Download as PDF, PPTX



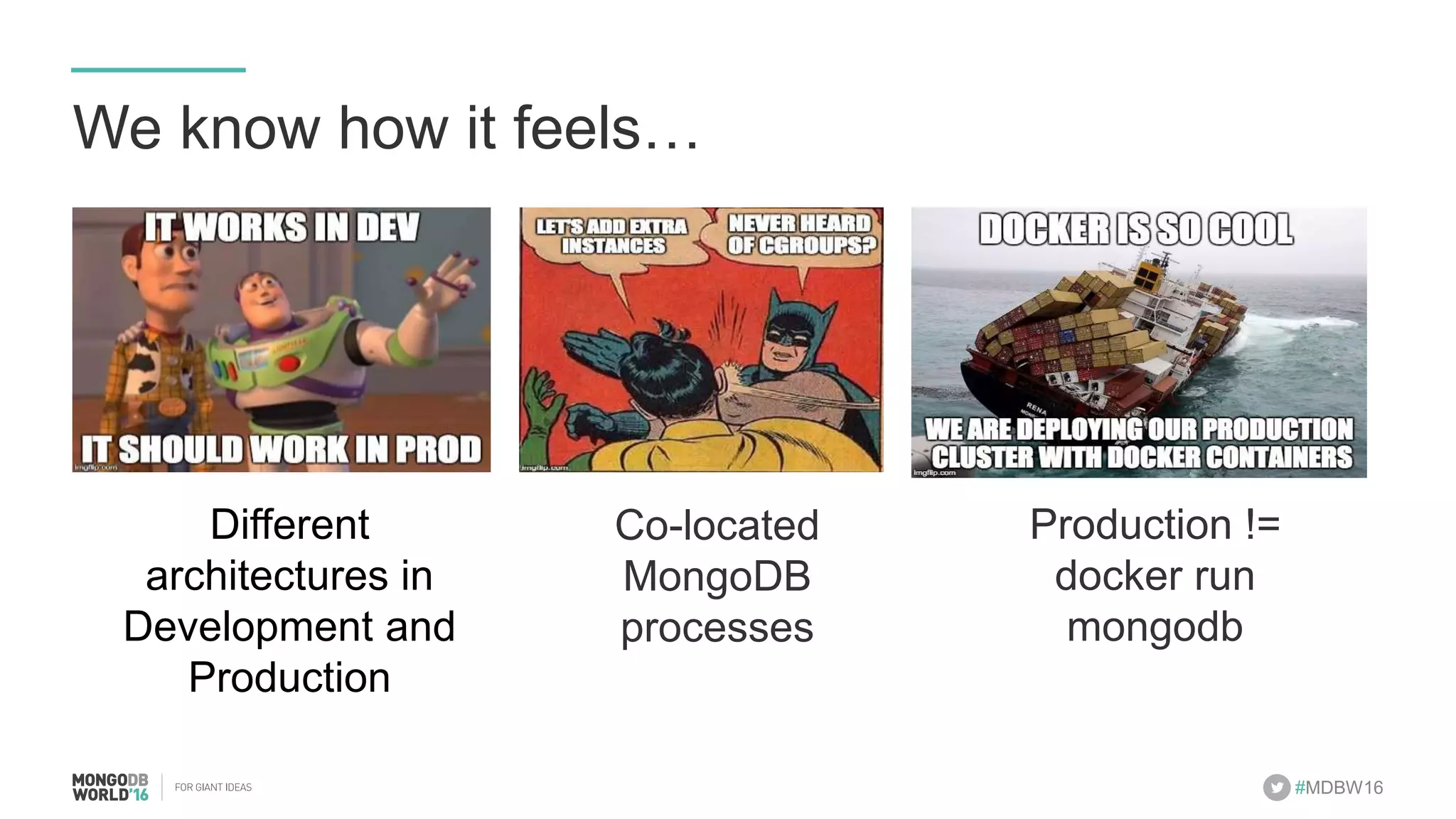

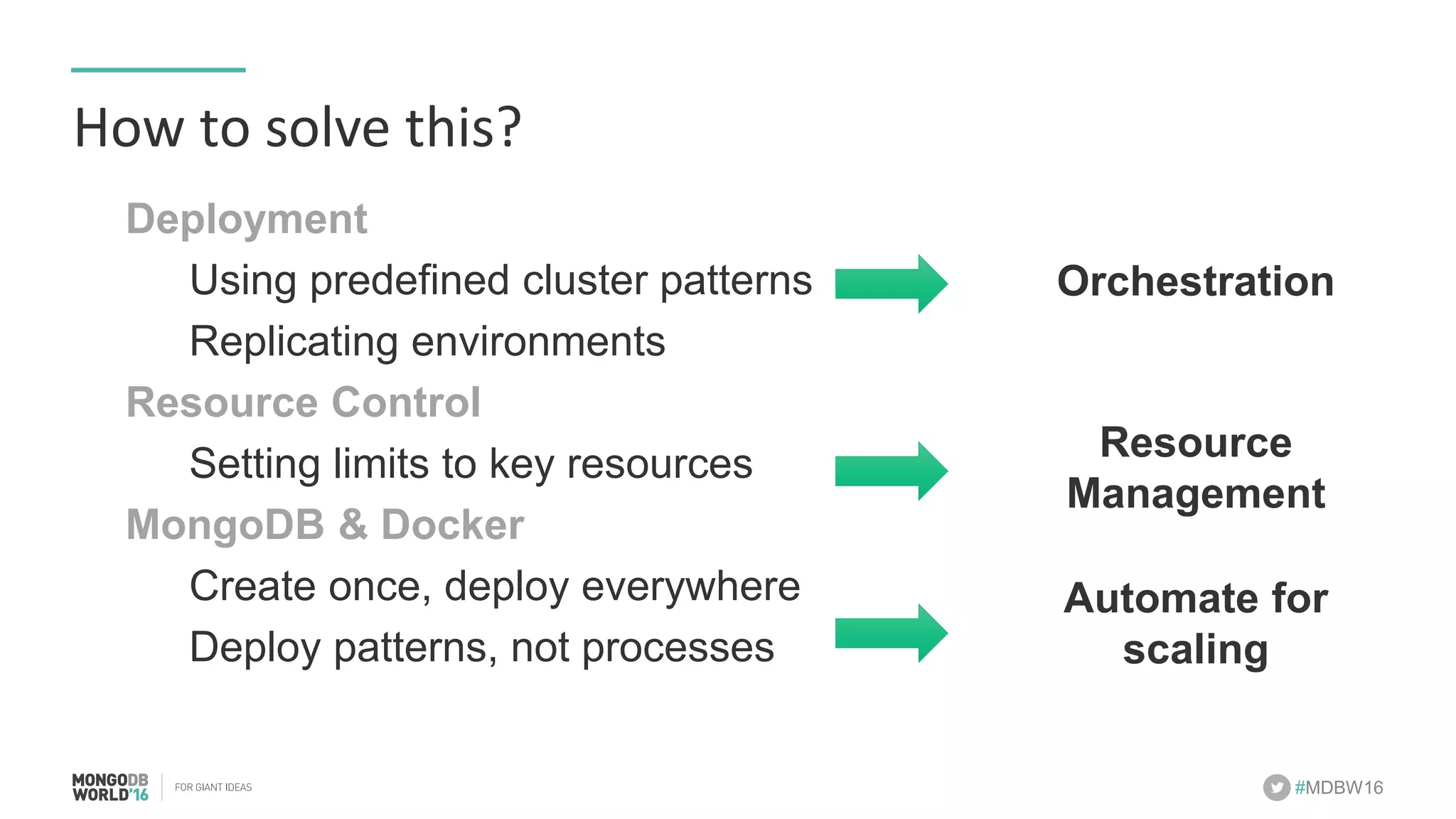

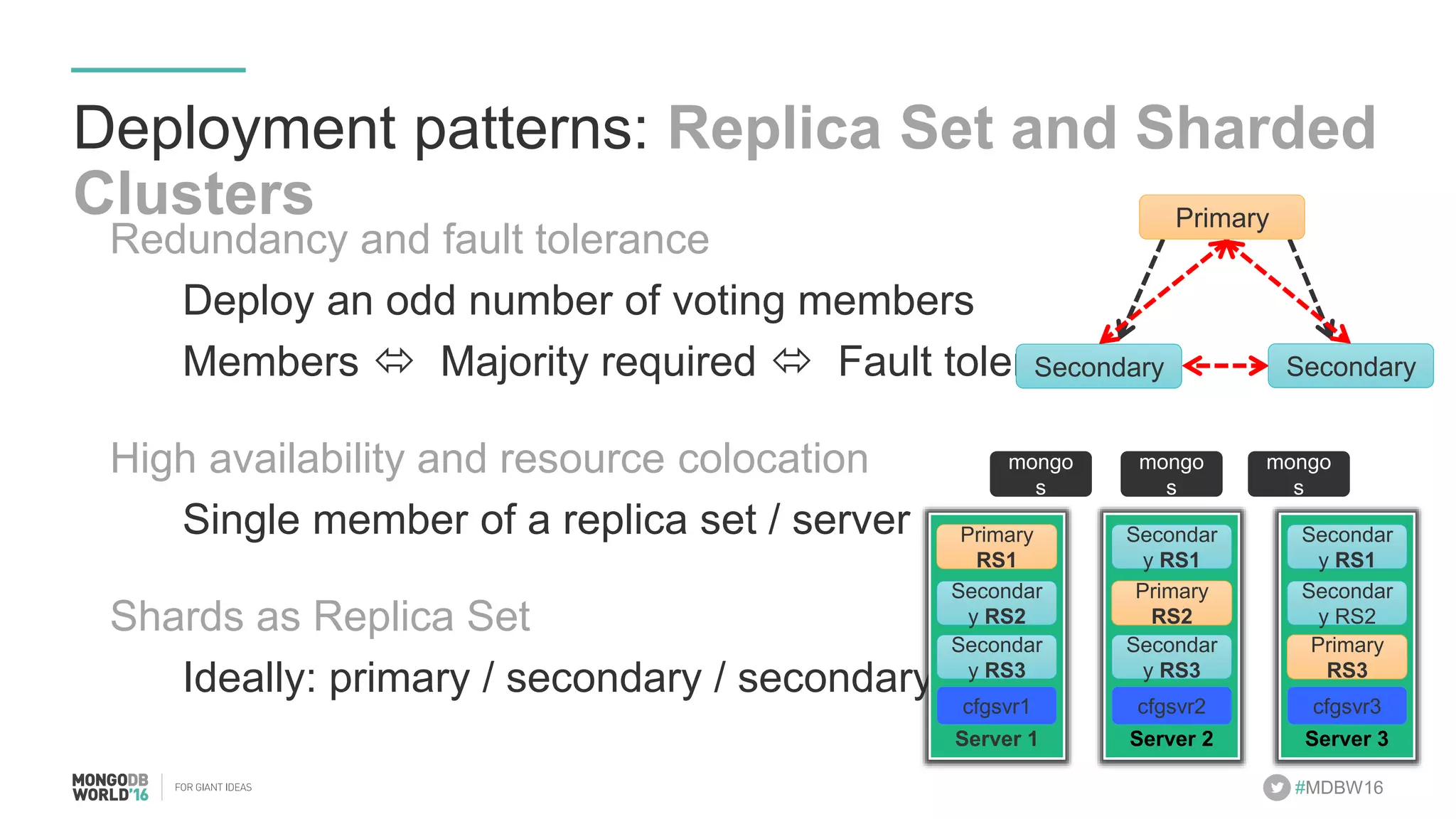
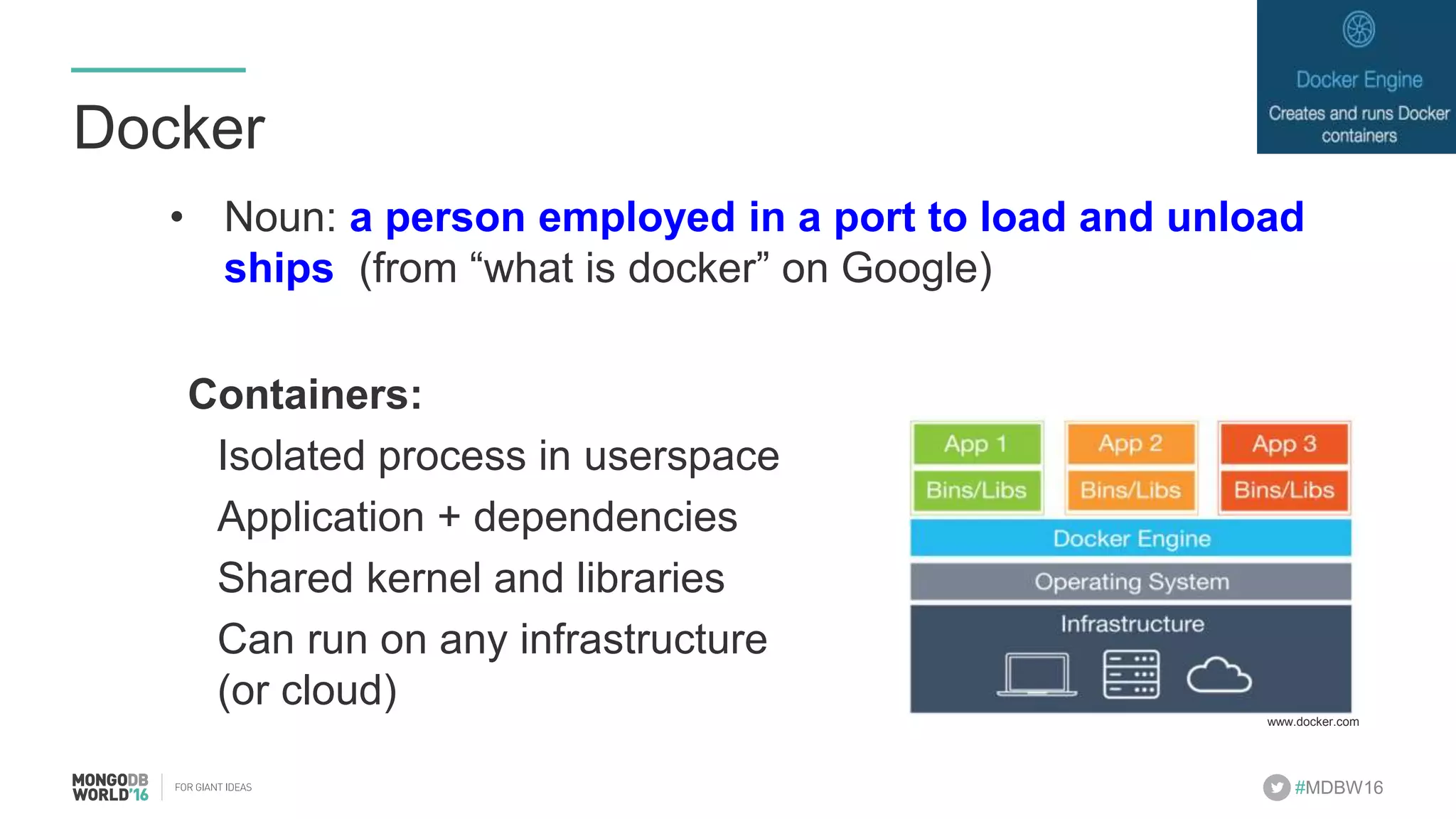
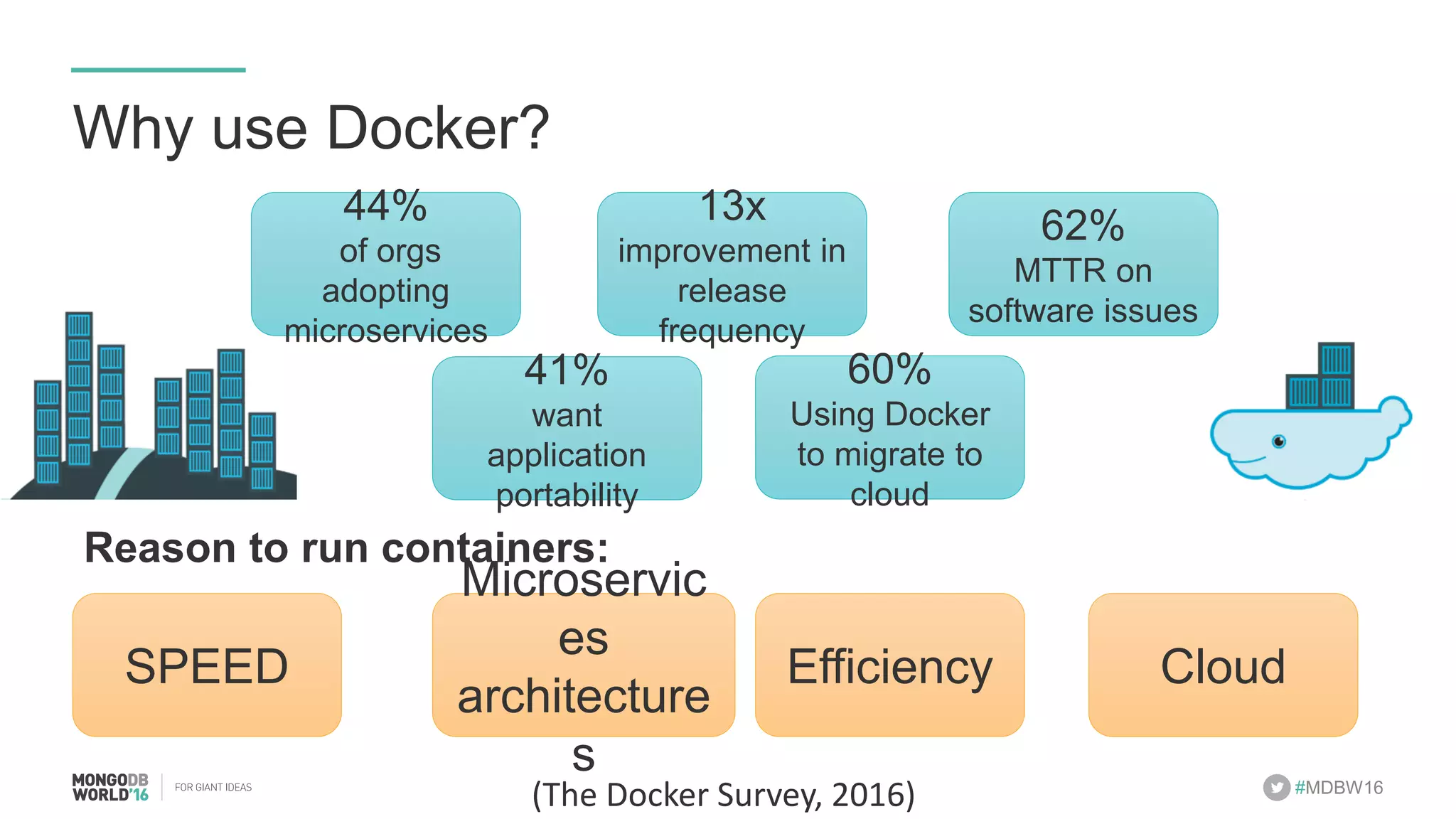


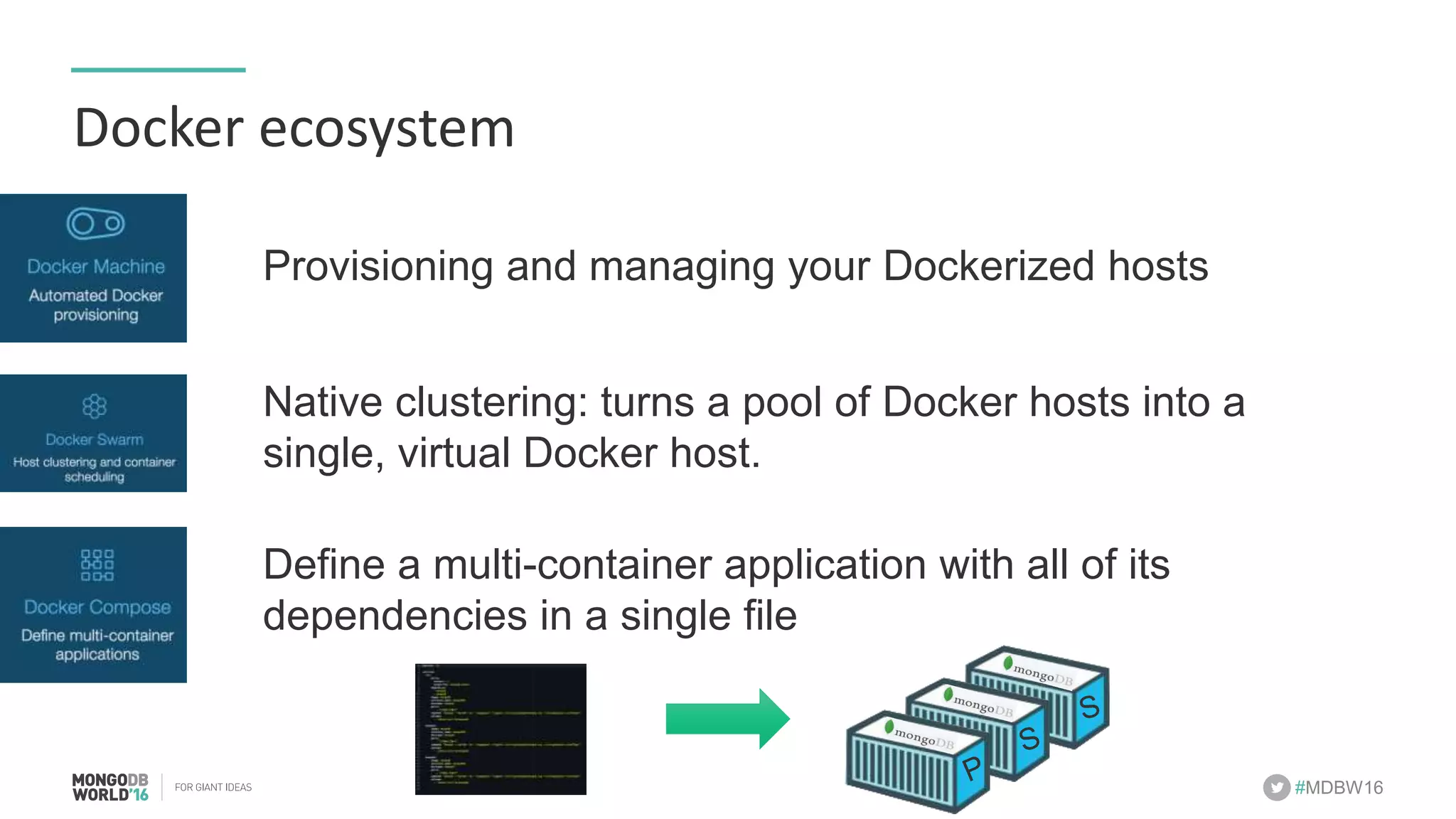
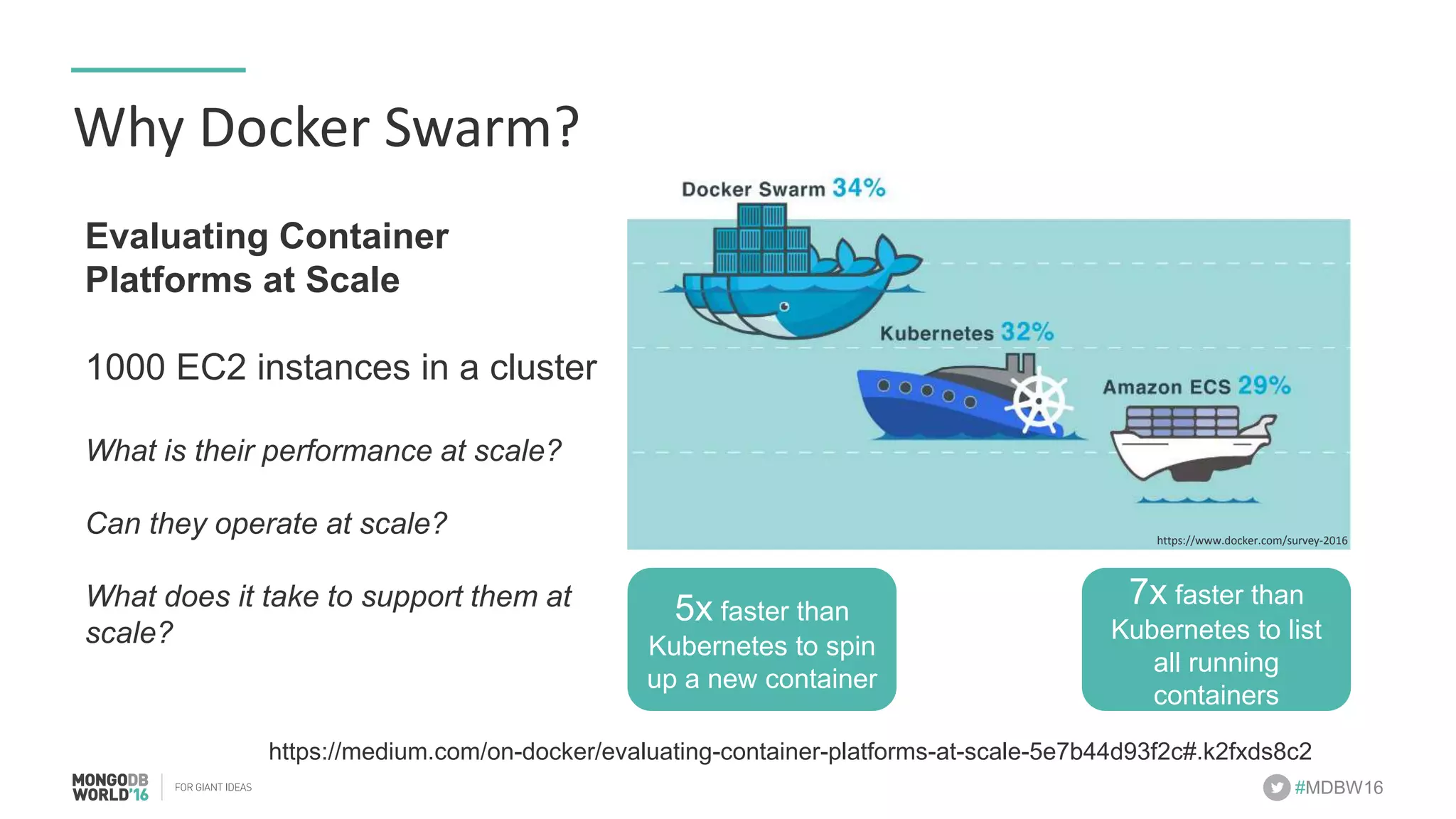
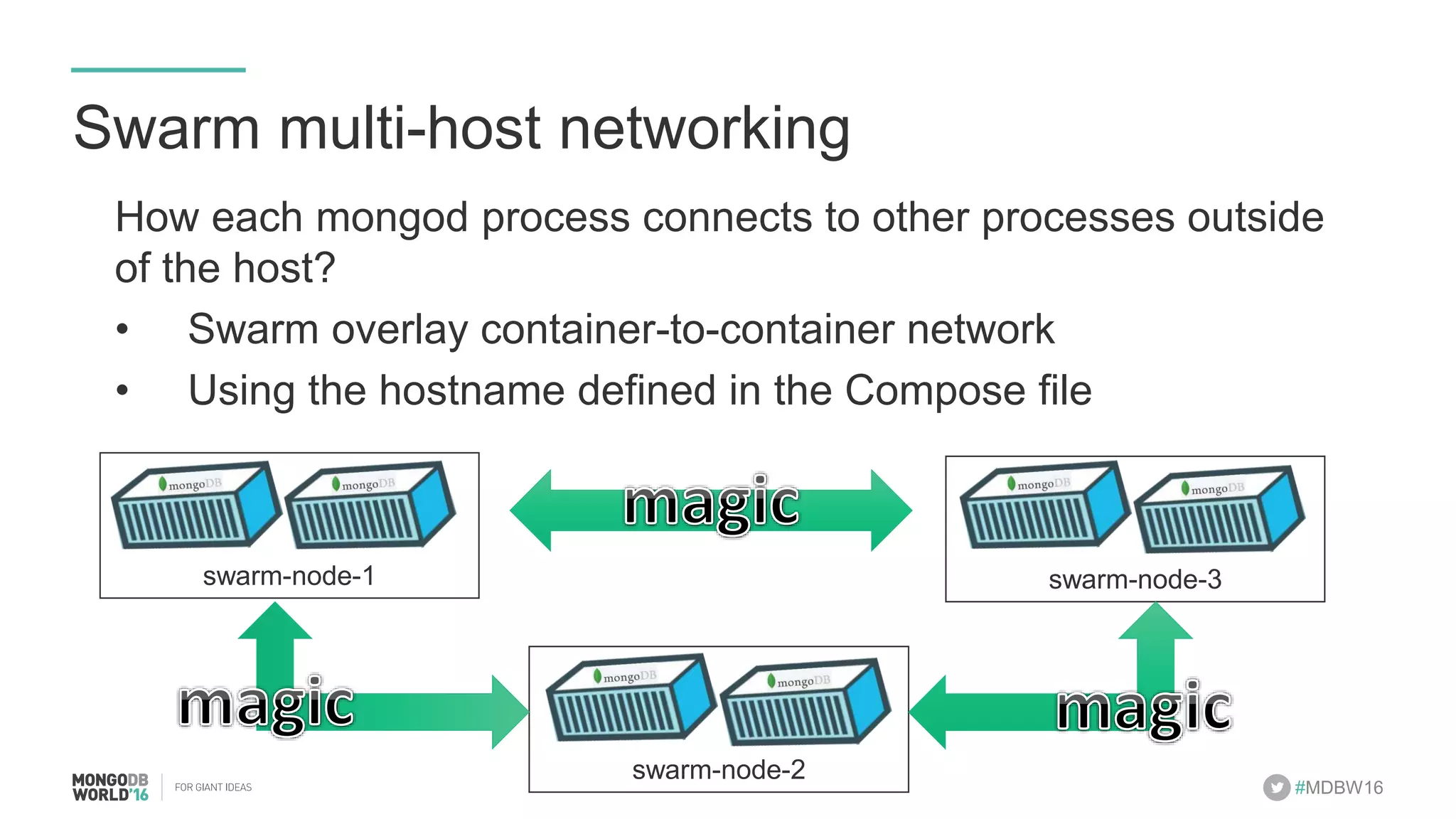
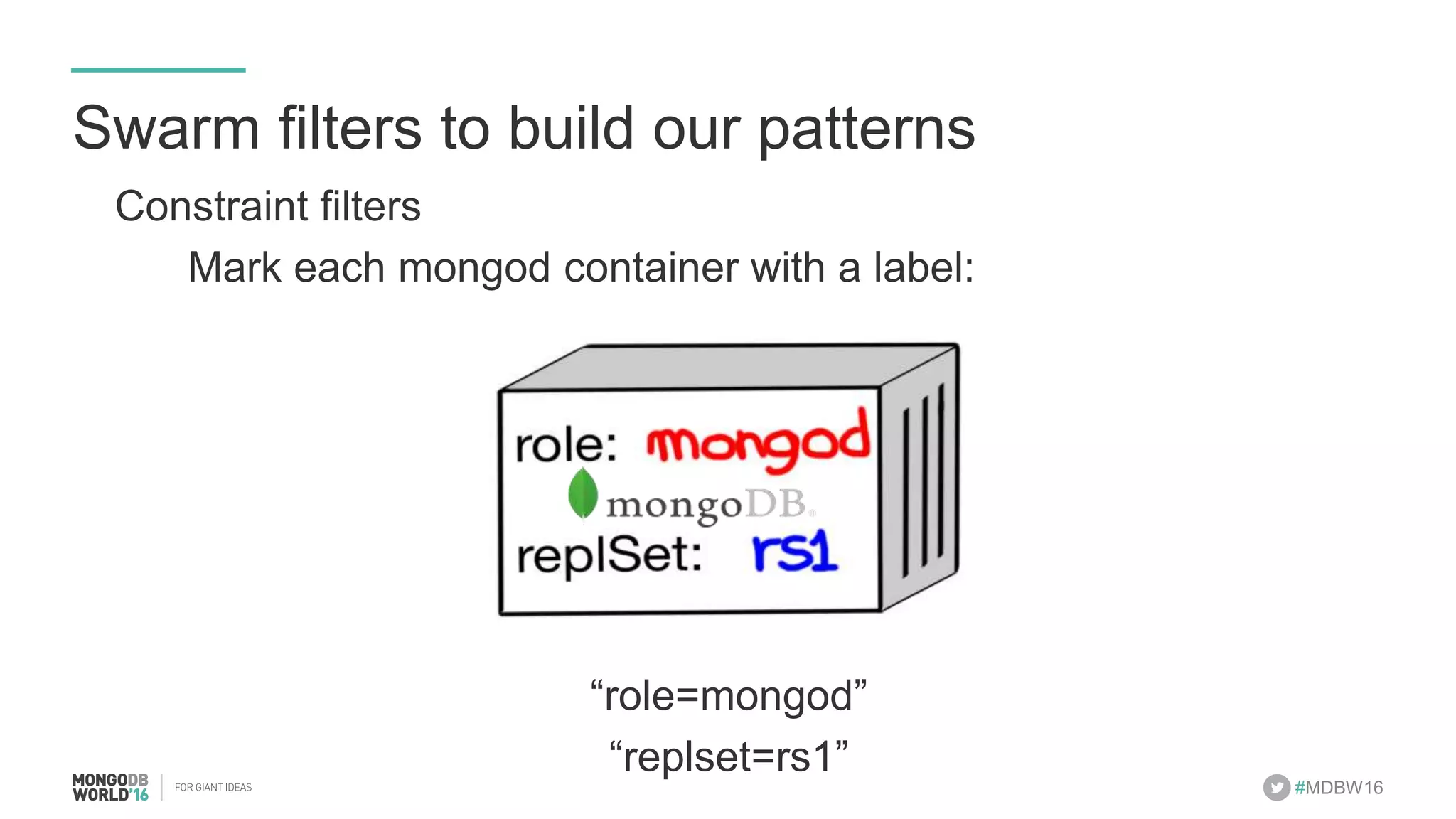


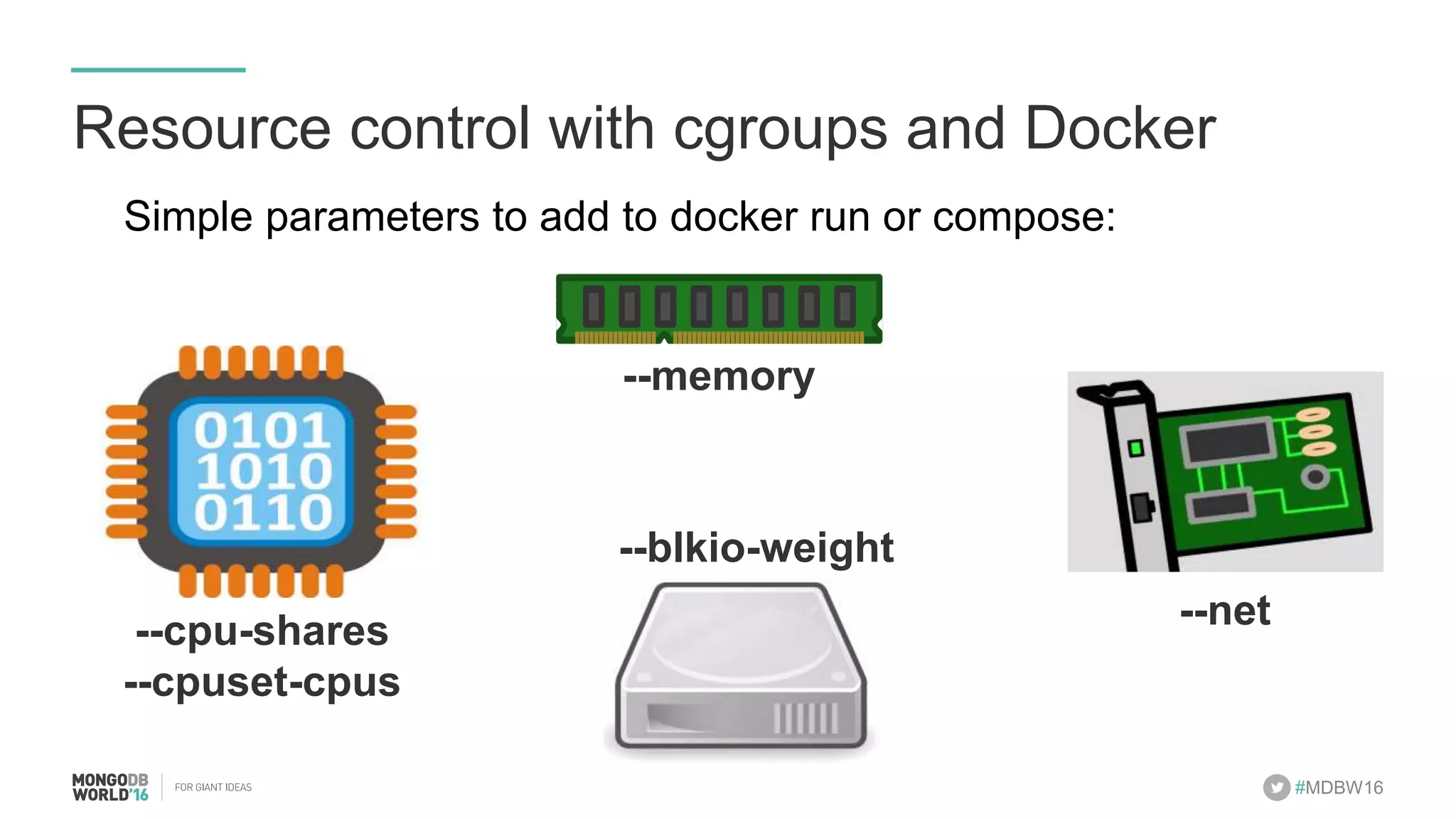

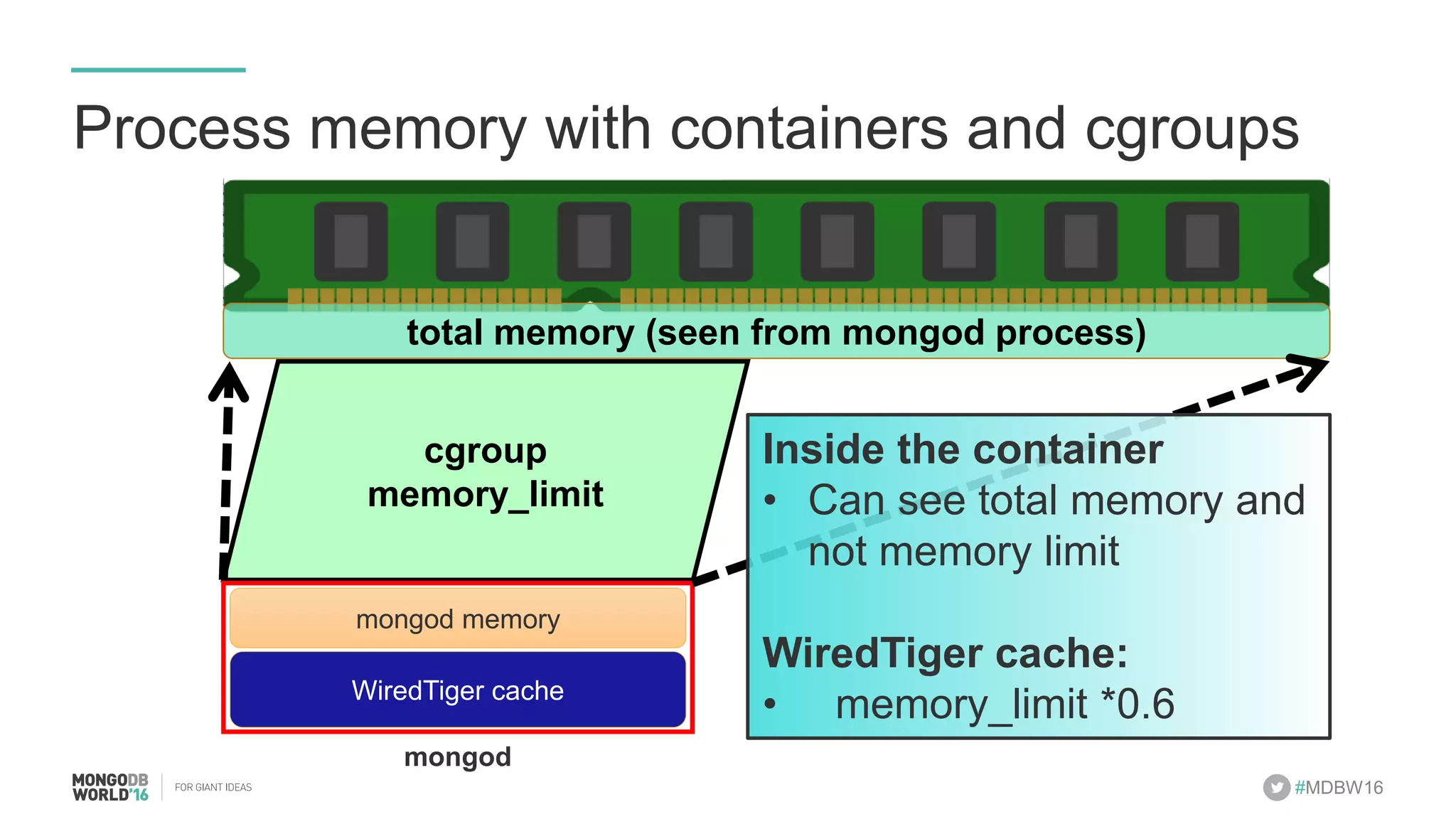
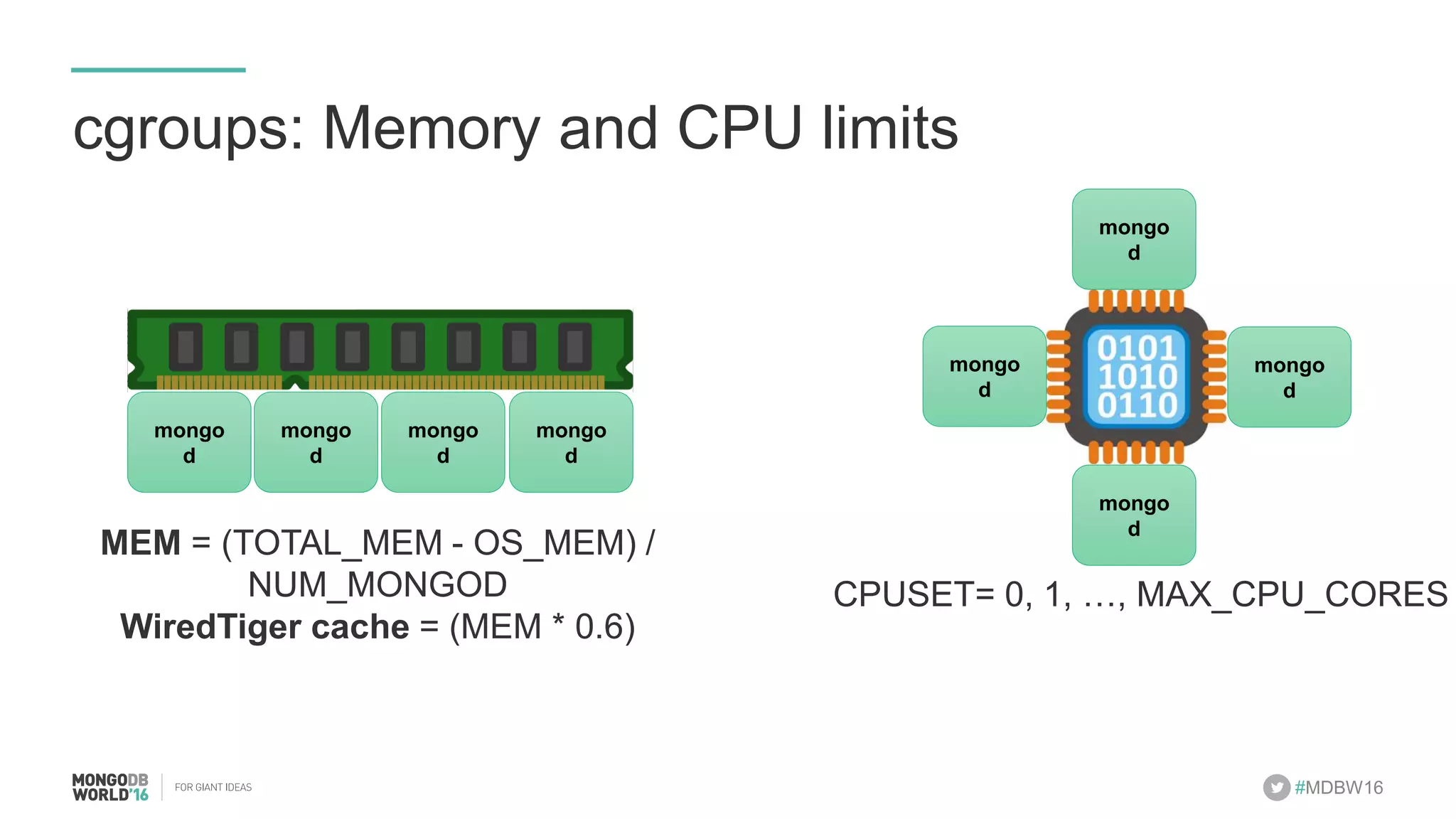
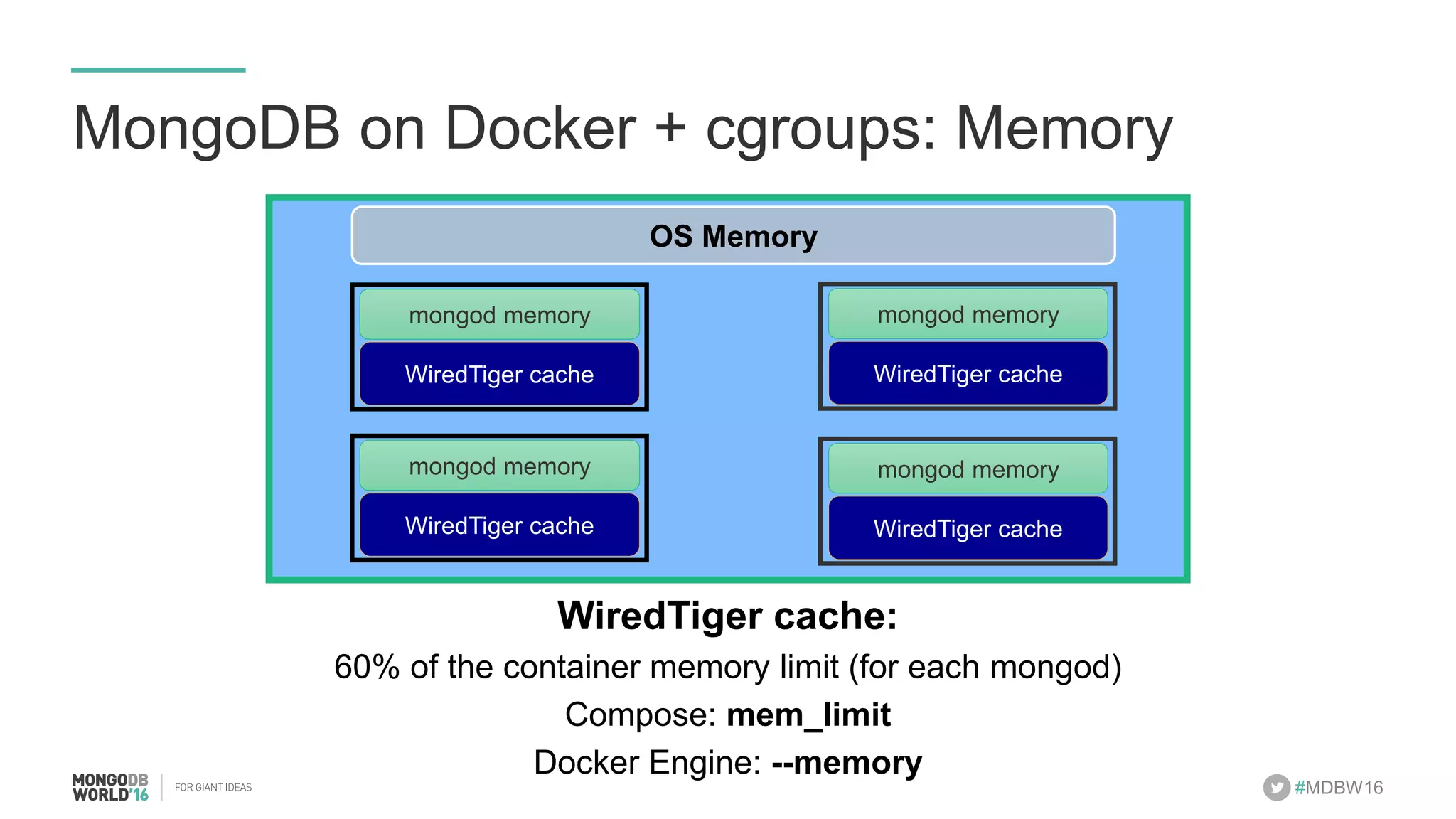
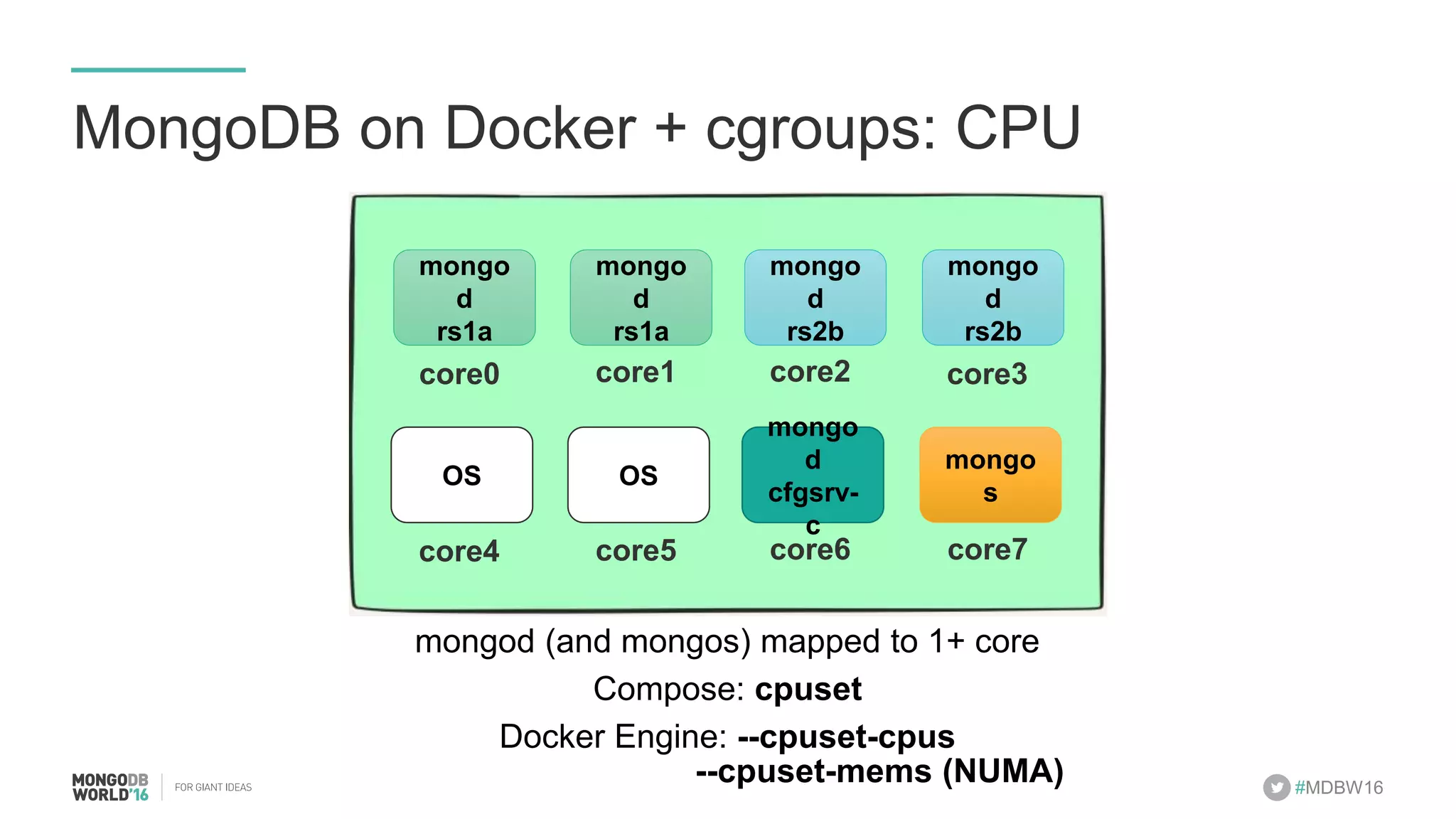

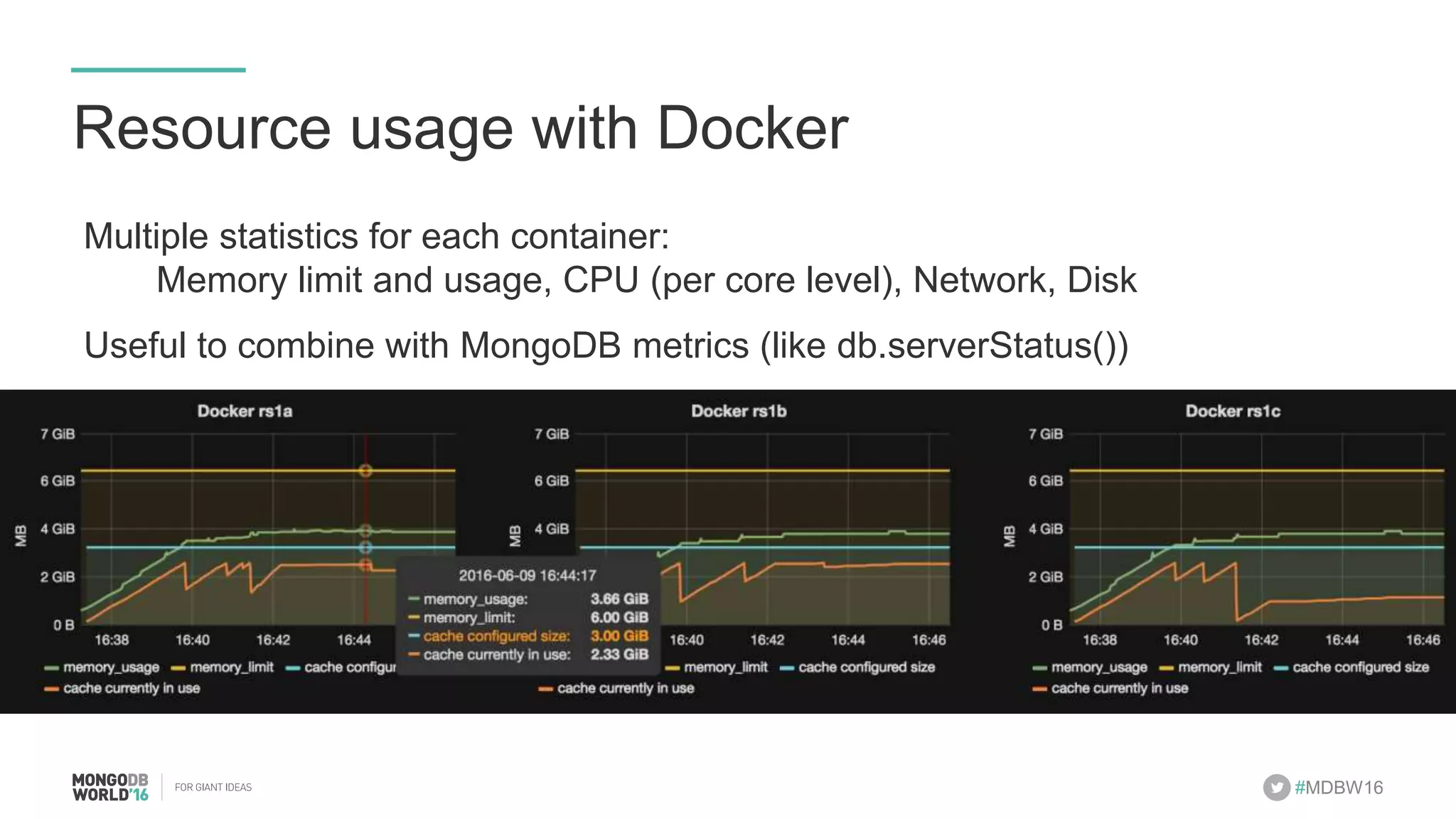
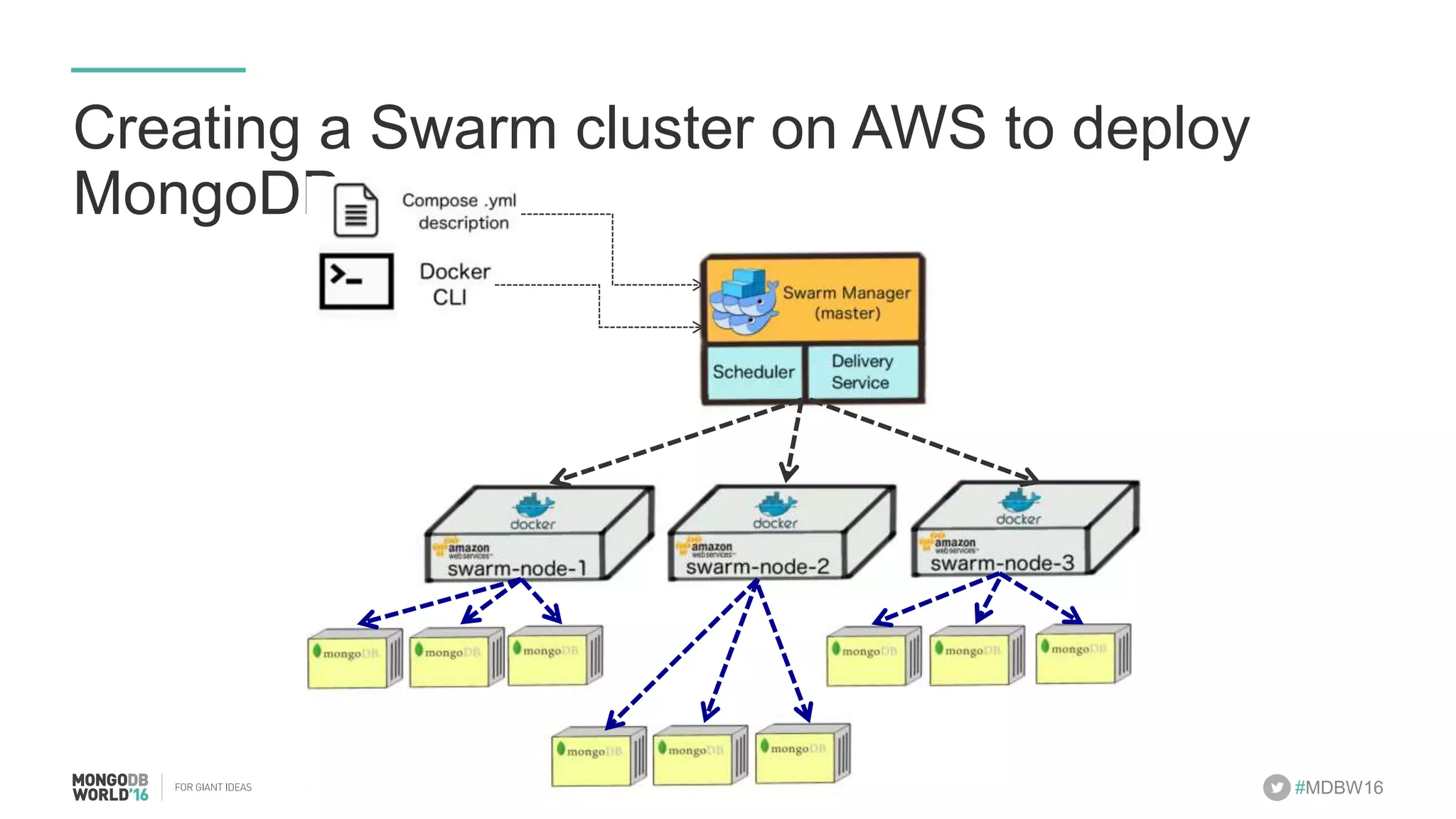
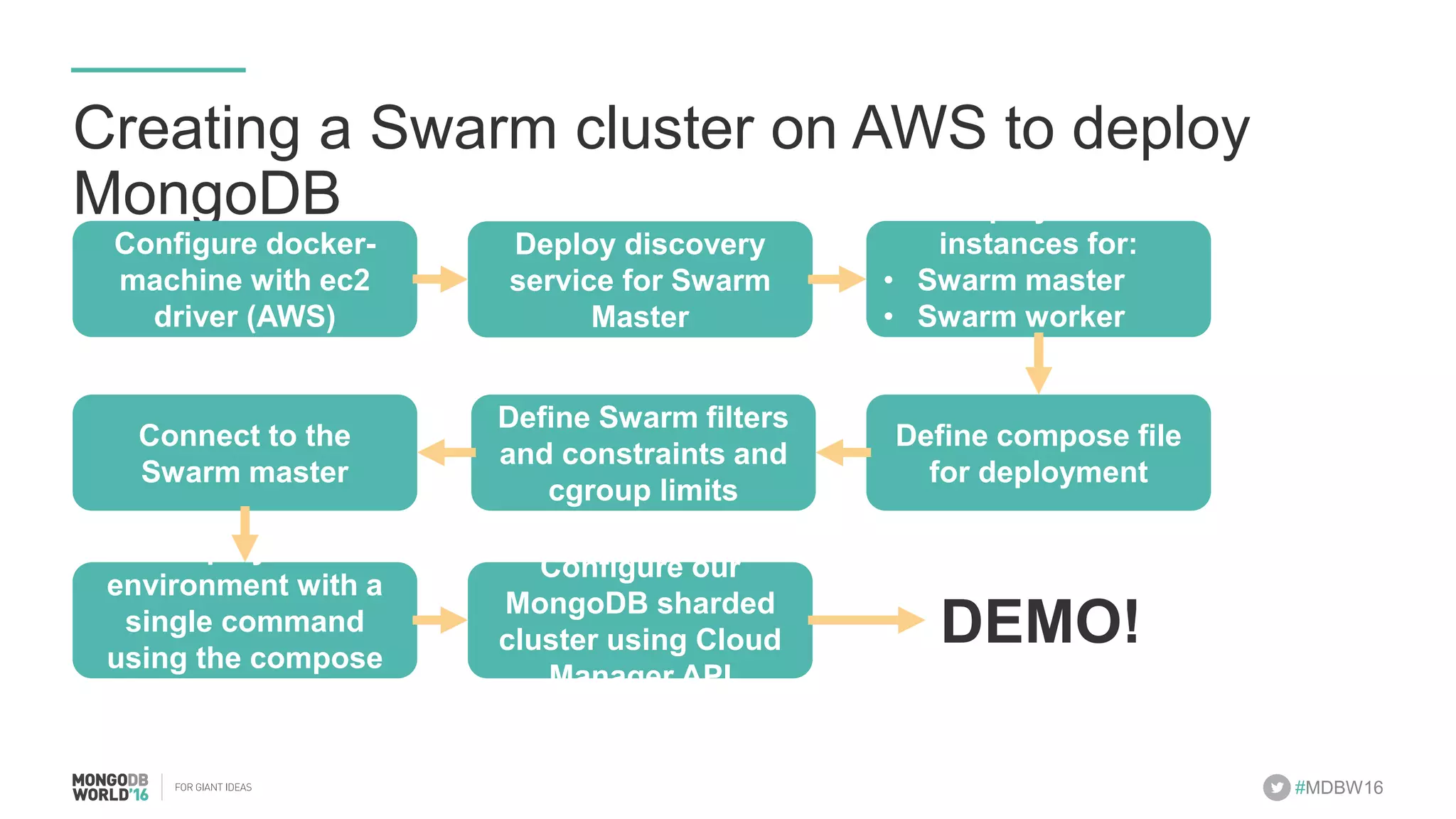
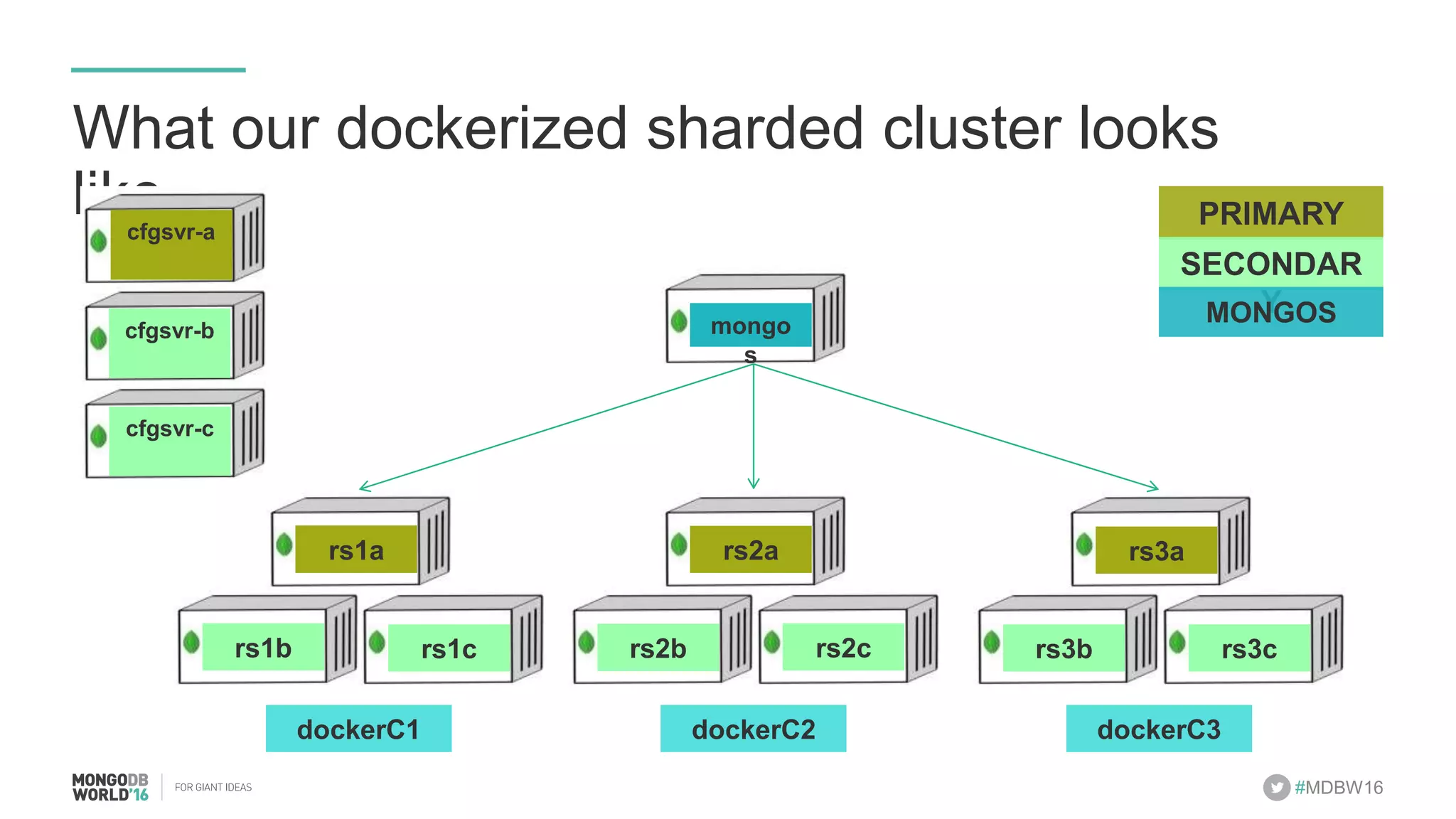






- The document discusses scaling MongoDB deployments using Docker and cgroups for resource management. It describes common pain points in deploying MongoDB at scale and how Docker can help address them through orchestration, resource control, and deployment patterns. - Key aspects covered include deploying MongoDB replica sets and sharded clusters on Docker Swarm for redundancy and high availability, using constraints and affinity filters for container distribution, and setting memory and CPU limits on containers with cgroups to control resources and avoid contention issues. - The talk demonstrates deploying a MongoDB sharded cluster on an AWS Swarm cluster using Docker Compose and discusses advantages of the approach like speed, control, agility and flexibility.