








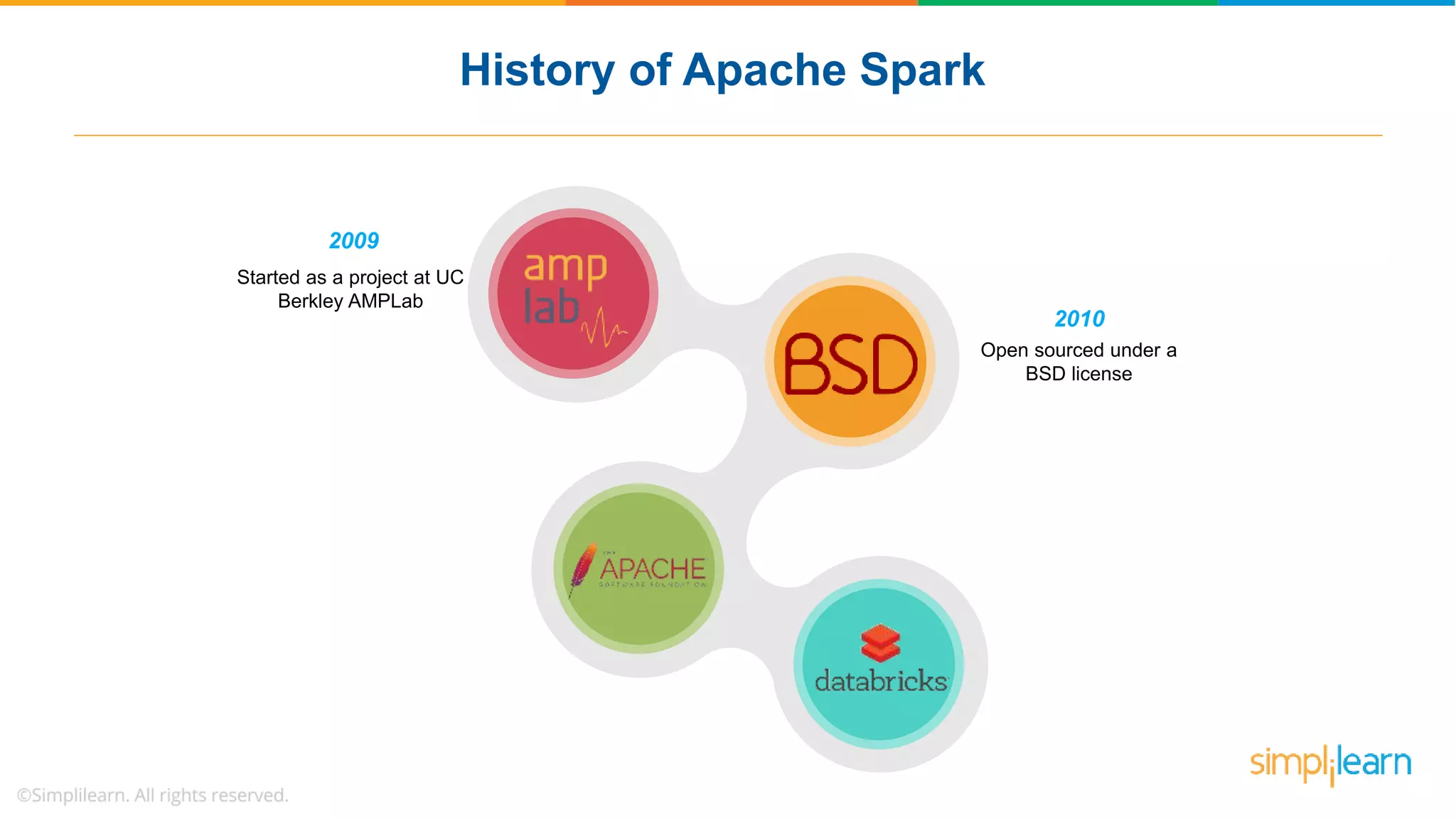
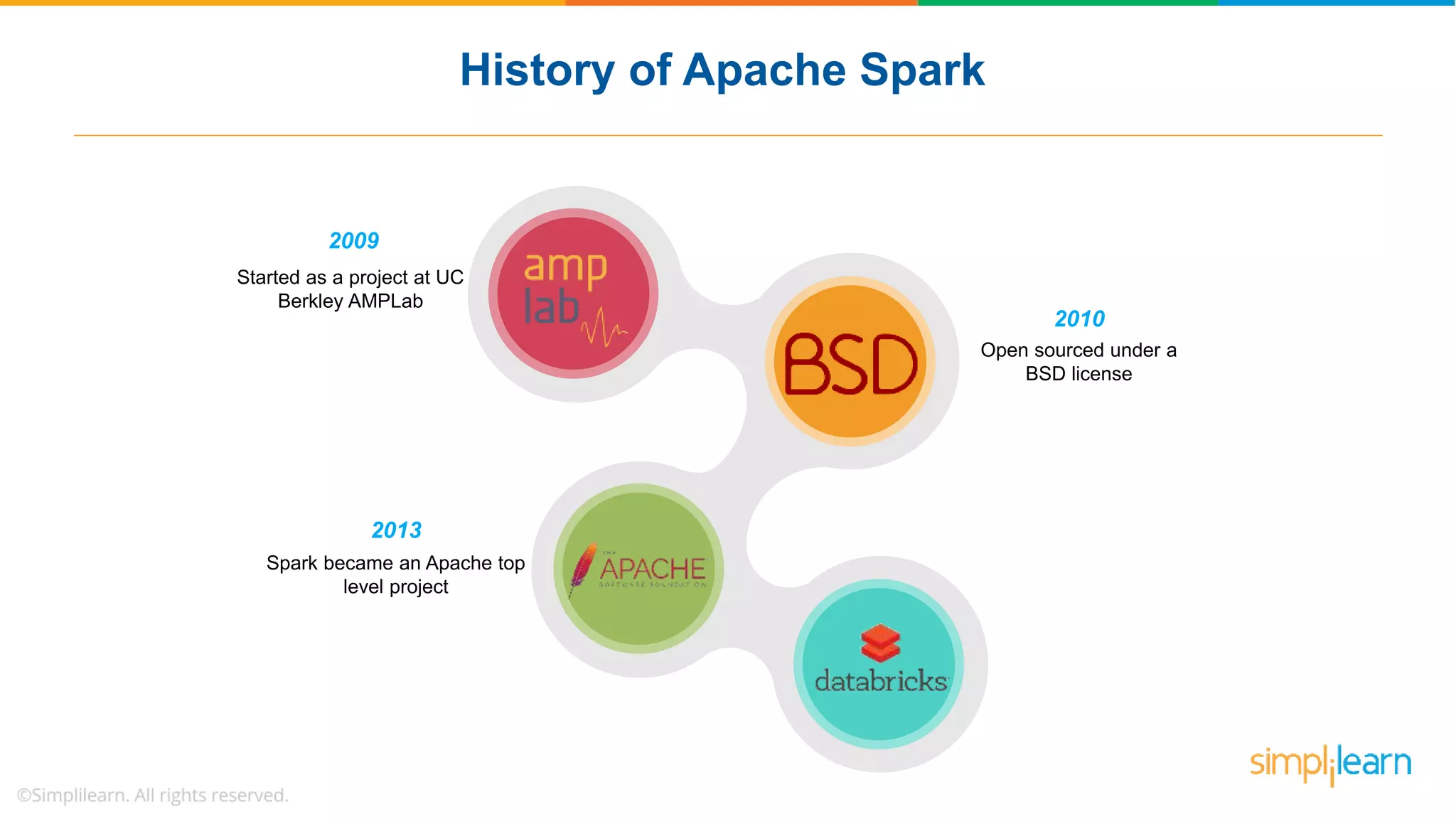
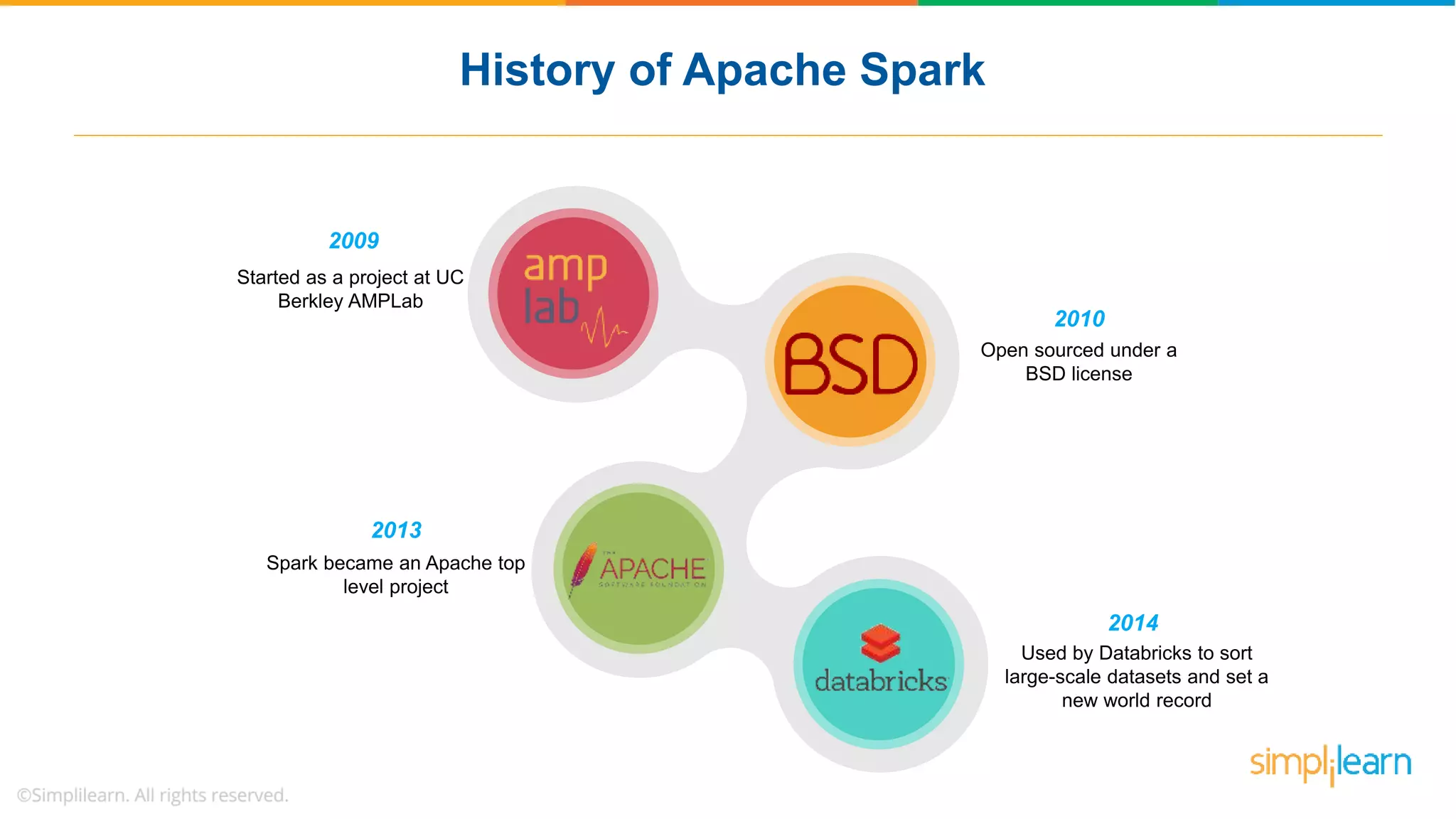




















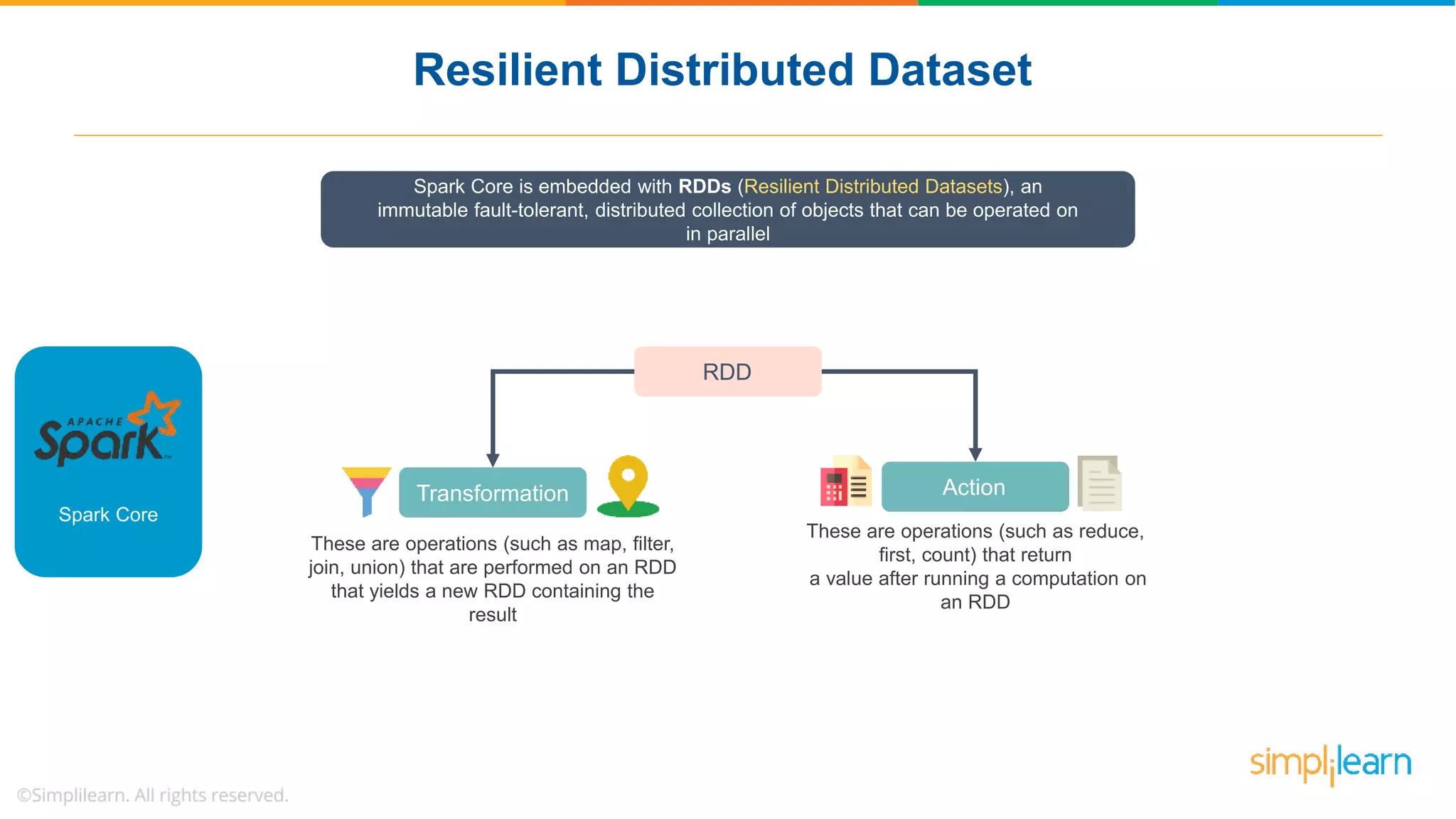


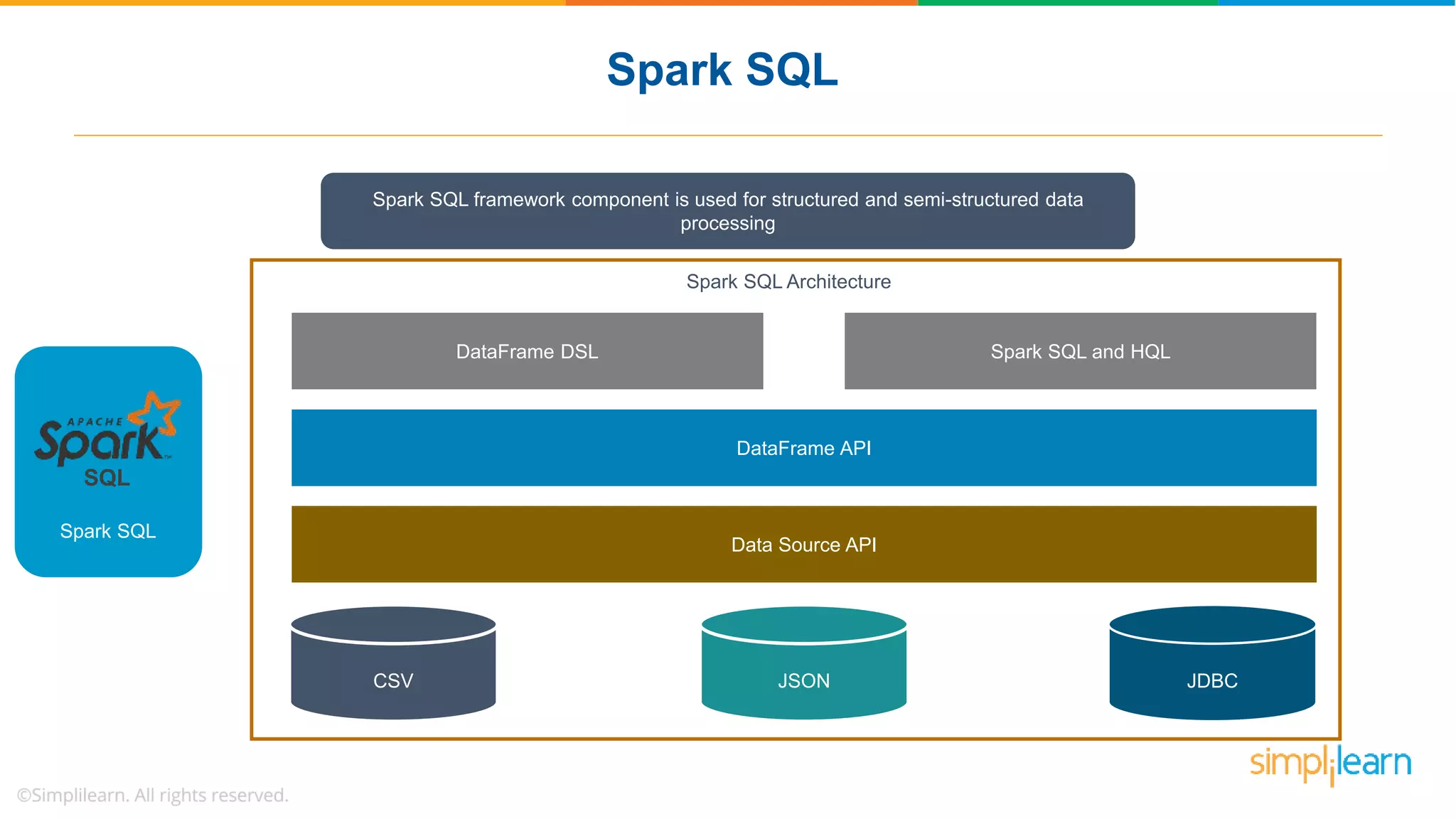


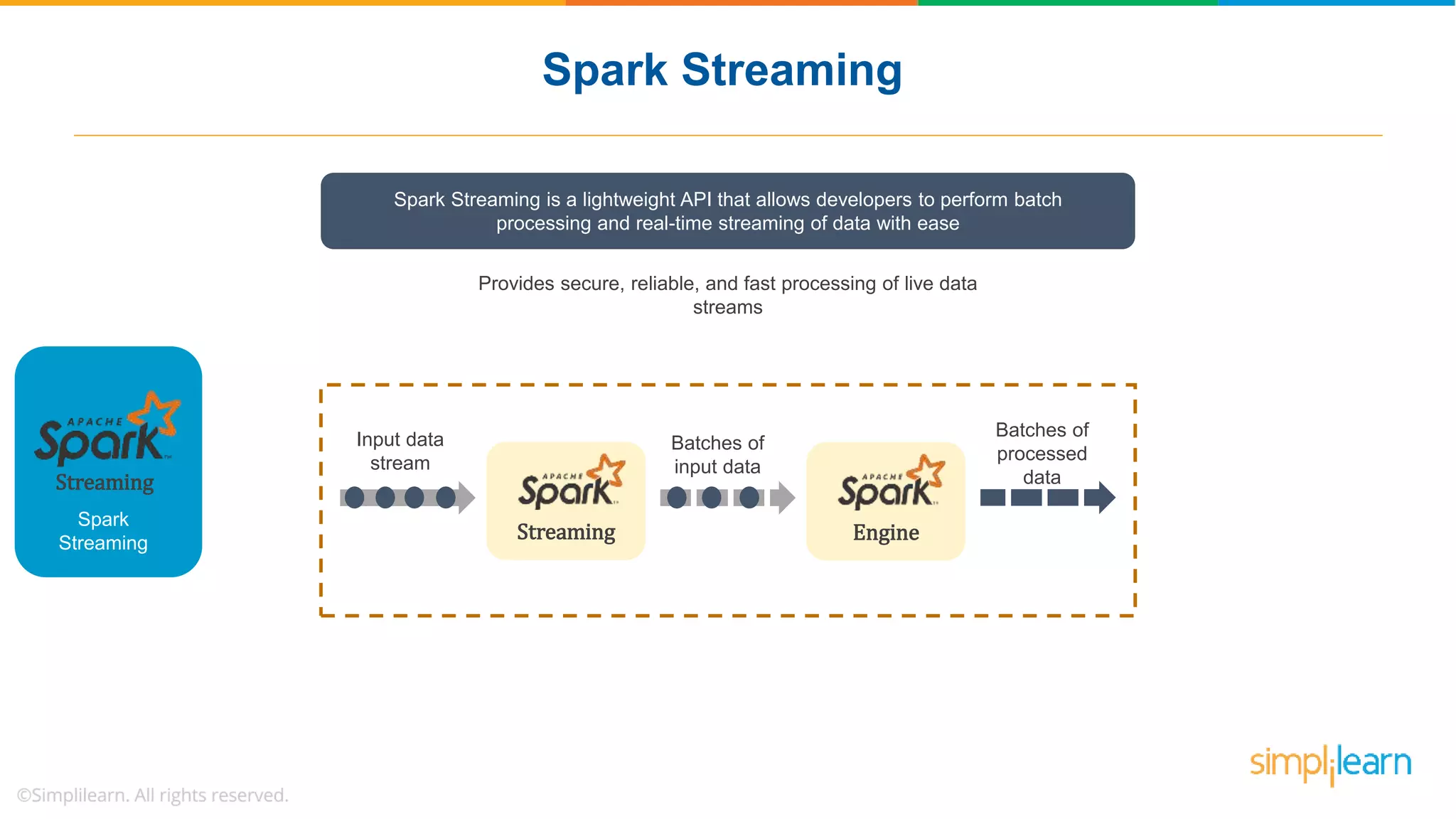






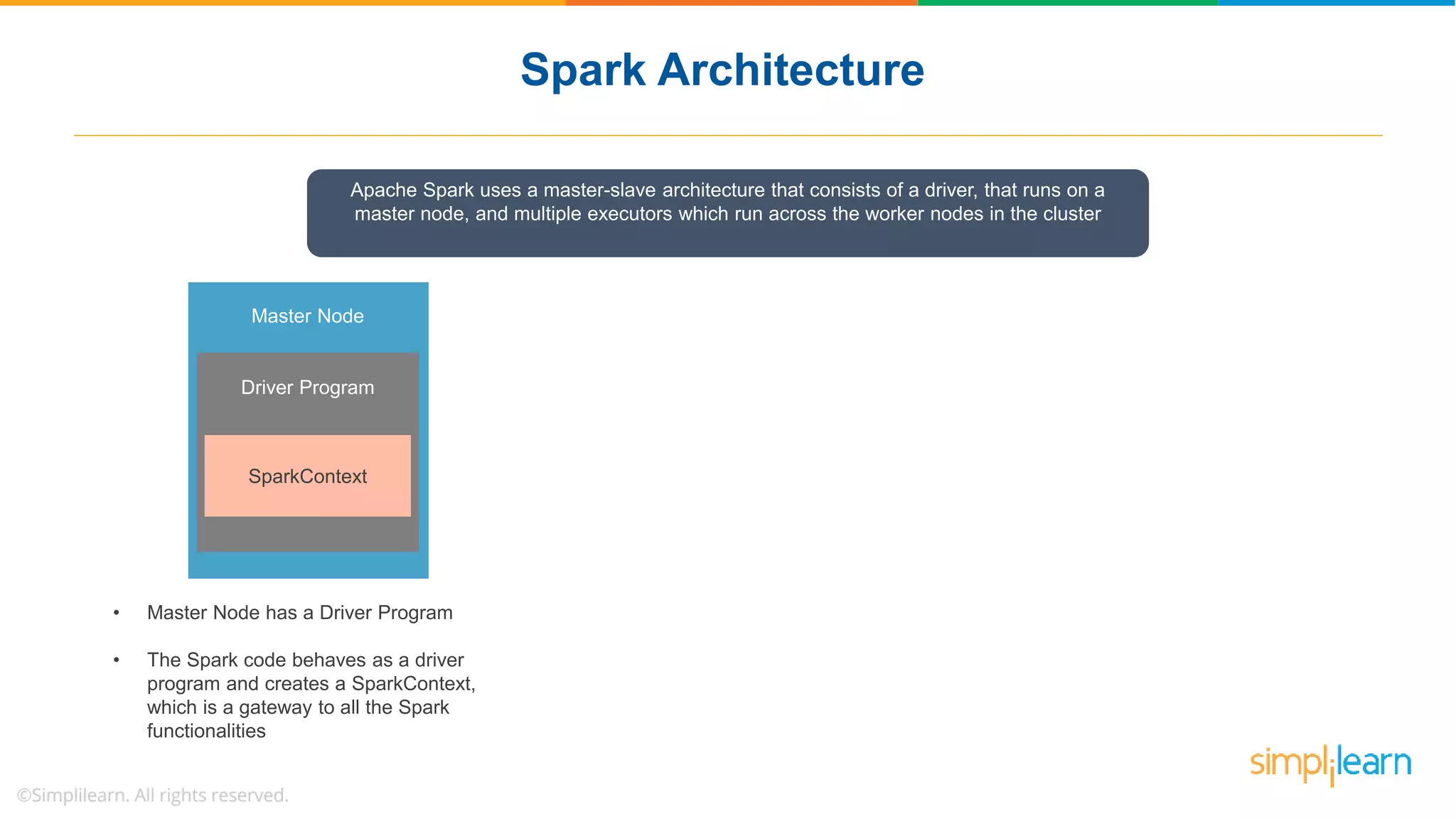
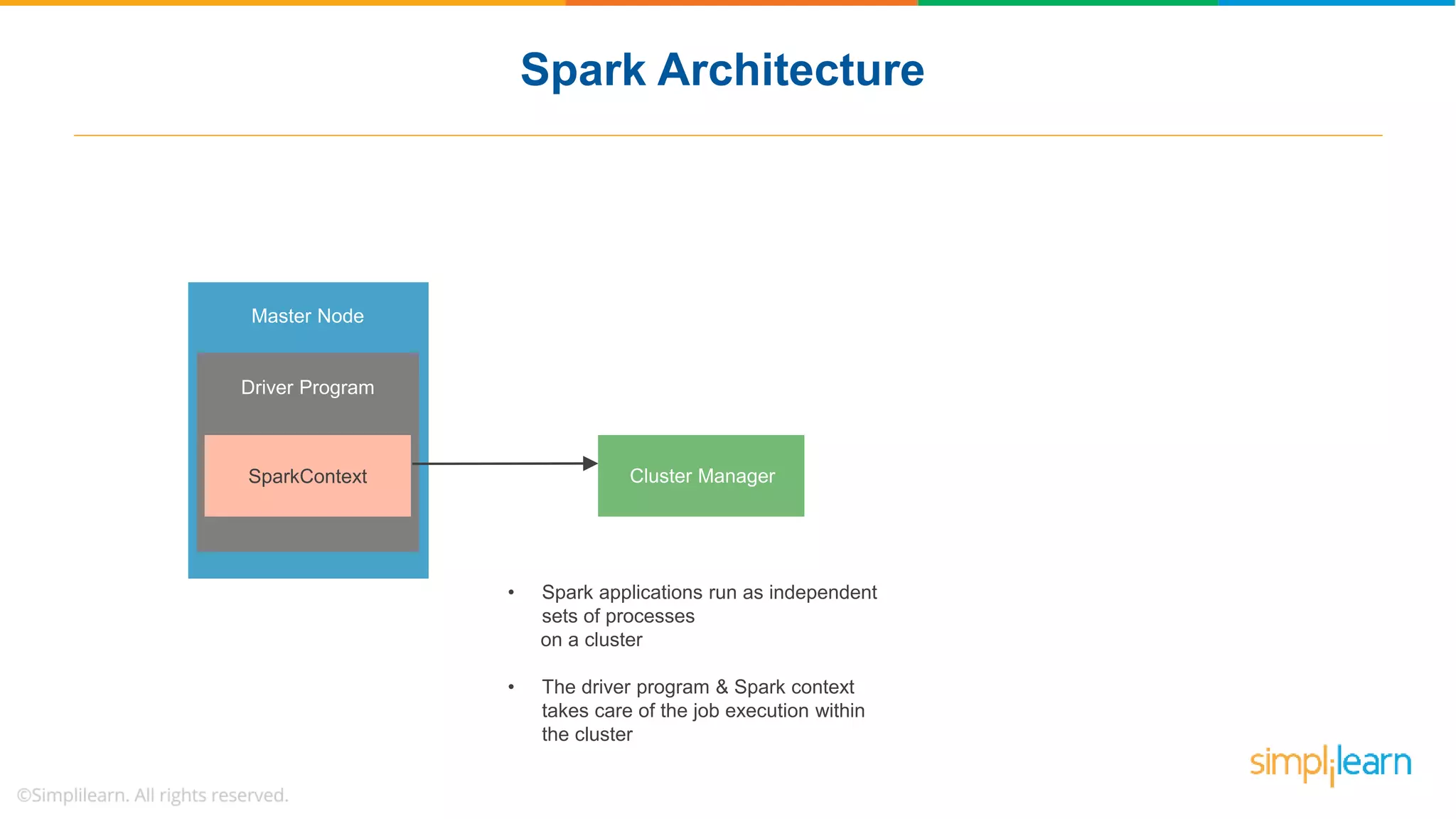
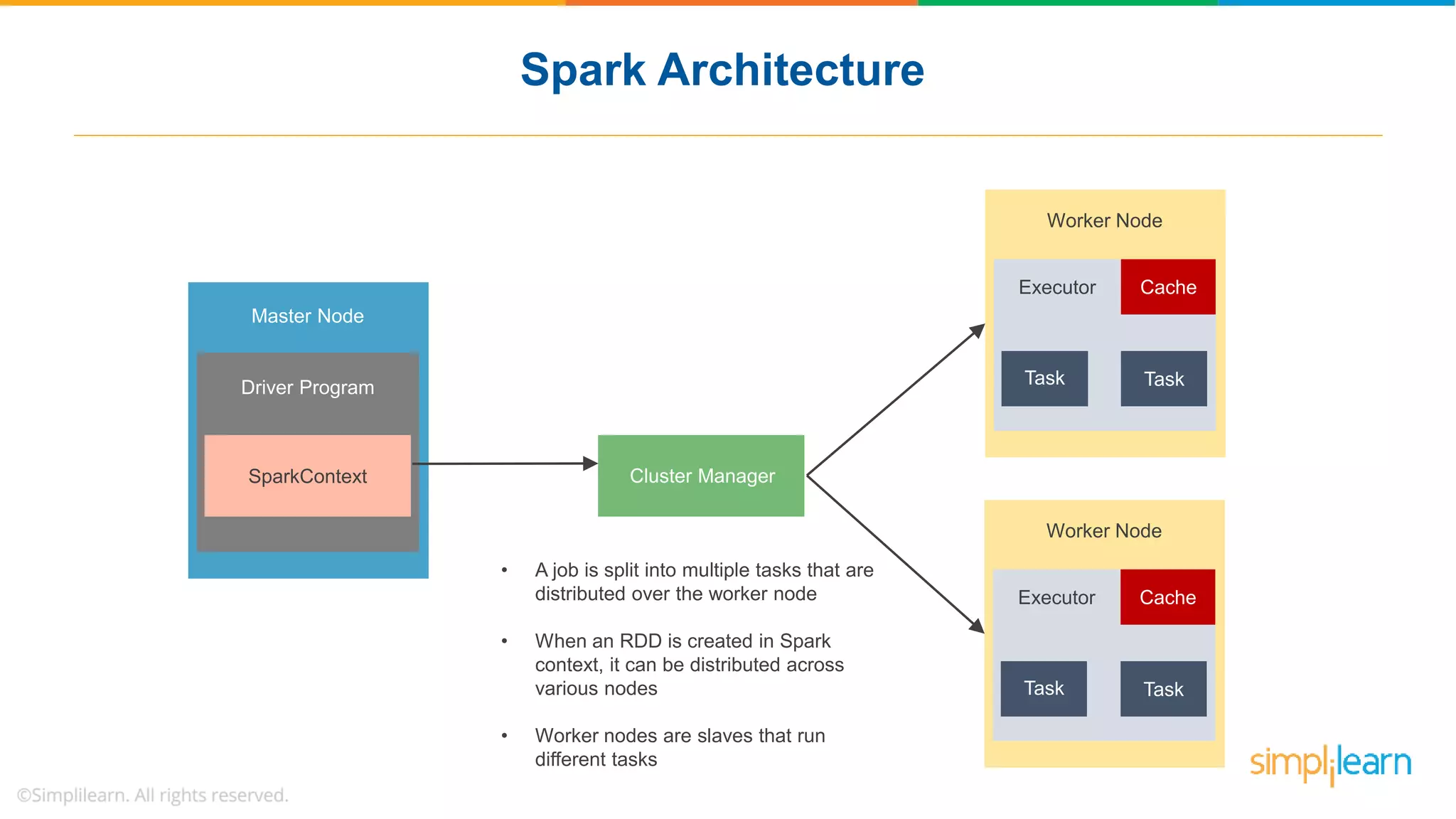
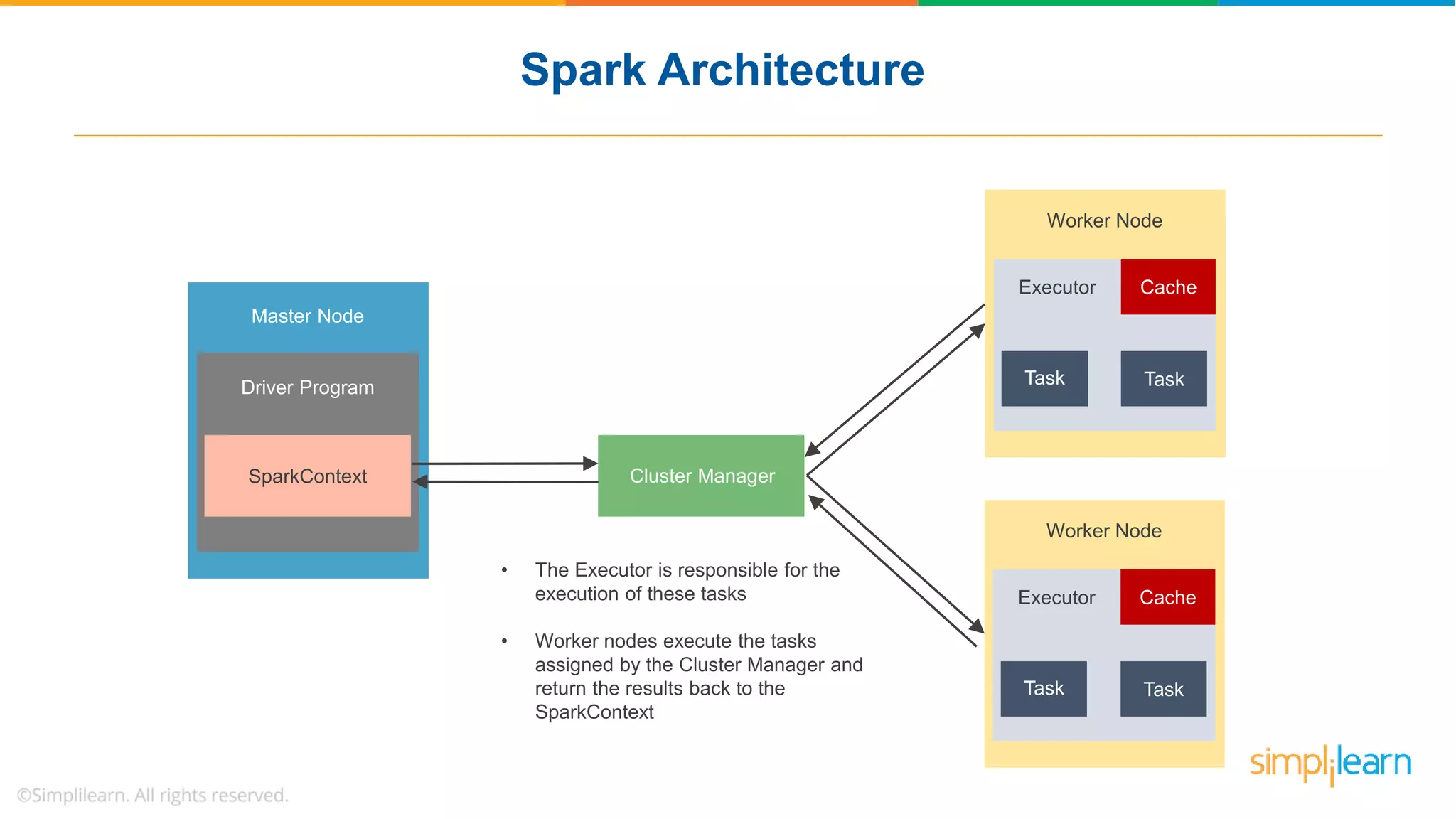

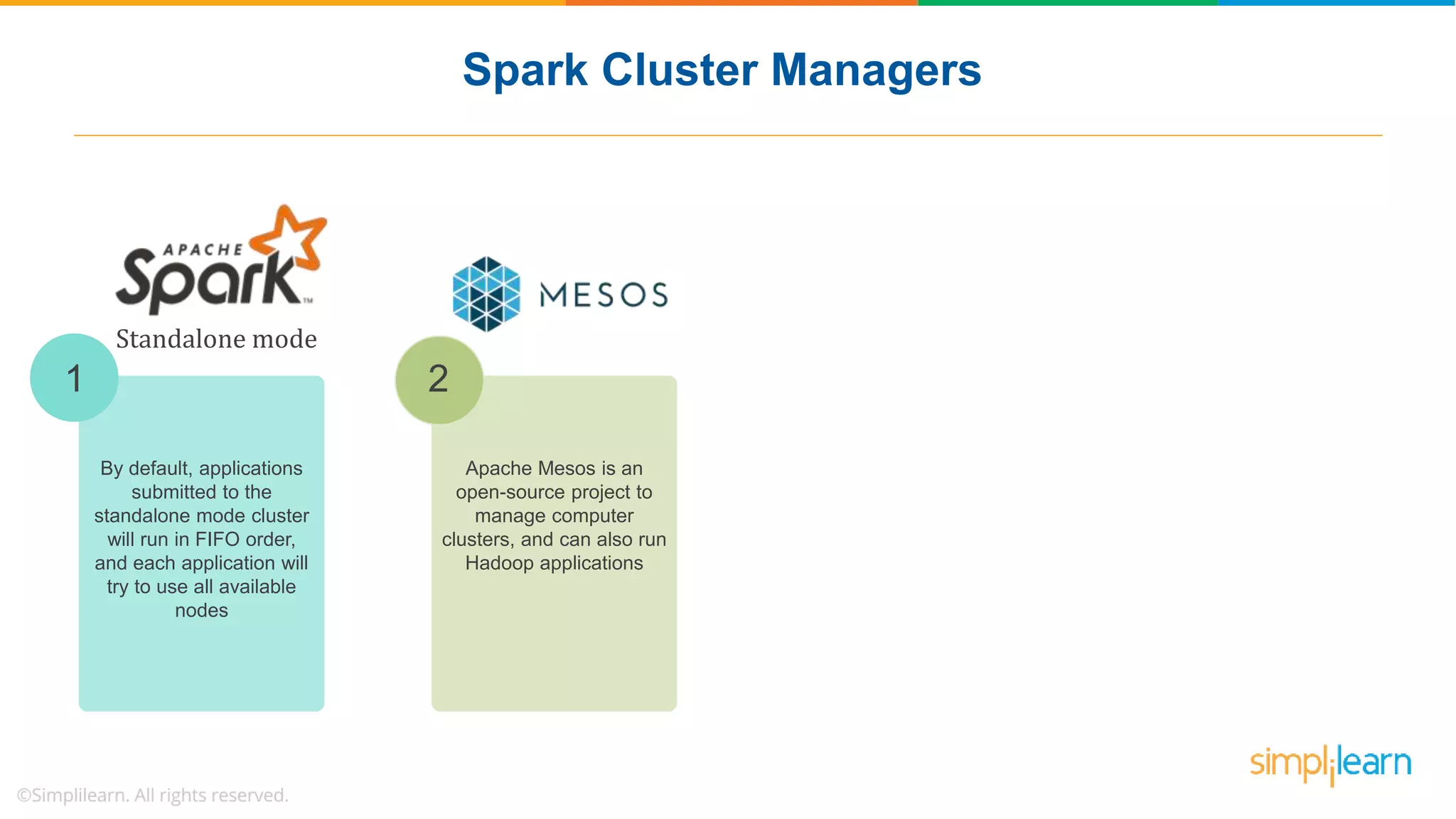
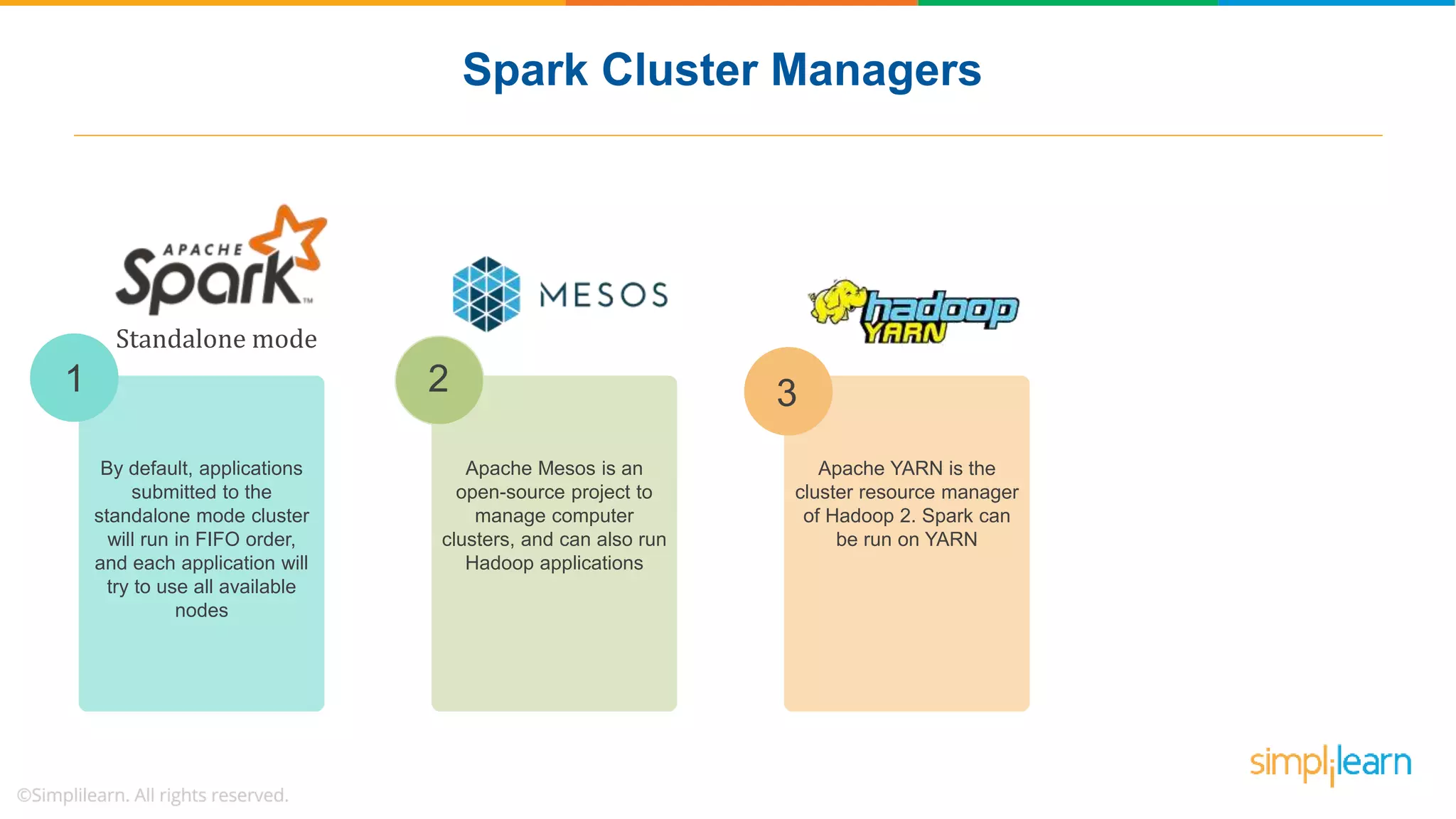
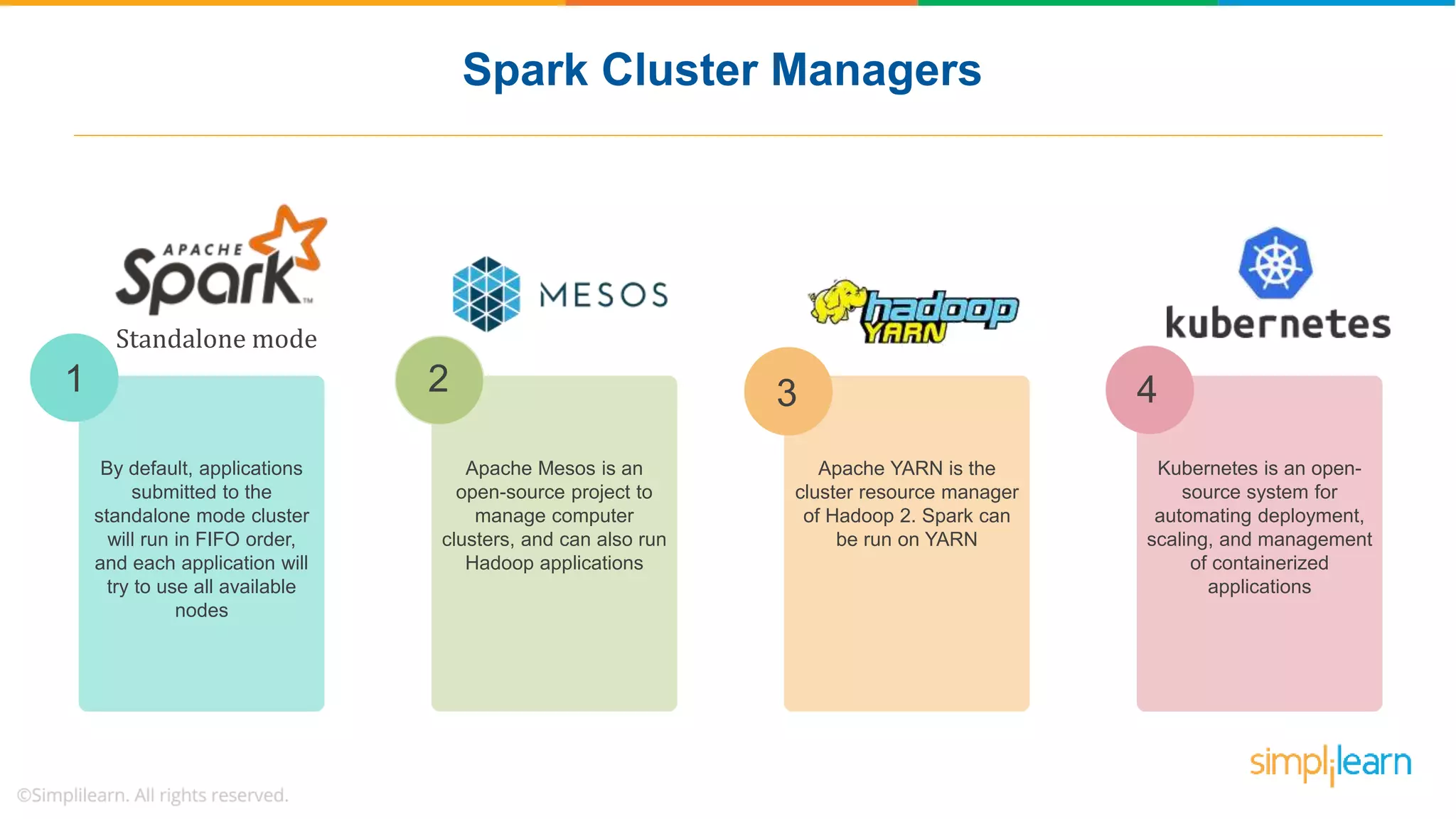



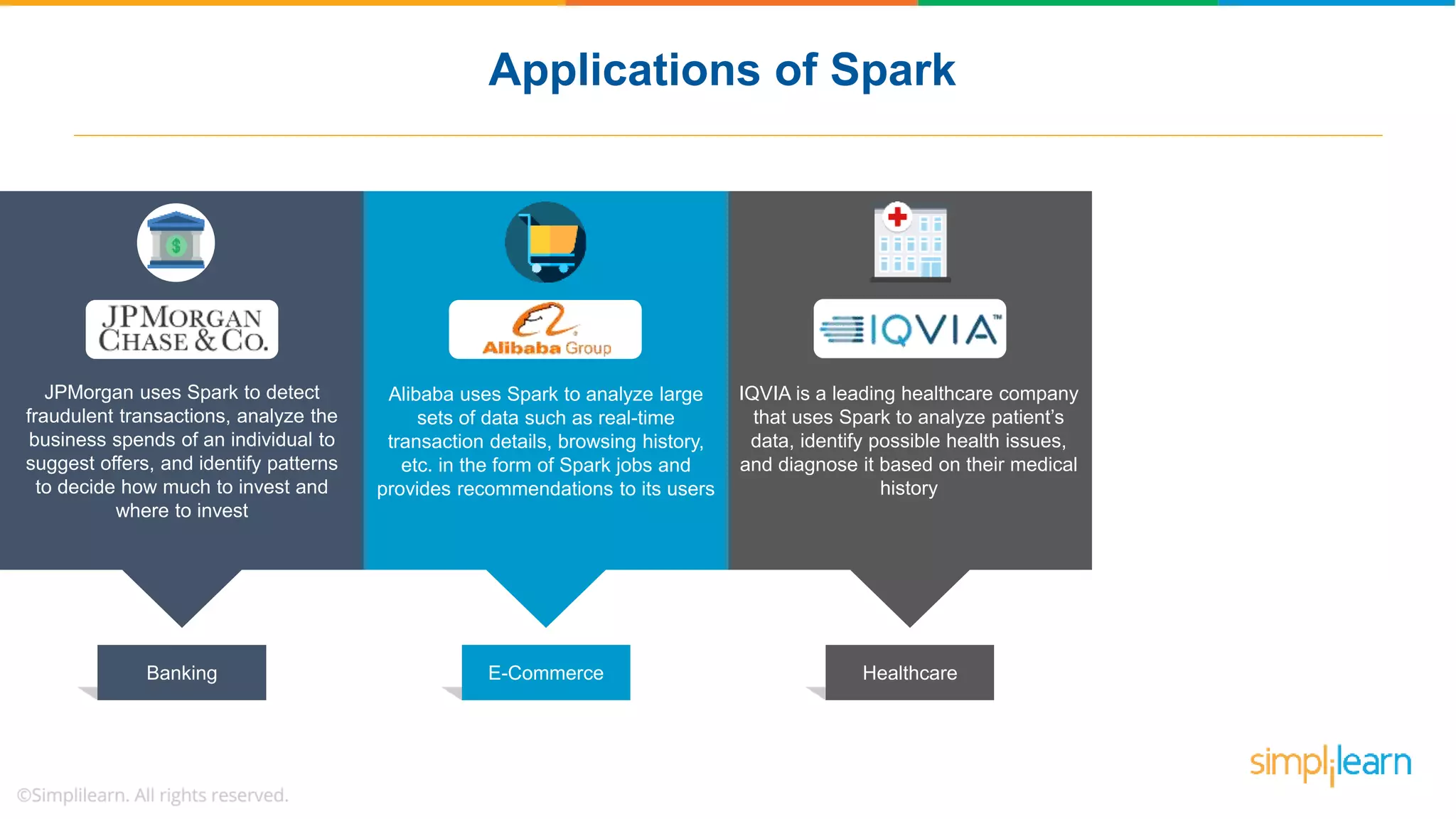
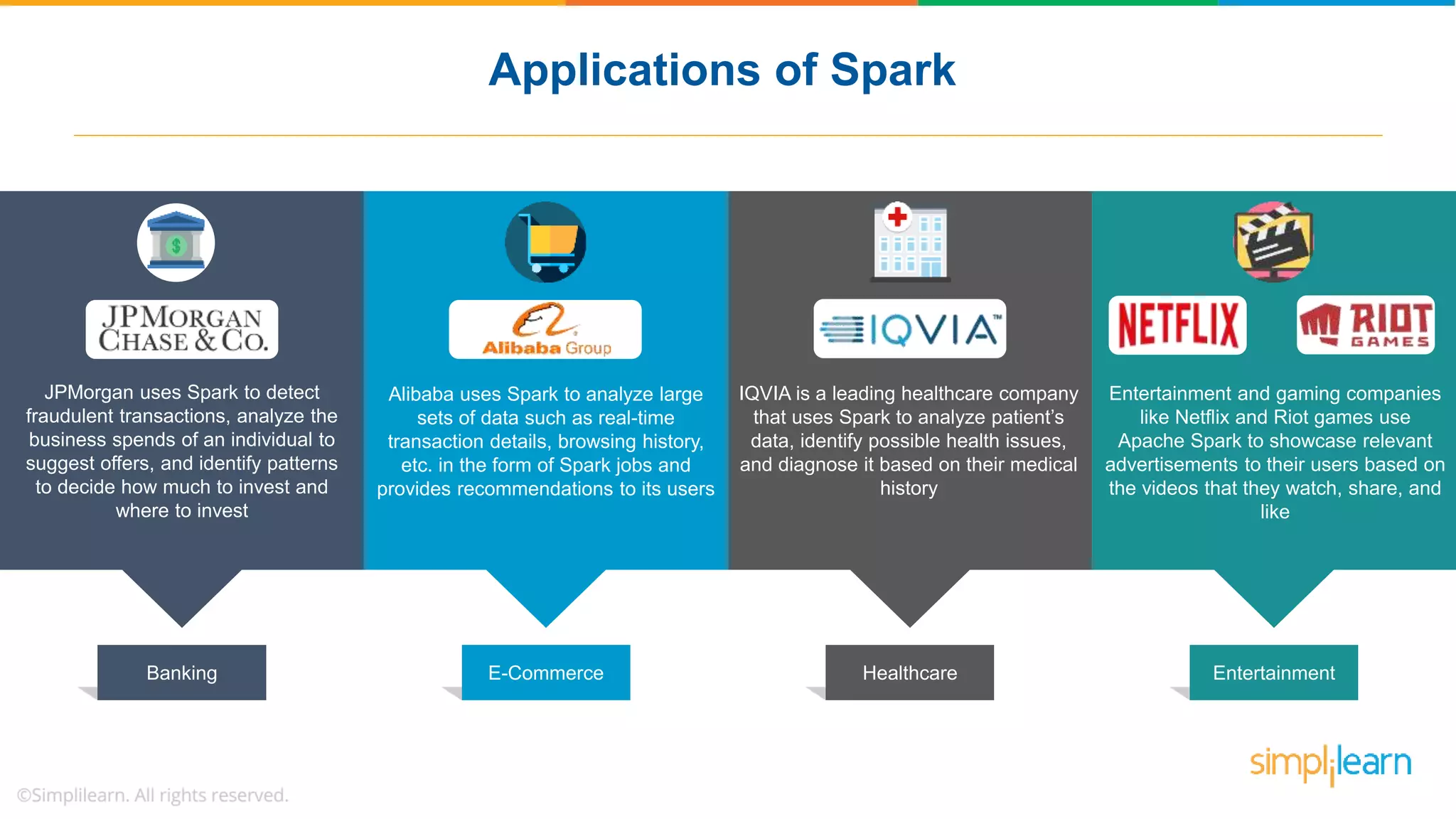


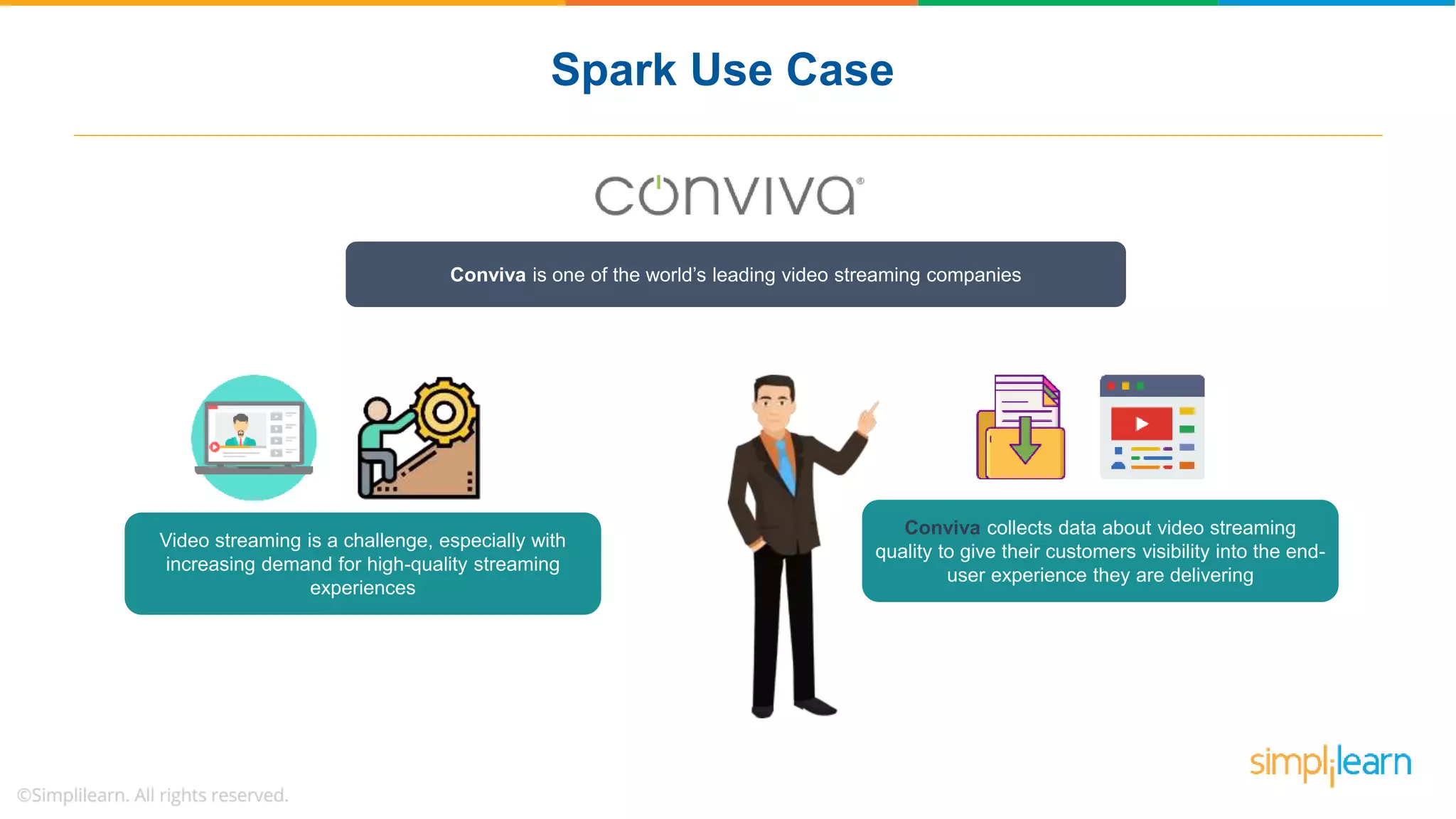



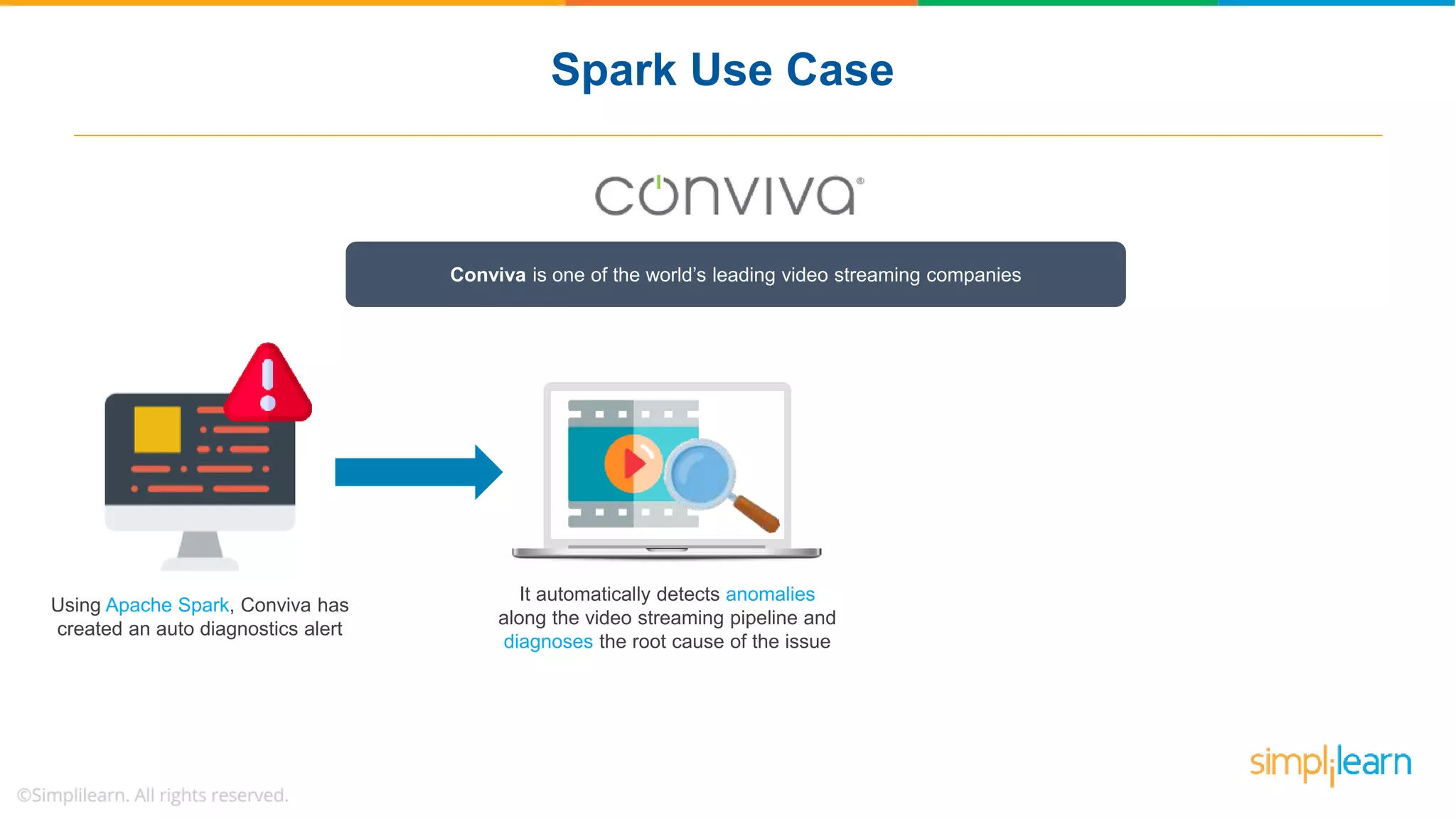
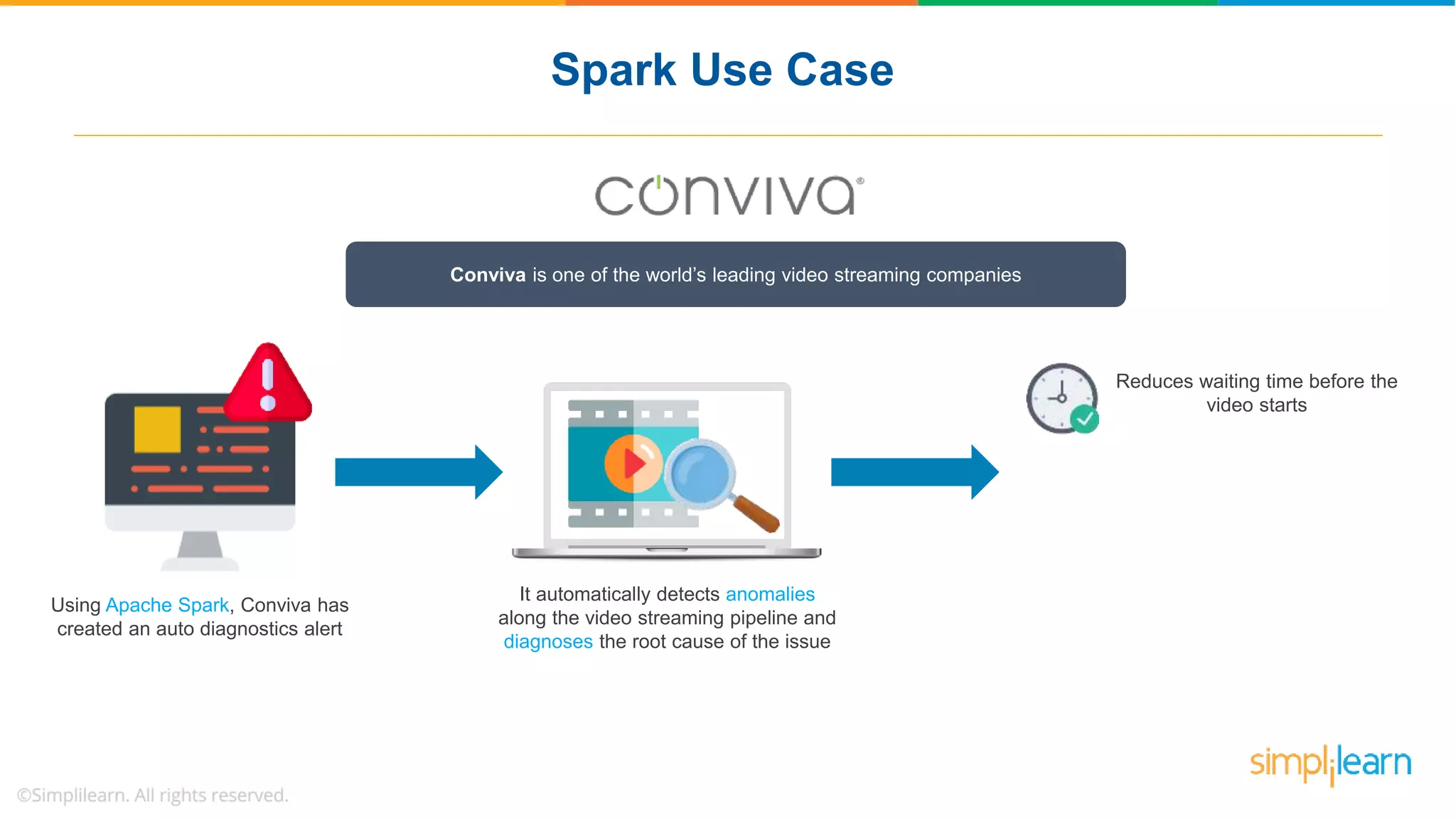
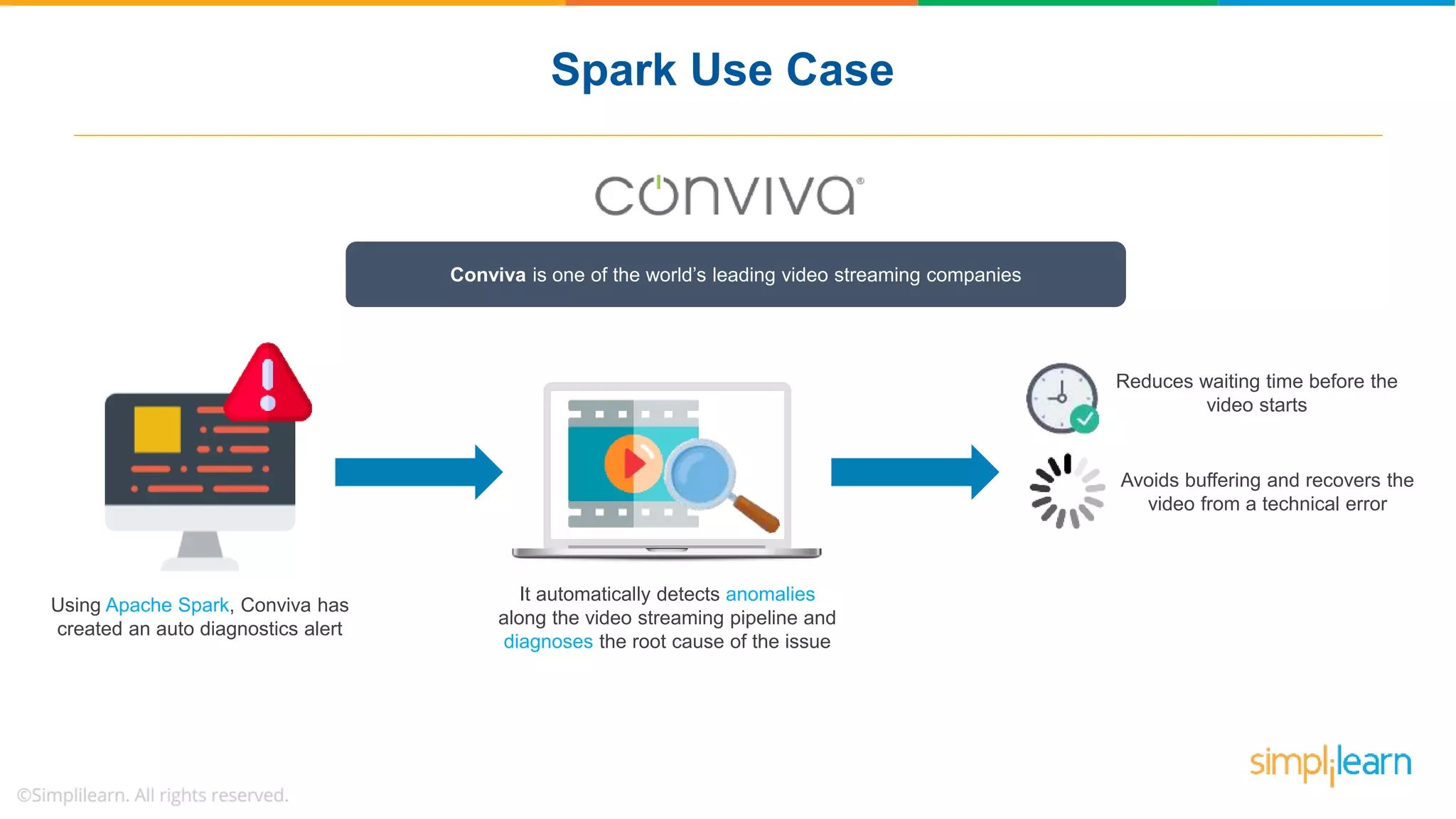
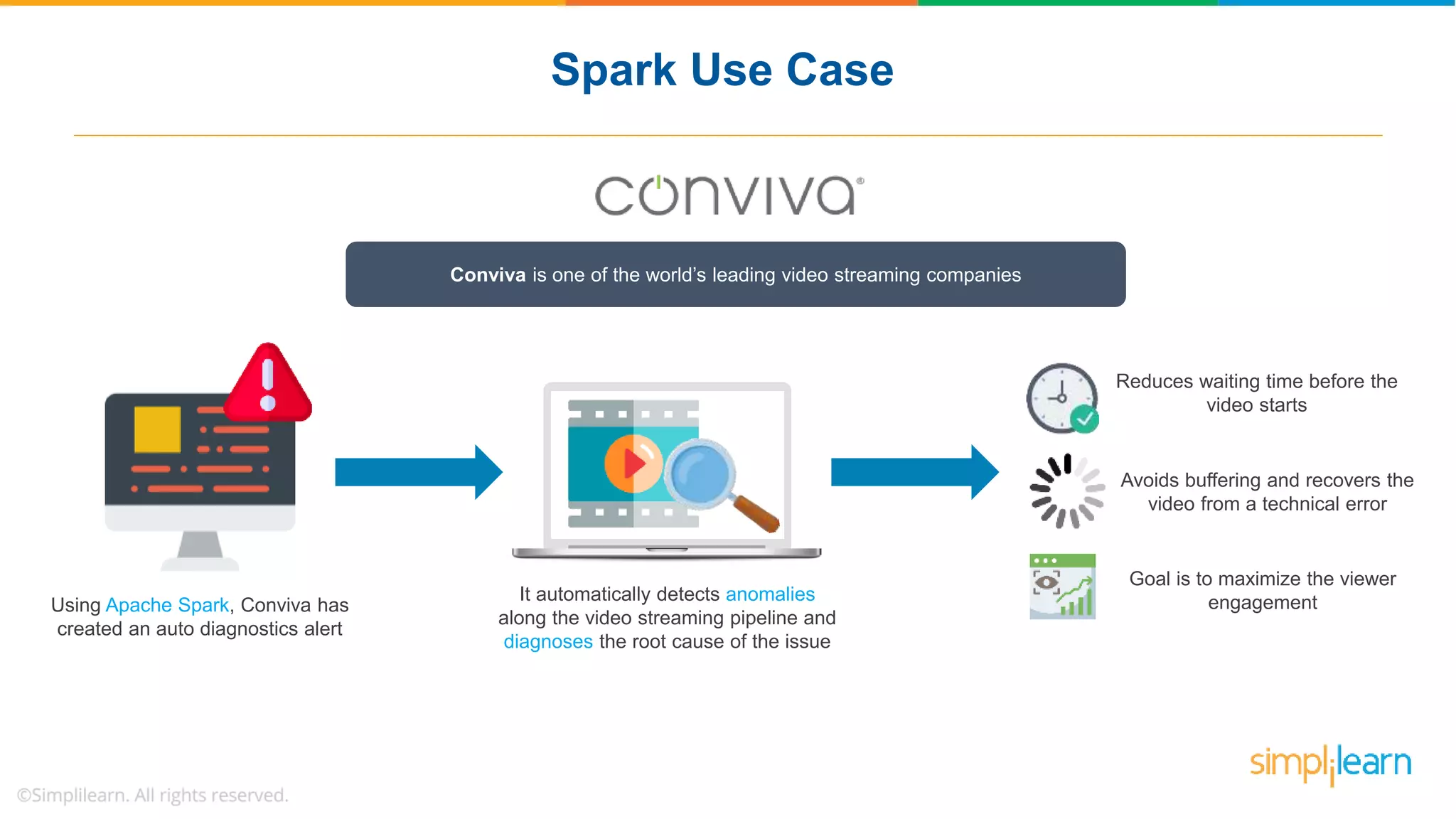


The document provides a comprehensive overview of Apache Spark, including its history, key features, and various applications across industries. It highlights the advantages of Spark over Hadoop, such as faster data processing and flexible programming support, while detailing its components like Spark SQL, Spark Streaming, and Spark MLlib. Additionally, it emphasizes real-world use cases, demonstrating how companies like JPMorgan and Alibaba leverage Spark for data analysis and fraud detection.