Downloaded 199 times










![cd spark-1.4.1-bin-hadoop2.6 spark-1.4.1-bin-hadoop2.6 $ ./bin/spark-shell --master local[2] The --master option specifies the master URL for a distributed cluster, or local to run locally with one thread, or local[N] to run locally with N threads.](https://image.slidesharecdn.com/reactivedashboardsusingapachespark-150819153013-lva1-app6891/75/Reactive-dashboard-s-using-apache-spark-23-2048.jpg)
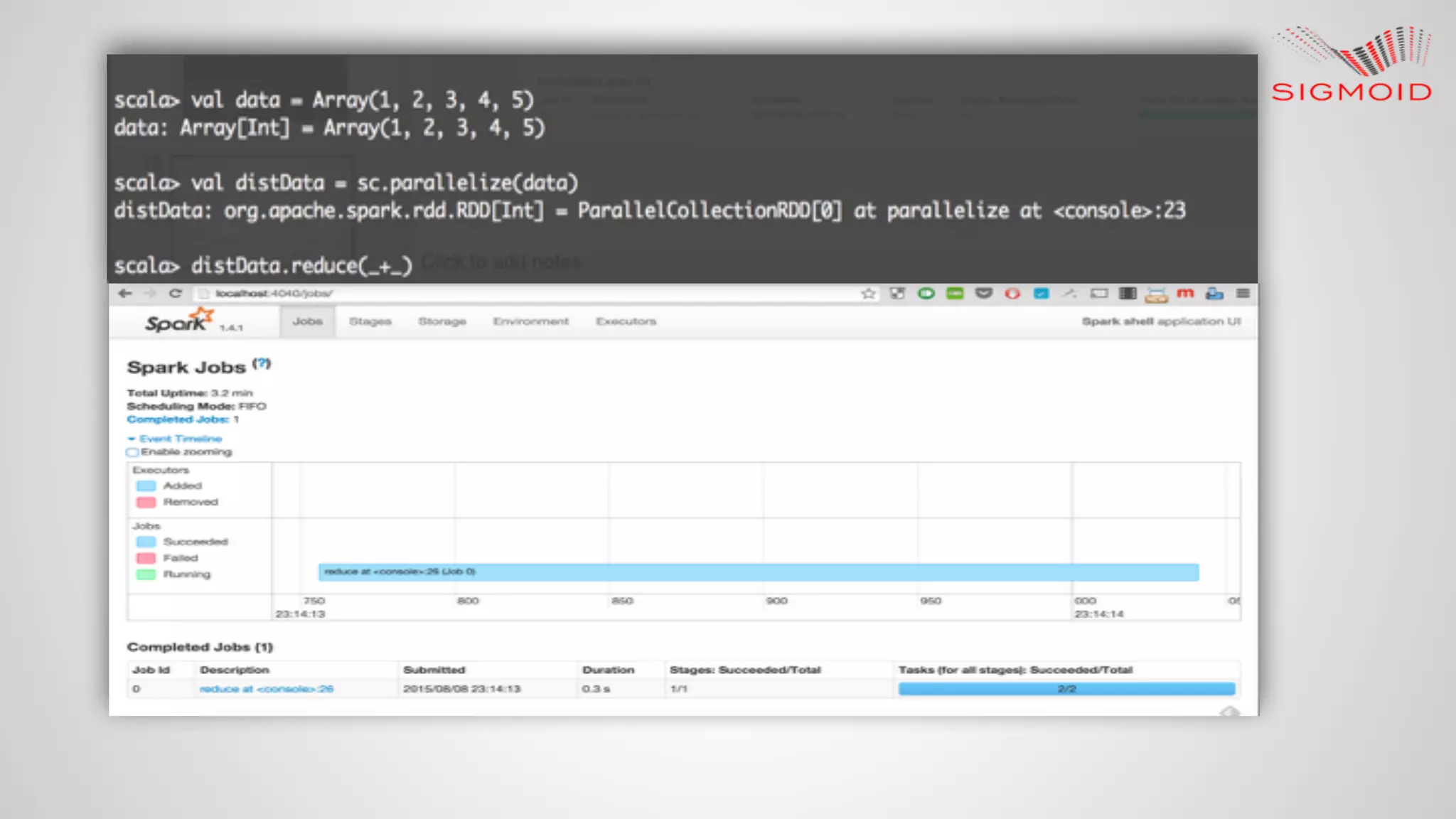

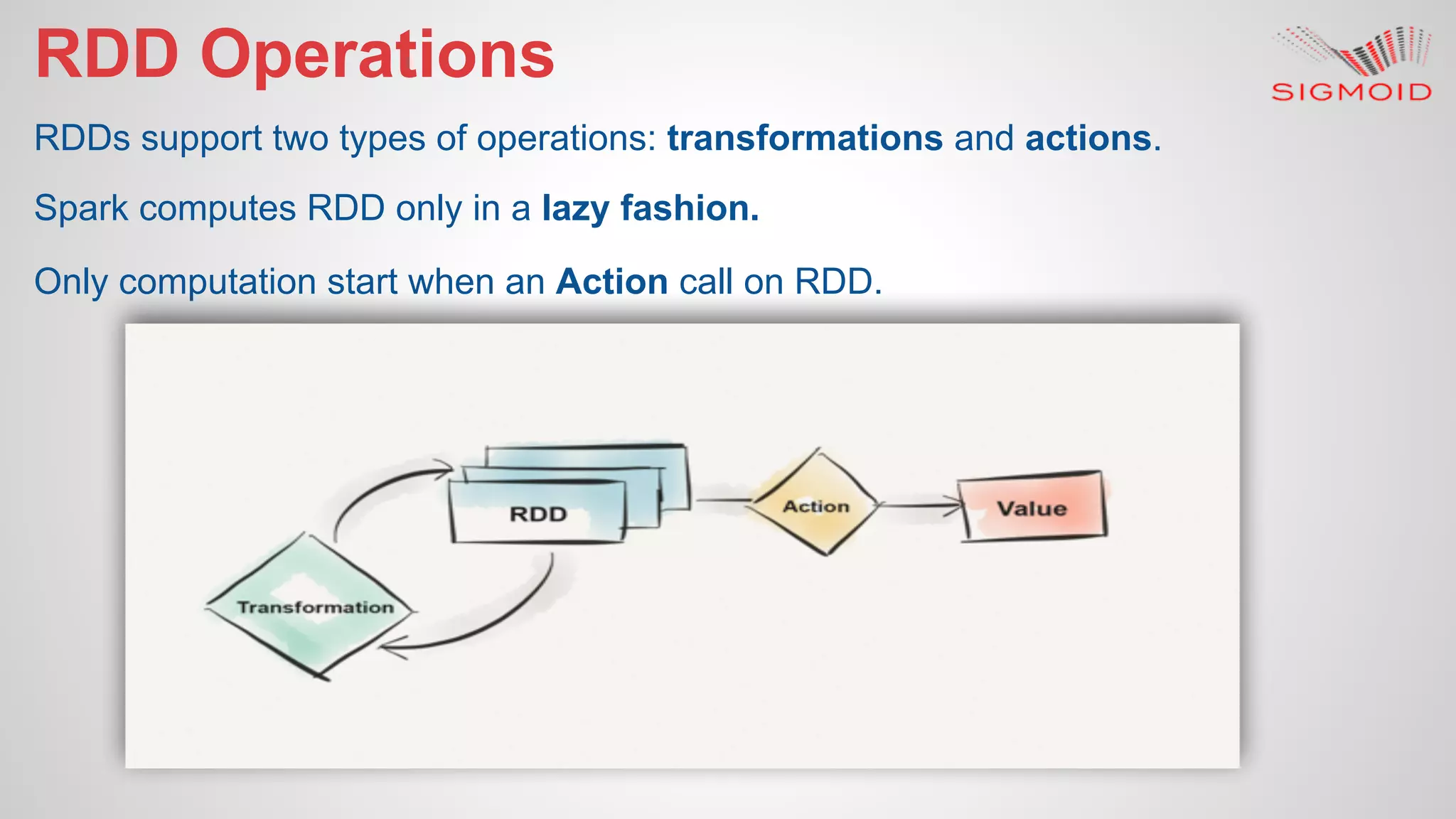
![● Simple SBT project setup https://github.com/rahulkumar-‐aws/HelloWorld $ mkdir HelloWorld $ cd HelloWorld $ mkdir -p src/main/scala $ mkdir -p src/main/resources $ mkdir -p src/test/scala $ vim build.sbt name := “HelloWorld” version := “1.0” scalaVersion := “2.10.4” $ mkdir project $ cd project $ vim build.properties sbt.version=0.13.8 $ vim scr/main/scala/HelloWorld.scala object HelloWorld { def main(args: Array[String]) = println("HelloWorld!") } $ sbt run](https://image.slidesharecdn.com/reactivedashboardsusingapachespark-150819153013-lva1-app6891/75/Reactive-dashboard-s-using-apache-spark-27-2048.jpg)
![First Spark Application $git clone https://github.com/rahulkumar-aws/WordCount.git import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ object SparkWordCount { def main(args: Array[String]): Unit = { val sc = new SparkContext("local","SparkWordCount") val wordsCounted = sc.textFile(args(0)).map(line=> line.toLowerCase) .flatMap(line => line.split("""W+""")) .groupBy(word => word) .map{ case(word, group) => (word, group.size)} wordsCounted.saveAsTextFile(args(1)) sc.stop() } } $sbt "run-main ScalaWordCount src/main/resources/sherlockholmes.txt out"](https://image.slidesharecdn.com/reactivedashboardsusingapachespark-150819153013-lva1-app6891/75/Reactive-dashboard-s-using-apache-spark-28-2048.jpg)

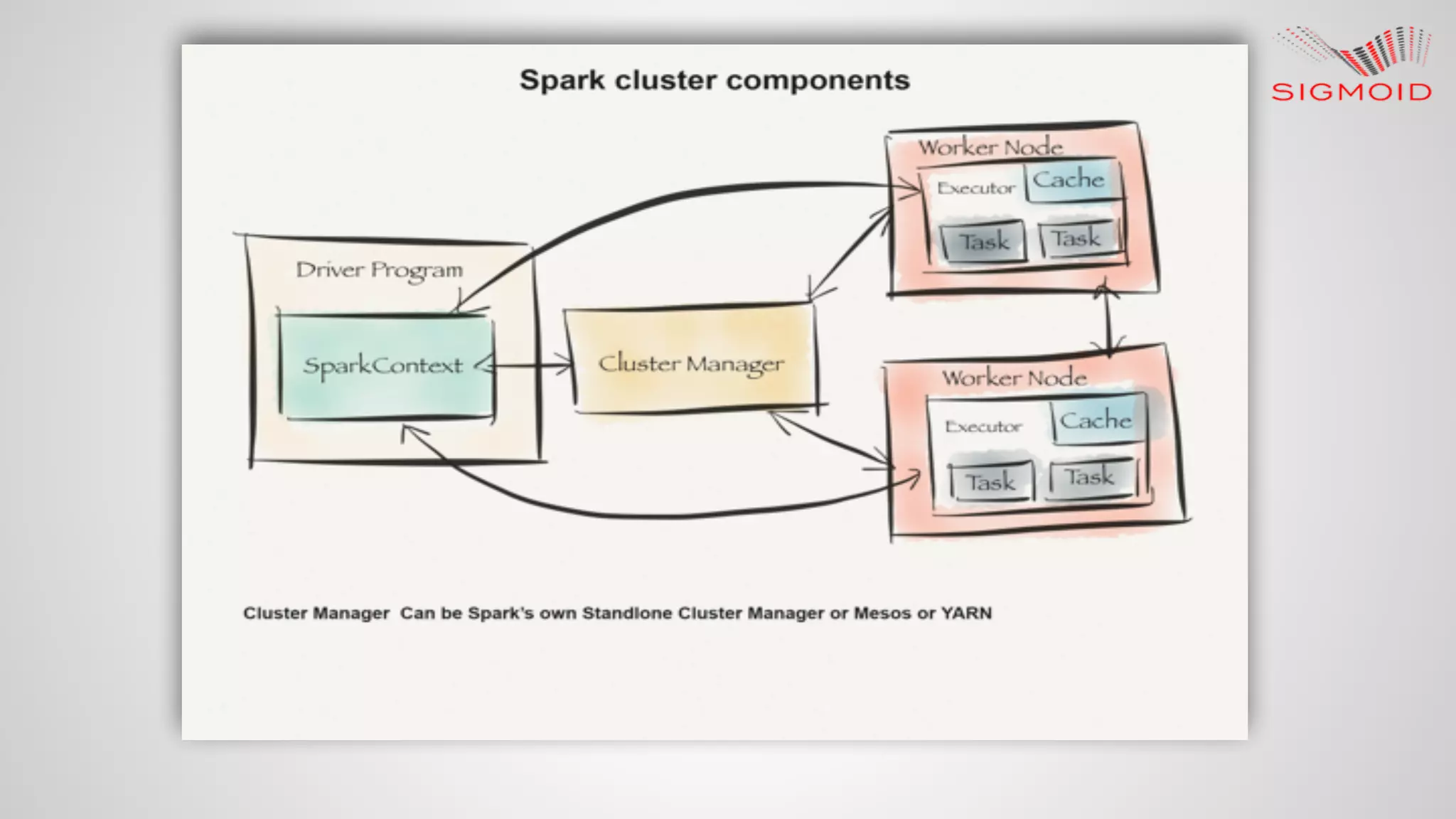
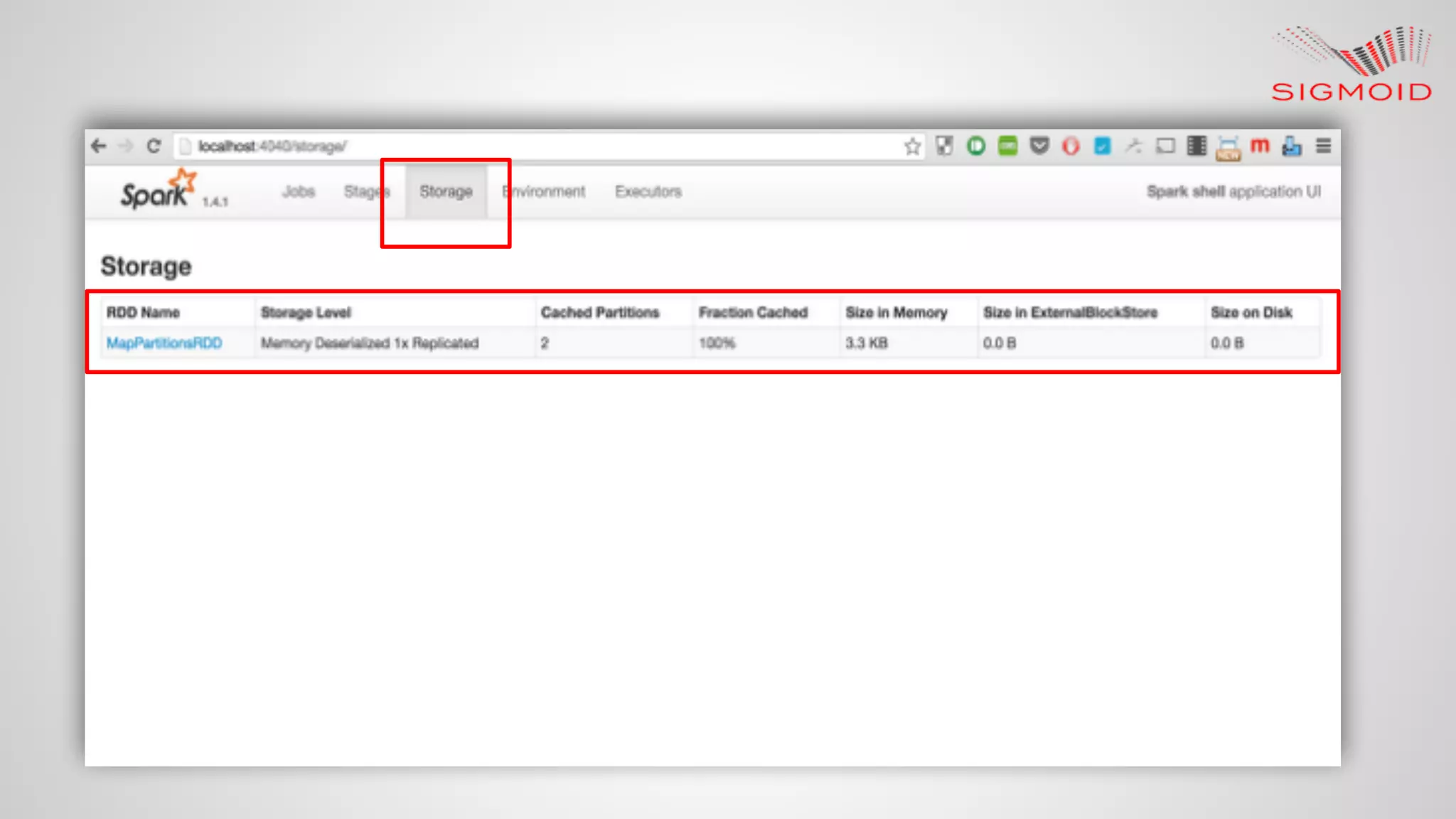
![Spark Cache Introduction Spark supports pulling data sets into a cluster-wide in-memory cache. scala> val textFile = sc.textFile("README.md") textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[12] at textFile at <console>:21 scala> val linesWithSpark = textFile.filter(line => line.contains("Spark")) linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[13] at filter at <console>:23 scala> linesWithSpark.cache() res11: linesWithSpark.type = MapPartitionsRDD[13] at filter at <console>:23 scala> linesWithSpark.count() res12: Long = 19](https://image.slidesharecdn.com/reactivedashboardsusingapachespark-150819153013-lva1-app6891/75/Reactive-dashboard-s-using-apache-spark-31-2048.jpg)

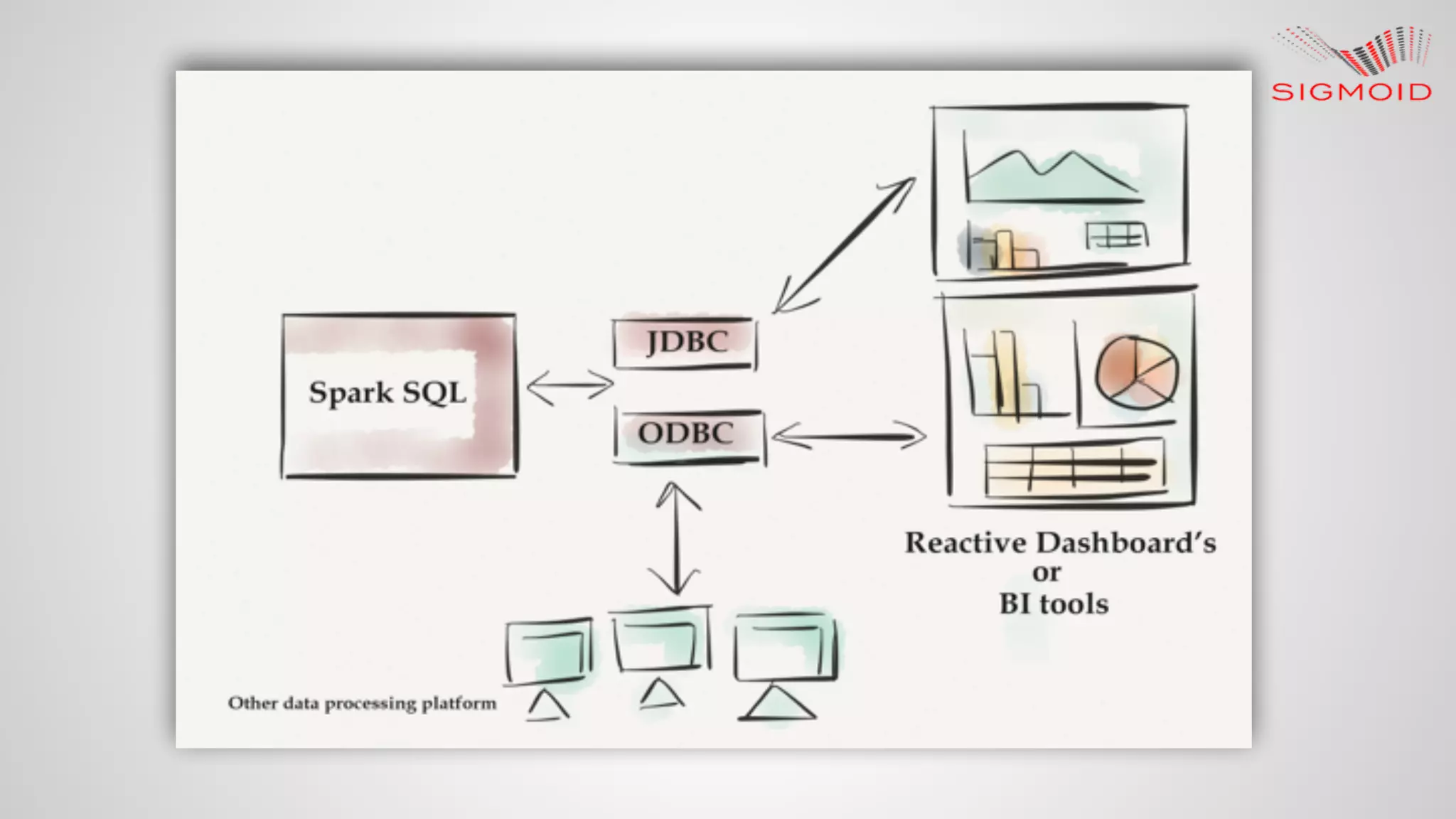
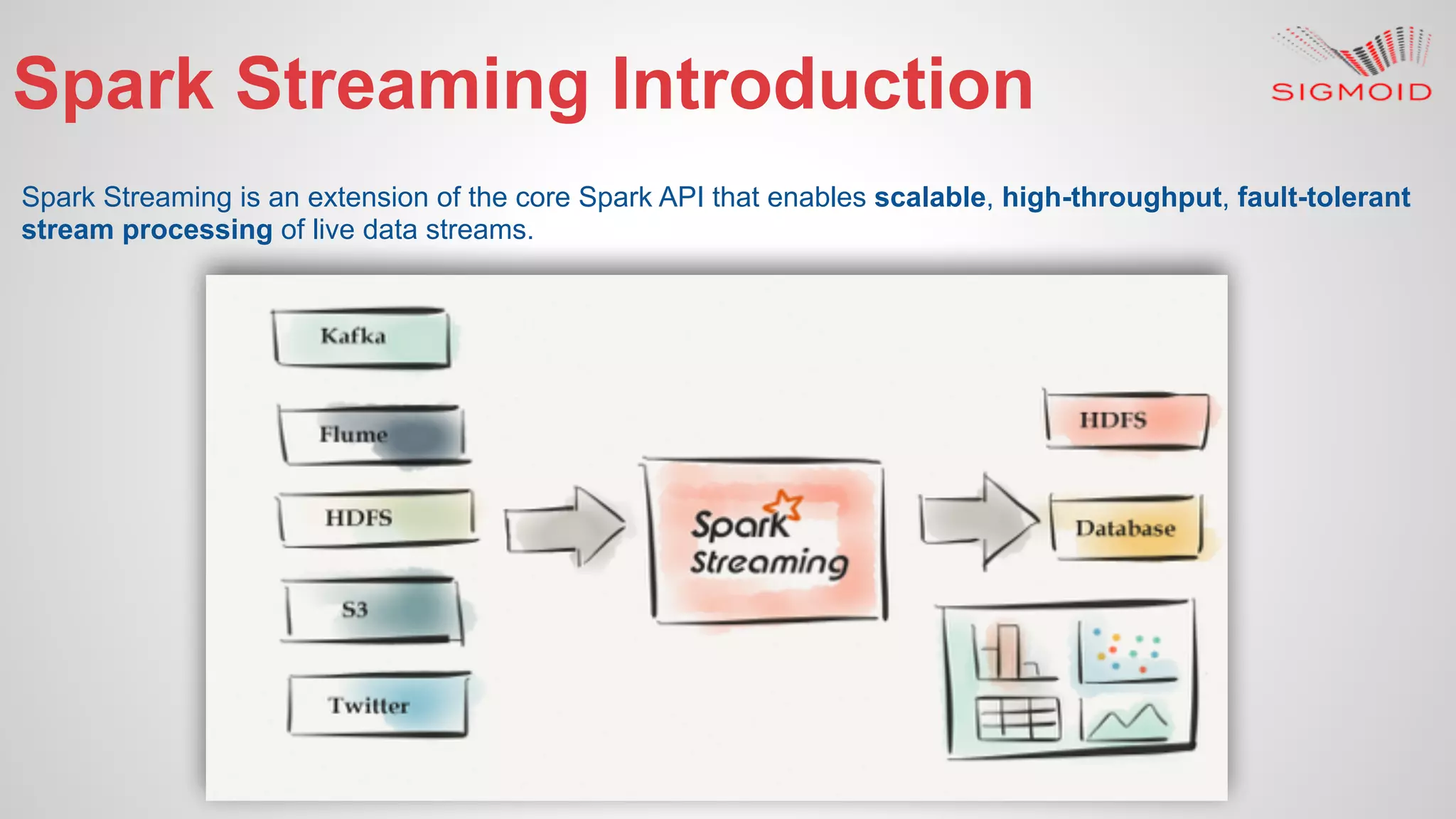
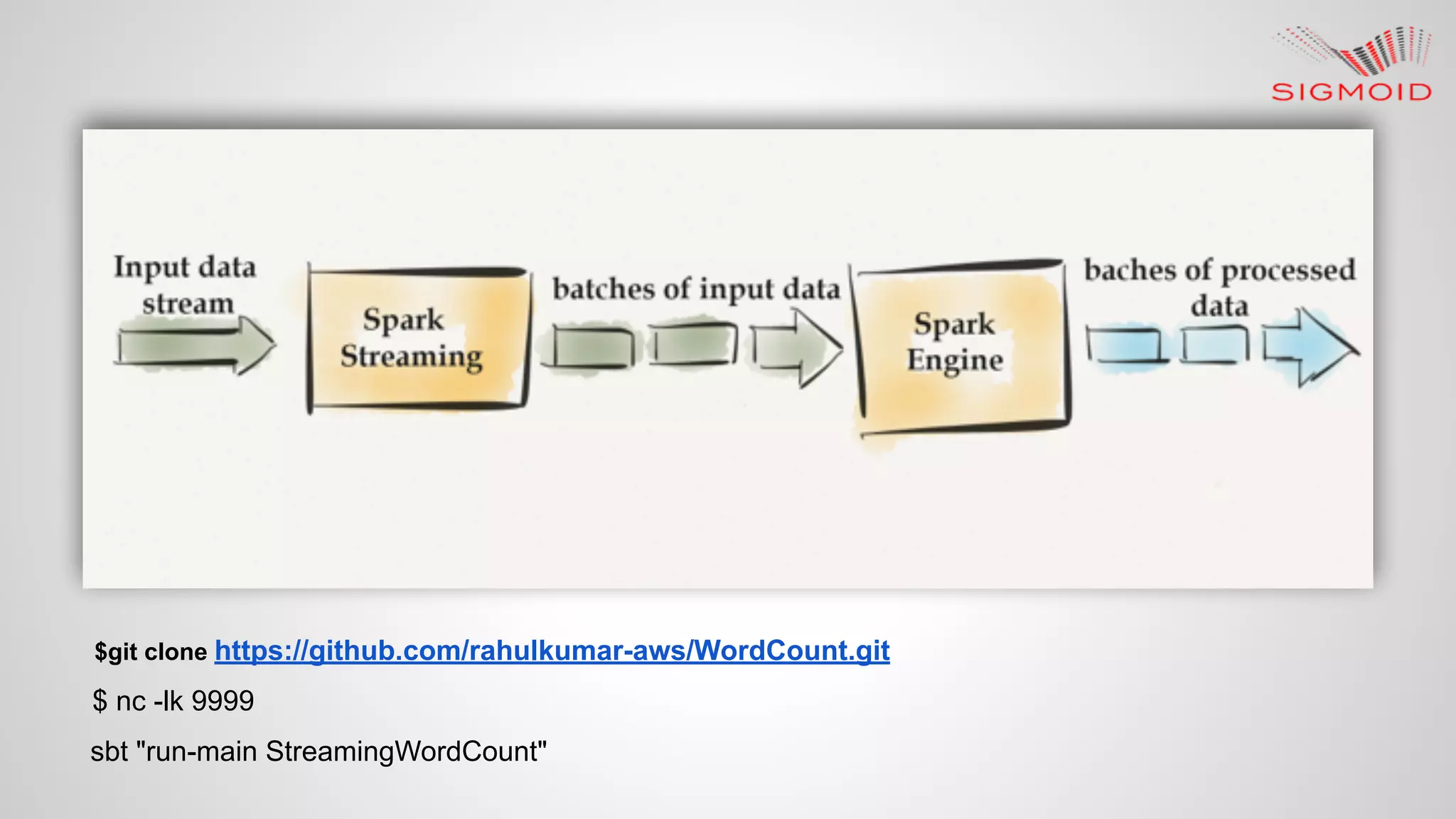

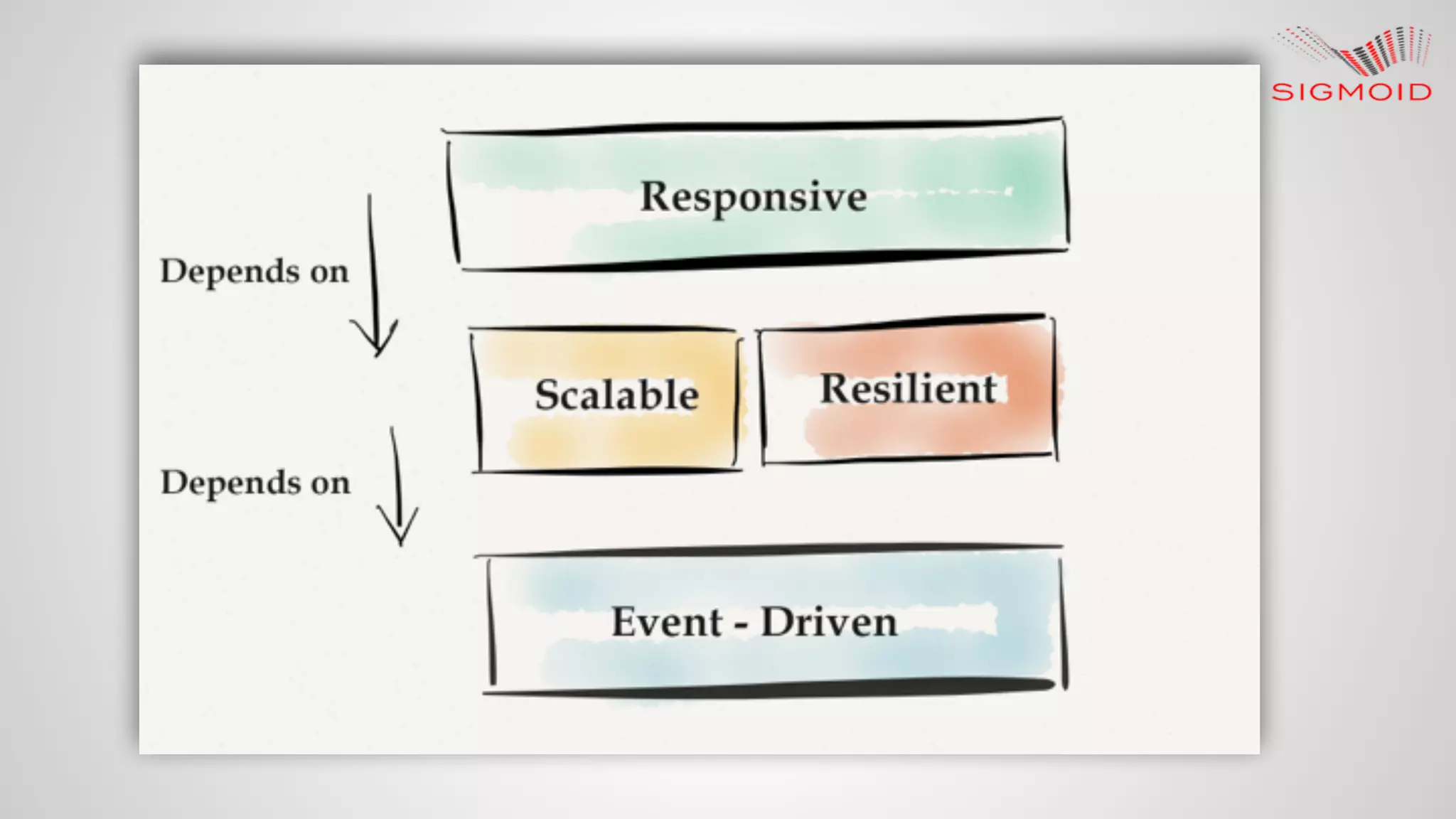







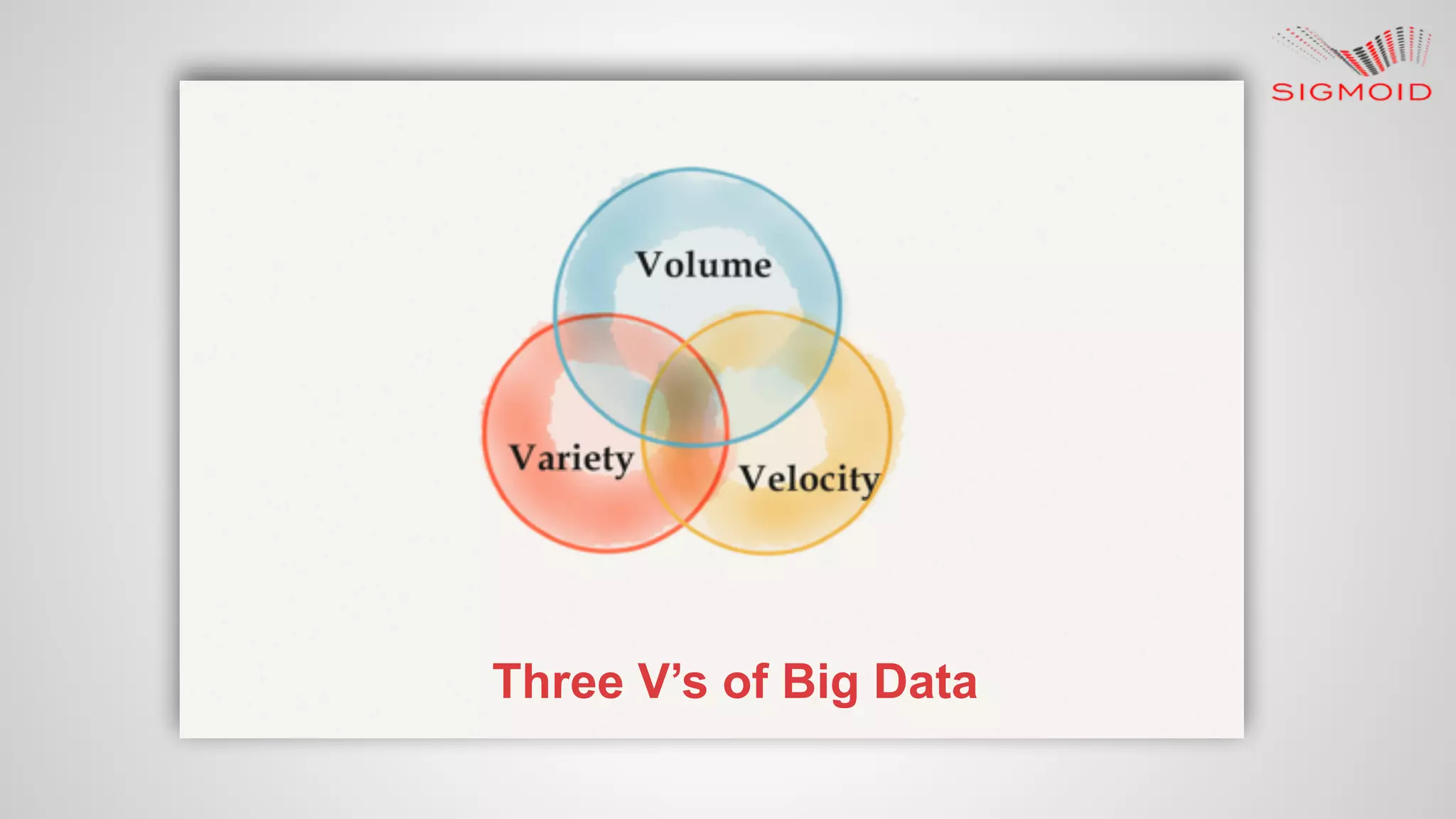
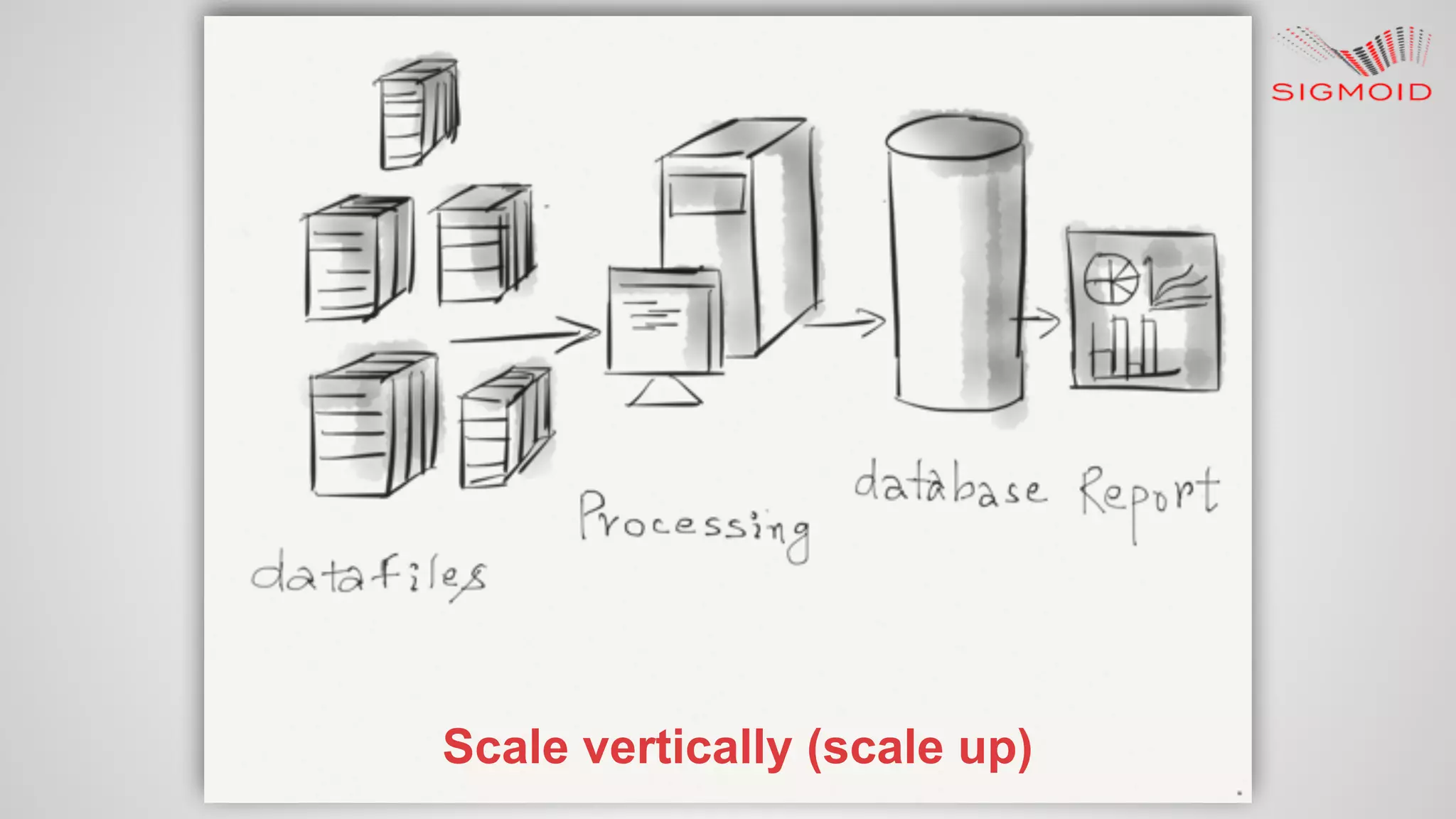
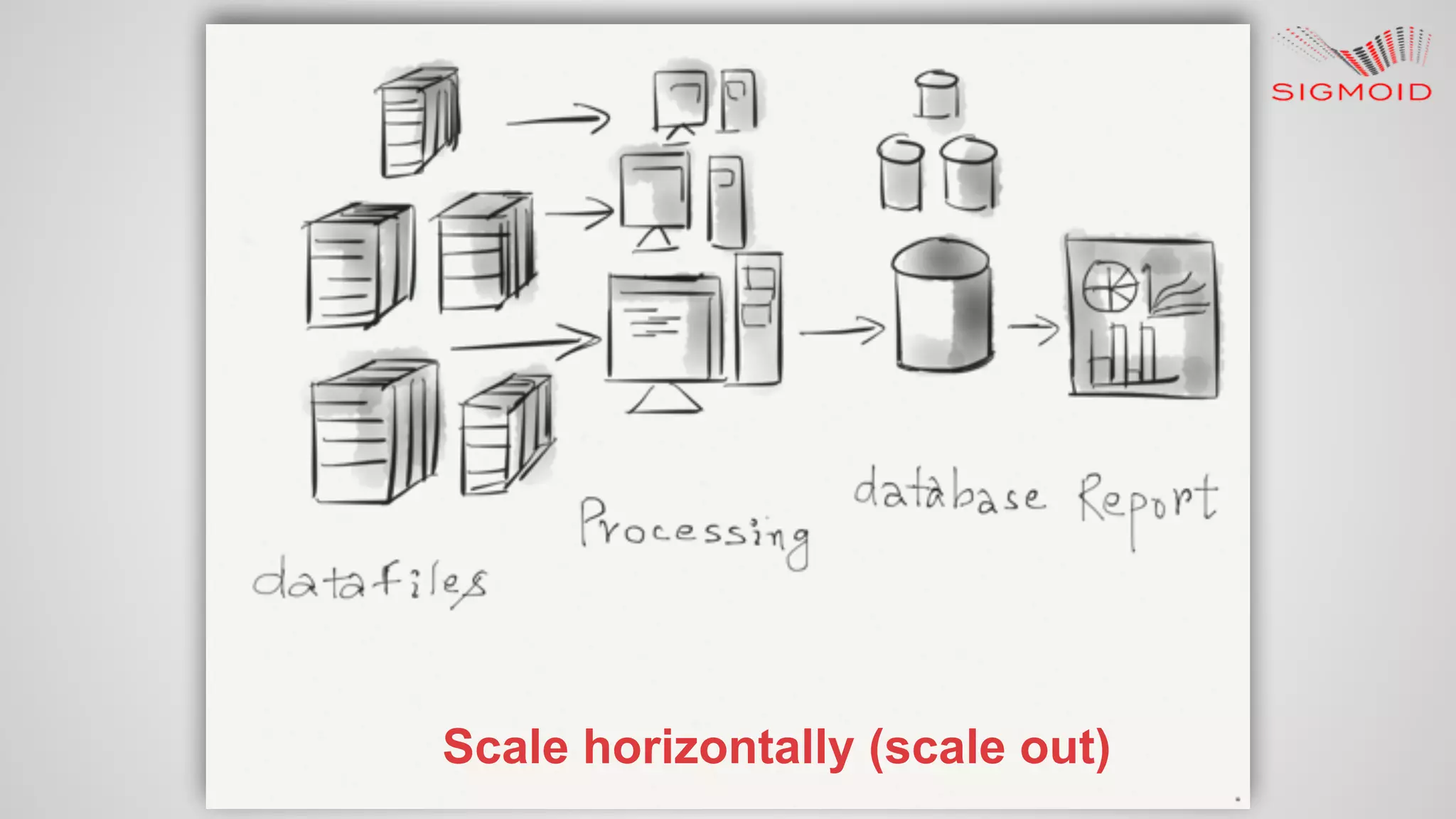
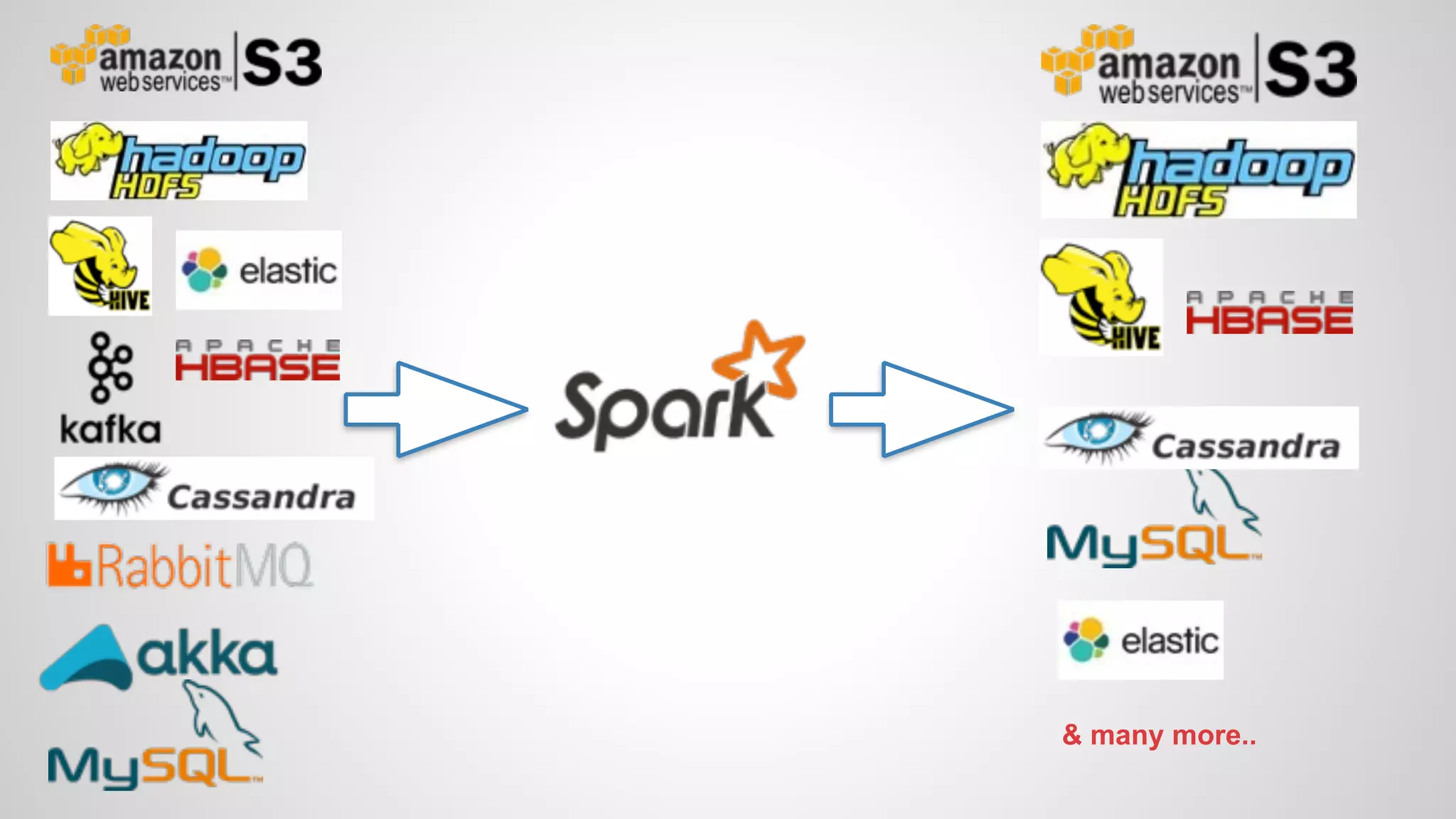
Rahul Kumar's presentation at LinuxCon 2015 covers the creation of reactive dashboards using Apache Spark, detailing key features like real-time data updates and interactivity. It provides an overview of Spark's capabilities, RDDs (Resilient Distributed Datasets), and Spark SQL for structured data, along with practical examples and setup instructions. The session emphasizes building responsive and resilient applications through reactive programming with tools like Play Framework and Akka.