Downloaded 59 times













![#MDBW17 COMPUTE RESOURCES FOR CONTAINERS We can define how much CPU and memory each container needs CPU Memory Requests Limits How much I’d like to get (scheduling) The most I can get (contention) CPU Units: spec.containers[].resources.limits.cpu spec.containers[].resources.requests.cpu Bytes: spec.containers[].resources.limits.memory spec.containers[].resources.requests.memory Scheduler Ensures that the sum of the resource requests of the scheduled containers is less than the capacity of the node.](https://image.slidesharecdn.com/crystaladay21140-1220marcobonezzicreatinghighly-availablemongodbmicroserviceswithdockercontainersand-170621223531/75/Creating-Highly-Available-MongoDB-Microservices-with-Docker-Containers-and-Kubernetes-27-2048.jpg)






The document discusses deploying highly available MongoDB microservices using Docker and Kubernetes, focusing on building stateful sets for MongoDB deployments. Key topics include Kubernetes benefits, managing pods and services, persistent storage, and ensuring high availability through replica sets. The presentation also covers best practices for resource allocation, scheduling, and scaling in a microservices architecture.
Presentation by Marco Bonezzi introducing MongoDB microservices through Docker and Kubernetes.
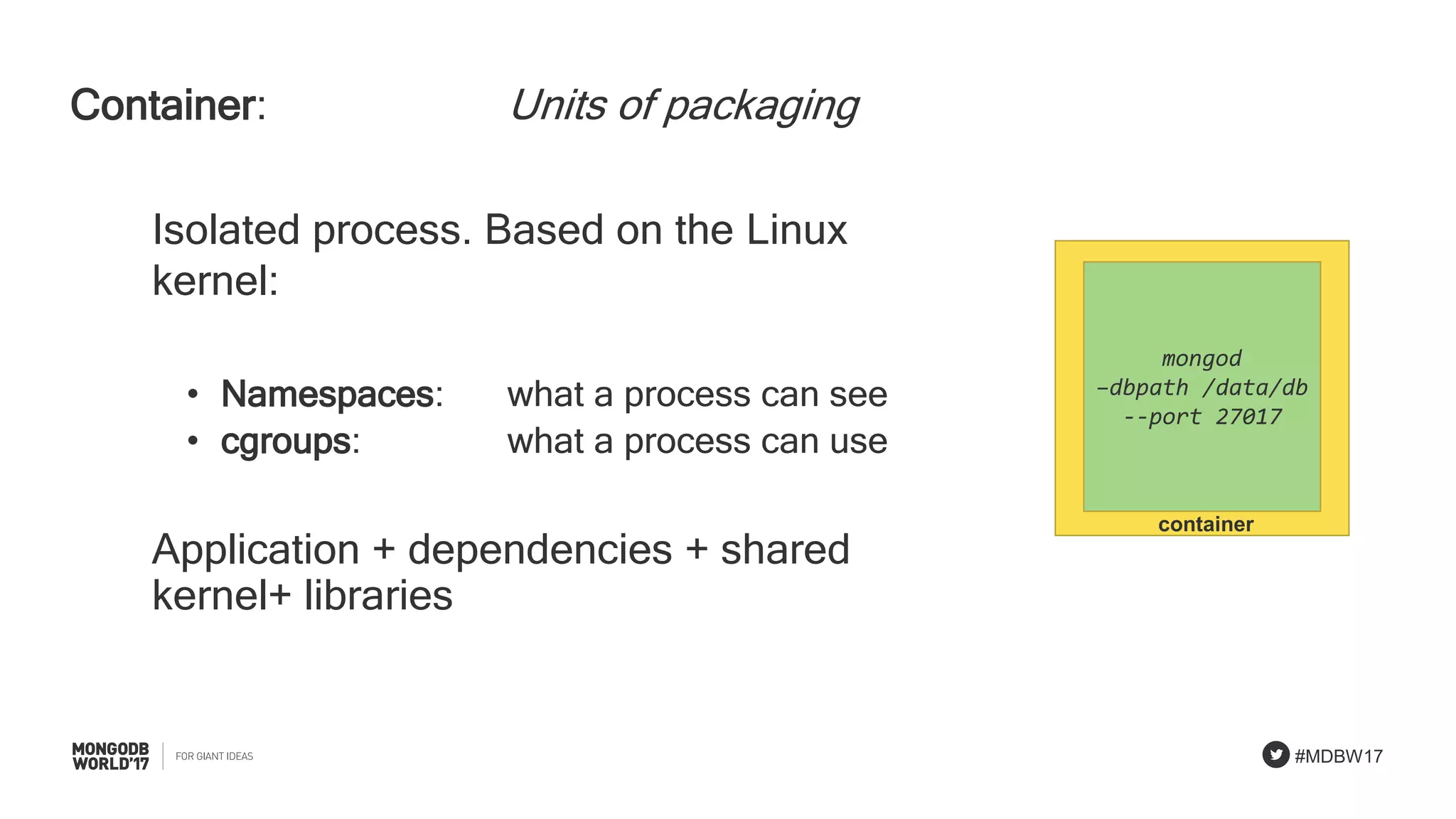
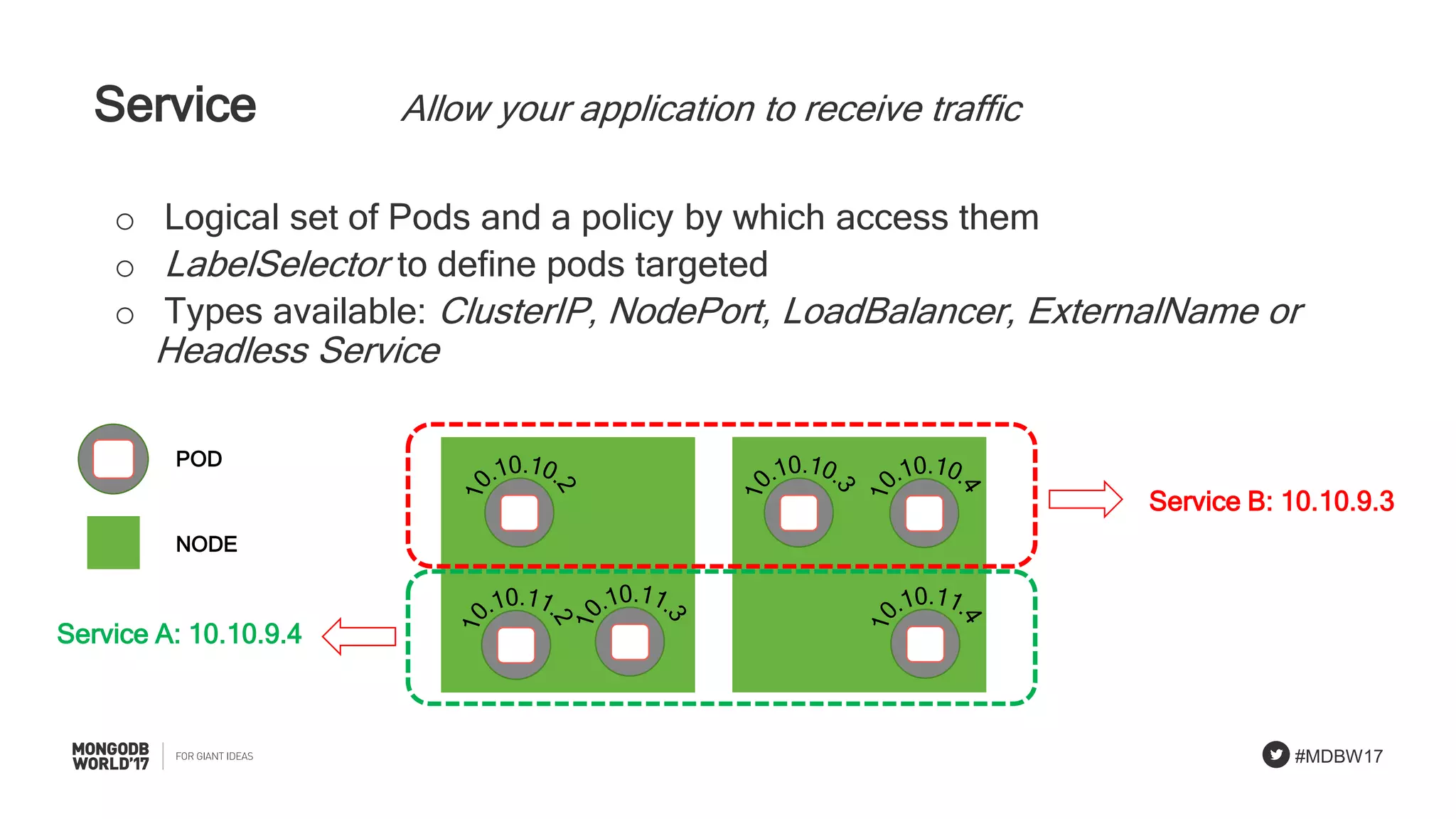
Discussion on common problems in using containers including capacity, connectivity, state, and isolation.
Learning to deploy MongoDB on Kubernetes, build a StatefulSet, and consider high-availability.
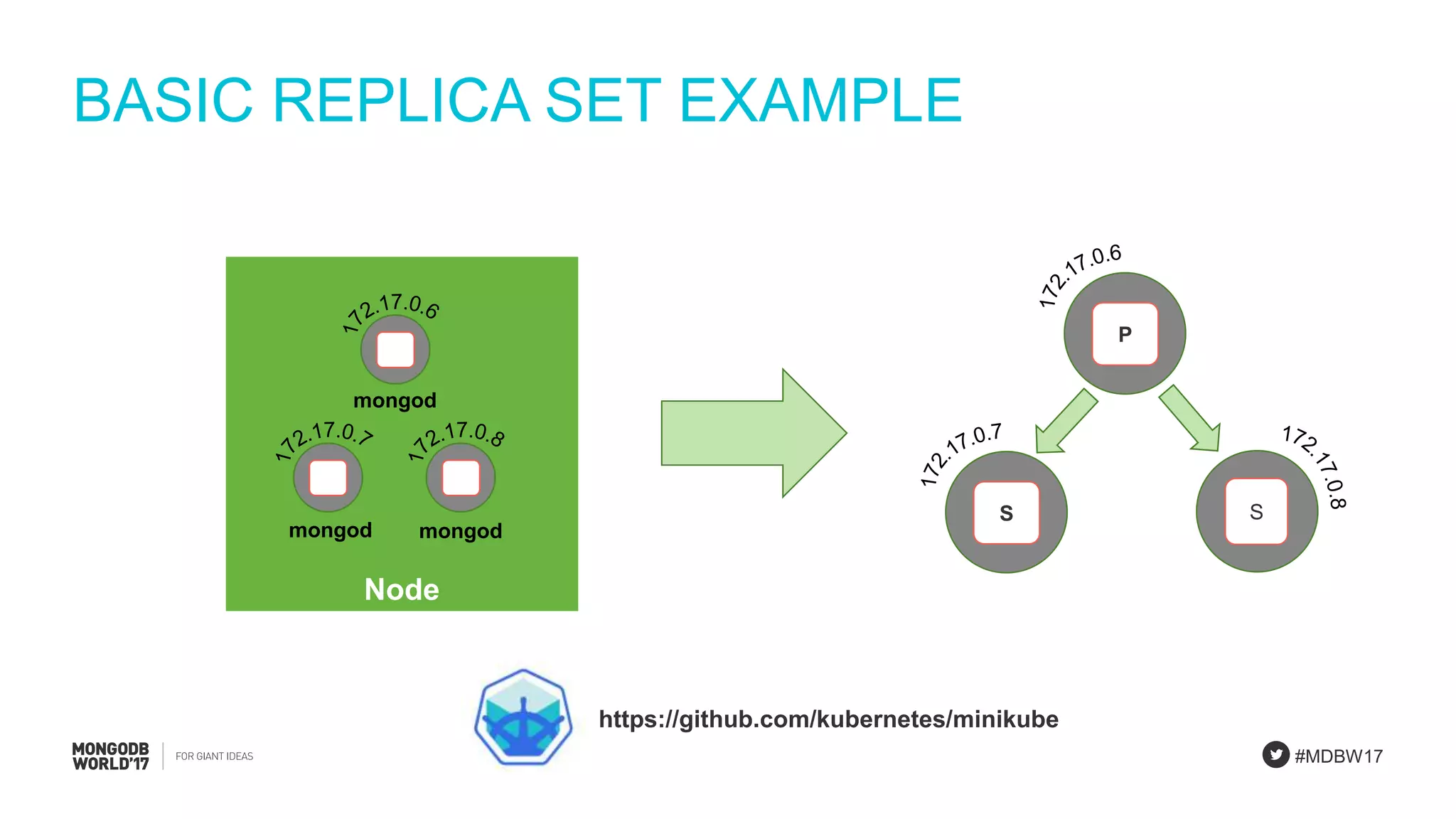
Benefits of MongoDB with Kubernetes include scalability, resiliency, and improved deployment efficiency.
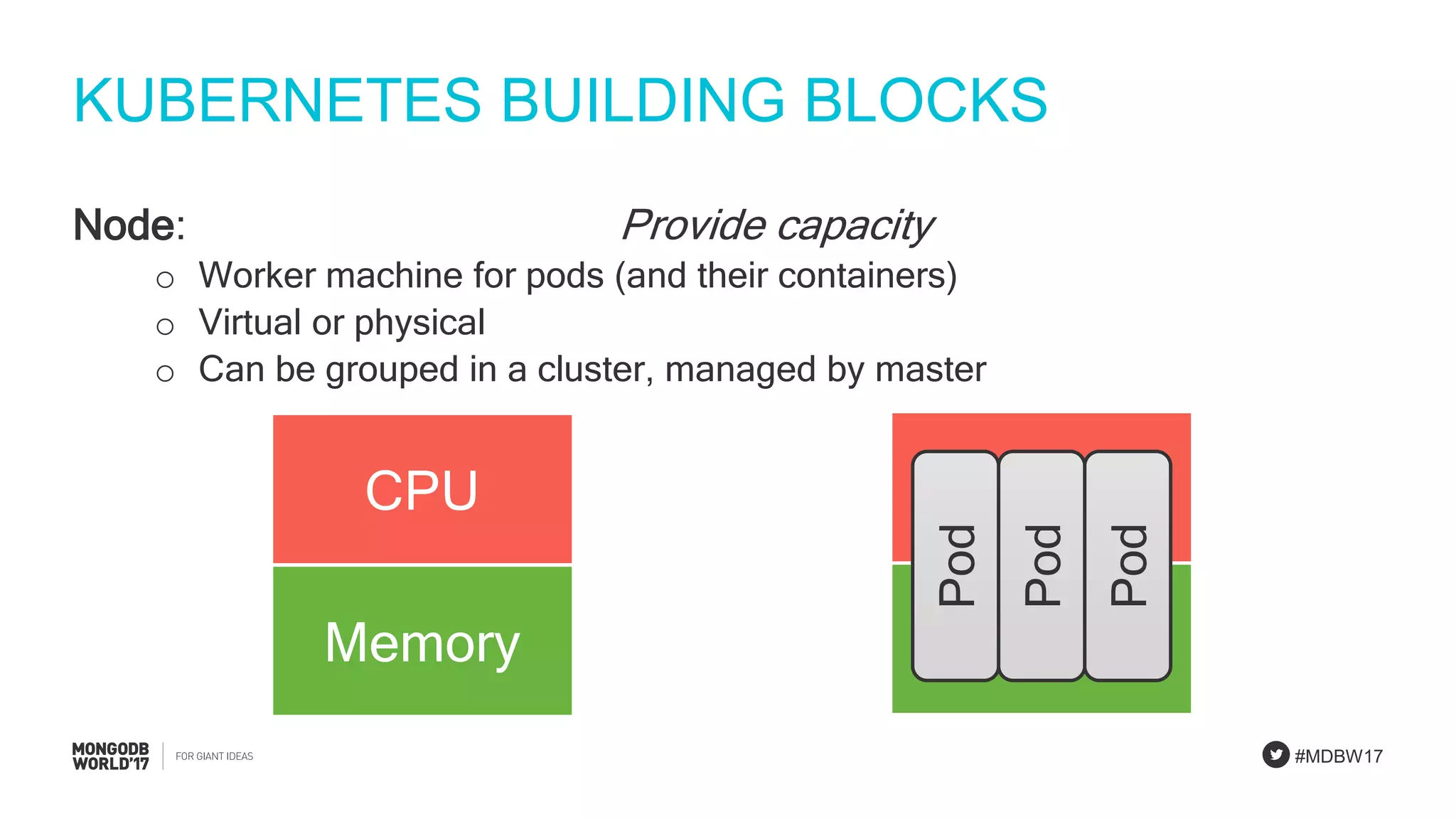
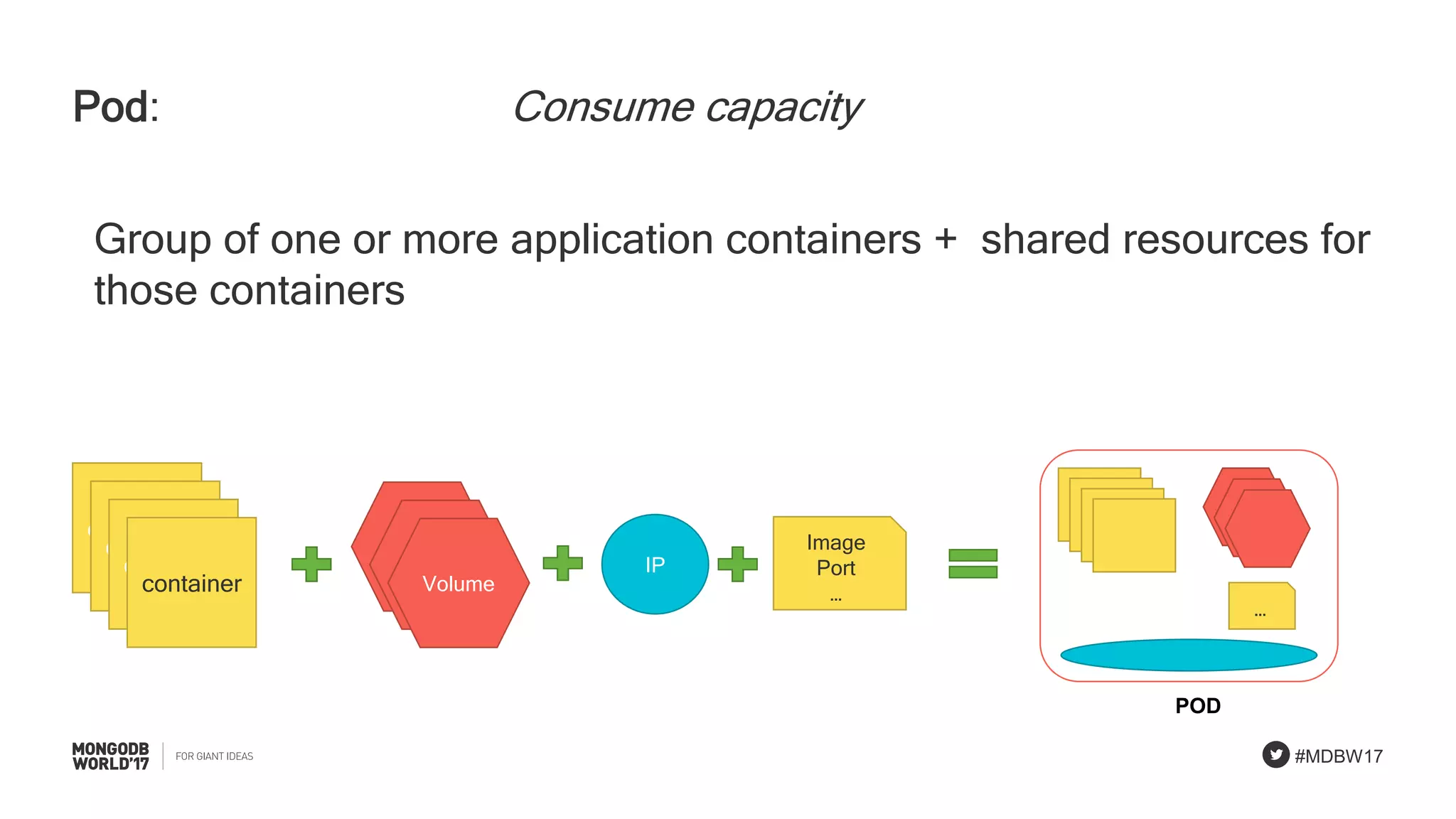
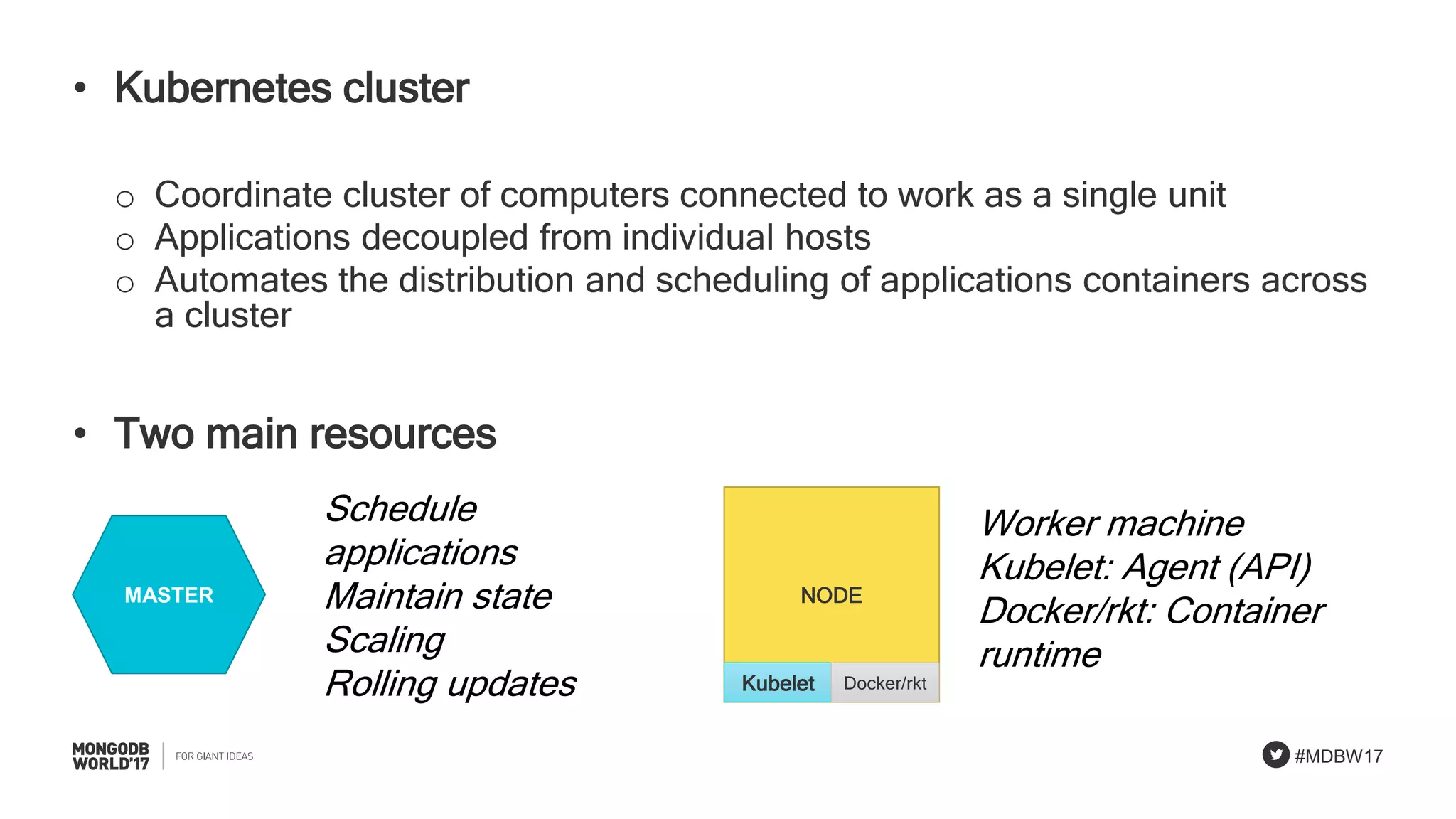
Overview of Kubernetes building blocks: nodes, pods, containers, and services involved in deployments.
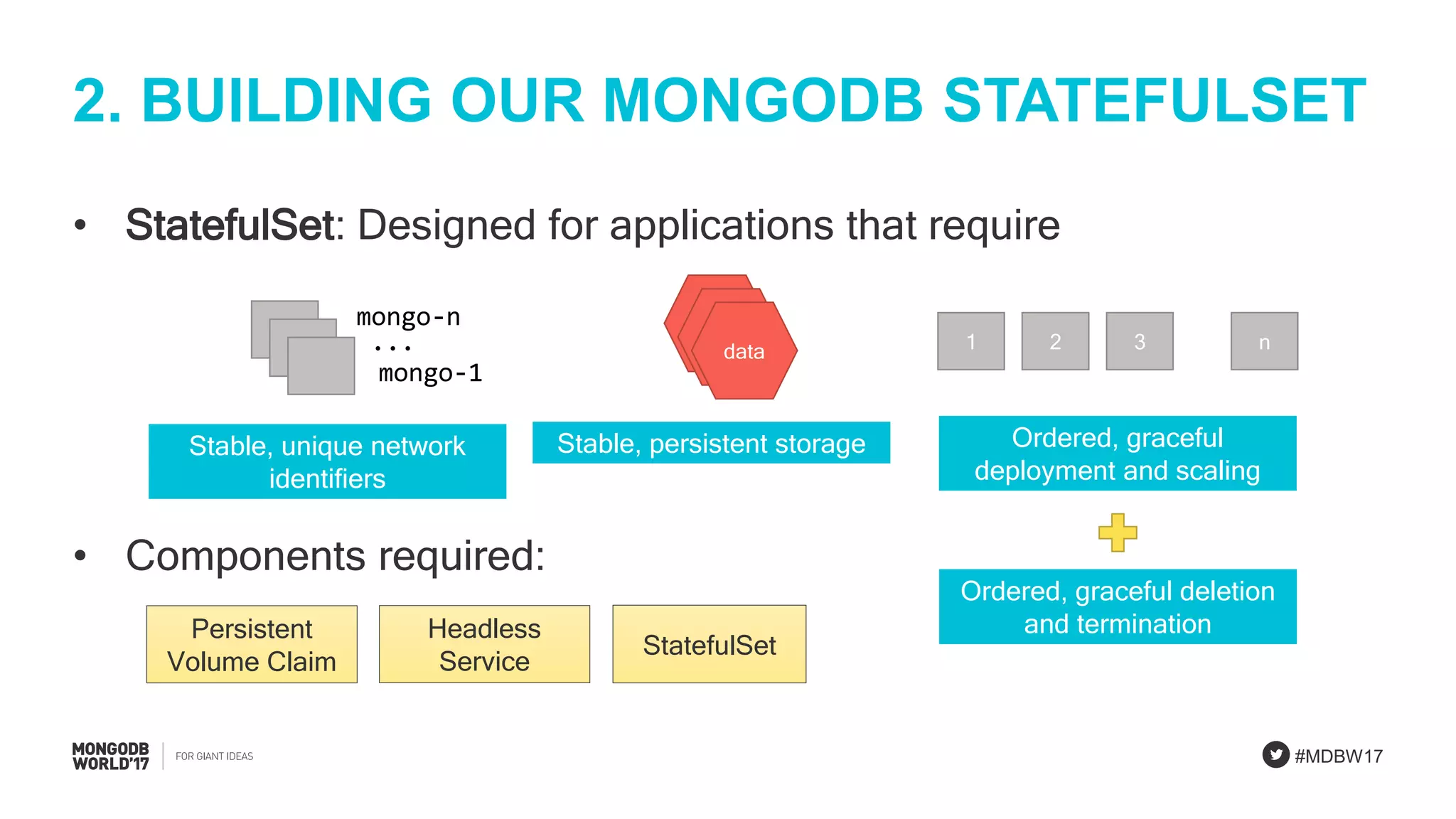
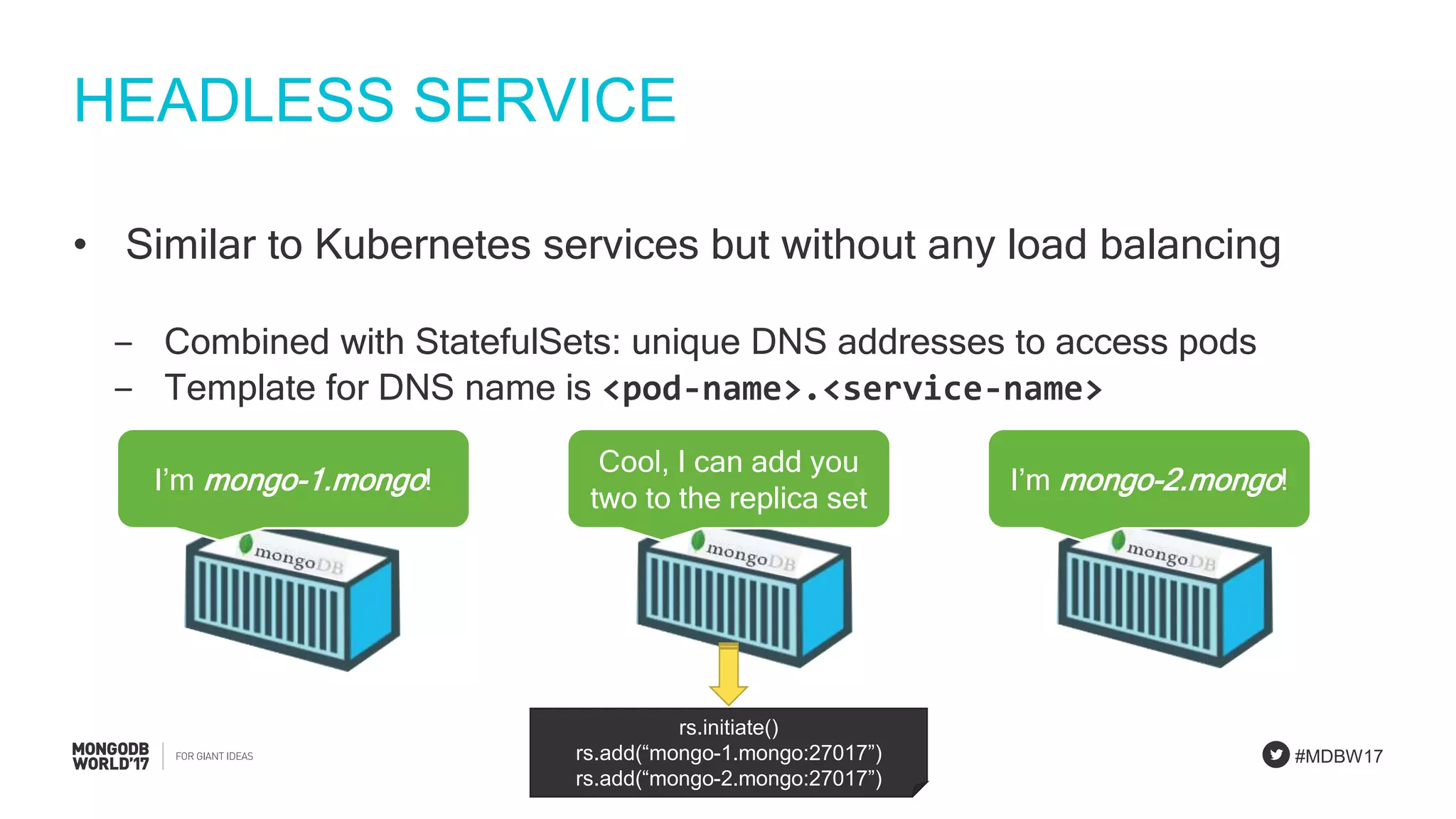
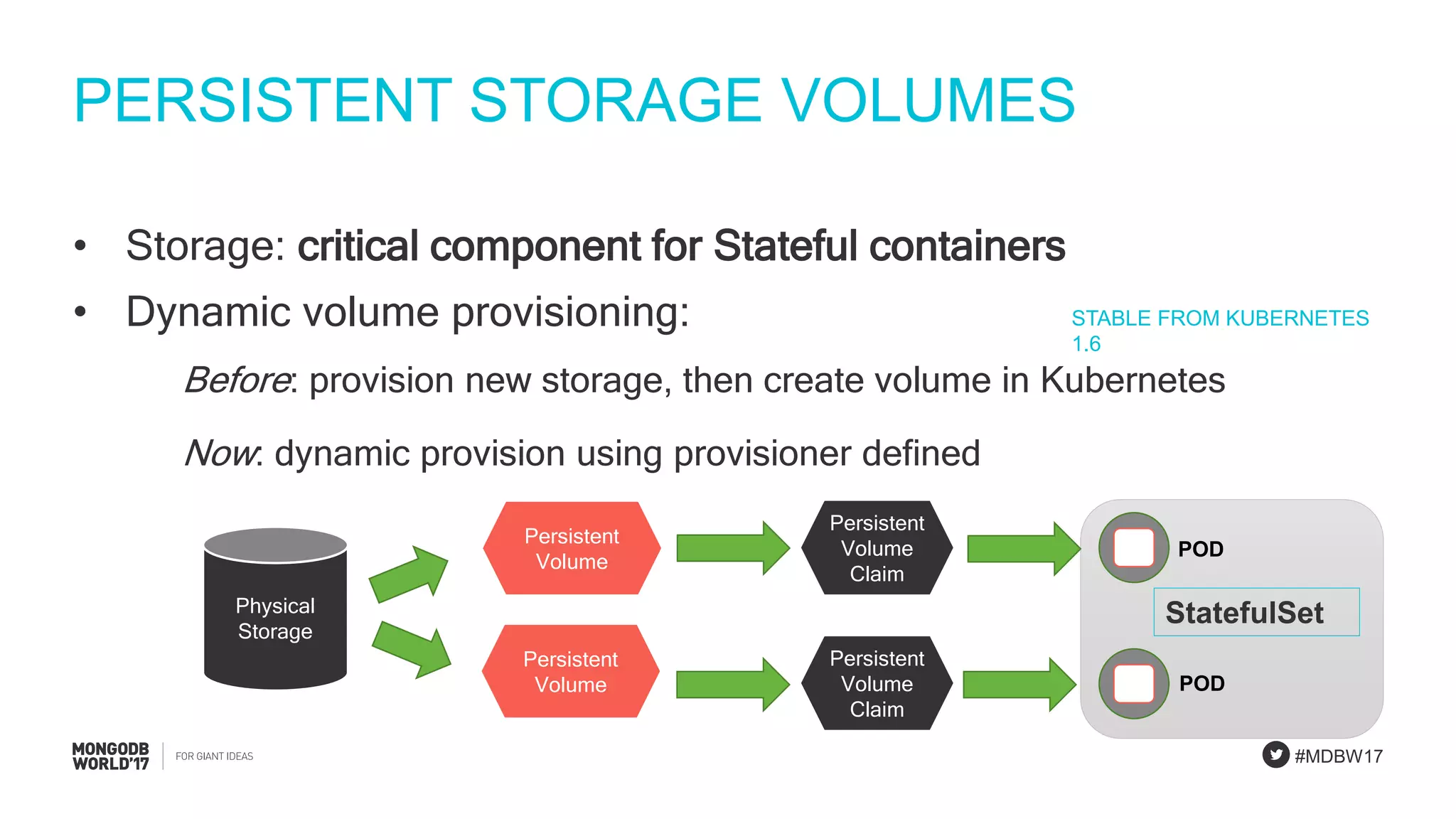
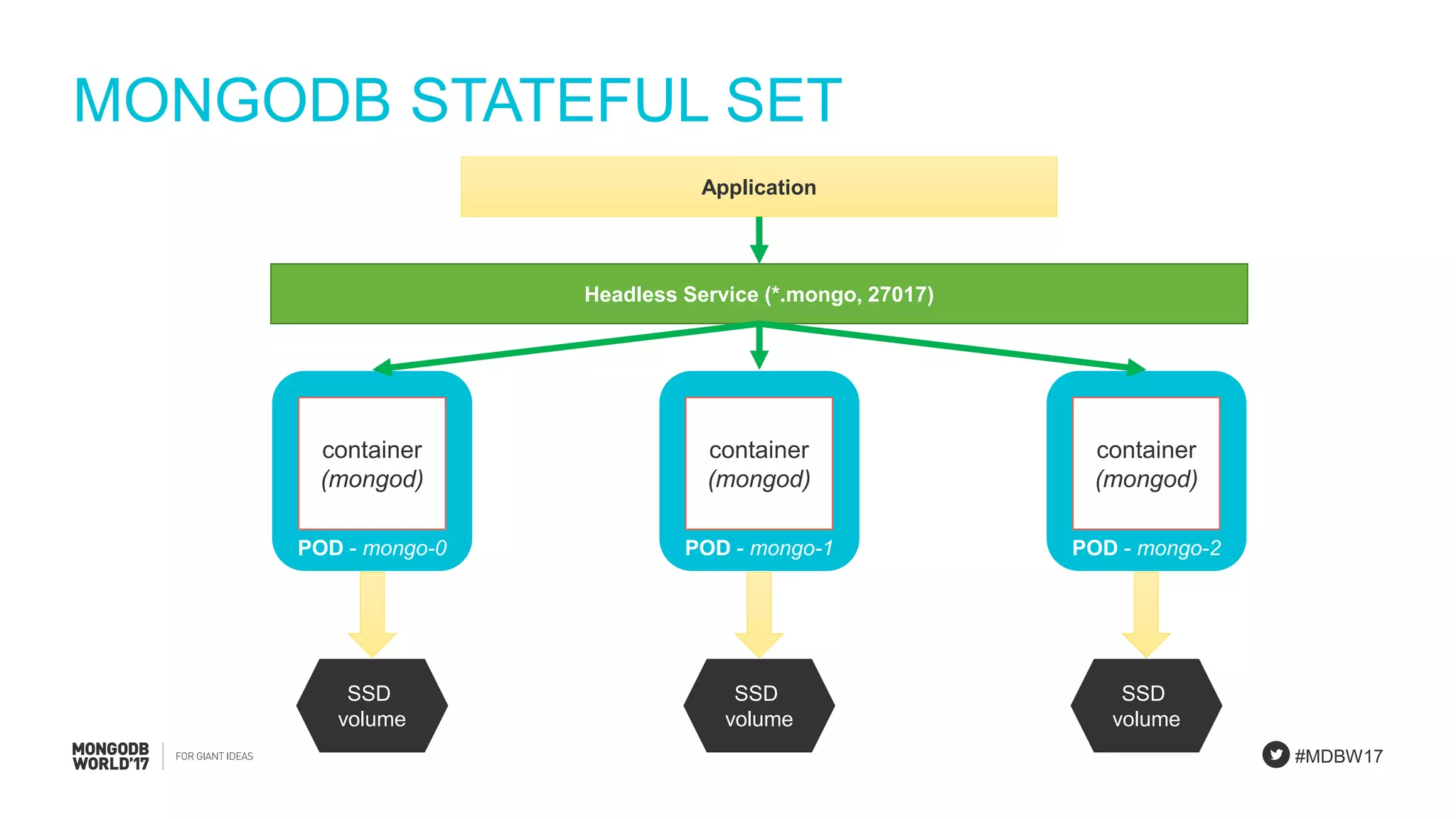
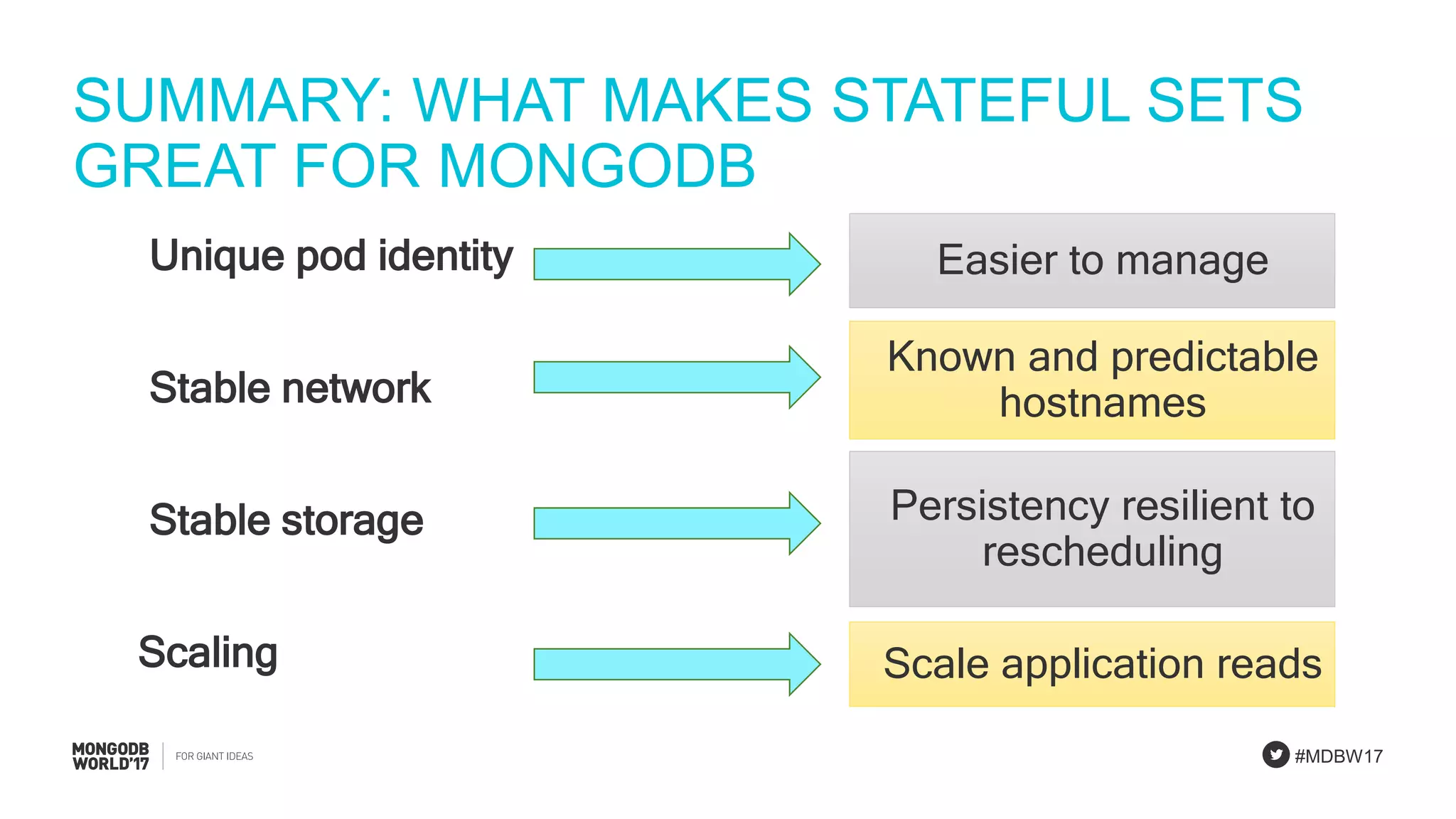
StatefulSet concepts emphasizing unique identities and storage stability for MongoDB applications.
Detailed explanation of MongoDB StatefulSets focusing on scalability, unique identities, and resilience.
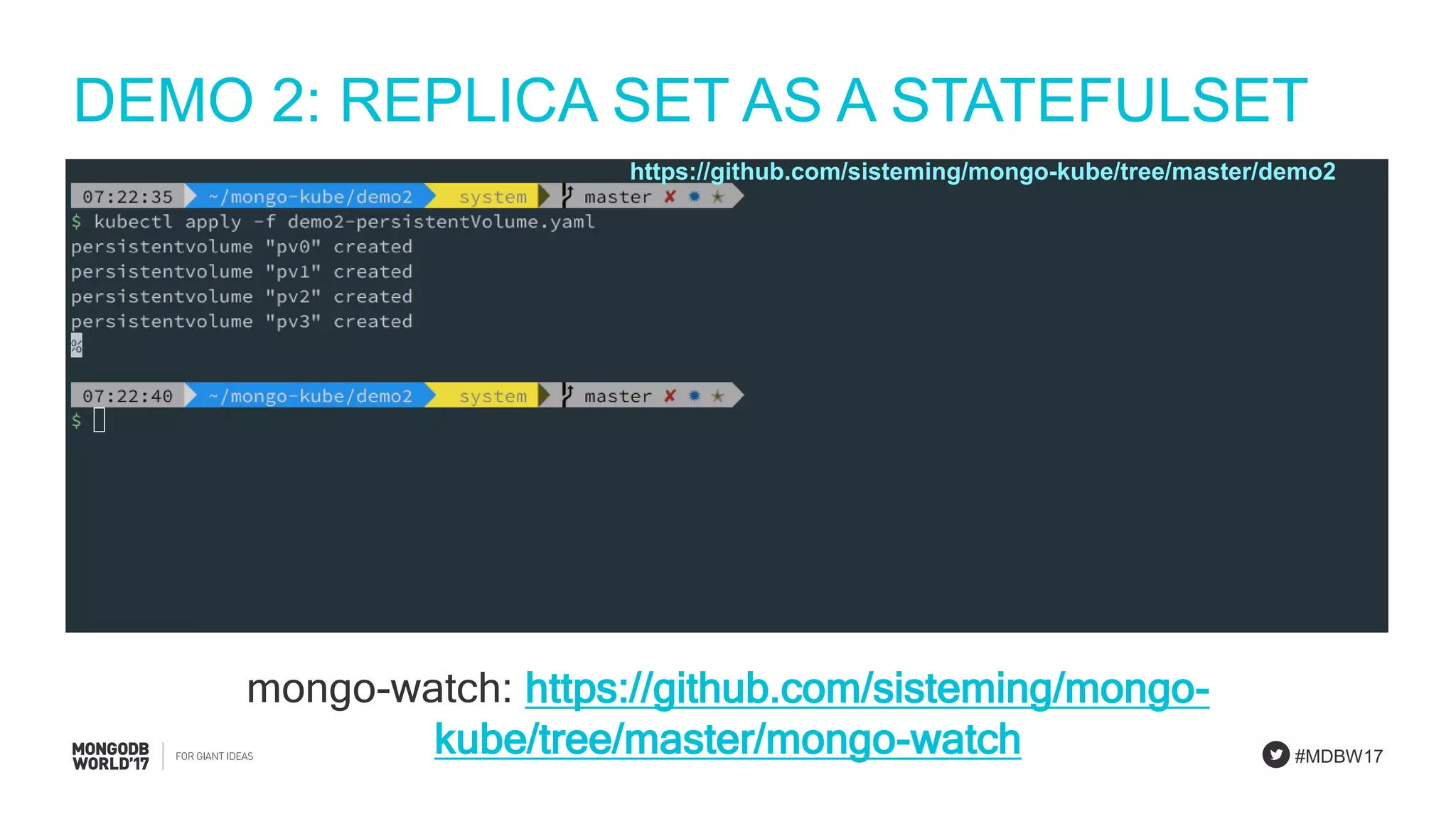
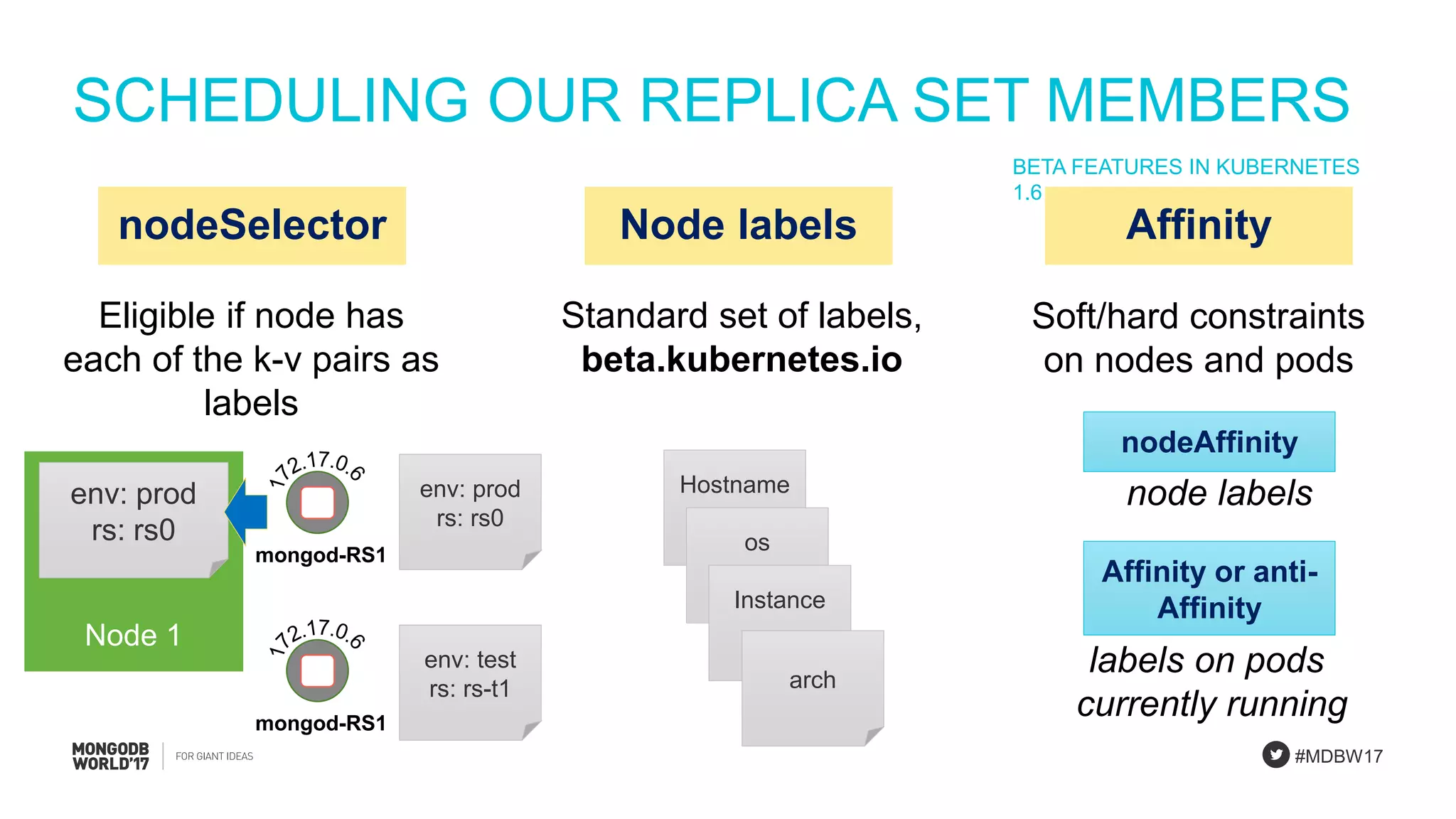
Orchestrating production-like StatefulSets with a focus on high availability and effective scheduling.
Integrating microservice applications with MongoDB StatefulSets, handling high availability and failover.
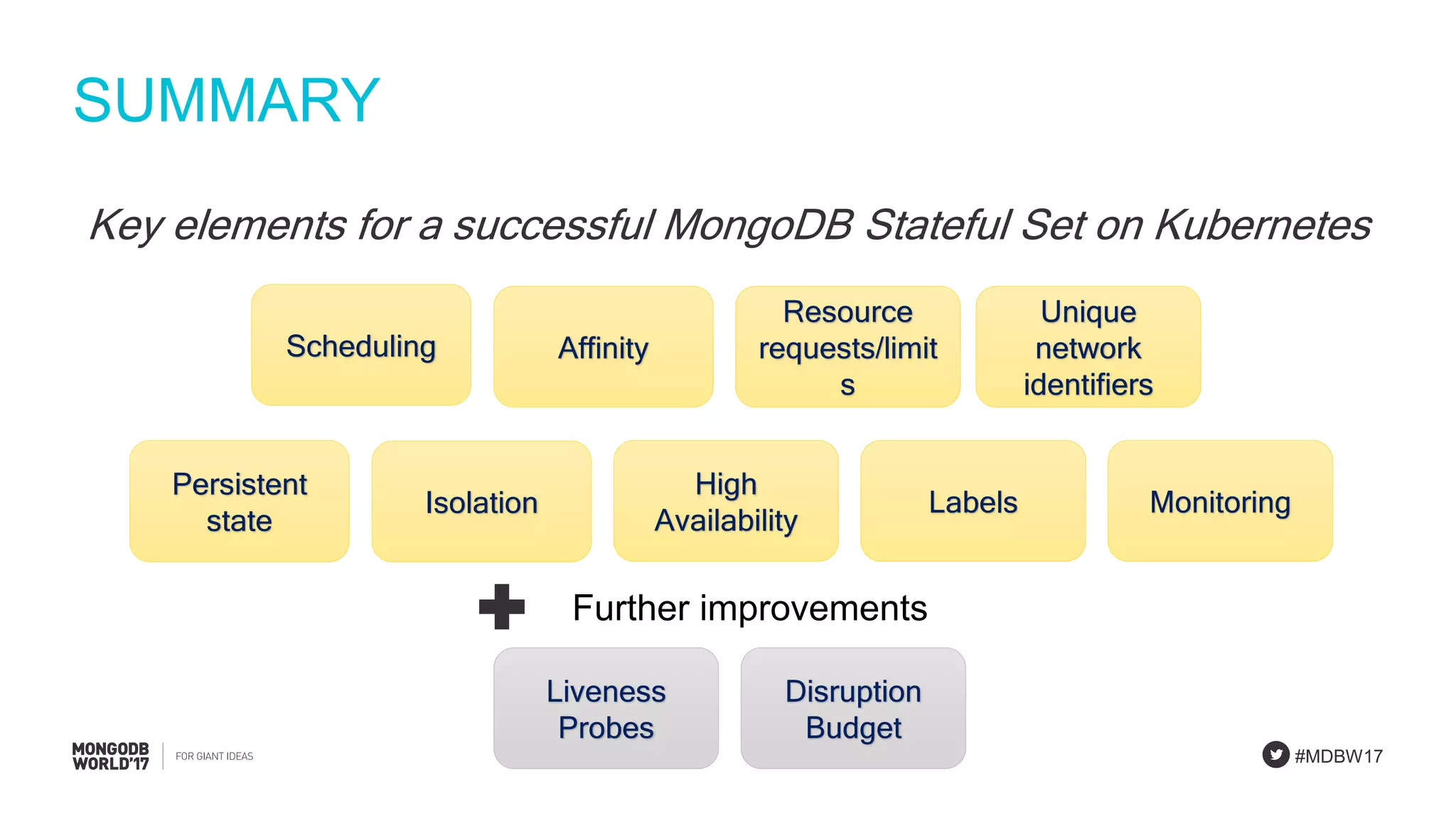
Summarizing key elements for effective MongoDB Stateful Sets on Kubernetes, including resource management.
Thank you slide with additional resource links for further learning.