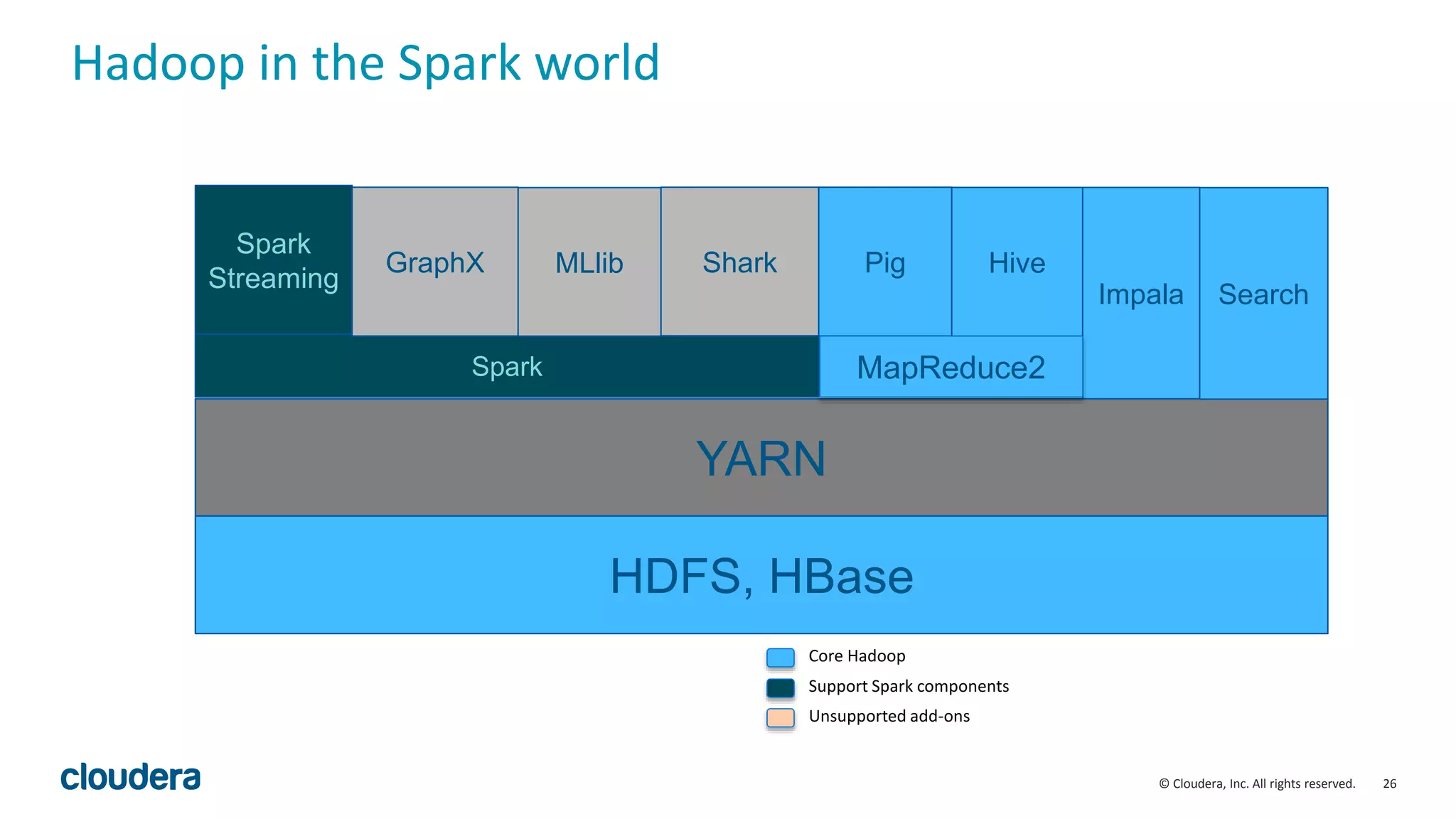
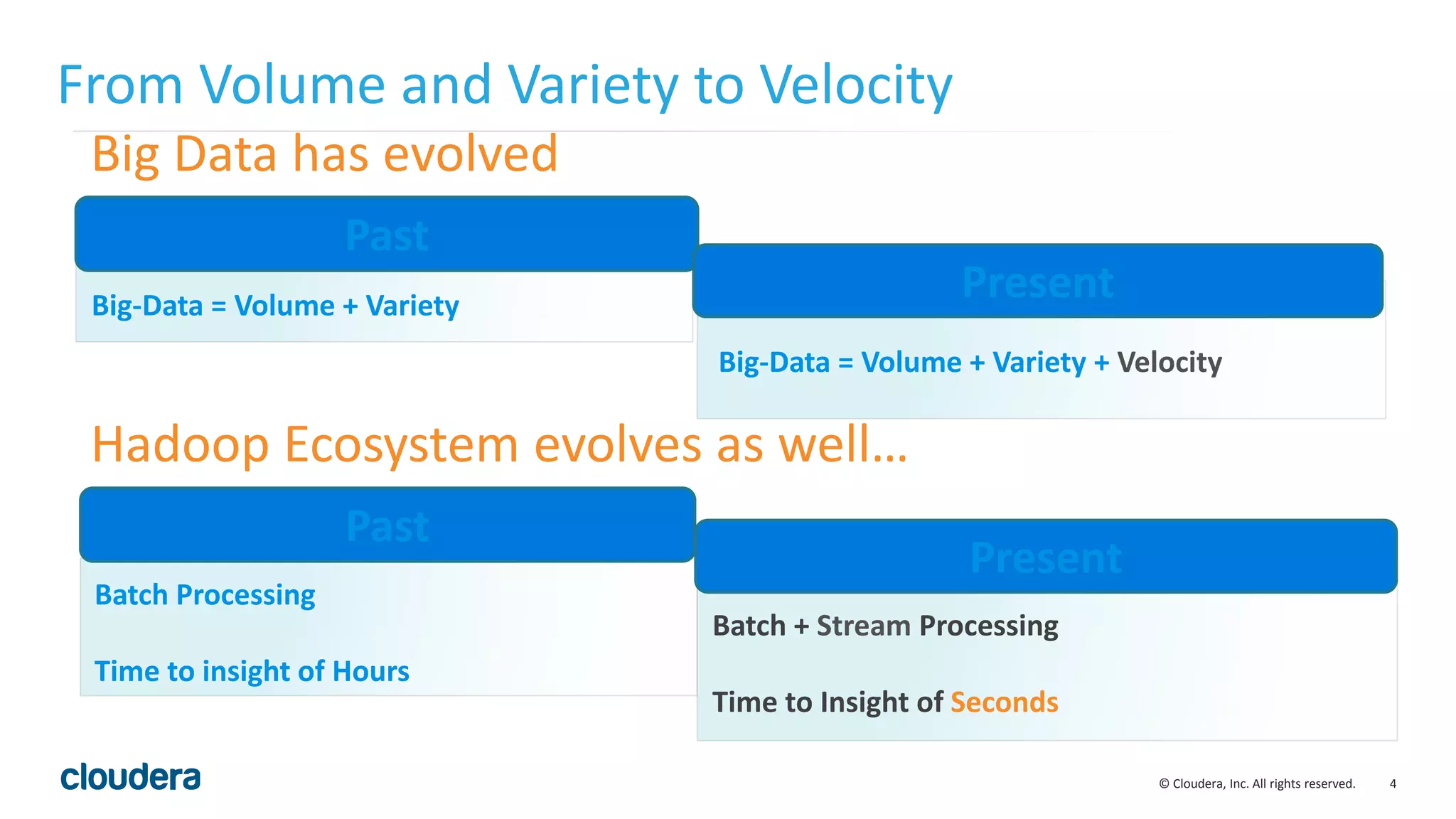
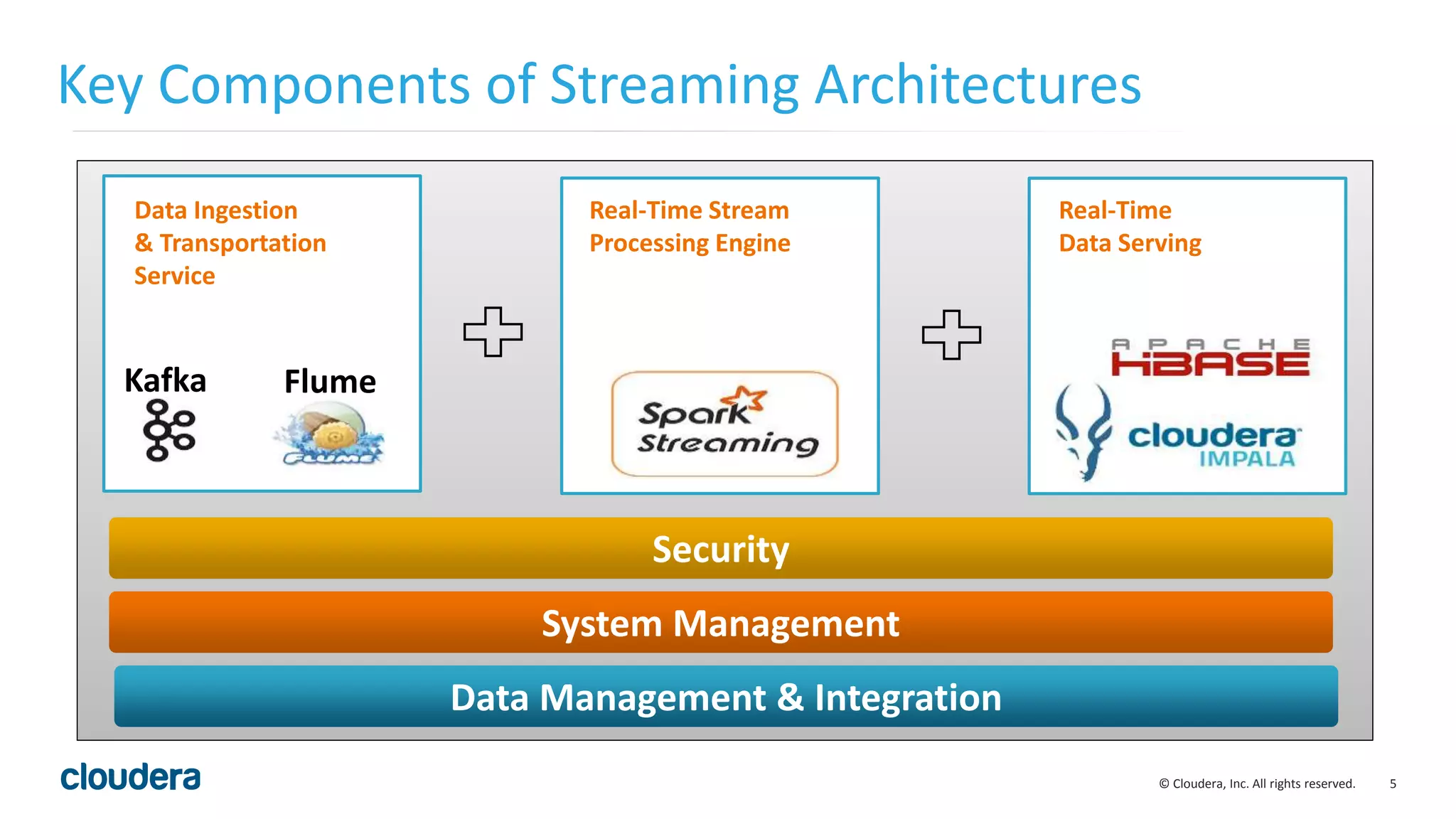
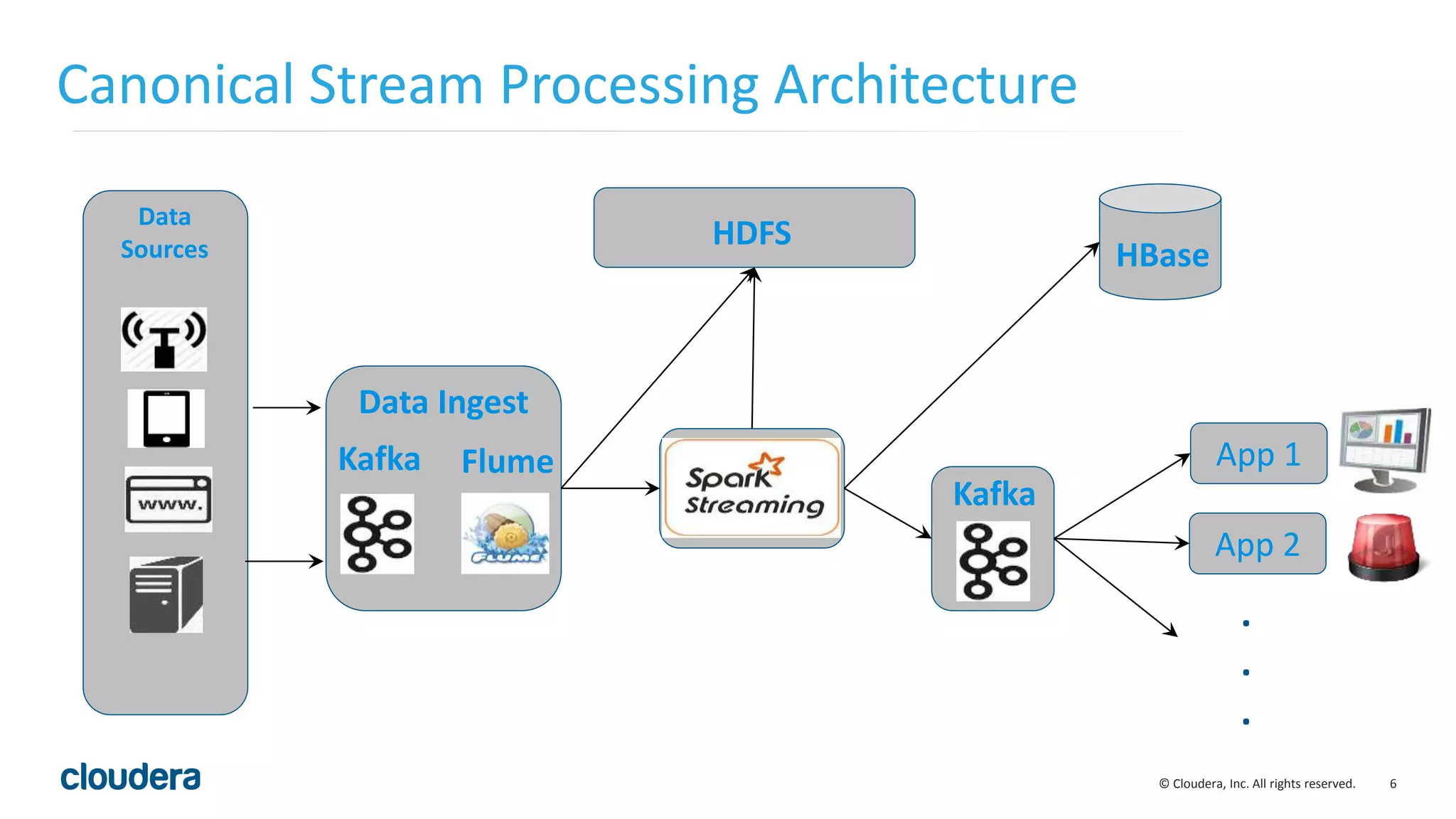
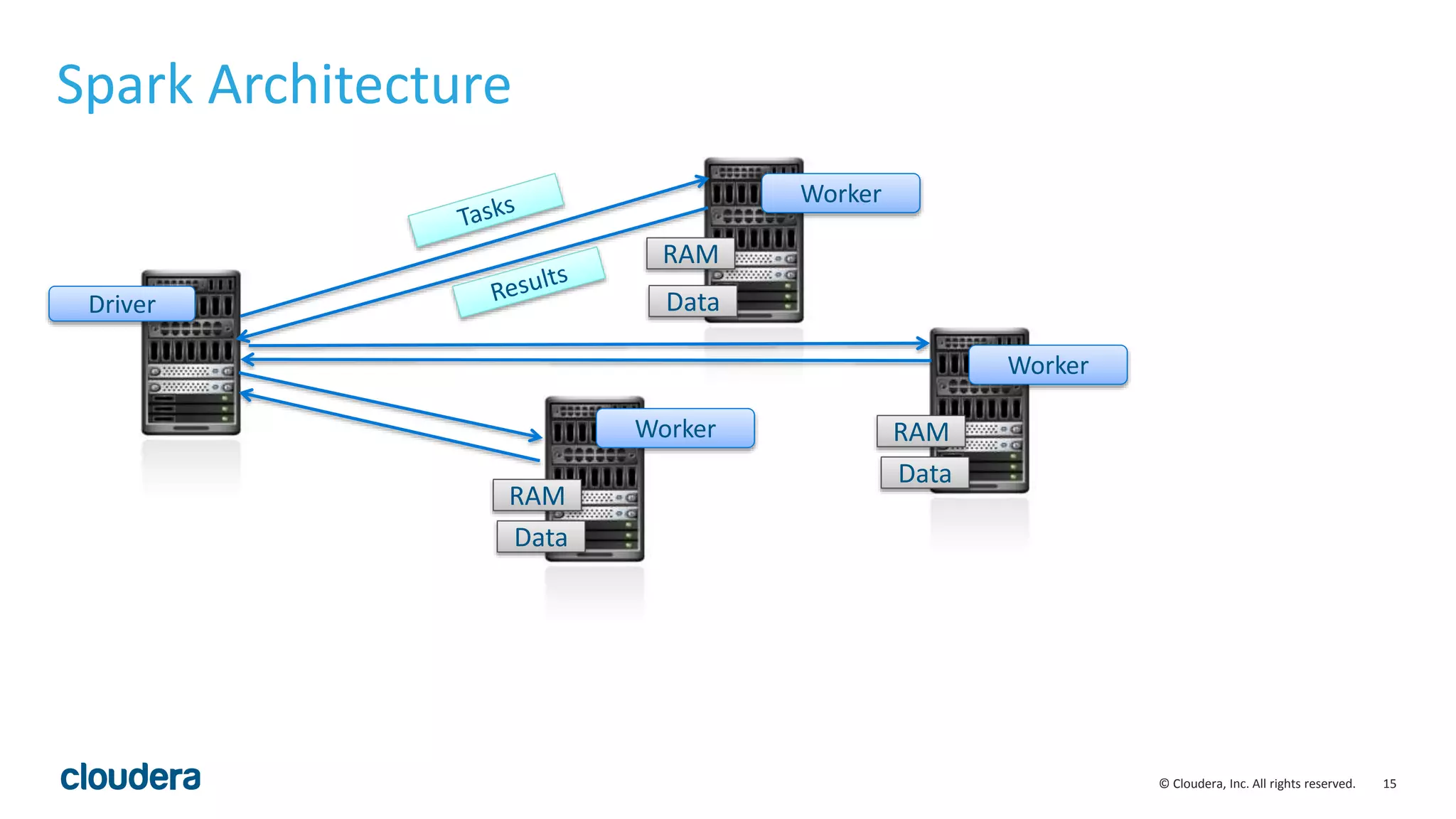
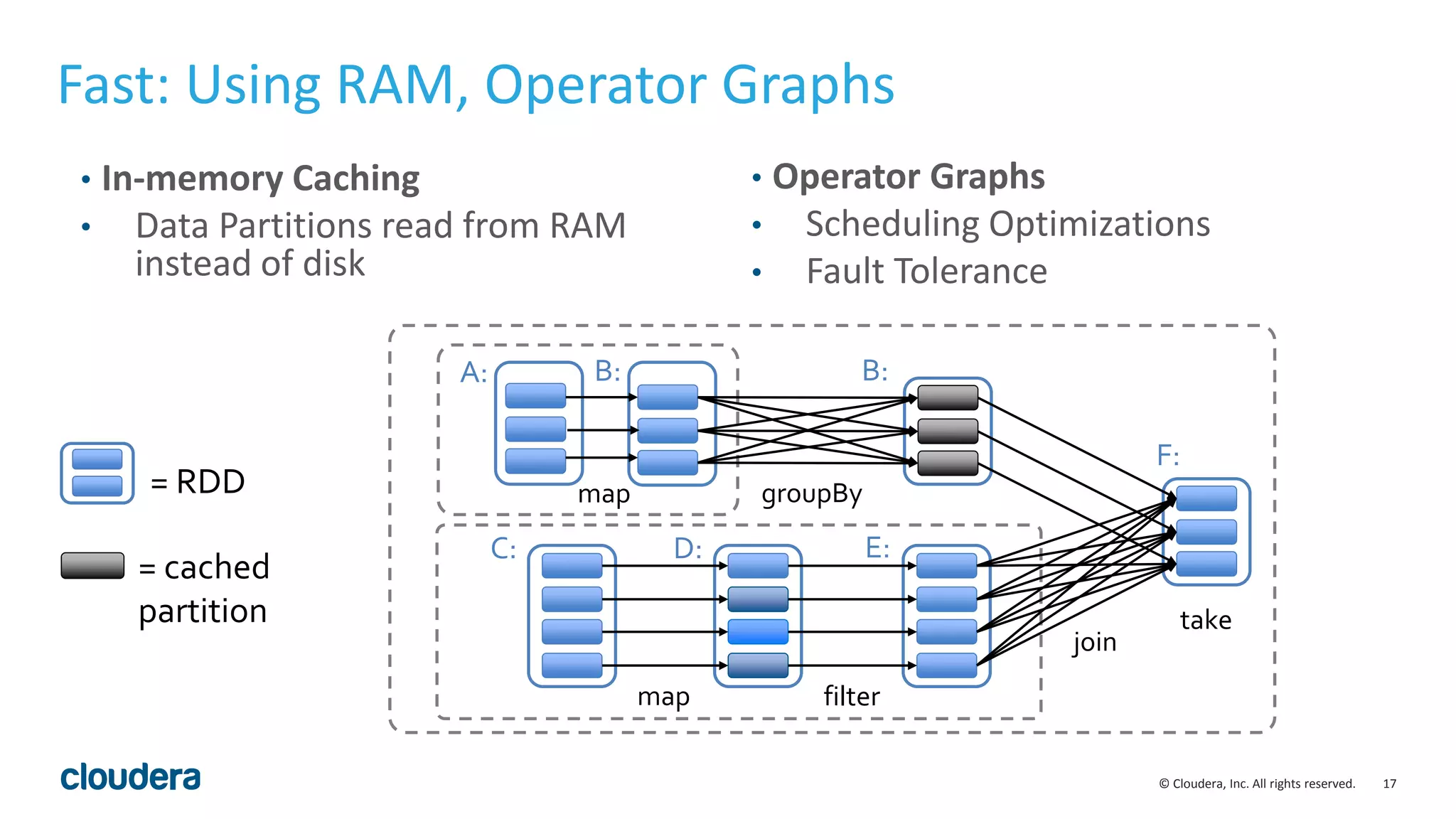
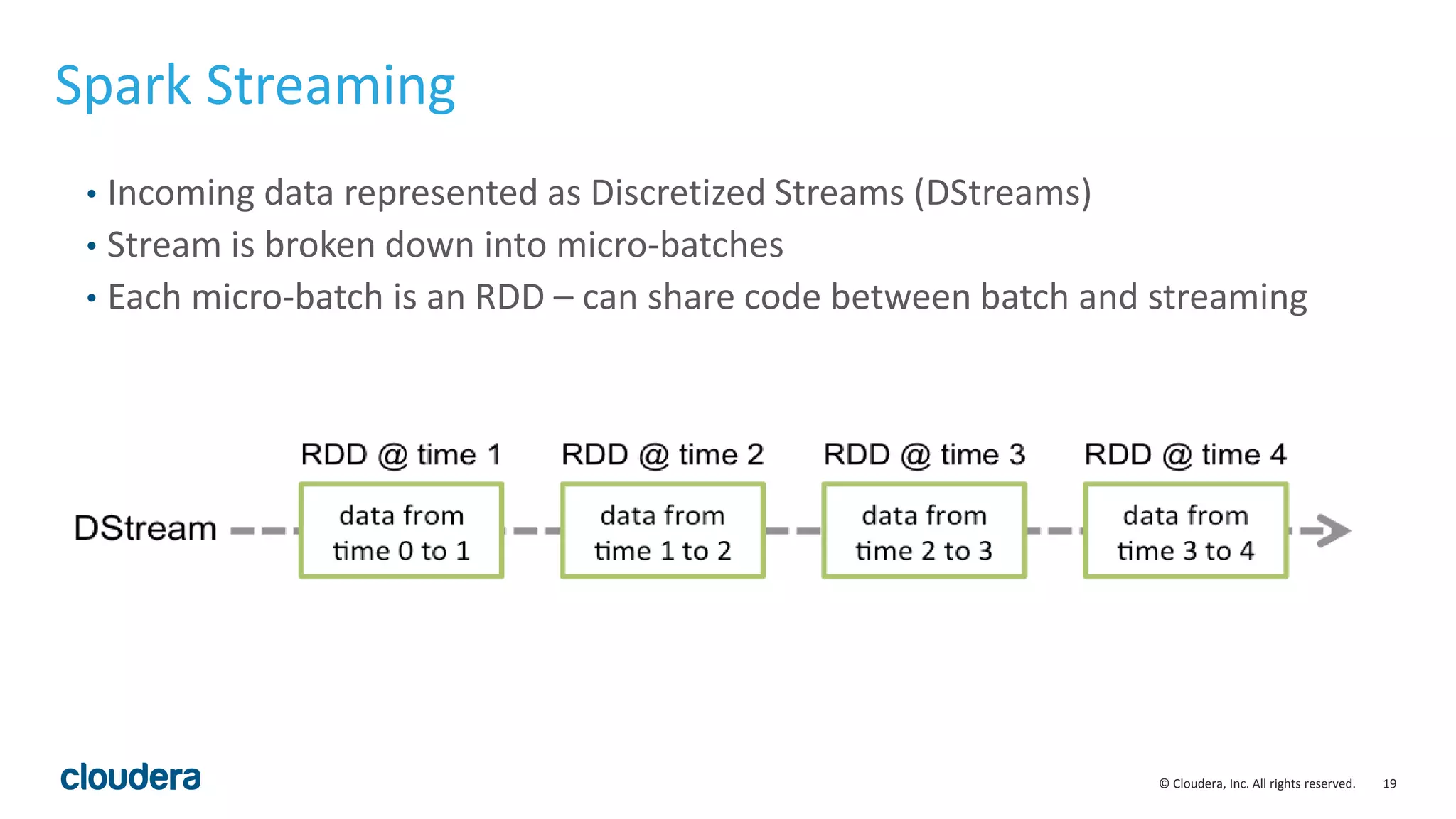
The document discusses the need for real-time stream processing due to the exponential growth of data from various sources and its applications across several industries. It highlights Apache Spark as a flexible framework that optimizes big data processing with features like in-memory storage and supports various programming languages. Spark Streaming, an extension of Spark, allows real-time data processing using micro-batches, integrating seamlessly with data ingestion tools and enabling efficient handling of streaming data.








![13© Cloudera, Inc. All rights reserved. Easy: Example – Word Count (Spark) val spark = new SparkContext(master, appName, [sparkHome], [jars]) val file = spark.textFile("hdfs://...") val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/sparkstreamingdatadaytexas-150110212353-conversion-gate01/75/Real-Time-Data-Processing-Using-Spark-Streaming-13-2048.jpg)




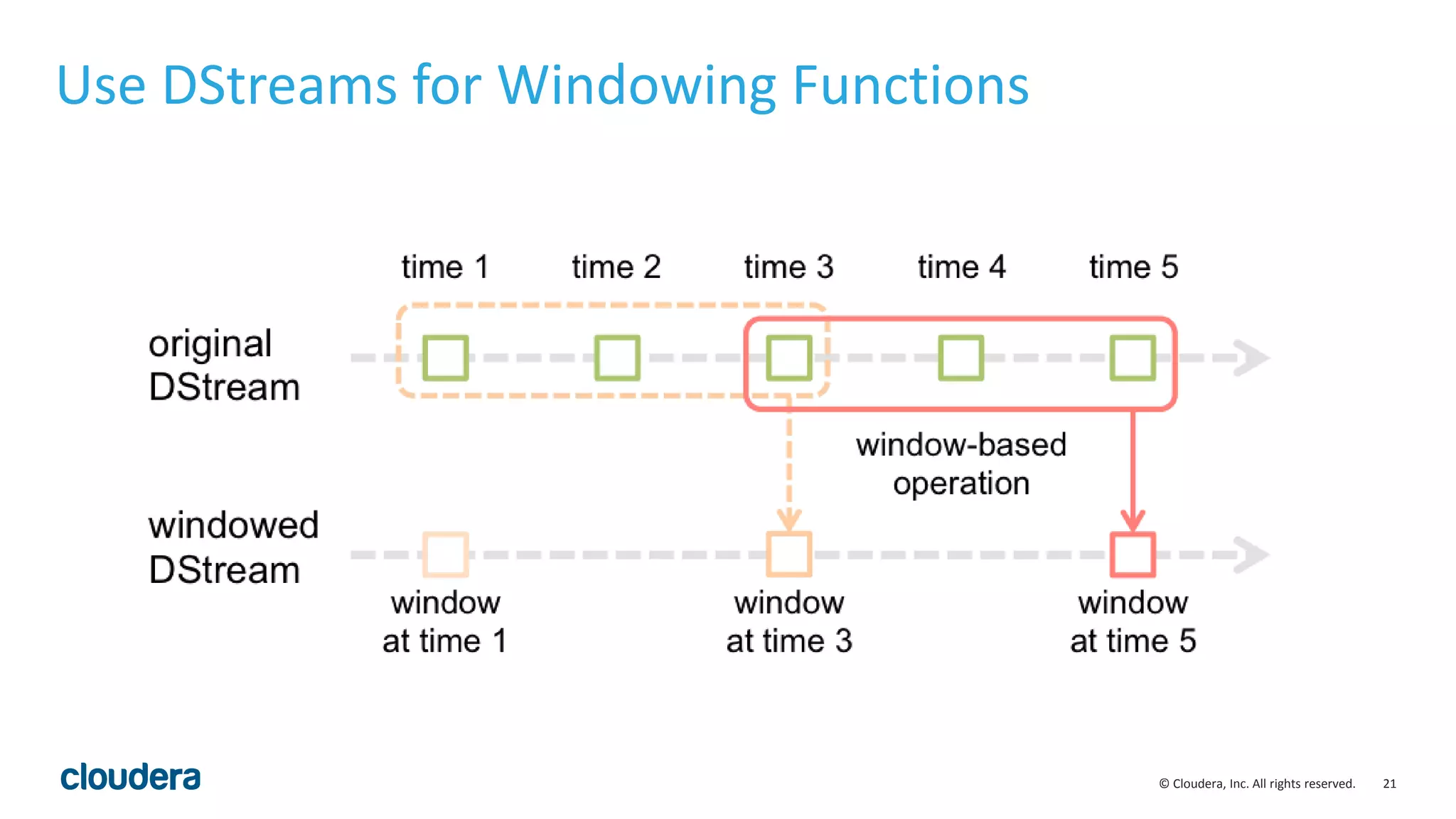

![23© Cloudera, Inc. All rights reserved. Sharing Code between Batch and Streaming def filterErrors (rdd: RDD[String]): RDD[String] = { rdd.filter(s => s.contains(“ERROR”)) } Library that filters “ERRORS” • Streaming generates RDDs periodically • Any code that operates on RDDs can therefore be used in streaming as well](https://image.slidesharecdn.com/sparkstreamingdatadaytexas-150110212353-conversion-gate01/75/Real-Time-Data-Processing-Using-Spark-Streaming-23-2048.jpg)
![24© Cloudera, Inc. All rights reserved. Sharing Code between Batch and Streaming val lines = sc.textFile(…) val filtered = filterErrors(lines) filtered.saveAsTextFile(...) Spark: val dStream = FlumeUtils.createStream(ssc, "34.23.46.22", 4435) val filtered = dStream.foreachRDD((rdd: RDD[String], time: Time) => { filterErrors(rdd) })) filtered.saveAsTextFiles(…) Spark Streaming:](https://image.slidesharecdn.com/sparkstreamingdatadaytexas-150110212353-conversion-gate01/75/Real-Time-Data-Processing-Using-Spark-Streaming-24-2048.jpg)