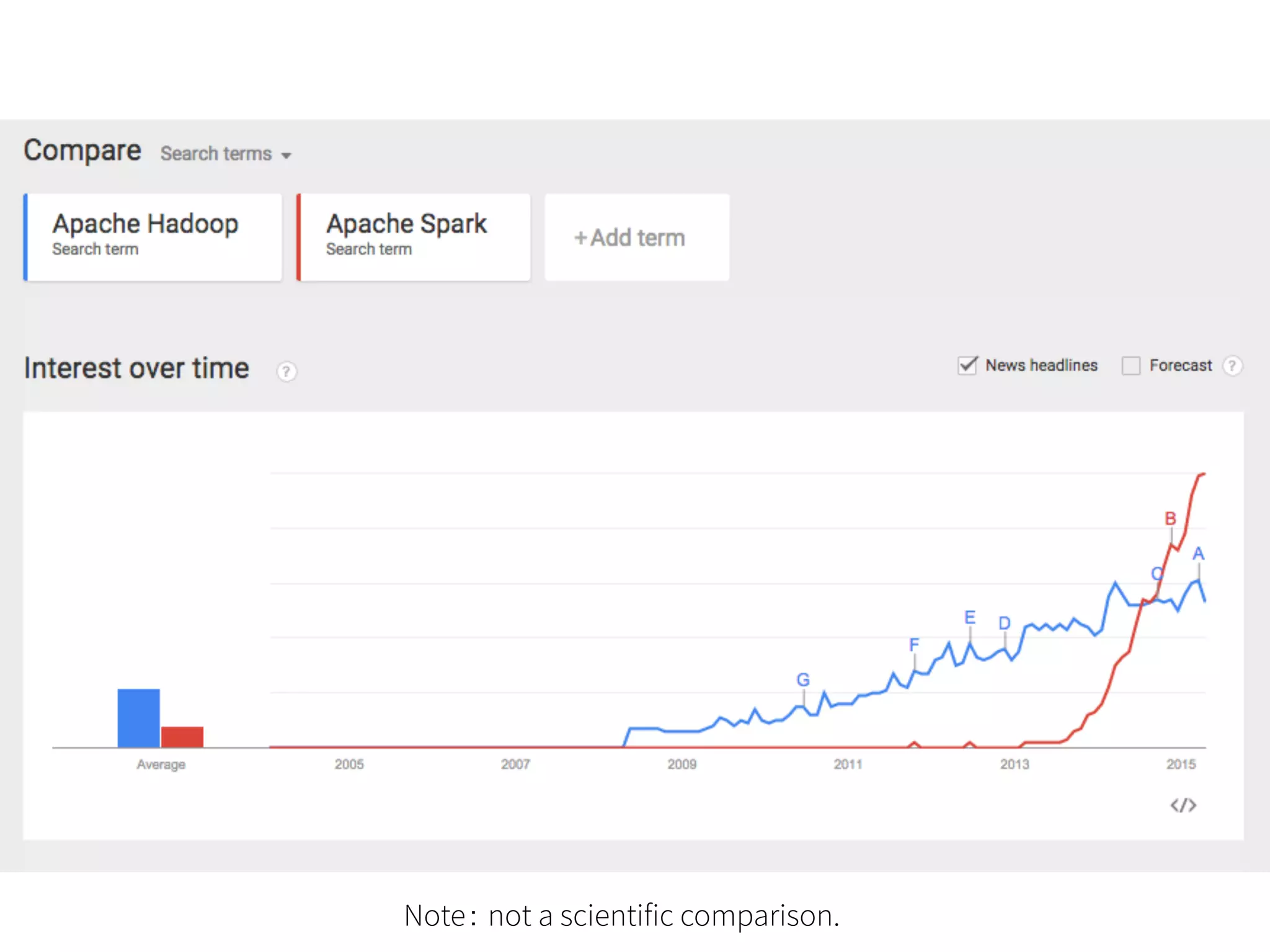
The guest lecture by Reynold Xin at Stanford University discusses Spark and its advantages over MapReduce, emphasizing the simplicity of programming and performance benefits for large datasets. It introduces the concept of Resilient Distributed Datasets (RDDs) as a core abstraction in Spark, highlighting their fault-tolerance and parallel processing capabilities. The lecture also covers Spark's application in streaming, machine learning, and SQL, showcasing its versatility in data processing tasks.
Stanford CS347 guest lecture by Reynold Xin on Spark, covering his background as a cofounder of Databricks.
The agenda includes sections on MapReduce review, introduction to Spark and RDDs, DataFrames, and Spark internals.
Discusses programming challenges in traditional distributed systems, highlighting complexity and failure management.
Introduction to data-parallel models and the MapReduce programming model, emphasizing difficulties and inefficiencies.
Identifies limitations of MapReduce and introduces the development of higher-level frameworks and specialized systems.
A historical overview of Spark's development and its ecosystem's structure compared to specialized systems.
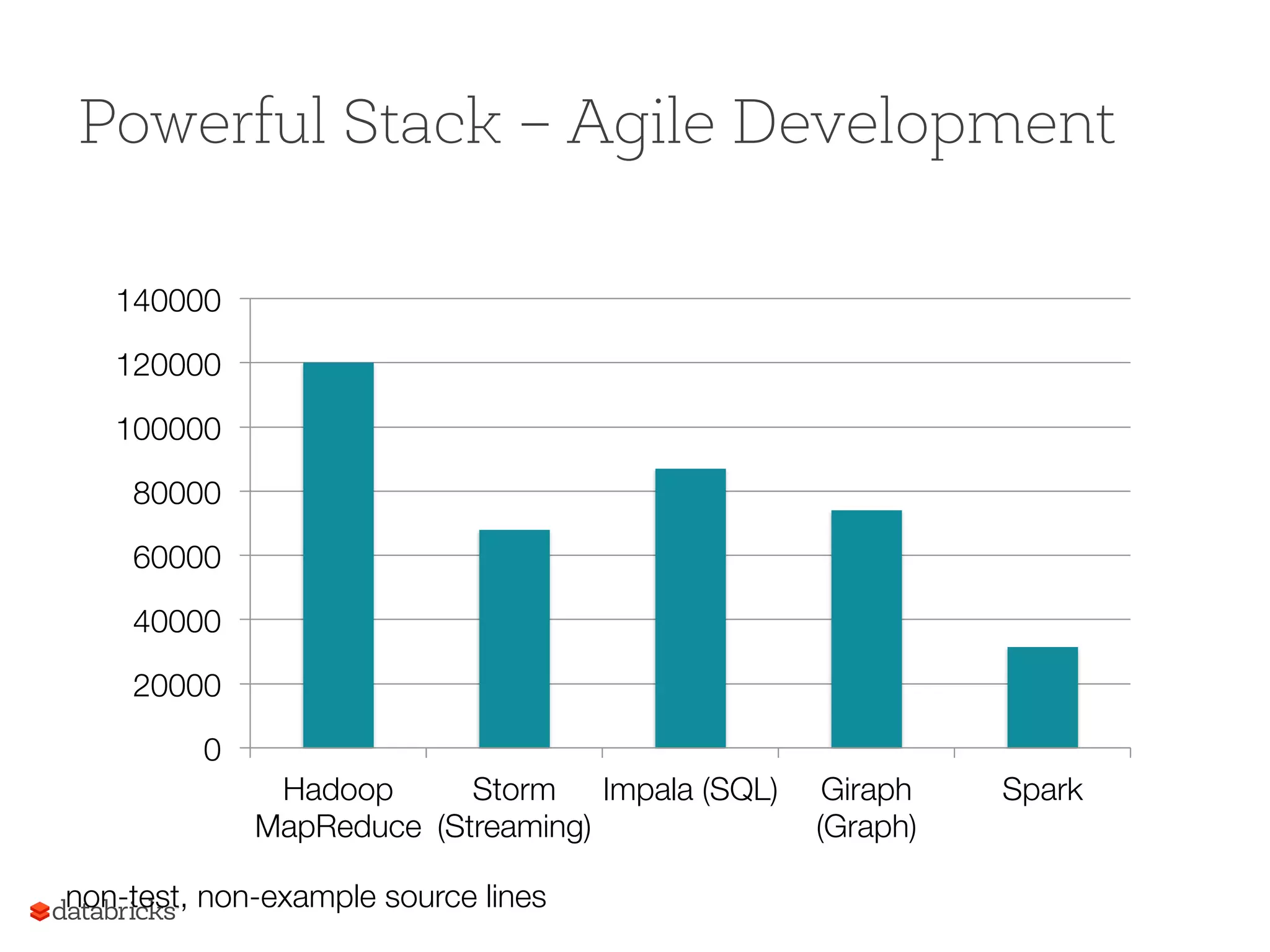
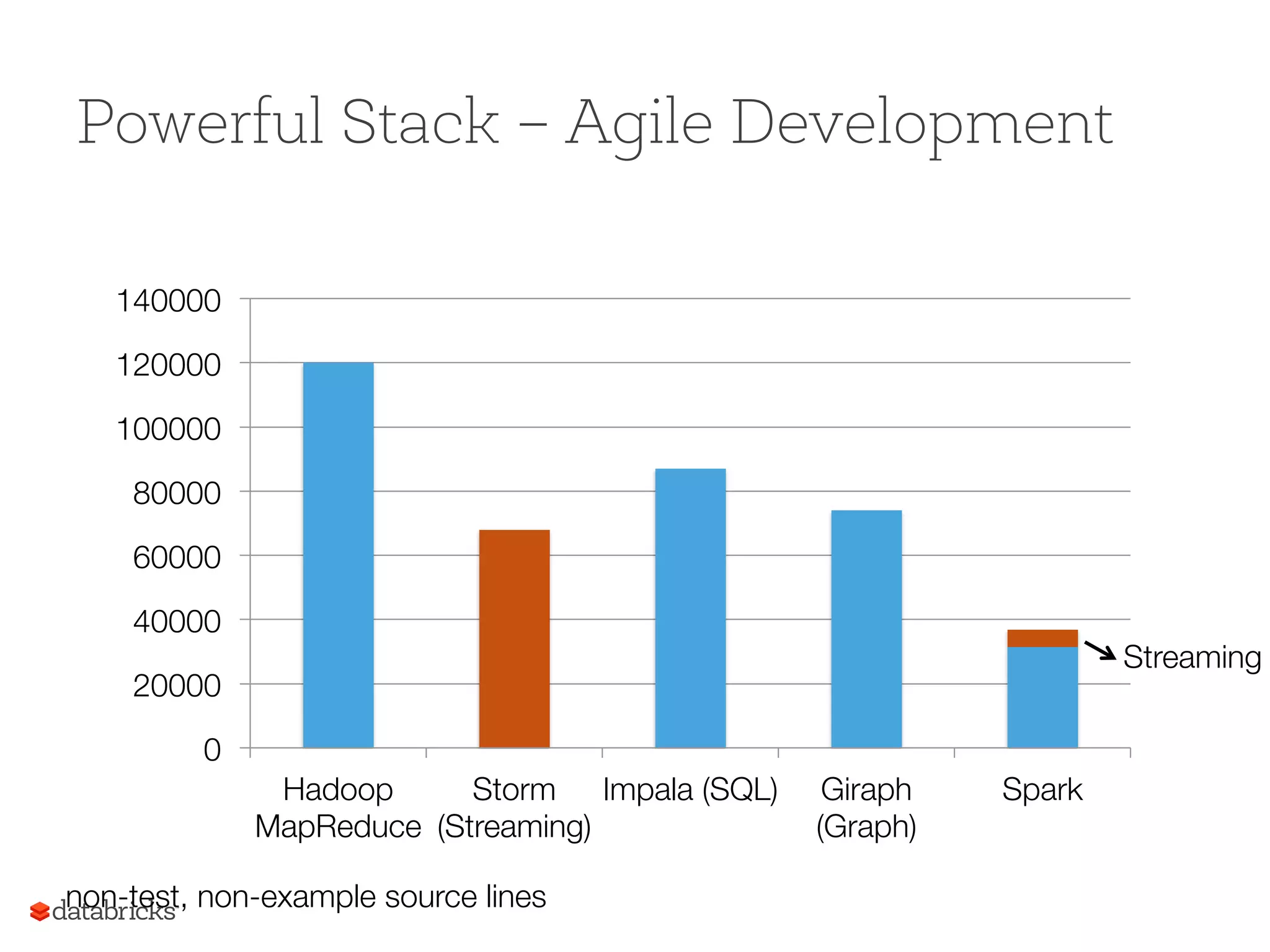
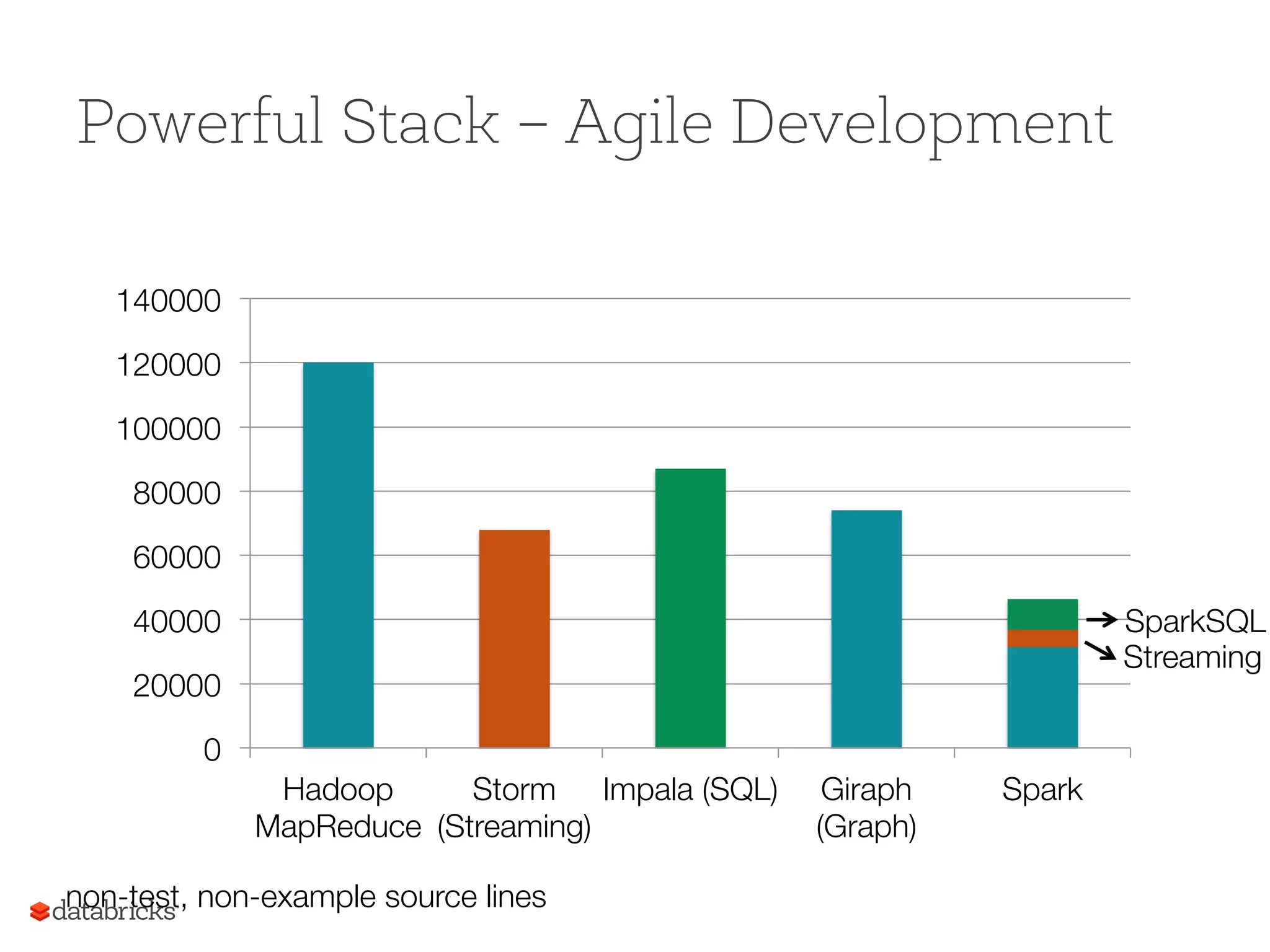
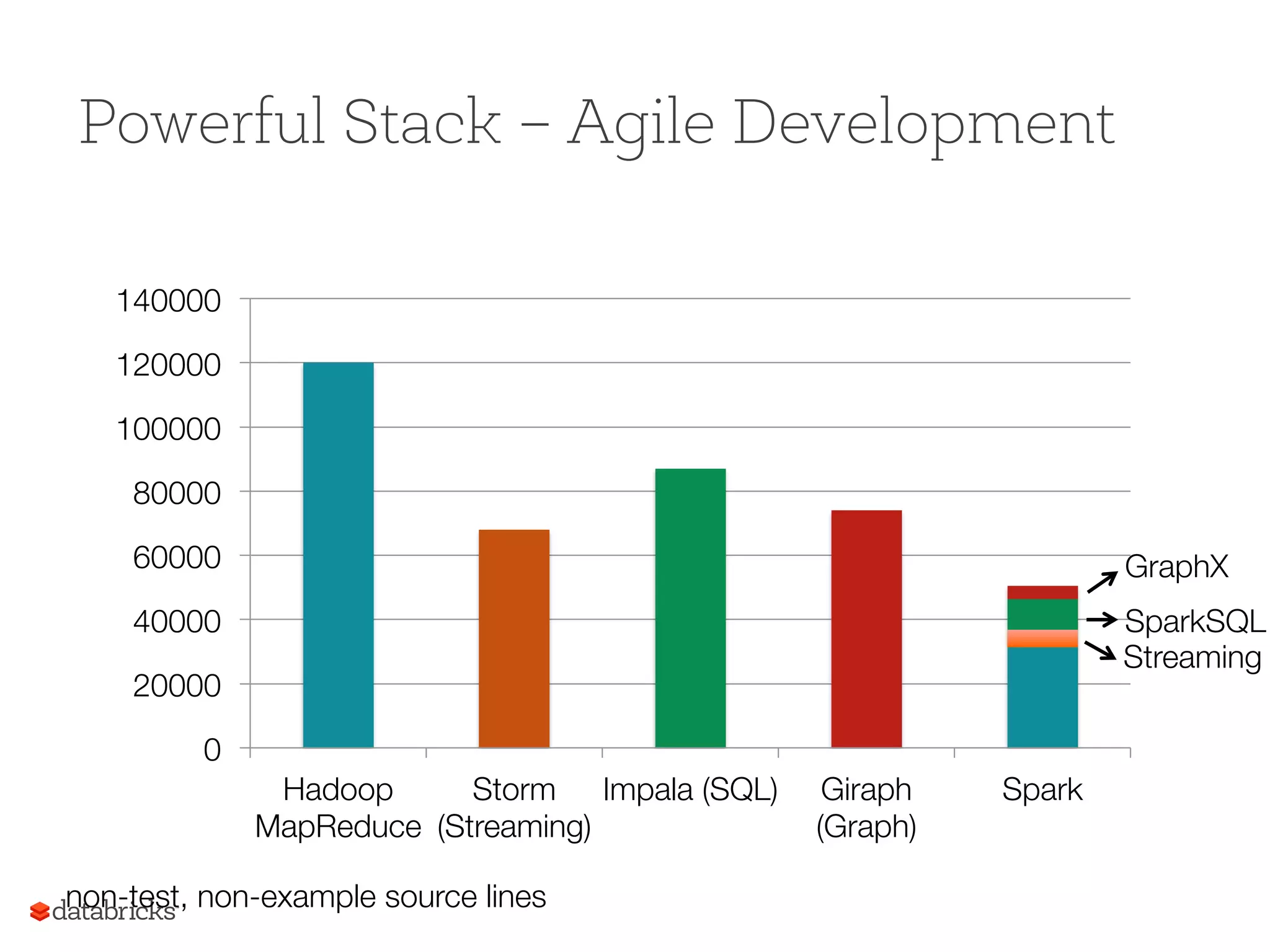
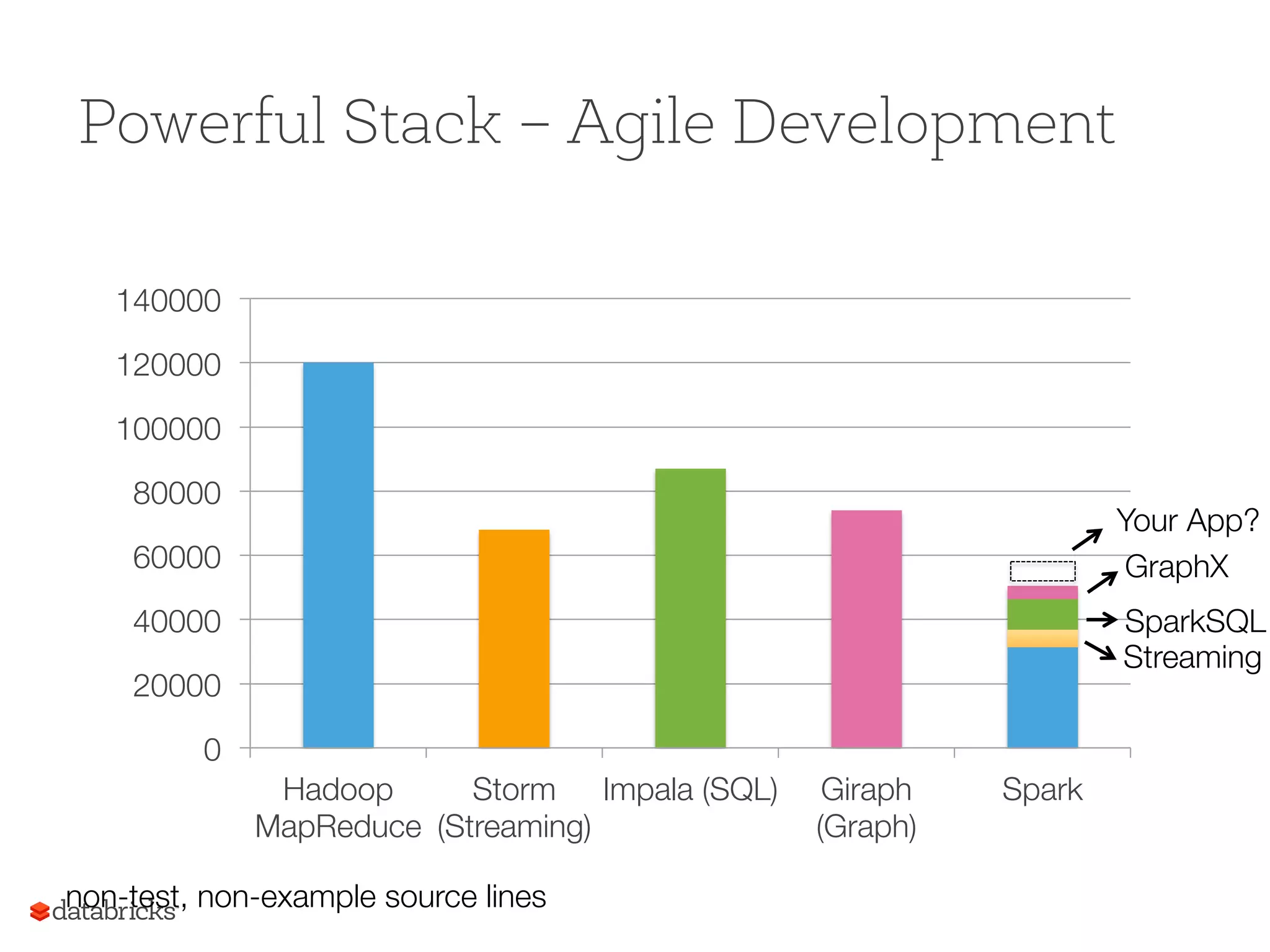
Spark's programming capabilities exemplified with a simple WordCount and performance benchmarks, showing significant speed improvements.
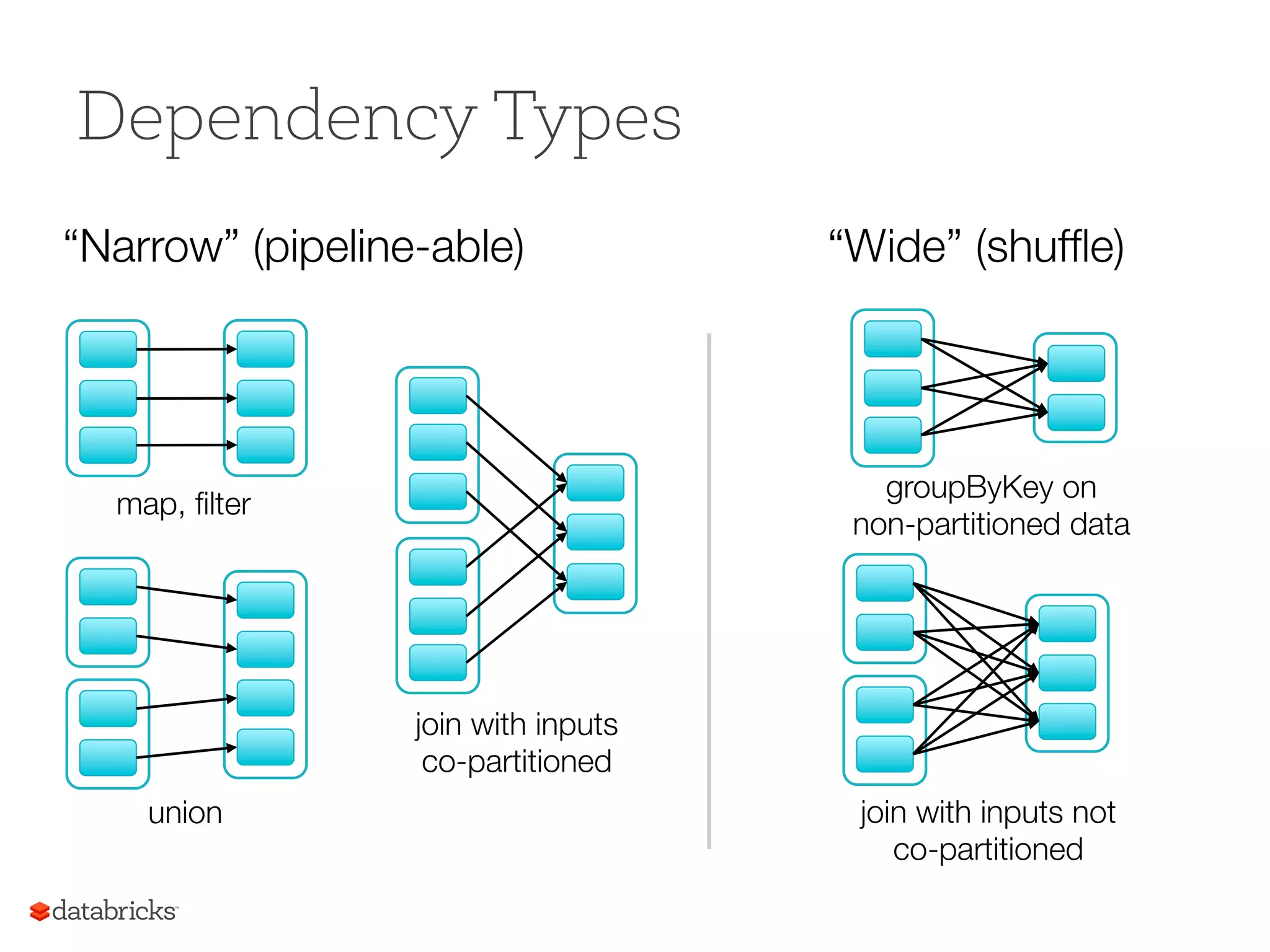
Introduces Resilient Distributed Datasets (RDDs), their features, types, and core operations in Spark.
Various manipulation strategies for RDDs including transformations and actions with practical examples.
Detailed example of using Spark for log file analysis, implementing RDD operations for filtering and data extraction.
Discusses language support in Spark (Python, Scala, Java) and expressive API capabilities for advanced data operations.
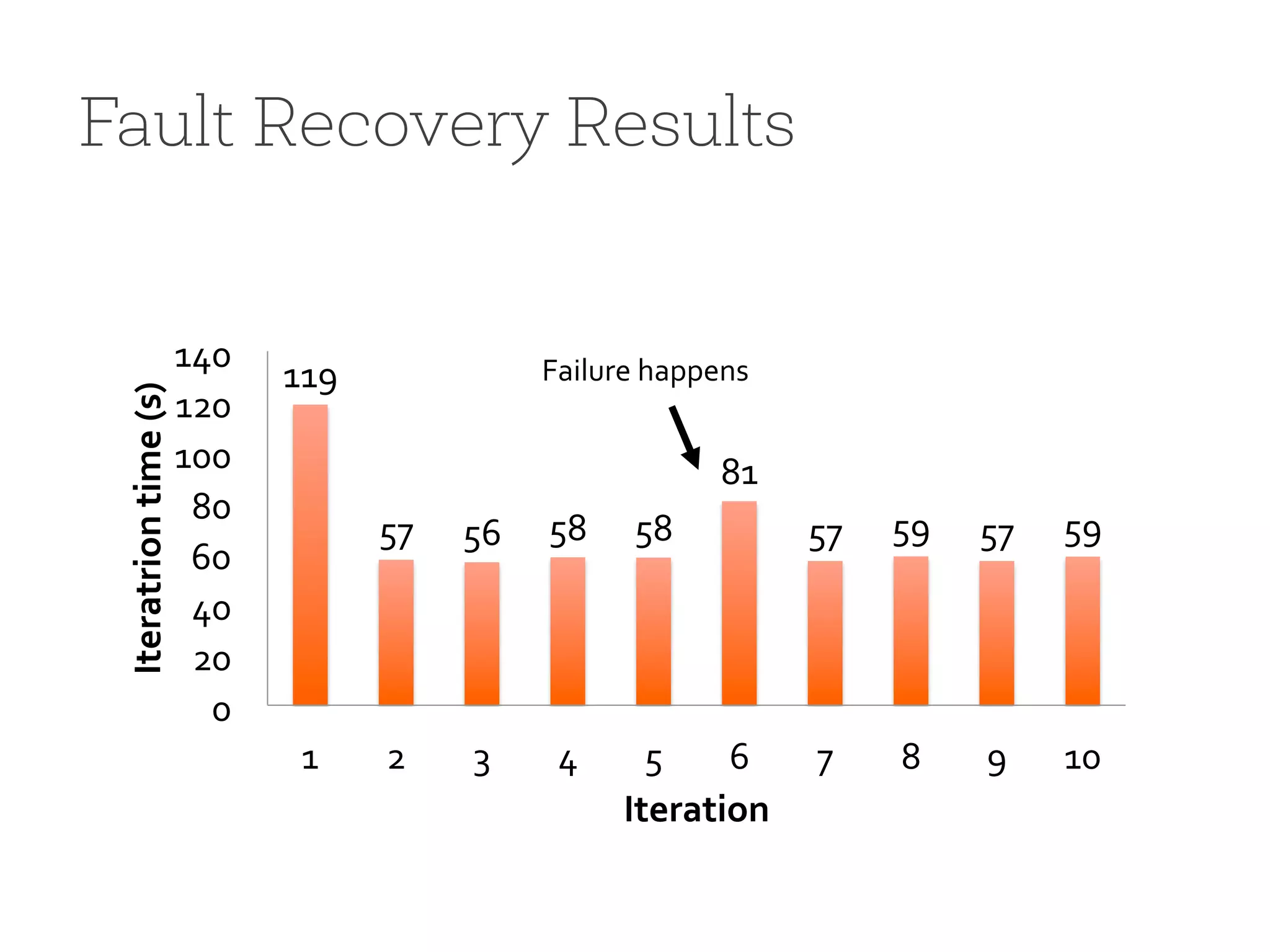
Highlights Spark's support for machine learning, fault tolerance through RDD lineage, and performance metrics.
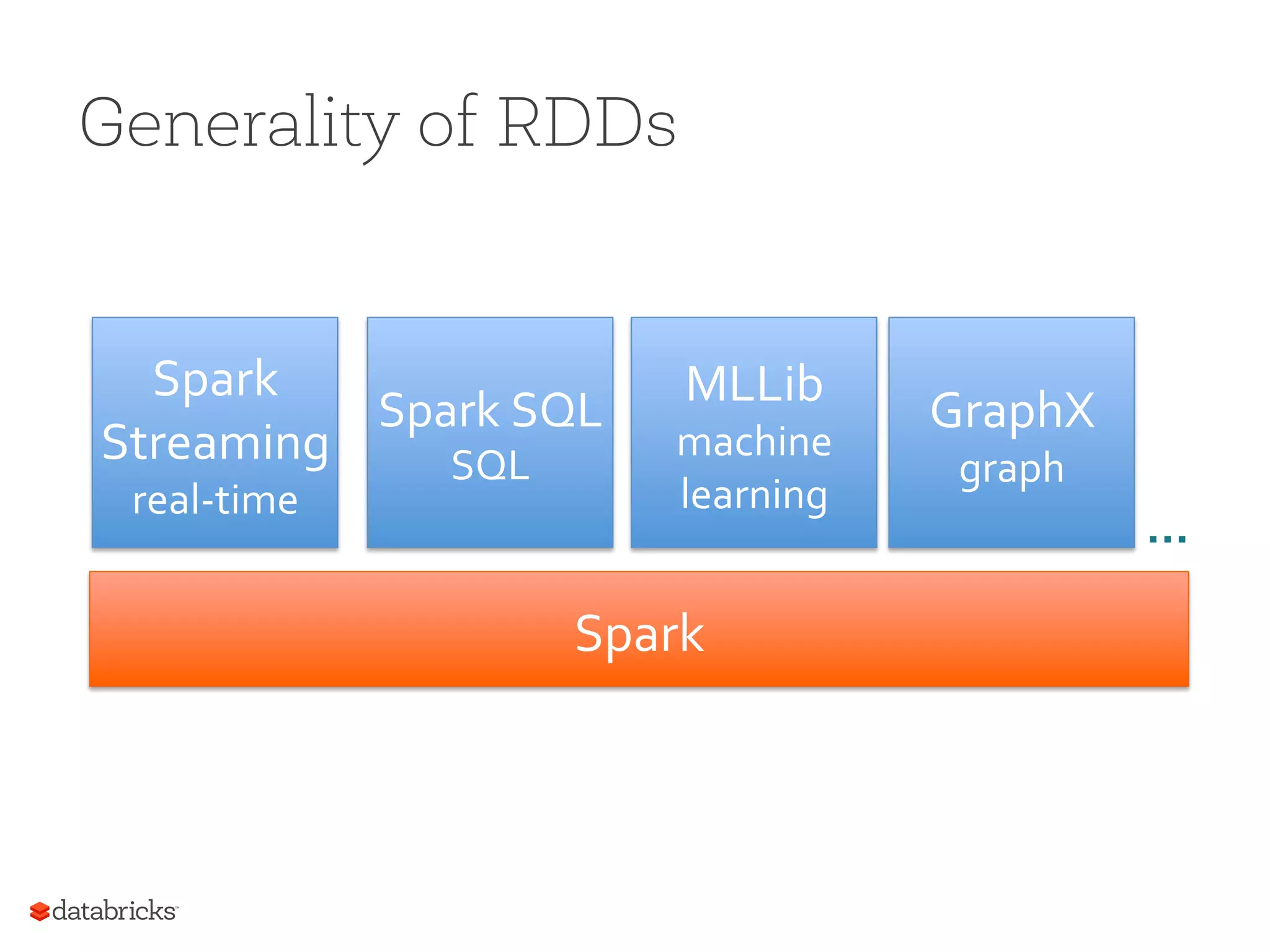
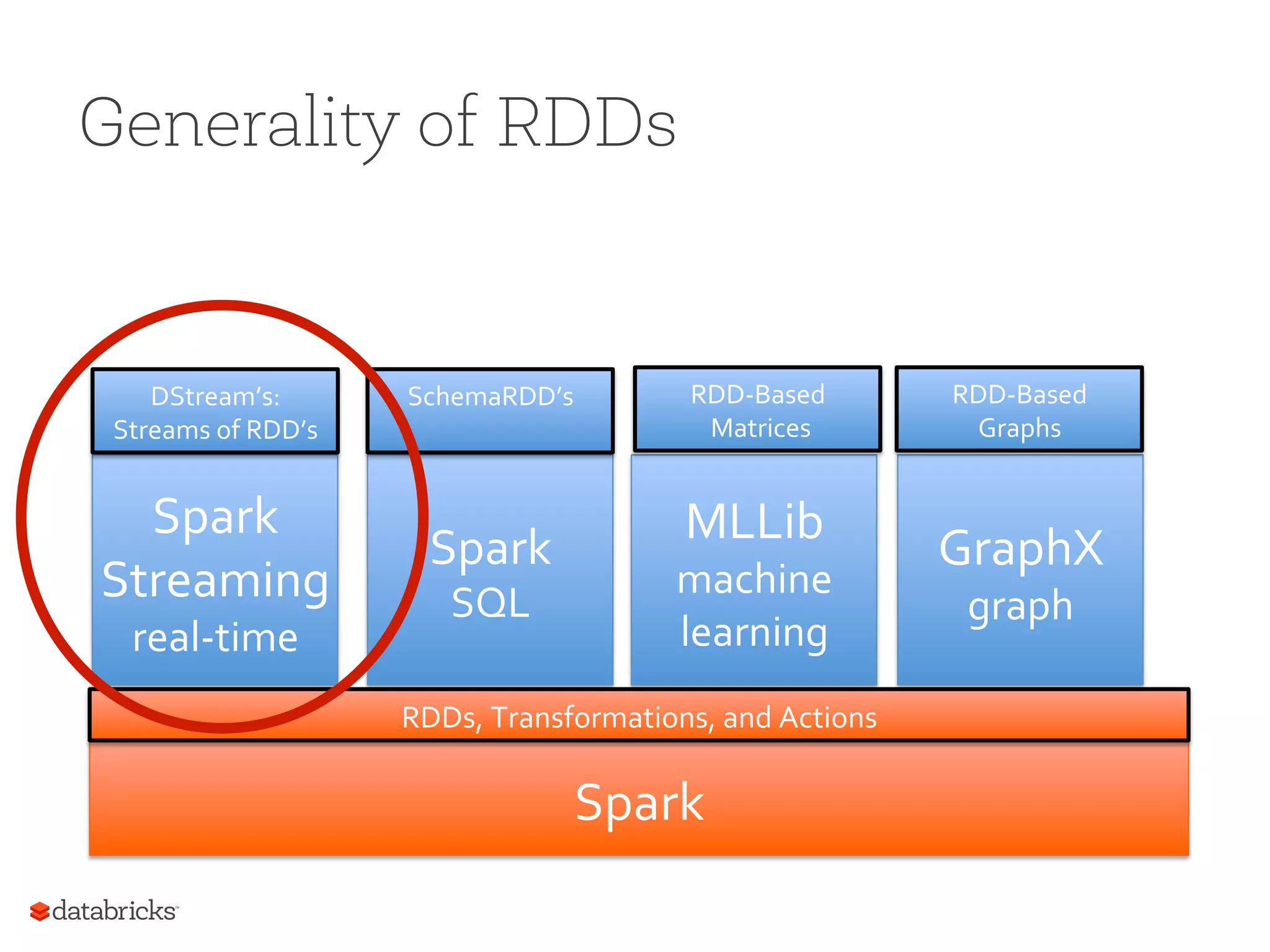
Explains how Spark supports different applications such as streaming and machine learning via RDDs.
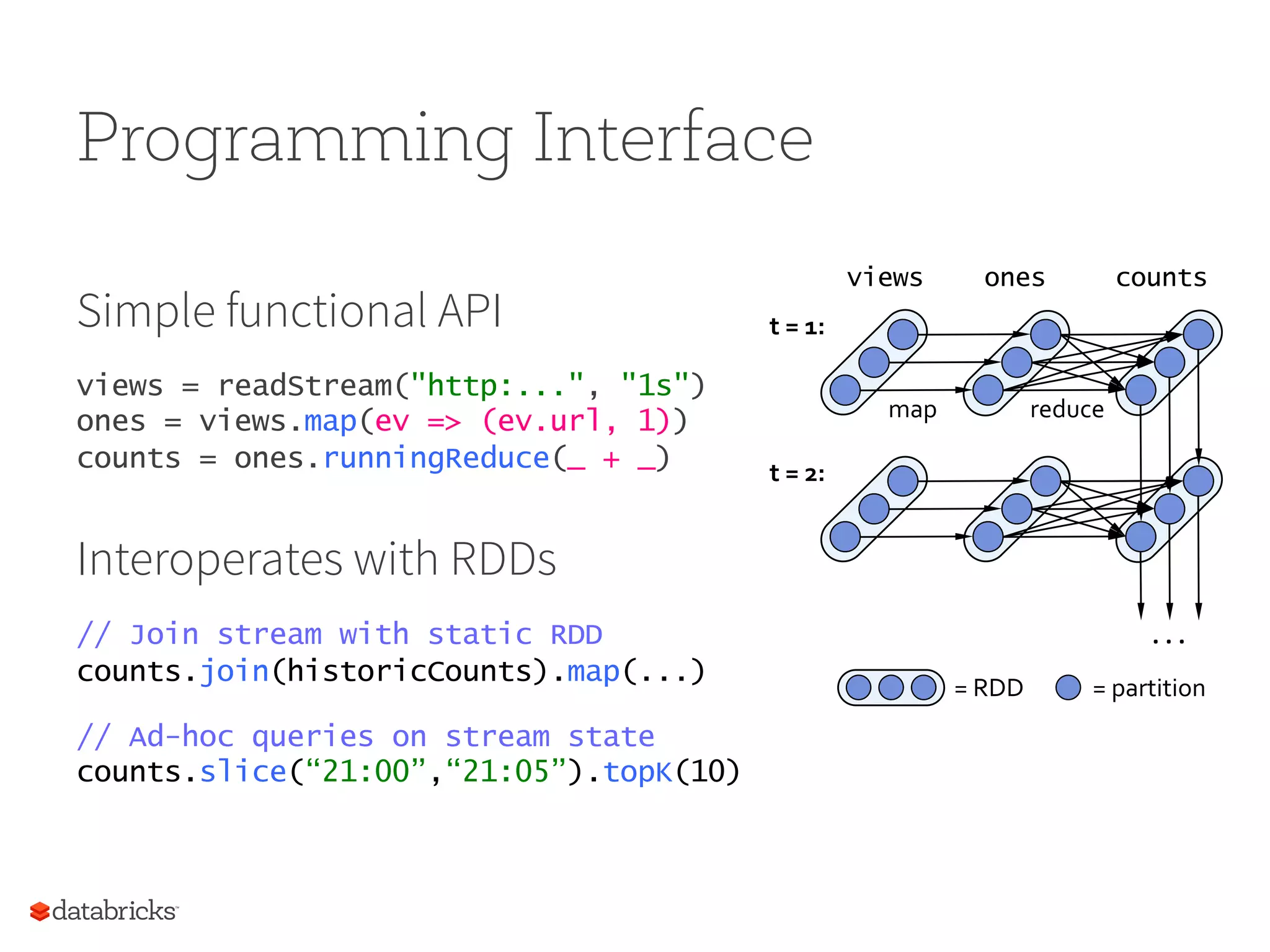
Description of Spark Streaming's programming interface, its integration with RDDs, and benefits in speed and efficiency.
Introduces DataFrames as a powerful abstraction for structured data processing in Spark with examples of usage.Details on building machine learning pipelines in Spark, demonstrating the ease of scaling machine learning workflows.
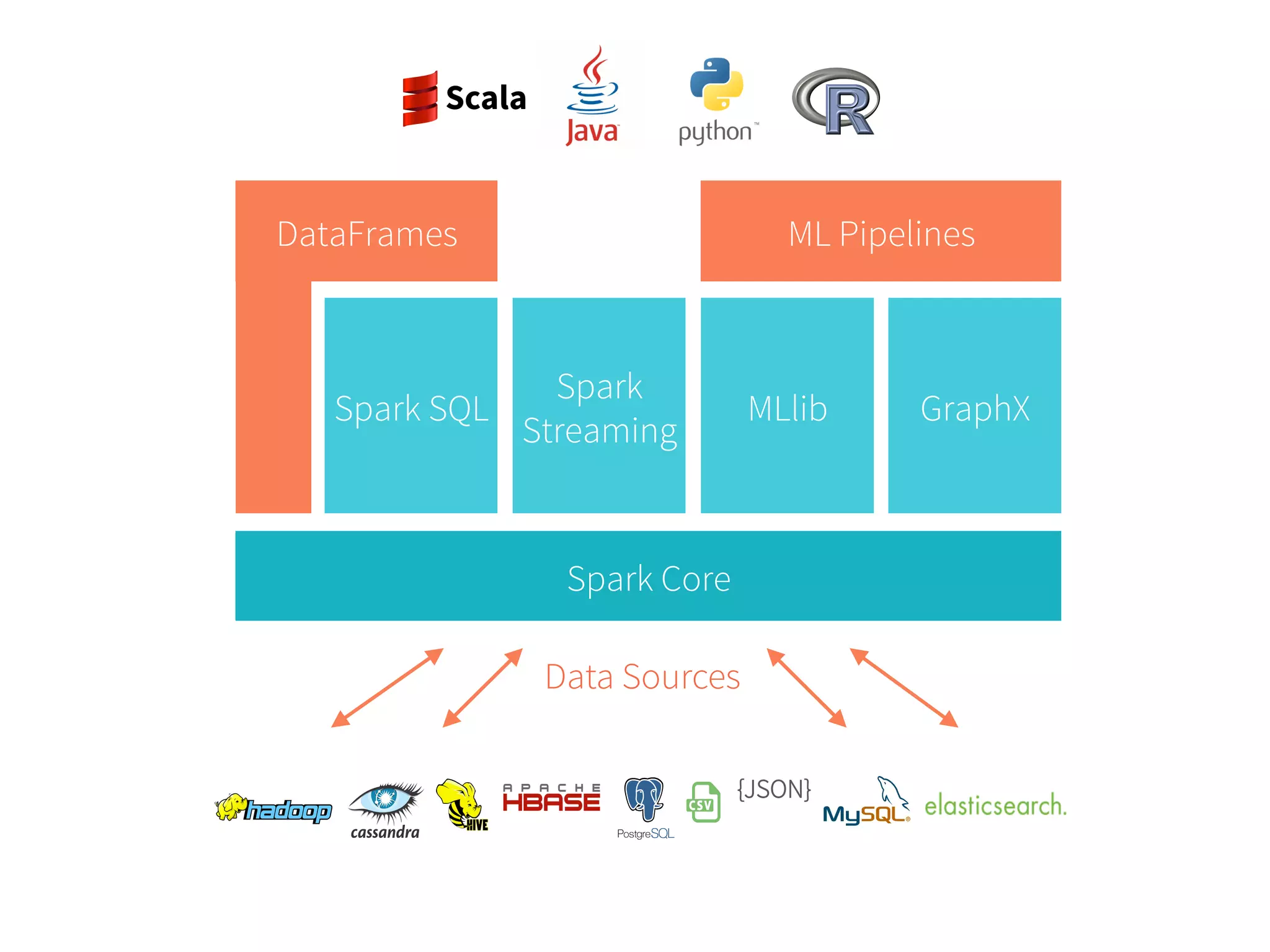
Overview of Spark's aim for a unified engine across various workloads and data sources, ensuring effective integration.
Traditional Network Programming Message-passingbetween nodes (MPI, RPC, etc) Really hard to do at scale: • How to split problem across nodes? – Important to consider network and data locality • How to deal with failures? – If a typical server fails every 3 years, a 10,000-node cluster sees 10 faults/day! • Even without failures: stragglers (a node is slow) Almost nobody does this! 6
7.
Data-Parallel Models Restrict theprogramming interface so that the system can do more automatically “Here’s an operation, run it on all of the data” • I don’t care where it runs (you schedule that) • In fact, feel free to run it twice on different nodes 7
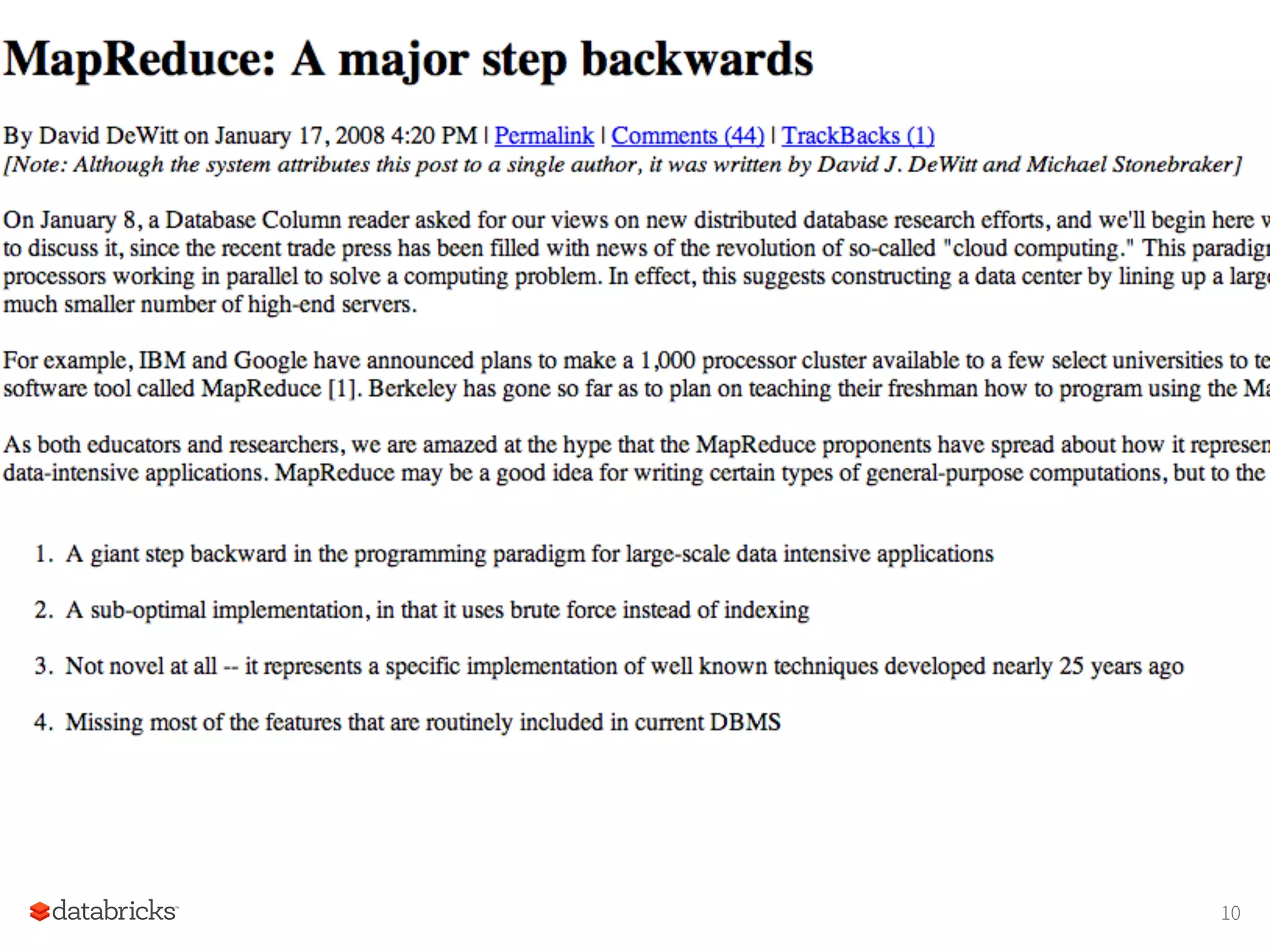
Problems with MapReduce MapReduceuse cases showed two major limitations: 1. difficulty of programming directly in MR. 2. Performance bottlenecks In short, MR doesn’t compose well for large applications Therefore, people built high level frameworks and specialized systems. 11
12.
Higher Level Frameworks SELECTcount(*) FROM users A = load 'foo'; B = group A all; C = foreach B generate COUNT(A); In reality, 90+% of MR jobs are generated by Hive SQL 12
13.
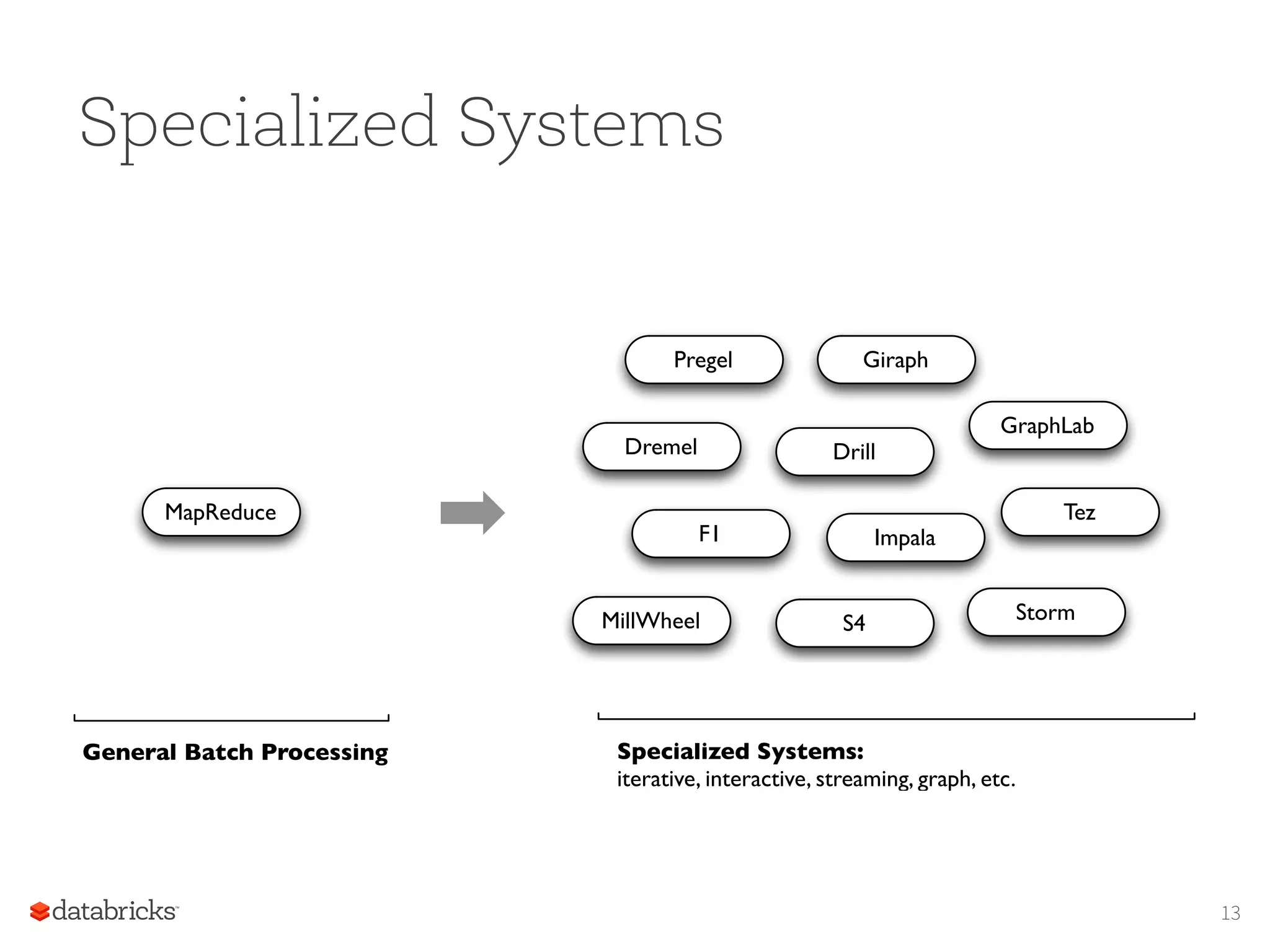
Specialized Systems MapReduce General BatchProcessing Specialized Systems: iterative, interactive, streaming, graph, etc. Pregel Giraph Dremel Drill Tez Impala GraphLab StormS4 F1 MillWheel 13
14.
Agenda 1. MapReduce Review 2. Introduction to Spark and RDDs 3. Generality of RDDs (e.g. streaming, ML) 4. DataFrames 5. Internals (time permitting) 14
15.
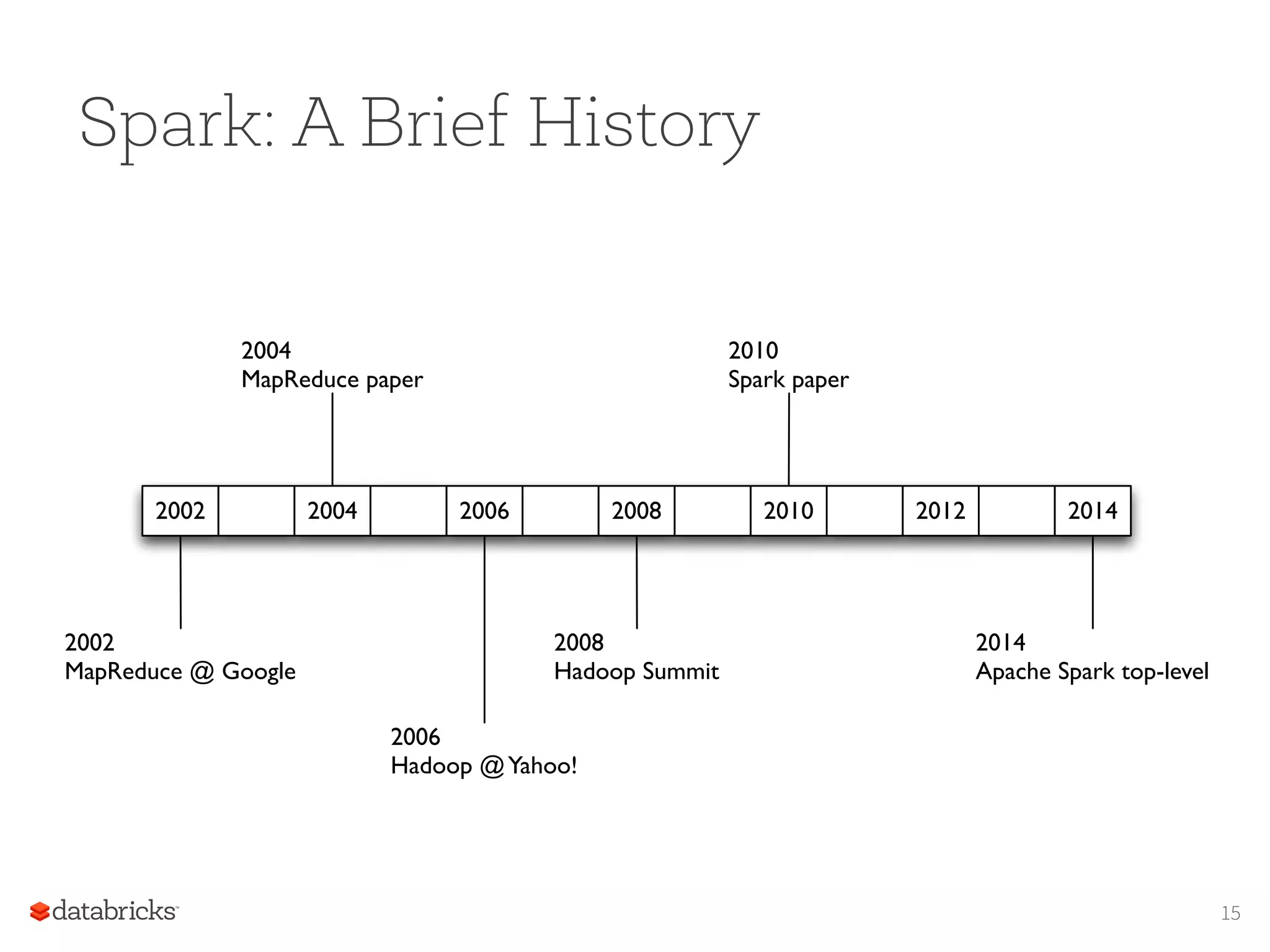
Spark: A BriefHistory 15 2002 2002 MapReduce @ Google 2004 MapReduce paper 2006 Hadoop @Yahoo! 2004 2006 2008 2010 2012 2014 2014 Apache Spark top-level 2010 Spark paper 2008 Hadoop Summit
16.
Spark Summary Unlike thevarious specialized systems, Spark’s goal was to generalize MapReduce to support new apps Two small additions are enough: • fast data sharing • general DAGs More efficient engine, and simpler for the end users. 16
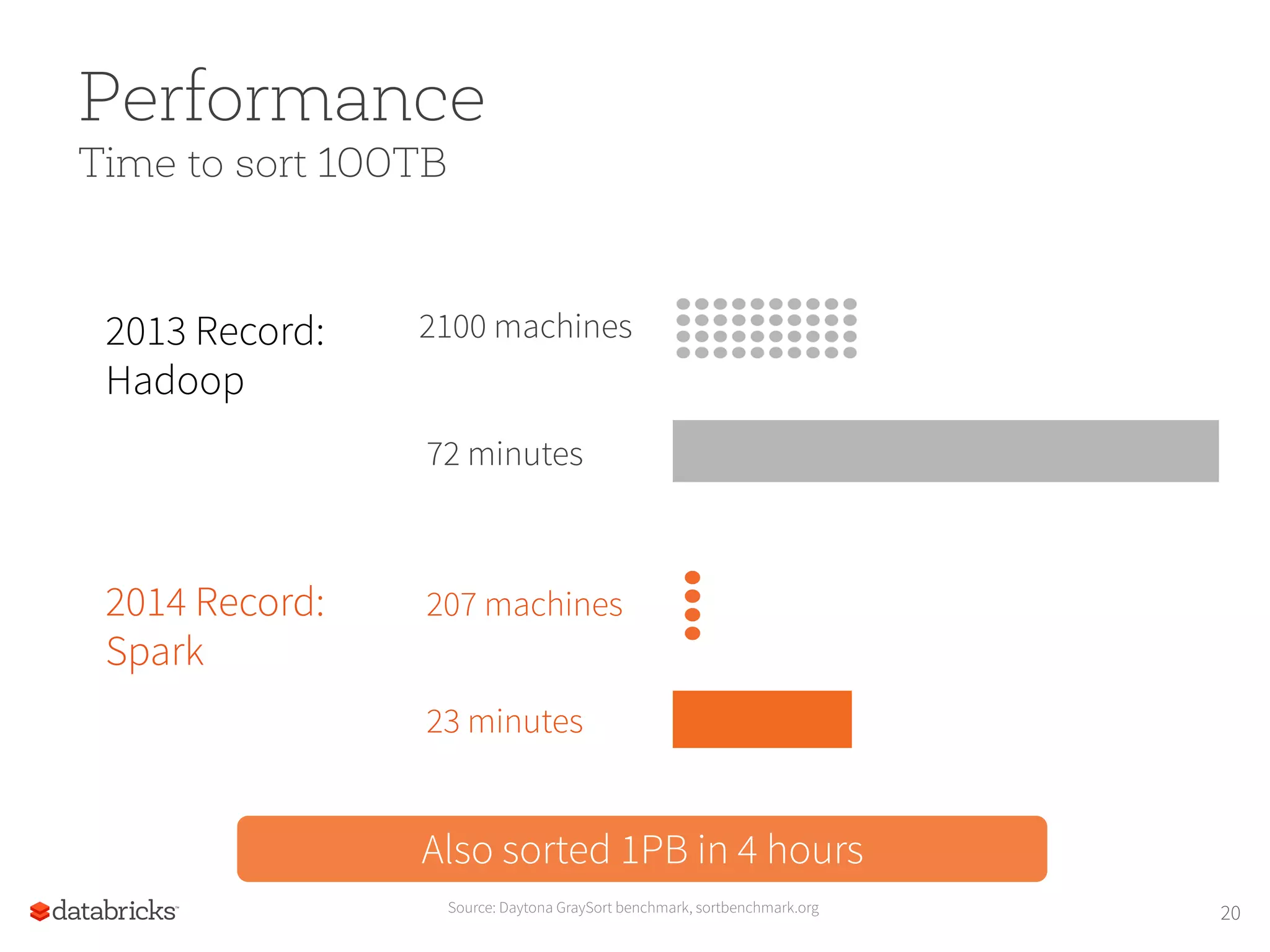
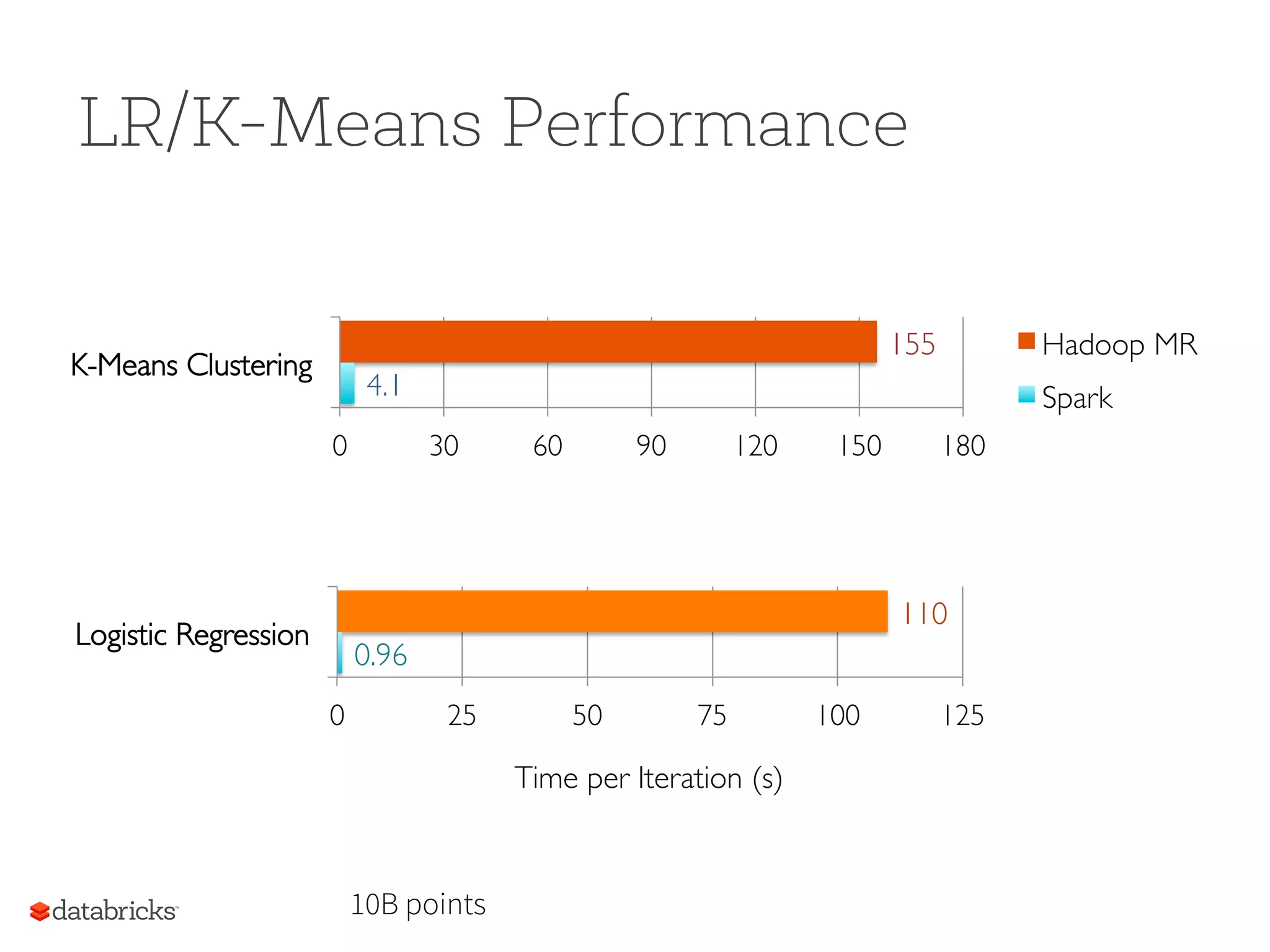
Performance Time to sort100TB 2100 machines2013 Record: Hadoop 2014 Record: Spark Source: Daytona GraySort benchmark, sortbenchmark.org 72 minutes 207 machines 23 minutes Also sorted 1PB in 4 hours 20
21.
RDD: Core Abstraction ResilientDistributed Datasets • Collections of objects spread across a cluster, stored in RAM or on Disk • Built through parallel transformations • Automatically rebuilt on failure Operations • Transformations (e.g. map, filter, groupBy) • Actions (e.g. count, collect, save) Write programs in terms of distributed datasets and operations on them
22.
RDD Resilient Distributed Datasetsare the primary abstraction in Spark – a fault-tolerant collection of elements that can be operated on in parallel Two types: • parallelized collections – take an existing single-node collection and parallel it • Hadoop datasets: files on HDFS or other compatible storage 22
23.
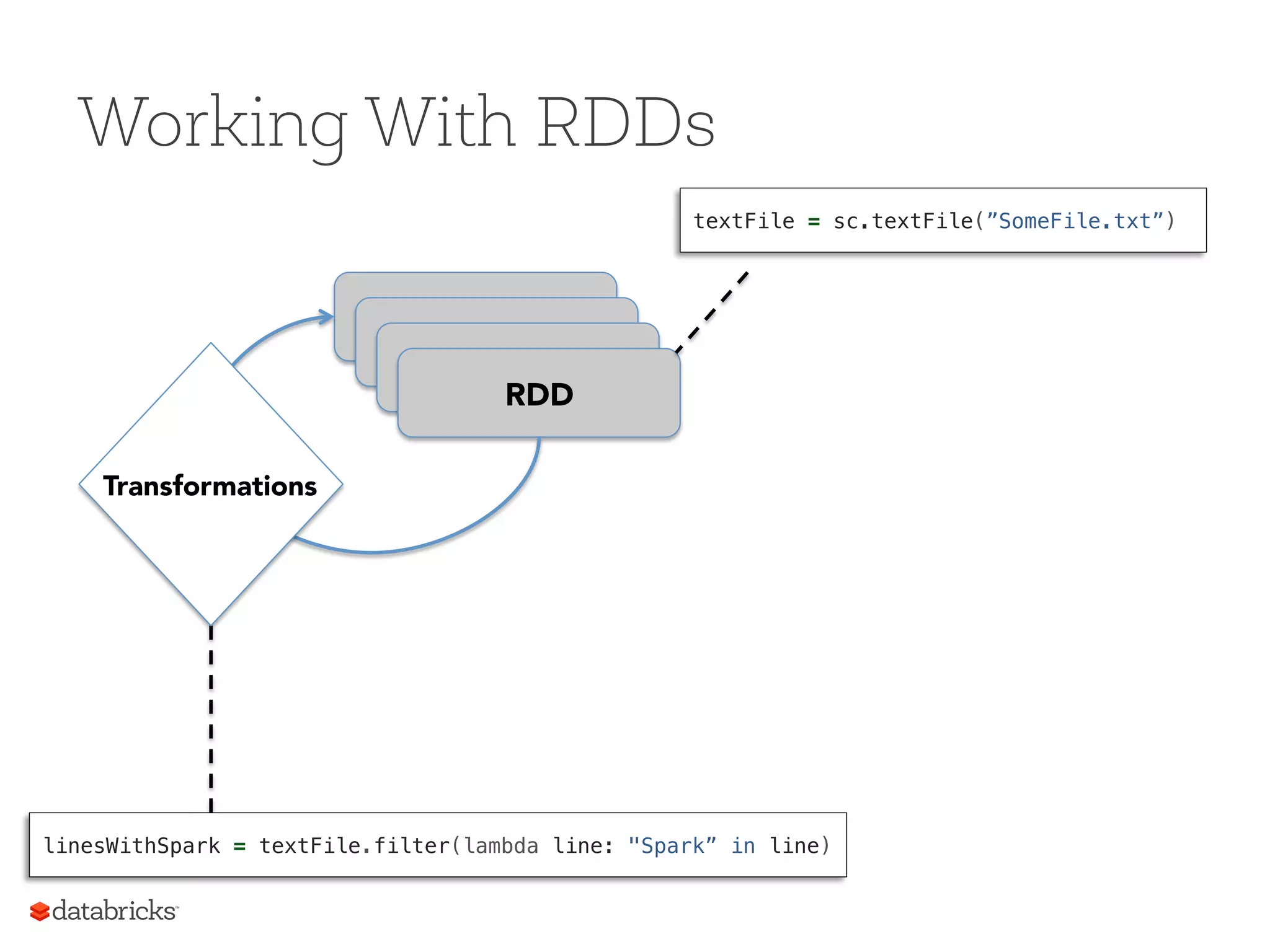
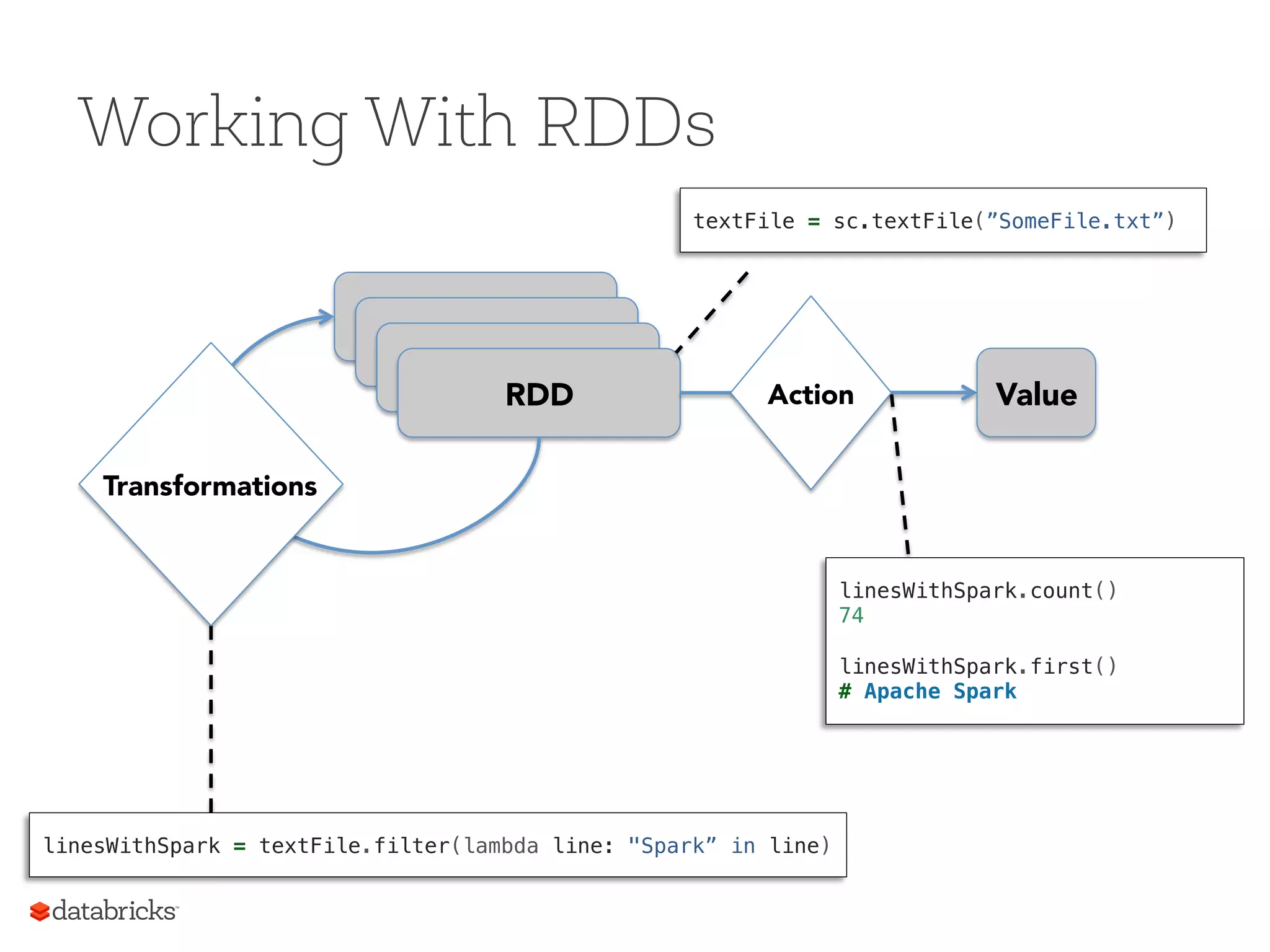
Operations on RDDs Transformationsf(RDD) => RDD § Lazy (not computed immediately) § E.g. “map” Actions: § Triggers computation § E.g. “count”, “saveAsTextFile” 23
Working With RDDs RDD RDD RDD RDD Transformations ActionValue linesWithSpark = textFile.filter(lambda line: "Spark” in line)! linesWithSpark.count()! 74! ! linesWithSpark.first()! # Apache Spark! textFile = sc.textFile(”SomeFile.txt”)!
27.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns
28.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns Worker Worker Worker Driver
29.
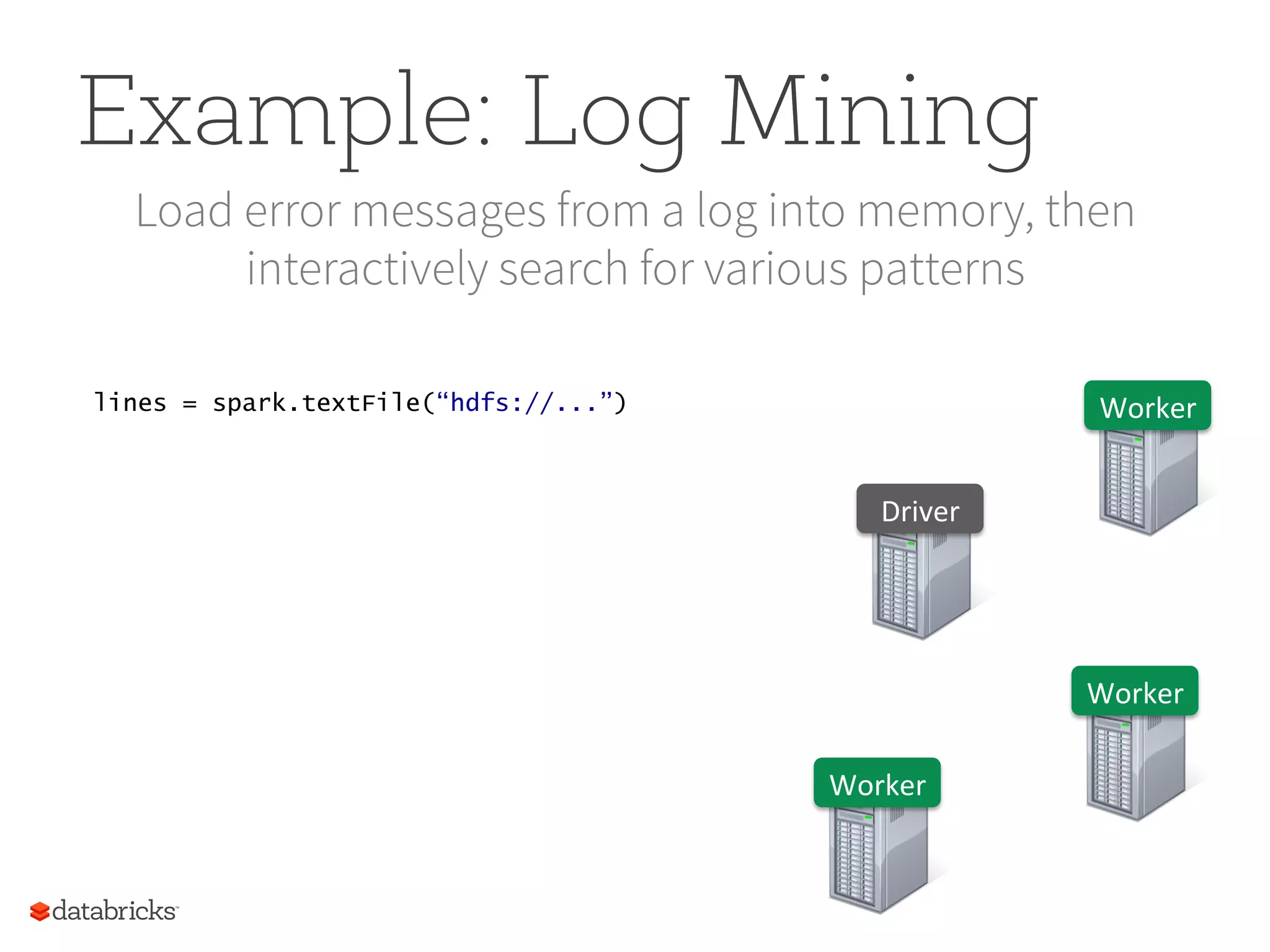
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns Worker Worker Worker Driver lines = spark.textFile(“hdfs://...”)
30.
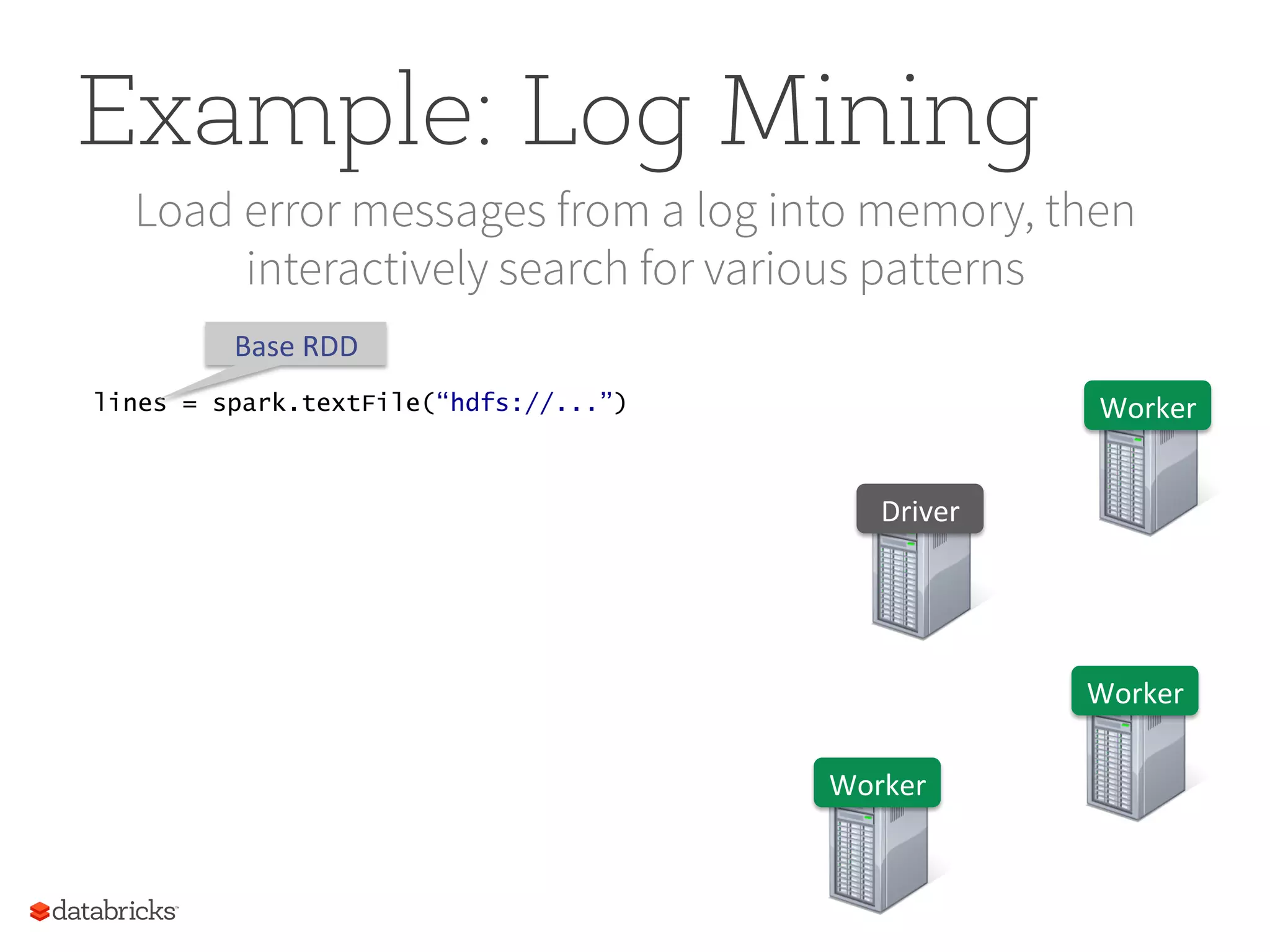
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns Worker Worker Worker Driver lines = spark.textFile(“hdfs://...”) Base RDD
31.
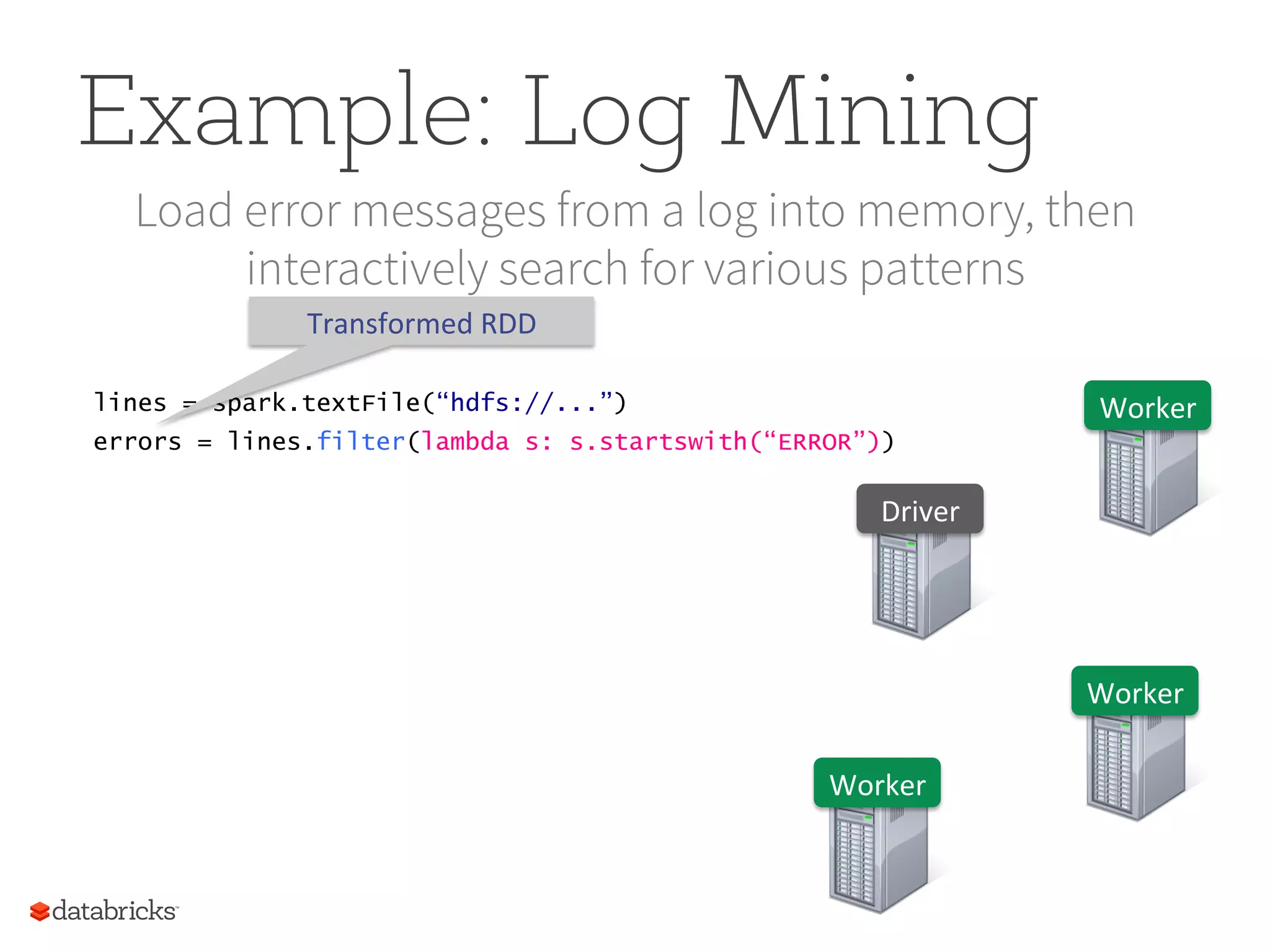
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) Worker Worker Worker Driver
32.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) Worker Worker Worker Driver Transformed RDD
33.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker Driver messages.filter(lambda s: “mysql” in s).count()
34.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker Driver messages.filter(lambda s: “mysql” in s).count() Ac5on
35.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker Driver messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3
36.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver tasks tasks tasks
37.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Read HDFS Block Read HDFS Block Read HDFS Block
38.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 Process & Cache Data Process & Cache Data Process & Cache Data
39.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 results results results
40.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count()
41.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() tasks tasks tasks Driver
42.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() Driver Process from Cache Process from Cache Process from Cache
43.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() Driver results results results
44.
Example: Log Mining Loaderror messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() Driver Cache your data è Faster Results Full-text search of Wikipedia • 60GB on 20 EC2 machines • 0.5 sec from mem vs. 20s for on-disk
45.
Language Support Standalone Programs Python,Scala, & Java Interactive Shells Python & Scala Performance Java & Scala are faster due to static typing …but Python is often fine Python lines = sc.textFile(...) lines.filter(lambda s: “ERROR” in s).count() Scala val lines = sc.textFile(...) lines.filter(x => x.contains(“ERROR”)).count() Java JavaRDD<String> lines = sc.textFile(...); lines.filter(new Function<String, Boolean>() { Boolean call(String s) { return s.contains(“error”); } }).count();
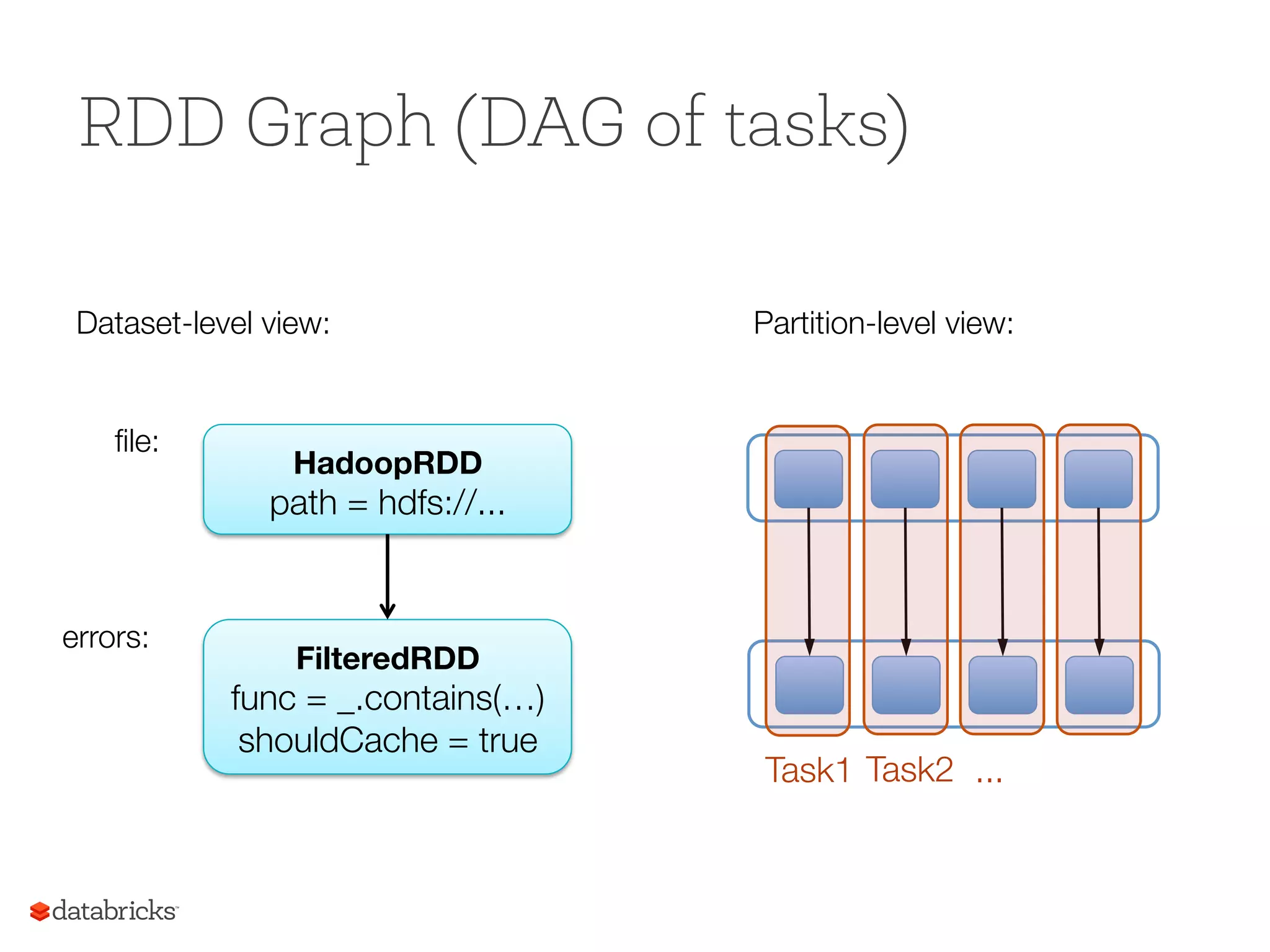
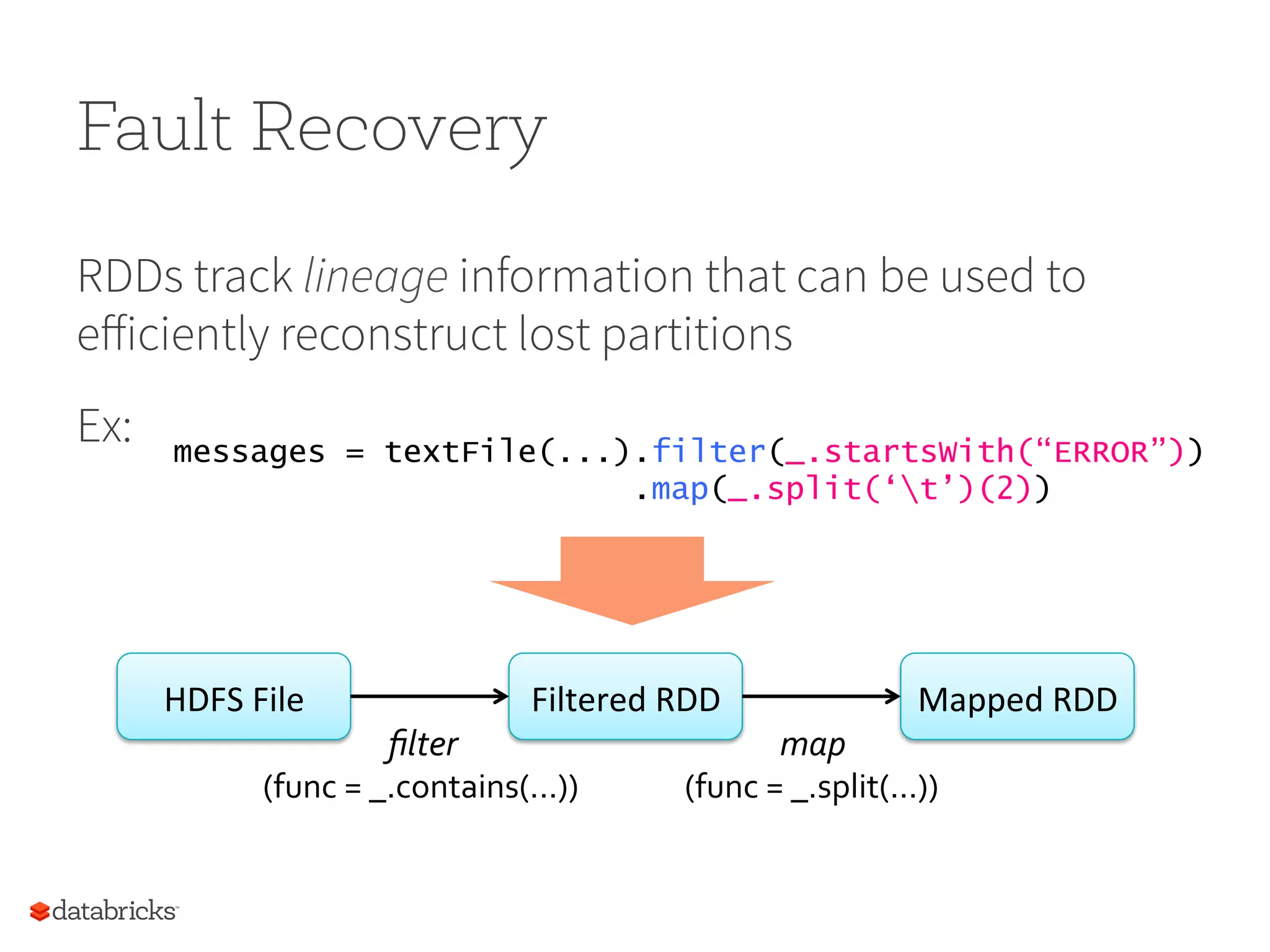
Fault Recovery RDDs tracklineage information that can be used to efficiently reconstruct lost partitions Ex: messages = textFile(...).filter(_.startsWith(“ERROR”)) .map(_.split(‘t’)(2)) HDFS File Filtered RDD Mapped RDD filter (func = _.contains(...)) map (func = _.split(...))
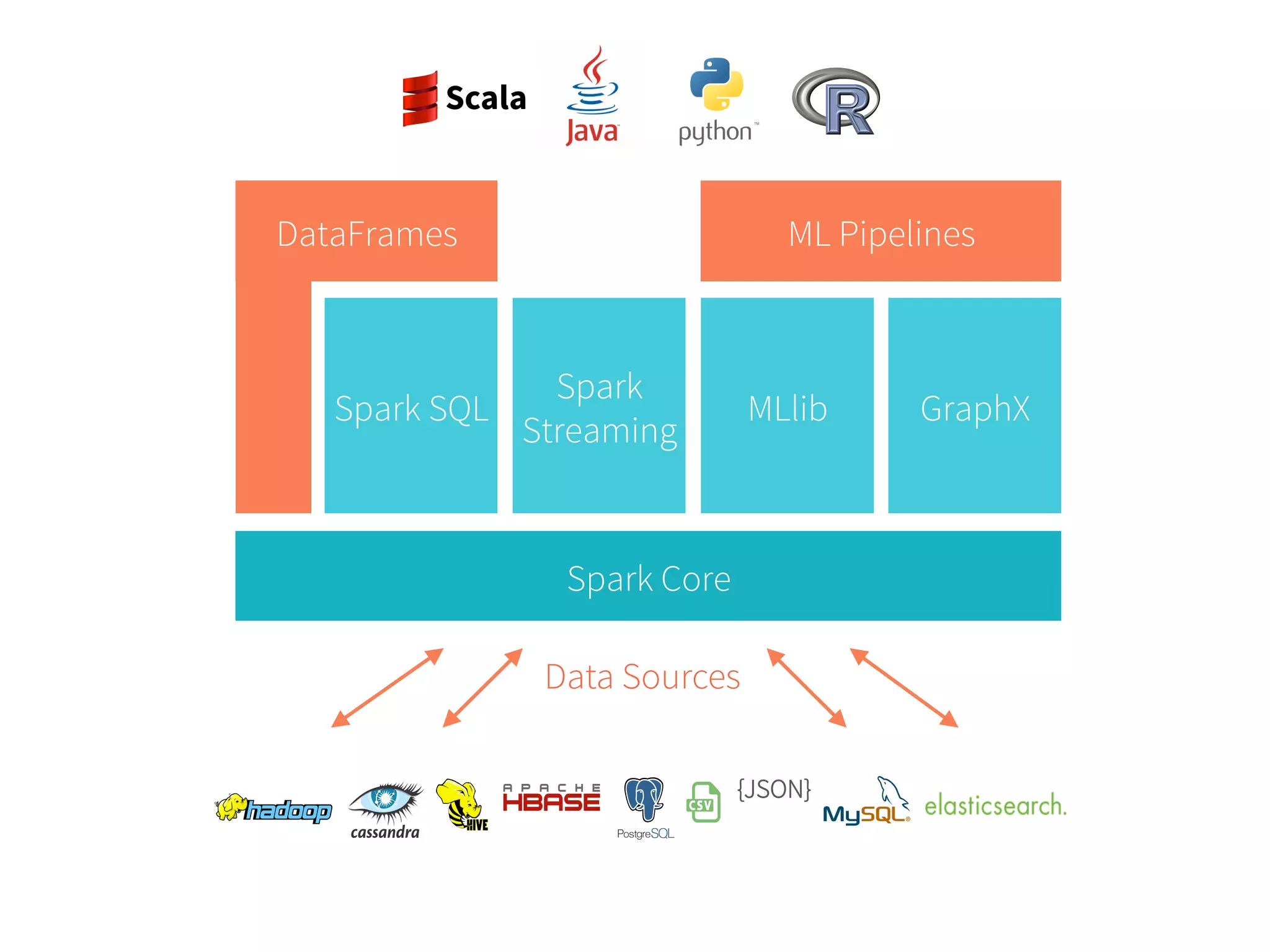
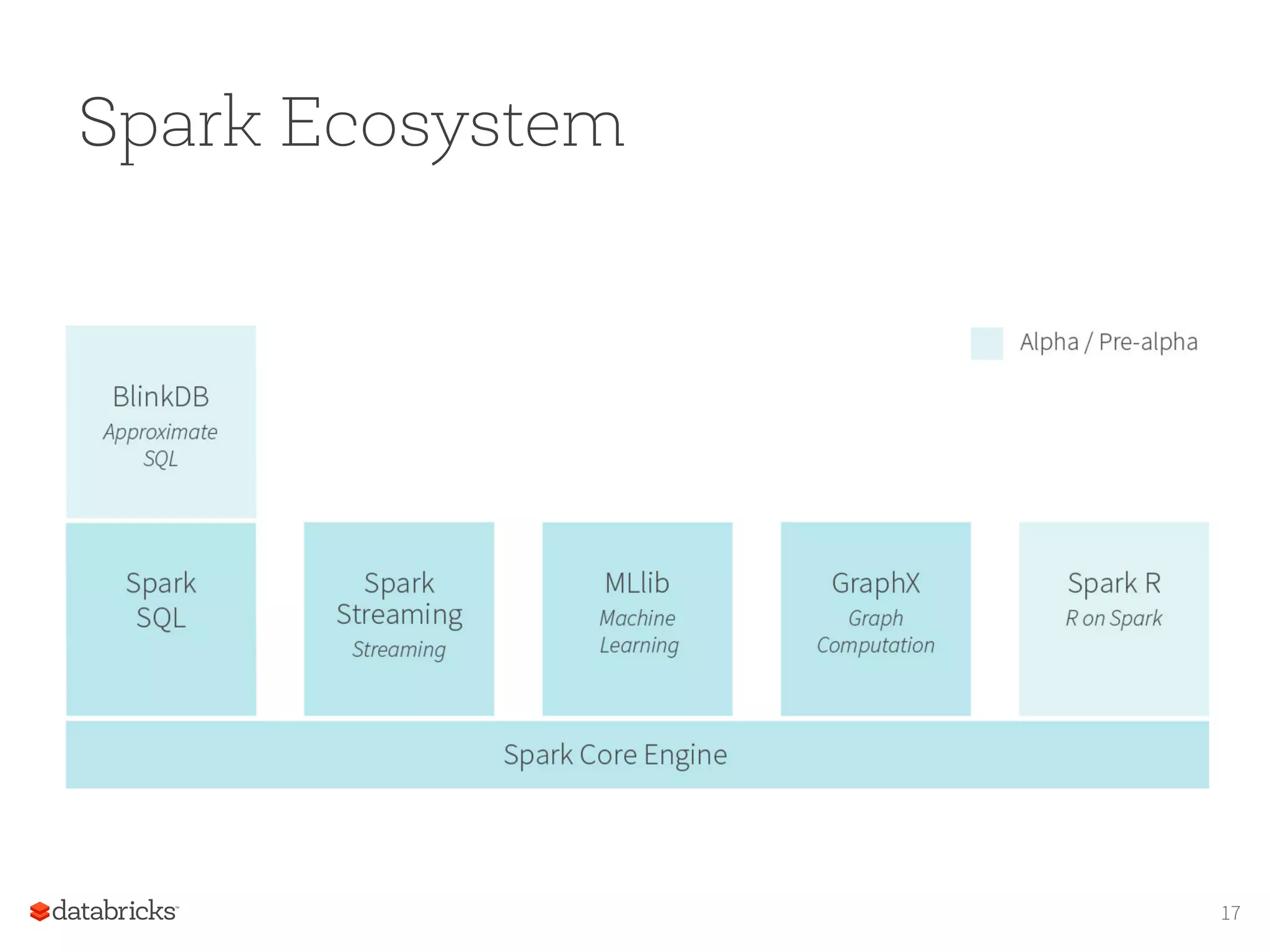
Generality of RDDs Spark RDDs, Transformations, and Actions Spark Streaming real-‐time Spark SQL GraphX graph MLLib machine learning DStream’s: Streams of RDD’s SchemaRDD’s RDD-‐Based Matrices RDD-‐Based Graphs
56.
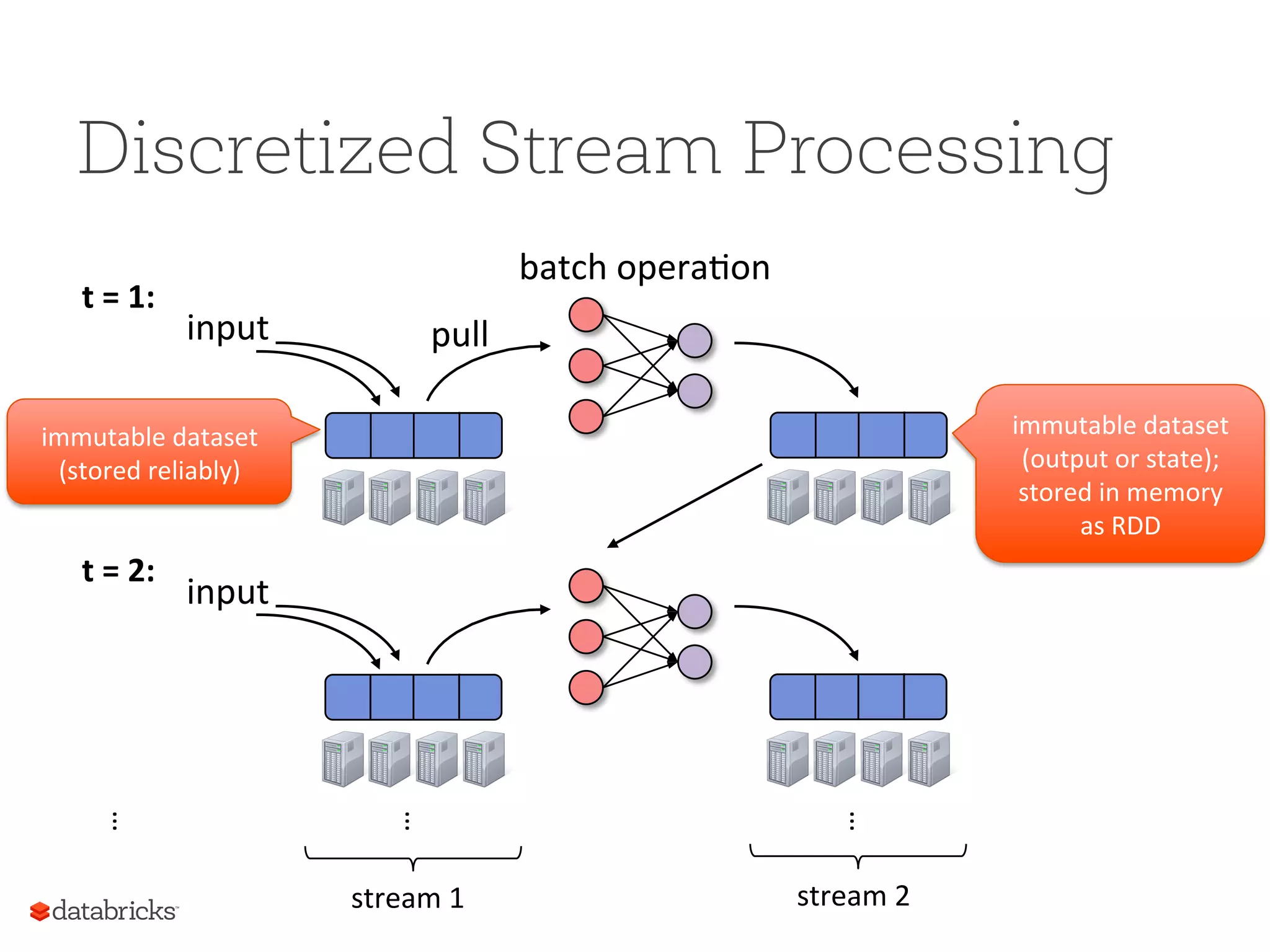
Many important appsmust process large data streams at second-scale latencies • Site statistics, intrusion detection, online ML To build and scale these apps users want: • Integration: with offline analytical stack • Fault-tolerance: both for crashes and stragglers • Efficiency: low cost beyond base processing Spark Streaming: Motivation
57.
Discretized Stream Processing t = 1: t = 2: stream 1 stream 2 batch opera5on pull input … … input immutable dataset (stored reliably) immutable dataset (output or state); stored in memory as RDD …
58.
Programming Interface Simple functionalAPI views = readStream("http:...", "1s") ones = views.map(ev => (ev.url, 1)) counts = ones.runningReduce(_ + _) Interoperates with RDDs ! // Join stream with static RDD counts.join(historicCounts).map(...) ! // Ad-hoc queries on stream state counts.slice(“21:00”,“21:05”).topK(10) t = 1: t = 2: views ones counts map reduce . . . = RDD = partition
59.
Inherited “for free”from Spark RDD data model and API Data partitioning and shuffles Task scheduling Monitoring/instrumentation Scheduling and resource allocation
Benefits for Users Highperformance data sharing • Data sharing is the bottleneck in many environments • RDD’s provide in-place sharing through memory Applications can compose models • Run a SQL query and then PageRank the results • ETL your data and then run graph/ML on it Benefit from investment in shared functionality • E.g. re-usable components (shell) and performance optimizations
66.
Agenda 1. MapReduce Review 2. Introduction to Spark and RDDs 3. Generality of RDDs (e.g. streaming, ML) 4. DataFrames 5. Internals (time permitting) 66
DataFrames in Spark Distributedcollection of data grouped into named columns (i.e. RDD with schema) DSL designed for common tasks • Metadata • Sampling • Project, filter, aggregation, join, … • UDFs Available in Python, Scala, Java, and R (via SparkR) 70
71.
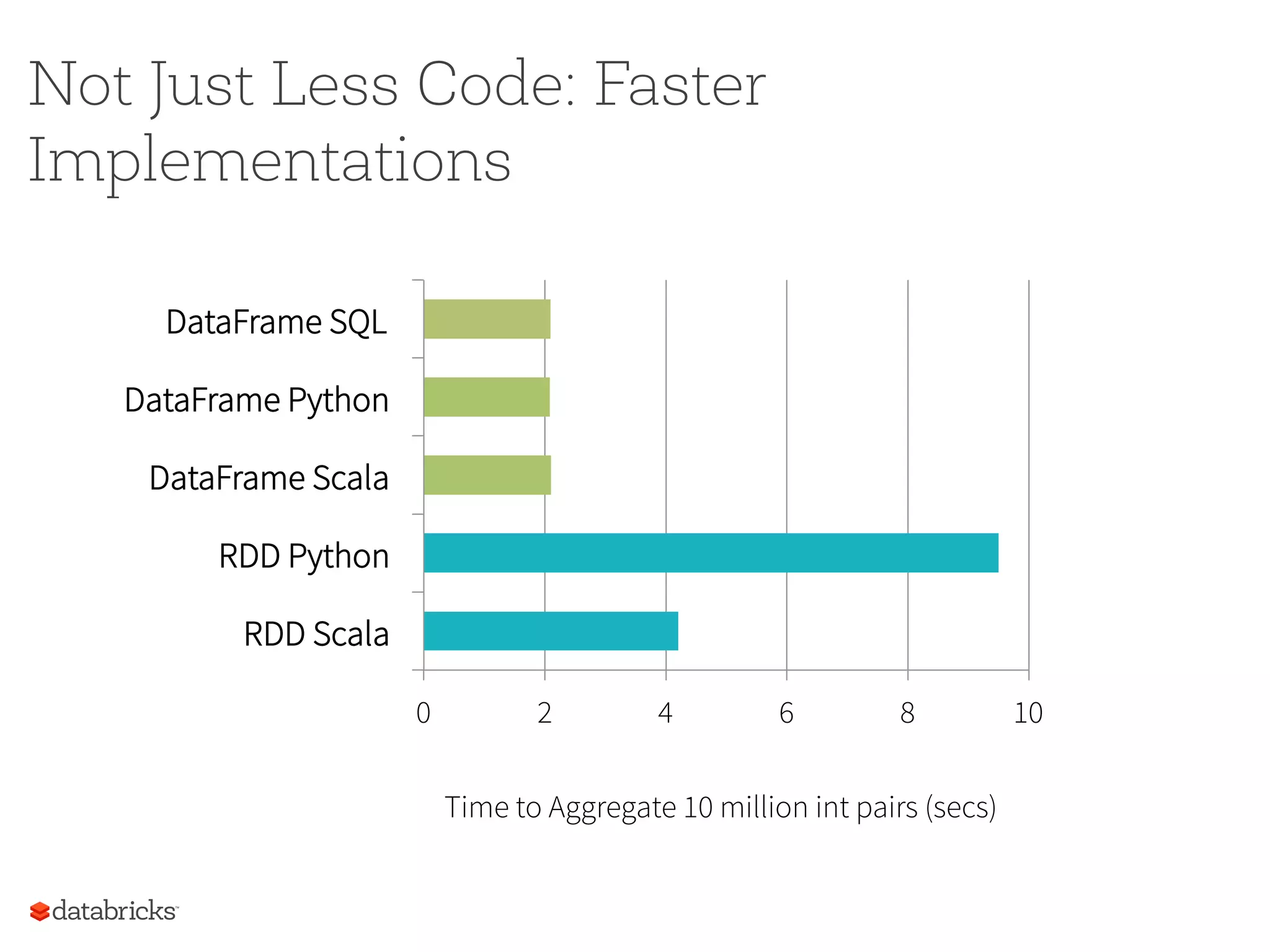
Not Just LessCode: Faster Implementations 0 2 4 6 8 10 RDD Scala RDD Python DataFrame Scala DataFrame Python DataFrame SQL Time to Aggregate 10 million int pairs (secs)
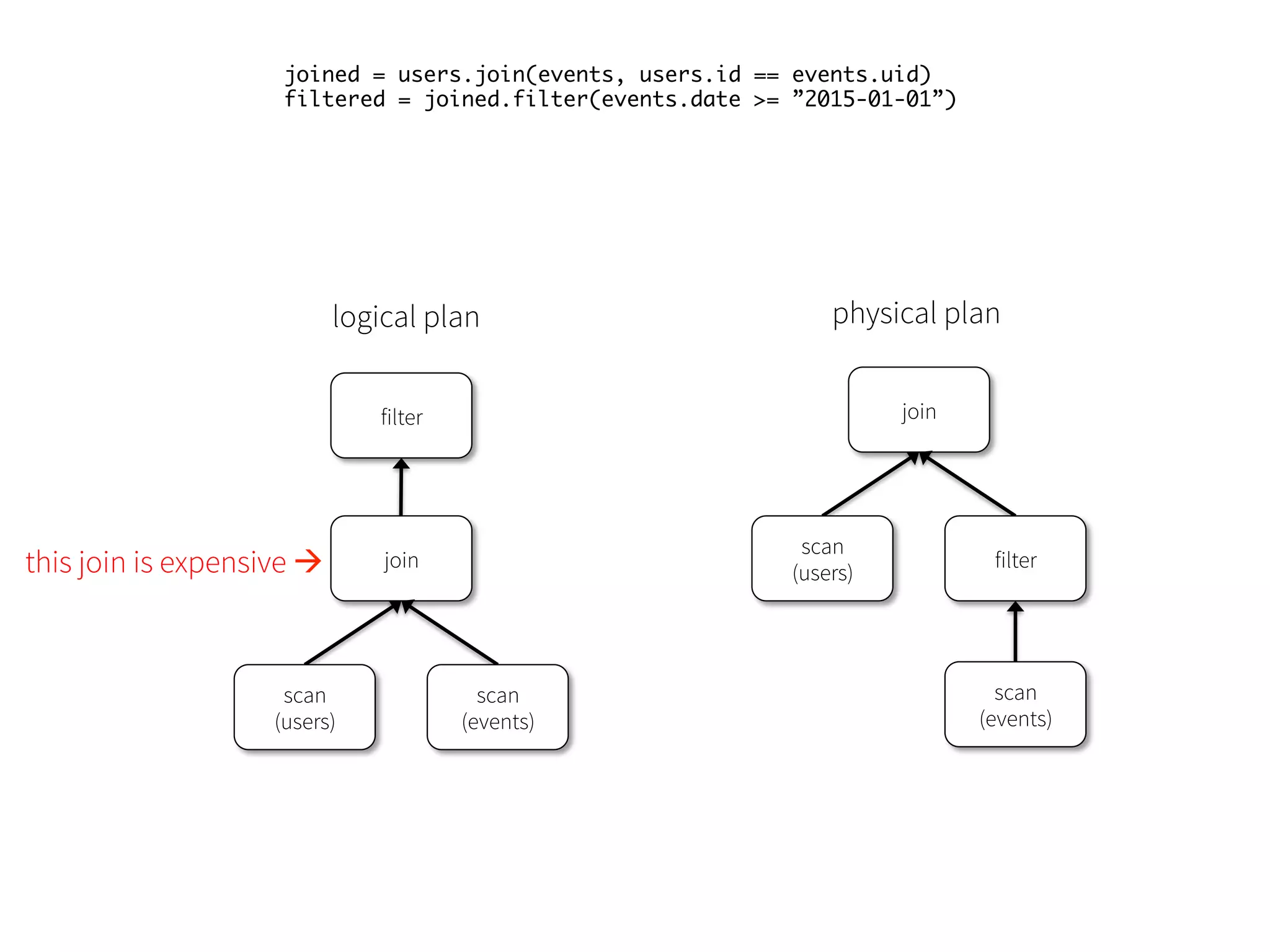
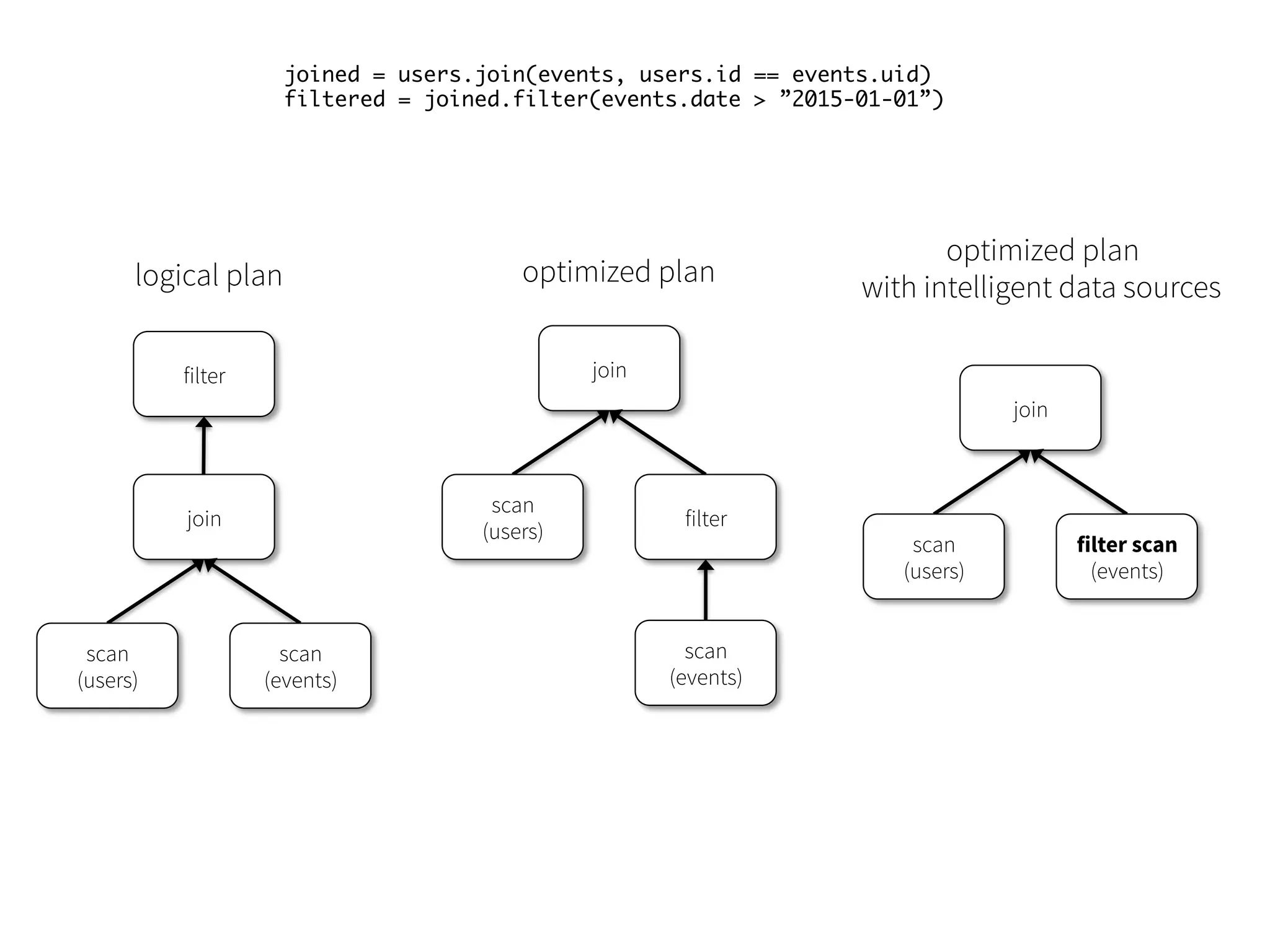
More Than NaïveScans Data Sources API can automatically prune columns and push filters to the source • Parquet: skip irrelevant columns and blocks of data; turn string comparison into integer comparisons for dictionary encoded data • JDBC: Rewrite queries to push predicates down 76
77.
77 joined = users.join(events,users.id == events.uid) filtered = joined.filter(events.date > ”2015-01-01”) logical plan filter join scan (users) scan (events) optimized plan join scan (users) filter scan (events) optimized plan with intelligent data sources join scan (users) filter scan (events)
78.
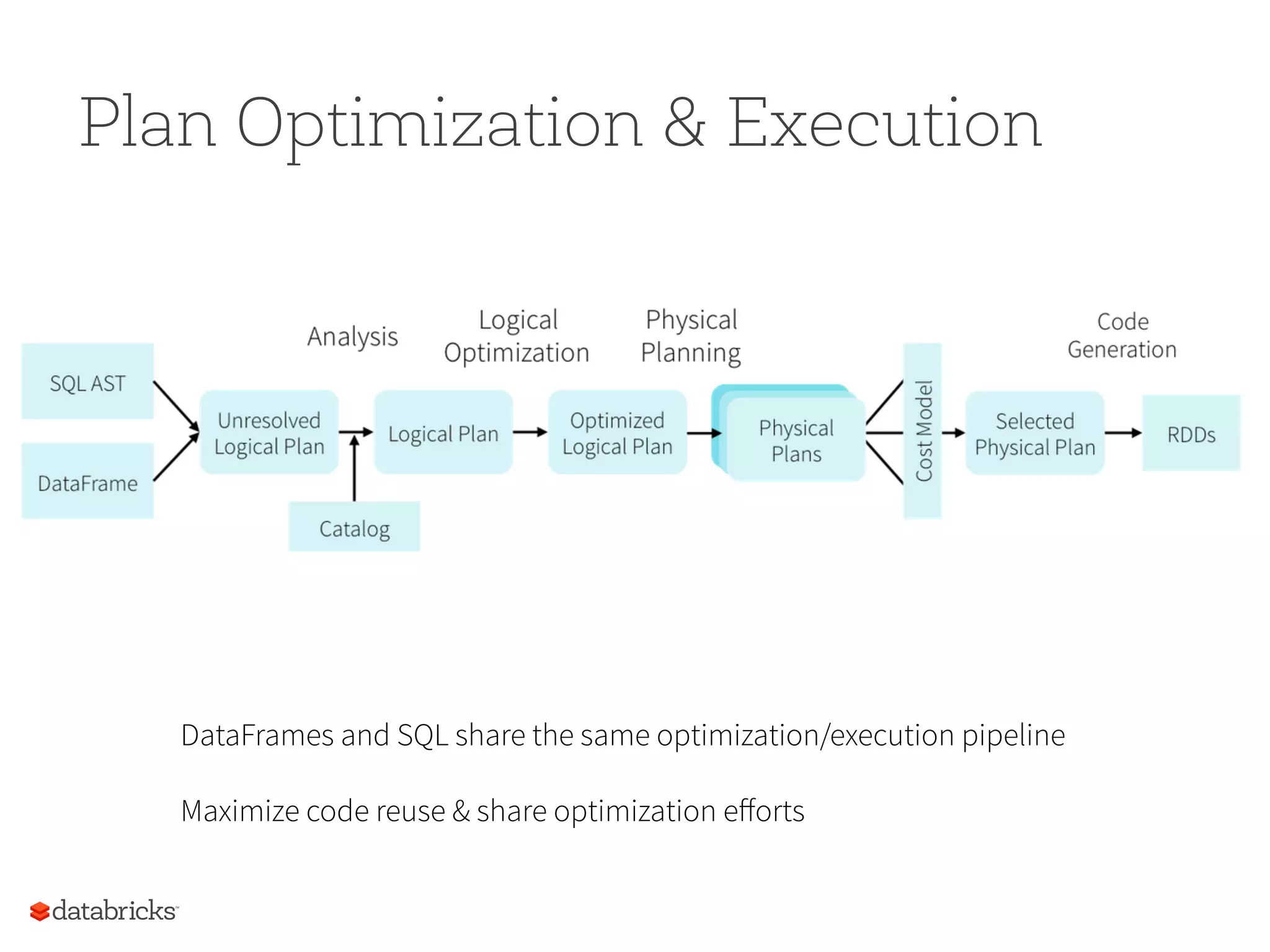
Our Experience SoFar SQL is wildly popular and important • 100% of Databricks customers use some SQL Schema is very useful • Most data pipelines, even the ones that start with unstructured data, end up having some implicit structure • Key-value too limited • That said, semi-/un-structured support is paramount Separation of logical vs physical plan • Important for performance optimizations (e.g. join selection)
79.
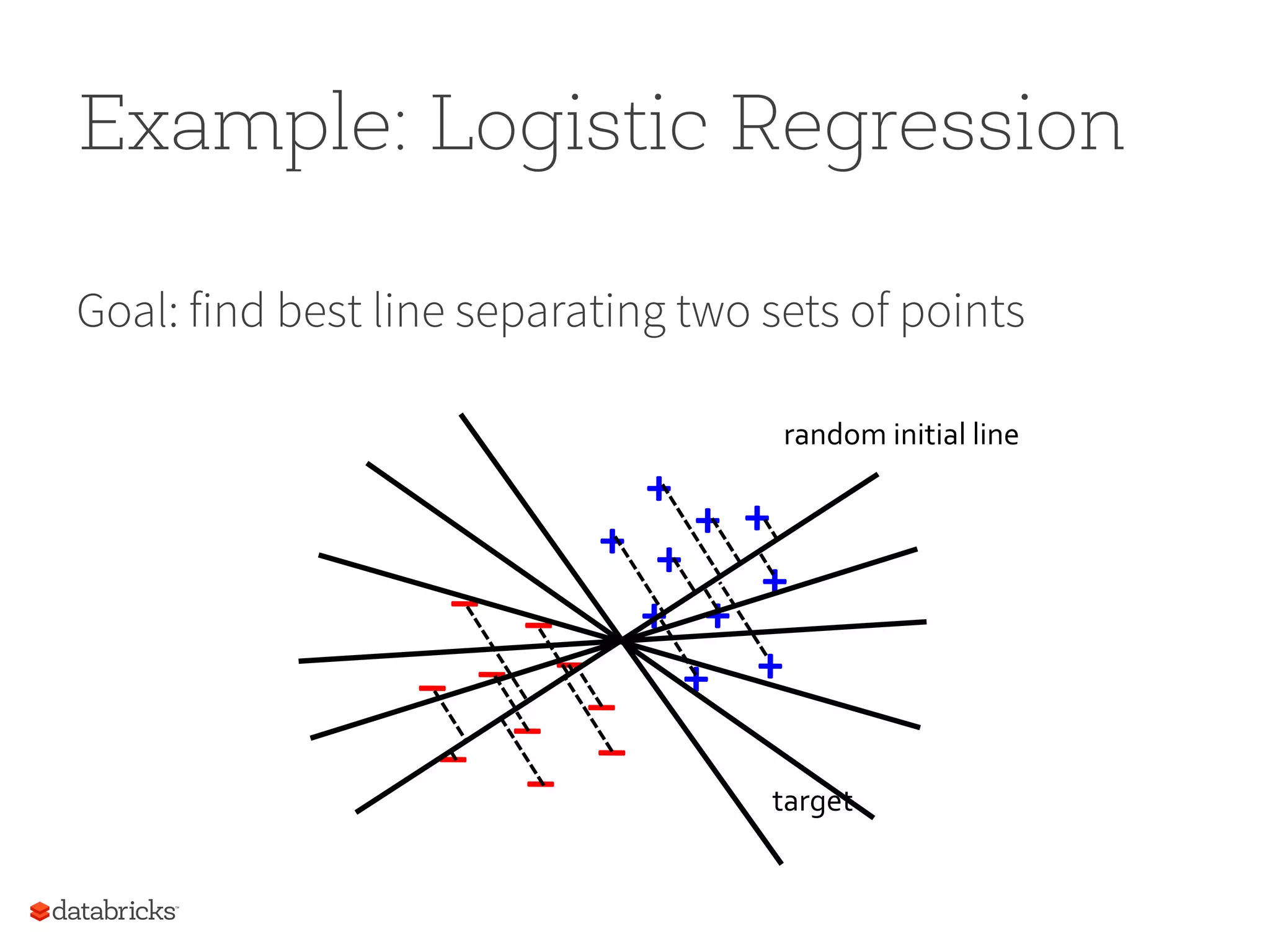
Machine Learning Pipelines tokenizer = Tokenizer(inputCol="text", outputCol="words”) hashingTF = HashingTF(inputCol="words", outputCol="features”) lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr]) df = sqlCtx.load("/path/to/data") model = pipeline.fit(df) df0 df1 df2 df3tokenizer hashingTF lr.model lr Pipeline Model
80.
80 R Interface (SparkR) Spark1.4 (June) Exposes DataFrames, and ML library in R df = jsonFile(“tweets.json”) summarize( group_by( df[df$user == “matei”,], “date”), sum(“retweets”))
81.
Data Science atScale Higher level interfaces in Scala, Java, Python, R Drastically easier to program Big Data • With APIs similar to single-node tools 81
Agenda 1. MapReduce Review 2. Introduction to Spark and RDDs 3. Generality of RDDs (e.g. streaming, ML) 4. DataFrames 5. Internals (time permitting) 84
85.
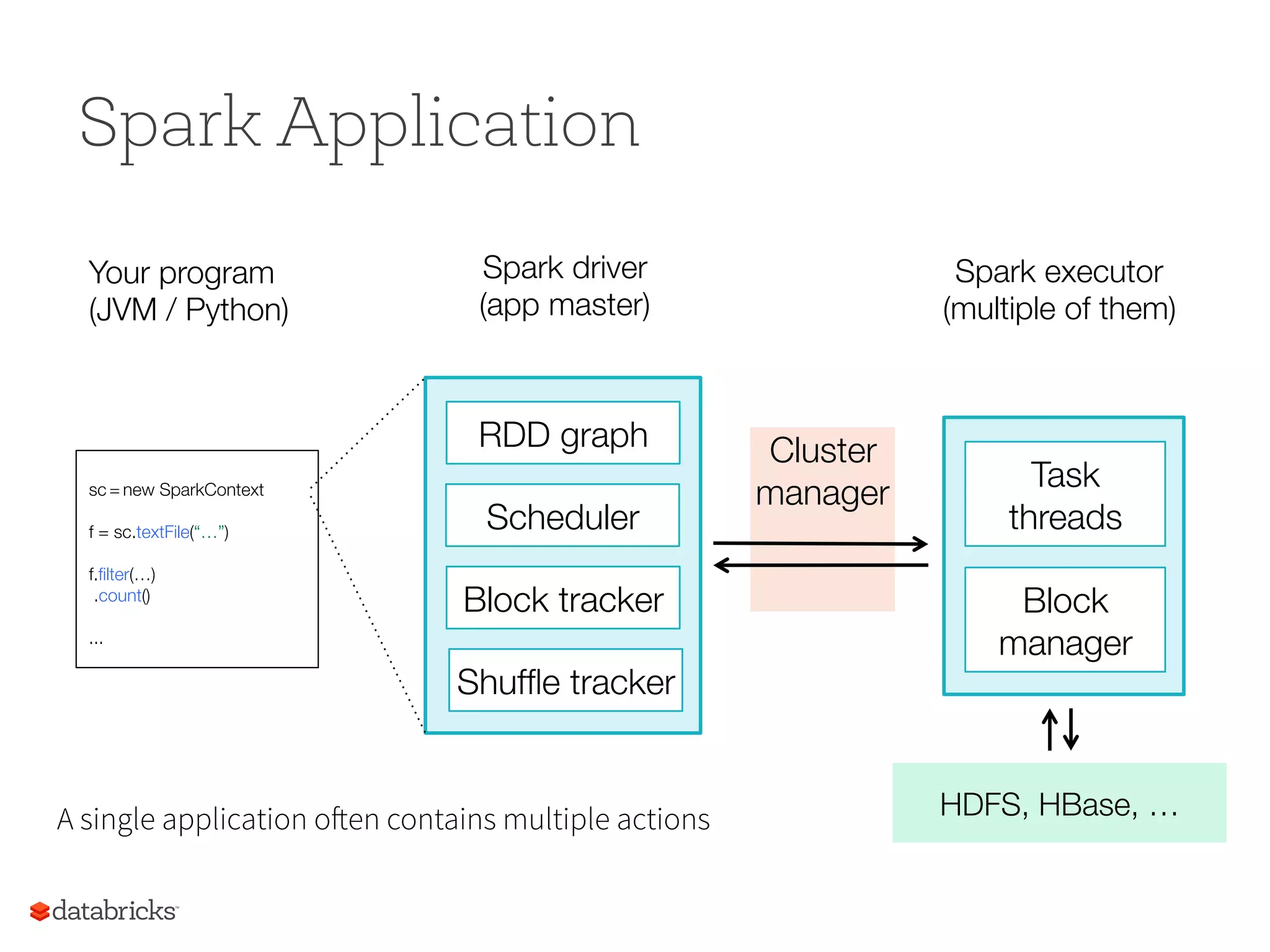
Spark Application sc =new SparkContext f = sc.textFile(“…”)" " f.filter(…)" .count()" " ... Your program (JVM / Python) Spark driver" (app master) Spark executor (multiple of them) HDFS, HBase, … Block manager Task threads RDD graph Scheduler Block tracker Shuffle tracker Cluster" manager A single application often contains multiple actions
86.
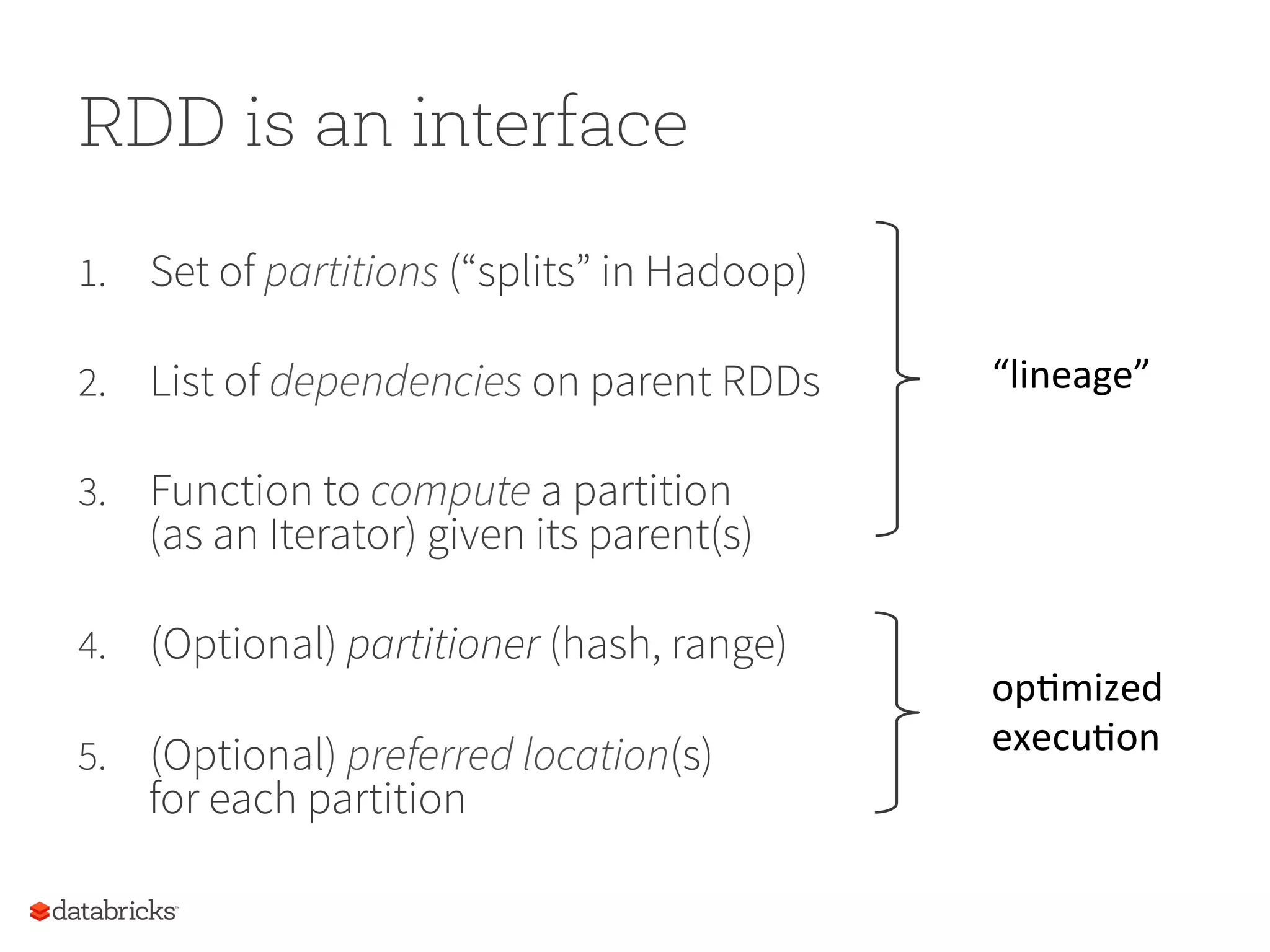
RDD is aninterface 1. Set of partitions (“splits” in Hadoop) 2. List of dependencies on parent RDDs 3. Function to compute a partition (as an Iterator) given its parent(s) 4. (Optional) partitioner (hash, range) 5. (Optional) preferred location(s) for each partition “lineage” op5mized execu5on
Example: JoinedRDD partitions =one per reduce task dependencies = “shuffle” on each parent compute(partition) = read and join shuffled data preferredLocations(part) = none partitioner = HashPartitioner(numTasks) Spark will now know this data is hashed!
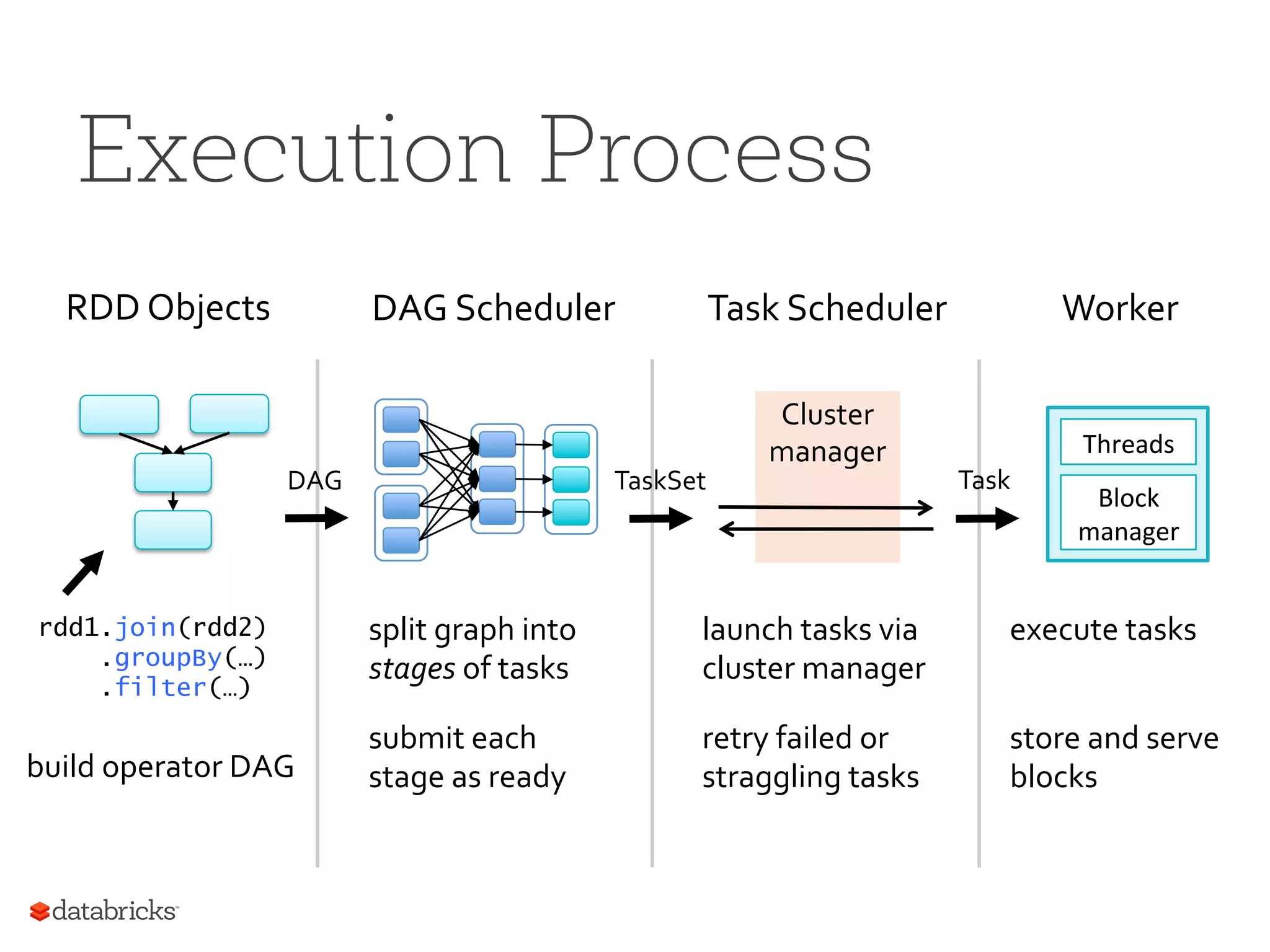
Execution Process rdd1.join(rdd2) .groupBy(…) .filter(…) RDD Objects build operator DAG DAG Scheduler split graph into stages of tasks submit each stage as ready DAG Task Scheduler TaskSet launch tasks via cluster manager retry failed or straggling tasks Cluster manager Worker execute tasks store and serve blocks Block manager Threads Task
93.
DAG Scheduler Input: RDDand partitions to compute Output: output from actions on those partitions Roles: • Build stages of tasks • Submit them to lower level scheduler (e.g. YARN, Mesos, Standalone) as ready • Lower level scheduler will schedule data based on locality • Resubmit failed stages if outputs are lost
94.
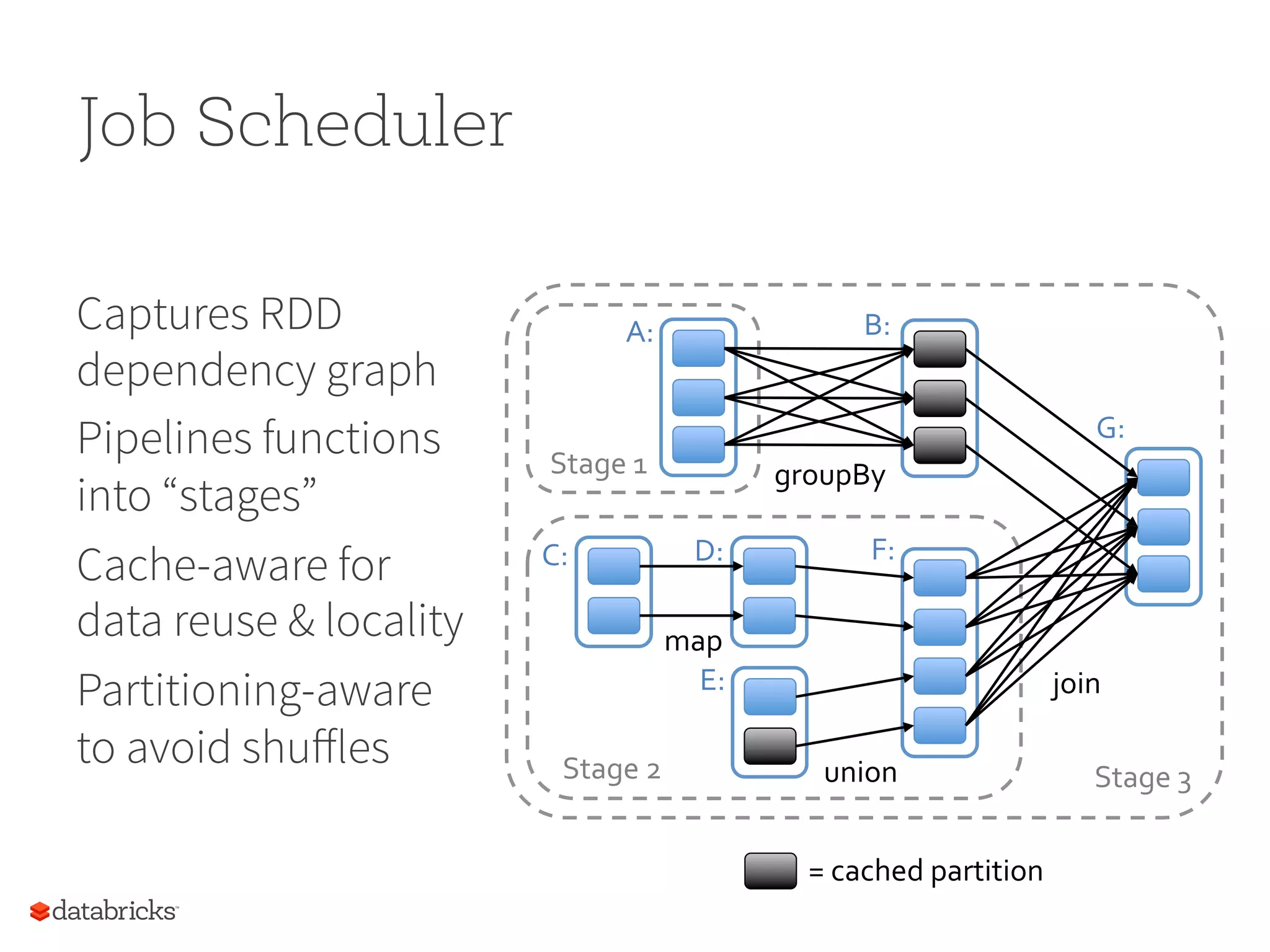
Job Scheduler Captures RDD dependencygraph Pipelines functions into “stages” Cache-aware for data reuse & locality Partitioning-aware to avoid shuffles join union groupBy map Stage 3 Stage 1 Stage 2 A: B: C: D: E: F: G: = cached partition




















![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker Driver messages.filter(lambda s: “mysql” in s).count()](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-33-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker Driver messages.filter(lambda s: “mysql” in s).count() Ac5on](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-34-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker Driver messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-35-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver tasks tasks tasks](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-36-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Read HDFS Block Read HDFS Block Read HDFS Block](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-37-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 Process & Cache Data Process & Cache Data Process & Cache Data](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-38-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 results results results](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-39-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count()](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-40-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() tasks tasks tasks Driver](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-41-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() Driver Process from Cache Process from Cache Process from Cache](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-42-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() Driver results results results](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-43-2048.jpg)
![Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(lambda s: s.startswith(“ERROR”)) messages = errors.map(lambda s: s.split(“t”)[2]) messages.cache() Worker Worker Worker messages.filter(lambda s: “mysql” in s).count() Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 messages.filter(lambda s: “php” in s).count() Driver Cache your data è Faster Results Full-text search of Wikipedia • 60GB on 20 EC2 machines • 0.5 sec from mem vs. 20s for on-disk](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-44-2048.jpg)
















![Machine Learning Pipelines tokenizer = Tokenizer(inputCol="text", outputCol="words”) hashingTF = HashingTF(inputCol="words", outputCol="features”) lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr]) df = sqlCtx.load("/path/to/data") model = pipeline.fit(df) df0 df1 df2 df3tokenizer hashingTF lr.model lr Pipeline Model](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-79-2048.jpg)
![80 R Interface (SparkR) Spark 1.4 (June) Exposes DataFrames, and ML library in R df = jsonFile(“tweets.json”) summarize( group_by( df[df$user == “matei”,], “date”), sum(“retweets”))](https://image.slidesharecdn.com/2015-05-18cs347-stanford-150519052758-lva1-app6891/75/Stanford-CS347-Guest-Lecture-Apache-Spark-80-2048.jpg)