Download to read offline





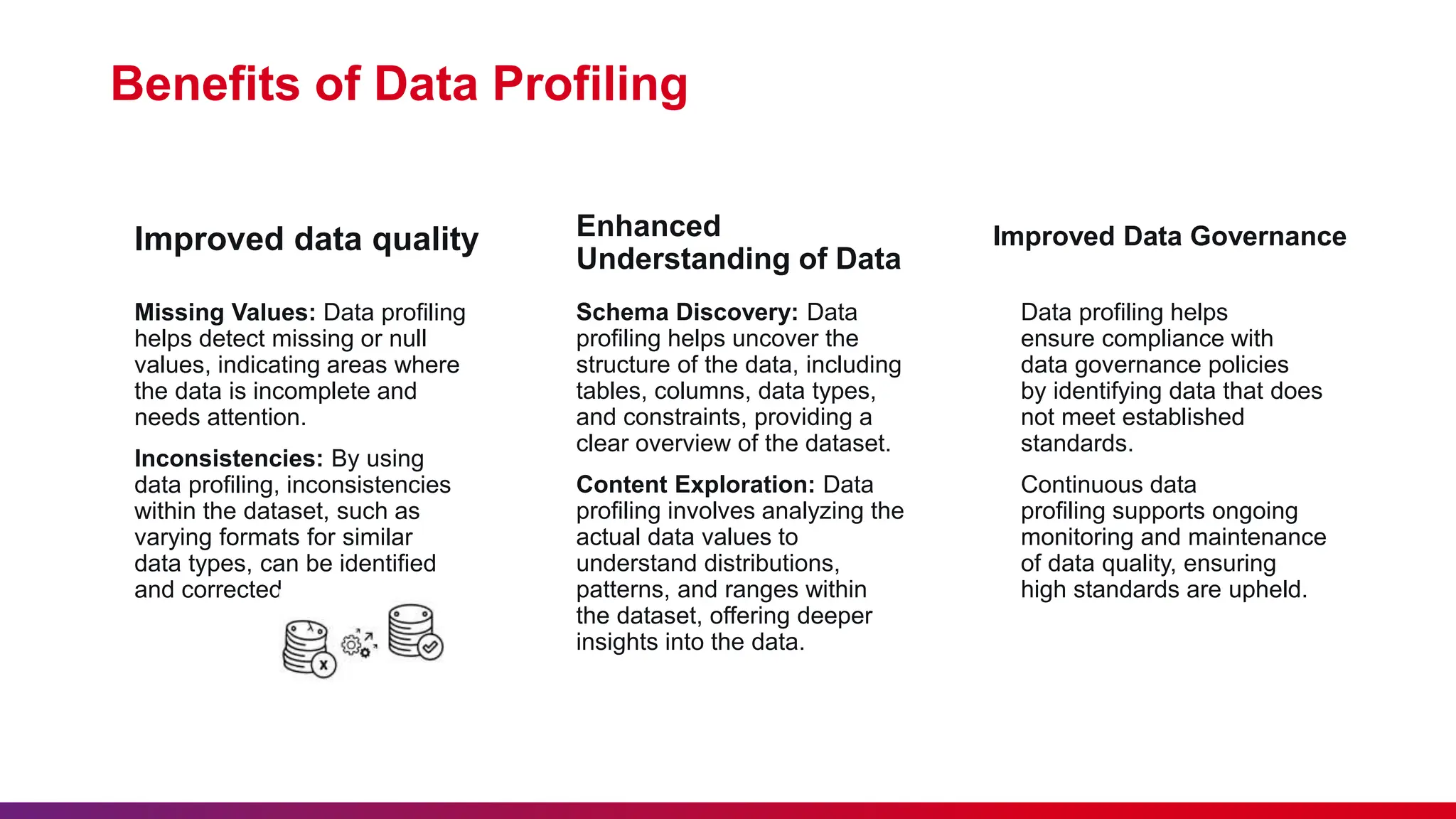



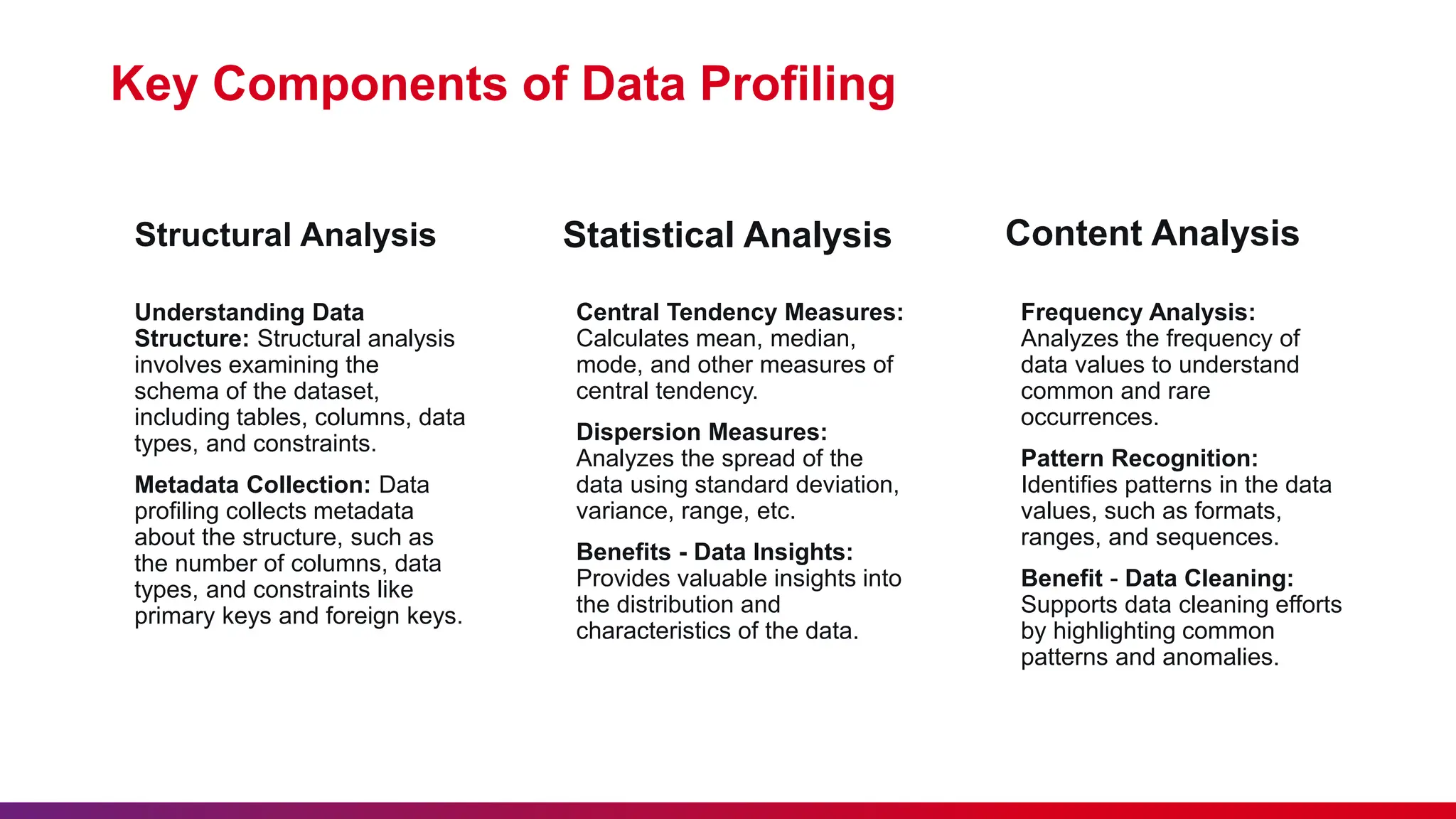




















The document outlines a data profiling and quality analysis framework aimed at enhancing data quality for effective test automation. It discusses the benefits, key components, and challenges of data profiling, as well as the role of AI and machine learning in improving data quality. Strategies for data quality improvement and best practices for effective data profiling and analysis are also provided to ensure accurate and reliable data management.