Download as PDF, PPTX

![Background: What is in an RDD? •Dependencies •Partitions (with optional locality info) •Compute function: Partition => Iterator[T] 2](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-2-2048.jpg)
![Background: What is in an RDD? •Dependencies •Partitions (with optional locality info) •Compute function: Partition => Iterator[T] 3 Opaque Computation](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-3-2048.jpg)
![Background: What is in an RDD? •Dependencies •Partitions (with optional locality info) •Compute function: Partition => Iterator[T] 4 Opaque Data](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-4-2048.jpg)
![Struc·ture [ˈstrək(t)SHər] verb 1. construct or arrange according to a plan; give a pattern or organization to. 5](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-5-2048.jpg)


![Type-safe: operate on domain objects with compiled lambda functions 8 Datasets API val df = ctx.read.json("people.json") // Convert data to domain objects. case class Person(name: String, age: Int) val ds: Dataset[Person] = df.as[Person] ds.filter(_.age > 30) // Compute histogram of age by name. val hist = ds.groupBy(_.name).mapGroups { case (name, people: Iter[Person]) => val buckets = new Array[Int](10) people.map(_.age).foreach { a => buckets(a / 10) += 1 } (name, buckets) }](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-8-2048.jpg)
![DataFrame = Dataset[Row] •Spark 2.0 will unify these APIs •Stringly-typed methods will downcast to generic Row objects •Ask Spark SQL to enforce types on generic rows using df.as[MyClass] 9](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-9-2048.jpg)
![What about ? Some of the goals of the Dataset API have always been available! 10 df.map(lambda x: x.name) df.map(x => x(0).asInstanceOf[String])](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-10-2048.jpg)
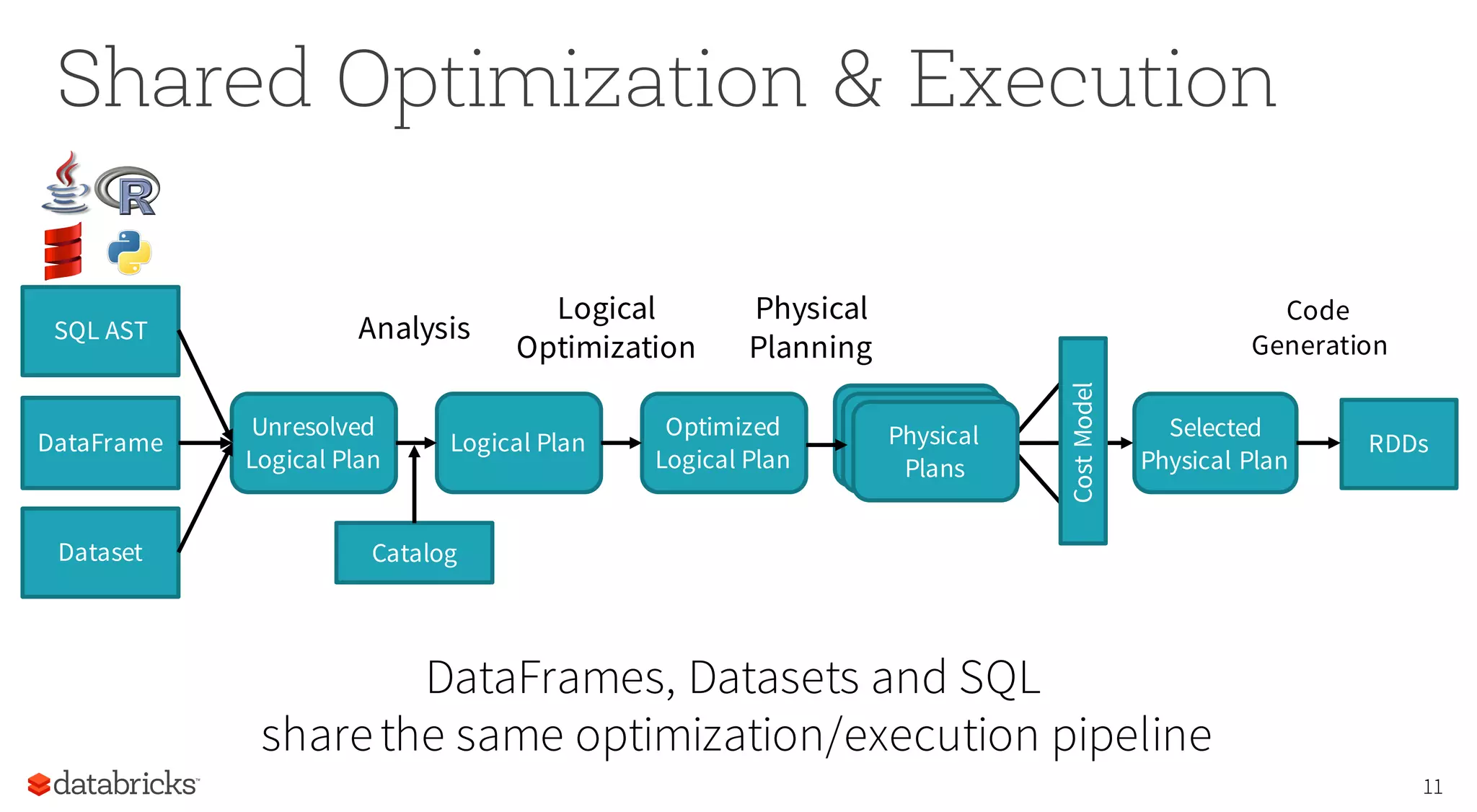







![Spark's Structured Data Model • Primitives: Byte, Short, Integer,Long, Float, Double, Decimal,String, Binary, Boolean, Timestamp, Date • Array[Type]: variable length collection • Struct: fixed # of nested columns with fixed types • Map[Type, Type]: variable length association 19](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-19-2048.jpg)
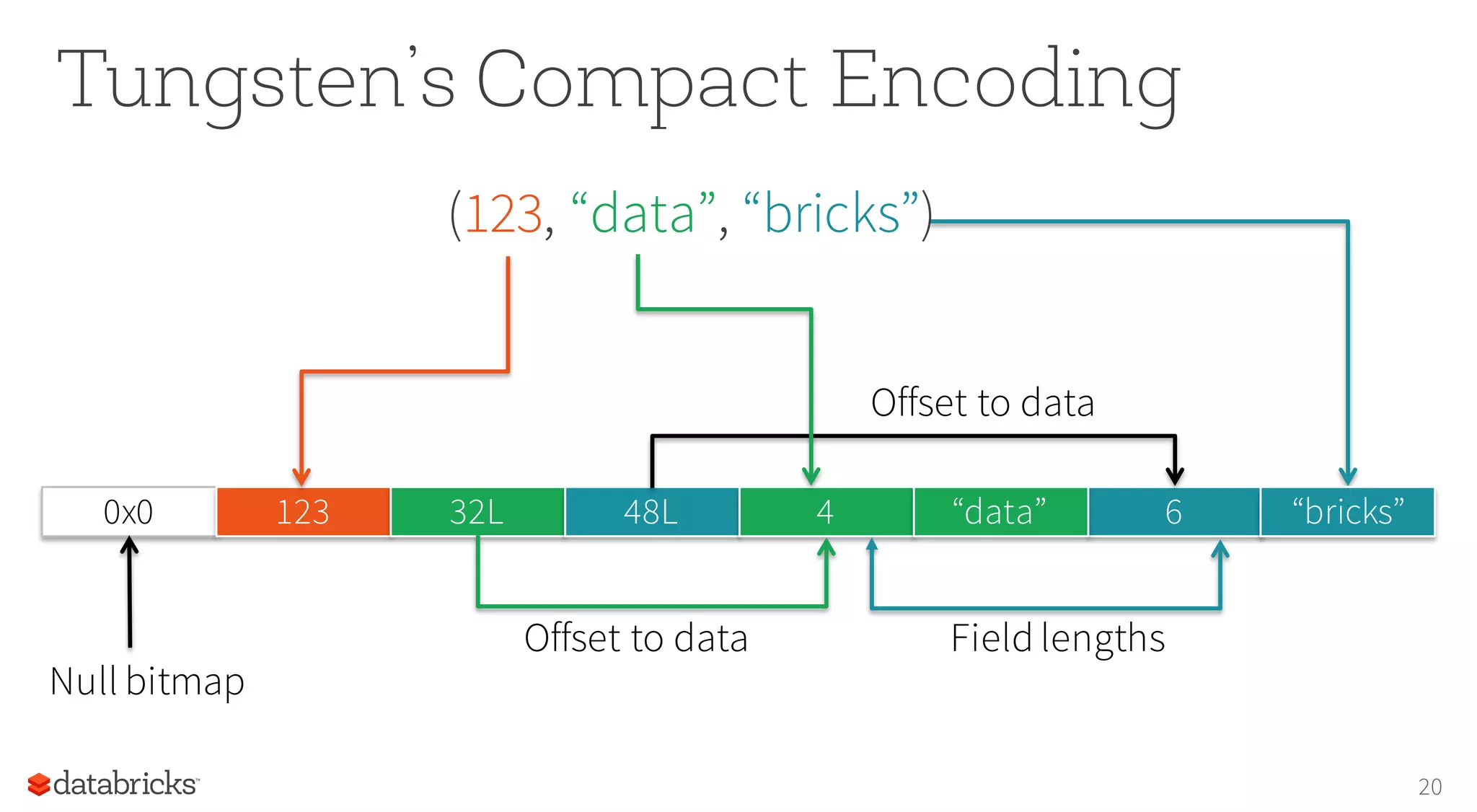

![Bridge Objects with Data Sources 22 { "name": "Michael", "zip": "94709" "languages": ["scala"] } case class Person( name: String, languages: Seq[String], zip: Int) Encoders map columns to fields by name { JSON } JDBC](https://image.slidesharecdn.com/structuringsparksse2016-160219225657/75/Structuring-Spark-DataFrames-Datasets-and-Streaming-22-2048.jpg)

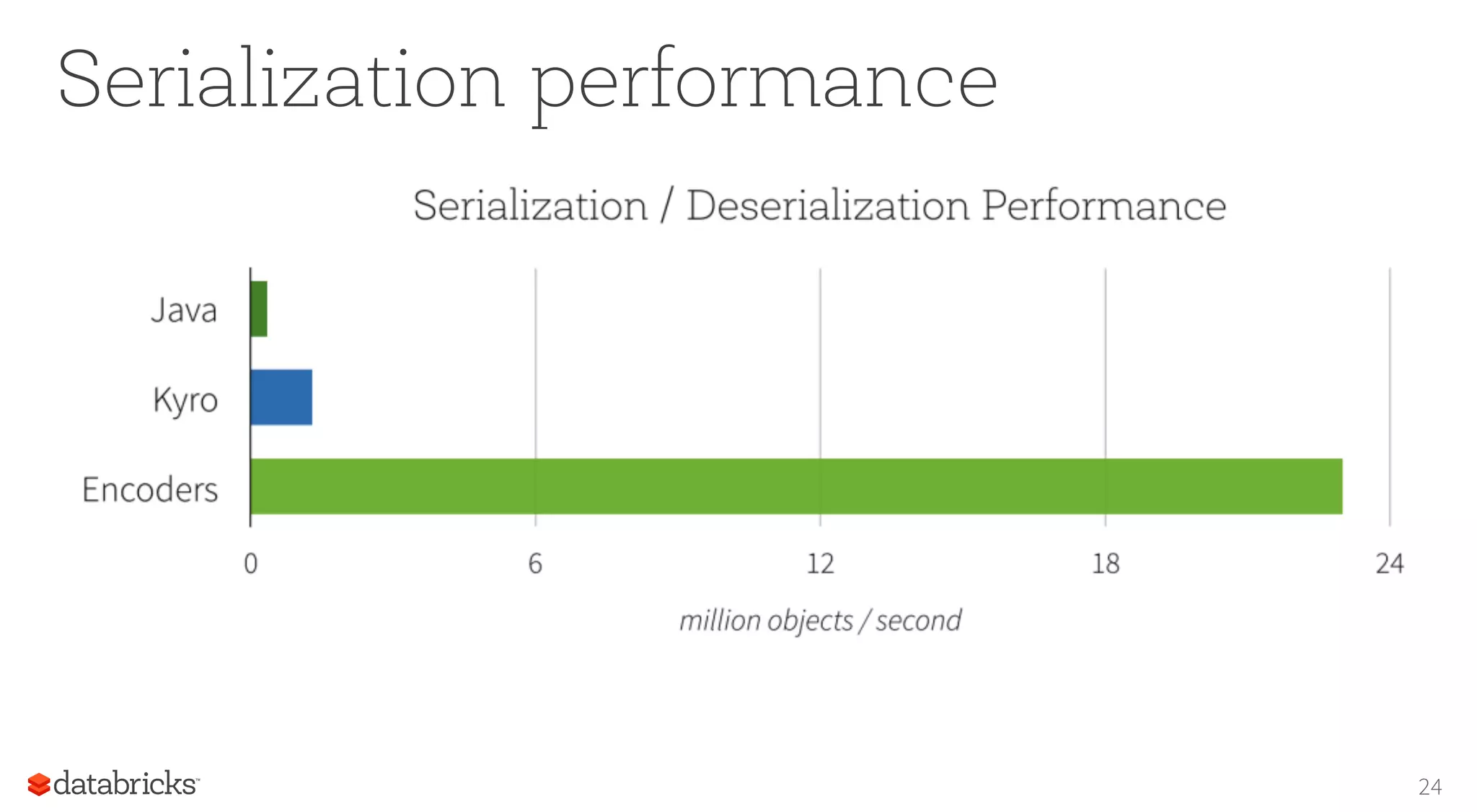



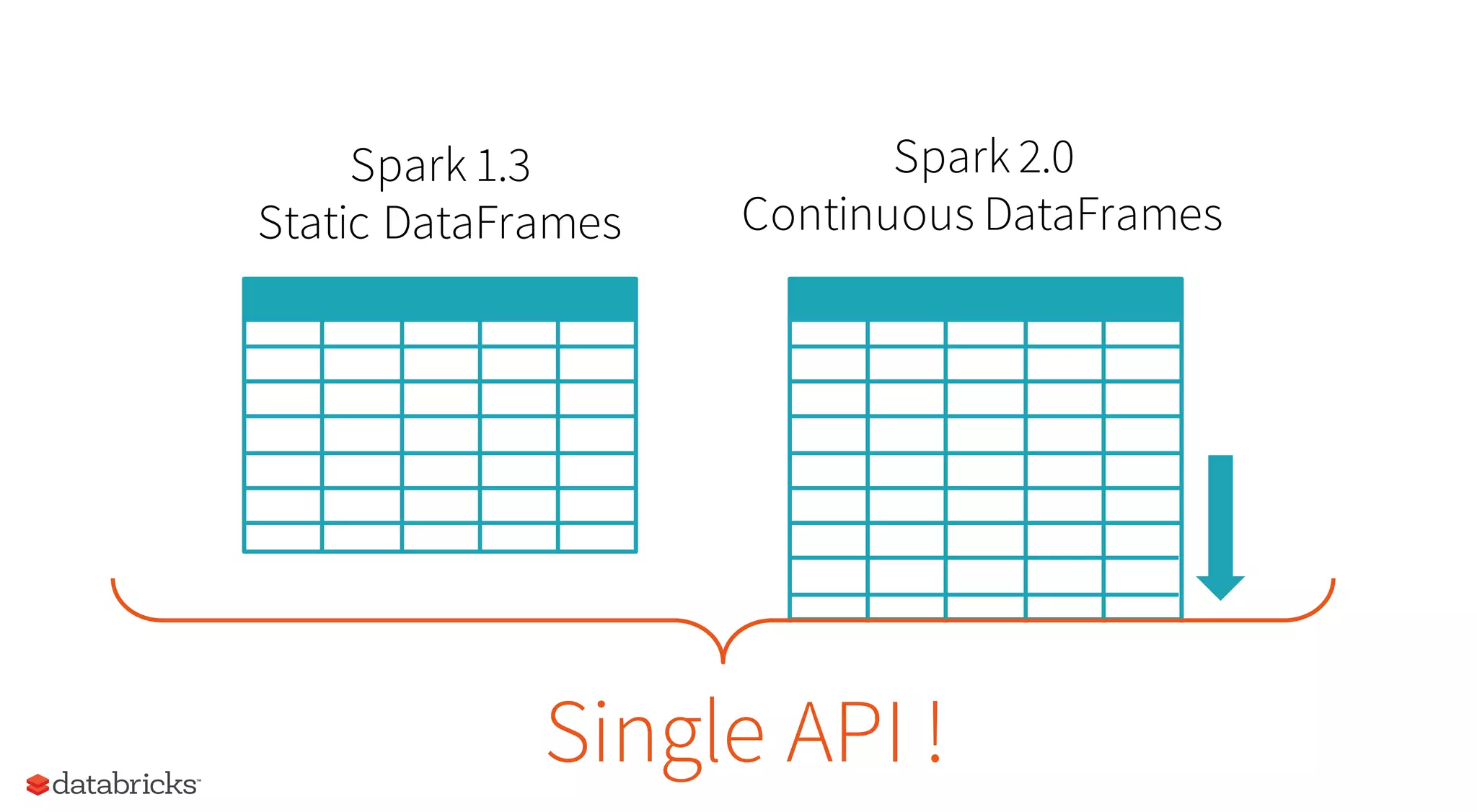



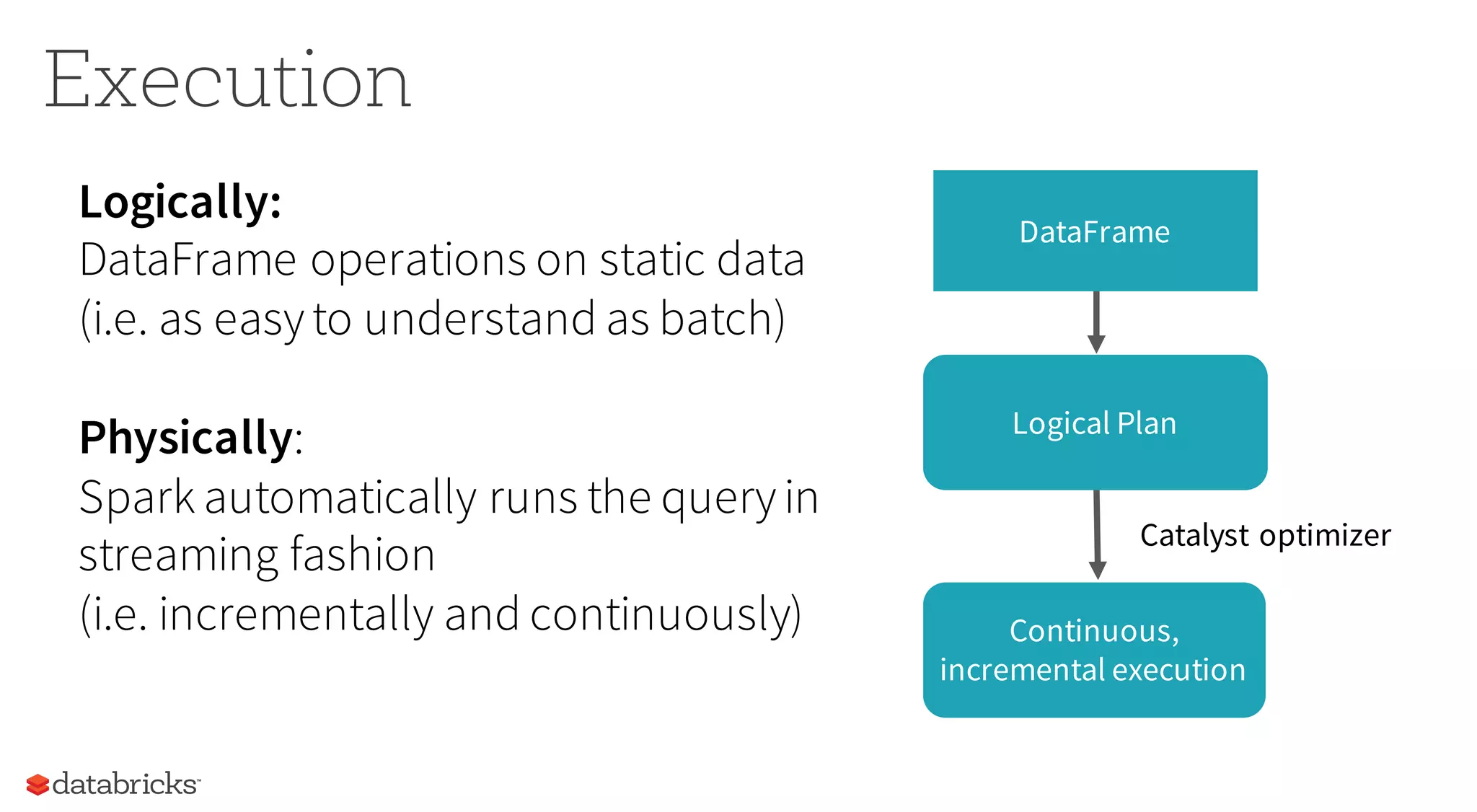
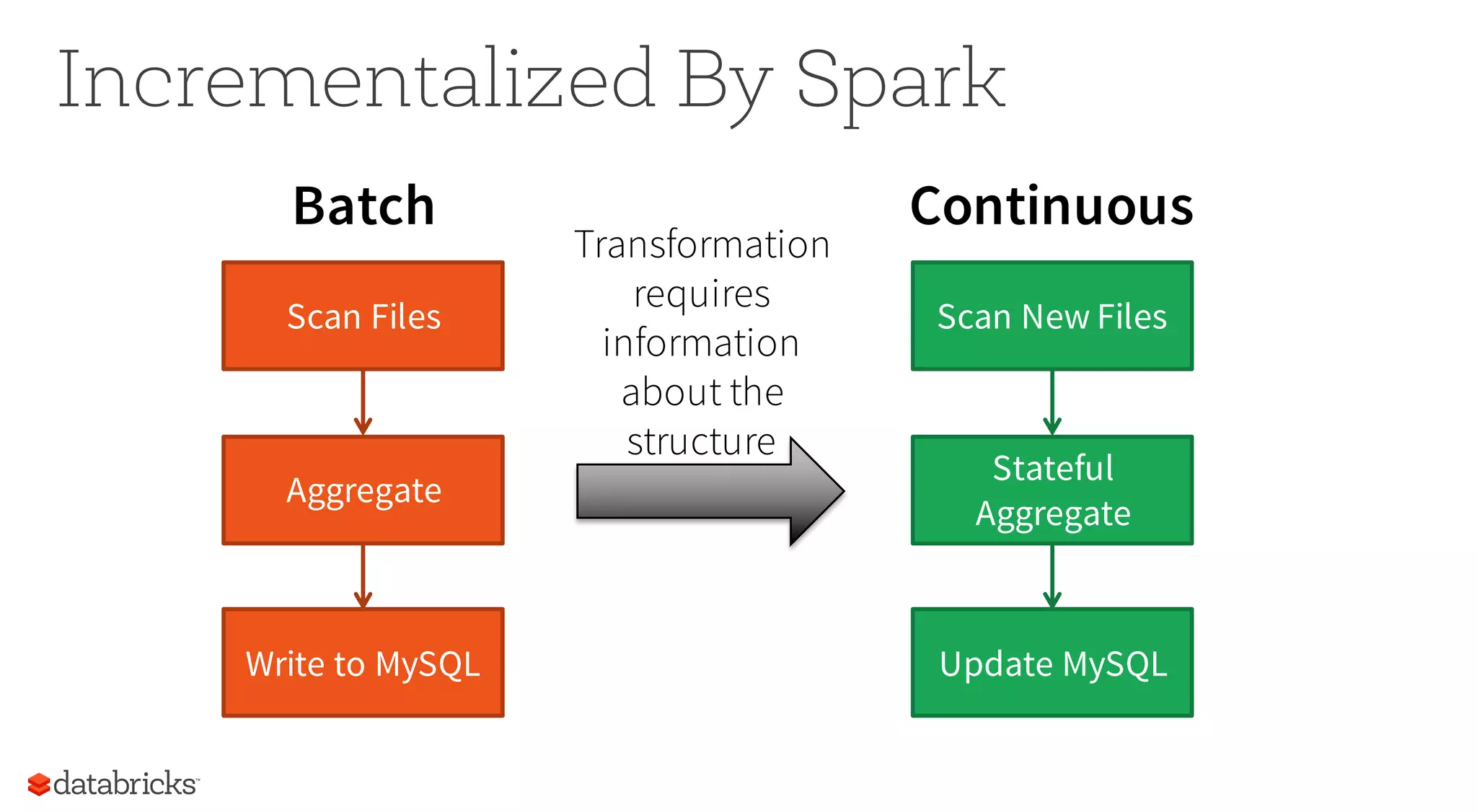



This document discusses how Spark provides structured APIs like SQL, DataFrames, and Datasets to organize data and computation. It describes how these APIs allow Spark to optimize queries by understanding their structure. The document outlines how Spark represents data internally and how encoders translate between this format and user objects. It also introduces Spark's new structured streaming functionality, which allows batch queries to run continuously on streaming data using the same API.