Downloaded 100 times












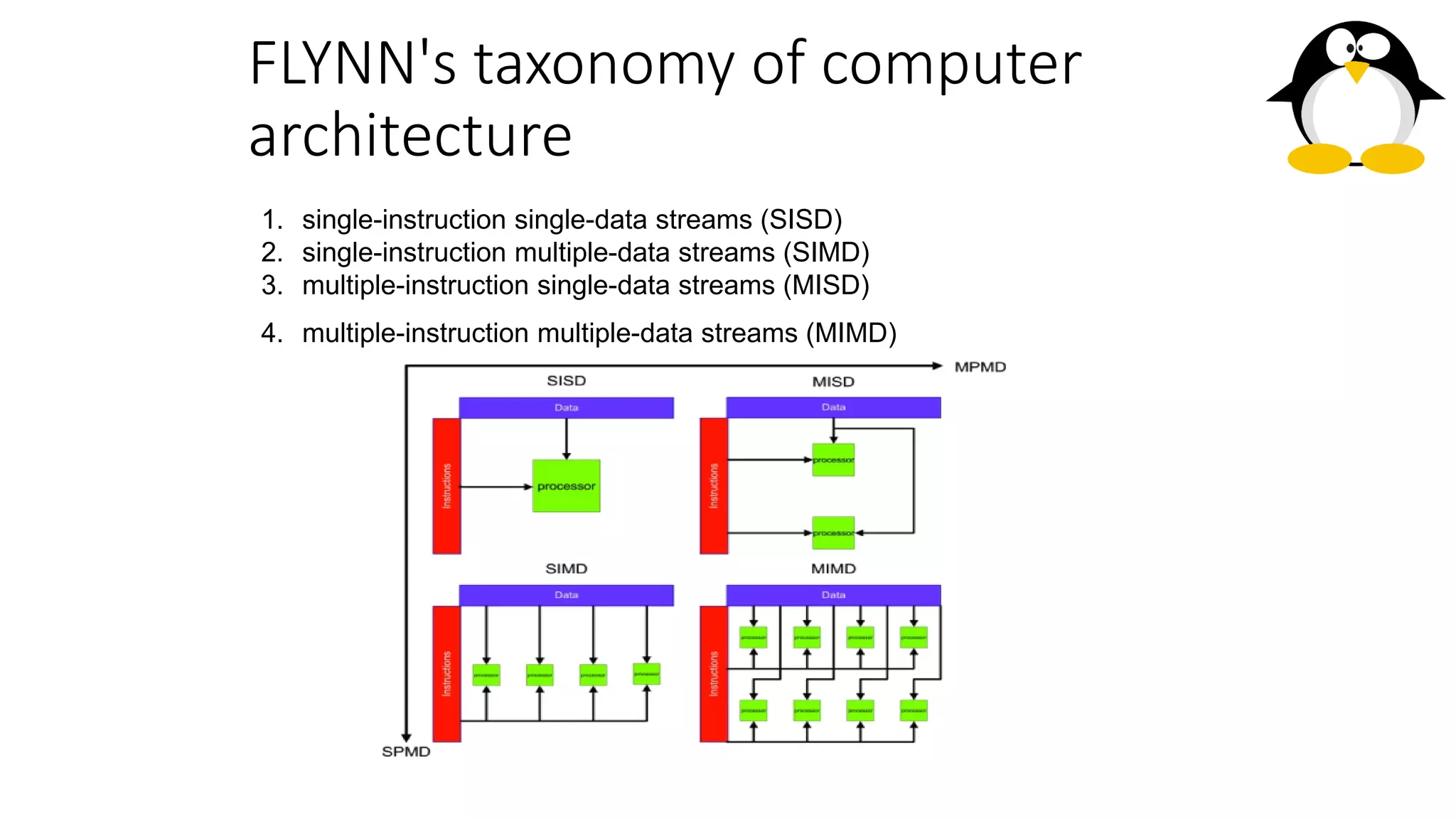
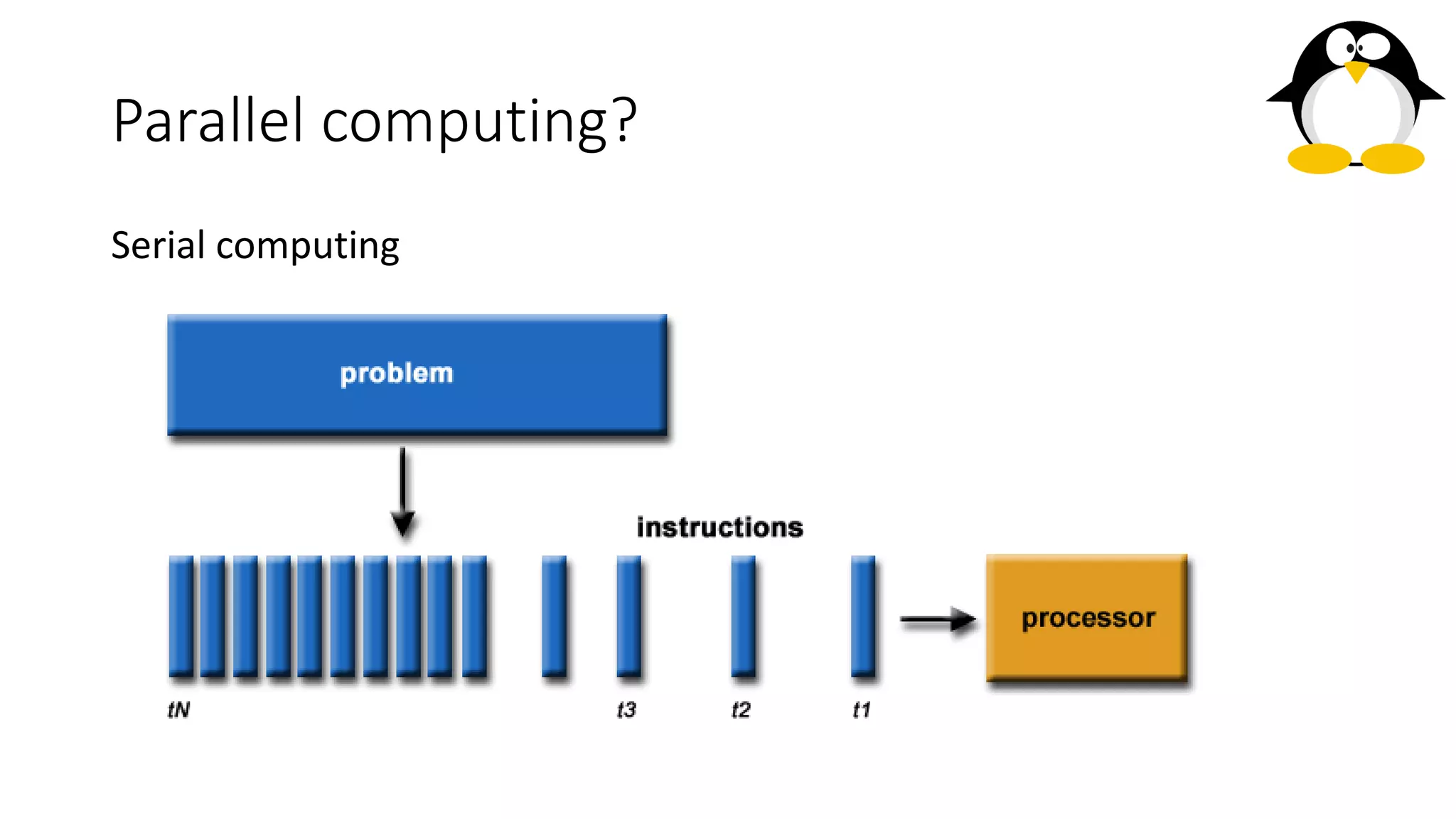
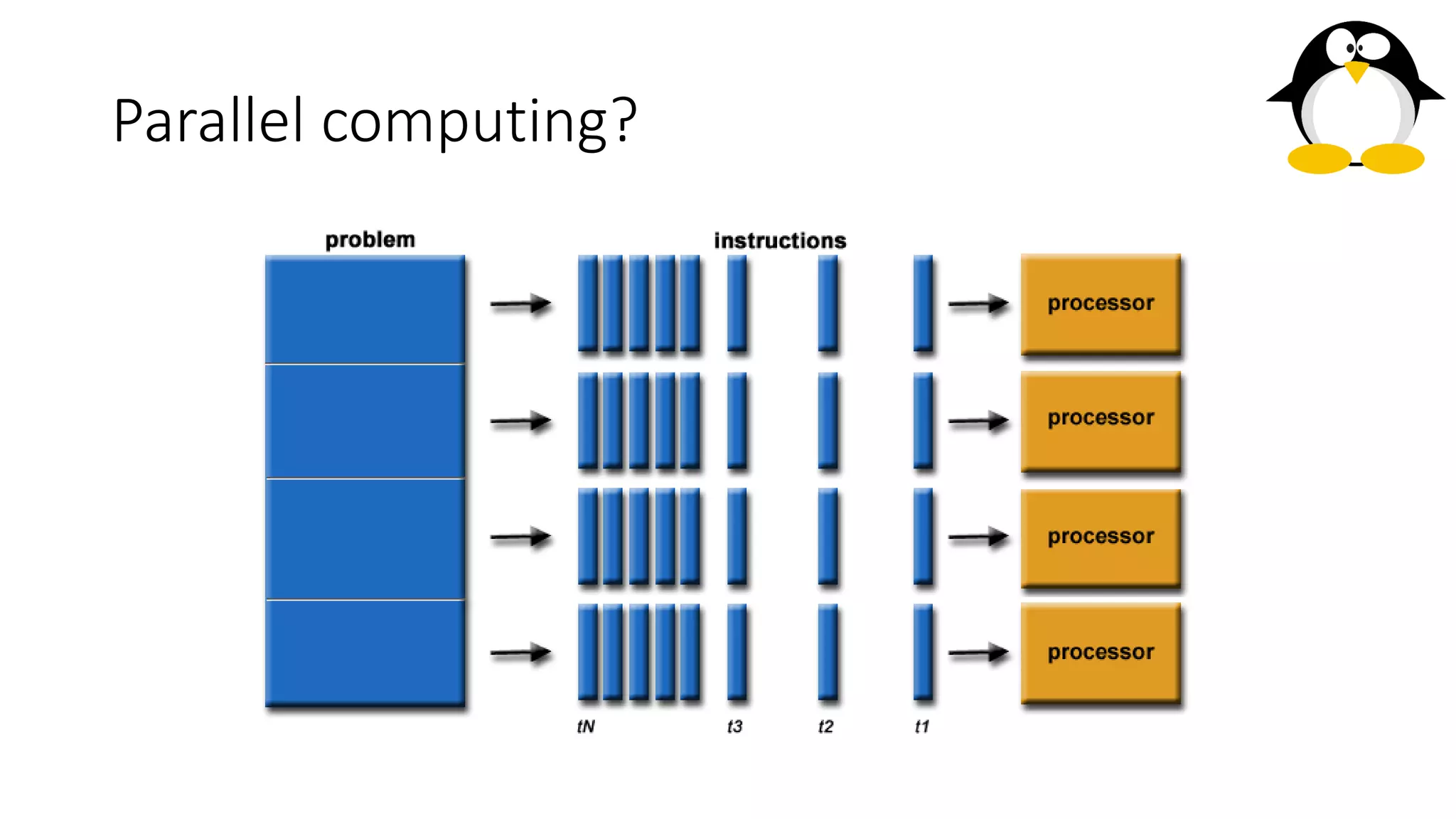





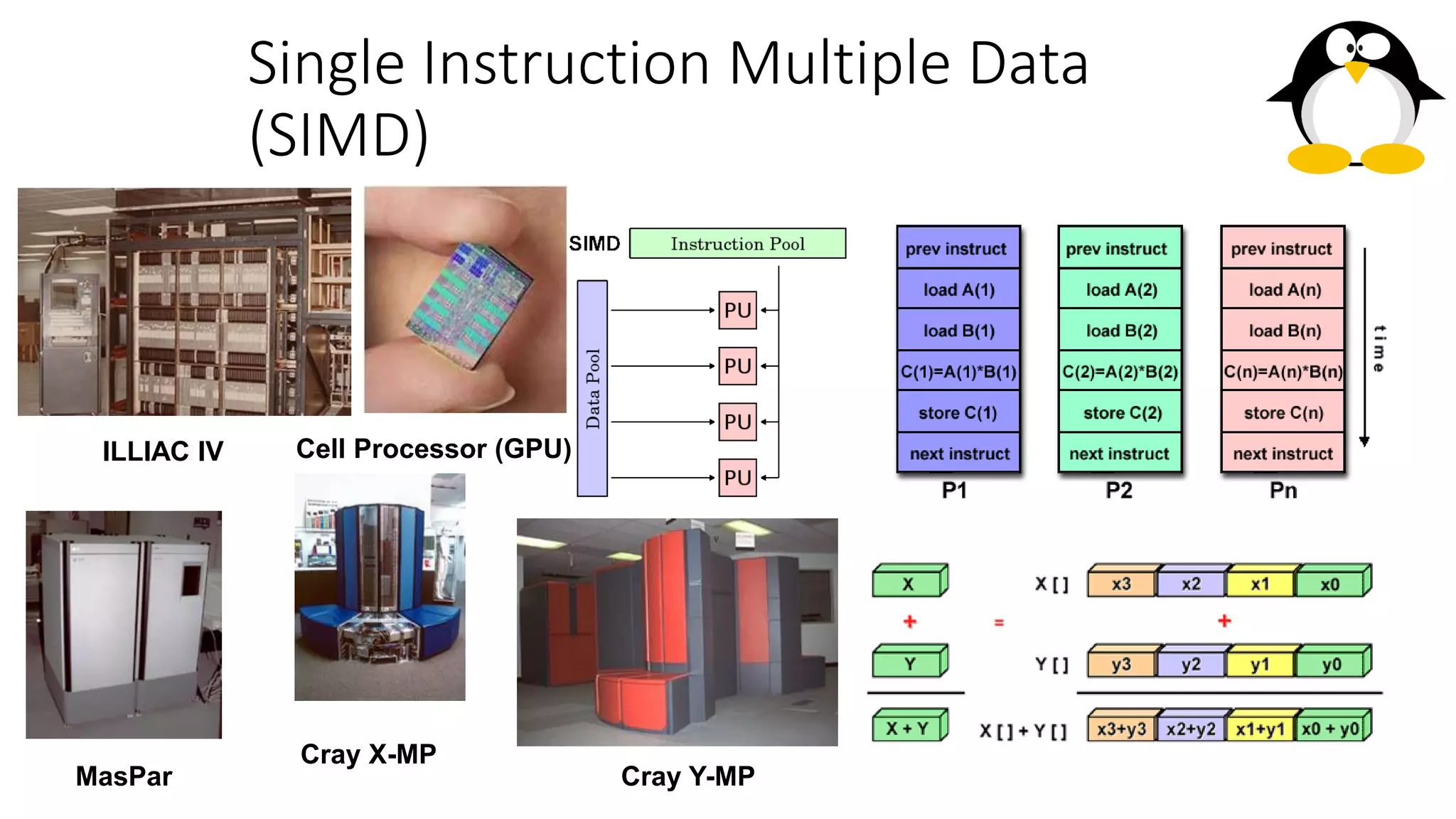
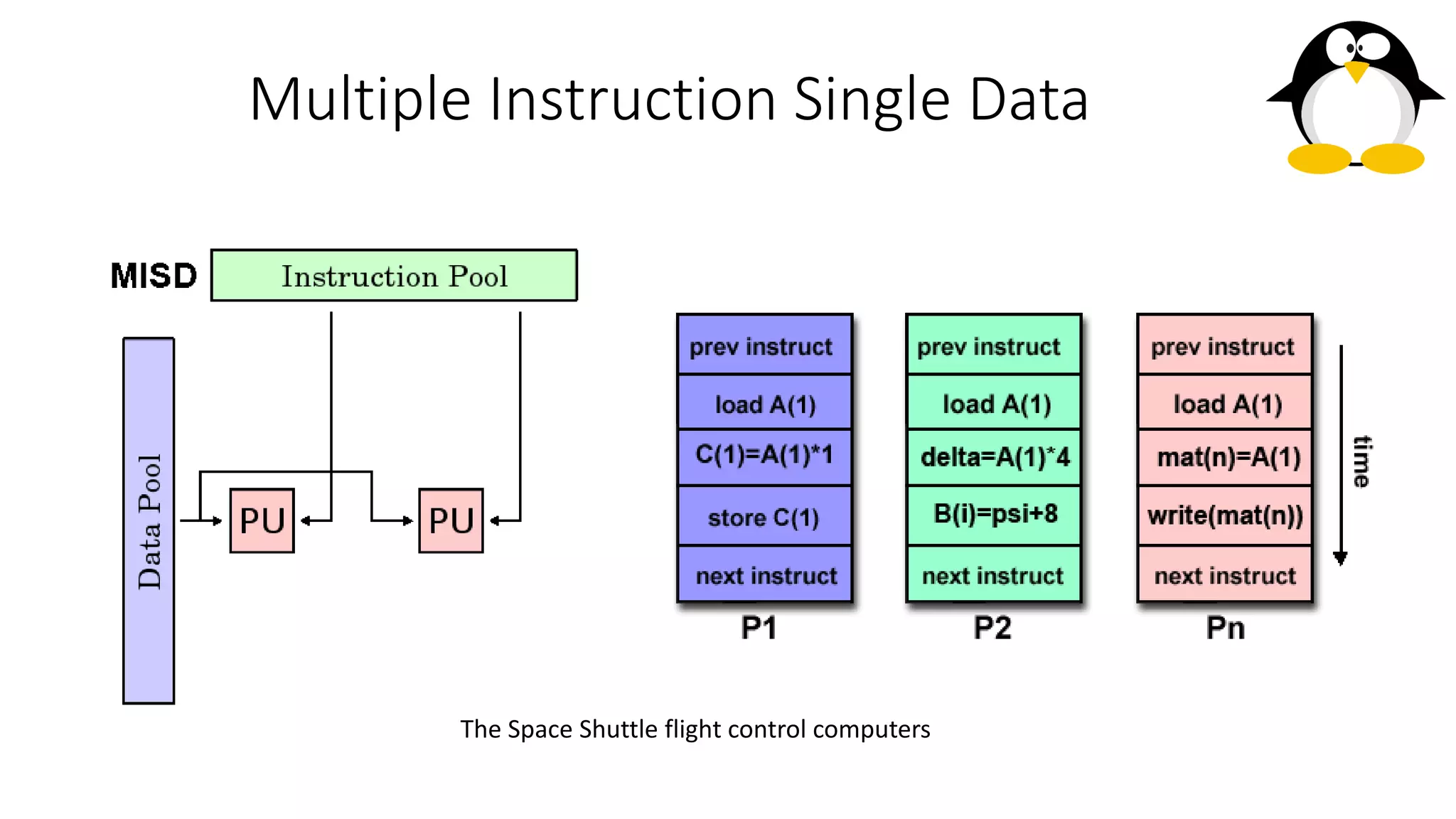
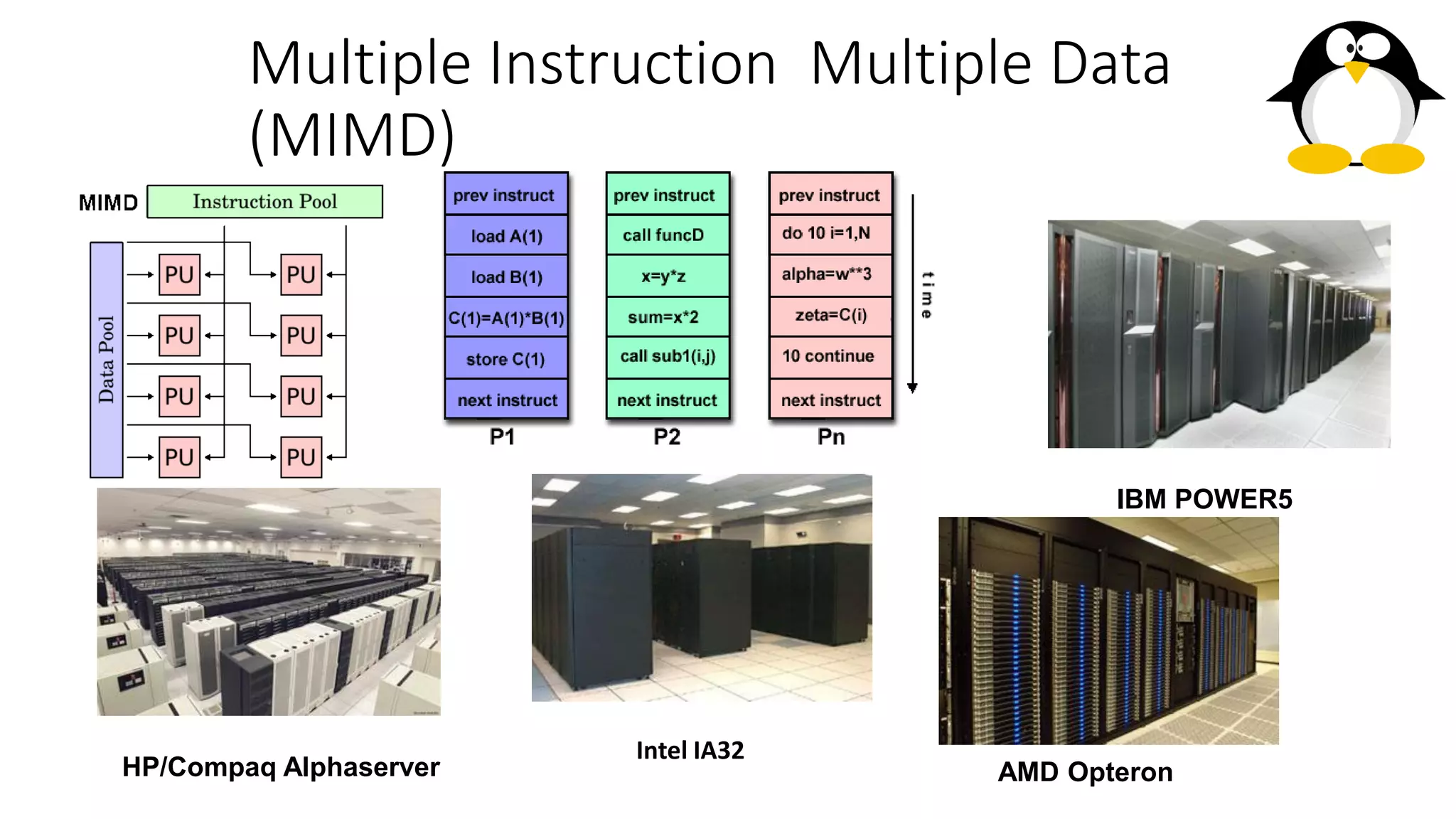


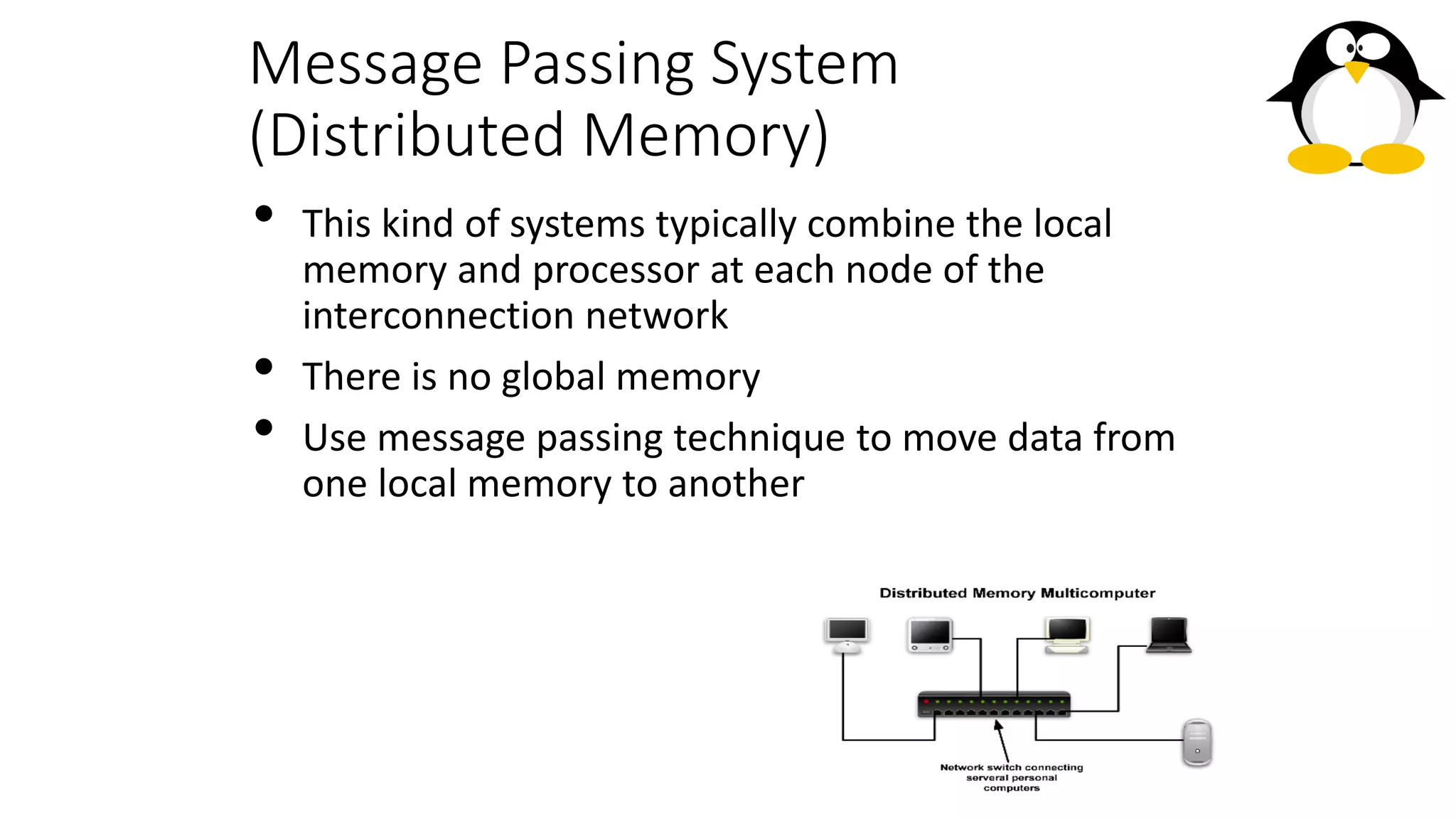

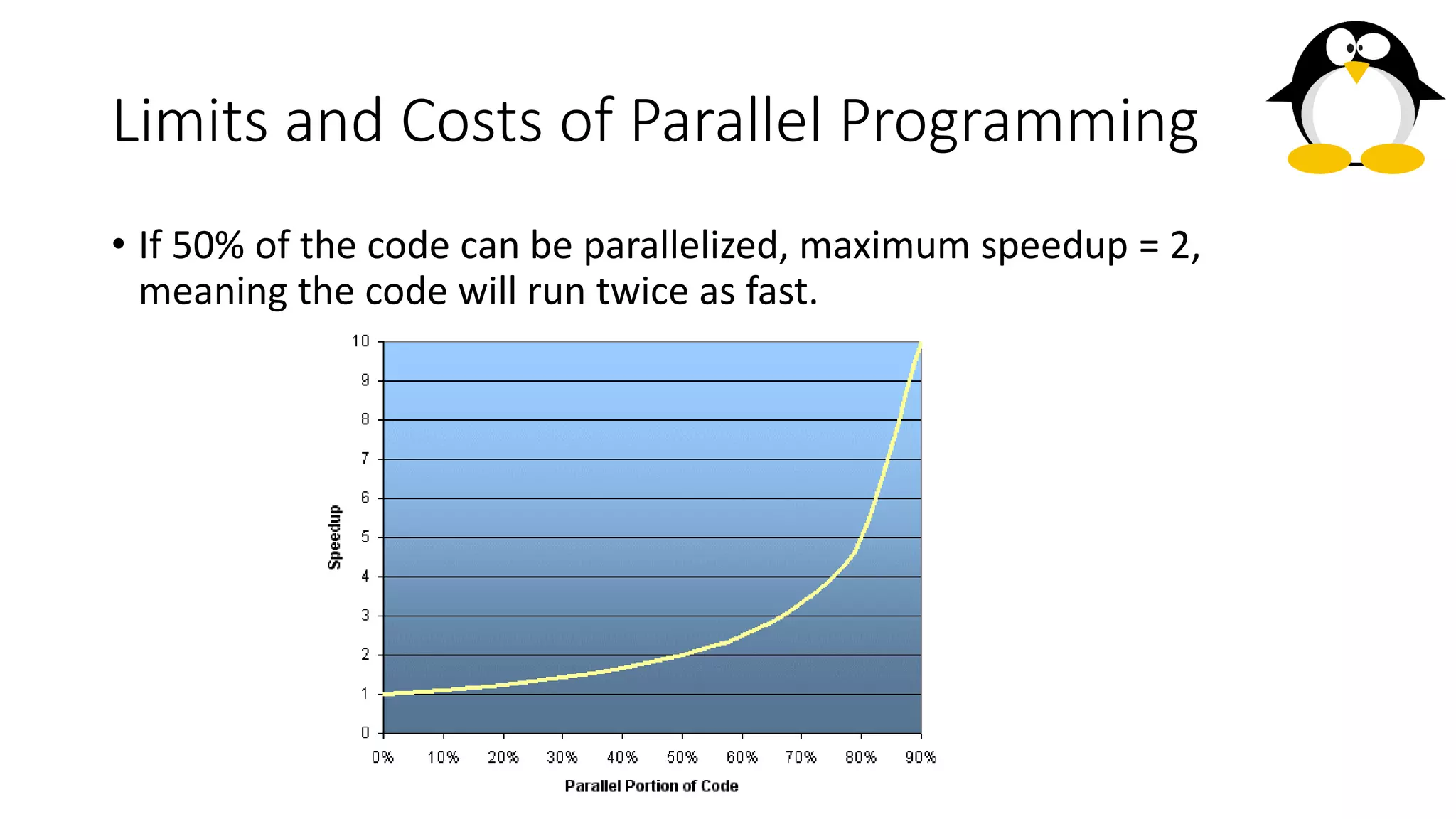

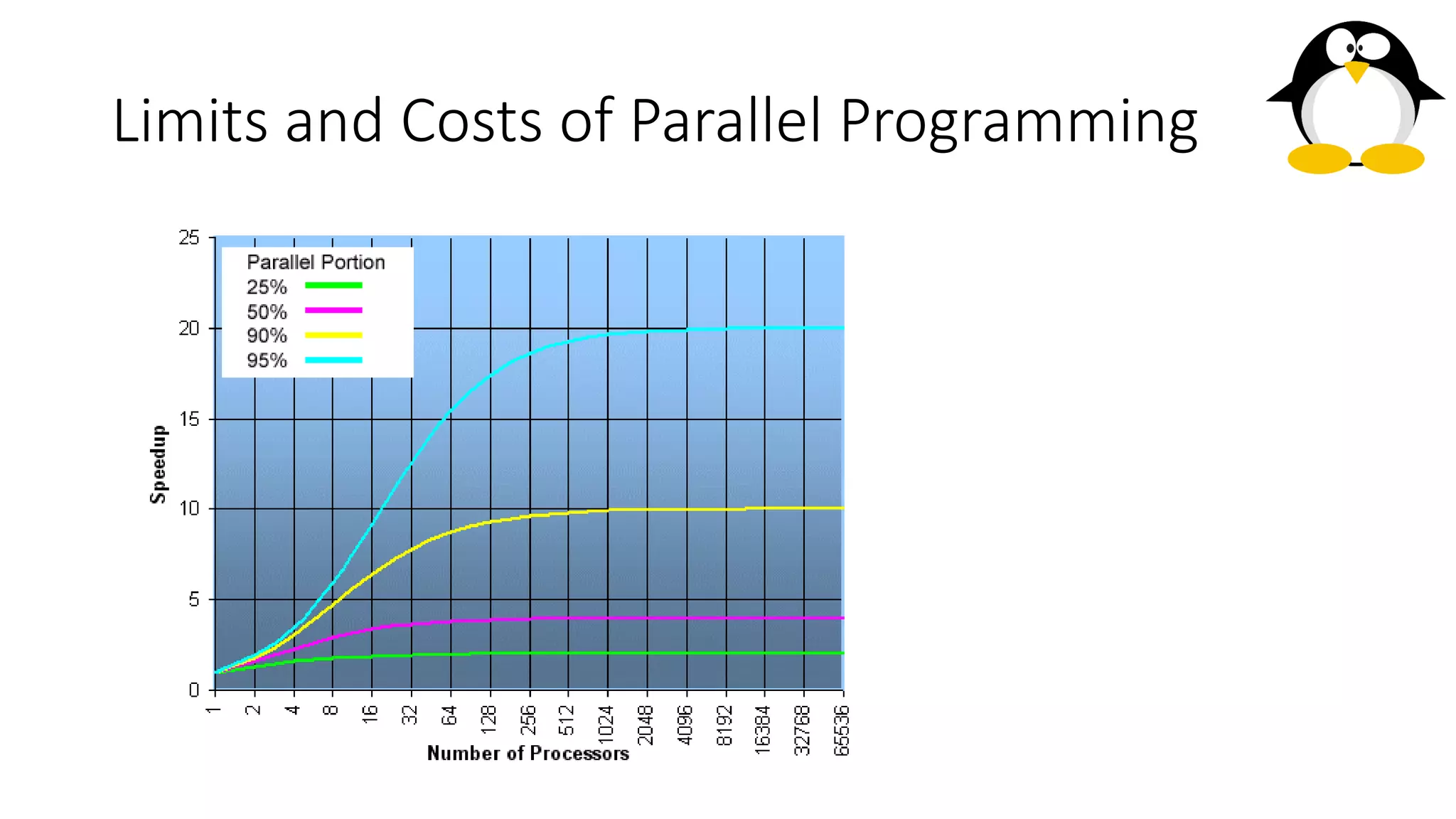


The course on parallel and distributed computing aims to equip students with skills in parallel algorithms, performance analysis, task decomposition, and parallel programming. It covers a wide range of topics including the history of computing, Flynn's taxonomy, various parallel architectures, and the principles of distributed systems. Assessment includes lab assignments and exams, while optional references provide additional resources for deeper understanding.