Downloaded 11 times


















The document discusses best practices for enabling speculative execution in large-scale platforms, particularly in the context of Apache Spark at LinkedIn. It outlines configuration parameters, motivation for improvements, and metrics for analyzing speculative execution's impact on task performance and resource utilization. The findings indicate that tailored speculative execution parameters can enhance performance, reduce job completion times, and lead to more predictable system behavior.
Overview of speculative execution and agenda outlining motivation, enhancements, metrics, and future work.
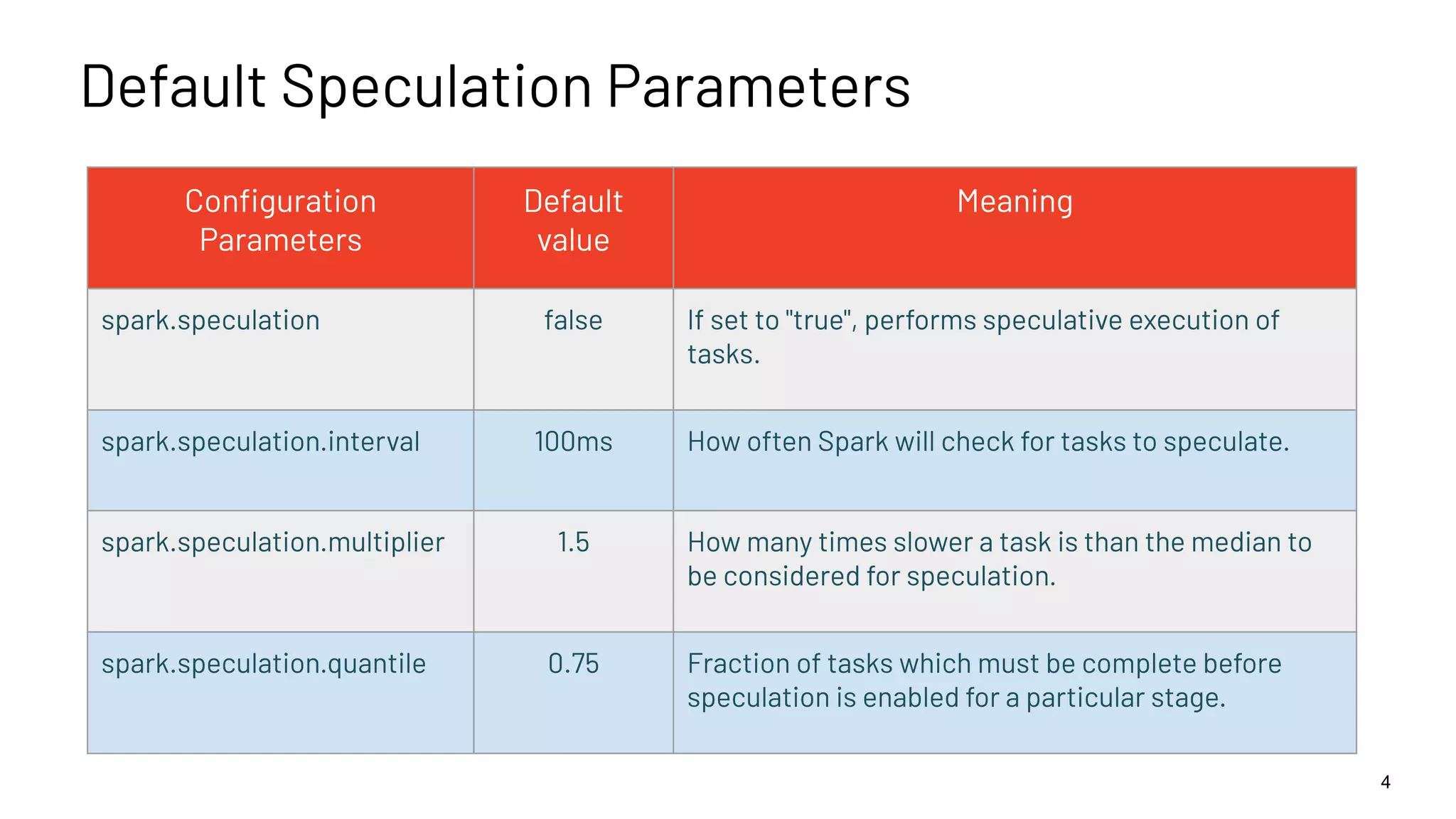
Speculative execution mechanism explained with default configuration parameters for managing tasks.
Motivation for speculation includes speeding up tasks, analyzing impacts of data skews, and introducing configuration to limit wasted resources.
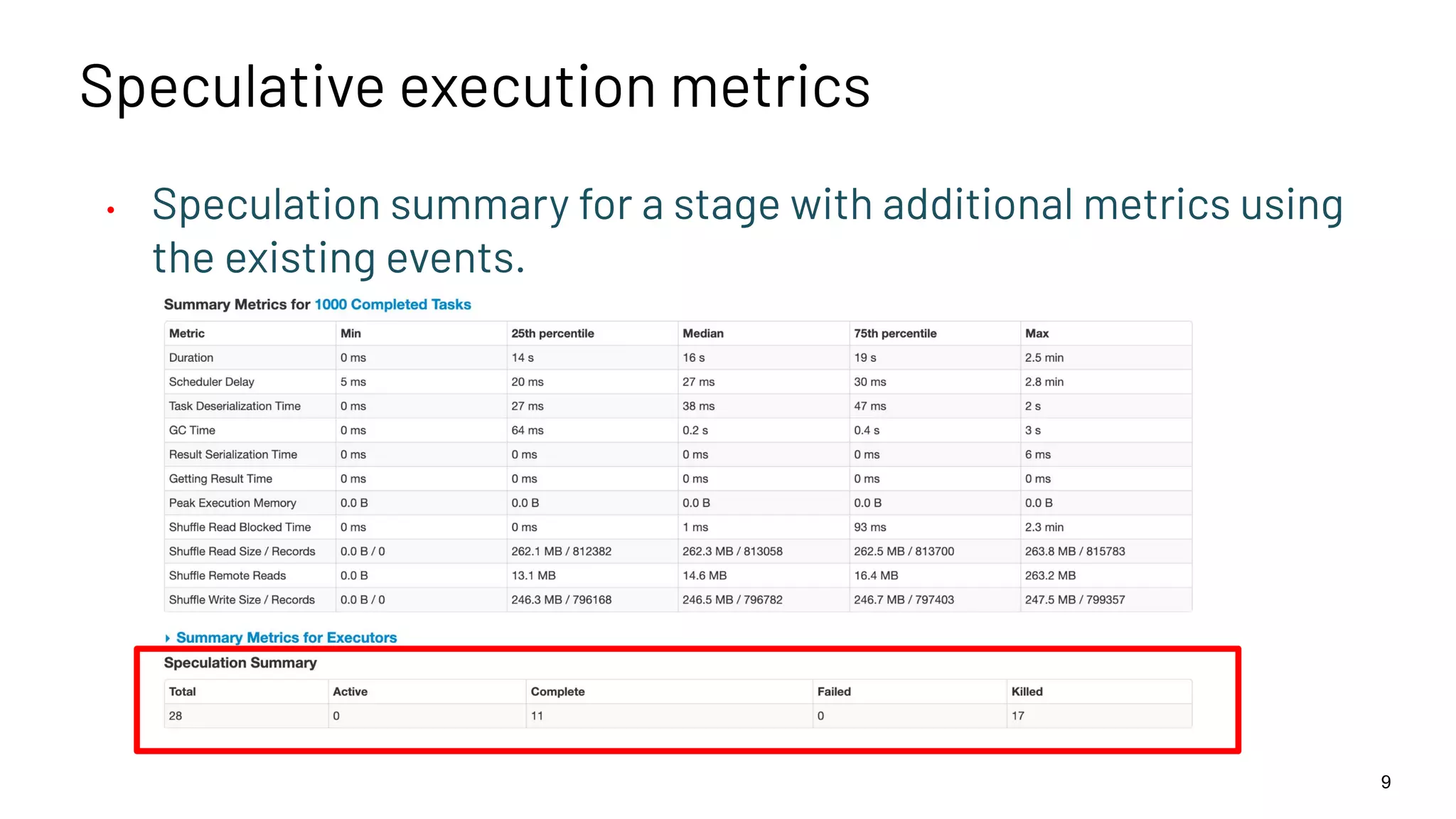
Need for additional metrics to analyze speculative execution's effectiveness; summary metrics for tasks are proposed.
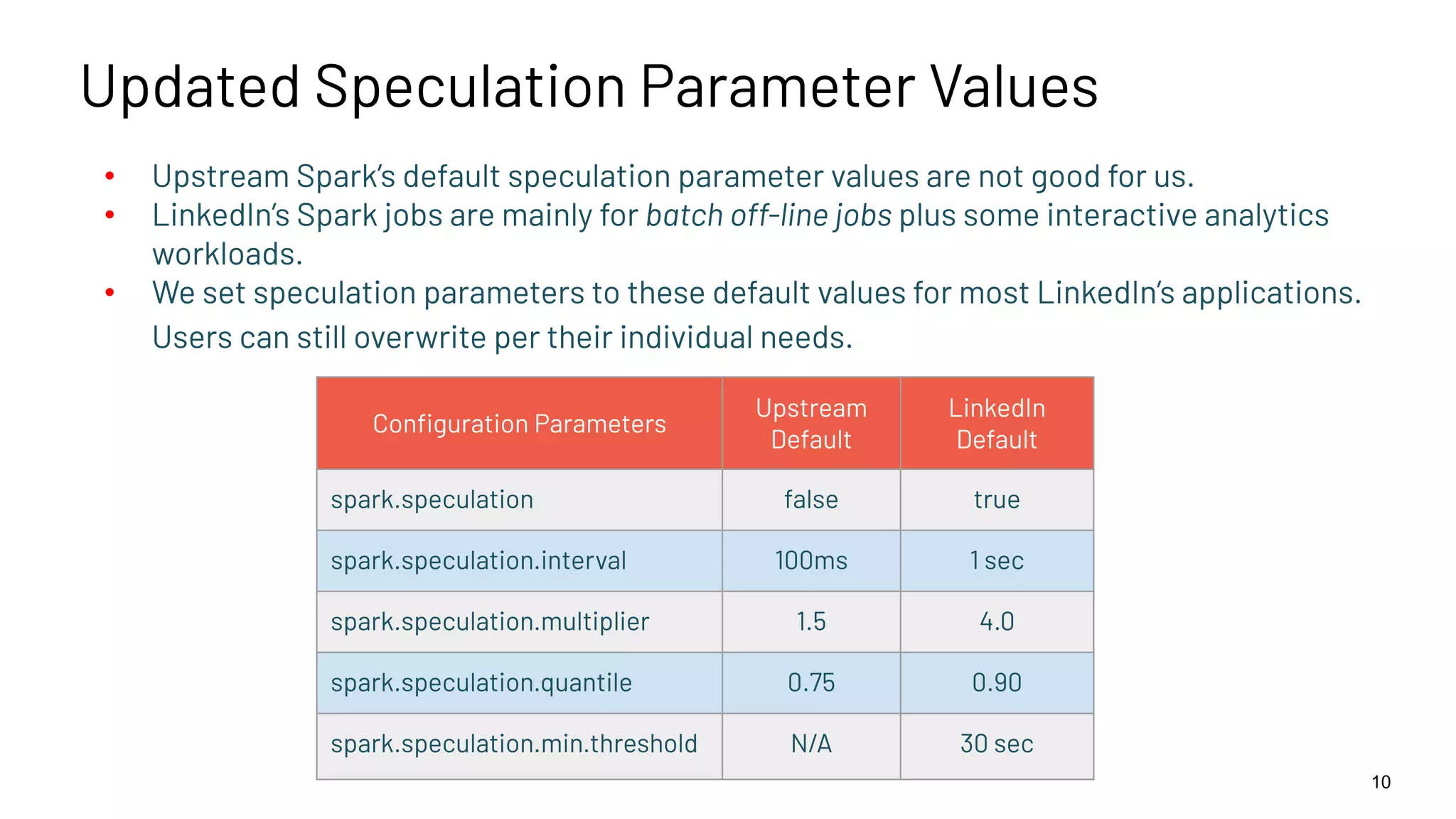
LinkedIn's custom speculative execution parameters set to better optimize performance for batch jobs.
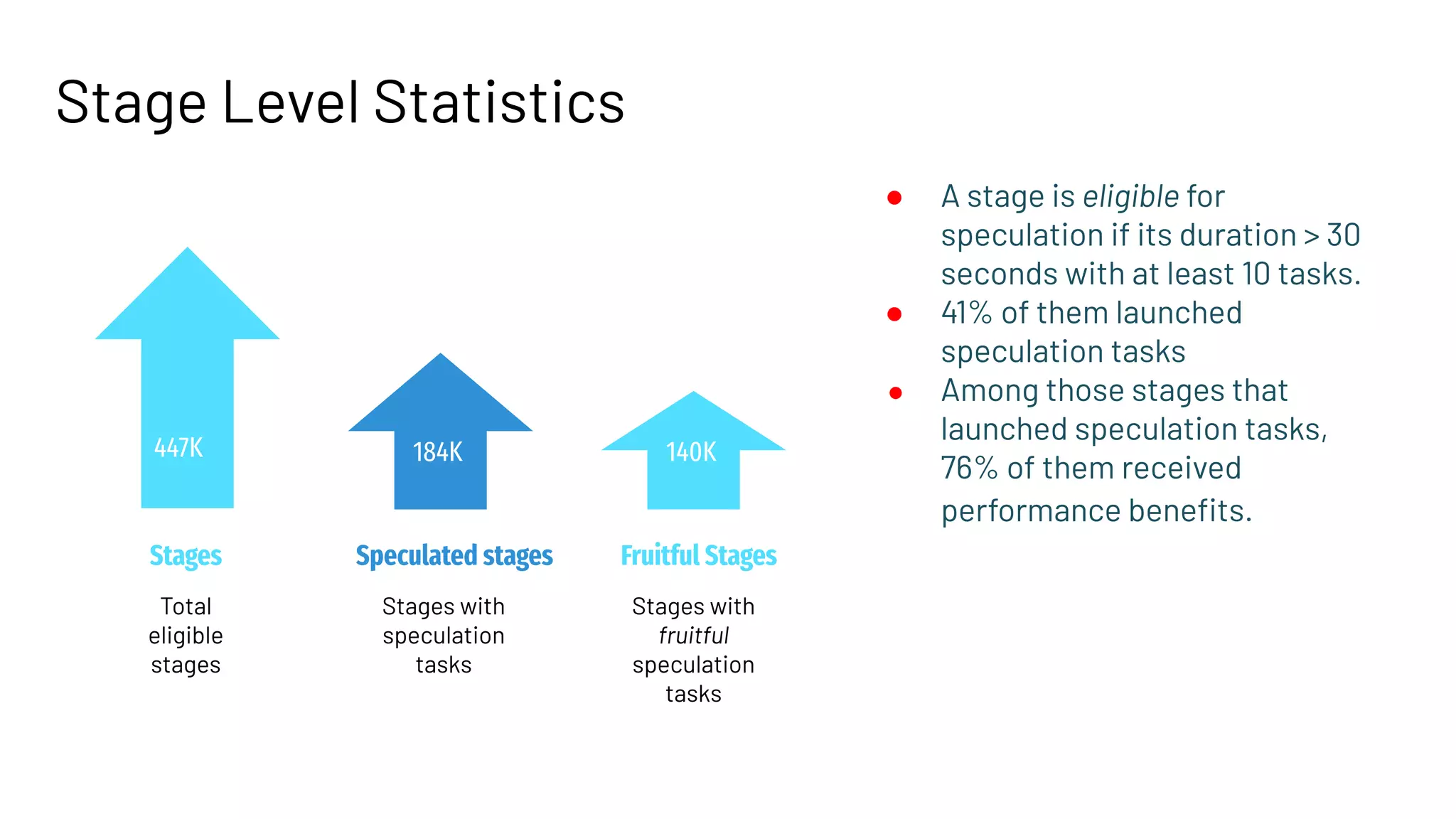
Analysis of performance gains vs. overhead in a multi-tenant environment using metrics from over 40K applications.
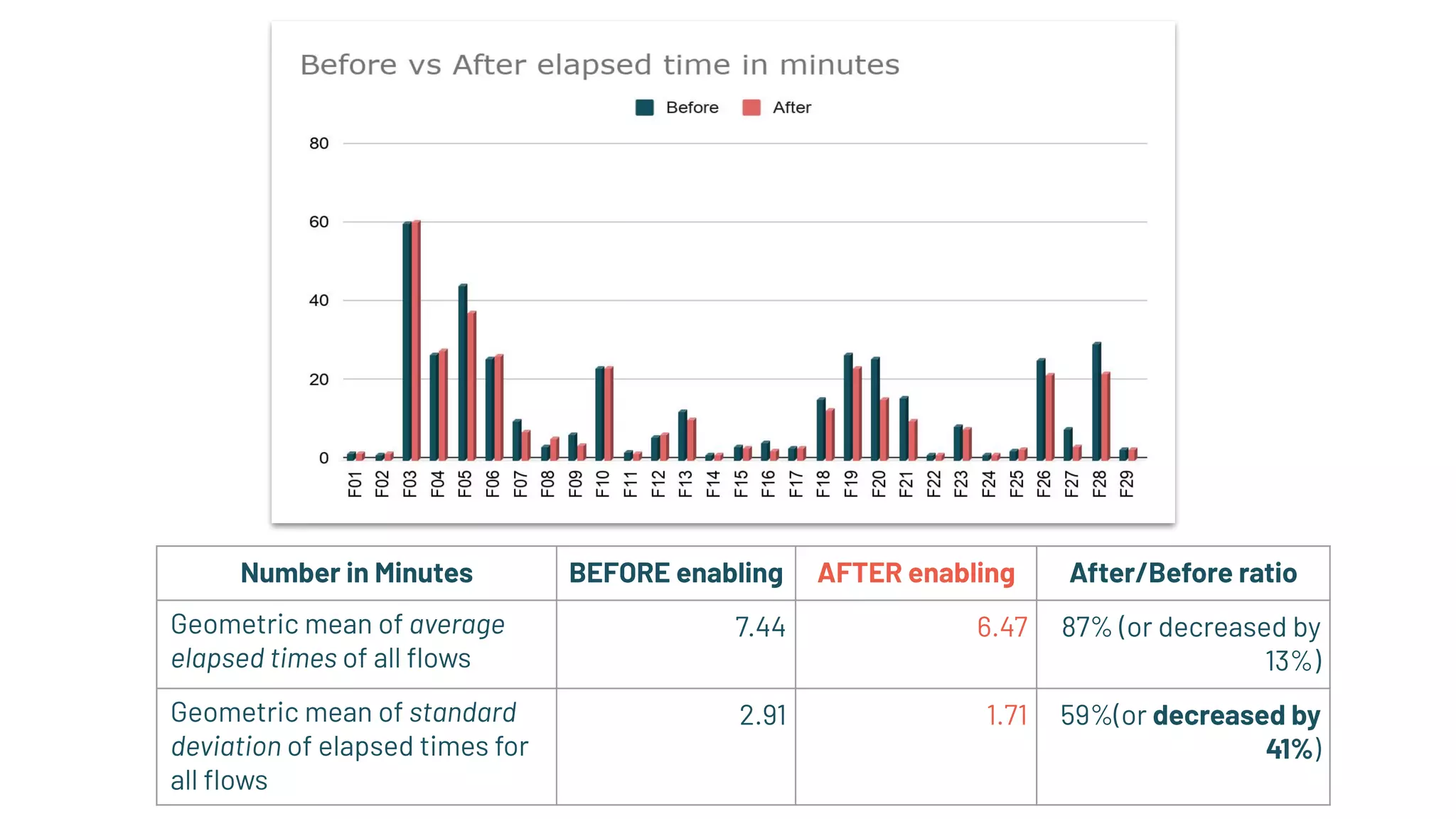
Impact analysis on mission-critical applications before and after speculation enabling, showing time decrease.
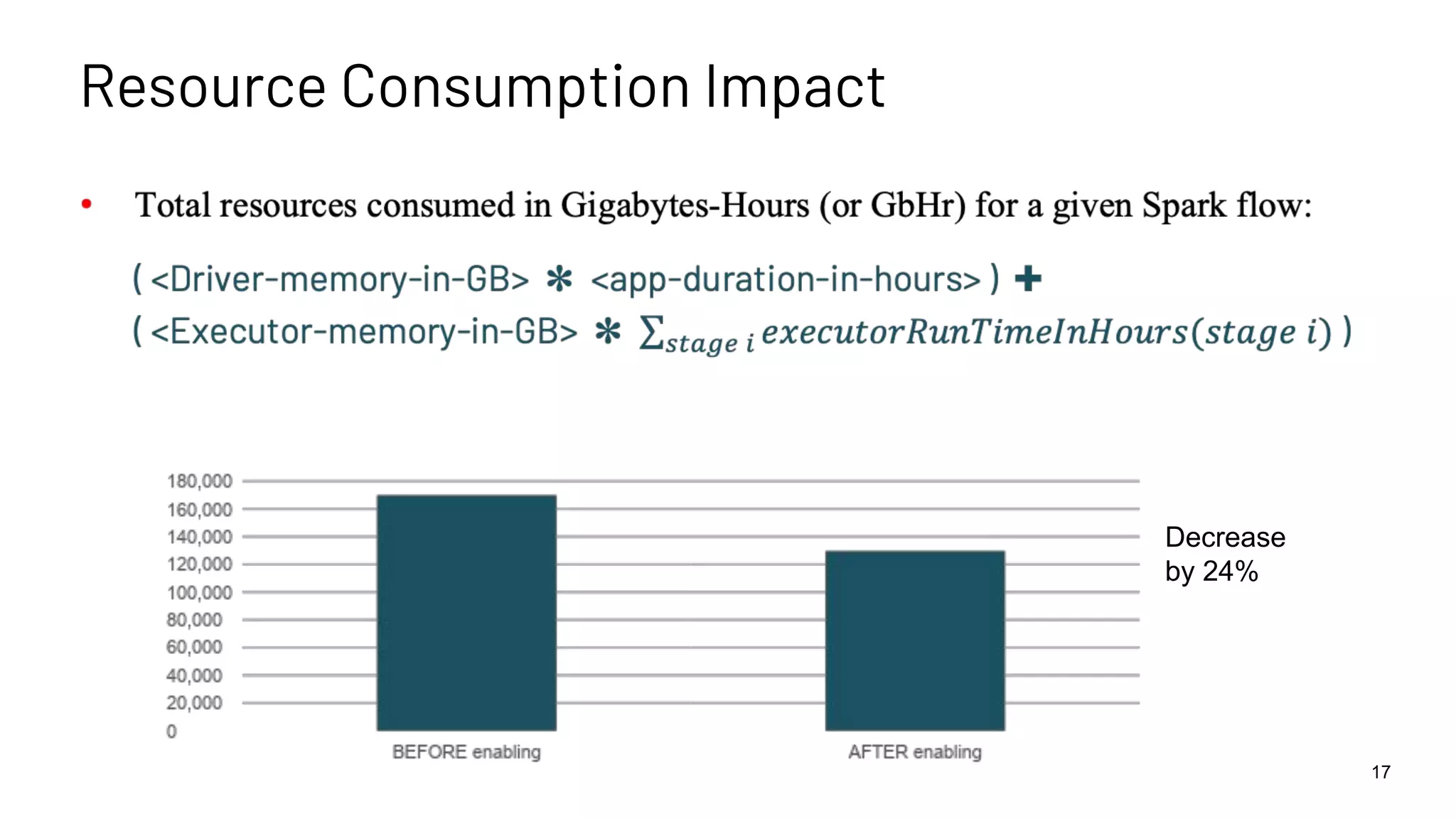
Impact analysis indicating a 24% decrease in resource consumption after implementing speculation.
Guidance on when speculation can assist or hinder tasks affected by data skews or overloaded services.
Summary of speculation enhancement benefits and future work to improve Spark's intelligence in task management.
Expressing gratitude to contributors and encouraging feedback on the session.