














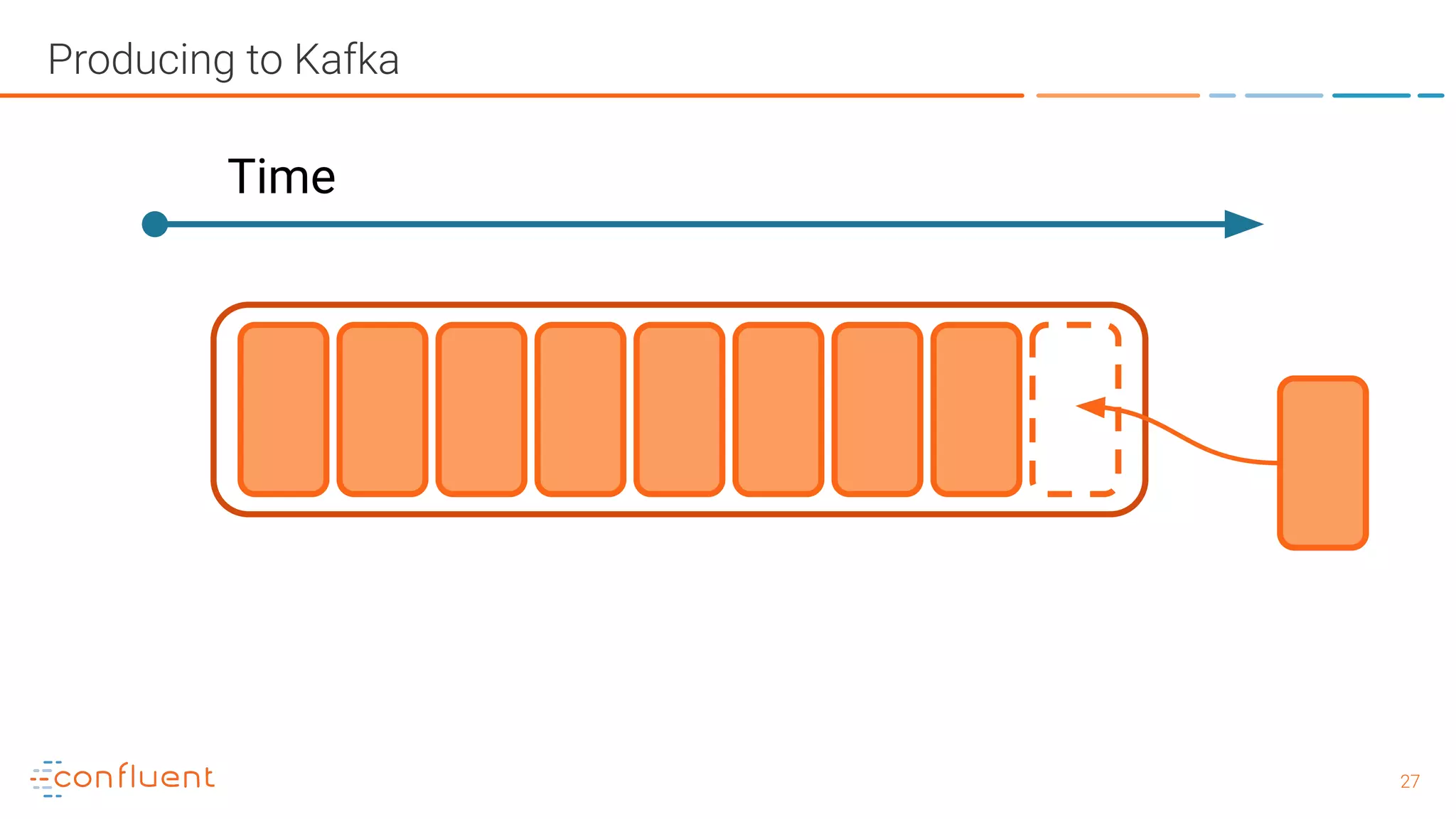

![3232 Producer Clients - Producer Design Producer Record Topic [Partition] [Timestamp] Value Serializer Partitioner Topic A Partition 0 Batch 0 Batch 1 Batch 2 Topic B Partition 1 Batch 0 Batch 1 Batch 2 Kafka Broker Send() Retry ? Fail ? Yes No Can’t retry, throw exception Success: return metadata Yes [Headers] [Key]](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-32-2048.jpg)

![3535 Producer Record Topic [Partition] [Key] Value Record keys determine the partition with the default kafka partitioner If a key isn’t provided, messages will be produced in a round robin fashion partitioner Record Keys and why they’re important - Ordering](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-35-2048.jpg)
![3636 Producer Record Topic [Partition] AAAA Value Record keys determine the partition with the default kafka partitioner, and therefore guarantee order for a key Keys are used in the default partitioning algorithm: partition = hash(key) % numPartitions partitioner Record Keys and why they’re important - Ordering](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-36-2048.jpg)
![3737 Producer Record Topic [Partition] BBBB Value Keys are used in the default partitioning algorithm: partition = hash(key) % numPartitions partitioner Record keys determine the partition with the default kafka partitioner, and therefore guarantee order for a key Record Keys and why they’re important - Ordering](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-37-2048.jpg)
![3838 Producer Record Topic [Partition] CCCC Value Keys are used in the default partitioning algorithm: partition = hash(key) % numPartitions partitioner Record keys determine the partition with the default kafka partitioner, and therefore guarantee order for a key Record Keys and why they’re important - Ordering](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-38-2048.jpg)
![3939 Record Keys and why they’re important - Ordering Producer Record Topic [Partition] DDDD Value Keys are used in the default partitioning algorithm: partition = hash(key) % numPartitions partitioner Record keys determine the partition with the default kafka partitioner, and therefore guarantee order for a key](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-39-2048.jpg)

![4545 Use Kafka’s Headers Reference https://cwiki.apache.org/confluence/display/KAFKA/KIP-82+-+Add+Record+Headers Producer Record Topic [Partition] [Timestamp] Value [Headers] [Key] Kafka Headers are simply an interface that requires a key of type String, and a value of type byte[], the headers are stored in an iterator in the ProducerRecord . Example Use Cases ● Data lineage: reference previous topic partition/offsets ● Producing host/application/owner ● Message routing ● Encryption metadata (which key pair was this message payload encrypted with?)](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-45-2048.jpg)
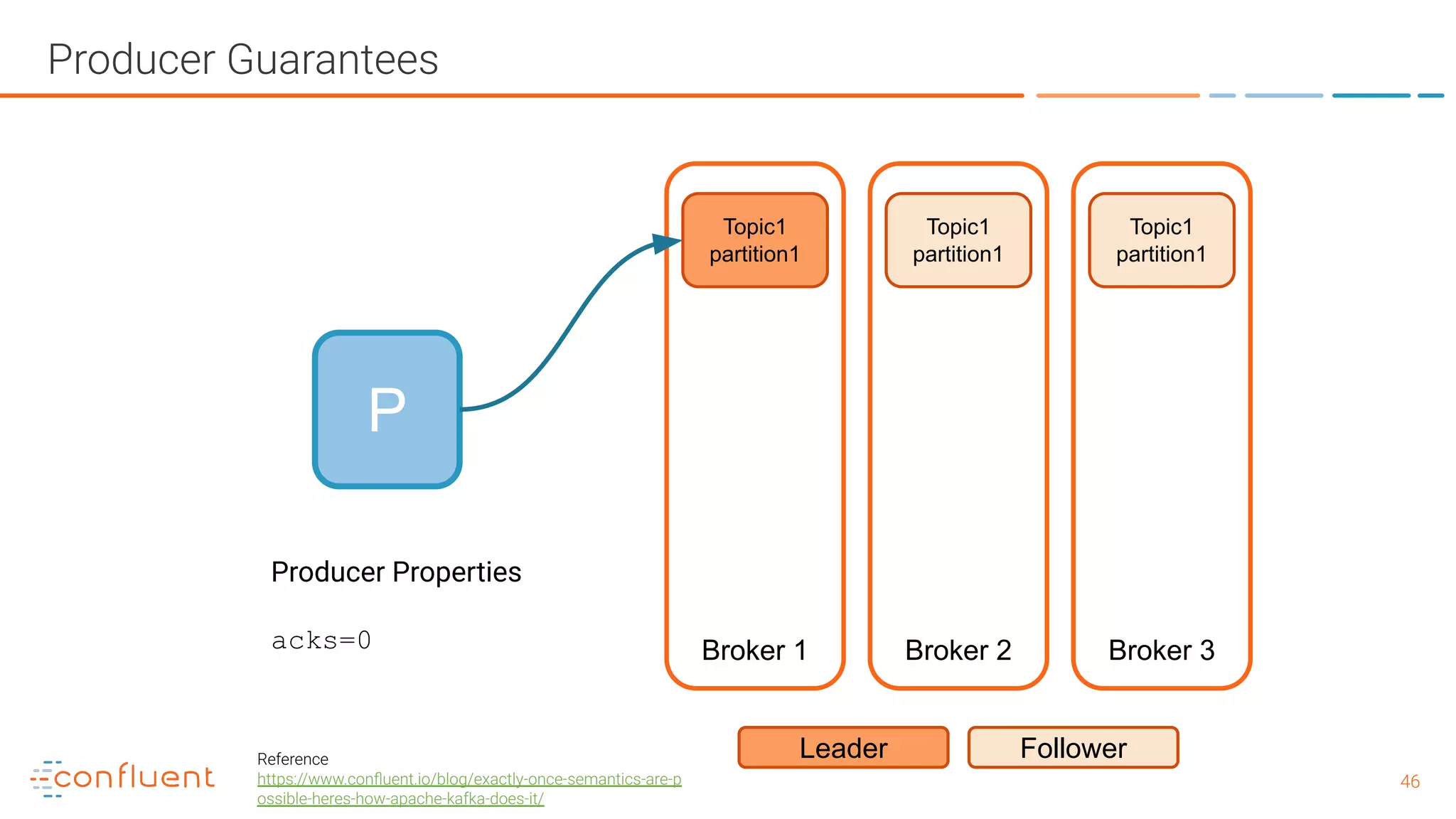
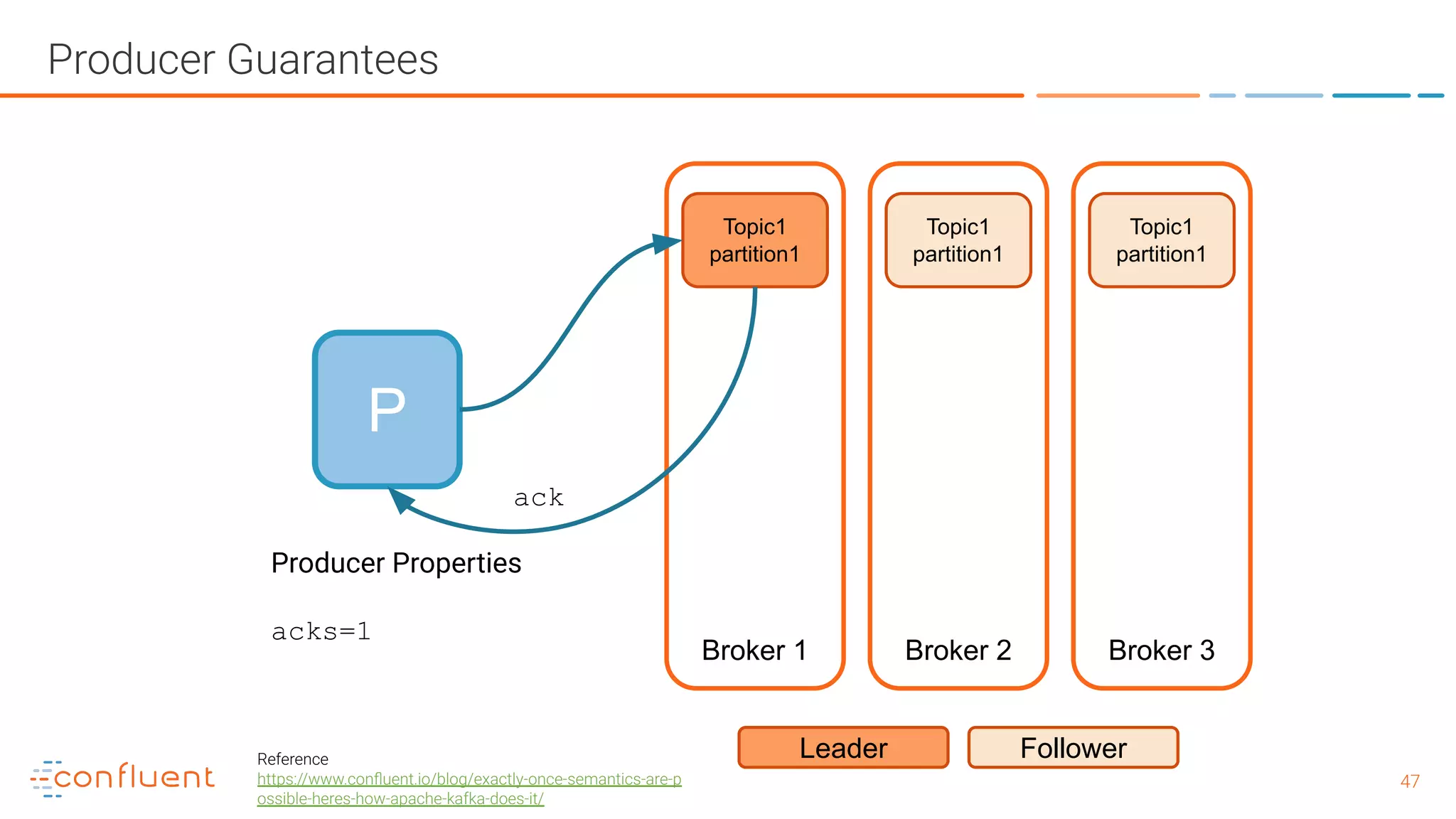
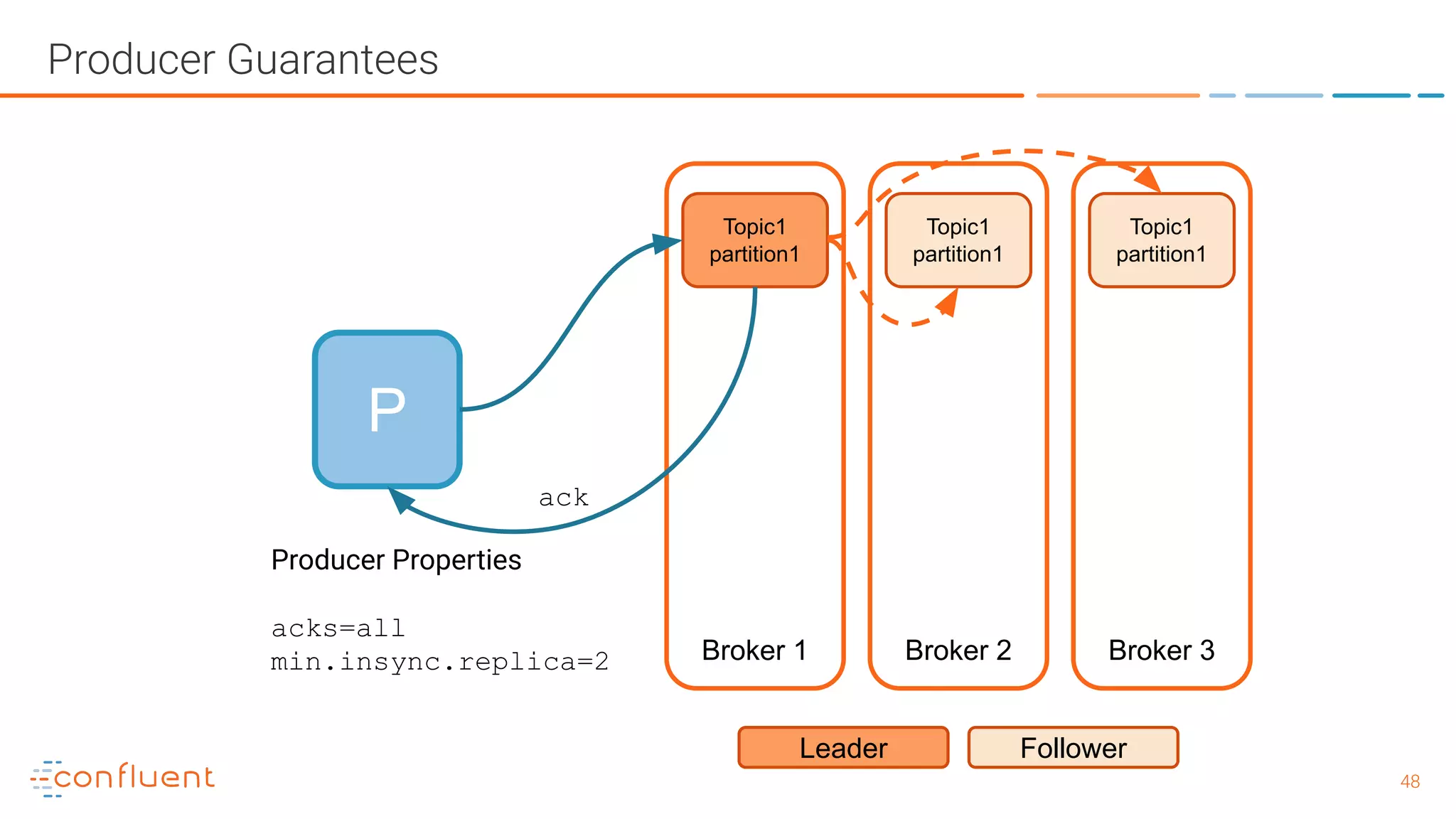
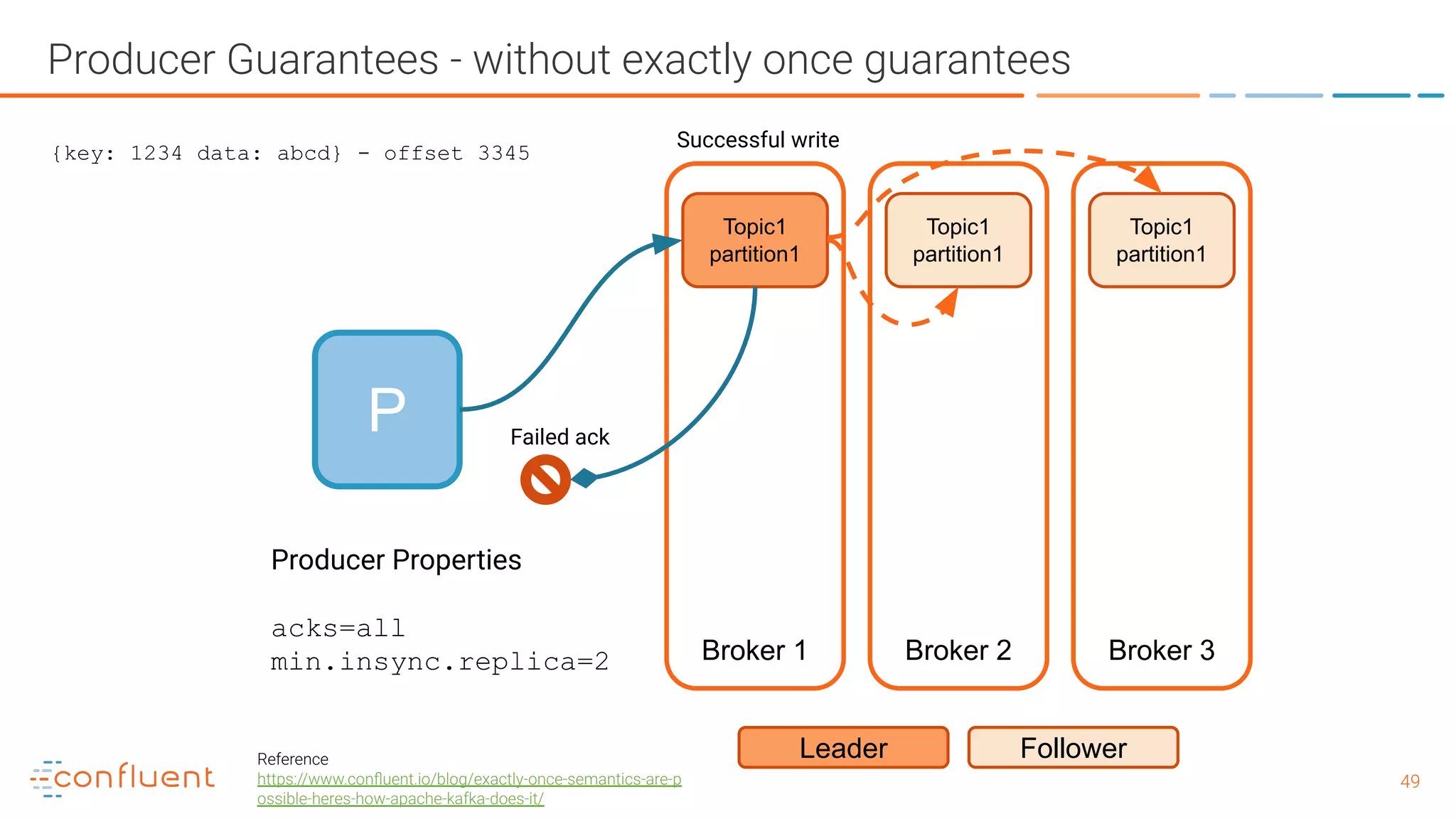
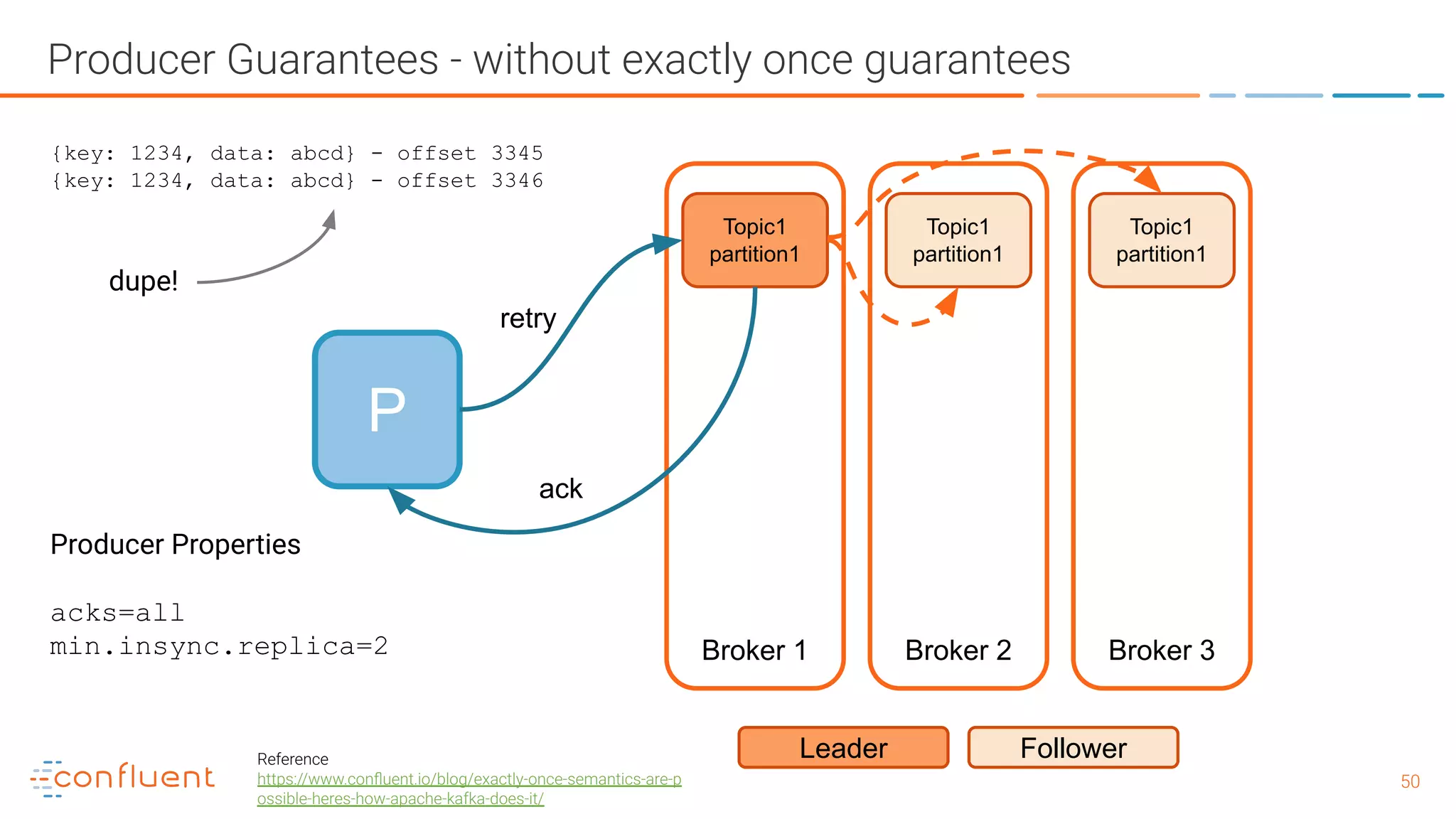
![5151 Producer Guarantees - with exactly once guarantees P Broker 1 Broker 2 Broker 3 Topic1 partition1 Leader Follower Topic1 partition1 Topic1 partition1 Producer Properties enable.idempotence=true max.inflight.requests.per.connection=5 acks = "all" retries > 0 (preferably MAX_INT) (pid, seq) [payload] (100, 1) {key: 1234, data: abcd} - offset 3345 (100, 1) {key: 1234, data: abcd} - rejected, ack re-sent (100, 2) {key: 5678, data: efgh} - offset 3346 retry ack no dupe! Reference https://www.confluent.io/blog/exactly-once-semantics-are-p ossible-heres-how-apache-kafka-does-it/](https://image.slidesharecdn.com/whatisapachekafkaandwhatisanevnetstreamingplatform-190505042303/75/What-is-Apache-Kafka-and-What-is-an-Event-Streaming-Platform-51-2048.jpg)
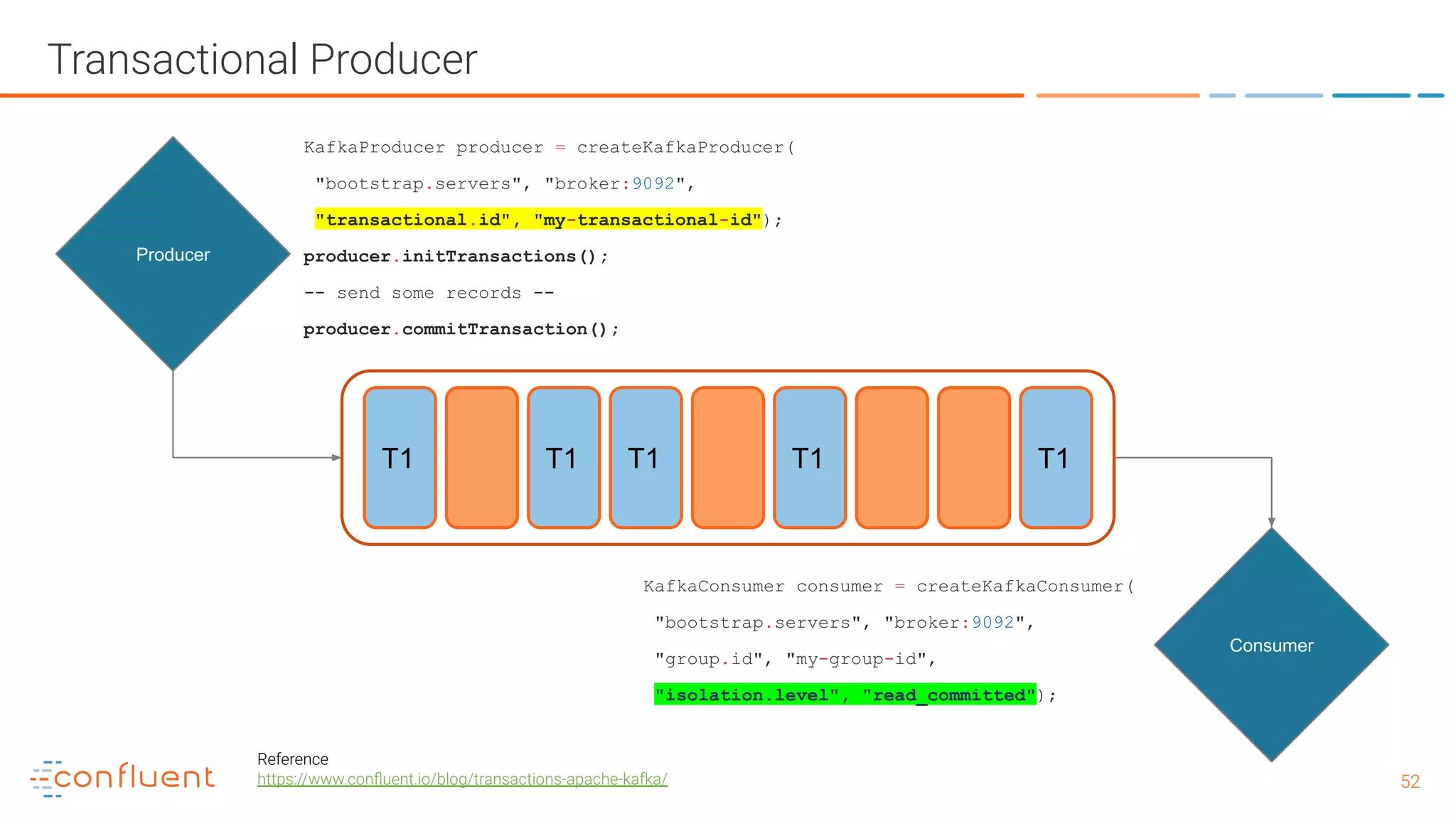

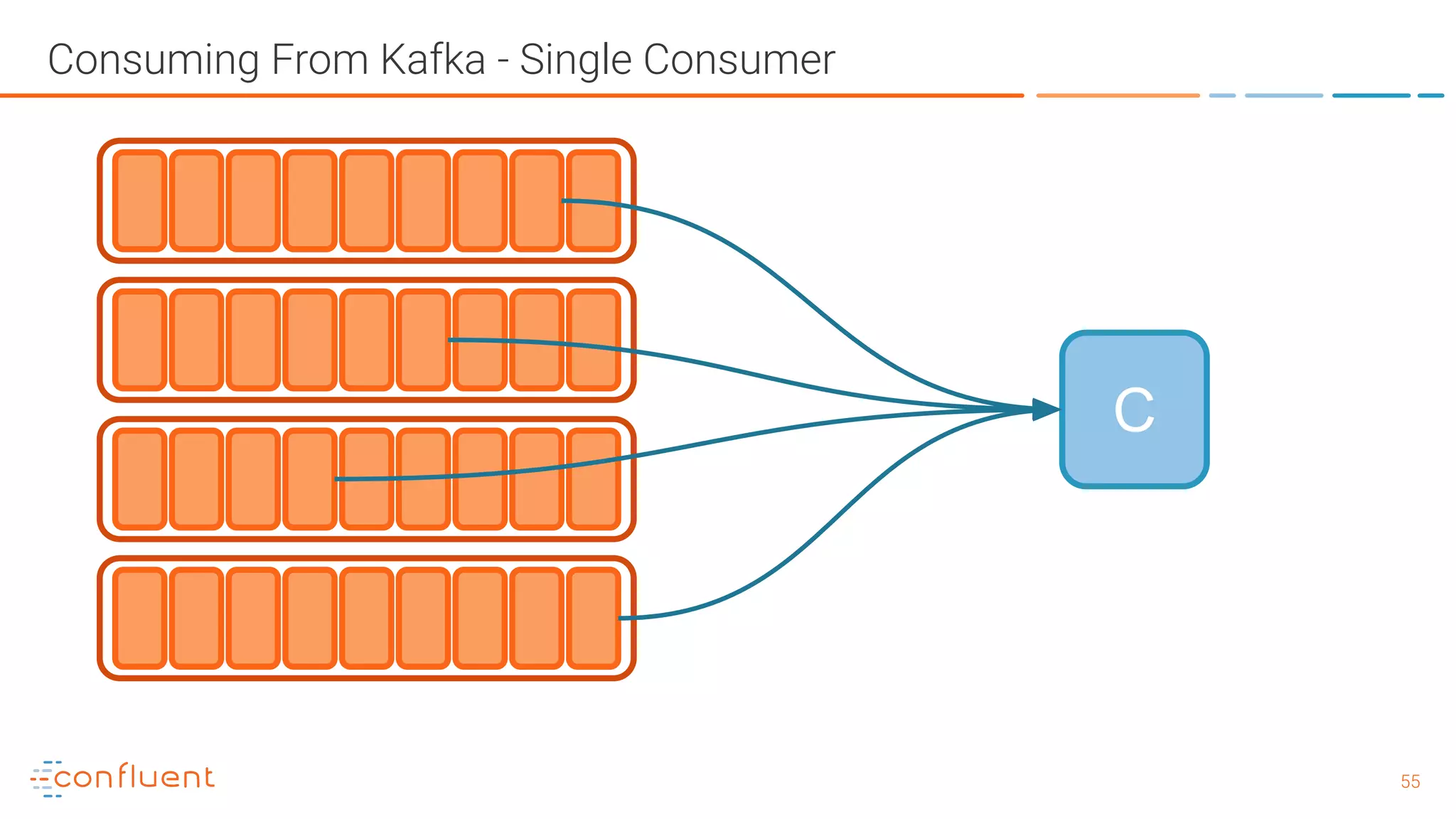
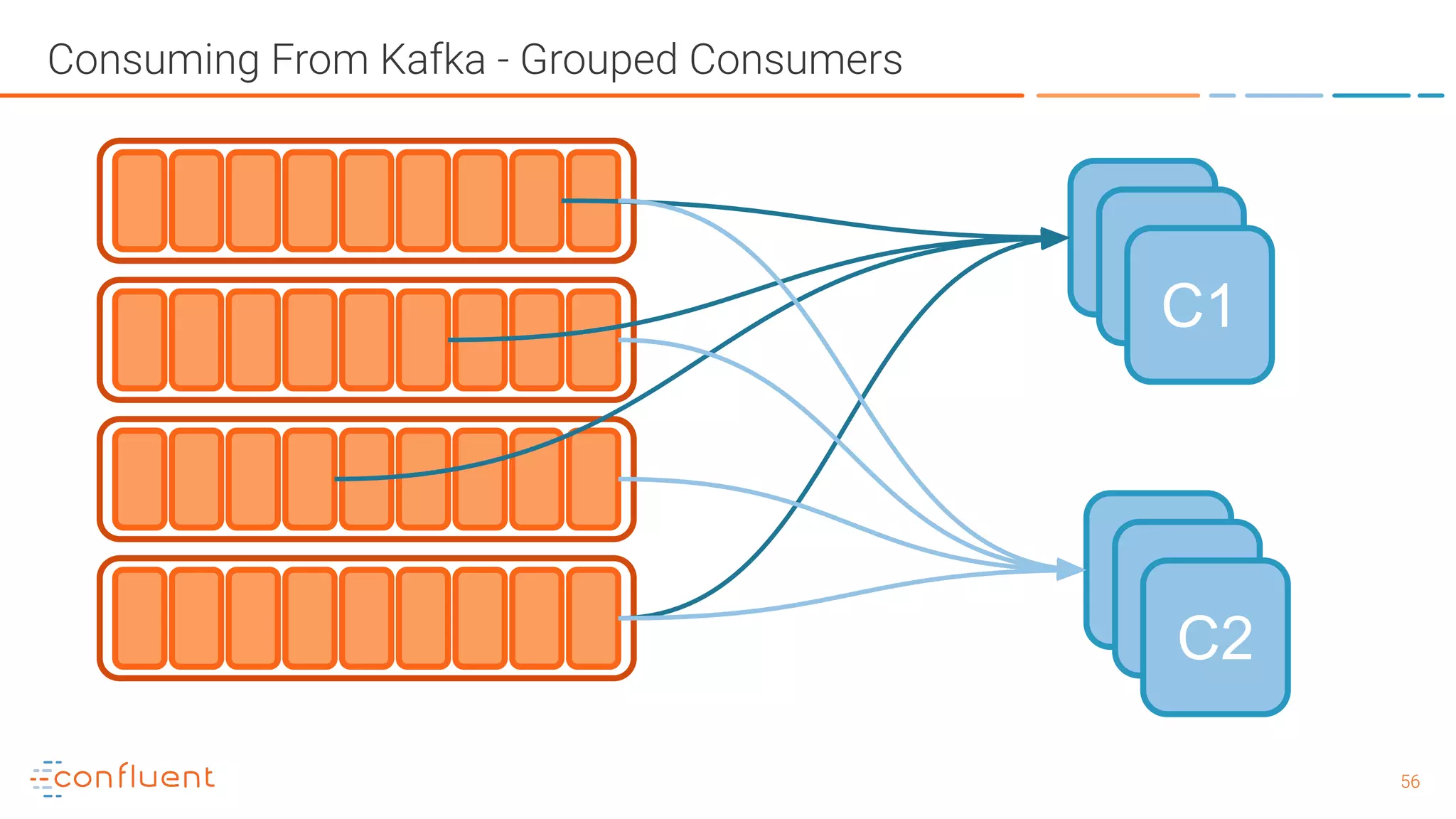
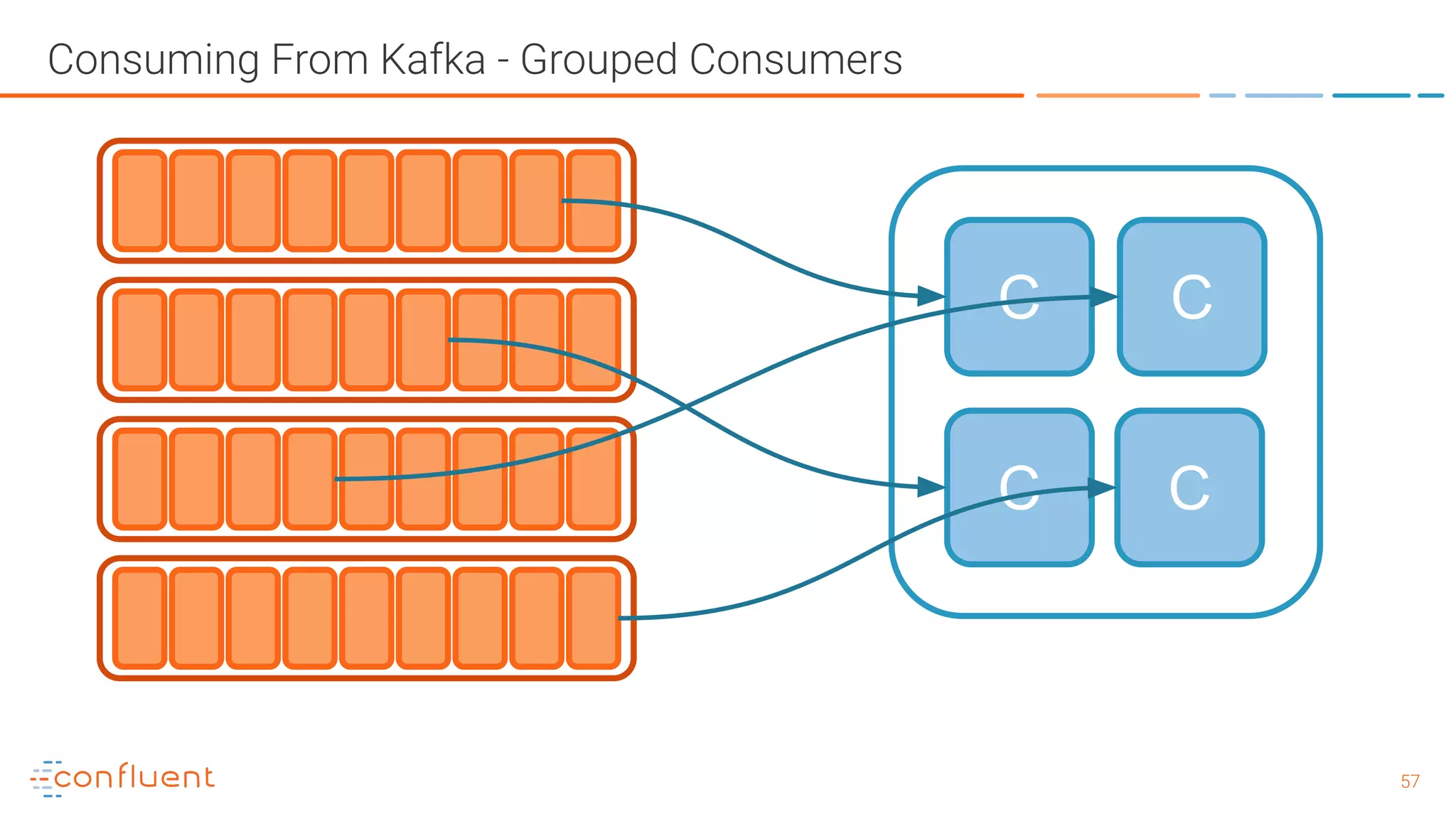
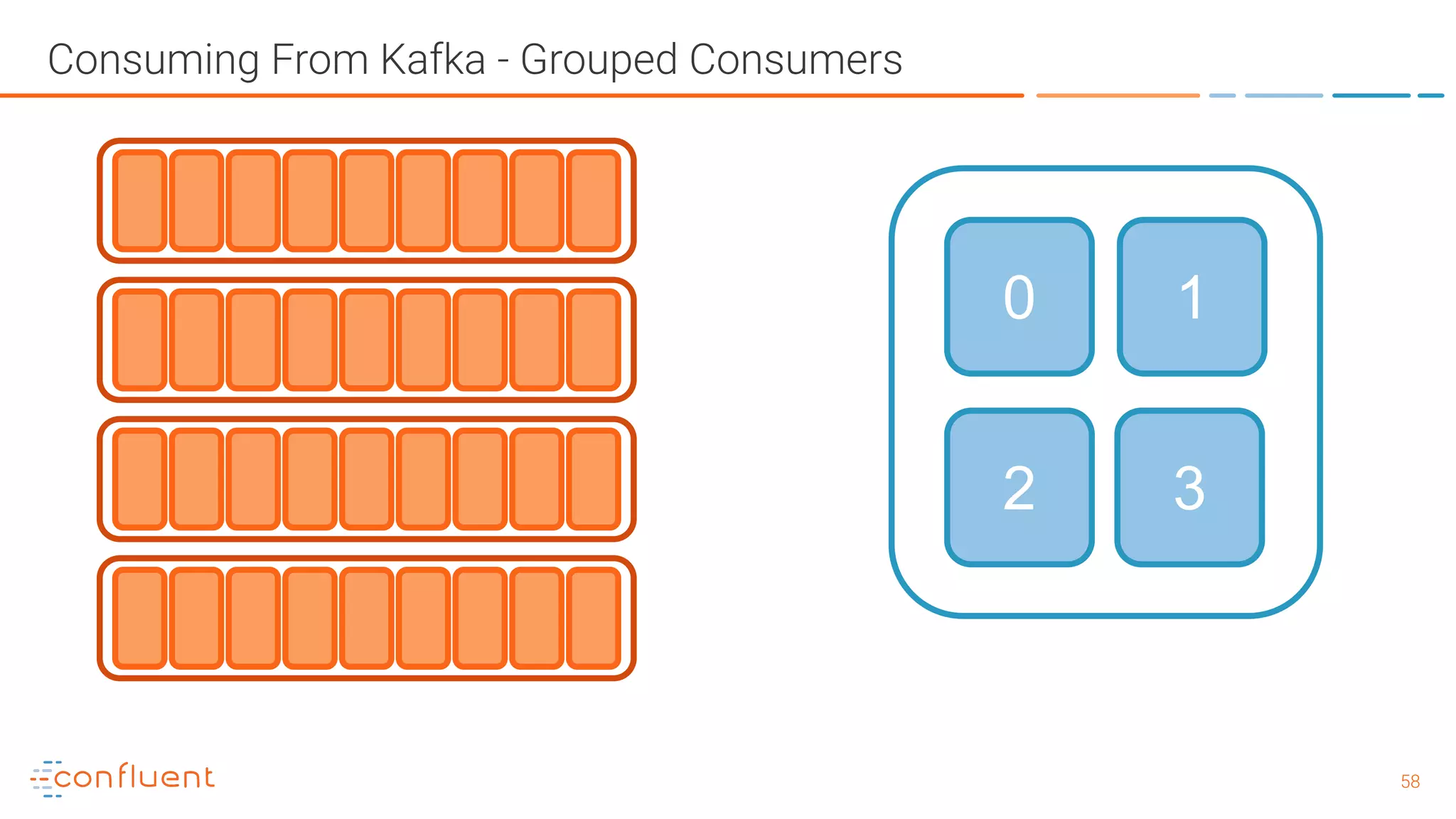
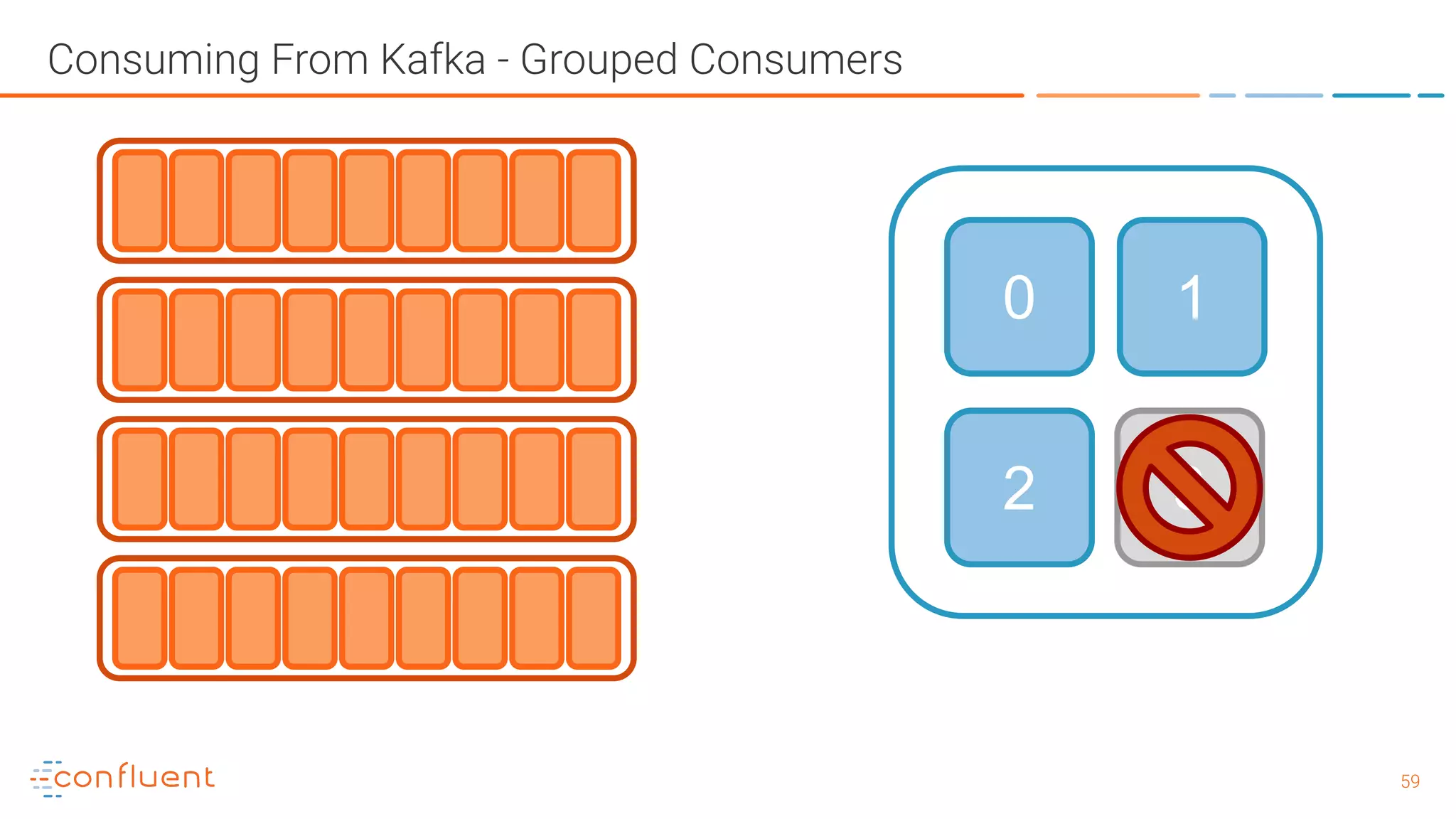
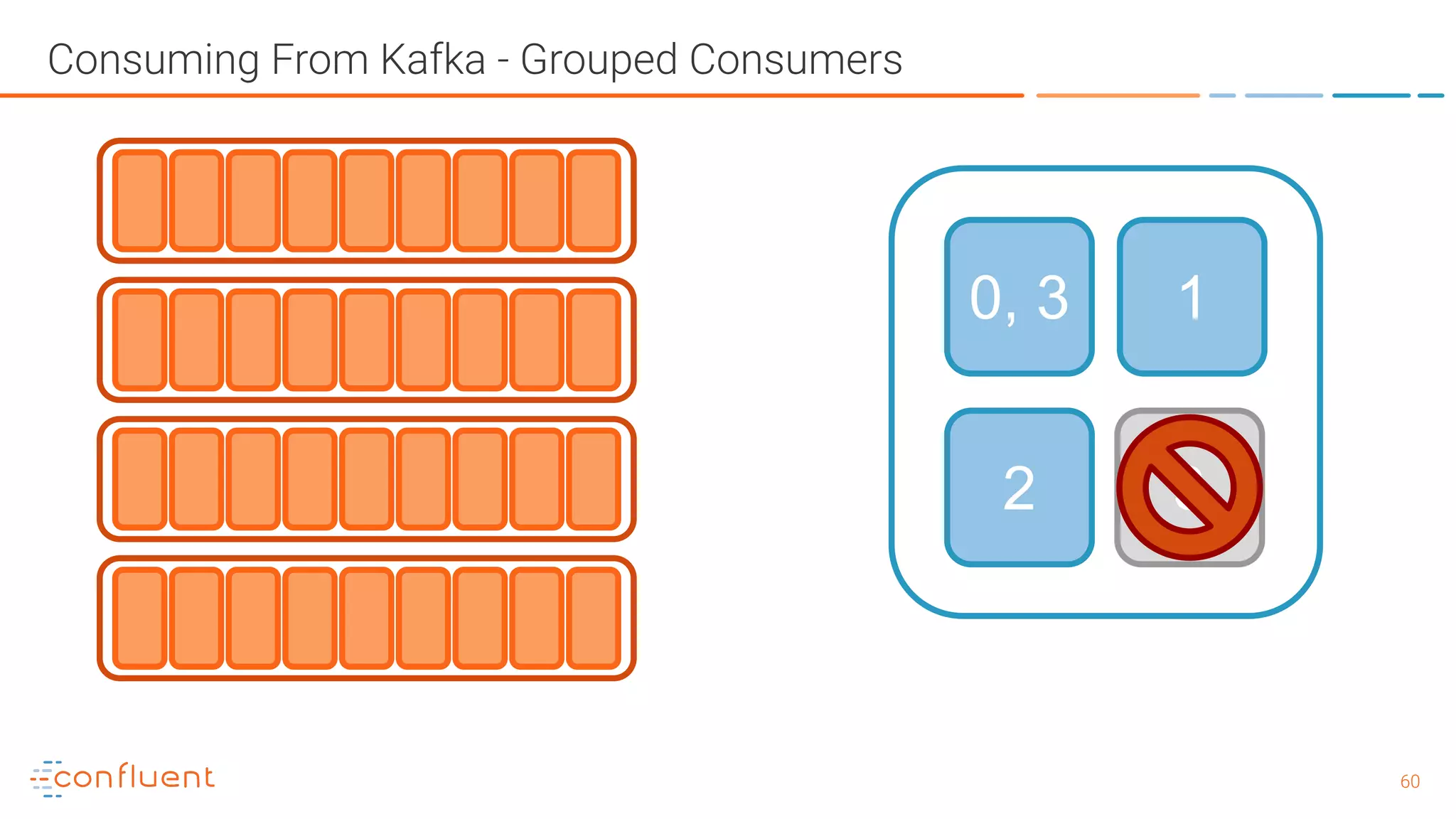




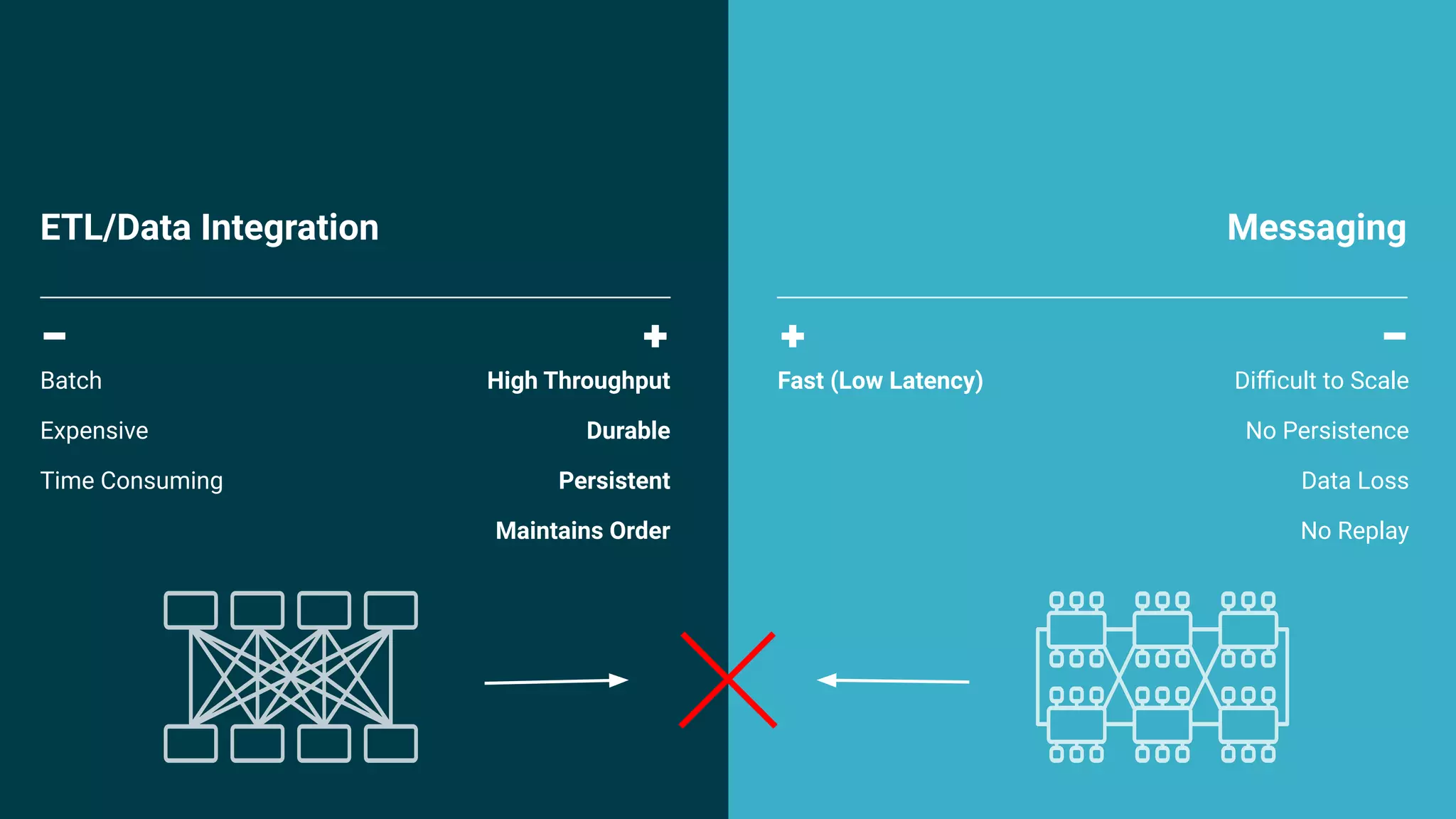
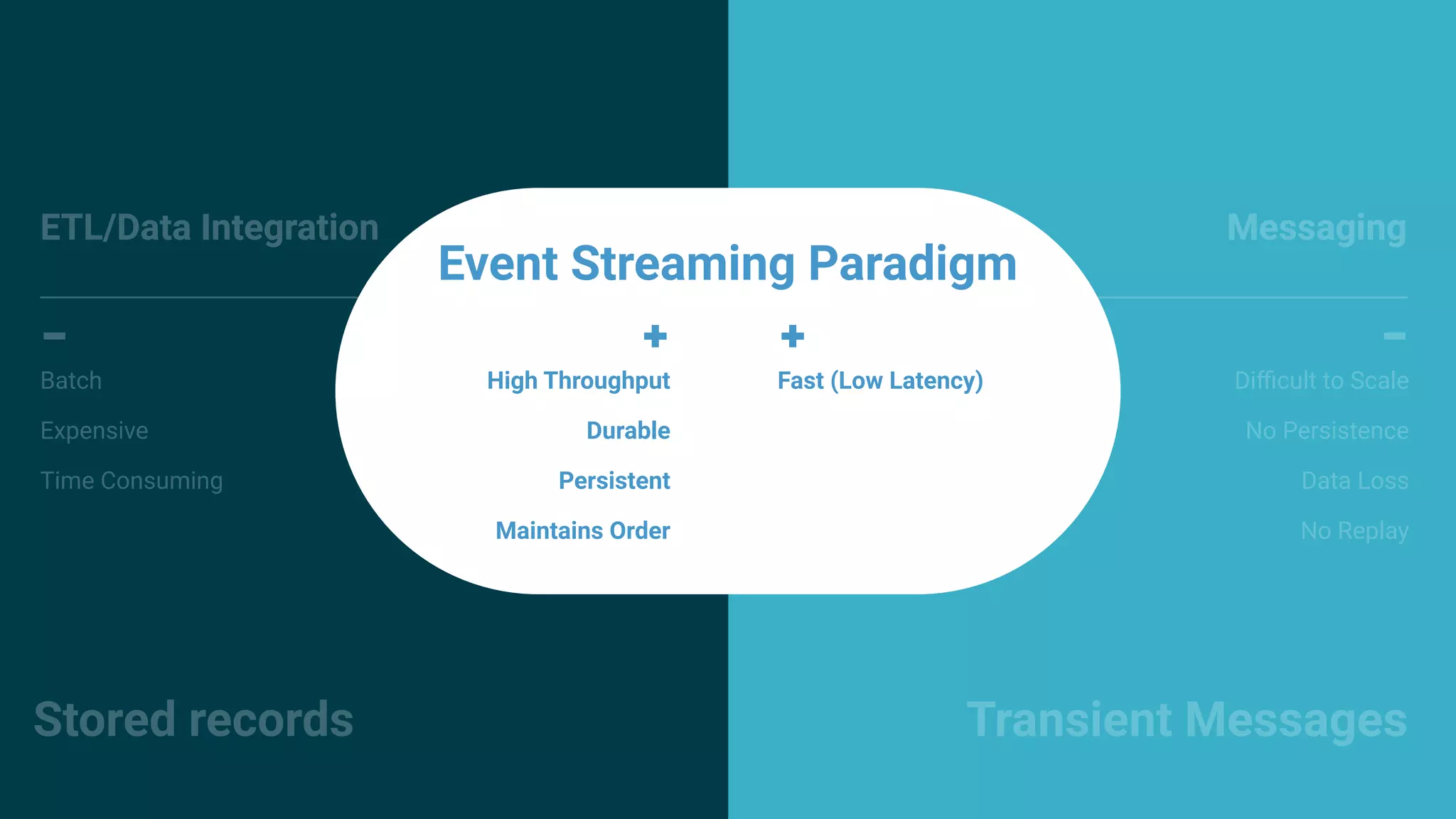
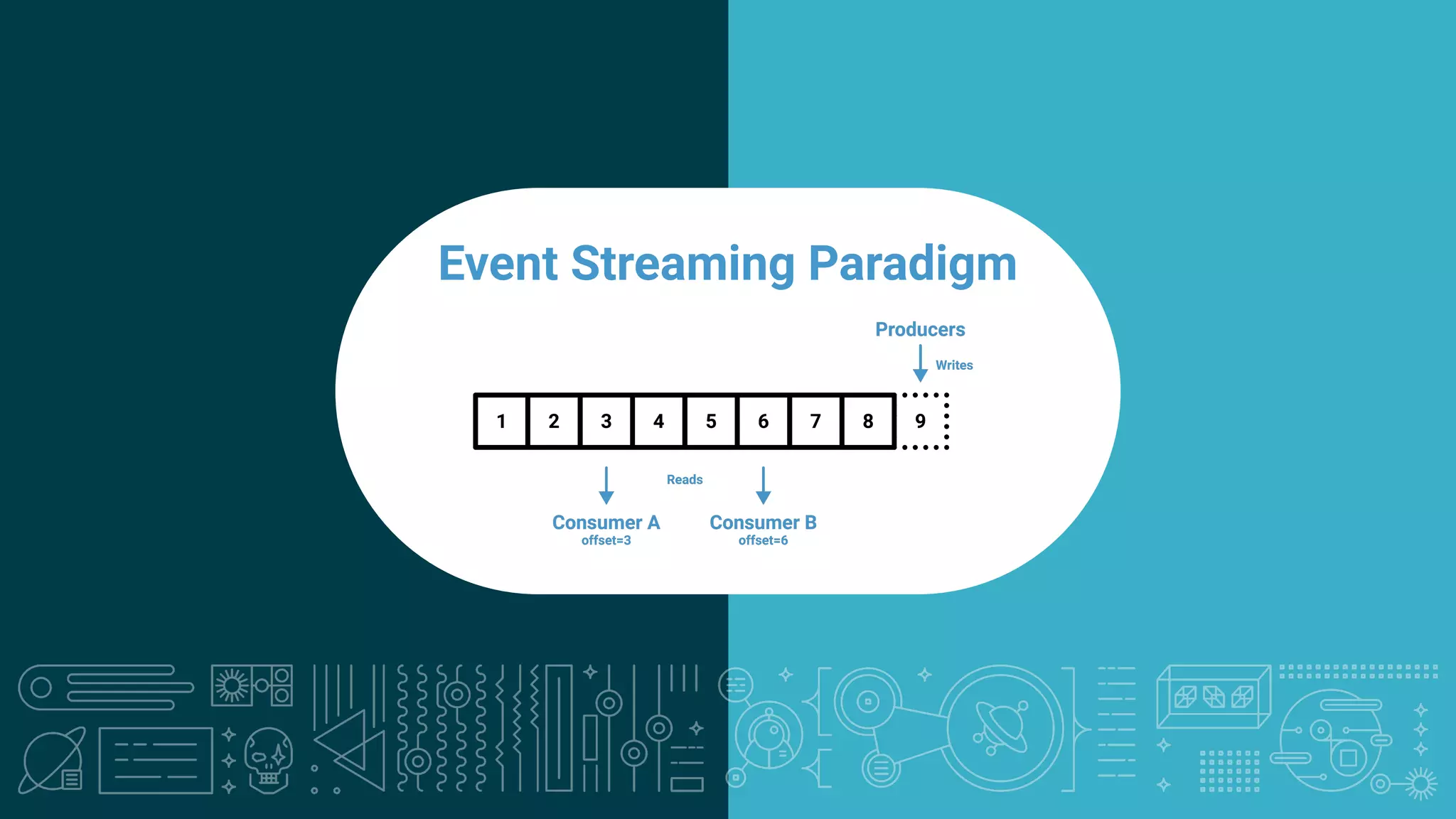
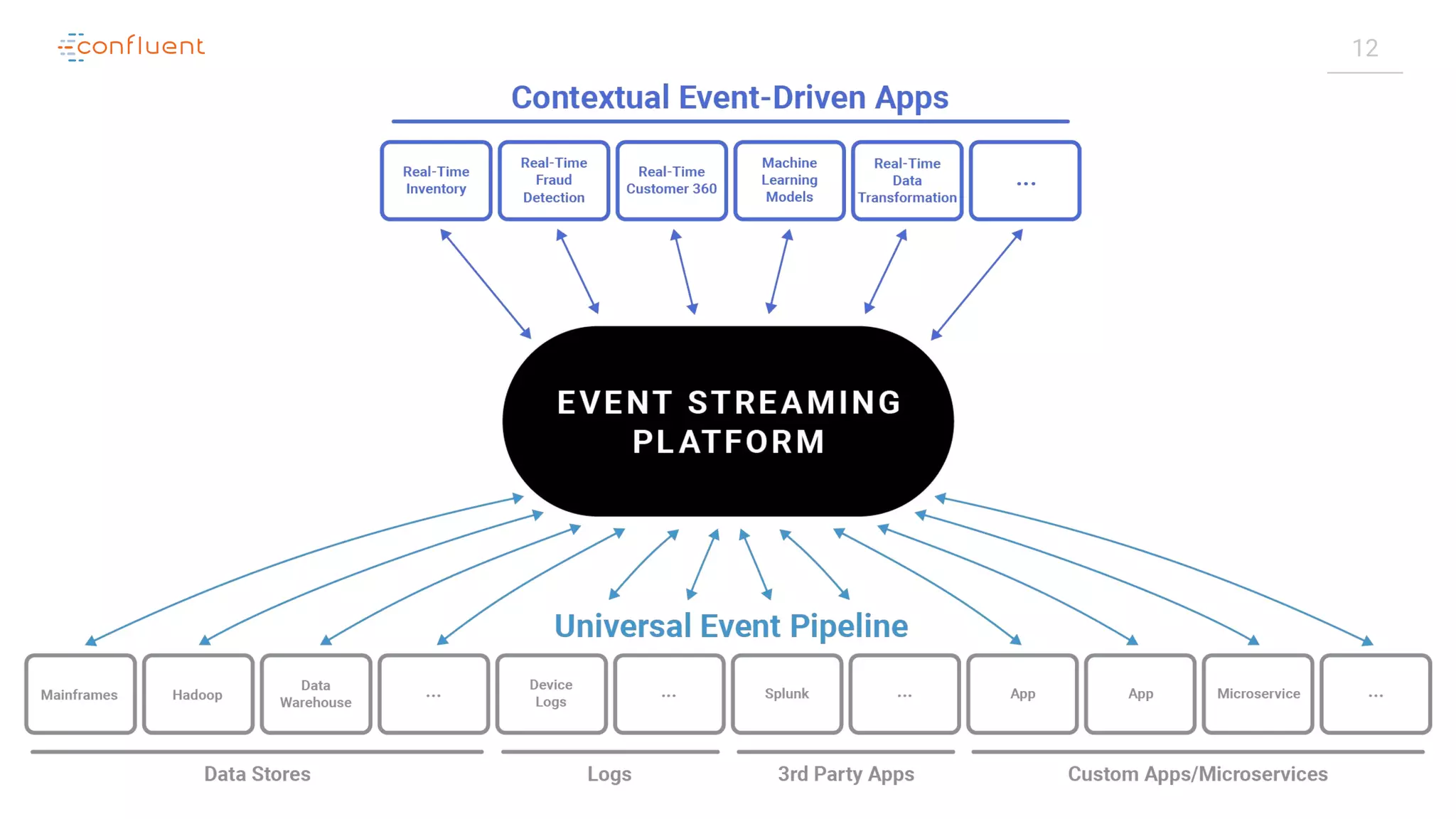
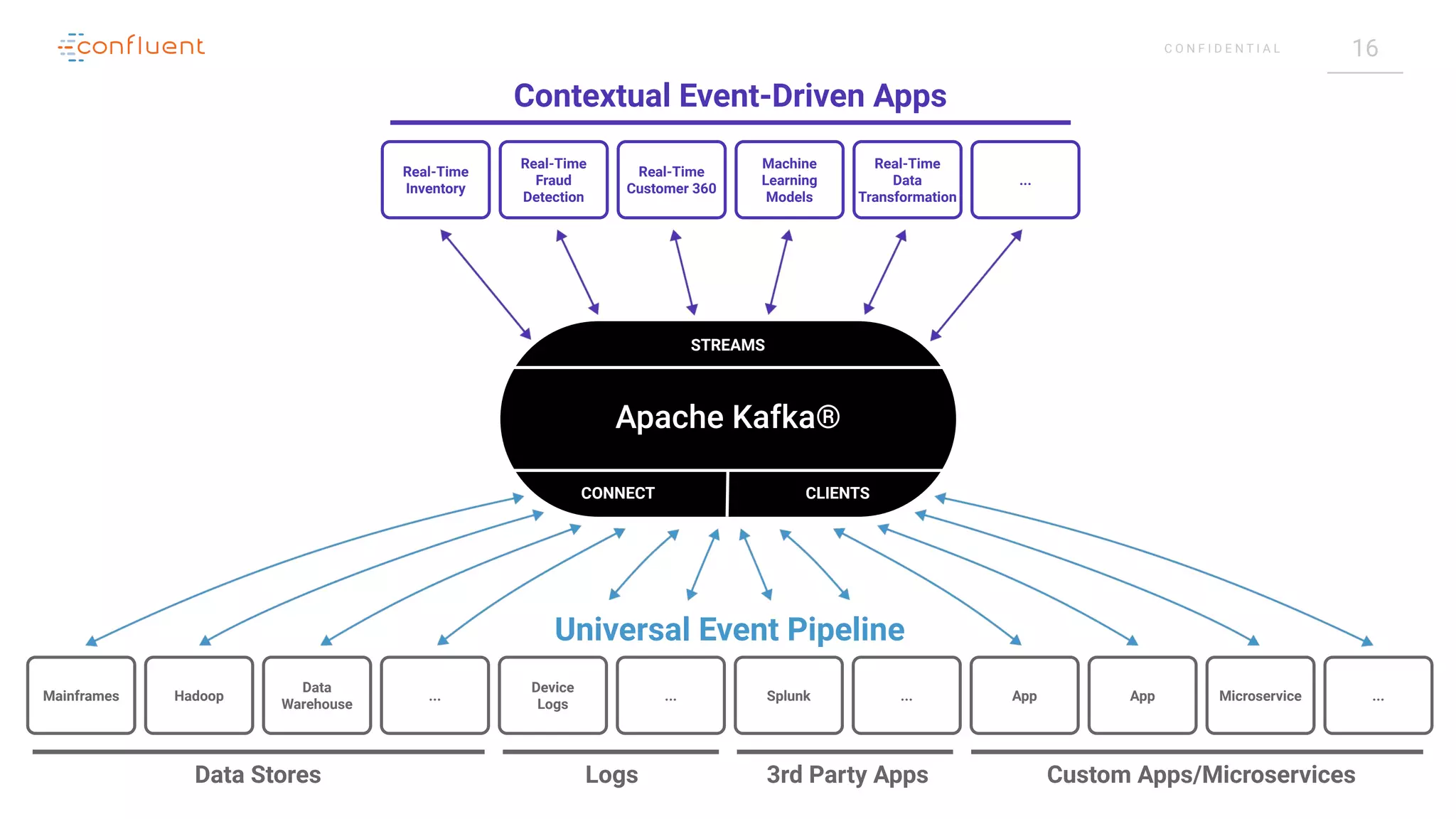
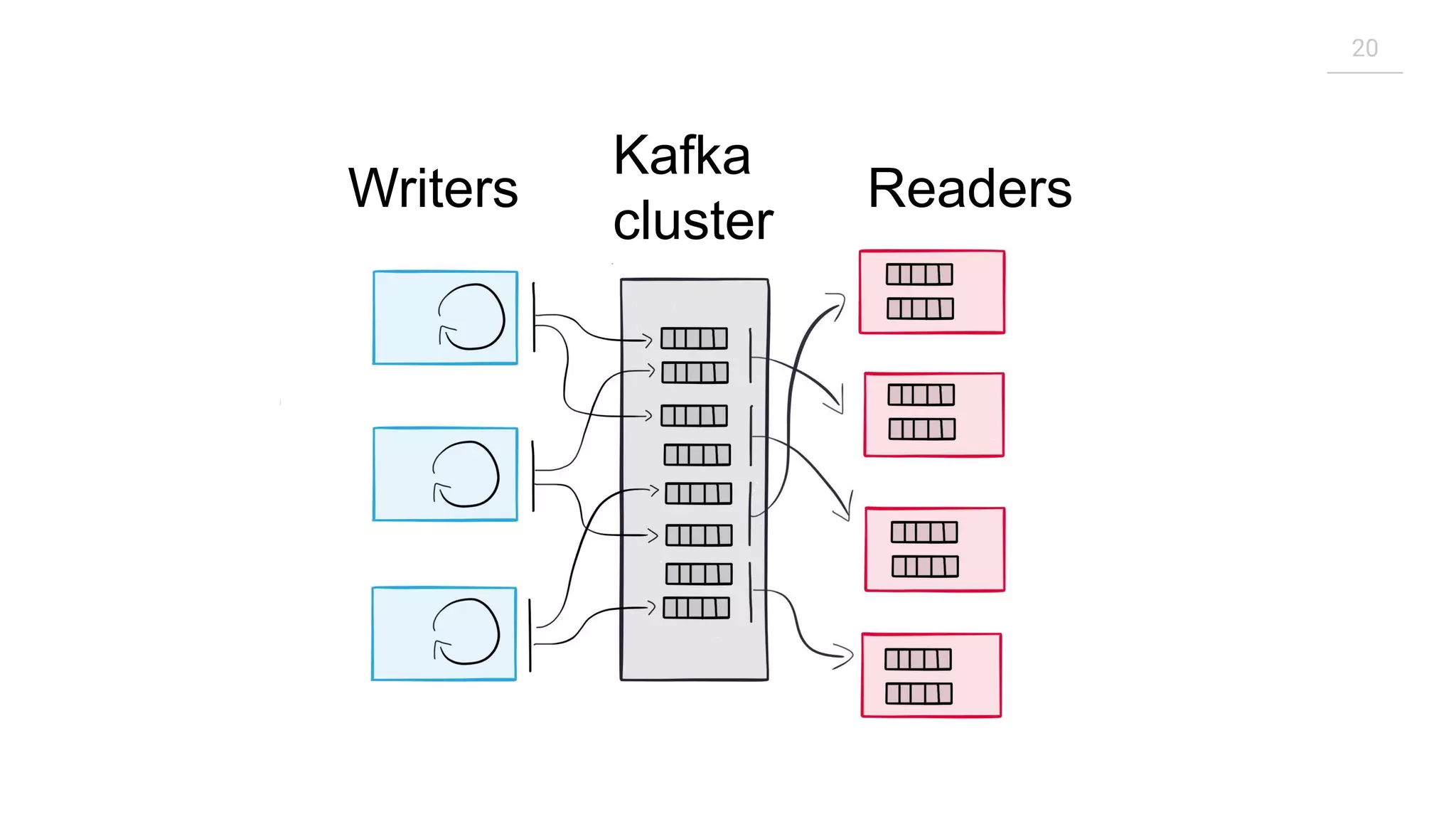
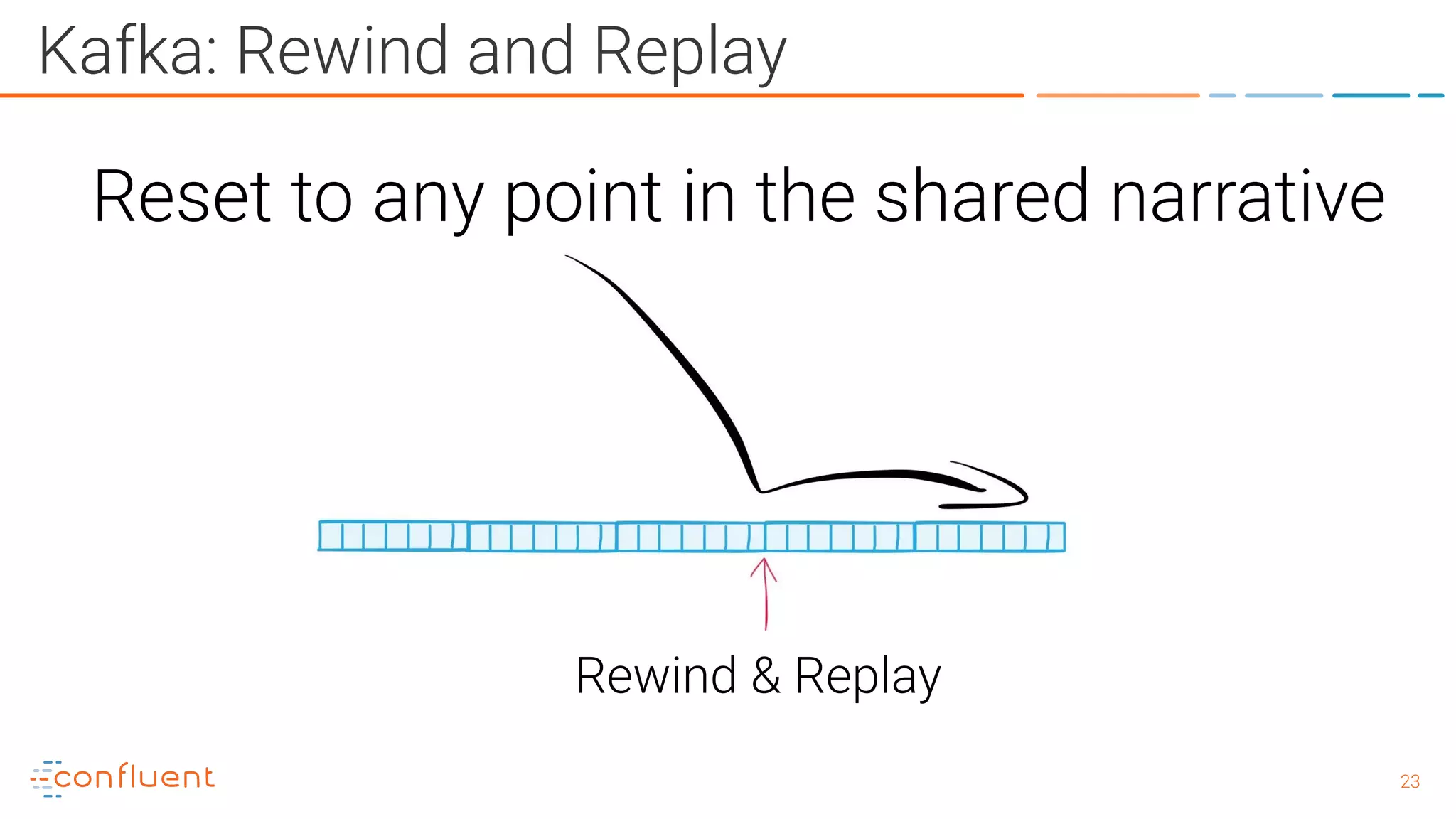
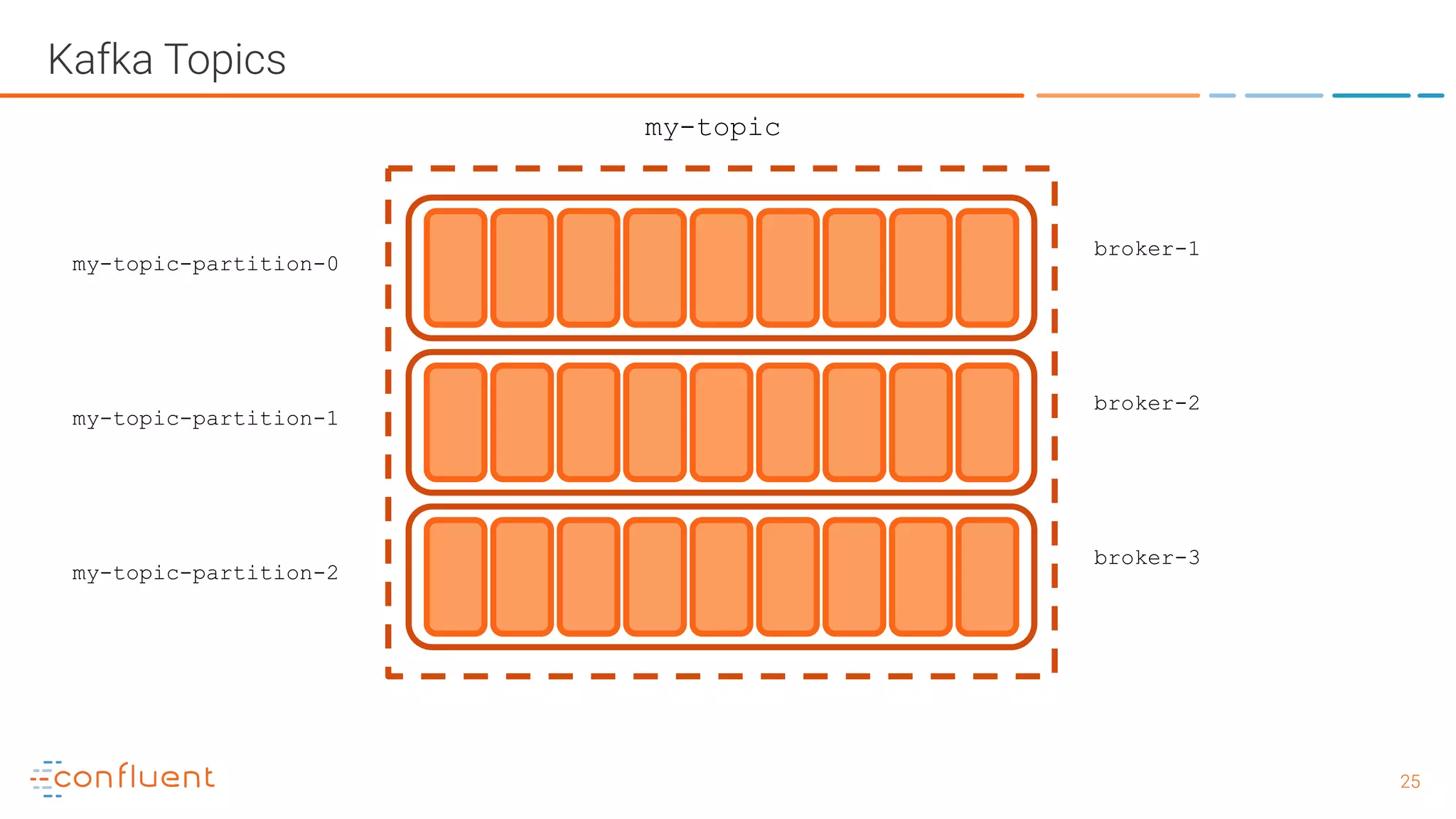
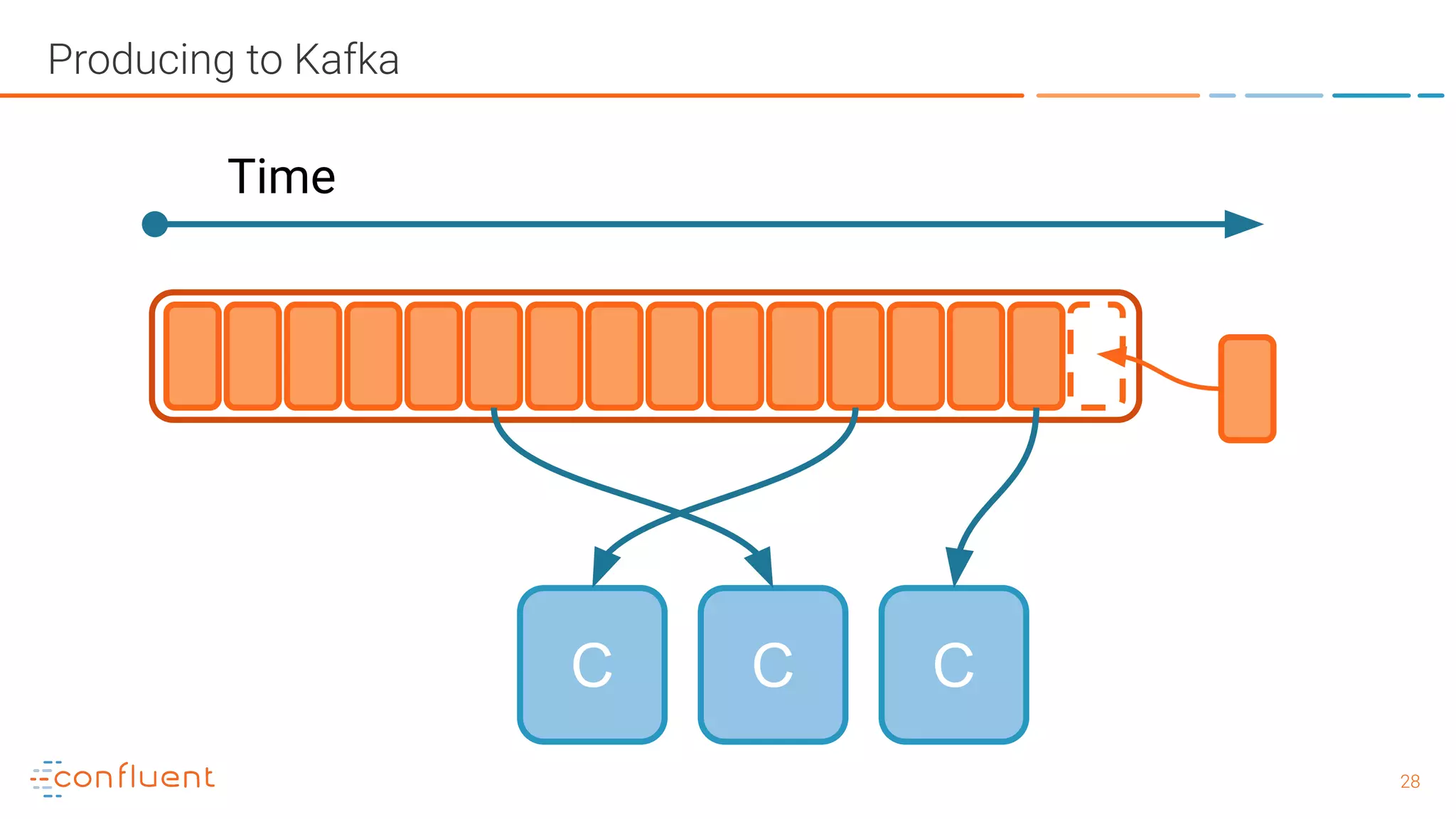
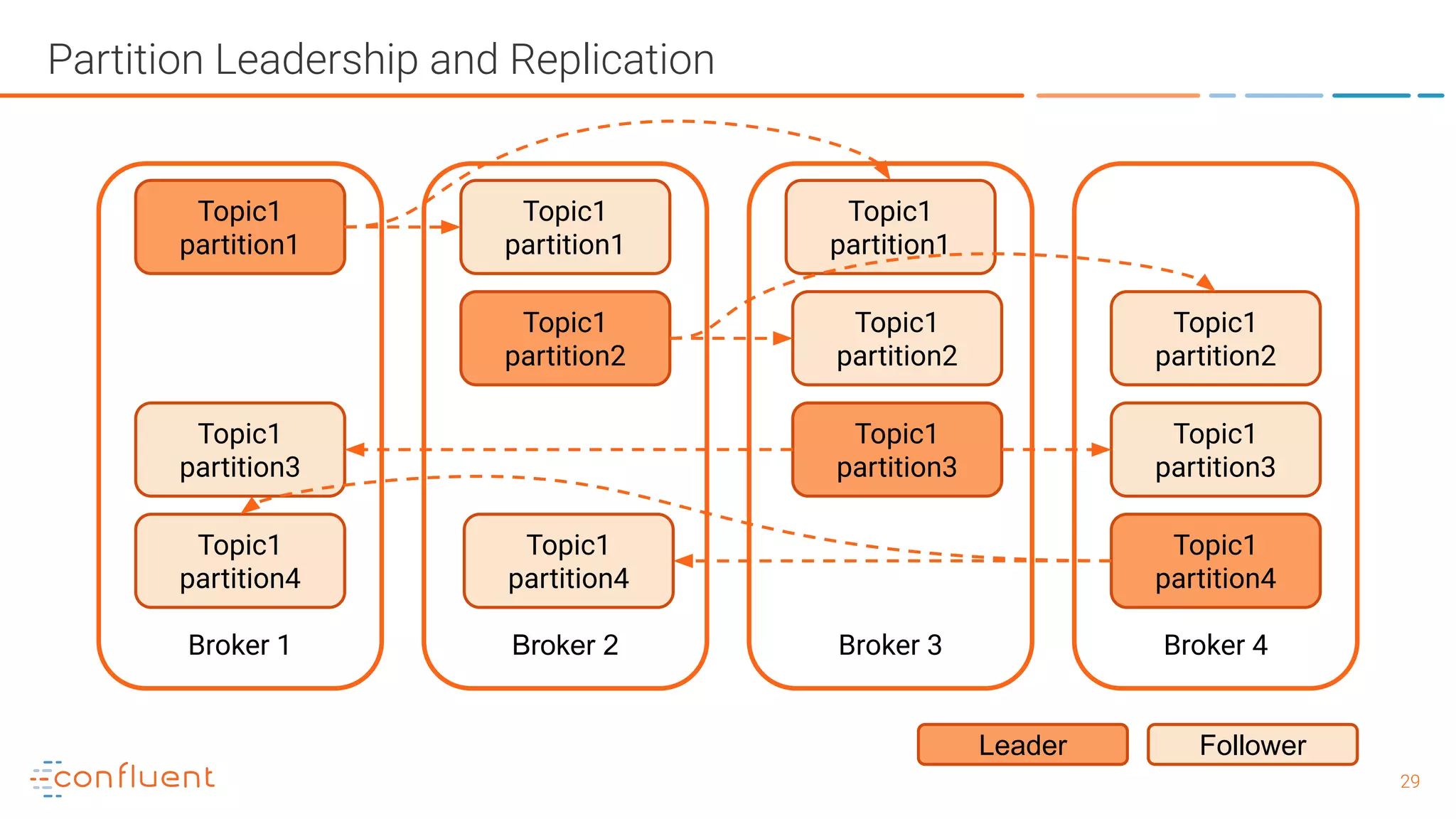
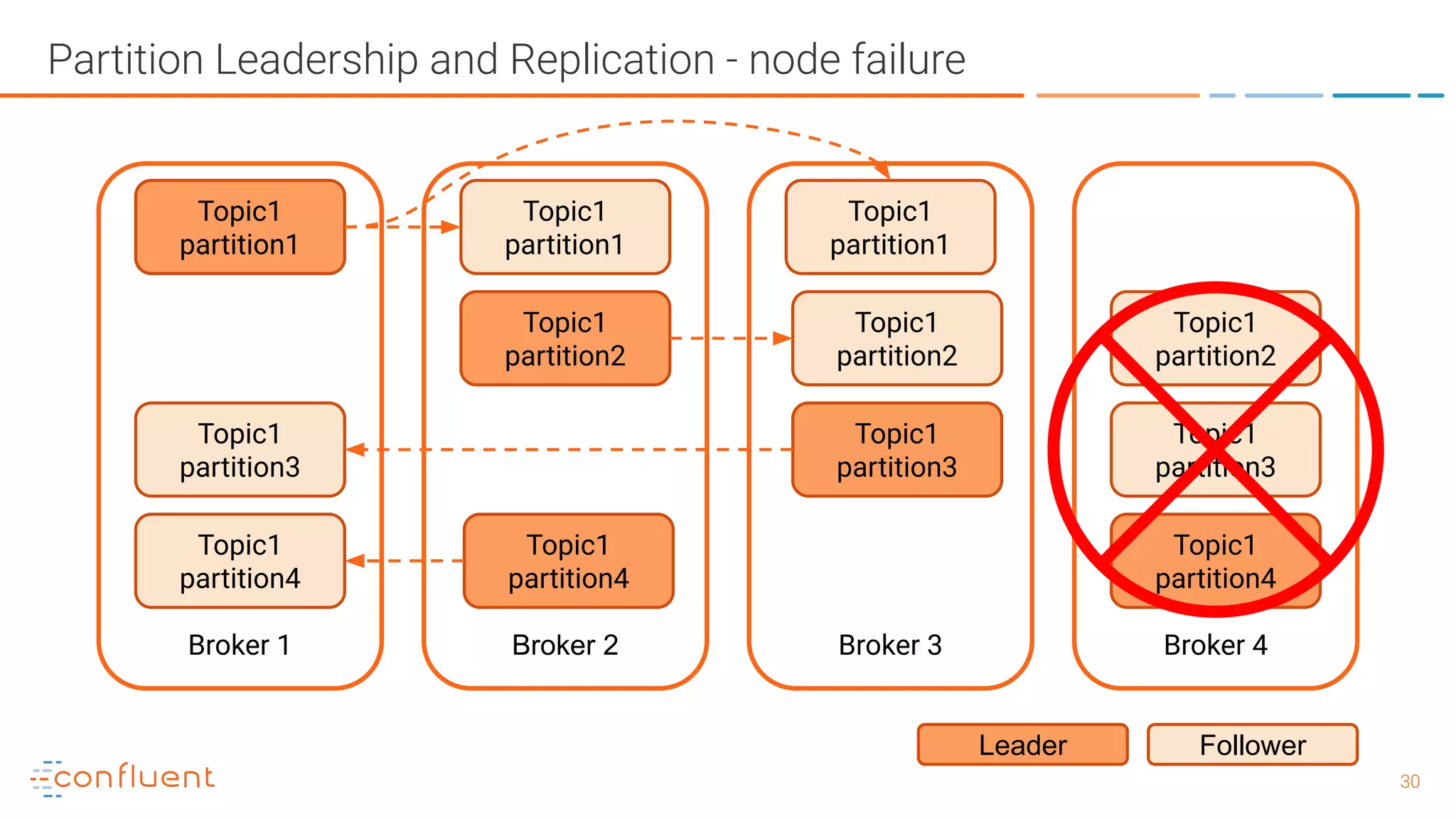
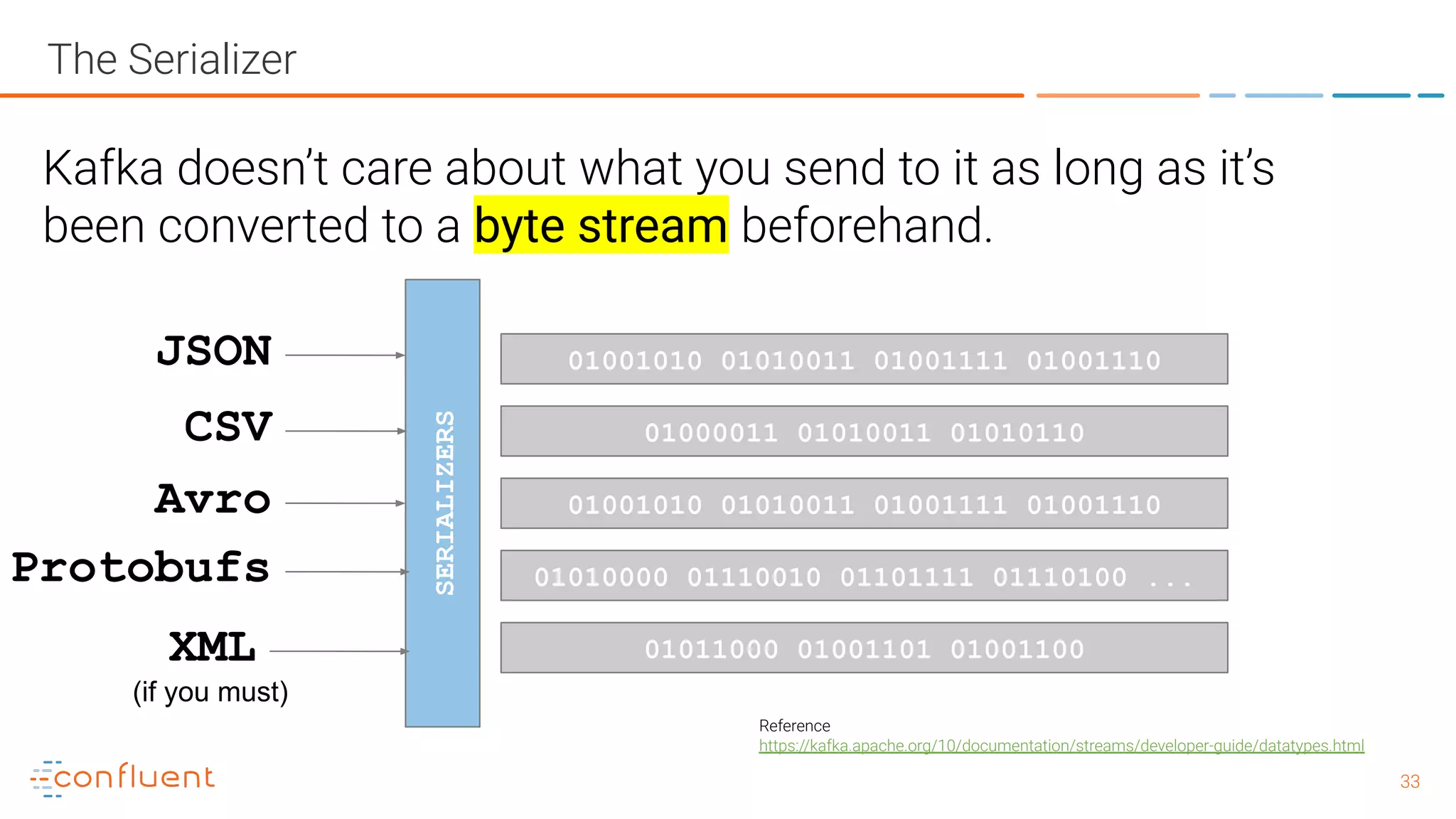
The document outlines a meetup in Bern focused on Apache Kafka and event streaming platforms, detailing the agenda and speakers such as Matthias Imsand and Gabriel Schenker. It explains the functionalities of Apache Kafka, emphasizing scalable, durable, and persistent event processing and storage. Additionally, it covers topics like producer and consumer design, schema registration, and guaranteeing message integrity.