Downloaded 84 times






















![In Practice 1: line count (defn line-count [lines] (->> lines count)) (defn process [f] (with-open [rdr (clojure.java.io/reader "in.log")] (let [result (f (line-seq rdr))] (if (seq? result) (doall result) result)))) (process line-count)](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-29-2048.jpg)
![In Practice 2: line count cont'd (defn line-count* [lines] (->> lines s/count)) (defn new-spark-context [] (let [c (-> (s-conf/spark-conf) (s-conf/master "local[*]") (s-conf/app-name "sparkling") (s-conf/set "spark.akka.timeout" "300") (s-conf/set conf) (s-conf/set-executor-env { "spark.executor.memory" "4G", "spark.files.overwrite" "true"}))] (s/spark-context c) )) (defonce sc (delay (new-spark-context))) (defn process* [f] (let [lines-rdd (s/text-file @sc "in.log")] (f lines-rdd))) (defn line-count [lines] (->> lines count)) (defn process [f] (with-open [rdr (clojure.java.io/reader "in.log")] (let [result (f (line-seq rdr))] (if (seq? result) (doall result) result)))) (process line-count)](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-30-2048.jpg)
![Only go on when your tests are green! (deftest test-line-count*
(let [conf (test-conf)]
(spark/with-context
sc conf
(testing
"no lines return 0"
(is (= 0 (line-count* (spark/parallelize sc [])))))
(testing
"a single line returns 1"
(is (= 1 (line-count* (spark/parallelize sc ["this is a single line"])))))
(testing
"multiple lines count correctly"
(is (= 10 (line-count* (spark/parallelize sc (repeat 10 "this is a single line"))))))
)))](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-31-2048.jpg)



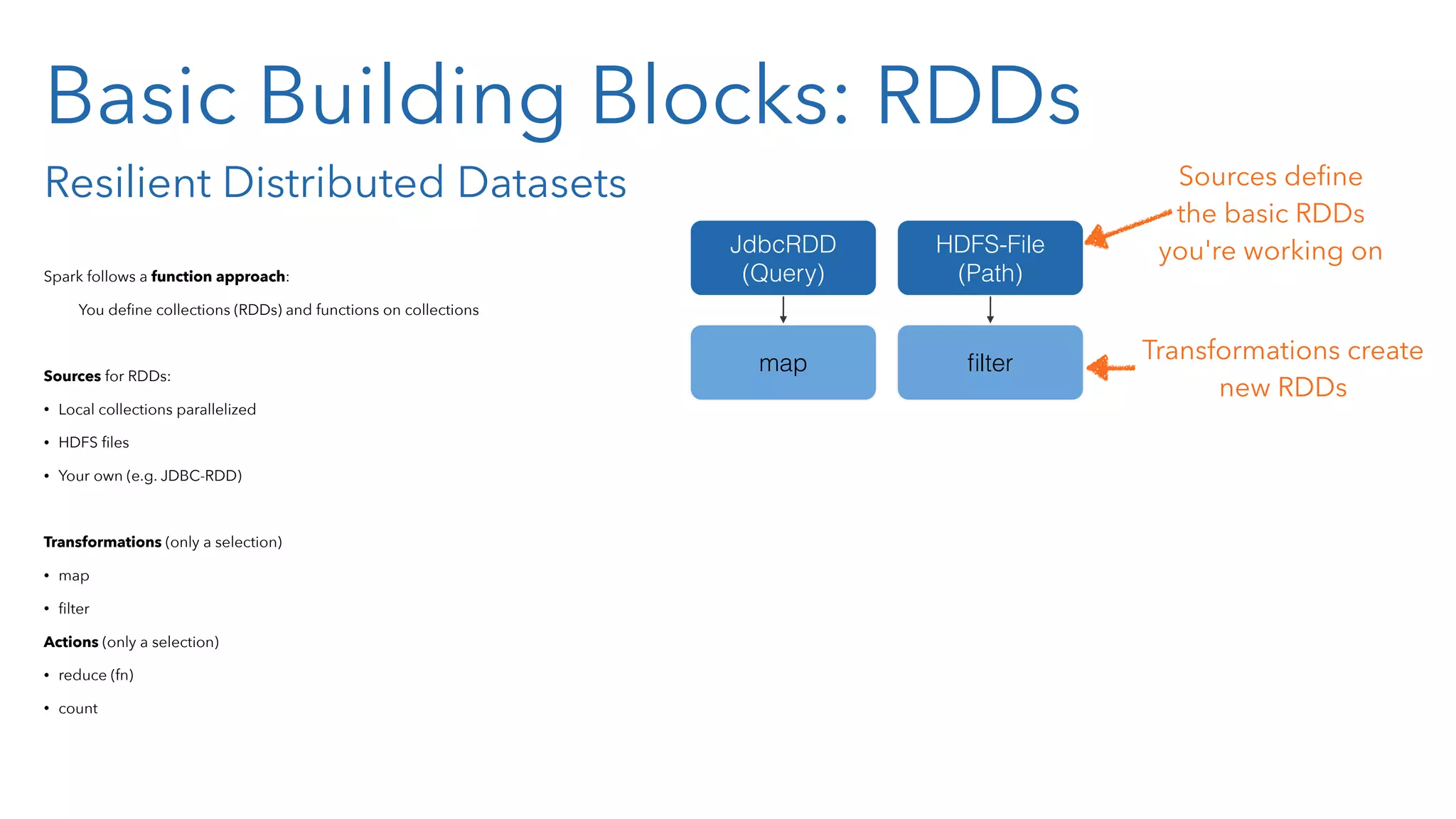
![What's an RDD? What's in it? Take e.g. an JdbcRDD (we all know relational databases...): campaign_id from to active 1 123 2014-01-01 2014-01-31 true 2 234 2014-01-06 2014-01-14 true 3 345 2014-02-01 2014-03-31 false 4 456 2014-02-10 2014-03-09 true That's your table [ {:campaign-id 123 :active true} {:campaign-id 234 :active true} {:campaign-id 345 :active false} {:campaign-id 456 :active true}]](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-35-2048.jpg)
![What's an RDD? What's in it? Take e.g. an JdbcRDD (we all know relational databases...): campaign_id from to active 1 123 2014-01-01 2014-01-31 true 2 234 2014-01-06 2014-01-14 true 3 345 2014-02-01 2014-03-31 false 4 456 2014-02-10 2014-03-09 true That's your table [ {:campaign-id 123 :active true} {:campaign-id 234 :active true} {:campaign-id 345 :active false} {:campaign-id 456 :active true}] RDDs are lists of objects](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-36-2048.jpg)
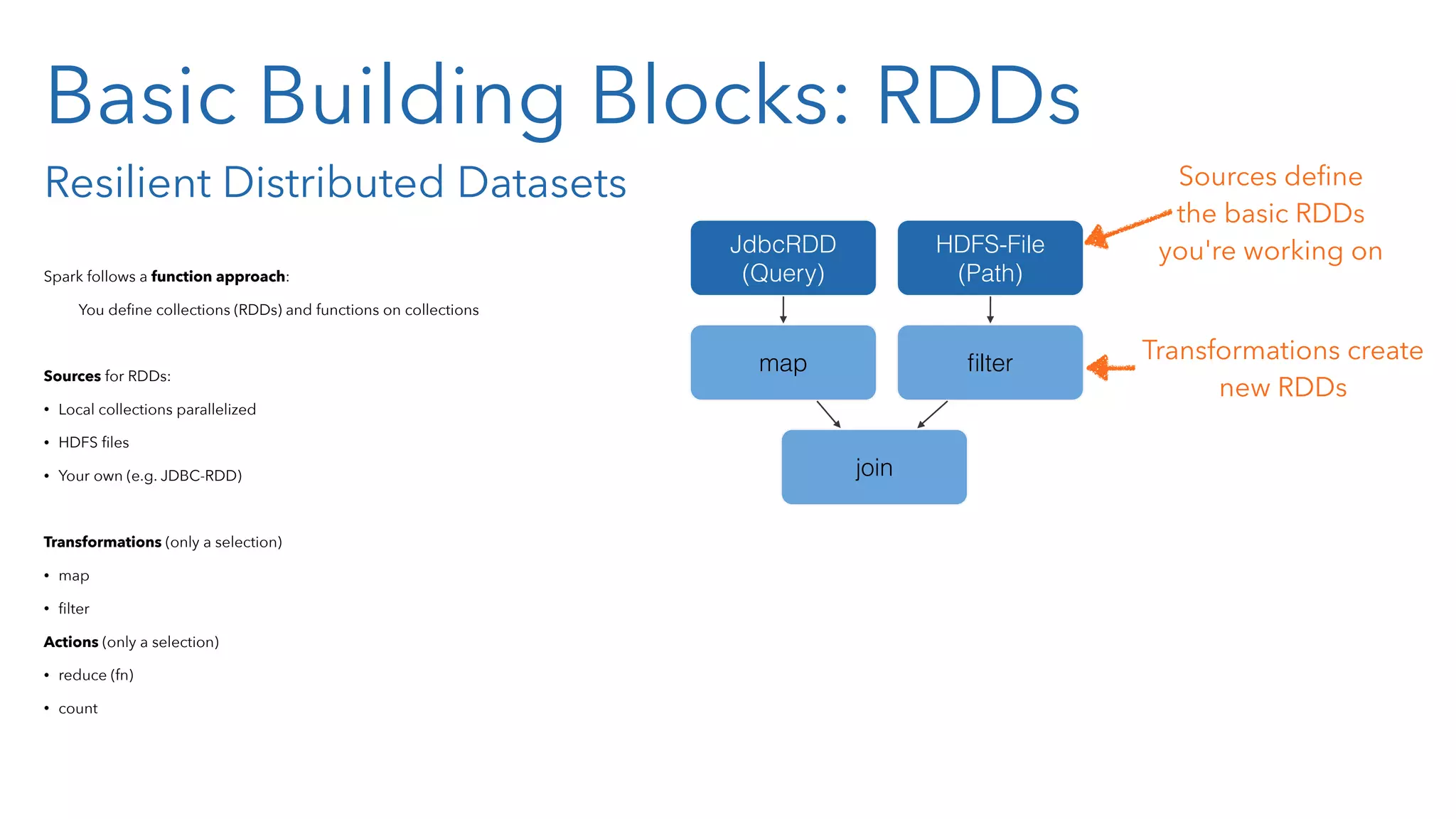
![What's an RDD? What's in it? Take e.g. an JdbcRDD (we all know relational databases...): campaign_id from to active 1 123 2014-01-01 2014-01-31 true 2 234 2014-01-06 2014-01-14 true 3 345 2014-02-01 2014-03-31 false 4 456 2014-02-10 2014-03-09 true That's your table [ {:campaign-id 123 :active true} {:campaign-id 234 :active true} {:campaign-id 345 :active false} {:campaign-id 456 :active true}] RDDs are lists of objects [ #t[123 {:campaign-id 123 :active true}] #t[234 {:campaign-id 234 :active true}]] [ #t[345 {:campaign-id 345 :active false}] #t[456 {:campaign-id 456 :active true}]](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-37-2048.jpg)
![What's an RDD? What's in it? Take e.g. an JdbcRDD (we all know relational databases...): campaign_id from to active 1 123 2014-01-01 2014-01-31 true 2 234 2014-01-06 2014-01-14 true 3 345 2014-02-01 2014-03-31 false 4 456 2014-02-10 2014-03-09 true That's your table [ {:campaign-id 123 :active true} {:campaign-id 234 :active true} {:campaign-id 345 :active false} {:campaign-id 456 :active true}] RDDs are lists of objects [ #t[123 {:campaign-id 123 :active true}] #t[234 {:campaign-id 234 :active true}]] [ #t[345 {:campaign-id 345 :active false}] #t[456 {:campaign-id 456 :active true}] PairRDDs handle key-value pairs, may have partitioners assigned, keys not necessarily unique!](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-38-2048.jpg)
![In Practice 3: status codes (defn parse-line [line] (some->> line (re-matches common-log-regex) rest (zipmap [:ip :timestamp :request :status :length :referer :ua :duration]) transform-log-entry)) (defn group-by-status-code [lines] (->> lines (map parse-line) (map (fn [entry] [(:status entry) 1])) (reduce (fn [a [k v]] (update-in a [k] #((fnil + 0) % v))) {}) (map identity)))](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-39-2048.jpg)
![In Practice 4: status codes cont'd (defn parse-line [line] (some->> line (re-matches common-log-regex) rest (zipmap [:ip :timestamp :request :status :length :referer :ua :duration]) transform-log-entry)) (defn group-by-status-code [lines] (->> lines (map parse-line) (map (fn [entry] [(:status entry) 1])) (reduce (fn [a [k v]] (update-in a [k] #((fnil + 0) % v))) {}) (map identity))) (defn group-by-status-code* [lines] (-> lines (s/map parse-line) (s/map-to-pair (fn [entry] (s/tuple (:status entry) 1))) (s/reduce-by-key +) (s/map (sd/key-value-fn vector)) (s/collect)))](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-40-2048.jpg)


![In Practice 7: top errors (defn top-errors [lines] (->> lines (map parse-line) (filter (fn [entry] (not= "200" (:status entry)))) (map (fn [entry] [(:uri entry) 1])) (reduce (fn [a [k v]] (update-in a [k] #((fnil + 0) % v))) {}) (sort-by val >) (take 10)))](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-43-2048.jpg)
![In Practice 8: top errors cont'd (defn top-errors* [lines] (-> lines (s/map parse-line) (s/filter (fn [entry] (not= "200" (:status entry)))) s/cache (s/map-to-pair (fn [entry] (s/tuple (:uri entry) 1))) (s/reduce-by-key +) ;; flip (s/map-to-pair (sd/key-value-fn (fn [a b] (s/tuple b a)))) (s/sort-by-key false) ;; descending order ;; flip (s/map-to-pair (sd/key-value-fn (fn [a b] (s/tuple b a)))) (s/map (sd/key-value-fn vector)) (s/take 10)))](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-44-2048.jpg)




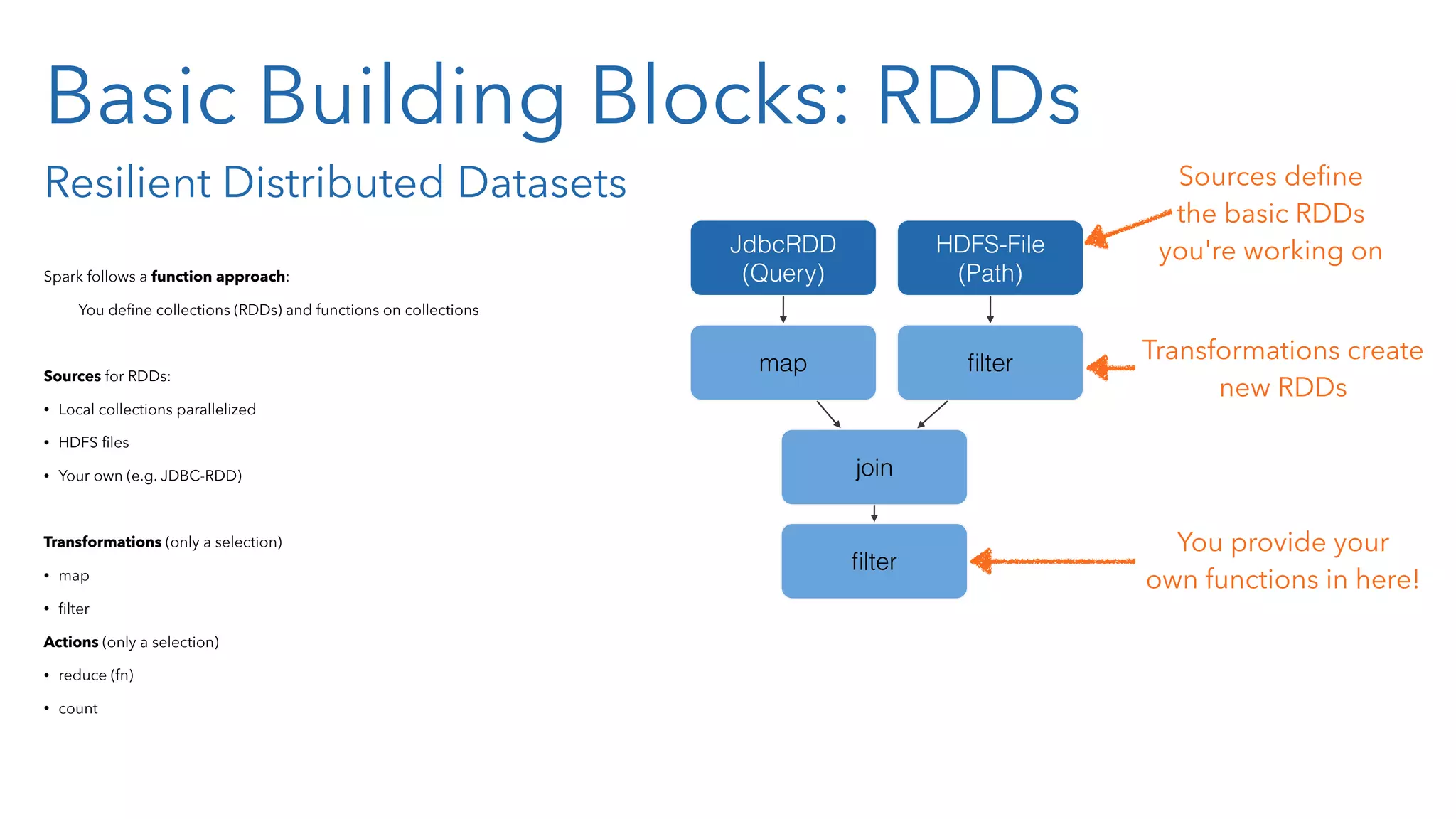
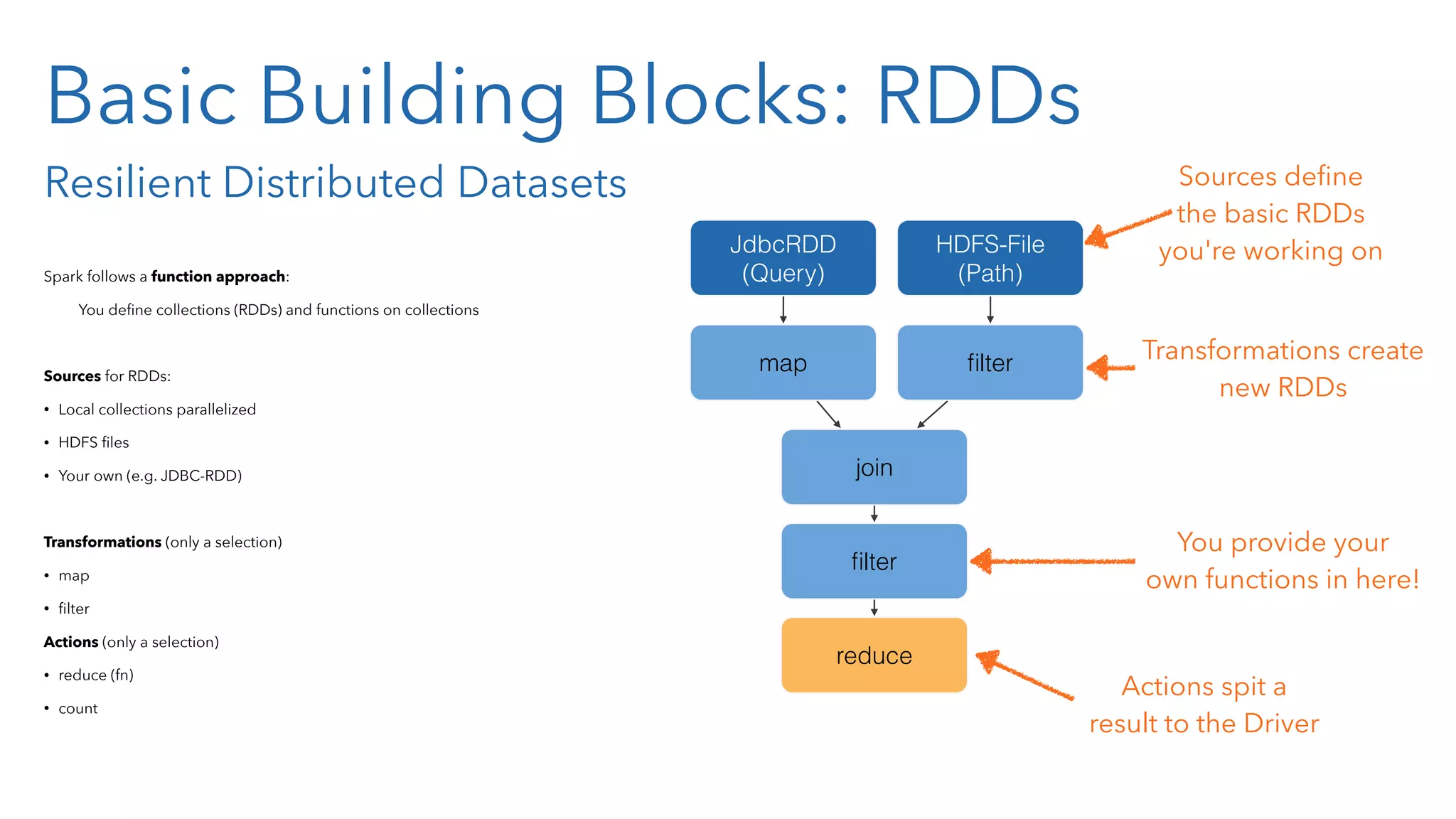
![Processing RDDs So your application • defines (source) RDDs, • transforms them (which creates new RDDs with dependencies on the source RDDs) • and runs actions on them to get results back to the driver. This defines a Directed Acyclic Graph (DAG) of operators. Spark compiles this DAG of operators into a set of stages, where the boundary between two stages is a shuffle phase. Each stage contains tasks, working on one partition each. Example sc.textFile("/some-hdfs-data") map#map# reduceByKey# collect#textFile# .map(line => line.split("t")) .map(parts => (parts[0], int(parts[1]))) .reduceByKey(_ + _, 3) .collect() RDD[String] RDD[List[String]] RDD[(String, Int)] Array[(String, Int)] RDD[(String, Int)]](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-49-2048.jpg)
![Processing RDDs So your application • defines (source) RDDs, • transforms them (which creates new RDDs with dependencies on the source RDDs) • and runs actions on them to get results back to the driver. This defines a Directed Acyclic Graph (DAG) of operators. Spark compiles this DAG of operators into a set of stages, where the boundary between two stages is a shuffle phase. Each stage contains tasks, working on one partition each. Example sc.textFile("/some-hdfs-data") map#map# reduceByKey# collect#textFile# .map(line => line.split("t")) .map(parts => (parts[0], int(parts[1]))) .reduceByKey(_ + _, 3) .collect() RDD[String] RDD[List[String]] RDD[(String, Int)] Array[(String, Int)] RDD[(String, Int)] Execution Graph map#map# reduceByKey# collect#textFile# map# Stage#2#Stage#1# map# reduceByKey# collect#textFile#](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-50-2048.jpg)
![Processing RDDs So your application • defines (source) RDDs, • transforms them (which creates new RDDs with dependencies on the source RDDs) • and runs actions on them to get results back to the driver. This defines a Directed Acyclic Graph (DAG) of operators. Spark compiles this DAG of operators into a set of stages, where the boundary between two stages is a shuffle phase. Each stage contains tasks, working on one partition each. Example sc.textFile("/some-hdfs-data") map#map# reduceByKey# collect#textFile# .map(line => line.split("t")) .map(parts => (parts[0], int(parts[1]))) .reduceByKey(_ + _, 3) .collect() RDD[String] RDD[List[String]] RDD[(String, Int)] Array[(String, Int)] RDD[(String, Int)] Execution Graph map#map# reduceByKey# collect#textFile# map# Stage#2#Stage#1# map# reduceByKey# collect#textFile# Execution Graph map# Stage#2#Stage#1# map# reduceByKey# collect#textFile# Stage#2#Stage#1# read HDFS split apply both maps partial reduce write shuffle data read shuffle data final reduce send result to driver](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-51-2048.jpg)




![Running your spark code Run locally: e.g. inside tests. Use "local" or "local[*]" as SparkMaster. Run on cluster: either directly addressing Spark or (our case): run on top of YARN Both open a Web interface on http://host:4040/. Using the REPL: Open a SparkContext, define RDDs and store them in vars, perform transformations on these. Develop stuff in the REPL transfer your REPL stuff into tests. Run inside of tests: Open local SparcContext, feed mock data, run jobs. Therefore: design for testability! Submit a Spark Job using "spark-submit" with proper arguments (see upload.sh, run.sh).](https://image.slidesharecdn.com/sparkandclojure2-150126034509-conversion-gate01/75/Big-Data-Processing-using-Apache-Spark-and-Clojure-56-2048.jpg)


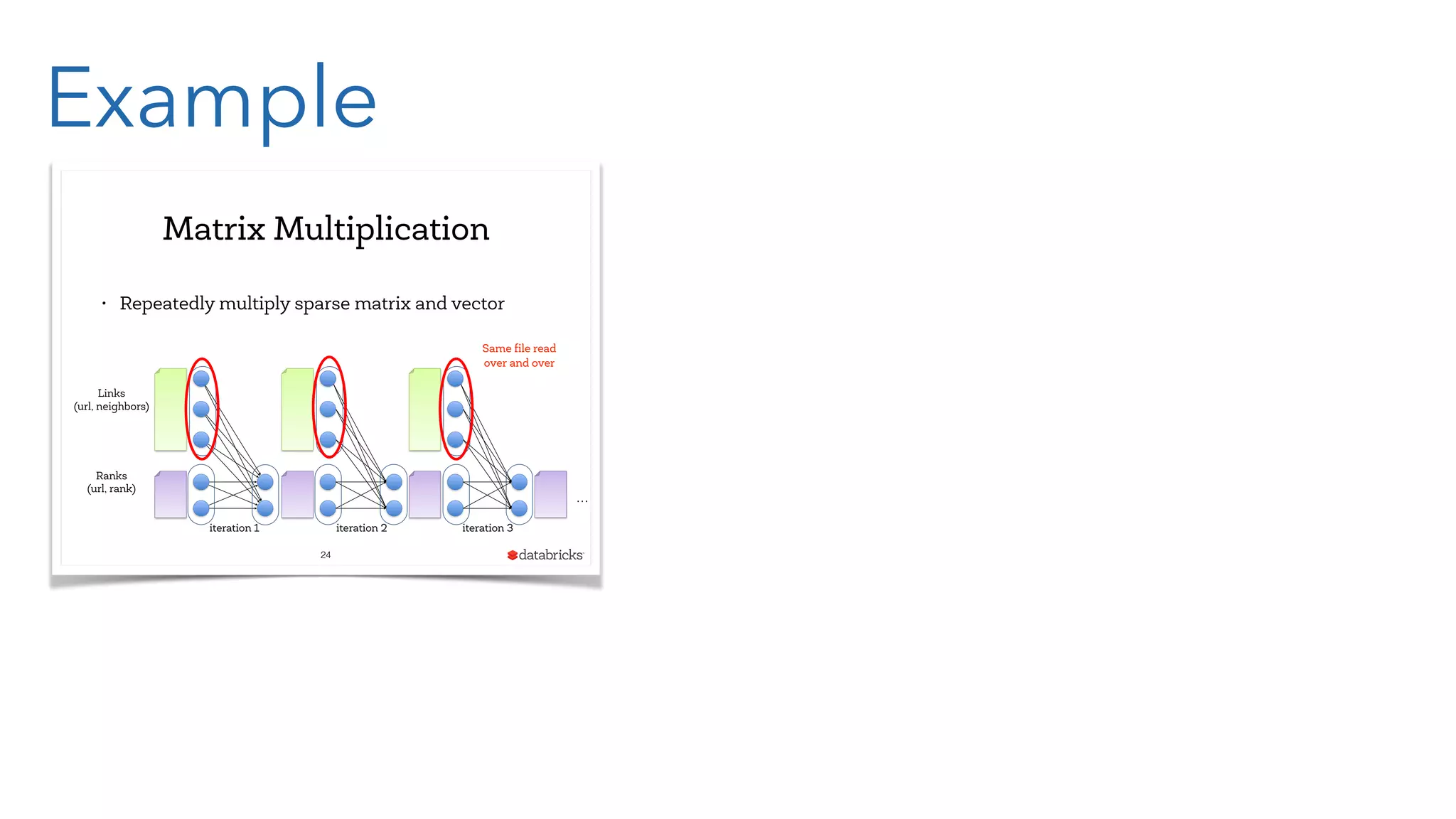
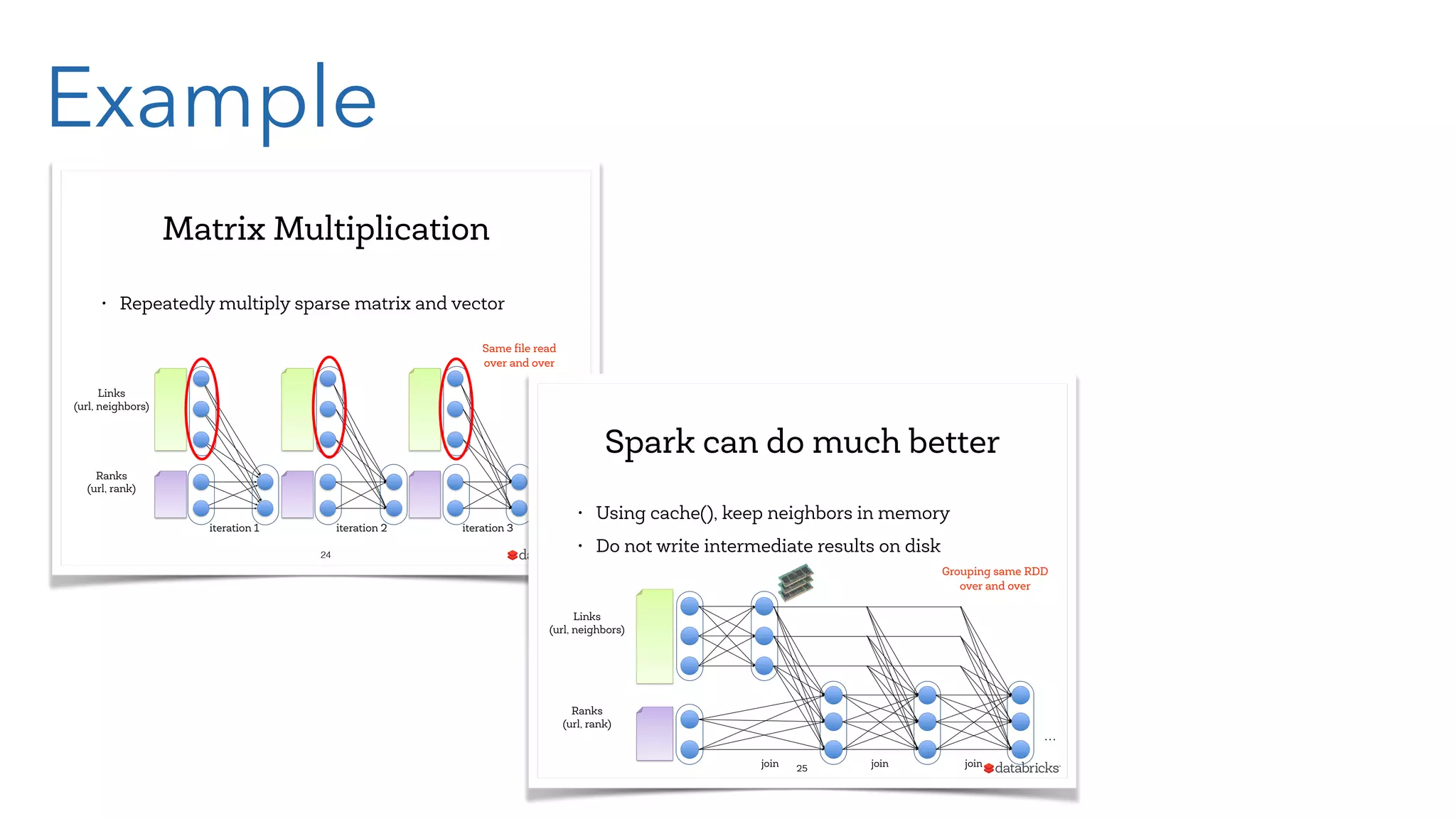









The document provides an overview of big data processing using Apache Spark with a focus on Clojure. It discusses the advantages of Spark's in-memory processing over Hadoop's traditional disk I/O, introduces Resilient Distributed Datasets (RDDs), and presents practical examples of RDD manipulation and transformations. The authors highlight the functional programming aspects of Spark that align well with Clojure, promoting its use for developing Spark applications.