Download to read offline








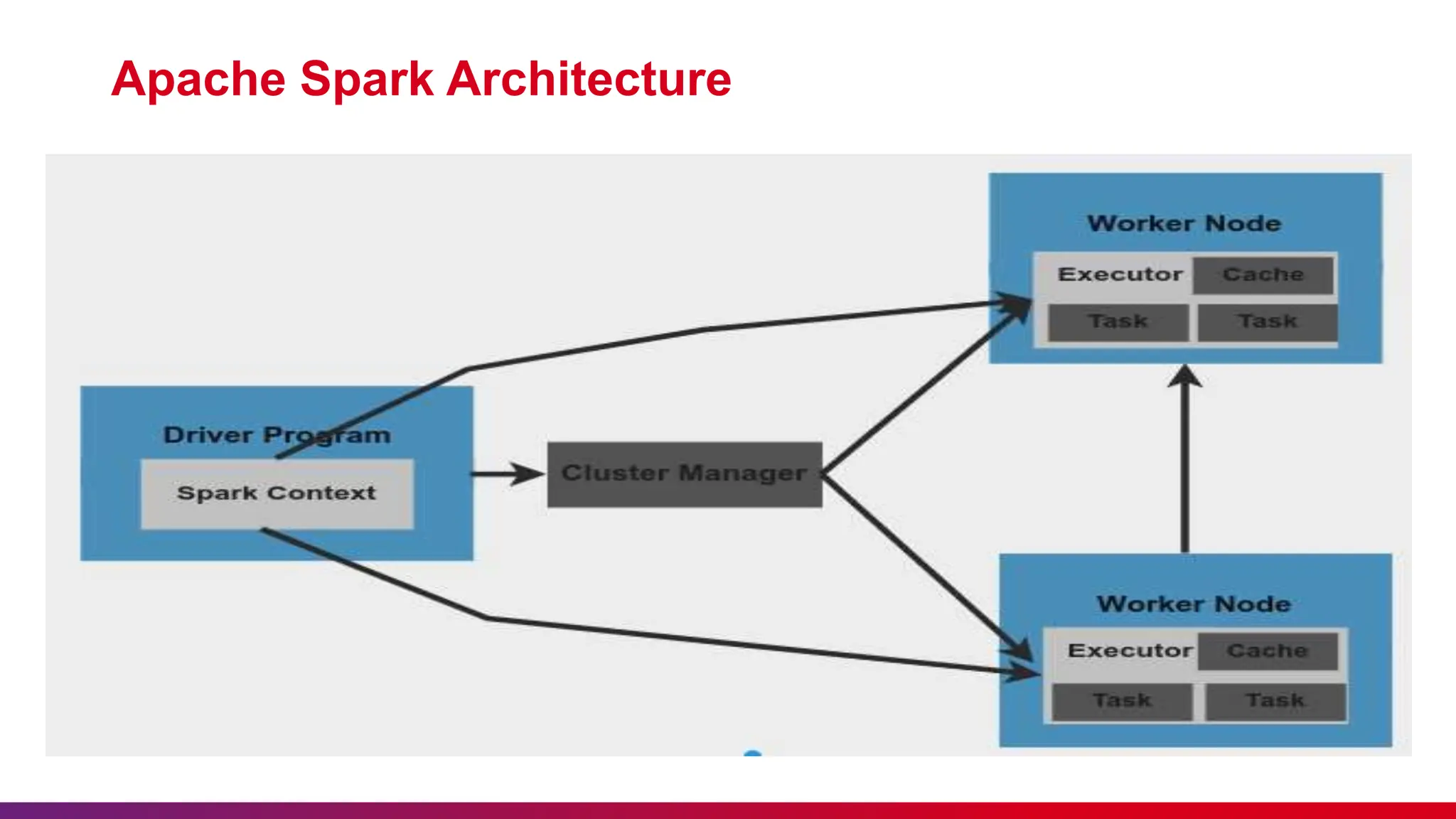






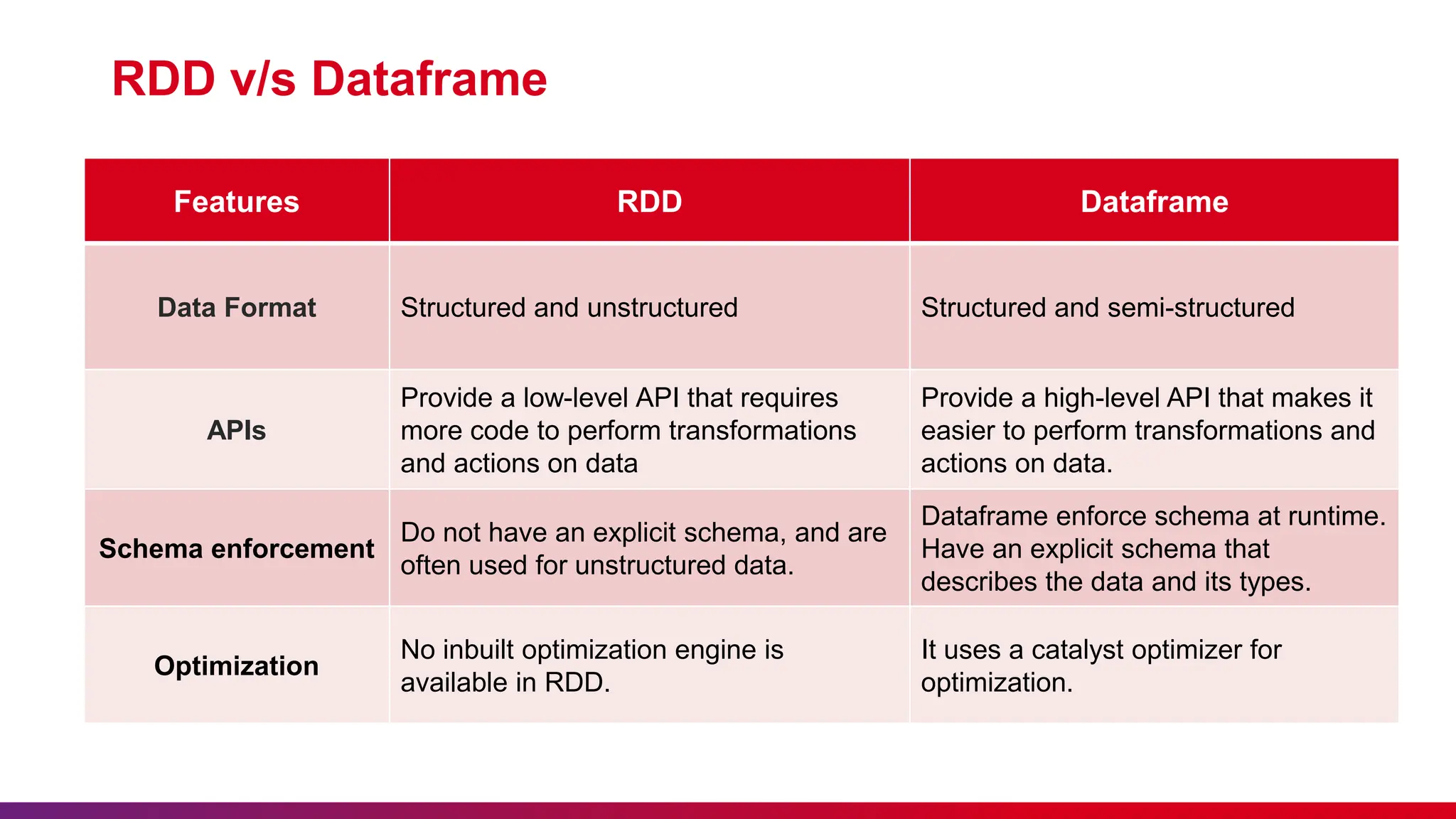







The document provides a comprehensive overview of Apache Spark, detailing its significance in processing large data sets and its architecture, components, and features such as in-memory computation and distributed processing. It includes a discussion of big data, highlighting its characteristics and comparing Spark's Resilient Distributed Datasets (RDD) with DataFrames. Additionally, it outlines the advantages and disadvantages of using Apache Spark and emphasizes the importance of etiquette during the presentation.