Download as PDF, PPTX























![MongoDB explain plan We can request explanation of how a query will be handled (showing possible index use) > db.newcoll.find().explain() { "queryPlanner" : { "plannerVersion" : 1, "namespace" : "test.newcoll", "indexFilterSet" : false, "parsedQuery" : { "$and" : [ ] }, "winningPlan" : { "stage" : "COLLSCAN", "filter" : { "$and" : [ ] }, "direction" : "forward" }, "rejectedPlans" : [ ] }, "serverInfo" : { "host" : "MJBRIGHT7", "port" : 27017, "version" : "3.2.3", "gitVersion" : "b326ba837cf6f49d65c2f85e1b70f6f31ece7937" }, "ok" : 1 }](https://image.slidesharecdn.com/2016-feb-23pyugrepymongo-160223212849/75/Using-MongoDB-and-Python-27-2048.jpg)


![MongoDB aggregation example pipeline = [ { "$project": { // Select fields of interest 'year': { "$dateToString": { 'format': "%Y", 'date': "$date" } }, 'tags': 1, 'value': 1, }, }, { "$match": { 'year': str(year) }}, { "$group": {"_id": "$tags", "total": {"$sum": {"$abs": "$value"}}} }, { "$sort": SON([("total", -1), ("_id", -1)]) } ] cursor = db.collection.aggregate(pipeline)](https://image.slidesharecdn.com/2016-feb-23pyugrepymongo-160223212849/75/Using-MongoDB-and-Python-30-2048.jpg)
![MongoDB aggregation example pipeline = [ { "$project": { 'year': { "$dateToString": { 'format': "%Y", 'date': "$date" } }, 'tags': 1, 'value': 1, }, }, { "$match": { 'year': str(year) }}, // match on fields { "$group": {"_id": "$tags", "total": {"$sum": {"$abs": "$value"}}} }, { "$sort": SON([("total", -1), ("_id", -1)]) } ] cursor = db.collection.aggregate(pipeline)](https://image.slidesharecdn.com/2016-feb-23pyugrepymongo-160223212849/75/Using-MongoDB-and-Python-31-2048.jpg)
![MongoDB aggregation example pipeline = [ { "$project": { 'year': { "$dateToString": { 'format': "%Y", 'date': "$date" } }, 'tags': 1, 'value': 1, }, }, { "$match": { 'year': str(year) }}, { "$group": {"_id": "$tags", "total": {"$sum": {"$abs": "$value"}}} }, // ‘reduce’ { "$sort": SON([("total", -1), ("_id", -1)]) } ] cursor = db.collection.aggregate(pipeline)](https://image.slidesharecdn.com/2016-feb-23pyugrepymongo-160223212849/75/Using-MongoDB-and-Python-32-2048.jpg)
![MongoDB aggregation example pipeline = [ { "$project": { 'year': { "$dateToString": { 'format': "%Y", 'date': "$date" } }, 'tags': 1, 'value': 1, }, }, { "$match": { 'year': str(year) }}, { "$group": {"_id": "$tags", "total": {"$sum": {"$abs": "$value"}}} }, { "$sort": SON([("total", -1), ("_id", -1)]) } // sort the results ] cursor = db.collection.aggregate(pipeline)](https://image.slidesharecdn.com/2016-feb-23pyugrepymongo-160223212849/75/Using-MongoDB-and-Python-33-2048.jpg)




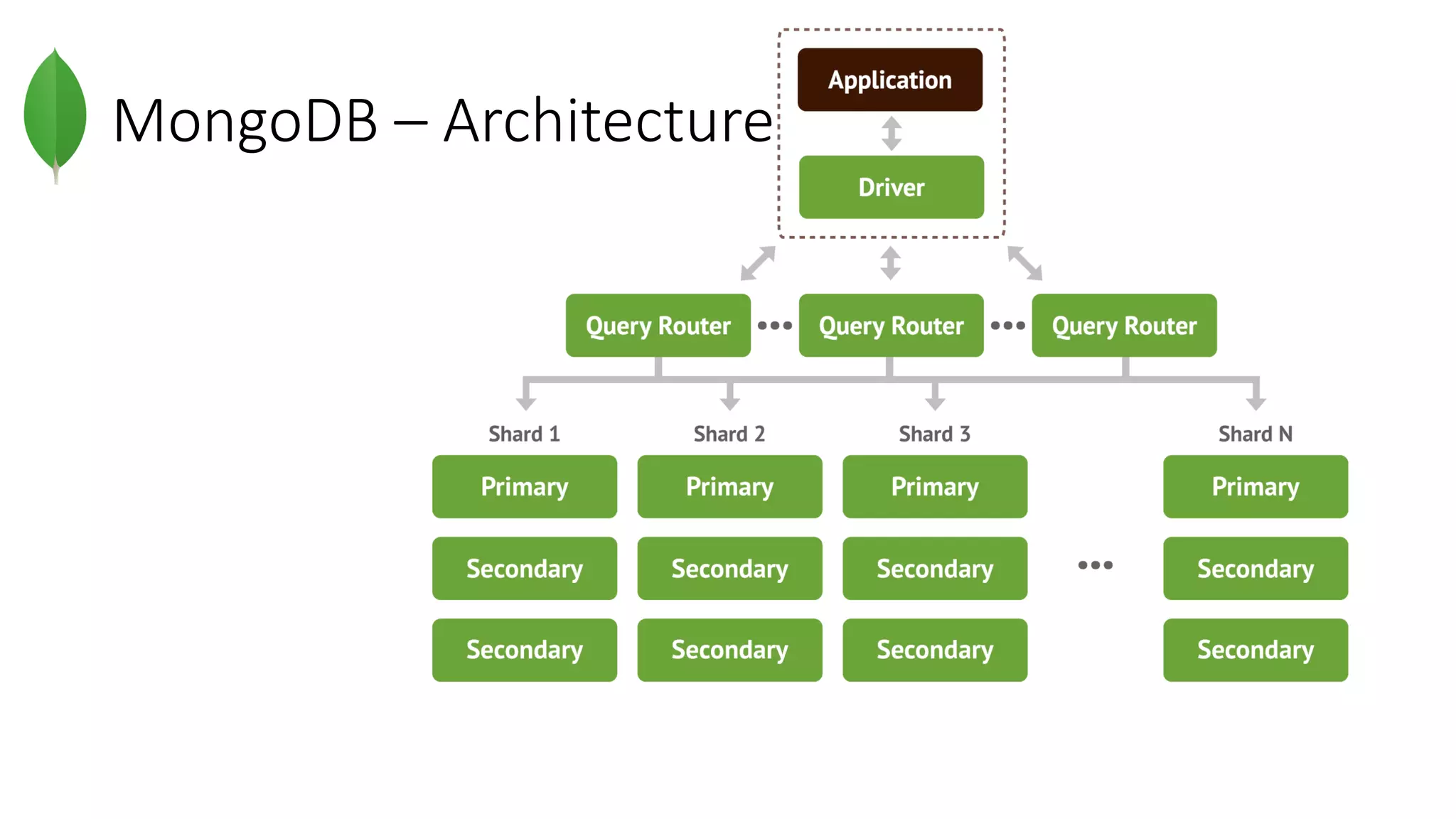
MongoDB can be used to store and query document-oriented data, and provides scalability through horizontal scaling. The document stores provide more flexibility than relational databases by allowing dynamic schemas with embedded documents. MongoDB combines the rich querying of relational databases with the flexibility and scalability of NoSQL databases. It uses indexes to improve query performance and supports features like aggregation, geospatial queries, and text search.