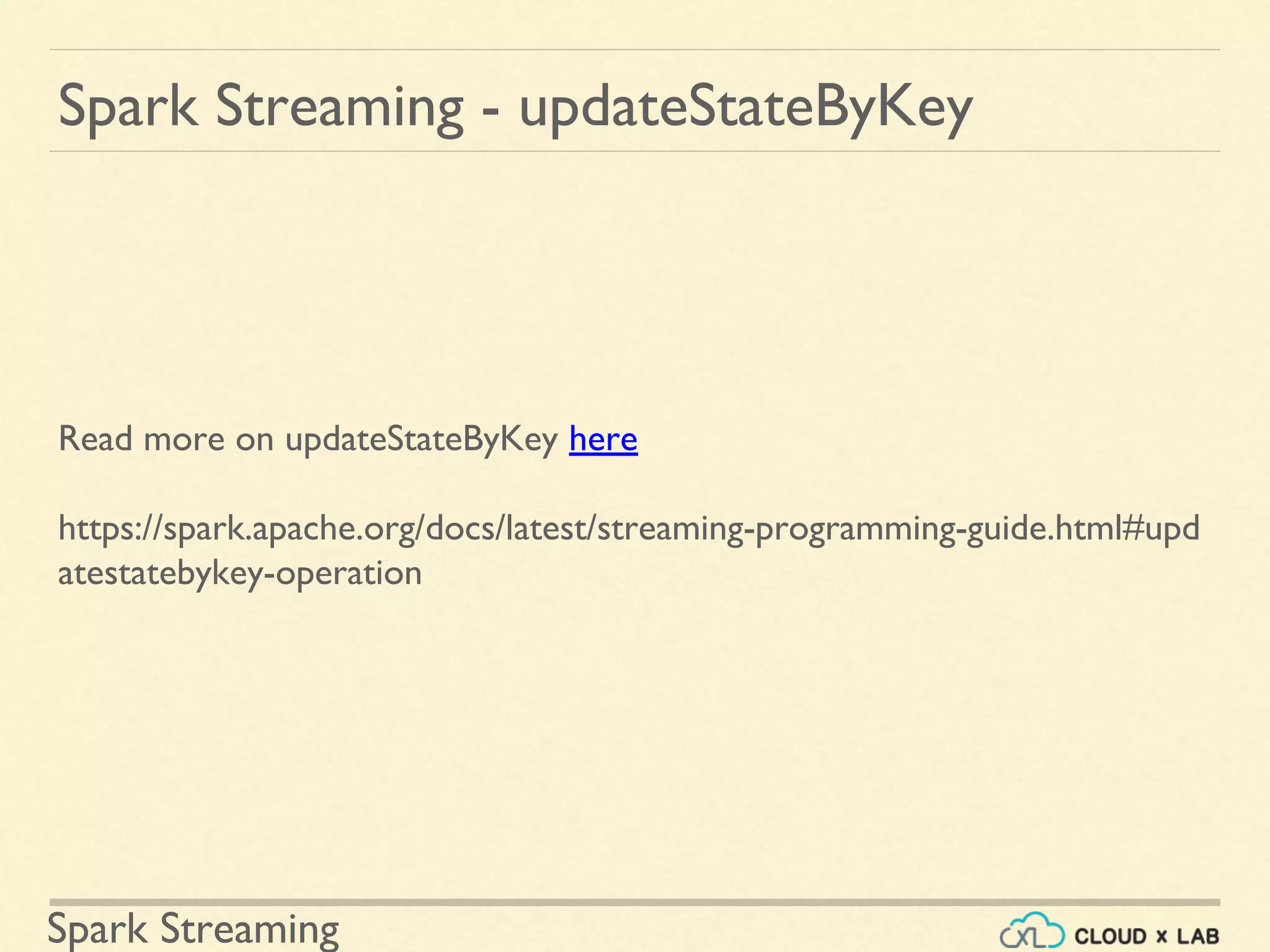
Detailed usage of updateStateByKey for maintaining state in streaming applications.
Using arbitrary RDD-to-RDD functions on DStreams for extended functionality in streaming.
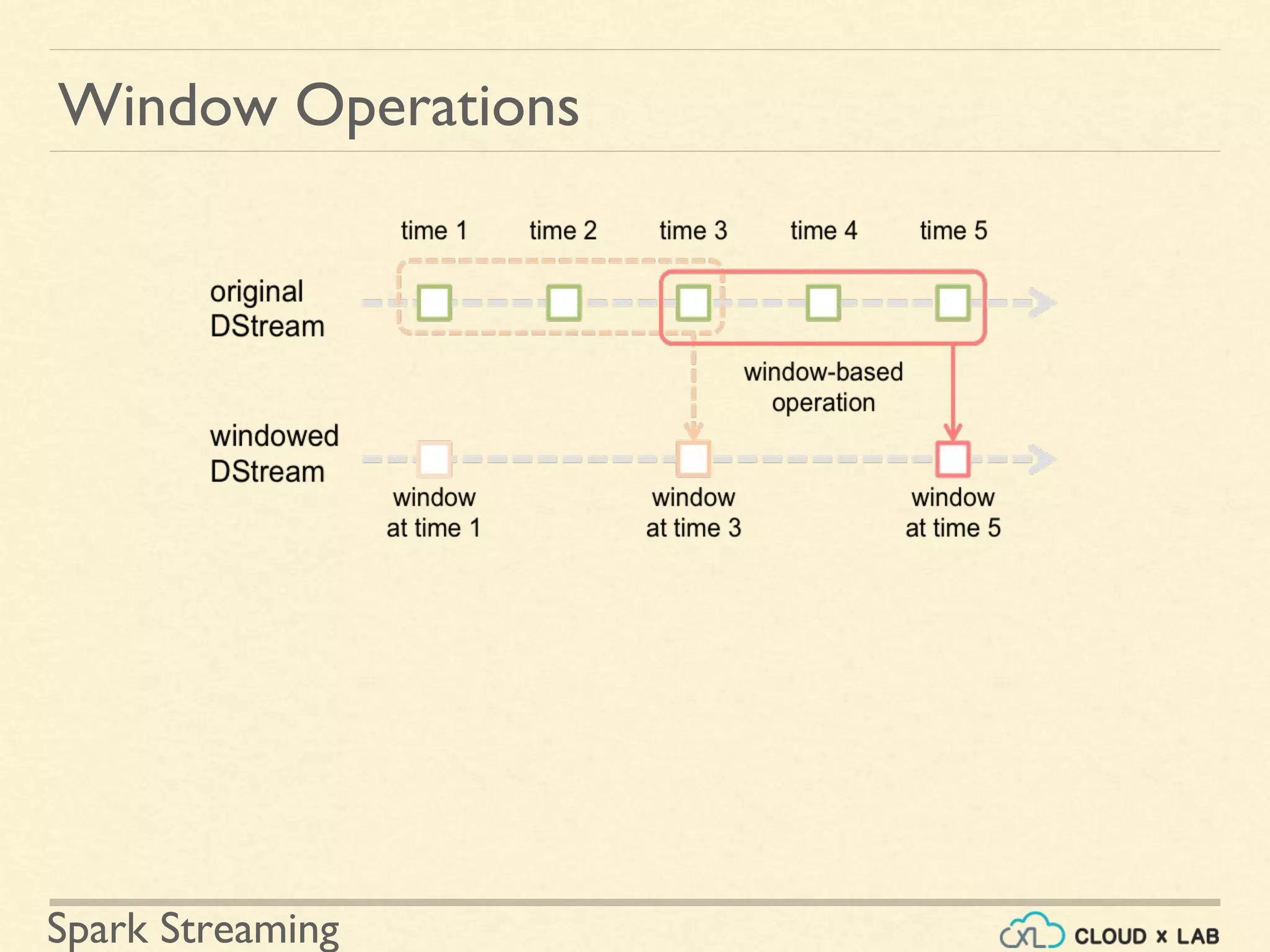
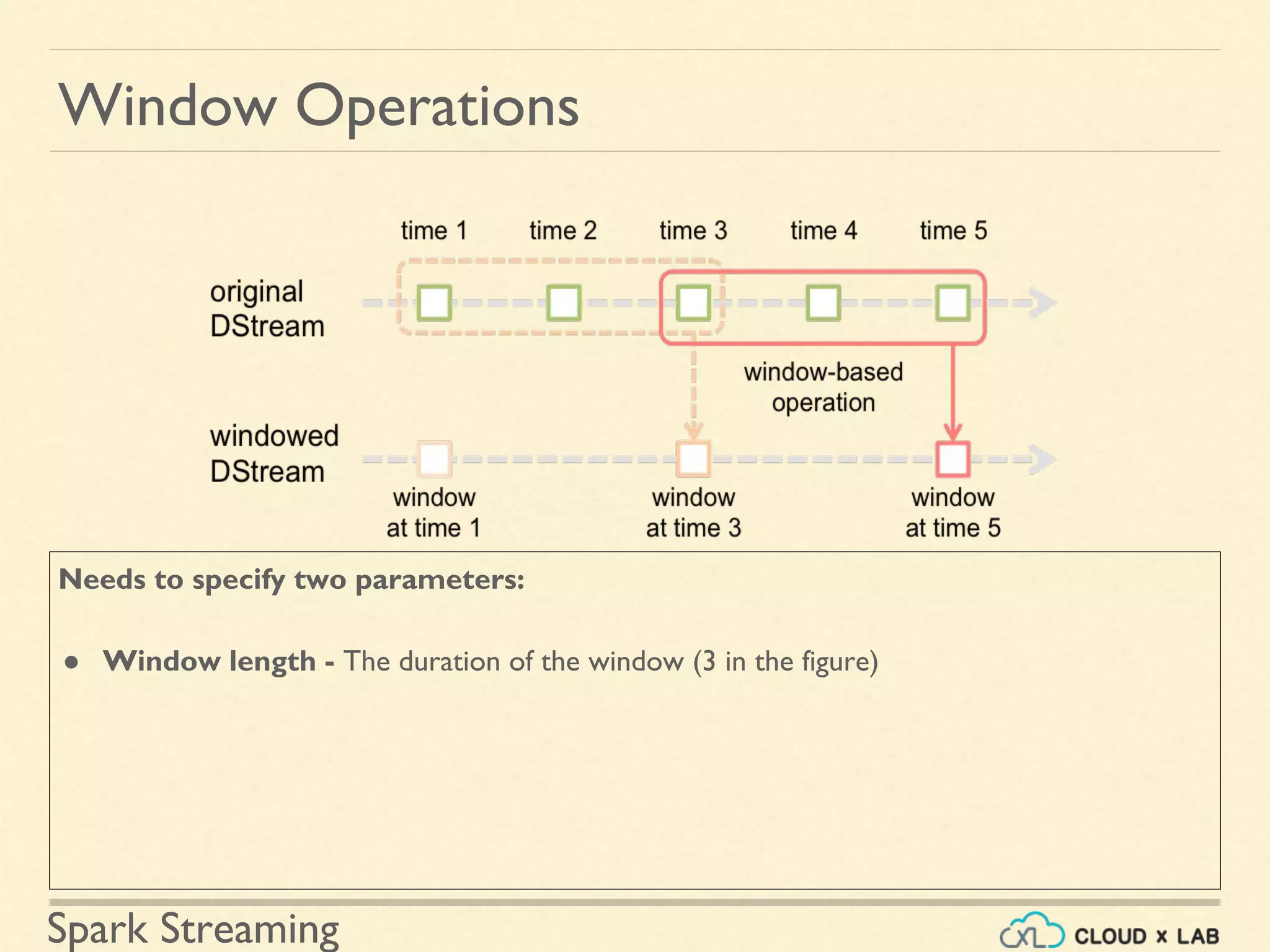
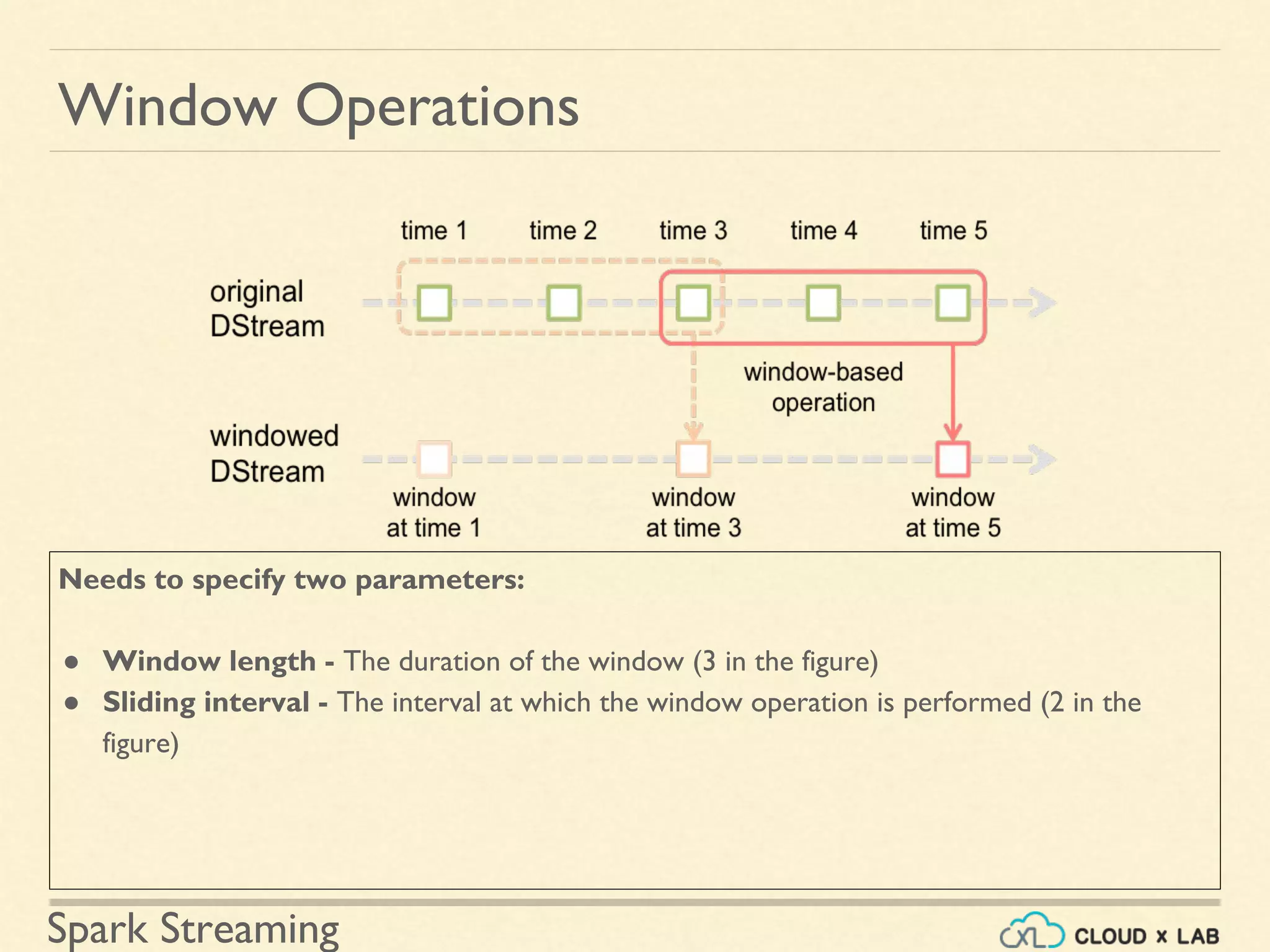
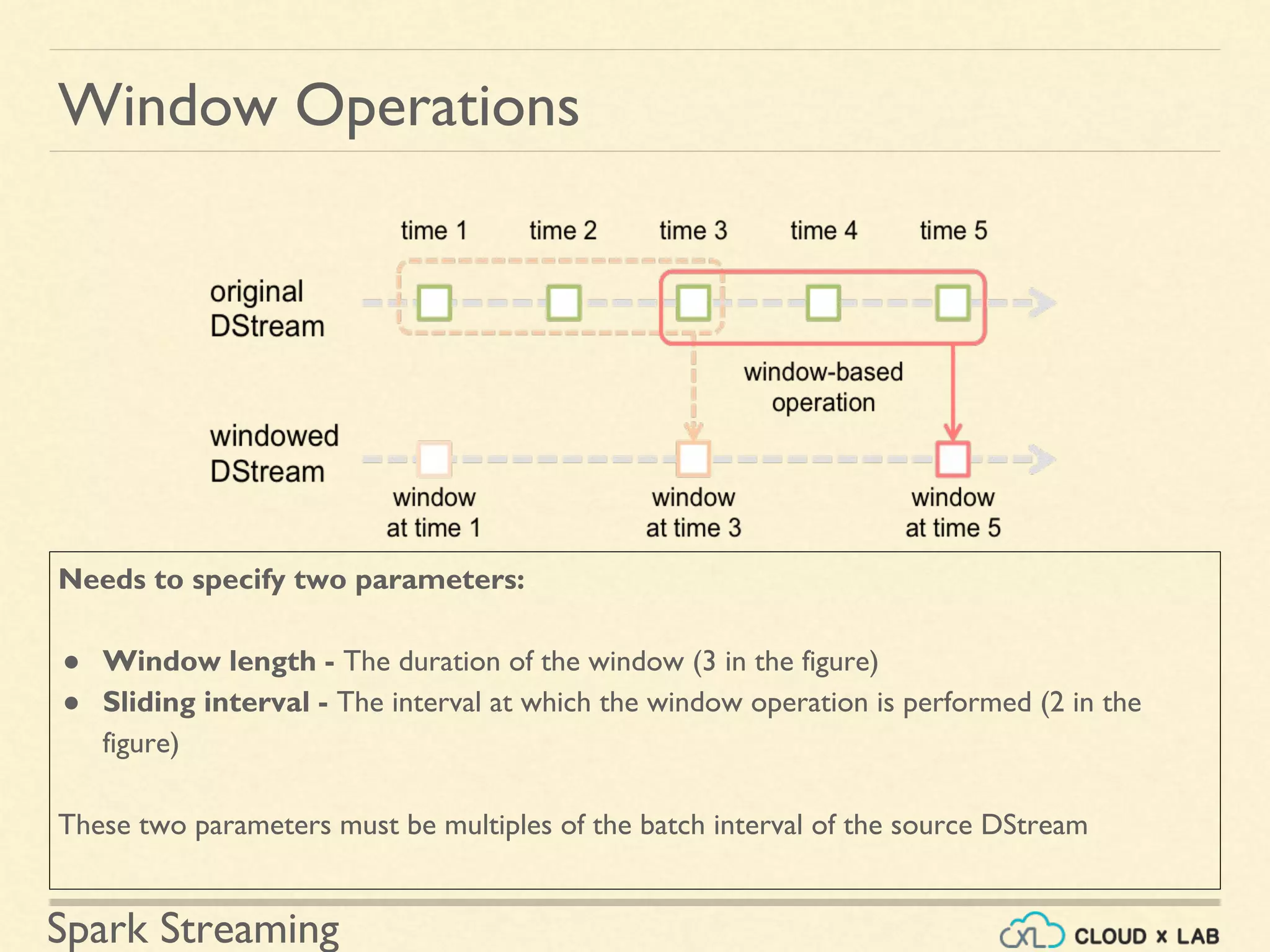
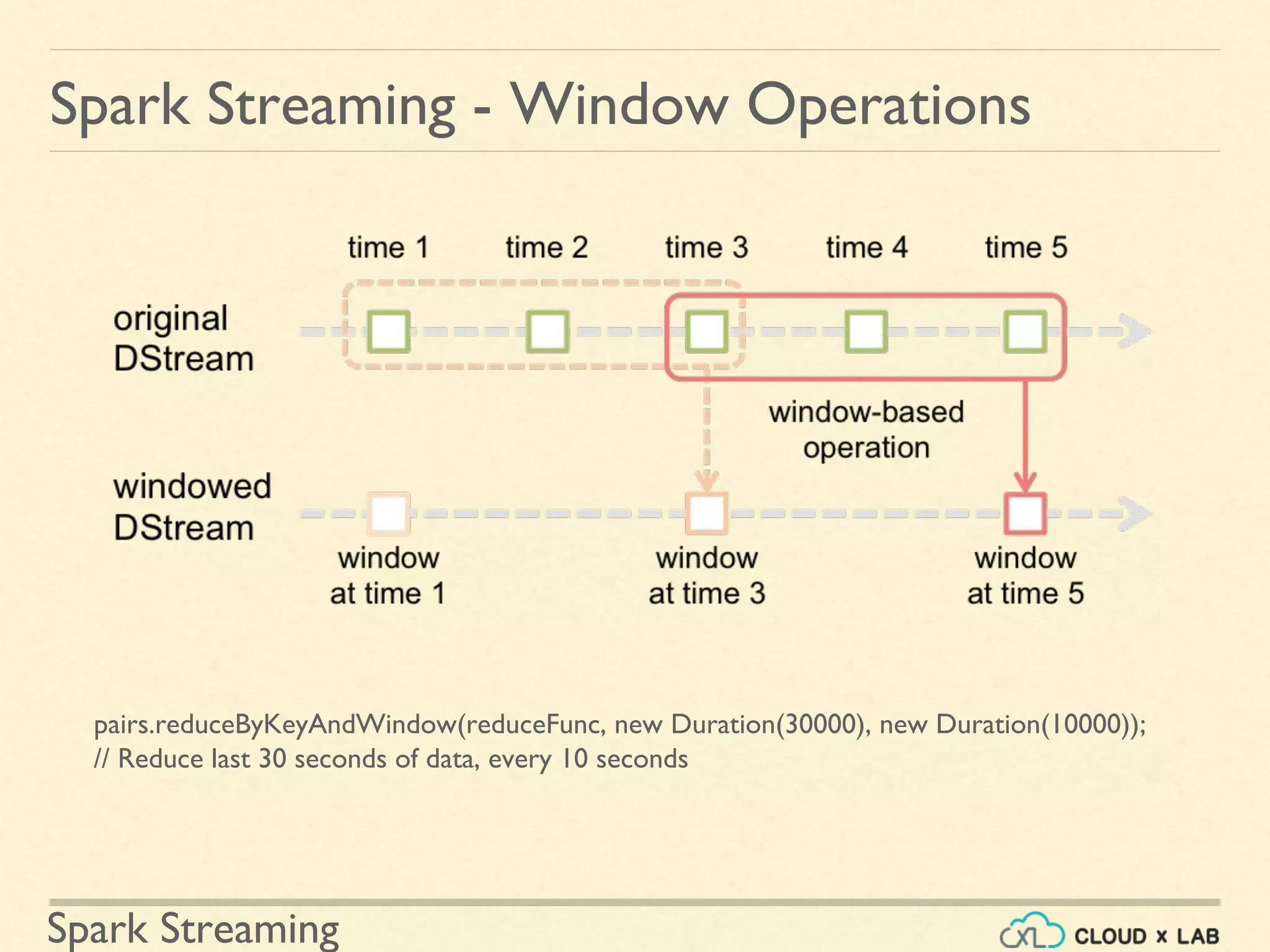
Description of applying transformations over time-based windows within streaming data.
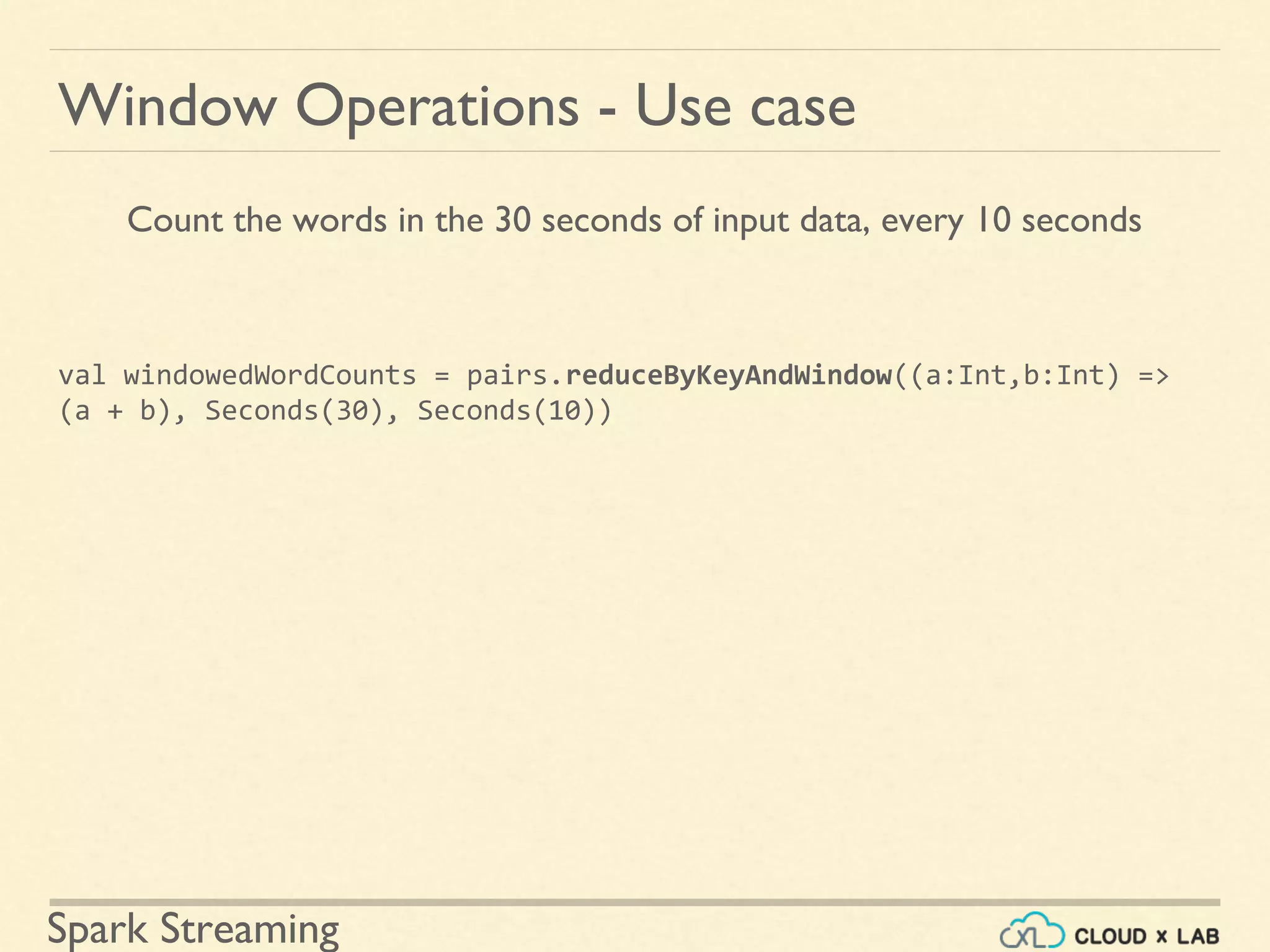
Practical example of counting words in sliding window intervals using time-based operations.
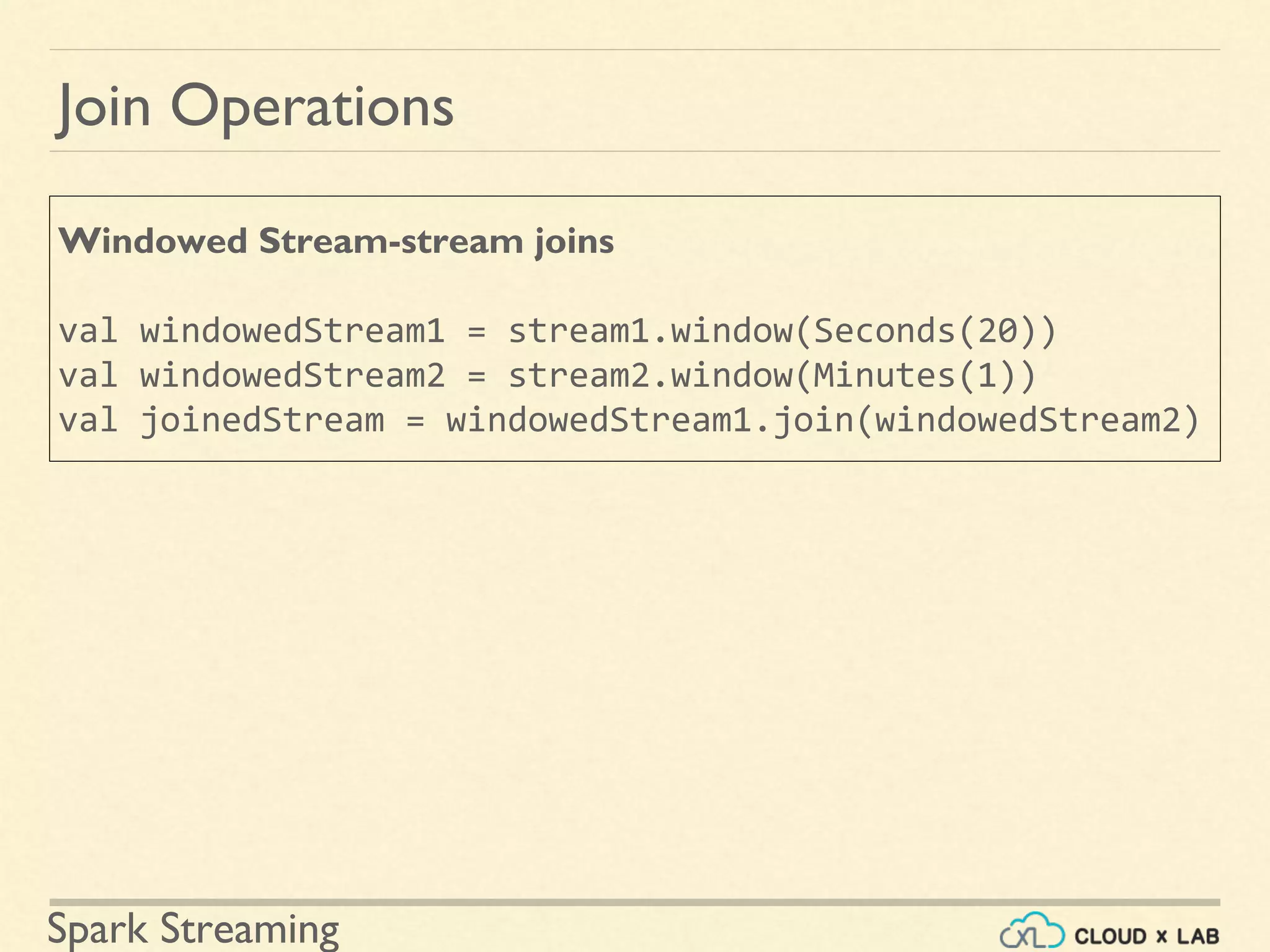
Stream manipulation through various join operations including stream-stream and stream-dataset joins.
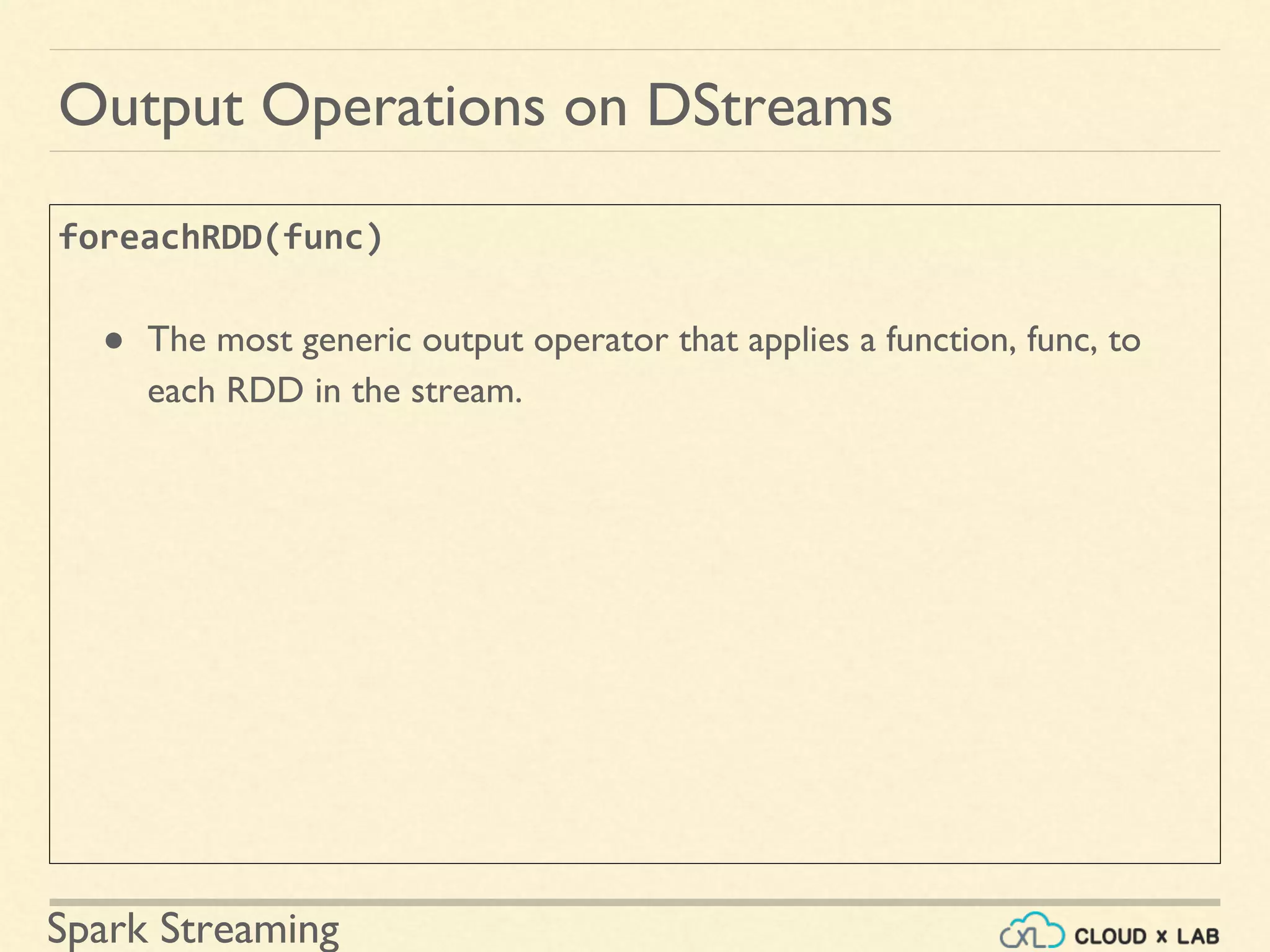
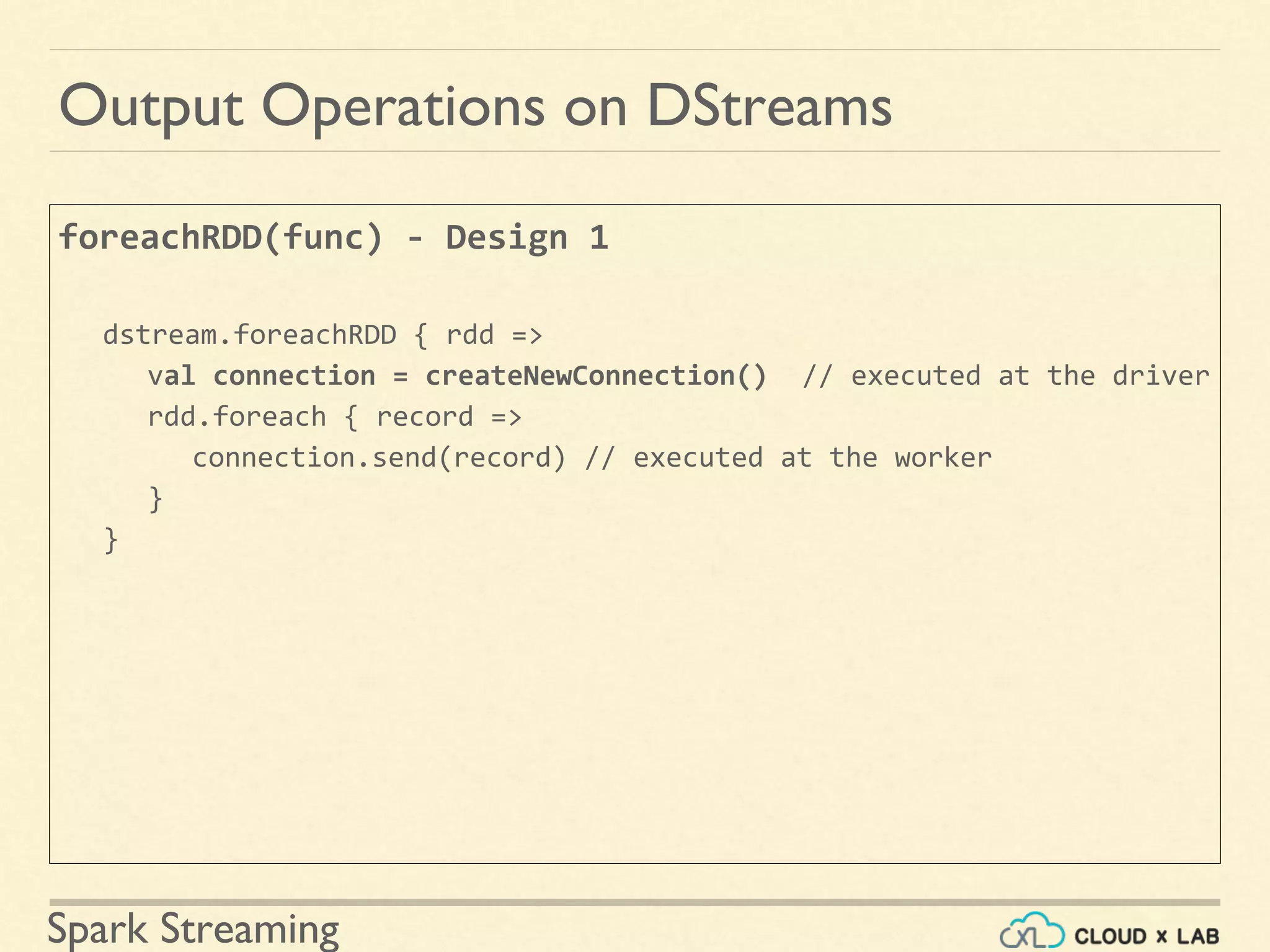
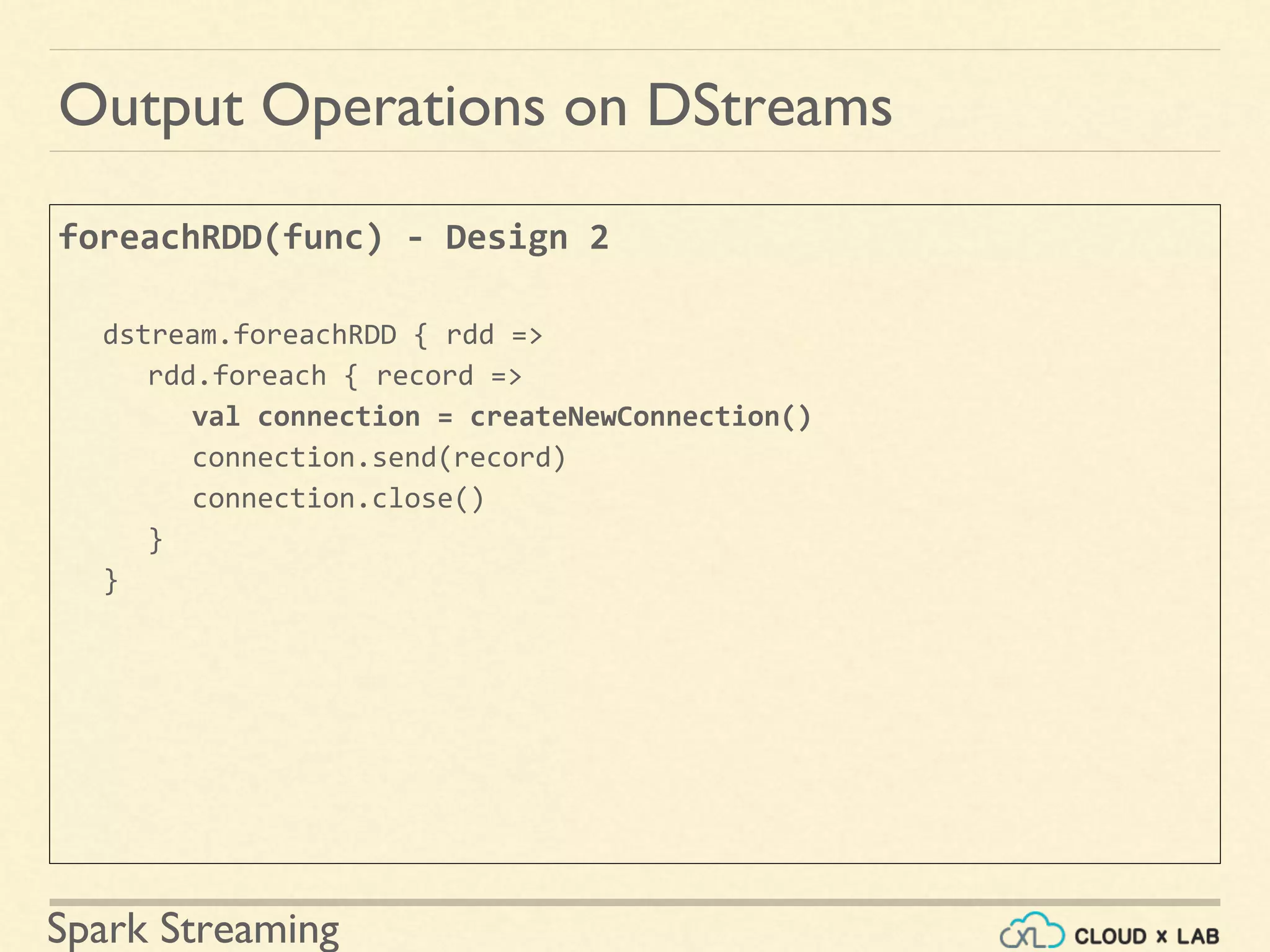
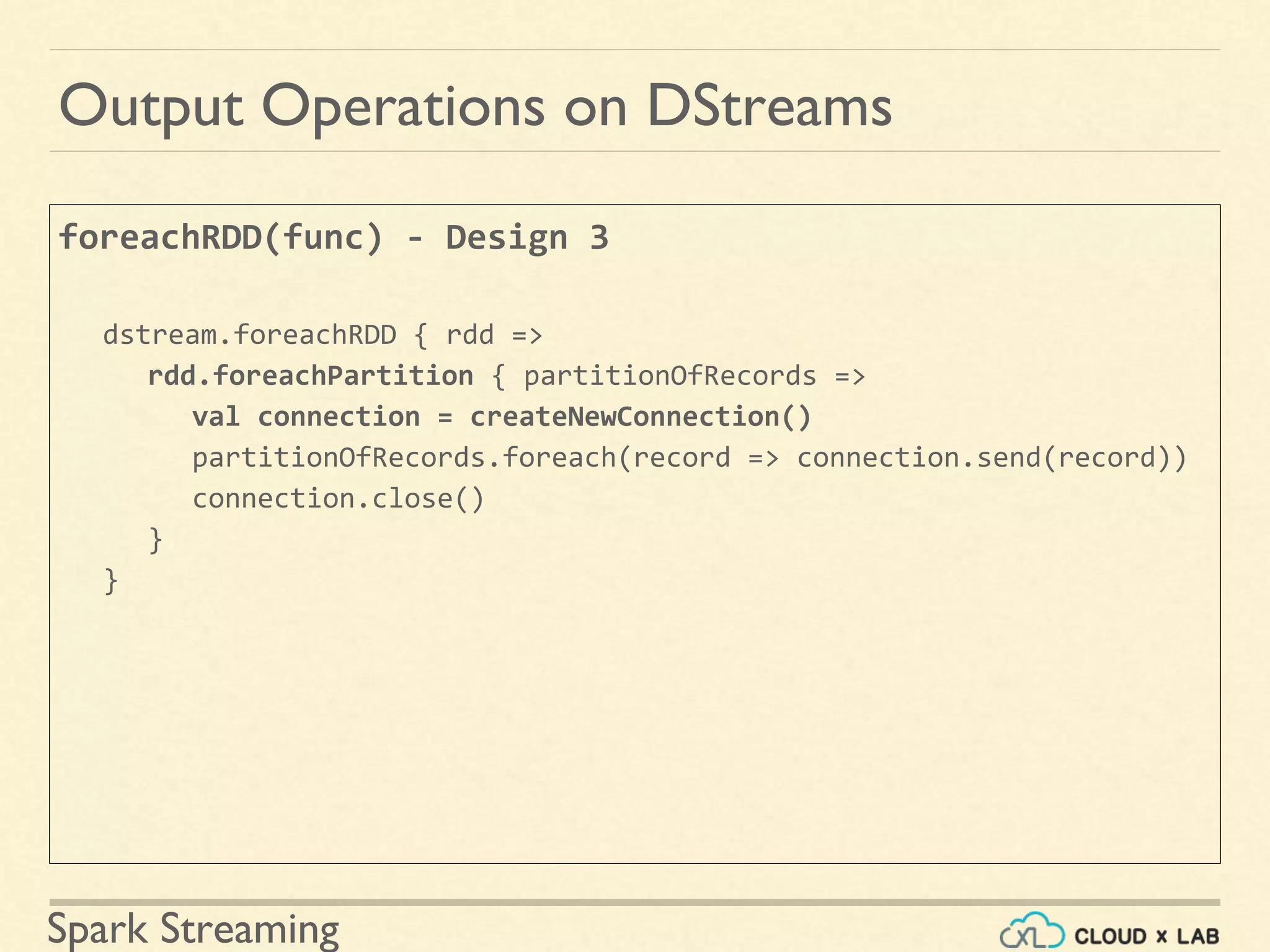
Understanding output operations and patterns for pushing DStream data to external systems.
Detailed step-by-step example of a streaming word count application implemented with Spark.
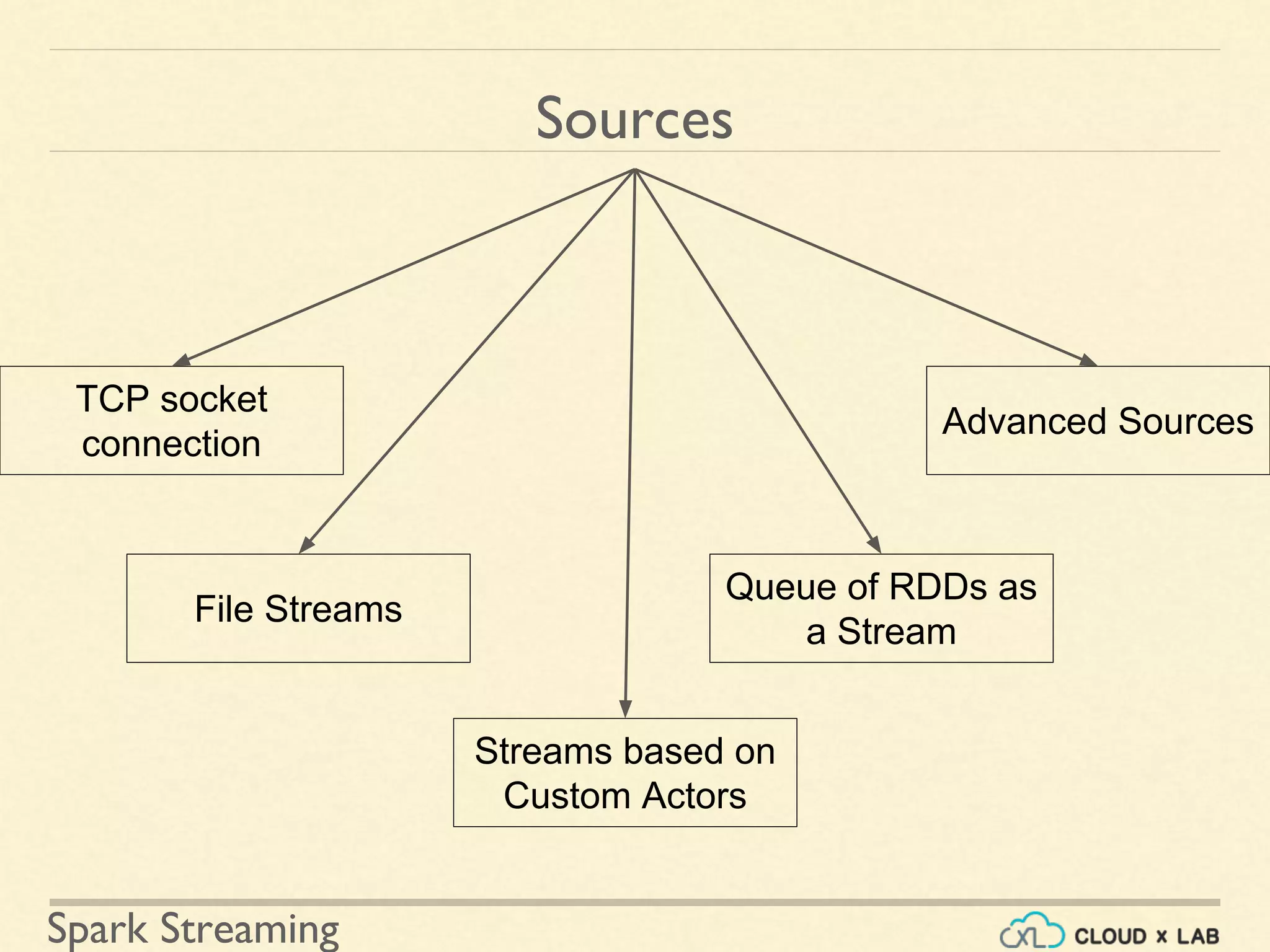
Flexible sources for data ingestion including file streams, custom actors, and queues in Spark Streaming.
Guide on configuring Kafka and Spark integration with prerequisite installations for processing streams.