Download as PDF, PPTX













![Including and Excluding Fields { _id: 12345, subject: "Hello There", words: 218, from:"norberto@mongodb.com" to: [ "marc@mongodb.com", "sam@mongodb.com" ], account: "mongodb mail", date: ISODate("2012-08-05"), replies: 3, folder: "Inbox", ... } { $project: { _id: 0, subject: 1, from: 1 }} { subject: "Hello There", from:"norberto@mongodb.com" }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-17-2048.jpg)
![Including and Excluding Fields { _id: 12345, subject: "Hello There", words: 218, from:"norberto@mongodb.com" to: [ "marc@mongodb.com", "sam@mongodb.com" ], account: "mongodb mail", date: ISODate("2012-08-05"), replies: 3, folder: "Inbox", ... } { $project: { _id: 0, subject: 1, from: 1 }} { subject: "Hello There", from:"norberto@mongodb.com" }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-18-2048.jpg)
![Renaming and Computing Fields { $project: { spamIndex: { $mul: ["$words", "$replies"] }, user: "$from" }} { _id: 12345, spamIndex: 72.6666 , user: "norberto@mongodb.com" } { _id: 12345, subject: "Hello There", words: 218, from:"norberto@mongodb.com" to: [ "marc@mongodb.com", "sam@mongodb.com" ], account: "mongodb mail", date: ISODate("2012-08-05"), replies: 3, folder: "Inbox", ... }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-19-2048.jpg)
![Creating Sub-Document Fields { $project: { subject: 1, stats: { replies: "$replies", from: "$from", date: "$date" }}} { _id: 375, subject: "Hello There", stats: { replies: 3, from: "norberto@mongodb.com", date: ISODate("2012-08-05") }} { _id: 12345, subject: "Hello There", words: 218, from:"norberto@mongodb.com" to: [ "marc@mongodb.com", "sam@mongodb.com" ], account: "mongodb mail", date: ISODate("2012-08-05"), replies: 3, folder: "Inbox", ... }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-20-2048.jpg)


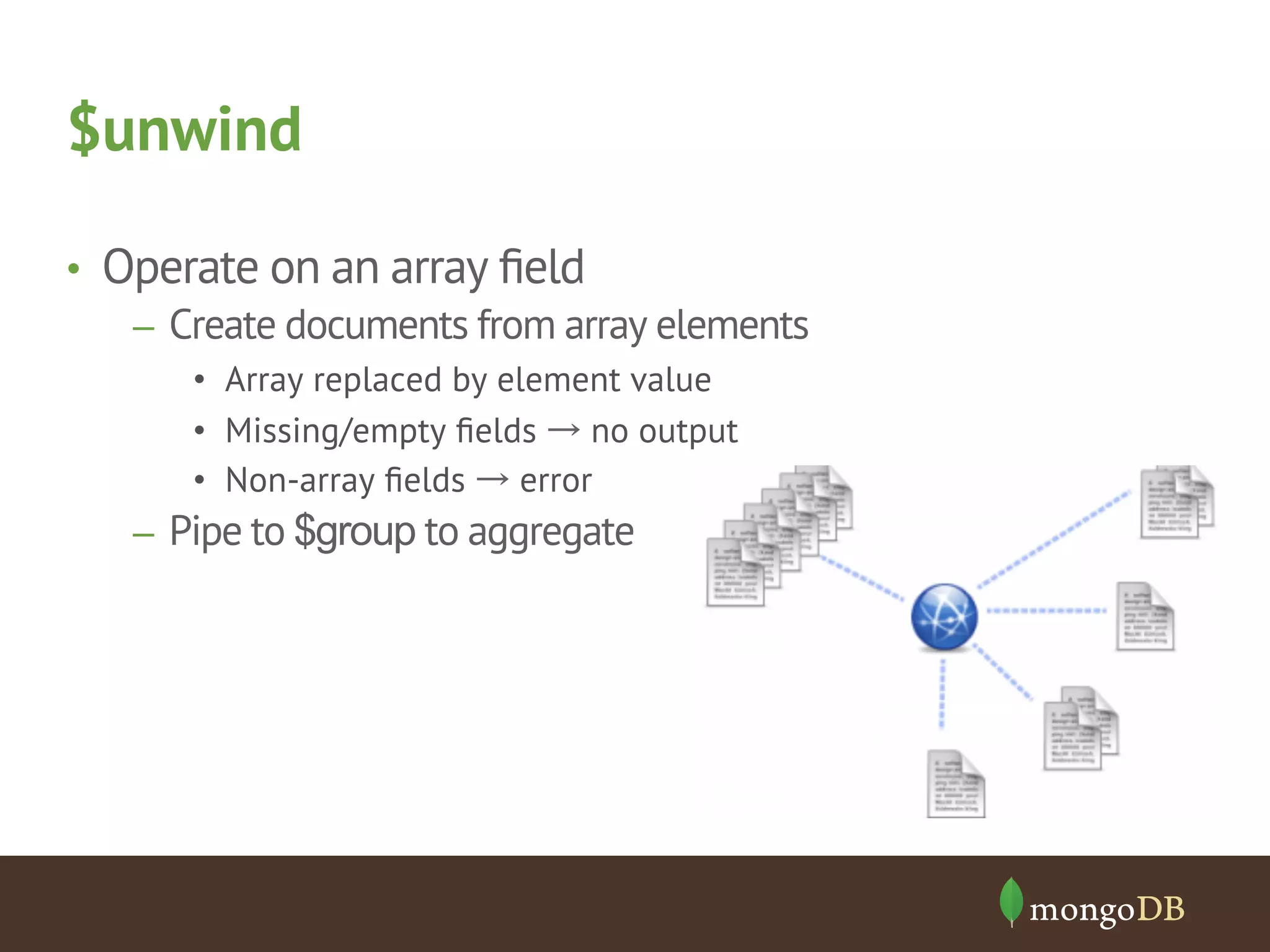
![Collecting Distinct Values { $unwind: "$to" } { subject: "2.8 will be great!", to: "marc@mongodb.com", account : "mongodb mail” } { _id: 2222, subject: "2.8 will be great!", to: [ "marc@mongodb.com", "eliot@mongodb.com", "asya@mongodb.com", ], account: "mongodb mail" } { subject: "2.8 will be great!", to: "eliot@mongodb.com", account : "mongodb mail” } { subject: "2.8 will be great!", to: "asya@mongodb.com", account : "mongodb mail” }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-25-2048.jpg)



![Query by Security Level security = 0 db.catalog.aggregate([ { $match: {item: /^.*XBR55X900A*/} }, { $redact: { $cond: { if: { $lte: [ "$security", ?? ] }, then: "$$DESCEND", else: "$$PRUNE" } } }]) { "_id" : 375, "item" : "Sony XBR55X900A 55Inch 4K Ultra High Definition TV", "Manufacturer" : "Sony”, "security" : 0, "quantity" : 12, "list" : 4999 } { "_id" : 375, "item" : "Sony XBR55X900A 55Inch 4K Ultra High Definition TV", "Manufacturer" : "Sony", "security" : 0, "quantity" : 12, "list" : 4999, "pricing" : { "security" : 1, "sale" : 2698, "wholesale" : { "security" : 2, "amount" : 2300 } } } security = 2](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-29-2048.jpg)

![$geonear Example Data { "_id" : 35089, "city" : “Sony”, "loc" : [ -86.048397, 32.979068 ], "pop" : 1584, "state" : "AL” }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-31-2048.jpg)
![Query by Proximity db.catalog.aggregate([ { $geoNear : { near: [ -86.000, 33.000 ], distanceField: "dist", maxDistance: .050, spherical: true, num: 3 } }]) { "_id" : "35089", "city" : "KELLYTON", "loc" : [ -86.048397, 32.979068 ], "pop" : 1584, "state" : "AL", "dist" : 0.0007971432165364155 }, { "_id" : "35010", "city" : "NEW SITE", "loc" : [ -85.951086, 32.941445 ], "pop" : 19942, "state" : "AL", "dist" : 0.0012479615347306806 }, { "_id" : "35072", "city" : "GOODWATER", "loc" : [ -86.078149, 33.074642 ], "pop" : 3813, "state" : "AL", "dist" : 0.0017333719627032555 }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-32-2048.jpg)

![Usage • collection.aggregate([…], {<options>}) – Returns a cursor – Takes an optional document to specify aggregation options • allowDiskUse, explain – Use $out to send results to a Collection • db.runCommand({aggregate:<collection>, pipeline:[…]}) – Returns a document, limited to 16 MB](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-34-2048.jpg)
![Collection db.books.aggregate([ { $project: { language: 1 }}, { $group: { _id: "$language", numTitles: { $sum: 1 }}} ]) { _id: "Russian", numTitles: 1 }, { _id: "English", numTitles: 2 }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-35-2048.jpg)
![Database Command db.runCommand({ aggregate: "books", pipeline: [ { $project: { language: 1 }}, 1 } {} }$ group: { _id: "$language", numTitles: { $sum: ] }) { result : [ { _id: "Russian", numTitles: 1 }, { _id: "English", numTitles: 2 } ], “ok” : 1 }](https://image.slidesharecdn.com/aggfmk-141113143655-conversion-gate01/75/Aggregation-Framework-MongoDB-Days-Munich-36-2048.jpg)


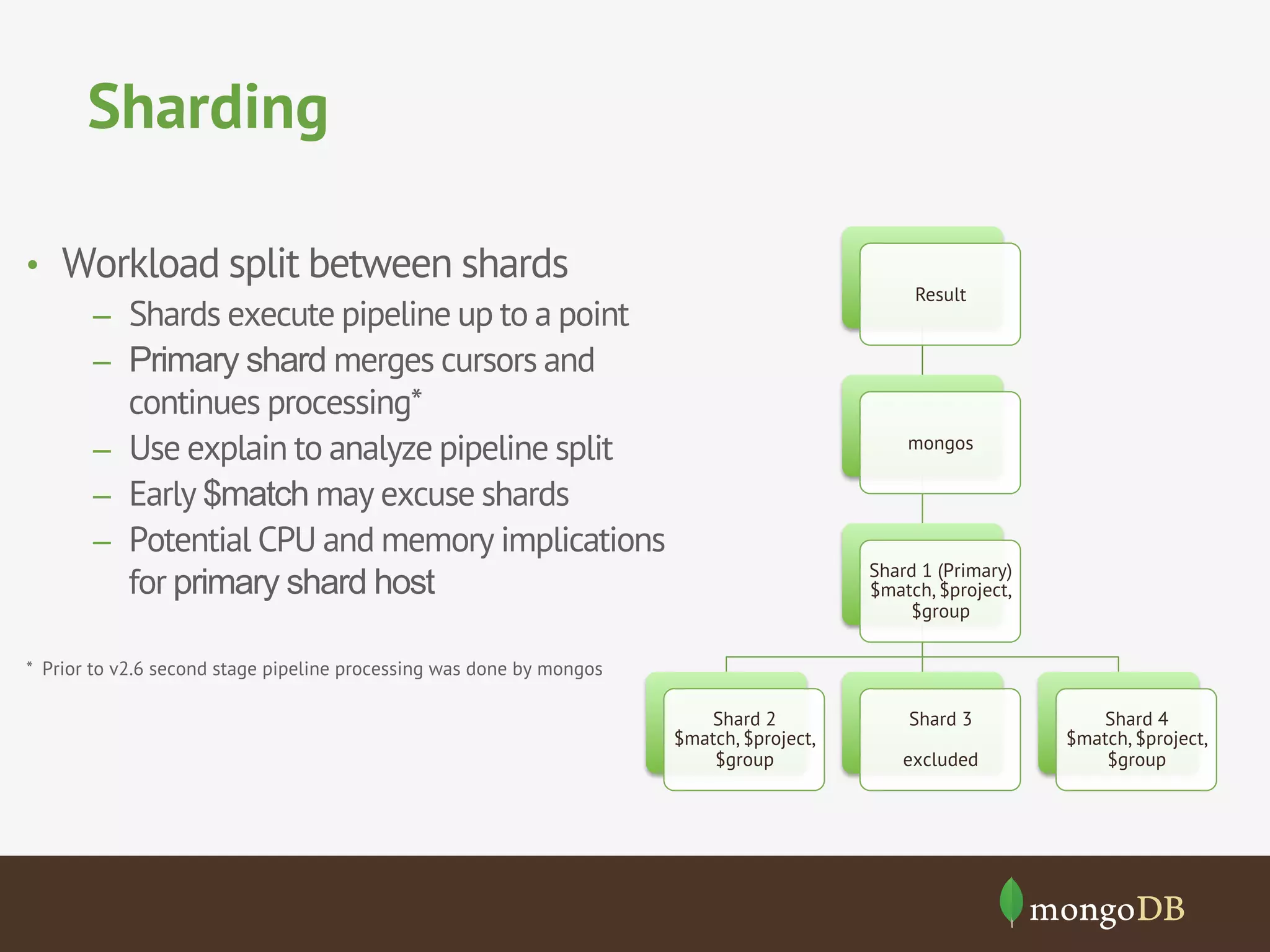







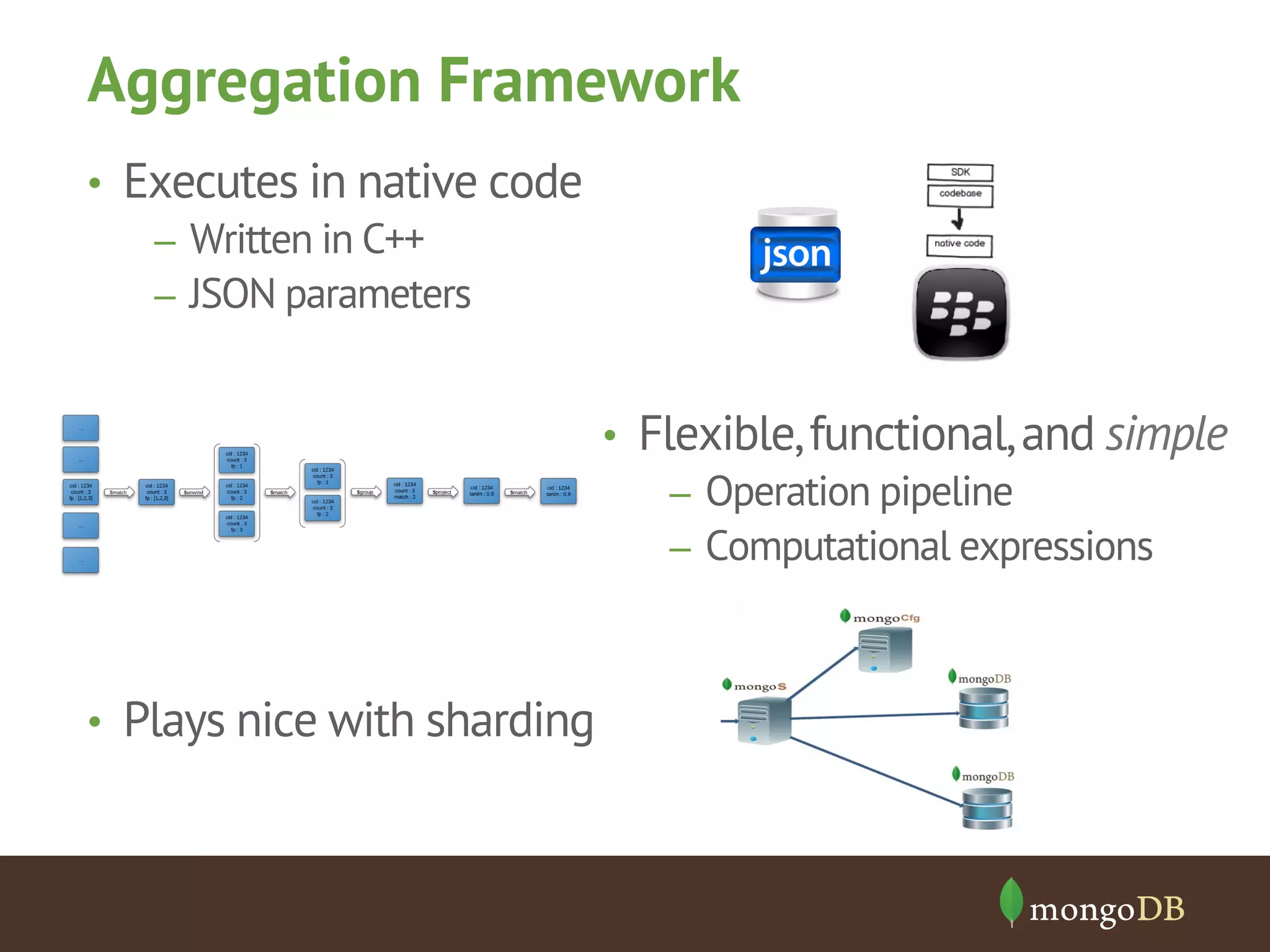
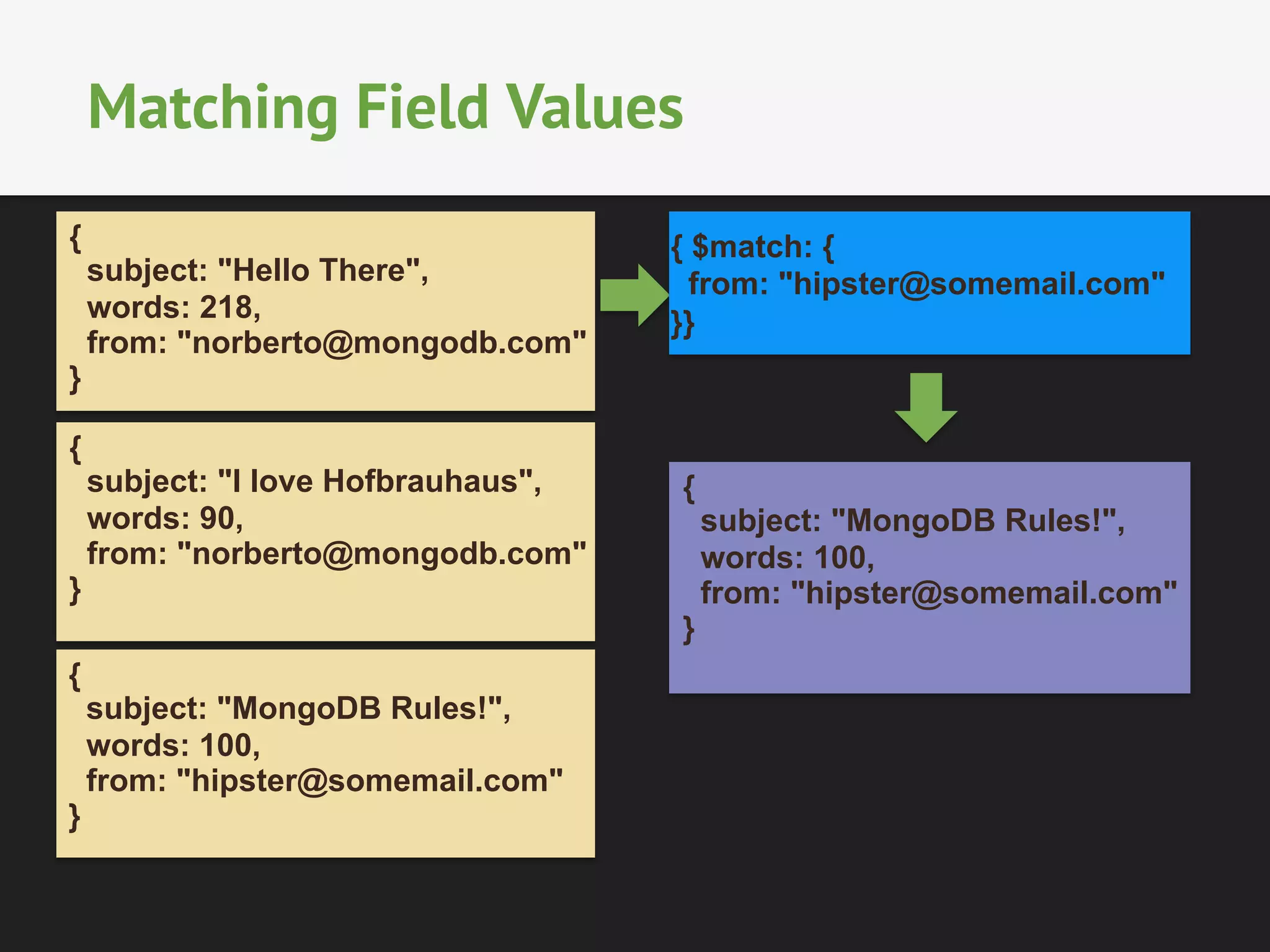
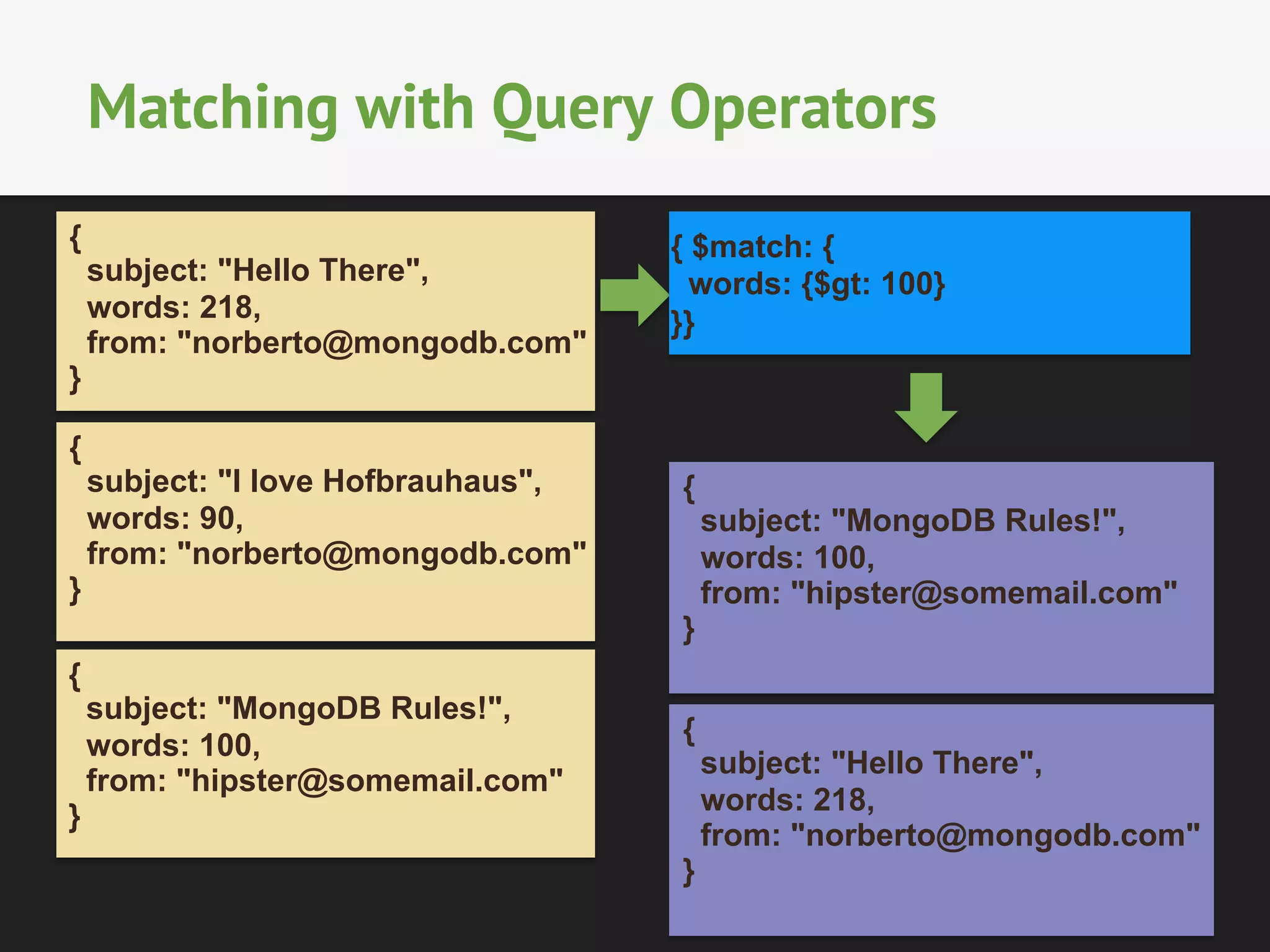
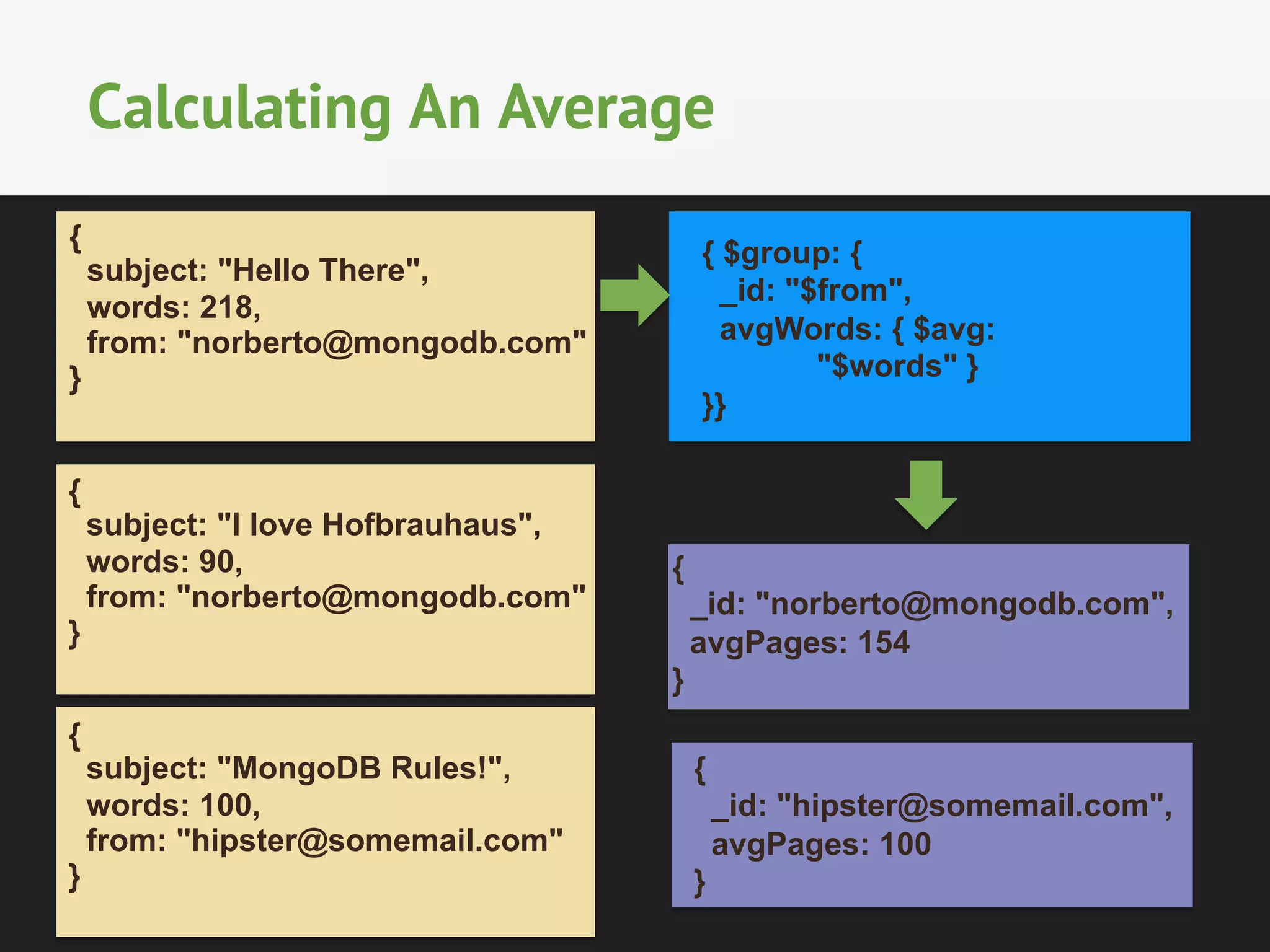
The document provides an overview of MongoDB's aggregation framework, detailing its components such as the aggregation pipeline, usage, limitations, and how it integrates with sharding. It explains various operators like $match, $project, $group, and $unwind, showcasing examples of document transformation and data aggregation. Additionally, the document addresses practical applications of the framework, future enhancements, and the potential for improved performance in data handling.