Professor In Charge: Dr Amsaprabhaa Mathivaanan Shiv Nadar University Chennai R Hridya Shree (220111011086) Sannidhay Jangam (220111011100) Introduction To Spark SQL
2.
• Apache Sparkis a lightning-fast, open-source cluster computing technology designed for big data analytics, offering exceptional performance through in-memory computation and support for a wide array of workloads including batch, streaming, interactive, graph, and machine learning processing. Introduction To Spark SQL
3.
• Spark wascreated at UC Berkeley’s AMPLab to overcome limitations of Hadoop MapReduce, especially the delays and complexity in query execution and iterative algorithms. • It was open-sourced and later became an Apache top-level project, marking milestones in unified DataFrame/Dataset APIs and distributed machine learning support. • The need for Spark grew from the requirement to process real-time streams as well as batch data, respond quickly to queries, and efficiently use system memory. Evolution and Motivation
4.
• Spark architecturecomprises a master node orchestrating slave (worker) nodes. Workloads are divided and distributed for parallel execution: • Standalone Mode: Runs atop HDFS with explicit space allocation. Spark jobs coexist with MapReduce tasks. • YARN Mode: Integrates with the Hadoop ecosystem, allowing seamless co-existence with other computation frameworks without requiring admin access. • SIMR (Spark in MapReduce): Launches Spark jobs within the MapReduce context, providing administrative flexibility. • The master-slave arrangement ensures scalability and fault tolerance with automatic recovery. Architecture and Deployment
5.
Speed: Spark is100x faster than Hadoop in in- memory operations and 10x faster on disk due to reduced disk reads/writes and memory caching. Multiple Language Support: Native APIs available for Scala, Java, Python, and R, enhancing accessibility for developers and data scientists. Advanced Analytics: Supports SQL, streaming, machine learning, and graph computation within a unified platform. Core Features
6.
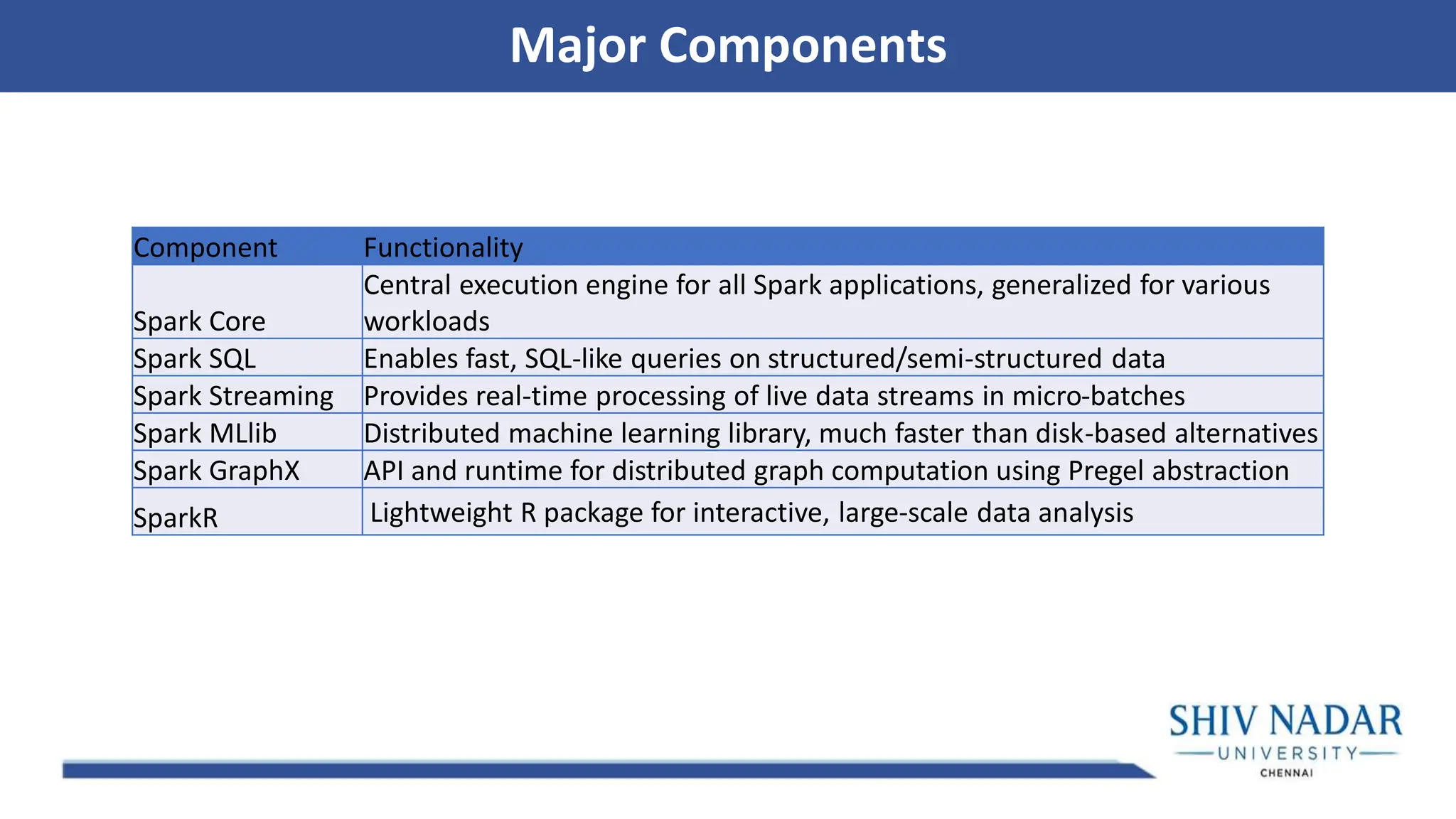
Major Components Component Functionality SparkCore Central execution engine for all Spark applications, generalized for various workloads Spark SQL Enables fast, SQL-like queries on structured/semi-structured data Spark Streaming Provides real-time processing of live data streams in micro-batches Spark MLlib Distributed machine learning library, much faster than disk-based alternatives Spark GraphX API and runtime for distributed graph computation using Pregel abstraction SparkR Lightweight R package for interactive, large-scale data analysis
7.
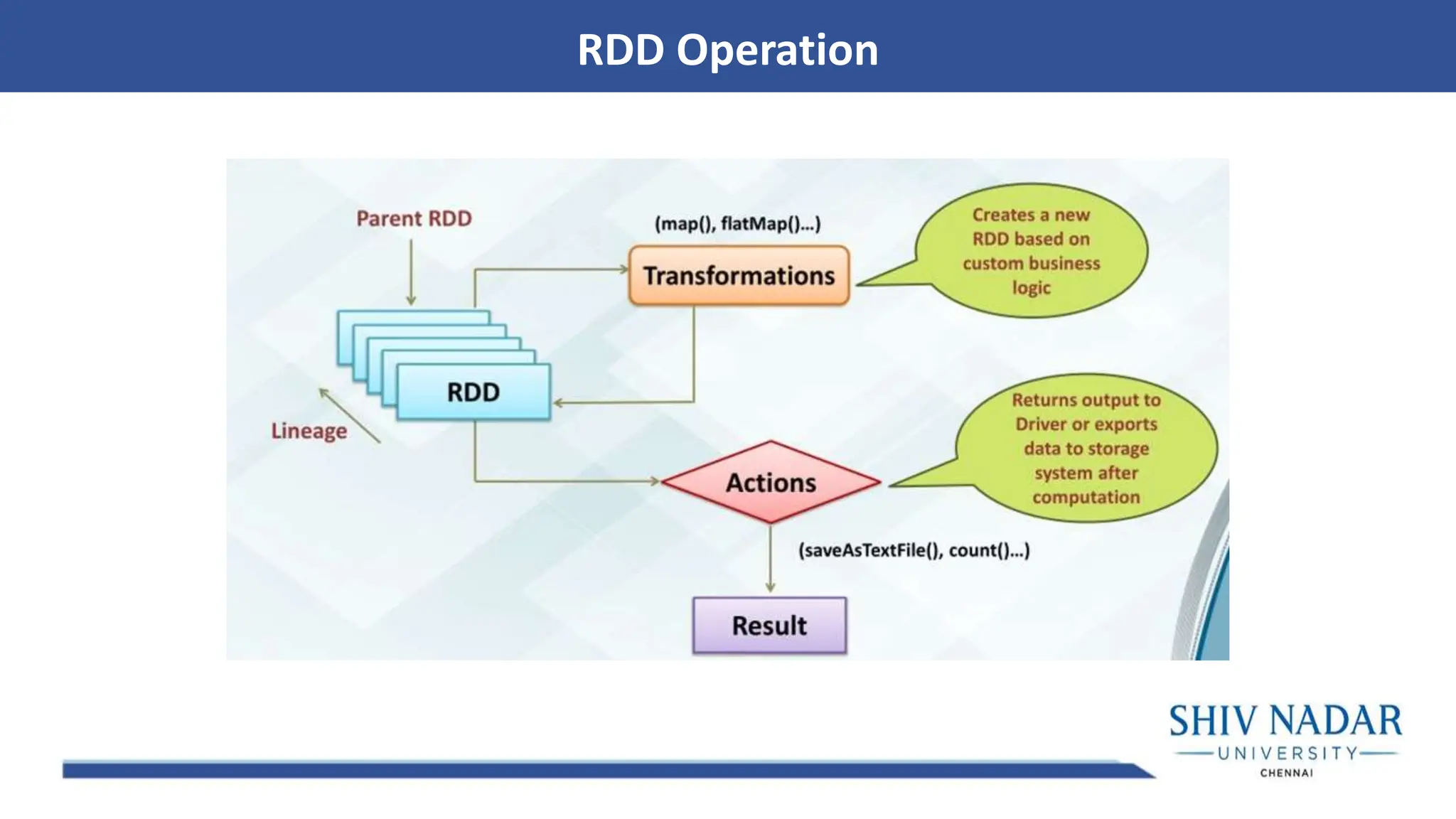
• Resilient DistributedDataset (RDD): Immutable, partitioned data collections allowing parallel processing. RDDs support transformations (e.g., map, filter) and actions (collect, reduce). • RDDs can contain data objects in Scala, Java, Python, or R, each partition processed across cluster nodes. • Lineage ensures fault-tolerance by tracking dependencies and enabling data regeneration. • Transformation is lazily evaluated, optimizing execution: computation starts only with an action (e.g., count, collect). RDDs and Data Structures
• In-memory computingaccelerates iterative algorithms and interactive queries. • Lazy operation optimization enables Spark to restructure jobs for efficiency before execution. • Compatibility with Hadoop permits Spark to process existing Hadoop data through its ecosystem. • Fault tolerance and recovery are built into RDD and Spark architecture, enabling robust cluster operations. Technical Advantages
10.
• Data Integration(ETL): Combines diverse, inconsistent data sources rapidly and cost-effectively. • Stream Processing: Handles real-time logs and large-scale data feeds, often for timeliness and fraud detection. • Machine Learning: In-memory computation enables repeated algorithm runs, essential for model training and large-scale analytics. • Interactive Analytics: Spark helps users interactively explore and analyze data without slow, batch-oriented queries. Common Use Cases
11.
Comparison: Spark vs.Hadoop MapReduce Feature Spark (In-memory) Hadoop MapReduce Speed 100x faster Moderate Languages Supported Scala, Java, Python, R Java Streaming Support Yes Limited Advanced Analytics MLlib, GraphX, SQL Mahout, Hive Fault Tolerance Yes Yes Ease of Use High (rich APIs) Moderate (Java focus)