Downloaded 106 times












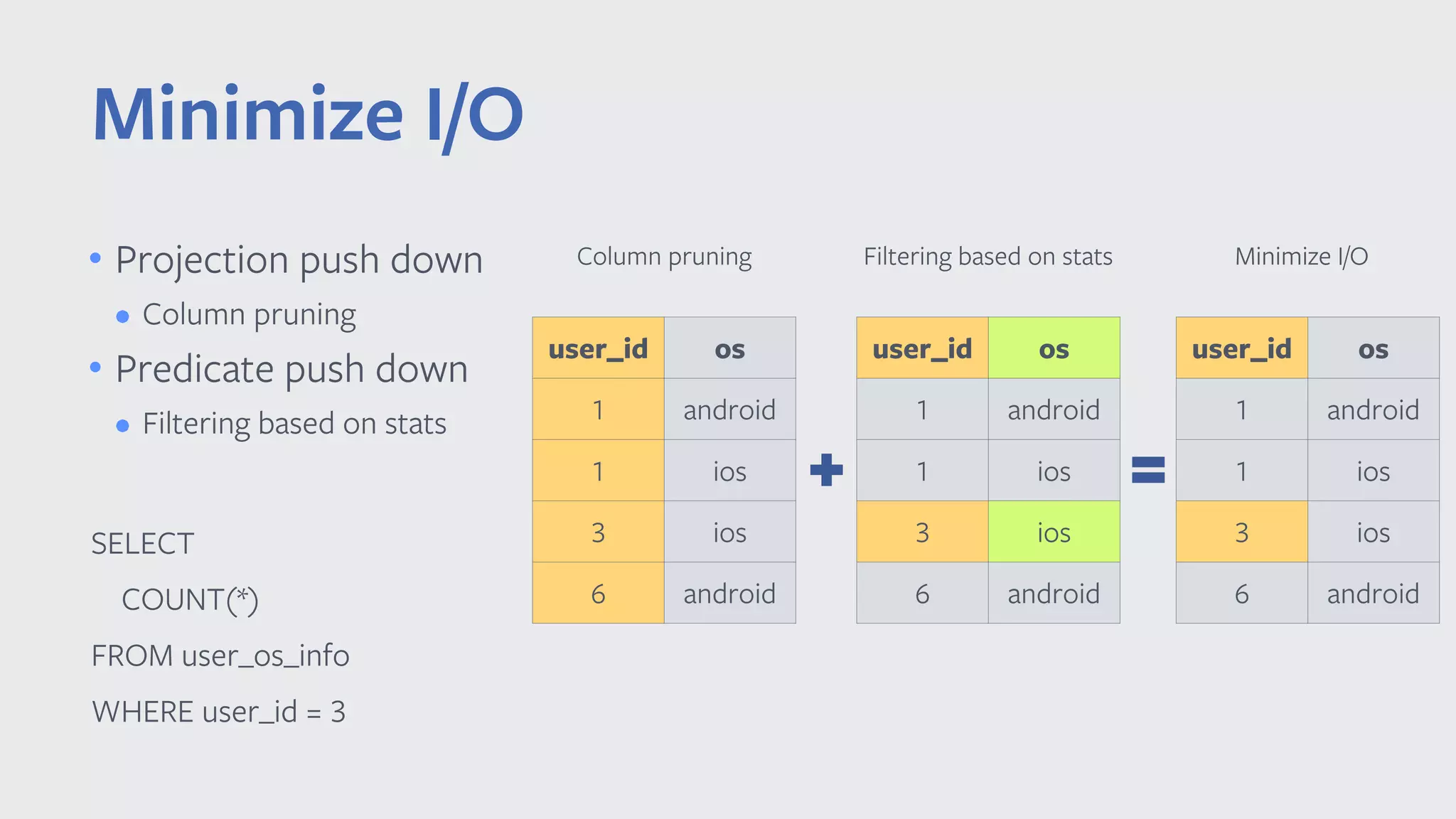







![SELECT COUNT(*) FROM user_os_info WHERE user_id = 3 Vector-at-a-time processing Orc Reader VectorizedRowBatch Orc Writer VectorizedRowBatch private void agg_doAggregateWithoutKey() { while (orc_scan_batch != null) { int numRows = orc_scan_batch.size; while (orc_scan_batch_idx < numRows) { value = orc_scan_col_0.vector[orc_scan_row_idx]; orc_scan_batch_idx++; // do aggr } nextBatch(); } } private void nextBatch() { if (orc_scan_input.hasNext()) { batch = orc_scan_input.next(); col_0 = orc_scan_batch.cols[0]; } } 1 1 3 6 VectorizedRowBatch](https://image.slidesharecdn.com/032014chenyang-190508000548/75/Vectorized-Query-Execution-in-Apache-Spark-at-Facebook-22-2048.jpg)
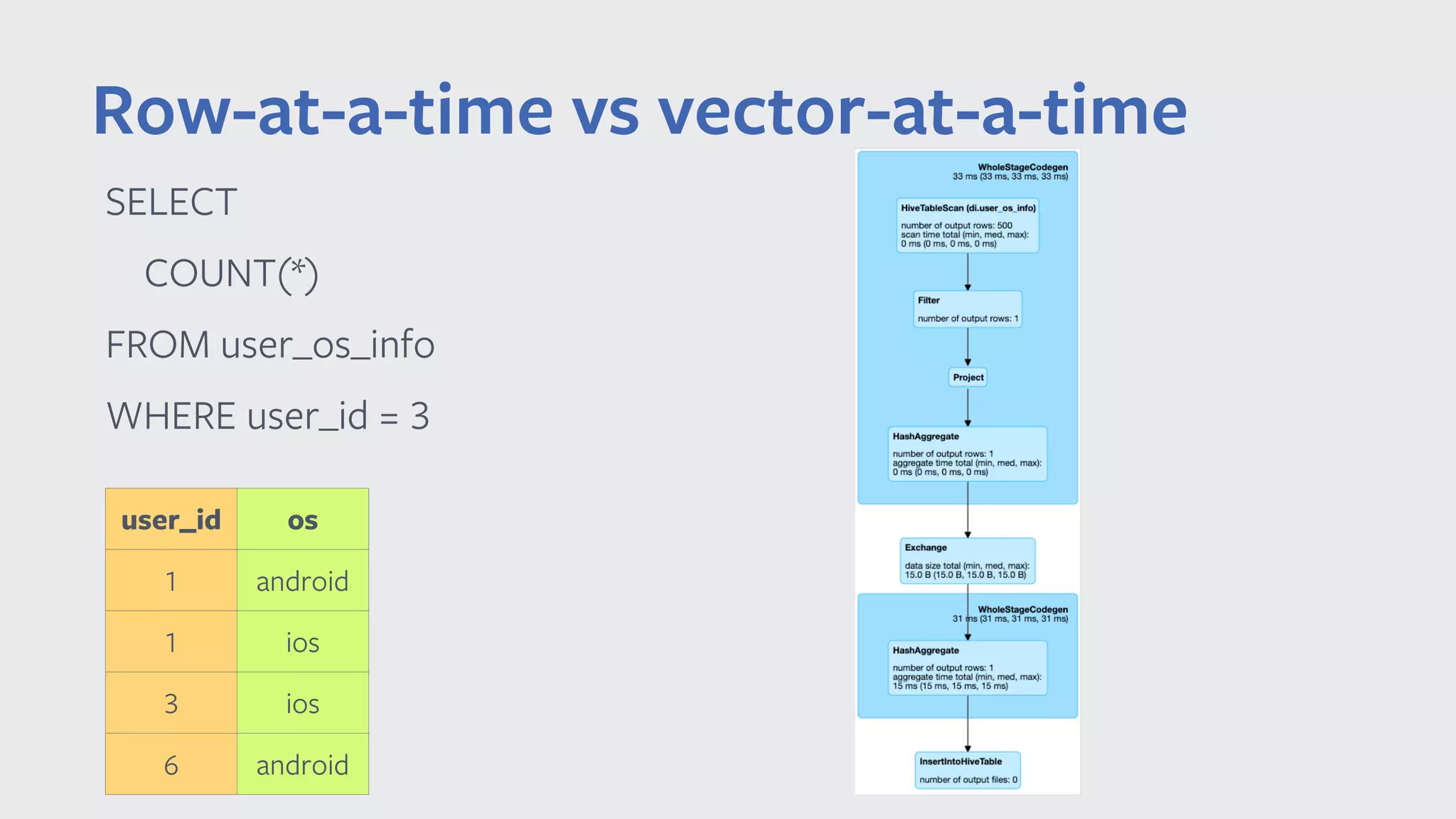
![Row-at-a-time vs vector-at-a-time private void agg_doAggregateWithoutKey() { while (inputadapter_input.hasNext()) { row = inputadapter_input.next(); value = inputadapter_row.getLong(0); // do aggr } } private void agg_doAggregateWithoutKey() { while (orc_scan_batch != null) { int numRows = orc_scan_batch.size; while (orc_scan_batch_idx < numRows) { value = col_0.vector[orc_scan_row_idx]; orc_scan_batch_idx++; // do aggr } nextBatch(); } } private void nextBatch() { if (orc_scan_input.hasNext()) { batch = orc_scan_input.next(); col_0 = orc_scan_batch.cols[0]; } } • Lower overhead per row • Avoid virtual function dispatch cost per row • Better cache locality • Avoid unnecessary copy/conversion • No need to convert between OrcLazyRow and UnsafeRow Row-at-a-time processing Vector-at-a-time processing](https://image.slidesharecdn.com/032014chenyang-190508000548/75/Vectorized-Query-Execution-in-Apache-Spark-at-Facebook-23-2048.jpg)
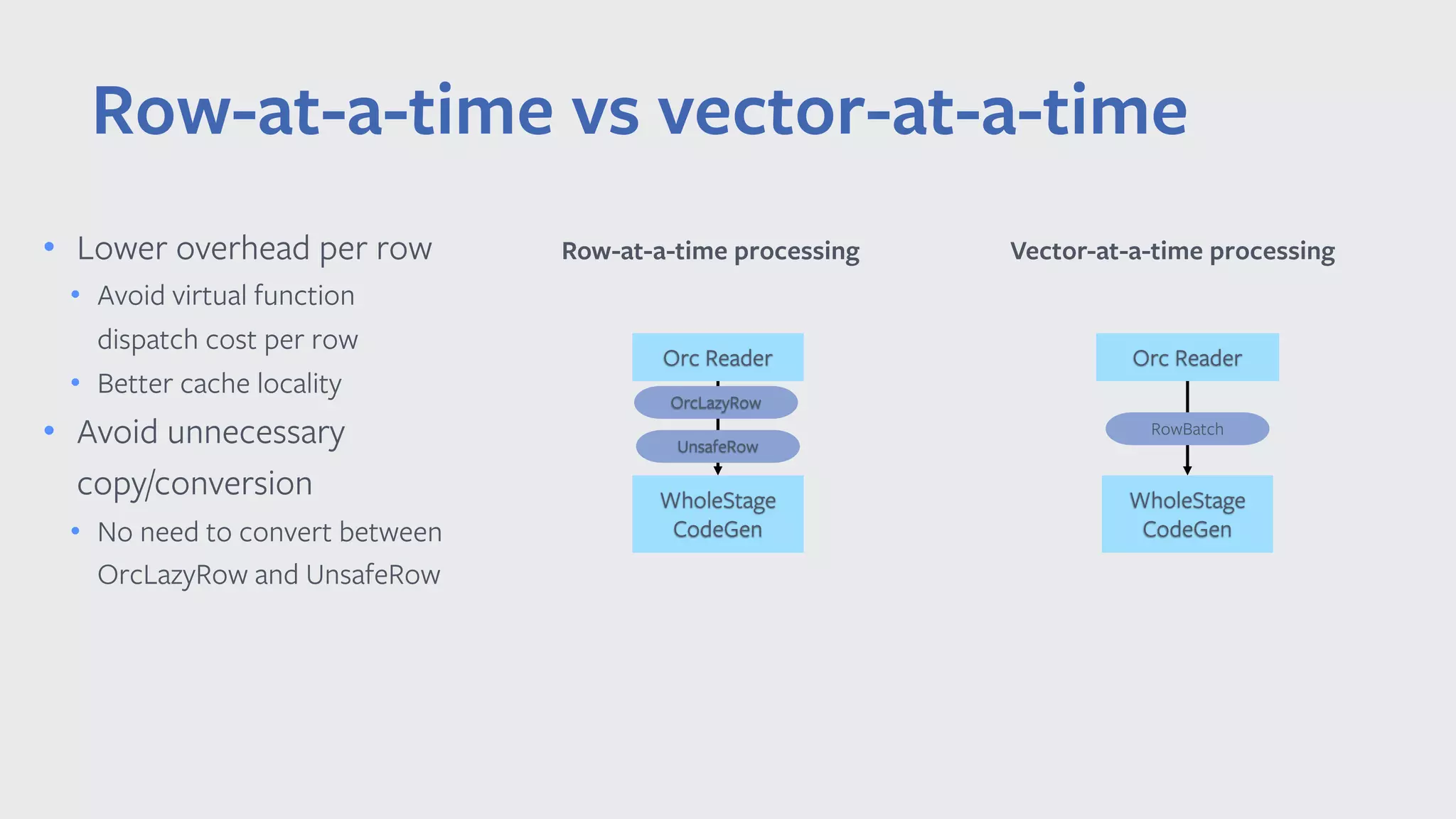



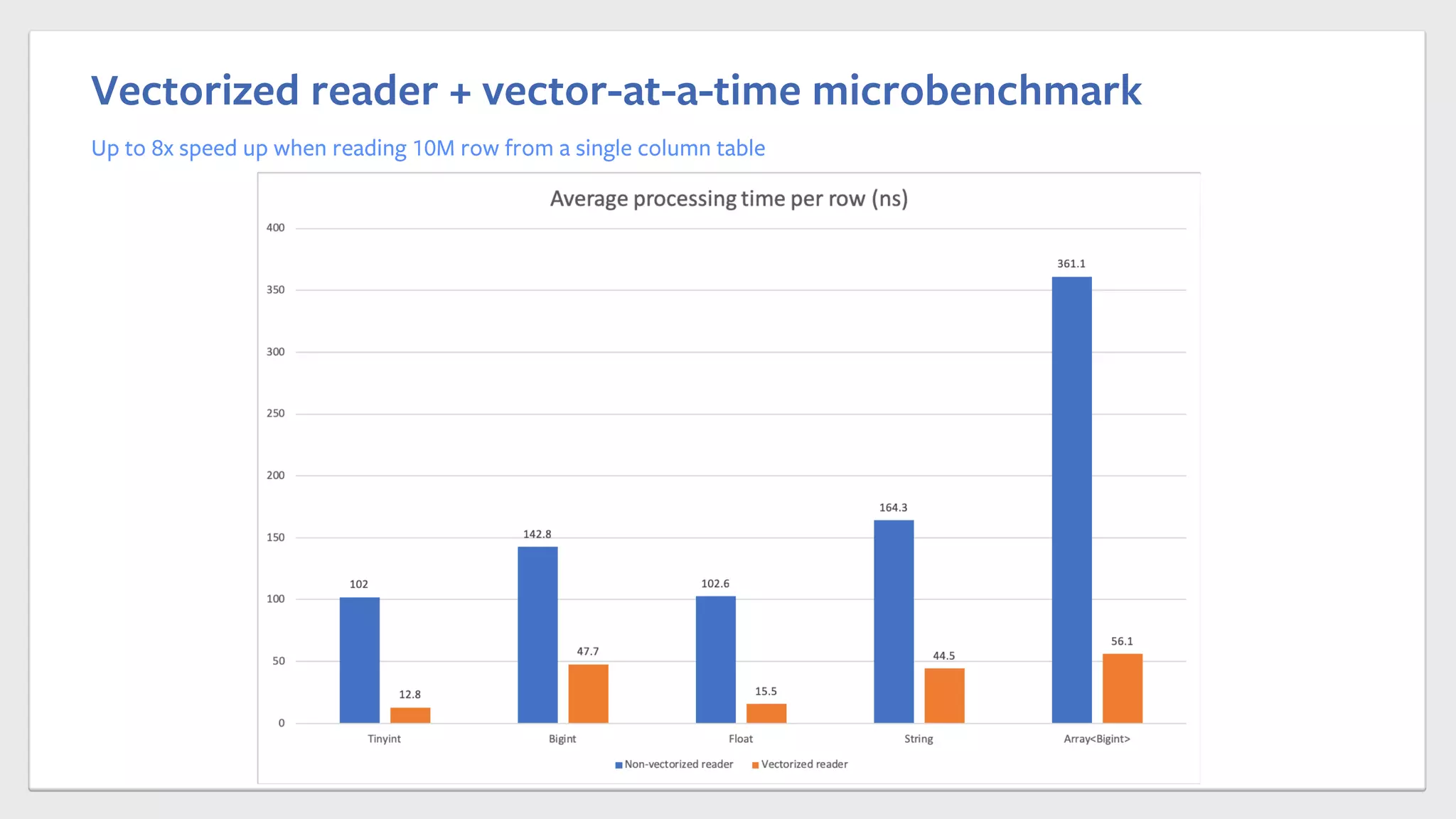
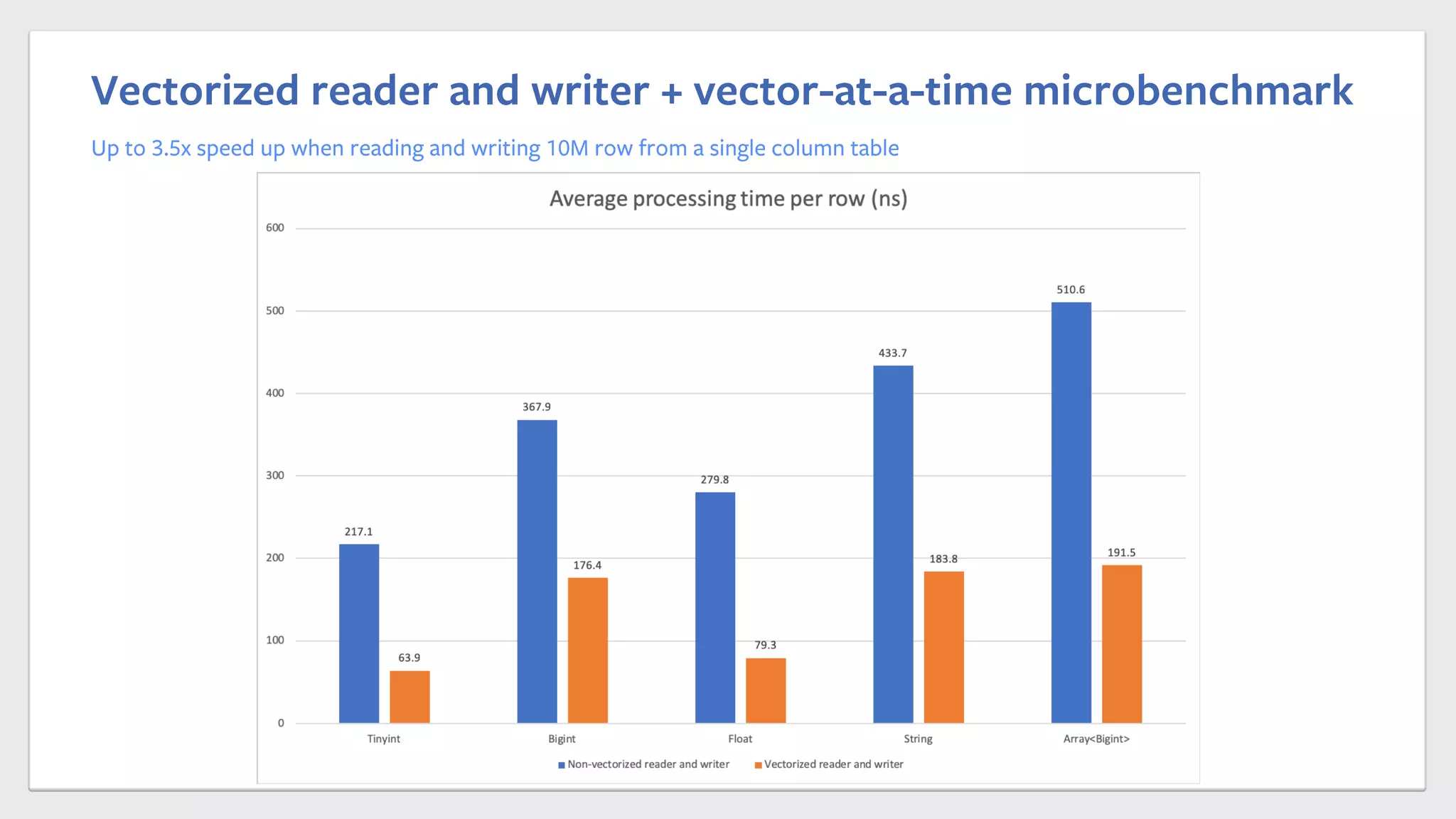





This document summarizes Chen Yang's presentation on vectorized query execution in Apache Spark at Facebook. The key points are: 1) Spark is the largest SQL query engine at Facebook and uses columnar formats like ORC to improve storage efficiency. 2) Vectorized processing can improve performance over row-at-a-time processing by reducing per-row overhead and improving cache locality. 3) Facebook has implemented a vectorized ORC reader and writer in Spark that shows up to 8x speedup on microbenchmarks compared to the row-at-a-time approach.