Downloaded 73 times








![Spark SQL & Dataframes Getting Started Spark context Web UI available at http://172.31.60.179:4040 Spark context available as 'sc' (master = local[*], app id = local-1498489557917). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/_,_/_/ /_/_ version 2.0.2 /_/ Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_91) Type in expressions to have them evaluated. Type :help for more information. scala>](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-14-2048.jpg)
![Spark SQL & Dataframes Getting Started Spark context Web UI available at http://172.31.60.179:4040 Spark context available as 'sc' (master = local[*], app id = local-1498489557917). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/_,_/_/ /_/_ version 2.0.2 /_/ Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_91) Type in expressions to have them evaluated. Type :help for more information. scala>](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-15-2048.jpg)
















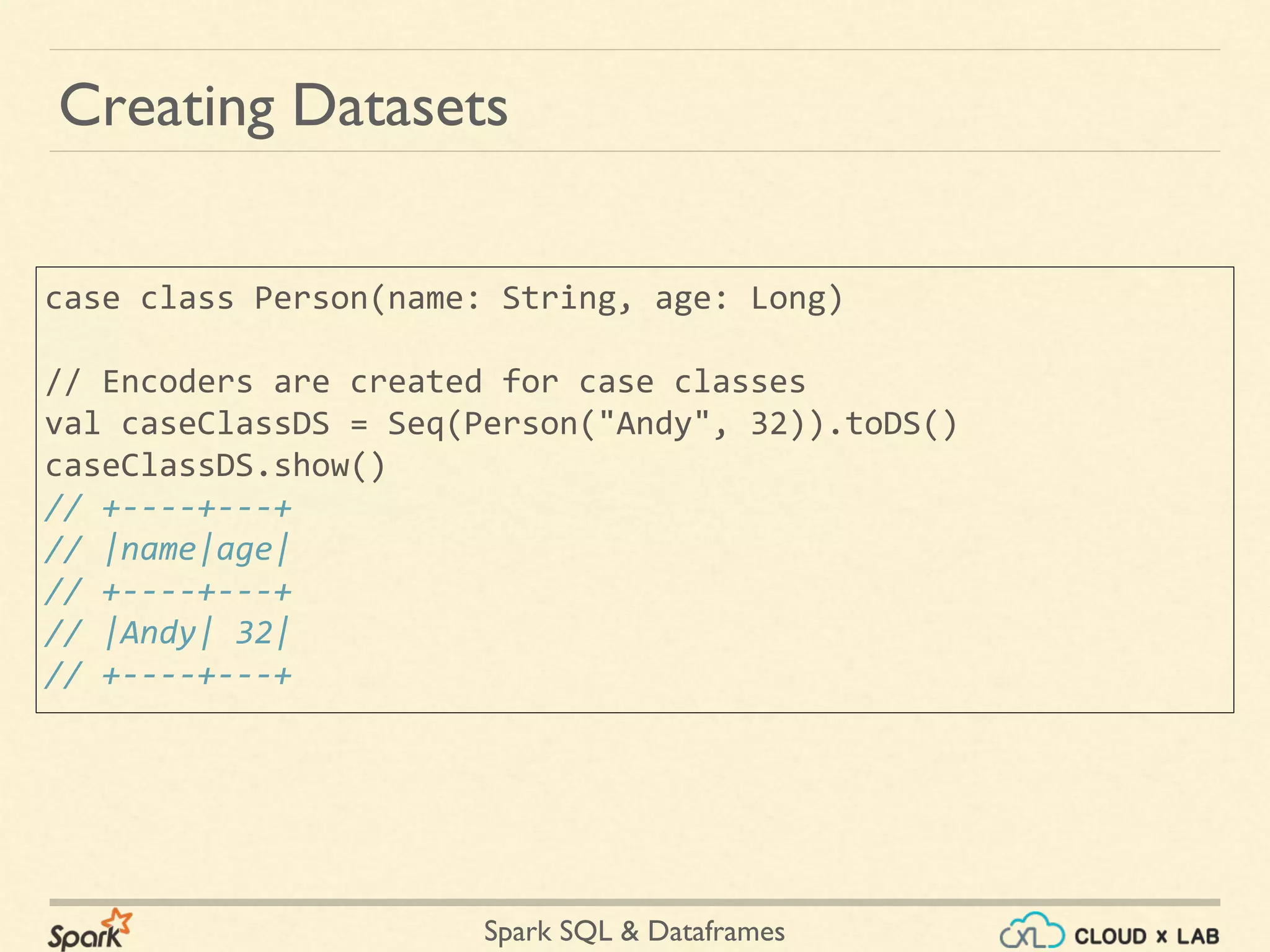
![Spark SQL & Dataframes val path = "/data/spark/people.json" val peopleDS = spark.read.json(path).as[Person] peopleDS.show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +----+-------+ Creating Datasets](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-33-2048.jpg)



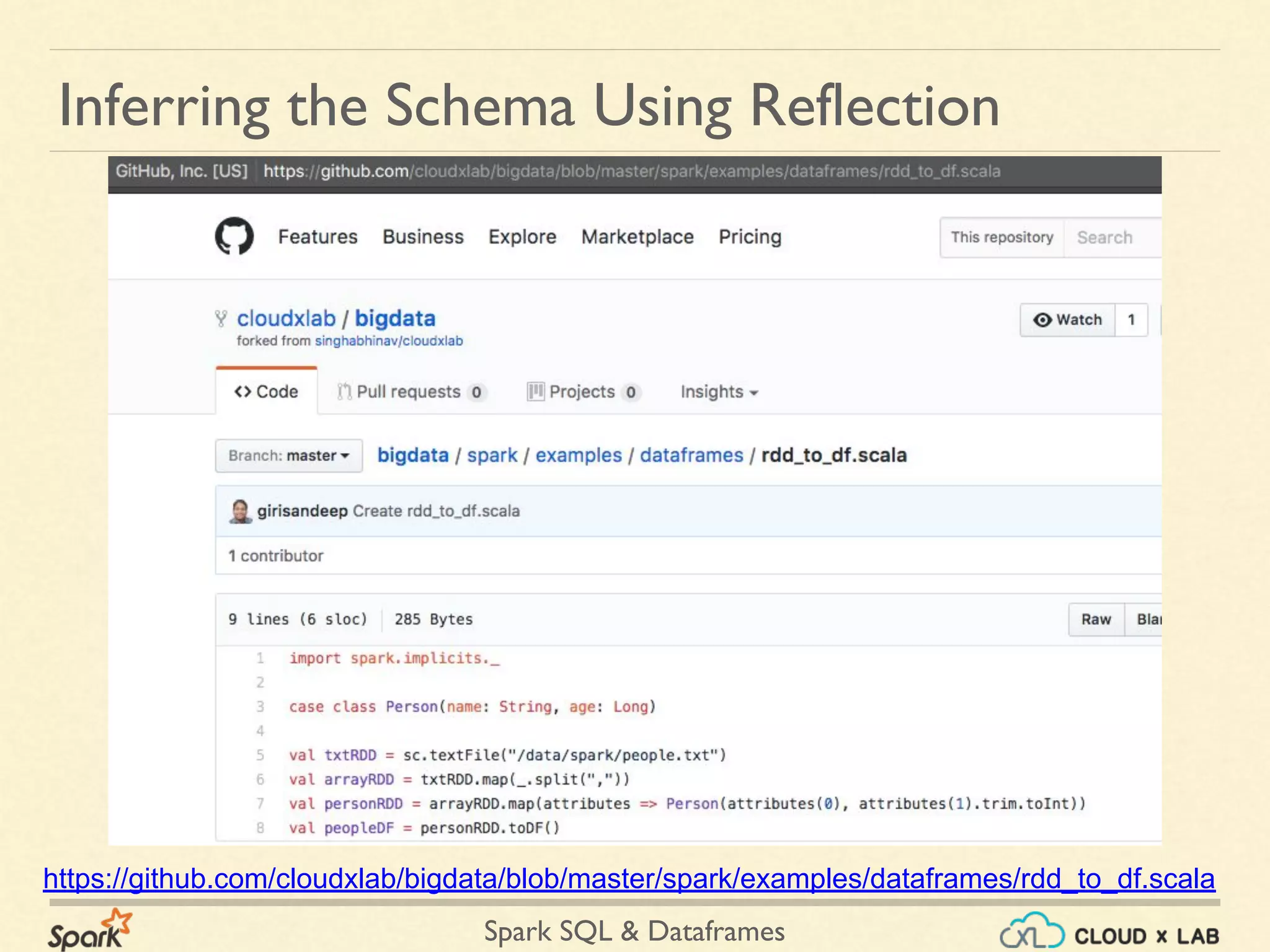


![Spark SQL & Dataframes scala> import spark.implicits._ import spark.implicits._ scala> case class Person(name: String, age: Long) defined class Person scala> val textRDD = sc.textFile("/data/spark/people.txt") textRDD: org.apache.spark.rdd.RDD[String] = /data/spark/people.txt MapPartitionsRDD[3] at textFile at <console>:30 Inferring the Schema Using Reflection](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-41-2048.jpg)
![Spark SQL & Dataframes scala> import spark.implicits._ import spark.implicits._ scala> case class Person(name: String, age: Long) defined class Person scala> val textRDD = sc.textFile("/data/spark/people.txt") textRDD: org.apache.spark.rdd.RDD[String] = /data/spark/people.txt MapPartitionsRDD[3] at textFile at <console>:30 scala> val arrayRDD = textRDD.map(_.split(",")) arrayRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[4] at map at <console>:32 Inferring the Schema Using Reflection](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-42-2048.jpg)
![Spark SQL & Dataframes scala> import spark.implicits._ import spark.implicits._ scala> case class Person(name: String, age: Long) defined class Person scala> val textRDD = sc.textFile("/data/spark/people.txt") textRDD: org.apache.spark.rdd.RDD[String] = /data/spark/people.txt MapPartitionsRDD[3] at textFile at <console>:30 scala> val arrayRDD = textRDD.map(_.split(",")) arrayRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[4] at map at <console>:32 scala> val personRDD = arrayRDD.map(attributes => Person(attributes(0), attributes(1).trim.toInt)) personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[5] at map at <console>:36 Inferring the Schema Using Reflection](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-43-2048.jpg)
![Spark SQL & Dataframes scala> val peopleDF = personRDD.toDF() peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: bigint] Inferring the Schema Using Reflection](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-44-2048.jpg)
![Spark SQL & Dataframes scala> val peopleDF = personRDD.toDF() peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: bigint] scala> peopleDF.show() +-------+---+ | name|age| +-------+---+ |Michael| 29| | Andy| 30| | Justin| 19| +-------+---+ Inferring the Schema Using Reflection](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-45-2048.jpg)


).show() // +------------+ // | value| // +------------+ // |Name: Justin| // +------------+ Inferring the Schema Using Reflection](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-48-2048.jpg)
![Spark SQL & Dataframes Inferring the Schema Using Reflection // No pre-defined encoders for Dataset[Map[K,V]], define explicitly implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]] // Primitive types and case classes can be also defined as // implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder() // row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T] teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect() // Array(Map("name" -> "Justin", "age" -> 19))](https://image.slidesharecdn.com/copyofspark-dataframessparksqlpart1-180525110550/75/Apache-Spark-Dataframes-Spark-SQL-Part-1-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-49-2048.jpg)









The document provides an overview of Spark SQL and DataFrames, detailing their functionalities such as data processing, integration with SQL queries, and data source compatibility. It explains how to create and manipulate DataFrames, utilize Spark SQL for querying, and convert RDDs to DataFrames, as well as using encoders for Datasets. Additionally, it includes code examples for getting started with Spark SQL and DataFrames and performing operations like filtering, grouping, and joining datasets.