This document describes the LZW compression algorithm. It is a dictionary-based algorithm that is lossless and commonly used to compress image files and in the Unix 'compress' command. The algorithm works by building a dictionary of strings as it encodes the data, replacing repeated strings with codes. When decoding, the same dictionary is rebuilt to map codes back to strings. An example shows how a short string is compressed from 80 bits to 63 bits using LZW encoding by extending the symbol size from 8 to 9 bits.
Introduction to the LZW compression algorithm presented by Keyvan Moazami as part of a multimedia course in Spring 2015.
Discusses probability base algorithms, including Huffman coding that adapts based on context, with strategies for efficient encoding.
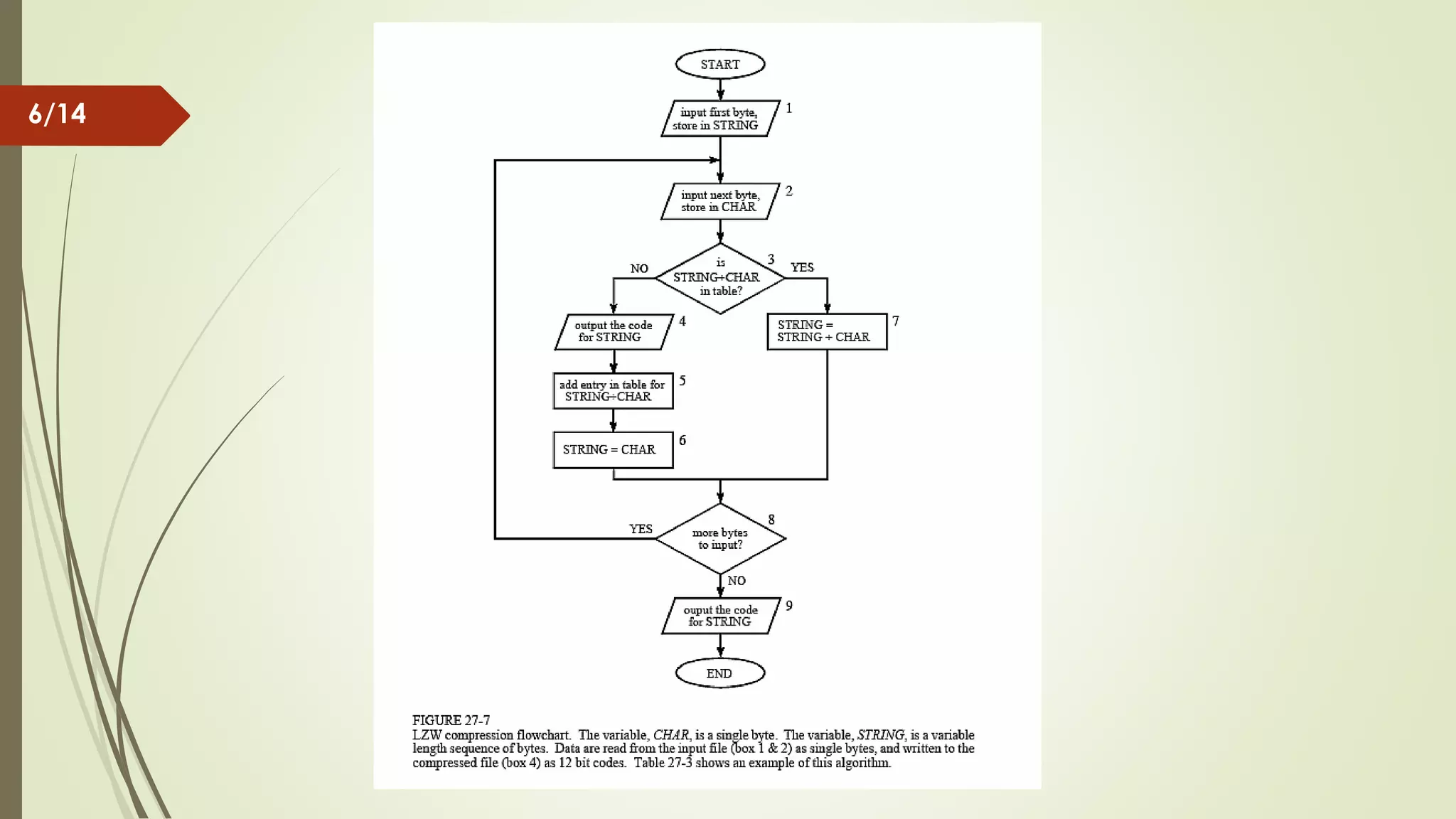
Describes LZW as a dictionary-based, lossless compression algorithm utilized in image files and Unix commands, noting the non-transmission of the dictionary table.
Examines LZW’s approach using ASCII code, extending storage from 8 to 9-12 bits per character for better compression of redundant data.
Demonstrates compression of the string 'Thisisthe' using LZW, showing initial bit count of 80 bits and improvement.
Details the step-by-step process of LZW compression, including how pairs are added to the dictionary and the final bit length of 63 bits.
Explains the uncompressing process in LZW, highlighting the need for bit count knowledge and dictionary rebuilding.
Provides a detailed example of the decompression of the string '116 104 105 115 258 256 101' into 'thisisthe', explaining dictionary behavior during this process.
Thanks audience after completing the presentation.
Probability base algorithmsproblems First approach analyze a few books and estimate the probabilities of different letters Then apply Huffman coding o probability depend on context Adaptive encoding two pass process Huffman code customized (letter and group letter) o strategy is expensive but workable o symbol grouping (larger or smaller) o We need different approach for adaptive algorithm 1/14
3.
Lempel-Ziv-Welch (LZW) algorithm Dictionary base Used to compress image file , Unix ‘compress’ command , … Lossless * Dictionary table never transmitted 2/14
4.
How work LZW Example : ASCII code. Typically, every character is stored with 8 binary bits, allowing up to 256 unique symbols for the data . This algorithm tries to extend this library to 9 to 12 bits per character. The new unique symbols are made up of combinations of symbols that occurred previously in the string. Does not always compress well , especially with short, diverse strings. But is good for compressing redundant data, and does not have to save the new dictionary with the data :this method can both compress and uncompressing data . 3/14
5.
Example : Iwant to compress the following string : Thisisthe By default using uncompressed ASCII , this is equal to 01110100011010000110100101110011011010010111001101110100011010000110010101110011 Or 116 104 105 115 105 115 116 104 101 115 * That’s 80 bits. We can do better 4/14
6.
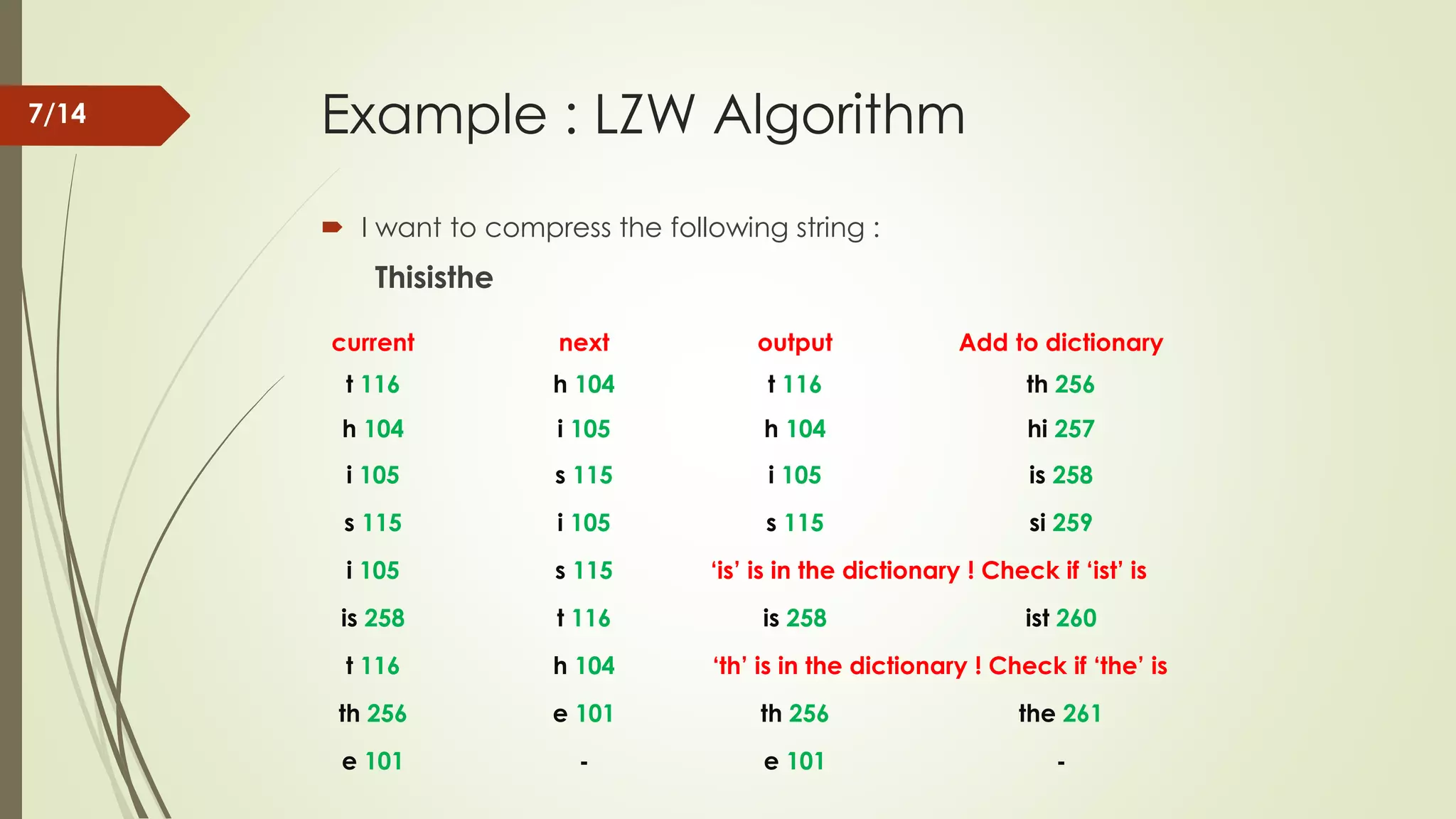
Example : LZWAlgorithm I want to compress the following string : Thisisthe Start adding pairs of symbols to dictionary of words . When we reach a pair that we’ve already placed in the dictionary , replace that pair with our new dictionary value. For this tiny string , we will only need 9-bits , allowing up to 512 unique symbols . 5/14
Example : LZWAlgorithm I want to compress the following string : Thisisthe current next output Add to dictionary t 116 h 104 t 116 th 256 h 104 i 105 h 104 hi 257 i 105 s 115 i 105 is 258 s 115 i 105 s 115 si 259 i 105 s 115 ‘is’ is in the dictionary ! Check if ‘ist’ is is 258 t 116 is 258 ist 260 t 116 h 104 ‘th’ is in the dictionary ! Check if ‘the’ is th 256 e 101 th 256 the 261 e 101 - e 101 - 7/14
9.
Example : LZWAlgorithm I want to compress the following string : Thisisthe current next output Add to dictionary t 116 h 104 t 116 th 256 h 104 i 105 h 104 hi 257 i 105 s 115 i 105 is 258 s 115 i 105 s 115 si 259 i 105 s 115 ‘is’ is in the dictionary ! Check if ‘ist’ is is 258 t 116 is 258 ist 260 t 116 h 104 ‘th’ is in the dictionary ! Check if ‘the’ is th 256 e 101 th 256 the 261 e 101 - e 101 - 8/14
10.
Example : LZWAlgorithm I want to compress the following string : Thisisthe 116 104 105 115 258 256 101 Or 001110100 001101000 001101001 001110011 100000010 100000000 001100101 Notice that our symbols are now made up of 9 bits each instead of 8 . This is 63 bits long , instead of the original 80 bits. That’s 78.75 % of what it used to be ! Dictionary table not Save ! How decompress data ? 9/14
11.
Uncompressing: To uncompressing,we do need to know how many bits were used in the compression, the one new information that is kept with the data when saved to a file (else, the number of bits is specified by a program or a user). We can read in the characters and build the new dictionary the same way as we did for compressing .When we reach a symbol outside the ASCII range (>255},then we should have that value ready to be seen in the dictionary. 10/14
12.
Example : decompressingLZW I want to decompress the following string : 116 104 105 115 258 256 101 current next output Add to dictionary 116 104 116 116 104 (256) 104 105 104 104 105 (257) 105 115 105 105 115 (258) 115 258 115 115 105 115 (259) 258 256 105 115 105 115 116 (260) 256 101 116 104 116 104 101 (261) 101 - 101 - 11/14
13.
Example : decompressingLZW I want to decompress the following string : 116 104 105 115 258 256 101 current next output Add to dictionary 116 104 116 116 104 (256) 104 105 104 104 105 (257) 105 115 105 105 115 (258) 115 258 115 115 105 115 (259) 258 256 105 115 105 115 116 (260) 256 101 116 104 116 104 101 (261) 101 - 101 - 116 104 105 115 105 115 116 104 101 Or “thisisthe” 12/14
14.
Example : decompressingLZW I want to decompress the following string : 116 104 105 115 258 256 101 115 258 115 115 105 115 (259) 258 256 105 115 105 115 116 (260) 256 101 116 104 116 104 101 (261) Why didn’t we add 258 256 ( 105 115 116 104 ) to the dictionary at (260) ? Weird case : remember , dictionary is made with combinations one character at a time , so you would only add the first symbol of the combination to the current combination when rebuilding the dictionary . 13/14