Download as PDF, PPTX



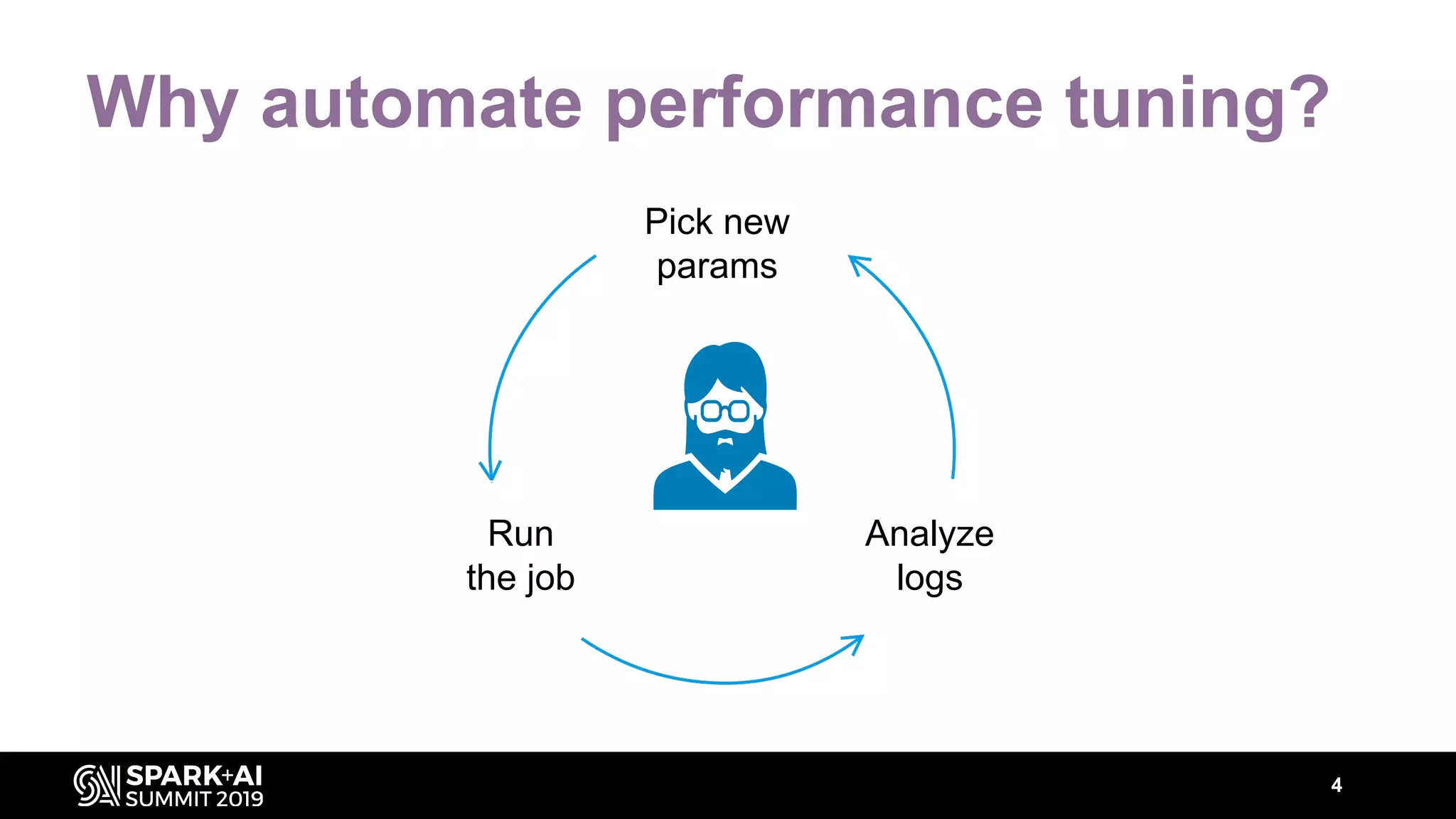
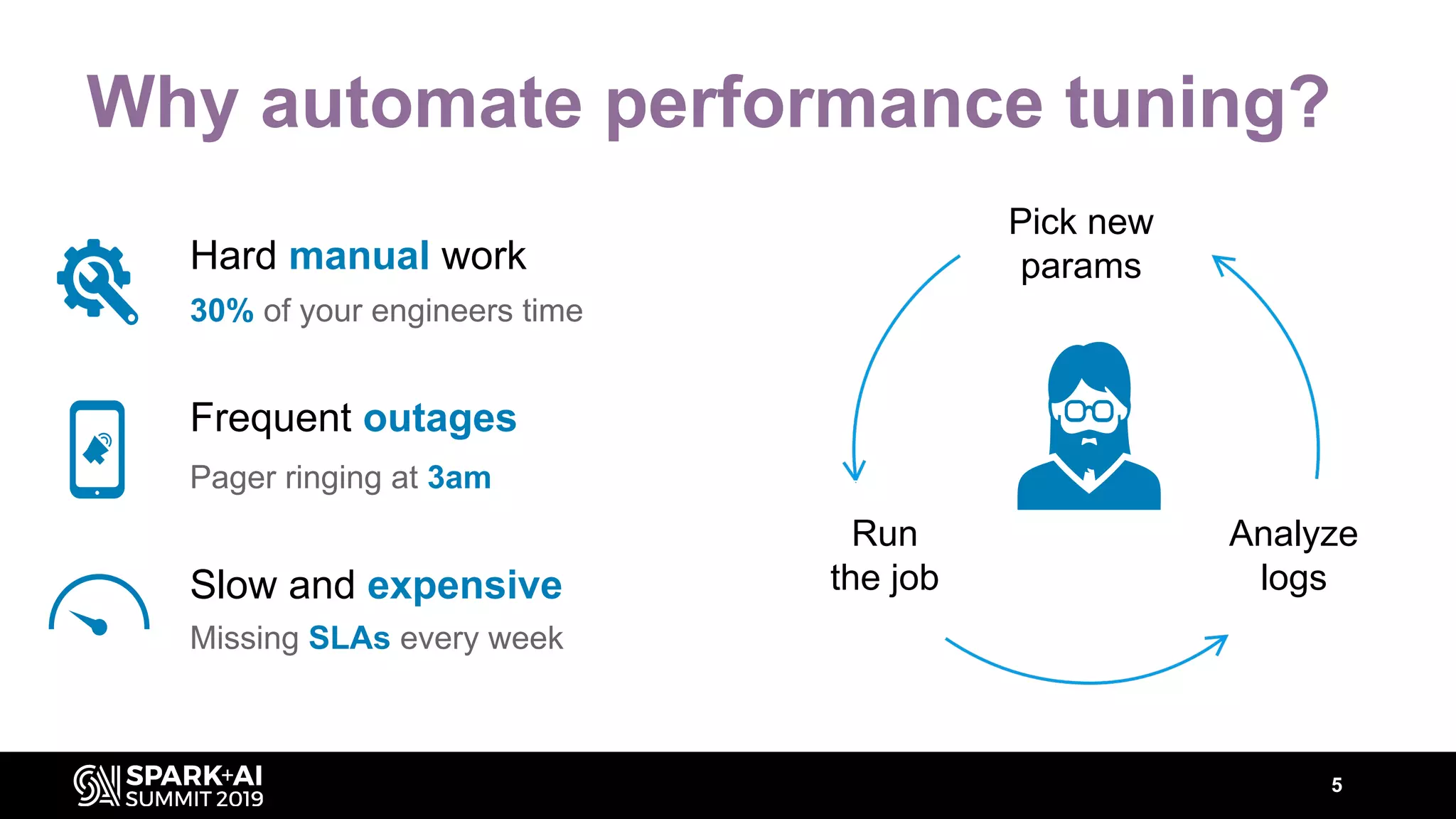


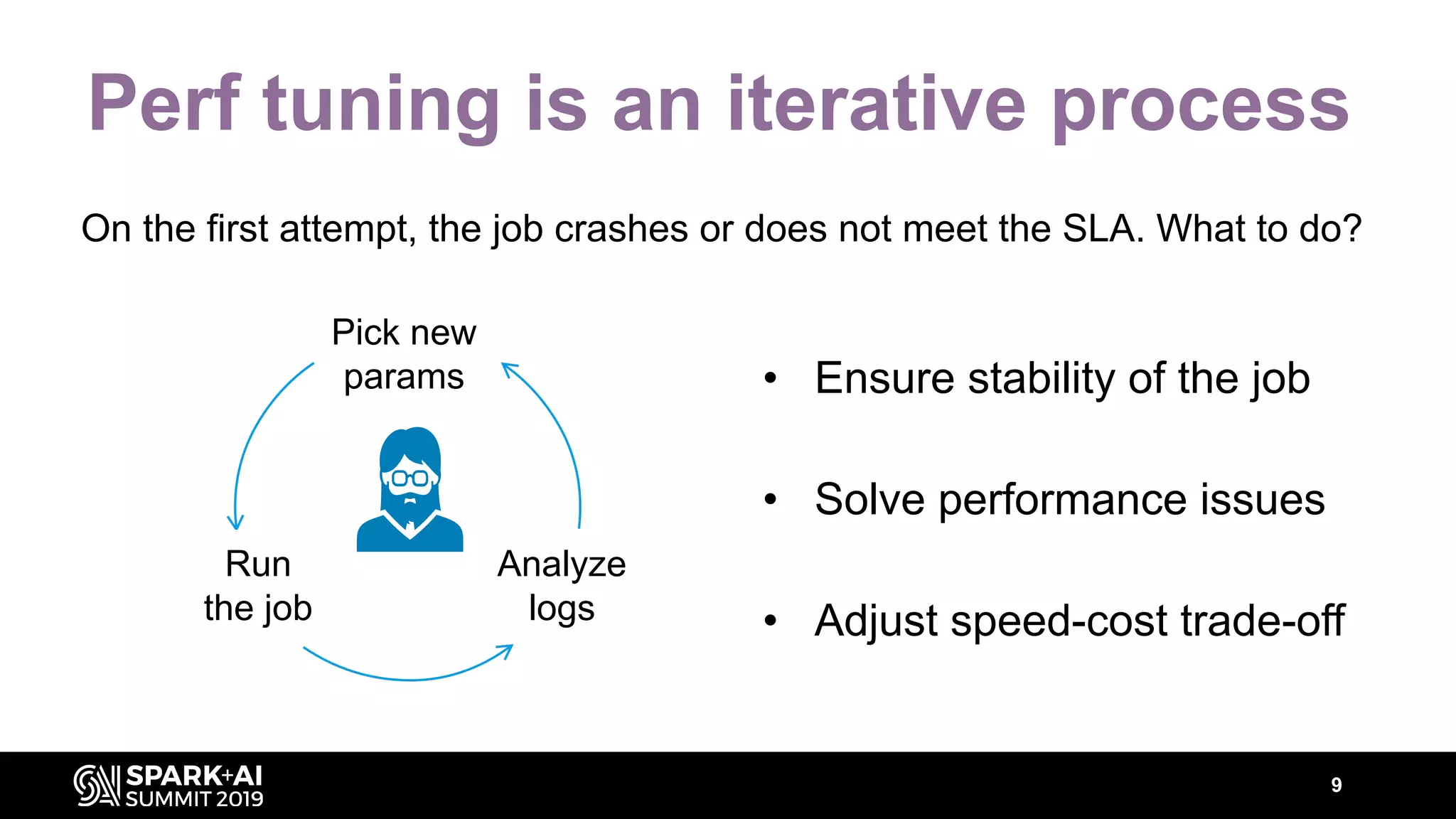
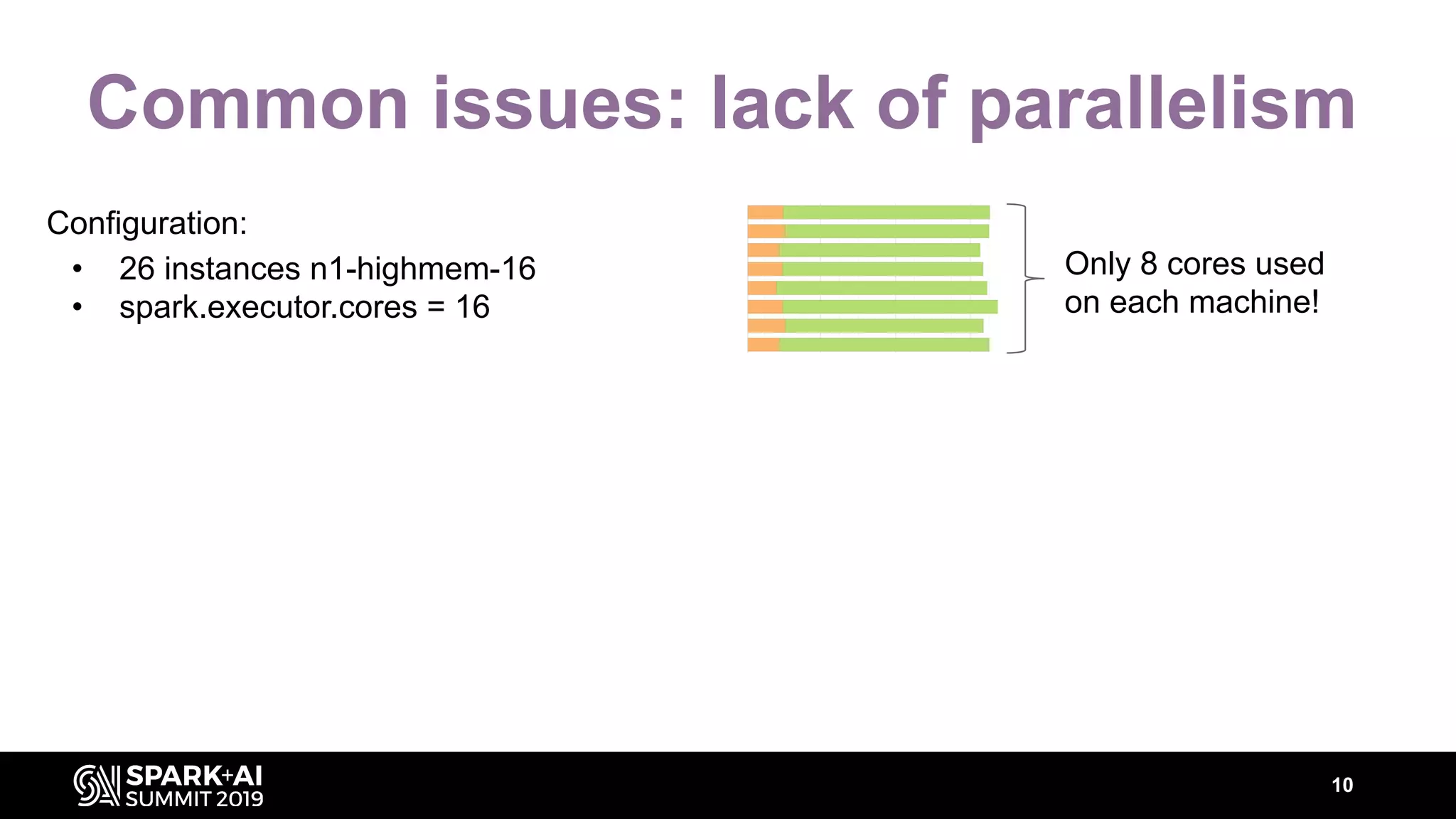
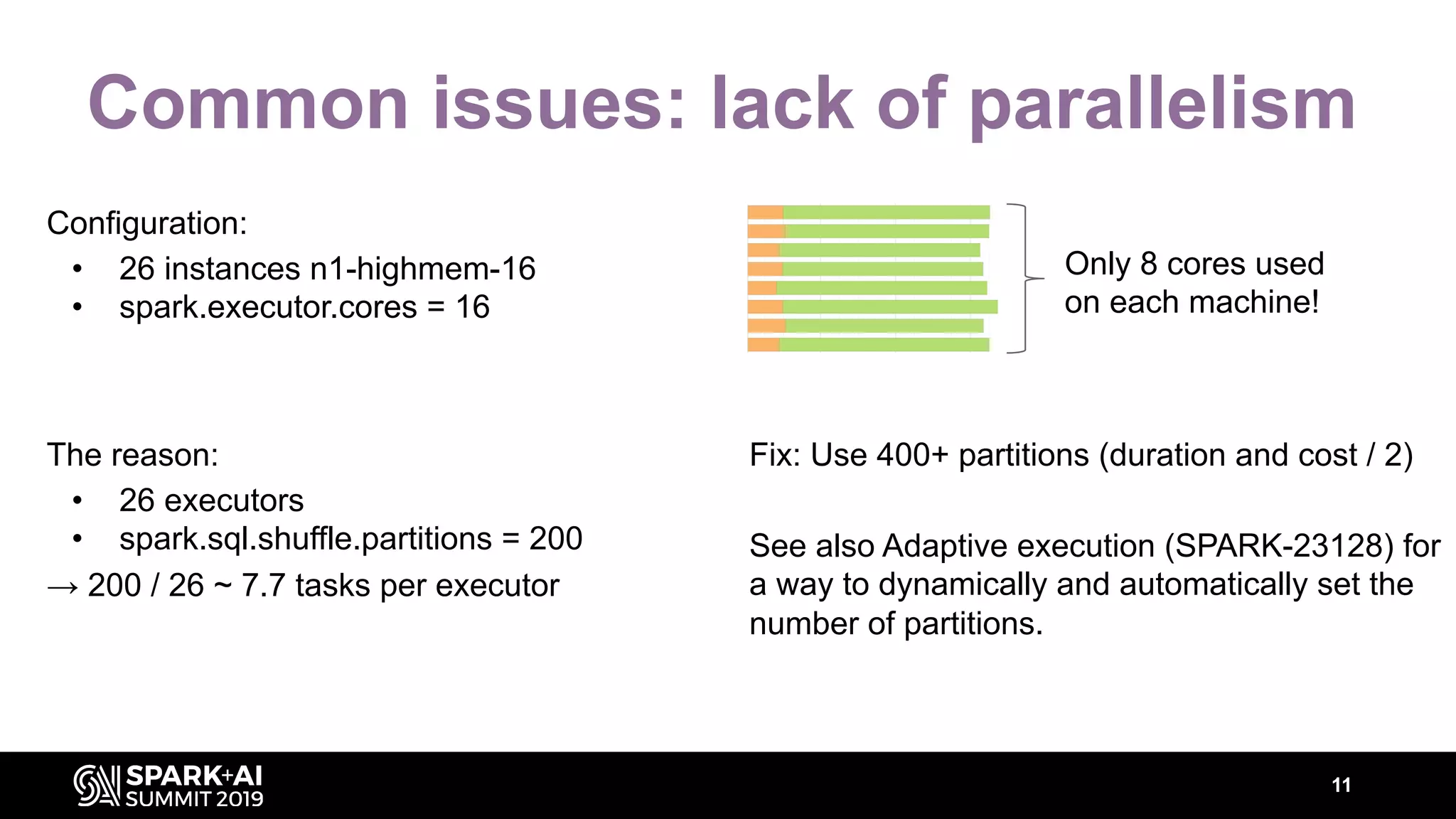

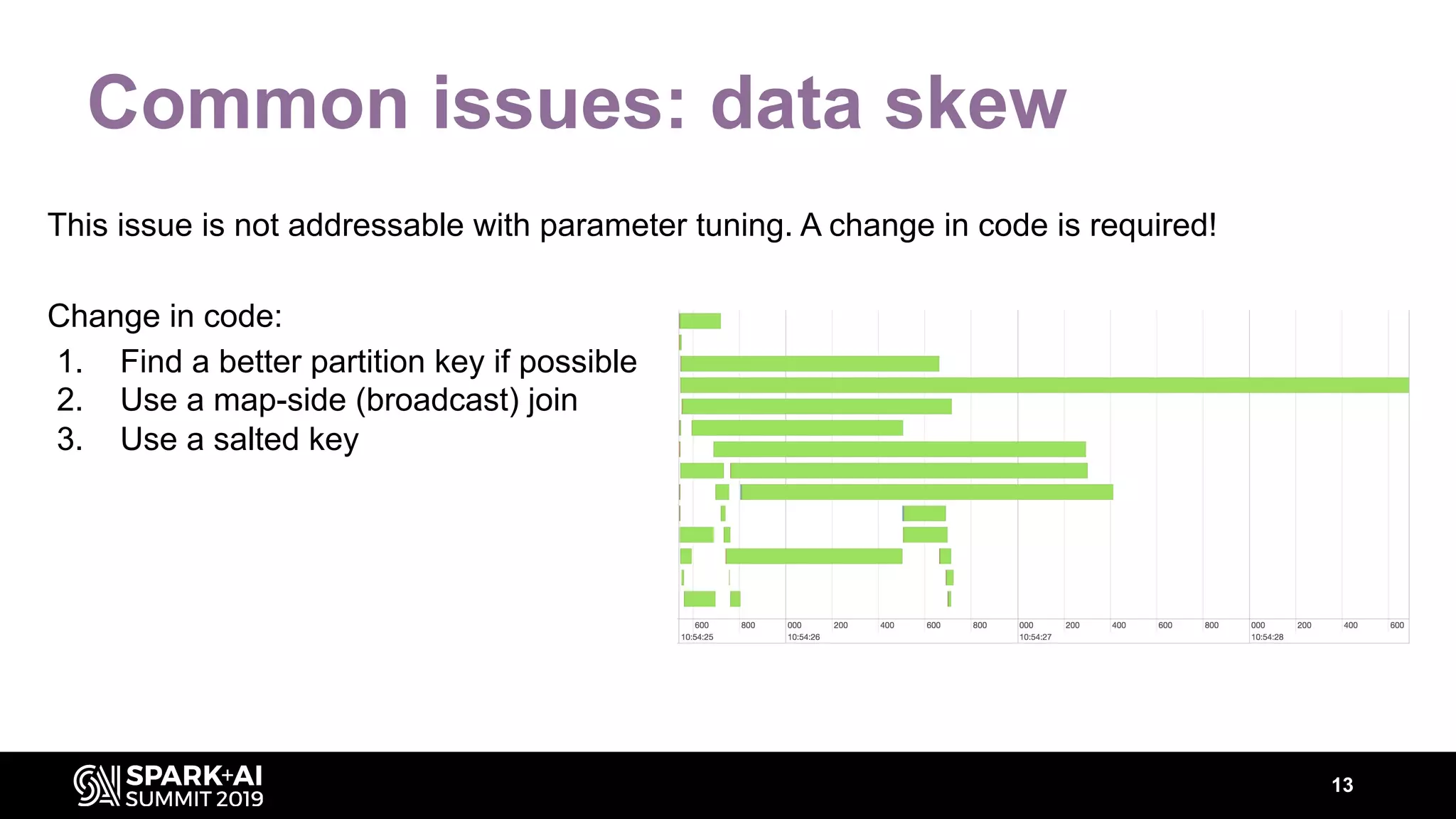

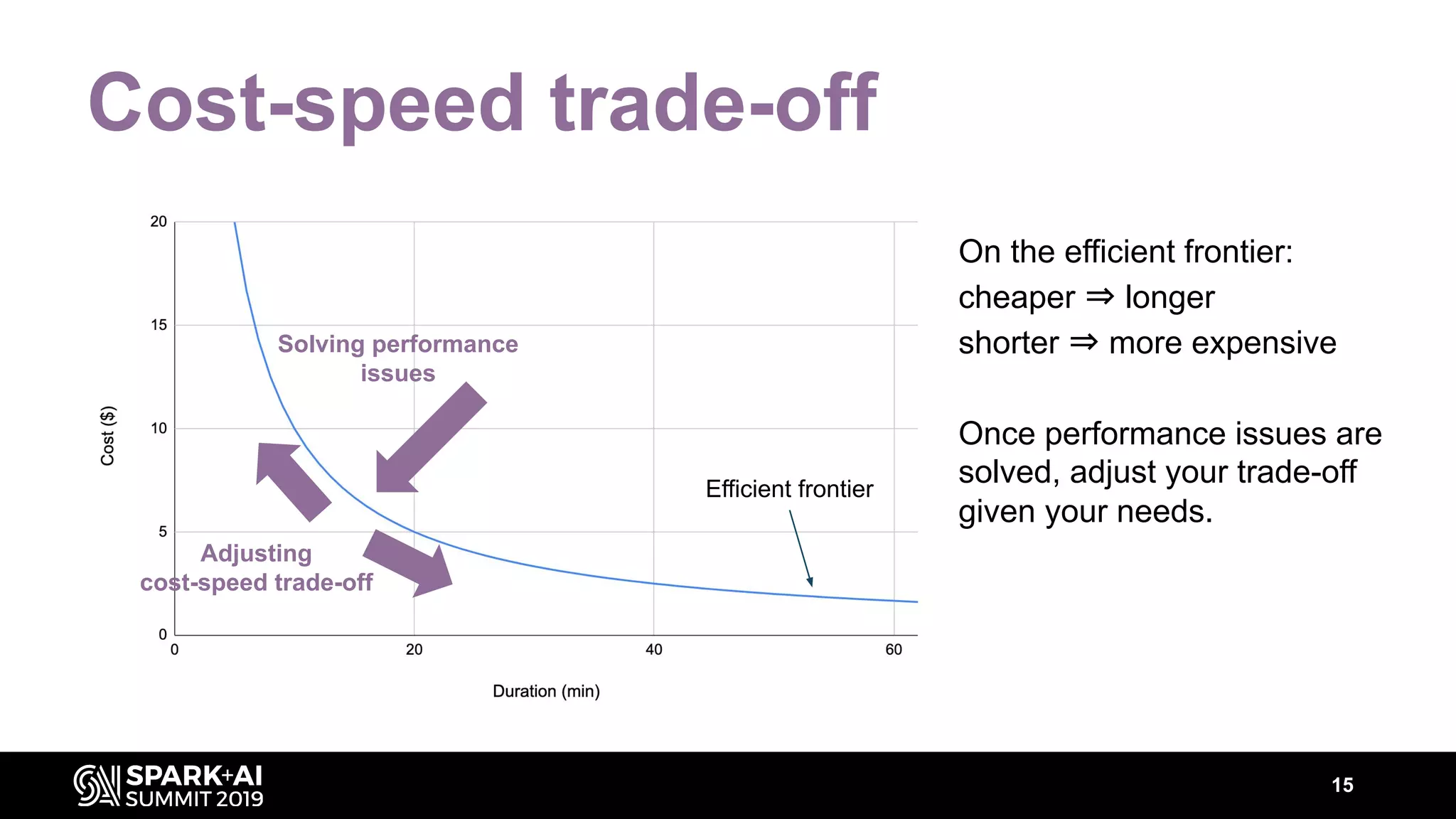
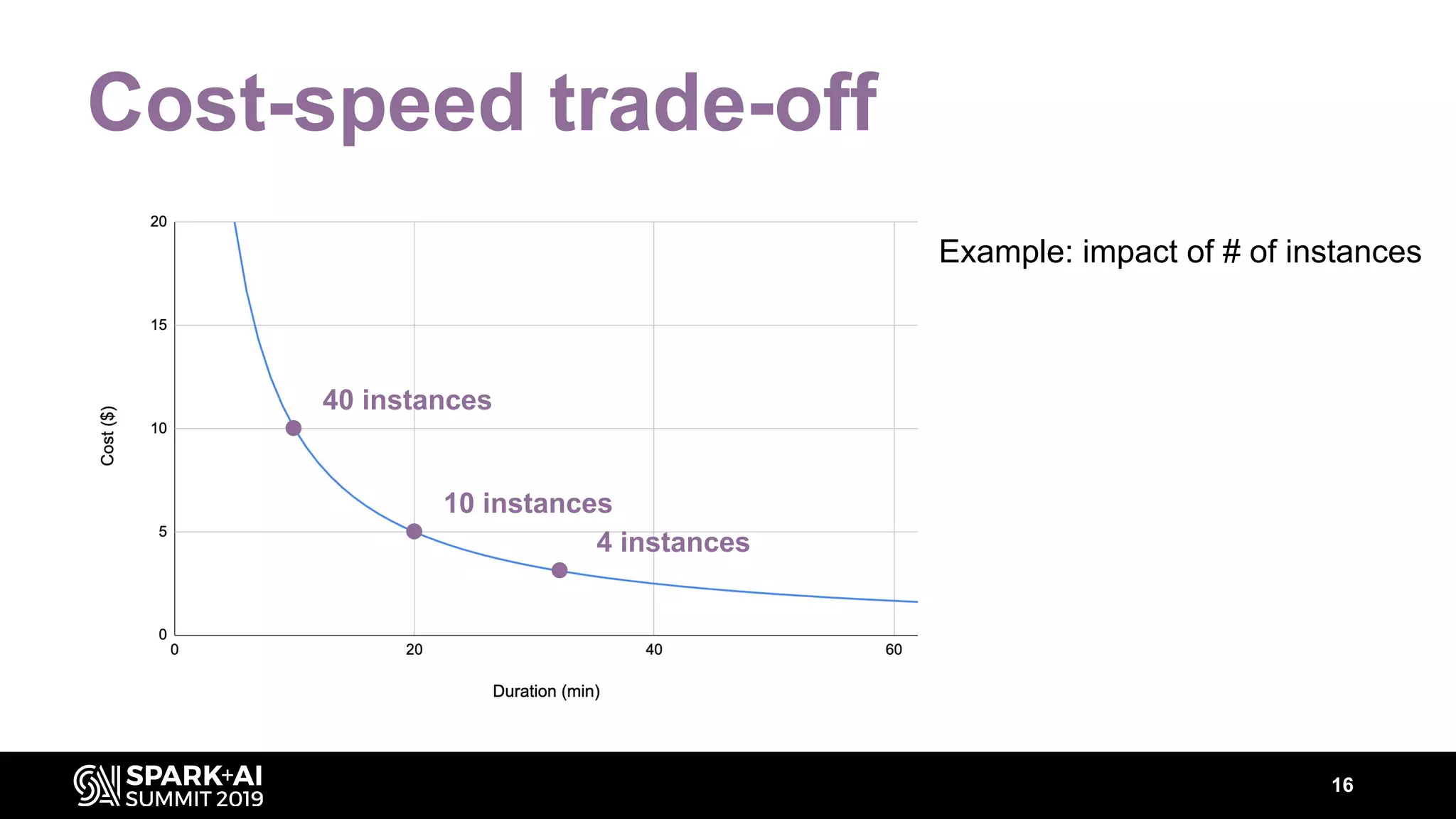
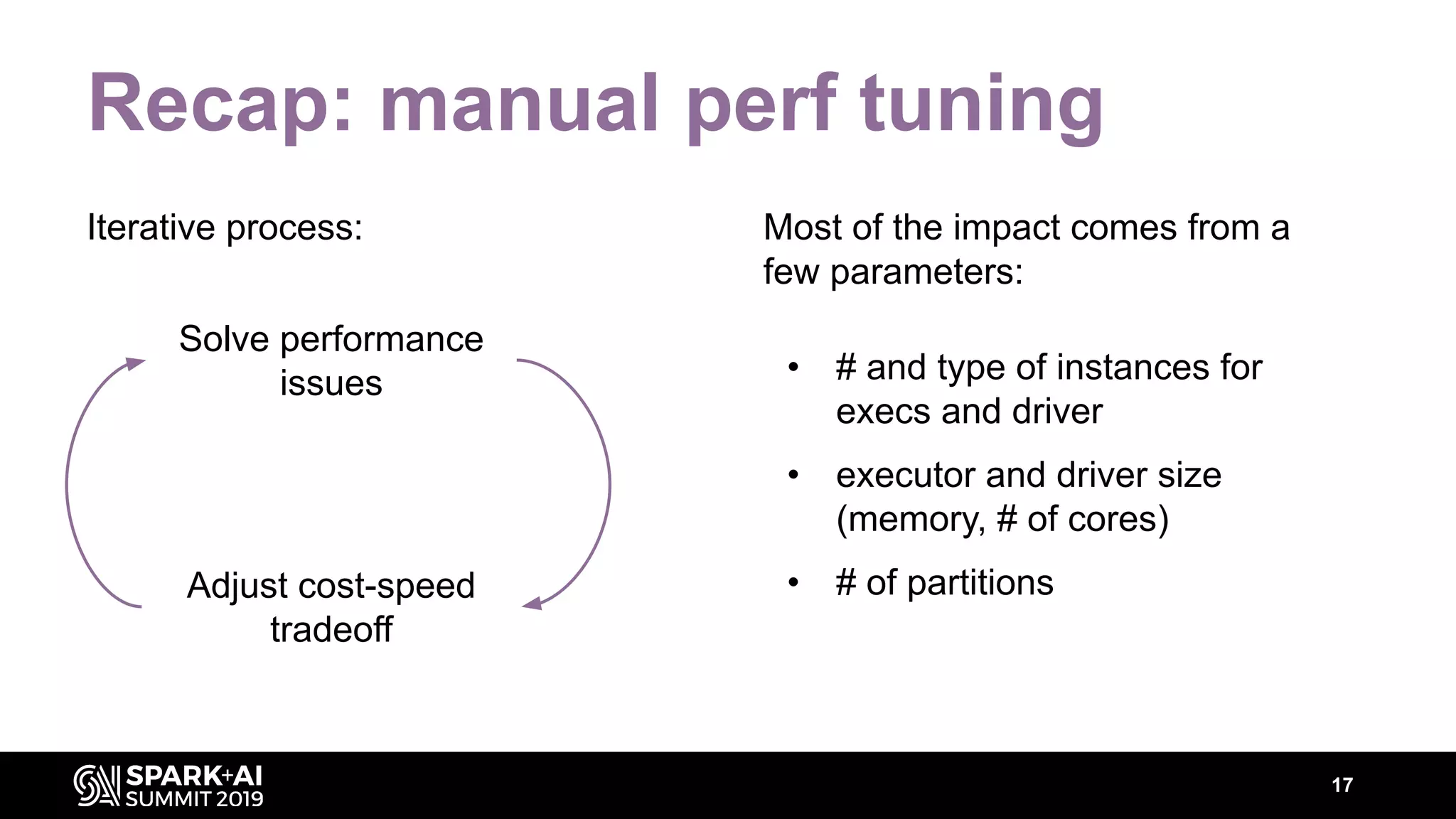


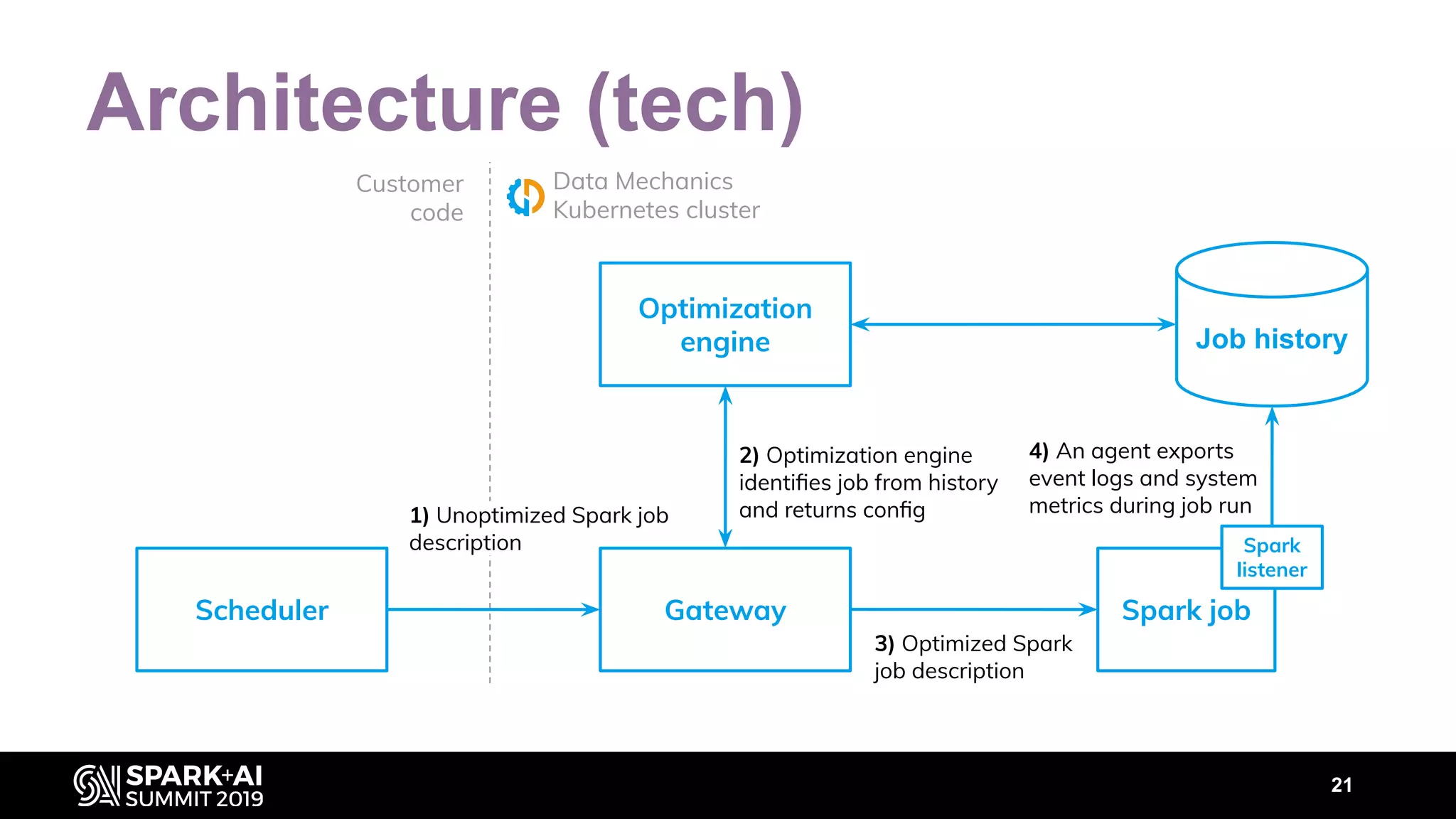
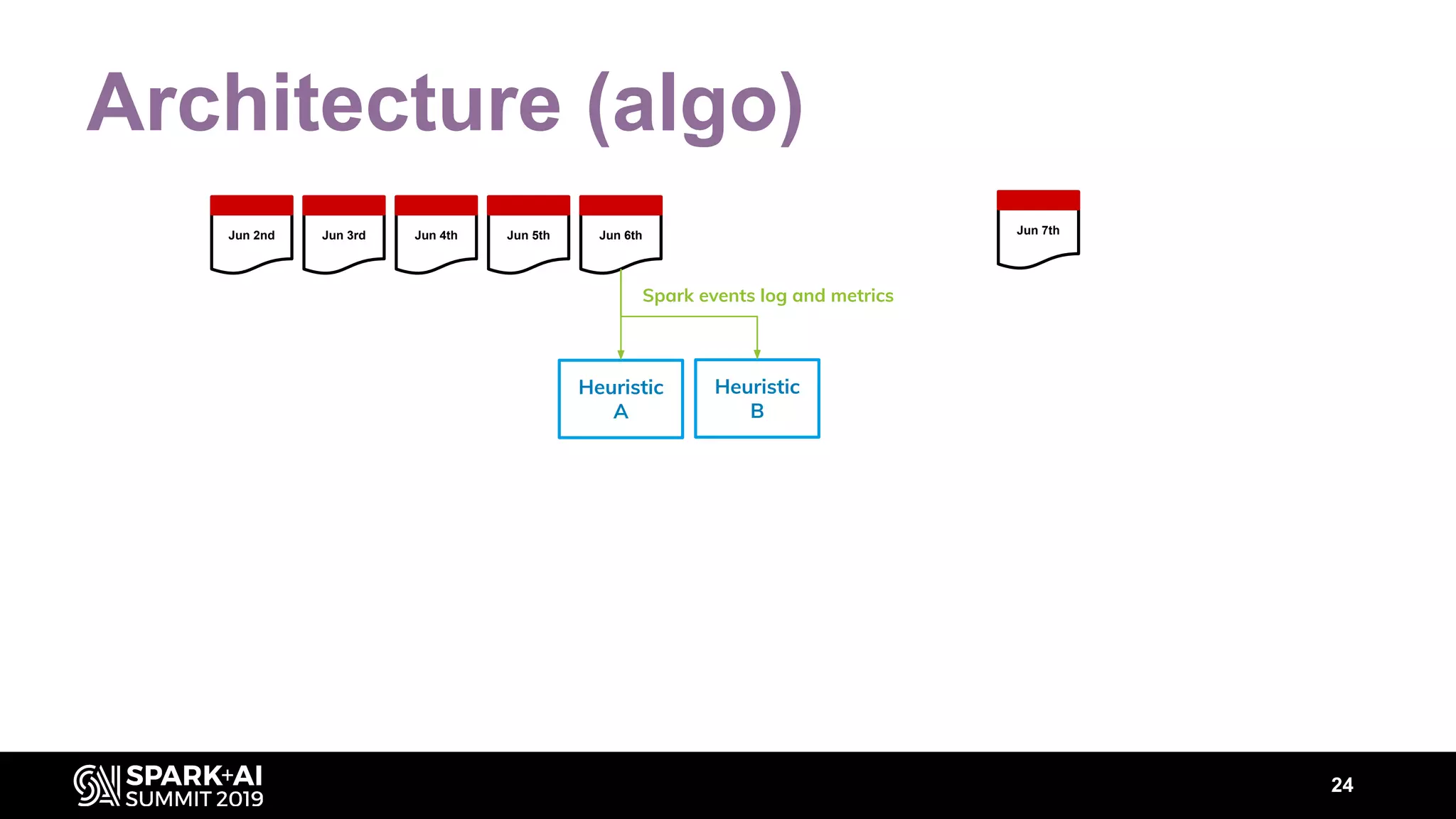
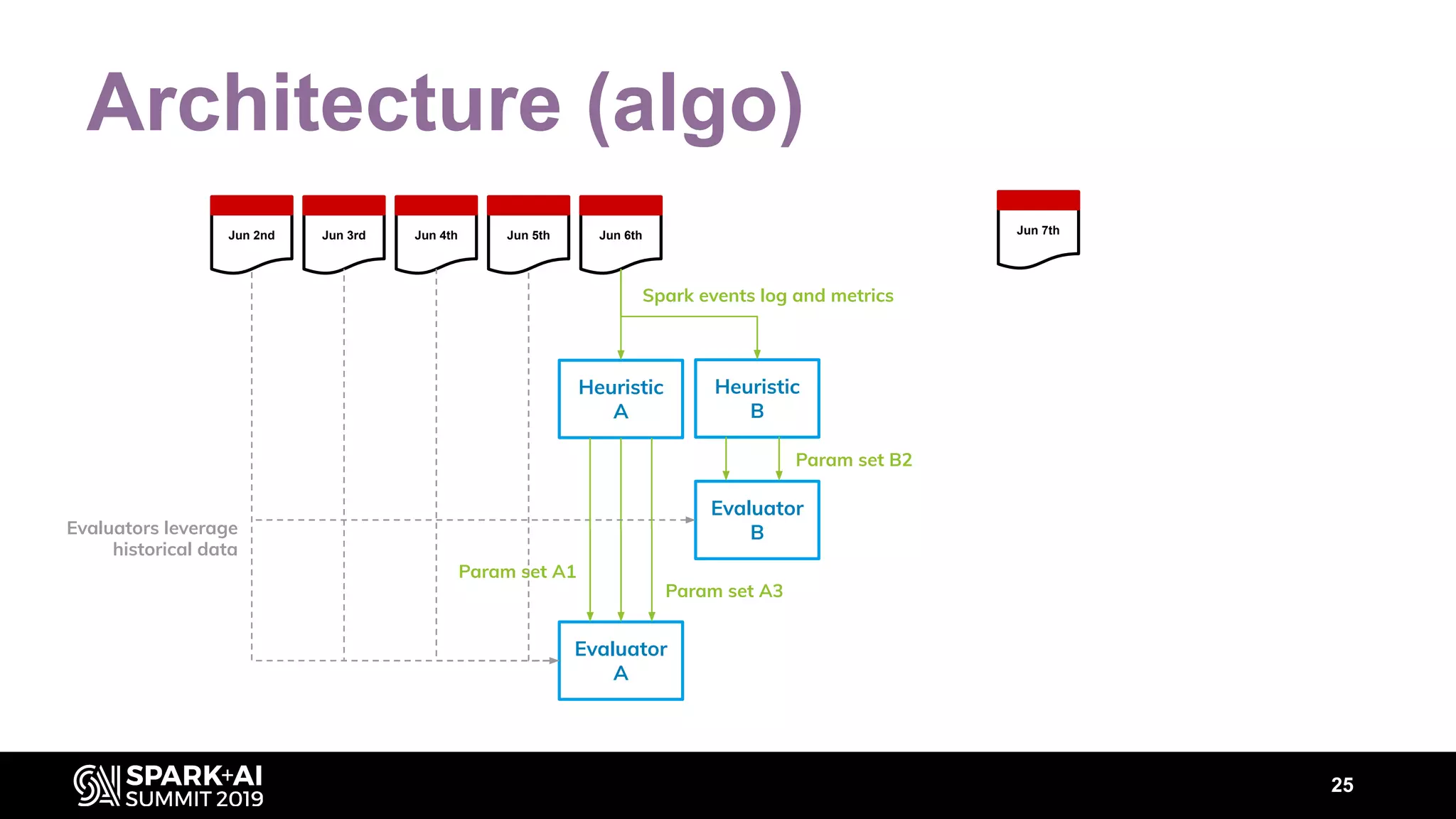
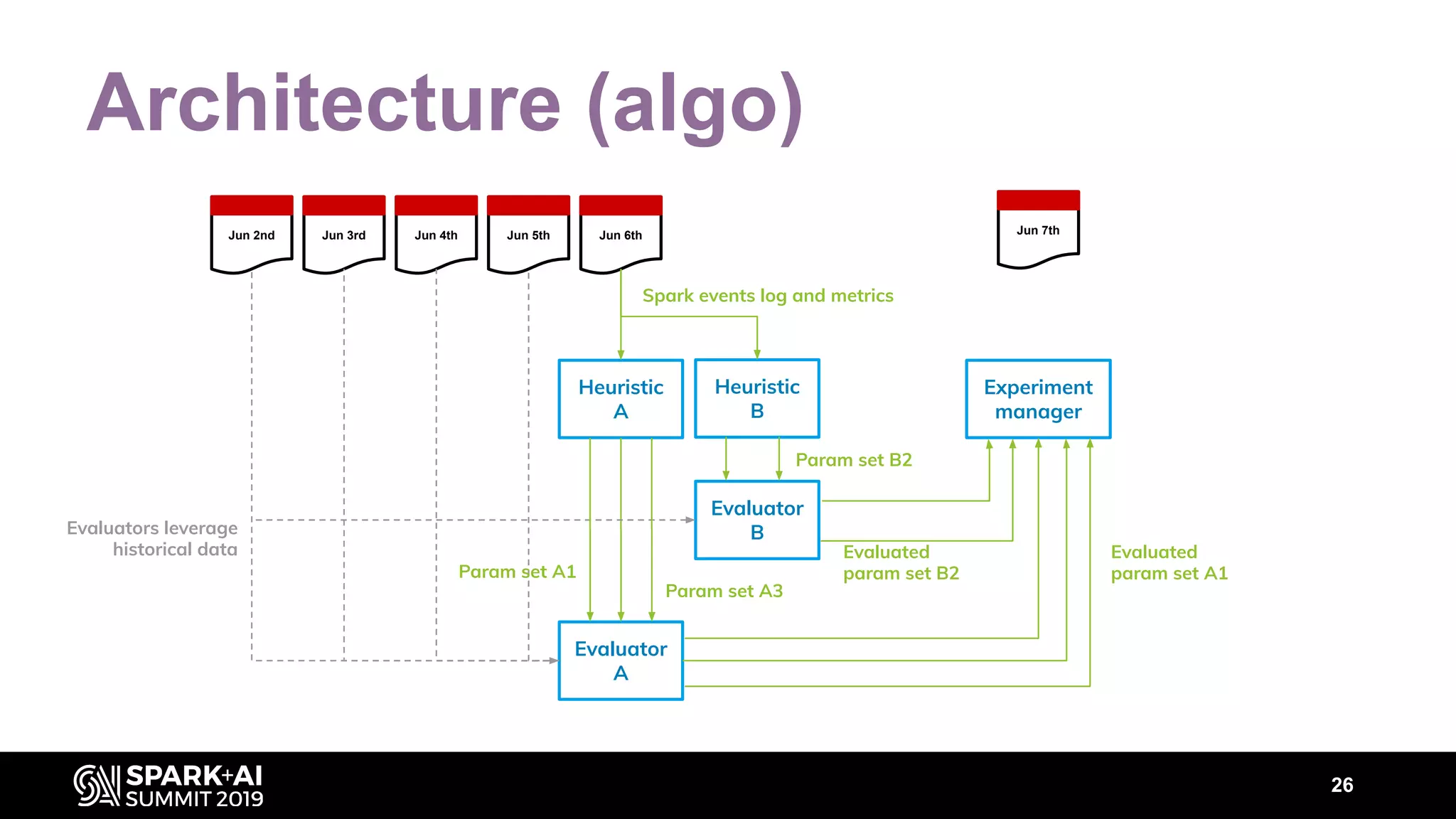
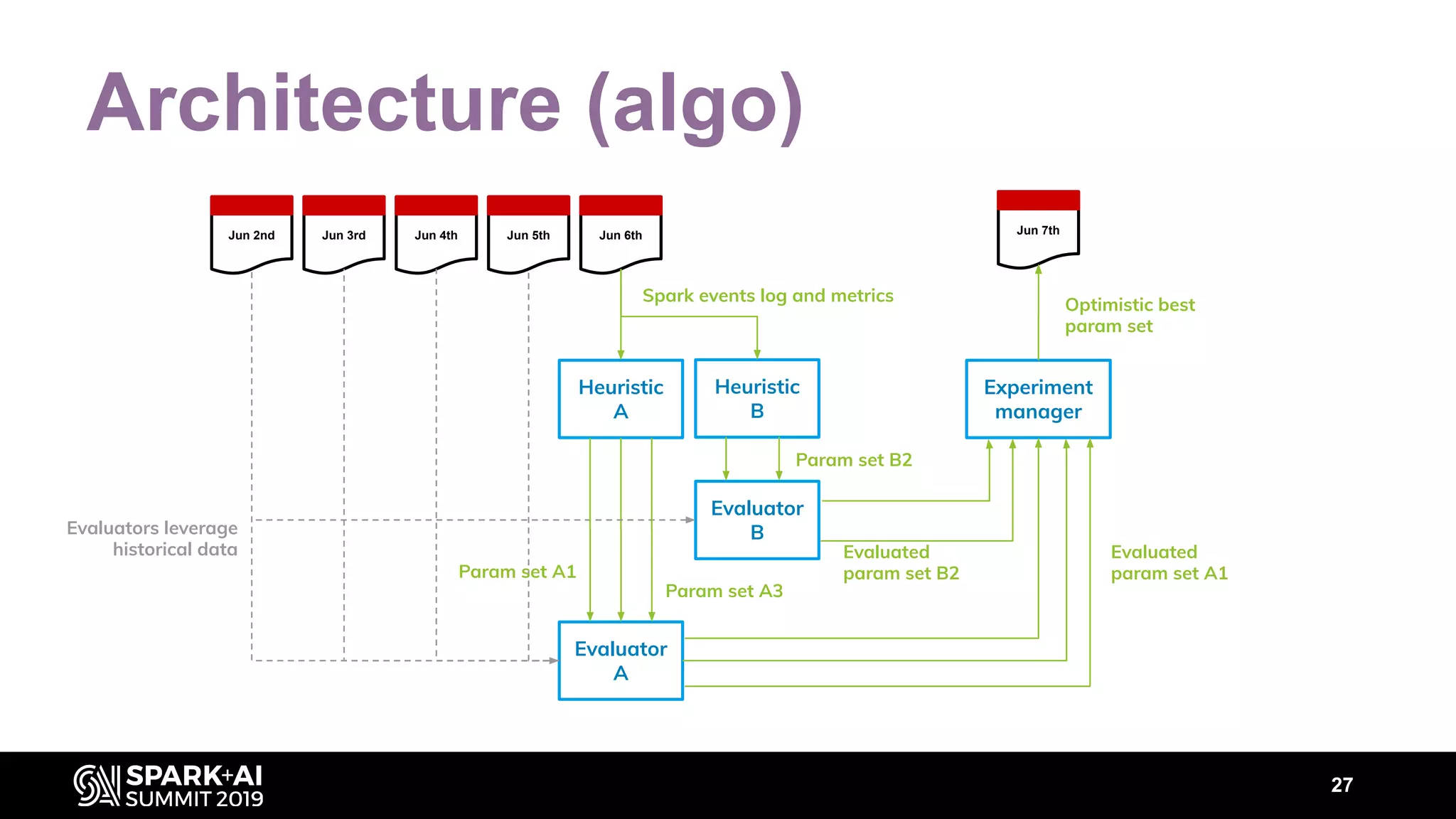


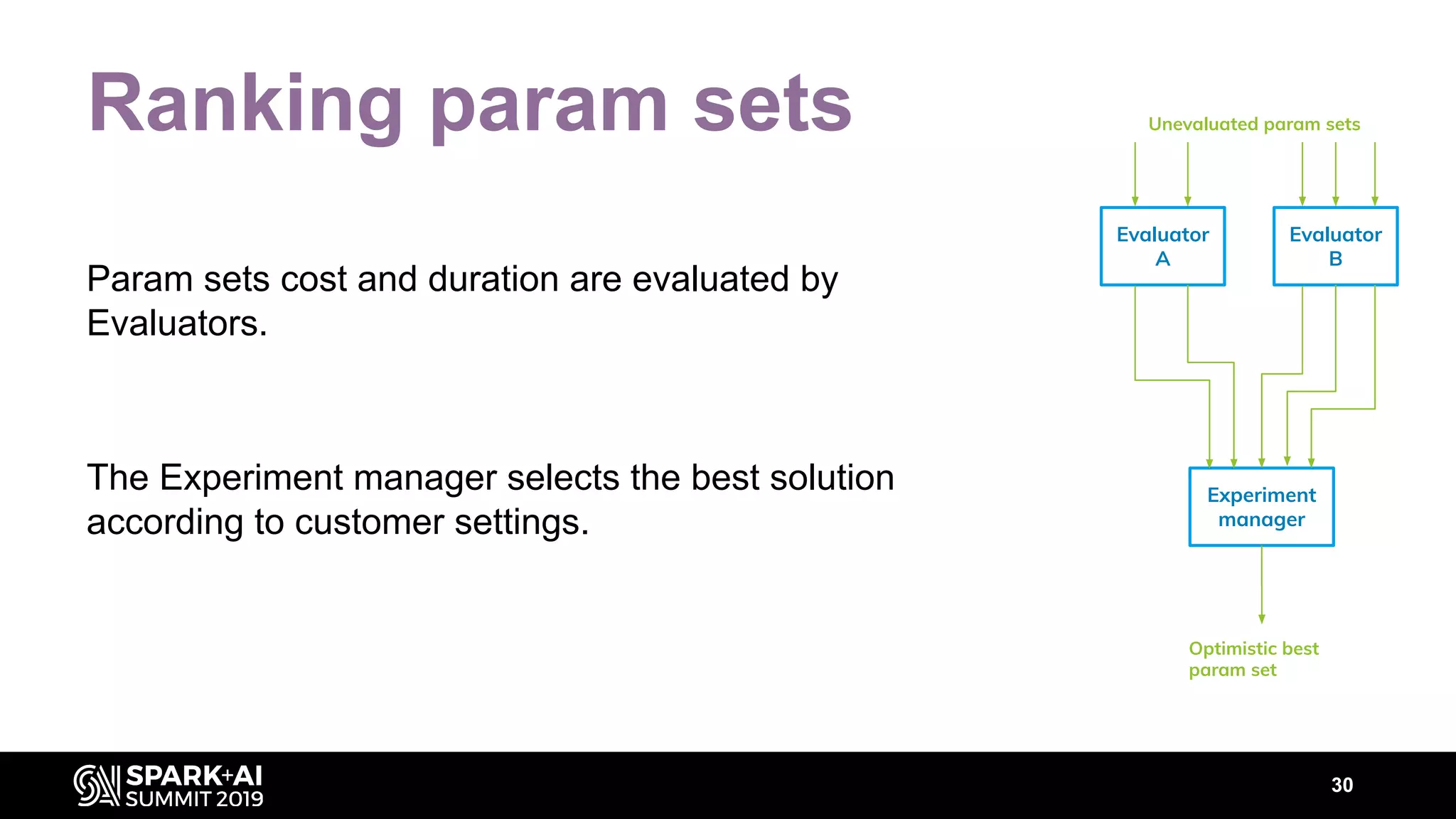


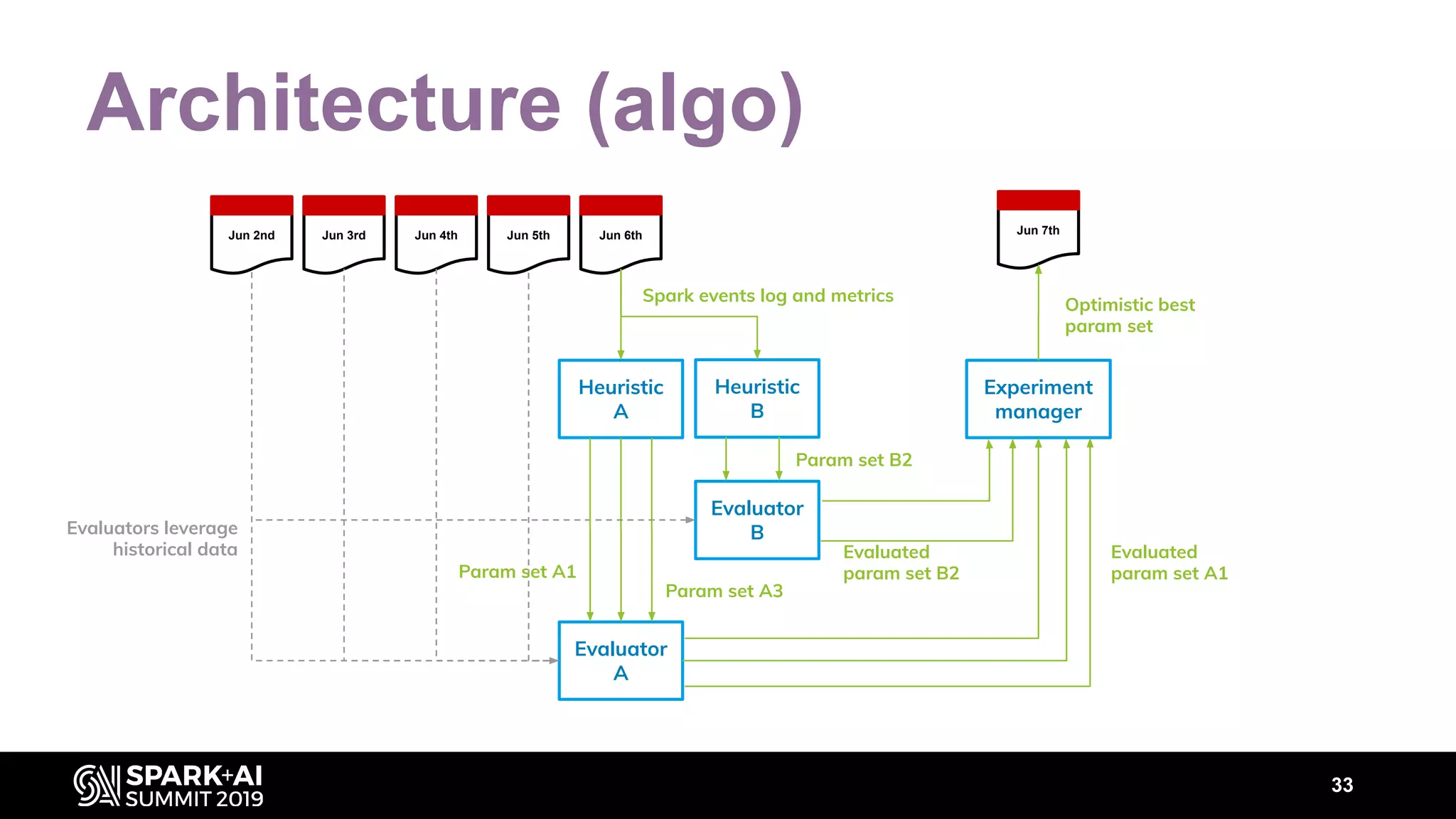
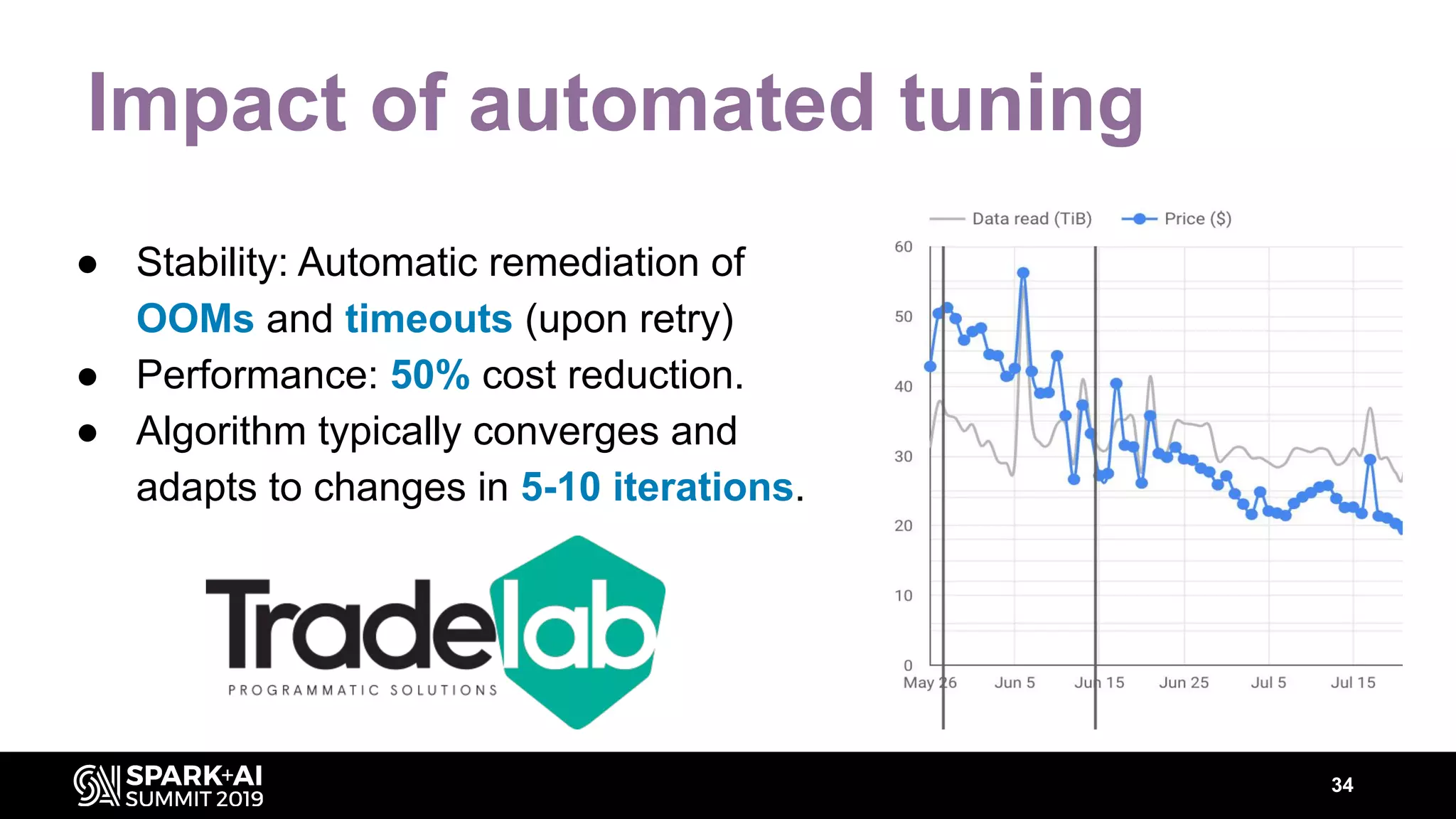
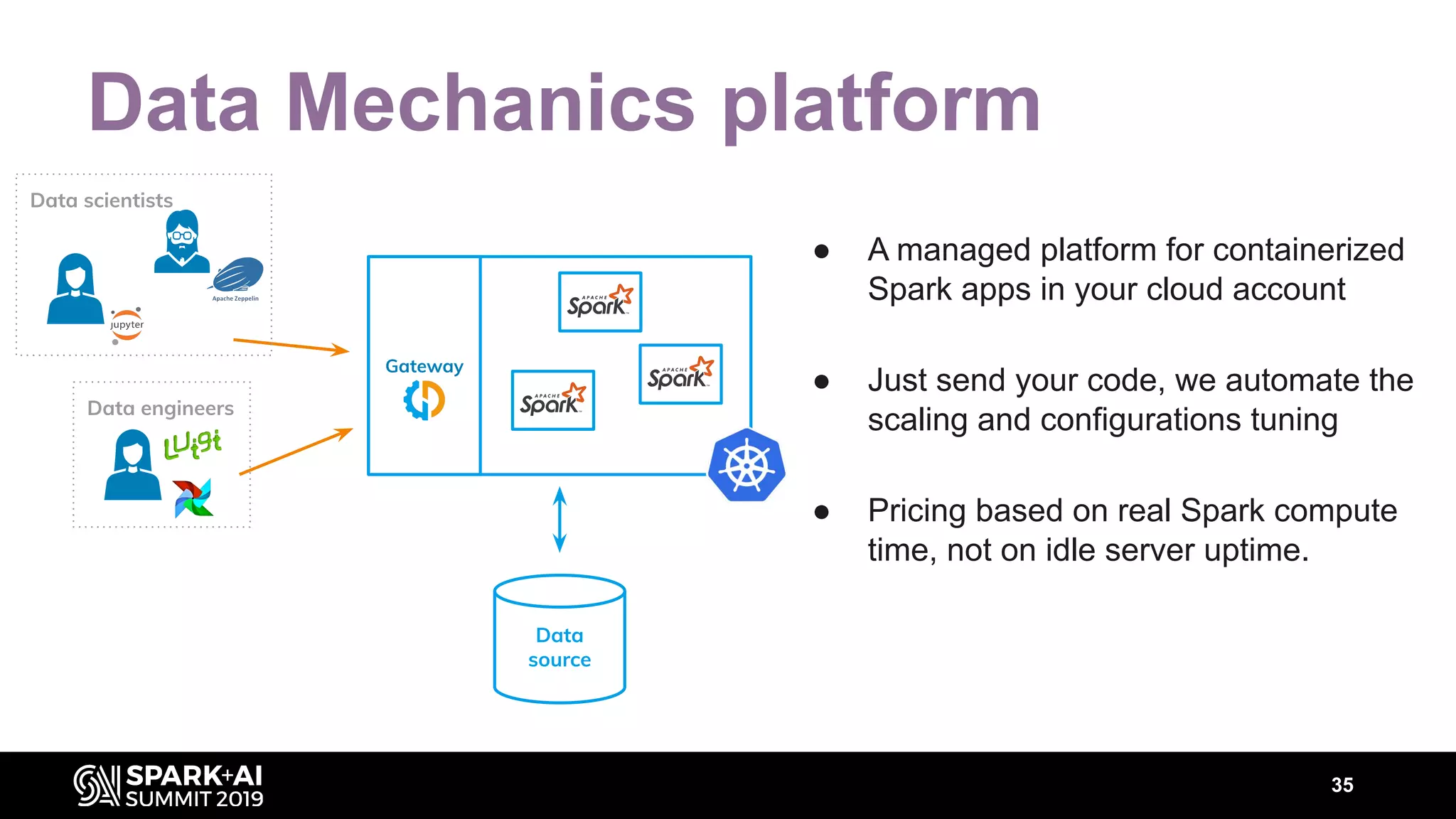



The document discusses performance tuning for Apache Spark, highlighting key parameters and configurations that can dramatically affect performance. It emphasizes the need for automation in performance tuning to alleviate the tedious and time-consuming manual processes that consume significant engineering resources. Additionally, the architecture of an automated tuning solution is outlined, showcasing its ability to optimize Spark jobs based on historical data and heuristics.