


















![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns Base RTDraDn sformed RDD lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(‘t’)[2]) messages.cache() Block 1 Block 2 Block 3 Worker Worker Worker Driver messages.filter(lambda s: “foo” in s).count() messages.filter(lambda s: “bar” in s).count() . . . results tasks Cache 1 Cache 2 Cache 3 Action Full-text search of Wikipedia in <1 sec (vs 20 sec for on-disk data)](https://image.slidesharecdn.com/untitled-141215093512-conversion-gate02/75/Unified-Big-Data-Processing-with-Apache-Spark-21-2048.jpg)











![MLlib Vectors, Matrices = RDD[Vector] Iterative computation points = sc.textFile(“data.txt”).map(parsePoint) model = KMeans.train(points, 10) model.predict(newPoint)](https://image.slidesharecdn.com/untitled-141215093512-conversion-gate02/75/Unified-Big-Data-Processing-with-Apache-Spark-33-2048.jpg)


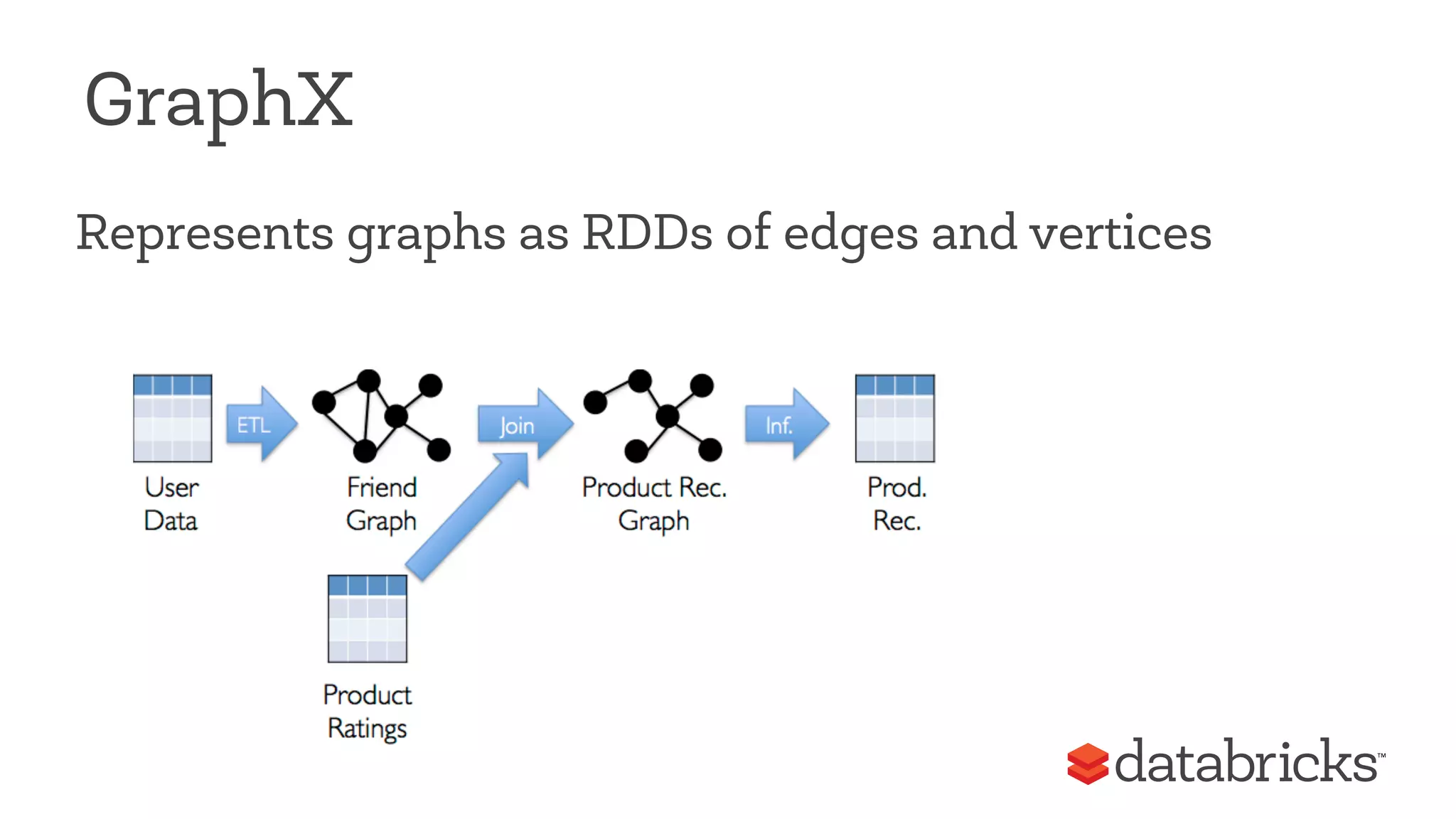






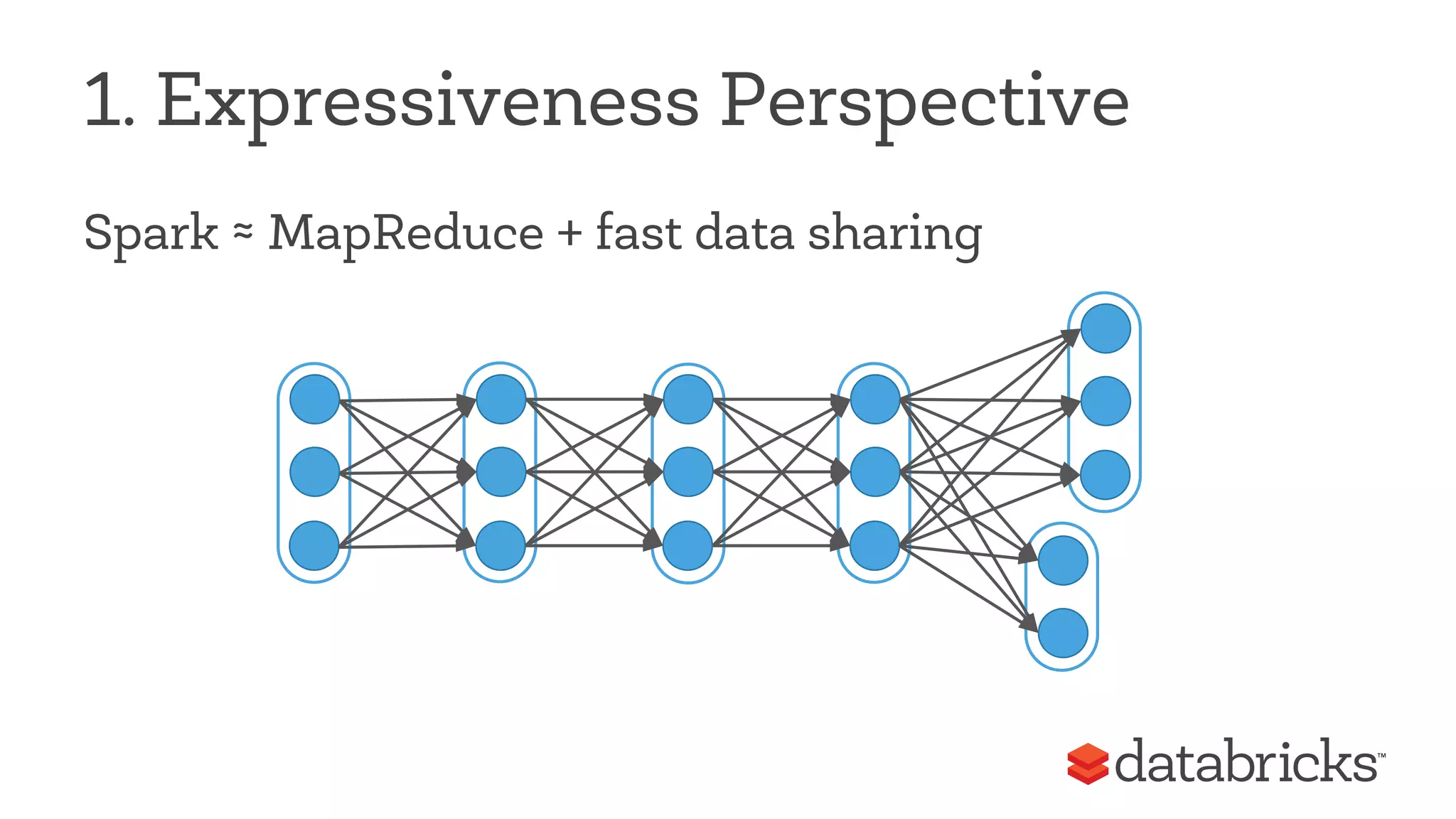
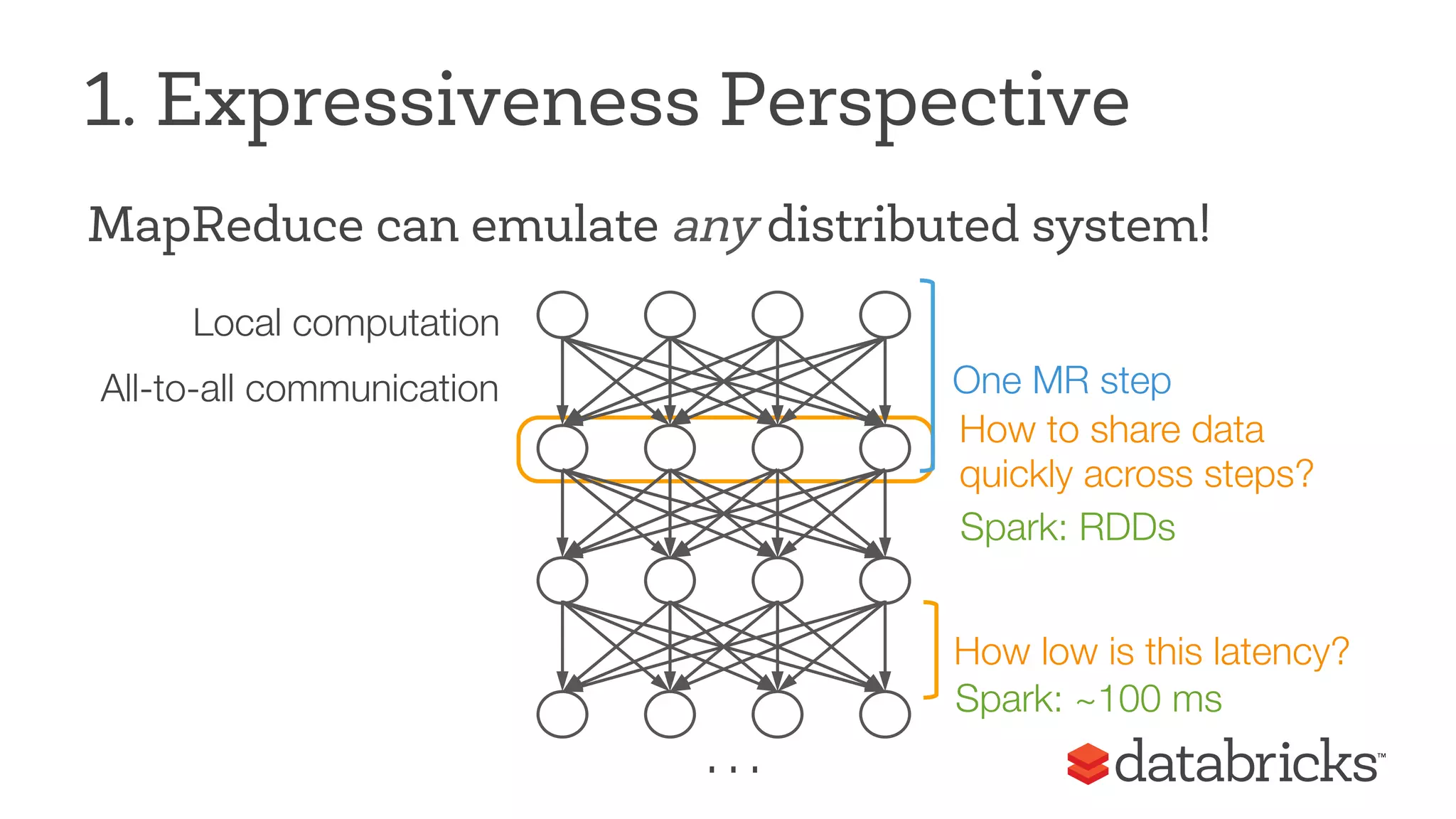












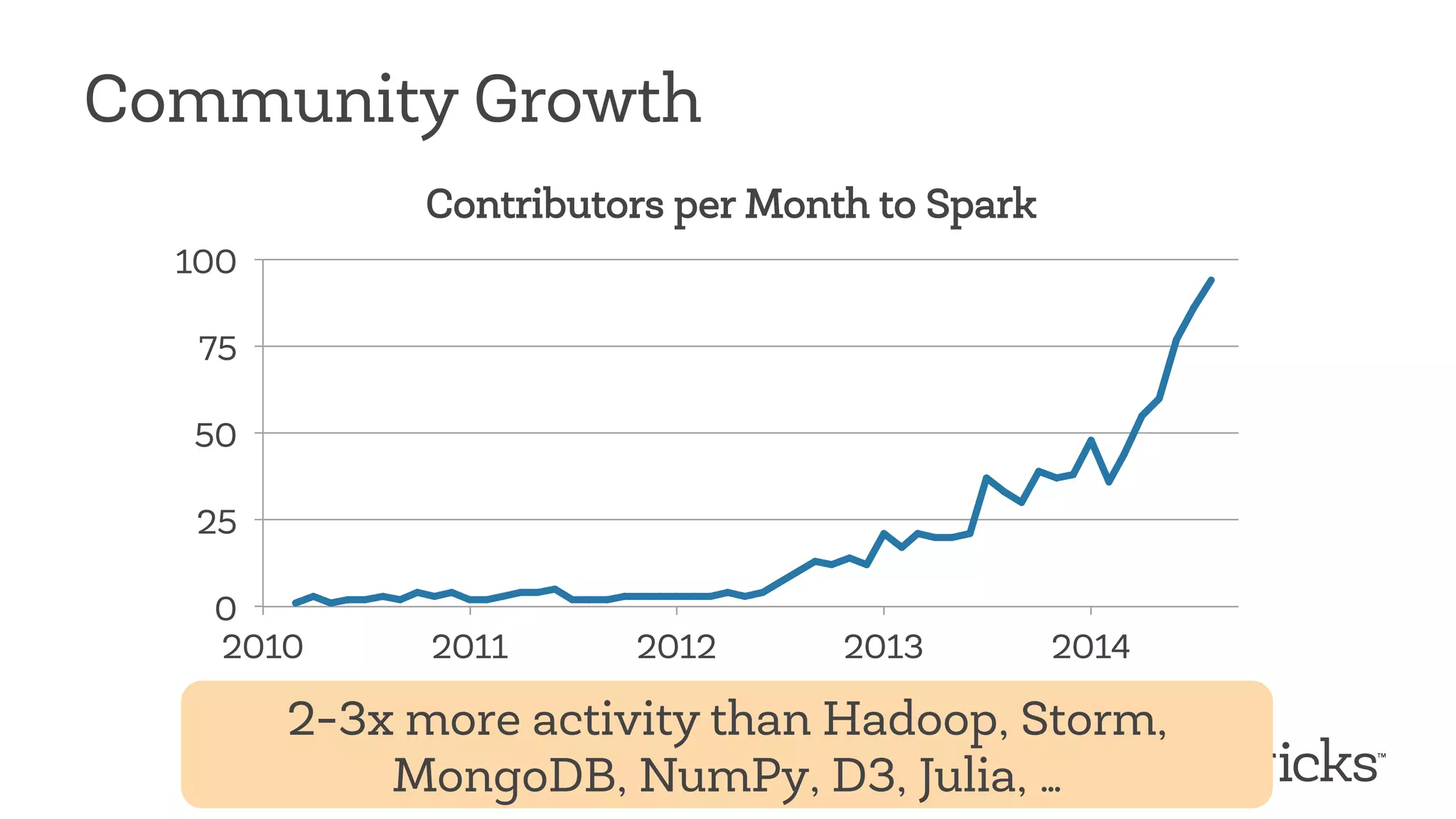
The document discusses Apache Spark, highlighting its role as a fast and general engine for big data processing that transcends the limitations of MapReduce. It emphasizes Spark's unified execution model, which allows various processing types including batch, streaming, and machine learning, all within a single framework. Furthermore, it covers the growth of the Spark community, notable features, and future developments aimed at enhancing its functionality and integration with other data processing systems.