Downloaded 13,234 times











![Example book data { _id: 375, title: "The Great Gatsby", ISBN: "9781857150193", available: true, pages: 218, chapters: 9, subjects: [ "Long Island", "New York", "1920s" ], language: "English" } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-16-2048.jpg)

![Including and Excluding Fields { { $project: { _id: 375, _id: 0, title: "Great Gatsby", title: 1, ISBN: "9781857150193", language: 1 available: true, }} pages: 218, subjects: [ "Long Island", "New York", "1920s" { ], title: " Great Gatsby", language: "English" language: "English" } } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-21-2048.jpg)
![Renaming and Computing Fields { { $project: { _id: 375, avgChapterLength: { title: "Great Gatsby", $divide: ["$pages", ISBN: "9781857150193", "$chapters"] available: true, }, pages: 218, lang: "$language" chapters: 9, }} subjects: [ "Long Island", "New York", "1920s" { ], _id: 375, language: "English" avgChapterLength: 24.2222 , } lang: "English" } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-22-2048.jpg)
![Creating Sub-Document Fields { $project: { { title: 1, _id: 375, stats: { title: "Great Gatsby", pages: "$pages", ISBN: "9781857150193", language: "$language", available: true, } pages: 218, }} subjects: [ "Long Island", "New York", "1920s" { ], _id: 375, language: "English" title: " Great Gatsby", } stats: { pages: 218, language: "English" } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-23-2048.jpg)



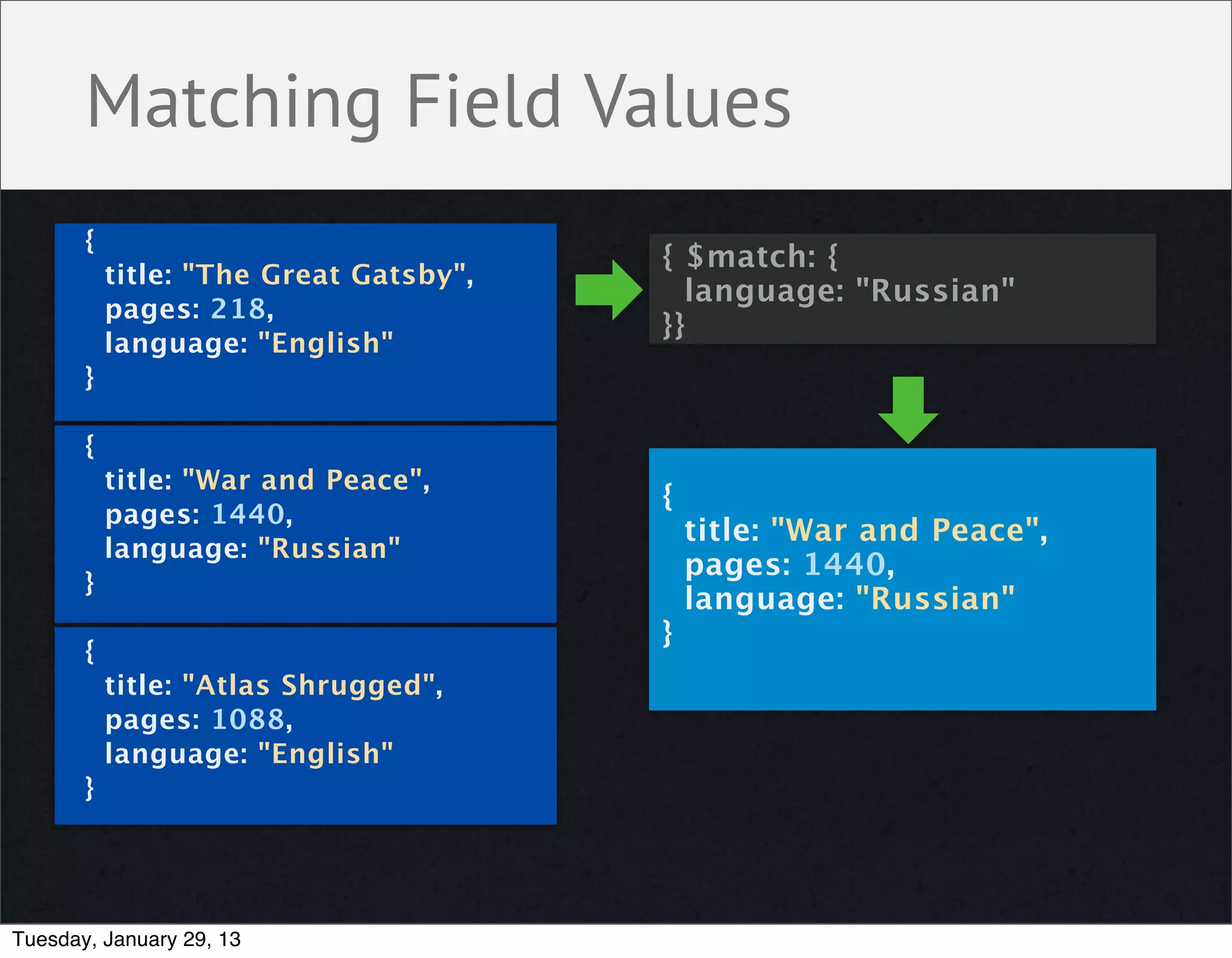
![Collecting Distinct Values { { $group: { title: "The Great Gatsby", _id: "$language", pages: 218, titles: { $addToSet: "$title" } language: "English" }} } { { title: "War and Peace", _id: "Russian", titles: [ "War and Peace" ] pages: 1440, } language: "Russian" } { _id: "English", { titles: [ title: "Atlas Shrugged", "Atlas Shrugged", pages: 1088, "The Great Gatsby" language: "English" ] } } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-27-2048.jpg)

![Yielding Multiple Documents from One { { $unwind: "$subjects" } title: "The Great Gatsby", ISBN: "9781857150193", { subjects: [ title: "The Great Gatsby", "Long Island", ISBN: "9781857150193", "New York", subjects: "Long Island" "1920s" } ] } { title: "The Great Gatsby", ISBN: "9781857150193", subjects: "New York" } { title: "The Great Gatsby", ISBN: "9781857150193", subjects: "1920s" } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-29-2048.jpg)



![Collection db.books.aggregate([ { $project: { language: 1 }}, { $group: { _id: "$language", numTitles: { $sum: 1 }}} ]) { result: [ { _id: "Russian", numTitles: 1 }, { _id: "English", numTitles: 2 } ], ok: 1 } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-36-2048.jpg)
![Database Command db.runCommand({ aggregate: "books", pipeline: [ { $project: { language: 1 }}, { $group: { _id: "$language", numTitles: { $sum: 1 }}} ] }) { result: [ { _id: "Russian", numTitles: 1 }, { _id: "English", numTitles: 2 } ], ok: 1 } Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-37-2048.jpg)



![Sharding [ { $match: { /* filter by shard key */ }}, { $project: { /* select fields */ }}, { $group: { /* group by some field */ }}, { $sort: { /* sort by some field */ }}, { $project: { /* reshape result */ }} ] Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-41-2048.jpg)



![Boolean Operators • Input array of one or more values – $and, $or – Short-circuit logic • Invert values with $not • Evaluation of non-boolean types – null, undefined, zero ▶ false – Non-zero, strings, dates, objects ▶ true { $and: [true, false] } ▶ false { $or: ["foo", 0] } ▶ true { $not: null } ▶ true Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-45-2048.jpg)
![Comparison Operators • Compare numbers, strings, and dates • Input array with two operands – $cmp, $eq, $ne – $gt, $gte, $lt, $lte { $cmp: [3, 4] } ▶ -1 { $eq: ["foo", "bar"] } ▶ false { $ne: ["foo", "bar"] } ▶ true { $gt: [9, 7] } ▶ true Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-46-2048.jpg)
![Arithmetic Operators • Input array of one or more numbers – $add, $multiply • Input array of two operands – $subtract, $divide, $mod { $add: [1, 2, 3] } ▶ 6 { $multiply: [2, 2, 2] } ▶ 8 { $subtract: [10, 7] } ▶ 3 { $divide: [10, 2] } ▶ 5 { $mod: [8, 3] } ▶ 2 Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-47-2048.jpg)
![String Operators • $strcasecmp case-insensitive comparison – $cmp is case-sensitive • $toLower and $toUpper case change • $substr for sub-string extraction • Not encoding aware (assumes ASCII alphabet) { $strcasecmp: ["foo", "bar"] } ▶ 1 { $substr: ["foo", 1, 2] } ▶ "oo" { $toUpper: "foo" } ▶ "FOO" { $toLower: "BAR" } ▶ "bar" Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-48-2048.jpg)
![Conditional Operators • $cond ternary operator • $ifNull { $cond: [{ $eq: [1, 2] }, "same", "different"] } ▶ "different” { $ifNull: ["foo", "bar"] } ▶ "foo" { $ifNull: [null, "bar"] } ▶ "bar" Tuesday, January 29, 13](https://image.slidesharecdn.com/pdfaggregationframeworkboulder-130131142150-phpapp01/75/Aggregation-Framework-50-2048.jpg)





This document summarizes the agenda for a presentation on the MongoDB aggregation framework. The presentation will cover the state of aggregation in MongoDB, how the aggregation pipeline works, usage and limitations of the pipeline, optimization techniques, and how aggregation works with sharding. Example aggregation operations like $match, $project, and $group will also be demonstrated using sample book data.